
Omni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
MemoryAgentAutoresearchUNCUPennUCSCUC BerkeleyCiscoOmni-SimpleMem:由自动研究引导发现的终身多模态智能体记忆
Abstract
AI agents increasingly operate over extended time horizons, yet their ability to retain, organize, and recall multimodal experiences remains a critical bottleneck. Building effective lifelong memory requires navigating a vast design space spanning architecture, retrieval strategies, prompt engineering, and data pipelines; this space is too large and interconnected for manual exploration or traditional AutoML to explore effectively. We deploy an autonomous research pipeline to discover Omni-SimpleMem, a unified multimodal memory framework for lifelong AI agents. Starting from a naive baseline (F1 = 0.117 on LoCoMo), the pipeline autonomously executes
AI 智能体越来越多地在更长时间跨度上运行,但它们保留、组织和回忆多模态经历的能力仍是关键瓶颈。 构建有效的终身记忆需要穿越一个庞大的设计空间,覆盖架构、检索策略、提示工程和数据流水线;这个空间过大且相互关联过强,人工探索或传统 AutoML 都难以有效覆盖。 我们部署一个自主研究流水线来发现 Omni-SimpleMem,这是一个面向终身 AI 智能体的统一多模态记忆框架。 从一个朴素基线(LoCoMo 上 F1 = 0.117)出发,该流水线在两个基准上自主执行约
1. Introduction
Recent advances in large language models have given rise to AI agents capable of tool use, multi-step reasoning, and cross-modal comprehension. These agents interact with users over extended time horizons, accumulating diverse streams of text, images, audio, and video throughout their operation. However, their ability to retain, organize, and recall past experiences remains a critical bottleneck. Building effective lifelong multimodal memory requires navigating a vast design space spanning architectural choices (how to structure storage), retrieval strategies (how to find relevant information), prompt engineering (how to present context to the LLM), and data pipeline configurations (how to ingest and process heterogeneous inputs).
大语言模型的近期进展催生了能够使用工具、进行多步推理和跨模态理解的 AI 智能体。 这些智能体会在长时间跨度上与用户交互,并在运行过程中积累文本、图像、音频和视频等多样化信息流。 然而,它们保留、组织和回忆过往经历的能力仍然是关键瓶颈。 构建有效的终身多模态记忆需要穿越一个庞大的设计空间,覆盖架构选择(如何组织存储)、检索策略(如何找到相关信息)、提示工程(如何向 LLM 呈现上下文)以及数据流水线配置(如何摄取和处理异构输入)。
Existing approaches to agent memory fall into two broad categories, each with notable limitations. The first stores raw inputs and retrieves them via embedding similarity, suffering from storage bloat and retrieval noise as the memory grows. The second introduces structured memory management with explicit operations, but typically operates on text alone, discarding rich visual and auditory signals. Crucially, both categories are products of manual research cycles: a human researcher hypothesizes an improvement, implements it, evaluates on a benchmark, and iterates. A single researcher may explore only a handful of configurations per day, and important interactions between tightly coupled components are easily missed. Traditional AutoML methods can search over predefined numerical hyperparameter spaces, but cannot perform the code comprehension, bug diagnosis, architectural redesign, and cross-component reasoning that account for the largest performance gains in complex systems. As a result, existing memory systems inherit the blind spots of their designers--limitations that a more systematic search could avoid.
现有智能体记忆方法大致分为两类,每一类都有显著局限。 第一类存储原始输入,并通过嵌入相似性检索;随着记忆增长,它们会遭遇存储膨胀和检索噪声。 第二类引入带有显式操作的结构化记忆管理,但通常只处理文本,丢弃了丰富的视觉和听觉信号。 关键的是,这两类方法都是人工研究循环的产物:人类研究者提出改进假设、实现它、在基准上评估,然后迭代。 单个研究者每天可能只能探索少数配置,而紧密耦合组件之间的重要相互作用很容易被遗漏。 传统 AutoML 方法可以在预定义的数值超参数空间中搜索,但无法执行代码理解、错误诊断、架构重设计和跨组件推理,而这些正是复杂系统中最大性能增益的来源。 因此,现有记忆系统继承了其设计者的盲点,也就是更系统化的搜索本可以避免的局限。
Recent work on autonomous scientific discovery has shown that LLM agents can autonomously discover novel algorithms that outperform human-designed baselines, provided the target domain admits well-defined, quantitative evaluation signals. We ask whether this paradigm extends to complex, multi-component AI systems and answer affirmatively. We deploy AutoResearchClaw, a 23-stage autonomous research pipeline, to discover Omni-SimpleMem, a unified multimodal memory framework for lifelong AI agents. Starting from a naive baseline (F1 = 0.117 on LoCoMo), the pipeline autonomously executes
自主科学发现方面的近期工作已经表明,只要目标领域具有定义明确的定量评估信号,LLM 智能体就能够自主发现优于人工设计基线的新算法。 我们追问这一范式是否能扩展到复杂的多组件 AI 系统,并给出肯定回答。 我们部署 AutoResearchClaw,这是一个 23 阶段的自主研究流水线,用来发现 Omni-SimpleMem,即一个面向终身 AI 智能体的统一多模态记忆框架。 从一个朴素基线(LoCoMo 上 F1 = 0.117)出发,该流水线在两个基准上自主执行约
Among the pipeline's most consequential discoveries are three architectural principles that define Omni-SimpleMem. First, selective ingestion: lightweight perceptual encoders measure the information novelty of each incoming signal and discard redundant content before storage, significantly reducing storage requirements. Second, unified representation: all memories, regardless of modality, are represented as Multimodal Atomic Units (MAUs) that separate lightweight metadata from heavy raw data, enabling fast search over compact metadata while preserving full-content access on demand. Third, progressive retrieval: a pyramid mechanism expands information in three stages (summaries, details, raw evidence), each gated by a token budget, backed by a hybrid search strategy combining dense vector retrieval with sparse keyword matching via set-union merging, a strategy autonomously discovered by the pipeline. Our key observation is that multimodal memory is particularly well-suited for autonomous research pipelines due to four properties: immediate scalar evaluation metrics enabling tight optimization loops, modular architecture allowing isolated component modification, fast iteration cycles (1--2 hours per experiment) supporting dozens of hypotheses within days, and version-controlled code modifications allowing failed experiments to be cleanly reverted.
该流水线最重要的发现之一,是定义 Omni-SimpleMem 的三条架构原则。 第一,选择性摄取:轻量级感知编码器衡量每个传入信号的信息新颖性,并在存储前丢弃冗余内容,从而显著降低存储需求。 第二,统一表示:无论模态如何,所有记忆都表示为 Multimodal Atomic Units(MAUs),它们把轻量级元数据与沉重的原始数据分离,使系统能够在紧凑元数据上快速搜索,同时按需保留完整内容访问。 第三,渐进式检索:金字塔机制分三阶段扩展信息(摘要、细节、原始证据),每一阶段都受 token 预算门控,并由一种混合搜索策略支持,该策略通过集合并合并把密集向量检索与稀疏关键词匹配结合起来,也是流水线自主发现的策略。 我们的关键观察是,多模态记忆由于四个性质而特别适合自主研究流水线:即时标量评估指标支持紧密优化循环,模块化架构允许隔离修改组件,快速迭代周期(每次实验 1--2 小时)支持在数天内测试数十个假设,版本控制的代码修改允许干净地回退失败实验。
In summary, our primary contribution is Omni-SimpleMem, a unified multimodal memory framework whose architecture and configuration are discovered through AutoResearchClaw and that achieves state-of-the-art results on both evaluated benchmarks. Beyond the system itself, we provide a comprehensive taxonomy of autonomous discoveries across
总之,我们的主要贡献是 Omni-SimpleMem,这是一个统一的多模态记忆框架,其架构和配置由 AutoResearchClaw 发现,并且在两个评估基准上都达到最先进结果。 除系统本身之外,我们还给出约
2. Related Work
Autonomous Scientific Discovery. The vision of AI-driven research has advanced rapidly. The AI Scientist demonstrated end-to-end paper generation at
自主科学发现。 AI 驱动研究的愿景正在快速推进。 The AI Scientist 展示了在三个机器学习领域中以每篇约
Multimodal Memory Systems. Memory-augmented LLM agents have evolved from text-only systems, including MemGPT with OS-inspired memory hierarchies, Generative Agents with recency-importance-relevance scoring, SimpleMem with efficient lifelong memory, and A-Mem with LLM-directed reorganization, to multimodal architectures. MemVerse combines episodic-semantic memory with multimodal knowledge graphs but requires three LLM calls per ingested item. Mem0 offers dynamic fact extraction with optional graph memory. VisRAG indexes visual pages directly, avoiding text extraction losses. Claude-Mem provides commercial embedding-based dialogue memory. These systems all require extensive manual tuning of retrieval strategies, ingestion pipelines, and prompt configurations, which is precisely the kind of optimization that autonomous research pipelines can accelerate.
多模态记忆系统。 增强记忆的 LLM 智能体已经从纯文本系统演进到多模态架构,包括采用类操作系统记忆层次结构的 MemGPT、带有新近性-重要性-相关性评分的 Generative Agents、具有高效终身记忆的 SimpleMem,以及由 LLM 引导重组的 A-Mem。 MemVerse 将情景-语义记忆与多模态知识图结合起来,但每个摄取条目需要三次 LLM 调用。 Mem0 提供动态事实抽取,并可选配图记忆。 VisRAG 直接索引视觉页面,避免文本抽取损失。 Claude-Mem 提供商业化的基于嵌入的对话记忆。 这些系统都需要对检索策略、摄取流水线和提示配置进行大量人工调优,而这正是自主研究流水线能够加速的优化类型。
Automated Machine Learning. Neural Architecture Search automates model design but operates primarily on well-defined architectural search spaces with differentiable or reinforcement-learning-based objectives. Hyperparameter optimization methods efficiently navigate continuous and categorical spaces, while systems like Auto-sklearn 2.0 automate full ML pipelines including preprocessing and model selection via meta-learning. More recently, LLM-based agents have been applied to ML tasks: MLAgentBench benchmarks LLM agents on ML research tasks involving code modification, demonstrating the potential of language-guided optimization. Our setting differs fundamentally: the "search space" includes not only hyperparameters and architectural choices, but also prompt engineering, data pipeline bug detection and repair, evaluation format alignment, and cross-component interaction diagnosis, all of which require natural language understanding and code modification capabilities beyond traditional AutoML.
自动化机器学习。 神经架构搜索会自动化模型设计,但主要运行在定义清晰的架构搜索空间中,并使用可微目标或基于强化学习的目标。 超参数优化方法能高效穿越连续空间和类别空间,而 Auto-sklearn 2.0 等系统通过元学习自动化完整机器学习流水线,包括预处理和模型选择。 更近期,基于 LLM 的智能体已经被应用到机器学习任务:MLAgentBench 在涉及代码修改的机器学习研究任务上评测 LLM 智能体,展示了语言引导优化的潜力。 我们的设定有根本不同:“搜索空间”不仅包括超参数和架构选择,还包括提示工程、数据流水线错误检测与修复、评估格式对齐以及跨组件相互作用诊断,这些都需要超越传统 AutoML 的自然语言理解和代码修改能力。
3. Autoresearch-Guided Discovery of Omni-SimpleMem
In this section, we describe the autonomous optimization process and the system it produces. We first overview the pipeline (Section 3.1), then present the discovered Omni-SimpleMem architecture (Section 3.2), followed by the benchmark-specific optimization strategy (Section 3.3).
在本节中,我们描述自主优化过程以及它产出的系统。 我们首先概述流水线(第 3.1 节),然后介绍发现得到的 Omni-SimpleMem 架构(第 3.2 节),最后说明面向具体基准的优化策略(第 3.3 节)。
3.1 Pipeline Overview
As discussed in Section 1, the design space of multimodal memory systems is too large and interconnected for manual exploration to cover effectively. To address this, we deploy AutoResearchClaw, a 23-stage autonomous research pipeline, to systematically optimize Omni-SimpleMem. The pipeline receives three inputs: (1) the SimpleMem codebase, a unimodal text-only lifelong memory framework, as a starting point, (2) two benchmark evaluation harnesses with quantitative metrics (F1), and (3) API access to LLM providers. It then enters an iterative loop: at each step, the pipeline analyzes prior results, generates a hypothesis for improvement, implements the change in code, evaluates on a benchmark, and decides whether to proceed (metric improved by
如第 1 节所讨论,多模态记忆系统的设计空间过大且相互关联过强,人工探索难以有效覆盖。 为解决这一问题,我们部署 AutoResearchClaw,这是一个 23 阶段的自主研究流水线,用来系统性优化 Omni-SimpleMem。 该流水线接收三类输入:(1) SimpleMem 代码库,它是一个单模态纯文本终身记忆框架,作为起点;(2) 两个带有定量指标(F1)的基准评测框架;(3) 对 LLM 提供方的 API 访问。 随后它进入一个迭代循环:在每一步,流水线分析此前结果,生成改进假设,在代码中实现修改,在基准上评估,并决定是否继续(指标提升
3.2 The Discovered Architecture
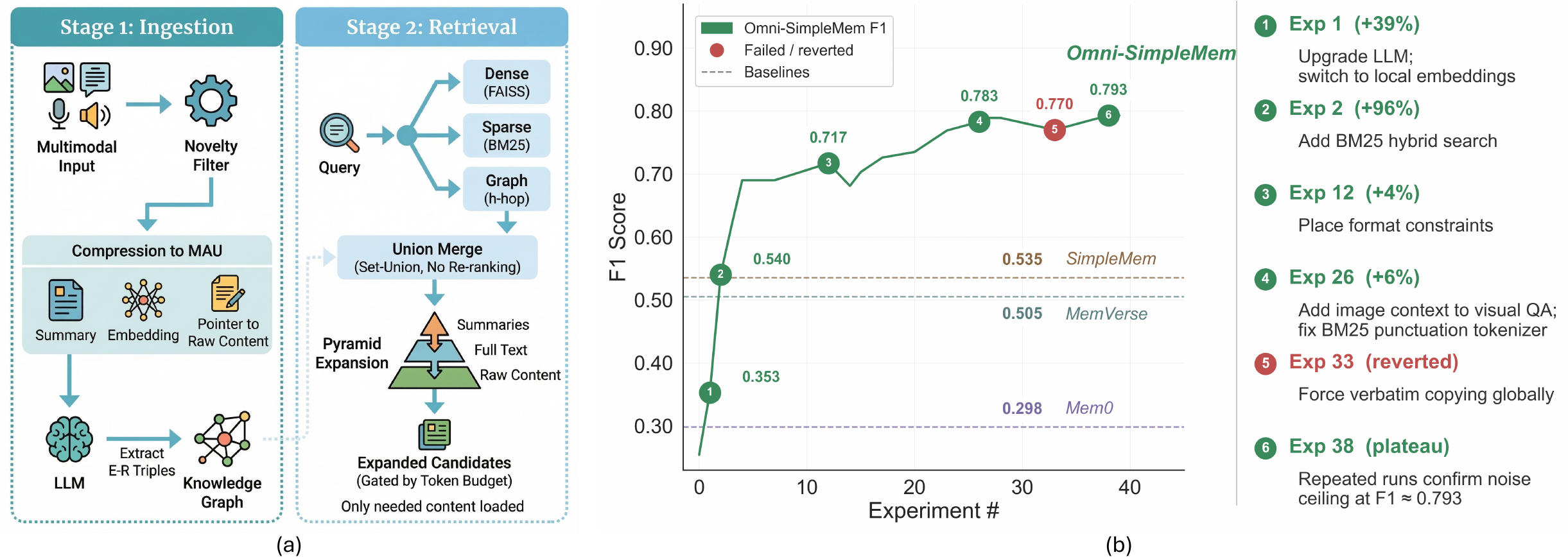
The pipeline takes SimpleMem, a unimodal text-only lifelong memory framework, as its starting point. We provide AutoResearchClaw with the SimpleMem codebase and instruct it to extend the system from text-only memory to full multimodal support, autonomously designing the necessary architectural components for ingesting, storing, and retrieving heterogeneous signals (text, images, audio, video). Through iterative experimentation, the pipeline converges to an architecture organized around three principles: selective ingestion, progressive retrieval, and structured knowledge (Figure 2).
该流水线以 SimpleMem 作为起点,SimpleMem 是一个单模态纯文本终身记忆框架。 我们向 AutoResearchClaw 提供 SimpleMem 代码库,并指示它将系统从纯文本记忆扩展到完整多模态支持,自主设计摄取、存储和检索异构信号(文本、图像、音频、视频)所需的架构组件。 通过迭代实验,该流水线收敛到一种围绕三条原则组织的架构:选择性摄取、渐进式检索和结构化知识(图2)。
3.2.1 Selective Ingestion
The first principle is selective ingestion: the system first filters redundant inputs, then encapsulates the retained signals into a unified multimodal representation.
第一条原则是选择性摄取:系统首先过滤冗余输入,然后把保留下来的信号封装为统一的多模态表示。
Novelty-Based Filtering. Before any data enters the memory store, lightweight perceptual encoders assess the novelty of incoming information and discard redundant content. For vision, CLIP embeddings are compared across consecutive frames to detect scene changes; for audio, VAD speech probability gates retention to reject silence; for text, Jaccard overlap with recent summaries filters near-duplicates. This filtering significantly reduces storage requirements without losing semantic content.
基于新颖性的过滤。 在任何数据进入记忆存储之前,轻量级感知编码器会评估传入信息的新颖性并丢弃冗余内容。 对于视觉,系统比较连续帧之间的 CLIP 嵌入以检测场景变化;对于音频,VAD 语音概率门控保留过程以拒绝静音;对于文本,近期摘要的 Jaccard 重叠用于过滤近重复内容。 这种过滤在不丢失语义内容的情况下显著降低了存储需求。
Multimodal Atomic Units. Signals that pass the novelty filter are encapsulated as Multimodal Atomic Units (MAUs),
多模态原子单元。 通过新颖性过滤的信号会被封装为 Multimodal Atomic Units(MAUs),
3.2.2 Progressive Retrieval with Hybrid Search
Once memories are ingested and stored as MAUs, the next challenge is how to retrieve them efficiently at query time. The second principle is progressive retrieval: rather than loading all retrieved content into the LLM context at once, Omni-SimpleMem expands information in stages under explicit token budgets.
一旦记忆被摄取并存储为 MAU,下一个挑战就是如何在查询时高效检索它们。 第二条原则是渐进式检索:Omni-SimpleMem 不会一次性把所有检索内容加载到 LLM 上下文中,而是在显式 token 预算下分阶段扩展信息。
Hybrid Dense-Sparse Search. Given a user query
混合密集-稀疏搜索。 给定用户查询
Pyramid Retrieval. The hybrid search above produces a candidate set
金字塔检索。 上述混合搜索产生候选集合
3.2.3 Knowledge Graph-Augmented Retrieval
While hybrid search and pyramid retrieval handle queries that can be answered from individual MAUs, many real-world queries require reasoning over multiple connected facts (e.g., "What gift did I give to the person I met at the conference in March?"). The third principle is therefore structured knowledge: Omni-SimpleMem maintains a knowledge graph
虽然混合搜索和金字塔检索可以处理能由单个 MAU 回答的查询,但许多真实世界查询需要对多个相互连接的事实进行推理(例如,“我给三月在会议上遇到的那个人送了什么礼物?”)。 因此,第三条原则是结构化知识:Omni-SimpleMem 维护一个知识图
During MAU creation, an LLM extracts entities and directed relations from each summary, producing entity-relation triples. Each entity carries a type label from 7 categories (Person, Location, Event, Concept, Time, Organization, Object) and is linked back to its source MAU. As new MAUs are ingested, the same real-world entity may appear under different surface forms (e.g., "Dr. Smith" vs. "John Smith"). To prevent node fragmentation, entity resolution merges entities whose hybrid similarity, combining cosine similarity over name embeddings with Jaro-Winkler string similarity, exceeds a threshold.
在创建 MAU 时,LLM 会从每个摘要中抽取实体和有向关系,产出实体-关系三元组。 每个实体都带有来自 7 个类别(人物、地点、事件、概念、时间、组织、对象)的类型标签,并链接回其来源 MAU。 随着新 MAU 被摄取,同一个真实世界实体可能以不同表面形式出现(例如,“Dr. Smith”和“John Smith”)。 为防止节点碎片化,实体消解会合并混合相似度超过阈值的实体,该混合相似度结合了名称嵌入的余弦相似度与 Jaro-Winkler 字符串相似度。
At query time, the system identifies seed entities
在查询时,系统识别查询中提到的种子实体
3.3 Benchmark-Specific Optimization
Having described the multimodal architecture that the pipeline discovers from SimpleMem, we now turn to how it optimizes this architecture for each target benchmark. The pipeline employs a two-phase strategy: rapid iteration on a small training subset, followed by evaluation on the held-out test set.
在描述了流水线从 SimpleMem 发现的多模态架构之后,我们现在转向它如何针对每个目标基准优化该架构。 该流水线采用两阶段策略:先在小训练子集上快速迭代,然后在留出测试集上评估。
Development subset for fast iteration. For each benchmark, the pipeline selects a small representative subset for rapid experimentation during the optimization loop. On LoCoMo, a small subset of conversations is used for iterative development, enabling each experiment to complete in under 2 hours. On Mem-Gallery, a small subset of datasets is used, with each experiment completing in minutes. This design enables the pipeline to explore dozens of hypotheses within days. After the optimization trajectory converges, the final configuration is evaluated on the complete benchmark to ensure generalization and to maintain consistency with the evaluation protocols used by prior memory systems.
用于快速迭代的开发子集。 对于每个基准,流水线都会选择一个小型代表性子集,用于在优化循环中快速实验。 在 LoCoMo 上,系统使用一个小型对话子集进行迭代开发,使每个实验能在 2 小时内完成。 在 Mem-Gallery 上,系统使用一个小型数据集子集,每个实验可在数分钟内完成。 这种设计使流水线能够在数天内探索数十个假设。 在优化轨迹收敛后,最终配置会在完整基准上评估,以确保泛化,并保持与先前记忆系统所用评估协议的一致性。
Iterative diagnosis and repair. During each optimization cycle, the pipeline autonomously diagnoses and repairs failures at two levels. At the execution level, when an experiment fails or produces unexpected outputs, a self-healing module classifies the error (API error, dependency error, runtime exception, output format mismatch) and generates a targeted fix. For example, when the embedding service returned 403 errors due to an expired API key, the module detected the authentication failure pattern and switched to a local sentence-transformer backend without manual intervention. At the semantic level, when experiments succeed but produce unexpectedly poor metrics, the pipeline performs deeper analysis.
迭代诊断与修复。 在每个优化周期中,流水线会在两个层级自主诊断和修复失败。 在执行层级,当实验失败或产出异常输出时,自愈模块会对错误进行分类(API 错误、依赖错误、运行时异常、输出格式不匹配),并生成定向修复。 例如,当嵌入服务由于 API key 过期返回 403 错误时,该模块检测到认证失败模式,并在没有人工介入的情况下切换到本地 sentence-transformer 后端。 在语义层级,当实验成功运行但产生异常糟糕的指标时,流水线会执行更深入分析。
4. Experiments
We evaluate Omni-SimpleMem along two dimensions: (1) the autonomous optimization process, specifically whether the pipeline discovers meaningful improvements across diverse benchmarks, and (2) final system quality, examining whether the discovered architecture achieves state-of-the-art results and whether individual components contribute meaningfully.
我们从两个维度评估 Omni-SimpleMem:(1) 自主优化过程,尤其是流水线是否能在多样基准上发现有意义的改进;(2) 最终系统质量,考察发现得到的架构是否达到最先进结果,以及各个组件是否具有实质贡献。
4.1 Experimental Setup
Benchmarks. We evaluate on two benchmarks spanning complementary types of memory-dependent reasoning: LoCoMo (1,986 QA pairs across multi-session dialogues, token-level F1) and Mem-Gallery (1,711 QA pairs from 240 multimodal dialogues with 1,003 grounded images, F1). Detailed benchmark descriptions are provided in the appendix.
基准。 我们在两个基准上评估,它们覆盖互补类型的依赖记忆推理:LoCoMo(跨多会话对话的 1,986 个 QA 对,token 级 F1)和 Mem-Gallery(来自 240 个多模态对话、含 1,003 张落地图像的 1,711 个 QA 对,F1)。 详细基准描述见附录。
Baselines. We compare against six memory systems representing diverse design philosophies: MemVerse (hierarchical episodic-semantic memory with multimodal knowledge graph), Mem0 (dynamic fact extraction with optional graph memory), Claude-Mem (commercial embedding-based dialogue memory), A-MEM (LLM-directed memory reorganization), MemGPT (OS-inspired memory hierarchies), and SimpleMem (efficient lifelong memory with atomization and adaptive pruning). All are evaluated under identical splits and protocols.
基线。 我们与六个代表不同设计理念的记忆系统比较:MemVerse(带有多模态知识图的层级情景-语义记忆)、Mem0(动态事实抽取,可选图记忆)、Claude-Mem(商业化的基于嵌入的对话记忆)、A-MEM(由 LLM 引导的记忆重组)、MemGPT(受操作系统启发的记忆层次结构)和 SimpleMem(带有原子化与自适应剪枝的高效终身记忆)。 所有系统都在相同划分和协议下评估。
Implementation. Dense retrieval uses FAISS with all-MiniLM-L6-v2 embeddings (384d); sparse retrieval uses BM25; visual novelty filtering uses frozen CLIP ViT-B/32. Knowledge graph extraction uses GPT-4o in JSON mode. Default configuration: top-
实现。 密集检索使用 FAISS 和 all-MiniLM-L6-v2 嵌入(384d);稀疏检索使用 BM25;视觉新颖性过滤使用冻结的 CLIP ViT-B/32。 知识图抽取使用 JSON 模式下的 GPT-4o。 默认配置为:top-
4.2 Optimization Trajectories
| Backbone | Method | LoCoMo | Mem-Gallery | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MH | SH | Tmp | Open | Adv | All | F1 | EM | B | B-1 | B-2 | ||
| GPT-4o | MemVerse | 0.260 | 0.157 | 0.196 | 0.192 | 0.944 | 0.365 | 0.505 | 0.330 | 0.270 | 0.440 | 0.355 |
| Mem0 | 0.309 | 0.156 | 0.217 | 0.295 | 0.857 | 0.397 | 0.298 | 0.192 | 0.182 | 0.268 | 0.224 | |
| Claude-Mem | 0.294 | 0.153 | 0.167 | 0.243 | 0.915 | 0.383 | 0.210 | 0.148 | 0.148 | 0.194 | 0.170 | |
| A-MEM | 0.295 | 0.174 | 0.200 | 0.266 | 0.898 | 0.394 | 0.370 | 0.252 | 0.240 | 0.332 | 0.285 | |
| MemGPT | 0.305 | 0.188 | 0.246 | 0.305 | 0.843 | 0.404 | 0.435 | 0.298 | 0.275 | 0.390 | 0.335 | |
| SimpleMem | 0.318 | 0.195 | 0.235 | 0.308 | 0.802 | 0.432 | 0.535 | 0.348 | 0.310 | 0.468 | 0.390 | |
| Omni-SimpleMem | 0.556 | 0.365 | 0.255 | 0.641 | 0.835 | 0.598 | 0.797 | 0.449 | 0.366 | 0.627 | 0.505 | |
| GPT-4o-mini | MemVerse | 0.147 | 0.074 | 0.106 | 0.093 | 0.747 | 0.290 | 0.450 | 0.295 | 0.248 | 0.395 | 0.330 |
| Mem0 | 0.285 | 0.112 | 0.179 | 0.297 | 0.761 | 0.364 | 0.291 | 0.188 | 0.185 | 0.265 | 0.223 | |
| Claude-Mem | 0.245 | 0.102 | 0.122 | 0.215 | 0.845 | 0.338 | 0.272 | 0.175 | 0.172 | 0.245 | 0.210 | |
| A-MEM | 0.278 | 0.091 | 0.163 | 0.260 | 0.823 | 0.357 | 0.330 | 0.222 | 0.205 | 0.298 | 0.252 | |
| MemGPT | 0.283 | 0.113 | 0.182 | 0.289 | 0.776 | 0.364 | 0.398 | 0.262 | 0.242 | 0.355 | 0.298 | |
| SimpleMem | 0.300 | 0.128 | 0.178 | 0.312 | 0.891 | 0.404 | 0.498 | 0.318 | 0.290 | 0.435 | 0.368 | |
| Omni-SimpleMem | 0.544 | 0.196 | 0.177 | 0.588 | 0.779 | 0.519 | 0.749 | 0.403 | 0.334 | 0.583 | 0.465 | |
| GPT-4.1-nano | MemVerse | 0.146 | 0.061 | 0.169 | 0.115 | 0.711 | 0.256 | 0.470 | 0.308 | 0.255 | 0.410 | 0.340 |
| Mem0 | 0.290 | 0.134 | 0.194 | 0.277 | 0.537 | 0.310 | 0.268 | 0.176 | 0.156 | 0.238 | 0.199 | |
| Claude-Mem | 0.087 | 0.029 | 0.119 | 0.047 | 0.705 | 0.246 | 0.303 | 0.194 | 0.172 | 0.268 | 0.223 | |
| A-MEM | 0.045 | 0.016 | 0.142 | 0.050 | 0.747 | 0.216 | 0.365 | 0.242 | 0.225 | 0.325 | 0.275 | |
| MemGPT | 0.287 | 0.130 | 0.234 | 0.279 | 0.556 | 0.316 | 0.360 | 0.238 | 0.218 | 0.318 | 0.268 | |
| SimpleMem | 0.298 | 0.145 | 0.210 | 0.285 | 0.648 | 0.342 | 0.518 | 0.338 | 0.300 | 0.452 | 0.380 | |
| Omni-SimpleMem | 0.477 | 0.216 | 0.244 | 0.583 | 0.722 | 0.492 | 0.780 | 0.430 | 0.353 | 0.610 | 0.488 | |
| GPT-5.1 | MemVerse | 0.287 | 0.173 | 0.277 | 0.297 | 0.780 | 0.383 | 0.478 | 0.312 | 0.262 | 0.418 | 0.345 |
| Mem0 | 0.292 | 0.160 | 0.261 | 0.298 | 0.819 | 0.390 | 0.270 | 0.175 | 0.157 | 0.240 | 0.200 | |
| Claude-Mem | 0.289 | 0.171 | 0.264 | 0.292 | 0.814 | 0.388 | 0.305 | 0.203 | 0.188 | 0.279 | 0.230 | |
| A-MEM | 0.287 | 0.164 | 0.246 | 0.284 | 0.826 | 0.385 | 0.408 | 0.268 | 0.242 | 0.365 | 0.302 | |
| MemGPT | 0.288 | 0.165 | 0.249 | 0.294 | 0.806 | 0.385 | 0.425 | 0.275 | 0.250 | 0.378 | 0.315 | |
| SimpleMem | 0.305 | 0.178 | 0.272 | 0.305 | 0.807 | 0.418 | 0.538 | 0.350 | 0.312 | 0.470 | 0.395 | |
| Omni-SimpleMem | 0.598 | 0.367 | 0.307 | 0.676 | 0.747 | 0.613 | 0.810 | 0.460 | 0.374 | 0.639 | 0.515 | |
| GPT-5-nano | MemVerse | 0.208 | 0.203 | 0.168 | 0.252 | 0.741 | 0.366 | 0.478 | 0.315 | 0.262 | 0.420 | 0.345 |
| Mem0 | 0.264 | 0.143 | 0.237 | 0.270 | 0.737 | 0.352 | 0.283 | 0.176 | 0.165 | 0.250 | 0.210 | |
| Claude-Mem | 0.091 | 0.063 | 0.092 | 0.088 | 0.736 | 0.275 | 0.350 | 0.249 | 0.217 | 0.315 | 0.264 | |
| A-MEM | 0.260 | 0.149 | 0.223 | 0.257 | 0.745 | 0.348 | 0.505 | 0.332 | 0.290 | 0.445 | 0.368 | |
| MemGPT | 0.267 | 0.151 | 0.226 | 0.271 | 0.744 | 0.355 | 0.388 | 0.255 | 0.230 | 0.345 | 0.288 | |
| SimpleMem | 0.278 | 0.200 | 0.245 | 0.282 | 0.824 | 0.388 | 0.522 | 0.340 | 0.302 | 0.458 | 0.385 | |
| Omni-SimpleMem | 0.357 | 0.371 | 0.253 | 0.561 | 0.719 | 0.522 | 0.787 | 0.437 | 0.357 | 0.617 | 0.494 | |
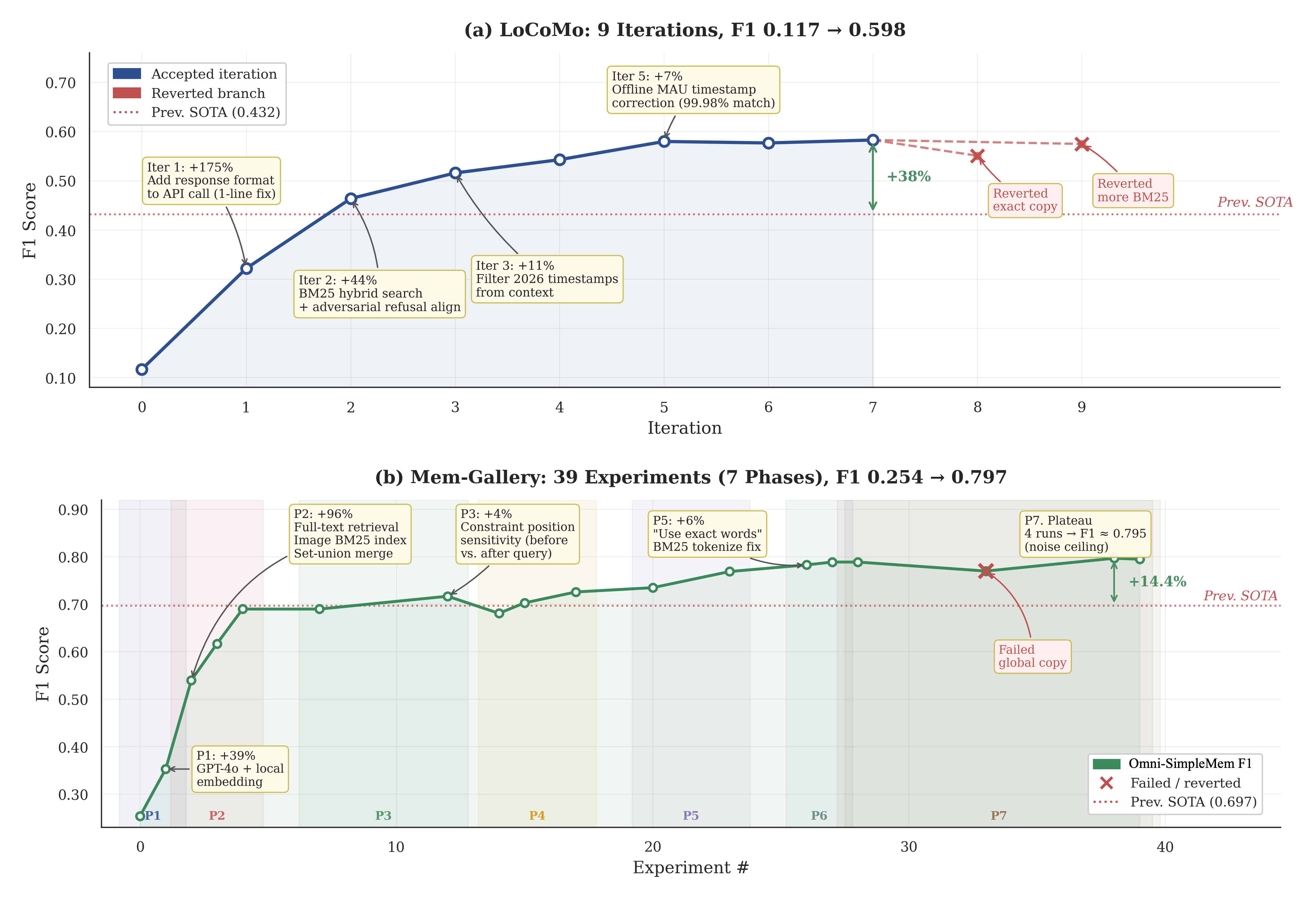
Figure 3 visualizes the optimization trajectories. The pipeline completed
图3 展示了优化轨迹。 该流水线在两个基准上用约
LoCoMo (9 iterations, F1: 0.117 response_format parameter, a one-line bug causing 9
LoCoMo(9 次迭代,F1:0.117 response_format 参数,这是一个一行错误,会导致输出冗长度增加 9
Mem-Gallery (39 experiments, F1: 0.254
Mem-Gallery(39 次实验,F1:0.254
4.3 Main Results
To contextualize these results against existing memory systems, we conduct a controlled comparison of Omni-SimpleMem against six baselines across five LLM backbones (GPT-4o, GPT-4o-mini, GPT-4.1-nano, GPT-5.1, and GPT-5-nano). Table 1 reports per-category F1 on LoCoMo and five evaluation metrics on Mem-Gallery across all backbones.
为了将这些结果置于现有记忆系统的背景中,我们在五个 LLM backbone(GPT-4o、GPT-4o-mini、GPT-4.1-nano、GPT-5.1 和 GPT-5-nano)上,对 Omni-SimpleMem 与六个基线进行了受控比较。 表1 报告了所有 backbone 上 LoCoMo 的逐类别 F1,以及 Mem-Gallery 的五个评估指标。
On LoCoMo, Omni-SimpleMem achieves the highest overall F1 across all backbones, ranging from 0.492 (GPT-4.1-nano) to 0.613 (GPT-5.1), substantially outperforming SimpleMem (0.342--0.432), the current state-of-the-art on LoCoMo. Omni-SimpleMem dominates on multi-hop, single-hop, and open-domain categories, with particularly large margins on open-domain questions.
在 LoCoMo 上,Omni-SimpleMem 在所有 backbone 上都取得最高 overall F1,范围从 0.492(GPT-4.1-nano)到 0.613(GPT-5.1),显著优于当前 LoCoMo 最先进系统 SimpleMem(0.342--0.432)。 Omni-SimpleMem 在 multi-hop、single-hop 和 open-domain 类别上占据主导,尤其是在 open-domain 问题上优势很大。
On Mem-Gallery, Omni-SimpleMem achieves F1 ranging from 0.749 to 0.810, consistently outperforming all memory baselines by a wide margin. SimpleMem is again the strongest baseline (F1 up to 0.538 with GPT-5.1), but still trails Omni-SimpleMem by over 25 percentage points. These patterns confirm that Omni-SimpleMem's gains come from its architectural design (hybrid search, pyramid retrieval, knowledge graph augmentation) rather than from a single dominant component.
在 Mem-Gallery 上,Omni-SimpleMem 的 F1 位于 0.749 到 0.810 之间,始终以较大幅度优于所有记忆基线。 SimpleMem 再次是最强基线(使用 GPT-5.1 时 F1 最高 0.538),但仍落后 Omni-SimpleMem 超过 25 个百分点。 这些模式确认,Omni-SimpleMem 的增益来自其架构设计(混合搜索、金字塔检索、知识图增强),而不是来自某一个占主导的单一组件。
4.4 Analysis
4.4.1 Ablation Studies
| Component Removed | Rel. | |
|---|---|---|
| w/o Pyramid Expansion | −10.2 | −17% |
| w/o BM25 Hybrid | −8.5 | −14% |
| w/o LLM Summarization | −7.3 | −12% |
Reduced top- | −4.2 | −7% |
| w/o Metadata Context | −1.4 | −2% |
Table 2 presents an ablation study on LoCoMo that validates key design choices discovered by the pipeline. Specifically, we remove individual components and report the mean
表2 给出了 LoCoMo 上的消融研究,验证了流水线发现的关键设计选择。 具体而言,我们移除单个组件,并报告 4 个 LLM backbone 上的平均
4.4.2 Efficiency
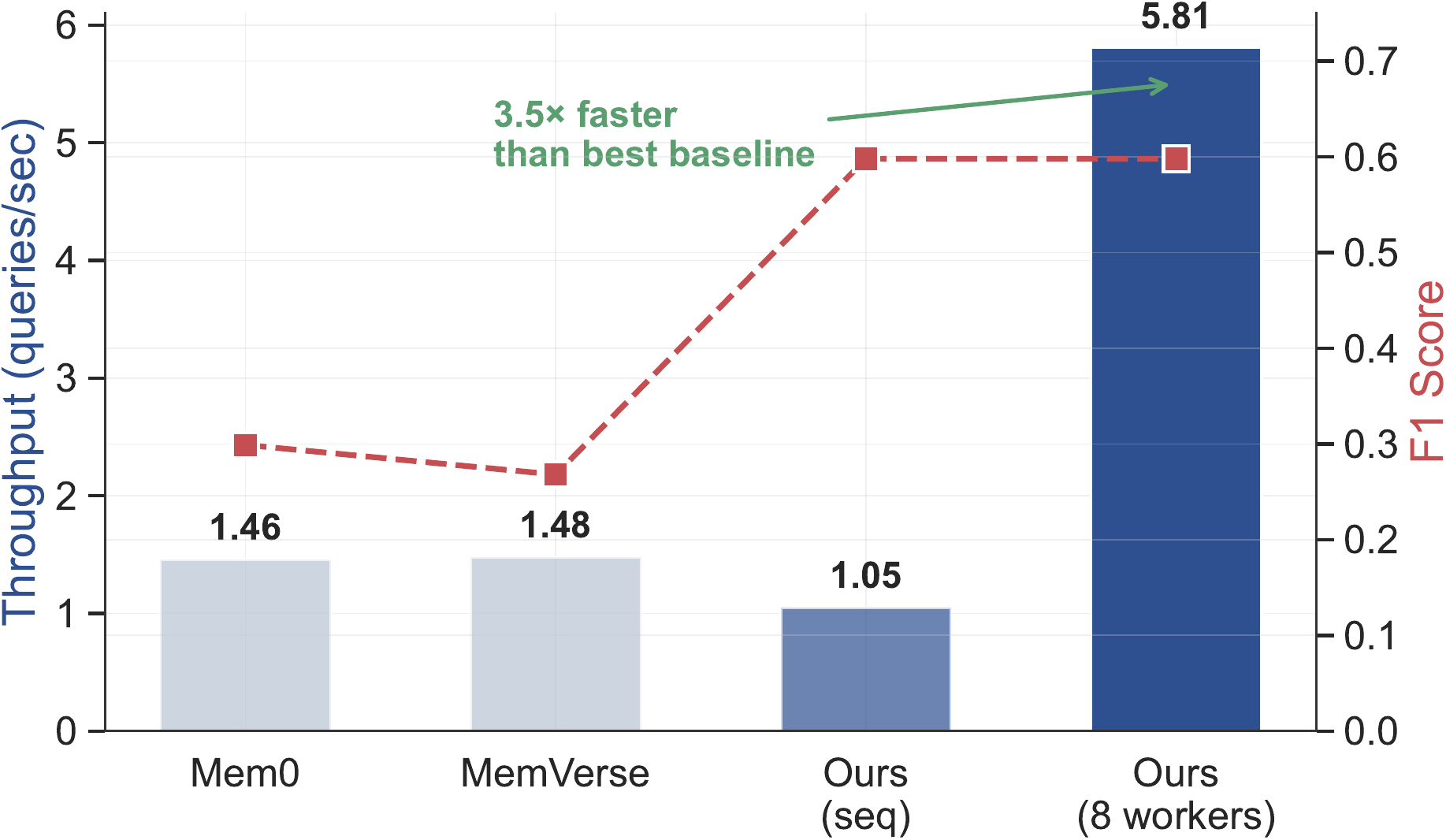
| Method | q/s | Ret. | Gen. |
|---|---|---|---|
| SimpleMem | 1.68 | 45 | 550 |
| MemVerse | 1.48 | 70 | 596 |
| Mem0 | 1.46 | 18 | 665 |
| Omni-SimpleMem (w=1) | 1.05 | 118 | 846 |
| Omni-SimpleMem (w=8) | 5.81 | 461 | 821 |
Omni-SimpleMem achieves 5.81 queries/sec with 8 parallel workers (3.5
Omni-SimpleMem 使用 8 个并行 worker 时达到 5.81 queries/sec(比最快基线快 3.5
4.4.3 Case Study: Multi-Hop Retrieval
We illustrate Omni-SimpleMem's retrieval pipeline on a real multi-hop query from LoCoMo that requires synthesizing facts across separate conversation sessions. The query asks: "What subject have Caroline and Melanie both painted?" The gold answer is "sunsets," but answering correctly requires retrieving each person's painting history from different sessions and identifying the overlap.
我们用 LoCoMo 中一个真实的 multi-hop 查询来说明 Omni-SimpleMem 的检索流水线,该查询需要综合不同对话会话中的事实。 查询是:“Caroline 和 Melanie 都画过什么主题?” 标准答案是“sunsets”,但正确回答需要从不同会话中检索每个人的绘画历史,并识别二者的重叠。
Hybrid search. Dense retrieval returns MAUs mentioning Caroline's paintings (e.g., "Caroline painted a sunset") and Melanie's art projects (e.g., "Mel and her kids painted a sunset with a tree"), but these appear in separate sessions with different surrounding context. BM25 recovers additional MAUs containing the keyword "paint" that rank lower in dense results. Set-union merging preserves the dense ordering and appends BM25-only matches.
混合搜索。 密集检索返回提到 Caroline 画作的 MAU(例如,“Caroline painted a sunset”)以及 Melanie 艺术项目的 MAU(例如,“Mel and her kids painted a sunset with a tree”),但它们出现在不同会话中,周围上下文也不同。 BM25 找回了包含关键词 “paint” 的额外 MAU,这些条目在密集结果中的排名较低。 集合并合并保留密集排序,并附加 BM25 独有匹配。
Knowledge graph expansion. The query processor extracts seed entities Caroline (Person) and Melanie (Person). Neighborhood expansion links both entities to painting (Concept) and sunset (Concept) through separate relation paths, surfacing MAUs that mention each person's painting activities even when the surface text does not co-mention both names.
知识图扩展。 查询处理器抽取种子实体 Caroline(Person)和 Melanie(Person)。 邻域扩展通过不同关系路径把两个实体都连接到 painting(Concept)和 sunset(Concept),从而浮现提到每个人绘画活动的 MAU,即便表层文本没有同时提到两个名字。
Pyramid retrieval and answer. Level 1 summaries from both relation paths are loaded; their similarity scores exceed
金字塔检索与答案。 两条关系路径的 Level 1 摘要被加载;它们的相似度分数超过
5. Conclusion
We have presented Omni-SimpleMem, a unified multimodal memory framework whose architecture and configuration are discovered through AutoResearchClaw, an autonomous research pipeline. Starting from a naive baseline, the pipeline autonomously executed
我们提出了 Omni-SimpleMem,这是一个统一的多模态记忆框架,其架构和配置通过自主研究流水线 AutoResearchClaw 发现。 从一个朴素基线出发,该流水线在约