
MEM1:学习协同记忆与推理以构建高效长程智能体
Abstract
Modern language agents must operate over long-horizon, multi-turn interactions, where they retrieve external information, adapt to observations, and answer interdependent queries. Yet, most LLM systems rely on full-context prompting, appending all past turns regardless of their relevance. This leads to unbounded memory growth, increased computational costs, and degraded reasoning performance on out-of-distribution input lengths. We introduce MEM1, an end-to-end reinforcement learning framework that enables agents to operate with constant memory across long multi-turn tasks. At each turn, MEM1 updates a compact shared internal state that jointly supports memory consolidation and reasoning. This state integrates prior memory with new observations from the environment while strategically discarding irrelevant or redundant information. To support training in more realistic and compositional settings, we propose a simple yet effective and scalable approach to constructing multi-turn environments by composing existing datasets into arbitrarily complex task sequences. Experiments across three domains, including internal retrieval QA, open-domain web QA, and multi-turn web shopping, show that MEM1-7B improves performance by
现代语言智能体必须在长程、多轮交互中运行,在此过程中检索外部信息、适应观测结果,并回答相互依赖的问题。 然而,大多数 LLM 系统仍依赖完整上下文提示,不管历史轮次是否相关,都会把所有过去交互追加到提示中。 这会导致记忆无界增长、计算成本增加,并使模型在分布外输入长度上推理性能下降。 本文提出 MEM1,这是一个端到端强化学习框架,使智能体能够在长程多轮任务中以常数记忆运行。 在每一轮中,MEM1 会更新一个紧凑的共享内部状态,同时支持记忆整合与推理。 该状态会把先前记忆与来自环境的新观测整合起来,同时有策略地丢弃无关或冗余信息。 为了支持更真实、更具组合性的训练设置,作者提出一种简单、有效且可扩展的方法:通过组合已有数据集来构造任意复杂的多轮环境。 在内部检索 QA、开放域 Web QA 和多轮 Web 购物三个领域的实验表明,在
1. Introduction
Large language models (LLMs) have shown remarkable performance in single-turn tasks such as question answering, summarization, and code generation. However, emerging real-world applications increasingly operate over multiple turns: searching documents, interacting with environments, and making decisions based on evolving external information. Examples include research agents such as OpenAI and Gemini Deep Research that automate complex tasks by iteratively gathering information, and web-navigation agents such as OpenManus and BrowserUse, which must complete goals across dozens of interactive turns.
大型语言模型(LLM)已经在问答、摘要和代码生成等单轮任务中展现出显著表现。 然而,新兴真实应用越来越多地运行在多轮场景中:搜索文档、与环境交互,并基于不断变化的外部信息做出决策。 例如 OpenAI 和 Gemini Deep Research 这类研究智能体会通过迭代收集信息来自动完成复杂任务;OpenManus 和 BrowserUse 这类网页导航智能体则需要在数十轮交互中完成目标。
Unlike traditional tasks where the input is static or self-contained, long-horizon settings often involve answering a sequence of related questions, requiring the agent to continuously retrieve new information, revise beliefs, and adapt to evolving contexts over time. For instance, consider a research assistant tasked with "What is the evidence for X?". Subsequent queries like "Who published it?" require further information retrieval, while "Is the source credible?" calls for self-reflection and assessment. Each query builds on the previously collected and accumulated information.
传统任务中的输入通常是静态或自包含的,而长程场景往往涉及一系列相关问题,要求智能体持续检索新信息、修正信念,并随着上下文变化不断适应。 例如,一个研究助手可能被要求回答“X 的证据是什么?”。 后续问题如“是谁发表的?”需要进一步检索信息,而“这个来源可靠吗?”则需要自我反思和评估。 每个问题都建立在此前已经收集并积累的信息之上。
A central challenge in multi-turn LLM agents is memory management: how to retain relevant past information while preventing memory growth. Many existing systems rely on full-context prompting, where all past interactions, intermediate reasoning, retrieved documents, and tool outputs are appended to the prompt. This strategy guarantees access to the history but causes context length and memory usage to grow linearly with the number of turns. Long contexts are also known to degrade reasoning, because irrelevant or redundant tokens make it harder for the model to attend to the useful information.
多轮 LLM 智能体的核心挑战之一是记忆管理:如何保留相关历史信息,同时避免记忆持续增长。 许多现有系统依赖完整上下文提示,也就是把所有历史交互、中间推理、检索文档和工具输出都追加进提示。 这种策略可以保证模型访问完整历史,但上下文长度和记忆使用会随着轮次数线性增长。 长上下文还会削弱推理,因为无关或冗余 token 会让模型更难关注真正有用的信息。
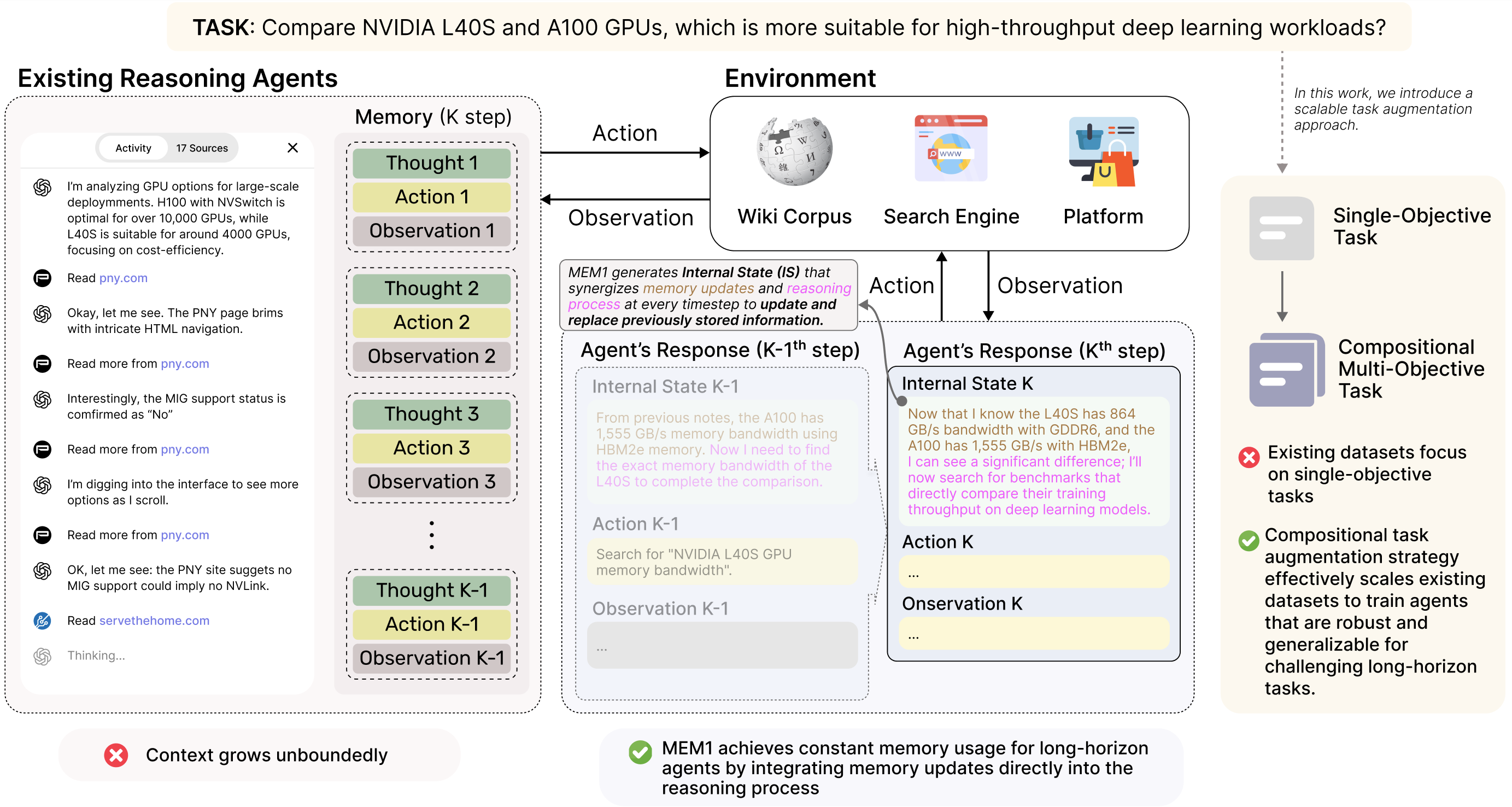
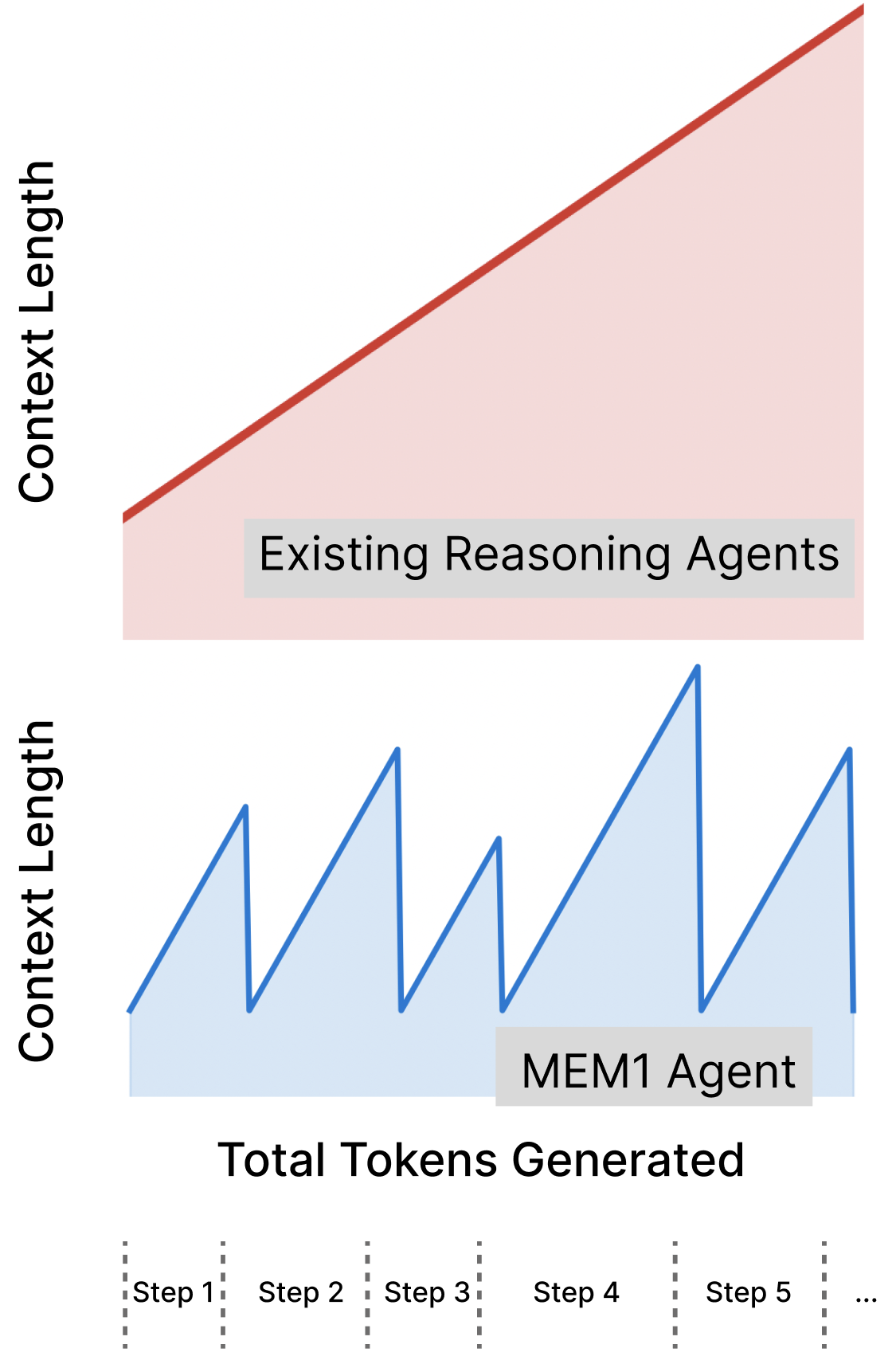
Motivated by this question, the authors present MEM1: Memory-Efficient Mechanism via learning 1-step integrated reasoning and consolidation, a method for training LLM agents that maintain constant memory usage across arbitrarily long horizons. As illustrated in Figure 1, at each turn, the model updates a consolidated state composed of prior memory and newly obtained information. This consolidated state becomes the agent's only retained memory, allowing all external tool outputs to be discarded after use, which prevents prompt expansion altogether as illustrated by Figure 2. A key insight of the method is that inference-time reasoning serves a dual function: it not only provides deeper insight into the current query but also acts as a form of working memory.
围绕这个问题,作者提出 MEM1:Memory-Efficient Mechanism via learning 1-step integrated reasoning and consolidation,即通过学习一步式集成推理与整合来实现记忆高效机制。 如图1所示,在每一轮中,模型都会更新一个由先前记忆和新获得信息组成的整合状态。 这个整合状态成为智能体唯一保留的记忆,使所有外部工具输出都能在使用后被丢弃,从而彻底避免提示膨胀,如图2所示。 该方法的关键洞见是:推理时生成的 reasoning 具有双重作用,它不仅能帮助回答当前问题,也可以作为一种工作记忆。
The authors train this behavior end-to-end with reinforcement learning, optimizing for task success via verifiable rewards. Although the agent is not explicitly optimized for memory efficiency through reward signals, it learns to manage memory as part of its policy, resulting in near-constant memory usage across long horizons. They also introduce a scalable task augmentation approach, transforming existing single-objective QA datasets into complex multi-objective tasks through compositions of
作者使用强化学习端到端训练这种行为,并通过可验证奖励来优化任务成功率。 虽然奖励信号并没有显式优化记忆效率,但智能体会把记忆管理学习为策略的一部分,从而在长程任务中实现近似常数记忆。 作者还提出一种可扩展的任务增强方法:通过组合
To evaluate the method comprehensively, the authors employ diverse multi-turn environments, including internal retrieval-augmented QA, open-domain Web QA, and complex multi-turn agent shopping scenarios in WebShop. Across these scenarios, MEM1 consistently rivals the performance of leading baselines while delivering efficiency gains up to
为了全面评估该方法,作者使用多种多轮环境,包括内部检索增强 QA、开放域 Web QA,以及 WebShop 中复杂的多轮购物智能体场景。 在这些场景中,MEM1 的性能稳定接近或超过强基线,同时在记忆使用上带来最高
2. Related Work
2.1. LLM Agents in Multi-Turn Environment
LLM-based agents have evolved from handling single-turn queries to serving as autonomous agents capable of multi-turn interactions such as web navigation and complex research. To enable such capabilities, ReAct introduced a framework that enhances LLMs' ability to interact with external environments by interleaving reasoning and action. Building on this reasoning-acting prompting paradigm, subsequent works have explored ways to improve agent performance through natural language feedback, enabling iterative refinement. Recently, inference-time scaling has emerged as a promising direction for enabling complex reasoning, with prior research incorporating evaluators or world models.
基于 LLM 的智能体已经从处理单轮查询,发展为能够进行网页导航和复杂研究等多轮交互的自主智能体。 为了支持这些能力,ReAct 提出了一种通过交错推理与行动来增强 LLM 外部环境交互能力的框架。 在这种 reasoning-acting 提示范式基础上,后续工作探索了利用自然语言反馈改进智能体表现的方法,使其能够迭代修正。 近期,推理时扩展成为支持复杂推理的一个有前景方向,已有研究引入 verifier、reward model 或 world model 等评估器。
In addition, there are two major lines of training approaches: behavior cloning, which imitates expert trajectories through supervised fine-tuning, and reinforcement learning, which optimizes agent policies by incentivizing desirable outcomes through rewards. These methods aim to align the agents' behaviors with task objectives, enabling more robust and generalizable performance.
此外,训练方法主要有两条路线:行为克隆,通过监督微调模仿专家轨迹;强化学习,通过奖励激励期望结果来优化智能体策略。 这些方法旨在让智能体行为与任务目标对齐,从而获得更稳健、更具泛化性的表现。
2.2. Memory Management for LLM Agents
A widely adopted approach to memory management in LLM-based agent systems involves appending all prior information, such as observations, intermediate thoughts, and actions, into the prompt at each interaction turn. While this method is straightforward and effective when the number of required interactions is small, it results in unbounded context growth and linearly scaled inference memory. Moreover, long contexts often contain irrelevant or redundant information, which impairs the model's reasoning capabilities.
LLM 智能体系统中一种常见的记忆管理方法,是在每轮交互中把所有先前信息追加到提示里,包括观测、中间思考和动作。 当所需交互轮数较少时,这种方法简单且有效,但它会导致上下文无界增长,并使推理内存线性扩张。 此外,长上下文通常包含无关或冗余信息,会损害模型的推理能力。
To mitigate these issues, recent studies have proposed external memory frameworks, including retrieval-augmented generation and summarization modules. However, these methods are typically trained or used independently of the agent's policy, creating a disconnect between memory and the reasoning process. In addition, managing and integrating such modules often incurs extra computational overhead and system complexity. In this work, the authors seek to bridge this gap by tightly integrating memory with the agent's reasoning process, thereby enabling more efficient and context-aware decision-making.
为了缓解这些问题,近期研究提出了外部记忆框架,包括检索增强生成和摘要模块。 然而,这些方法通常独立于智能体策略进行训练或使用,从而造成记忆与推理过程之间的脱节。 此外,管理和集成这类模块往往会带来额外计算开销和系统复杂度。 在本文中,作者希望通过把记忆与智能体推理过程紧密整合来弥合这一缺口,从而实现更高效、更具上下文感知能力的决策。
3. MEM1
Complex reasoning tasks often require an iterative process of information gathering and synthesis, as seen in applications such as deep research and web-based agents. Recent advances in agent design involve interaction loops that interleave chain-of-thought reasoning, environment interaction, and real-world feedback collection. To explicitly capture these core elements, the authors annotate each component using XML-style tags: <IS> for internal state, <query> for environment queries, <answer> for the agent's responses, and <info> for external observations or tool outputs. MEM1 adopts a learned approach to iterative state updating and consolidation, ensuring that only the most recent set of these elements is retained in the prompt at any given time. This design maintains a bounded and semantically relevant context, promoting efficient and coherent multi-step reasoning.
复杂推理任务通常需要迭代地收集和综合信息,例如 deep research 和基于 Web 的智能体应用。 近期智能体设计中的交互循环通常会交错执行链式思考推理、环境交互和真实反馈收集。 为了显式刻画这些核心元素,作者用 XML 风格标签标注各组成部分:<IS> 表示内部状态,<query> 表示环境查询,<answer> 表示智能体回答,<info> 表示外部观测或工具输出。 MEM1 采用一种学习得到的迭代状态更新与整合方法,确保任意时刻提示中只保留这些元素的最新集合。 这一设计保持了有界且语义相关的上下文,从而支持高效、连贯的多步推理。
3.1. Memory as Part of Reasoning
To achieve constant memory, MEM1 is trained to iteratively refine its understanding by processing new information in conjunction with a consolidation of its prior state. At each turn <IS_t> element, which summarizes past information and reasons about subsequent actions. Following this, the agent generates an action: either a <query_t> to interact with the environment, or an <answer_t> if a direct response is warranted. If the agent issues a <query_t>, the corresponding feedback from the environment is appended as <info_t>. At the next turn, (<IS_t>, <query_t>, <info_t>) into a new <IS_(t+1)>, which serves as the basis for further interactions.
为了实现常数记忆,MEM1 被训练成通过结合新信息与先前状态整合,来迭代修正自己的理解。 在每一轮 <IS_t> 元素,用于总结历史信息并推理后续动作。 随后,智能体会生成一个动作:要么生成 <query_t> 与环境交互,要么在可以直接回答时生成 <answer_t>。 如果智能体发出 <query_t>,环境反馈会作为 <info_t> 被追加进来。 在下一轮 (<IS_t>, <query_t>, <info_t>) 这个元组整合成新的 <IS_(t+1)>,作为后续交互的基础。
After each turn, all tags from the previous turn are pruned from the context, effectively compressing memory and preventing prompt bloat. Figure 3 illustrates the evolution of the model's context over time. At any given turn, the agent retains at most two <IS> elements, two <query> elements, and one <info> element, ensuring bounded and efficient memory usage. Reinforcement learning offers a mechanism for shaping this behavior through reward signals: the agent is rewarded only when it strategically retains and integrates useful information.
每一轮结束后,上一轮中的所有标签都会从上下文中剪除,从而有效压缩记忆并防止提示膨胀。 图3展示了模型上下文随时间演化的过程。 在任意一轮,智能体最多只保留两个 <IS> 元素、两个 <query> 元素和一个 <info> 元素,从而确保记忆有界且高效。 强化学习通过奖励信号塑造这种行为:只有当智能体有策略地保留并整合有用信息时,才会获得奖励。
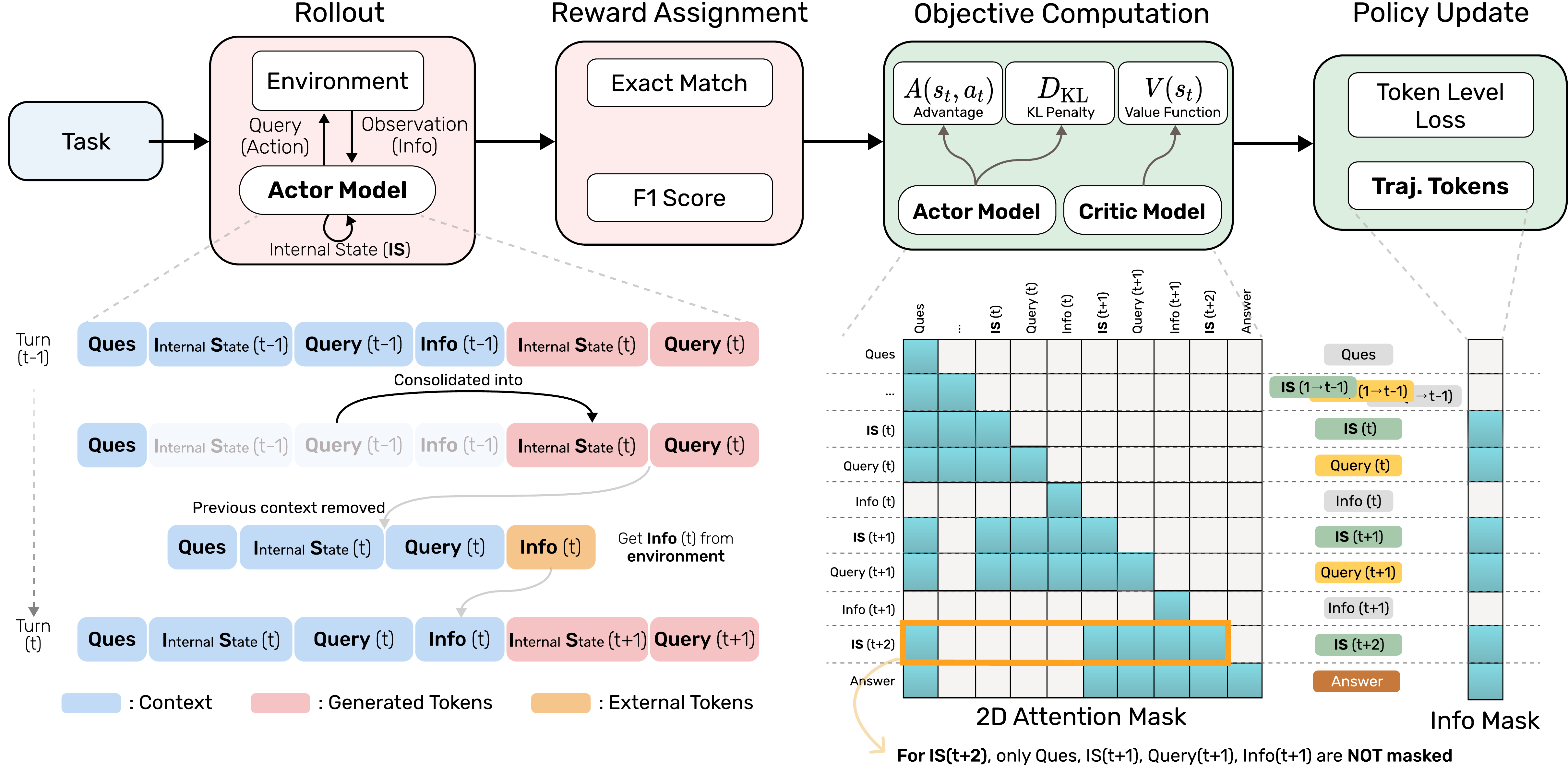
<IS>、<query>、<info> 会随着新状态进入上下文而被清除;右下为 objective computation 阶段使用的 2D attention mask。3.2. Masked Trajectory for Policy Optimization
Unlike conventional multi-turn agents that preserve a static context during generation, MEM1 continuously updates the context at each turn by consolidating prior memory and pruning irrelevant tokens. This dynamic context update disrupts the continuity of the token generation trajectory, complicating the estimation of token-wise advantages in algorithms such as PPO and Reinforce++. To address this, the authors introduce a masked trajectory approach that reconstructs a logically coherent full trajectory by stitching together multiple interaction turns with evolving contexts.
与在生成过程中保留静态上下文的传统多轮智能体不同,MEM1 会在每一轮通过整合先前记忆并剪除无关 token 来持续更新上下文。 这种动态上下文更新会打断 token 生成轨迹的连续性,使 PPO 和 Reinforce++ 等算法中逐 token advantage 的估计变得更复杂。 为了解决这一问题,作者提出 masked trajectory 方法,把具有演化上下文的多个交互轮次拼接起来,重构出逻辑上连贯的完整轨迹。
To ensure that policy gradients are correctly computed under this consolidated memory regime, the authors apply a two-dimensional attention mask across the full trajectory. This mask restricts each token's attention to only the tokens retained in memory when that token was generated. For a token position
为了确保在这种整合记忆机制下正确计算 policy gradient,作者在完整轨迹上应用二维 attention mask。 这个 mask 限制每个 token 只能关注该 token 生成时仍被保留在记忆中的 token。 对于 token 位置
3.3. Multi-Objective Task Design
Although MEM1 is designed for agentic multi-turn interaction with the external world, there are limited publicly available datasets that support training for such long-horizon interactive processes. Existing benchmarks such as HotpotQA, Bamboogle, and 2Wiki are often cited as multi-hop benchmarks, yet they typically involve only two information-seeking steps. Moreover, these datasets are not explicitly structured to support long-horizon interactions that require the agent to manage memory state.
虽然 MEM1 面向与外部世界进行多轮交互的智能体任务,但公开可用于训练这种长程交互过程的数据集仍然有限。 HotpotQA、Bamboogle 和 2Wiki 等已有 benchmark 常被视为多跳 benchmark,但它们通常只涉及两个信息搜索步骤。 此外,这些数据集并没有被显式设计成支持要求智能体管理记忆状态的长程交互。
To bridge this gap, the authors introduce multi-objective question answering, a task that extends the number of reasoning steps required to solve a problem. Building on existing multi-turn datasets such as HotpotQA and Natural Questions, they interleave multiple questions from the original QA corpus and construct a single composite query that requires answering all constituent sub-questions. This formulation compels the agent to perform multiple search queries, each targeting a distinct sub-question or sub-objective, and then integrate the retrieved answers into a comprehensive final response.
为了弥合这一缺口,作者提出 multi-objective question answering,这是一种增加问题求解所需推理步骤数的任务。 基于 HotpotQA 和 Natural Questions 等已有多轮数据集,作者交错组合原始 QA 语料中的多个问题,并构造一个单一复合查询,要求回答所有子问题。 这种形式迫使智能体执行多次搜索查询,每次针对不同子问题或子目标,然后把检索到的答案整合为完整最终回答。
4. Experiments & Results
The authors empirically demonstrate the effectiveness of MEM1 in training agents to perform multi-turn tasks while preserving a near-constant-sized memory state. They evaluate MEM1 against several baselines using accuracy metrics such as Exact Match, F1 score, and environment reward, as well as efficiency metrics such as peak token usage, dependency length, and inference time. All MEM1 variants are fine-tuned from the Qwen2.5-7B Base model, and PPO is used as the RL algorithm because it computes token-level advantages and stabilizes training.
作者通过实验验证 MEM1 在训练智能体执行多轮任务、同时保持近似常数大小记忆状态方面的有效性。 他们使用准确性指标(Exact Match、F1 score、environment reward)和效率指标(peak token usage、dependency length、inference time)将 MEM1 与多个基线比较。 所有 MEM1 变体都从 Qwen2.5-7B Base 微调而来,并使用 PPO 作为 RL 算法,因为 PPO 可以计算逐 token advantage 并稳定训练。
The experiments are conducted in two standard environments, each reflecting real-world scenarios that require multi-turn agent interactions. The first environment is question answering with retrieval-augmented generation, where the agent must answer queries by retrieving relevant information from an external knowledge store. The second environment is WebShop navigation, where the agent assists users in online shopping by browsing a website and selecting items based on natural language descriptions.
实验在两个标准环境中进行,每个环境都反映了需要多轮智能体交互的真实场景。 第一个环境是带检索增强生成的问答任务,智能体必须从外部知识库中检索相关信息来回答查询。 第二个环境是 WebShop 导航,智能体需要根据自然语言描述浏览购物网站并选择商品,帮助用户完成在线购物。
4.1. Implementation Details
For long-horizon QA, the authors augment the multi-hop QA dataset that mixes HotpotQA and Natural Questions to form a 2-objective composite task. For the web agent, they use the WebShop environment, which also produces a reward during training. During RL training, exact match is used for QA tasks and environment reward is used for WebShop. To evaluate efficiency, the authors consider peak token usage, average dependency, and average inference time.
对于长程 QA,作者增强了混合 HotpotQA 和 Natural Questions 的多跳 QA 数据集,以形成 2-objective 复合任务。 对于 Web 智能体,作者使用 WebShop 环境,该环境在训练时也会产生奖励。 在 RL 训练中,QA 任务使用 exact match,WebShop 使用环境奖励。 为了评估效率,作者考虑 peak token usage、average dependency 和 average inference time。
To compare accuracy and efficiency, the authors benchmark MEM1 against Search-R1, DeepResearcher, Qwen2.5-14B-Instruct, Agent-FLAN, Agent-R, AgentLM, truncation baselines, A-MEM, and an SFT model trained from GPT-4o-curated trajectories. Because MEM1 truncates past context after each turn, the agent may have difficulty determining when to terminate. To address this, the authors prepend a hint such as [HINT: YOU HAVE {turns_left} TURNS LEFT] to each <info> tag.
为了比较准确性和效率,作者将 MEM1 与 Search-R1、DeepResearcher、Qwen2.5-14B-Instruct、Agent-FLAN、Agent-R、AgentLM、truncation 基线、A-MEM,以及用 GPT-4o 筛选轨迹训练的 SFT 模型进行对比。 由于 MEM1 会在每轮结束后截断过去上下文,智能体可能难以判断何时终止。 为了解决这一点,作者会在每个 <info> 标签前加入类似 [HINT: YOU HAVE {turns_left} TURNS LEFT] 的提示。
4.2. MEM1 on Multi-Objective Multi-Hop Tasks
One key advantage of MEM1 agents lies in their efficient management of long-horizon interactions with the environment. To demonstrate this, the authors train MEM1 with a 2-objective augmentation of the QA dataset and test it against other models on held-out multi-objective test datasets. As shown in Table 1, on 2-objective datasets, MEM1 achieves better EM and F1 scores than other 7B counterparts while using significantly fewer peak tokens and achieving faster inference.
MEM1 智能体的一个关键优势是能够高效管理与环境之间的长程交互。 为了证明这一点,作者用 QA 数据集的 2-objective 增强版本训练 MEM1,并在保留的多目标测试数据集上与其他模型比较。 如表1所示,在 2-objective 数据集上,MEM1 相比其他 7B 模型取得更好的 EM 和 F1,同时显著降低 peak token 并实现更快推理。
The advantage becomes even more evident in tasks requiring longer-horizon interactive processes. Figure 4 illustrates the scaling trends of task performance and memory efficiency as the number of objectives increases. While the peak token usage of other methods and models scales nearly linearly, MEM1 maintains an almost constant peak token count with only a slight increase. At 16 objectives, MEM1 surpasses the Qwen2.5-14B-Instruct baseline while using
在需要更长程交互过程的任务中,这一优势更加明显。 图4展示了随着目标数量增加,任务性能和记忆效率的 scaling 趋势。 其他方法和模型的 peak token usage 几乎线性增长,而 MEM1 的 peak token 数基本保持常数,只略有增加。 在 16-objective 设置下,MEM1 超过 Qwen2.5-14B-Instruct 基线,同时 peak token 减少
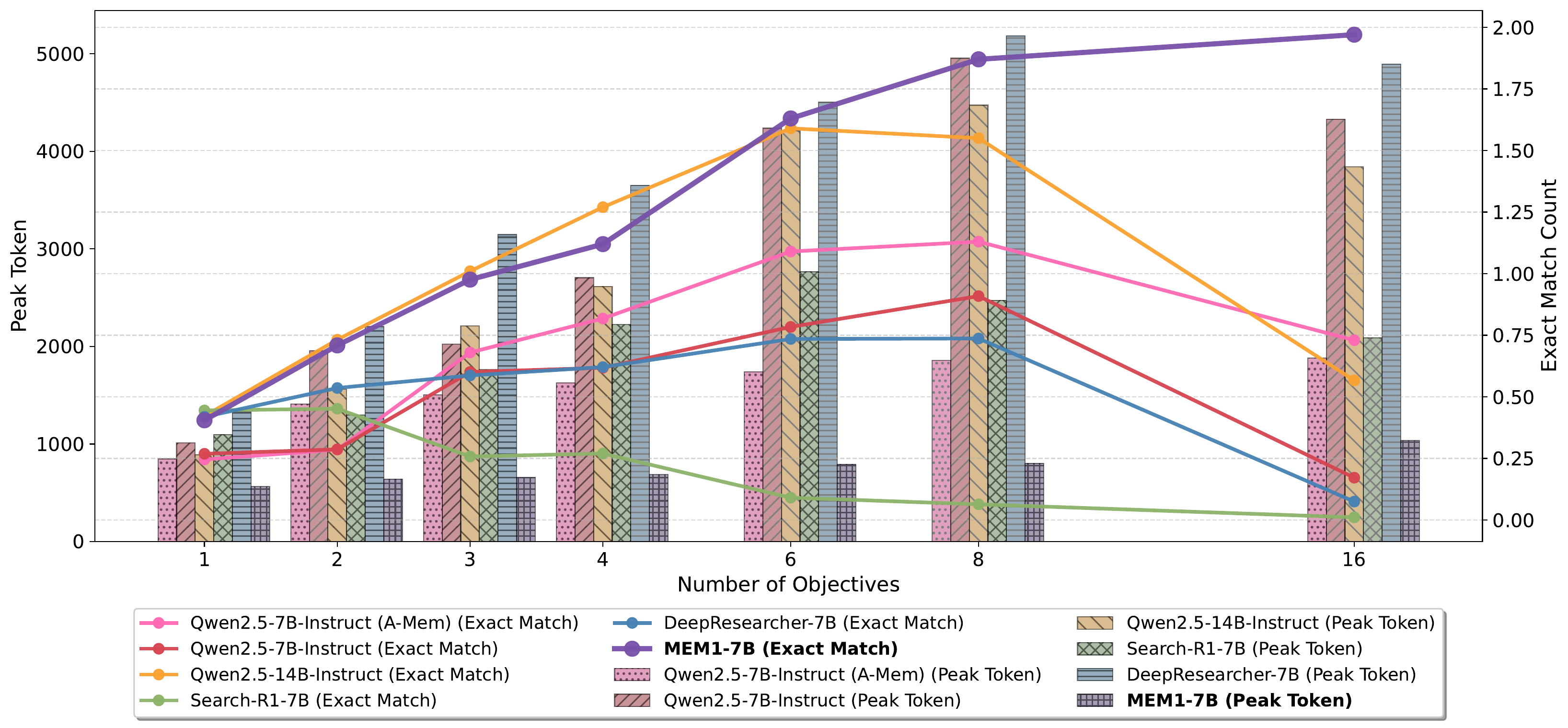
truncate 表示使用 MEM1 的 prompt 和 rollout pipeline;A-MEM 表示在 MEM1 prompt 和 rollout pipeline 下使用 A-Mem 外部记忆模块;MEM1-QA 表示在 2-objective QA 任务上训练的 MEM1。| Model | 2-Objective | |||
|---|---|---|---|---|
| EM ↑ | F1 ↑ | Peak (×10²) ↓ | Time (s) ↓ | |
| Qwen2.5-14B-Inst | 0.732 | 0.902 | 15.6 ± 0.19 | 5.49 ± 0.16 |
| Qwen2.5-7B-Inst | 0.268 | 0.366 | 19.6 ± 0.33 | 4.60 ± 0.08 |
| Qwen2.5-7B-Inst (A-MEM) | 0.286 | 0.371 | 14.1 ± 0.10 | 24.6 ± 0.51 |
| Qwen2.5-7B-Inst (truncate) | 0.262 | 0.336 | 8.28 ± 0.06 | 5.89 ± 0.16 |
| Search-R1 | 0.452 | 0.531 | 13.0 ± 0.08 | 4.09 ± 0.23 |
| DeepResearcher | 0.536 | 0.650 | 22.0 ± 0.43 | 4.01 ± 0.07 |
| MEM1-QA | 0.709 | 0.838 | 6.40 ± 0.02 | 6.49 ± 0.07 |
| Model | 8-Objective | |||
|---|---|---|---|---|
| EM ↑ | F1 ↑ | Peak (×10²) ↓ | Time (s) ↓ | |
| Qwen2.5-14B-Inst | 1.55 | 1.87 | 44.7 ± 0.37 | 16.2 ± 0.27 |
| Qwen2.5-7B-Inst | 0.87 | 1.10 | 49.5 ± 0.40 | 13.9 ± 0.18 |
| Qwen2.5-7B-Inst (A-MEM) | 1.13 | 1.43 | 18.6 ± 0.10 | 53.7 ± 1.26 |
| Qwen2.5-7B-Inst (truncate) | 0.97 | 1.23 | 11.8 ± 0.10 | 11.9 ± 0.20 |
| Search-R1 | 0.064 | 0.08 | 24.7 ± 0.19 | 4.25 ± 0.16 |
| DeepResearcher | 0.73 | 0.90 | 51.8 ± 0.35 | 11.3 ± 0.14 |
| MEM1-QA | 1.87 | 2.31 | 8.01 ± 0.06 | 8.68 ± 0.12 |
| Model | 16-Objective | |||
|---|---|---|---|---|
| EM ↑ | F1 ↑ | Peak (×10²) ↓ | Time (s) ↓ | |
| Qwen2.5-14B-Inst | 0.567 | 0.703 | 38.4 ± 0.71 | 29.7 ± 0.75 |
| Qwen2.5-7B-Inst | 0.165 | 0.213 | 43.3 ± 0.62 | 15.5 ± 0.23 |
| Qwen2.5-7B-Inst (A-MEM) | 0.730 | 0.961 | 18.8 ± 0.14 | 91.2 ± 2.44 |
| Qwen2.5-7B-Inst (truncate) | 0.396 | 0.497 | 13.3 ± 0.16 | 22.1 ± 0.60 |
| Search-R1 | 0.009 | 0.011 | 20.9 ± 0.03 | 4.75 ± 0.18 |
| DeepResearcher | 0.071 | 0.106 | 48.9 ± 0.66 | 15.8 ± 0.19 |
| MEM1-QA | 1.97 | 2.39 | 10.4 ± 0.09 | 8.70 ± 0.12 |
4.3. MEM1 on Single-Objective Multi-Hop Tasks
While MEM1 is designed to train agents for very long-horizon tasks, the training method also delivers improved capability on existing multi-hop tasks while achieving much greater efficiency. Beyond QA tasks, the authors evaluate MEM1 in WebShop, where agents must manage long-horizon interactions through web navigation. As shown in Table 2, MEM1 outperforms other agent-training baselines of similar size and even surpasses AgentLM-13B, a model with roughly twice the parameter count.
虽然 MEM1 的目标是训练面向超长程任务的智能体,但该训练方法在已有多跳任务上也能提升能力,同时显著提高效率。 除了 QA 任务,作者还在 WebShop 中评估 MEM1,其中智能体需要通过网页导航管理长程交互。 如表2所示,MEM1 超过了类似规模的其他智能体训练基线,甚至超过了参数量约为两倍的 AgentLM-13B。
| Model | Avg Final Reward ↑ | Peak Token (×10³) ↓ | Dependency (×10⁶) ↓ | Inference Time Per Traj (s) ↓ |
|---|---|---|---|---|
| GPT-4o | 25.48 | 5.30 ± 1.23 | 3.99 ± 1.16 | N/A |
| GPT-4o (truncate) | 13.82 | 0.99 ± 0.99 | 0.81 ± 0.23 | N/A |
| GPT-4o (A-MEM) | 24.50 | 1.84 ± 0.06 | 0.31 ± 0.11 | N/A |
| Qwen2.5-7B-Instruct | 18.42 | 5.64 ± 1.34 | 3.38 ± 0.89 | 12.31 ± 1.82 |
| Qwen2.5-14B-Instruct | 12.34 | 5.44 ± 0.92 | 3.30 ± 0.61 | 18.17 ± 2.32 |
| Agent-FLAN-7B | 40.35 | 3.37 ± 1.12 | 2.18 ± 1.62 | 9.95 ± 6.19 |
| Agent-R-8B | 63.91 | N/A | N/A | N/A |
| AgentLM-7B | 63.60 | 2.24 ± 0.40 | 0.28 ± 0.07 | 3.91 ± 1.07 |
| AgentLM-13B | 70.80 | 2.36 ± 0.46 | 0.30 ± 0.08 | 5.23 ± 1.59 |
| MEM1-WebShop | 70.87 | 0.81 ± 0.10 | 0.15 ± 0.16 | 2.61 ± 0.48 |
For single-objective QA in Wikipedia, Table 3 presents accuracy and efficiency metrics where the agent can make retrieval requests from a Wikipedia datastore via RAG. The MEM1 model used here is trained solely on a 2-objective task. Overall, MEM1 demonstrates superior efficiency across all three efficiency metrics, while achieving the highest EM score and an F1 score comparable to Qwen2.5-14B-Instruct. The authors also observe that SFT significantly underperforms RL, highlighting the necessity of RL-based training.
对于 Wikipedia 中的单目标 QA,表3给出了准确性和效率指标;在该环境中,智能体可以通过 RAG 向 Wikipedia 数据库发起检索请求。 这里使用的 MEM1 模型仅在 2-objective 任务上训练。 总体而言,MEM1 在三个效率指标上都表现更优,同时取得最高 EM 分数,F1 也与 Qwen2.5-14B-Instruct 相当。 作者还观察到 SFT 明显弱于 RL,这说明基于 RL 的训练是必要的。
To validate transferability and generalizability, the authors perform zero-shot transfer to an online Web-QA environment unseen during training. In this environment, agents conduct web searches through an API service that returns titles, snippets, and URLs. As shown in Table 3, MEM1 consistently exhibits improved efficiency alongside comparable effectiveness in this unseen setting.
为了验证迁移能力和泛化能力,作者将模型零样本迁移到训练时未见过的在线 Web-QA 环境。 在该环境中,智能体通过 API 服务执行网页搜索,API 会返回标题、摘要片段和 URL。 如表3所示,MEM1 在未见环境中保持相当效果的同时,始终展现出更高效率。
SFT 表示用 SFT 训练并应用 MEM1 的 prompt 与 rollout。DeepResearcher 专门在单目标 Online Web-QA 上以 F1 为目标训练,Search-R1 专门在单目标 Wiki-RAG 上以 EM 为目标训练。| Environment | System | EM ↑ | F1 ↑ | Peak Token (×10²) ↓ | Dependency (×10⁵) ↓ | Inference Time ↓ |
|---|---|---|---|---|---|---|
| Wiki RAG | Qwen2.5-7B-Inst (truncate) | 0.287 | 0.382 | 6.28 ± 0.05 | 1.65 ± 0.04 | 2.26 ± 0.04 |
| Qwen2.5-7B-Inst (A-MEM) | 0.246 | 0.373 | 8.47 ± 0.12 | 0.92 ± 0.03 | 11.2 ± 0.40 | |
| Qwen2.5-7B-Inst | 0.269 | 0.390 | 9.32 ± 0.19 | 1.17 ± 0.04 | 2.31 ± 0.04 | |
| Qwen2.5-14B-Inst | 0.422 | 0.534 | 8.89 ± 0.21 | 2.22 ± 0.10 | 6.73 ± 0.24 | |
| Search-R1 | 0.445 | 0.516 | 11.0 ± 0.25 | 1.50 ± 0.05 | 2.23 ± 0.14 | |
| DeepResearcher | 0.419 | 0.503 | 13.3 ± 0.34 | 7.04 ± 0.33 | 3.86 ± 0.09 | |
| MEM1-QA (SFT) | 0.302 | 0.358 | 6.54 ± 0.05 | 3.30 ± 0.13 | 4.84 ± 0.21 | |
| MEM1-QA | 0.405 | 0.471 | 5.63 ± 0.03 | 0.76 ± 0.02 | 3.79 ± 0.07 | |
| Online Web-QA | Qwen2.5-7B-Inst | 0.334 | 0.451 | 8.37 ± 0.18 | 1.39 ± 0.06 | 2.20 ± 0.04 |
| DeepResearcher | 0.372 | 0.492 | 10.27 ± 0.19 | 2.86 ± 0.14 | 2.87 ± 0.06 | |
| MEM1-QA | 0.397 | 0.485 | 5.79 ± 0.06 | 0.44 ± 0.02 | 1.84 ± 0.03 |
4.4. Analysis on Emergent Agent Behaviors

Through analyzing MEM1's multi-turn interaction traces trained on 2-objective QA, the authors observe a range of emergent behaviors that are critical for long-horizon, multi-objective tasks. First, MEM1 learns to manage multiple questions concurrently by maintaining a structured internal state. As shown in Figure 5, when faced with two multi-hop questions, the agent stores and updates memory for each question separately, guiding subsequent searches based on identified information gaps. MEM1 also learns to interleave reasoning and memory in its internal state <IS>, weaving important information into decision-making to support both information retention and action selection.
通过分析在 2-objective QA 上训练得到的 MEM1 多轮交互轨迹,作者观察到一系列对长程、多目标任务至关重要的涌现行为。 首先,MEM1 学会通过维护结构化内部状态来并行管理多个问题。 如图5所示,面对两个多跳问题时,智能体会分别存储和更新每个问题的记忆,并基于识别出的信息缺口指导后续搜索。 MEM1 还学会在内部状态 <IS> 中交错组织推理和记忆,把重要信息编织进决策过程,同时支持信息保留和动作选择。
Beyond behaviors unique to the multi-objective setup and memory architecture, MEM1 also exhibits several general-purpose search strategies. It performs self-verification, decomposes complex queries into manageable subgoals, extracts key information from search results, and re-scopes overly specific queries when retrieval fails. Many of these behaviors, including verification, planning, and iterative search, are also reported in recent studies on deep research agents.
除了多目标设置和记忆架构特有的行为外,MEM1 还表现出若干通用搜索策略。 它会进行自我验证,把复杂查询分解为可管理的子目标,从搜索结果中提取关键信息,并在过于具体的查询失败时重新界定查询范围。 这些行为中的许多,例如验证、规划和迭代搜索,也出现在近期 deep research 智能体研究中。
5. Conclusion, Limitations, and Future Work
The authors introduced MEM1, a reinforcement learning framework that enables language agents to perform long-horizon reasoning with consolidated memory. By integrating inference-time reasoning and memory consolidation into a unified internal state, MEM1 addresses the scalability challenges of prompt growth and achieves competitive performance across QA and web navigation benchmarks, with substantially reduced memory usage and inference latency. Despite these advantages, MEM1 assumes access to environments with well-defined and verifiable rewards. While this assumption holds in domains such as QA, math, and web navigation, many open-ended tasks present ambiguous or noisy reward structures. Fully realizing the potential of MEM1 therefore requires advances in modeling such tasks and designing suitable reward mechanisms. A promising future direction is to explore methods for training MEM1 agents in open-ended settings where reward signals are sparse, delayed, or implicit.
作者提出了 MEM1,这是一个强化学习框架,使语言智能体能够借助整合记忆执行长程推理。 通过把推理时 reasoning 和记忆整合统一到同一个内部状态中,MEM1 解决了提示增长带来的可扩展性挑战,并在 QA 和网页导航 benchmark 上取得有竞争力的性能,同时显著降低记忆使用和推理延迟。 尽管有这些优势,MEM1 假设环境能够提供明确定义且可验证的奖励。 这一假设在 QA、数学和网页导航等领域成立,但许多开放式任务的奖励结构模糊或噪声较大。 因此,要充分释放 MEM1 的潜力,还需要进一步研究如何建模这类任务并设计合适的奖励机制。 一个有前景的未来方向,是探索如何在奖励稀疏、延迟或隐式的开放式设置中训练 MEM1 智能体。
Appendix A. Details of MEM1
A.1. Computing Resources and Training Details
All trainings of MEM1 are conducted on
MEM1 的所有训练都在
A.2. RAG Configuration
For RAG on the local Wiki corpus, the authors use Faiss-GPU serving an E5 Base model. The Wiki corpus is taken from a Wikipedia 2018 dump. For fair comparison with other methods, the number of passages retrieved each time is set to
对于本地 Wiki 语料上的 RAG,作者使用 Faiss-GPU 提供 E5 Base 模型的检索服务。 Wiki 语料来自 Wikipedia 2018 dump。 为了与其他方法公平比较,每次检索返回的 passage 数量设为
A.3. Prompts
| Prompt | 任务 | 核心约束 |
|---|---|---|
| Multi-Objective Task (QA) | 多个复杂问题的迭代问答 | 每步维护累计摘要到 <think>;如果仍有未回答问题,每次只搜索一个问题;最终用分号分隔多个答案,并放入 <answer>。 |
| Single-Objective Task (QA) | 单个复杂问题的迭代问答 | 每步基于历史摘要、搜索查询和返回信息继续推理;在 <think> 中保留必要信息;若答案已明确则直接输出 <answer>。 |
| Single-Objective Task (WebShop) | WebShop 商品导航任务 | 根据当前页面状态选择 search[...] 或 click[...] 等动作;找到最匹配商品后点击 buy now。 |
A.4. Implementation Details of Metrics and Baselines
In QA tasks, the authors use exact match (EM) both as the verifiable reward for the RL pipeline and as the evaluation metric for the final output. The final response is extracted from between the <answer> and </answer> tags. In multi-objective settings, the response should contain answers to all questions, separated by semicolons. If the XML tags are mismatched, or if the number of provided answers does not match the number of questions, the score is assigned as
在 QA 任务中,作者使用 exact match(EM)作为 RL pipeline 的可验证奖励,同时也作为最终输出的评测指标。 最终回答会从 <answer> 和 </answer> 标签之间提取。 在多目标设置中,回答需要包含所有问题的答案,并用分号分隔。 如果 XML 标签不匹配,或者给出的答案数量与问题数量不一致,则分数记为
The F1 score computes the harmonic mean between precision
F1 分数计算 precision
If multiple ground-truth answers are present, the maximum F1 score over all ground truths is chosen. For multi-objective tasks, the final F1 is the sum of the F1 scores for all sub-questions. Peak token usage is the maximum number of tokens, measured with the GPT-4o-mini tokenizer, in any single sequence throughout the agent's trajectory. For fair comparison, the system prompt is excluded from this sequence length. This metric acts as a proxy for inference-time memory requirement.
如果存在多个标准答案,则取所有标准答案中最高的 F1 分数。 对于多目标任务,最终 F1 是所有子问题 F1 分数之和。 Peak token usage 表示智能体整个轨迹中任意单个序列的最大 token 数,使用 GPT-4o-mini tokenizer 计算。 为了公平比较,计算该序列长度时会排除 system prompt。 这个指标可以近似反映推理时的记忆需求。
Following prior work, dependency length is defined as the total number of historical tokens on which each generated token effectively depends. Let
沿用已有工作,dependency length 被定义为每个生成 token 实际依赖的历史 token 总量。 令
At a high level, this metric quantifies the cumulative computational cost associated with generating an output trajectory. In MEM1, prefix tokens from previous steps are consolidated into a new internal state instead of being continuously accumulated. The authors ignore system-prompt tokens when calculating dependency length. Inference time is recorded as the total elapsed time required to generate the complete output trajectory. These measurements are conducted on a single H200 GPU with
从高层来看,这个指标衡量生成整条输出轨迹所涉及的累计计算成本。 在 MEM1 中,前面步骤的 prefix token 会被整合进新的内部状态,而不是持续累积。 作者在计算 dependency length 时会忽略 system prompt 中的 token。 Inference time 记录生成完整输出轨迹所需的总耗时。 这些测量在单块 H200 GPU 上完成,并使用
For baselines, Search-R1 is trained on the
对于基线方法,Search-R1 使用与 MEM1 相同的数据集在
A.5. Algorithm
The appendix provides an outline of the MEM1 rollout algorithm, which actively manages context during interaction. Given a task prompt
附录给出了 MEM1 rollout 算法的概要,它会在交互过程中主动管理上下文。 给定任务提示
A.6. MEM1 on WebShop Training Details
For WebShop, the authors use the same rollout pipeline and policy update mechanism as in the QA tasks. Compared with QA tasks, they use a tailored prompt that preserves the idea of memory consolidation while adding instructions specific to the WebShop environment. Another difference is that WebShop has its own reward function for each state. Therefore, the authors do not use exact match; instead, they use the built-in WebShop reward as the training signal. The train, validation, and test splits follow the original WebShop paper: the first
在 WebShop 上,作者使用与 QA 任务相同的 rollout pipeline 和 policy update 机制。 与 QA 任务相比,WebShop 使用了专门定制的 prompt:它保留了记忆整合的核心思想,同时加入了 WebShop 环境特有的操作说明。 另一个区别是,WebShop 环境本身会为每个状态提供奖励函数。 因此,作者没有使用 exact match,而是使用 WebShop 内置奖励作为训练信号。 训练、验证和测试划分沿用原始 WebShop 论文:前
A.7. Additional Discussion on the Attention Matrix Design
The authors note that their modification to the attention matrix does not fully recover the attention of the original trajectories, because the position ids change. Prior works that use the attention matrix to compress multiple trajectories mainly target tree exploration, where multiple generated sequences share the same prefix. For those methods, the position ids can also be adjusted so that each trajectory follows consecutive increasing position ids. In MEM1, however, the prefix does not remain the same because memory consolidation changes the internal state. As a result, each <IS> token has two possible position ids: one for the previous turn and one for the next turn. To exactly recover the original attention, one would need to duplicate each <IS> token and assign different position ids to the two copies. Such duplication would significantly slow down training because the trajectories become much longer. For efficiency, the authors do not duplicate <IS> tokens and instead assign the position ids from the previous trajectory. Although this slightly deviates from the ideal implementation, it can effectively be viewed as adding white spaces in the training trajectories and has no significant impact on the experimental results.
作者指出,他们对 attention matrix 的修改并不能完全恢复原始轨迹中的 attention,因为 position ids 发生了变化。 此前使用 attention matrix 压缩多条轨迹的工作,主要面向 tree exploration,也就是多条生成序列共享同一个 prefix 的情况。 在这些方法中,position ids 也可以相应调整,使每条轨迹都遵循连续递增的 position ids。 但在 MEM1 中,由于记忆整合会改变内部状态,prefix 并不会保持不变。 因此,每个 <IS> token 会有两个可能的 position ids:一个对应上一轮,一个对应下一轮。 如果要精确恢复原始 attention,就需要复制每个 <IS> token,并为两个副本分配不同的 position ids。 但这种复制会显著拖慢训练,因为训练轨迹会变得更长。 为了训练效率,作者没有复制 <IS> token,而是给它们分配上一条轨迹中的 position ids。 虽然这与理想实现略有偏差,但实际效果可以看作只是在训练轨迹中添加了一些空白,对实验结果没有显著影响。