
Mem-α:通过强化学习学习记忆构建
Abstract
Large language model (LLM) agents are constrained by limited context windows, necessitating external memory systems for long-term information understanding. Current memory-augmented agents typically depend on pre-defined instructions and tools for memory updates. However, language models may lack the ability to determine which information to store, how to structure it, and when to update it—especially as memory systems become more complex. This results in suboptimal memory construction and information loss. To this end, we propose Mem-α, a reinforcement learning framework that trains agents to effectively manage complex memory systems through interaction and feedback. We also construct a specialized training dataset spanning diverse multi-turn interaction patterns paired with comprehensive evaluation questions designed to teach effective memory management. During training, agents process sequential information chunks, learn to extract, store, and update the memory system. The reward signal derives from downstream question-answering accuracy over the full interaction history, directly optimizing for memory construction. To illustrate the effectiveness of our training framework, we design a memory architecture comprising core, episodic, and semantic components, equipped with multiple tools for memory operations. Empirical evaluation demonstrates that Mem-α achieves significant improvements over existing memory-augmented agent baselines. Despite being trained exclusively on instances with a maximum length of 30k tokens, our agents exhibit remarkable generalization to sequences exceeding 400k tokens—over 13× the training length, highlighting the robustness of Mem-α.
大型语言模型(LLM)智能体受到有限上下文窗口的约束,因此需要外部记忆系统来支持长期信息理解。 当前的记忆增强智能体通常依赖预定义指令和工具来进行记忆更新。 然而,语言模型可能缺乏判断“哪些信息应该存储、应该如何组织、应该何时更新”的能力,尤其是当记忆系统变得更加复杂时,这一问题会更加明显,最终导致记忆构建效果不佳和信息损失。 为此,作者提出 Mem-α,这是一个强化学习框架,通过交互和反馈训练智能体有效管理复杂记忆系统。 作者还构建了一个专门的训练数据集,覆盖多样化的多轮交互模式,并配套设计了全面的评估问题,用来教授有效的记忆管理。 在训练过程中,智能体会处理连续的信息块,学习如何提取、存储和更新记忆系统。 奖励信号来自基于完整交互历史的下游问答准确率,从而直接优化记忆构建。 为了展示训练框架的有效性,作者设计了一种由核心记忆、情节记忆和语义记忆组成的记忆架构,并为记忆操作配备了多种工具。 实验评估表明,Mem-α 相比现有记忆增强智能体基线取得了显著提升。 尽管训练时仅使用最大长度为 30k token 的样本,智能体仍能泛化到超过 400k token 的序列,也就是训练长度的 13 倍以上,这体现了 Mem-α 的鲁棒性。
1. Introduction
Large language model (LLM) agents are fundamentally constrained by limited context windows when processing long information streams, leading to the development of memory-augmented agents. These agents are equipped with persistent, updatable memory systems that actively store long-term information and manage the context seen by the language model. Most existing memory systems rely entirely on pre-defined instructions and fixed tool sets without any training to optimize memory construction, such as Mem0, MemGPT, and MIRIX. These memory systems provide agents with various memory update tools, ranging from simple fact extraction to complex multi-component memory architectures, but expect models to utilize these tools effectively out-of-the-box. However, models lack the inherent ability to determine what to store, how to structure, and when to update different memory components. Although complicated system prompts can partially mitigate this issue, manual adjustment of system prompts is challenging to address all scenarios. For small language models with weak instruction-following abilities, complicated instructions may even confuse the model.
大型语言模型智能体在处理长信息流时,从根本上受到有限上下文窗口的限制,因此研究者开始发展记忆增强智能体。 这类智能体配备持久且可更新的记忆系统,用来主动存储长期信息,并管理语言模型实际看到的上下文。 现有大多数记忆系统完全依赖预定义指令和固定工具集,并没有通过训练来优化记忆构建,例如 Mem0、MemGPT 和 MIRIX。 这些系统会为智能体提供各种记忆更新工具,从简单的事实抽取到复杂的多组件记忆架构都有,但它们默认模型可以开箱即用地使用这些工具。 然而,模型本身并不天然具备判断“应该存什么、如何组织、何时更新不同记忆组件”的能力。 虽然复杂系统提示可以部分缓解这一问题,但手工调提示很难覆盖所有场景;对于指令遵循能力较弱的小模型,复杂指令甚至可能让模型更加困惑。
To address this challenge, we turn to reinforcement learning (RL) as a principled approach for training agents to learn effective memory management strategies. Unlike supervised fine-tuning, which requires ground-truth memory construction traces, RL enables agents to discover optimal memory strategies through trial and error. This approach is necessary across all model scales: even state-of-the-art models like GPT-4o struggle with proper tool selection for memory updates, while smaller models become completely overwhelmed by complex tool sets. Since we cannot obtain reliable supervision signals from any existing model, we instead directly optimize for downstream task performance, using question-answering accuracy and memory quality metrics as reward signals. Existing works including MEM1, MemAgent and Memory-R1 are the first works exploring this direction. However, they employ relatively simple memory structures, such as memory rewriting or maintaining a list of facts, that are insufficient for handling complex data such as long narratives, procedural rules, evolving knowledge, or even multi-modal information.
为了解决这个问题,作者转向强化学习,把它作为训练智能体学习有效记忆管理策略的一种原则性方法。 与需要真实记忆构建轨迹的监督微调不同,强化学习允许智能体通过试错发现更优的记忆策略。 这种方法在不同规模模型上都有必要:即使是 GPT-4o 这类先进模型,在记忆更新时也可能难以正确选择工具;而更小的模型面对复杂工具集时则更容易被压垮。 由于我们无法从任何现有模型那里获得可靠监督信号,作者改为直接优化下游任务表现,也就是把问答准确率和记忆质量指标作为奖励信号。 MEM1、MemAgent 和 Memory-R1 等工作是这一方向的早期探索。 但它们采用的记忆结构相对简单,例如重写一段记忆或维护事实列表,难以处理长篇叙事、程序规则、不断演化的知识,甚至多模态信息等复杂数据。
To this end, we propose Mem-α, a reinforcement learning framework that trains agents to effectively manage complex memory systems through interaction and feedback. Unlike existing approaches that either provide sophisticated tools without teaching models how to use them, or train models on simplistic memory operations, Mem-α enables agents to learn memory construction strategies for complex, multi-component memory architectures, as shown in Figure 1. Our approach addresses three key challenges in memory-augmented agent training. First, we formulate memory construction as a sequential decision-making problem where agents process information chunks, decide which memory operations to perform, and receive multiple rewards based on downstream question-answering accuracy over the full interaction history. Second, we construct a specialized training dataset spanning diverse multi-turn interaction patterns, including conversations, document sharing, pattern recognition, and storytelling, paired with comprehensive evaluation questions. Lastly, we adopt a comprehensive memory architecture comprising core, episodic, and semantic components, each equipped with specialized tools for memory operations.
基于此,作者提出 Mem-α,这是一个强化学习框架,通过交互与反馈训练智能体有效管理复杂记忆系统。 不同于已有方法要么只提供复杂工具却不教模型如何使用,要么只在非常简单的记忆操作上训练模型,Mem-α 让智能体能够面向复杂的多组件记忆架构学习记忆构建策略,如图1所示。 该方法主要解决记忆增强智能体训练中的三个挑战。 第一,作者把记忆构建形式化为一个序列决策问题:智能体逐块处理信息,决定执行哪些记忆操作,并根据完整交互历史上的下游问答准确率获得多个奖励。 第二,作者构建了专门的训练数据集,覆盖对话、文档分享、模式识别和故事叙述等多样化多轮交互模式,并配套设计全面的评估问题。 第三,作者采用由核心记忆、情节记忆和语义记忆组成的综合记忆架构,每个组件都配有专门的记忆操作工具。
Empirical evaluation demonstrates that Mem-α achieves significant improvements over existing memory-augmented agent baselines across diverse benchmarks. Most remarkably, despite being trained exclusively on instances with a maximum length of 30k tokens, our agents exhibit robust generalization to sequences exceeding 400k tokens, over 13× the training length. This exceptional length generalization suggests that reinforcement learning enables agents to learn fundamental memory management principles rather than merely memorizing specific patterns, highlighting the potential of learning-based approaches for long-context retention.
实验评估表明,Mem-α 在多种基准上相比现有记忆增强智能体基线取得了显著提升。 最值得注意的是,尽管训练样本最长只有 30k token,训练出的智能体仍能稳健泛化到超过 400k token 的序列,也就是训练长度的 13 倍以上。 这种出色的长度泛化说明,强化学习让智能体学到的不是某些固定模式,而是更基础的记忆管理原则,也体现了基于学习的方法在长上下文保留任务中的潜力。
2. Related Work
2.1. Latent-Space Memory
These methods encode new information directly into a model's internal components, such as hidden states, key-value caches, soft prompts, model parameters, or learnable external matrices. The main advantage is efficient compression: for instance, SELF-PARAM can memorize hundreds of contexts without external storage. However, these approaches face two key limitations. First, their memory capacity remains bounded; M+ achieves retention of approximately 160k tokens, which falls short of state-of-the-art memory agents like MIRIX. Second, they require direct access to model internals, making them incompatible with proprietary systems such as GPT-4/5. Since open-weight alternatives typically underperform leading proprietary models, these constraints limit practical deployment.
这类方法会把新信息直接编码进模型内部组件,例如隐藏状态、KV 缓存、软提示、模型参数,或可学习的外部矩阵。 它们的主要优势是压缩效率高,例如 SELF-PARAM 可以在不依赖外部存储的情况下记住数百段上下文。 但这类方法有两个关键限制。 第一,它们的记忆容量仍然有上限;例如 M+ 大约能保留 160k token,仍低于 MIRIX 这类先进记忆智能体。 第二,它们需要直接访问模型内部,因此无法兼容 GPT-4/5 这类闭源专有系统。 由于开源权重模型通常弱于领先的专有模型,这些限制会影响实际部署。
2.2. LLM Agents with External Memory
An alternative approach equips language models with external memory systems built on databases or vector stores, as demonstrated by MemGAS, SCM, A-MEM, MemTree, MemGPT, Mem0, Zep, Nemori, EgoMem, MIRIX, Memobase, MemoChat and similar frameworks. These architectures offer two key advantages: they work seamlessly with proprietary frontier models and can efficiently organize, retrieve, and update large amounts of information through well-designed schemas and controllers. However, their effectiveness depends heavily on the base model's ability to follow instructions and use tools, capabilities that smaller, more cost-effective models often lack. Meanwhile, when the system becomes complex, even proprietary models may not update the memory systems well. This limitation motivates approaches that explicitly train models to manage memory rather than relying purely on prompting.
另一类方法是为语言模型配备基于数据库或向量存储的外部记忆系统,例如 MemGAS、SCM、A-MEM、MemTree、MemGPT、Mem0、Zep、Nemori、EgoMem、MIRIX、Memobase、MemoChat 等框架。 这类架构有两个关键优势:它们可以无缝配合专有前沿模型使用,也可以通过精心设计的 schema 和控制器高效组织、检索、更新大量信息。 然而,它们的效果高度依赖基础模型遵循指令和使用工具的能力,而更小、更低成本的模型往往缺乏这种能力。 同时,当系统变复杂时,即使是专有模型也未必能很好地更新记忆系统。 因此,作者认为应该显式训练模型管理记忆,而不是完全依赖提示词。
2.3. Learning Memory Construction with Reinforcement Learning
Recent work explores training language models to construct memory using reinforcement learning, though results remain preliminary. Early efforts such as MEM1 and MemAgent train models to update simple, text-only memories. Memory-R1, Learn-to-Memorize and REMEMBER introduce a slightly richer memory representation and a simplified tool-calling interface, but focus on LoCoMo settings with relatively short maximum context and train on subsets of the same distribution, which makes the task comparatively easier. In this paper, we develop an RL framework that trains a model to operate a substantially more capable memory system and demonstrate significant improvements across multiple dimensions of memory quality and efficiency.
近期也有工作开始探索使用强化学习训练语言模型构建记忆,不过结果仍处于早期阶段。 MEM1 和 MemAgent 等早期方法训练模型更新简单的纯文本记忆。 Memory-R1、Learn-to-Memorize 和 REMEMBER 引入了稍微丰富一些的记忆表示和简化的工具调用接口,但它们主要关注 LoCoMo 设置,最大上下文较短,并且在同分布子集上训练,因此任务相对更容易。 本文则提出一个强化学习框架,用来训练模型操作能力更强的记忆系统,并在记忆质量和效率的多个维度上展示显著提升。
3. Method
3.1. Reinforcement Learning Framework
We formulate memory construction as a reinforcement learning problem where the agent learns to optimize memory building policies. The quality of the constructed memory is evaluated through a separate question-answering process using retrieval-augmented generation (RAG). The complete training framework is shown in Figure 2.
作者把记忆构建形式化为一个强化学习问题:智能体需要学习如何优化记忆构建策略。 构建出的记忆质量会通过一个独立的问答流程来评估,该流程使用检索增强生成(RAG)。 完整训练框架如图2所示。
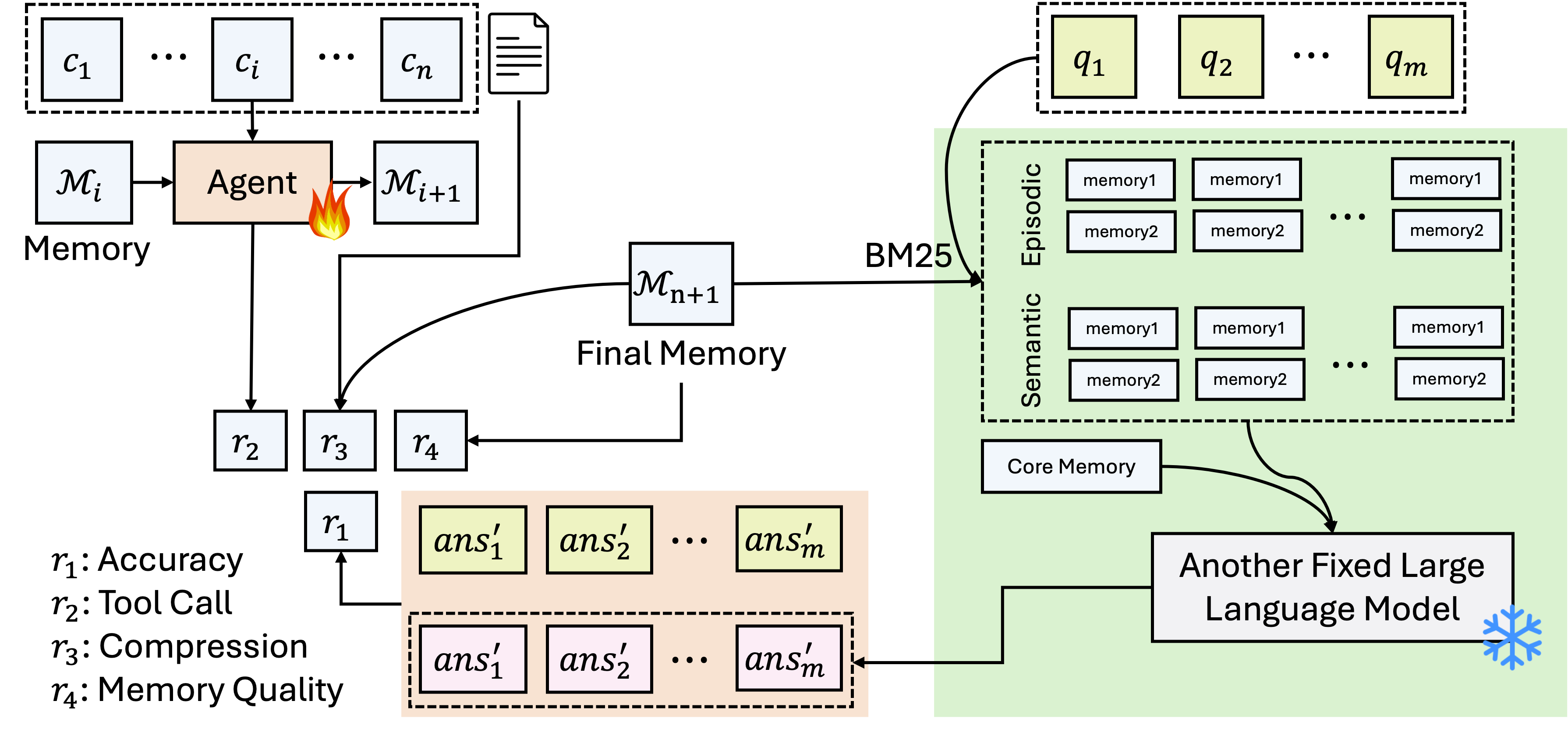
3.1.1. Task Setup
We consider a memory construction task where an agent processes a sequence of conversations
作者考虑的任务是:一个智能体处理用户和助手之间的一系列对话
Each operation
其中每个操作
These function calls are then applied to the previous memory:
随后,这些函数调用会被依次应用到上一轮记忆上:
After processing all chunks in
处理完
3.1.2. Reward Functions
The correctness reward
正确性奖励
The tool call format reward
工具调用格式奖励
The compression reward is defined as
压缩奖励定义为
The memory content reward
记忆内容奖励
The final reward for action
最终,第
Here
其中
3.1.3. Memory Comprehensiveness Evaluation via RAG
The comprehensiveness of the learned memory is evaluated by a decoupled RAG pipeline, where only the write policy is learnable and both retrieval and generation components remain fixed. After all context chunks are processed, the agent outputs the terminal memory state
学到的记忆是否全面,是通过一个解耦的 RAG 流程来评估的。 在这个流程里,只有写入策略是可学习的,检索和生成组件都是固定的。 处理完所有上下文块后,智能体输出最终记忆状态
Finally,
最后,将
3.2. Policy Optimization
The authors employ Group Relative Policy Optimization (GRPO). After the reward for each action
作者使用 Group Relative Policy Optimization(GRPO)进行策略优化。 在得到每个动作
Here
这里
The objective of Mem-α is to maximize the expected reward over all actions in the sequence. For readability, we first define the policy ratio:
Mem-α 的目标是在整个动作序列上最大化期望奖励。 为了让公式更易读,先定义策略比率:
Then the GRPO-style objective can be written as:
于是,GRPO 风格的目标函数可以写成:
The KL term in GRPO is discarded to encourage policy exploration.
为了鼓励策略探索,作者在这里去掉了 GRPO 中的 KL 项。
3.3. Memory Instantiation
The authors design a memory architecture comprising three complementary components. Core Memory maintains a persistent text summary with a maximum of 512 tokens, which remains continuously accessible in the agent context and provides immediate access to essential information. Semantic Memory stores factual knowledge and declarative information as a structured collection of discrete factual statements. Episodic Memory captures temporally grounded events and experiences as a chronologically organized collection of timestamped events. Figure 3 illustrates the complete memory architecture and the interactions between these components.
作者设计的记忆架构包含三个互补组件。 核心记忆维护一段最长 512 token 的持久文本摘要,它始终放在智能体上下文中,让模型可以直接访问最关键的信息。 语义记忆用于存储事实知识和陈述性信息,被实现为一组离散事实陈述。 情节记忆用于捕捉有时间基础的事件和经历,被实现为按时间组织的带时间戳事件集合。 图3展示了完整记忆架构以及这些组件之间的关系。

Each memory component is equipped with specialized operations tailored to its functional requirements. Semantic and episodic memories support fine-grained manipulation through three operations: memory_insert, memory_update, and memory_delete. In contrast, core memory supports only memory_update, requiring complete rewriting to maintain coherence in its condensed representation. Importantly, this memory architecture is modular and decoupled from the reinforcement learning framework. Researchers can substitute alternative memory designs without modifying the training methodology.
每个记忆组件都配备了符合自身功能需求的专门操作。 语义记忆和情节记忆支持三种细粒度操作:memory_insert、memory_update 和 memory_delete。 相比之下,核心记忆只支持 memory_update,因为它是一段浓缩摘要,需要整体重写才能保持连贯性。 重要的是,这套记忆架构与强化学习框架是模块化解耦的。 研究者可以替换为其他更简单或更复杂的记忆设计,而不需要修改训练方法本身。
3.4. Training Dataset Preparation
MemoryAgentBench evaluates memory agents across four dimensions: Accurate Retrieval, Test-Time Learning, Long-Range Understanding, and Conflict Resolution. This work focuses on the first three dimensions and excludes Conflict Resolution because realistic benchmarks for that dimension are still lacking. The authors compile a training dataset comprising 4,139 instances. Since reinforcement learning is computationally expensive and the full dataset is imbalanced, they use stratified sampling to create a balanced subset of 562 instances.
MemoryAgentBench 从四个维度评估记忆智能体:准确检索、测试时学习、长程理解和冲突解决。 本文关注前三个维度,并排除冲突解决,因为这一维度目前缺乏足够真实的评测基准。 作者整理了一个包含 4,139 个样本的训练数据集。 由于强化学习计算开销较大,而且完整数据集类别不平衡,作者采用分层采样构建了一个包含 562 个样本的平衡子集。
4. Experiments
4.1. Experimental Setup
Following MemoryAgentBench, the authors select representative datasets from three categories to comprehensively evaluate Mem-α. For Accurate Retrieval, they use Single-Doc, Multi-Doc and LME(S*) as evaluation tasks. For Test-Time Learning, they evaluate on five multi-class classification datasets: TREC-C, TREC-F, NLU, CLINIC, and BANKING77. For Long-Range Understanding, they use InfBench-Sum as the summarization task.
作者遵循 MemoryAgentBench,从三个类别中选择代表性数据集来全面评估 Mem-α。 对于准确检索任务,使用 Single-Doc、Multi-Doc 和 LME(S*);对于测试时学习任务,使用五个多分类数据集:TREC-C、TREC-F、NLU、CLINIC 和 BANKING77;对于长程理解任务,使用 InfBench-Sum 作为摘要评估任务。
The baselines include Long-Context, which simply uses Qwen3-32B with a maximum context window of 32k; RAG-Top2, which uses BM25 to retrieve the top two chunks with the question as query and then uses Qwen3-32B to answer; MemAgent, which lets an agent read all chunks and answer according to accumulated memory; and MEM1, which requires the agent to maintain a paragraph of memory, retrieve chunks, update memory, and answer based on that memory.
基线包括四类。Long-Context 直接使用 Qwen3-32B,最大上下文窗口为 32k;RAG-Top2 使用 BM25,以问题作为查询,从所有历史块中检索 top-2 片段,再用 Qwen3-32B 回答;MemAgent 给智能体任务描述,让它遍历所有信息块,并根据累积记忆回答;MEM1 要求智能体维护一段记忆、检索部分信息块、更新记忆,并基于该记忆回答问题。
For reproducibility, Mem-α is implemented with the verl framework and uses Qwen3-4B as the backbone model. The authors also tried Qwen3-8B but obtained worse performance. Training uses 32 H100 GPUs with learning_rate = 1e-6, batch_size = 32, and grpo_rollout_n = 8 for three days. The complete training lasts 205 steps, and the best checkpoint is selected according to validation performance. In the main experiments, the hyperparameters in the reward equation are set to
为了保证可复现性,Mem-α 使用 verl 框架实现,并选择 Qwen3-4B 作为骨干模型。 作者也尝试过 Qwen3-8B,但效果不如 Qwen3-4B。 训练使用 32 张 H100 GPU,learning_rate = 1e-6,batch_size = 32,grpo_rollout_n = 8,训练三天。 完整训练共 205 步,并根据验证集表现选择最佳 checkpoint。 在主实验中,奖励公式里的超参数设置为
4.2. Overall Performance Comparison
The authors report performance on validation datasets matching the training distribution in Table 1 and on out-of-distribution MemoryAgentBench test datasets in Table 2. The results show four key findings. First, Mem-α significantly outperforms existing baselines across metrics, especially on Accurate Retrieval and Long-Range Understanding. Second, compared with Long-Context and RAG-Top2, Mem-α reduces memory footprint by roughly 50% while maintaining stronger performance. Third, the poor performance of flat-memory baselines such as MEM1 and MemAgent shows that unstructured memory is inadequate for complex information processing. Fourth, despite training only on documents averaging below 20K tokens, Mem-α generalizes to documents exceeding 400K tokens.
作者在表1中报告了与训练分布一致的验证集表现,在表2报告了分布外 MemoryAgentBench 测试集表现。 结果有四个关键发现。 第一,Mem-α 在多个指标上明显优于现有基线,尤其在准确检索和长程理解任务上提升明显。 第二,相比 Long-Context 和 RAG-Top2,Mem-α 在保持更强性能的同时,将记忆占用减少约 50%。 第三,MEM1 和 MemAgent 等扁平记忆基线表现有限,说明无结构记忆不足以处理复杂信息。 第四,尽管训练文档平均长度低于 20K token,Mem-α 仍能泛化到超过 400K token 的文档。
| Method | Metric | AR | TTL | LRU | Avg. | ||||
|---|---|---|---|---|---|---|---|---|---|
| SQuAD | HotpotQA | PerLTQA | TREC-C | NLU | Pubmed | BookSum | |||
| Long-Context | Perf. | 0.742 | 0.852 | 0.605 | 0.623 | 0.708 | 0.533 | 0.052 | 0.588 |
| Mem. | 10.6K | 9.7K | 13.1K | 3.9K | 6.1K | 16.7K | 15.4K | 10.8K | |
| RAG-Top2 | Perf. | 0.762 | 0.849 | 0.623 | 0.612 | 0.508 | 0.570 | 0.042 | 0.567 |
| Mem. | 10.6K | 9.7K | 16.7K | 3.9K | 6.1K | 16.7K | 15.6K | 11.3K | |
| MemAgent | Perf. | 0.091 | 0.140 | 0.052 | 0.562 | 0.290 | 0.343 | 0.103 | 0.236 |
| Mem. | 0.79K | 0.76K | 0.29K | 1.24K | 0.99K | 0.94K | 0.59K | 0.84K | |
| MEM1 | Perf. | 0.039 | 0.083 | 0.068 | 0.269 | 0.056 | 0.175 | 0.085 | 0.111 |
| Mem. | 0.16K | 0.22K | 0.14K | 0.23K | 0.22K | 0.08K | 0.16K | 0.17K | |
| Mem-α | Perf. | 0.786 | 0.832 | 0.659 | 0.666 | 0.658 | 0.545 | 0.187 | 0.642 |
| Mem. | 10.1K | 8.7K | 11.2K | 4.0K | 6.5K | 12.3K | 2.2K | 7.9K | |
| Method | Metric | AR | TTL | LRU | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Single- Doc | Multi- Doc | LME(S) | TREC- C | NLU | TREC- F | Clinic | Banking 77 | InfBench | |||
| Long-Context | Perf. | 0.280 | 0.270 | 0.292 | 0.640 | 0.740 | 0.340 | 0.860 | 0.770 | 0.125 | 0.461 |
| Mem. | 33K | 33K | 33K | 33K | 33K | 33K | 33K | 33K | 33K | 33K | |
| RAG-Top2 | Perf. | 0.690 | 0.450 | 0.581 | 0.690 | 0.650 | 0.210 | 0.700 | 0.750 | 0.065 | 0.502 |
| Mem. | 217K | 474K | 348K | 124K | 134K | 126K | 131K | 128K | 181K | 207K | |
| MemAgent | Perf. | 0.070 | 0.160 | 0.050 | 0.370 | 0.260 | 0.210 | 0.250 | 0.370 | 0.043 | 0.198 |
| Mem. | 1.02K | 1.02K | 0.56K | 1.02K | 1.02K | 0.77K | 1.02K | 1.02K | 0.73K | 0.92K | |
| MEM1 | Perf. | 0.070 | 0.180 | 0.090 | 0.180 | 0.000 | 0.000 | 0.090 | 0.000 | 0.029 | 0.071 |
| Mem. | 0.30K | 0.38K | 0.22K | 0.16K | 0.11K | 0.13K | 0.28K | 0.11K | 0.19K | 0.21K | |
| Mem-α-4B | Perf. | 0.740 | 0.680 | 0.520 | 0.710 | 0.710 | 0.410 | 0.730 | 0.700 | 0.129 | 0.592 |
| Mem. | 160K | 323K | 127K | 120K | 142K | 123K | 18K | 133K | 19K | 129K | |
4.3. Performance Boost from Reinforcement Learning
To demonstrate that the improvements come from reinforcement learning rather than the memory structure alone, the authors compare three configurations: the RL-tuned Mem-α model, the base Qwen3-4B model with the same memory framework, and gpt-4.1-mini with the same memory framework. Table 3 shows that base Qwen3-4B reaches only 0.389 average performance, below both RAG-Top2 and Long-Context. Although gpt-4.1-mini benefits from stronger instruction-following ability, RL-tuned Mem-α achieves the best overall performance. The improvement from 0.389 to 0.642 shows that reinforcement learning successfully teaches the base model to use the memory structure effectively.
为了证明性能提升来自强化学习,而不仅仅是记忆结构本身,作者比较了三种配置:经过 RL 调优的 Mem-α、使用相同记忆框架的基础 Qwen3-4B、以及使用相同记忆框架的 gpt-4.1-mini。 表3显示,基础 Qwen3-4B 平均性能只有 0.389,低于 RAG-Top2 和 Long-Context。 虽然 gpt-4.1-mini 受益于更强的指令遵循能力,但经过 RL 调优的 Mem-α 取得了最佳整体性能。 从 0.389 提升到 0.642,说明强化学习确实教会了基础模型如何有效使用记忆结构。
qwen3-32b 回答问题。| Method | Metric | AR | TTL | LRU | Avg. | ||||
|---|---|---|---|---|---|---|---|---|---|
| SQuAD | HotpotQA | PerLTQA | TREC-C | NLU | Pubmed | BookSum | |||
| Qwen3-4B | Perf. | 0.338 | 0.637 | 0.557 | 0.416 | 0.381 | 0.281 | 0.130 | 0.389 |
| Mem. | 3.3K | 4.8K | 9.0K | 2.3K | 2.9K | 4.4K | 0.9K | 3.9K | |
| gpt-4.1-mini | Perf. | 0.426 | 0.749 | 0.492 | 0.637 | 0.519 | 0.544 | 0.246 | 0.517 |
| Mem. | 3.8K | 4.9K | 3.7K | 3.4K | 5.9K | 10.6K | 1.5K | 4.8K | |
| Qwen3-4B w/ Mem-α | Perf. | 0.786 | 0.832 | 0.659 | 0.666 | 0.658 | 0.545 | 0.187 | 0.642 |
| Mem. | 10.1K | 8.7K | 11.2K | 4.0K | 6.5K | 12.3K | 2.2K | 7.9K | |
4.4. Ablation Studies
The reward function contains four components:
奖励函数包含四个部分:准确率奖励
| β | γ | Metric | AR | TTL | LRU | Avg. | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| SQuAD | HotpotQA | PerLTQA | TREC-C | NLU | Pubmed | BookSum | ||||
| 0.05 | 0.0 | Perf. | 0.701 | 0.802 | 0.652 | 0.423 | 0.542 | 0.501 | 0.183 | 0.543 |
| Mem. | 9.2K | 8.2K | 10.8K | 3.0K | 3.5K | 11.0K | 4.9K | 7.5K | ||
| 0.0 | 0.1 | Perf. | 0.817 | 0.853 | 0.678 | 0.605 | 0.629 | 0.572 | 0.183 | 0.630 |
| Mem. | 9.7K | 8.1K | 11.7K | 3.7K | 5.4K | 12.5K | 4.5K | 7.9K | ||
| 0.05 | 0.1 | Perf. | 0.786 | 0.832 | 0.659 | 0.666 | 0.658 | 0.545 | 0.187 | 0.642 |
| Mem. | 10.1K | 8.7K | 11.2K | 4.0K | 6.5K | 12.3K | 2.2K | 7.9K | ||
| 0.2 | 0.1 | Perf. | 0.822 | 0.838 | 0.615 | 0.558 | 0.176 | 0.401 | 0.193 | 0.525 |
| Mem. | 9.8K | 7.8K | 10.4K | 0.4K | 0.8K | 0.4K | 3.0K | 4.7K | ||
| 0.4 | 0.1 | Perf. | 0.691 | 0.810 | 0.533 | 0.475 | 0.405 | 0.455 | 0.201 | 0.509 |
| Mem. | 8.8K | 8.1K | 5.2K | 0.7K | 1.4K | 1.3K | 1.5K | 3.6K | ||
4.5. Case Studies
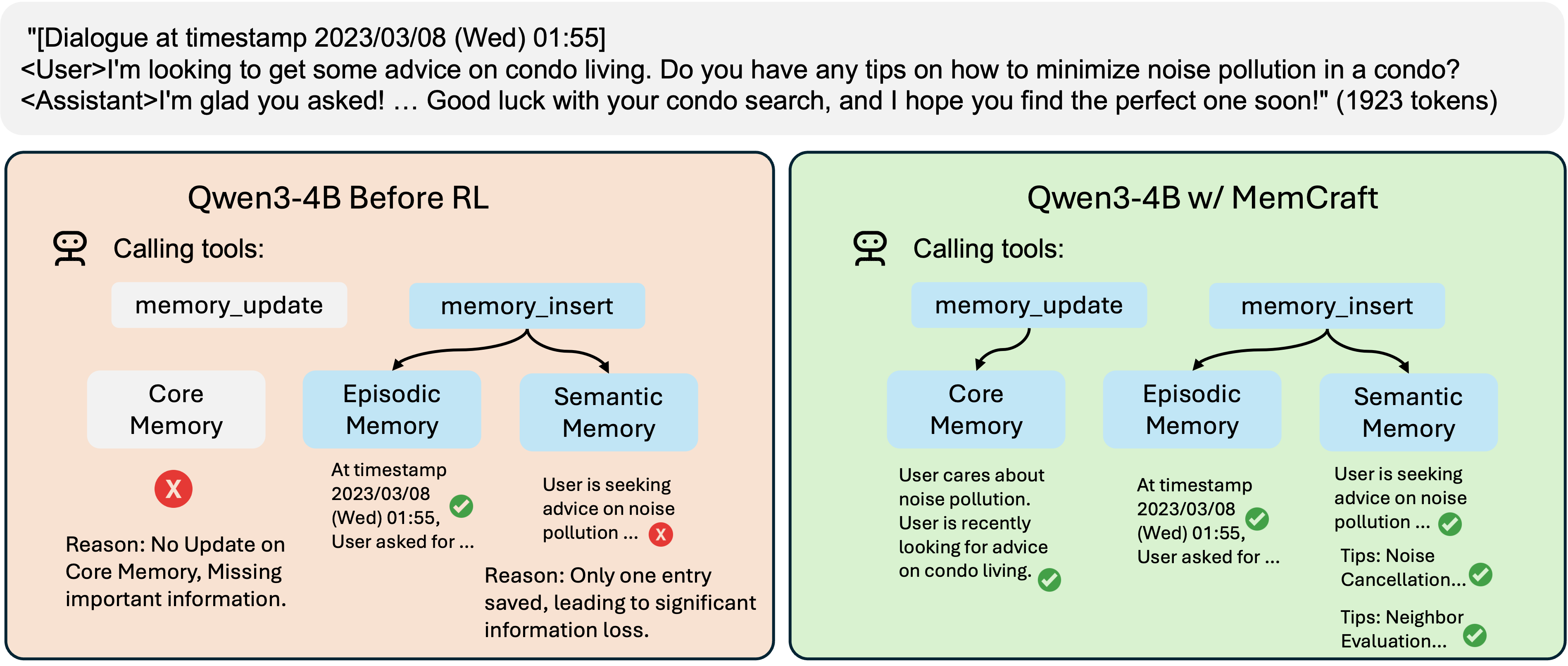
The case study compares memory construction traces from Mem-α with baseline models. Qwen3-4B fails to update core memory and compresses many distinct concepts into a single semantic entry, causing severe information loss. GPT-4.1-mini has better semantic organization, but creates multiple episodic entries with identical timestamps and records mainly user behavior while ignoring assistant responses. In contrast, Mem-α maintains an informative core memory, organizes semantic information into distinct entries, consolidates same-timestamp events, and records both user behavior and assistant responses.
案例分析比较了 Mem-α 与基线模型的记忆构建轨迹。 Qwen3-4B 没有更新核心记忆,并且把多个不同概念压缩成一个语义条目,造成严重信息损失。 GPT-4.1-mini 的语义组织更好,但它会为相同时间戳创建多个情节条目,并且主要记录用户行为,忽略助手回应。 相比之下,Mem-α 能维护信息充分的核心记忆,把语义信息组织成清晰独立的条目,合并相同时间戳事件,并同时记录用户行为和助手回应。
| 记忆类型 | Qwen3-4B | GPT-4.1-mini | Qwen3-4B w/ Mem-α |
|---|---|---|---|
| 核心记忆 | ∅,不应为空。 | 用户正在关注如何尽量减少噪声污染,并且目前正在寻找公寓,尤其是市中心区域的公寓。 | 用户正在寻求关于公寓生活的建议,并正在考虑市中心的公寓选项。 |
| 语义记忆 | 只记录了一个较笼统的条目,内容是关于噪声污染和配套设施建议;它本应记录更多相互区分的事实。 | 包含三个不同条目:降低噪声污染的建议、社区评估以及前期调研的重要性。内容完整,但略显冗长。 | 包含两个不同条目:隔音建议和调研方法。内容完整且更紧凑。 |
| 情节记忆 | 用一个简洁条目记录了用户提出问题,以及助手给出建议。 | 多个事件使用相同时间戳,本应合并;同时只记录了用户行为,缺少助手回应。 | 用一个合并后的时间戳事件,同时记录了用户关于公寓生活的问题和助手的回应。 |
5. Conclusion, Limitation and Future Work
In this work, the authors present Mem-α, a reinforcement learning framework that enables LLM agents to learn effective memory management strategies through interaction and feedback. By moving beyond pre-defined heuristics, the approach allows agents to discover suitable memory operations for diverse scenarios through a carefully designed training dataset and reward mechanism based on question-answering correctness. Experiments demonstrate that Mem-α achieves significant improvements over existing memory-augmented baselines, with agents developing robust memory management strategies that generalize well to much longer interaction patterns.
在这项工作中,作者提出 Mem-α,这是一个强化学习框架,使 LLM 智能体能够通过交互与反馈学习有效的记忆管理策略。 该方法不再依赖预定义启发式规则,而是通过精心设计的训练数据集和基于问答正确性的奖励机制,让智能体在多样化场景中发现合适的记忆操作。 实验表明,Mem-α 相比现有记忆增强基线取得了显著提升,并让智能体发展出稳健的记忆管理策略,能够很好地泛化到更长的交互模式。
Although the framework shows strong performance, several directions remain open. The current memory architecture could be integrated with more sophisticated systems such as MIRIX, which may provide additional structural advantages for complex reasoning tasks. Moreover, extending Mem-α from simulated environments to real-world applications would require connecting the RL framework with actual databases and production systems, introducing challenges around latency, scalability, and safety. These directions are promising opportunities to bridge learned memory management and practical deployment of memory-augmented LLM agents.
尽管该框架表现很强,仍有一些值得继续探索的方向。 当前记忆架构可以与 MIRIX 等更复杂的系统结合,这可能为复杂推理任务带来额外的结构优势。 此外,要把 Mem-α 从模拟环境扩展到真实应用,还需要将强化学习框架与实际数据库和生产系统连接起来,这会引入延迟、可扩展性和安全性方面的挑战。 这些方向有助于弥合“学到的记忆管理能力”和“记忆增强 LLM 智能体实际部署”之间的距离。