
Bag of Tricks and A Strong Baseline for Deep Person Re-identification
Person ReIDBaselineTraining Tricks1980+CVPR Workshop 2019ZJUCASXJTU
用于深度行人重识别的一组技巧与强基线
Abstract
This paper explores a simple and efficient baseline for person re-identification (ReID). Person re-identification (ReID) with deep neural networks has made progress and achieved high performance in recent years. However, many state-of-the-arts methods design complex network structure and concatenate multi-branch features. In the literature, some effective training tricks are briefly appeared in several papers or source codes. This paper will collect and evaluate these effective training tricks in person ReID. By combining these tricks together, the model achieves 94.5% rank-1 and 85.9% mAP on Market1501 with only using global features.
本文探索了一个用于行人重识别(ReID)的简单而高效的基线。 近年来,使用深度神经网络的行人重识别(ReID)已经取得进展并达到很高性能。 然而,许多最先进方法会设计复杂网络结构并拼接多分支特征。 在文献中,一些有效训练技巧只是简要出现在若干论文或源码中。 本文将收集并评估这些用于行人 ReID 的有效训练技巧。 通过把这些技巧组合起来,该模型仅使用全局特征就在 Market1501 上达到 94.5% 的 rank-1 和 85.9% 的 mAP。
1. Introduction
Person re-identification (ReID) with deep neural networks has made progress and achieved high performance in recent years. However, many state-of-the-arts methods design complex network structure and concatenate multi-branch features. In the literature, some effective training tricks or refinements are briefly appeared in several papers or source codes. This paper will collect and evaluate such effective training tricks in person ReID. With involved in all training tricks, ResNet50 reaches 94.5% rank-1 accuracy and 85.9% mAP on Market1501. It is worth mentioning that it achieves such surprising performance with global features of the model.
近年来,使用深度神经网络的行人重识别(ReID)已经取得进展并达到很高性能。 然而,许多最先进方法会设计复杂网络结构并拼接多分支特征。 在文献中,一些有效训练技巧或改进只是简要出现在若干论文或源码中。 本文将收集并评估这类用于行人 ReID 的有效训练技巧。 在加入所有训练技巧后,ResNet50 在 Market1501 上达到 94.5% 的 rank-1 准确率和 85.9% 的 mAP。 值得一提的是,它是用模型的全局特征取得这样惊人的性能。
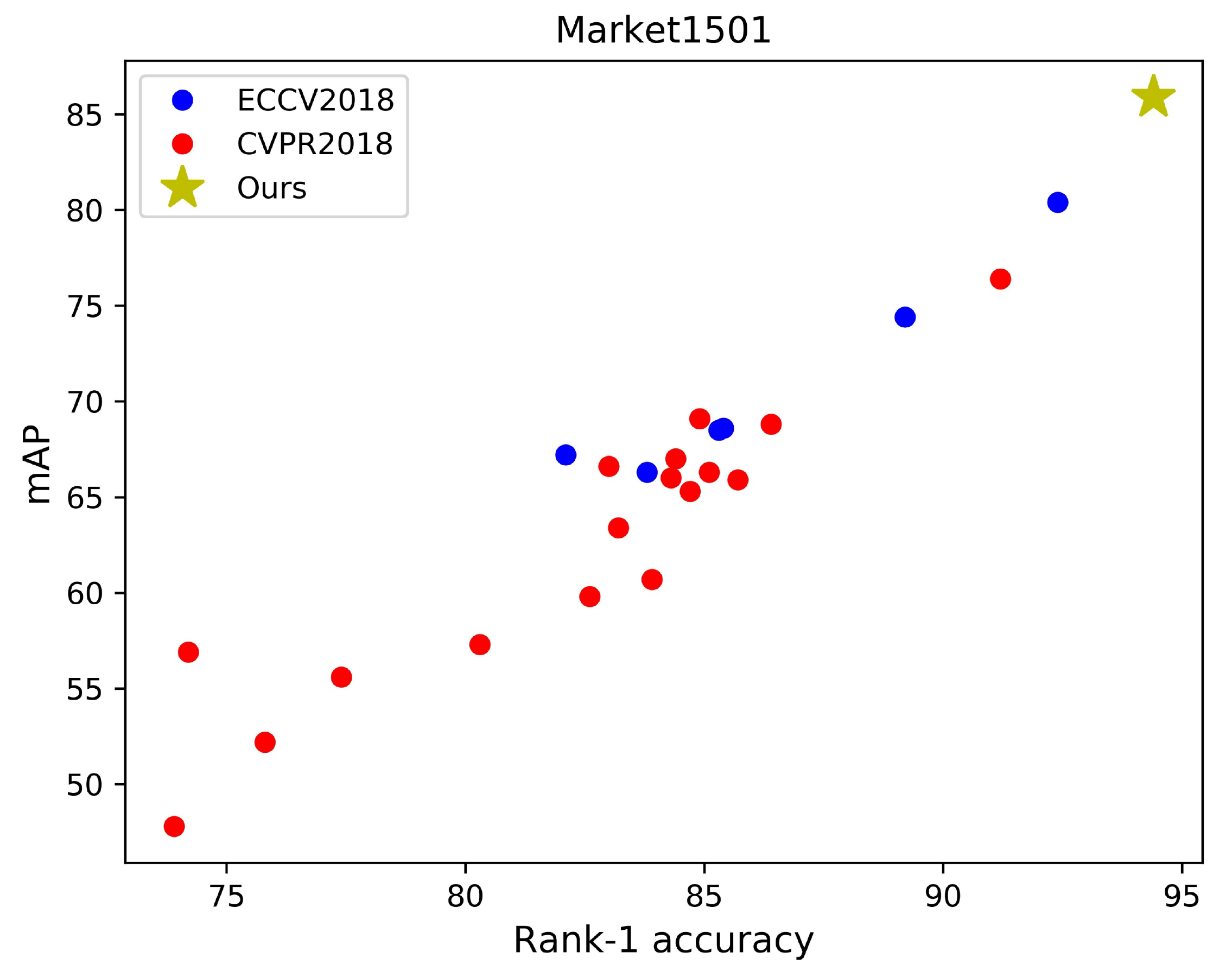
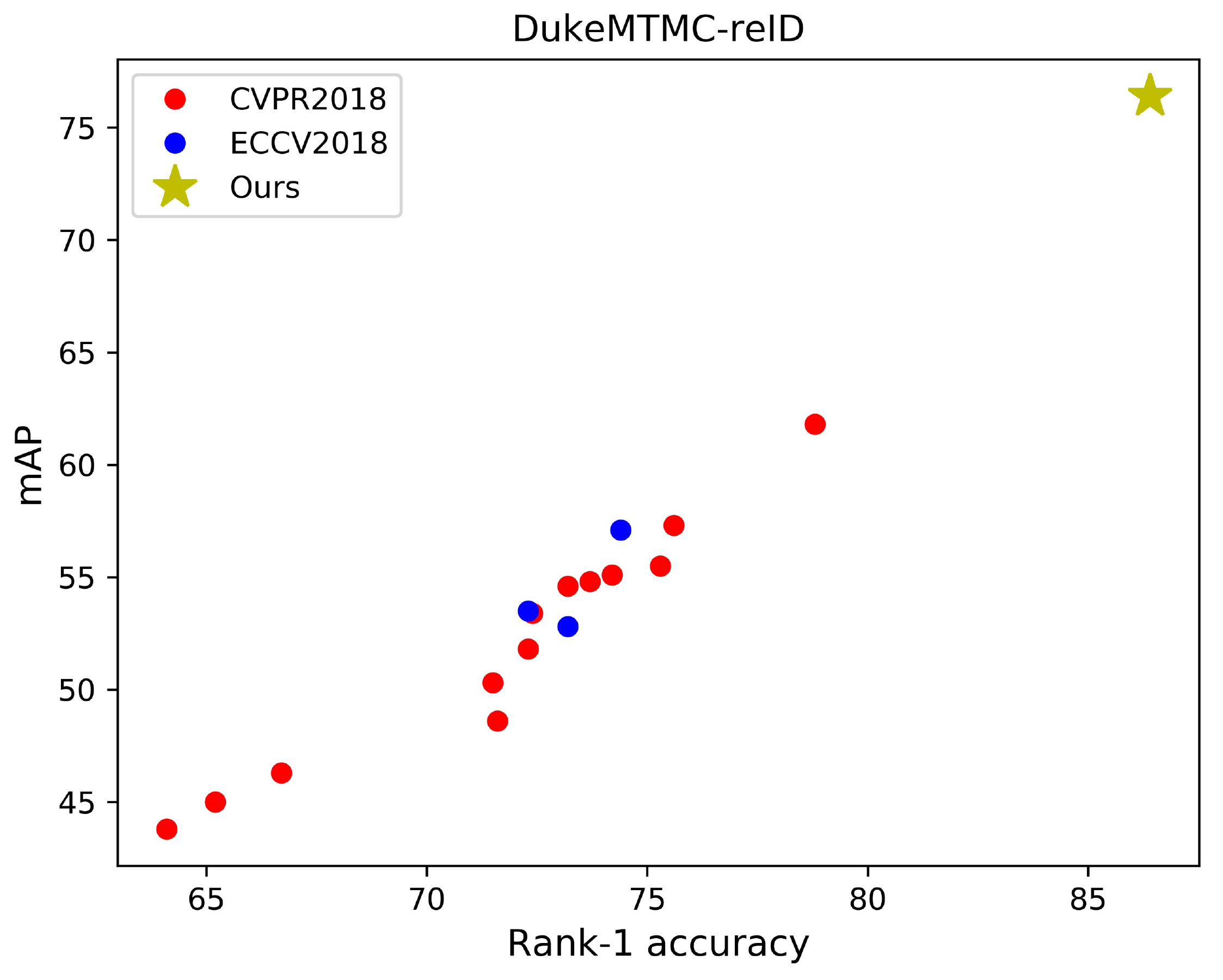
For comparison, we surveyed articles published at ECCV2018 and CVPR2018 of the past year. As shown in Figure Figure 1, most of previous works were expanded on poor baselines. On Market1501, only two baselines in 23 baselines surpassed 90% rank-1 accuracy. The rank-1 accuracies of four baselines even lower than 80%. On DukeMTMC-reID, all baselines did not surpass 80% rank-1 accuracy or 65% mAP. We think a strong baseline is very important to promote the development of research. Therefore, we modified the standard baseline with some training tricks to acquire a strong baseline. The code of our strong baseline has been open sourced.
为了进行比较,作者调研了过去一年发表在 ECCV2018 和 CVPR2018 上的文章。 如 图1 所示,大多数先前工作都是在较弱基线之上扩展的。 在 Market1501 上,23 个基线中只有 2 个超过 90% 的 rank-1 准确率。 有 4 个基线的 rank-1 准确率甚至低于 80%。 在 DukeMTMC-reID 上,所有基线都没有超过 80% 的 rank-1 准确率或 65% 的 mAP。 作者认为,一个强基线对推动研究发展非常重要。 因此,作者用一些训练技巧修改标准基线,以获得一个强基线。 作者的强基线代码已经开源。
In addition, we also found that some works were unfairly compared with other state-of-the-arts methods. Specifically, the improvements were mainly from training tricks rather than methods themselves. But the training tricks were understated in the paper so that readers ignored them. It would make the effectiveness of the method exaggerated. We suggest that reviewers need to take into account these tricks when commenting academic papers.
此外,作者还发现,一些工作与其他最先进方法的比较并不公平。 具体来说,提升主要来自训练技巧,而不是方法本身。 但这些训练技巧在论文中被弱化,以至于读者忽略了它们。 这会夸大方法的有效性。 作者建议审稿人在评论学术论文时需要考虑这些技巧。
Apart from aforementioned reasons, another consideration is that the industry prefers to simple and effective models rather than concatenating lots of local features in the inference stage. In pursuit of high accuracy, researchers in the academic always combine several local features or utilize the semantic information from pose estimation or segmentation models. Such methods bring too much extra consumption. Large features also greatly reduce the speed of retrieval process. Thus, we hope to use some tricks to improve the ability of the ReID model and only use global features to achieve high performance. The purposes of this paper are summarized as follow:
- We surveyed many works published on top conferences and found most of them were expanded on poor baselines.
- For the academia, we hope to provide a strong baseline for researchers to achieve higher accuracies in person ReID.
- For the community, we hope to give reviewers some references that what tricks will affect the performance of the ReID model. We suggest that when comparing the performance of the different methods, reviewers need to take these tricks into account.
- For the industry, we hope to provide some effective tricks to acquire better models without too much extra consumption.
除了上述原因,另一个考虑是工业界更偏好简单而有效的模型,而不是在推理阶段拼接大量局部特征。 为了追求高准确率,学术界研究者总是组合若干局部特征,或利用姿态估计、分割模型中的语义信息。 这类方法带来过多额外消耗。 大特征也会显著降低检索过程的速度。 因此,作者希望使用一些技巧来提升 ReID 模型能力,并且只使用全局特征就达到高性能。 本文目的总结如下:
- 作者调研了许多发表在顶级会议上的工作,发现其中大多数都是在较弱基线之上扩展的。
- 对学术界而言,作者希望为研究者提供一个强基线,以便在行人 ReID 中取得更高准确率。
- 对社区而言,作者希望给审稿人一些参考,说明哪些技巧会影响 ReID 模型性能。作者建议,在比较不同方法性能时,审稿人需要考虑这些技巧。
- 对工业界而言,作者希望提供一些有效技巧,在没有过多额外消耗的情况下获得更好的模型。
Fortunately, a lot of effective training tricks have been present in some papers or open-sourced projects. We collect many tricks and evaluate each of them on ReID datasets. After a lot of experiments, we choose six tricks to introduce in this paper. Some of them were designed or modified by us. We add these tricks into a widely used baseline to get our modified baseline, which achieves 94.5% rank-1 and 85.9% mAP on Market1501. Moreover, we found different works choose different image sizes and numbers of batch size, as a supplement, we also explore their impacts on model performance. In summary, the contributions of this paper are concluded as follow:
- We collect some effective training tricks for person ReID. Among them, we design a new neck structure named as BNNeck. In addition, we evaluate the improvements from each trick on two widely used datasets.
- We provide a strong ReID baseline, which achieves 94.5% and 85.9% mAP on Market1501. It is worth mentioned that the results are obtained with global features provided by ResNet50 backbone. To our best knowledge, it is the best performance acquired by global features in person ReID.
- As a supplement, we evaluate the influences of the image size and the number of batch size on the performance of ReID models.
幸运的是,许多有效训练技巧已经出现在一些论文或开源项目中。 作者收集了许多技巧,并在 ReID 数据集上逐一评估。 经过大量实验后,作者选择六个技巧在本文中介绍。 其中一些技巧由作者设计或修改。 作者把这些技巧加入一个广泛使用的基线,得到修改后的基线,它在 Market1501 上达到 94.5% 的 rank-1 和 85.9% 的 mAP。 此外,作者发现不同工作会选择不同图像尺寸和 batch size 数量;作为补充,作者还探索了它们对模型性能的影响。 总之,本文贡献总结如下:
- 作者收集了一些用于行人 ReID 的有效训练技巧。其中,作者设计了一种名为 BNNeck 的新 neck 结构。此外,作者在两个广泛使用的数据集上评估了每个技巧带来的提升。
- 作者提供了一个强 ReID 基线,它在 Market1501 上达到 94.5% 和 85.9% 的 mAP。值得一提的是,这些结果是使用 ResNet50 主干提供的全局特征获得的。据作者所知,这是行人 ReID 中由全局特征取得的最佳性能。
- 作为补充,作者评估了图像尺寸和 batch size 数量对 ReID 模型性能的影响。
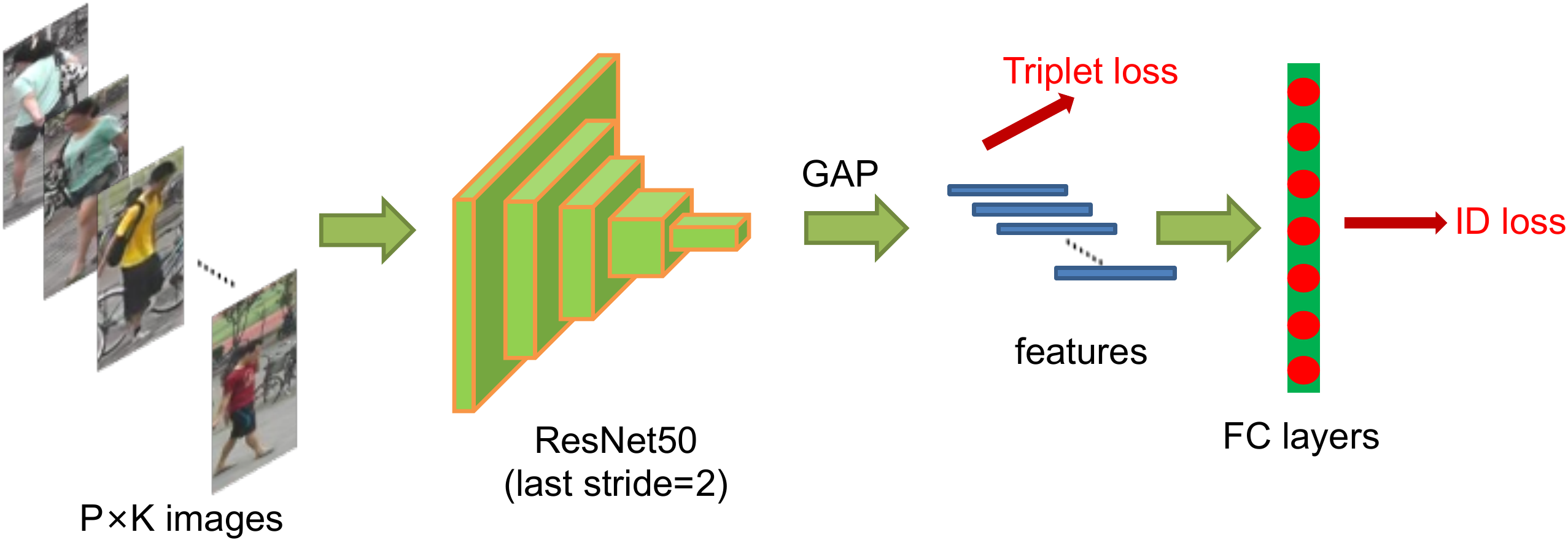
2. Standard Baseline
We follow a widely used open-source as our standard baseline. The backbone of the standard baseline is ResNet50. During the training stage, the pipeline includes following steps:
1. We initialize the ResNet50 with pre-trained parameters on ImageNet and change the dimension of the fully connected layer to
2. We randomly sample
3. We resize each image into
4. Each image is flipped horizontally with 0.5 probability.
5. Each image is decoded into 32-bit floating point raw pixel values in
6. The model outputs ReID features
7. ReID features
8. Adam method is adopted to optimize the model. The initial learning rate is set to be 0.00035 and is decreased by 0.1 at the 40th epoch and 70th epoch respectively. Totally there are 120 training epochs.
作者采用一个广泛使用的开源实现作为标准基线。 标准基线的主干是 ResNet50。 在训练阶段,流程包括以下步骤:
1. 作者用 ImageNet 上的预训练参数初始化 ResNet50,并把全连接层的维度改为
2. 作者随机采样
3. 作者把每张图像缩放到
4. 每张图像以 0.5 的概率进行水平翻转。
5. 每张图像被解码为
6. 模型输出 ReID 特征
7. ReID 特征
8. 作者采用 Adam 方法优化模型。初始学习率设置为 0.00035,并分别在第 40 个 epoch 和第 70 个 epoch 降低 0.1。总共训练 120 个 epoch。
3. Training Tricks
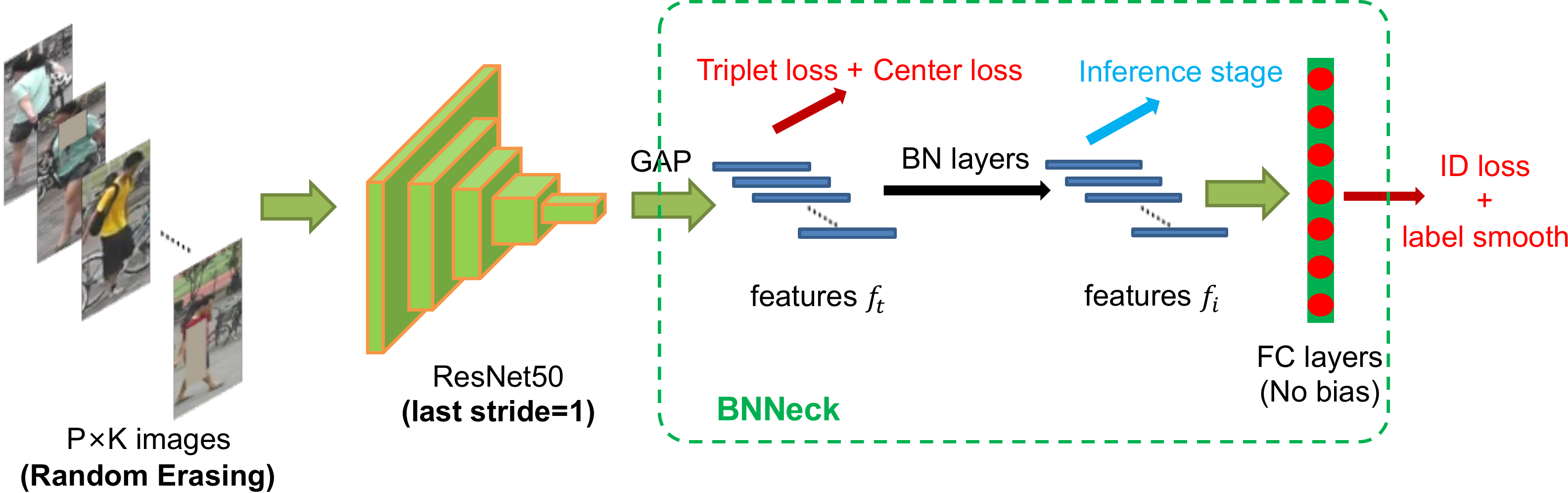
This section will introduce some effective training tricks in person ReID. Most of such tricks can be expanded on the standard baseline without changing the model architecture. The Figure Figure 2 (b) shows training strategies and the model architecture appeared in this section.
本节将介绍一些用于行人 ReID 的有效训练技巧。 大多数这类技巧都可以在不改变模型架构的情况下扩展到标准基线上。 图2 (b) 展示了本节出现的训练策略和模型架构。
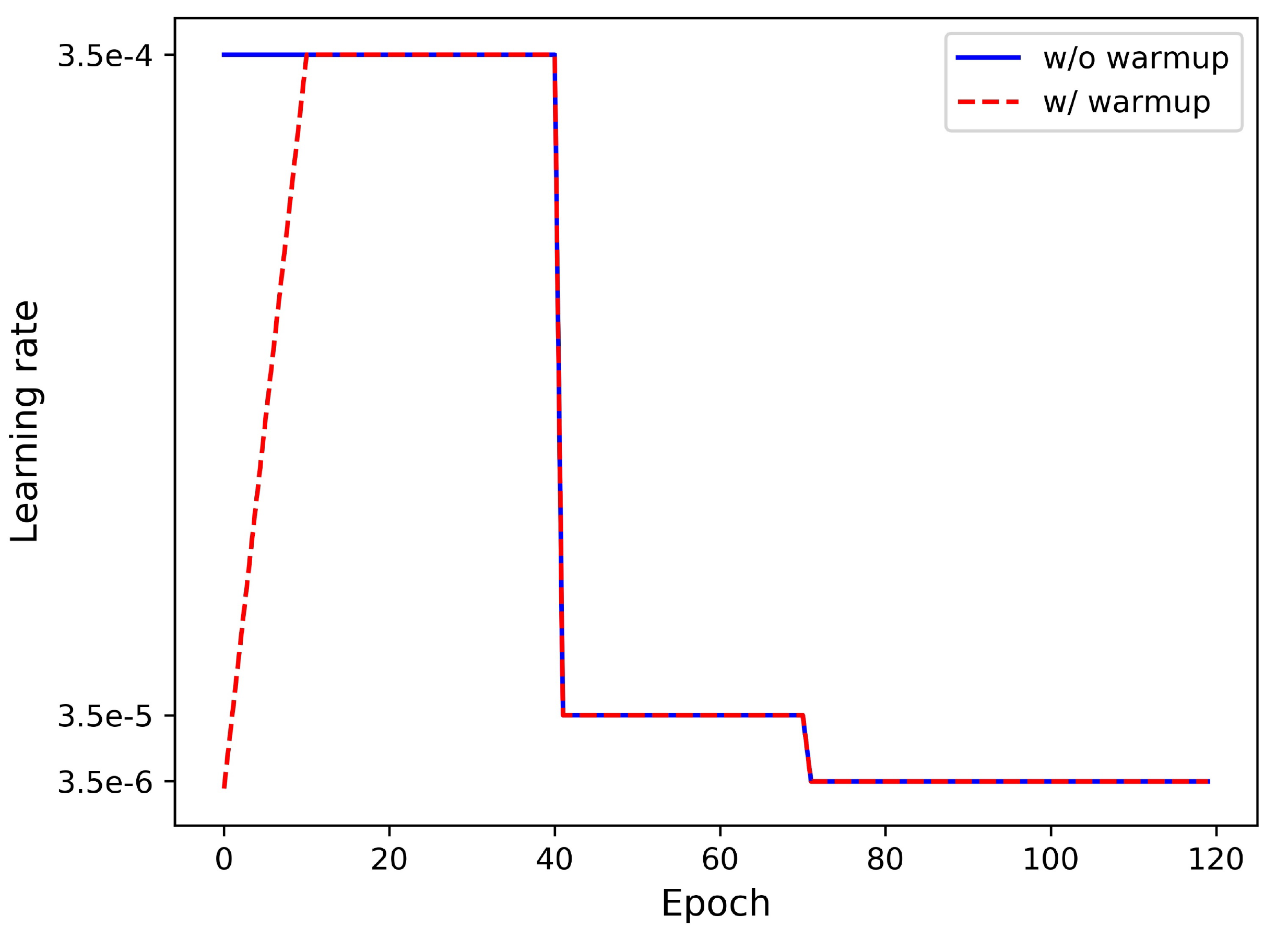
3.1. Warmup Learning Rate
Learning rate has a great impact for the performance of a ReID model. Standard baseline is initially trained with a large and constant learning rate. In Spherereid, a warmup strategy is applied to bootstrap the network for better performance. In practice, As shown in Figure Figure 3, we spent 10 epochs linearly increasing the learning rate from
学习率对 ReID 模型性能有很大影响。 标准基线最初使用较大且恒定的学习率进行训练。 在 Spherereid 中,warmup 策略用于引导网络,以获得更好性能。 实践中,如 图3 所示,作者用 10 个 epoch 将学习率从
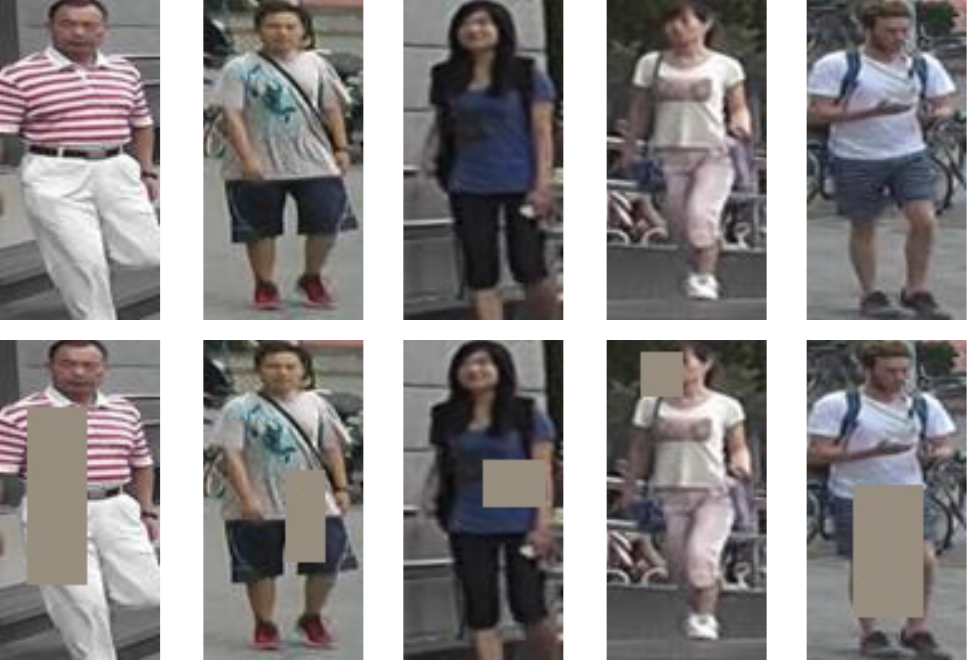
3.2. Random Erasing Augmentation
In person ReID, persons in the images are sometimes occluded by other objects. To address the occlusion problem and improve the generalization ability of ReID models, Zhong et al. proposed a new data augmentation approach named as Random Erasing Augmentation (REA). In practice, for an image
在行人 ReID 中,图像中的行人有时会被其他物体遮挡。 为了解决遮挡问题并提高 ReID 模型的泛化能力,Zhong 等人提出了一种名为随机擦除增强(Random Erasing Augmentation,REA)的新数据增强方法。 实践中,对于 mini-batch 中的一张图像
In this study, we set hyper-parameters to
在本研究中,作者分别设置超参数为
3.3. Label Smoothing
ID Embedding (IDE) network is a basic baseline in person ReID. The last layer of IDE, which outputs the ID prediction logits of images, is a fully-connected layer with a hidden size being equal to numbers of persons
ID Embedding(IDE)网络是行人 ReID 中的一个基本基线。 IDE 的最后一层输出图像的 ID 预测 logit,是一个隐藏大小等于行人数量
Because the category of the classification is determined by the person ID, we call such loss function as ID loss in this paper. Nevertheless, person ReID can be regard as one-shot learning task because person IDs of the testing set have not appeared in the training set. So it is pretty important to prevent the ReID model from overfitting training IDs. Label smoothing (LS) proposed in Rethinking the Inception Architecture for Computer Vision is a widely used method to prevent overfitting for a classification task. It changes the construction of
由于分类类别由行人 ID 决定,本文把这种损失函数称为 ID loss。 然而,行人 ReID 可以被视为 one-shot learning 任务,因为测试集中的行人 ID 没有出现在训练集中。 因此,防止 ReID 模型过拟合训练 ID 非常重要。 《Rethinking the Inception Architecture for Computer Vision》中提出的标签平滑(LS)是一种广泛用于防止分类任务过拟合的方法。 它将
where
其中
3.4. Last Stride
Higher spatial resolution always enriches the granularity of feature. In Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline), Sun et al. removed the last spatial down-sampling operation in the backbone network to increase the size of the feature map. For convenience, we denote the last spatial down-sampling operation in the backbone network as last stride. The last stride of ResNet50 is set to be 2. When fed into a image of
更高的空间分辨率总能丰富特征粒度。 在《Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline)》中,Sun 等人移除了主干网络中的最后一次空间下采样操作,以增大特征图尺寸。 为方便起见,作者把主干网络中的最后一次空间下采样操作称为 last stride。 ResNet50 的 last stride 设置为 2。 当输入一张
3.5. BNNeck
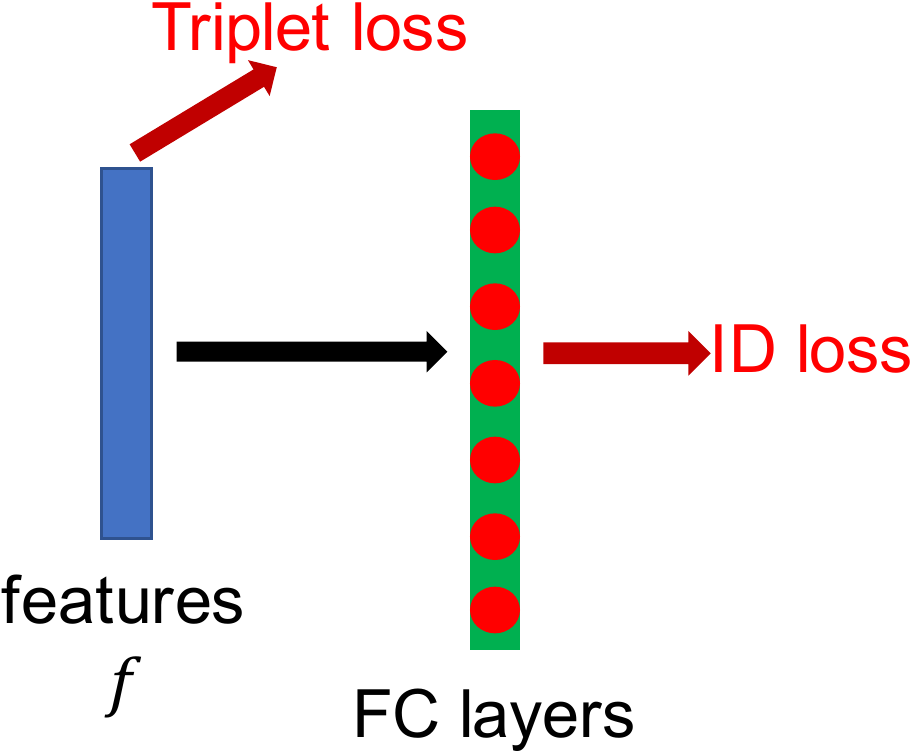
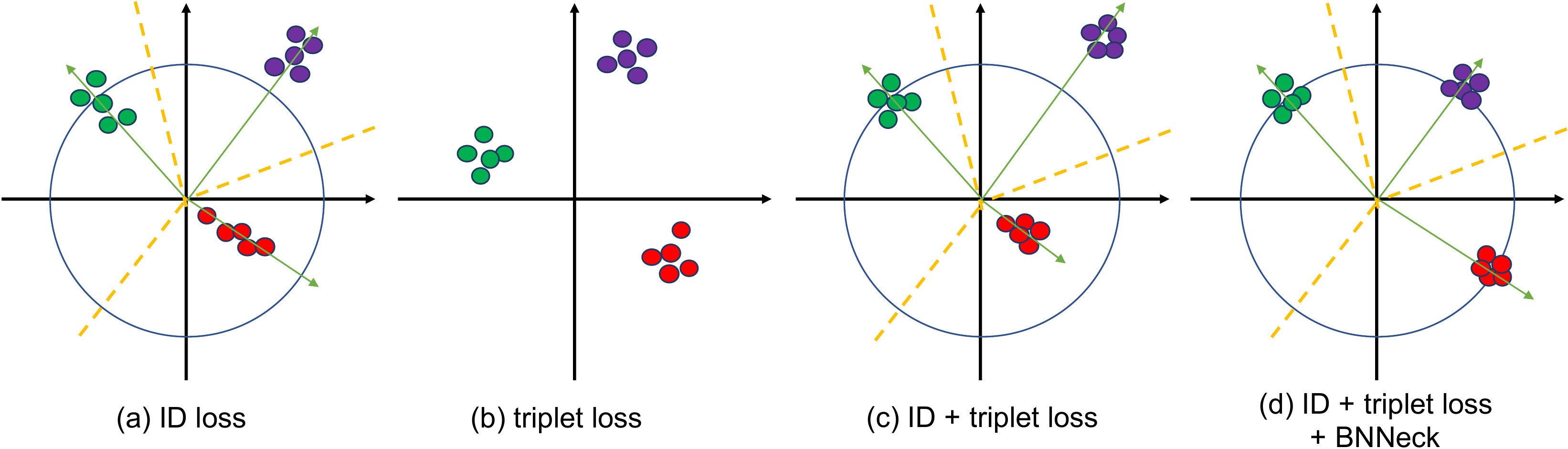
Most of works combined ID loss and triplet loss together to train ReID models. As shown in Figure Figure 5(a), in the standard baseline, ID loss and triplet loss constrain the same feature
大多数工作会把 ID loss 和 triplet loss 结合起来训练 ReID 模型。 如 图5(a) 所示,在标准基线中,ID loss 和 triplet loss 约束同一个特征
As shown in Figure Figure 6(a), ID loss constructs several hyperplanes to separate the embedding space into different sub-spaces. The features of each class are distributed in different subspaces. In this case, cosine distance is more suitable than Euclidean distance for the model optimized by ID loss in the inference stage. On the other hand, as shown in Figure Figure 6(b), triplet loss enhances the intra-class compactness and inter-class separability in the Euclidean space. Because triplet loss can not provide globally optimal constraint, inter-class distance sometimes is smaller than intra-class distance. A widely used method is to combine ID loss and triplet loss to train the model together. This approach let the model learn more discriminative features. Nevertheless, for image pairs in the embedding space, ID loss mainly optimizes the cosine distances while triplet loss focuses on the Euclidean distances. If we use these two losses to simultaneously optimize a feature vector, their goals may be inconsistent. In the training process, a possible phenomenon is that one loss is reduced, while the other loss is oscillating or even increased.
如 图6(a) 所示,ID loss 构造多个超平面,把嵌入空间分割为不同子空间。 每个类别的特征分布在不同子空间中。 在这种情况下,对于由 ID loss 优化的模型,推理阶段余弦距离比欧氏距离更合适。 另一方面,如 图6(b) 所示,triplet loss 在欧氏空间中增强类内紧凑性和类间可分性。 由于 triplet loss 不能提供全局最优约束,类间距离有时会小于类内距离。 一种广泛使用的方法是结合 ID loss 和 triplet loss 一起训练模型。 这种方法让模型学习更具判别性的特征。 然而,对于嵌入空间中的图像对,ID loss 主要优化余弦距离,而 triplet loss 关注欧氏距离。 如果作者使用这两个损失同时优化一个特征向量,它们的目标可能不一致。 在训练过程中,一种可能现象是一个损失降低,而另一个损失震荡甚至升高。
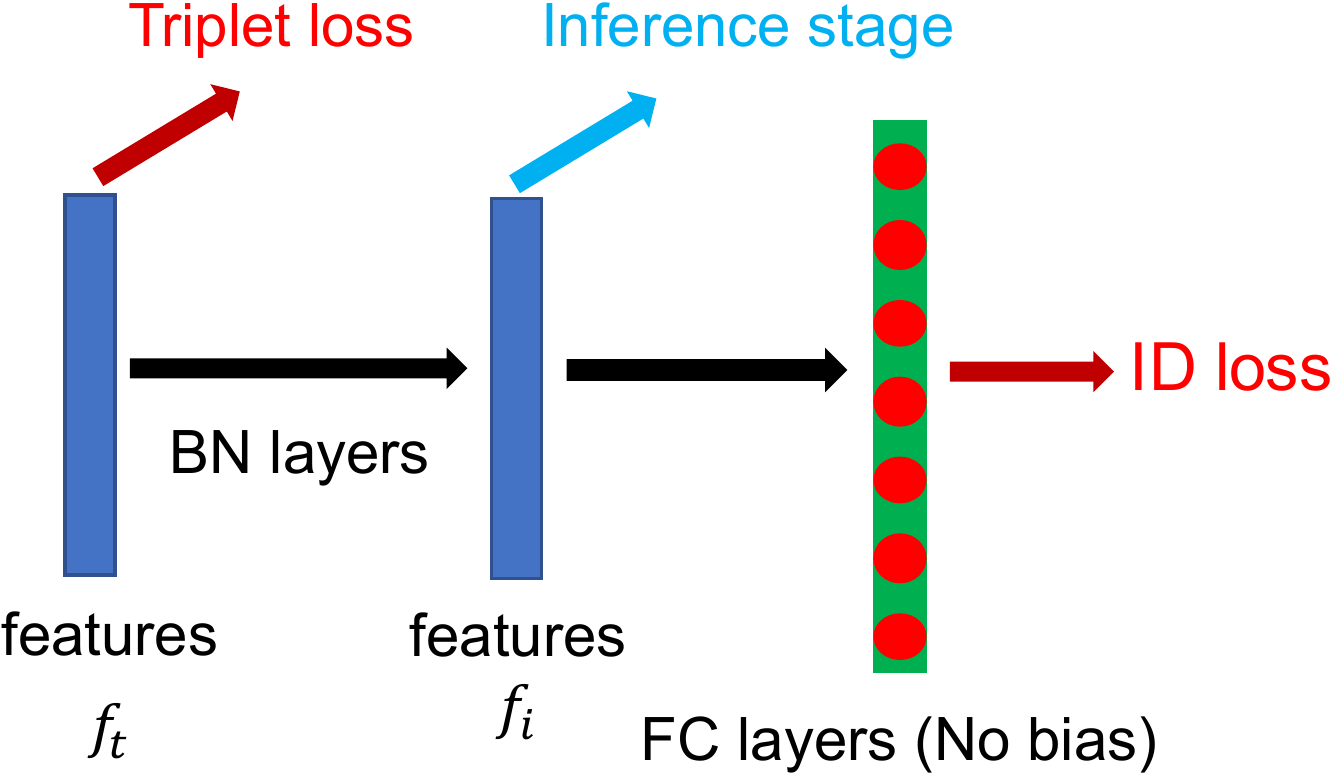
To overcome the aforementioned problem, we design a structure named as BNNeck shown in Figure Figure 5(b). BNNeck only adds a batch normalization (BN) layer after features (and before classifier FC layers). The feature before the BN layer is denoted as
为克服上述问题,作者设计了如 图5(b) 所示的结构,命名为 BNNeck。 BNNeck 只是在特征之后(分类器全连接层之前)添加一个批归一化(BN)层。 BN 层之前的特征记为
Because the hypersphere is almost symmetric about the origin of the coordinate axis, another trick of BNNeck is removing the bias of classifier FC layer. It constrains the classification hyperplanes to pass through the origin of the coordinate axis. We initialize the FC layer with Kaiming initialization proposed in Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.
由于超球面几乎关于坐标轴原点对称,BNNeck 的另一个技巧是移除分类器全连接层的偏置。 它约束分类超平面穿过坐标轴原点。 作者使用《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》中提出的 Kaiming 初始化来初始化全连接层。
In the inference stage, we choose
在推理阶段,作者选择
3.6. Center Loss
Triplet loss is computed as:
triplet loss 计算如下:
where
其中
Center loss, which simultaneously learns a center for deep features of each class and penalizes the distances between the deep features and their corresponding class centers, makes up for the drawbacks of the triplet loss. The center loss function is formulated as:
center loss 同时为每个类别的深度特征学习一个中心,并惩罚深度特征与其对应类别中心之间的距离,从而弥补 triplet loss 的缺点。 center loss 函数表示为:
where
其中
4. Experimental Results
In this section, we will evaluate our models on Market1501 and DukeMTMC-reID datasets. The Rank-1 accuracy and mean Average Precision (mAP) are reported as evaluation metrics. We add tricks on the standard baseline successively and do not change any training settings. The results of ablation studies present the performance boost from each trick. In order to prevent being misled by overfitting, we also show the results of cross-domain experiments.
在本节中,作者将在 Market1501 和 DukeMTMC-reID 数据集上评估模型。 作者报告 Rank-1 准确率和 mean Average Precision(mAP)作为评估指标。 作者在标准基线上依次添加技巧,并且不改变任何训练设置。 消融研究结果展示了每个技巧带来的性能提升。 为了避免被过拟合误导,作者还展示了跨域实验结果。
4.1. Influences of Each Trick (Same domain)
| Model | Market1501 | DukeMTMC | ||
|---|---|---|---|---|
| r = 1 | mAP | r = 1 | mAP | |
| Baseline-S | 87.7 | 74.0 | 79.7 | 63.7 |
| +warmup | 88.7 | 75.2 | 80.6 | 65.1 |
| +REA | 91.3 | 79.3 | 81.5 | 68.3 |
| +LS | 91.4 | 80.3 | 82.4 | 69.3 |
| +stride=1 | 92.0 | 81.7 | 82.6 | 70.6 |
| +BNNeck | 94.1 | 85.7 | 86.2 | 75.9 |
| +center loss | 94.5 | 85.9 | 86.4 | 76.4 |
The standard baseline introduced in section 2 achieves 87.7% and 79.7% rank-1 accuracies on Market1501 and DukeMTMC-reID, respectively. The performance of standard baseline is similar with most of baselines reported in other papers. Then, we add warmup strategy, random erasing augmentation, label smoothing, stride change, BNNeck and center loss to the model training process, one by one. Our designed BNNeck boosts more performance than other tricks, especially on DukeMTMC-reID. Finally, these tricks make baseline acquire 94.5% rank-1 accuracy and 85.9% mAP on Market1501. On DukeMTMC-reID, it reaches 86.4% rank-1 accuracy and 76.4% mAP. In other works, these training tricks boost the performance of the standard baseline by more than 10% mAP. In addition, to get such improvement, we only involve an extra BN layer and do not increase training time.
第 2 节介绍的标准基线在 Market1501 和 DukeMTMC-reID 上分别达到 87.7% 和 79.7% 的 rank-1 准确率。 标准基线的性能与其他论文报告的大多数基线相似。 然后,作者逐一把 warmup 策略、随机擦除增强、标签平滑、stride 改动、BNNeck 和 center loss 加入模型训练过程。 作者设计的 BNNeck 比其他技巧带来更多性能提升,尤其是在 DukeMTMC-reID 上。 最终,这些技巧使基线在 Market1501 上获得 94.5% 的 rank-1 准确率和 85.9% 的 mAP。 在 DukeMTMC-reID 上,它达到 86.4% 的 rank-1 准确率和 76.4% 的 mAP。 在其他工作中,这些训练技巧使标准基线性能提升超过 10% mAP。 此外,为了获得这样的提升,作者只引入一个额外 BN 层,并没有增加训练时间。
4.2. Analysis of BNNeck
| Feature | Metric | Market1501 | DukeMTMC | ||
|---|---|---|---|---|---|
| r = 1 | mAP | r = 1 | mAP | ||
| f (w/o BNNeck) | Euclidean | 92.0 | 81.7 | 82.6 | 70.6 |
| ft | Euclidean | 94.2 | 85.5 | 85.7 | 74.4 |
| ft | Cosine | 94.2 | 85.7 | 85.5 | 74.6 |
| fi | Euclidean | 93.8 | 83.7 | 86.6 | 73.0 |
| fi | Cosine | 94.1 | 85.7 | 86.2 | 75.9 |
In this section, we evaluate the performance of two different features (
在本节中,作者使用欧氏距离度量和余弦距离度量评估两个不同特征(
In overall, BNNeck significantly improve the performance of ReID models. We choose
总体而言,BNNeck 显著提升了 ReID 模型性能。 作者在推理阶段选择
4.3. Influences of Each Trick (Cross domain)
| Model | M→D | D→M | ||
|---|---|---|---|---|
| r = 1 | mAP | r = 1 | mAP | |
| Baseline | 24.4 | 12.9 | 34.2 | 14.5 |
| +warmup | 26.3 | 14.1 | 39.7 | 17.4 |
| +REA | 21.5 | 10.2 | 32.5 | 13.5 |
| +LS | 23.2 | 11.3 | 36.5 | 14.9 |
| +stride=1 | 23.1 | 11.8 | 37.1 | 15.4 |
| +BNNeck | 26.7 | 15.2 | 47.7 | 21.6 |
| +center loss | 27.5 | 15.0 | 47.4 | 21.4 |
| -REA | 41.4 | 25.7 | 54.3 | 25.5 |
To further explore effectiveness, we also present the results of cross-domain experiments in Table Table 3. In overview, three tricks including warmup strategy, label smoothing and BNNeck significantly boost the cross-domain performance of ReID models. Stride change and center loss seem to have no big impact on the performance. However, REA does harm to models in cross-domain ReID task. In particularly, when our modified baseline is trained without REA, it achieves 41.4% and 54.3% rank-1 accuracies on Market1501 and DukeMTMC-reID datasets, respectively. Its performance surpass the ones of the standard baseline by a large margin. We infer that REA masking the regions of training images lets the model learn more knowledge in the training domain. It causes the model to perform worse in the testing domain.
为了进一步探索有效性,作者还在 表3 中展示了跨域实验结果。 总体来看,warmup 策略、标签平滑和 BNNeck 三个技巧显著提升了 ReID 模型的跨域性能。 stride 改动和 center loss 似乎对性能没有很大影响。 然而,REA 会损害模型在跨域 ReID 任务上的表现。 特别是,当作者修改后的基线在没有 REA 的情况下训练时,它在 Market1501 和 DukeMTMC-reID 数据集上分别达到 41.4% 和 54.3% 的 rank-1 准确率。 其性能大幅超过标准基线。 作者推断,REA 对训练图像区域的遮挡使模型在训练域中学习到更多知识。 这会导致模型在测试域中表现更差。
4.4. Comparison of State-of-the-Arts
| Type | Method | Nf | Market1501 | DukeMTMC | ||
|---|---|---|---|---|---|---|
| r = 1 | mAP | r = 1 | mAP | |||
| Pose-guided | GLAD | 4 | 89.9 | 73.9 | - | - |
| PIE | 3 | 87.7 | 69.0 | 79.8 | 62.0 | |
| PSE | 3 | 78.7 | 56.0 | - | - | |
| Mask-guided | SPReID | 5 | 92.5 | 81.3 | 84.4 | 71.0 |
| MaskReID | 3 | 90.0 | 75.3 | 78.8 | 61.9 | |
| Stripe-based | AlignedReID | 1 | 90.6 | 77.7 | 81.2 | 67.4 |
| SCPNet | 1 | 91.2 | 75.2 | 80.3 | 62.6 | |
| PCB | 6 | 93.8 | 81.6 | 83.3 | 69.2 | |
| Pyramid | 1 | 92.8 | 82.1 | - | - | |
| Pyramid | 21 | 95.7 | 88.2 | 89.0 | 79.0 | |
| BFE | 2 | 94.5 | 85.0 | 88.7 | 75.8 | |
| Attention-based | Mancs | 1 | 93.1 | 82.3 | 84.9 | 71.8 |
| DuATM | 1 | 91.4 | 76.6 | 81.2 | 62.3 | |
| HA-CNN | 4 | 91.2 | 75.7 | 80.5 | 63.8 | |
| GAN-based | Camstyle | 1 | 88.1 | 68.7 | 75.3 | 53.5 |
| PN-GAN | 9 | 89.4 | 72.6 | 73.6 | 53.2 | |
| Global feature | IDE | 1 | 79.5 | 59.9 | - | - |
| SVDNet | 1 | 82.3 | 62.1 | 76.7 | 56.8 | |
| TriNet | 1 | 84.9 | 69.1 | - | - | |
| AWTL | 1 | 89.5 | 75.7 | 79.8 | 63.4 | |
| Ours | 1 | 94.5 | 85.9 | 86.4 | 76.4 | |
| Ours(RK) | 1 | 95.4 | 94.2 | 90.3 | 89.1 | |
We compare out strong baseline with state-of-the-arts methods in Table Table 4. All methods have been divided into different types. Pyramid achieves surprising performance on two datasets. However, it concatenates 21 local features of different scale. If only utilizing the global feature, it obtains 92.8% rank-1 accuracy and 82.1% mAP on Market1501. Ours strong baseline can reach 94.5% rank-1 accuracy and 85.9% mAP on Market1501. BFE obtains similar performance with our strong baseline. But it combines features of two branches. Throughout all methods that only use global features, our strong baseline beats AWTL by more than 10% mAP on both Market1501 and DukeMTMC-reID. With
作者在 表4 中将强基线与最先进方法进行比较。 所有方法被分成不同类型。 Pyramid 在两个数据集上取得了惊人性能。 然而,它拼接了 21 个不同尺度的局部特征。 如果只使用全局特征,它在 Market1501 上获得 92.8% 的 rank-1 准确率和 82.1% 的 mAP。 作者的强基线在 Market1501 上可以达到 94.5% 的 rank-1 准确率和 85.9% 的 mAP。 BFE 取得了与作者强基线相似的性能。 但它组合了两个分支的特征。 在所有只使用全局特征的方法中,作者的强基线在 Market1501 和 DukeMTMC-reID 上都以超过 10% mAP 的幅度超过 AWTL。 借助
5. Supplementary Experiments
We observed that some previous works were done with different the numbers of batch size or image sizes. In this section, as a supplementary we explore the affects of them on model performance.
作者观察到,一些先前工作使用了不同 batch size 数量或图像尺寸。 在本节中,作为补充,作者探索它们对模型性能的影响。
5.1. Influences of the Number of Batch Size
| Batch Size | Market1501 | DukeMTMC | ||
|---|---|---|---|---|
| P × K | r = 1 | mAP | r = 1 | mAP |
| 8×3 | 92.6 | 79.2 | 84.4 | 68.1 |
| 8×4 | 92.9 | 80.0 | 84.7 | 69.4 |
| 8×6 | 93.5 | 81.6 | 85.1 | 70.7 |
| 8×8 | 93.9 | 82.0 | 85.8 | 71.5 |
| 16×3 | 93.8 | 83.1 | 86.8 | 72.1 |
| 16×4 | 93.8 | 83.7 | 86.6 | 73.0 |
| 16×6 | 94.0 | 82.8 | 85.1 | 69.9 |
| 16×8 | 93.1 | 81.6 | 86.7 | 72.1 |
| 32×3 | 94.5 | 84.1 | 86.0 | 71.4 |
| 32×4 | 93.2 | 82.8 | 86.5 | 73.1 |
The mini-batch of triplet loss includes
triplet loss 的 mini-batch 包含
5.2. Influences of Image Size
| Image Size | Market1501 | DukeMTMC | ||
|---|---|---|---|---|
| r = 1 | mAP | r = 1 | mAP | |
| 256×128 | 93.8 | 83.7 | 86.6 | 73.0 |
| 224×224 | 94.2 | 83.3 | 86.1 | 72.2 |
| 384×128 | 94.0 | 82.7 | 86.4 | 73.2 |
| 384×192 | 93.8 | 83.1 | 87.1 | 72.9 |
We trained models without center loss and set
作者在没有 center loss 的情况下训练模型,并设置
6. Conclusions and Outlooks
In this paper, we collect some effective training tricks and design a strong baseline for person ReID. To demonstrate the influences of each trick on the performance of ReID models, we do a lot of experiments on both same-domain and cross-domain ReID tasks. Finally, only using global features, our strong baseline achieve 94.5% rank-1 accuracy and 85.9% mAP on Market1501. We hope that this work can promote the ReID research in academia and industry.
在本文中,作者收集了一些有效训练技巧,并为行人 ReID 设计了一个强基线。 为了展示每个技巧对 ReID 模型性能的影响,作者在同域和跨域 ReID 任务上做了大量实验。 最终,仅使用全局特征,作者的强基线就在 Market1501 上达到 94.5% 的 rank-1 准确率和 85.9% 的 mAP。 作者希望这项工作能够推动学术界和工业界的 ReID 研究。
However, the purpose of our work is not to improve performance roughly. Compared with face recognition, person ReID still has a long way to explore. We think some training tricks can speed up the exploration and there are many effective tricks not discovered. We welcome researchers to share some other effective tricks with us. We will evaluate them based on this work.
然而,作者工作的目的并不是粗暴提升性能。 与人脸识别相比,行人 ReID 仍有很长的路要探索。 作者认为,一些训练技巧可以加快这种探索,并且仍有许多有效技巧尚未被发现。 作者欢迎研究者与作者分享其他有效技巧。 作者将基于这项工作对它们进行评估。
In the future, we will continue to design more experiments to analyze the principles of these trciks. For example, when we replace the BNNeck with L2 normalization, what does the performance of this network become? In addition, whether can some state-of-the-arts methods such as PCB, MGN and AlignedReID, etc. be expanded on our strong baseline? More visualization also is helpful for others to understand this work.
未来,作者将继续设计更多实验来分析这些技巧的原理。 例如,当作者用 L2 归一化替换 BNNeck 时,这个网络的性能会变成什么样? 此外,PCB、MGN 和 AlignedReID 等一些最先进方法是否可以扩展到作者的强基线上? 更多可视化也有助于他人理解这项工作。