
δ-mem:面向大语言模型的高效在线记忆
Abstract
Large language models increasingly need to accumulate and reuse historical information in long-term assistants and agent systems. Simply expanding the context window is costly and often fails to ensure effective context utilization. We propose δ-mem, a lightweight memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory. δ-mem compresses past information into a fixed-size state matrix updated by delta-rule learning, and uses its readout to generate low-rank corrections to the backbone's attention computation during generation. With only an
大语言模型越来越需要在长期助手和智能体系统中积累并复用历史信息。 单纯扩展上下文窗口代价很高,而且往往无法保证模型有效利用上下文。 作者提出 δ-mem,这是一种轻量级记忆机制,用紧凑的在线联想记忆状态来增强冻结的全注意力骨干模型。 δ-mem 将过去的信息压缩到一个由 delta-rule learning 更新的固定大小状态矩阵中,并利用其读出结果,在生成过程中为骨干模型的注意力计算产生低秩修正。 仅使用一个
1. Introduction
As large language models (LLMs) are increasingly deployed in memory-heavy scenarios requiring continuous interaction, such as long-term personalized assistants and long-horizon agent systems, their life-cycle must go beyond responding to isolated prompts and instead accumulate, update, and reuse historical information over extended memory-heavy tasks. In these settings, model performance depends not only on understanding the current input, but also on effectively leveraging relevant past context during test-time.
随着大语言模型(LLM)越来越多地部署到需要持续交互的记忆密集型场景中,例如长期个性化助手和长程智能体系统,它们的生命周期必须超越对孤立提示的响应,转而在扩展的记忆密集型任务中积累、更新并复用历史信息。 在这些场景下,模型表现不仅取决于对当前输入的理解,也取决于在测试时有效利用相关过去上下文的能力。
An intuitive way is to simply expand the input context and retain more interaction history. However, this strategy only reduces the memory problem to a long-context processing problem, which is both computationally expensive and increasingly difficult to harness. On the one hand, standard attention incurs quadratic cost with respect to context length. On the other hand, simply increasing the context window does not guarantee effective use of the additional information, as models often suffer from context degradation or context rot when the context becomes very long, which suggests that even million-token context windows do not fundamentally solve the memory problem. These limitations call for more advanced memory mechanisms (MMs) that can represent historical information more compactly within a given context window, maintain it dynamically across interactions, and make it effectively usable by the backbone model during test-time.
一种直观做法是直接扩展输入上下文并保留更多交互历史。 然而,这种策略只是把记忆问题转化为长上下文处理问题,既计算代价高,也越来越难以有效驾驭。 一方面,标准注意力相对于上下文长度具有二次复杂度。 另一方面,单纯增大上下文窗口并不能保证模型有效利用额外信息,因为当上下文变得很长时,模型经常遭遇上下文退化或上下文腐烂,这说明即便百万 token 上下文窗口也没有从根本上解决记忆问题。 这些限制要求更先进的记忆机制(MMs):它们需要在给定上下文窗口内更紧凑地表示历史信息,在交互过程中动态维护历史,并让骨干模型在测试时能够有效使用这些信息。
From a unified perspective, existing memory mechanisms can be characterized along two dimensions under a given context window: memory state, which defines how historical information is stored, and memory steering, which determines how stored information influences backbone reasoning. Under this framework, prior methods fall into three paradigms. Textual memory mechanisms (TMMs) store memory as text and inject it through the input context, offering flexibility without architectural changes but suffering from context-window limits, retrieval noise, and inevitable compaction loss. Outside-channel memory mechanisms (OMMs) keep memory in external modules and interact with the backbone via retrieval or encoding on outside pathways, enabling modularity but introducing overhead, integration complexity, and potential misalignments with the backbone. Parametric memory mechanisms (PMMs) encode memory into parameters of prefixes or adapters, making them efficient and compatible with frozen backbones, but their static nature limits adaptation to dynamically evolving information. Taken together, these limitations point to a need for a memory mechanism that can maintain a compact and dynamically evolving memory state while steering the backbone through a pathway tightly aligned with its internal attention computation.
从统一视角看,在给定上下文窗口下,现有记忆机制可以沿两个维度刻画:记忆状态,即历史信息如何存储;记忆 steering,即存储的信息如何影响骨干模型推理。 在这一框架下,既有方法可归为三类范式。 文本记忆机制(TMMs)把记忆存为文本,并通过输入上下文注入;它们不需要架构改动,较为灵活,但受到上下文窗口限制、检索噪声和不可避免的压缩损失影响。 外部通道记忆机制(OMMs)把记忆保存在外部模块中,并通过外部路径上的检索或编码与骨干模型交互;它们具备模块化优势,但会引入额外开销、集成复杂性以及与骨干模型的潜在错配。 参数化记忆机制(PMMs)把记忆编码到 prefix 或 adapter 参数中,因此高效且兼容冻结骨干,但其静态性质限制了它们适应动态演化信息的能力。 综合来看,这些限制表明需要一种记忆机制:既能维护紧凑且动态演化的记忆状态,又能通过与模型内部注意力计算紧密对齐的路径来 steering 骨干模型。
Following this motivation, we propose δ-mem, a memory mechanism that keeps a compact and dynamically updated memory alongside a frozen full-attention backbone. Instead of storing all historical tokens in the input context, δ-mem compresses past information into an online state of associative memory (OSAM). This state is continuously updated via delta-rule learning as new tokens arrive, allowing the model to maintain useful historical information in a fixed-size matrix representation of associative memories.
基于这一动机,作者提出 δ-mem:一种在冻结全注意力骨干旁维护紧凑、动态更新记忆的机制。 δ-mem 并不把所有历史 token 存入输入上下文,而是把过去信息压缩到一个在线联想记忆状态(OSAM)中。 随着新 token 到来,该状态会通过 delta-rule learning 持续更新,使模型能够用固定大小的矩阵形式维护有用历史信息。
During generation, δ-mem does not simply retrieve text from memory. Instead, the current input queries the online state to extract context-relevant associative memory signals, which are then transformed into a low-rank correction to the backbone’s attention components. In this way, associative memory directly participates in the backbone’s forward computation while leaving the backbone frozen. The online state is further updated after each interaction, enabling δ-mem to evolve its associative memory over time.
在生成过程中,δ-mem 并不是简单地从记忆中检索文本。 相反,当前输入会查询在线状态,抽取与上下文相关的联想记忆信号,然后把这些信号转换为对骨干模型注意力组件的低秩修正。 这样一来,联想记忆可以在保持骨干冻结的同时,直接参与骨干模型的前向计算。 在线状态还会在每次交互后继续更新,使 δ-mem 的联想记忆能够随时间演化。
Finally, we evaluate δ-mem on memory-heavy benchmarks, including HotpotQA, LoCoMo, and MemoryAgentBench, together with general capability benchmarks IFEval and GPQA-Diamond. With only a fixed
最后,作者在 HotpotQA、LoCoMo 和 MemoryAgentBench 等记忆密集型基准,以及 IFEval 和 GPQA-Diamond 等通用能力基准上评估 δ-mem。 仅使用固定
Our contributions can be summarized as follows:
- We propose δ-mem, a memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory, enabling historical information to be dynamically maintained and directly coupled with the backbone's attention computation.
- We show that an extremely small memory state, implemented as an
matrix, can retain useful historical signals through OSAM and help the model recover context-relevant information even after explicit history is removed. - We evaluate δ-mem on multiple memory-heavy and general capability benchmarks with significant gains on memory-heavy tasks such as MemoryAgentBench and LoCoMo, without full fine-tuning or replacing the backbone architecture.
本文贡献可总结如下:
- 作者提出 δ-mem,这是一种用紧凑在线联想记忆状态增强冻结全注意力骨干的记忆机制,使历史信息能够被动态维护,并直接耦合到骨干模型的注意力计算中。
- 作者表明,即使是实现为
矩阵的极小记忆状态,也能通过 OSAM 保留有用历史信号,并在显式历史被移除后帮助模型恢复与上下文相关的信息。 - 作者在多个记忆密集型和通用能力基准上评估 δ-mem;在 MemoryAgentBench 和 LoCoMo 等记忆密集型任务上,δ-mem 在不进行完整微调、不替换骨干架构的情况下取得显著提升。
2. Preliminaries
In terms of a Transformer for sequence modeling, let
对于用于序列建模的 Transformer,令
Concretely, δ-mem maintains a matrix
具体来说,δ-mem 维护一个矩阵
This memory update can then be regarded as optimizing an online regression loss using SGD:
于是,这一记忆更新可以被视为使用 SGD 优化一个在线回归损失:
This formulation writes only the residual information along the key direction. Consequently, well-learned associations induce negligible updates, whereas predictive discrepancies dynamically correct the memory state. Inspired by gated retention design in Qwen-Next, we further introduce a forget gate to control long-range state evolution:
这种形式只会沿 key 方向写入残差信息。 因此,已经学好的关联只会引发很小更新,而预测差异会动态修正记忆状态。 受 Qwen-Next 中门控 retention 设计启发,作者进一步引入遗忘门来控制长程状态演化:
Here
这里
3. δ-mem
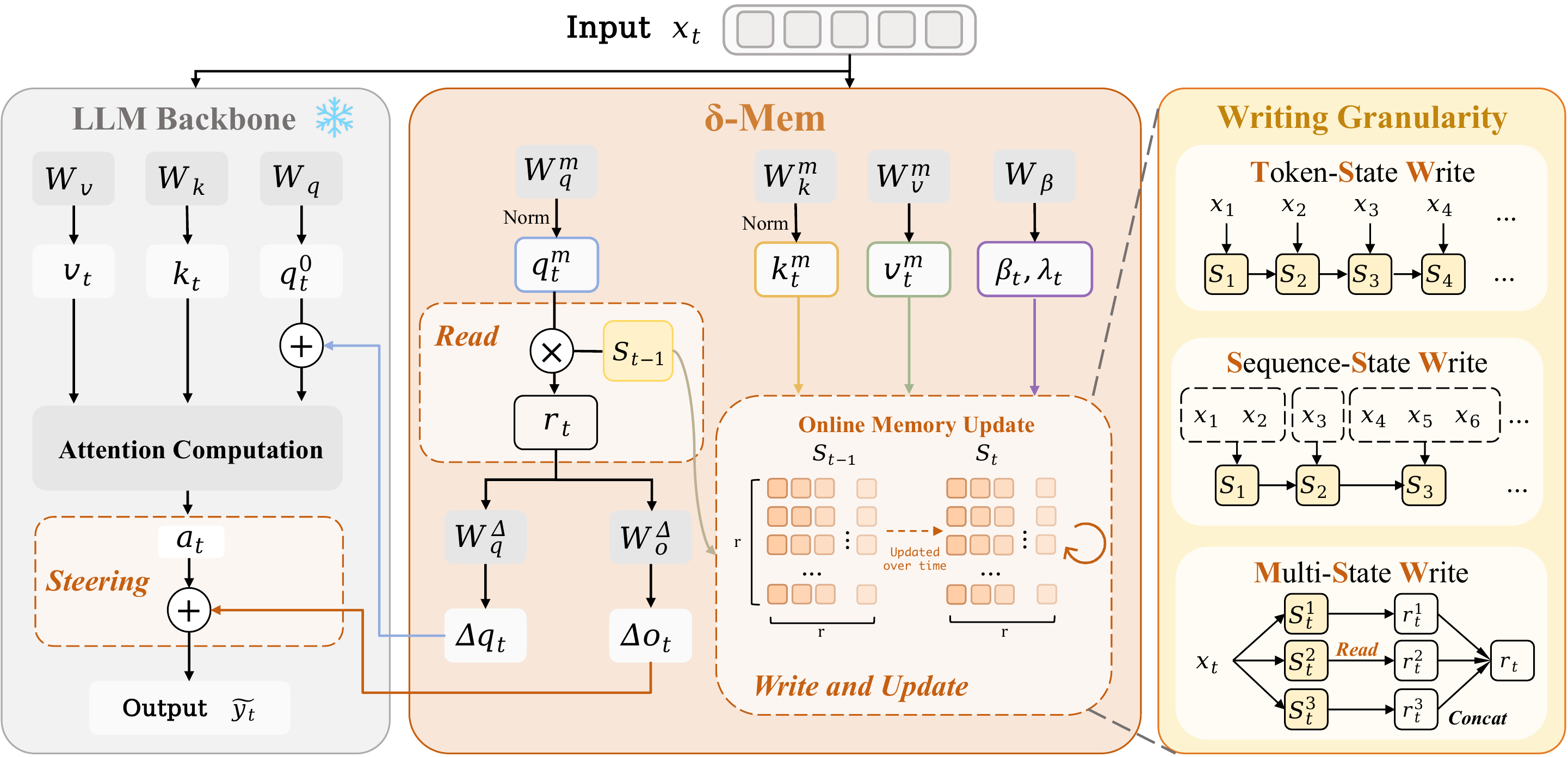
At each position, δ-mem follows the same computation order: read associative memory signals from the old state, use the signals to steer attention, and then write the current information into the state. In this way, the model can compress history into a state that evolves with the sequence and use it in later reasoning, without updating the backbone parameters. Figure 1 provides an overview of this design. The frozen backbone performs the standard attention computation, while δ-mem reads from the previous state, generates query-side and output-side attention corrections, and updates the online state with the current memory key-value information. The figure also summarizes the three writing strategies studied in this work, corresponding to token-level updates, segment-level updates, and multi-state memory organization.
在每个位置,δ-mem 都遵循相同的计算顺序:从旧状态读取联想记忆信号,用这些信号 steering 注意力,然后把当前信息写入状态。 这样,模型可以把历史压缩到一个随序列演化的状态中,并在后续推理中使用它,同时无需更新骨干参数。 图1 展示了该设计的概览。 冻结骨干执行标准注意力计算,而 δ-mem 从先前状态读取,生成 query 侧和 output 侧的注意力修正,并用当前记忆 key-value 信息更新在线状态。 该图还总结了本文研究的三种写入策略,分别对应 token 级更新、segment 级更新和多状态记忆组织。
3.1. Memory Projections
To form the online state of associative memory, given a hidden state
为了形成联想记忆的在线状态,给定当前位置的隐藏状态
where
其中
The write gate and retention gate are also determined by the current hidden state:
写入门和保留门也由当前隐藏状态决定:
where
其中
3.2. Reading from Online State of Associative Memory
Before writing the current information, δ-mem first reads from the old state:
在写入当前信息之前,δ-mem 首先从旧状态读取:
The read vector
读取向量
This reading form is complementary to standard attention. Attention compares the query with all keys within the explicit context, while δ-mem directly obtains continuous associative memory signals from the compressed state. It does not return text segments or add context tokens. Instead, it provides history-dependent steering signals before the attention computation.
这种读取形式与标准注意力互补。 注意力会将 query 与显式上下文中的所有 key 比较,而 δ-mem 直接从压缩状态中获得连续的联想记忆信号。 它不会返回文本片段,也不会添加上下文 token。 相反,它会在注意力计算前提供依赖历史的 steering 信号。
3.3. Steering Attention through Low-Rank Corrections
The associative memory signals steer the attention computation through two lightweight linear mappings. First, the read signal
联想记忆信号通过两个轻量线性映射来 steering 注意力计算。 首先,读取信号
The query-side correction is then added to the original query of the frozen backbone:
随后,query 侧修正被加入冻结骨干的原始 query:
The attention output
之后,注意力输出
The main implementation only uses the two correction terms on the query and output sides, and we detail these choices in Section 5. The low-rank correction here is different from a static adapter. Although
主实现只在 query 侧和 output 侧使用两个修正项,作者会在第 5 节详细说明这些选择。 这里的低秩修正不同于静态 adapter。 虽然
3.4. Writing into Online State of Associative Memory
After the current attention computation is completed, δ-mem writes the information at the current position into the online state. Given the current memory key-value pair
当前注意力计算完成后,δ-mem 会把当前位置的信息写入在线状态。 给定当前记忆 key-value 对
Expanding the update gives:
展开该更新可得:
The three terms have clear roles: the first term retains the previous state, the second term removes the old prediction component along the current key direction, and the third term writes the new value into the same direction. Thus, the memory state is updated by error correction with controlled forgetting, rather than by unselectively accumulating new outer products.
这三项各有清晰作用:第一项保留先前状态,第二项沿当前 key 方向移除旧预测分量,第三项把新 value 写入同一方向。 因此,记忆状态是通过带受控遗忘的误差修正来更新,而不是无选择地累积新的外积。
The dimension-wise nature of the gates can be seen by expanding the update row by row. Let
通过逐行展开更新,可以看到门控的按维度性质。 令
This shows that each memory dimension can independently control how much old information is retained and how strongly the current residual is written. Such dimension-wise gating is useful for continuous interactions, where the state must preserve stable historical information while still adapting to new inputs.
这表明每个记忆维度都可以独立控制保留多少旧信息,以及当前残差被写入的强度。 这种按维度门控对连续交互很有用,因为状态既需要保留稳定历史信息,又需要适应新输入。
3.5. Writing Granularity of Online State
The above formulas explain how a single write operation is performed, but the memory mechanism also depends on the definition of writing granularity. A token is the finest granularity, but it is not always the most suitable one. In conversations and agent trajectories, messages, semantic segments, or stage-level events are often more stable. We therefore examine three writing strategies. As illustrated in Figure 1, TSW writes at every token, SSW averages the hidden states within each segment and writes per segment, and MSW writes into multiple parallel sub-states and then aggregates their readouts.
上述公式解释了单次写入操作如何执行,但记忆机制还依赖于写入粒度的定义。 token 是最细粒度,但并不总是最合适的粒度。 在对话和智能体轨迹中,消息、语义片段或阶段级事件往往更稳定。 因此,作者考察三种写入策略。 如 图1 所示,TSW 在每个 token 写入,SSW 对每个片段内隐藏状态取平均并按片段写入,MSW 写入多个并行子状态,再聚合它们的读出。
Token-State Write (TSW). Token-State Write updates the online state at each token position:
Token-State Write(TSW)。 Token-State Write 在每个 token 位置更新在线状态:
It preserves the finest-grained information and is suitable for scenarios that need to capture local changes. However, since every token triggers a write operation, the state is also more easily affected by format symbols, repeated expressions, and short-term noise.
它保留最细粒度信息,适用于需要捕捉局部变化的场景。 然而,由于每个 token 都会触发一次写入操作,状态也更容易受到格式符号、重复表达和短期噪声影响。
Sequence-State Write (SSW). Sequence-State Write raises the writing granularity from unit tokens to a message segment. Let
Sequence-State Write(SSW)。 Sequence-State Write 将写入粒度从单个 token 提升到消息片段。 令
Then, each message updates the online state once. Let
随后,每条消息只更新一次在线状态。 令
SSW reduces redundant writes and smooths the state evolution. The cost is that some fine-grained token-level details are absorbed by the averaged segment representation.
SSW 减少了冗余写入,并平滑状态演化。 代价是一些细粒度 token 级细节会被平均后的片段表示吸收。
Multi-State Write (MSW). The first two strategies adjust the writing granularity, while MSW adjusts the state organization. A single state needs to contain facts, preferences, task progress, and local events at the same time, which may easily lead to overwriting and interference. MSW decomposes memory into multiple parallel sub-states:
Multi-State Write(MSW)。 前两种策略调整写入粒度,而 MSW 调整状态组织方式。 单一状态需要同时包含事实、偏好、任务进度和局部事件,这很容易导致覆盖和干扰。 MSW 将记忆分解为多个并行子状态:
where
其中
3.6. Training Objective
δ-mem is trained with the standard SFT loss. For each example, the context tokens are first written into the online state, producing
δ-mem 使用标准 SFT 损失进行训练。 对于每个样本,上下文 token 首先被写入在线状态,得到
where
其中
4. Experiments
4.1. Experimental Setup
Evaluation and Benchmarks. To independently measure general reasoning and memory effectiveness, we evaluate our method on general tasks and memory-heavy benchmarks. General multi-hop reasoning, knowledge-intensive QA, and instruction-following are assessed using HotpotQA, GPQA-Diamond, and IFEval. For the memory-heavy side, we utilize LoCoMo (following Mem0, the adversarial question category is excluded), alongside MemoryAgentBench to evaluate the retention, retrieval, and utilization of memory information across extended interaction histories.
评估与基准。 为了独立衡量通用推理能力和记忆有效性,作者在通用任务和记忆密集型基准上评估该方法。 通用多跳推理、知识密集型问答和指令遵循分别用 HotpotQA、GPQA-Diamond 和 IFEval 评估。 在记忆密集型方面,作者使用 LoCoMo(遵循 Mem0,排除 adversarial 问题类别),并结合 MemoryAgentBench,来评估扩展交互历史中记忆信息的保留、检索和利用能力。
Baselines. We compare δ-mem against representative memory mechanisms. All methods are built on the same Qwen3-4B-Instruct backbone. For textual memory mechanisms, we consider BM25 RAG, which retrieves relevant historical text and prepends it to the context; LLMLingua-2, which compresses long histories into a shorter textual context; and MemoryBank, which maintains continuous interaction history through textual memory entries. For parametric memory mechanisms, we compare with Context2LoRA and MemGen, which encode memory or context-dependent adaptation into additional trainable parameters. For outside-channel memory, we include an MLP Memory baseline that retrieves information in a separate module and then fuses back into the model. We additionally report trainable parameter counts for rank-8 configurations to compare memory effectiveness under similar or smaller adaptation budgets in Appendix.
基线。 作者将 δ-mem 与代表性记忆机制进行比较。 所有方法都构建在同一个 Qwen3-4B-Instruct 骨干上。 对于文本记忆机制,作者考虑 BM25 RAG,它检索相关历史文本并前置到上下文中;LLMLingua-2,它把长历史压缩成较短文本上下文;以及 MemoryBank,它通过文本记忆条目维护连续交互历史。 对于参数化记忆机制,作者与 Context2LoRA 和 MemGen 比较,它们把记忆或上下文依赖适应编码进额外可训练参数。 对于外部通道记忆,作者加入 MLP Memory 基线,它在单独模块中检索信息,再融合回模型。 作者还在附录中报告 rank-8 配置的可训练参数量,以比较相似或更小适配预算下的记忆有效性。
Implementation Details. We select LLM backbones of varying sizes, including Qwen3-8B, Qwen3-4B-Instruct, and SmolLM3-3B. More training setup and evaluation configurations are listed in Appendix.
实现细节。 作者选择不同规模的 LLM 骨干,包括 Qwen3-8B、Qwen3-4B-Instruct 和 SmolLM3-3B。 更多训练设置和评估配置列于附录。
4.2. Main Results across Memory Mechanisms
| Model | IFEval | HotpotQA | GPQA-D | Memory Agent Bench | LoCoMo | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EM | F1 | Avg. | AR | TTL | LRU | SF | Avg. | Multi | Temp | Open | Single | ||||
| Qwen3-4B-Instruct | 81.89 | 42.35 | 56.00 | 39.39 | 29.54 | 35.30 | 26.14 | 47.08 | 14.37 | 40.79 | 38.39 | 32.89 | 10.77 | 48.05 | 46.79 |
| Textual Memory | |||||||||||||||
| + BM25 RAG | - | 40.35 | 52.83 | - | 24.49 | 32.20 | 9.74 | 37.86 | 15.00 | 36.68 | 38.12 | 20.34 | 9.99 | 45.47 | 44.56 |
| + LLMLingua-2 | - | 36.93 | 50.03 | - | 15.63 | 21.45 | 1.43 | 38.45 | 8.62 | 40.98 | 39.07 | 30.13 | 10.98 | 49.19 | 42.96 |
| + MemoryBank | - | - | - | - | 17.65 | 22.65 | 7.67 | 36.36 | 9.88 | 38.14 | 37.88 | 21.76 | 13.35 | 47.31 | 43.88 |
| Parametric Memory | |||||||||||||||
| + Context2LoRA | 76.71 | 37.85 | 50.88 | 29.29 | 32.53 | 40.00 | 29.86 | 25.15 | 17.75 | 48.11 | 37.95 | 34.99 | 16.75 | 60.11 | 44.90 |
| + MemGen | 39.37 | 5.36 | 16.27 | 38.89 | 29.61 | 34.85 | 28.45 | 44.30 | 14.38 | 40.05 | 32.93 | 33.30 | 12.67 | 48.13 | 30.66 |
| Outside-channel Memory | |||||||||||||||
| + MLP Memory | 24.95 | 10.94 | 25.83 | 22.73 | 28.80 | 35.35 | 26.00 | 31.19 | 14.38 | 26.85 | 32.87 | 16.72 | 8.81 | 30.75 | 22.85 |
| δ-Mem | |||||||||||||||
| + δ-Mem (SSW) | 81.70 | 49.22 | 63.43 | 41.41 | 37.84 | 41.50 | 50.50 | 43.02 | 16.50 | 47.05 | 41.00 | 36.48 | 14.08 | 56.88 | 51.44 |
| + δ-Mem (TSW) | 82.99 | 49.41 | 63.66 | 40.40 | 36.48 | 42.45 | 40.64 | 46.08 | 15.88 | 46.53 | 42.14 | 37.20 | 13.35 | 55.36 | 51.66 |
| + δ-Mem (MSW) | 81.52 | 46.86 | 60.47 | 37.37 | 38.85 | 44.40 | 47.29 | 41.55 | 17.00 | 49.12 | 42.57 | 39.31 | 18.12 | 58.59 | 50.74 |
Table 1 compares δ-mem with representative memory-augmented baselines on general reasoning, instruction following, and memory-heavy benchmarks. δ-mem achieves the strongest performance across all methods. The TSW variant reaches the best average score of 51.66%, improving over the Qwen3-4B-Instruct backbone (46.79%) by +4.87 points and over Context2LoRA (44.90%) by +6.76 points. SSW and MSW also perform strongly, achieving 51.44% and 50.74%, respectively. The gains are most pronounced on memory-heavy benchmarks. On MemoryAgentBench, δ-mem improves the average score from 29.54% to 38.85%, with MSW performing best. On LoCoMo, MSW achieves the highest average of 49.12% and performs best on Multi, Temporal, and Open subsets. On HotpotQA, TSW improves EM/F1 from 42.35%/56.00% to 49.41%/63.66%.
表1 比较了 δ-mem 与代表性记忆增强基线在通用推理、指令遵循和记忆密集型基准上的表现。 δ-mem 在所有方法中取得最强表现。 TSW 变体达到最佳平均分 51.66%,相较 Qwen3-4B-Instruct 骨干(46.79%)提升 +4.87 分,相较 Context2LoRA(44.90%)提升 +6.76 分。 SSW 和 MSW 也表现强劲,分别达到 51.44% 和 50.74%。 这些提升在记忆密集型基准上最明显。 在 MemoryAgentBench 上,δ-mem 将平均分从 29.54% 提升到 38.85%,其中 MSW 表现最佳。 在 LoCoMo 上,MSW 取得最高平均分 49.12%,并在 Multi、Temporal 和 Open 子集上表现最佳。 在 HotpotQA 上,TSW 将 EM/F1 从 42.35%/56.00% 提升到 49.41%/63.66%。
Across baselines, different memory mechanisms exhibit distinct limitations. Textual memory methods show inconsistent gains, likely due to retrieval noise and information loss introduced by compressing memory into token space. Parametric memory methods such as Context2LoRA tend to generalize less robustly across tasks, as their memory is statically encoded in parameters and can overfit to training distributions. The MLP Memory baseline performs relatively limited, indicating it lacks sequential state accumulation and cannot explicitly model long-range dependencies, while also introducing information loss by approximating instance-level retrieval. In contrast, δ-mem consistently improves performance across both general and memory-heavy evaluations, suggesting that maintaining memory as an online state provides a more robust memory mechanism.
不同基线中的记忆机制呈现出不同限制。 文本记忆方法的收益不稳定,可能是因为把记忆压缩进 token 空间会引入检索噪声和信息损失。 Context2LoRA 等参数化记忆方法在跨任务上往往泛化不够稳健,因为它们的记忆被静态编码进参数,可能过拟合训练分布。 MLP Memory 基线表现相对有限,说明它缺少顺序状态累积,无法显式建模长程依赖,同时也会通过近似实例级检索引入信息损失。 相比之下,δ-mem 在通用评估和记忆密集型评估上都持续提升表现,说明把记忆维护为在线状态可以提供更稳健的记忆机制。
4.3. Main Results Across Different Backbone Models
| Model | IFEval | HotpotQA | GPQA-D | Memory Agent Bench | LoCoMo | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EM | F1 | Avg. | AR | TTL | LRU | SF | Avg. | Multi | Temp | Open | Single | ||||
| Qwen3-4B-Instruct | 81.89 | 42.35 | 56.00 | 39.39 | 29.54 | 35.30 | 26.14 | 47.08 | 14.37 | 40.79 | 38.39 | 32.89 | 10.77 | 48.05 | 46.79 |
| + δ-Mem (SSW) | 81.70 | 49.22 | 63.43 | 41.41 | 37.84 | 41.50 | 50.50 | 43.02 | 16.50 | 47.05 | 41.00 | 36.48 | 14.08 | 56.88 | 51.44 |
| + δ-Mem (TSW) | 82.99 | 49.41 | 63.66 | 40.40 | 36.48 | 42.45 | 40.64 | 46.08 | 15.88 | 46.53 | 42.14 | 37.20 | 13.35 | 55.36 | 51.66 |
| + δ-Mem (MSW) | 81.52 | 46.86 | 60.47 | 37.37 | 38.85 | 44.40 | 47.29 | 41.55 | 17.00 | 49.12 | 42.57 | 39.31 | 18.12 | 58.59 | 50.74 |
| + Context2LoRA | 76.71 | 37.85 | 50.88 | 29.29 | 32.53 | 40.00 | 29.86 | 25.15 | 17.75 | 48.11 | 37.95 | 34.99 | 16.75 | 60.11 | 44.90 |
| Qwen3-8B | 79.67 | 32.48 | 41.42 | 44.95 | 31.87 | 45.10 | 12.79 | 48.22 | 12.00 | 47.02 | 41.28 | 30.43 | 14.20 | 59.03 | 47.20 |
| + δ-Mem (SSW) | 80.41 | 43.81 | 56.61 | 45.45 | 33.63 | 45.55 | 19.52 | 46.11 | 13.50 | 51.01 | 46.46 | 35.36 | 20.05 | 62.05 | 50.86 |
| + δ-Mem (TSW) | 82.81 | 41.97 | 53.61 | 44.95 | 32.97 | 45.65 | 16.43 | 46.41 | 12.88 | 50.70 | 44.35 | 34.76 | 17.90 | 62.66 | 50.68 |
| + δ-Mem (MSW) | 80.96 | 40.15 | 51.34 | 49.49 | 32.66 | 45.55 | 14.95 | 44.60 | 13.38 | 50.92 | 45.52 | 34.82 | 21.21 | 62.27 | 50.84 |
| + Context2LoRA | 77.26 | 36.22 | 49.19 | 38.38 | 30.52 | 43.15 | 10.05 | 34.04 | 16.13 | 47.20 | 35.18 | 35.05 | 20.49 | 58.92 | 45.92 |
| SmolLM3-3B | 67.10 | 1.67 | 14.40 | 23.23 | 14.21 | 12.57 | 5.53 | 30.72 | 8.00 | 24.18 | 22.41 | 16.49 | 10.87 | 29.22 | 26.08 |
| + δ-Mem (SSW) | 70.61 | 27.35 | 43.26 | 26.77 | 19.22 | 16.80 | 6.50 | 37.84 | 15.75 | 39.39 | 29.12 | 27.09 | 22.57 | 49.45 | 36.67 |
| + δ-Mem (TSW) | 66.36 | 24.90 | 41.28 | 26.26 | 20.74 | 17.98 | 8.71 | 41.63 | 15.75 | 35.46 | 27.48 | 25.34 | 17.04 | 44.10 | 34.74 |
| + δ-Mem (MSW) | 67.47 | 31.61 | 46.77 | 25.76 | 20.54 | 18.10 | 8.32 | 39.63 | 16.12 | 39.41 | 29.78 | 27.15 | 19.59 | 49.59 | 36.96 |
| + Context2LoRA | 62.29 | 30.28 | 44.39 | 26.77 | 17.62 | 16.08 | 2.86 | 36.77 | 14.75 | 37.74 | 26.35 | 26.05 | 15.41 | 48.58 | 34.94 |
Table 2 evaluates δ-mem across three backbone models, demonstrating consistent improvements in average scores across the board. δ-mem improves the average score on all backbones. Specifically, it boosts Qwen3-4B-Instruct from 46.79% to 51.66%, Qwen3-8B from 47.20% to 50.86%, and SmolLM3-3B from 26.08% to 36.96%. Notably, the effectiveness of the writing strategies varies by model capacity. On the more capable Qwen3-8B, the improvements are more modest but steady, with SSW securing the top average score of 50.86%. This suggests that for backbones with stronger inherent reasoning, segment-level writing (SSW) smooths state updates and effectively mitigates token-level noise. In contrast, the smaller SmolLM3-3B exhibits a substantial performance leap (from 26.08% to 36.96%) driven by MSW, indicating that smaller backbones benefit significantly from separating memory into multiple states to minimize interference.
表2 在三个骨干模型上评估 δ-mem,展示了平均分的一致提升。 δ-mem 在所有骨干上都提升了平均分。 具体而言,它将 Qwen3-4B-Instruct 从 46.79% 提升到 51.66%,将 Qwen3-8B 从 47.20% 提升到 50.86%,并将 SmolLM3-3B 从 26.08% 提升到 36.96%。 值得注意的是,写入策略的有效性会随模型容量变化。 在能力更强的 Qwen3-8B 上,提升更温和但稳定,SSW 取得最高平均分 50.86%。 这表明对于内在推理能力更强的骨干,segment 级写入(SSW)可以平滑状态更新,并有效缓解 token 级噪声。 相比之下,较小的 SmolLM3-3B 在 MSW 驱动下表现大幅跃升(从 26.08% 到 36.96%),说明较小骨干显著受益于把记忆分离到多个状态中以减少干扰。
5. Ablative Study
5.1. Context Recovery
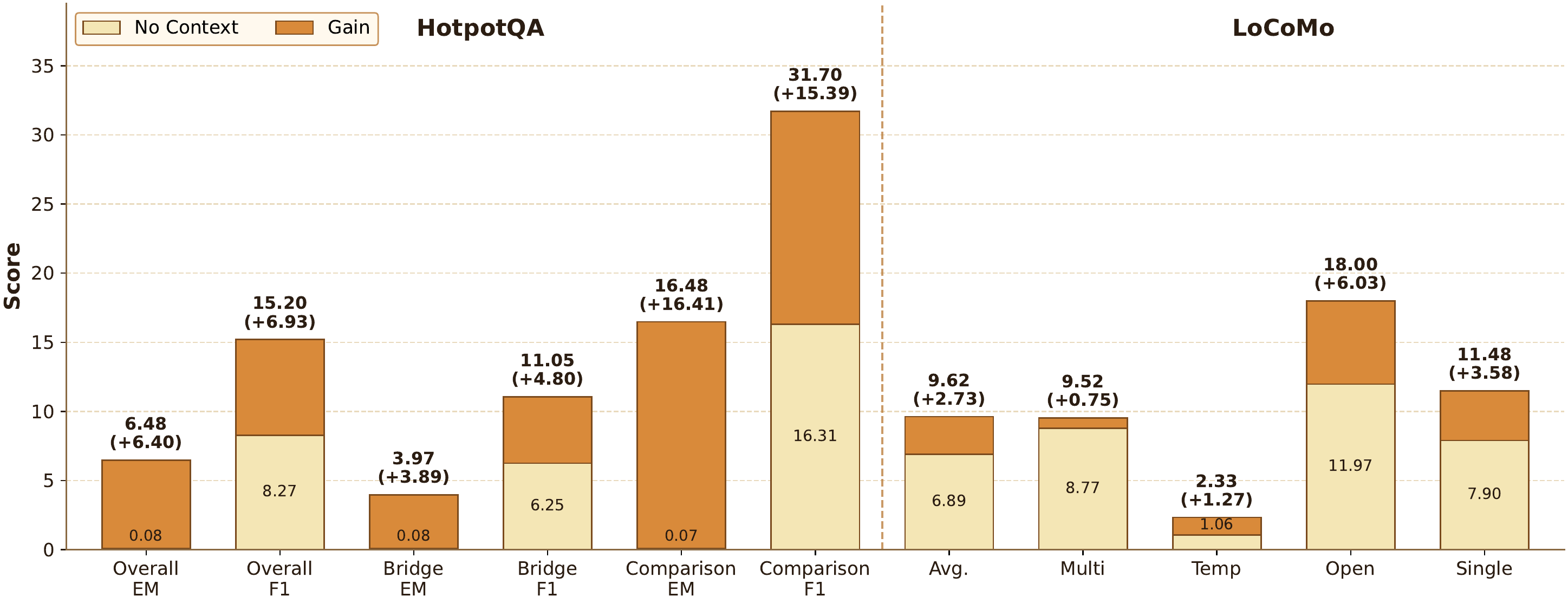
To examine whether the online state of associative memory can preserve useful historical information without explicit context replay, we evaluate δ-mem under a no-context setting, where the original historical context is removed and only the compressed memory state is injected. As shown in Figure 2, δ-mem consistently improves over the no-context baseline on both HotpotQA and LoCoMo. On HotpotQA, the overall EM increases from 0.08% to 6.48%, and the overall F1 improves from 8.27% to 15.20%. The gains are especially large on the Bridge subset, where EM rises from 0.08% to 3.97% and F1 increases from 6.25% to 11.05%, indicating that the online state can recover part of the missing multi-hop evidence. On LoCoMo, δ-mem also improves the overall average from 3.49% to 8.05%, with clear gains across multi-hop, temporal, open-domain, and single-hop questions. These results suggest that the online state of associative memory stores context-relevant historical signals that can be reused when explicit context is unavailable.
为了考察在线联想记忆状态是否能在没有显式上下文回放的情况下保留有用历史信息,作者在 no-context 设置下评估 δ-mem,其中原始历史上下文被移除,只注入压缩后的记忆状态。 如 图2 所示,δ-mem 在 HotpotQA 和 LoCoMo 上都持续优于 no-context 基线。 在 HotpotQA 上,整体 EM 从 0.08% 提升到 6.48%,整体 F1 从 8.27% 提升到 15.20%。 Bridge 子集上的收益尤其明显,EM 从 0.08% 上升到 3.97%,F1 从 6.25% 上升到 11.05%,说明在线状态能够恢复部分缺失的多跳证据。 在 LoCoMo 上,δ-mem 也将整体平均分从 3.49% 提升到 8.05%,并在多跳、时间、开放域和单跳问题上都有明显收益。 这些结果说明,在线联想记忆状态存储了与上下文相关的历史信号,可在显式上下文不可用时复用。
5.2. Heads Ablation
| Head | HotpotQA | LoCoMo | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Bridge | Comparison | Avg. | Multi | Temp | Open | Single | |||||
| EM | F1 | EM | F1 | EM | F1 | |||||||
| q | 45.87 | 60.59 | 44.96 | 60.34 | 49.50 | 61.58 | 43.15 | 42.43 | 33.60 | 10.03 | 50.82 | 44.51 |
| k | 43.39 | 57.28 | 42.35 | 56.82 | 47.55 | 59.09 | 40.98 | 38.44 | 33.12 | 10.93 | 48.26 | 42.19 |
| v | 46.12 | 60.95 | 45.07 | 60.54 | 50.30 | 62.57 | 42.35 | 39.54 | 34.24 | 11.11 | 49.95 | 44.24 |
| o | 48.94 | 63.69 | 47.67 | 63.58 | 54.00 | 64.15 | 45.15 | 39.68 | 36.31 | 12.77 | 54.06 | 47.05 |
| qk | 45.46 | 59.62 | 44.19 | 59.12 | 50.50 | 61.59 | 42.94 | 40.64 | 33.65 | 10.09 | 51.01 | 44.20 |
| qv | 47.02 | 61.95 | 45.86 | 61.64 | 51.65 | 63.20 | 43.24 | 40.38 | 35.57 | 10.76 | 50.84 | 45.13 |
| qo | 49.41 | 63.66 | 47.65 | 63.22 | 56.42 | 65.42 | 46.53 | 42.14 | 37.20 | 13.35 | 55.36 | 47.97 |
| kv | 45.67 | 60.43 | 44.90 | 60.25 | 48.76 | 61.14 | 42.02 | 39.45 | 33.91 | 11.00 | 49.52 | 43.85 |
| qko | 48.24 | 62.42 | 46.79 | 62.11 | 54.00 | 63.66 | 46.01 | 40.89 | 36.82 | 12.61 | 55.05 | 47.13 |
| qkv | 47.47 | 62.56 | 46.40 | 62.25 | 51.71 | 63.81 | 42.42 | 39.40 | 34.70 | 10.04 | 50.08 | 44.95 |
| qkvo | 49.94 | 65.01 | 48.39 | 64.63 | 56.09 | 66.56 | 46.15 | 41.08 | 37.25 | 13.14 | 55.02 | 48.05 |
We first study where the memory-induced correction should be injected within the attention block. As shown in Table 3, applying δ-mem to both query and output branches already yields strong performance, suggesting that query-side and output-side corrections provide an effective interface for memory injection. Among single-branch variants, the output branch performs best, achieving an average score of 47.05%, while the key branch is less effective. Combining multiple branches further improves performance. The full qkvo configuration achieves the best average score of 48.05%. These results suggest that associative memory signals are most effective when they can jointly influence query formation, key-value interaction, and output representation. While qkvo yields the highest average score, its marginal gain over qo does not justify the extra parameter overhead. Thus, we default to qo for an optimal performance-efficiency trade-off.
作者首先研究记忆诱导的修正应当注入注意力块的哪个位置。 如 表3 所示,同时把 δ-mem 应用于 query 分支和 output 分支已经能带来强劲表现,说明 query 侧和 output 侧修正为记忆注入提供了有效接口。 在单分支变体中,output 分支表现最好,平均分达到 47.05%,而 key 分支效果较弱。 组合多个分支可以进一步提升表现。 完整 qkvo 配置取得最佳平均分 48.05%。 这些结果说明,当联想记忆信号能够共同影响 query 形成、key-value 交互和 output 表示时最有效。 虽然 qkvo 取得最高平均分,但它相较 qo 的边际收益不足以证明额外参数开销合理。 因此,作者默认使用 qo,以取得最佳性能-效率权衡。
5.3. Insertion Depth Ablation
| Layer | HotpotQA | LoCoMo | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Bridge | Comparison | Avg. | Multi | Temp | Open | Single | |||||
| EM | F1 | EM | F1 | EM | F1 | |||||||
| Front 12 | 45.52 | 61.01 | 45.32 | 61.08 | 46.33 | 60.77 | 43.26 | 39.06 | 33.65 | 10.19 | 52.10 | 44.39 |
| Middle 12 | 47.44 | 60.59 | 45.56 | 60.06 | 54.94 | 62.71 | 45.87 | 44.00 | 35.75 | 13.09 | 54.10 | 46.66 |
| Back 12 | 44.58 | 59.04 | 43.56 | 58.65 | 48.62 | 60.58 | 43.53 | 40.60 | 36.31 | 11.11 | 50.97 | 44.06 |
| All Layers | 49.41 | 63.66 | 47.65 | 63.22 | 56.42 | 65.42 | 46.53 | 42.14 | 37.20 | 13.35 | 55.36 | 47.97 |
Table 4 studies the insertion depth of δ-mem across model's layers. Applying memory correction to all layers achieves the best overall performance, with an average score of 47.97%. It also obtains the strongest HotpotQA result, improving the overall EM/F1 to 49.41%/63.66%, and reaches the best LoCoMo average of 46.53%. These results suggest that associative memory signals are most effective when they can influence the representation hierarchy across the full depth of the backbone. Among partial-layer variants, the middle-layer configuration performs best, reaching an average score of 46.66%. It clearly outperforms both the front-layer and back-layer configurations on the final average score. This indicates that intermediate layers provide a particularly effective interface for memory injection, balancing semantic abstraction and task-specific computation. In contrast, front-layer injections act on overly local representations, while back-layer injections leave insufficient depth for associative memory signals to propagate through subsequent computations.
表4 研究 δ-mem 在模型各层中的插入深度。 把记忆修正应用到所有层取得最佳整体表现,平均分为 47.97%。 它还取得最强 HotpotQA 结果,将整体 EM/F1 提升到 49.41%/63.66%,并达到最佳 LoCoMo 平均分 46.53%。 这些结果说明,当联想记忆信号能够影响骨干模型完整深度上的表示层级时最有效。 在部分层变体中,中间层配置表现最好,平均分达到 46.66%。 它在最终平均分上明显优于前层和后层配置。 这表明中间层为记忆注入提供了特别有效的接口,能够平衡语义抽象和任务特定计算。 相比之下,前层注入作用于过于局部的表示,而后层注入留给联想记忆信号在后续计算中传播的深度不足。
6. Related Work
Textual Memory Mechanisms. Textual memory mechanisms externalize memory as text entries, summaries, or retrievable documents, and re-inject selected evidence into the input context or retrieval-augmented generation process. Early retrieval-augmented systems demonstrate the effectiveness of scalable textual stores for knowledge-intensive generation, while later agent-oriented methods extend this paradigm to continuous interaction by organizing past history and experience through logging, summarization, and reflection. Despite their flexibility, textual memory remains constrained by its tokenized form: memory use is sensitive to compression fidelity, retrieval noise, and context budget. δ-mem does not route compressed history back through token space. Instead, it maintains a compact online state and uses its readout to steer the frozen Transformer through low-rank attention corrections, separating memory maintenance from prompt-level reinsertion.
文本记忆机制。 文本记忆机制把记忆外部化为文本条目、摘要或可检索文档,并把选中的证据重新注入输入上下文或检索增强生成过程。 早期检索增强系统展示了可扩展文本存储在知识密集型生成中的有效性,而后续面向智能体的方法通过日志、摘要和反思组织过去历史与经验,把这一范式扩展到连续交互。 尽管灵活,文本记忆仍受到其 token 化形式限制:记忆使用对压缩保真度、检索噪声和上下文预算敏感。 δ-mem 不会把压缩历史重新路由回 token 空间。 相反,它维护一个紧凑在线状态,并用其读出来通过低秩注意力修正 steering 冻结 Transformer,从而把记忆维护与提示级重新插入分离开。
Outside-Channel Memory Mechanisms. A related line of work stores memory outside the backbone while preserving it in latent rather than textual form. Memorizing Transformers store past internal representations as non-differentiable key-value memories and retrieve them with approximate kNN, while LongMem uses a frozen backbone as a memory encoder and an adaptive residual side network to read from an external memory bank. Compared with textual memory, latent memory can avoid part of the information loss introduced by natural-language summarization and preserve richer internal representations. However, memory still interacts with the backbone through a separate retrieval or reader pathway, introducing retrieval overhead, fusion complexity, and possible mismatch between stored and current representations. δ-mem differs in that its memory is not retrieved as an auxiliary external source; instead, its compact online state directly produces low-rank corrections to the attention computation, allowing memory to participate in the current forward pass.
外部通道记忆机制。 另一类相关工作把记忆存储在骨干模型之外,同时以 latent 而非文本形式保存。 Memorizing Transformers 把过去内部表示存成不可微 key-value 记忆,并用近似 kNN 检索;LongMem 则使用冻结骨干作为记忆编码器,并用自适应残差侧网络从外部记忆库读取。 相比文本记忆,latent 记忆可以避免自然语言摘要引入的部分信息损失,并保留更丰富的内部表示。 然而,记忆仍然通过单独的检索或读取路径与骨干交互,会引入检索开销、融合复杂性,以及存储表示与当前表示之间可能的错配。 δ-mem 的不同之处在于,它的记忆不是作为辅助外部来源被检索;相反,其紧凑在线状态会直接产生对注意力计算的低秩修正,使记忆参与当前前向传播。
Parametric Memory Mechanisms. Parametric memory mechanisms encode memory into additional parameters or localized weight edits. Prefix-Tuning learns continuous virtual tokens for a frozen model, while LoRA injects low-rank trainable updates into selected layers, showing that small parameter additions can effectively steer model behavior. Model-editing methods such as ROME and MEMIT further treat parameters as a writable memory substrate by inserting factual associations through localized or low-rank weight updates. However, these methods are less suited to online memory: their memory is usually fixed after training or updated through discrete editing steps, rather than evolving continuously with the sequence. Their write granularity is also less aligned with interaction history, which often unfolds at token-, message-, or segment-level resolution. As a result, parametric memory often acts as a persistent modification to model behavior, rather than a state-conditioned memory mechanism whose influence changes with the current history. δ-mem is close to LoRA in its low-rank interface, but differs fundamentally in that LoRA's low-rank update is static, whereas δ-mem generates low-rank attention corrections from a compact online state at runtime.
参数化记忆机制。 参数化记忆机制把记忆编码进额外参数或局部权重编辑中。 Prefix-Tuning 为冻结模型学习连续虚拟 token,而 LoRA 把低秩可训练更新注入选定层,说明小规模参数添加可以有效 steering 模型行为。 ROME 和 MEMIT 等模型编辑方法进一步把参数视为可写记忆基底,通过局部或低秩权重更新插入事实关联。 然而,这些方法不太适合在线记忆:它们的记忆通常在训练后固定,或通过离散编辑步骤更新,而不是随序列连续演化。 它们的写入粒度也不太符合交互历史,因为交互历史往往以 token、message 或 segment 级分辨率展开。 因此,参数化记忆往往像是对模型行为的持久修改,而不是一种受状态条件控制、其影响随当前历史变化的记忆机制。 δ-mem 在低秩接口上接近 LoRA,但根本区别在于 LoRA 的低秩更新是静态的,而 δ-mem 会在运行时从紧凑在线状态生成低秩注意力修正。
7. Conclusion
In this work, we introduced δ-mem, a lightweight memory mechanism that equips a frozen full-attention backbone with a compact and dynamically updated online state of associative memory. δ-mem compresses past information into a fixed-size online state and uses its readout to generate low-rank corrections to the backbone's attention components. This design allows memory to be maintained online and to directly participate in forward computation without full fine-tuning or replacing the backbone architecture.
本文提出 δ-mem,一种轻量级记忆机制,为冻结全注意力骨干配备紧凑且动态更新的在线联想记忆状态。 δ-mem 将过去信息压缩到固定大小的在线状态中,并用其读出结果为骨干模型的注意力组件生成低秩修正。 这一设计使记忆能够在线维护,并直接参与前向计算,而无需完整微调或替换骨干架构。
Empirically, δ-mem improves performance on memory-heavy benchmarks while largely preserving the general capabilities of the frozen backbone. Notably, even with an extremely small
在经验结果上,δ-mem 提升了记忆密集型基准表现,同时基本保留冻结骨干的通用能力。 尤其值得注意的是,即使使用极小的