
Memory, Benchmark & Robots: A Benchmark for Solving Complex Tasks with Reinforcement Learning
MemoryRLBenchmark100+ICLR 2026CCF-A记忆、基准与机器人:用于通过强化学习解决复杂任务的基准
Abstract
Memory is crucial for enabling agents to tackle complex tasks with temporal and spatial dependencies. While many reinforcement learning (RL) algorithms incorporate memory, the field lacks a universal benchmark to assess an agent's memory capabilities across diverse scenarios. This gap is particularly evident in tabletop robotic manipulation, where memory is essential for solving tasks with partial observability and ensuring robust performance, yet no standardized benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills Assessment Suite for Agents), a comprehensive benchmark for memory RL, with three key contributions: (1) we propose a comprehensive classification framework for memory-intensive RL tasks, (2) we collect MIKASA-Base -- a unified benchmark that enables systematic evaluation of memory-enhanced agents across diverse scenarios, and (3) we develop MIKASA-Robo (pip install mikasa-robo-suite) -- a novel benchmark of 32 carefully designed memory-intensive tasks that assess memory capabilities in tabletop robotic manipulation. Our work introduces a unified framework to advance memory RL research, enabling more robust systems for real-world use.
记忆对于使智能体处理具有时间和空间依赖的复杂任务至关重要。 虽然许多强化学习(RL)算法都引入了记忆,但该领域仍缺少一个通用基准,用于在多样场景中评估智能体的记忆能力。 这一缺口在桌面机器人操作中尤其明显,因为记忆对于解决具有部分可观测性的任务并确保鲁棒性能至关重要,但目前尚不存在标准化基准。 为解决这一问题,作者提出 MIKASA(Memory-Intensive Skills Assessment Suite for Agents),这是一个用于记忆型 RL 的综合基准,包含三项关键贡献:(1) 作者提出一个用于记忆密集型 RL 任务的综合分类框架,(2) 作者收集 MIKASA-Base -- 一个统一基准,可在多样场景中系统评估记忆增强型智能体,(3) 作者开发 MIKASA-Robo(pip install mikasa-robo-suite)-- 一个由 32 个精心设计的记忆密集型任务构成的新基准,用于评估桌面机器人操作中的记忆能力。 本文提出了一个统一框架,以推进记忆型 RL 研究,并支持面向真实世界使用的更鲁棒系统。
1. Introduction
Many real-world problems involve partial observability, where an agent lacks full access to the environment's state. These tasks often include sequential decision-making, delayed or sparse rewards, and long-term information retention. One approach to tackling these challenges is to equip the agent with memory, allowing it to utilize historical information. While there are well-established benchmarks in Natural Language Processing, the evaluation of memory in reinforcement learning (RL) remains fragmented. Existing benchmarks, such as POPGym, DMLab-30 and MemoryGym, focus on specific aspects of memory utilization, as they are designed around particular problem domains.
许多真实世界问题都涉及部分可观测性,即智能体无法完全访问环境状态。 这些任务通常包含序贯决策、延迟或稀疏奖励,以及长期信息保留。 应对这些挑战的一种方法是为智能体配备记忆,使其能够利用历史信息。 虽然自然语言处理中已有成熟基准,但强化学习(RL)中的记忆评估仍然碎片化。 现有基准,如 POPGym、DMLab-30 和 MemoryGym,关注记忆利用的特定方面,因为它们围绕特定问题领域设计。
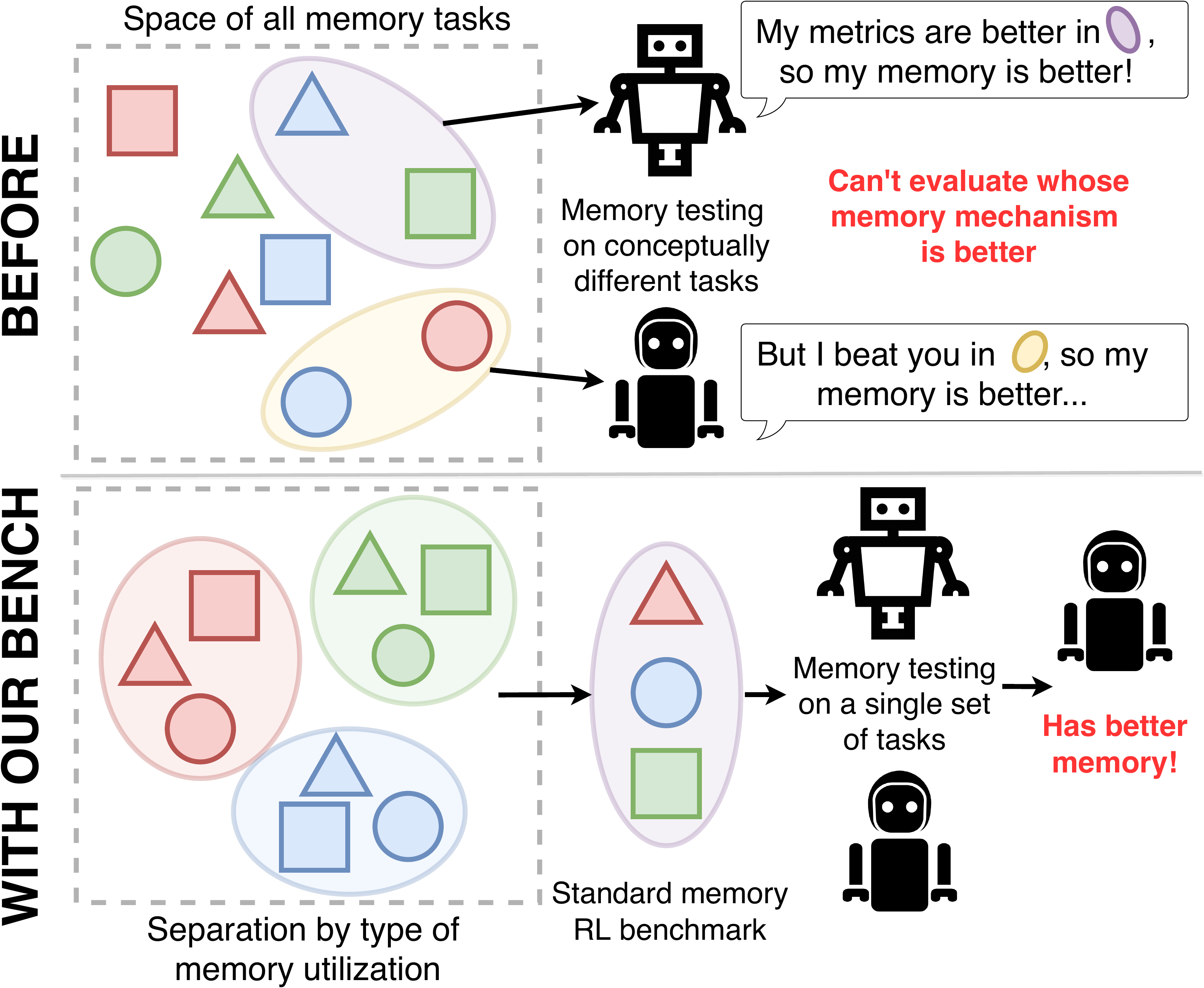
In contrast to classical RL, where benchmarks like Atari and MuJoCo serve as universal standards, memory-enhanced agents are typically evaluated on custom environments developed alongside their proposals Table 2. This fragmented evaluation landscape obscures important performance variations across different memory tasks. For instance, an agent might excel at maintaining object attributes over extended periods while struggling with sequential recall challenges. Such task-specific strengths and limitations often remain hidden due to narrow evaluation scopes, underscoring the need for a comprehensive benchmark that spans diverse memory-intensive scenarios.
相比之下,在经典 RL 中,Atari 和 MuJoCo 等基准可作为通用标准,而记忆增强型智能体通常在随其方法一起开发的自定义环境上评估(表2)。 这种碎片化的评估格局遮蔽了不同记忆任务之间的重要性能差异。 例如,一个智能体可能擅长在较长时间内保持对象属性,却在序列回忆挑战上表现不佳。 由于评估范围狭窄,这类任务特定的优势和局限常常被隐藏起来,这凸显了需要一个覆盖多样记忆密集型场景的综合基准。
The challenge of memory evaluation becomes particularly evident in robotics. While some robotic tasks naturally involve partial observability, e.g. navigation tasks, many studies artificially create partially observable scenarios from Markov Decision Processes (MDPs) by introducing observation noise or masking parts of the state space. However, these approaches do not fully capture the complexity of real-world robotic challenges, where tasks may require the agent to recall past object configurations, manipulate occluded objects, or perform multi-step procedures that depend heavily on memory. Such tasks include, for example, situations where a service robot needs to memorize occluded objects (e.g., a plate hidden under a towel) or where a home robot needs to accurately wipe the door of a microwave oven several times. Without memory, the robot wouldn't detect the plate in the first case, and in the second, it would wipe the door endlessly, unsure whether it has cleaned the area or if it's time to stop.
记忆评估的挑战在机器人领域变得尤其明显。 虽然一些机器人任务天然涉及部分可观测性,例如导航任务,但许多研究通过引入观测噪声或遮蔽状态空间的一部分,从马尔可夫决策过程(MDP)人为构造部分可观测场景。 然而,这些方法无法充分捕捉真实世界机器人挑战的复杂性;在这些挑战中,任务可能要求智能体回忆过去的对象配置、操作被遮挡的对象,或执行高度依赖记忆的多步流程。 这类任务包括,例如服务机器人需要记住被遮挡的物体(如藏在毛巾下的盘子),或者家用机器人需要准确地多次擦拭微波炉门。 如果没有记忆,机器人在第一种情况下无法检测到盘子;在第二种情况下,它会无休止地擦门,不确定自己是否已经清洁了该区域,也不知道是否该停止。
In this paper, we aim to address these challenges with the following four contributions:
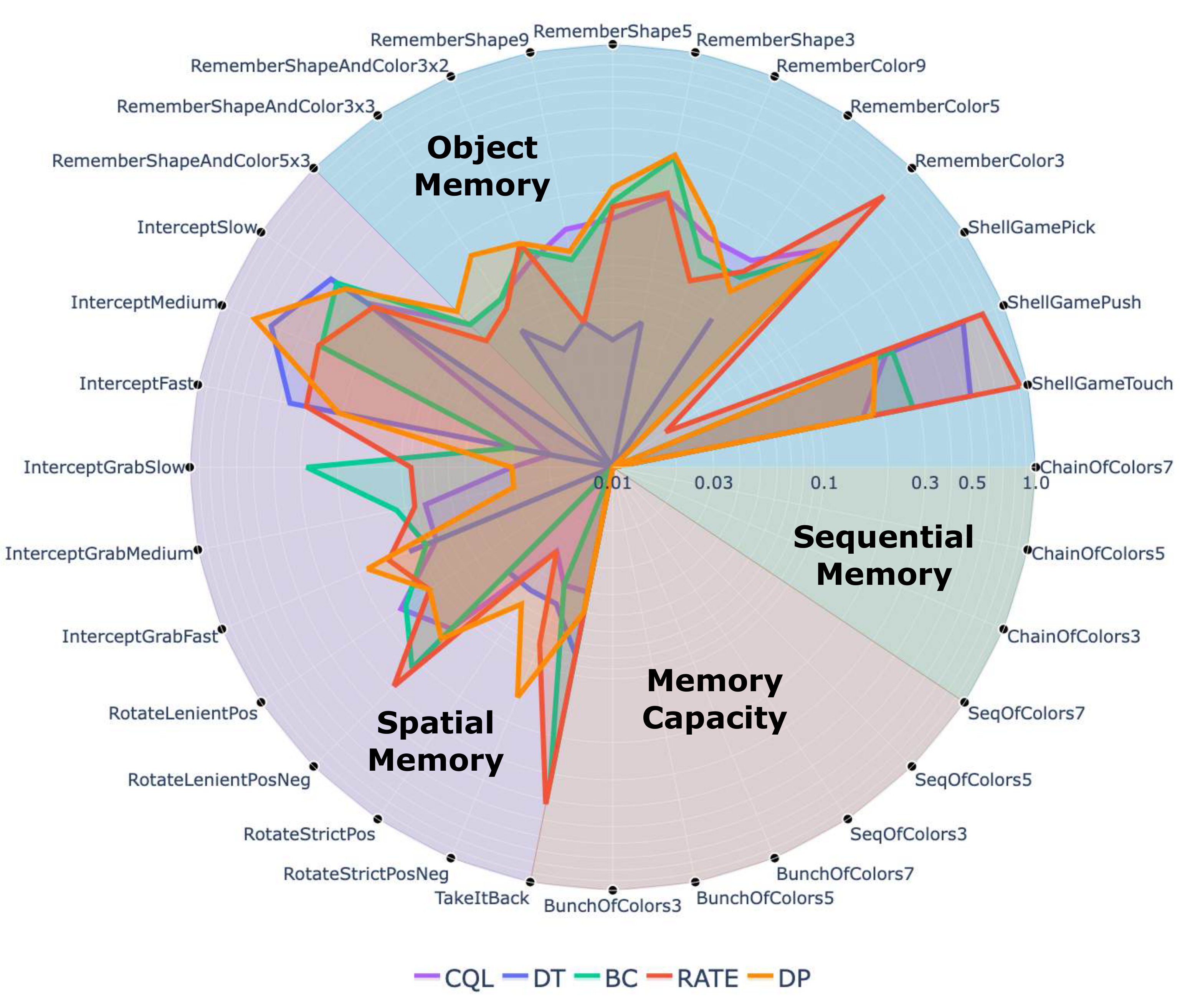
- Memory Tasks Classification. We propose a simple yet comprehensive framework that organizes memory-intensive tasks into four key categories. This structure enables systematic evaluation without added complexity (Figure 1), offering a clear guide for selecting environments that reflect core memory challenges in RL and robotics (Section 4).
- Memory-RL Benchmark. We introduce MIKASA-Base, a Gymnasium-based framework for evaluating memory-enhanced RL agents (Section 5).
- Robotic Manipulation Tasks. We introduce MIKASA-Robo, an open-source benchmark (MIT license) comprising 32 robotic tasks that target specific memory-dependent skills in realistic settings (Section 6). We evaluate it using popular Online RL baselines (Section 6.2) as well as Visual-Language-Action (VLA) models (Section 6.4). Guidelines for customizing environments and configuring time horizons are provided in the Appendix.
- Robotic Manipulation Datasets. We release datasets with expert quality trajectories for all 32 MIKASA-Robo memory-intensive tasks to support Offline RL research (see Appendix), and conduct extensive evaluations using a range of Offline RL baselines (Section 6.3).
在本文中,作者旨在通过以下四项贡献解决这些挑战:
- 记忆任务分类。 作者提出一个简单而全面的框架,将记忆密集型任务组织为四个关键类别。该结构在不增加复杂性的情况下支持系统评估(图1),并为选择能够反映 RL 和机器人中核心记忆挑战的环境提供清晰指南(第 4 节)。
- 记忆型 RL 基准。 作者提出 MIKASA-Base,这是一个基于 Gymnasium 的框架,用于评估记忆增强型 RL 智能体(第 5 节)。
- 机器人操作任务。 作者提出 MIKASA-Robo,这是一个基于 MIT 许可证开源的基准,包含 32 个机器人任务,针对真实设置中的特定记忆依赖技能(第 6 节)。作者使用流行的在线 RL 基线(第 6.2 节)以及视觉-语言-动作(VLA)模型(第 6.4 节)对其进行评估。用于自定义环境和配置时间范围的指南见附录。
- 机器人操作数据集。 作者发布了面向全部 32 个 MIKASA-Robo 记忆密集型任务的专家质量轨迹数据集,以支持离线 RL 研究(见附录),并使用一系列离线 RL 基线进行了广泛评估(第 6.3 节)。
| Memory Task | Mode | Brief description of the task | T | Oracle Info | Prompt | Memory |
|---|---|---|---|---|---|---|
| ShellGame | Touch Push Pick | Memorize the position of the ball after some time being covered by the cups and then interact with the cup the ball is under | 90 | cup_with_ball_number | --- | Object |
| Intercept | Slow Medium Fast | Memorize the positions of the rolling ball, estimate its velocity through those positions, and then aim the ball at the target | 90 | initial_velocity | --- | Spatial |
| InterceptGrab | Slow Medium Fast | Memorize the positions of the rolling ball, estimate its velocity through those positions, and then catch the ball with the gripper and lift it up | 90 | initial_velocity | --- | Spatial |
| RotateLenient | Pos PosNeg | Memorize the initial position of the peg and rotate it by a given angle | 90 | y_angle_diff | target_angle | Spatial |
| RotateStrict | Pos PosNeg | Memorize the initial position of the peg and rotate it to a given angle without shifting its center | 90 | y_angle_diff | target_angle | Spatial |
| TakeItBack-v0 | --- | Memorize the initial position of the cube, move it to the target region, and then return it to its initial position | 180 | xyz_initial | --- | Spatial |
| RememberColor | 3 \ 5 \ 9 | Memorize the color of the cube and choose among other colors | 60 | true_color_indices | --- | Object |
| RememberShape | 3 \ 5 \ 9 | Memorize the shape of the cube and choose among other shapes | 60 | true_shape_indices | --- | Object |
| RememberShape-AndColor | 3×2 \ 3×3 \ 5×3 | Memorize the shape and color of the cube and choose among other shapes and colors | 60 | true_shapes_infotrue_colors_info | --- | Object |
| BunchOfColors | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown simultaneously in the bunch and touch them in any order | 120 | true_color_indices | --- | Capacity |
| SeqOfColors | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown sequentially and then select them in any order | 120 | true_color_indices | --- | Capacity |
| ChainOfColors | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown sequentially and then select them in the same order | 120 | true_color_indices | --- | Sequential |
| Total: 32 tabletop robotic manipulation memory-intensive tasks in 12 groups | ||||||
| Environment | DRQN | DTQN | HCAM | AMAGO | GTrXL | R2I | RATE | R2A | Modified S5 | Neural Map | GBMR | EMDQN | MRA | FMRQN | ADRQN | DCEM | R2D2 | ERLAM | AdaMemento |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Atari w/o FrameStack | ✓ | ✓ | ✓ | ||||||||||||||||
| Atari with FrameStack | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||
| gym-gridverse | ✓ | ||||||||||||||||||
| car flag | ✓ | ||||||||||||||||||
| memory card | ✓ | ||||||||||||||||||
| Hallway | ✓ | ||||||||||||||||||
| HeavenHell | ✓ | ||||||||||||||||||
| Ballet | ✓ | ||||||||||||||||||
| Object Permanence | ✓ | ||||||||||||||||||
| DMLab-30 | ✓ | ✓ | ✓ | ||||||||||||||||
| POPGym | ✓ | ✓ | ✓ | ✓ | |||||||||||||||
| Passive T-Maze | ✓ | ✓ | |||||||||||||||||
| ViZDoom-Two-Colors | ✓ | ||||||||||||||||||
| Numpad | ✓ | ||||||||||||||||||
| Memory Maze | ✓ | ✓ | |||||||||||||||||
| Memory Maze (apples) | ✓ | ||||||||||||||||||
| Minigrid-Memory | ✓ | ||||||||||||||||||
| BSuite | ✓ | ✓ | |||||||||||||||||
| Goal-Search | ✓ | ||||||||||||||||||
| Doom Maze | ✓ | ||||||||||||||||||
| PsychLab | ✓ | ||||||||||||||||||
| Spot the Difference | ✓ | ||||||||||||||||||
| Goal Navigation | ✓ | ||||||||||||||||||
| Transitive Inference | ✓ | ||||||||||||||||||
| I-Maze | ✓ | ||||||||||||||||||
| Pattern Matching | ✓ | ||||||||||||||||||
| Random Maze | ✓ | ||||||||||||||||||
| Unity Fast-Mapping Task | ✓ | ||||||||||||||||||
| Action Associative Retrieval | ✓ | ||||||||||||||||||
| BabyAI | ✓ |
2. Related Works
Multiple RL benchmarks are designed to assess agents' memory capabilities. DMLab-30 provides 3D navigation and puzzle tasks, focusing on long-horizon exploration and spatial recall. PsychLab extends DMLab by incorporating tasks that probe cognitive processes, including working memory. MiniGrid and MiniWorld emphasize partial observability in lightweight 2D and 3D environments, while MiniHack builds on NetHack, offering small roguelike scenarios that require both short- and long-term memory. BabyAI combines natural language instructions with grid-based tasks, requiring memory for multi-step command execution. POPGym standardizes memory evaluation with tasks ranging from pattern-matching puzzles to complex sequential decision-making. BSuite offers a suite of carefully designed experiments that test core RL capabilities, including memory, through controlled tasks on exploration, credit assignment, and scalability. Memory Gym offers a suite of 2D grid environments with partial observability, designed to benchmark memory capabilities in decision-making agents, including endless versions of tasks for evaluating memory over extremely long time intervals. Memory Maze presents 3D maze navigation tasks that require memory to solve efficiently.
多个 RL 基准被设计用来评估智能体的记忆能力。 DMLab-30 提供 3D 导航和解谜任务,重点关注长程探索和空间回忆。 PsychLab 通过加入探测认知过程的任务扩展了 DMLab,其中包括工作记忆。 MiniGrid 和 MiniWorld 强调轻量级 2D 与 3D 环境中的部分可观测性,而 MiniHack 基于 NetHack 构建,提供需要短期和长期记忆的小型类 Rogue 场景。 BabyAI 将自然语言指令与基于网格的任务结合,需要记忆来完成多步命令执行。 POPGym 用从模式匹配谜题到复杂序贯决策的任务来标准化记忆评估。 BSuite 提供了一组精心设计的实验,通过探索、信用分配和可扩展性上的受控任务测试包括记忆在内的核心 RL 能力。 Memory Gym 提供一组具有部分可观测性的 2D 网格环境,旨在对决策智能体的记忆能力进行基准测试,其中包括用于评估极长时间间隔记忆的无尽版本任务。 Memory Maze 提供需要记忆才能高效解决的 3D 迷宫导航任务。
While these benchmarks offer valuable insights into memory mechanisms, they generally focus on abstract puzzles or navigation tasks. However, none of them fully encompass the broad range of memory utilization scenarios an agent may encounter, and the tasks themselves often differ fundamentally across benchmarks, making direct comparison of memory-enhanced agents difficult. In the robotics domain, memory requirements become particularly challenging due to the physical nature of manipulation tasks. Unlike abstract environments, robotic manipulation involves complex physical interactions and multi-step procedures demanding both spatial and temporal memory. Existing memory-intensive benchmarks, while useful for diagnostic purposes, struggle to capture these domain-specific challenges. The physical control and object interaction inherent in manipulation tasks introduce additional complexities not addressed by traditional memory evaluation frameworks.
虽然这些基准为记忆机制提供了有价值的洞见,但它们通常关注抽象谜题或导航任务。 然而,它们都没有完全覆盖智能体可能遇到的广泛记忆利用场景,而且各基准中的任务本身往往存在根本差异,使得记忆增强型智能体难以直接比较。 在机器人领域,由于操作任务的物理性质,记忆需求变得尤其具有挑战。 不同于抽象环境,机器人操作涉及复杂物理交互和多步流程,同时需要空间记忆和时间记忆。 现有记忆密集型基准虽然有助于诊断,但难以捕捉这些领域特定挑战。 操作任务内在的物理控制和对象交互引入了传统记忆评估框架未处理的额外复杂性。
Efforts have been made to classify memory-intensive environments by specific attributes. For example, Ni et al. divides them into memory/credit assignment based on temporal horizons. Yue et al. proposes memory dependency pairs to model how past events influence current decisions, aiding imitation learning in partially observable tasks. Cherepanov et al. defines agent memory types: long-term vs. short-term (based on context length), and declarative vs. procedural (based on environments and episodes), and formalizes memory-intensive environments. Leibo et al. instead adapts tasks from cognitive psychology and psychophysics to evaluate agents on human cognitive benchmarks. While these classifications highlight aspects of memory, they overlook physical dimensions in robotics. The link between physical interaction and memory remains underexplored, motivating a framework for spatio-temporal memory in real-world tasks.
已有工作尝试按特定属性对记忆密集型环境进行分类。 例如,Ni 等人根据时间跨度将其划分为记忆/信用分配。 Yue 等人提出记忆依赖对,用来建模过去事件如何影响当前决策,从而帮助部分可观测任务中的模仿学习。 Cherepanov 等人定义了智能体记忆类型:长期与短期(基于上下文长度),以及陈述性与程序性(基于环境和回合),并形式化了记忆密集型环境。 Leibo 等人则改编认知心理学和心理物理学中的任务,以在人类认知基准上评估智能体。 虽然这些分类突出了记忆的若干方面,但它们忽略了机器人中的物理维度。 物理交互与记忆之间的联系仍缺乏充分探索,这促使作者为真实世界任务中的时空记忆构建一个框架。
Concurrent with our work, Fang et al. also proposed MemoryBench, a benchmark for memory-intensive manipulation consisting of only three tasks designed to access only one type of memory, spatial memory. This benchmark is based on RLBench, which does not allow efficient parallelization of training.
与本文同期,Fang 等人也提出了 MemoryBench,这是一个用于记忆密集型操作的基准,仅包含三个任务,并且设计上只评估一种记忆,即空间记忆。 该基准基于 RLBench,而 RLBench 不支持高效并行化训练。

ShellGameTouch-v0 要求智能体记住球在杯子下的位置并触碰正确杯子;RememberColor9-v0 要求智能体记住立方体颜色并随后选择匹配颜色;RotateLenientPos-v0 要求智能体旋转桩,同时跟踪其先前旋转。3. Background
3.1 Partially Observable Markov Decision Process
Partially Observable Markov Decision Process (POMDP) extend MDP to account for partial observability, where an agent observes only noisy or incomplete information about the true environments state. POMDP defined by a tuple
部分可观测马尔可夫决策过程(POMDP)将 MDP 扩展到部分可观测场景,其中智能体只能观察到关于真实环境状态的有噪声或不完整信息。 POMDP 由元组
where
其中
3.2 Memory-intensive environments
Memory-intensive environment is an environment where agents must leverage past experiences to make decisions, often in problems with long-term dependencies or delayed rewards. More formally, following Cherepanov et al., a memory-intensive task is a POMDP where there exists a correlation horizon
记忆密集型环境是一种智能体必须利用过去经验来做决策的环境,常见于具有长期依赖或延迟奖励的问题。 更形式化地说,按照 Cherepanov 等人的定义,记忆密集型任务是一种 POMDP,其中存在相关跨度
3.3 Robotic Tabletop Manipulation
Robotic tabletop manipulation involves robots manipulating objects on flat surfaces through actions like grasping, pushing, and picking. While crucial for real-world applications, most existing simulators treat these tasks as MDPs without memory requirements, failing to capture the spatio-temporal dependencies present in real scenarios. This limitation hinders the development of memory-enhanced agents for practical applications.
桌面机器人操作指机器人通过抓取、推动、拿取等动作在平面表面上操作物体。 尽管这对真实世界应用至关重要,但大多数现有模拟器将这些任务视为没有记忆需求的 MDP,无法捕捉真实场景中的时空依赖。 这一局限阻碍了面向实际应用的记忆增强型智能体的发展。
4. Classification of memory-intensive tasks
The evaluation of memory capabilities in RL faces two major challenges. First, as shown in Table 2, research studies use different sets of environments with minimal overlap, making it difficult to compare memory-enhanced agents across studies. Second, even within individual studies, benchmarks may focus on testing similar memory aspects (e.g., remembering object locations) while neglecting others (e.g., reconstructing sequential events), leading to incomplete evaluation of agents' memory.
RL 中记忆能力的评估面临两大挑战。 第一,如 表2 所示,研究使用的环境集合各不相同且重叠极少,使得跨研究比较记忆增强型智能体变得困难。 第二,即使在单个研究内部,基准也可能集中测试相似的记忆方面(例如记住对象位置),而忽略其他方面(例如重建序列事件),导致对智能体记忆的评估不完整。
Different architectures may exhibit varying performance across memory tasks. For instance, an architecture optimized for long-term object property recall might struggle with sequential memory tasks, yet these limitations often remain undetected due to the narrow focus of existing evaluation approaches.
不同架构可能在各类记忆任务上表现不同。 例如,一个针对长期对象属性回忆优化的架构可能在序列记忆任务上遇到困难,但由于现有评估方法关注范围狭窄,这些局限往往未被发现。
To address these challenges, we propose a systematic approach to memory evaluation in RL. Drawing from established research in developmental psychology and cognitive science, where similar memory challenges have been extensively studied in humans, we develop a categorization framework consisting of four distinct memory task classes, detailed in Section 4.2.
为解决这些挑战,作者提出一种面向 RL 记忆评估的系统方法。 借鉴发展心理学和认知科学中的成熟研究,这些领域已在人类身上广泛研究类似记忆挑战;作者开发了一个由四种不同记忆任务类别构成的分类框架,详见第 4.2 节。
4.1 Memory: From Cognitive Science to RL
In developmental psychology and cognitive science, memory is classified into categories based on cognitive processes. Key concepts include object permanence, which involves remembering the existence of objects out of sight, and categorical perception, where objects are grouped based on attributes like color or shape. Working memory and memory span refer to the ability to hold and manipulate information over time, while causal reasoning and transitive inference involve understanding cause-and-effect relationships and deducing hidden relationships, respectively.
在发展心理学和认知科学中,记忆会根据认知过程被分类。 关键概念包括对象恒存,即记住视线外对象的存在;以及类别知觉,即根据颜色或形状等属性对对象进行分组。 工作记忆和记忆广度指在一段时间内保持并操作信息的能力,而因果推理和传递推断分别涉及理解因果关系和推断隐藏关系。
The RL field has attempted to utilize these concepts in the design of specific memory-intensive environments, but these have been limited at the task design level. Of particular interest, however, is how existing memory-intensive tasks can be categorized using these concepts to develop a benchmark on which to test the greatest number of memory capabilities of memory-enhanced agents, and it is this problem that we address in this paper. Thus, we aim to provide a balanced framework that covers important aspects of memory for real-world applications while maintaining practical simplicity (see Figure 3).
RL 领域曾尝试在特定记忆密集型环境的设计中利用这些概念,但这些尝试局限在任务设计层面。 然而,特别值得关注的是,如何使用这些概念对现有记忆密集型任务进行分类,以开发一个能够测试记忆增强型智能体尽可能多记忆能力的基准;这正是本文要解决的问题。 因此,作者旨在提供一个平衡框架,在保持实用简洁的同时,覆盖真实世界应用中的重要记忆方面(见 图3)。
4.2 Taxonomy of Memory Tasks

We introduce a comprehensive task classification framework for evaluating memory mechanisms in RL. Our framework categorizes memory-intensive tasks into four fundamental types, each targeting distinct aspects of memory capabilities:
- Object Memory. Tasks that evaluate an agent's ability to maintain object-related information over time, particularly when objects become temporarily unobservable. These tasks align with the cognitive concept of object permanence, requiring agents to track object properties when occluded, maintain object state representations, and recognize encountered objects. Example: a robot remembers which fruit it put in the fridge.
- Spatial Memory. Tasks focused on environmental awareness and navigation, where agents must remember object locations, maintain mental maps of environment layouts, and navigate based on previously observed spatial information. Example: the robot remembers the position of a mug it moved while cleaning and returns it to its place.
- Sequential Memory. Tasks that test an agent's ability to process and utilize temporally ordered information, similar to human serial recall and working memory. These tasks require remembering action sequences, maintaining order-dependent information, and using past decisions to inform future actions. Example: a robot memorizes the order of the ingredients it has added to a soup.
- Memory Capacity. Tasks that challenge an agent's ability to manage multiple pieces of information simultaneously, analogous to human memory span. These tasks evaluate information retention limits and multi-task information processing. Example: a robot is able to memorize the positions of several different objects while cleaning a table.
作者提出一个用于评估 RL 中记忆机制的综合任务分类框架。 该框架将记忆密集型任务划分为四种基本类型,每种类型都针对记忆能力的不同方面:
- 对象记忆。 这类任务评估智能体在一段时间内保持对象相关信息的能力,尤其是在对象暂时不可见时。这些任务对应对象恒存这一认知概念,要求智能体在对象被遮挡时跟踪对象属性、保持对象状态表示,并识别曾经遇到的对象。示例:机器人记住自己把哪种水果放进了冰箱。
- 空间记忆。 这类任务关注环境感知和导航,智能体必须记住对象位置、维持关于环境布局的心理地图,并基于先前观察到的空间信息进行导航。示例:机器人记住清洁时移动过的杯子位置,并把它放回原位。
- 序列记忆。 这类任务测试智能体处理和利用时间有序信息的能力,类似于人类序列回忆和工作记忆。这些任务要求记住动作序列、保持依赖顺序的信息,并使用过去决策来指导未来动作。示例:机器人记住已经加入汤中的食材顺序。
- 记忆容量。 这类任务挑战智能体同时管理多条信息的能力,类似于人类记忆广度。这些任务评估信息保留限制和多任务信息处理能力。示例:机器人在清洁桌子时能够记住几个不同对象的位置。
This classification framework enables systematic evaluation of memory-enhanced RL agents across diverse scenarios. By providing a structured approach to memory task categorization, we establish a foundation for comprehensive benchmarking that spans the wide spectrum of memory requirements. In the following section, we present a carefully curated set of tasks based on this classification, forming the basis of our proposed MIKASA benchmark.
这一分类框架支持在多样场景中对记忆增强型 RL 智能体进行系统评估。 通过提供一种结构化的记忆任务分类方法,作者为覆盖广泛记忆需求谱系的综合基准测试奠定基础。 在下一节中,作者基于这一分类提出一组精心筛选的任务,形成所提出 MIKASA 基准的基础。
5. MIKASA-Base
| Robotics Framework with Manipulation Tasks | Memory Tasks | ||
|---|---|---|---|
| Manipulation | Atomic | Low-level actions | |
| MIKASA-Robo (Ours) | ✓ | ✓ | ✓ |
| MemoryBench* | ✓ | ✓ | ✓ |
| ManiSkill3 | × | × | × |
| ManiSkill-HAB | × | × | × |
| FetchBench | × | × | × |
| RoboCasa | × | × | × |
| Gymnasium-Robotics† | × | × | × |
| BEHAVIOR-1K | ✓ | × | × |
| LIBERO | ✓ | × | × |
| ARNOLD | × | × | × |
| LoHoRavens | × | × | × |
| iGibson 2.0 | ✓ | × | × |
| VIMA | ✓ | ✓ | × |
| Isaac Sim | × | × | × |
| panda-gym | × | × | × |
| Ravens | × | × | × |
| Habitat 2.0 | × | × | × |
| Meta-World | × | × | × |
| CausalWorld | × | × | × |
| RLBench | × | × | × |
| robosuite | × | × | × |
| dm_control | × | × | × |
| Franka Kitchen | × | × | × |
| SURREAL | × | × | × |
| AI2-THOR | × | × | × |
Motivation and Overview. Despite the importance of memory in decision-making, the RL community lacks standardized tools for benchmarking memory capabilities. Existing studies typically introduce bespoke environments tailored to their proposed algorithms, leading to fragmentation and limited comparability across works (see Table 2). Moreover, many popular memory benchmarks focus narrowly on specific memory types, overlooking the diversity of memory demands found in real-world applications. To address this gap, we introduce MIKASA-Base, a unified benchmark that consolidates widely used open-source memory-intensive environments under a common Gym-like API. Our goal is to streamline reproducibility, support fair comparisons, and promote systematic evaluation of memory in RL.
动机与概览。 尽管记忆在决策中很重要,但 RL 社区缺少用于对记忆能力进行基准测试的标准化工具。 现有研究通常引入针对其所提算法定制的环境,导致不同工作之间碎片化且可比性有限(见 表2)。 此外,许多流行记忆基准狭窄地关注特定记忆类型,忽略了真实世界应用中记忆需求的多样性。 为解决这一缺口,作者提出 MIKASA-Base,这是一个统一基准,将广泛使用的开源记忆密集型环境整合到一个共同的类 Gym API 下。 作者的目标是简化可复现性、支持公平比较,并推动 RL 中记忆的系统评估。
Benchmark Design Principles. MIKASA-Base is designed around core principles that support rigorous and interpretable evaluation of memory in RL. To disentangle memory from unrelated challenges, we organize tasks into two tiers. The first tier consists of diagnostic vector-based environments that isolate specific memory mechanisms. The second tier includes complex image-based tasks that incorporate realistic perception challenges, thus more closely resembling real-world settings. This hierarchical structure enables researchers to validate memory capabilities incrementally -- from atomic reasoning to high-dimensional sensory input.
基准设计原则。 MIKASA-Base 围绕支持严谨且可解释地评估 RL 记忆的核心原则设计。 为将记忆与无关挑战解耦,作者将任务组织为两个层级。 第一层由诊断性向量环境构成,用来隔离特定记忆机制。 第二层包括复杂图像任务,它们结合真实感知挑战,因此更接近真实世界设置。 这一层次结构使研究者能够从原子级推理到高维感知输入,逐步验证记忆能力。
Task Classification and Selection. Building on our taxonomy from Section 4.2, we systematically reviewed open-source memory benchmarks and categorized their tasks into four distinct types of memory usage. We selected a diverse yet representative subset of environments to cover this taxonomy -- ranging from object permanence to sequential planning. All selected tasks are unified under a single, consistent API. Descriptions are provided in the Appendix, and an overview of MIKASA-Base tasks appears in Appendix Table 1. This consolidation supports architectural ablations, direct comparison of methods, and simplified evaluation pipelines. Implementation details can be found in the Appendix.
任务分类与选择。 基于第 4.2 节的分类体系,作者系统回顾了开源记忆基准,并将其任务划分为四种不同的记忆使用类型。 作者选择了一组多样但具有代表性的环境来覆盖这一分类体系 -- 从对象恒存到序列规划。 所有选定任务都统一在单一且一致的 API 下。 任务描述见附录,MIKASA-Base 任务概览见 附表1。 这种整合支持架构消融、方法直接比较和简化的评估流程。 实现细节见附录。
| Environment | Memory Task | Brief description of the task | Observation Space | Action Space |
|---|---|---|---|---|
| Memory Cards | Capacity | Memorize the positions of revealed cards and correctly match pairs while minimizing incorrect guesses. | vector | discrete |
| Numpad | Sequential | Memorize the sequence of movements and navigate the rolling ball on a 3×3 grid by following the correct order while avoiding mistakes. | image, vector | discrete, continuous |
| BSuite Memory Length | Object | Memorize the initial context signal and recall it after a given number of steps to take the correct action. | vector | discrete |
| Minigrid-Memory | Object | Memorize the object in the starting room and use this information to select the correct path at the junction. | image | discrete |
| Ballet | Sequential, Object | Memorize the sequence of movements performed by each uniquely colored and shaped dancer, then identify and approach the dancer who executed the given pattern. | image | discrete |
| Passive Visual Match | Object | Memorize the target color displayed on the wall during the initial phase. After a brief distractor phase, identify and select the target color among the distractors by stepping on the corresponding ground pad. | image | discrete |
| Passive-T-Maze | Object | Memorize the goal's location upon initial observation, navigate through the maze with limited sensory input, and select the correct path at the junction. | vector | discrete |
| ViZDoom-two-colors | Object | Memorize the color of the briefly appearing pillar (green or red) and collect items of the same color to survive in the acid-filled room. | image | discrete |
| Memory Maze | Spatial | Memorize the locations of objects and the maze structure using visual clues, then navigate efficiently to find objects of a specific color and score points. | image | discrete |
| MemoryGym Mortar Mayhem | Capacity, Sequential | Memorize a sequence of movement commands and execute them in the correct order. | image | discrete |
| MemoryGym Mystery Path | Capacity, Spatial | Memorize the invisible path and navigate it without stepping off. | image | discrete |
| POPGym Repeat First | Object | Memorize the initial value presented at the first step and recall it correctly after receiving a sequence of random values. | vector | discrete |
| POPGym Repeat Previous | Sequential, Object | Memorize the value observed at each step and recall the value from k steps earlier when required. | vector | discrete |
| POPGym Autoencode | Sequential | Memorize the sequence of cards presented at the beginning and reproduce them in the same order when required. | vector | discrete |
| POPGym Count Recall | Object, Capacity | Memorize unique values encountered and count how many times a specific value has appeared. | vector | discrete |
| POPGym vectorless Cartpole | Sequential | Memorize velocity data over time and integrate it to infer the position of the pole for balance control. | vector | continuous |
| POPGym vectorless Pendulum | Sequential | Memorize angular velocity over time and integrate it to infer the pendulum's position for successful swing-up control. | vector | continuous |
| POPGym Multiarmed Bandit | Object, Capacity | Memorize the reward probabilities of different slot machines by exploring them and identify the one with the highest expected reward. | vector | discrete |
| POPGym Concentration | Capacity | Memorize the positions of revealed cards and match them with previously seen cards to find all matching pairs. | vector | discrete |
| POPGym Battleship | Spatial | Memorize the coordinates of previous shots and their HIT or MISS feedback to build an internal representation of the board, avoid repeat shots, and strategically target ships for maximum rewards. | vector | discrete |
| POPGym Mine Sweeper | Spatial | Memorize revealed grid information and use numerical clues to infer safe tiles while avoiding mines. | vector | discrete |
| POPGym Labyrinth Explore | Spatial | Memorize previously visited cells and navigate the maze efficiently to discover new, unexplored areas and maximize rewards. | vector | discrete |
| POPGym Labyrinth Escape | Spatial | Memorize the maze layout while exploring and navigate efficiently to find the exit and receive a reward. | vector | discrete |
| POPGym Higher Lower | Object, Sequential | Memorize previously revealed card ranks and predict whether the next card will be higher or lower, updating the reference card after each prediction to maximize rewards. | vector | discrete |
MIKASA-Base provides the first systematic and unified benchmark for evaluating memory in RL. It mitigates fragmentation by standardizing task access and evaluation, and its structured progression enables precise attribution of memory-related agent failures. By covering a broad spectrum of memory challenges within a common framework, MIKASA-Base offers a foundation for robust, reproducible research in memory-centric RL.
MIKASA-Base 提供了第一个用于评估 RL 记忆的系统化统一基准。 它通过标准化任务访问和评估来缓解碎片化问题,其结构化推进方式使与记忆相关的智能体失败能够被精确归因。 通过在共同框架内覆盖广泛的记忆挑战,MIKASA-Base 为以记忆为中心的 RL 中鲁棒、可复现的研究提供基础。
6. MIKASA-Robo
The landscape of robotic manipulation frameworks reveals significant limitations in addressing memory-intensive tasks. While partial observability is well-studied in navigation, manipulation scenarios are still predominantly evaluated under full observability, with limited focus on memory demands (see Table 3). Among frameworks that do consider memory, BEHAVIOR-1k and iGibson 2.0 include highly complex, non-atomic tasks, which obscure the evaluation of specific memory mechanisms. VIMA relies on high-level action abstractions, limiting temporal memory assessment. To address these gaps, we introduce MIKASA-Robo, a benchmark specifically designed to evaluate diverse memory skills in robotic manipulation through well-isolated, fine-grained tasks.
机器人操作框架的整体格局显示出,在处理记忆密集型任务方面仍存在显著局限。 虽然导航中的部分可观测性已被充分研究,但操作场景仍主要在完全可观测条件下评估,对记忆需求关注有限(见 表3)。 在确实考虑记忆的框架中,BEHAVIOR-1k 和 iGibson 2.0 包含高度复杂且非原子的任务,这会模糊对特定记忆机制的评估。 VIMA 依赖高层动作抽象,限制了时间记忆评估。 为解决这些缺口,作者提出 MIKASA-Robo,这是一个专门设计的基准,用于通过良好隔离的细粒度任务评估机器人操作中的多样记忆技能。
Concurrently with our work, Fang et al. proposed MemoryBench, a benchmark focused on spatial memory with three robotic tasks. In contrast, MIKASA-Robo spans four memory categories and 32 tasks, enabling broader and more systematic evaluation of memory mechanisms in RL agents.
与本文同期,Fang 等人提出了 MemoryBench,这是一个聚焦空间记忆且包含三个机器人任务的基准。 相比之下,MIKASA-Robo 覆盖四个记忆类别和 32 个任务,能够对 RL 智能体的记忆机制进行更广泛且更系统的评估。
MIKASA-Robo is a benchmark designed for memory-intensive robotic tabletop manipulation tasks, simulating real-world challenges commonly encountered by robots. These tasks include locating occluded objects, recalling previous configurations, and executing complex sequences of actions over extended time horizons. By incorporating meaningful partial observability, this framework offers a systematic approach to test an agent's memory mechanisms.
MIKASA-Robo 是为记忆密集型桌面机器人操作任务设计的基准,用于模拟机器人常遇到的真实世界挑战。 这些任务包括定位被遮挡对象、回忆先前配置,以及在较长时间范围内执行复杂动作序列。 通过引入有意义的部分可观测性,该框架提供了一种系统方法来测试智能体的记忆机制。
Building upon the robust foundation of ManiSkill3 framework, our benchmark leverages its efficient parallel GPU-based training capabilities to create and evaluate these tasks.
基于 ManiSkill3 框架的稳健基础,作者的基准利用其高效的基于 GPU 的并行训练能力来创建并评估这些任务。
6.1 MIKASA-Robo Manifestation
In designing the tasks, we drew inspiration from the four memory types identified in our classification framework (Section 4.2). We developed 32 tasks across 12 categories of robotic tabletop manipulation, each targeting specific aspects of object memory, spatial memory, sequential memory, and memory capacity. These tasks feature varying levels of complexity, allowing for systematic evaluation of different memory mechanisms. For instance, some tasks test object permanence by requiring the agent to track occluded objects, while others challenge sequential memory by requiring the reproduction of a strict order of actions. A summary of these tasks and their corresponding memory types is provided in Table 1, with detailed descriptions in the Appendix. Information on task customization, including adjustments of time horizons and environment parameters, can be found in the Appendix.
在设计任务时,作者从第 4.2 节分类框架中识别出的四种记忆类型获得启发。 作者开发了横跨 12 个桌面机器人操作类别的 32 个任务,每个任务都针对对象记忆、空间记忆、序列记忆和记忆容量的特定方面。 这些任务具有不同复杂度,从而允许系统评估不同记忆机制。 例如,一些任务通过要求智能体跟踪被遮挡对象来测试对象恒存,而另一些任务则通过要求复现严格动作顺序来挑战序列记忆。 这些任务及其对应记忆类型的总结见 表1,详细描述见附录。 关于任务自定义的信息,包括调整时间范围和环境参数,见附录。
To illustrate the concept of our memory-intensive framework, we present ShellGameTouch-v0, RememberColor-v0, and RotateLenientPos-v0 tasks in Figure 2. In the ShellGameTouch-v0 task, the agent observes a red ball placed in one of three positions over the first 5 steps (Touch), the agent only needs to touch the correct mug, whereas in other modes, it must either push or lift the mug. In the RememberColor-v0 task, the agent observes a cube of a specific color for 5 steps (RotateLenientPos-v0 task, the agent must rotate a randomly oriented peg by a specified clockwise angle.
为说明作者的记忆密集型框架概念,作者在 图2 中展示了 ShellGameTouch-v0、RememberColor-v0 和 RotateLenientPos-v0 任务。 在 ShellGameTouch-v0 任务中,智能体在最初 5 步(Touch)中,智能体只需触碰正确杯子;而在其他模式中,它必须推动或提起杯子。 在 RememberColor-v0 任务中,智能体观察一个具有特定颜色的立方体 5 步(RotateLenientPos-v0 任务中,智能体必须将一个随机朝向的桩按指定顺时针角度旋转。
state 模式下训练的 PPO-MLP 表现,即在不需要记忆的 MDP 模式中训练。这些结果表明,所提出任务本身可达到 100% 成功率。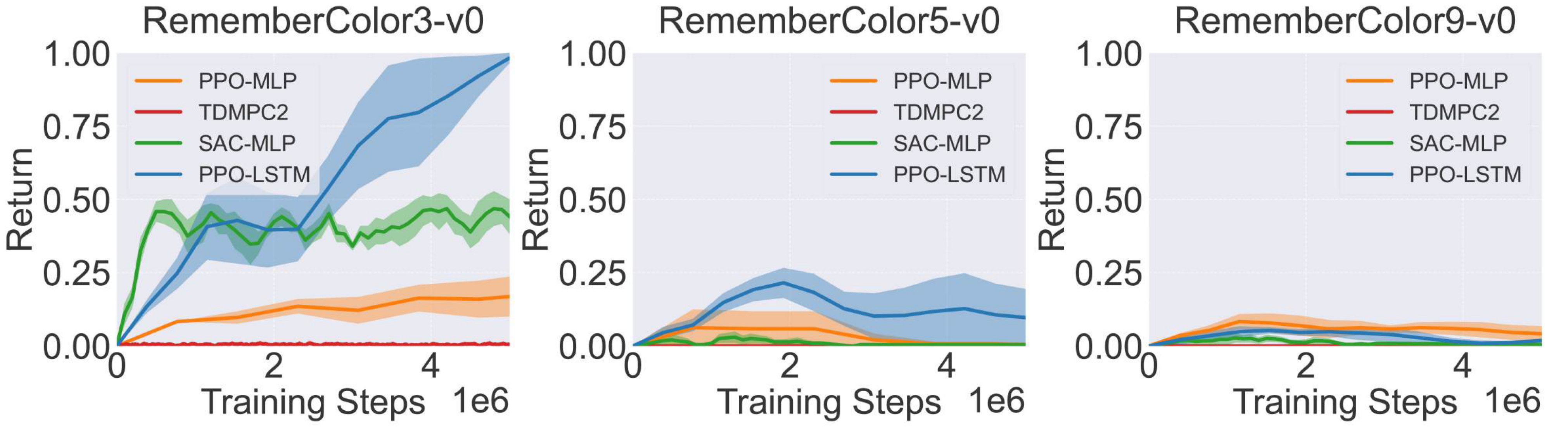
RememberColor-v0 环境上以 RGB+joints 模式和密集奖励训练。两种架构都无法解决中等和高复杂度任务。The MIKASA-Robo benchmark offers multiple training modes: state (complete vector information including oracle data and Tool Center Point (TCP) pose), RGB (top-view and gripper-camera images with TCP position), joints (joint states and TCP pose), oracle (task-specific environment data for debugging), and prompt (static task instructions). While any mode combination is possible, RGB+joints serves as the standard memory testing configuration, with state mode reserved for MDP-based tasks.
MIKASA-Robo 基准提供多种训练模式:state(包括 oracle 数据和工具中心点(TCP)姿态在内的完整向量信息)、RGB(带 TCP 位置的俯视图和夹爪相机图像)、joints(关节状态和 TCP 姿态)、oracle(用于调试的任务特定环境数据),以及 prompt(静态任务指令)。 虽然任意模式组合都是可能的,但 RGB+joints 是标准记忆测试配置,而 state 模式保留用于基于 MDP 的任务。
The MIKASA-Robo benchmark implements two types of reward functions: dense and sparse. The dense reward provides continuous feedback based on the agent's progress towards the goal, while the sparse reward only signals task completion. While dense rewards facilitate faster learning in our experiments, sparse rewards better reflect real-world scenarios where intermediate feedback is often unavailable, making them crucial for evaluating practical applicability of memory-enhanced agents.
MIKASA-Robo 基准实现了两类奖励函数:密集奖励和稀疏奖励。 密集奖励会根据智能体朝目标推进的进展提供连续反馈,而稀疏奖励只指示任务完成。 虽然密集奖励在作者实验中促进更快学习,但稀疏奖励更好地反映中间反馈通常不可用的真实世界场景,因此对于评估记忆增强型智能体的实际适用性至关重要。
6.2 Online RL baselines
For the experimental evaluation, we chose on-policy Proximal Policy Optimization (PPO) with two underlying architectures: Multilayer Perceptron (MLP) and Long Short-Term Memory (LSTM), as well as popular in robotics off-policy Soft Actor-Critic (SAC) and model-based Temporal Difference Learning for Model Predictive Control (TD-MPC2).
在实验评估中,作者选择了同策略近端策略优化(PPO),并配备两种底层架构:多层感知机(MLP)和长短期记忆网络(LSTM);同时还选择了机器人领域流行的异策略软演员-评论家算法(SAC)以及基于模型的模型预测控制时序差分学习(TD-MPC2)。
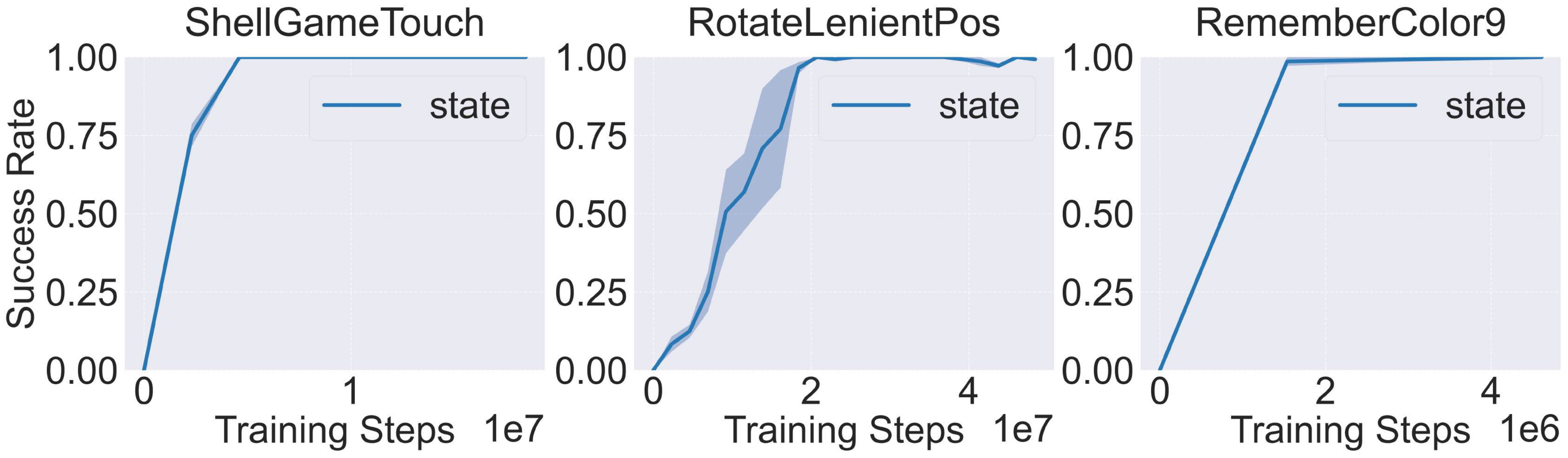
The MLP variant serves as a memory-less baseline, while LSTM represents a widely-adopted memory mechanism in RL, known for its effectiveness in solving POMDPs. This choice of architectures enables direct comparison between memory-less and memory-enhanced agents while validating our benchmark's ability to assess memory. We focus specifically on these fundamental architectures as they align with our primary goal of benchmark validation rather than comprehensive algorithm comparison. To demonstrate that all proposed environments are solvable with 100% success rate (SR), we trained a PPO-MLP agent using state mode, where it had full access to system information. Results for select tasks are shown in Figure 4; full results are in the Appendix.
MLP 变体作为无记忆基线,而 LSTM 代表 RL 中广泛采用的记忆机制,以解决 POMDP 的有效性而著称。 这种架构选择可以直接比较无记忆智能体和记忆增强型智能体,同时验证作者基准评估记忆的能力。 作者特别关注这些基础架构,因为它们符合作者以基准验证为主而非全面算法比较的主要目标。 为证明所有提出的环境都能以 100% 成功率(SR)解决,作者使用 state 模式训练了一个 PPO-MLP 智能体,在该模式中它可以完全访问系统信息。 部分任务结果如 图4 所示;完整结果见附录。
Training under the RGB+joints mode with dense rewards reveals the memory-intensive nature of our tasks. Using the RememberColor-v0 task as an example, PPO-LSTM demonstrates superior performance compared to PPO-MLP when distinguishing between three colors (see Figure 5). However, both agents' success rates drop dramatically to near-zero as the task complexity increases to five or nine colors. Moreover, under sparse reward conditions, both architectures fail to solve even the three-color variant (see Appendix). Additionally, our findings indicate that, while SAC and TD-MPC2 exhibit higher sample efficiency compared to PPO-MLP, when faced with more complex challenges, the lack of an explicit memory mechanism becomes a critical shortcoming, resulting in low performance, which also emphasizes the inappropriateness of algorithms common in the robotics community for memory-intensive tasks. These results validate our benchmark's effectiveness in evaluating agents' memory, showing clear performance degradation as memory demands increase.
在 RGB+joints 模式下使用密集奖励训练,揭示了作者任务的记忆密集型性质。 以 RememberColor-v0 任务为例,在区分三种颜色时,PPO-LSTM 相比 PPO-MLP 表现出更优性能(见 图5)。 然而,随着任务复杂度增加到五种或九种颜色,两个智能体的成功率都急剧下降到接近零。 此外,在稀疏奖励条件下,两种架构甚至无法解决三色变体(见附录)。 此外,作者发现,虽然 SAC 和 TD-MPC2 相比 PPO-MLP 展现出更高样本效率,但面对更复杂挑战时,缺少显式记忆机制会成为关键短板并导致低性能,这也强调了机器人社区常用算法并不适合记忆密集型任务。 这些结果验证了作者基准在评估智能体记忆方面的有效性,并显示出随着记忆需求增加,性能会明显下降。
6.3 Offline RL baselines
RGB 模式下使用稀疏奖励(成功条件)进行。Since dense rewards are typically not available in the real world, it is of particular interest to train on sparse rewards represented as a binary flag of a successfully completed episode. Whereas models with online learning are extremely hard to handle in this setting, we also conducted experiments with five Offline RL models: Decision Transformer (DT) and Recurrent Action Transformer with Memory (RATE) based on the Transformer architecture, Standard Behavioral Cloning (BC) and Conservative Q-Learning (CQL) with MLP backbones, as well as Diffusion Policy (DP) -- a recent and popular approach in robotic manipulation that leverages diffusion models for direct action prediction.
由于密集奖励在真实世界中通常不可用,因此在由成功完成回合的二元标志表示的稀疏奖励上进行训练尤其值得关注。 尽管带在线学习的模型在这一设置下极难处理,作者也使用五种离线 RL 模型进行了实验:基于 Transformer 架构的决策 Transformer(DT)和带记忆的循环动作 Transformer(RATE),带 MLP 骨干网络的标准行为克隆(BC)和保守 Q 学习(CQL),以及扩散策略(DP)-- 一种近期流行的机器人操作方法,利用扩散模型直接预测动作。
Experimental results with Offline RL models trained using two RGB camera views and sparse rewards are presented in Figure 6. As can be seen from Figure 6, none of the models -- including those explicitly designed for sequence modeling -- were able to successfully solve the majority of MIKASA-Robo tasks, demonstrating the challenge posed by the benchmark. Training was performed using datasets consisting of 1000 successful trajectories per task, obtained by using PPO with oracle-level information about the environment (see details in the Appendix).
使用两个 RGB 相机视角和稀疏奖励训练的离线 RL 模型实验结果见 图6。 从 图6 可以看出,没有任何模型 -- 包括那些明确为序列建模设计的模型 -- 能够成功解决大多数 MIKASA-Robo 任务,这展示了该基准带来的挑战。 训练使用的数据集由每个任务 1000 条成功轨迹组成,这些轨迹通过使用具有环境预言机级信息的 PPO 获得(详情见附录)。
Notably, none of the evaluated models were able to solve tasks requiring high Memory Capacity or Sequential Memory, further underscoring their complexity. More detailed results for Offline RL algorithms are presented in Appendix, Table of all MIKASA-Robo results.
值得注意的是,所有被评估模型都无法解决需要高记忆容量或序列记忆的任务,这进一步凸显了其复杂性。 离线 RL 算法的更详细结果见附录中的 MIKASA-Robo 全结果表。
6.4 VLA baselines
To investigate the capabilities of state-of-the-art Visual-Language-Action (VLA) models in memory-intensive robotic tasks, we selected four representative baselines: Octo, OpenVLA,
为研究最先进的视觉-语言-动作(VLA)模型在记忆密集型机器人任务中的能力,作者选择了四个代表性基线:Octo、OpenVLA、
Octo is a transformer with diffusion heads pretrained on Open X-Embodiment; we fine-tuned only the readout heads, using the full pretrained context length of 10 and action chunk size (K=4). OpenVLA uses a Prismatic-7B backbone, fine-tuned with LoRA adapters, chunking, and K=4 and K=8. All models were trained on 250 expert trajectories per task, using
Octo 是一个带扩散头的 Transformer,在 Open X-Embodiment 上预训练;作者只微调读出头,使用完整的预训练上下文长度 10 和动作块大小 (K=4)。 OpenVLA 使用 Prismatic-7B 骨干网络,并通过 LoRA 适配器、分块和 K=4 和 K=8。 所有模型都在每个任务 250 条专家轨迹上训练,使用
ShellGameTouch、InterceptMedium)和基于颜色的记忆检索(RememberColor3/5/9)。| Model | ShellGameTouch | InterceptMedium | RememberColor3 | RememberColor5 | RememberColor9 |
|---|---|---|---|---|---|
| Octo-small | 0.46 ± 0.05 | 0.39 ± 0.04 | 0.45 ± 0.06 | 0.17 ± 0.03 | 0.11 ± 0.03 |
| OpenVLA (K=4) | 0.12 ± 0.05 | 0.06 ± 0.02 | 0.21 ± 0.00 | 0.09 ± 0.02 | 0.08 ± 0.02 |
| OpenVLA (K=8) | 0.47 ± 0.05 | 0.14 ± 0.03 | 0.59 ± 0.04 | 0.16 ± 0.03 | 0.06 ± 0.02 |
| SpatialVLA (K=4) | 0.23 ± 0.04 | 0.27 ± 0.04 | 0.27 ± 0.05 | 0.17 ± 0.03 | 0.11 ± 0.03 |
| π₀ (K=4) | 0.33 ± 0.05 | 0.42 ± 0.03 | 0.35 ± 0.04 | 0.22 ± 0.04 | 0.15 ± 0.02 |
Experimental results (Table 4) reveal notable trends. Octo (context size 10) outperforms random on simpler tasks, suggesting some innate memory capacity, but degrades with complexity, indicating limited scalability. OpenVLA behaves differently across chunk sizes: with RememberColor3 and ShellGameTouch, despite lacking step-wise history. However, performance drops on harder tasks. With
实验结果(表4)揭示了若干显著趋势。 Octo(上下文大小 10)在较简单任务上优于随机,表明其具有某些内在记忆能力,但会随复杂度增加而退化,说明可扩展性有限。 OpenVLA 在不同块大小下表现不同:在 RememberColor3 和 ShellGameTouch 等任务上超过随机水平。 然而,在更难任务上性能会下降。 在
We also conducted real-world experiments using the
作者还使用
The sharp decline on harder tasks underscores the need for dedicated memory architectures and validates the multi-difficulty hierarchy in MIKASA-Robo to prevent such “shortcuts.” Our experiments with Octo, OpenVLA,
更难任务上的急剧下降凸显了专门记忆架构的必要性,也验证了 MIKASA-Robo 中多难度层级能够防止这类“捷径”。 作者对 Octo、OpenVLA、
7. Limitations and Future Work
Future work could explore more extensive adaptation of large VLA models within MIKASA to obtain a clearer picture of their memory capabilities. A complementary direction is to broaden the benchmark to encompass memory phenomena that fall outside the current focus on spatio-temporal dependencies within single episodes. The present tasks do not capture higher-level processes such as meta-RL. These settings require problem formulations that extend beyond the POMDP structure instantiated in the benchmark, since they involve reasoning over distributions of tasks rather than isolated trajectories. It would also be valuable to study how agents cope with spurious correlations, interference between stored representations, and the dynamics of memory overwriting or forgetting under limited memory capacity, all of which remain unexplored in the current framework. Finally, developing of additional evaluation metrics, instead of relying solely on success rates or returns, offers a promising path toward more precise and discriminative assessment of memory mechanisms.
未来工作可以在 MIKASA 内探索对大型 VLA 模型更广泛的适配,以更清晰地了解其记忆能力。 一个互补方向是扩展该基准,使其涵盖超出当前单个回合内时空依赖关注范围的记忆现象。 当前任务没有捕捉元强化学习等更高层过程。 这些设置需要超出该基准中所实例化 POMDP 结构的问题形式化,因为它们涉及对任务分布而非孤立轨迹的推理。 研究智能体如何处理虚假相关、存储表征之间的干扰,以及有限记忆容量下记忆覆写或遗忘的动态,也会很有价值;这些在当前框架中都仍未探索。 最后,开发额外评估指标,而不是仅依赖成功率或回报,为更精确且更具区分度地评估记忆机制提供了一条有前景的路径。
8. Conclusion
We present MIKASA, a unified benchmark suite for evaluating memory in RL. Our work addresses key gaps in the field by introducing: (1) a taxonomy of memory types, spanning object, spatial, sequential, and capacity requirements; (2) MIKASA-Base, a standardized collection of open-source memory tasks; (3) MIKASA-Robo, a suite of 32 robotic manipulation tasks designed to isolate and stress specific forms of memory; and (4) accompanying offline datasets to support reproducible large-scale evaluation. Experiments with online, offline, and VLA agents consistently show that existing methods struggle when memory requirements become substantial, which highlights the need for architectures with explicit and robust long-horizon memory mechanisms.
作者提出 MIKASA,这是一个用于评估 RL 中记忆的统一基准套件。 本文通过引入以下内容解决了该领域的关键缺口:(1) 一种记忆类型分类体系,覆盖对象、空间、序列和容量需求;(2) MIKASA-Base,一个标准化的开源记忆任务集合;(3) MIKASA-Robo,一个由 32 个机器人操作任务组成的套件,旨在隔离并强调特定形式的记忆;(4) 配套离线数据集,以支持可复现的大规模评估。 使用在线、离线和 VLA 智能体的实验一致显示,当记忆需求变得显著时,现有方法会遇到困难,这凸显了需要具有显式且鲁棒长程记忆机制的架构。
We further validated our findings through real-world experiments on a physical robot platform. The results mirror the simulation hierarchy, with reliable performance in fully observable tasks, partial degradation under dynamic but non-occluded conditions, and failure when long-horizon occlusion is introduced. This consistency confirms that memory, rather than embodiment or perception noise, is the primary limitation.
作者进一步通过物理机器人平台上的真实世界实验验证了这些发现。 结果与仿真层级相呼应:在完全可观测任务中表现可靠,在动态但非遮挡条件下部分退化,而在引入长程遮挡时失败。 这种一致性确认了主要限制来自记忆,而不是具身性或感知噪声。
MIKASA is intended to guide and accelerate progress in memory-intensive RL for real-world applications. The MIKASA-Robo suite is open-source under the MIT license and can be conveniently installed via pip install mikasa-robo-suite.
MIKASA 旨在引导并加速面向真实世界应用的记忆密集型 RL 进展。 MIKASA-Robo 套件基于 MIT 许可证开源,并可通过 pip install mikasa-robo-suite 便捷安装。