
Memory OS of AI Agent
Memory1.4k+140+EMNLP 2025CCF-B北京邮电大学腾讯Kang J, Ji M, Zhao Z, et al. Memory OS of AI Agent[J]. arXiv preprint arXiv:2506.06326v1, 2025.
MemoryOS:AI 智能体的记忆操作系统
Abstract
Large Language Models (LLMs) face a crucial challenge from fixed context windows and inadequate memory management, leading to a severe shortage of long-term memory capabilities and limited personalization in the interactive experience with AI agents. To overcome this challenge, we innovatively propose a Memory Operating System, i.e., MemoryOS, to achieve comprehensive and efficient memory management for AI agents. Inspired by the memory management principles in operating systems, MemoryOS designs a hierarchical storage architecture and consists of four key modules: Memory Storage, Updating, Retrieval, and Generation. Specifically, the architecture comprises three levels of storage units: short-term memory, mid-term memory, and long-term personal memory. Key operations within MemoryOS include dynamic updates between storage units: short-term to mid-term updates follow a dialogue-chain-based FIFO principle, while mid-term to long-term updates use a segmented page organization strategy. Our pioneering MemoryOS enables hierarchical memory integration and dynamic updating. Extensive experiments on the LoCoMo benchmark show an average improvement of 49.11% on F1 and 46.18% on BLEU-1 over the baselines on GPT-4o-mini, showing contextual coherence and personalized memory retention in long conversations. The implementation code is open-sourced at https://github.com/BAI-LAB/MemoryOS.
大型语言模型(LLM)面临一个关键挑战:固定上下文窗口和不充分的记忆管理会导致长期记忆能力严重不足,并限制 AI 智能体交互体验中的个性化程度。 为克服这一挑战,作者创新性地提出 Memory Operating System,即 MemoryOS,以实现面向 AI 智能体的全面且高效的记忆管理。 受操作系统中内存管理原则启发,MemoryOS 设计了一种分层存储架构,并由四个关键模块组成:记忆存储、更新、检索和生成。 具体而言,该架构包含三个层级的存储单元:短期记忆(STM)、中期记忆(MTM)和长期人格记忆(LPM)。 MemoryOS 中的关键操作包括存储单元之间的动态更新:短期到中期的更新遵循基于对话链的 FIFO 原则,而中期到长期的更新使用分段页面组织策略。 作者开创性的 MemoryOS 支持分层记忆整合和动态更新。 在 LoCoMo 基准上的大量实验表明,在 GPT-4o-mini 上,相比基线方法,MemoryOS 在 F1 上平均提升 49.11%,在 BLEU-1 上平均提升 46.18%,展现出长对话中的上下文连贯性和个性化记忆保留能力。 实现代码已开源于 https://github.com/BAI-LAB/MemoryOS。
1. Introduction
Large Language Models (LLMs) demonstrate impressive capabilities in text comprehension and generation, but face inherent limitations in sustaining dialogue coherence due to their reliance on fixed-length contextual windows for memory management. This fixed-length design inherently struggles to preserve continuity in dialogues with significant temporal gaps, often resulting in disjointed memory that manifests as factual inconsistencies and reduced personalization. Long-term memory coherence is critical in scenarios requiring persistent user adaptation, multi-session knowledge retention, or stable persona representation across extended interactions, where the limitations of fixed-length memory management in default LLMs become particularly acute, constituting a significant open challenge in the field.
大型语言模型在文本理解和生成方面展现出令人印象深刻的能力,但由于依赖固定长度上下文窗口来进行记忆管理,它们在维持对话连贯性方面面临内在限制。 这种固定长度设计天然难以在存在显著时间间隔的对话中保持连续性,经常导致割裂的记忆,并表现为事实不一致和个性化降低。 在需要持久用户适应、多会话知识保留或跨长时间交互保持稳定人格表示的场景中,长期记忆连贯性至关重要;在这些场景下,默认 LLM 的固定长度记忆管理限制尤其突出,构成了该领域一个重要的开放挑战。
To address this challenge, current memory mechanisms in default LLMs can be broadly categorized into three methodological types: (1) Knowledge-organization methods, such as A-Mem structure memory into interconnected semantic networks or notes to enable adaptive management and flexible retrieval; (2) Retrieval mechanism-oriented approaches, e.g., MemoryBank integrates semantic retrieval with a memory forgetting curve mechanism to allow long-term memory updating; and (3) Architecture-driven methods, such as MemGPT use hierarchical structures with explicit read and write operations to dynamically manage context. Although these diverse strategies typically operate in isolation, i.e., each focusing on single dimensions such as storage structure, retrieval machinism, or update strategies, no unified operating system has been proposed to enable systematic and comprehensive memory management for AI agents.
为解决这一挑战,当前默认 LLM 中的记忆机制大体可以分为三类方法。 (1)知识组织方法,例如 A-Mem 将记忆组织成互连的语义网络或笔记,以支持自适应管理和灵活检索;(2)面向检索机制的方法,例如 MemoryBank 将语义检索与记忆遗忘曲线机制结合,以支持长期记忆更新;(3)架构驱动的方法,例如 MemGPT 使用带有显式读写操作的分层结构来动态管理上下文。 虽然这些多样化策略通常彼此独立运行,也就是各自聚焦于存储结构、检索机制或更新策略等单一维度,但尚未有统一的操作系统被提出,用于实现 AI 智能体系统化且全面的记忆管理。
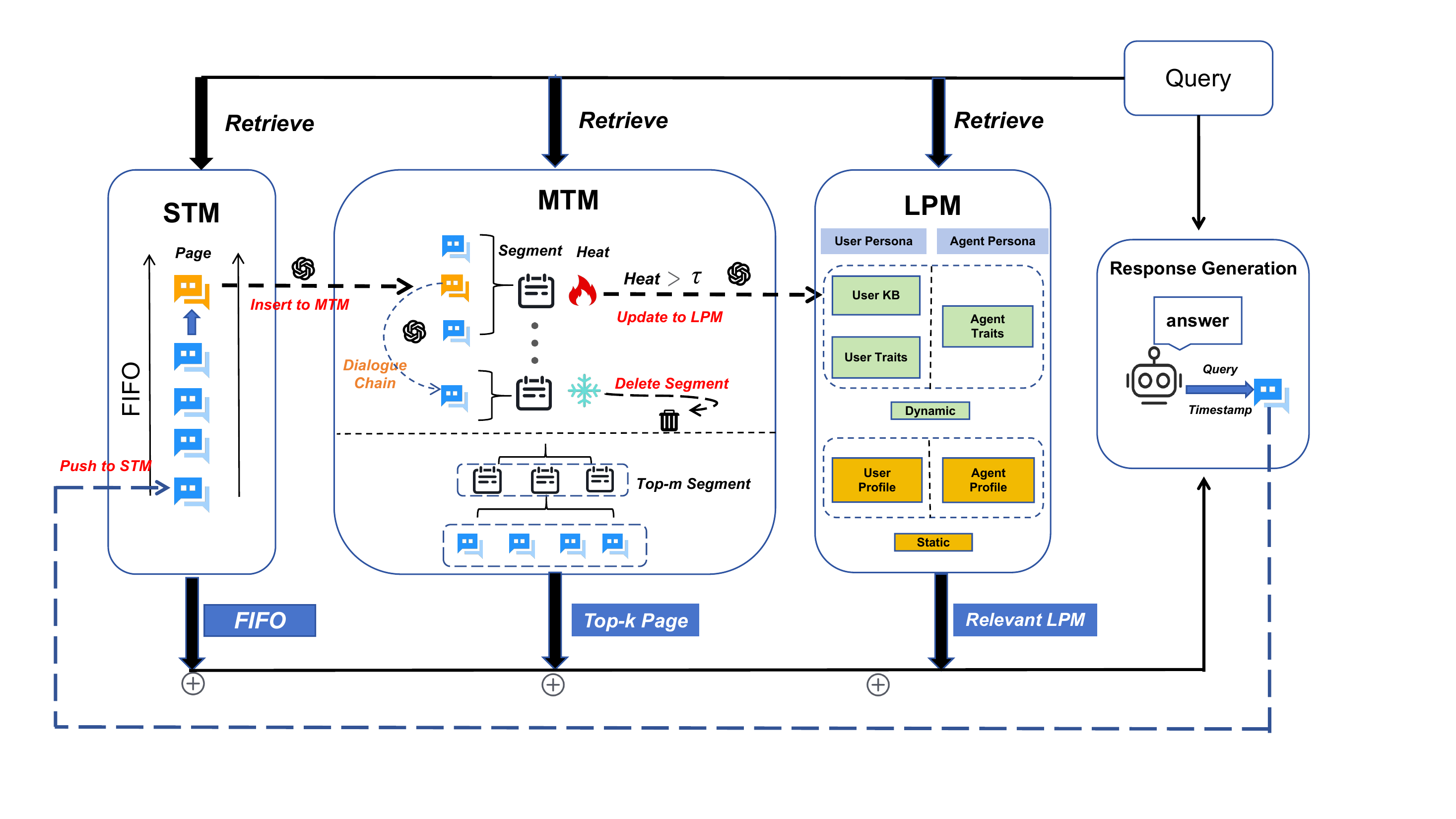
Inspired by memory management principles in operating systems, we pioneer the proposal of a comprehensive memory operating system, termed MemoryOS. As illustrated in Figure 1, MemoryOS comprises four core functional modules: memory Storage, Updating, Retrieval, and Generation. Through their coordinated collaboration, the system establishes a unified memory management framework encompassing hierarchical storage, dynamic updating, adaptive retrieval, and contextual generation. Specifically, Memory Storage organizes information into short-term, mid-term, and long-term storage units. Memory Updating dynamically refreshes via a segmented paging architecture based on the dialogue-chain and heat-based mechanisms. Memory Retrieval leverages semantic segmentation to query these tiers, then Response Generation integrates retrieved memory information to generate coherent and personalized responses. This synergistic workflow ensures holistic management of long-term conversational memory, enabling contextual coherence and personalized recall in extended dialogues.
受操作系统中内存管理原则启发,作者率先提出一种全面的记忆操作系统,称为 MemoryOS。 如 图1 所示,MemoryOS 包含四个核心功能模块:记忆存储、更新、检索和生成。 通过这些模块的协同配合,系统建立了一个统一的记忆管理框架,涵盖分层存储、动态更新、自适应检索和上下文生成。 具体而言,记忆存储 将信息组织进短期、中期和长期存储单元。 记忆更新 基于对话链机制和热度机制,通过分段分页架构进行动态刷新。 记忆检索 利用语义分段查询这些层级,随后响应生成整合检索到的记忆信息,以生成连贯且个性化的响应。 这一协同工作流确保了对长期对话记忆的整体管理,使扩展对话中的上下文连贯性和个性化回忆成为可能。
The primary contributions of our work are summarized as: We make the first innovative attempt to introduce a systematic operating system, termed MemoryOS, for memory management, empowering AI agents with long-term conversational coherence and user persona persistence in long conversational interactions. MemoryOS introduces a pioneering three-tier hierarchical memory storage architecture and integrates four core functional modules (i.e, storage, updating, retrieval, and generation) for memory management, enabling dynamic capture and evolution of user preferences across extended dialogues. Comprehensive experiments validate MemoryOS's effectiveness and efficiency in maintaining response correctness and coherence across diverse benchmark datasets, demonstrating its capability to handle long conversational interactions.
本文工作的主要贡献总结如下: 作者首次创新性地引入一个用于记忆管理的系统化操作系统 MemoryOS,使 AI 智能体在长对话交互中具备长期对话连贯性和用户人格持久性。 MemoryOS 提出开创性的三层分层记忆存储架构,并整合四个核心功能模块(即存储、更新、检索和生成)用于记忆管理,从而支持跨扩展对话动态捕获并演化用户偏好。 全面实验验证了 MemoryOS 在多样 benchmark 数据集上维持响应正确性和连贯性的有效性与效率,展示了其处理长对话交互的能力。
2. Related Work
2.1. Memory for LLM Agents
Existing Large Language Models (LLMs) face fundamental challenges in handling complex scenarios requiring long-term coherence. These challenges stem from the inherent limitations of fixed-length designs, which struggle to maintain continuity in dialogues with significant temporal gaps, resulting in fragmented memory that manifests as factual inconsistencies and diminished personalization. Advancements in memory systems of LLMs addressing this problem can be broadly grouped into three categories: knowledge-organization, retrieval mechanism-oriented, and architecture-driven frameworks.
现有大型语言模型在处理需要长期连贯性的复杂场景时面临根本挑战。 这些挑战源于固定长度设计的内在限制;这种设计难以在存在显著时间间隔的对话中保持连续性,导致碎片化记忆,并表现为事实不一致和个性化下降。 为解决这一问题,LLM 记忆系统的进展大体可以分为三类:知识组织、面向检索机制以及架构驱动框架。
Knowledge-organization methods focus on capturing and structuring the intermediate reasoning states of large language models. For example, Think-in-Memory (TiM) stores evolving chains-of-thought, enabling consistency through continual updates. A-Mem organizes knowledge into an interconnected note network that spans sessions. Grounded Memory integrates vision-language models for perception, knowledge graphs for structured memory representation to enable context-aware reasoning in smart personal assistants.
知识组织方法关注捕获并结构化大型语言模型的中间推理状态。 例如,Think-in-Memory(TiM)存储不断演化的思维链,并通过持续更新实现一致性。 A-Mem 将知识组织成跨会话的互连笔记网络。 Grounded Memory 将视觉语言模型用于感知,将知识图谱用于结构化记忆表示,从而在智能个人助手中支持上下文感知推理。
Retrieval mechanism–oriented approaches enrich the model with an external memory library. MemoryBank logs conversations, events, and user traits in a vector database and refreshes them using a forgetting-curve schedule; AI-town keeps memories in natural language and adds a reflection loop for relevance filtering. EmotionalRAG retrieves memory entries by combining semantic similarity with the agent’s current emotional state using a hybrid strategy.
面向检索机制的方法通过外部记忆库增强模型。 MemoryBank 将对话、事件和用户特征记录在向量数据库中,并使用遗忘曲线计划对其刷新;AI-town 以自然语言保存记忆,并增加反思循环用于相关性过滤。 EmotionalRAG 使用混合策略,将语义相似性与智能体当前情绪状态结合起来检索记忆条目。
Architecture-driven designs alter the core control flow to manage context explicitly. For example, MemGPT adopts an OS-like hierarchy with dedicated read/write calls, while Self-Controlled Memory (SCM) introduces dual buffers and a memory controller that gates selective recall.
架构驱动设计会改变核心控制流,以显式管理上下文。 例如,MemGPT 采用类似操作系统的层级结构,并配备专门的 read/write 调用;Self-Controlled Memory(SCM)则引入双缓冲区和一个记忆控制器,用于门控选择性回忆。
2.2. Memory Management in OS
Modern operating systems (OS) use combined segment-page memory management to balance logical structure with efficient physical utilization. Classic approaches like Multics organize memory into segments divided into pages, supporting efficient management, protection, and sharing. Segment metadata (size, access permissions) prevents external fragmentation, while paging reduces internal fragmentation. Advanced OS use priority-based eviction (e.g., LRU, working-set models) to maintain hot data, and Zheng et al. show that combining coarse-grained segmentation with fine-grained paging minimizes overhead on many-core processors.
现代操作系统使用段页结合的内存管理,以平衡逻辑结构和高效物理利用。 Multics 等经典方法将内存组织为由页面划分的段,从而支持高效管理、保护和共享。 段元数据(大小、访问权限)可以防止外部碎片,而分页可以减少内部碎片。 先进操作系统使用基于优先级的淘汰策略(如 LRU、工作集模型)来维护热数据,Zheng 等人也表明,在众核处理器上结合粗粒度分段和细粒度分页可以最小化开销。
Inspired by the management in OS, our MemoryOS applies these principles by structuring its memory into logical segments (conversation topics) subdivided into pages. It uses heat-based prioritization to retain relevant content and efficiently discard or archive less-accessed information, enhancing context management and personalization.
受操作系统管理方式启发,MemoryOS 通过将记忆结构化为逻辑段(对话主题),并进一步将其划分为页面,来应用这些原则。 它使用基于热度的优先级策略保留相关内容,并高效丢弃或归档较少访问的信息,从而增强上下文管理和个性化能力。
3. MemoryOS
MemoryOS is a comprehensive memory management system for AI agents that dynamically updates memory and retrieves semantically relevant context, ensuring coherent and personalized interactions in long conversations.
MemoryOS 是一个面向 AI 智能体的全面记忆管理系统,它动态更新记忆并检索语义相关上下文,从而确保长对话中的连贯且个性化交互。
3.1. Overview Architecture
The overview architecture of MemoryOS is illustrated in Figure 1. It consists of four modules: memory storage, update, retrieval, and generation.
MemoryOS 的总体架构如 图1 所示。 它由四个模块组成:记忆存储、更新、检索和生成。
Memory Storage: This module is responsible for organizing and storing memory information by a three-tier hierarchical structure: Short-Term Memory (STM) for timely conversations, Mid-Term Memory (MTM) for recurring topic summaries, and Long-term Personal Memory (LPM) for user or agent preferences, ensuring memory integrity and effective utilization.
记忆存储: 该模块负责通过三层分层结构组织和存储记忆信息:短期记忆(STM)用于即时对话,中期记忆(MTM)用于反复出现的主题摘要,长期人格记忆(LPM)用于用户或智能体偏好,从而确保记忆完整性和有效利用。
Memory Updating: This module manages dynamic memory refreshing, including STM-to-MTM updates via dialogue-chain FIFO and MTM-to-LPM updates using a segmented page strategy with heat-based replacement.
记忆更新: 该模块管理动态记忆刷新,包括通过对话链 FIFO 进行的 STM 到 MTM 更新,以及使用带有基于热度替换的分段页面策略进行的 MTM 到 LPM 更新。
Memory Retrieval: This module retrieves relevant memory via specific queries, employing a two-tiered approach in MTM: semantic relevance identifies segments first, followed by retrieving pertinent dialogue pages. Finally, it combines persona attributes from LPM and contextual information from STM to generate responses, integrating all relevant memories for response generation.
记忆检索: 该模块通过特定查询检索相关记忆,并在 MTM 中采用两层方法:先由语义相关性识别分段,再检索相关对话页面。 最后,它结合来自 LPM 的人格属性和来自 STM 的上下文信息来生成响应,将所有相关记忆整合进响应生成过程。
Response Generation: It processes the data and generates appropriate responses. It integrates retrieval outcomes from STM, MTM, and LPM into a coherent prompt, enabling the generation of contextually coherent and personalized responses.
响应生成: 该模块处理数据并生成适当响应。 它将来自 STM、MTM 和 LPM 的检索结果整合为连贯提示,从而支持生成上下文连贯且个性化的响应。
3.2. Memory Storage Module
Memory storage module is implemented via a hierarchical structure consisting of three type store units, i.e., Short-Term Memory (STM), Mid-Term Memory (MTM), and Long-term Personal Memory (LPM) store units.
记忆存储模块通过一种分层结构实现,该结构由三类存储单元组成,即短期记忆(STM)、中期记忆(MTM)和长期人格记忆(LPM)存储单元。
Short-Term Memory (STM): It stores real-time conversation data in units called dialogue pages. Each dialogue page contains the user's query
短期记忆(STM): 它以称为对话页面的单元存储实时对话数据。 每个对话页面包含用户查询
where the meta information is generated by an LLM in two steps: first, evaluating a new page’s contextual relevance to prior pages to determine chain linkage or resetting to the current page if semantically discontinuous; second, summarizing all chain pages into
其中,元信息由 LLM 分两步生成:第一,评估新页面与先前页面的上下文相关性,以确定链路连接;如果语义不连续,则重置到当前页面;第二,将所有链页面汇总为
Mid-Term Memory (MTM): Inspired by the memory management principles in Operating Systems, it adopts a Segmented Paging storage architecture. Dialogue pages with the same topic are grouped into segments, each containing multiple pages for a unique topic. The segment in MTM is defined as:
中期记忆(MTM): 受操作系统中内存管理原则启发,它采用分段分页存储架构。 具有相同主题的对话页面会被分组到分段中,每个分段包含某一唯一主题下的多个页面。 MTM 中的分段定义如下:
where the content of a segment is summarized by a LLM based on the related dialogue pages.
其中,分段内容由 LLM 基于相关对话页面进行摘要。
where
其中,
Long-term Persona Memory (LPM): This module ensures that both the user and the assistant maintain a persistent memory of important personal details and characteristics, ensuring consistency and personalization over long-term interactions. It consists of two components: the User Persona and the AI Agent Persona.
长期人格记忆(LPM): 该模块确保用户和助手都能对重要个人细节和特征保持持久记忆,从而确保长期交互中的一致性和个性化。 它由两个组件组成:用户人格和 AI 智能体人格。
- User Persona. The User Profile comprises a static component with fixed attributes (gender, name, birth year), a User Knowledge Base (User KB) that dynamically stores factual information extracted and incrementally updated from past interactions, and User Traits that contains the evolving interests, habits, and preferences of users over time.
- Agent Persona. It contains the Agent Profile, which includes fixed settings like the role the AI agent assistant plays or its character traits, providing a consistent self-description. The Agent Traits are dynamic attributes that develop through interactions with the user, potentially including new settings added by the user or interaction history, e.g., recommended items, during conversations.
- 用户人格。用户画像包含一个具有固定属性(性别、姓名、出生年份)的静态组件,一个用于动态存储从过往交互中抽取并增量更新事实信息的用户知识库(User KB),以及包含用户随时间演化的兴趣、习惯和偏好的用户特征。
- 智能体人格。它包含智能体画像,其中包括 AI 智能体助手扮演的角色或其性格特征等固定设定,从而提供一致的自我描述。智能体特征是在与用户交互过程中发展出的动态属性,可能包括用户新增的设定或对话过程中的交互历史,例如推荐过的项目。
3.3. Memory Update Module
Key updating operations include updates within each unit itself and the update mechanism from STM to MTM, MTM to LPM store units.
关键更新操作包括每个单元自身内部的更新,以及从 STM 到 MTM、从 MTM 到 LPM 存储单元的更新机制。
STM-MTM Update: STM stores information in the form of dialogue pages in a queue with fixed length. We employ a First-In-First-Out (FIFO) update strategy for information migration to the Mid-Term Memory (MTM). New dialogue page is appended to the queue's end. When the STM queue reaches its maximum capacity, the oldest dialogue page is transferred from the STM to the MTM according to the FIFO principle.
STM-MTM 更新: STM 以对话页面的形式将信息存储在固定长度队列中。 作者采用先进先出(FIFO)更新策略,将信息迁移到中期记忆(MTM)。 新的对话页面会被追加到队列末尾。 当 STM 队列达到最大容量时,最旧的对话页面会根据 FIFO 原则从 STM 转移到 MTM。
MTM-LPM Update: MTM updates involve two operations, i.e., segment deletion and segment-to-LPM updates, both based on the Heat score of segments, defined as:
MTM-LPM 更新: MTM 更新涉及两个操作,即分段删除和分段到 LPM 的更新,这二者都基于分段的 Heat 分数,定义如下:
where coefficients
其中,系数
These three metrics, i.e., retrieval count (
这三个指标,即检索次数(
LPM Update: Segments with heat exceeding a threshold
LPM 更新: 热度超过阈值
3.4. Memory Retrieval Module
The Memory Retrieval Module retrieves information from three parts: STM for recent context, MTM using a two-stage retrieval (segment and page level), and LPM for personalized knowledge. Given a query from the user, the memory retrieval module retrieves from the stored memory, i.e., STM, MTM, and LPM, to return the most relevant information to generate the responses, defined as:
记忆检索模块从三个部分检索信息:用于近期上下文的 STM,使用两阶段检索(分段级和页面级)的 MTM,以及用于个性化知识的 LPM。 给定用户查询时,记忆检索模块会从已存储记忆中检索,也就是从 STM、MTM 和 LPM 中检索,以返回最相关的信息用于生成响应,定义如下:
where
其中,
STM retrieval: All dialogue pages are retrieved as STM holds the most recent contextual memory for the current conversation.
STM 检索: 所有对话页面都会被检索,因为 STM 保存当前对话中最近的上下文记忆。
MTM retrieval: Inspired by psychological memory recall mechanisms, a two-stage retrieval process is employed: first selecting segments via a matching score (defined in Eq. (2)) to select top-m candidate segments, then selecting the top-k most relevant dialogue pages within these segments based on semantic similarity. After retrieval, the segment’s visit counter
MTM 检索: 受心理学记忆回忆机制启发,系统采用两阶段检索过程:首先通过匹配分数(定义见公式 (2))选择 top-m 候选分段,然后基于语义相似性在这些分段内选择 top-k 个最相关对话页面。 检索之后,分段的访问计数器
LPM retrieval: The User KB and Assistant Traits each retrieve the top-10 entries with the highest semantic relevance to the query vector as background knowledge. All information in the User Profile, Agent Profile, and User Traits is utilized, as they store user preference information, agent characteristic information, and user-specific trait information.
LPM 检索: User KB 和 Assistant Traits 会分别检索与查询向量语义相关性最高的 top-10 条目作为背景知识。 用户画像、智能体画像和用户特征中的所有信息都会被使用,因为它们分别存储用户偏好信息、智能体特征信息和用户特定特征信息。
3.5. Response Generation Module
Given the user query, the final prompt is constructed by integrating the above three types of retrieved content from STM, MTM and LPM, along with the user's query, form the final prompt input for the LLM to generate the final response. The incorporation of memory from recent dialogue (STM), relevant conversation pages (MTM), and persona information (LPM) ensures responses remain contextually coherent with current interactions, draw on historical dialogue details and summaries for depth, and align with user and assistant identities, respectively, enabling coherent, accurate, and personalized interaction experiences of AI agent systems.
给定用户查询时,最终提示会通过整合上述三类来自 STM、MTM 和 LPM 的检索内容以及用户查询来构建,形成输入给 LLM 以生成最终响应的最终提示。 结合来自近期对话的记忆(STM)、相关对话页面(MTM)和人格信息(LPM),可以确保响应分别与当前交互保持上下文连贯,利用历史对话细节和摘要获得深度,并与用户和助手身份保持一致,从而使 AI 智能体系统具备连贯、准确且个性化的交互体验。
4. Experiments
4.1. Experimental Settings
Datasets. We conduct our experiments on GVD and LoCoMo benchmark datasets. The GVD dataset consists of multi-turn dialogues simulated from interactions between 15 virtual users and an assistant over a 10-day period, covering at least two topics per day. The LoCoMo benchmark is specifically designed for assessing long-term conversational memory capabilities, consisting of ultra-long dialogues averaging 300 turns and about 9K tokens per conversation. Questions are categorized into four types: Single-hop, Multi-hop, Temporal, and Open-domain, to systematically evaluate the memory abilities of LLMs.
数据集。 作者在 GVD 和 LoCoMo benchmark 数据集上进行实验。 GVD 数据集由多轮对话组成,这些对话模拟 15 个虚拟用户与一个助手在 10 天期间的交互,每天覆盖至少两个话题。 LoCoMo benchmark 专门用于评估长期对话记忆能力,其中包含超长对话,平均每段对话 300 轮、约 9K token。 问题被分为四类:Single-hop、Multi-hop、Temporal 和 Open-domain,用于系统评估 LLM 的记忆能力。
Evaluation Metrics. For the GVD dataset, we use three evaluation metrics: Memory Retrieval Accuracy (Acc.), Response Correctness (Corr.), and Contextual Coherence (Cohe.). Memory Retrieval Accuracy is evaluated as a binary indicator (0 or 1), while Correctness and Coherence are assessed on a three-point scale (0, 0.5, or 1). All evaluations on the GVD dataset are automatically scored by the DeepSeek-R1. On the LoCoMo benchmark, standard F1 and BLEU-1 are employed to evaluate the model’s performance.
评估指标。 对于 GVD 数据集,作者使用三个评估指标:记忆检索准确率(Acc.)、响应正确性(Corr.)和上下文连贯性(Cohe.)。 记忆检索准确率以二元指标(0 或 1)评估,而正确性和连贯性则以三点量表(0、0.5 或 1)评估。 GVD 数据集上的所有评估都由 DeepSeek-R1 自动打分。 在 LoCoMo benchmark 上,作者使用标准 F1 和 BLEU-1 来评估模型表现。
Compared Methods. We compare MemoryOS with representative memory methods, including:
比较方法。 作者将 MemoryOS 与代表性记忆方法进行比较,包括:
TiM (Think-in-Memory): This approach mimics human memory by storing reasoning outcomes instead of raw dialogues. It uses locality-sensitive hashing (LSH) to retrieve relevant context before generating responses and updates memory through post-hoc reflection. TiM manages memory via insertion, forgetting, and merging to reduce redundant reasoning and improve consistency.
TiM(Think-in-Memory): 该方法通过存储推理结果而不是原始对话来模拟人类记忆。 它使用局部敏感哈希(LSH)在生成响应前检索相关上下文,并通过事后反思更新记忆。 TiM 通过插入、遗忘和合并来管理记忆,以减少冗余推理并提升一致性。
MemoryBank: This framework dynamically adjusts memory strength based on the Ebbinghaus Forgetting Curve, prioritizing important content over time. It further builds a user portrait through continuous interaction analysis to support personalized responses.
MemoryBank: 该框架基于艾宾浩斯遗忘曲线动态调整记忆强度,随着时间推移优先保留重要内容。 它还通过持续交互分析构建用户画像,以支持个性化响应。
MemGPT: This method introduces a dual-tier memory, featuring a main context for fast access and an external context for long-term storage. This design aims to enable scalable memory extension beyond the fixed context window of LLMs.
MemGPT: 该方法引入双层记忆,包括用于快速访问的主上下文和用于长期存储的外部上下文。 这一设计旨在支持超越 LLM 固定上下文窗口的可扩展记忆延伸。
A-Mem (Agentic Memory): it dynamically generates structured notes and links them to form interconnected knowledge networks, enabling continuous memory evolution and adaptive management for LLMs.
A-Mem(Agentic Memory): 它动态生成结构化笔记,并将其连接起来形成互连知识网络,从而支持 LLM 的持续记忆演化和自适应管理。
MemoryOS: It is a comprehensive memory management framework. Through coordinated collaboration with four core functional modules: memory Storage, Updating, Retrieval, and Generation. MemoryOS achieves dialogue coherence and user persona persistence in long interactions.
MemoryOS: 它是一个全面的记忆管理框架。 通过四个核心功能模块的协同配合:记忆存储、更新、检索和生成。 MemoryOS 在长期交互中实现对话连贯性和用户人格持久性。
| Model | Method | Acc. ↑ | Corr. ↑ | Cohe. ↑ |
|---|---|---|---|---|
| GPT-4o-mini | TiM | 84.5 | 78.8 | 90.8 |
| MemoryBank | 78.4 | 73.3 | 91.2 | |
| MemGPT | 87.9 | 83.2 | 89.6 | |
| A-Mem | 90.4 | 86.5 | 91.4 | |
| Ours | 93.3 | 91.2 | 92.3 | |
| Improvement (%) | 3.2%↑ | 5.4%↑ | 1.0%↑ | |
| Qwen2.5-7B | TiM | 82.2 | 73.2 | 85.5 |
| MemoryBank | 76.3 | 70.3 | 82.7 | |
| MemGPT | 85.1 | 80.2 | 86.9 | |
| A-Mem | 87.2 | 79.5 | 87.8 | |
| Ours | 91.8 | 82.3 | 90.5 | |
| Improvement (%) | 5.3%↑ | 3.5%↑ | 3.1%↑ | |
| Method | Single Hop | Multi Hop | Temporal | Open Domain | Avg. Rank ↓ | Avg. Rank ↓ | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 ↑ | BLEU-1 ↑ | F1 ↑ | BLEU-1 ↑ | F1 ↑ | BLEU-1 ↑ | F1 ↑ | BLEU-1 ↑ | (F1) | (BLEU-1) | |
| GPT-4o-mini | ||||||||||
| TiM | 16.25 | 13.12 | 18.43 | 17.35 | 8.35 | 7.32 | 23.74 | 22.05 | 3.8 | 4.0 |
| MemoryBank | 5.00 | 4.77 | 9.68 | 6.99 | 5.56 | 5.94 | 6.61 | 5.16 | 5.0 | 5.0 |
| MemGPT | 26.65 | 17.72 | 25.52 | 19.44 | 9.15 | 7.44 | 41.04 | 34.34 | 2.2 | 2.5 |
| A-Mem | 27.02 | 20.09 | 45.85 | 36.67 | 12.14 | 12.00 | 44.65 | 37.06 | -- | -- |
| A-Mem* | 22.61 | 15.25 | 33.23 | 29.11 | 8.04 | 7.81 | 34.13 | 27.73 | 3.0 | 2.5 |
| Ours | 35.27 | 25.22 | 41.15 | 30.76 | 20.02 | 16.52 | 48.62 | 42.99 | 1.0 | 1.0 |
| Improvement (%) | 32.35%↑ | 42.33%↑ | 23.83%↑ | 5.67%↑ | 118.80%↑ | 111.52%↑ | 18.47%↑ | 25.19%↑ | -- | -- |
| Qwen2.5-3B | ||||||||||
| TiM | 4.37 | 5.01 | 2.54 | 3.21 | 6.20 | 5.37 | 6.35 | 7.34 | 4.3 | 3.5 |
| MemoryBank | 3.60 | 3.39 | 1.72 | 1.97 | 6.63 | 6.58 | 4.11 | 3.32 | 4.8 | 4.8 |
| MemGPT | 5.07 | 4.31 | 2.94 | 2.95 | 7.04 | 7.10 | 7.26 | 5.52 | 2.8 | 3.8 |
| A-Mem | 12.57 | 9.01 | 27.59 | 25.07 | 7.12 | 7.28 | 17.23 | 13.12 | -- | -- |
| A-Mem* | 10.31 | 8.76 | 16.31 | 11.07 | 6.94 | 7.31 | 12.34 | 10.62 | 2.3 | 2.0 |
| Ours | 23.26 | 15.39 | 21.44 | 14.95 | 10.18 | 8.18 | 26.23 | 22.39 | 1.0 | 1.0 |
| Improvement (%) | 125.61%↑ | 75.68%↑ | 31.45%↑ | 35.05%↑ | 46.69%↑ | 11.90%↑ | 112.56%↑ | 110.83%↑ | -- | -- |
| Method | Tokens | Avg.Calls | Avg. F1 |
|---|---|---|---|
| MemoryBank | 432 | 3.0 | 6.84 |
| TiM | 1,274 | 2.6 | 18.01 |
| MemGPT | 16,977 | 4.3 | 29.13 |
| A-Mem* | 2,712 | 13.0 | 26.55 |
| Ours | 3,874 | 4.9 | 36.23 |
Implementation Details. The experiments are conducted on hardware equipped with 8-H20 GPUs. The fixed length of the dialogue page queue in STM is 7. The maximum length of segments in MTM is set to 200. The maximum capacity for both the User KB and Agent Traits is set to 100 entries. The predefined
实现细节。 实验在配备 8 张 H20 GPU 的硬件上进行。 STM 中对话页面队列的固定长度为 7。 MTM 中分段的最大长度设为 200。 User KB 和 Agent Traits 的最大容量都设为 100 条。 预定义的
4.2. Main Results
The experimental resutls in GVD and LoCoMo benchmark datasets are shown in Table 1 and Table 2. We have the following observations:
GVD 和 LoCoMo benchmark 数据集上的实验结果如 表1 和 表2 所示。 作者有以下观察:
(1) Among all memory methods, MemoryBank performs the worst. This indicates that simply applying memory decay mechanisms is insufficient for managing conversational memory effectively. TiM outperforms MemoryBank by mitigating repetitive reasoning by saving "thoughts" rather than raw turns, but its single-stage hash retrieval cannot preserve cross-topic dependencies.
(1)在所有记忆方法中,MemoryBank 表现最差。 这表明,仅仅应用记忆衰减机制不足以有效管理对话记忆。 TiM 通过保存“thoughts”而非原始轮次来缓解重复推理,因此优于 MemoryBank,但其单阶段哈希检索无法保留跨主题依赖。
(2) A-Mem and MemGPT demonstrate relatively strong performance in long-form dialogue, But both of them lack systematic memory management mechanisms, giving rise to certain issues. For instance, MemGPT extends context via OS-style paging, yet its flat FIFO queue causes topic mixing as dialogue length grows; A-Mem organizes memories into a graph that enriches semantics, but the heavy, multi-step link generation inflates latency and error accumulation. By contrast, our Memory OS fuses a hierarchical STM/MTM/LPM architecture via segmented paging with heat-based eviction and a persona module, thereby ensuring that topic-aligned content remains accessible while maintaining consistency with users' specific preferences.
(2)A-Mem 和 MemGPT 在长篇对话中表现相对较强,但二者都缺乏系统化记忆管理机制,由此产生了一些问题。 例如,MemGPT 通过 OS 风格分页扩展上下文,但其扁平 FIFO 队列会随着对话长度增加而导致主题混杂;A-Mem 将记忆组织成图以丰富语义,但沉重的多步骤链接生成会增加延迟和错误累积。 相比之下,作者的 Memory OS 通过带有热度淘汰和人格模块的分段分页,将分层 STM/MTM/LPM 架构融合起来,从而确保主题对齐内容保持可访问,同时维持与用户特定偏好的一致性。
(3) Our proposed MemoryOS achieves superior performance across all benchmark datasets due to its hierarchical storage design, semantic retrieval capabilities, and persona-driven dynamic updating, which ensure coherent and accurate memory management. Notably, the model’s advantages are particularly pronounced in more challenging memory management tasks. For example, on the LoCoMo benchmark with gpt-4o-mini, it achieves average improvements of 49.11% on F1 score and 46.18% on BLEU-1, while on the easier GVD dataset, in which all methods achieve higher baseline accuracy, our MemoryOS still surpasses the SOTA baseline A-Mem by 3.2% in accuracy, showing robust handling of complex long-context tasks requiring semantic consistency.
(3)作者提出的 MemoryOS 凭借分层存储设计、语义检索能力和由人格驱动的动态更新,在所有 benchmark 数据集上都取得了更优表现,这些机制确保了连贯且准确的记忆管理。 值得注意的是,该模型的优势在更具挑战性的记忆管理任务中尤其明显。 例如,在使用 gpt-4o-mini 的 LoCoMo benchmark 上,它在 F1 分数上平均提升 49.11%,在 BLEU-1 上平均提升 46.18%;而在更容易的 GVD 数据集上,尽管所有方法都取得了更高的基线准确率,MemoryOS 仍然在准确率上超过 SOTA 基线 A-Mem 3.2%,展现出对需要语义一致性的复杂长上下文任务的稳健处理能力。
(4) To evaluate model efficiency, we employed two metrics: tokens consumed ( in memory retrieval) and average LLM calls in each response. As shown in Table 3, our method outperforms the Top-2 baselines (i.e., MemGPT and A-Mem) in both aspects, requiring significantly fewer LLM calls than A-Mem* (4.9 vs.13) and much lower token consumption than MemGPT (3,874 vs. 16,977).
(4)为评估模型效率,作者使用了两个指标:消耗的 token(在记忆检索中)以及每次响应的平均 LLM 调用次数。 如 表3 所示,作者方法在这两个方面都优于 Top-2 基线(即 MemGPT 和 A-Mem),相比 A-Mem* 需要显著更少的 LLM 调用(4.9 vs.13),并且相比 MemGPT 消耗低得多的 token(3,874 vs. 16,977)。

4.3. Ablation Study
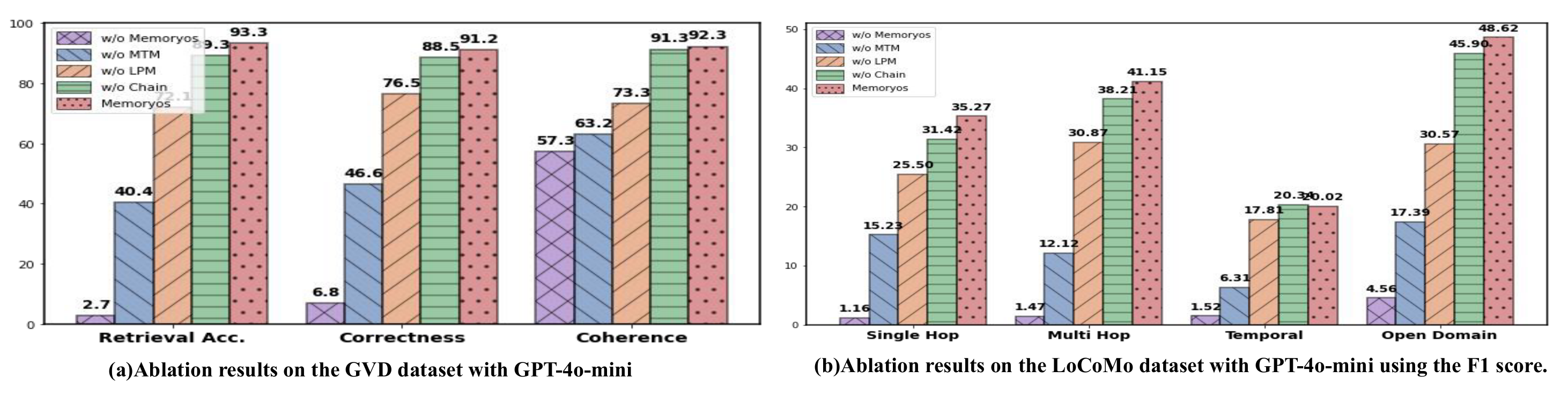
To assess the contribution of each core module in our framework, we perform an ablation study by individually removing three key components: the Mid-Term Memory (-MTM), the Long-term Persona Module (-LPM), and the Diague page Chain (-Chain) and the entire memory system (-MemoryOS). The results are presented in Figure 2. We can see that the memory system plays a pivotal role in the quality of responses during long dialogues. Without MemoryOS, the model's performance drastically reduces. In MemoryOS, the Mid-Term Memory (MTM) has the most significant impact, followed by the Long-Term Memory (LPM), while the Chain has the least impact.
为评估框架中各核心模块的贡献,作者进行了消融研究,分别移除三个关键组件:中期记忆(-MTM)、长期人格模块(-LPM)、Diague page Chain(-Chain),以及整个记忆系统(-MemoryOS)。 结果如 图2 所示。 可以看到,记忆系统在长对话响应质量中发挥关键作用。 没有 MemoryOS 时,模型性能会大幅下降。 在 MemoryOS 中,中期记忆(MTM)的影响最大,其次是长期记忆(LPM),而 Chain 的影响最小。
4.4. Hyperparameter Analysis
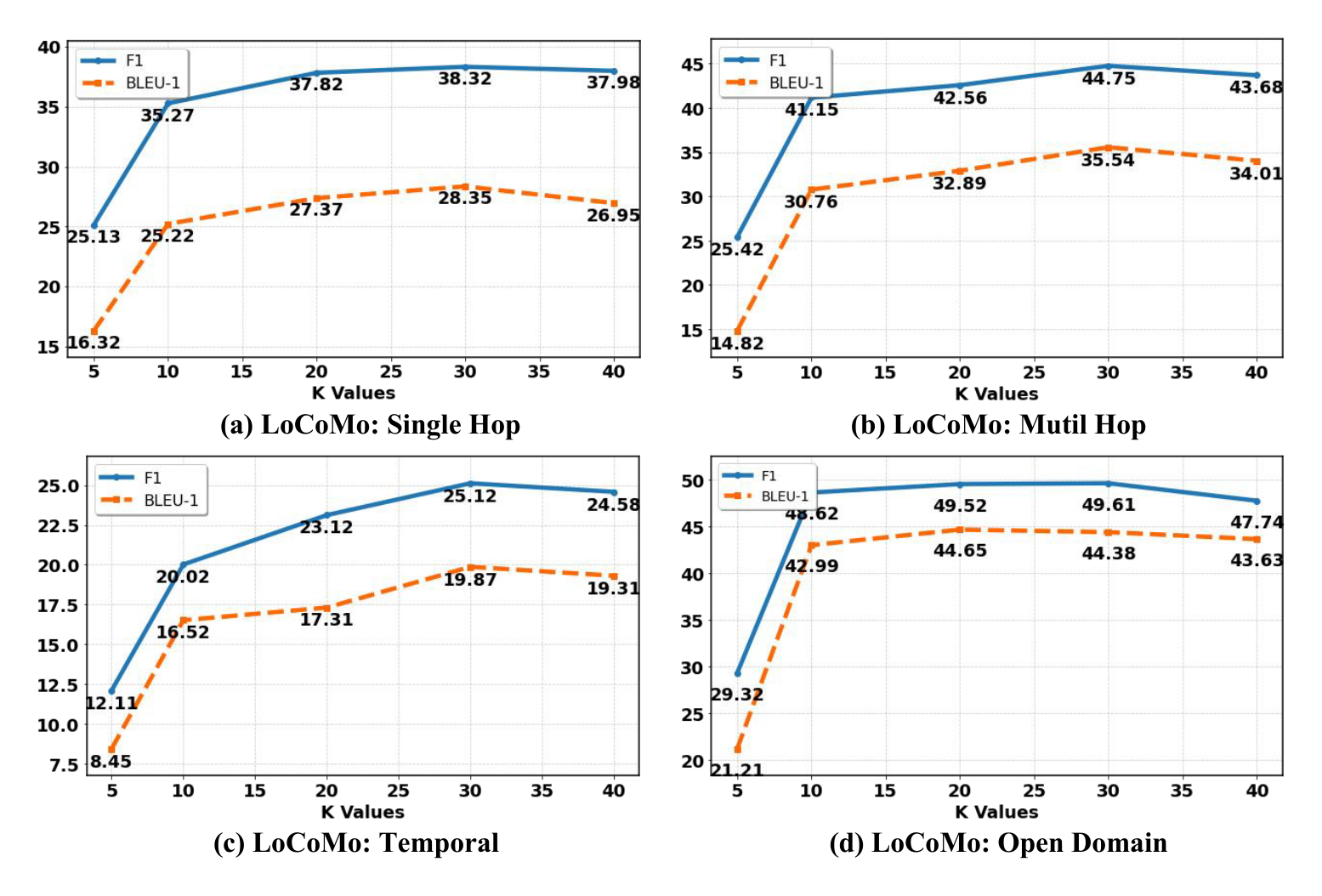
We analyze the impact of top-k retrieved dialogue pages from Mid-Term Memory (MTM) on model performance. As shown in Figure 3, by setting the hyperparameter
作者分析了从中期记忆(MTM)中检索 top-k 个对话页面对模型性能的影响。 如 图3 所示,通过在 LoCoMo benchmark 上将超参数
4.5. Case Study
To visually demonstrate the role of our memory system, specifically how user long-term memory maintenance enhances conversational consistency. We present case studies in Figure 4. Based on the conversation history, we show the responses of default LLMs and our LLMs with MemoryOS. We can see that MemoryOS exhibits excellent capabilities in recalling users' long-term conversations and preferences. For example, MemoryOS recalls details like "seeing the scenery, running, and spotting squirrels in the wetland park." from the initially mentioned a few weeks ago, “I went to the wetland park ...". These details are retrieved through the interplay and mutual support of mid-term memory's segment-page storage and the dialogue page chain. In addition, since the system integrates a personalization module, it can remember the user's goal of “wanting to get fit” and later proactively reminds the user when they express a desire to eat a burger: “Don’t forget you want to get slimmer”. This highlights the crucial role of the memory module in enhancing dialogue coherence and user experience.
为直观展示作者记忆系统的作用,尤其是用户长期记忆维护如何增强对话一致性。 作者在 图4 中给出了案例研究。 基于对话历史,作者展示了默认 LLM 和带有 MemoryOS 的 LLM 的响应。 可以看到,MemoryOS 在回忆用户长期对话和偏好方面表现出优秀能力。 例如,MemoryOS 能从几周前最初提到的 “I went to the wetland park ...” 中回忆起 “seeing the scenery, running, and spotting squirrels in the wetland park.” 这类细节。 这些细节通过中期记忆的分段-页面存储与对话页面链之间的相互作用和相互支持被检索出来。 此外,由于系统整合了个性化模块,它可以记住用户“wanting to get fit”的目标,并在用户后来表达想吃汉堡时主动提醒:“Don’t forget you want to get slimmer”。 这突出了记忆模块在增强对话连贯性和用户体验方面的关键作用。
5. Conclusion
Inspired by memory management mechanisms in operating systems, we pioneers propose a novel memory management system, MemoryOS, for AI agents. Implemented by a hierarchical memory storage architecture, MemoryOS addresses the fixed context window limitations in long conversations. By adapting OS-style segment-paging storage for dialogue history, MemoryOS enables efficient memory storage, updating, and semantic retrieval using heat-driven eviction to dynamically prioritize critical information across memory tiers. The integrated persona module captures evolving user preferences via personalized trait extraction, ensuring responses align with long conversation contexts. By bridging OS principles with AI memory management, MemoryOS empowers LLMs to sustain coherent, personalized conversations over extended interactions, enhancing human-like dialogue capabilities in real-world applications.
受操作系统中的内存管理机制启发,作者开创性地提出一种用于 AI 智能体的新型记忆管理系统 MemoryOS。 MemoryOS 通过分层记忆存储架构实现,解决了长对话中固定上下文窗口的限制。 通过为对话历史适配 OS 风格的分段分页存储,MemoryOS 利用热度驱动淘汰在不同记忆层级间动态优先保留关键信息,从而实现高效记忆存储、更新和语义检索。 集成的人格模块通过个性化特征抽取捕获不断演化的用户偏好,确保响应与长对话上下文对齐。 通过将 OS 原则与 AI 记忆管理连接起来,MemoryOS 使 LLM 能够在扩展交互中维持连贯且个性化的对话,增强其在真实应用中的类人对话能力。