
A-Mem: Agentic Memory for LLM Agents
NeurIPS 2025Code for benchmark evaluation: https://github.com/WujiangXu/AgenticMemory
Code for production-ready agentic memory: https://github.com/WujiangXu/A-mem-sys
A-Mem:面向 LLM 智能体的智能体式记忆
Abstract
While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems' fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution -- as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines.
大型语言模型(LLM)智能体虽然能够有效使用外部工具来完成复杂真实任务,但仍然需要记忆系统来利用历史经验。 当前记忆系统可以完成基本的存储与检索,即便近期已有工作尝试引入图数据库,它们仍然缺乏精细的记忆组织能力。 此外,这些系统固定的操作方式和结构也限制了它们在多样化任务中的适应性。 为了解决这一限制,本文提出了一种用于 LLM 智能体的新型智能体式记忆系统,它能够以更具自主性的方式动态组织记忆。 遵循 Zettelkasten 方法的基本原则,作者设计的记忆系统通过动态索引和链接来创建相互连接的知识网络。 当新记忆被加入时,系统会生成一条包含多种结构化属性的完整笔记,包括上下文描述、关键词和标签。 随后,系统会分析历史记忆以识别相关连接,并在存在有意义相似性时建立链接。 此外,这一过程还支持记忆演化:随着新记忆被整合,它们可以触发已有历史记忆的上下文表示和属性更新,使整个记忆网络持续修正自身理解。 该方法结合了 Zettelkasten 的结构化组织原则和智能体驱动决策的灵活性,从而实现更具适应性、也更能感知上下文的记忆管理。 在六个基础模型上的实验证明,该方法相较现有 SOTA 基线取得了更优提升。
1. Introduction
Large Language Model (LLM) agents have demonstrated remarkable capabilities in various tasks, with recent advances enabling them to interact with environments, execute tasks, and make decisions autonomously. They integrate LLMs with external tools and delicate workflows to improve reasoning and planning abilities. Though LLM agent has strong reasoning performance, it still needs a memory system to provide long-term interaction ability with the external environment.
大型语言模型(LLM)智能体已经在多种任务中展现出显著能力,近期进展也使它们能够与环境交互、执行任务并自主决策。 这类智能体通常将 LLM 与外部工具和精细工作流结合起来,以提升推理和规划能力。 虽然 LLM 智能体具备较强推理表现,但它仍然需要记忆系统,才能与外部环境进行长期交互。
Existing memory systems for LLM agents provide basic memory storage functionality. These systems require agent developers to predefine memory storage structures, specify storage points within the workflow, and establish retrieval timing. Meanwhile, to improve structured memory organization, Mem0 incorporates graph databases for storage and retrieval processes. While graph databases provide structured organization for memory systems, their reliance on predefined schemas and relationships fundamentally limits their adaptability. This limitation manifests clearly in practical scenarios: when an agent learns a novel mathematical solution, current systems can only categorize and link this information within their preset framework, unable to forge innovative connections or develop new organizational patterns as knowledge evolves. Such rigid structures, coupled with fixed agent workflows, severely restrict these systems' ability to generalize across new environments and maintain effectiveness in long-term interactions. Therefore, how to design a flexible and universal memory system that supports LLM agents' long-term interactions remains a crucial challenge.
现有 LLM 智能体记忆系统提供了基本的记忆存储功能。 这些系统要求智能体开发者预先定义记忆存储结构,在工作流中指定存储位置,并规定何时进行检索。 与此同时,为了改进结构化记忆组织,Mem0 将图数据库引入存储和检索过程。 虽然图数据库能为记忆系统提供结构化组织,但它依赖预定义模式和关系,这从根本上限制了适应性。 这种限制在实践中非常明显:当智能体学到一种新的数学解法时,当前系统只能在预设框架内对信息分类和链接,无法随着知识演化创造新的连接或发展新的组织模式。 这种刚性结构再加上固定智能体工作流,会严重限制系统在新环境中的泛化能力,也会削弱长期交互中的有效性。 因此,如何设计一个灵活且通用、能够支持 LLM 智能体长期交互的记忆系统仍然是关键挑战。
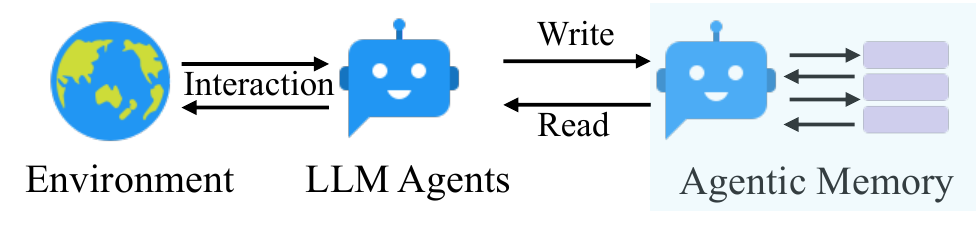
In this paper, we introduce a novel agentic memory system, named A-Mem, for LLM agents that enables dynamic memory structuring without relying on static, predetermined memory operations. Our approach draws inspiration from the Zettelkasten method, a sophisticated knowledge management system that creates interconnected information networks through atomic notes and flexible linking mechanisms. Our system introduces an agentic memory architecture that enables autonomous and flexible memory management for LLM agents. For each new memory, we construct comprehensive notes that integrate multiple representations: structured textual attributes and embedding vectors for similarity matching. Then A-Mem analyzes the historical memory repository to establish meaningful connections based on semantic similarities and shared attributes. This integration process not only creates new links but also enables dynamic evolution: when new memories are incorporated, they can trigger updates to contextual representations of existing memories, allowing the entire memory system to refine and deepen its understanding over time. The distinction between traditional memory systems and A-Mem is shown in Figure 1.
本文提出一种面向 LLM 智能体的新型智能体式记忆系统 A-Mem,它能够动态构建记忆结构,而不依赖静态、预先确定的记忆操作。 该方法受到 Zettelkasten 方法启发;Zettelkasten 是一种复杂知识管理系统,通过原子笔记和灵活链接机制创建互联的信息网络。 A-Mem 引入一种智能体式记忆架构,使 LLM 智能体能够自主、灵活地管理记忆。 对于每条新记忆,系统会构造综合笔记,将多种表示整合起来:包括结构化文本属性,以及用于相似度匹配的嵌入向量。 随后,A-Mem 会分析历史记忆库,并基于语义相似性和共享属性建立有意义的连接。 这一整合过程不仅会创建新链接,还支持动态演化:当新记忆被纳入时,它们可以触发已有记忆上下文表示的更新,使整个记忆系统随着时间不断修正并深化理解。 传统记忆系统与 A-Mem 的区别如图1所示。
The contributions are summarized as follows. First, we present A-Mem, an agentic memory system for LLM agents that enables autonomous generation of contextual descriptions, dynamic establishment of memory connections, and intelligent evolution of existing memories based on new experiences. Second, we design an agentic memory update mechanism where new memories automatically trigger two key operations: link generation and memory evolution. Link generation automatically establishes connections between memories by identifying shared attributes and similar contextual descriptions. Memory evolution enables existing memories to dynamically adapt as new experiences are analyzed, leading to the emergence of higher-order patterns and attributes. Third, we conduct comprehensive evaluations using a long-term conversational dataset, compare six foundation models across six evaluation metrics, and provide t-SNE visualizations to illustrate the structured organization of A-Mem.
本文贡献可以概括如下。 第一,作者提出 A-Mem,这是一个面向 LLM 智能体的智能体式记忆系统,能够基于新经验自主生成上下文描述、动态建立记忆连接,并智能演化已有记忆。 第二,作者设计了一种智能体式记忆更新机制,新记忆会自动触发两个关键操作:链接生成和记忆演化。 链接生成会通过识别共享属性和相似上下文描述,自动在记忆之间建立连接。 记忆演化使已有记忆在分析新经验时动态适应,从而产生更高阶的模式和属性。 第三,作者使用长期对话数据集进行全面评估,在六个基础模型和六类评估指标上进行比较,并提供 t-SNE 可视化来展示 A-Mem 的结构化组织效果。
2. Related Work
2.1. Memory for LLM Agents
Prior works on LLM agent memory systems have explored various mechanisms for memory management and utilization. Some approaches store complete interactions, maintaining comprehensive historical records through dense retrieval models or read-write memory structures. Moreover, MemGPT leverages cache-like architectures to prioritize recent information. Similarly, SCM proposes a Self-Controlled Memory framework that enhances LLMs' capability to maintain long-term memory through a memory stream and controller mechanism. However, these approaches face significant limitations in handling diverse real-world tasks. While they can provide basic memory functionality, their operations are typically constrained by predefined structures and fixed workflows. Such inflexibility leads to poor generalization in new environments and limited effectiveness in long-term interactions. Therefore, designing a flexible and universal memory system that supports agents' long-term interactions remains a crucial challenge.
已有 LLM 智能体记忆系统研究探索了多种记忆管理与使用机制。 有些方法会存储完整交互,并通过密集检索模型或读写记忆结构维护全面历史记录。 此外,MemGPT 利用类似缓存的架构来优先保留近期信息。 类似地,SCM 提出 Self-Controlled Memory 框架,通过记忆流和控制器机制增强 LLM 维护长期记忆的能力。 然而,这些方法在处理多样化真实任务时面临显著限制。 它们虽然可以提供基本记忆功能,但操作通常受限于预定义结构和固定工作流。 这种不灵活性会导致模型在新环境中泛化较差,并限制长期交互中的有效性。 因此,设计一个支持智能体长期交互的灵活通用记忆系统仍然是关键挑战。
2.2. Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) has emerged as a powerful approach to enhance LLMs by incorporating external knowledge sources. The standard RAG process involves indexing documents into chunks, retrieving relevant chunks based on semantic similarity, and augmenting the LLM's prompt with this retrieved context for generation. Advanced RAG systems have evolved to include sophisticated pre-retrieval and post-retrieval optimizations. Building upon these foundations, recent research has introduced agentic RAG systems that demonstrate more autonomous and adaptive behaviors in the retrieval process. These systems can dynamically determine when and what to retrieve, generate hypothetical responses to guide retrieval, and iteratively refine their search strategies based on intermediate results.
检索增强生成(RAG)已经成为增强 LLM 的重要方法,它通过引入外部知识源来补充模型能力。 标准 RAG 流程通常包括:将文档切分并建立索引,基于语义相似度检索相关片段,再把检索到的上下文加入 LLM 提示中用于生成。 更高级的 RAG 系统进一步发展出复杂的检索前和检索后优化。 在这些基础上,近期研究提出了 agentic RAG 系统,使检索过程呈现出更强的自主性和适应性。 这些系统可以动态决定何时检索、检索什么,生成假设回答来引导检索,并根据中间结果迭代优化搜索策略。
However, while agentic RAG approaches demonstrate agency in the retrieval phase by autonomously deciding when and what to retrieve, our agentic memory system exhibits agency at a more fundamental level through the autonomous evolution of its memory structure. Inspired by the Zettelkasten method, our system allows memories to actively generate their own contextual descriptions, form meaningful connections with related memories, and evolve both their content and relationships as new experiences emerge. This fundamental distinction in agency between retrieval versus storage and evolution distinguishes our approach from agentic RAG systems, which maintain static knowledge bases despite their sophisticated retrieval mechanisms.
然而,agentic RAG 的自主性主要体现在检索阶段,即自主决定何时检索和检索什么;A-Mem 的智能体式记忆则在更基础的层面体现自主性,也就是记忆结构本身可以自主演化。 受到 Zettelkasten 方法启发,A-Mem 允许记忆主动生成自身上下文描述,与相关记忆形成有意义连接,并随着新经验出现不断演化内容与关系。 这种“检索阶段的自主性”和“存储与演化层面的自主性”之间的根本差异,使 A-Mem 区别于那些虽然检索机制复杂、但知识库仍然静态的 agentic RAG 系统。
3. Methodology
The proposed agentic memory system draws inspiration from the Zettelkasten method, implementing a dynamic and self-evolving memory system that enables LLM agents to maintain long-term memory without predetermined operations. The system's design emphasizes atomic note-taking, flexible linking mechanisms, and continuous evolution of knowledge structures. The overall architecture is shown in Figure 2.
本文提出的智能体式记忆系统受到 Zettelkasten 方法启发,实现了一个动态且自演化的记忆系统,使 LLM 智能体能够在没有预设操作的情况下维持长期记忆。 系统设计强调原子化笔记、灵活链接机制和知识结构的持续演化。 整体架构如图2所示。
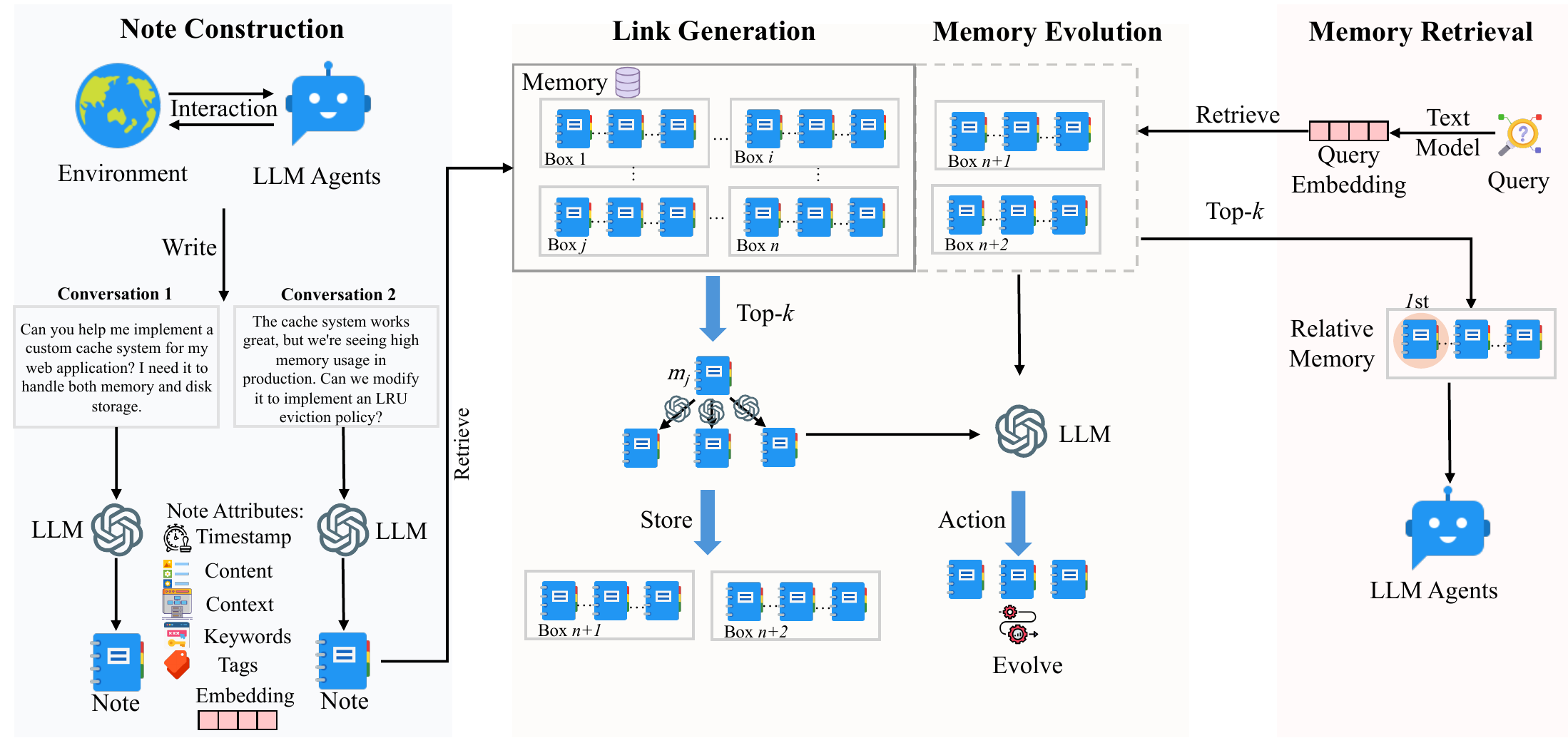
3.1. Note Construction
Building upon the Zettelkasten method's principles of atomic note-taking and flexible organization, the authors introduce an LLM-driven approach to memory note construction. When an agent interacts with its environment, the system constructs structured memory notes that capture both explicit information and LLM-generated contextual understanding. Each memory note
基于 Zettelkasten 方法中的原子化笔记和灵活组织原则,作者提出了一种由 LLM 驱动的记忆笔记构建方法。 当智能体与环境交互时,系统会构造结构化记忆笔记,同时捕捉显式信息和由 LLM 生成的上下文理解。 记忆集合
Here
其中,
Following the Zettelkasten principle of atomicity, each note captures a single, self-contained unit of knowledge. The multi-faceted note structure creates rich representations that capture different aspects of memory, facilitating nuanced organization and retrieval. The combination of LLM-generated semantic components and dense vector representations provides both context and computationally efficient similarity matching.
遵循 Zettelkasten 的原子性原则,每条笔记捕捉一个单一且自包含的知识单元。 这种多面向笔记结构能形成丰富表示,捕捉记忆的不同侧面,从而支持更细粒度的组织和检索。 LLM 生成的语义组件与密集向量表示结合起来,既提供上下文信息,也支持计算上高效的相似度匹配。
3.2. Link Generation
A-Mem implements an autonomous link generation mechanism that enables new memory notes to form meaningful connections without predefined rules. When a newly constructed memory note
A-Mem 实现了一种自主链接生成机制,使新记忆笔记无需预定义规则即可形成有意义的连接。 当新构造的记忆笔记
The system identifies the top-
系统会识别最相关的 top-
Embedding-based retrieval serves as an initial filter, enabling scalability while maintaining semantic relevance. More importantly, LLM-driven analysis allows for nuanced understanding of relationships that go beyond simple similarity metrics. The language model can identify subtle patterns, causal relationships, and conceptual connections that might not be apparent from embedding similarity alone.
基于嵌入的检索首先充当过滤器,使系统既能扩展到较大记忆集合,又能维持语义相关性。 更重要的是,由 LLM 驱动的分析可以理解超越简单相似度指标的细微关系。 语言模型能够识别单靠嵌入相似度不一定显现的微妙模式、因果关系和概念连接。
3.3. Memory Evolution
After creating links for the new memory, A-Mem evolves the retrieved memories based on their textual information and relationships with the new memory. For each memory
在为新记忆创建链接之后,A-Mem 会根据被检索记忆的文本信息以及它们与新记忆的关系,对这些记忆进行演化。 对于最近邻集合
The evolved memory
随后,演化后的记忆
3.4. Retrieve Relative Memory
In each interaction, A-Mem performs context-aware memory retrieval to provide the agent with relevant historical information. Given a query text
在每次交互中,A-Mem 会执行上下文感知的记忆检索,为智能体提供相关历史信息。 给定当前交互中的查询文本
The retrieved memories provide relevant historical context that helps the agent better understand and respond to the current interaction. The retrieved context enriches the agent's reasoning process by connecting the current interaction with related past experiences stored in the memory system.
检索出的记忆会提供相关历史上下文,帮助智能体更好地理解并回应当前交互。 这些检索上下文会把当前交互与记忆系统中存储的相关过去经验连接起来,从而丰富智能体的推理过程。
4. Experiment
4.1. Dataset and Evaluation
To evaluate the effectiveness of instruction-aware recommendation in long-term conversations, the authors utilize the LoCoMo dataset, which contains significantly longer dialogues compared to existing conversational datasets. While previous datasets contain dialogues with around 1K tokens over 4-5 sessions, LoCoMo features much longer conversations averaging 9K tokens spanning up to 35 sessions. This makes LoCoMo particularly suitable for evaluating models' ability to handle long-range dependencies and maintain consistency over extended conversations. The dataset contains five question types: single-hop, multi-hop, temporal reasoning, open-domain knowledge, and adversarial questions. In total, LoCoMo contains 7,512 question-answer pairs across these categories. The authors also use DialSim, a question-answering dataset derived from long-term multi-party dialogues from popular TV shows.
为了评估长期对话中指令感知推荐的有效性,作者使用了 LoCoMo 数据集;与已有对话数据集相比,它包含明显更长的对话。 以往数据集通常包含 4-5 个会话、约 1K token 的对话,而 LoCoMo 的对话平均约 9K token,最多跨越 35 个会话。 因此,LoCoMo 非常适合评估模型处理长程依赖、并在扩展对话中保持一致性的能力。 该数据集包含五类问题:单跳、多跳、时间推理、开放域知识和对抗问题。 LoCoMo 总共包含 7,512 个覆盖这些类别的问答对。 作者还使用 DialSim,这是一个来自热门电视剧长期多人对话的问答数据集。
For comparison baselines, the authors compare against LoCoMo, ReadAgent, MemoryBank, and MemGPT. For evaluation, they employ two primary metrics: F1 score to assess answer accuracy by balancing precision and recall, and BLEU-1 to evaluate generated response quality by measuring word overlap with ground truth responses. The paper also reports average token length for answering one question and provides additional metrics in the appendix.
在对比基线方面,作者比较了 LoCoMo、ReadAgent、MemoryBank 和 MemGPT。 评估时主要使用两个指标:F1 分数用于通过平衡精确率与召回率评估答案准确性,BLEU-1 用于通过与真实答案的词重叠衡量生成回答质量。 论文还报告了回答单个问题的平均 token 长度,并在附录中提供更多指标。
4.2. Implementation Details
For all baselines and the proposed method, the authors maintain consistency by employing identical system prompts. The deployment of Qwen-1.5B/3B and Llama 3.2 1B/3B models is accomplished through local instantiation using Ollama, with LiteLLM managing structured output generation. For GPT models, the authors utilize the official structured output API. In the memory retrieval process, the method primarily employs
对于所有基线和本文方法,作者使用相同系统提示来保持一致性。 Qwen-1.5B/3B 和 Llama 3.2 1B/3B 通过 Ollama 在本地部署,并使用 LiteLLM 管理结构化输出生成。 对于 GPT 模型,作者使用官方结构化输出 API。 在记忆检索过程中,方法主要使用
4.3. Empirical Results
In the empirical evaluation, A-Mem is compared with four competitive baselines on the LoCoMo dataset. For non-GPT foundation models, A-Mem consistently outperforms all baselines across different categories, demonstrating the effectiveness of the agentic memory approach. For GPT-based models, LoCoMo and MemGPT show strong performance in certain categories such as Open Domain and Adversarial tasks due to their robust pre-trained knowledge in simple fact retrieval. However, A-Mem demonstrates superior performance in Multi-Hop tasks that require complex reasoning chains, achieving at least two times better performance in several settings. The complete LoCoMo results are shown in Table 1.
在实证评估中,作者在 LoCoMo 数据集上将 A-Mem 与四个有竞争力的基线进行了比较。 对于非 GPT 基础模型,A-Mem 在不同类别上持续优于所有基线,体现了智能体式记忆方法的有效性。 对于 GPT 系模型,由于它们在简单事实检索方面具备较强预训练知识,LoCoMo 和 MemGPT 在 Open Domain 和 Adversarial 等特定类别上表现较强。 然而,在需要复杂推理链的 Multi-Hop 任务上,A-Mem 展现出更优性能,并在多个设置中至少取得两倍以上提升。 完整 LoCoMo 结果见表1。
| Model | Method | Category | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Multi Hop | Temporal | Open Domain | Single Hop | Adversarial | Ranking | Token Length | |||||||||
| F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | ||||
| GPT | 4o-mini | LoCoMo | 25.02 | 19.75 | 18.41 | 14.77 | 12.04 | 11.16 | 40.36 | 29.05 | 69.23 | 68.75 | 2.4 | 2.4 | 16,910 |
| ReadAgent | 9.15 | 6.48 | 12.60 | 8.87 | 5.31 | 5.12 | 9.67 | 7.66 | 9.81 | 9.02 | 4.2 | 4.2 | 643 | ||
| MemoryBank | 5.00 | 4.77 | 9.68 | 6.99 | 5.56 | 5.94 | 6.61 | 5.16 | 7.36 | 6.48 | 4.8 | 4.8 | 432 | ||
| MemGPT | 26.65 | 17.72 | 25.52 | 19.44 | 9.15 | 7.44 | 41.04 | 34.34 | 43.29 | 42.73 | 2.4 | 2.4 | 16,977 | ||
| A-Mem | 27.02 | 20.09 | 45.85 | 36.67 | 12.14 | 12.00 | 44.65 | 37.06 | 50.03 | 49.47 | 1.2 | 1.2 | 2,520 | ||
| 4o | LoCoMo | 28.00 | 18.47 | 9.09 | 5.78 | 16.47 | 14.80 | 61.56 | 54.19 | 52.61 | 51.13 | 2.0 | 2.0 | 16,910 | |
| ReadAgent | 14.61 | 9.95 | 4.16 | 3.19 | 8.84 | 8.37 | 12.46 | 10.29 | 6.81 | 6.13 | 4.0 | 4.0 | 805 | ||
| MemoryBank | 6.49 | 4.69 | 2.47 | 2.43 | 6.43 | 5.30 | 8.28 | 7.10 | 4.42 | 3.67 | 5.0 | 5.0 | 569 | ||
| MemGPT | 30.36 | 22.83 | 17.29 | 13.18 | 12.24 | 11.87 | 60.16 | 53.35 | 34.96 | 34.25 | 2.4 | 2.4 | 16,987 | ||
| A-Mem | 32.86 | 23.76 | 39.41 | 31.23 | 17.10 | 15.84 | 48.43 | 42.97 | 36.35 | 35.53 | 1.6 | 1.6 | 1,216 | ||
| Qwen2.5 | 1.5B | LoCoMo | 9.05 | 6.55 | 4.25 | 4.04 | 9.91 | 8.50 | 11.15 | 8.67 | 40.38 | 40.23 | 3.4 | 3.4 | 16,910 |
| ReadAgent | 6.61 | 4.93 | 2.55 | 2.51 | 5.31 | 12.24 | 10.13 | 7.54 | 5.42 | 27.32 | 4.6 | 4.6 | 752 | ||
| MemoryBank | 11.14 | 8.25 | 4.46 | 2.87 | 8.05 | 6.21 | 13.42 | 11.01 | 36.76 | 34.00 | 2.6 | 2.6 | 284 | ||
| MemGPT | 10.44 | 7.61 | 4.21 | 3.89 | 13.42 | 11.64 | 9.56 | 7.34 | 31.51 | 28.90 | 3.4 | 3.4 | 16,953 | ||
| A-Mem | 18.23 | 11.94 | 24.32 | 19.74 | 16.48 | 14.31 | 23.63 | 19.23 | 46.00 | 43.26 | 1.0 | 1.0 | 1,300 | ||
| 3B | LoCoMo | 4.61 | 4.29 | 3.11 | 2.71 | 4.55 | 5.97 | 7.03 | 5.69 | 16.95 | 14.81 | 3.2 | 3.2 | 16,910 | |
| ReadAgent | 2.47 | 1.78 | 3.01 | 3.01 | 5.57 | 5.22 | 3.25 | 2.51 | 15.78 | 14.01 | 4.2 | 4.2 | 776 | ||
| MemoryBank | 3.60 | 3.39 | 1.72 | 1.97 | 6.63 | 6.58 | 4.11 | 3.32 | 13.07 | 10.30 | 4.2 | 4.2 | 298 | ||
| MemGPT | 5.07 | 4.31 | 2.94 | 2.95 | 7.04 | 7.10 | 7.26 | 5.52 | 14.47 | 12.39 | 2.4 | 2.4 | 16,961 | ||
| A-Mem | 12.57 | 9.01 | 27.59 | 25.07 | 7.12 | 7.28 | 17.23 | 13.12 | 27.91 | 25.15 | 1.0 | 1.0 | 1,137 | ||
| Llama 3.2 | 1B | LoCoMo | 11.25 | 9.18 | 7.38 | 6.82 | 11.90 | 10.38 | 12.86 | 10.50 | 51.89 | 48.27 | 3.4 | 3.4 | 16,910 |
| ReadAgent | 5.96 | 5.12 | 1.93 | 2.30 | 12.46 | 11.17 | 7.75 | 6.03 | 44.64 | 40.15 | 4.6 | 4.6 | 665 | ||
| MemoryBank | 13.18 | 10.03 | 7.61 | 6.27 | 15.78 | 12.94 | 17.30 | 14.03 | 52.61 | 47.53 | 2.0 | 2.0 | 274 | ||
| MemGPT | 9.19 | 6.96 | 4.02 | 4.79 | 11.14 | 8.24 | 10.16 | 7.68 | 49.75 | 45.11 | 4.0 | 4.0 | 16,950 | ||
| A-Mem | 19.06 | 11.71 | 17.80 | 10.28 | 17.55 | 14.67 | 28.51 | 24.13 | 58.81 | 54.28 | 1.0 | 1.0 | 1,376 | ||
| 3B | LoCoMo | 6.88 | 5.77 | 4.37 | 4.40 | 10.65 | 9.29 | 8.37 | 6.93 | 30.25 | 28.46 | 2.8 | 2.8 | 16,910 | |
| ReadAgent | 2.47 | 1.78 | 3.01 | 3.01 | 5.57 | 5.22 | 3.25 | 2.51 | 15.78 | 14.01 | 4.2 | 4.2 | 461 | ||
| MemoryBank | 6.19 | 4.47 | 3.49 | 3.13 | 4.07 | 4.57 | 7.61 | 6.03 | 18.65 | 17.05 | 3.2 | 3.2 | 263 | ||
| MemGPT | 5.32 | 3.99 | 2.68 | 2.72 | 5.64 | 5.54 | 4.32 | 3.51 | 21.45 | 19.37 | 3.8 | 3.8 | 16,956 | ||
| A-Mem | 17.44 | 11.74 | 26.38 | 19.50 | 12.53 | 11.83 | 28.14 | 23.87 | 42.04 | 40.60 | 1.0 | 1.0 | 1,126 | ||
In addition to experiments on LoCoMo, the authors also compare A-Mem on DialSim against LoCoMo and MemGPT. A-Mem consistently outperforms all baselines across evaluation metrics, achieving an F1 score of 3.45, a 35% improvement over LoCoMo's 2.55 and 192% higher than MemGPT's 1.18. The DialSim results are shown in Table 2.
除了 LoCoMo 实验之外,作者还在 DialSim 上将 A-Mem 与 LoCoMo 和 MemGPT 进行比较。 A-Mem 在所有评估指标上都持续优于基线,F1 达到 3.45,相比 LoCoMo 的 2.55 提升 35%,相比 MemGPT 的 1.18 高出 192%。 DialSim 结果见表2。
| Method | F1 | BLEU-1 | ROUGE-L | ROUGE-2 | METEOR | SBERT Similarity |
|---|---|---|---|---|---|---|
| LoCoMo | 2.55 | 3.13 | 2.75 | 0.90 | 1.64 | 15.76 |
| MemGPT | 1.18 | 1.07 | 0.96 | 0.42 | 0.95 | 8.54 |
| A-Mem | 3.45 | 3.37 | 3.54 | 3.60 | 2.05 | 19.51 |
4.4. Cost-Efficiency Analysis
A-Mem demonstrates significant computational and cost efficiency alongside strong performance. The system requires approximately 1,200 tokens per memory operation, achieving an 85-93% reduction in token usage compared to baseline methods such as LoCoMo and MemGPT with approximately 16,900 tokens. This substantial token reduction directly translates to lower operational costs, with each memory operation costing less than $0.0003 when using commercial API services. Processing times average 5.4 seconds using GPT-4o-mini and only 1.1 seconds with locally hosted Llama 3.2 1B on a single GPU. This balance of low computational cost and superior reasoning capability highlights A-Mem's practical advantage for deployment in the real world.
A-Mem 在保持强性能的同时,也展现出显著的计算效率和成本效率。 系统每次记忆操作大约需要 1,200 个 token,与 LoCoMo、MemGPT 等约 16,900 token 的基线相比,token 使用量降低了 85-93%。 这种显著 token 降低会直接转化为更低运营成本;使用商业 API 服务时,每次记忆操作成本低于 0.0003 美元。 处理时间方面,使用 GPT-4o-mini 平均为 5.4 秒,使用单张 GPU 本地部署的 Llama 3.2 1B 仅为 1.1 秒。 低计算成本与更强推理能力之间的平衡,体现了 A-Mem 在真实部署中的实际优势。
4.5. Ablation Study
To evaluate the effectiveness of Link Generation (LG) and Memory Evolution (ME), the authors conduct ablation studies by systematically removing key components. When both LG and ME are removed, the system exhibits substantial performance degradation, particularly in Multi-Hop reasoning and Open Domain tasks. The system with only LG active shows intermediate performance, maintaining significantly better results than the version without both modules. The full A-Mem model consistently achieves the best performance across all evaluation categories. The ablation results are shown in Table 3.
为了评估链接生成(LG)和记忆演化(ME)的有效性,作者通过系统移除关键组件进行消融实验。 当 LG 和 ME 都被移除时,系统性能明显下降,尤其是在 Multi-Hop 推理和 Open Domain 任务上。 只保留 LG 的系统表现居中,明显优于同时移除两个模块的版本。 完整 A-Mem 模型在所有评估类别上持续取得最佳表现。 消融结果见表3。
| Method | Multi Hop | Temporal | Open Domain | Single Hop | Adversarial | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| w/o LG & ME | 9.65 | 7.09 | 24.55 | 19.48 | 7.77 | 6.70 | 13.28 | 10.30 | 15.32 | 18.02 |
| w/o ME | 21.35 | 15.13 | 31.24 | 27.31 | 10.13 | 10.85 | 39.17 | 34.70 | 44.16 | 45.33 |
| A-Mem | 27.02 | 20.09 | 45.85 | 36.67 | 12.14 | 12.00 | 44.65 | 37.06 | 50.03 | 49.47 |
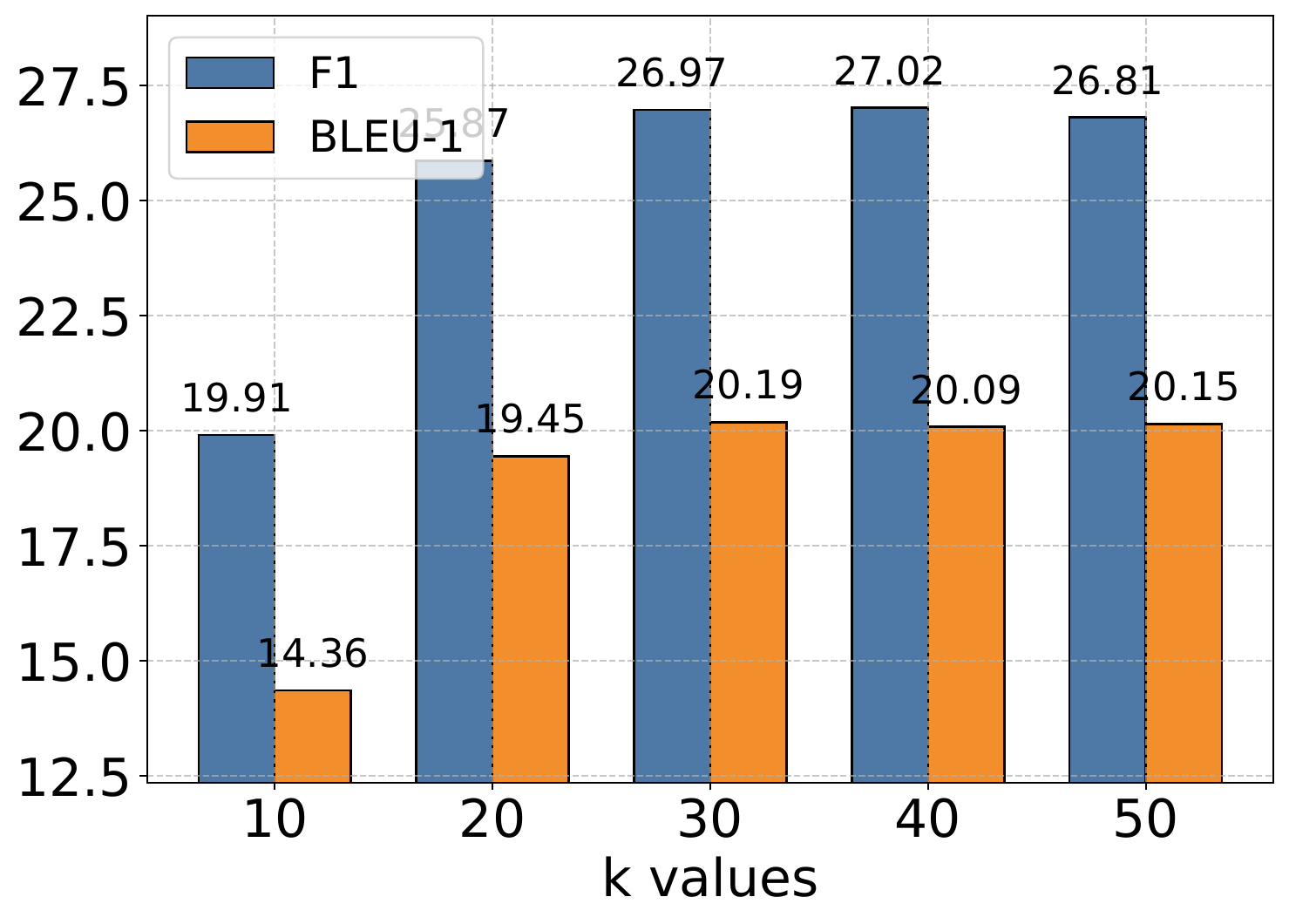
4.6. Hyperparameter Analysis
The authors conduct extensive experiments to analyze the impact of the memory retrieval parameter
作者进行了大量实验来分析记忆检索参数
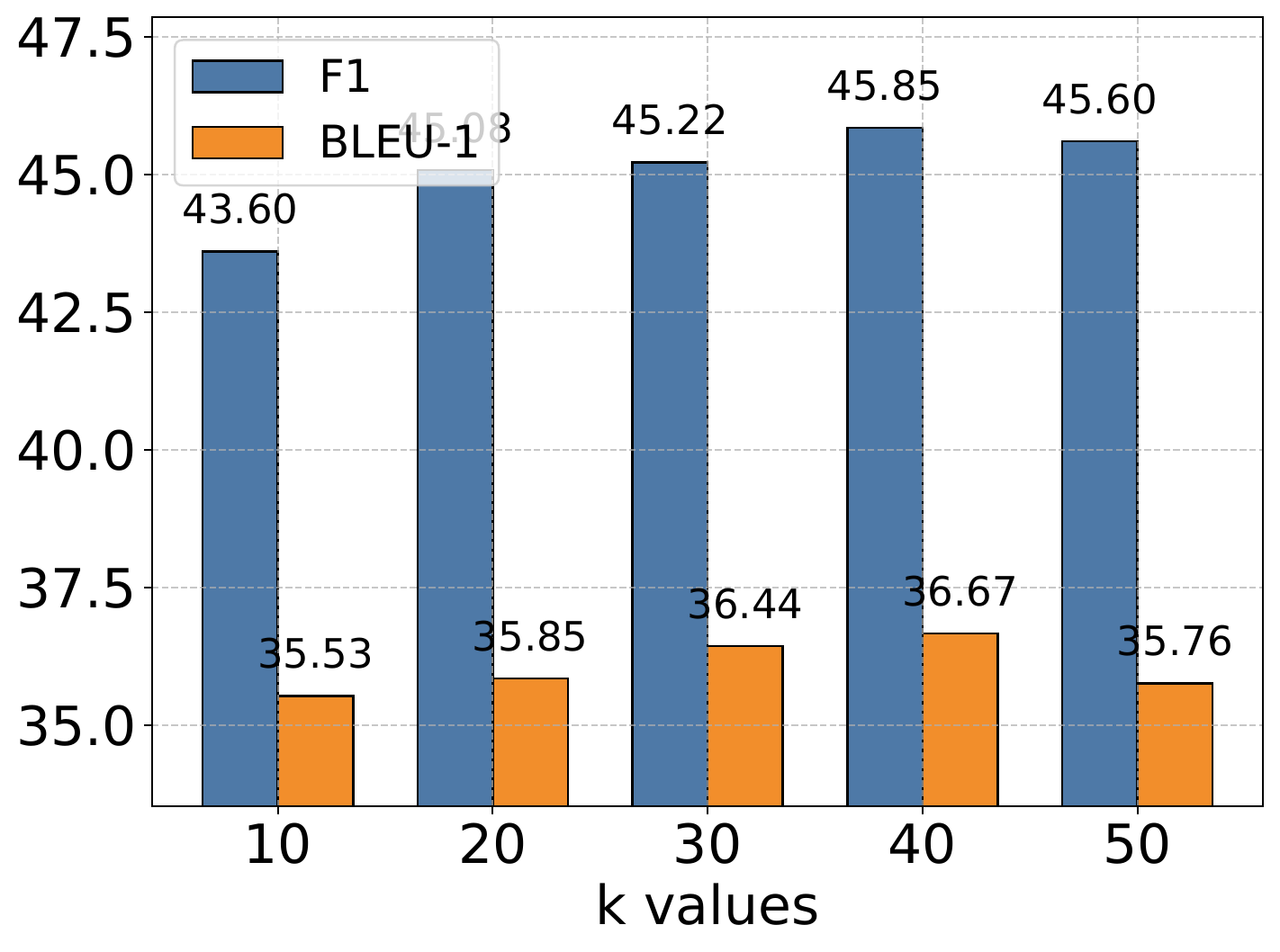
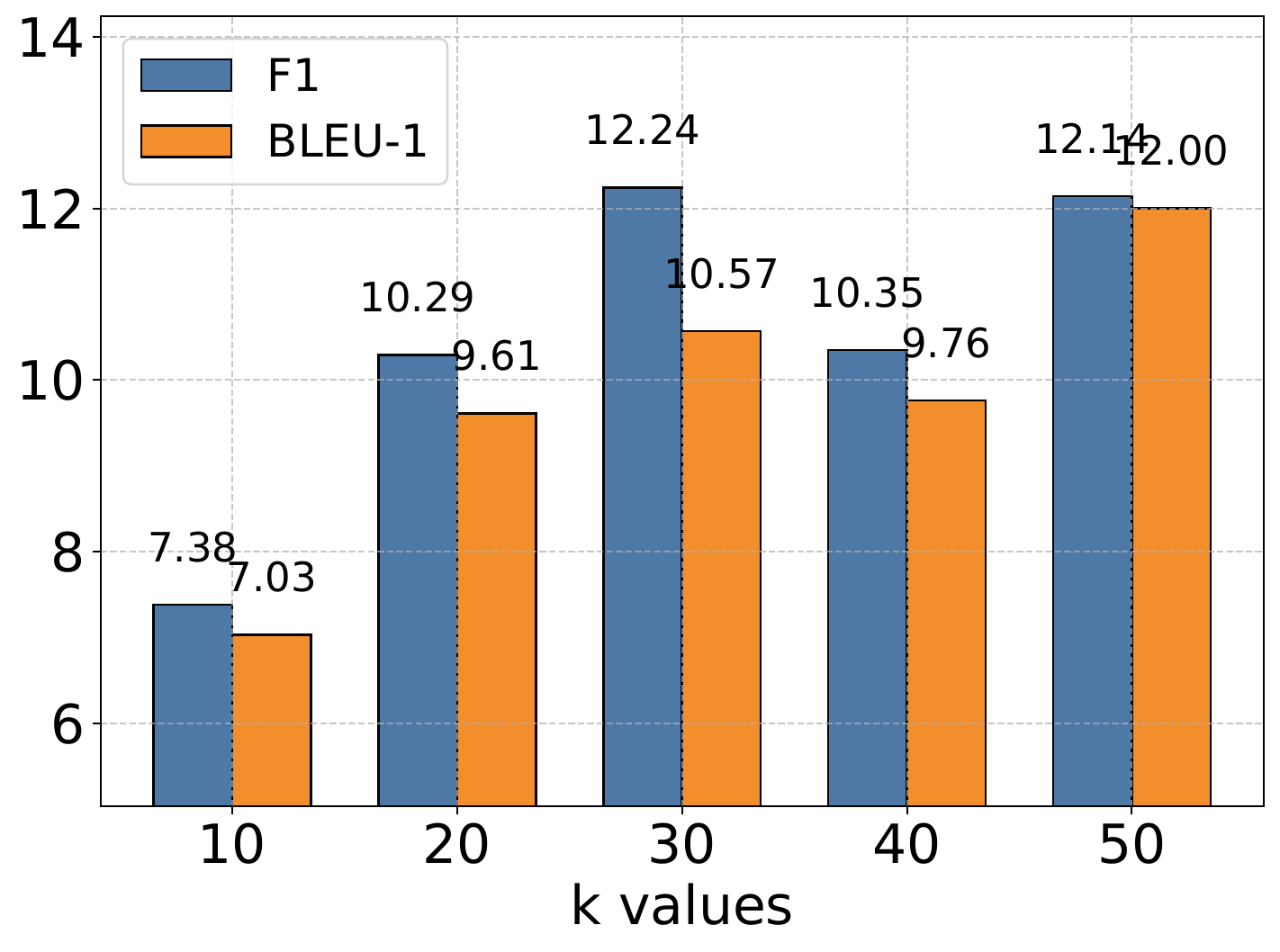
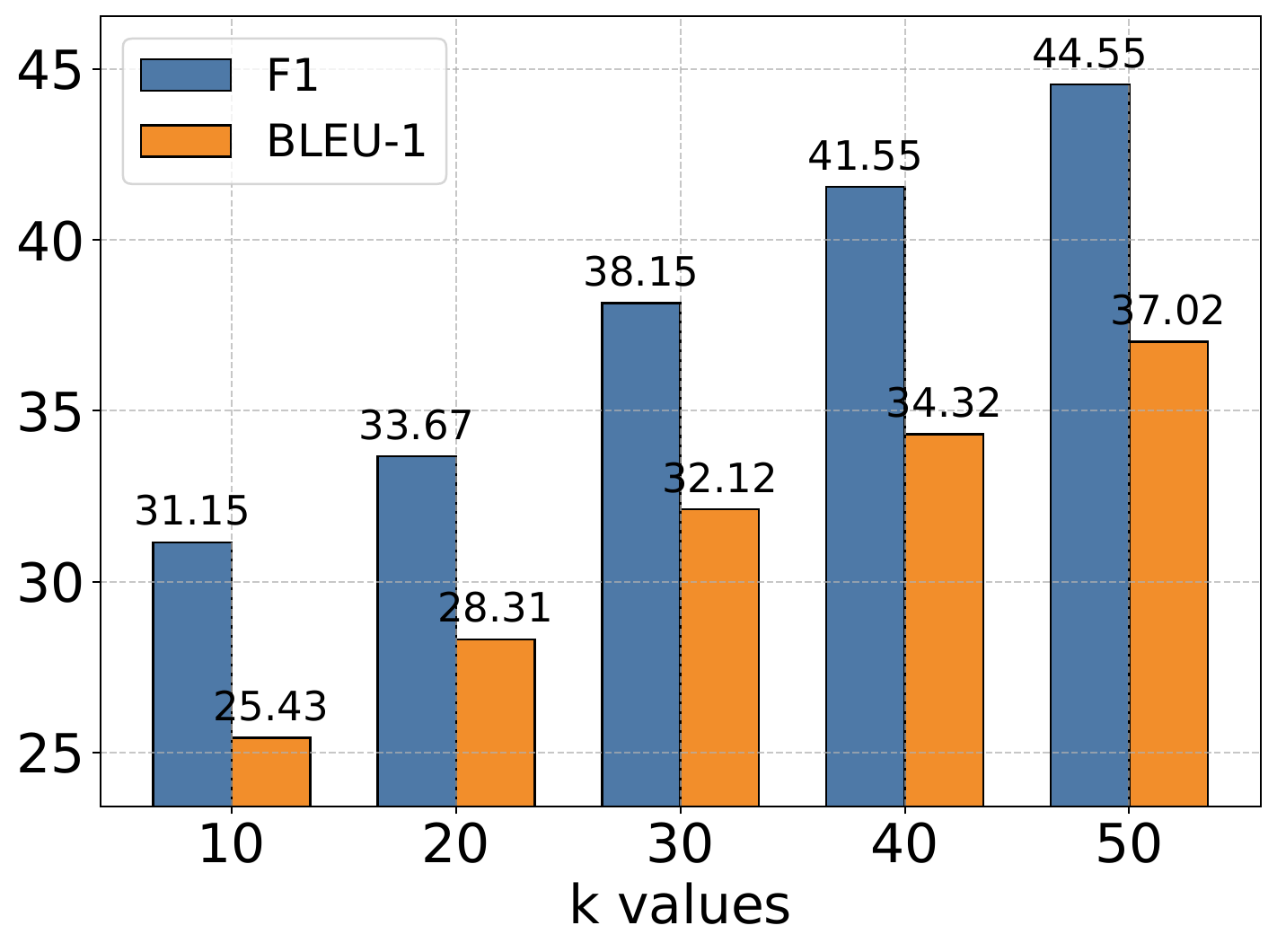
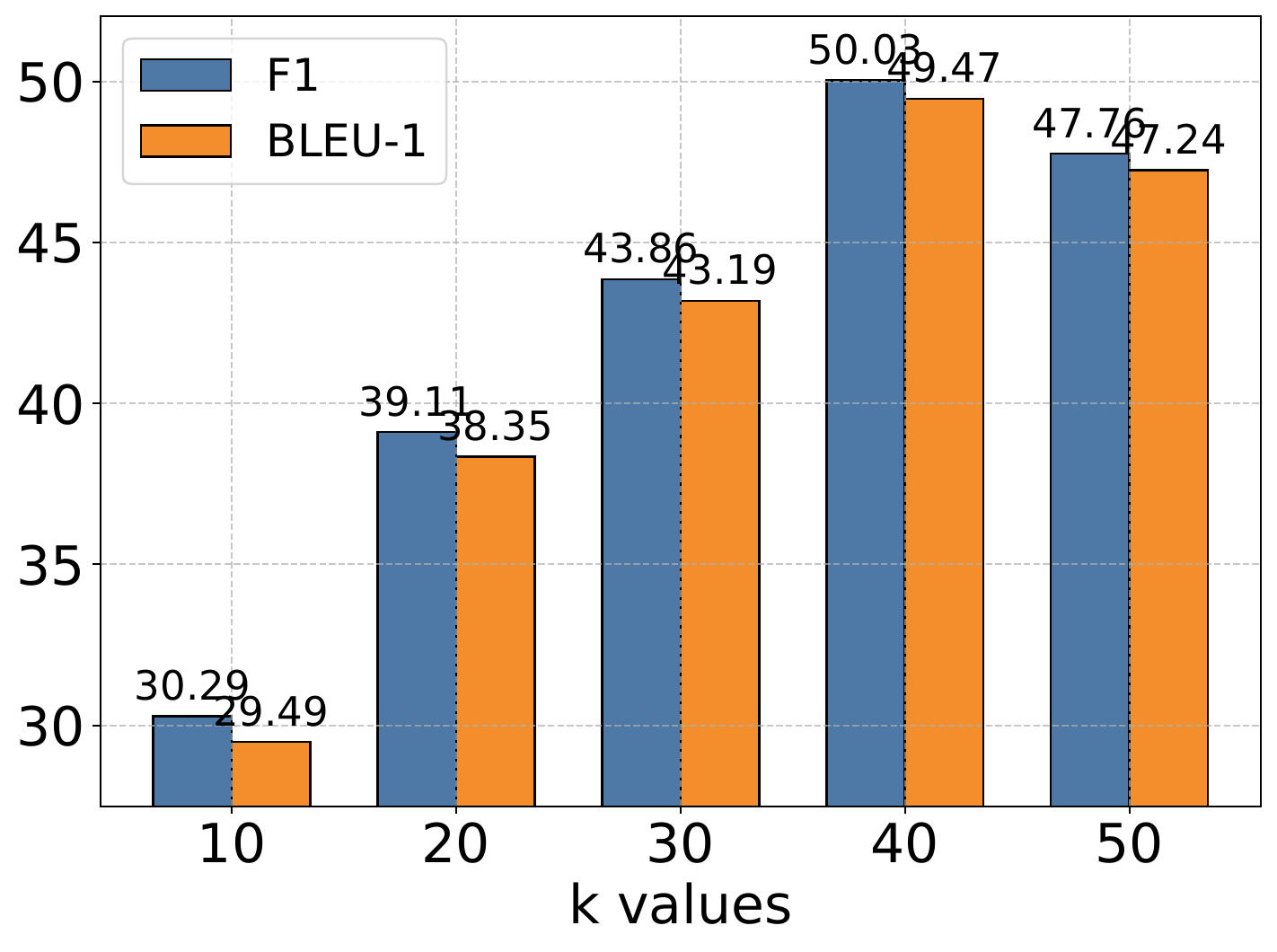
4.7. Scaling Analysis
To evaluate storage costs with accumulating memory, the authors examine the relationship between storage size and retrieval time across A-Mem, MemoryBank, and ReadAgent. They evaluate the three memory systems with identical memory content at four scale points: 1,000, 10,000, 100,000, and 1,000,000 entries. The results in Table 4 show that all three systems exhibit identical linear memory usage scaling, as expected for vector-based retrieval systems. For retrieval time, A-Mem demonstrates excellent efficiency with minimal increases as memory size grows. Even at one million memories, A-Mem's retrieval time increases only from 0.31 μs to 3.70 μs.
为了评估记忆不断累积时的存储成本,作者比较了 A-Mem、MemoryBank 和 ReadAgent 的存储规模与检索时间关系。 三种记忆系统使用相同记忆内容,在 1,000、10,000、100,000 和 1,000,000 条记忆四个规模点上进行评估。 表4显示,三种系统的记忆使用量都呈现相同的线性增长,这与向量检索系统的预期一致。 在检索时间方面,A-Mem 表现出很高效率,随着记忆规模增长只出现很小增加。 即使扩展到一百万条记忆,A-Mem 的检索时间也只是从 0.31 μs 增加到 3.70 μs。
| Memory Size | Method | Memory Usage (MB) | Retrieval Time (μs) |
|---|---|---|---|
| 1,000 | A-Mem | 1.46 | 0.31 ± 0.30 |
| MemoryBank | 1.46 | 0.24 ± 0.20 | |
| ReadAgent | 1.46 | 43.62 ± 8.47 | |
| 10,000 | A-Mem | 14.65 | 0.38 ± 0.25 |
| MemoryBank | 14.65 | 0.26 ± 0.13 | |
| ReadAgent | 14.65 | 484.45 ± 93.86 | |
| 100,000 | A-Mem | 146.48 | 1.40 ± 0.49 |
| MemoryBank | 146.48 | 0.78 ± 0.26 | |
| ReadAgent | 146.48 | 6,682.22 ± 111.63 | |
| 1,000,000 | A-Mem | 1464.84 | 3.70 ± 0.74 |
| MemoryBank | 1464.84 | 1.91 ± 0.31 | |
| ReadAgent | 1464.84 | 120,069.68 ± 1,673.39 |
4.8. Memory Analysis
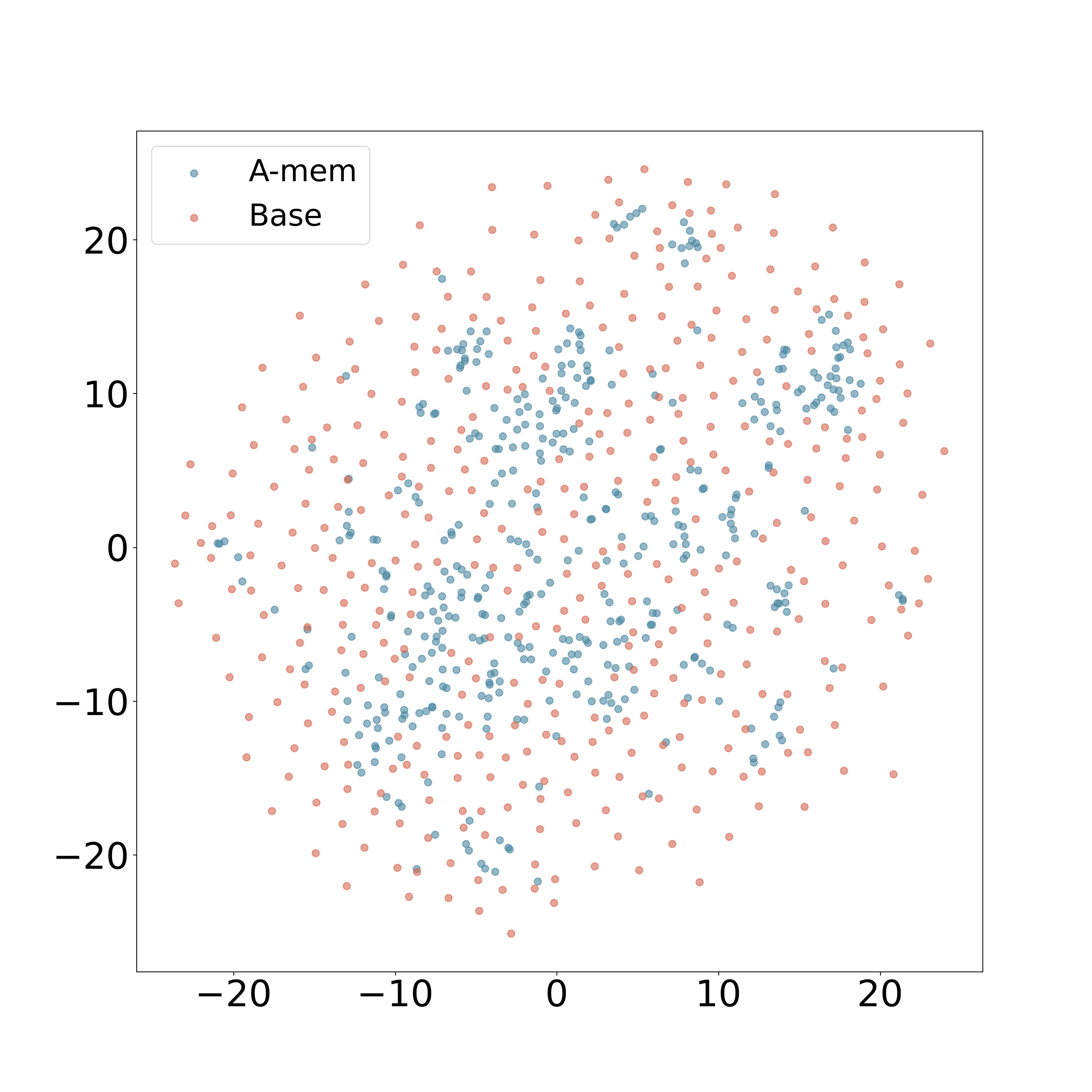
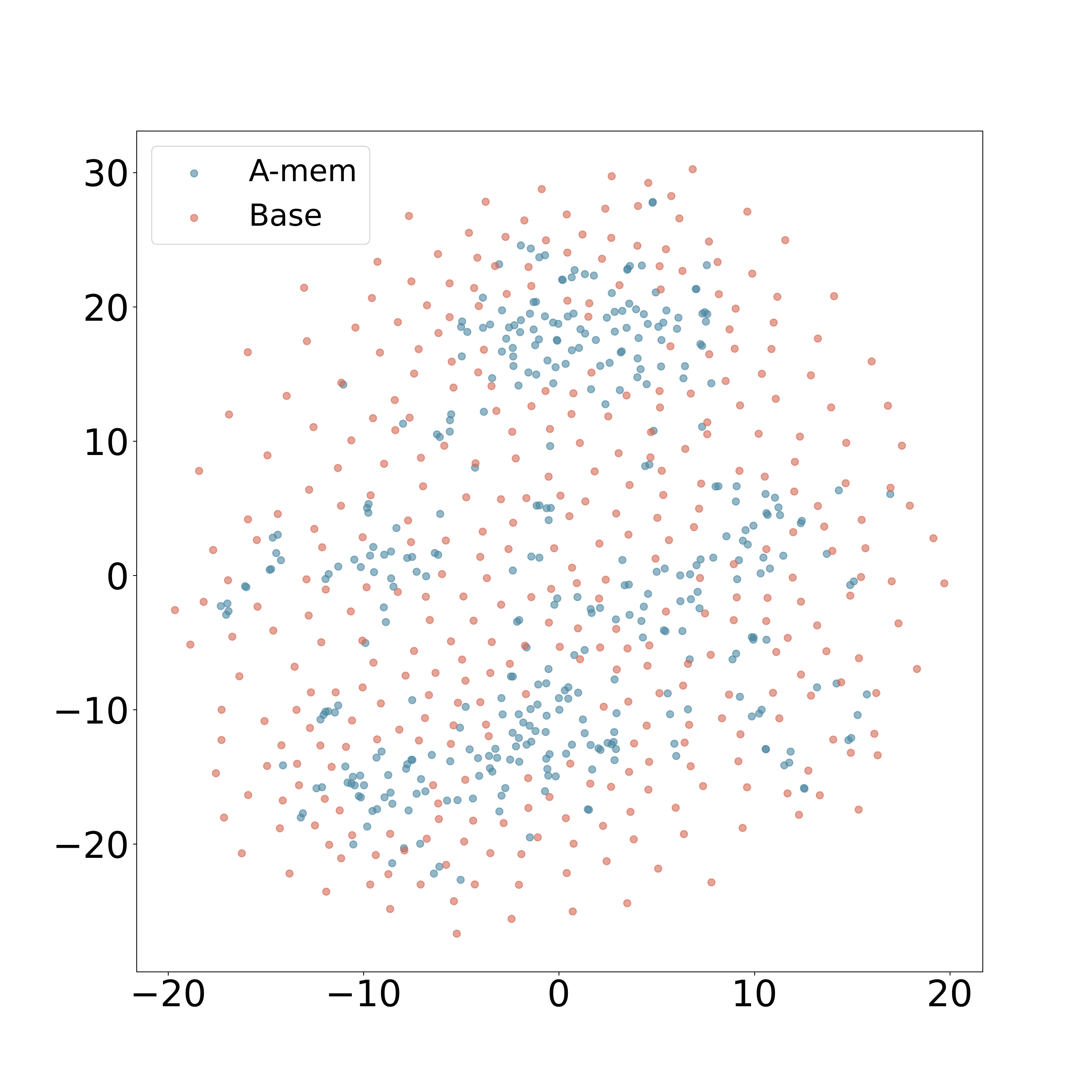
The authors present t-SNE visualizations of memory embeddings to demonstrate the structural advantages of A-Mem. Analyzing two dialogues sampled from long-term conversations in LoCoMo, they observe that A-Mem, shown in blue, consistently exhibits more coherent clustering patterns compared to the baseline system, shown in red. This structural organization is particularly evident in Dialogue 2, where well-defined clusters emerge in the central region. In contrast, baseline memory embeddings display a more dispersed distribution, showing that memories lack structural organization without link generation and memory evolution. The visualization results are shown in Figure 4.
作者通过记忆嵌入的 t-SNE 可视化来展示 A-Mem 的结构优势。 在分析 LoCoMo 长期对话中采样的两段对话时,作者观察到蓝色的 A-Mem 相比红色的基线系统,持续呈现出更连贯的聚类模式。 这种结构化组织在 Dialogue 2 中尤其明显,其中心区域出现了边界较清晰的簇。 相比之下,基线记忆嵌入分布更加分散,说明如果没有链接生成和记忆演化,记忆缺乏结构化组织。 可视化结果如图4所示。
5. Conclusions
In this work, the authors introduce A-Mem, a novel agentic memory system that enables LLM agents to dynamically organize and evolve their memories without relying on predefined structures. Drawing inspiration from the Zettelkasten method, the system creates an interconnected knowledge network through dynamic indexing and linking mechanisms that adapt to diverse real-world tasks. The system's core architecture features autonomous generation of contextual descriptions for new memories and intelligent establishment of connections with existing memories based on shared attributes. Furthermore, the approach enables continuous evolution of historical memories by incorporating new experiences and developing higher-order attributes through ongoing interactions. Through extensive empirical evaluation across six foundation models, A-Mem achieves superior performance compared to existing state-of-the-art baselines in long-term conversational tasks. Visualization analysis further validates the effectiveness of the memory organization approach. These results suggest that agentic memory systems can significantly enhance LLM agents' ability to utilize long-term knowledge in complex environments.
在这项工作中,作者提出 A-Mem,这是一种新型智能体式记忆系统,使 LLM 智能体能够在不依赖预定义结构的情况下动态组织和演化记忆。 受到 Zettelkasten 方法启发,该系统通过能够适应多样化真实任务的动态索引和链接机制,创建互联知识网络。 系统核心架构包括为新记忆自主生成上下文描述,并基于共享属性与已有记忆智能建立连接。 此外,该方法还支持历史记忆的持续演化:通过不断纳入新经验,并在持续交互中发展高阶属性。 通过在六个基础模型上的广泛实证评估,A-Mem 在长期对话任务中相比现有 SOTA 基线取得了更优表现。 可视化分析进一步验证了这种记忆组织方法的有效性。 这些结果说明,智能体式记忆系统可以显著增强 LLM 智能体在复杂环境中利用长期知识的能力。
6. Limitations
While the agentic memory system achieves promising results, the authors acknowledge several areas for potential future exploration. First, although the system dynamically organizes memories, the quality of these organizations may still be influenced by the inherent capabilities of the underlying language models. Different LLMs might generate slightly different contextual descriptions or establish varying connections between memories. Additionally, while the current implementation focuses on text-based interactions, future work could explore extending the system to handle multimodal information, such as images or audio, which could provide richer contextual representations.
尽管智能体式记忆系统取得了有希望的结果,作者也承认仍有一些值得未来探索的方向。 首先,虽然系统可以动态组织记忆,但组织质量仍可能受到底层语言模型固有能力的影响。 不同 LLM 可能生成略有差异的上下文描述,也可能在记忆之间建立不同连接。 此外,当前实现主要聚焦文本交互;未来工作可以探索将系统扩展到图像或音频等多模态信息,以提供更丰富的上下文表示。