
Mem-T: Densifying Rewards for Long-Horizon Memory Agents
MemoryAgentRLMoT-GRPOPKUNTUMem-T:为长程记忆智能体稠密化奖励
Abstract
Memory agents, which depart from predefined memory-processing pipelines by endogenously managing the processing, storage, and retrieval of memories, have garnered increasing attention for their autonomy and adaptability. However, existing training paradigms remain constrained: agents often traverse long-horizon sequences of memory operations before receiving sparse and delayed rewards, which hinders truly end-to-end optimization of memory management policies. To address this limitation, we introduce Mem-T, an autonomous memory agent that interfaces with a lightweight hierarchical memory database to perform dynamic updates and multi-turn retrieval over streaming inputs. To effectively train long-horizon memory management capabilities, we further propose MoT-GRPO, a tree-guided reinforcement learning framework that transforms sparse terminal feedback into dense, step-wise supervision via memory operation tree backpropagation and hindsight credit assignment, thereby enabling the joint optimization of memory construction and retrieval. Extensive experiments demonstrate that Mem-T is high-performing, surpassing frameworks such as A-Mem and Mem0 by up to
记忆智能体脱离预定义的记忆处理流程,通过内生方式管理记忆的处理、存储和检索,因此其自主性和适应性正受到越来越多关注。 然而,现有训练范式仍受限制:智能体往往要经过长程的记忆操作序列,之后才收到稀疏且延迟的奖励,这妨碍了对记忆管理策略进行真正端到端优化。 为了解决这一局限,我们提出 Mem-T,这是一个自主记忆智能体,它连接轻量级层级记忆数据库,对流式输入执行动态更新和多轮检索。 为了有效训练长程记忆管理能力,我们进一步提出 MoT-GRPO,这是一个树引导的强化学习框架,它通过记忆操作树反向传播和 hindsight credit assignment,将稀疏终端反馈转化为稠密的逐步监督,从而支持联合优化记忆构建和检索。 大量实验表明,Mem-T 性能很高,最多比 A-Mem 和 Mem0 等框架高出
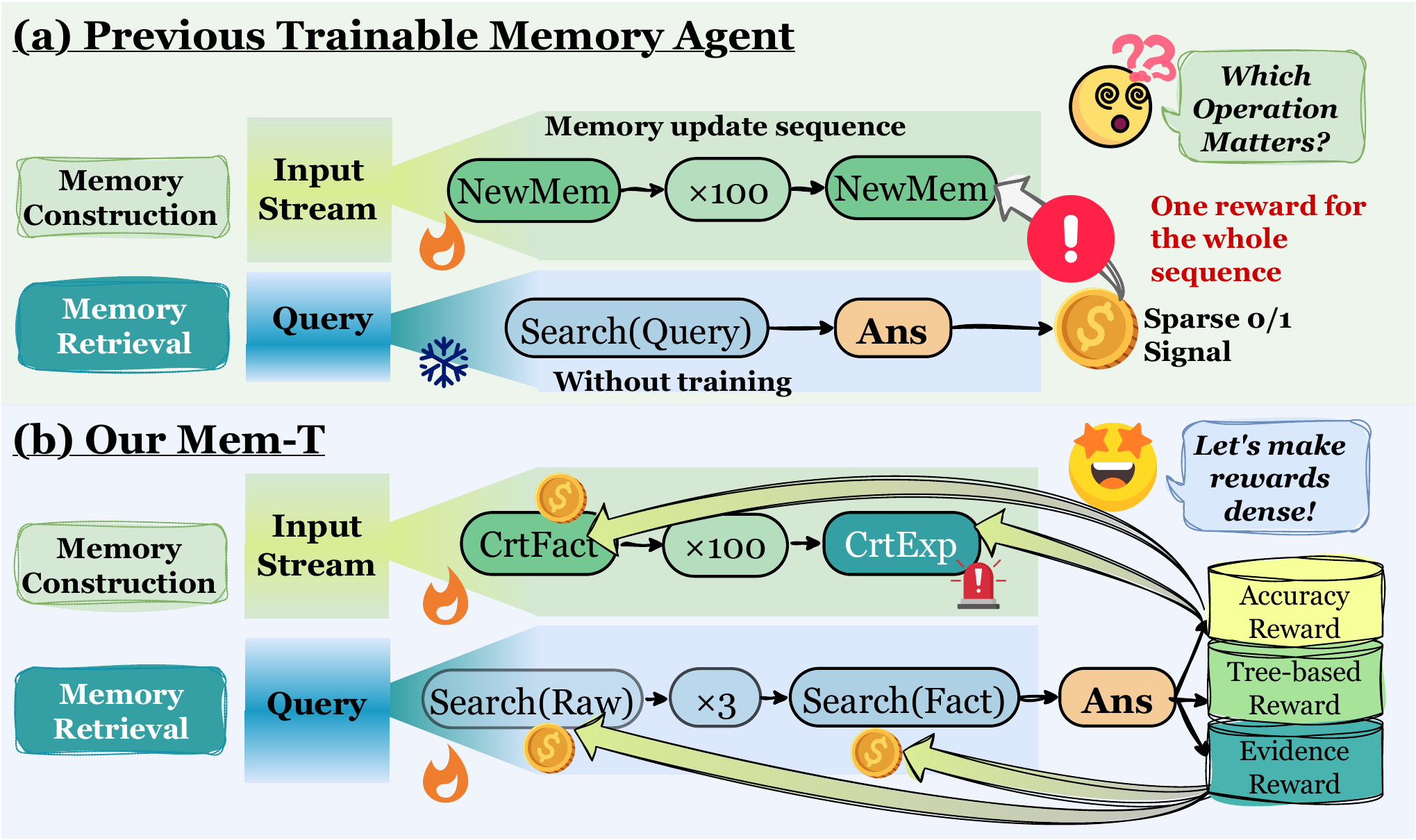
1. Introduction
As Large Language Models (LLMs) rapidly evolve into powerful AI agents, they have achieved significant success across various fields. However, constrained by the finite context windows of foundation models, AI agents face inherent challenges with long-term inconsistency and context forgetting during extended multi-turn interactions. As a promising frontier, memory systems dynamically construct and leverage memories from historical interactions, thereby sustaining temporal coherence and long-term intelligence beyond finite context windows, and have consequently emerged as a core component of modern agentic systems.
随着大语言模型(LLMs)迅速演化为强大的 AI 智能体,它们已经在各个领域取得显著成功。 然而,由于基础模型的上下文窗口有限,AI 智能体在扩展的多轮交互中面临长期不一致和上下文遗忘这两类内在挑战。 作为一个有前景的前沿方向,记忆系统会从历史交互中动态构建并利用记忆,从而在有限上下文窗口之外维持时间一致性和长期智能,并因此成为现代智能体系统的核心组件。
Tracing the evolution of memory systems, early frameworks such as MemGPT, Mem0, and A-Mem predominantly rely on hand-crafted prompts and heuristic rules to guide frozen LLMs in populating predefined memory structures. As a result, their performance is inherently bounded by the base model's instruction-following capacity and rigid human priors, often leading to suboptimal outcomes. By contrast, recent approaches such as Memory-R1, Mem-
回顾记忆系统的演进,MemGPT、Mem0 和 A-Mem 等早期框架主要依赖人工设计的提示和启发式规则,引导冻结的 LLM 填充预定义记忆结构。 因此,它们的性能本质上受限于基础模型的指令遵循能力和僵硬的人类先验,常常导致次优结果。 相比之下,Memory-R1、Mem-
However, current paradigms for training memory agents remain fundamentally constrained by temporal credit assignment, the challenge of attributing sparse and delayed rewards to causative actions along long-horizon memory operation sequences. This limitation is particularly acute in memory-centric tasks, where agents may execute hundreds of memory operations across
然而,当前训练记忆智能体的范式仍从根本上受限于时间信用分配,也就是把稀疏且延迟的奖励归因到长程记忆操作序列中致因动作的挑战。 这种局限在以记忆为中心的任务中尤其严重,因为智能体可能要在百万 token 上下文中的
Research Question. How can we implement a fully trainable memory agent framework that jointly optimizes memory construction and retrieval, supervised with dense rewards and accurate process-level attribution?
研究问题。 我们如何实现一个完全可训练的记忆智能体框架,在稠密奖励和准确过程级归因的监督下,联合优化记忆构建与检索?
To address this challenge, we introduce Mem-T, a streamlined hierarchical memory agent optimized under a process-supervised, attribution-centric training paradigm termed Memory Operation Tree-guided GRPO (MoT-GRPO). Functionally, Mem-T integrates three core capabilities: (i) formation and (ii) evolution operations that maintain and refine the hierarchical memory database over dynamic information streams, and (iii) a retrieval operation that conducts multi-turn, autonomous search to provide accurate memory clues. To jointly optimize these components, MoT-GRPO employs a dual-track training mechanism integrating memory retrieval and construction. To refine memory retrieval, it constructs multiple Memory operation Trees (MoT) to explore diverse trajectories, leveraging the branching topology to back-propagate sparse outcome rewards to intermediate nodes, thereby generating dense process-level signals and identifying critical search paths. To refine memory construction, the utility of the MoT is explicitly attributed back to source memory items via hindsight credit assignment, supervising the corresponding formation and evolution operations. This paradigm effectively mitigates reward sparsity and attribution ambiguity, rendering memory interactions both interpretable and learnable. Our contributions can be summarized as:
为了解决这一挑战,我们提出 Mem-T,这是一个精简的层级记忆智能体,它在一种以过程监督和归因为中心的训练范式下优化,该范式称为 Memory Operation Tree-guided GRPO(MoT-GRPO)。 在功能上,Mem-T 集成三项核心能力:(i) formation 和 (ii) evolution 操作,用于在动态信息流上维护并细化层级记忆数据库;以及 (iii) retrieval 操作,用于执行多轮自主搜索并提供准确的记忆线索。 为了联合优化这些组件,MoT-GRPO 采用一种双轨训练机制,将记忆检索和记忆构建结合起来。 为了细化记忆检索,它构建多个 Memory operation Trees(MoT)来探索多样轨迹,利用分支拓扑把稀疏结果奖励反向传播到中间节点,从而生成稠密的过程级信号并识别关键搜索路径。 为了细化记忆构建,MoT 的效用会通过 hindsight credit assignment 显式归因回源记忆条目,从而监督相应的 formation 和 evolution 操作。 这一范式有效缓解了奖励稀疏性和归因歧义,使记忆交互既可解释又可学习。 我们的贡献可总结如下:
- Unified Memory Framework. We propose Mem-T, a streamlined memory management agent with a hierarchical architecture that integrates factual, experiential, and working memory, and agentically orchestrates the full lifecycle of memory operations.
- Tree-Guided Optimization. We present MoT-GRPO, a memory operation tree-based paradigm that tackles temporal credit assignment via node-wise reward backpropagation and hindsight credit assignment.
By transforming sparse terminal rewards into dense supervision for intermediate operations, it enables the joint optimization of memory formation, evolution, and retrieval.
- Experimental Evaluation. Comprehensive evaluations on four memory benchmarks demonstrate that Mem-T achieves state-of-the-art performance while maintaining a superior Pareto frontier, delivering up to
F1 gains and reducing inference tokens per query by compared with GAM and A-Mem baselines.
- 统一记忆框架。 我们提出 Mem-T,这是一个精简的记忆管理智能体,采用层级架构整合事实记忆、经验记忆和工作记忆,并以智能体方式编排记忆操作的完整生命周期。
- 树引导优化。 我们提出 MoT-GRPO,这是一种基于记忆操作树的范式,通过节点级奖励反向传播和 hindsight credit assignment 处理时间信用分配。
通过把稀疏终端奖励转化为针对中间操作的稠密监督,它能够联合优化记忆形成、演化和检索。
- 实验评估。 在四个记忆基准上的综合评估表明,Mem-T 达到最先进性能,同时保持更优的 Pareto 前沿;与 GAM 和 A-Mem 基线相比,它最多带来
的 F1 提升,并将每个查询的推理 token 减少 。
2. Related Work
| Method | Functions | Operations | Proc. Attr. | ||||
|---|---|---|---|---|---|---|---|
| Fact. | Exp. | Work. | Form. | Evol. | Retr. | ||
| MemAgent | × | × | ◆ | ◆ | ◆ | × | × |
| Context-Folding | × | × | ◆ | ◆ | ◇ | × | × |
| Memory-R1 | ◆ | × | × | ◇ | ◆ | ◇ | × |
Mem- | ◆ | × | ◆ | ◆ | ◆ | ◇ | × |
| MemSearcher | ◆ | × | × | × | × | ◆ | × |
| LightSearcher | × | ◆ | × | ◇ | × | ◆ | × |
| Mem-T | ◆ | ◆ | ◆ | ◆ | ◆ | ◆ | ◆ |
Memory Agent Architectures. In recent years, memory agents have advanced rapidly, evolving from heuristic-based systems such as MemoryBank and MemGPT to more agentic architectures, including Mem0, MemOS, and A-Mem. Functionally, prior work spans three categories: (I) Factual Memory, preserving declarative knowledge for long-term consistency; (II) Experiential Memory, distilling experience from trajectories to support continual self-improvement; and (III) Working Memory, managing dynamic context for ongoing tasks. Operationally, the memory lifecycle comprises (I) Formation, transforming raw context into high-value memory; (II) Evolution, integrating new insights with existing memory store; and (III) Retrieval, performing accurate retrieval from the memory base. As shown in Table 1, our Mem-T, despite its streamlined design, spans all three functional classes and operational stages.
记忆智能体架构。 近年来,记忆智能体快速发展,从 MemoryBank 和 MemGPT 等基于启发式的系统演化到更具智能体特性的架构,包括 Mem0、MemOS 和 A-Mem。 从功能上看,已有工作涵盖三类:(I) 事实记忆,保存声明性知识以维持长期一致性;(II) 经验记忆,从轨迹中提炼经验以支持持续自我改进;以及 (III) 工作记忆,管理进行中任务的动态上下文。 从操作上看,记忆生命周期包括 (I) 形成,把原始上下文转化为高价值记忆;(II) 演化,把新洞察与既有记忆存储整合起来;以及 (III) 检索,从记忆库中执行准确检索。 如表1所示,尽管 Mem-T 设计精简,但它覆盖了全部三类功能和操作阶段。
Reinforcement Learning for Memory Agents. As memory systems scale in complexity, the efficacy of foundation models in managing memory increasingly becomes the primary performance bottleneck. Consequently, reinforcement learning (RL) has emerged as a central paradigm for endowing LLMs with adaptive memory management capabilities. Current research spans a broad spectrum, from short-term working memory to long-term factual and experiential memory. Working Memory. RL has been used to enable agents to autonomously manage execution context within a single task, particularly in settings such as deep research and web browsing. Long-term Factual Memory. Prior work targets different stages of memory management: Memory-R1 emphasizes memory evolution, Mem-
面向记忆智能体的强化学习。 随着记忆系统复杂度提高,基础模型管理记忆的有效性日益成为主要性能瓶颈。 因此,强化学习(RL)已经成为赋予 LLM 自适应记忆管理能力的核心范式。 当前研究覆盖范围很广,从短期工作记忆到长期事实记忆和经验记忆。 工作记忆。 RL 已被用于使智能体在单个任务中自主管理执行上下文,尤其是在深度研究和网页浏览等场景中。 长期事实记忆。 既有工作针对记忆管理的不同阶段:Memory-R1 强调记忆演化,Mem-
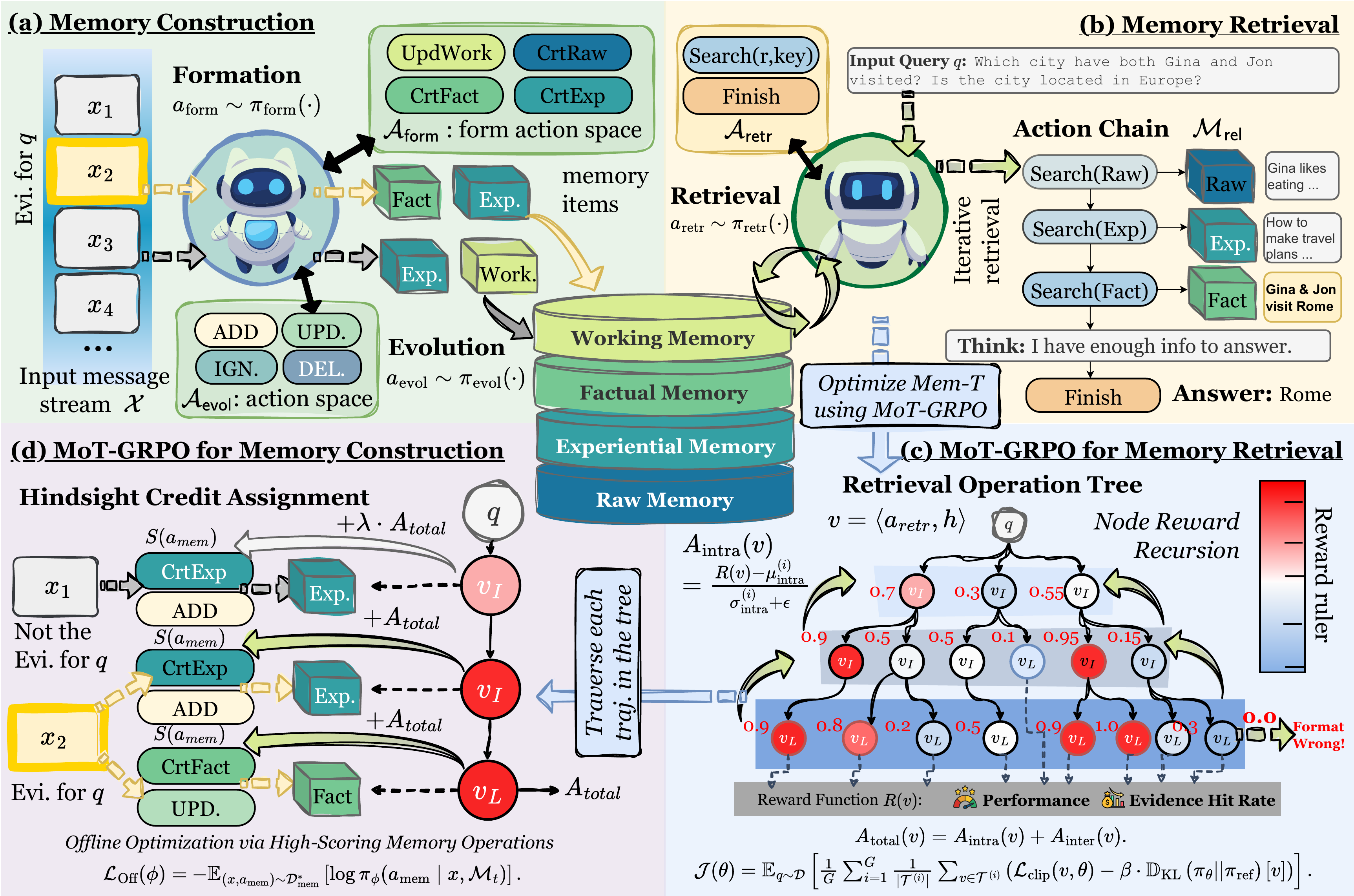
3. Method
3.1 Mem-T Workflow
Hierarchical Memory Definition. We consider the agent interacting with a continuous information stream
层级记忆定义。 我们考虑智能体与连续信息流
Within this hierarchy, Working Memory (
在这一层级中,工作记忆(
where each
其中每个
Memory Operation Pipeline. Building upon this hierarchical memory, we formulate the agent's interaction as a dual-track decision process, comprising continuous memory construction and on-demand memory utilization. Phase I: Continuous Memory Construction. As the agent processes the input stream CrtFact, CrtExp, and CrtRaw extract atomic declarative facts, procedural strategies, and raw data, respectively, while UpdWork updates the session-level working summary. Formally, the formation process is defined as:
记忆操作流程。 基于这一层级记忆,我们把智能体交互形式化为一个双轨决策过程,包括持续记忆构建和按需记忆利用。 阶段 I:持续记忆构建。 当智能体处理输入流 CrtFact、CrtExp 和 CrtRaw 分别抽取原子声明性事实、程序性策略和原始数据,而 UpdWork 更新会话级工作摘要。 形式化地,形成过程定义为:
where
其中
Consequently, the memory store is updated accordingly:
因此,记忆库会相应更新:
Phase II: On-Demand Memory Retrieval. Based on the constructed memory store
阶段 II:按需记忆检索。 基于已构建的记忆库
where
其中
This iterative process accumulates the relevant memory set Finish action, signaling that the gathered information is sufficient to support the final answer
这一迭代过程通过聚合每个搜索步骤的观测来累积相关记忆集合 Finish 动作时,循环终止,表示已收集的信息足以支持最终答案
3.2 MoT-GRPO for Memory Retrieval
In long-horizon scenarios, memory operation chains become extremely long, making credit assignment and reward sparsity major challenges. To address these issues, we propose Memory Operation Tree GRPO (MoT-GRPO), inspired by prior RL methods. Memory Operation Tree Construction. In the retrieval phase, to achieve efficient rollout generation while obtaining dense intermediate signals, we employ an Iterative Branching Rollout to construct the Memory Operation Tree(MoT). Formally, we define a node in MoT as a tuple
在长程场景中,记忆操作链会变得极长,使信用分配和奖励稀疏性成为主要挑战。 为了解决这些问题,我们提出 Memory Operation Tree GRPO(MoT-GRPO),其灵感来自既有 RL 方法。 记忆操作树构建。 在检索阶段,为了在获得稠密中间信号的同时高效生成 rollout,我们采用 Iterative Branching Rollout 来构建 Memory Operation Tree(MoT)。 形式化地,我们把 MoT 中的节点定义为元组
For each query, we initialize an ensemble of
对于每个查询,我们初始化
Subsequently, we iteratively densify each
随后,我们在
The newly generated trajectories are then grafted onto the tree, updating its state to
随后,新生成的轨迹会嫁接到树上,并把其状态更新为
Node-wise Reward Backpropagation. Instead of relying solely on sparse terminal rewards, we assign a dense reward
节点级奖励反向传播。 我们不是只依赖稀疏终端奖励,而是为每个节点
Here,
这里,
This formulation ensures that high-reward nodes should adhere to valid formats, retrieve relevant evidence, and lead to high-quality outcomes.
这一形式化确保高奖励节点应该遵循有效格式、检索相关证据,并导向高质量结果。
Dual-Scale Advantage Estimation. To enable tree-based credit assignment, we perform grouped advantage estimation at both the intra-tree and inter-tree levels. The Intra-Tree Advantage
双尺度优势估计。 为了实现基于树的信用分配,我们在树内和树间两个层级执行分组优势估计。 树内优势
Simultaneously, to capture each node's global advantage, we compute the Inter-Tree Advantage
同时,为了捕获每个节点的全局优势,我们基于整个集合
The final advantage
最终优势
Through this dual-scale design, the intra-tree advantage supports reliable local comparisons sharing similar contexts and effective credit assignment to identify nodes that critically influence the final outcome. Meanwhile, inter-tree advantages encourage cross-tree competition, guiding the optimization toward globally high-quality solutions.
通过这一双尺度设计,树内优势支持在共享相似上下文的节点之间进行可靠局部比较,并进行有效信用分配,以识别对最终结果有关键影响的节点。 同时,树间优势鼓励跨树竞争,引导优化走向全局高质量解。
Optimization Objective. Following the GRPO paradigm, we directly utilize the dual-scale advantage
优化目标。 沿用 GRPO 范式,我们直接利用双尺度优势
where
其中
3.3 MoT-GRPO for Memory Construction
Unlike retrieval, memory construction spans hundreds of steps with rewards delayed until downstream queries, and its quality is irrelevant to most queries, resulting in severe credit assignment ambiguity. To address this, we propose Hindsight Credit Assignment, which back-propagates advantage signals from downstream retrieval trajectories to upstream construction actions. Hindsight Credit Assignment. Let
不同于检索,记忆构建跨越数百个步骤,其奖励延迟到下游查询之后才出现,而且其质量与大多数查询无关,这导致严重的信用分配歧义。 为了解决这一问题,我们提出 Hindsight Credit Assignment,它把优势信号从下游检索轨迹反向传播到上游构建动作。 Hindsight Credit Assignment。 令
The credit coefficient
信用系数
The Evidence Alignment Gate attributes credit by linking the construction quality of ideal evidence turn
Evidence Alignment Gate 通过把理想证据轮次
| Method | Base LLM | Single-Hop | Multi-Hop | Temporal | Open Domain | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | ||
| Training-free Methods | |||||||||||
| VANILLA | Qwen3-4B | 40.68 | 31.54 | 23.23 | 16.76 | 18.97 | 13.42 | 13.87 | 10.70 | 31.50 | 23.94 |
| RAG | Qwen3-4B | 49.45 | 44.94 | 23.50 | 17.13 | 43.07 | 37.35 | 20.23 | 14.94 | 41.59 | 36.45 |
| MemGPT | Qwen3-4B | 14.00 | 11.77 | 16.68 | 13.99 | 12.56 | 10.94 | 11.61 | 9.16 | 14.05 | 11.84 |
| MemoryBank | Qwen3-4B | 26.65 | 17.72 | 25.52 | 19.44 | 9.15 | 7.44 | 16.42 | 12.39 | 22.34 | 15.66 |
| Mem0 | Qwen3-4B | 47.28 | 40.72 | 35.40 | 27.36 | 46.84 | 39.48 | 26.64 | 21.04 | 43.71 | 36.78 |
| MemoryOS | Qwen3-4B | 48.35 | 42.57 | 35.24 | 27.30 | 40.98 | 32.68 | 22.08 | 17.93 | 42.83 | 36.26 |
| LightMem | Qwen3-4B | 43.78 | 38.84 | 30.78 | 25.80 | 44.71 | 40.72 | 18.93 | 14.42 | 40.01 | 35.27 |
| A-Mem | Qwen3-4B | 44.62 | 38.26 | 27.24 | 21.07 | 43.85 | 35.97 | 15.40 | 12.71 | 39.43 | 33.04 |
| GAM | Qwen3-4B | 32.23 | 25.54 | 32.23 | 28.66 | 26.26 | 22.52 | 18.45 | 14.47 | 30.17 | 24.81 |
| GAM† | gpt-4o-mini† | 57.75 | 52.10 | 42.29 | 34.44 | 59.45 | 53.11 | 29.73 | 24.74 | 53.48 | 47.33 |
| Trained Methods | |||||||||||
| MEM1 | MEM1-7B | 27.48 | 22.10 | 18.98 | 15.56 | 30.52 | 23.48 | 14.21 | 11.43 | 25.68 | 20.50 |
| MemAgent | MemAgent-14B | 35.86 | 29.64 | 27.86 | 22.72 | 37.93 | 31.85 | 20.31 | 16.47 | 33.82 | 27.97 |
| Memory-R1-PPO‡ | Mem-R1-8B‡ | 32.52 | 24.47 | 26.86 | 23.47 | 41.57 | 26.11 | 45.30 | 39.18 | 34.08 | 25.54 |
| Memory-R1-GRPO‡ | Mem-R1-8B‡ | 35.73 | 27.70 | 35.65 | 30.77 | 49.86 | 38.27 | 47.42 | 41.24 | 39.25 | 31.21 |
| Our Method Mem-T | |||||||||||
| w/o training | Qwen3-4B | 53.97 | 49.15 | 38.44 | 31.70 | 53.99 | 48.08 | 26.44 | 23.37 | 49.38 | 44.11 |
| with GRPO | Qwen3-4B | 59.43 | 54.65 | 38.40 | 30.51 | 60.78 | 56.10 | 23.46 | 20.16 | 53.56 | 48.33 |
| with MoT-GRPO | Qwen3-4B | 63.75 | 57.95 | 45.09 | 36.58 | 65.13 | 60.12 | 32.97 | 28.94 | 58.65 | 52.63 |
Policy Refinement. To optimize memory construction policies, we employ rank-based sampling to curate a high-quality training dataset
策略细化。 为了优化记忆构建策略,我们采用基于排名的采样来整理高质量训练数据集
This offline optimization effectively distills the "hindsight wisdom" derived from the downstream MoT-GRPO search trees into the forward-looking memory construction policy.
这一离线优化有效地把来自下游 MoT-GRPO 搜索树的“事后智慧”蒸馏进面向未来的记忆构建策略。
4. Experiments
4.1 Experimental Setup
Evaluation and Benchmarks. We evaluate the proposed framework across four challenging long-context benchmarks, including LoCoMo, LongMemEval, HotpotQA, and NarrativeQA. LoCoMo and LongMemEval focus on long-term conversational question answering. Following Memory-R1, we use the same training data configuration by splitting the LoCoMo dataset into a 1:1:8 train/validation/test split to ensure a fair comparison. The remaining three benchmarks are treated as out-of-domain datasets to evaluate the generalization ability of our method. Specifically, for HotpotQA, following prior work, we construct long-context inputs by concatenating the gold supporting documents with 400 irrelevant Wikipedia documents. More details about the dataset are in the supplementary experimental setup.
评估与基准。 我们在四个具有挑战性的长上下文基准上评估所提出框架,包括 LoCoMo、LongMemEval、HotpotQA 和 NarrativeQA。 LoCoMo 和 LongMemEval 聚焦长期对话问答。 沿用 Memory-R1,我们使用相同的训练数据配置,把 LoCoMo 数据集按 1:1:8 划分为训练/验证/测试集,以确保公平比较。 其余三个基准被视为域外数据集,用于评估我们方法的泛化能力。 具体而言,对于 HotpotQA,我们沿用既有工作,通过把黄金支持文档与 400 篇无关 Wikipedia 文档拼接来构造长上下文输入。 关于数据集的更多细节见补充实验设置。
Baselines. We compare Mem-T against thirteen baselines, categorized into two groups: (I) Training-free Methods: This group includes memory-free approaches, such as vanilla long-LLM and retrieval-augmented generation (RAG), as well as memory-based methods, including MemGPT, MemoryBank, Mem0, LightMem, A-Mem, and GAM. (II) Training-based Methods: This group includes MemAgent and Mem1, which primarily focus on working memory, and Memory-R1 and Mem-
基线。 我们将 Mem-T 与十三个基线比较,并将它们分为两组:(I) 无训练方法: 这一组包括无记忆方法,例如普通 long-LLM 和检索增强生成(RAG),以及基于记忆的方法,包括 MemGPT、MemoryBank、Mem0、LightMem、A-Mem 和 GAM。 (II) 基于训练的方法: 这一组包括主要聚焦工作记忆的 MemAgent 和 Mem1,以及主要为增强事实记忆而设计的 Memory-R1 和 Mem-
Implementation Details. We select LLM backbones of varying sizes, including Qwen3-4B and Qwen3-8B. All methods use BGE-M3 as the embedding model. During training with MoT-GRPO, we generate three trees for each query (
实现细节。 我们选择不同规模的 LLM backbone,包括 Qwen3-4B 和 Qwen3-8B。 所有方法都使用 BGE-M3 作为 embedding model。 在使用 MoT-GRPO 训练时,我们为每个查询生成三棵树(
4.2 Main Results
High Performance. As shown in Table 2 and Appendix Table 1, Mem-T achieves substantially better performance on the LoCoMo benchmark than both training-free and training-based baselines. When using Qwen3-4B and Qwen3-8B, Mem-T improves F1 by
高性能。 如表2和附表1所示,Mem-T 在 LoCoMo 基准上的表现显著优于无训练和基于训练的基线。 在使用 Qwen3-4B 和 Qwen3-8B 时,Mem-T 分别将 F1 提升
| Method | LLM | Single-Hop | Multi-Hop | Temporal | Open Domain | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | F1↑ | B1↑ | ||
| Training-free Methods | |||||||||||
| RAG | Qwen3-8B | 49.62 | 43.98 | 23.64 | 17.82 | 37.93 | 33.80 | 21.39 | 16.33 | 40.77 | 35.43 |
| MemGPT | Qwen3-8B | 16.23 | 13.08 | 18.13 | 13.72 | 15.87 | 11.39 | 14.18 | 10.66 | 16.38 | 12.71 |
| MemoryBank | Qwen3-8B | 26.50 | 19.48 | 26.52 | 18.93 | 15.49 | 11.36 | 15.92 | 12.09 | 23.66 | 17.31 |
| Mem0 | Qwen3-8B | 45.92 | 39.93 | 27.80 | 19.97 | 43.64 | 33.82 | 18.37 | 13.84 | 40.41 | 33.42 |
| MemoryOS | Qwen3-8B | 48.77 | 43.47 | 29.19 | 24.87 | 42.98 | 35.27 | 18.50 | 15.09 | 42.12 | 36.65 |
| LightMem | Qwen3-8B | 49.89 | 44.48 | 33.98 | 27.60 | 44.53 | 39.65 | 19.37 | 14.05 | 43.98 | 38.51 |
| A-Mem | Qwen3-8B | 47.75 | 41.36 | 32.35 | 24.82 | 36.80 | 30.71 | 18.62 | 14.98 | 40.92 | 34.56 |
| GAM | Qwen3-8B | 46.62 | 40.15 | 32.18 | 24.96 | 46.42 | 39.71 | 13.56 | 10.32 | 41.84 | 35.39 |
| Trained Methods | |||||||||||
| MEM1 | MEM1-7B | 27.48 | 22.10 | 18.98 | 15.56 | 30.52 | 23.48 | 14.21 | 11.43 | 25.68 | 20.50 |
| MemAgent | MemAgent-14B | 35.86 | 29.64 | 27.86 | 22.72 | 37.93 | 31.85 | 20.31 | 16.47 | 33.82 | 27.97 |
| Memory-R1-PPO‡ | Mem-R1-8B | 32.52 | 24.47 | 26.86 | 23.47 | 41.57 | 26.11 | 45.30 | 39.18 | 34.08 | 25.54 |
| Memory-R1-GRPO‡ | Mem-R1-8B | 35.73 | 27.70 | 35.65 | 30.77 | 49.86 | 38.27 | 47.42 | 41.24 | 39.25 | 31.21 |
| Our Method | |||||||||||
| w/o training | Qwen3-8B | 55.89 | 51.14 | 38.13 | 30.33 | 53.30 | 47.02 | 23.55 | 20.18 | 50.08 | 44.55 |
| with MoT-GRPO | Qwen3-8B | 63.65 | 57.97 | 42.38 | 34.72 | 66.85 | 62.29 | 34.33 | 31.47 | 58.53 | 52.89 |
| Method | HotpotQA | LongMemEval | NarrativeQA | Avg. |
|---|---|---|---|---|
| F1↑ | Acc↑ | F1↑ | ||
| Training-free Methods | ||||
| VANILLA | 21.89 | 38.80 | 18.09 | 26.26 |
| RAG | 50.13 | 56.60 | 21.17 | 42.63 |
| MemGPT | 18.24 | 23.00 | 8.39 | 16.54 |
| MemoryBank | 16.90 | 26.20 | 9.65 | 17.58 |
| A-Mem | 30.46 | 61.30 | 25.18 | 38.98 |
| Mem0 | 31.96 | 53.60 | 27.63 | 37.73 |
| MemoryOS | 26.86 | 46.80 | 23.45 | 32.37 |
| LightMem | 38.62 | 63.10 | 16.78 | 39.50 |
| GAM | 52.98 | 61.80 | 28.32 | 47.70 |
| Trained Methods | ||||
| MEM1 | 55.36 | 19.00 | 13.49 | 29.28 |
Mem- | 58.80 | 52.00 | 28.56 | 46.45 |
| Mem-T | 66.35 | 65.80 | 30.29 | 54.15 |
Cross-domain generalization. To evaluate whether the memory management capabilities learned by MoT-GRPO can transfer across tasks, we assess the performance of Mem-T on three out-of-domain tasks. As shown in Table 3, baselines such as LightMem achieve suboptimal performance on LongMemEval but fail to generalize to other benchmarks, trailing Mem-T by
跨域泛化。 为了评估 MoT-GRPO 学到的记忆管理能力能否跨任务迁移,我们评估 Mem-T 在三个域外任务上的性能。 如表3所示,LightMem 等基线在 LongMemEval 上取得次优性能,但无法泛化到其他基准,在 HotpotQA 和 NarrativeQA 上分别落后 Mem-T
Token-economical. As illustrated in Figure 3 and Figure 4, Mem-T demonstrates superior cost-effectiveness, lying on the Pareto front for both the LoCoMo and HotpotQA datasets. Compared to GAM, Mem-T not only achieves a
Token 经济性。 如图3和图4所示,Mem-T 展现出更优的成本效益,在 LoCoMo 和 HotpotQA 两个数据集上都位于 Pareto 前沿。 相比 GAM,Mem-T 不仅让 F1 Score 提升
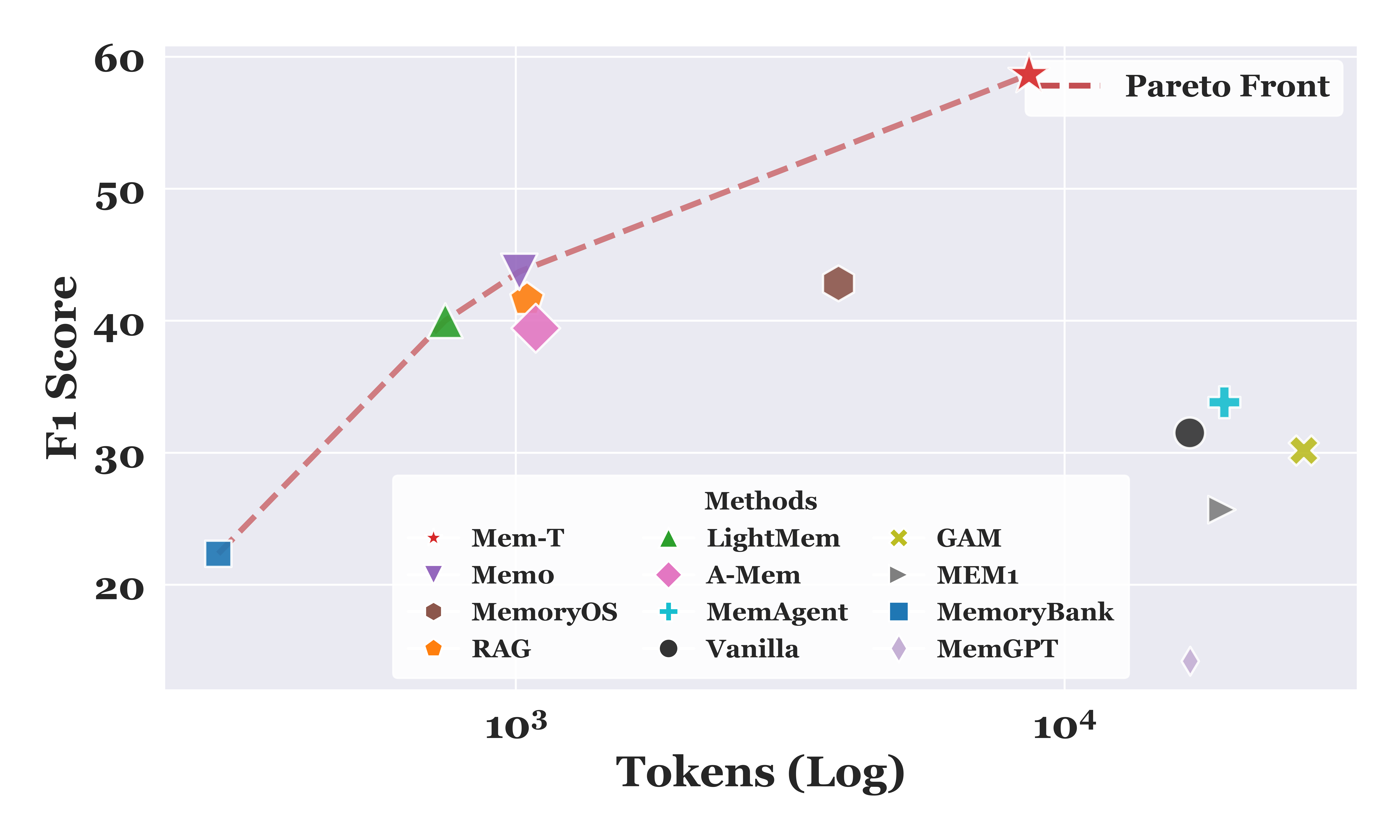
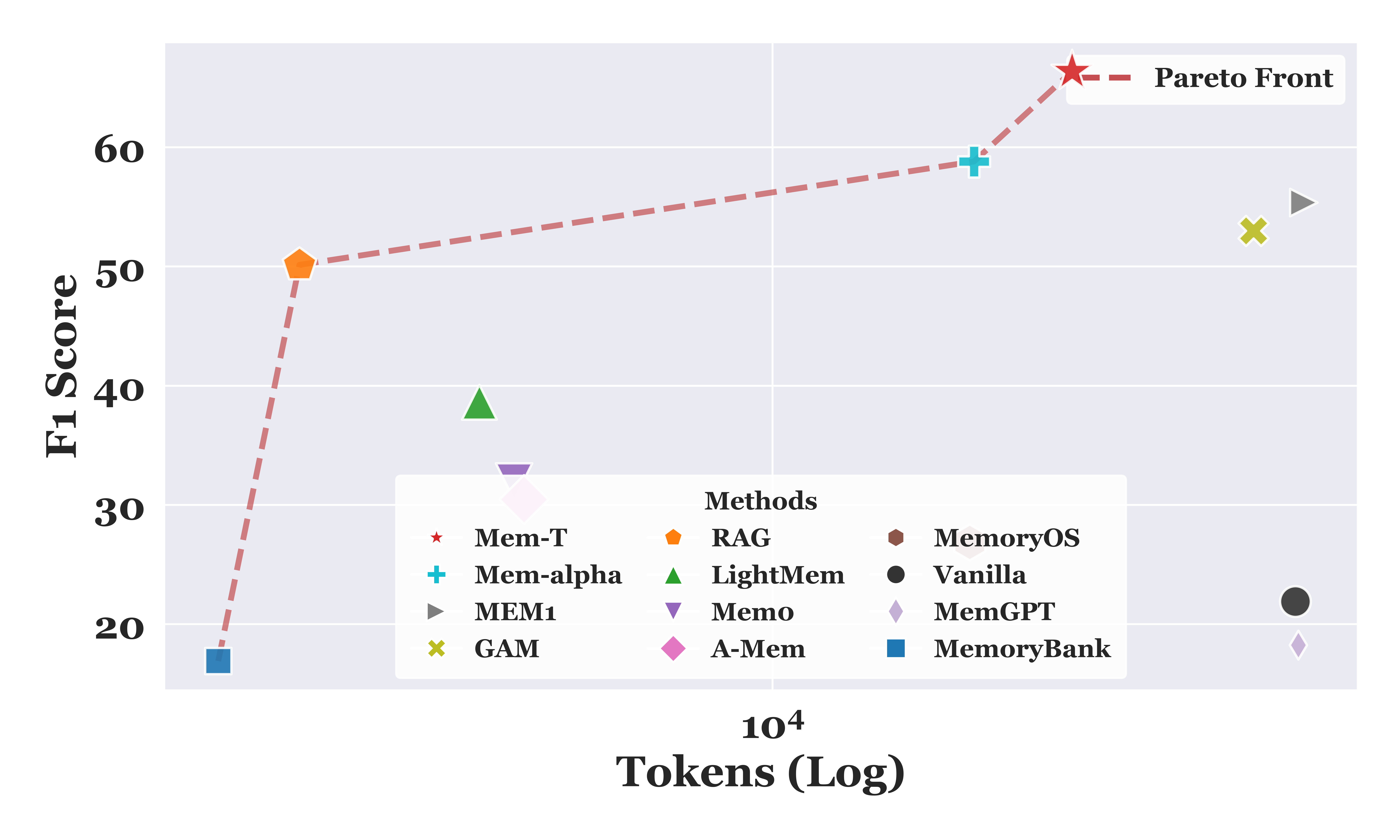
4.3 Framework Analysis
| Method | Single | Multi | Temporal | Open | Overall |
|---|---|---|---|---|---|
| Vanilla Mem-T | 63.75 | 45.09 | 65.13 | 32.97 | 58.65 |
| Ablation of Memory Modules | |||||
w/o | 63.24 | 43.42 | 63.38 | 30.90 | 57.59 |
w/o | 60.80 | 40.10 | 64.23 | 22.39 | 55.25 |
w/o | 61.94 | 43.96 | 62.64 | 27.42 | 56.60 |
w/o | 62.19 | 42.84 | 62.41 | 29.38 | 56.61 |
| Ablation of MoT-GRPO | |||||
| w/o Retr. Opt. | 57.91 | 43.85 | 56.69 | 30.73 | 53.37 |
| w/o Cons. Opt. | 61.41 | 41.15 | 61.17 | 25.24 | 55.36 |
w/o | 62.08 | 43.08 | 63.52 | 31.53 | 56.95 |
w/o | 58.33 | 43.52 | 59.58 | 30.59 | 54.09 |
Ablation Study. We conduct an ablation study on the hierarchical memory architecture and the MoT-GRPO training paradigm, with results presented in Table 4: (1) w/o Memory Modules, which individually removes the working (
消融研究。 我们对层级记忆架构和 MoT-GRPO 训练范式进行消融研究,结果见表4:(1) w/o Memory Modules,分别移除工作记忆(
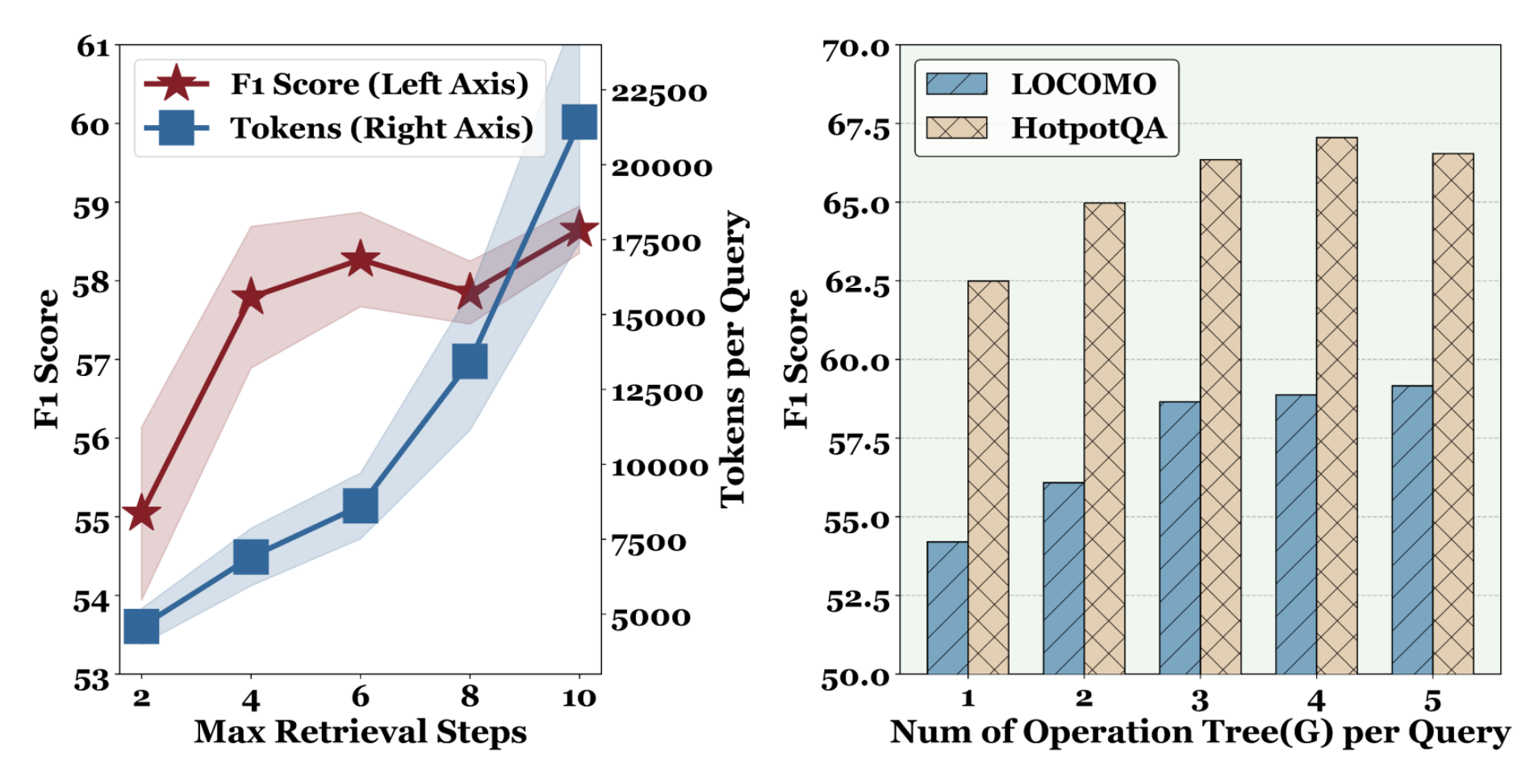
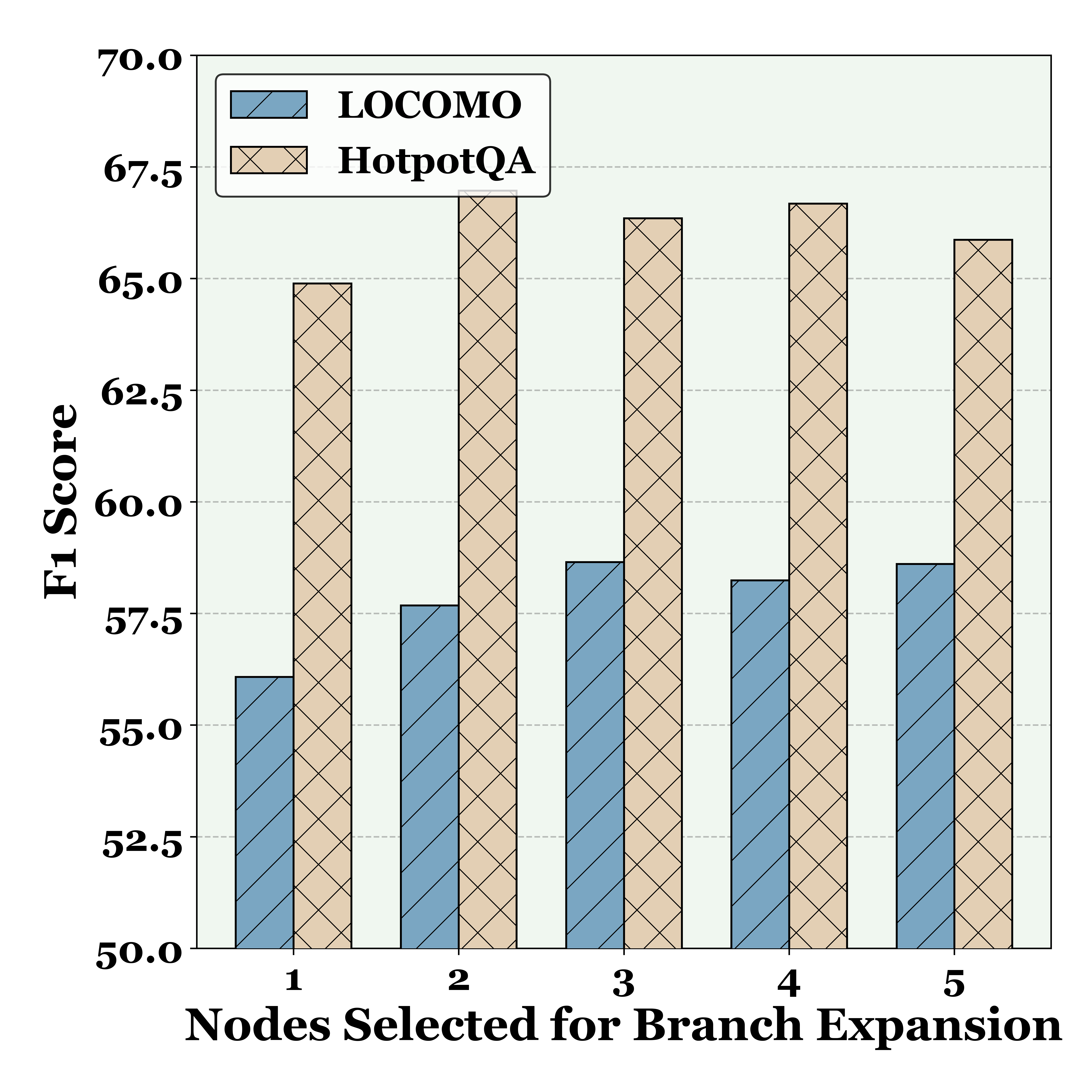
Sensitivity Analysis. We analyze the sensitivity of Mem-T to three core parameters. The results are presented in Figure 5 and Appendix Figure 1. For the maximum retrieval steps, we observe a substantial performance improvement as the steps increase from
敏感性分析。 我们分析 Mem-T 对三个核心参数的敏感性。 结果见图5和附图1。 对于最大检索步数,我们观察到当步数从
4.4 Case Study
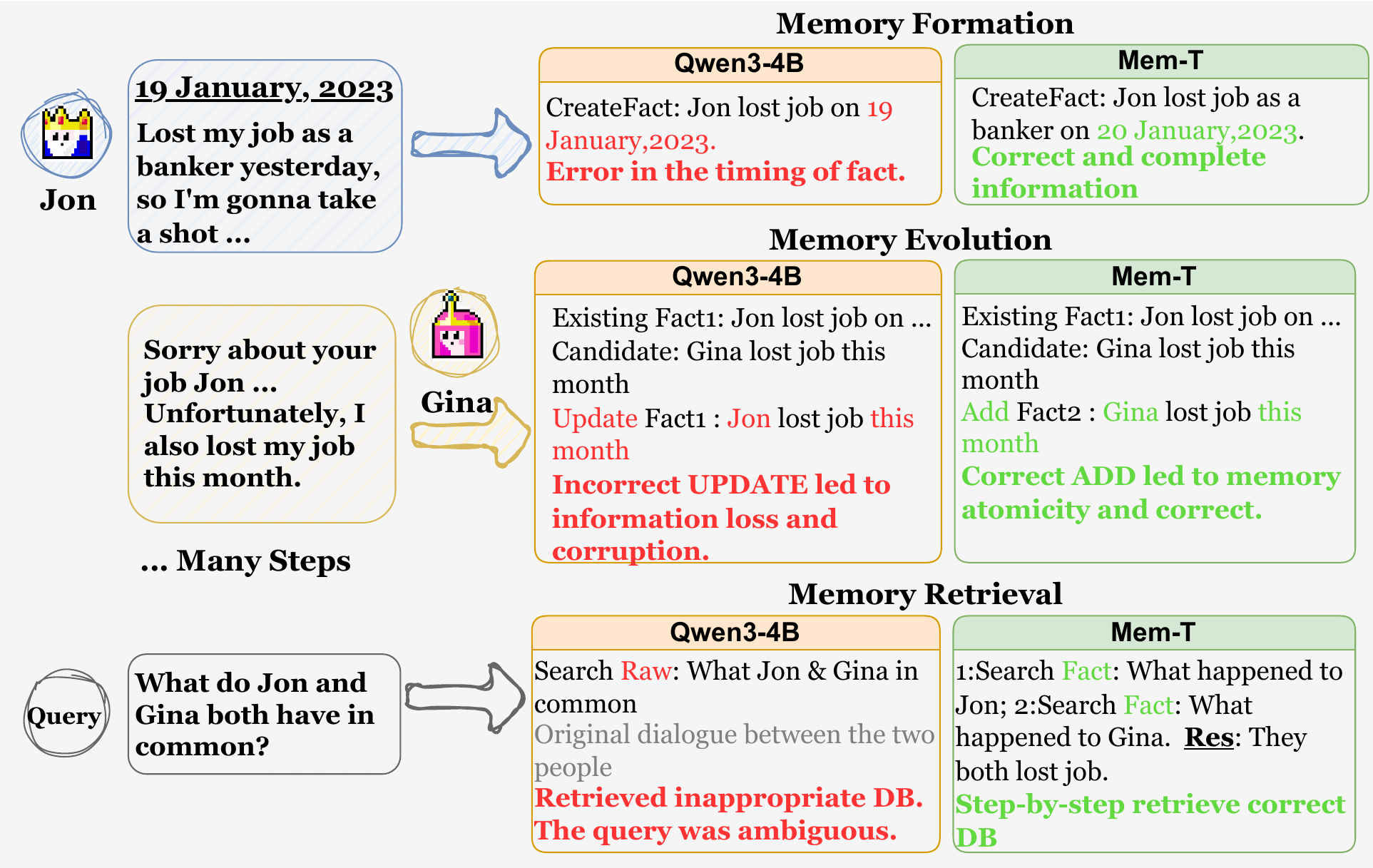
We present a case study comparing the memory processing trajectories of Mem-T against the Qwen3-4B baseline in Figure 6 to demonstrate the enhanced capabilities acquired through our training paradigm.
我们在图6中展示了一个案例研究,将 Mem-T 的记忆处理轨迹与 Qwen3-4B 基线进行比较,以说明通过我们的训练范式获得的增强能力。
As illustrated, the baseline exhibits severe limitations across the entire memory lifecycle. In the formation phase, it lacks an accurate information extraction capability, failing to resolve relative timestamps (e.g., "yesterday") into specific dates. During evolution, it fails to distinguish between Update and Add operations, erroneously overwriting existing entity records with unrelated new memory. Finally, its retrieval mechanism is limited to ambiguous raw queries, lacking the logical depth to handle multi-step reasoning.
如图所示,基线在整个记忆生命周期中都表现出严重局限。 在 formation 阶段,它缺少准确的信息抽取能力,无法把相对时间戳(例如 “yesterday”)解析成具体日期。 在 evolution 阶段,它无法区分 Update 和 Add 操作,错误地用无关的新记忆覆盖已有实体记录。 最后,它的 retrieval 机制局限于含糊的原始查询,缺乏处理多步推理的逻辑深度。
In contrast, Mem-T demonstrates superior capabilities in three aspects: Accurate Information Extraction: It accurately processes raw information (e.g., converting "yesterday" to a correct specific date), ensuring initial memory entries are temporally grounded and factually complete; Rational Memory Evolution: It exhibits a deep understanding of the usage criteria for memory evolution tools. By explicitly distinguishing between state updates and new knowledge acquisition, it preserves memory atomicity and prevents key information forgetting. Multi-step Retrieval: Instead of vague searches, it autonomously decomposes complex queries into sub-questions and retrieves from a suitable store. This step-by-step memory lookups synthesize the answer from distinct memory entries.
相比之下,Mem-T 在三个方面展现出更强能力:准确信息抽取: 它准确处理原始信息(例如把 “yesterday” 转换为正确的具体日期),确保初始记忆条目有时间依据且事实完整;理性记忆演化: 它对记忆演化工具的使用标准展现出深入理解。 通过明确区分状态更新和新知识获取,它保留了记忆原子性,并防止关键信息遗忘。 多步检索: 它不是进行模糊搜索,而是自主把复杂查询分解成子问题,并从合适的存储中检索。 这种逐步记忆查找会从不同记忆条目中综合出答案。
5. Conclusion
In this paper, we introduce Mem-T, a comprehensive hierarchical memory framework, and MoT-GRPO, a novel RL paradigm for memory agents. By decomposing sparse terminal rewards into dense, step-wise supervision via memory operation trees, MoT-GRPO enables the joint optimization of memory construction and retrieval policies. The extensive experiments demonstrate that Mem-T not only achieves state-of-the-art performance across in-domain and out-of-domain benchmarks but also realizes a superior Pareto efficiency between task accuracy and inference overhead. We believe Mem-T represents a shift from heuristic-based storage to fully learnable, attribution-centric memory systems, paving the way for the development of self-evolving agents capable of lifelong learning.
在本文中,我们提出 Mem-T,一个综合的层级记忆框架,以及 MoT-GRPO,一个用于记忆智能体的新型 RL 范式。 通过利用记忆操作树把稀疏终端奖励分解成稠密的逐步监督,MoT-GRPO 能够联合优化记忆构建和检索策略。 大量实验表明,Mem-T 不仅在域内和域外基准上达到最先进性能,还在任务准确率和推理开销之间实现了更优的 Pareto 效率。 我们认为,Mem-T 代表了从基于启发式的存储到完全可学习、以归因为中心的记忆系统的转变,为开发具备终身学习能力的自演化智能体铺平了道路。