
Muon is Scalable for LLM Training
LLMOptimizerMuon1.5k+230+Moonshot AILiu J, Su J, Yao X, et al. Muon is Scalable for LLM Training. Technical Report, 2025.
Muon 可扩展用于 LLM 训练
Abstract
Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves
最近,基于矩阵正交化的 Muon 优化器在训练小规模语言模型时展示了强劲结果,但其向更大模型扩展的能力尚未得到证明。 作者识别出扩展 Muon 的两项关键技术:(1) 加入权重衰减,(2) 仔细调整逐参数更新尺度。 这些技术使 Muon 能够在大规模训练中开箱即用,而无需超参数调优。 缩放律实验表明,在计算最优训练下,Muon 相比 AdamW 实现了约
1. Introduction
The rapid advancement of large language models (LLMs) has significantly pushed forward the progress in artificial general intelligence. However, training capable LLMs remains a computationally intensive and resource-demanding process due to scaling laws. Optimizers play a crucial role in efficiently and effectively training of LLMs, with Adam and its variant AdamW being the standard choice for most large-scale training.
大语言模型(LLM)的快速发展显著推动了通用人工智能的进展。 然而,由于缩放律的存在,训练能力强的 LLM 仍然是计算密集且资源需求很高的过程。 优化器在高效且有效地训练 LLM 中起着关键作用,其中 Adam 及其变体 AdamW 是大多数大规模训练的标准选择。
Recent developments in optimization algorithms have shown potential to improve training efficiency beyond AdamW. Among these, Jordan et al. proposed Muon, which updates matrix parameters with orthogonalized gradient momentum using Newton-Schulz iteration. Initial experiments with Muon have demonstrated promising results in small-scale language model training. However, as discussed in this blog, several critical challenges remain unaddressed: (1) how to effectively scale optimizers based on matrix orthogonalization to larger models with billions of parameters trained with trillions of tokens, (2) how to compute approximate orthogonalization in a distributed setting, and (3) whether such optimizers can generalize across different training stages including pre-training and supervised finetuning (SFT).
优化算法的近期发展显示出进一步提升 AdamW 之外训练效率的潜力。 其中,Jordan 等人提出了 Muon,它使用 Newton-Schulz 迭代,以正交化的梯度动量来更新矩阵参数。 Muon 的初始实验已经在小规模语言模型训练中展示了有前景的结果。 然而,正如这篇博客中讨论的,若干关键挑战仍未解决:(1) 如何有效地将基于矩阵正交化的优化器扩展到拥有数十亿参数、使用数万亿 token 训练的更大模型;(2) 如何在分布式设置中计算近似正交化;(3) 这类优化器是否能够泛化到不同训练阶段,包括预训练和监督微调(SFT)。
In this technical report, we present a comprehensive study addressing these challenges. Our work builds upon Muon while systematically identifying and resolving its limitations in large-scale training scenarios. Our technical contributions include:
在这份技术报告中,作者给出了一项全面研究来应对这些挑战。 作者的工作建立在 Muon 之上,同时系统地识别并解决其在大规模训练场景中的局限。 作者的技术贡献包括:
- Analysis for Effective Scaling of Muon: Through extensive analysis, we identify that weight decay plays a crucial role in Muon's scalability. Besides, we propose scale adjustments to Muon's parameter-wise update rule. Such adjustments allow Muon to work out-of-the-box without hyper-parameter tuning, and also significantly improve training stability.
- Efficient Distributed Implementation: We develop a distributed version of Muon with ZeRO-1 style optimization, achieving optimal memory efficiency and reduced communication overhead while preserving the mathematical properties of the algorithm.
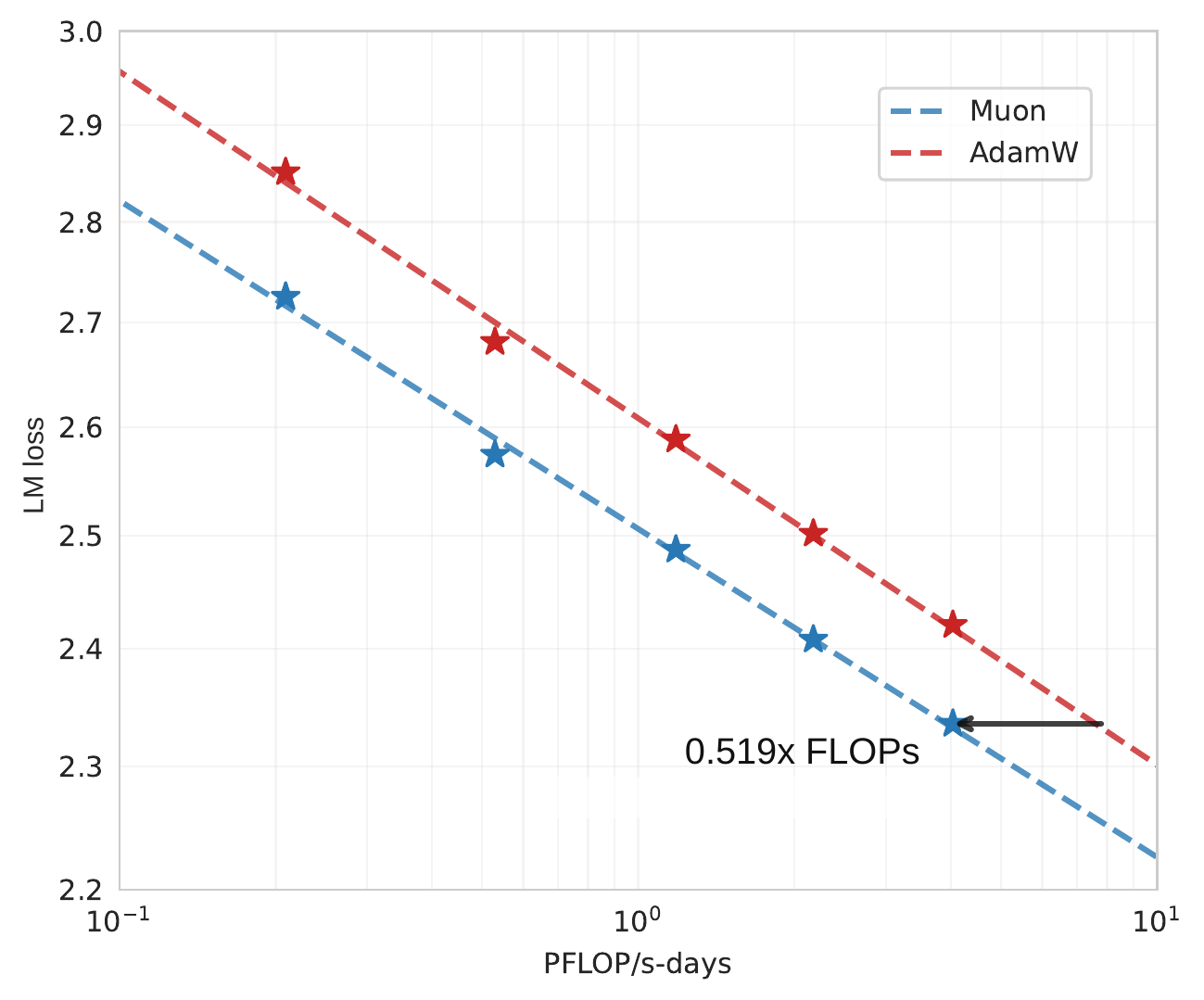
- Scaling Law Validation: We performed scaling law research that compares Muon with strong AdamW baselines, and showed the superior performance of Muon (Figure Figure 1(a)). Based on the scaling law results, Muon achieves comparable performance to AdamW trained counterparts while requiring only approximately 52% of the training FLOPs.
- Muon 有效扩展分析:通过大量分析,作者发现权重衰减在 Muon 的可扩展性中起着关键作用。此外,作者提出了对 Muon 逐参数更新规则的尺度调整。这些调整使 Muon 无需超参数调优即可开箱即用,并且还显著改善了训练稳定性。
- 高效分布式实现:作者开发了采用 ZeRO-1 风格优化的 Muon 分布式版本,在保持算法数学性质的同时,实现了最优内存效率并降低了通信开销。
- 缩放律验证:作者开展了缩放律研究,将 Muon 与强 AdamW 基线进行比较,并展示了 Muon 的优越性能(图1(a))。基于缩放律结果,Muon 在仅需约 52% 训练 FLOPs 的情况下,即可达到 AdamW 训练对应模型的相当性能。
Our comprehensive experiments demonstrate that Muon can effectively replace AdamW as the de facto optimizer for large-scale LLM training, offering significant improvements in both training efficiency and model performance. As a result of this work, we release Moonlight, a 16B-parameter MoE model trained using Muon, along with our implementation and intermediate training checkpoints to facilitate further research in scalable optimization techniques for LLMs.
作者的全面实验表明,Muon 可以有效取代 AdamW,成为大规模 LLM 训练的事实标准优化器,并在训练效率和模型性能两方面带来显著提升。 作为这项工作的成果,作者发布了 Moonlight,这是一个使用 Muon 训练的 16B 参数 MoE 模型,同时还发布实现和中间训练检查点,以促进 LLM 可扩展优化技术的后续研究。
2. Methods
2.1 Background
The Muon Optimizer. Muon has recently been proposed to optimize neural network weights representable as matrices. At iteration
Muon 优化器。 Muon 最近被提出用于优化可表示为矩阵的神经网络权重。 在第
Here,
这里,
Newton-Schulz Iterations for Matrix Orthogonalization. The equation above is calculated in an iterative process. At the beginning, we set
用于矩阵正交化的 Newton-Schulz 迭代。 上式通过迭代过程计算。 开始时,作者设
Where
其中
Steepest Descent Under Norm Constraints. Bernstein and Newhouse proposed to view the optimization process in deep learning as steepest descent under norm constraints. From this perspective, we can view the difference between Muon and Adam as the difference in norm constraints. Whereas Adam is a steepest descent under the a norm constraint dynamically adjusted from a Max-of-Max norm, Muon offers a norm constraint that lies in a static range of Schatten-
范数约束下的最速下降。 Bernstein 和 Newhouse 提出,可以把深度学习中的优化过程看作范数约束下的最速下降。 从这一视角看,Muon 与 Adam 的差异可以理解为范数约束的差异。 Adam 是在由 Max-of-Max 范数动态调整出的范数约束下进行最速下降,而 Muon 提供的范数约束位于某个较大
2.2 Scaling Up Muon
Weight Decay. While Muon performs significantly better than AdamW on a small scale as shown by Jordan et al., we found the performance gains diminish when we scale up to train a larger model with more tokens. We observed that both the weight and the layer output's RMS keep growing to a large scale, exceeding the high-precision range of bf16, which might hurt the model's performance. To resolve this issue, we introduced the standard AdamW weight decay mechanism into Muon.
权重衰减。 尽管 Jordan 等人表明 Muon 在小规模上明显优于 AdamW,但作者发现,当扩展到用更多 token 训练更大模型时,性能收益会减小。 作者观察到,权重和层输出的 RMS 都持续增长到很大尺度,超过 bf16 的高精度范围,这可能损害模型性能。 为解决这一问题,作者将标准 AdamW 权重衰减机制引入 Muon。
We experimented on Muon both with and without weight decay to understand its impact on the training dynamics of LLMs. Based on our scaling law research in Section 3.2, we trained an 800M parameters model with 100B tokens (
作者分别在带权重衰减和不带权重衰减的 Muon 上进行实验,以理解其对 LLM 训练动态的影响。 基于第 3.2 节中的缩放律研究,作者用 100B token(约为最优训练 token 数的
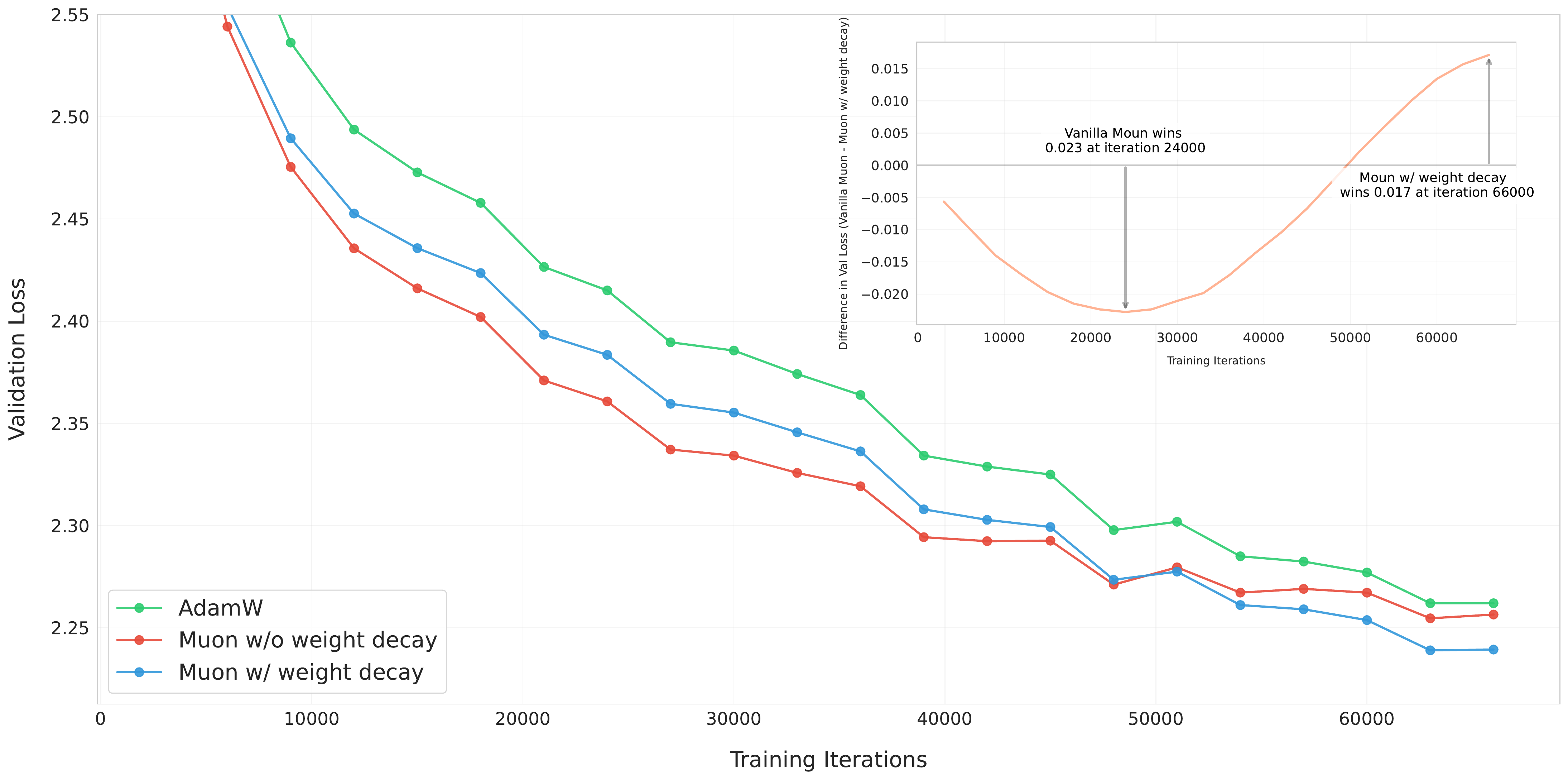
Consistent update RMS. An important property of Adam and AdamW is that they maintain a theoretical update RMS around 1. However, we show that Muon's update RMS varies depending on the shape of the parameters, according to the following lemma:
一致的更新 RMS。 Adam 和 AdamW 的一个重要性质是,它们会维持理论上约为 1 的更新 RMS。 然而,作者根据下面的引理表明,Muon 的更新 RMS 会随参数形状而变化:
Lemma 1. For a full-rank matrix parameter of shape
引理 1。 对于形状为
The proof can be found in the appendix. We monitored Muon's update RMS during training and found it typically close to the theoretical value given above. We note that such inconsistency can be problematic when scaling up the model size:
证明见附录。 作者在训练期间监控 Muon 的更新 RMS,发现它通常接近上面给出的理论值。 作者注意到,当扩展模型规模时,这种不一致可能会带来问题:
- When
is too large, e.g. the dense MLP matrix, the updates become too small, thus limiting the model's representational capacity and leading to suboptimal performances. - When
is too small, e.g. treating each KV head in GQA or MLA as a separate parameter, the updates become too large, thus causing training instabilities and leading to suboptimal performances as well.
- 当
过大时,例如稠密 MLP 矩阵,更新会变得过小,从而限制模型表示能力并导致次优性能。 - 当
过小时,例如把 GQA 或 MLA 中的每个 KV head 当作独立参数,更新会变得过大,从而造成训练不稳定,也会导致次优性能。
In order to maintain consistent update RMS among matrices of different shapes, we propose to scale the Muon update for each matrix by its
为了在不同形状矩阵之间维持一致的更新 RMS,作者提出将每个矩阵的 Muon 更新按其
Matching update RMS of AdamW. Muon is designed to update matrix-based parameters. In practice, AdamW is used in couple with Muon to handle non-matrix based parameters, like RMSNorm, LM head, and embedding parameters. We would like the optimizer hyper-parameters (learning rate
匹配 AdamW 的更新 RMS。 Muon 被设计用于更新基于矩阵的参数。 实践中,AdamW 会与 Muon 配合使用,以处理非矩阵参数,例如 RMSNorm、LM head 和 embedding 参数。 作者希望优化器超参数(学习率
We validated this choice with empirical results. Moreover, we highlighted that with this adjustment, Muon can directly reuse the learning rate and weight decay tuned for AdamW. Other Hyper-parameters. Muon contains two other tunnable hyper-parameters: Newton-Schulz iteration steps and momentum
作者用经验结果验证了这一选择。 此外,作者强调,通过这一调整,Muon 可以直接复用为 AdamW 调好的学习率和权重衰减。 其他超参数。 Muon 包含另外两个可调超参数:Newton-Schulz 迭代步数和动量
2.3 Distributed Muon
ZeRO-1 and Megatron-LM. Rajbhandari et al. introduced the ZeRO-1 technique that partitions the expensive optimizer states (e.g. master weights, momentum) all over the cluster. Megatron-LM integrated ZeRO-1 into its native parallel designs. Based on Megatron-LM's sophisticated parallel strategies, e.g. Tensor-Parallel (TP), Pipeline Parallel (PP), Expert Parallel (EP) and Data Parallel (DP), the communication workload of ZeRO-1 can be reduced from gathering all over the distributed world to only gathering over the data parallel group.
ZeRO-1 与 Megatron-LM。 Rajbhandari 等人提出了 ZeRO-1 技术,用于在整个集群中划分昂贵的优化器状态(例如主权重、动量)。 Megatron-LM 将 ZeRO-1 集成进其原生并行设计。 基于 Megatron-LM 复杂的并行策略,例如张量并行(TP)、流水线并行(PP)、专家并行(EP)和数据并行(DP),ZeRO-1 的通信工作量可以从在整个分布式世界中 gather,降低为只在数据并行组内 gather。
Method. ZeRO-1 is efficient for AdamW because it calculates updates in an element-wise fashion. However, Muon requires the full gradient matrix to calculate the updates. Therefore, vanilla ZeRO-1 is not directly applicable to Muon. We propose a new distributed solution based on ZeRO-1 for Muon, referred to as Distributed Muon. Distributed Muon follows ZeRO-1 to partition the optimizer states on DP, and introduces two additional operations compared to a vanilla Zero-1 AdamW optimizer:
方法。 ZeRO-1 对 AdamW 很高效,因为它以逐元素方式计算更新。 然而,Muon 需要完整梯度矩阵来计算更新。 因此,原始 ZeRO-1 不能直接应用于 Muon。 作者提出一种基于 ZeRO-1 的 Muon 新分布式方案,称为 Distributed Muon。 Distributed Muon 遵循 ZeRO-1 在 DP 上划分优化器状态,并相比原始 Zero-1 AdamW 优化器引入两项额外操作:
DP Gather. For a local DP partitioned master weight (the size of the model weight), this operation is to gather the corresponding partitioned gradients into a full gradient matrix. Calculate Full Update. After the above gathering, perform Newton-Schulz iteration steps on the full gradient matrix as described in Section 2.1. Note that we will then discard part of the full update matrix, as we only need the partition corresponding to the local parameters to perform update.
DP Gather。 对于本地 DP 划分的主权重(大小为模型权重的),该操作会把对应的划分梯度 gather 成完整梯度矩阵。 Calculate Full Update。 在上述 gather 之后,如第 2.1 节所述,在完整梯度矩阵上执行 Newton-Schulz 迭代步骤。注意,随后作者会丢弃完整更新矩阵的一部分,因为执行更新只需要与本地参数对应的分区。
The implementation of Distributed Muon is described in Algorithm Algorithm 1. The additional operations introduced by Distributed Muon are colored in blue.
Distributed Muon 的实现见 算法1。 Distributed Muon 引入的额外操作以蓝色标出。
Algorithm 1: Distributed Muon
Require: Full Gradients
- // Reduce-scatter
on DP for correct gradients - // Apply momentum to
using local partitioned momentum - // DP Gather: gathering
across DP into a full matrix - // Calculate Muon update
- // Discard the rest of
and only keep the local partition , then apply the update rule - // All-gather updated
into - // Return the update RMS for logging
- return
Analysis. We compared Distributed Muon to a classic ZeRO-1 based distributed AdamW (referred as Distributed AdamW for simplicity) in several aspects:
分析。 作者从几个方面将 Distributed Muon 与经典的基于 ZeRO-1 的分布式 AdamW(为简洁起见称为 Distributed AdamW)进行比较:
Memory Usage. Muon uses only one momentum buffer, while AdamW uses two momentum buffers. Therefore, the additional memory used by the Muon optimizer is half of Distributed AdamW.Communication Overhead. For each device, the additional DP gathering is only required by the local DP partitioned parameters. Therefore, the communication cost is less than the reduce-scatter of or the all-gather of . Besides, Muon only requires the Newton-Schulz iteration steps in bf16, thus further reducing the communication overhead to 50% comparing to fp32. Overall, the communication workload of Distributed Muon is of that of Distributed AdamW. Latency. Distributed Muon has larger end-to-end latencies than Distributed AdamW because it introduces additional communication and requires running Newton-Schulz iteration steps. However, this is not a significant issue because only about 5 Newton-Schultz iteration steps are needed for a good result, and the end-to-end latency caused by the optimizer is negligible compared to the model's forward-backward pass time.
Memory Usage。 Muon 只使用一个动量缓冲区,而 AdamW 使用两个动量缓冲区。因此,Muon 优化器使用的额外内存是 Distributed AdamW 的一半。Communication Overhead。 对于每个设备,额外 DP gathering 只需要作用于本地 DP 划分参数。因此,通信成本低于 的 reduce-scatter 或 的 all-gather。此外,Muon 只需要以 bf16 执行 Newton-Schulz 迭代步骤,因此相比 fp32 进一步将通信开销降低到 50%。总体而言,Distributed Muon 的通信工作量是 Distributed AdamW 的 。 Latency。 Distributed Muon 的端到端延迟大于 Distributed AdamW,因为它引入额外通信并需要运行 Newton-Schulz 迭代步骤。然而,这不是显著问题,因为良好结果只需要约 5 个 Newton-Schultz 迭代步骤,而且优化器造成的端到端延迟相较模型前向-反向传播时间可以忽略。
Moreover, several engineering techniques, such as overlapping gather and computation, and overlapping optimizer reduce-scatter with parameter gather, can further reduce latency. When training large-scale models in our distributed cluster, Distributed Muon has no noticeable latency overhead compared to its AdamW counterparts. We will soon release a pull request that implements Distributed Muon for the open-source Megatron-LM project.
此外,若干工程技术,例如重叠 gather 与计算,以及重叠优化器 reduce-scatter 与参数 gather,可以进一步降低延迟。 在作者的分布式集群中训练大规模模型时,与 AdamW 对应实现相比,Distributed Muon 没有可感知的延迟开销。 作者将很快发布一个 pull request,为开源 Megatron-LM 项目实现 Distributed Muon。
3. Experiments
3.1 Consistent Update RMS
As discussed in Section 2.2, we aim to match the update RMS across all matrix parameters and also match it with that of AdamW. We experimented with two methods to control the Muon update RMS among parameters and compared them to a baseline that only maintains a consistent RMS with AdamW:
如第 2.2 节所讨论,作者旨在匹配所有矩阵参数之间的更新 RMS,并使其也与 AdamW 的更新 RMS 匹配。 作者实验了两种控制参数间 Muon 更新 RMS 的方法,并将它们与只维持和 AdamW 一致 RMS 的基线进行比较:
Baseline. We multiplied the update matrix by( is the model hidden size) to maintain a consistent update RMS with AdamW. Note that equals to for most matrices. Update Norm. We can directly normalize the updates calculated via Newton-Schulz iterations so its RMS strictly becomes 0.2.Adjusted LR. For each update matrix, we can scale its learning rate by a factor ofbased on its shape.
Baseline。 作者将更新矩阵乘以( 为模型隐藏维度),以维持与 AdamW 一致的更新 RMS。注意,对多数矩阵而言, 等于 。 Update Norm。 作者可以直接归一化通过 Newton-Schulz 迭代计算出的更新,使其 RMS 严格变为 0.2。Adjusted LR。 对于每个更新矩阵,作者可以根据其形状将学习率按因子缩放。
Analysis. We designed experiments to illustrate the impact of Muon update RMS at an early training stage, because we observed that unexpected behaviors happened very quickly when training models at larger scale. We experimented with small scale 800M models as described in Section 3.2. The problem of inconsistent update RMS is more pronounced when the disparity between matrix dimensions increases. To highlight the problem for further study, we slightly modify the model architecture by replacing the Swiglu MLP with a standard 2-layer MLP, changing the shape of its matrix parameters from
分析。 作者设计实验来说明 Muon 更新 RMS 在早期训练阶段的影响,因为作者观察到,在更大规模训练模型时,意外行为会很快发生。 作者使用第 3.2 节所述的小规模 800M 模型进行实验。 当矩阵维度差异增大时,更新 RMS 不一致的问题更明显。 为突出该问题以便进一步研究,作者略微修改模型架构,将 Swiglu MLP 替换为标准 2 层 MLP,把其矩阵参数形状从
| Methods | Training loss | Validation loss | query weight RMS | MLP weight RMS |
|---|---|---|---|---|
| Baseline | 2.734 | 2.812 | 3.586e-2 | 2.52e-2 |
| Update Norm | 2.72 | 2.789 | 4.918e-2 | 5.01e-2 |
| Adjusted LR | 2.721 | 2.789 | 3.496e-2 | 4.89e-2 |
- Both
Update NormandAdjusted LRachieved better performances thanBaseline. - For the MLP weight matrix of shape
, both Update NormandAdjusted LRobtain a weight RMS that is roughly doubled comparing toBaseline. This is reasonable as, so the update RMS of Update NormandAdjusted LRis roughly two times ofBaseline. - For the attention query weight matrix of shape
, Update Normstill norms the update, whileAdjusted LRdoes not because. As a result, Adjusted LRresults in a similar weight RMS asBaseline, butUpdate Normhas a larger weight rms similar to its MLP.
Update Norm和Adjusted LR都取得了比Baseline更好的性能。- 对于形状为
的 MLP 权重矩阵, Update Norm和Adjusted LR得到的权重 RMS 都约为Baseline的两倍。这是合理的,因为,所以 Update Norm和Adjusted LR的更新 RMS 约为Baseline的两倍。 - 对于形状为
的 attention query 权重矩阵, Update Norm仍会归一化更新,而Adjusted LR不会,因为。因此, Adjusted LR得到与Baseline类似的权重 RMS,而Update Norm会得到与其 MLP 类似的更大权重 RMS。
Based on these findings, we choose the Adjusted LR method for future experiments because it has lower cost.
基于这些发现,作者在后续实验中选择 Adjusted LR 方法,因为它成本更低。
3.2 Scaling Law of Muon
For a fair comparison with AdamW, we performed scaling law experiments on a series of dense models in Llama architecture. Building a strong baseline is of crucial importance in optimizer research. Hence, we perform a grid search for hyper-parameters of AdamW, following the compute-optimal training setup. Details of the model architecture and hyper-parameters can be found in Table Table 2. For Muon, as discussed in Section 2.2, since we matched Muon's update RMS to AdamW, we directly reused the hyper-parameters that are optimal for the AdamW baseline.
为了与 AdamW 进行公平比较,作者在一系列 Llama 架构的稠密模型上进行了缩放律实验。 构建强基线在优化器研究中至关重要。 因此,作者遵循计算最优训练设置,对 AdamW 的超参数进行网格搜索。 模型架构和超参数细节见 表2。 对于 Muon,如第 2.2 节所讨论,由于作者将 Muon 的更新 RMS 匹配到 AdamW,因而直接复用了对 AdamW 基线最优的超参数。
| # Params. w/o Embedding | Head | Layer | Hidden | Tokens | LR | Batch Size* |
|---|---|---|---|---|---|---|
| 399M | 12 | 12 | 1536 | 8.92B | 9.503e-4 | 96 |
| 545M | 14 | 14 | 1792 | 14.04B | 9.143e-4 | 128 |
| 822M | 16 | 16 | 2048 | 20.76B | 8.825e-4 | 160 |
| 1.1B | 18 | 18 | 2304 | 28.54B | 8.561e-4 | 192 |
| 1.5B | 20 | 20 | 2560 | 38.91B | 8.305e-4 | 256 |
*In terms of number of examples in 8K context length.
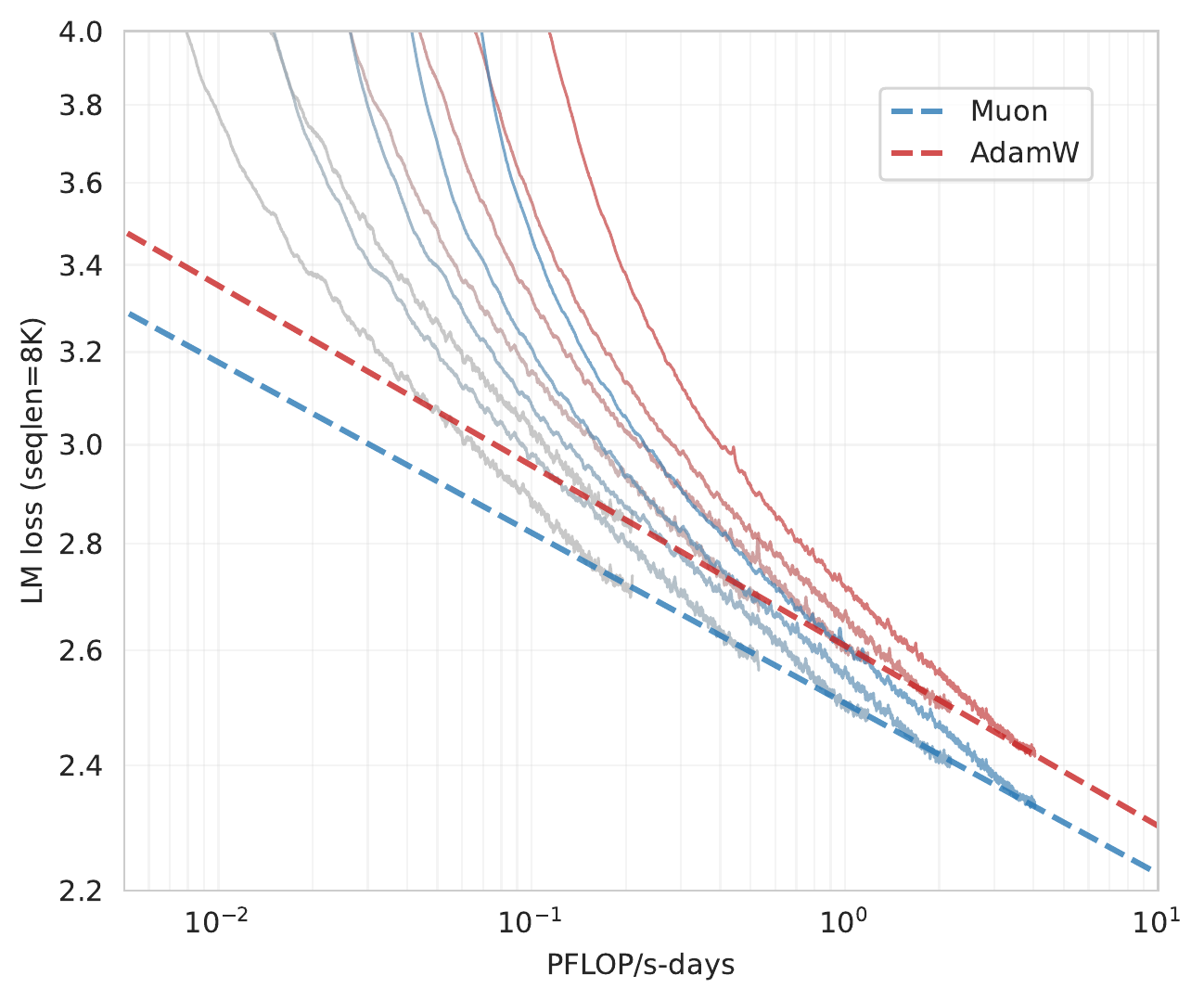
The fitted scaling law curve can be found in Figure Figure 3, and the fitted equations are detailed in Table Table 3. As shown in Figure Figure 1, Muon only requires about 52% training FLOPs to match the performance of AdamW under compute-optimal setting.
拟合得到的缩放律曲线见 图3,拟合方程详见 表3。 如 图1 所示,在计算最优设置下,Muon 只需要约 52% 训练 FLOPs 即可匹配 AdamW 的性能。
| Muon | AdamW | |
|---|---|---|
| LM loss (seqlen=8K) |
3.3 Pretraining with Muon
Model Architecture. To evaluate Muon against contemporary model architectures, we pretrained from scratch using the deepseek-v3-small architecture as it demonstrates strong performance and the original results serve as a reference for comparison. Our pretrained model has 2.24B activated and 15.29B total parameters (3B activated and 16B total when including embedding). Minor modifications to the architecture are detailed in the appendix. Pretraining Data. Our pretraining data details can be found in Kimi k1.5. The maximum context length during pretraining is 8K.
模型架构。 为了在当代模型架构上评估 Muon,作者使用 deepseek-v3-small 架构从头预训练,因为该架构展示出强性能,且原始结果可作为比较参考。 作者的预训练模型拥有 2.24B 激活参数和 15.29B 总参数(若包含 embedding,则为 3B 激活参数和 16B 总参数)。 架构上的小修改详见附录。 预训练数据。 作者的预训练数据细节可见 Kimi k1.5。 预训练期间的最大上下文长度为 8K。
Pretraining. The model is trained in several stages. We use a 1e-3 auxfree bias update rate in stage 1 and 2, and 0.0 auxfree bias update rate in stage 3. The weight decay is set to 0.1 for all stages. More details and discussions of model training can be found in the appendix.
预训练。 模型分多个阶段训练。 作者在第 1 和第 2 阶段使用 1e-3 的 auxfree bias 更新率,在第 3 阶段使用 0.0 的 auxfree bias 更新率。 所有阶段的权重衰减都设为 0.1。 更多模型训练细节和讨论见附录。
0 to 33B tokens:In this stage, the learning rate linearly increases to 4.2e-4 in 2k steps. The batch size is kept at 2048 examples.33B to 5.2T tokens:In this stage, the learning rate decays from 4.2e-4 to 4.2e-5 in a cosine style. We keep the batch size at 2048 until 200B tokens, and then doubled to 4096 for the remaining.5.2T to 5.7T tokens:In this stage (also referred as the cooldown stage), the learning rate increases to 1e-4 in in 100 steps, and then linearly decays to 0 in 500B tokens, and we keep a constant 4096 batch size. In this stage, we use the highest quality data, focusing on math, code, and reasoning.
0 to 33B tokens:在这一阶段,学习率在 2k 步内线性升至 4.2e-4。批大小保持为 2048 个样本。33B to 5.2T tokens:在这一阶段,学习率按余弦方式从 4.2e-4 衰减到 4.2e-5。作者在 200B token 前将批大小保持为 2048,之后在剩余训练中将其翻倍到 4096。5.2T to 5.7T tokens:在这一阶段(也称为 cooldown 阶段),学习率在 100 步内升至 1e-4,然后在 500B token 内线性衰减到 0,作者保持恒定的 4096 批大小。在这一阶段,作者使用最高质量的数据,重点关注数学、代码和推理。
Evaluation Benchmarks. Our evaluation encompasses four primary categories of benchmarks, each designed to assess distinct capabilities of the model:
评估基准。 作者的评估涵盖四个主要类别的基准,每个类别都旨在评估模型的不同能力:
- English Language Understanding and Reasoning: MMLU(5-shot), MMLU-pro(5-shot), BBH(3-shot), TriviaQA(5-shot).
- Code Generation: HumanEval(pass@1), MBPP(pass@1).
- Mathematical Reasoning: GSM8K(4-shot), MATH, CMATH.
- Chinese Language Understanding and Reasoning: C-Eval(5-shot), CMMLU(5-shot).
- 英语语言理解与推理: MMLU(5-shot)、MMLU-pro(5-shot)、BBH(3-shot)、TriviaQA(5-shot)。
- 代码生成: HumanEval(pass@1)、MBPP(pass@1)。
- 数学推理: GSM8K(4-shot)、MATH、CMATH。
- 中文语言理解与推理: C-Eval(5-shot)、CMMLU(5-shot)。
Performance. We named our model trained with Muon "Moonlight". We compared Moonlight with different public models on a similar scale. We first evaluated Moonlight at 1.2T tokens and compared it with the following models that have the same architecture and trained with comparable number of tokens:
性能。 作者将使用 Muon 训练的模型命名为 “Moonlight”。 作者将 Moonlight 与相近规模的不同公开模型进行比较。 作者首先在 1.2T token 处评估 Moonlight,并将其与以下具有相同架构且训练 token 数相当的模型进行比较:
Deepseek-v3-Smallis a 2.4B/16B-parameter MoE model trained with 1.33T tokens.Moonlight-Afollows the same training settings as Moonlight, except that it uses the AdamW optimizer.
Deepseek-v3-Small是一个使用 1.33T token 训练的 2.4B/16B 参数 MoE 模型。Moonlight-A采用与 Moonlight 相同的训练设置,区别是它使用 AdamW 优化器。
For Moonlight and Moonlight-A, we used the intermediate 1.2T token checkpoint of the total 5.7T pretraining, where the learning rate is not decayed to minimal and the model has not gone through the cooldown stage yet.
对于 Moonlight 和 Moonlight-A,作者使用总计 5.7T 预训练中的 1.2T token 中间检查点,此时学习率尚未衰减到最小值,模型也尚未经过 cooldown 阶段。
| Benchmark (Metric) | DSV3-Small | Moonlight-A@1.2T | Moonlight@1.2T | |
|---|---|---|---|---|
| Activated Params† | 2.24B | 2.24B | 2.24B | |
| Total Params† | 15.29B | 15.29B | 15.29B | |
| Training Tokens | 1.33T | 1.2T | 1.2T | |
| Optimizer | AdamW | AdamW | Muon | |
| English | MMLU | 53.3 | 60.2 | 60.4 |
| MMLU-pro | - | 26.8 | 28.1 | |
| BBH | 41.4 | 45.3 | 43.2 | |
| TriviaQA | - | 57.4 | 58.1 | |
| Code | HumanEval | 26.8 | 29.3 | 37.2 |
| MBPP | 36.8 | 49.2 | 52.9 | |
| Math | GSM8K | 31.4 | 43.8 | 45.0 |
| MATH | 10.7 | 16.1 | 19.8 | |
| CMath | - | 57.8 | 60.2 | |
| Chinese | C-Eval | - | 57.2 | 59.9 |
| CMMLU | - | 58.2 | 58.8 |
† The reported parameter counts exclude the embedding parameters.
As shown in Table Table 4, Moonlight-A, our AdamW-trained baseline model, demonstrates strong performance compared to similar public models. Moonlight performs significantly better than Moonlight-A, proving the scaling effectiveness of Muon. We observed that Muon especially excels on Math and Code related tasks, and we encourage the research community to further investigate this phenomena. After Moonlight is fully trained to 5.7T tokens, we compared it with public models at similar scale and showed the results in Table Table 5:
如 表4 所示,作者使用 AdamW 训练的基线模型 Moonlight-A 相比类似公开模型表现强劲。 Moonlight 明显优于 Moonlight-A,证明了 Muon 的缩放有效性。 作者观察到 Muon 在数学和代码相关任务上尤其出色,并鼓励研究社区进一步研究这一现象。 当 Moonlight 完整训练到 5.7T token 后,作者将其与相近规模的公开模型比较,结果见 表5:
LLAMA3-3Bfrom Llama 3 is a 3B-parameter dense model trained with 9T tokens.Qwen2.5-3Bis a 3B-parameter dense model trained with 18T tokens.Deepseek-v2-Liteis a 2.4B/16B-parameter MOE model trained with 5.7T tokens.
LLAMA3-3B来自 Llama 3,是一个使用 9T token 训练的 3B 参数稠密模型。Qwen2.5-3B是一个使用 18T token 训练的 3B 参数稠密模型。Deepseek-v2-Lite是一个使用 5.7T token 训练的 2.4B/16B 参数 MOE 模型。
| Benchmark (Metric) | Llama3.2-3B | Qwen2.5-3B | DSV2-Lite | Moonlight | |
|---|---|---|---|---|---|
| Activated Param† | 2.81B | 2.77B | 2.24B | 2.24B | |
| Total Params† | 2.81B | 2.77B | 15.29B | 15.29B | |
| Training Tokens | 9T | 18T | 5.7T | 5.7T | |
| Optimizer | AdamW | Unknown | AdamW | Muon | |
| English | MMLU | 54.7 | 65.6 | 58.3 | 70.0 |
| MMLU-pro | 25.0 | 34.6 | 25.5 | 42.4 | |
| BBH | 46.8 | 56.3 | 44.1 | 65.2 | |
| TriviaQA‡ | 59.6 | 51.1 | 65.1 | 66.3 | |
| Code | HumanEval | 28.0 | 42.1 | 29.9 | 48.1 |
| MBPP | 48.7 | 57.1 | 43.2 | 63.8 | |
| Math | GSM8K | 34.0 | 79.1 | 41.1 | 77.4 |
| MATH | 8.5 | 42.6 | 17.1 | 45.3 | |
| CMath | - | 80.0 | 58.4 | 81.1 | |
| Chinese | C-Eval | - | 75.0 | 60.3 | 77.2 |
| CMMLU | - | 75.0 | 64.3 | 78.2 |
† The reported parameter counts exclude the embedding parameters. ‡ We tested all listed models with the full set of TriviaQA.
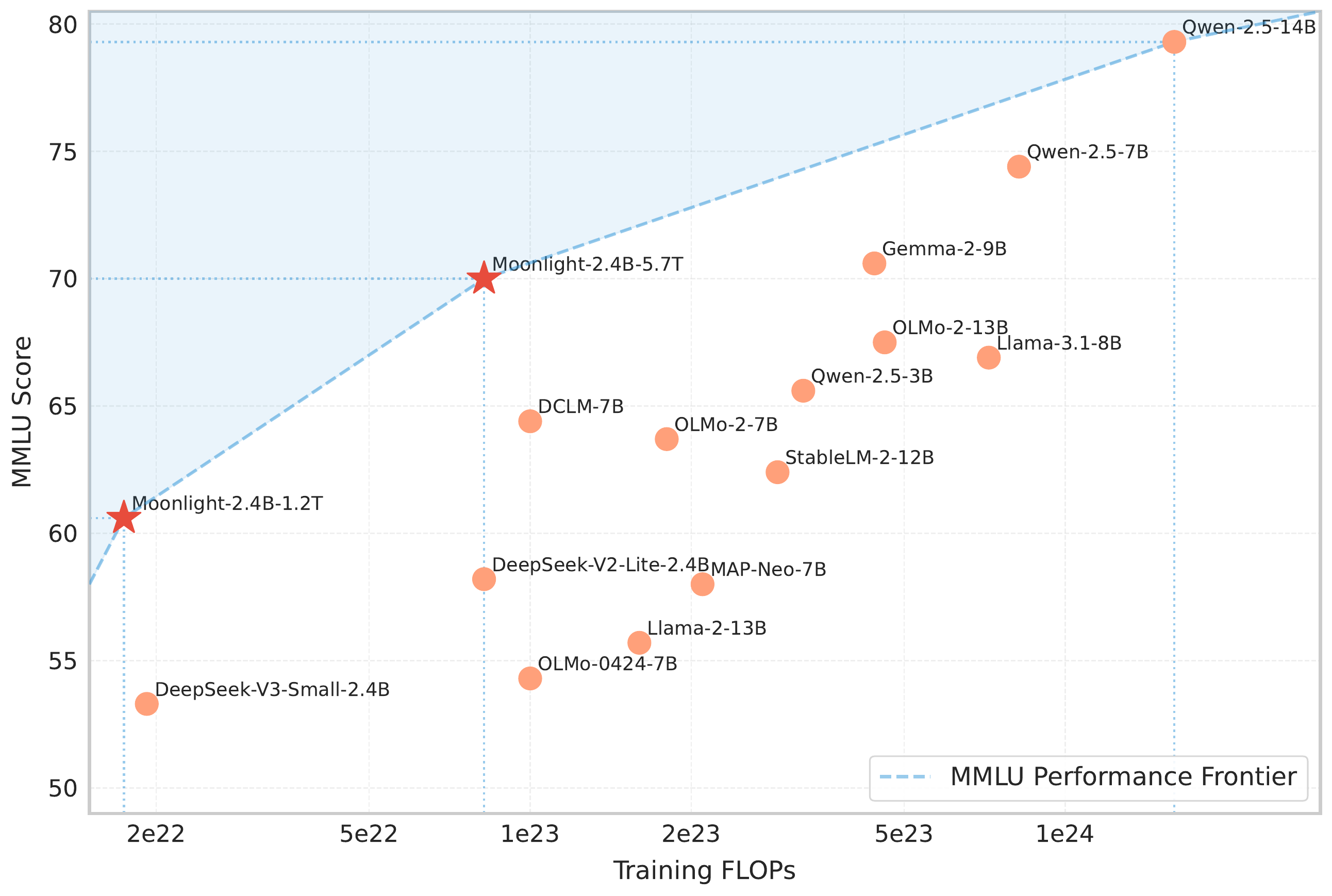
As shown in Table Table 5, Moonlight outperforms models with similar architectures trained with an equivalent number of tokens. Even when compared to dense models trained on substantially larger datasets, Moonlight maintains competitive performance. Detailed comparisons can be found in the appendix. The performance of Moonlight is further compared with other well-known language models on MMLU and GSM8k, as illustrated in Figure Figure 1 and appendix. Notably, Moonlight lies on the Pareto frontier of model performance versus training budget, outperforming many other models across various sizes.
如 表5 所示,Moonlight 优于使用等量 token 训练的类似架构模型。 即使与在大得多的数据集上训练的稠密模型相比,Moonlight 仍保持有竞争力的性能。 详细比较见附录。 Moonlight 在 MMLU 和 GSM8k 上的表现还进一步与其他知名语言模型比较,如 图1 和附录所示。 值得注意的是,Moonlight 位于模型性能与训练预算的 Pareto 前沿,在多种规模上优于许多其他模型。
3.4 Dynamics of Singular Spectrum
In order to validate the intuition that Muon can optimize the weight matrices in more diverse directions, we conducted a spectral analysis of the weight matrices trained with Muon and AdamW. For a weight matrix with singular values
为了验证 Muon 能够在更多样方向上优化权重矩阵的直觉,作者对用 Muon 和 AdamW 训练的权重矩阵进行了谱分析。 对于奇异值为
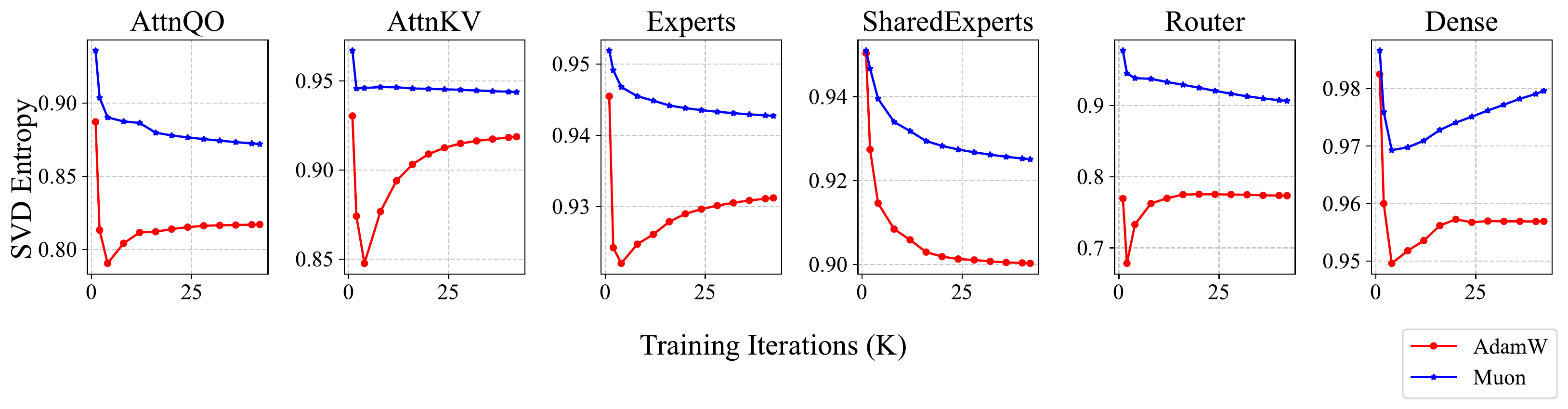
As shown in Figure Figure 4, we visualized the average SVD entropy of the weight matrices across different training checkpoints during pretraining with 1.2T tokens. We can see that across all training checkpoints and all groups of weight matrices, the SVD entropy of Muon is higher than that of AdamW, which verifies the intuition that Muon can provide a more diverse spectrum of updates for the weight matrices. This discrepancy is more significant in the router weights for expert selection, which indicates that mixture-of-expert models can benefit more from Muon. Moreover, we visualized the singular value distributions of each weight matrix at the checkpoint trained with 1.2T tokens as demonstrated in the appendix. We find that, for over 90% of the weight matrices, the SVD entropy when optimized by Muon is higher than that of AdamW, providing strong empirical evidence for Muon's superior capability in exploring diverse optimization directions.
如 图4 所示,作者可视化了使用 1.2T token 预训练期间,不同训练检查点上权重矩阵的平均 SVD entropy。 可以看到,在所有训练检查点和所有权重矩阵分组中,Muon 的 SVD entropy 都高于 AdamW,这验证了 Muon 可以为权重矩阵提供更多样更新谱的直觉。 这种差异在用于专家选择的 router 权重中更加显著,这表明混合专家模型可以从 Muon 中获益更多。 此外,作者还可视化了在 1.2T token 检查点处每个权重矩阵的奇异值分布,如附录所示。 作者发现,对于超过 90% 的权重矩阵,使用 Muon 优化时的 SVD entropy 高于 AdamW,这为 Muon 在探索多样优化方向上的更强能力提供了有力经验证据。
3.5 Supervised Finetuning (SFT) with Muon
In this section, we present ablation studies on the Muon optimizer within the standard SFT stage of LLM training. Our findings demonstrate that the benefits introduced by Muon persist during the SFT stage. Specifically, a model that is both Muon-pretrained and Muon-finetuned outperforms others in the ablation studies. However, we also observe that when the SFT optimizer differs from the pretraining optimizer, SFT with Muon does not show a significant advantage over AdamW. This suggests that there is still considerable room for further exploration, which we leave for future work.
在本节中,作者展示了标准 LLM 训练 SFT 阶段中针对 Muon 优化器的消融研究。 作者的发现表明,Muon 带来的收益会延续到 SFT 阶段。 具体而言,同时由 Muon 预训练和 Muon 微调的模型在消融研究中优于其他模型。 然而,作者也观察到,当 SFT 优化器不同于预训练优化器时,使用 Muon 进行 SFT 并不会相较 AdamW 展示出显著优势。 这表明仍有相当大的进一步探索空间,作者将其留待未来工作。
3.5.1 Ablation Studies on the Interchangeability of Pretrain and SFT Optimizers
To further investigate Muon’s potential, we finetuned Moonlight@1.2T and Moonlight-A@1.2T using both the Muon and AdamW optimizers. These models were finetuned for two epochs on the open-source tulu-3-sft-mixture dataset, which contains 4k sequence length data. The learning rate followed a linear decay schedule, starting at
为进一步研究 Muon 的潜力,作者使用 Muon 和 AdamW 优化器分别微调 Moonlight@1.2T 与 Moonlight-A@1.2T。 这些模型在开源 tulu-3-sft-mixture 数据集上微调两个 epoch,该数据集包含 4k 序列长度的数据。 学习率遵循线性衰减日程,从
| Benchmark (Metric) | # Shots | Muon / Muon | AdamW / Muon | Muon / AdamW | AdamW / AdamW |
|---|---|---|---|---|---|
| Pretraining Optimizer | - | Muon | AdamW | Muon | AdamW |
| SFT Optimizer | - | Muon | Muon | AdamW | AdamW |
| MMLU (EM) | 0-shot (CoT) | 55.7 | 55.3 | 50.2 | 52.0 |
| HumanEval (Pass@1) | 0-shot | 57.3 | 53.7 | 52.4 | 53.1 |
| MBPP (Pass@1) | 0-shot | 55.6 | 55.5 | 55.2 | 55.2 |
| GSM8K (EM) | 5-shot | 68.0 | 62.1 | 64.9 | 64.6 |
Column headers show Pretraining Optimizer / SFT Optimizer for Moonlight-1.2T.
3.5.2 SFT with Muon on public pretrained models
We further applied Muon to the supervised fine-tuning (SFT) of a public pretrained model, specifically the Qwen2.5-7B base model, using the open-source tulu-3-sft-mixture dataset. The dataset was packed with an 8k sequence length, and we employed a cosine decay learning rate schedule, starting at
作者进一步将 Muon 应用于公开预训练模型的监督微调(SFT),具体而言是 Qwen2.5-7B base 模型,并使用开源 tulu-3-sft-mixture 数据集。 该数据集被打包为 8k 序列长度,作者采用余弦衰减学习率日程,从
| Benchmark (Metric) | # Shots | Adam-SFT | Muon-SFT |
|---|---|---|---|
| Pretrained Model | - | Qwen2.5-7B | Qwen2.5-7B |
| MMLU (EM) | 0-shot (CoT) | 71.4 | 70.8 |
| HumanEval (Pass@1) | 0-shot | 79.3 | 77.4 |
| MBPP (Pass@1) | 0-shot | 71.9 | 71.6 |
| GSM8K (EM) | 5-shot | 89.8 | 85.8 |
4. Discussions
There are several possible directions for future research that could further explore and expand upon the current findings.
未来研究有若干可能方向,可以进一步探索并扩展当前发现。
Incorporating All Parameters into the Muon Framework. Currently, the Muon optimizer is utilized in conjunction with the Adam optimizer, where certain parameters remain under the purview of Adam optimization. This hybrid approach, while functional, presents an opportunity for improvement. The integration of the optimization of all parameters exclusively within the Muon framework is a topic of significant research interest.
将所有参数纳入 Muon 框架。 目前,Muon 优化器与 Adam 优化器结合使用,其中某些参数仍由 Adam 优化负责。 这种混合方法虽然可用,但也提供了改进机会。 将所有参数的优化完全整合到 Muon 框架中,是一个具有重要研究价值的课题。
Extending Muon to Schatten Norms. The Muon optimizer can be interpreted as the steepest descent method under the spectral norm. Given the broad applicability and versatility of Schatten norms, extending Muon to encompass the general Schatten norm is a promising direction. This extension may unlock additional optimization capabilities and potentially yield superior results compared to the current spectral norm-based implementation.
将 Muon 扩展到 Schatten 范数。 Muon 优化器可以解释为谱范数下的最速下降方法。 鉴于 Schatten 范数具有广泛适用性和多样性,将 Muon 扩展到涵盖一般 Schatten 范数是一个很有前景的方向。 这一扩展可能释放额外的优化能力,并且相较当前基于谱范数的实现,潜在地取得更优结果。
Understanding and Solving the Pretraining-Finetuning Mismatch. A notable phenomenon observed in practice is the suboptimal performance of models pretrained with AdamW when fine-tuned with Muon, and vice versa. This optimizer mismatch presents a significant barrier to effectively leveraging the extensive repository of AdamW-pretrained checkpoints, thereby necessitating a rigorous theoretical investigation. A precise understanding of the underlying mechanisms is essential for devising robust and effective solutions.
理解并解决预训练-微调不匹配。 实践中观察到的一个显著现象是,使用 AdamW 预训练的模型在用 Muon 微调时表现不佳,反过来也一样。 这种优化器不匹配对有效利用大量 AdamW 预训练检查点构成了重要障碍,因此需要严格的理论研究。 精确理解其底层机制,对于设计稳健且有效的解决方案至关重要。
5. Conclusions
In this technical report, we presented a comprehensive study on the scalability of Muon in LLM training. Through systematic analysis and improvements, we successfully applied Muon to a 3B/16B-parameter MoE model trained on 5.7 trillion tokens. Our results demonstrate that Muon can effectively replace AdamW as the standard optimizer for large-scale LLM training, offering significant advantages in both training efficiency and model performance. By open-sourcing our implementation, the Moonlight model, and intermediate training checkpoints, we aim to facilitate further research in scalable optimization techniques and accelerate the development of training methods for LLMs.
在这份技术报告中,作者对 Muon 在 LLM 训练中的可扩展性进行了全面研究。 通过系统分析与改进,作者成功将 Muon 应用于一个在 5.7 万亿 token 上训练的 3B/16B 参数 MoE 模型。 结果表明,Muon 可以有效取代 AdamW,成为大规模 LLM 训练的标准优化器,并在训练效率和模型性能方面提供显著优势。 通过开源实现、Moonlight 模型和中间训练检查点,作者旨在促进可扩展优化技术的进一步研究,并加速 LLM 训练方法的发展。