
Beyond Semantic Organization: Memory as Execution State Management for Long-Horizon Agents
MemoryMicrosoft中科大超越语义组织:将记忆作为长程智能体的执行状态管理
Abstract
LLM-based agents increasingly tackle long-horizon tasks with interdependent decisions, where each action reshapes future constraints and intermediate errors can cascade. Existing RAG and agent memory systems organize histories by semantic similarity, retrieving content-relevant entries at decision time. We argue that this design mismatches execution-state dependencies: it fragments decision trajectories and mixes valid and erroneous traces, hindering coherent state reconstruction and error isolation. We propose Mage (Memory as Agent-Guided Exploration), an active execution-state manager that stores interactions in a hierarchical state tree. The agent derives its state from the active root-to-current path, combining subgoal summaries, recent traces, and hints from prior branches. Four coupled operations maintain the tree: Grow records new traces, Compress summarizes completed subgoals, Maintain validates summaries, and Revise restores a target boundary and resumes on a new branch. This design bounds context growth while preserving state integrity and isolating flawed segments from the active path. Experiments on MemoryArena show that Mage improves the average task success rate by
基于 LLM 的智能体越来越多地处理具有相互依赖决策的长程任务,其中每个动作都会重塑未来约束,而中间错误可能级联扩散。 现有 RAG 和智能体记忆系统按语义相似性组织历史,并在决策时检索内容相关的条目。 作者认为,这种设计与执行状态依赖不匹配:它会割裂决策轨迹,并混合有效和错误轨迹,从而阻碍连贯的状态重建和错误隔离。 作者提出 Mage(Memory as Agent-Guided Exploration),这是一个主动的执行状态管理器,将交互存储在层次化状态树中。 智能体从活动的 root-to-current 路径推导自身状态,结合子目标摘要、近期轨迹以及来自先前分支的提示。 四个耦合操作维护这棵树:Grow 记录新轨迹,Compress 总结已完成子目标,Maintain 验证摘要,Revise 恢复目标边界并在新分支上继续。 这一设计在限制上下文增长的同时保持状态完整性,并将有缺陷的片段从活动路径中隔离出来。 在 MemoryArena 上的实验表明,相比基线,Mage 将平均任务成功率提高
1. Introduction
With the growing ability of large language models (LLMs) to interact with complex environments through tool use and multi-step reasoning, LLM-based agents are increasingly deployed for long-horizon tasks with interdependent decisions. These tasks involve hundreds of steps where each action reshapes future choices, and intermediate errors can cascade to invalidate subsequent progress. Unlike recall-oriented memory benchmarks that answer questions over past conversations or agentic traces, the interdependent long-horizon agent tasks we study require maintaining a coherent, evolving execution state, as each decision depends on the cumulative outcome of prior steps.
随着大语言模型(LLM)通过工具使用和多步推理与复杂环境交互的能力不断增强,基于 LLM 的智能体越来越多地被部署到具有相互依赖决策的长程任务中。 这些任务涉及数百个步骤,其中每个动作都会重塑未来选择,中间错误也可能级联扩散并使后续进展失效。 不同于面向回忆的记忆基准,它们回答关于过去对话或智能体轨迹的问题;本文研究的相互依赖长程智能体任务需要维持一个连贯且不断演化的执行状态,因为每个决策都依赖先前步骤的累积结果。
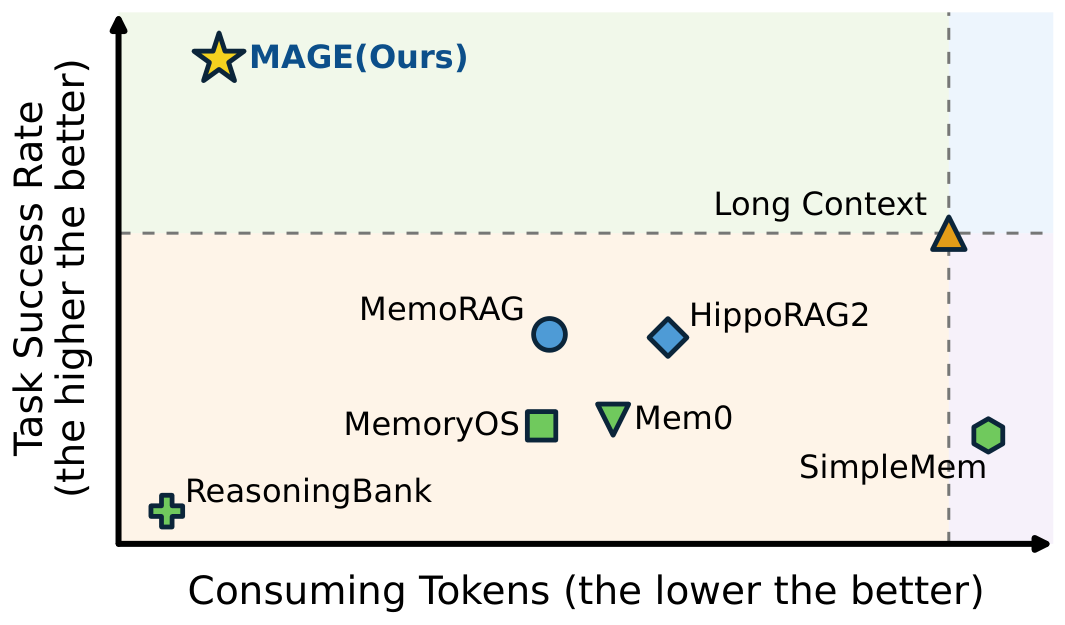
This requirement becomes harder as exploration history grows beyond the model's effective context window. To address this, recent works introduce memory systems that record past information as compact entries and retrieve relevant ones on demand. Yet recent benchmarks reveal a counter-intuitive pattern: these systems often fail to improve long-horizon agent performance and sometimes underperform approaches that simply retain the full history in context. As shown in Figure 1, many such systems consume substantial tokens while still trailing the long-context approach.
随着探索历史增长并超出模型的有效上下文窗口,这一需求变得更加困难。 为解决这一问题,近期工作引入了记忆系统,它们将过去信息记录为紧凑条目,并按需检索相关条目。 然而,近期基准揭示了一个反直觉模式:这些系统经常无法提升长程智能体表现,有时甚至不如简单地在上下文中保留完整历史的方法。 如 图1 所示,许多这类系统消耗了大量 token,却仍落后于长上下文方法。
We argue that a key cause lies in the shared design philosophy. Although these systems vary in their data structures, ranging from flat vector stores to entity-relation graphs to hierarchical architectures, they generally rely on semantic relationships to organize and retrieve information, surfacing entries by their content relevance to the current query rather than their role in the execution trajectory.
作者认为,一个关键原因在于这些系统共享的设计哲学。 尽管这些系统在数据结构上各不相同,从扁平向量存储,到实体关系图,再到层次化架构,但它们通常依赖语义关系来组织和检索信息,根据条目与当前查询的内容相关性而不是它们在执行轨迹中的作用来呈现条目。
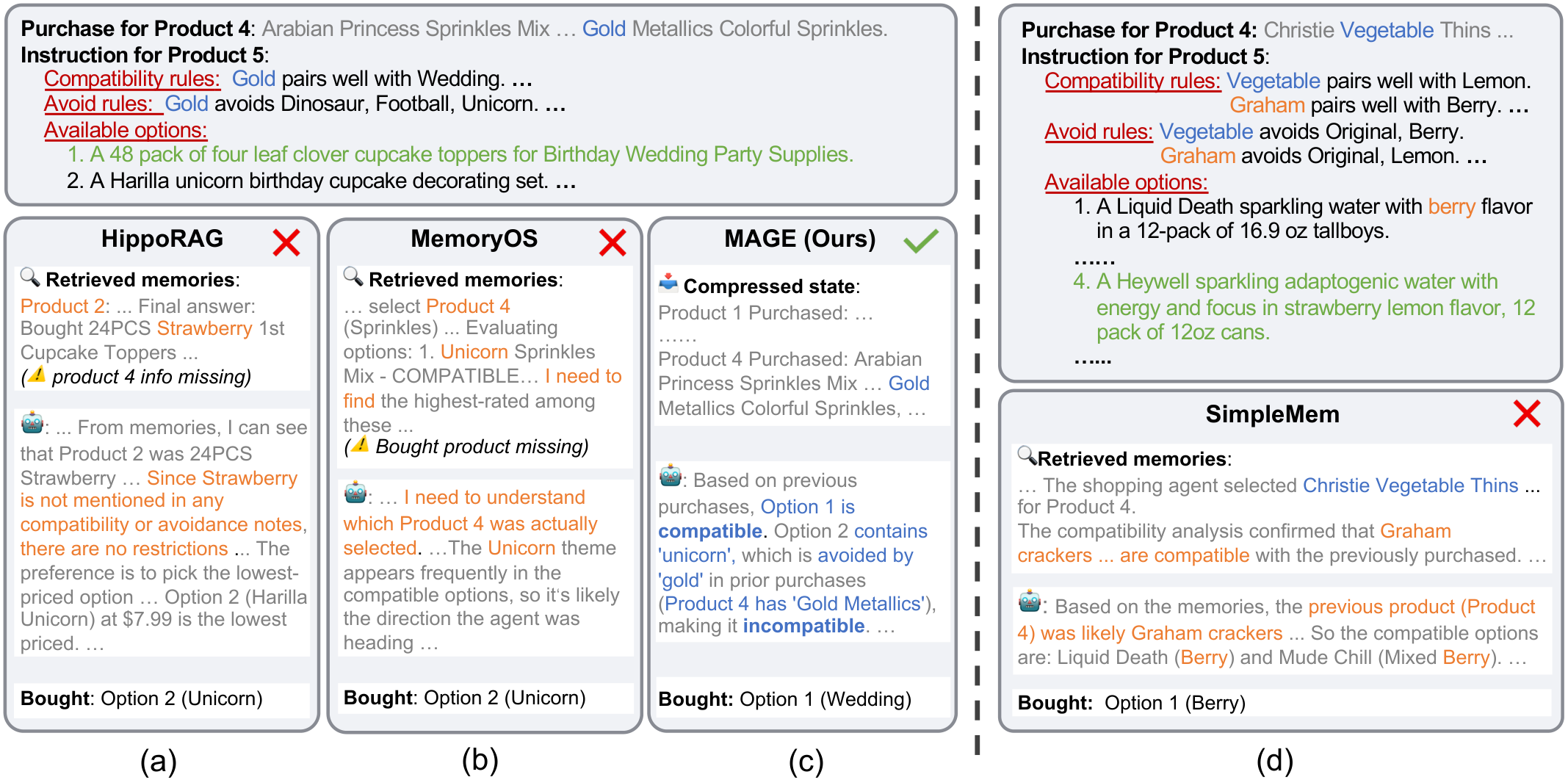
Such similarity-driven organization leads to two recurring problems when handling interdependent long-horizon tasks. First, it causes state fragmentation that weakens execution state integrity. The agent's execution state is built up through a chain of dependent decisions where each step is conditioned on the context established by prior steps. Existing systems, even those with graph structures, organize this state as entries linked by semantic or topical relationships rather than state dependencies, discarding critical execution context that binds them together. As a result, the system may fail to reconstruct a complete, coherent execution state, leading to erroneous actions based on incomplete information (Figure 2(a)--(b)).
在处理相互依赖的长程任务时,这种由相似性驱动的组织方式会反复导致两个问题。 第一,它会造成状态碎片化,削弱执行状态完整性。 智能体的执行状态是通过一条相互依赖的决策链建立起来的,其中每一步都以先前步骤建立的上下文为条件。 现有系统即使带有图结构,也会把该状态组织为由语义或主题关系连接的条目,而不是由状态依赖连接的条目,从而丢弃将它们绑定在一起的关键执行上下文。 因此,系统可能无法重建完整、连贯的执行状态,进而基于不完整信息采取错误动作(图2(a)--(b))。
Second, it hinders effective error isolation. Similarity-based memory mixes entries from different trajectories or exploration attempts in the same relevance space, so erroneous and valid traces can be surfaced together and contaminate subsequent reasoning (Figure 2(d)). Without explicit path structure and revision boundaries, it is also difficult to trace an error back to its origin or isolate the affected segment, allowing errors to propagate and accumulate over the course of execution.
第二,它会阻碍有效错误隔离。 基于相似性的记忆会把来自不同轨迹或探索尝试的条目混合在同一个相关性空间中,因此错误轨迹和有效轨迹可能一起浮现,并污染后续推理(图2(d))。 如果没有显式路径结构和修订边界,也很难把错误追溯到其源头或隔离受影响的片段,导致错误在执行过程中传播并累积。
These observations suggest that memory for interdependent long-horizon agents should shift from a similarity-driven archive to an execution-state manager. To this end, we propose Mage (Memory as Agent-Guided Exploration), which treats memory as an execution state structure rather than a pool of retrievable facts. Mage organizes the agent's history as a persistent two-layer hierarchical state tree. The bottom layer records the step-by-step action-observation trace, while the top layer stores summaries generated at subgoal or decision boundaries. This boundary-aware compression reduces context without interrupting an active trace or breaking execution-state integrity. The current execution state is read from the active tree path instead of being assembled from semantically similar entries, combining compressed state, recent raw state, and execution hints from sibling branches. This path-based representation addresses state fragmentation by keeping the agent-facing state coherent while still bounding the context size.
这些观察表明,相互依赖长程智能体的记忆应当从由相似性驱动的档案,转向执行状态管理器。 为此,作者提出 Mage(Memory as Agent-Guided Exploration),它把记忆视为一种执行状态结构,而不是可检索事实的池子。 Mage 将智能体历史组织为一棵持久的两层层次化状态树。 底层记录逐步的动作-观测轨迹,而顶层存储在子目标或决策边界处生成的摘要。 这种边界感知压缩在不打断活动轨迹、不破坏执行状态完整性的情况下减少上下文。 当前执行状态从活动树路径读取,而不是由语义相似的条目拼装而成;它结合了压缩状态、近期原始状态,以及来自兄弟分支的执行提示。 这种基于路径的表示通过保持面向智能体的状态连贯,同时限制上下文大小,从而解决状态碎片化问题。
Building on this tree, Mage further supports error isolation by making memory an agent-manipulable object rather than a shared pool of mixed entries. Through a closed-loop execution cycle, Grow extends the raw trace and Compress summarizes the accumulated trace at subgoal or decision boundaries. Before a new summary becomes trusted memory, Maintain validates the summary and its underlying trace against the task, catching missing information or execution errors before they propagate. If an error is detected, Revise restores the execution state to the target boundary and resumes execution as a new branch. The erroneous segment is therefore excluded from the active path, while the valid progress before the target boundary is preserved, isolating the error from subsequent decisions. As shown in Figure 1, Mage occupies the optimal upper-left quadrant, achieving stronger task progress with lower token consumption.
基于这棵树,Mage 进一步通过让记忆成为智能体可操作对象,而不是混合条目的共享池,来支持错误隔离。 通过一个闭环执行周期,Grow 扩展原始轨迹,Compress 在子目标或决策边界处总结累积轨迹。 在新摘要成为可信记忆之前,Maintain 会根据任务验证该摘要及其底层轨迹,在错误传播前捕获缺失信息或执行错误。 如果检测到错误,Revise 会把执行状态恢复到目标边界,并作为新分支继续执行。 因此,错误片段会被排除在活动路径之外,而目标边界之前的有效进展会被保留,从而把错误从后续决策中隔离出来。 如 图1 所示,Mage 位于最优的左上象限,以更低 token 消耗取得更强任务进展。
Our contributions are as follows. (1) We propose Mage, which organizes agentic memory as a two-layer hierarchical tree whose root-to-current path provides a complete execution state by construction, shifting memory from similarity-driven retrieval to compact execution-state management. (2) We design four coupled operations that make this tree an agent-manipulable object, forming a closed-loop state-management cycle that isolates errors into separate branches and keeps the active execution state free from erroneous traces. (3) On MemoryArena, Mage improves the task success rate by
本文贡献如下。 (1) 作者提出 Mage,它将智能体记忆组织为两层层次化树,其 root-to-current 路径通过构造提供完整执行状态,从而将记忆从相似性驱动检索转向紧凑的执行状态管理。 (2) 作者设计了四个耦合操作,使这棵树成为智能体可操作对象,形成闭环状态管理周期,将错误隔离到独立分支中,并让活动执行状态不含错误轨迹。 (3) 在 MemoryArena 上,相比基线,Mage 平均将任务成功率提高
2. Background and Related Work
2.1. Problem Setting
Long-horizon agent tasks with interdependent decisions can be formulated as a Markov decision process (MDP). At step
具有相互依赖决策的长程智能体任务可以被表述为马尔可夫决策过程(MDP)。 在步骤
This formulation highlights two requirements. First, since
这一表述突出了两个要求。 第一,由于
2.2. Memory and Retrieval Systems for Agents
A natural approach to managing long histories is retrieval-augmented generation (RAG), which augments the LLM context with information retrieved from an external store. Existing RAG methods include direct retrieval with sparse or dense matching, iterative retrieval with query refinement, graph-structured RAG for multi-hop reasoning, and memory-augmented RAG that uses a lightweight model to form global memory or retrieval clues. These methods are effective for grounding generation in external knowledge, but the retrieved corpus is typically static and independent of the agent's action-conditioned state.
管理长历史的一种自然方法是检索增强生成(RAG),它用从外部存储中检索到的信息增强 LLM 上下文。 现有 RAG 方法包括使用稀疏或稠密匹配的直接检索、带查询细化的迭代检索、用于多跳推理的图结构 RAG,以及使用轻量模型形成全局记忆或检索线索的记忆增强 RAG。 这些方法能有效地把生成建立在外部知识之上,但被检索的语料通常是静态的,并且独立于智能体由动作条件化的状态。
Agent memory systems instead store the agent's evolving history. They differ in storage design: flat systems keep independent records retrieved by embedding similarity; graph-based systems organize memories through entity or event relations; hierarchical systems maintain multiple granularities to balance detail and compression; and hybrid systems combine granularities or narrative structures for compact coverage. Other work improves retrieval with prospective indexing or retrospective reflection.
智能体记忆系统则存储智能体不断演化的历史。 它们在存储设计上各不相同:扁平系统保留由 embedding 相似性检索的独立记录;基于图的系统通过实体或事件关系组织记忆;层次化系统维护多种粒度以平衡细节和压缩;混合系统则结合多种粒度或叙事结构来实现紧凑覆盖。 其他工作通过前瞻索引或回顾反思改进检索。
Despite this diversity, these systems commonly expose memory through similarity-driven update and retrieval: they maintain a store
尽管存在这种多样性,这些系统通常通过相似性驱动的更新和检索来暴露记忆:它们通过
3. Method
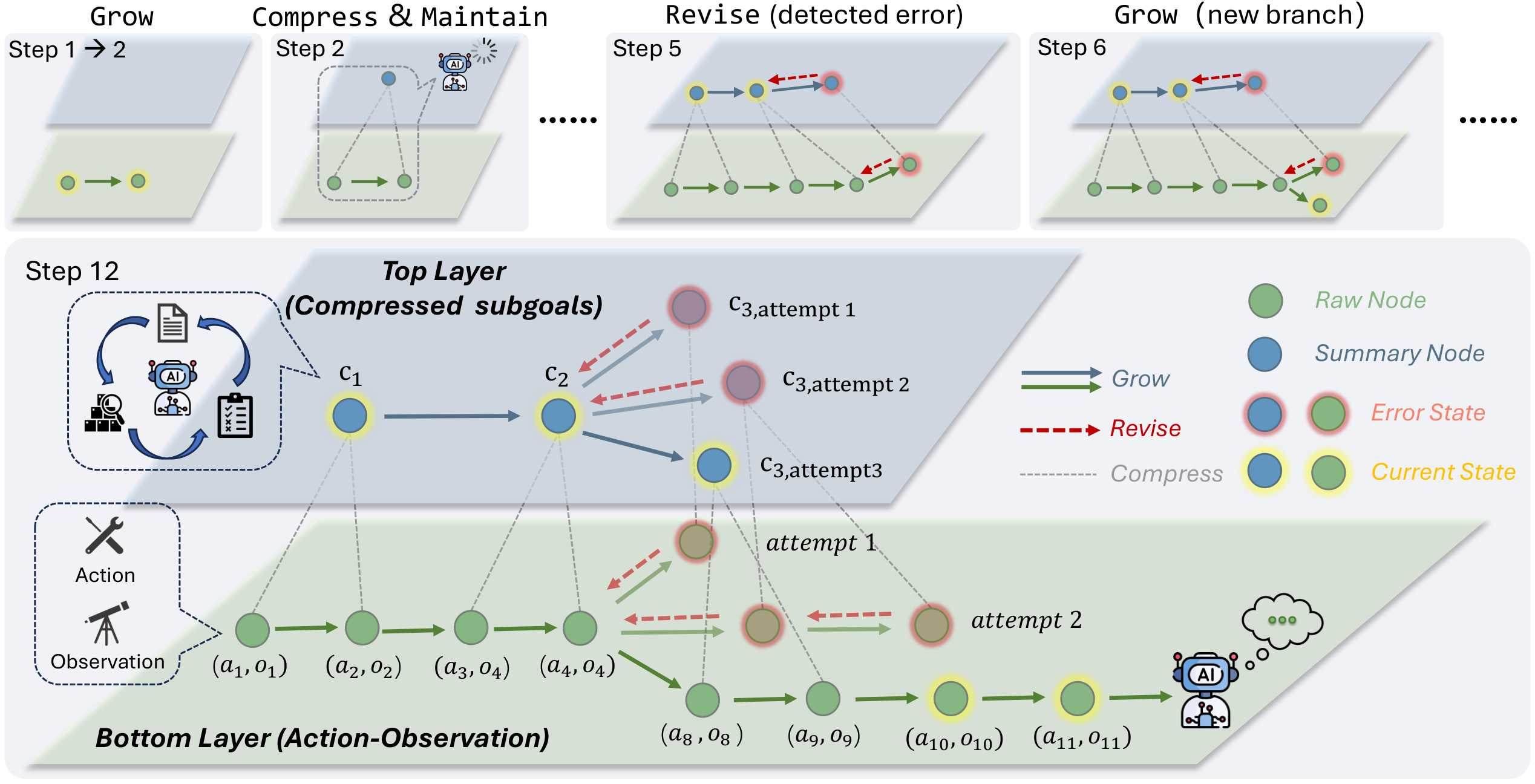
To address the issues inherent in similarity-driven memory systems, we propose Mage, which shifts agentic memory from passive semantic storage and retrieval to active execution state management. Figure 3 illustrates the overall design.
为解决相似性驱动记忆系统的内在问题,作者提出 Mage,将智能体记忆从被动语义存储和检索转向主动执行状态管理。 图3 展示了总体设计。
3.1. Overview
Cognitive science suggests that humans performing complex sequential tasks rely on coordinated neural mechanisms. The prefrontal cortex organizes behavior into hierarchical subgoals and chunks completed segments to free working memory for subsequent planning. The anterior cingulate cortex monitors execution and signals failures at subgoal boundaries before they propagate to downstream decisions. After detecting errors, executive control selectively backtracks to the relevant boundary and repairs the affected segment while preserving unaffected goal structure. This cycle of chunking, monitoring, and correction motivates a memory system that manages execution state actively rather than merely storing past information.
认知科学表明,人类执行复杂序列任务时依赖协调的神经机制。 前额叶皮层将行为组织为层次化子目标,并把已完成片段分块,以释放工作记忆用于后续规划。 前扣带皮层监控执行,并在失败传播到下游决策之前,在子目标边界处发出失败信号。 检测到错误后,执行控制会选择性回退到相关边界,并在保留未受影响目标结构的同时修复受影响片段。 这种分块、监控和纠正的循环,启发了一种主动管理执行状态而不只是存储过去信息的记忆系统。
Motivated by this architecture, we propose Mage (Memory as Agent-Guided Exploration), which represents the agent's execution history as a two-layer hierarchical state tree. The bottom layer records raw action-observation nodes in execution order, preserving fine-grained state dependencies. The top layer stores summary nodes that cover completed bottom-layer segments, progressively chunking long local traces into compact subgoal-level states. Together, these two layers keep the root-to-current path complete rather than fragmented, while bounding the context and retaining the boundaries needed for future revision. Based on this tree, Mage constructs the agent-facing execution state
受这种架构启发,作者提出 Mage(Memory as Agent-Guided Exploration),将智能体的执行历史表示为一棵两层层次化状态树。 底层按执行顺序记录原始动作-观测节点,保留细粒度状态依赖。 顶层存储覆盖已完成底层片段的摘要节点,将长局部轨迹逐步分块为紧凑的子目标级状态。 这两层共同保持 root-to-current 路径完整而非碎片化,同时限制上下文并保留未来修订所需边界。 基于这棵树,Mage 构建面向智能体的执行状态
Given this state representation, we design four operations to maintain the tree and refresh Grow appends each new action-observation pair to the bottom-layer tree, extending the recent raw trace Compress moves completed raw segments from Maintain acts as a boundary-level error monitor, validating each new summary before it becomes trusted memory and recording diagnostic notes. Upon detecting an error, Revise provides selective correction by restoring
给定这一状态表示,作者设计四个操作来维护这棵树,并在闭环中刷新 Grow 将每个新的动作-观测对追加到底层树中,扩展近期原始轨迹 Compress 将已完成原始片段从 Maintain 充当边界级错误监控器,在每个新摘要成为可信记忆之前验证它,并记录诊断备注。 检测到错误后,Revise 通过将
| Cognitive Mechanism | Function | Operation |
|---|---|---|
| Hierarchical chunking | Organize subgoals; free working memory | Grow + Compress |
| Error monitoring | Detect errors at subgoal boundaries | Maintain |
| Selective correction | Backtrack to error origin; correct affected branch | Revise |
This closed-loop design directly addresses state fragmentation and ineffective error isolation. First, Mage constructs the current execution state from one path of the tree, combining compressed summaries for completed segments with raw traces for recent steps instead of retrieving disconnected memory entries based on similarity. Second, boundary-level maintenance and revision prevent erroneous segments from entering or contaminating the active execution state. When an error is detected, Revise branches from the target boundary, isolating the affected segment while preserving valid progress elsewhere. We next present the hierarchical execution state tree and the four state-transition operations.
这一闭环设计直接解决状态碎片化和无效错误隔离问题。 第一,Mage 从树的一条路径构造当前执行状态,把已完成片段的压缩摘要与近期步骤的原始轨迹结合起来,而不是基于相似性检索断开的记忆条目。 第二,边界级维护和修订可以防止错误片段进入或污染活动执行状态。 当检测到错误时,Revise 从目标边界分支,隔离受影响片段,同时保留其他位置的有效进展。 接下来介绍层次化执行状态树和四个状态转移操作。
3.2. Hierarchical Execution State Tree
Mage organizes the agent's execution history as a two-layer hierarchical tree with a unified node structure (Table 2). The bottom layer records every raw action-observation pair as a node, preserving the fine-grained state of the execution. The root-to-current path through this layer yields the complete execution trajectory, while children of each node expose previously explored alternatives that can help the agent avoid repeating errors. When the agent revises a decision, new actions branch as siblings of the failed path, structurally isolating erroneous traces from valid ones. The top layer compresses contiguous bottom-layer segments into summary nodes, bounding the context as the task progresses. Each top-layer node corresponds to a completed subgoal, and we apply Maintain and Revise at these subgoal boundaries, the same locus where the prefrontal cortex chunks completed segments and the anterior cingulate cortex monitors for errors before they propagate (Table 1).
Mage 将智能体执行历史组织为一棵两层层次化树,并采用统一节点结构(表2)。 底层把每个原始动作-观测对记录为一个节点,保留执行的细粒度状态。 穿过这一层的 root-to-current 路径产生完整执行轨迹,而每个节点的子节点暴露先前探索过的替代选项,可帮助智能体避免重复错误。 当智能体修订某个决策时,新动作会作为失败路径的兄弟节点分支出来,从结构上将错误轨迹与有效轨迹隔离。 顶层把连续的底层片段压缩为摘要节点,随着任务推进限制上下文。 每个顶层节点对应一个已完成子目标,作者在这些子目标边界处应用 Maintain 和 Revise;这也是前额叶皮层分块已完成片段、前扣带皮层在错误传播前监控错误的位置(表1)。
| Field | Description |
|---|---|
id | Unique identifier |
content | Action-observation pair (bottom layer) or compressed summary (top layer) |
parent | Pointer to parent node |
children | Set of child node pointers |
cover_nodes | Ordered bottom-node pointers covered by this summary (top layer only) |
note | Diagnostic feedback (top layer only) |
At runtime, Mage navigates this two-layer structure with pointers
运行时,Mage 使用指针
Based on the hierarchical tree, Mage derives the agent's execution state
基于层次化树,Mage 通过组合三部分推导智能体的执行状态
3.3. State-Transition Operations
The hierarchical tree becomes an active execution manager through four operations that transition the execution state as the agent progresses. Algorithm 1 provides the pseudocode of these operations.
随着智能体推进,层次化树通过四个操作转移执行状态,从而成为主动执行管理器。 算法1 给出了这些操作的伪代码。
Grow. When the agent executes an action and receives an observation, Mage automatically invokes Grow to update the bottom layer. If
Grow. 当智能体执行一个动作并收到一个观测时,Mage 会自动调用 Grow 来更新底层。 如果
The raw state
随后,原始状态
This informs the agent of continuations attempted in prior explorations and helps it avoid repeating failed strategies.
这会告知智能体先前探索中尝试过的延续方式,并帮助它避免重复失败策略。
Compress. Compress bounds context growth by replacing a completed bottom-layer segment with a top-layer summary node, freeing space while preserving the decision boundary needed for later recovery. It is invoked when the agent marks a subgoal complete with summary content provided as an argument, or by Mage as a fallback when the raw state
Compress. Compress 通过用顶层摘要节点替换已完成的底层片段来限制上下文增长,释放空间,同时保留后续恢复所需的决策边界。 当智能体将某个子目标标记为完成并以参数形式提供摘要内容时,或者当原始状态
Operationally, Compress traces the bottom-layer tree from
在操作上,Compress 会从
Then, Compress clears the current raw state
然后,Compress 清空当前原始状态
This exposes previously attempted subgoals from the new boundary while keeping the compressed state compact.
这会从新边界暴露先前尝试过的子目标,同时保持压缩状态紧凑。
Maintain. Immediately after compression, Maintain validates the just-completed subgoal before the new summary becomes a trusted part of memory. This check protects the execution state from incorrect memory writes, allowing Mage to detect missing information, unsatisfied task requirements, or broken dependencies before such errors accumulate. An LLM examines the compressed subtree together with the summary content and task instruction:
Maintain. 压缩后,Maintain 会立即验证刚完成的子目标,然后新摘要才会成为记忆中的可信部分。 这一检查保护执行状态免受错误记忆写入影响,使 Mage 能够在这类错误累积前检测缺失信息、未满足的任务要求或断裂的依赖。 一个 LLM 会结合摘要内容和任务指令检查压缩子树:
If validation passes, execution continues. Otherwise, Maintain records the diagnostic feedback
如果验证通过,执行继续。 否则,Maintain 会把诊断反馈
Revise. Triggered by a Maintain failure or invoked proactively by the agent upon detecting an error, Revise restores the active path to the target step Maintain or selected from exposed compressed-state boundaries. Mage rolls both pointers backward until the target is reached, where re-exploration begins:
Revise. Revise 由 Maintain 失败触发,或在智能体检测到错误时由其主动调用;它会将活动路径恢复到目标步骤 Maintain 返回,要么从暴露出的压缩状态边界中选择。 Mage 会将两个指针都向后回滚,直到到达重新探索开始的目标位置:
The compressed state
压缩状态
Subsequent actions branch from this restored point as sibling paths, achieving error isolation without discarding valid progress on other branches.
后续动作会从这个恢复点作为兄弟路径分支出来,在不丢弃其他分支有效进展的情况下实现错误隔离。
Algorithm 1: Mage state transition operations.
Global Variable: Pointers to the bottom-layer tree
Execution State:
- function
- for all
do - if
then ▷ merge node -
-
-
- return
- end if
- end for
-
; -
; -
; -
- end function
- function
▷ input summary content -
▷ compressed boundary -
▷ track nodes in execution order - for all
do ▷ merge node - if
then -
; -
; -
- return
- end if
- end for
-
-
; -
-
; -
- end function
- function
▷ input task instruction -
▷ flatten traces -
▷ LLM judge - if
then - return
- else
-
- return
- end if
- end function
- function
▷ input feedback and target step - while
do -
; - end while
-
-
▷ skip the failed compressed node -
; -
- end function
4. Experiments
4.1. Experimental Setup
Benchmark. We evaluate on MemoryArena, an interdependent long-horizon benchmark where agents operate in a continuous Memory-Agent-Environment loop for up to hundreds of steps. Unlike conventional benchmarks that test static fact retrieval or question answering over past dialogues and traces, MemoryArena follows action-conditioned MDPs: each action can reshape future constraints, so success requires tracking the evolving execution state rather than recalling facts.
Benchmark. 作者在 MemoryArena 上评估,这是一个相互依赖的长程基准,其中智能体在连续的 Memory-Agent-Environment 循环中运行,最多可达数百步。 不同于测试静态事实检索或关于过去对话和轨迹的问答的传统基准,MemoryArena 遵循动作条件化 MDP:每个动作都可能重塑未来约束,因此成功需要跟踪不断演化的执行状态,而不是回忆事实。
MemoryArena spans four domains with long dependency structures: Bundled Web Shopping, where the agent purchases a bundle of related products and later choices depend on earlier items; Group Travel Planning, in which the agent coordinates multi-person itineraries to satisfy interdependent preferences; Progressive Web Search, where the model answers complex queries progressively using information gathered from previous sub-queries; and Formal Reasoning, in which the agent proves complex claims through sequential derivations that build on previously established results.
MemoryArena 覆盖四个具有长依赖结构的领域:Bundled Web Shopping,智能体购买一组相关商品,后续选择依赖先前商品;Group Travel Planning,智能体协调多人行程以满足相互依赖的偏好;Progressive Web Search,模型使用先前子查询收集的信息逐步回答复杂查询;以及 Formal Reasoning,智能体通过建立在先前已证明结果之上的顺序推导来证明复杂命题。
Baselines. We compare Mage against representative methods across three paradigms. Long Context retains full interaction history. RAG systems include HippoRAG2, which builds a knowledge graph and applies Personalized PageRank for multi-hop retrieval, and MemoRAG, which uses a lightweight memory model to generate retrieval clues. Memory systems include Mem0, which extracts and consolidates facts into graph-based memory, ReasoningBank, which distills reusable reasoning strategies from past experiences, MemoryOS, which maintains hierarchical storage layers with dynamic cross-level updating, and SimpleMem, which performs semantic compression and recursive consolidation for efficient memory management. All methods use the default hyperparameters from their original papers.
Baselines. 作者将 Mage 与三种范式下的代表性方法比较。 Long Context 保留完整交互历史。 RAG systems 包括 HippoRAG2 和 MemoRAG;前者构建知识图并应用 Personalized PageRank 进行多跳检索,后者使用轻量记忆模型生成检索线索。 Memory systems 包括 Mem0、ReasoningBank、MemoryOS 和 SimpleMem;Mem0 将事实抽取并整合进基于图的记忆,ReasoningBank 从过去经验中蒸馏可复用推理策略,MemoryOS 维护带有动态跨层更新的层次化存储层,SimpleMem 则执行语义压缩和递归整合以实现高效记忆管理。 所有方法都使用其原论文中的默认超参数。
Model. All methods use Qwen3.6-27B as the backbone LLM with ReAct for agent exploration. Baselines requiring embeddings use Qwen3-8B-Embedding. Inference runs on NVIDIA A100 GPUs with vLLM 0.20.0 under Python 3.12. Results with additional backend models are reported in Appendix.
Model. 所有方法都使用 Qwen3.6-27B 作为骨干 LLM,并使用 ReAct 进行智能体探索。 需要 embedding 的基线使用 Qwen3-8B-Embedding。 推理在 NVIDIA A100 GPU 上运行,使用 Python 3.12 下的 vLLM 0.20.0。 其他后端模型的结果报告在附录中。
Metrics. Following MemoryArena, we report average Task Success Rate (SR, %), Task Progress Score (PS, %), and total token consumption. SR measures full task completion: all subtasks must be correct in Shopping and Travel Planning, while the final subtask determines success in the other two domains. PS measures completed-subtask fraction, and token consumption includes both prompt and generation tokens.
Metrics. 遵循 MemoryArena,作者报告平均任务成功率(SR,%)、任务进展分数(PS,%)和总 token 消耗。 SR 衡量完整任务完成情况:Shopping 和 Travel Planning 中所有子任务都必须正确,而另外两个领域由最终子任务决定成功与否。 PS 衡量已完成子任务比例,token 消耗同时包括 prompt token 和 generation token。
4.2. Main Results
| Bundled Web Shopping | Group Travel Planning | Progressive Web Search | Formal Reasoning | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | SR | PS | #tokens | SR | PS | #tokens | SR | PS | #tokens | Math SR | Math PS | Physics SR | Physics PS | #tokens |
| Long Context | 0.3333 | 0.7578 | 1528K | 0.0519 | 0.4070 | 3211K | 0.4842 | 0.2803 | 6045K | 0.4000 | 0.4124 | 0.6500 | 0.6977 | 1782K |
| HippoRAG2 | 0.2067 | 0.7189 | 1720K | 0.0963 | 0.5569 | 3153K | 0.3620 | 0.2133 | 2865K | 0.4500 | 0.4153 | 0.6000 | 0.7093 | 2268K |
| MemoRAG | 0.2067 | 0.7200 | 1251K | 0.0481 | 0.4731 | 2829K | 0.4208 | 0.2535 | 3535K | 0.4500 | 0.4237 | 0.6500 | 0.7209 | 1314K |
| Mem0 | 0.1933 | 0.6822 | 1753K | 0.0259 | 0.3498 | 2786K | 0.3529 | 0.2206 | 2715K | 0.4000 | 0.4040 | 0.5500 | 0.6977 | 1853K |
| ReasoningBank | 0.1133 | 0.6033 | 868K | 0.0000 | 0.2346 | 1463K | 0.3032 | 0.1993 | 1923K | 0.4250 | 0.4266 | 0.5500 | 0.6744 | 1187K |
| MemoryOS | 0.2000 | 0.7044 | 1448K | 0.0259 | 0.4405 | 2984K | 0.3303 | 0.2084 | 2973K | 0.4500 | 0.4209 | 0.5500 | 0.6977 | 1452K |
| SimpleMem | 0.1600 | 0.6767 | 2939K | 0.0222 | 0.3246 | 4616K | 0.3575 | 0.2310 | 3715K | 0.4000 | 0.4294 | 0.5500 | 0.6628 | 1656K |
| Mage (Ours) | 0.3933 | 0.7778 | 1015K | 0.1519 | 0.5351 | 1978K | 0.5656 | 0.3790 | 1727K | 0.4250 | 0.4492 | 0.6500 | 0.6977 | 1195K |
Table 3 presents task performance across four domains. On tasks with complex state dependencies, RAG and memory-based baselines underperform the long-context approach, with SR drops of
表3 展示了四个领域中的任务表现。 在具有复杂状态依赖的任务上,RAG 和基于记忆的基线表现低于长上下文方法:Web Shopping 上 SR 下降
Conversely, Mage outperforms the long-context approach by average margins of
相反,Mage 相比长上下文方法平均在 SR 上高出
4.3. Token Efficiency
Regarding efficiency, Table 3 also shows token consumption per task. While RAG and memory baselines theoretically reduce context length, this benefit primarily materializes in document-heavy environments like Web Search, where they reduce token usage by 38.5--68.2% compared with the long-context approach. In domains with shorter observations and frequent state updates, the overhead of memory maintenance (e.g., extraction, query rewriting), compounded by the additional reasoning and execution steps required to synthesize fragmented retrieved states, frequently eclipses the compression savings. Consequently, systems like HippoRAG2 and Mem0 end up consuming 12.6--14.7% more tokens than the long-context approach on Web Shopping. In contrast, Mage consistently reduces token usage by 32.9--71.4% across all domains. Unlike traditional memory systems that require continuous, token-heavy auxiliary LLM calls to extract entities or generate queries, Mage maintains the tree structure deterministically and invokes auxiliary LLMs only during Compress and Maintain at natural subgoal boundaries. This design minimizes maintenance overhead without compromising state integrity.
在效率方面,表3 也展示了每个任务的 token 消耗。 虽然 RAG 和记忆基线理论上会减少上下文长度,但这一收益主要体现在 Web Search 这类文档密集环境中;相比长上下文方法,它们在这里将 token 使用减少 38.5--68.2%。 在观测较短且状态更新频繁的领域中,记忆维护开销(例如抽取、查询改写)叠加合成碎片化检索状态所需的额外推理和执行步骤,常常超过压缩带来的节省。 因此,HippoRAG2 和 Mem0 等系统在 Web Shopping 上最终比长上下文方法多消耗 12.6--14.7% token。 相比之下,Mage 在所有领域中都稳定地将 token 使用减少 32.9--71.4%。 传统记忆系统需要持续进行 token 开销很高的辅助 LLM 调用来抽取实体或生成查询,而 Mage 确定性地维护树结构,并且只在自然子目标边界处的 Compress 和 Maintain 期间调用辅助 LLM。 这一设计在不损害状态完整性的情况下最小化维护开销。
4.4. Ablation Study
| Variant | Web Shopping | Travel Planning | ||||
|---|---|---|---|---|---|---|
| SR | PS | #tokens | SR | PS | #tokens | |
| Mage (Full) | 0.3933 | 0.7778 | 1015K | 0.1519 | 0.5351 | 1978K |
| w/o Compress | 0.3200 | 0.7233 | 2469K | 0.0852 | 0.4496 | 3539K |
| w/o Maintain | 0.3267 | 0.7389 | 887K | 0.1000 | 0.4683 | 1256K |
| w/o Revise | 0.3533 | 0.7378 | 1157K | 0.1000 | 0.4708 | 2551K |
To validate the contribution of the main state-management mechanisms, we evaluate Mage variants that remove one mechanism at a time. Table 4 shows that all three mechanisms contribute to reliable execution-state management.
为验证主要状态管理机制的贡献,作者评估了每次移除一个机制的 Mage 变体。 表4 表明,三个机制都对可靠执行状态管理有贡献。
Removing Compress consistently hurts task completion, reducing SR by Maintain must verify an increasingly long trajectory.
移除 Compress 会持续损害任务完成度,使 Web Shopping 上 SR 降低 Maintain 也必须验证越来越长的轨迹。
Removing Maintain leads to a different failure mode. Although it reduces token usage by avoiding boundary-level verification, SR drops by
移除 Maintain 会导致另一种失败模式。 虽然它通过避免边界级验证减少 token 使用,但两个领域上的 SR 会下降
Finally, removing Revise lowers SR by
最后,移除 Revise 会使两个领域上的 SR 降低
Notably, these weakened variants remain competitive with or superior to the baselines in Table 3. This suggests that organizing memory around the execution path mitigates the state fragmentation caused by semantic retrieval, while the full operation loop further prevents corrupted or failed segments from contaminating the active state.
值得注意的是,这些削弱后的变体仍然与 表3 中的基线有竞争力,或优于这些基线。 这表明,围绕执行路径组织记忆可以缓解语义检索导致的状态碎片化,而完整操作循环会进一步防止损坏或失败片段污染活动状态。
5. Conclusion
We presented Mage, a memory framework that reframes long-horizon agent memory as active execution-state management rather than similarity-driven retrieval. By organizing interaction history as a two-layer hierarchical state tree, Mage preserves the active root-to-current execution path while compressing completed subgoals and exposing execution hints from previously explored branches. Its four coupled operations allow agents to extend traces, bound context growth, validate newly compressed states, and isolate erroneous segments through branching. Experiments on MemoryArena show that this design improves task success across diverse long-horizon domains while substantially reducing token consumption. These results suggest that preserving execution-state structure is a key principle for building reliable and efficient memory systems for real-world LLM agents.
本文提出 Mage,这是一个记忆框架,将长程智能体记忆重新表述为主动执行状态管理,而不是相似性驱动检索。 通过将交互历史组织为一棵两层层次化状态树,Mage 在压缩已完成子目标、暴露来自先前探索分支的执行提示的同时,保留活动的 root-to-current 执行路径。 它的四个耦合操作允许智能体扩展轨迹、限制上下文增长、验证新压缩状态,并通过分支隔离错误片段。 MemoryArena 上的实验表明,该设计在多样长程领域中提升任务成功率,同时显著减少 token 消耗。 这些结果表明,保留执行状态结构是为真实世界 LLM 智能体构建可靠高效记忆系统的一项关键原则。