
TransReID: Transformer-based Object Re-Identification
Object ReIDTransformerPerson ReIDVehicle ReID1700+ICCV 2021AlibabaZJU
TransReID:基于 Transformer 的目标重识别
Abstract
Extracting robust feature representation is one of the key challenges in object re-identification (ReID). Although convolution neural network (CNN)-based methods have achieved great success, they only process one local neighborhood at a time and suffer from information loss on details caused by convolution and downsampling operators (e.g. pooling and strided convolution). To overcome these limitations, we propose a pure transformer-based object ReID framework named TransReID. Specifically, we first encode an image as a sequence of patches and build a transformer-based strong baseline with a few critical improvements, which achieves competitive results on several ReID benchmarks with CNN-based methods. To further enhance the robust feature learning in the context of transformers, two novel modules are carefully designed. (i) The jigsaw patch module (JPM) is proposed to rearrange the patch embeddings via shift and patch shuffle operations which generates robust features with improved discrimination ability and more diversified coverage. (ii) The side information embeddings (SIE) is introduced to mitigate feature bias towards camera/view variations by plugging in learnable embeddings to incorporate these non-visual clues. To the best of our knowledge, this is the first work to adopt a pure transformer for ReID research. Experimental results of TransReID are superior promising, which achieve state-of-the-art performance on both person and vehicle ReID benchmarks.
提取鲁棒的特征表示是目标重识别(ReID)中的关键挑战之一。 虽然基于卷积神经网络(CNN)的方法已经取得巨大成功,但它们每次只处理一个局部邻域,并且会因为卷积和下采样算子(例如池化和步幅卷积)而丢失细节信息。 为克服这些限制,作者提出了一个名为 TransReID 的纯 Transformer 目标 ReID 框架。 具体而言,作者首先把图像编码为 patch 序列,并构建一个带有若干关键改进的基于 Transformer 的强基线;该基线在多个 ReID 基准上取得了与基于 CNN 的方法有竞争力的结果。 为了在 Transformer 语境下进一步增强鲁棒特征学习,作者精心设计了两个新模块。 (i)作者提出拼图 patch 模块(JPM),通过 shift 和 patch shuffle 操作重新排列 patch 嵌入,从而生成判别能力更强、覆盖范围更多样的鲁棒特征。 (ii)作者引入侧信息嵌入(SIE),通过插入可学习嵌入来融合这些非视觉线索,以缓解面向相机/视角变化的特征偏差。 据作者所知,这是首个在 ReID 研究中采用纯 Transformer 的工作。 TransReID 的实验结果非常有前景,在行人和车辆 ReID 基准上都取得了最先进性能。
1. Introduction

Object re-identification (ReID) aims to associate a particular object across different scenes and camera views, such as in the applications of person ReID and vehicle ReID. Extracting robust and discriminative features is a crucial component of ReID, and has been dominated by CNN-based methods for a long time.
目标重识别(ReID)旨在跨不同场景和相机视角关联特定目标,例如行人 ReID 和车辆 ReID 应用。 提取鲁棒且有判别力的特征是 ReID 的关键组成部分,并且长期以来一直由基于 CNN 的方法主导。
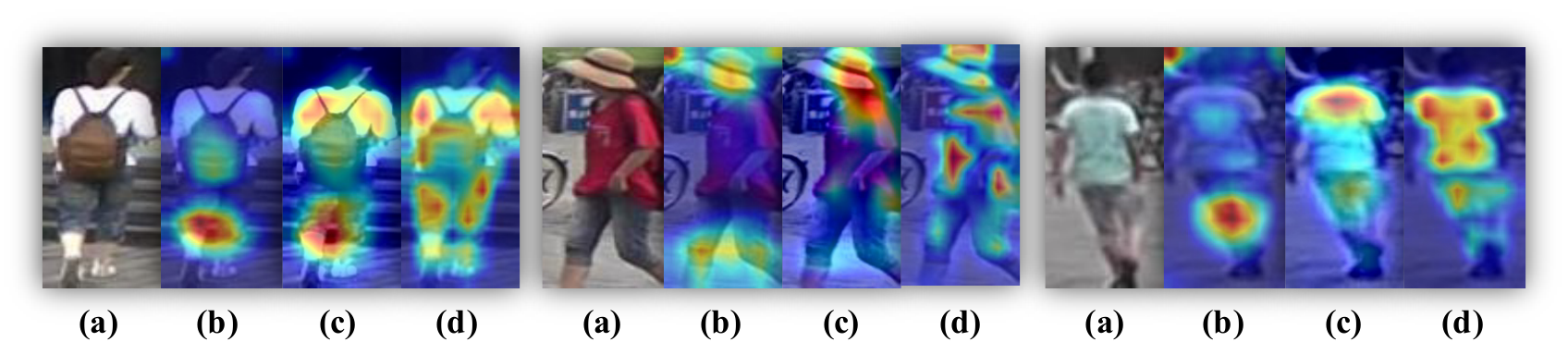
By reviewing CNN-based methods, we find two important issues which are not well addressed in the field of object ReID. (1) Exploiting the rich structural patterns in a global scope is crucial for object ReID. However, CNN-based methods mainly focus on small discriminative regions due to a Gaussian distribution of effective receptive fields. Recently, attention modules have been introduced to explore long-range dependencies, but most of them are embedded in the deep layers and do not solve the principle problem of CNN. Thus, attention-based methods still prefer large continuous areas and are hard to extract multiple diversified discriminative parts (see Figure Figure 1). (2) Fine-grained features with detail information are also important. However, the downsampling operators (e.g. pooling and strided convolution) of CNN reduce spatial resolution of output feature maps, which greatly affect the discrimination ability to distinguish objects with similar appearances. As shown in Figure Figure 2, the details of the backpack are lost in CNN-based feature maps, making it difficult to differentiate the two people.
通过回顾基于 CNN 的方法,作者发现目标 ReID 领域有两个重要问题尚未得到很好解决。 (1)利用全局范围内丰富的结构模式对目标 ReID 至关重要。 然而,由于有效感受野呈高斯分布,基于 CNN 的方法主要关注较小的判别区域。 近来,注意力模块被引入以探索长程依赖,但其中大多数嵌入在深层中,并没有解决 CNN 的根本问题。 因此,基于注意力的方法仍然偏好大的连续区域,并且难以提取多个多样化的判别部分(见 图1)。 (2)带有细节信息的细粒度特征也很重要。 然而,CNN 的下采样算子(例如池化和步幅卷积)会降低输出特征图的空间分辨率,这会极大影响区分外观相似目标的判别能力。 如 图2 所示,背包细节在基于 CNN 的特征图中丢失,使得区分这两个人变得困难。
Recently, Vision Transformer (ViT) and Data-efficient image Transformers (DeiT) have shown that pure transformers can be as effective as CNN-based methods on feature extraction for image recognition. With the introduction of multi-head attention modules and the removal of convolution and downsampling operators, transformer-based models are suitable to solve the aforementioned problems in CNN-based ReID for the following reasons. (1) The multi-head self-attention captures long range dependencies and drives the model to attend diverse human-body parts than CNN models (e.g. thighs, shoulders, waist in Figure Figure 1). (2) Without downsampling operators, transformer can keep more detailed information. For example, one can observe that the difference on feature maps around backpacks (marked by red boxes in Figure Figure 2) can help the model easily differentiate the two people. These advantages motivate us to introduce pure transformers in the object ReID.
近来,视觉 Transformer(ViT)和数据高效图像 Transformer(DeiT)表明,在用于图像识别的特征提取上,纯 Transformer 可以像基于 CNN 的方法一样有效。 随着多头注意力模块的引入以及卷积和下采样算子的移除,基于 Transformer 的模型适合解决上述基于 CNN 的 ReID 问题,原因如下。 (1)多头自注意力能够捕获长程依赖,并驱动模型比 CNN 模型关注更多样的人体部位(例如 图1 中的大腿、肩膀、腰部)。 (2)没有下采样算子时,Transformer 可以保留更多细节信息。 例如,可以观察到背包周围特征图的差异(图2 中红框标出)能够帮助模型轻松区分这两个人。 这些优势促使作者把纯 Transformer 引入目标 ReID。
Despite its great advantages as discussed above, transformers still need to be designed specifically for object ReID to tackle the unique challenges, such as the large variations (e.g. occlusions, diversity of poses, camera perspective) in images. Substantial efforts have been devoted to alleviating this challenge in CNN-based methods. Among them, local part features and side information (such as cameras and viewpoints), have been proven to be essential and effective to enhance the feature robustness. Learning part/stripe aggregated features makes it robust against occlusions and misalignments. However, extending the rigid stripe part methods from CNN-based methods to pure transformer-based methods may damage long-range dependencies due to global sequences splitting into several isolated subsequences. In addition, taking side information into consideration, such as camera and viewpoint-specific information, an invariant feature space can be constructed to diminish bias brought by side information variations. However, the complex designs for side information built on CNN, if directly applied to transformers, cannot make full use of the inherent encoding capabilities of transformers. As a result, specific designed modules are inevitable and essential for a pure transformer to successfully handle these challenges.
尽管如上所述 Transformer 具有很大优势,但它仍然需要面向目标 ReID 进行专门设计,以应对图像中的独特挑战,例如大的变化(例如遮挡、姿态多样性、相机视角)。 在基于 CNN 的方法中,已经有大量工作致力于缓解这一挑战。 其中,局部部件特征和侧信息(例如相机和视角)已被证明对增强特征鲁棒性至关重要且有效。 学习部件/条带聚合特征能让模型对遮挡和错位更鲁棒。 然而,把基于 CNN 方法中的刚性条带部件方法扩展到纯 Transformer 方法,可能会因为把全局序列拆分成若干孤立子序列而损害长程依赖。 此外,考虑相机和视角特定信息等侧信息时,可以构建一个不变特征空间,以减弱由侧信息变化带来的偏差。 然而,建立在 CNN 上的复杂侧信息设计如果直接应用于 Transformer,就无法充分利用 Transformer 固有的编码能力。 因此,专门设计的模块对于纯 Transformer 成功处理这些挑战是不可避免且必要的。
Therefore, we propose a new object ReID framework dubbed TransReID to learn robust feature representations. Firstly, by making several critical adaptations, we construct a strong baseline framework based on a pure transformer.
因此,作者提出了一个名为 TransReID 的新目标 ReID 框架,用于学习鲁棒特征表示。 首先,通过进行若干关键适配,作者构建了一个基于纯 Transformer 的强基线框架。
Secondly, in order to expand long-range dependencies and enhance feature robustness, we propose a jigsaw patches module (JPM) by rearranging the patch embeddings via shift and shuffle operations and re-grouping them for further feature learning. The JPM is employed on the last layer of the model to extract robust features in parallel with the global branch which does not include this special operation. Hence, the network tends to extract perturbation-invariant and robust features with global context. Thirdly, to further enhance the learning of robust features, a side information embedding (SIE) is introduced. Instead of the special and complex designs in CNN-based methods for utilizing these non-visual clues, we propose a unified framework that effectively incorporates non-visual clues through learnable embeddings to alleviate the data bias brought by cameras or viewpoints. Taking cameras for example, the proposed SIE helps address the vast pairwise similarity discrepancy between inter-camera and intra-camera matching (see Figure Figure 6). SIE can also be easily extended to include any non-visual clues other than the ones we have demonstrated.
其次,为了扩展长程依赖并增强特征鲁棒性,作者提出了一个拼图 patch 模块(JPM),它通过 shift 和 shuffle 操作重新排列 patch 嵌入,并把它们重新分组以进行进一步特征学习。 JPM 被用在模型最后一层,与不包含这一特殊操作的全局分支并行提取鲁棒特征。 因此,网络倾向于提取带有全局上下文的扰动不变且鲁棒的特征。 第三,为了进一步增强鲁棒特征学习,作者引入了侧信息嵌入(SIE)。 作者没有采用基于 CNN 方法中利用这些非视觉线索的特殊而复杂设计,而是提出一个统一框架,通过可学习嵌入有效融合非视觉线索,以缓解由相机或视角带来的数据偏差。 以相机为例,所提出的 SIE 有助于处理跨相机匹配与同相机匹配之间巨大的两两相似度差异(见 图6)。 SIE 也可以很容易地扩展到包含作者所展示之外的任何非视觉线索。
To our best knowledge, we are the first to investigate the application of pure transformers in the field of object ReID. The contributions of the paper are summarised:
- We propose a strong baseline that exploits the pure transformer for ReID tasks for the first time and achieve comparable performance with CNN-based frameworks.
- We design a jigsaw patches module (JPM), consisting of shift and patch shuffle operation, which facilitates perturbation-invariant and robust feature representation of objects.
- We introduce a side information embeddings (SIE) that encodes side information by learnable embeddings, and is shown to effectively mitigate the bias of learned features.
- The final framework TransReID achieves state-of-the-art performance on both person and vehicle ReID benchmarks including MSMT17, Market-1501, DukeMTMC-reID, Occluded-Duke, VeRi-776 and VehicleID.
据作者所知,作者是首个研究纯 Transformer 在目标 ReID 领域应用的团队。 本文贡献总结如下:
- 作者提出了首个利用纯 Transformer 处理 ReID 任务的强基线,并取得了与基于 CNN 的框架相当的性能。
- 作者设计了一个由 shift 和 patch shuffle 操作组成的拼图 patch 模块(JPM),它有助于获得目标的扰动不变且鲁棒的特征表示。
- 作者引入了侧信息嵌入(SIE),通过可学习嵌入编码侧信息,并证明它能有效缓解已学习特征的偏差。
- 最终框架 TransReID 在 MSMT17、Market-1501、DukeMTMC-reID、Occluded-Duke、VeRi-776 和 VehicleID 等行人与车辆 ReID 基准上取得了最先进性能。
2. Related Work
2.1 Object ReID
The studies of object ReID have been mainly focused on person ReID and vehicle ReID, with most state-of-the-art methods based on the CNN structure. A popular pipeline for object ReID is to design suitable loss functions to train a CNN backbone (e.g. ResNet), which is used to extract features of images. The cross-entropy loss (ID loss) and triplet loss are most widely used in the deep ReID. Luo et al. proposed the BNNeck to better combine ID loss and triplet loss. Sun et al. proposed a unified perspective for ID loss and triplet loss.
目标 ReID 研究主要集中在行人 ReID 和车辆 ReID 上,其中大多数最先进方法基于 CNN 结构。 目标 ReID 的一种流行流程是设计合适的损失函数来训练 CNN 主干(例如 ResNet),并用它提取图像特征。 交叉熵损失(ID 损失)和三元组损失在深度 ReID 中使用最广。 Luo 等人提出 BNNeck,以更好地结合 ID 损失和三元组损失。 Sun 等人提出了 ID 损失和三元组损失的统一视角。
Fine-grained Features. Fine-grained features have been learned to aggregate information from different part/region. The fine-grained parts are either automatically generated by roughly horizontal stripes or by semantic parsing. Methods like PCB, MGN, AlignedReID++, SAN, etc., divide an image into several stripes and extract local features for each stripe. Using parsing or keypoint estimation to align different parts or two objects has also been proven effective for both person and vehicle ReID.
细粒度特征。 细粒度特征已经被用于聚合来自不同部件/区域的信息。 这些细粒度部件要么由大致水平的条带自动生成,要么由语义解析生成。 PCB、MGN、AlignedReID++、SAN 等方法会把一张图像划分为若干条带,并为每个条带提取局部特征。 使用解析或关键点估计来对齐不同部件或两个目标,也已被证明对行人和车辆 ReID 都有效。
Side Information. For images captured in a cross-camera system, large variations exist in terms of pose, orientation, illumination, resolution, etc. caused by different camera setup and object viewpoints. Some works use side information such as camera ID or viewpoint information to learn invariant features. For example, Camera-based Batch Normalization (CBN) forces the image data from different cameras to be projected onto the same subspace, so that the distribution gap between inter- and intra- camera pairs is largely diminished. Viewpoint/Orientation-invariant feature learning is also important for both person and vehicle ReID.
侧信息。 对于跨相机系统中采集的图像,由不同相机设置和目标视角造成的姿态、朝向、光照、分辨率等方面存在巨大变化。 一些工作使用相机 ID 或视角信息等侧信息来学习不变特征。 例如,基于相机的批归一化(CBN)迫使来自不同相机的图像数据被投影到同一子空间,从而大幅减小跨相机对和同相机对之间的分布差距。 视角/朝向不变特征学习对行人和车辆 ReID 也都很重要。
2.2 Pure Transformer in Vision
The Transformer model is proposed by Vaswani et al. to handle sequential data in the field of natural language processing (NLP). Many studies also show its effectiveness for computer-vision tasks. Han et al. and Salman et al. have surveyed the application of the Transformer in the field of computer vision.
Transformer 模型由 Vaswani 等人提出,用于处理自然语言处理(NLP)领域中的序列数据。 许多研究也展示了它在计算机视觉任务中的有效性。 Han 等人和 Salman 等人已经综述了 Transformer 在计算机视觉领域的应用。
Pure Transformer models are becoming more and more popular. For example, Image Processing Transformer (IPT) takes advantage of transformers by using large scale pre-training and achieves the state-of-the-art performance on several image processing tasks like super-resolution, denoising and de-raining. ViT is proposed recently which applies a pure transformer directly to sequences of image patches. However, ViT requires a large-scale dataset to pretrain the model. To overcome this shortcoming, Touvron et al. propose a framework called DeiT which introduces a teacher-student strategy specific for transformers to speed up ViT training without the requirement of large-scale pretraining data.
纯 Transformer 模型正变得越来越流行。 例如,图像处理 Transformer(IPT)通过大规模预训练利用 Transformer 的优势,并在超分辨率、去噪和去雨等若干图像处理任务上取得最先进性能。 近来提出的 ViT 将纯 Transformer 直接应用于图像 patch 序列。 然而,ViT 需要大规模数据集来预训练模型。 为克服这一缺点,Touvron 等人提出了名为 DeiT 的框架,它引入了专门面向 Transformer 的教师-学生策略,在不需要大规模预训练数据的情况下加速 ViT 训练。
3. Methodology
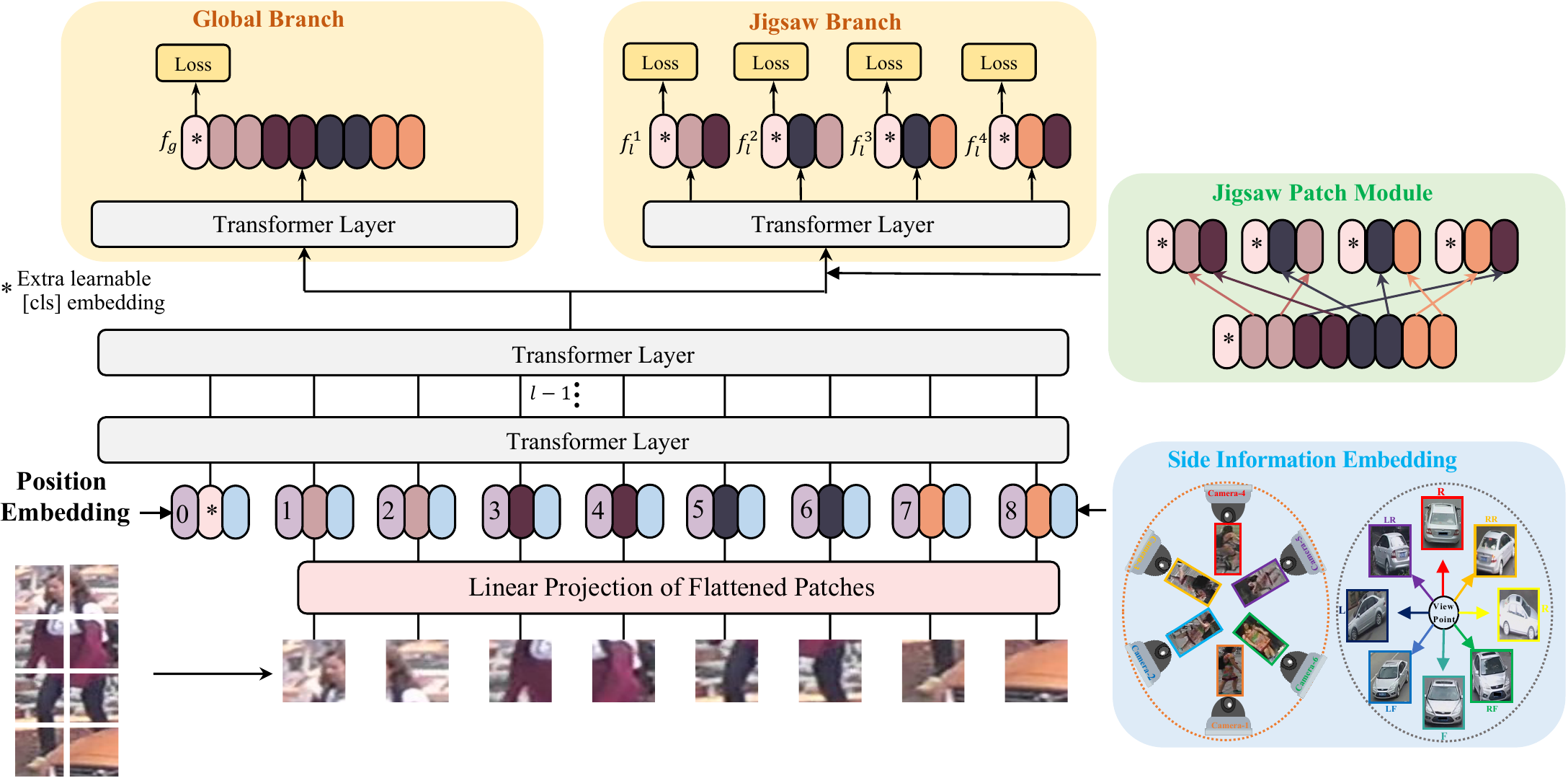
Our object ReID framework is based on transformer-based image classification, but with several critical improvements to capture robust feature (Section 3.1). To further boost the robust feature learning in the context of transformer, a jigsaw patch module (JPM) and a side information embeddings (SIE) are carefully devised in Section 3.2 and Section 3.3. The two modules are jointly trained in an end-to-end manner and shown in Figure Figure 4.
作者的目标 ReID 框架基于 Transformer 图像分类,但带有若干关键改进以捕获鲁棒特征(第 3.1 节)。 为了在 Transformer 语境下进一步促进鲁棒特征学习,作者在第 3.2 节和第 3.3 节中精心设计了拼图 patch 模块(JPM)和侧信息嵌入(SIE)。 这两个模块以端到端方式联合训练,并如 图4 所示。
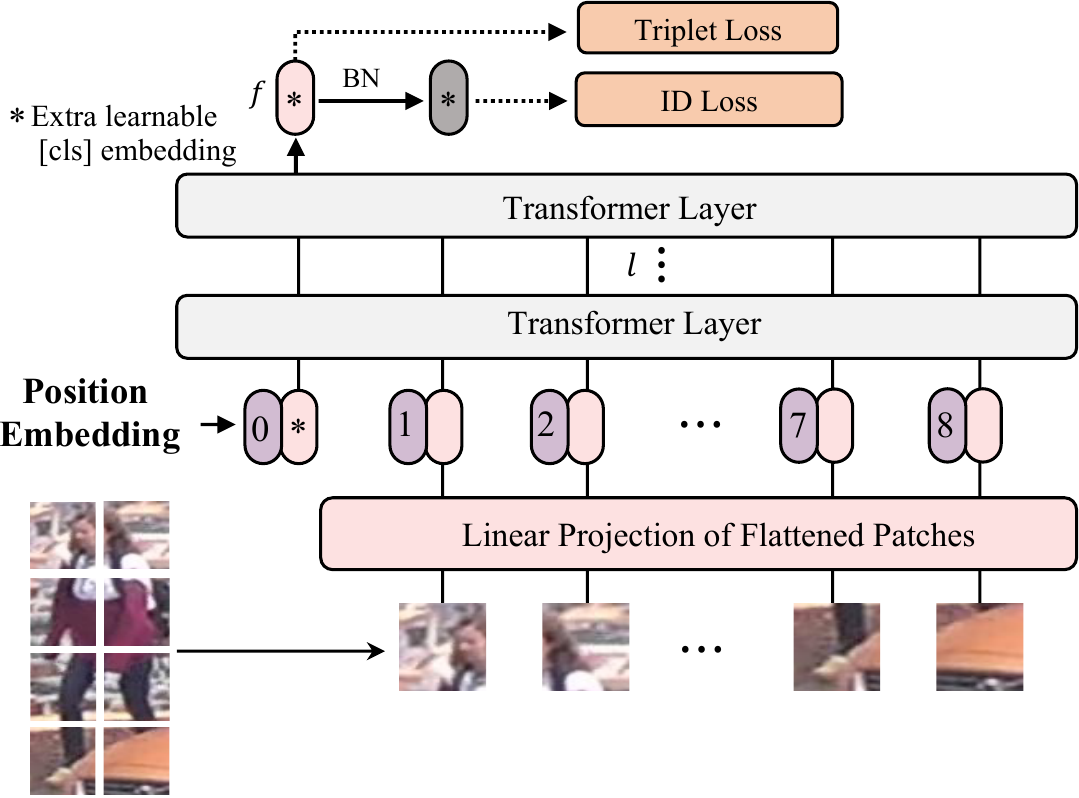
3.1 Transformer-based strong baseline
We build a transformer-based strong baseline for object ReID, following the general strong pipeline for object ReID. Our method has two main stages, i.e., feature extraction and supervision learning. As shown in Figure Figure 3. Given an image
作者按照目标 ReID 的通用强流程,为目标 ReID 构建了一个基于 Transformer 的强基线。 作者的方法有两个主要阶段,即特征提取和监督学习。 如 图3 所示。 给定图像
where
其中
Overlapping Patches. Pure transformer-based models (e.g. ViT, DeiT) split the images into non-overlapping patches, losing local neighboring structures around the patches. Instead, we use a sliding window to generate patches with overlapping pixels. Denoting the step size as
重叠 patch。 纯 Transformer 模型(例如 ViT、DeiT)会把图像划分为不重叠的 patch,从而丢失 patch 周围的局部邻近结构。 相反,作者使用滑动窗口来生成带有重叠像素的 patch。 将步长记为
where $ \lfloor \cdot \rfloor$ is the floor function and
其中 $ \lfloor \cdot \rfloor$ 是向下取整函数,且
Position Embeddings. As the image resolution for ReID tasks may be different from the original one in image classification, the position embedding pretrained on ImageNet cannot be directly loaded here. Therefore, a bilinear 2D interpolation is introduced to help handle any given input resolution. Similar to ViT, the position embedding is also learnable.
位置嵌入。 由于 ReID 任务的图像分辨率可能不同于图像分类中的原始分辨率,因此在 ImageNet 上预训练的位置嵌入不能直接加载到这里。 因此,作者引入双线性二维插值,以帮助处理任意给定输入分辨率。 与 ViT 类似,位置嵌入也是可学习的。
Supervision Learning. We optimize the network by constructing ID loss and triplet loss for global features. The ID loss
监督学习。 作者通过为全局特征构建 ID 损失和三元组损失来优化网络。 ID 损失
3.2 Jigsaw Patch Module
Although transformer-based strong baseline can achieve impressive performance in object ReID, it utilizes information from the entire image for object ReID. However, due to challenges like occlusions and misalignments, we may only have partial observation of an object. Learning fine-grained local features such as striped features has been widely used for CNN-based methods to tackle these challenges.
虽然基于 Transformer 的强基线能够在目标 ReID 中取得令人印象深刻的性能,但它会利用整张图像的信息进行目标 ReID。 然而,由于遮挡和错位等挑战,作者可能只能得到目标的部分观测。 学习条带特征等细粒度局部特征已被广泛用于基于 CNN 的方法,以应对这些挑战。
Suppose the hidden features input to the last layer are denoted as
假设输入最后一层的隐藏特征记为
To address the aforementioned issues, we propose a jigsaw patch module (JPM) to shuffle the patch embeddings and then re-group them into different parts, each of which contains several random patch embeddings of an entire image. In addition, extra perturbation introduced in training also helps improve the robustness of object ReID model. Inspired by ShuffleNet, the patch embeddings are shuffled via a shift operation and a patch shuffle operation. The sequences embeddings
- Step1: The shift operation. The first
patches (except for [cls] token) are moved to the end, i.e. is shifted in steps to become .
- Step2: The patch shuffle operation. The shifted patches are further shuffled by the patch shuffle operation with
groups. The hidden features become .
为解决上述问题,作者提出了拼图 patch 模块(JPM)来打乱 patch 嵌入,然后把它们重新分组到不同部分中,每个部分都包含整张图像的若干随机 patch 嵌入。 此外,训练中引入的额外扰动也有助于提升目标 ReID 模型的鲁棒性。 受 ShuffleNet 启发,patch 嵌入通过 shift 操作和 patch shuffle 操作被打乱。 序列嵌入
- 步骤 1:shift 操作。 前
个 patch([cls] token 除外)被移动到末尾,即 被平移 步,变成 。
- 步骤 2:patch shuffle 操作。 平移后的 patch 进一步通过带有
组的 patch shuffle 操作被打乱。隐藏特征变为 。
With the shift and shuffle operation, the local feature
通过 shift 和 shuffle 操作,局部特征
As shown in Figure Figure 4, paralleling with the jigsaw patch, another global branch which is a standard transformer encodes
如 图4 所示,与拼图 patch 并行,另一个作为标准 Transformer 的全局分支把
During inference, we concatenate the global feature and local features
推理期间,作者将全局特征和局部特征
3.3 Side Information Embeddings
After obtaining fine-grained feature representations, features are still susceptible to camera or viewpoint variations. In other words, the trained model may easily fail to distinguish the same object from different perspectives due to scene-bias. Therefore, we propose a Side Information Embedding (SIE) to incorporate the non-visual information, such as cameras or viewpoints, into embedding representations to learn invariant features.
在获得细粒度特征表示之后,特征仍然容易受到相机或视角变化的影响。 换言之,由于场景偏差,训练好的模型可能很容易无法从不同视角区分同一目标。 因此,作者提出侧信息嵌入(SIE),把相机或视角等非视觉信息融合到嵌入表示中,以学习不变特征。
Inspired by position embeddings which encode positional information adopting learnable embeddings, we plug learnable 1-D embeddings to retain side information. Particularly, as illustrated in Figure Figure 4, SIE is inserted into the transformer encoder together with patch embeddings and position embeddings. In specific, suppose there are
受位置嵌入采用可学习嵌入编码位置信息的启发,作者插入可学习的一维嵌入来保留侧信息。 具体而言,如 图4 所示,SIE 与 patch 嵌入和位置嵌入一起被插入 Transformer 编码器。 具体来说,假设总共有
Now comes the problem about how to integrate two different types of information. A trivial solution might be directly adding the two embeddings together like
接下来的问题是如何融合两种不同类型的信息。 一个简单方案可能是直接把两个嵌入相加,例如
Finally, the input sequences with camera ID
最后,带有相机 ID
where
其中
Here we have only demonstrate the usage of SIE with camera and viewpoint information which are both categorical variables. In practice, SIE can be further extended to encode more kinds of information, including both categorical and numerical variables. In our experiments on different benchmarks, camera and viewpoint information is included wherever available.
这里作者只展示了 SIE 对相机和视角信息的使用,而二者都是类别变量。 实践中,SIE 可以进一步扩展,以编码更多种类的信息,包括类别变量和数值变量。 在作者针对不同基准的实验中,只要可用,就会包含相机和视角信息。
4. Experiments
4.1 Datasets
We evaluate our proposed method on four person ReID datasets, Market-1501, DukeMTMC-reID, MSMT17, Occluded-Duke, and two vehicle ReID datasets, VeRi-776 and VehicleID. It is noted that, unlike other datasets, images in Occluded-Duke are selected from DukeMTMC-reID and the training/query/gallery set contains 9%/100%/10% occluded images respectively. All datasets except VehicleID provide camera ID for each image, while only VeRi-776 and VehicleID dataset provide viewpoint labels for each image. The details of these datasets are summarized in Table Table 1.
作者在四个行人 ReID 数据集 Market-1501、DukeMTMC-reID、MSMT17、Occluded-Duke,以及两个车辆 ReID 数据集 VeRi-776 和 VehicleID 上评估所提出方法。 需要注意的是,不同于其他数据集,Occluded-Duke 中的图像选自 DukeMTMC-reID,并且训练/查询/图库集合中分别包含 9%/100%/10% 的遮挡图像。 除 VehicleID 外,所有数据集都为每张图像提供相机 ID,而只有 VeRi-776 和 VehicleID 数据集为每张图像提供视角标签。 这些数据集的细节总结于 表1。
| Dataset | Object | #ID | #image | #cam | #view |
|---|---|---|---|---|---|
| MSMT17 | Person | 4,101 | 126,441 | 15 | - |
| Market-1501 | Person | 1,501 | 32,668 | 6 | - |
| DukeMTMC-reID | Person | 1,404 | 36,441 | 8 | - |
| Occluded-Duke | Person | 1,404 | 36,441 | 8 | - |
| VeRi-776 | Vehicle | 776 | 49,357 | 20 | 8 |
| VehicleID | Vehicle | 26,328 | 221,567 | - | 2 |
4.2 Implementation
Unless otherwise specified, all person images are resized to
除非另有说明,所有行人图像被缩放到
All the experiments are performed with one Nvidia Tesla V100 GPU using the PyTorch toolbox with FP16 training. The initial weights of ViT are pre-trained on ImageNet-21K and then finetuned on ImageNet-1K, while the initial weights of DeiT are trained only on ImageNet-1K.
所有实验都使用一张 Nvidia Tesla V100 GPU 和 PyTorch 工具箱,以 FP16 训练完成。 ViT 的初始权重先在 ImageNet-21K 上预训练,然后在 ImageNet-1K 上微调,而 DeiT 的初始权重仅在 ImageNet-1K 上训练。
Evaluation Protocols. Following conventions in the ReID community, we evaluate all methods with Cumulative Matching Characteristic (CMC) curves and the mean Average Precision (mAP).
评估协议。 遵循 ReID 社区惯例,作者使用累积匹配特性(CMC)曲线和平均精度均值(mAP)评估所有方法。
4.3 Results of Transform-based Baseline
| Backbone | Inference Time | MSMT17 | VeRi-776 | ||
|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | ||
| ResNet50 | 1x | 51.3 | 75.3 | 76.4 | 95.2 |
| ResNet101 | 1.48x | 53.8 | 77.0 | 76.9 | 95.2 |
| ResNet152 | 1.96x | 55.6 | 78.4 | 77.1 | 95.9 |
| ResNeSt50 | 1.86x | 61.2 | 82.0 | 77.6 | 96.2 |
| ResNeSt200 | 3.12x | 63.5 | 83.5 | 77.9 | 96.4 |
| DeiT-S/16 | 0.97x | 55.2 | 76.3 | 76.3 | 95.5 |
| DeiT-B/16 | 1.79x | 61.4 | 81.9 | 78.4 | 95.9 |
| ViT-B/16 | 1.79x | 61.0 | 81.8 | 78.2 | 96.5 |
| ViT-B/16s=14 | 2.14x | 63.7 | 82.7 | 78.6 | 96.4 |
| ViT-B/16s=12 | 2.81x | 64.4 | 83.5 | 79.0 | 96.5 |
In this section, we compare CNN-based and transformer-based backbones in Table Table 2. To show the trade-off between computation and performance, several different backbones are chosen. DeiT-small, DeiT-Base, ViT-Base denoted as DeiT-S, DeiT-B, ViT-B, respectively. ViT-B/16
在本节中,作者在 表2 中比较了基于 CNN 和基于 Transformer 的主干。 为了展示计算与性能之间的权衡,作者选择了若干不同主干。 DeiT-small、DeiT-Base、ViT-Base 分别记为 DeiT-S、DeiT-B、ViT-B。 ViT-B/16
We can observe a large gap in model capacity between the ResNet series and DeiT/ViT. DeiT-S/16 is a little bit better in performance and speed compared to ResNet50. DeiT-B/16 and ViT-B/16 achieve similar performance with ResNeSt50 backbone, with less inference time than ResNeSt50 (1.79x vs 1.86x). When we reduce the step size of the sliding window
可以观察到,ResNet 系列与 DeiT/ViT 之间存在很大的模型容量差距。 与 ResNet50 相比,DeiT-S/16 在性能和速度上略好。 DeiT-B/16 和 ViT-B/16 与 ResNeSt50 主干取得相似性能,但推理时间少于 ResNeSt50(1.79x 对 1.86x)。 当作者减小滑动窗口步长
| Backbone | #groups | MSMT17 | VeRi-776 | ||
|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | ||
| Baseline | - | 61.0 | 81.8 | 78.2 | 96.5 |
| +JPM | 1 | 62.9 | 82.5 | 78.6 | 97.0 |
| +JPM | 2 | 62.8 | 82.1 | 79.1 | 96.4 |
| +JPM | 4 | 63.6 | 82.5 | 79.2 | 96.8 |
| +JPM w/o rearrange | 4 | 63.1 | 82.4 | 79.0 | 96.7 |
| +JPM w/o local | 4 | 63.5 | 82.5 | 79.1 | 96.6 |
4.4 Ablation Study of JPM
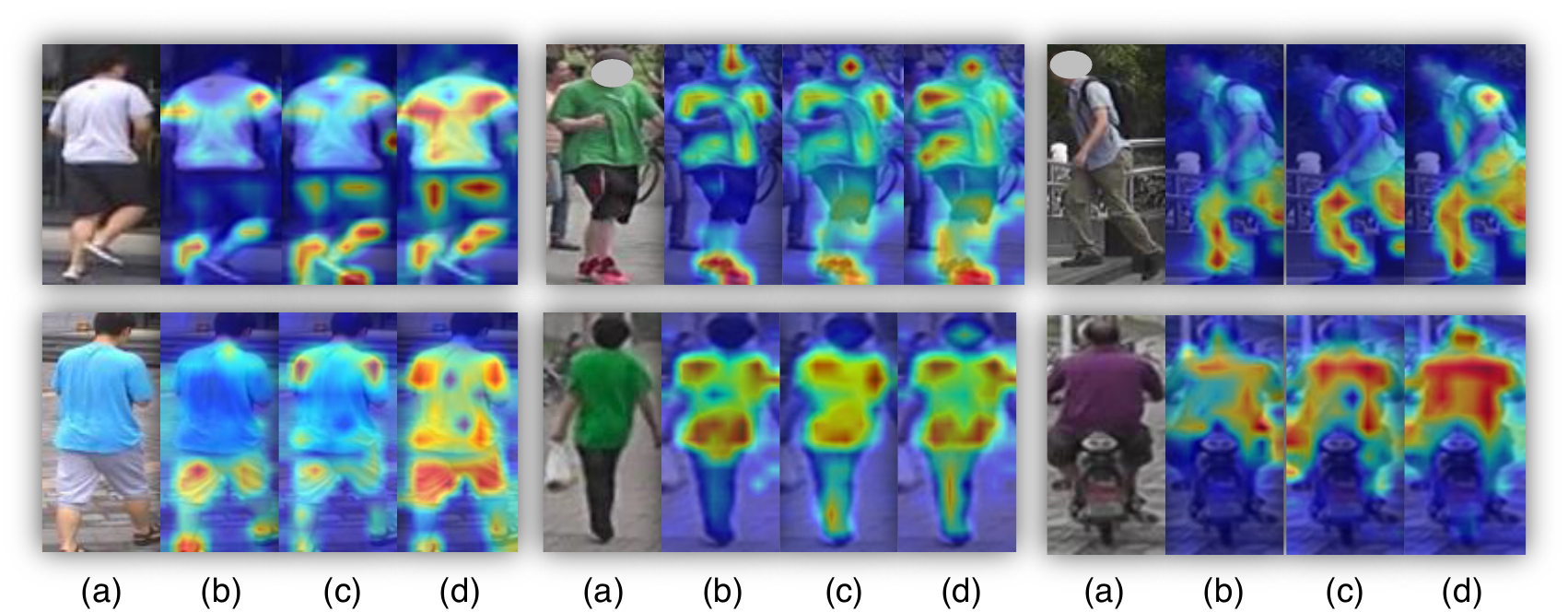
The effectiveness of the proposed JPM module is validated in Table Table 3. JPM provides +2.6% mAP and +1.0% mAP improvements compared to baseline on MSMT17 and VeRi-776, respectively. Increasing the number of groups
所提出 JPM 模块的有效性在 表3 中得到验证。 与基线相比,JPM 分别在 MSMT17 和 VeRi-776 上带来 +2.6% mAP 和 +1.0% mAP 提升。 增加组数
| Method | Camera | Viewpoint | MSMT17 | VeRi-776 | ||
|---|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | |||
| Baseline | 61.0 | 81.8 | 78.2 | 96.5 | ||
| + SC[r] | ✓ | 62.4 | 81.9 | 78.7 | 97.1 | |
| + SV[q] | ✓ | - | - | 78.5 | 96.9 | |
| + S(C,V) | ✓ | ✓ | - | - | 79.6 | 96.9 |
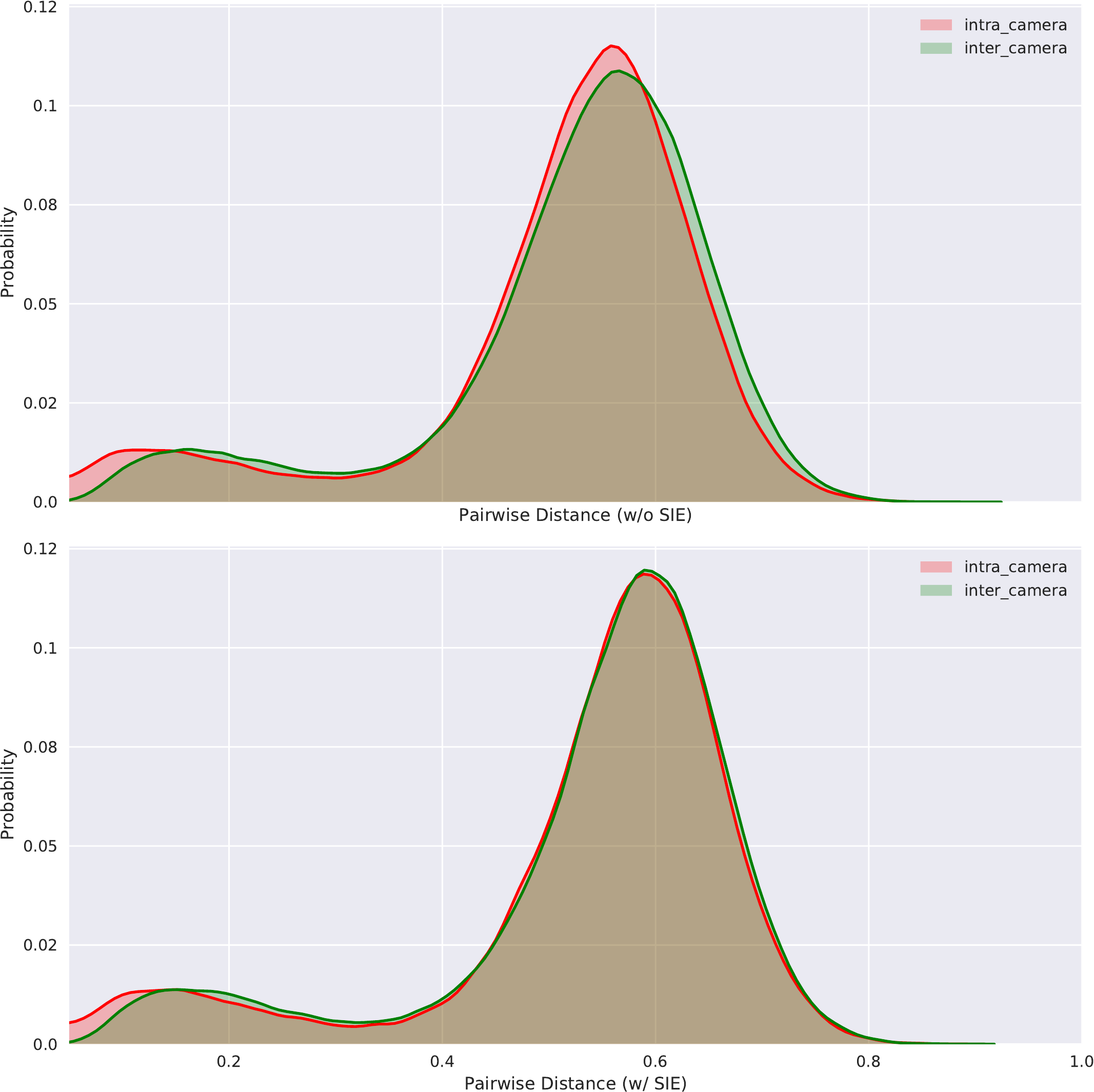
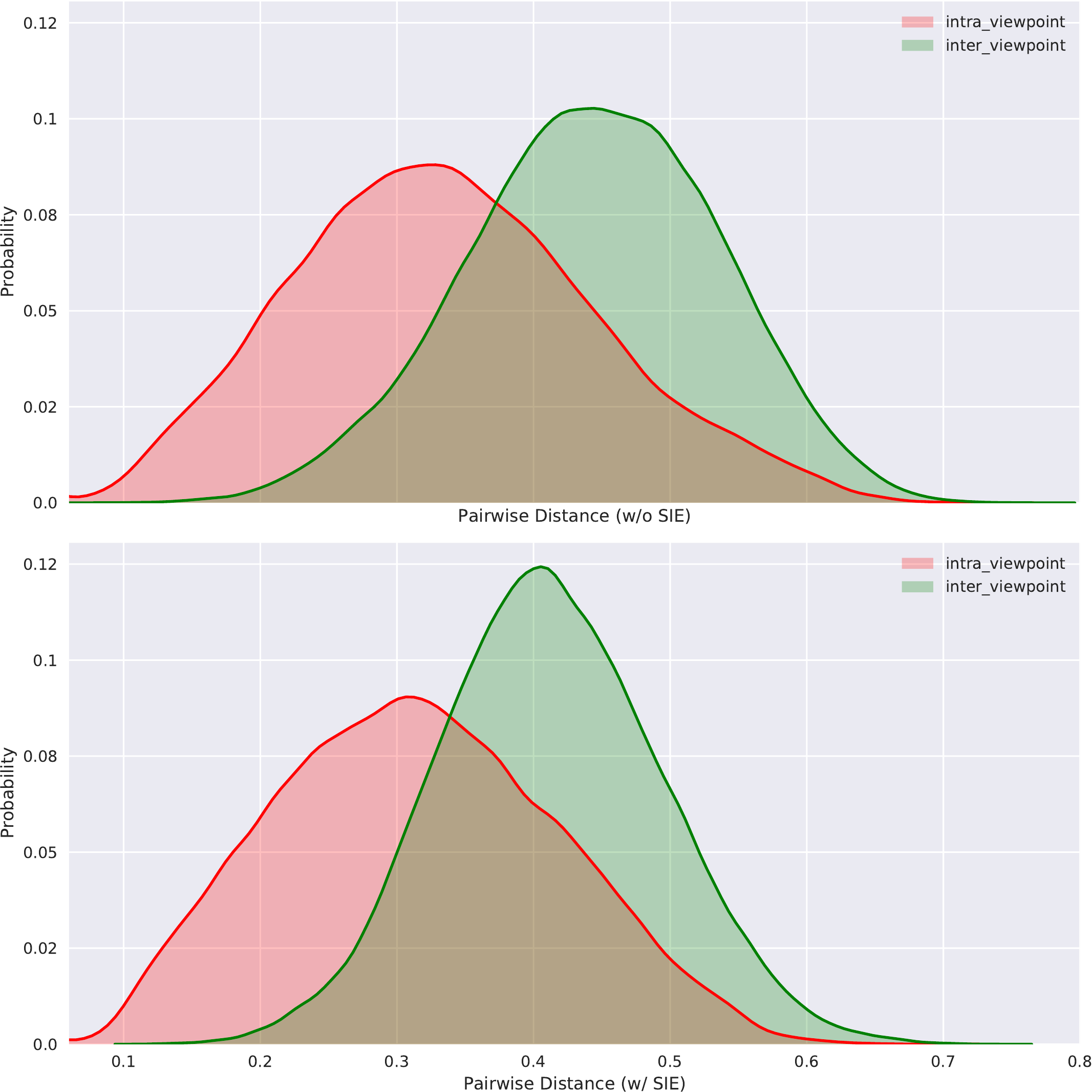
4.5 Ablation Study of SIE
Performance Analysis. In Table Table 4, we evaluate the effectiveness of the SIE on MSMT17 and VeRi-776. MSMT17 does not provide viewpoint annotations, so the results of SIE which only encode camera information are shown for MSMT17. VeRi-776 not only have a camera ID of each image, but is also annotated with 8 different viewpoints according to vehicle orientation. Therefore, the results are shown with SIE encoding various combinations of camera ID and/or viewpoints information.
性能分析。 在 表4 中,作者评估了 SIE 在 MSMT17 和 VeRi-776 上的有效性。 MSMT17 不提供视角标注,因此 MSMT17 上只展示编码相机信息的 SIE 结果。 VeRi-776 不仅有每张图像的相机 ID,还根据车辆朝向标注了 8 个不同视角。 因此,结果展示了 SIE 编码相机 ID 和/或视角信息各种组合时的情况。
When SIE encodes only the camera IDs of images, the model gains 1.4% mAP and 0.1% rank-1 accuracy improvements on MSMT17. Similar conclusion can be made on VeRi-776. Baseline obtains 78.5% mAP when SIE encodes viewpoint information. The accuracy increases to 79.6% mAP when both camera IDs and viewpoint labels are encoded at the same time. If the encoding is changed to
当 SIE 只编码图像的相机 ID 时,模型在 MSMT17 上获得 1.4% mAP 和 0.1% rank-1 准确率提升。 在 VeRi-776 上也可以得出类似结论。 当 SIE 编码视角信息时,Baseline 获得 78.5% mAP。 当相机 ID 和视角标签同时编码时,准确率提升到 79.6% mAP。 如果把编码改为
Visualization of Distance Distribution. As shown in Figure Figure 6, the distribution gaps with cameras and viewpoints variations are obvious in Figure Figure 6(a) and Figure Figure 6(b), respectively. When we introduce the SIE module into Baseline, the distribution gaps between inter-camera/viewpoint and intra-camera/viewpoint are reduced, which shows that the SIE module weakens the negative effect of the scene-bias caused by various cameras and viewpoints.
距离分布可视化。 如 图6 所示,相机和视角变化带来的分布差距分别在 图6(a) 和 图6(b) 中非常明显。 当作者把 SIE 模块引入 Baseline 后,跨相机/视角与同相机/视角之间的分布差距缩小,这说明 SIE 模块削弱了由不同相机和视角造成的场景偏差的负面影响。
Ablation Study of
4.6 Ablation Study of TransReID
Finally, we evaluate the benefits of introducing JPM and SIE in Table Table 5. For the Baseline, JPM and SIE improve the performance by +2.6%/+1.0% mAP and +1.4%/+1.4% mAP on MSMT17/VeRi-776, respectively. With these two modules used together, TransReID achieves 64.9% (+3.9%) mAP and 80.6% (+2.4%) mAP on MSMT17 and VeRi-776, respectively. The experimental results show the effectiveness of our proposed JPM, SIE, and the overall framework.
最后,作者在 表5 中评估了引入 JPM 和 SIE 的收益。 对于 Baseline,JPM 和 SIE 分别在 MSMT17/VeRi-776 上带来 +2.6%/+1.0% mAP 和 +1.4%/+1.4% mAP 的性能提升。 当这两个模块一起使用时,TransReID 分别在 MSMT17 和 VeRi-776 上达到 64.9%(+3.9%)mAP 和 80.6%(+2.4%)mAP。 实验结果显示了作者所提出 JPM、SIE 以及整体框架的有效性。
| Method | JPM | SIE | MSMT17 | VeRi-776 | ||
|---|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | |||
| Baseline | × | × | 61.0 | 81.8 | 78.2 | 96.5 |
| ✓ | × | 63.6 | 82.5 | 79.2 | 96.8 | |
| × | ✓ | 62.4 | 81.9 | 79.6 | 96.9 | |
| TransReID | ✓ | ✓ | 64.9 | 83.3 | 80.6 | 96.9 |
| MSMT17 | Market1501 | DukeMTMC | Occluded-Duke | VeRi-776 | VehicleID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Backbone | Method | Size | mAP | R1 | mAP | R1 | mAP | R1 | mAP | R1 | Method | mAP | R1 | R1 | R5 |
| CNN | CBNc | 256×128 | 42.9 | 72.8 | 77.3 | 91.3 | 67.3 | 82.5 | - | - | PRReID | 72.5 | 93.3 | 72.6 | 88.6 |
| OSNet | 256×128 | 52.9 | 78.7 | 84.9 | 94.8 | 73.5 | 88.6 | - | - | SAN | 72.5 | 93.3 | 79.7 | 94.3 | |
| MGN | 384×128 | 52.1 | 76.9 | 86.9 | 95.7 | 78.4 | 88.7 | - | - | UMTS | 75.9 | 95.8 | 80.9 | 87.0 | |
| RGA-SC | 256×128 | 57.5 | 80.3 | 88.4 | 96.1 | - | - | - | - | VANetv | 66.3 | 89.8 | 83.3 | 96.0 | |
| SAN | 256×128 | 55.7 | 79.2 | 88.0 | 96.1 | 75.7 | 87.9 | - | - | SPANv | 68.9 | 94.0 | - | - | |
| SCSN | 384×128 | 58.5 | 83.8 | 88.5 | 95.7 | 79.0 | 91.0 | - | - | PGAN | 79.3 | 96.5 | 78.0 | 93.2 | |
| ABDNet | 384×128 | 60.8 | 82.3 | 88.3 | 95.6 | 78.6 | 89.0 | - | - | PVENv | 79.5 | 95.6 | 84.7 | 97.0 | |
| PGFA | 256×128 | - | - | 76.8 | 91.2 | 65.5 | 82.6 | 37.3 | 51.4 | SAVER | 79.6 | 96.4 | 79.9 | 95.2 | |
| HOReID | 256×128 | - | - | 84.9 | 94.2 | 75.6 | 86.9 | 43.8 | 55.1 | CFVMNet | 77.1 | 95.3 | 81.4 | 94.1 | |
| ISP | 256×128 | - | - | 88.6 | 95.3 | 80.0 | 89.6 | 52.3 | 62.8 | GLAMOR | 80.3 | 96.5 | 78.6 | 93.6 | |
| DeiT-B/16 | Baseline | 256×128 | 61.4 | 81.9 | 86.6 | 94.4 | 78.9 | 89.3 | 53.1 | 60.6 | Baseline | 78.4 | 95.9 | 83.1 | 96.8 |
| TransReIDc | 256×128 | 63.9 | 82.7 | 88.0 | 94.7 | 81.2 | 90.1 | 55.6 | 62.8 | TransReIDv | 80.6 | 96.8 | 84.6 | 97.4 | |
| TransReIDc | 384×128 | 65.5 | 83.5 | 88.1 | 94.9 | 81.3 | 90.2 | - | - | TransReIDb | 81.2 | 96.8 | - | - | |
| TransReID*c | 256×128 | 66.2 | 84.3 | 88.4 | 95.0 | 81.9 | 91.1 | 58.1 | 66.4 | TransReID*v | 81.4 | 96.8 | 85.2 | 97.6 | |
| TransReID*c | 384×128 | 66.3 | 84.5 | 88.5 | 95.1 | 82.1 | 91.1 | - | - | TransReID*b | 82.3 | 97.1 | - | - | |
| ViT-B/16 | Baseline | 256×128 | 61.0 | 81.8 | 86.8 | 94.7 | 79.3 | 88.8 | 53.1 | 60.5 | Baseline | 78.2 | 96.5 | 82.3 | 96.1 |
| TransReIDc | 256×128 | 64.9 | 83.3 | 88.2 | 95.0 | 80.6 | 89.6 | 55.7 | 64.2 | TransReIDv | 79.6 | 97.0 | 83.6 | 97.1 | |
| TransReIDc | 384×128 | 66.6 | 84.6 | 88.8 | 95.0 | 81.8 | 90.4 | - | - | TransReIDb | 80.6 | 96.9 | - | - | |
| TransReID*c | 256×128 | 67.4 | 85.3 | 88.9 | 95.2 | 82.0 | 90.7 | 59.2 | 66.4 | TransReID*v | 80.5 | 96.8 | 85.2 | 97.5 | |
| TransReID*c | 384×128 | 69.4 | 86.2 | 89.5 | 95.2 | 82.6 | 90.7 | - | - | TransReID*b | 82.0 | 97.1 | - | - | |
4.7 Comparison with State-of-the-Art Methods
In Table Table 6, our TransReID is compared with state-of-the-art methods on six benchmarks including person ReID, occluded ReID and vehicle ReID.
在 表6 中,作者把 TransReID 与最先进方法在六个基准上进行比较,这些基准包括行人 ReID、遮挡 ReID 和车辆 ReID。
Person ReID. On MSMT17 and DukeMTMC-reID, TransReID
行人 ReID。 在 MSMT17 和 DukeMTMC-reID 上,TransReID
Occluded ReID. ISP implicitly uses human body semantic information through iterative clustering and HOReID introduces external pose models to align body parts. TransReID (DeiT-B/16) achieves 55.6% mAP with a large margin improvement (at least +3.3% mAP) compared to aforementioned methods, without requiring any semantic and pose information to align body parts, which shows the ability of TransReID to generate robust feature representations. Furthermore, TransReID
遮挡 ReID。 ISP 通过迭代聚类隐式使用人体语义信息,HOReID 则引入外部姿态模型来对齐身体部件。 与上述方法相比,TransReID(DeiT-B/16)在不需要任何语义和姿态信息来对齐身体部件的情况下达到 55.6% mAP,并取得很大幅度提升(至少 +3.3% mAP),这显示了 TransReID 生成鲁棒特征表示的能力。 此外,借助重叠 patch,TransReID
Vehicle ReID. On VeRi-776, TransReID
车辆 ReID。 在 VeRi-776 上,TransReID
DeiT vs ViT vs CNN. TransReID
DeiT vs ViT vs CNN。 在公平比较(ImageNet-1K 预训练)下,TransReID
5. Conclusion
In this paper, we investigate a pure transformer framework for the object ReID task, and propose two novel modules, i.e., jigsaw patch module (JPM) and side information embedding (SIE). The final framework TransReID outperforms all other state-of-the-art methods by a large margin on several popular person/vehicle ReID datasets including MSMT17, Market-1501, DukeMTMC-reID, Occluded-Duke, VeRi-776 and VehicleID. Based on the promising results achieved by TransReID, we believe the transformer has great potential to be further explored for ReID tasks. Based on the rich experience gained from CNN-based methods, it is in prospect that more efficient transformer-based networks can be designed with better representation power and less computational cost.
本文研究了用于目标 ReID 任务的纯 Transformer 框架,并提出两个新模块,即拼图 patch 模块(JPM)和侧信息嵌入(SIE)。 最终框架 TransReID 在 MSMT17、Market-1501、DukeMTMC-reID、Occluded-Duke、VeRi-776 和 VehicleID 等多个流行行人/车辆 ReID 数据集上,以很大幅度优于所有其他最先进方法。 基于 TransReID 取得的有前景结果,作者相信 Transformer 在 ReID 任务中具有进一步探索的巨大潜力。 基于从 CNN 方法中获得的丰富经验,有望设计出更高效、表示能力更强且计算成本更低的基于 Transformer 的网络。