
From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for LLMs
MemoryMemTreeAgentNeurIPS 2024从孤立对话到层级图式:面向 LLM 的动态树状记忆表示
Abstract
Recent advancements in large language models have significantly improved their context windows, yet challenges in effective long-term memory management remain. We introduce MemTree, an algorithm that leverages a dynamic, tree-structured memory representation to optimize the organization, retrieval, and integration of information, akin to human cognitive schemas. MemTree organizes memory hierarchically, with each node encapsulating aggregated textual content, corresponding semantic embeddings, and varying abstraction levels across the tree's depths. Our algorithm dynamically adapts this memory structure by computing and comparing semantic embeddings of new and existing information to enrich the model's context-awareness. This approach allows MemTree to handle complex reasoning and extended interactions more effectively than traditional memory augmentation methods, which often rely on flat lookup tables. Evaluations on benchmarks for multi-turn dialogue understanding and document question answering show that MemTree significantly enhances performance in scenarios that demand structured memory management.
大语言模型的最新进展显著扩大了上下文窗口,但有效的长期记忆管理仍然是挑战。 本文介绍 MemTree,这是一种利用动态树状记忆表示的算法,用来优化信息的组织、检索和整合,类似于人类的认知图式。 MemTree 以层级方式组织记忆,每个节点都封装聚合后的文本内容、对应的语义嵌入,以及树中不同深度上的抽象层级。 该算法通过计算并比较新信息和已有信息的语义嵌入,动态调整记忆结构,从而增强模型的上下文感知能力。 这种方法使 MemTree 相比通常依赖扁平查找表的传统记忆增强方法,能够更有效地处理复杂推理和长程交互。 在多轮对话理解和文档问答基准上的评估表明,MemTree 在需要结构化记忆管理的场景中显著提升了性能。
1. Introduction
Despite recent advances in large language models (LLMs) where the context window has expanded to millions of tokens, these models continue to struggle with reasoning over long-term memory. This challenge arises because LLMs rely primarily on a key-value (KV) cache of past interactions, processed through a fixed number of transformer layers, which lack the capacity to effectively aggregate extensive historical data. Unlike LLMs, the human brain employs dynamic memory structures known as schemas, which facilitate the efficient organization, retrieval, and integration of information as new experiences occur. This dynamic restructuring of memory is a cornerstone of human cognition, allowing for the flexible application of accumulated knowledge across varied contexts.
尽管大语言模型(LLM)近期取得进展,上下文窗口已经扩展到数百万 token,但这些模型在长期记忆推理上仍然表现困难。 这一挑战源于 LLM 主要依赖过去交互的键值(KV)缓存,并通过固定数量的 Transformer 层处理;这种机制缺乏有效聚合大量历史数据的能力。 与 LLM 不同,人脑会使用被称为图式的动态记忆结构;当新经验出现时,这些结构有助于高效组织、检索和整合信息。 记忆的这种动态重构是人类认知的基石,使得累积知识能够在不同上下文中灵活应用。
A prevalent method to address the limitations of long-term memory in LLMs involves the use of external memory. Weston et al. introduced the concept of utilizing external memory for the storage and retrieval of relevant information. More recent approaches in LLM research have explored various techniques to manage historical observations in databases, retrieving pertinent data for given queries through vector similarity searches in the embedding space. However, these methods primarily utilize a lookup table for memory representation, which fails to capture the inherent structure in data. Consequently, each past experience is stored as an isolated instance, lacking the interconnectedness and integrative capabilities of the human brain's schemas. This limitation becomes increasingly problematic as the size of the memory grows or when relevant information is distributed across multiple instances.
解决 LLM 长期记忆局限的一种常见方法是使用外部记忆。 Weston 等人提出了使用外部记忆来存储和检索相关信息的概念。 较新的 LLM 研究则探索了多种技术,用数据库管理历史观察,并通过嵌入空间中的向量相似度搜索为给定查询检索相关数据。 然而,这些方法主要使用查找表来表示记忆,无法捕获数据中的内在结构。 因此,每段过去经验都被作为孤立实例存储,缺少人脑图式所具备的相互关联与整合能力。 当记忆规模增长,或相关信息分散在多个实例中时,这一局限会变得越来越严重。
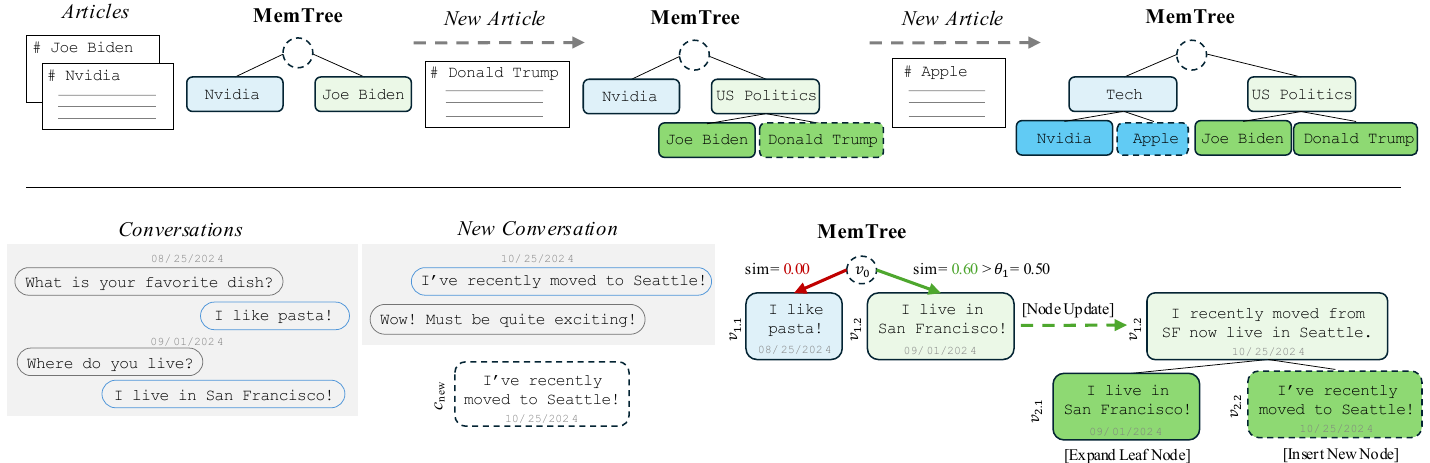
In this work, we introduce MemTree, an algorithm designed to emulate the schema-like structures of the human brain by maintaining a dynamically structured memory representation during interactions. Within MemTree, each memory unit is represented as a node within a tree, containing node-level information and links to child nodes.
在本文中,作者介绍 MemTree,这是一种在交互过程中维护动态结构化记忆表示的算法,旨在模拟人脑中的图式结构。 在 MemTree 中,每个记忆单元都表示为树中的一个节点,包含节点级信息以及指向子节点的链接。
Upon encountering new information, MemTree updates its memory structure starting from the root node. It evaluates at each node whether to instantiate a new child node or integrate the information into an existing child node. This decision process is governed by a traversal algorithm that efficiently adds new information with an insertion complexity of O(log N), where N denotes the number of conversational interactions. This structure facilitates the aggregation of knowledge at parent nodes, which evolve to capture high-level semantics as the tree expands. For knowledge retrieval, MemTree computes the cosine similarity between node embeddings and the query embedding. This method maintains the retrieval time complexity comparable to existing approaches, ensuring efficiency.
遇到新信息时,MemTree 从根节点开始更新其记忆结构。 它会在每个节点判断应当实例化一个新的子节点,还是把信息整合进已有子节点。 这一决策过程由遍历算法控制,能够以 O(log N) 的插入复杂度高效加入新信息,其中 N 表示对话交互数量。 这种结构有助于在父节点聚合知识;随着树扩展,父节点会逐渐捕获高层语义。 在知识检索时,MemTree 计算节点嵌入与查询嵌入之间的余弦相似度。 该方法使检索时间复杂度保持在与现有方法相当的水平,从而保证效率。
We evaluated MemTree across four benchmarks, covering both conversational and document question-answering tasks, and compared it against online and offline knowledge representation methods. MemTree enables seamless dynamic updates as new data becomes available, a capability characteristic of online methods. In contrast, offline methods require complete dataset access and are costly to update, as they involve periodic rebuilding to incorporate new information.
作者在四个基准上评估 MemTree,覆盖对话任务和文档问答任务,并将其与在线和离线知识表示方法进行比较。 当新数据可用时,MemTree 能够无缝动态更新,这是在线方法的典型能力。 相比之下,离线方法需要访问完整数据集,而且更新成本较高,因为它们需要周期性重建以纳入新信息。
- In extended conversations, MemTree consistently outperforms other online methods, including MemoryStream and MemGPT, maintaining superior accuracy as discussions progress.
- For document question-answering, MemTree excels in two key areas. On single-document tasks, it outperforms other online methods and reduces the performance gap with offline models, particularly surpassing RAPTOR on challenging questions that require deeper reasoning. In multi-document tasks, MemTree not only surpasses online methods but also approaches the performance of offline models, particularly outperforming GraphRAG. Moreover, on complex temporal queries requiring the analysis of event sequences across multiple documents, MemTree exceeds all offline methods.
- 在扩展对话中,MemTree 持续优于 MemoryStream 和 MemGPT 等其他在线方法,并随着对话推进保持更高准确率。
- 在文档问答方面,MemTree 在两个关键方面表现突出。在单文档任务上,它优于其他在线方法,并缩小了与离线模型的性能差距,尤其是在需要深层推理的困难问题上超过 RAPTOR。在多文档任务上,MemTree 不仅超过在线方法,也接近离线模型的性能,尤其超过 GraphRAG。此外,在需要分析跨多个文档事件序列的复杂时间查询上,MemTree 超过所有离线方法。
These results demonstrate that MemTree is a robust and scalable solution, delivering high accuracy across diverse and challenging tasks while retaining the efficiency of online systems.
这些结果表明,MemTree 是一种稳健且可扩展的方案,能够在多样且具有挑战性的任务上取得高准确率,同时保留在线系统的效率。
2. Related Work
Memory-Augmented LLMs
Recent advancements in memory-augmented LLMs have introduced various strategies for enhancing memory capabilities. Park et al. developed LLM-based agents that log experiences as timestamped descriptions, retrieving memories based on recency, importance, and relevance. Similarly, Cheng et al. developed Selfmem with a dedicated memory selector. MemGPT proposed automatic memory management through LLM function-calling for conversational agents and document analysis, providing a pre-prompt with detailed instructions on memory hierarchy and utilities, along with a schema for accessing and modifying the memory database. Zhong et al. introduced MemoryBank, a long-term memory framework that stores timestamped dialogues and uses exponential decay to forget outdated information. Additionally, Mitchell et al. proposed storing model edits in an explicit memory and learning to reason over them to adjust the base model's predictions. These methods represent common solutions for adding memory to LLMs, focusing on tabular memory storage and vector similarity retrieval. However, as memory scales or information becomes dispersed across multiple entries, their unstructured representations reveal significant limitations.
记忆增强 LLM 的近期进展提出了多种增强记忆能力的策略。 Park 等人开发了基于 LLM 的智能体,将经历记录为带时间戳的描述,并基于近因性、重要性和相关性检索记忆。 类似地,Cheng 等人开发了带有专门记忆选择器的 Selfmem。 MemGPT 为对话智能体和文档分析提出了通过 LLM 函数调用实现的自动记忆管理,提供带有记忆层级和工具详细说明的预提示,并给出访问和修改记忆数据库的 schema。 Zhong 等人提出 MemoryBank,这是一种长期记忆框架,用于存储带时间戳的对话,并使用指数衰减遗忘过时信息。 此外,Mitchell 等人提出将模型编辑存入显式记忆,并学习基于这些记忆推理,以调整基础模型预测。 这些方法代表了为 LLM 添加记忆的常见方案,重点在于表格化记忆存储和向量相似度检索。 然而,随着记忆扩展,或信息分散在多个条目中,它们的非结构化表示会暴露出显著局限。
Another line of work explores triplet-based memory. For example, Modarressi et al. proposed encoding relationships in triplets, and Anokhin et al. extended this approach to graph-based triplet memory for text-based games. While effective at encoding individual relations or scene graphs at the object level, these methods struggle with scalability and generalization to more complex data that do not fit neatly into a strict triplet format.
另一条研究路线探索基于三元组的记忆。 例如,Modarressi 等人提出用三元组编码关系,Anokhin 等人则将该方法扩展为面向文本游戏的图式三元组记忆。 虽然这些方法在对象层面编码单个关系或场景图时有效,但面对无法整齐适配严格三元组格式的更复杂数据时,它们在可扩展性和泛化方面会遇到困难。
Structured Retrieval-Augmented Generation Approaches
To address the limitations of unstructured memory representations, recent advances have integrated structured knowledge into RAG models, enhancing navigation and summarization in complex QA tasks. Trajanoska et al. leveraged LLMs to extract entities and relationships from unstructured text to construct knowledge graphs. Similarly, Yao et al. proposed techniques to fill in missing links and nodes in existing knowledge graphs by utilizing LLMs to infer unseen relationships. Ban et al. identified causal relationships within textual data and represented them in graph form to enhance understanding of causal structures. In the context of retrieval-augmented generation, Gao et al. provided a comprehensive review of existing RAG methods, and Baek et al. utilized knowledge graphs as indexes within RAG frameworks for efficient retrieval of structured information.
为了解决非结构化记忆表示的局限,近期进展将结构化知识整合进 RAG 模型,从而增强复杂问答任务中的导航和摘要能力。 Trajanoska 等人利用 LLM 从非结构化文本中抽取实体和关系,以构建知识图谱。 类似地,Yao 等人提出技术,利用 LLM 推断未见关系,从而补全现有知识图谱中的缺失链接和节点。 Ban 等人识别文本数据中的因果关系,并将其表示为图,以增强对因果结构的理解。 在检索增强生成语境下,Gao 等人全面综述了现有 RAG 方法,Baek 等人则在 RAG 框架中使用知识图谱作为索引,以高效检索结构化信息。
More relevant to our work, RAPTOR organizes text into a recursive tree, clustering and summarizing chunks at multiple layers to enable efficient retrieval of both high-level themes and detailed information. GraphRAG constructs a knowledge graph from LLM-extracted entities and relations, partitioning it into modular communities that are independently summarized and combined via a map-reduce framework. While these methods effectively structure large textual data to improve retrieval and generation capabilities, they are limited to static corpora, requiring full reconstruction to integrate new information, and do not support online memory updates.
与本文更相关的是,RAPTOR 将文本组织成递归树,通过在多个层级聚类和摘要文本块,实现对高层主题和细节信息的高效检索。 GraphRAG 从 LLM 抽取的实体和关系构建知识图谱,将其划分为模块化社区,并通过 map-reduce 框架独立摘要再组合。 这些方法虽然能有效结构化大规模文本数据,从而提升检索和生成能力,但它们局限于静态语料;要整合新信息就需要完整重建,也不支持在线记忆更新。
In this work, we propose a novel structured memory representation that overcomes these limitations by enabling dynamic updates and efficient retrieval in large-scale memory systems without necessitating full reconstruction.
在本文中,作者提出一种新的结构化记忆表示,通过在大规模记忆系统中支持动态更新和高效检索,同时无需完整重建,从而克服这些局限。
3. Method
MemTree represents memory as a tree
MemTree 将记忆表示为一棵树
where:
: the textual content aggregated at node . : an embedding vector derived using an embedding model . : the parent of node . : the set of children of node , with edges directed from to each . : the depth of node from the root node .
其中:
:节点 上聚合的文本内容。 :使用嵌入模型 得到的嵌入向量。 :节点 的父节点。 :节点 的子节点集合,边从 指向每个 。 :节点 相对于根节点 的深度。
Note that the root node
注意,根节点
MemTree utilizes this tree-structured representation to dynamically track and update the knowledge exchanged between the user and the LLM. While less flexible than a generic graph architecture, the tree structure inherently biases the model towards hierarchical representation. Additionally, trees offer efficient complexity for insertion and traversal, making the algorithm suitable for real-time online use cases.
MemTree 使用这种树状表示,动态追踪并更新用户与 LLM 之间交换的知识。 虽然它不如通用图结构灵活,但树结构天然会把模型偏置到层级表示上。 此外,树在插入和遍历上具有高效复杂度,使该算法适合实时在线场景。
When new information is observed, MemTree dynamically adapts by traversing the existing structure, identifying the appropriate subtree for integration, and updating relevant nodes (Section 3.1). This process, illustrated in Figure 2, ensures the proper integration of new information while preserving the underlying context and hierarchical relationships within the memory. When retrieving information from the memory, MemTree simply compares the embeddings of the query message with the embeddings of each node in the tree, returning the most relevant nodes (Section 3.2).
当观察到新信息时,MemTree 会遍历已有结构,识别适合整合的子树,并更新相关节点,从而动态适应新信息(第 3.1 节)。 这个过程如图2所示,它在保留记忆中底层上下文和层级关系的同时,确保新信息被正确整合。 当从记忆中检索信息时,MemTree 只需比较查询消息嵌入与树中每个节点嵌入,并返回最相关的节点(第 3.2 节)。
3.1 Memory Update
The memory update procedure in MemTree is triggered upon observing new information (e.g., a new conversation). This procedure ensures that the tree structure dynamically adapts and integrates new data while maintaining a coherent hierarchical representation. The complete memory update process is outlined in the appendix algorithm.
MemTree 的记忆更新过程会在观察到新信息时触发,例如一段新对话。 该过程确保树结构能够动态适应并整合新数据,同时维持一致的层级表示。 完整的记忆更新过程在附录算法中给出。
Attaching New Information by Traversing the Existing Tree
To integrate new information, we begin by creating a new node
为了整合新信息,作者首先创建一个新节点
This similarity evaluation drives the following decisions:
- Traverse Deeper: If a child node's similarity exceeds a depth-adaptive threshold
, traversal continues along that path. If multiple child nodes meet this criterion, the path with the highest similarity score is chosen. - Boundary: When traversal reaches a leaf node, the leaf is expanded to become a parent node, accommodating both the original leaf node and
as children. The parent's content is then updated to aggregate both the original leaf node's content and the new information . - Create New Leaf Node: If all child nodes' similarities are below the threshold
, is directly attached as a new leaf node under the current node.
这一相似度评估会驱动以下决策:
- 继续向深处遍历: 如果某个子节点的相似度超过深度自适应阈值
,遍历就沿该路径继续。如果多个子节点满足条件,则选择相似度最高的路径。 - 边界情况: 当遍历到叶节点时,该叶节点会被扩展为父节点,同时容纳原叶节点和
作为子节点。随后父节点内容会被更新,以聚合原叶节点内容和新信息 。 - 创建新叶节点: 如果所有子节点的相似度都低于阈值
,则将 直接挂接为当前节点下的新叶节点。
The similarity threshold
相似度阈值
where
其中
Updating Parent Nodes Along the Traversal Path
Once
一旦
where
其中
The embedding of the parent node is then updated as:
随后父节点的嵌入更新为:
ensuring that the parent node effectively represents both the new and existing information. This process maintains the hierarchical organization of the memory as the tree expands, enabling MemTree to adaptively and accurately represent the evolving conversation. A key advantage of this method is its computational efficiency: once the traversal path is defined, the content aggregation and embedding updates for parent nodes can be parallelized on the CPU. This significantly accelerates the update process, reducing bottlenecks as the memory grows.
这保证了父节点能够有效表示新信息和已有信息。 随着树扩展,该过程会维持记忆的层级组织,使 MemTree 能够自适应且准确地表示不断演化的对话。 这种方法的一个关键优势是计算效率:一旦遍历路径确定,父节点的内容聚合和嵌入更新就可以在 CPU 上并行化。 这会显著加速更新过程,并在记忆增长时减少瓶颈。
Connection to Online Hierarchical Clustering Algorithms
Our memory update algorithm can be viewed as an instance of online hierarchical clustering algorithms. We draw inspiration from the OTD (Online Top-Down Clustering) algorithm proposed by Menon et al., which enables efficient online updates by calculating inter- and intra-subtree similarities during the insertion process. This algorithm is known to provably approximate the Moseley-Wang revenue. In this work, we relax the inter- and intra-subtree similarity comparisons by utilizing semantic similarities in the embedding space. We achieve this by formatting the subtree representation (parent nodes) with LLMs as we traverse the MemTree during the memory update.
作者的记忆更新算法可以看作在线层级聚类算法的一个实例。 该方法受 Menon 等人提出的 OTD(Online Top-Down Clustering)算法启发;OTD 在插入过程中计算子树间和子树内相似度,从而支持高效在线更新。 该算法已知可以有证明地近似 Moseley-Wang revenue。 在本文中,作者通过使用嵌入空间中的语义相似度,放宽了对子树间和子树内相似度的比较。 具体而言,在记忆更新期间遍历 MemTree 时,作者使用 LLM 格式化子树表示(父节点)。
Theorem (Approximation Guarantee of MemTree, Informal). Assuming the data processed by MemTree satisfies the
定理(MemTree 的近似保证,非正式)。 假设 MemTree 处理的数据满足
where
其中
3.2 Memory Retrieval
Efficient and effective retrieval of relevant information is crucial for ensuring that MemTree can provide meaningful responses based on past conversations. Inspired by RAPTOR, we adopt the collapsed tree retrieval method, which offers significant advantages over traditional tree traversal-based retrieval.
高效且有效地检索相关信息,对于确保 MemTree 能够基于过去对话给出有意义的回复至关重要。 受 RAPTOR 启发,作者采用 collapsed tree retrieval 方法;相比传统基于树遍历的检索,它具有显著优势。
Collapsed Tree Retrieval
The collapsed tree approach enhances the search process by treating all nodes in the tree as a single set. Instead of conducting a sequential, layer-by-layer traversal, this method flattens the hierarchical structure, allowing for simultaneous comparison of all nodes. This technique simplifies the retrieval process and ensures a more efficient search.
collapsed tree 方法把树中的所有节点视为一个集合,从而增强搜索过程。 它不是逐层顺序遍历,而是将层级结构展平,使所有节点可以同时比较。 这一技术简化了检索过程,并确保搜索更加高效。
The retrieval process involves the following steps: 1. Query Embedding: Embed the query
检索过程包括以下步骤: 1. 查询嵌入:使用
4. Experiments
4.1 Datasets
We evaluate the effectiveness of MemTree across various settings using four datasets: Multi-Session Chat, Multi-Session Chat Extended, QuALITY, MultiHop RAG. These datasets were selected to represent different interactive contexts--dialogue interactions and information retrieval from multiple texts, respectively, providing a comprehensive test bed for our model. Additional statistics for each dataset can be found in the appendix.
作者使用四个数据集在多种设置下评估 MemTree 的有效性:Multi-Session Chat、Multi-Session Chat Extended、QuALITY 和 MultiHop RAG。 这些数据集分别代表不同交互上下文,包括对话交互以及从多篇文本中进行信息检索,从而为模型提供综合测试平台。 每个数据集的更多统计信息见附录。
- Multi-Session Chat (MSC): The dataset was introduced by Xu et al. In this work, we consider the processed version provided by Packer et al. The dataset consists of 500 sessions, each featuring approximately 15 rounds of synthetic dialogue between two agents. Each session includes follow-up questions that challenge the model to retrieve and utilize information from prior dialogues within the same session. For each session, a memory representation is independently built, capturing the dialogue rounds as they unfold.
- Multi-Session Chat(MSC):该数据集由 Xu 等人提出。在本文中,作者使用 Packer 等人提供的处理版本。该数据集包含 500 个 session,每个 session 大约包含两个智能体之间 15 轮合成对话。每个 session 都包含后续问题,要求模型从同一 session 的先前对话中检索并利用信息。对于每个 session,作者都会独立构建记忆表示,以捕获对话轮次随时间展开的过程。
- Multi-Session Chat Extended (MSC-E): To test the performance for even longer conversation rounds, we expanded MSC by generating an additional 70 sessions, each containing about 200 rounds of dialogue. In these extended sessions, a follow-up question follows each conversation round, demanding more precise and timely information retrieval across the dialogues. As in MSC, memory representations are constructed independently for each session. We detail the extension methodology in the appendix.
- Multi-Session Chat Extended(MSC-E):为了测试更长对话轮次下的表现,作者扩展了 MSC,额外生成 70 个 session,每个 session 包含约 200 轮对话。在这些扩展 session 中,每轮对话后都会跟随一个后续问题,要求在对话中进行更精确、及时的信息检索。与 MSC 一样,每个 session 都会独立构建记忆表示。扩展方法详见附录。
- Single-Document Question Answering (QuALITY): The QuALITY dataset, introduced by Pang et al., consists of context passages averaging 5,000 tokens, paired with multiple-choice questions that require reasoning across entire documents to answer. A memory representation is built independently for each document. The dataset is divided into two subsets: QuALITY-Easy and QuALITY-Hard. The latter contains questions that most human annotators found challenging to answer within the time constraints. While the original dataset was designed for multiple-choice question answering, in this paper we explore the more difficult setting where the model must generate the answer directly, without being provided with the four answer options.
- Single-Document Question Answering(QuALITY):QuALITY 数据集由 Pang 等人提出,包含平均 5,000 token 的上下文段落,以及需要跨完整文档推理才能回答的多选问题。每篇文档都会独立构建记忆表示。该数据集分为两个子集:QuALITY-Easy 和 QuALITY-Hard。后者包含大多数人工标注者在时间限制内都觉得难以回答的问题。虽然原始数据集设计用于多选问答,但本文探索更困难的设置:模型必须在不提供四个候选答案的情况下直接生成答案。
- Multi-Document Question Answering (MultiHop RAG): This dataset comprises 609 distinct news articles across six categories. It includes 2,556 multi-hop questions requiring the integration of information from multiple articles to formulate comprehensive answers. We consider three question types: inference, comparison, and temporal reasoning, each adding a layer of complexity to the information retrieval process. All news articles are used to construct a unified memory representation, which is queried to answer the multi-hop questions.
- Multi-Document Question Answering(MultiHop RAG):该数据集包含六个类别的 609 篇不同新闻文章。它包含 2,556 个多跳问题,需要整合多篇文章中的信息来形成完整答案。作者考虑三类问题:推断、比较和时间推理;每类都为信息检索过程增加了一层复杂性。所有新闻文章都被用来构建一个统一的记忆表示,然后通过查询该表示来回答多跳问题。
4.2 Baselines
We compare MemTree with various baseline methods along with a naive baseline, which involves concatenating all chat histories and feeding them into a large language model (LLM):
作者将 MemTree 与多种基线方法以及一个 naive baseline 进行比较;该 naive baseline 会拼接所有聊天历史,并将其输入大语言模型(LLM):
- MemoryStream: Park et al. propose a flat lookup-table style memory that logs chat histories through an embedding table. The primary distinction between MemTree and this baseline is that MemTree utilizes a structured tree representation for the memory and models high-level representations throughout the memory insertion process.
- MemGPT: MemGPT introduces a memory system designed to update and retrieve information efficiently. It uses an OS paging algorithm to evict less relevant memory into external storage. However, like MemoryStream, it does not format high-level representations.
- RAPTOR: RAPTOR constructs a structured knowledge base using hierarchical clustering over all available information. The key difference between MemTree and this baseline is that MemTree operates as an online algorithm, updating the tree memory representation on-the-fly based on incoming knowledge, while RAPTOR applies hierarchical clustering on a fixed dataset.
- GraphRAG: GraphRAG introduces a graph-based indexing approach designed to improve query-focused summarization and extract global insights from large text corpora. Like RAPTOR, GraphRAG assumes access to the entire corpus and applies the Leiden algorithm to identify community structures within the document graph. However, while MemTree expands its memory top-down to allow for efficient, online updates, GraphRAG generates community summaries in a bottom-up fashion, which is less suited for real-time adaptability.
- MemoryStream: Park 等人提出一种扁平查找表式记忆,通过嵌入表记录聊天历史。MemTree 与该基线的主要区别在于,MemTree 使用结构化树表示记忆,并在记忆插入过程中建模高层表示。
- MemGPT: MemGPT 引入一种记忆系统,用于高效更新和检索信息。它使用操作系统分页算法,将不太相关的记忆逐出到外部存储。然而,与 MemoryStream 一样,它不会格式化高层表示。
- RAPTOR: RAPTOR 通过对所有可用信息进行层级聚类来构建结构化知识库。MemTree 与该基线的关键区别在于,MemTree 是在线算法,会基于到来的知识即时更新树状记忆表示;而 RAPTOR 在固定数据集上应用层级聚类。
- GraphRAG: GraphRAG 引入一种基于图的索引方法,用于改进面向查询的摘要,并从大规模文本语料中抽取全局洞察。与 RAPTOR 一样,GraphRAG 假设可以访问完整语料,并应用 Leiden 算法识别文档图中的社区结构。然而,MemTree 以自顶向下方式扩展记忆以支持高效在线更新,而 GraphRAG 以自底向上方式生成社区摘要,因此不太适合实时适应。
To demonstrate the applicability of our approach, we consider both open-source and commercial models in our experiments. For LLMs, we used OpenAI's GPT-4o (version 2024-05-13) and Llama-3.1-70B-Instruct. For the embedding models, we employed text-embedding-3-large and E5-Mistral-7B-Instruct. In each experiment, we standardized the use of the LLM and embedding model across all baselines to ensure that any performance differences observed were attributable to the memory management methodologies, rather than variations in the models' capabilities or embeddings.
为了展示本文方法的适用性,作者在实验中同时考虑开源模型和商业模型。 对于 LLM,作者使用 OpenAI 的 GPT-4o(2024-05-13 版本)和 Llama-3.1-70B-Instruct。 对于嵌入模型,作者使用 text-embedding-3-large 和 E5-Mistral-7B-Instruct。 在每个实验中,作者在所有基线上统一使用 LLM 和嵌入模型,以确保观察到的性能差异来自记忆管理方法,而不是模型能力或嵌入本身的差异。
4.3 Implementation Details and Evaluation Metrics
Following previous work, we report the end-to-end question answering performance. Given each context-question-answer tuple, the experimental procedure involves four steps: 1. Load the corresponding dialogue/history into the memory. 2. Retrieve the relevant information from the memory based on the given query. 3. Use GPT-4o to answer the query based on the retrieved information. 4. Evaluate the generated answer using one of the following two metrics: 1) Use GPT-4o to compare the generated answer with the reference answer, resulting in a binary accuracy score; 2) Evaluate the ROUGE-L recall (R) metric of the generated answer compared to the relatively short gold answer labels, without involving the LLM judge. The detailed prompts for steps 3 and 4 can be found in the appendix. Other implementation details for MemTree can be found in the appendix.
遵循先前工作,作者报告端到端问答性能。 对于每个 context-question-answer 三元组,实验过程包括四步: 1. 将对应的对话或历史加载进记忆。 2. 基于给定查询从记忆中检索相关信息。 3. 使用 GPT-4o 基于检索信息回答查询。 4. 使用以下两种指标之一评估生成答案:1)使用 GPT-4o 比较生成答案和参考答案,得到二元准确率分数;2)在不使用 LLM 裁判的情况下,评估生成答案相对于较短标准答案标签的 ROUGE-L recall(R)指标。 步骤 3 和 4 的详细提示词见附录。 MemTree 的其他实现细节见附录。
5. Results
5.1 Multi-Session Chat
| Model | Context | Accuracy ↑ | ROUGE-L (R) ↑ |
|---|---|---|---|
| Results reported by MemGPT | |||
| GPT-4 Turbo | Query + Full history summary | 35 | 35 |
| GPT-4 Turbo | Query + Full history summary + MemGPT | 93 | 82 |
| Our results with GPT-4o and text-embedding-3-large | |||
| GPT-4o | Query + Full history | 95.6 | 88.0 |
| GPT-4o | Query + MemGPT | 70.4 | 68.6 |
| GPT-4o | Query + MemoryStream | 84.4 | 79.1 |
| GPT-4o | Query + MemTree | 84.8 | 79.9 |
| Model | Context | Position of the supporting evidence | Overall | ||||
|---|---|---|---|---|---|---|---|
| 0-40 | 40-80 | 80-120 | 120-160 | 160-200 | |||
| GPT-4o | Query + Full history | 84.5 | 78.3 | 75.5 | 74.4 | 76.7 | 78.0 |
| GPT-4o | Query + MemoryStream | 78.5 | 81.0 | 81.0 | 81.4 | 81.8 | 80.7 |
| GPT-4o | Query + MemTree | 82.1 | 82.1 | 82.3 | 82.3 | 84.2 | 82.5 |
15-round dialogue. We present the MSC results in Table 1. For the naive baseline, directly providing the full history to GPT-4o yields the best result, achieving an accuracy of 96%. This outcome is expected, given that the entire dialogue consists of only 15 rounds and fewer than one thousand tokens. We also note that providing a summary of the chat history significantly drops performance to 35%, even for the more powerful GPT-4 Turbo model. This decline occurs because the summary may not cover the topics the query is addressing. To directly compare the performance of different memory management algorithms, we consider the setting where only the query and the retrieved information are provided to the LLM. In this scenario, MemTree surpasses both MemStream and MemGPT.
15 轮对话。 作者在表1中展示 MSC 结果。 对于 naive baseline,直接把完整历史提供给 GPT-4o 会取得最佳结果,准确率达到 96%。 这一结果符合预期,因为整段对话只有 15 轮,且少于一千个 token。 作者还注意到,即使对于更强的 GPT-4 Turbo,提供聊天历史摘要也会使性能显著下降到 35%。 这种下降是因为摘要可能没有覆盖查询所涉及的话题。 为了直接比较不同记忆管理算法的性能,作者考虑只向 LLM 提供 query 和检索信息的设置。 在这种场景下,MemTree 超过了 MemStream 和 MemGPT。
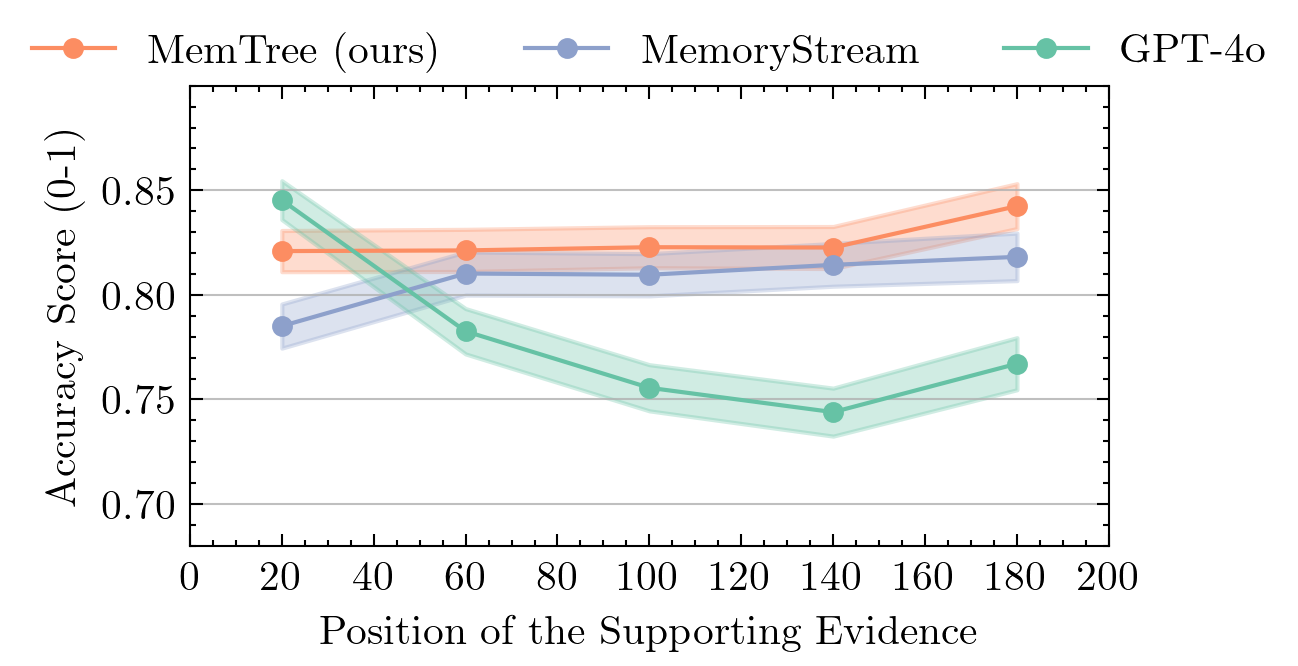
200-round dialogue. Table 2 presents the results on MSC-E. We observe that both MemoryStream and MemTree achieve better overall accuracy than the naive baseline, which directly uses the full history. This illustrates the importance of having an external memory system as the conversation history grows. When we break down the accuracies based on the positions of the supporting evidence within the entire dialogue, we find that the naive baseline performs best when the evidence is presented early on, likely due to position bias. It is worth noting that since MemTree updates the memory sequentially based on the order of the dialogue, it inherently favors more recent conversations over older ones. This bias is demonstrated in Table 2, where the accuracy increases from 82.1 to 84.2. Nevertheless, MemTree consistently outperforms MemoryStream across all positions (see Figure 3 for a visualization).
200 轮对话。 表2展示 MSC-E 上的结果。 可以看到,MemoryStream 和 MemTree 的总体准确率都高于直接使用完整历史的 naive baseline。 这说明随着对话历史增长,外部记忆系统变得非常重要。 当作者根据支持证据在完整对话中的位置分解准确率时,发现 naive baseline 在证据较早出现时表现最好,这可能源于位置偏差。 值得注意的是,由于 MemTree 会根据对话顺序依次更新记忆,因此它天然更偏向近期对话而非较早对话。 这种偏差在表2中有所体现,其中准确率从 82.1 提升到 84.2。 尽管如此,MemTree 在所有位置上都持续优于 MemoryStream(可视化见图3)。
5.2 Single-Document Question Answering
| Model | Context | Easy | Hard | Overall |
|---|---|---|---|---|
| Llama-3.1-70B | Query + Full text | 70.1 | 60.3 | 65.1 |
| Offline Method | ||||
| Llama-3.1-70B | Query + RAPTOR | 65.2 | 53.0 | 59.0 |
| Llama-3.1-70B | Query + GraphRAG | 65.9 | 59.8 | 62.8 |
| Online Method | ||||
| Llama-3.1-70B | Query + MemoryStream | 46.7 | 41.0 | 43.8 |
| Llama-3.1-70B | Query + MemTree | 63.3 | 56.5 | 59.8 |
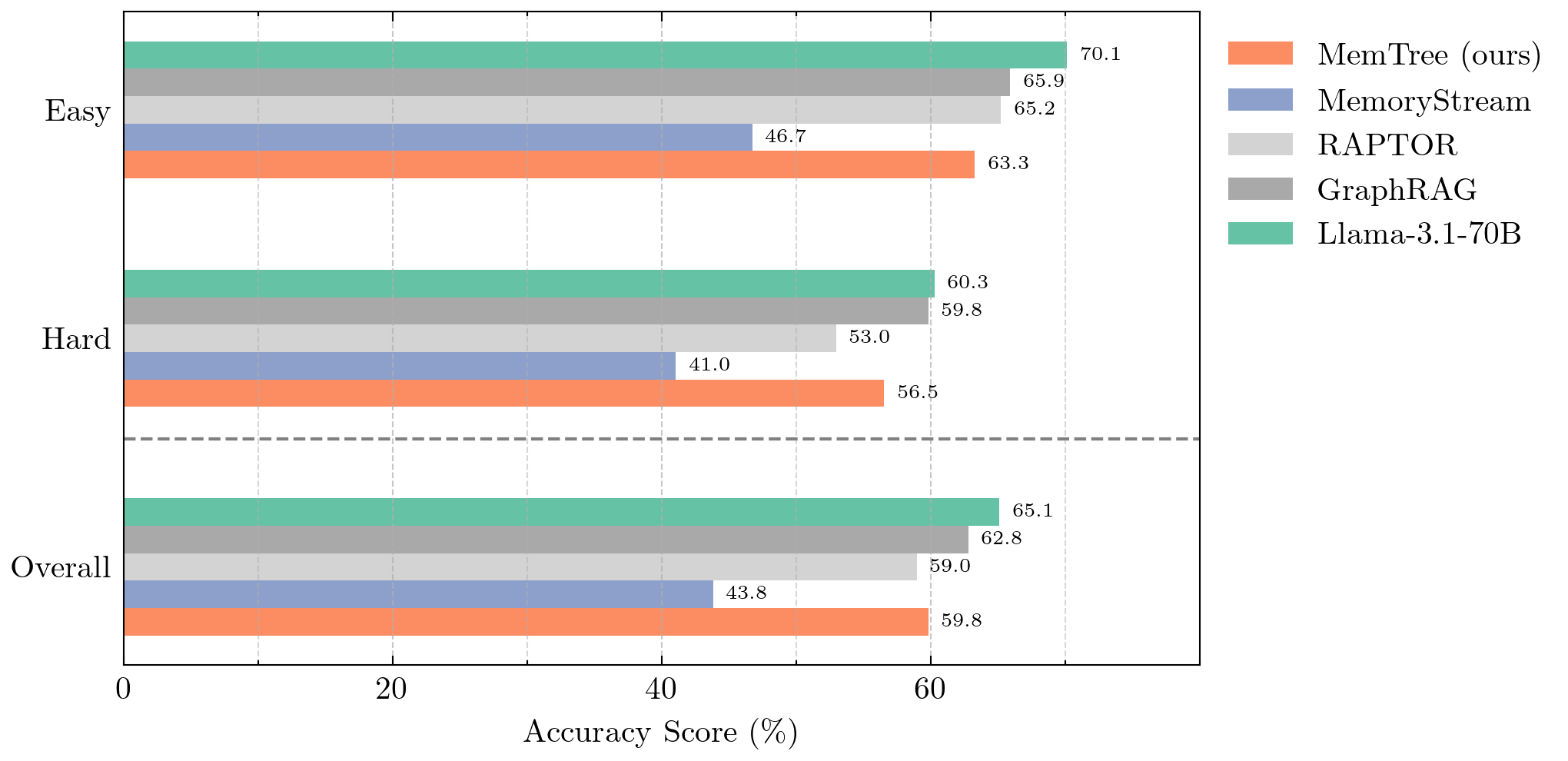
Table 3 presents the accuracy of various models on the QuALITY benchmark. Llama-3.1 70B, which processes the full text in a single pass, achieves the highest overall accuracy at 65.1%. This superior performance is attributed to the dataset's relatively short length (5000 tokens), a trend also observed with the MSC dataset. Offline RAG methods such as RAPTOR and GraphRAG, designed for handling knowledge retrieval over longer contexts, achieve lower accuracies of 59.0% and 62.8%, respectively. The current online memory update method, MemoryStream, struggles with efficiently extracting memory key-value pairs, resulting in a significantly lower accuracy of 43.8%. In contrast, our method, MemTree, matches the offline performance of RAPTOR with a slightly higher accuracy of 59.8%, especially excelling on hard questions that demand deeper reasoning and comprehension. Moreover, MemTree retains the advantage of being an online method, allowing for continuous memory updates at minimal computational cost. Refer to Figure 4 for a visualization of the results.
表3展示了不同模型在 QuALITY 基准上的准确率。 Llama-3.1 70B 以单次完整处理全文的方式取得最高总体准确率 65.1%。 这种更优表现归因于该数据集长度相对较短(5000 token),MSC 数据集中也观察到类似趋势。 RAPTOR 和 GraphRAG 等离线 RAG 方法面向更长上下文上的知识检索,但准确率分别较低,为 59.0% 和 62.8%。 当前在线记忆更新方法 MemoryStream 难以高效抽取记忆键值对,因此准确率显著更低,为 43.8%。 相比之下,本文方法 MemTree 以 59.8% 的略高准确率追平 RAPTOR 的离线性能,尤其擅长需要更深推理和理解的困难问题。 此外,MemTree 保留了在线方法的优势,可以用极低计算成本持续更新记忆。 结果可视化见图4。
5.3 Multi-document Question Answering
| Model | Context | Inference | Comparison | Temporal | Overall |
|---|---|---|---|---|---|
| GPT-4o | Human Annotated Evidence | 98.4 | 80.1 | 55.6 | 79.2 |
| Offline method | |||||
| GPT-4o | Query + RAPTOR | 96.6 | 76.5 | 66.0 | 81.0 |
| GPT-4o | Query + GraphRAG | 96.0 | 69.8 | 66.3 | 78.3 |
| Online method | |||||
| GPT-4o | Query + MemoryStream | 96.1 | 64.8 | 59.3 | 74.7 |
| GPT-4o | Query + MemTree | 96.0 | 73.9 | 68.4 | 80.5 |
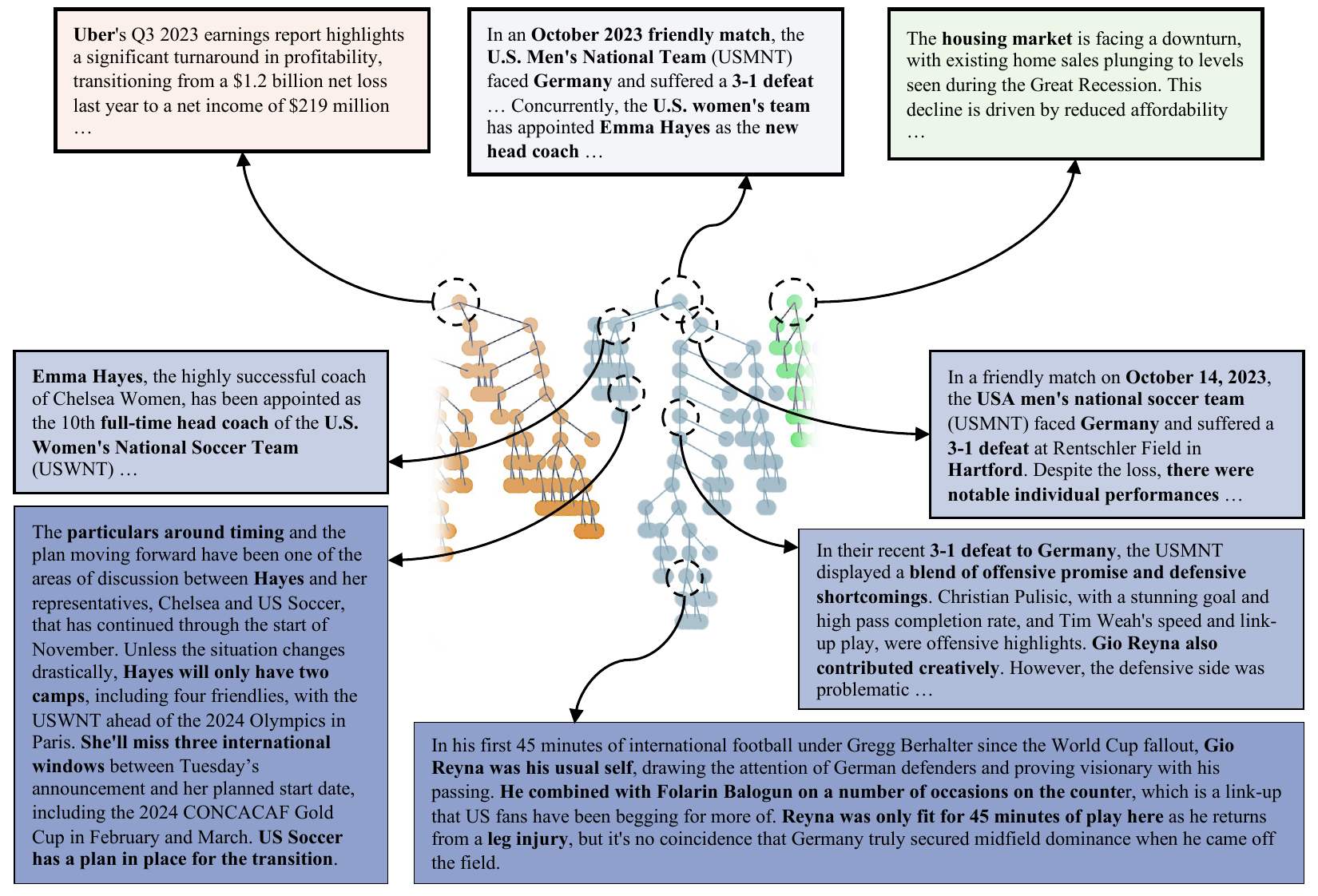
Table 4 summarizes the end-to-end performance of MultiHop RAG using various memory retrieval algorithms. All methods perform exceptionally well on inference-style questions, which focus on fact-checking based on a single document, consistently achieving over 95% accuracy. However, when it comes to more complex questions--those requiring the comparison of multiple documents or temporal reasoning--MemTree significantly outperforms MemoryStream, achieving a 9.1 percentage point advantage. Moreover, despite RAPTOR having full access to all information, MemTree's overall performance is within just 0.5 percentage points of this offline method. See Figure 6 for a detailed visualization of these results.
表4总结了使用不同记忆检索算法时 MultiHop RAG 的端到端性能。 所有方法在 inference 类型问题上都表现极好;这类问题关注基于单篇文档的事实核查,准确率始终超过 95%。 然而,对于更复杂的问题,也就是需要比较多篇文档或进行时间推理的问题,MemTree 显著优于 MemoryStream,取得 9.1 个百分点的优势。 此外,尽管 RAPTOR 可以访问所有信息,MemTree 的总体性能也只比该离线方法低 0.5 个百分点。 这些结果的详细可视化见图6。
Another observation from the table is that while humans can annotate evidence fairly accurately for inference and comparison-style questions, the annotated evidence for temporal questions is less precise. This results in worse performance than the model-derived memory for temporal questions. Importantly, MemTree excels on temporal reasoning tasks, surpassing all baselines, including offline approaches and human-annotated evidence.
表中另一个观察是,人类可以相当准确地为 inference 和 comparison 类型问题标注证据,但对 temporal 问题的证据标注不够精确。 这导致在人类标注证据下,时间问题表现反而不如模型生成的记忆。 重要的是,MemTree 在时间推理任务上表现突出,超过了包括离线方法和人类标注证据在内的所有基线。
| MemTree Property | Value |
|---|---|
| #Nodes | 3164 |
| #Leaf Nodes | 1706 |
| #Branching Nodes | 1458 |
| Depth (max) | 13 |
| Depth (average) | 4.9 |
| Branching Factor | 2.1 |
| Height to Width Ratio | 6.5 |
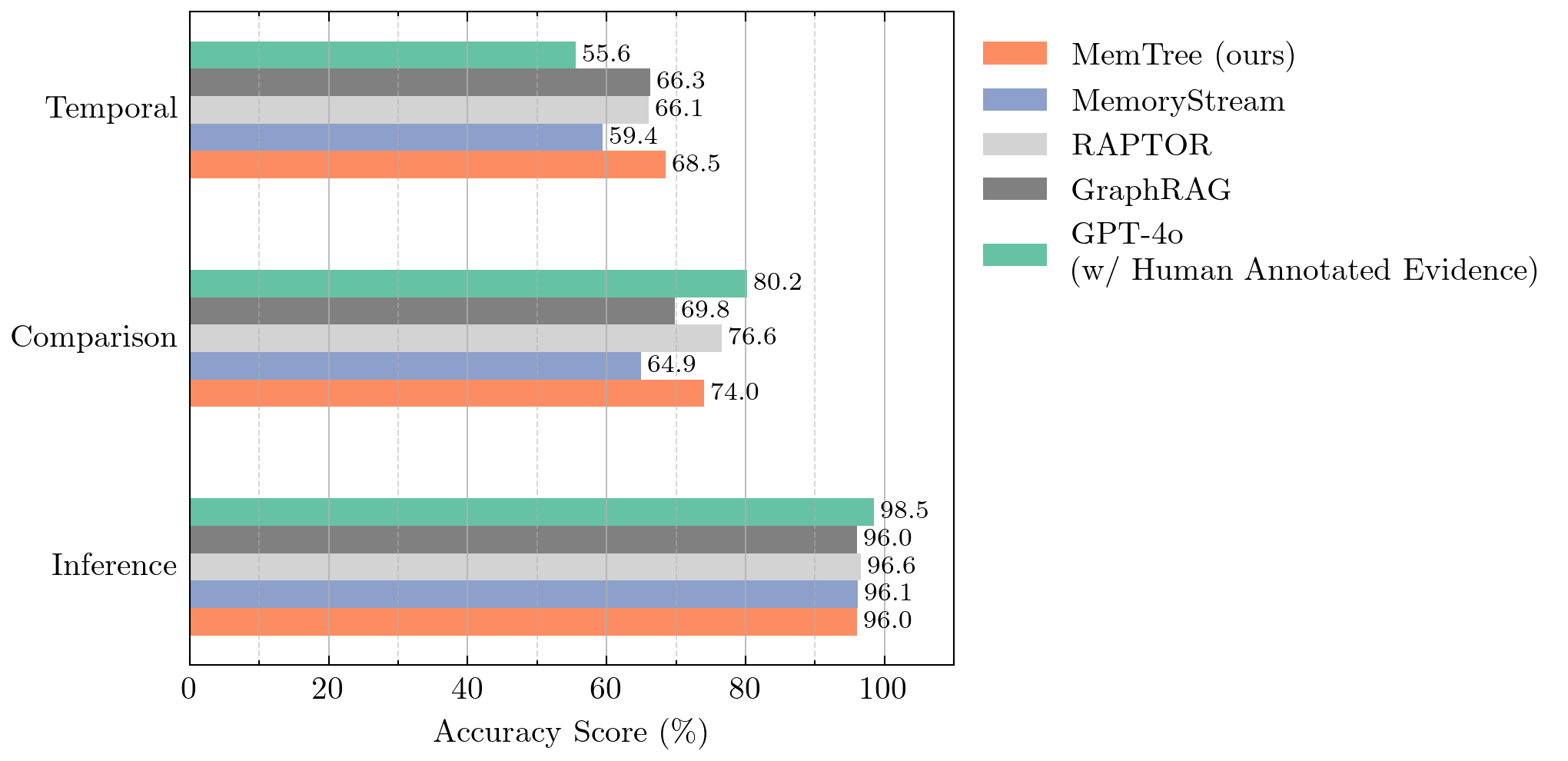
Statistics of the Learned MemTree. Table 5 presents statistics for the learned MemTree on the Multihop RAG dataset, which consists of 609 documents. The resulting tree contains 3,154 nodes, with a maximum depth of 13 and an average branching factor of 2.1. Figure 7 illustrates the distribution of nodes across different depth levels, revealing that the majority of nodes are concentrated between depths 3 to 5. As the tree deepens, the information stored in the nodes increases in length. For instance, at depth 1 (just below the root), the median token count is slightly over 200, with a small deviation. By depth 10 and beyond, the median token count grows to around 800, with greater variability.
学习到的 MemTree 统计。 表5展示了在 Multihop RAG 数据集上学习到的 MemTree 的统计信息;该数据集包含 609 篇文档。 得到的树包含 3,154 个节点,最大深度为 13,平均分支因子为 2.1。 图7展示了不同深度层级上的节点分布,显示大多数节点集中在深度 3 到 5 之间。 随着树加深,节点中存储的信息长度也会增加。 例如,在深度 1(根节点下方)处,中位 token 数略高于 200,偏差较小。 到深度 10 及更深处,中位 token 数增长到约 800,且变异更大。
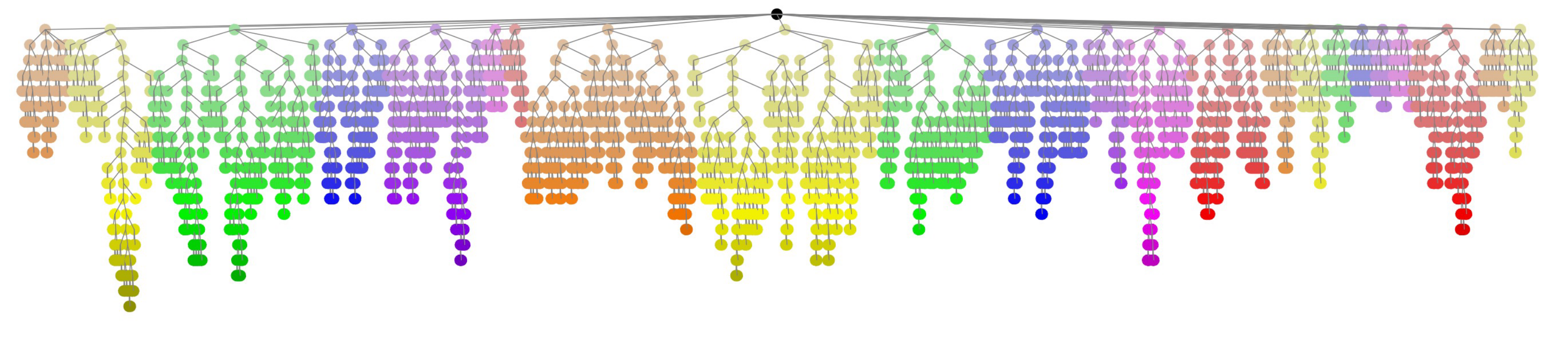
Hierarchical Representation of the MemTree. The hierarchical structure of the learned MemTree reflects a semantic organization. Higher-level nodes capture more abstract, generalized information, while deeper nodes store finer details. Figure 1 and Figure 5 further visualize this hierarchy. The model effectively groups related concepts, with intermediate parent nodes summarizing high-level information during memory insertion. This structure enables the MemTree to maintain a balance between abstract representations at the top and specific details at the bottom.
MemTree 的层级表示。 学习到的 MemTree 的层级结构反映了一种语义组织。 高层节点捕获更抽象、更泛化的信息,而更深节点存储更细粒度的细节。 图1和图5进一步可视化了这种层级结构。 模型能够有效地将相关概念分组,中间父节点会在记忆插入期间总结高层信息。 这种结构使 MemTree 能够在顶部的抽象表示和底部的具体细节之间保持平衡。
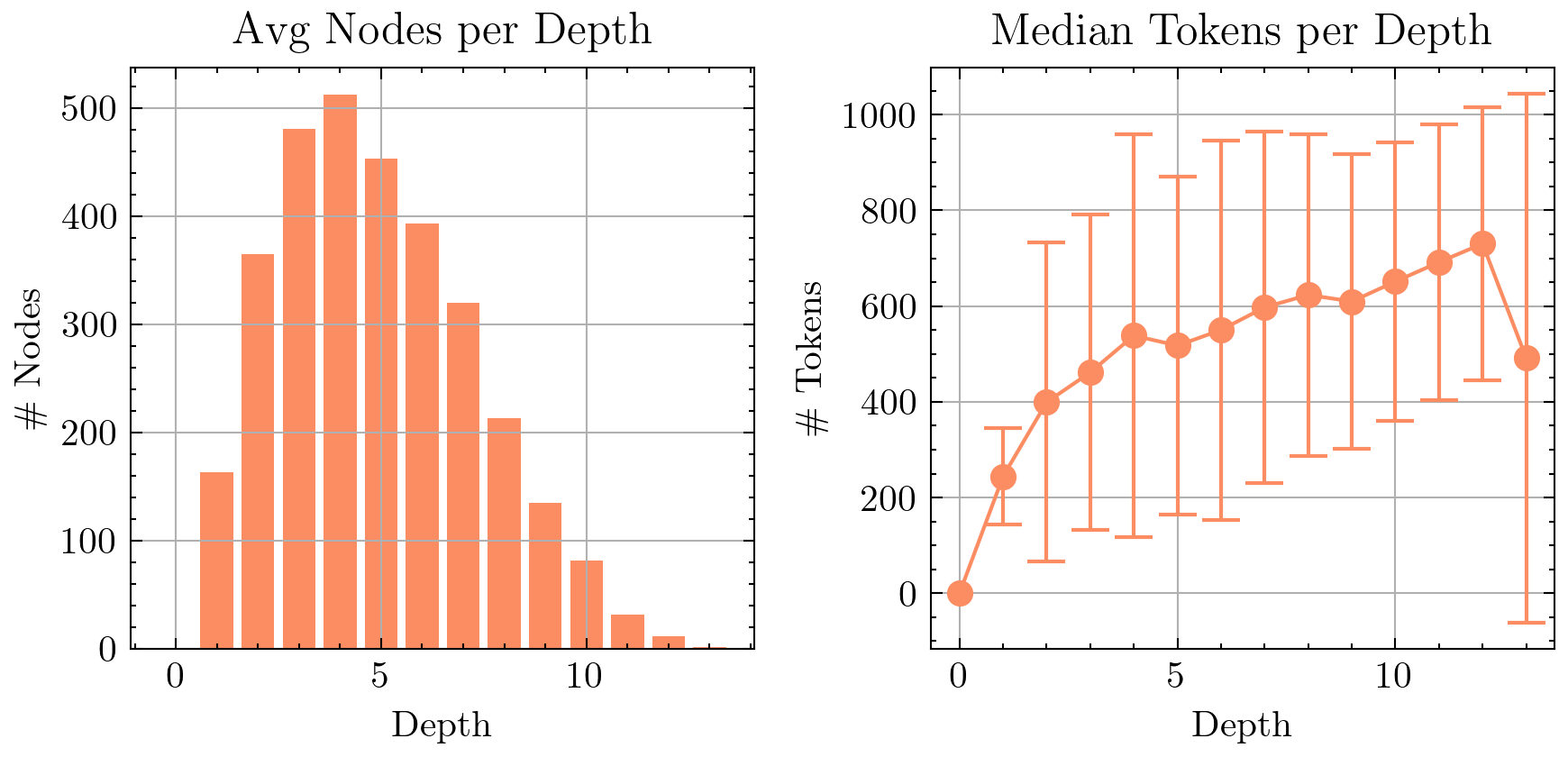
Time Efficiency of Online Algorithm vs Offline Algorithm. MemTree's continuous updates during conversations make it ideal for real-time scenarios. Once the traversal path is defined, its top-down insertion allows parent node updates to be parallelized on the CPU, accelerating the update process and reducing bottlenecks as memory grows. In contrast, RAPTOR and GraphRAG use clustering in a RAG setup, making memory updates after index construction impossible or costly. As shown in Figure 8, MemTree inserts new information in 10 seconds on average, while RAPTOR and GraphRAG take over an hour to build the full memory tree, making it impractical for real-time use. Although MemTree's cumulative time cost is 1.4x higher than RAPTOR's due to continuous updates, this trade-off enables maintaining an up-to-date memory in real time.
在线算法与离线算法的时间效率。 MemTree 在对话期间持续更新,因此非常适合实时场景。 一旦遍历路径确定,其自顶向下插入方式允许在 CPU 上并行更新父节点,从而加速更新过程,并随着记忆增长减少瓶颈。 相比之下,RAPTOR 和 GraphRAG 在 RAG 设置中使用聚类,使得索引构建后的记忆更新变得不可能或成本很高。 如图8所示,MemTree 平均 10 秒即可插入新信息,而 RAPTOR 和 GraphRAG 需要超过一小时来构建完整记忆树,因此不适合实时使用。 虽然由于持续更新,MemTree 的累计时间成本比 RAPTOR 高 1.4 倍,但这种权衡使其能够实时维护最新记忆。
6. Conclusion
MemTree effectively addresses the long-term memory limitations of large language models by emulating the schema-like structures of the human brain through a dynamic tree-based memory representation. This approach enables efficient integration and retrieval of extensive historical data, as demonstrated by its superior performance on four benchmarks with different interactive contexts. Our evaluations reveal that MemTree consistently maintains high performance and demonstrates human-like knowledge aggregation by capturing the semantics of the context within its tree memory structure. This advancement offers a promising solution for enhancing the reasoning capabilities of LLMs in handling long-term memory.
MemTree 通过动态树状记忆表示模拟人脑中的图式结构,从而有效解决大语言模型的长期记忆局限。 这种方法能够高效整合并检索大量历史数据;它在具有不同交互上下文的四个基准上取得更优表现,证明了这一点。 评估表明,MemTree 能够持续保持高性能,并通过在树状记忆结构中捕获上下文语义,展现出类似人类的知识聚合能力。 这一进展为增强 LLM 处理长期记忆时的推理能力提供了有前景的方案。