
评估 LLM 智能体的超长期对话记忆
Abstract
Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
已有关于长期开放域对话的工作,主要关注在不超过五个聊天会话的上下文中评估模型回复。 尽管长上下文大型语言模型(LLM)和检索增强生成(RAG)技术已经取得进展,但它们在超长期对话中的有效性仍未得到充分探索。 为弥补这一研究空白,我们提出了一套人机协作流程:借助基于 LLM 的智能体架构,并将对话建立在人设和时间事件图之上,生成高质量的超长期对话。 此外,我们还为每个智能体加入了分享图片和对图片作出回应的能力。 生成出的对话会由人工标注者进行验证和编辑,以确保长程一致性,并保证内容与事件图相对应。 基于这套流程,我们构建了 LoCoMo,这是一个超长期对话数据集,其中每段对话平均包含 300 轮、9000 个 token,最多跨越 35 个会话。 基于 LoCoMo,我们提出了一个综合评测基准,用于衡量模型的长期记忆能力,涵盖问答、事件摘要和多模态对话生成任务。 实验结果表明,LLM 在理解长对话,以及把握对话中的长程时间关系和因果动态方面仍然面临挑战。 使用长上下文 LLM 或 RAG 等策略可以带来改进,但这些模型的表现仍明显落后于人类水平。
1. Introduction
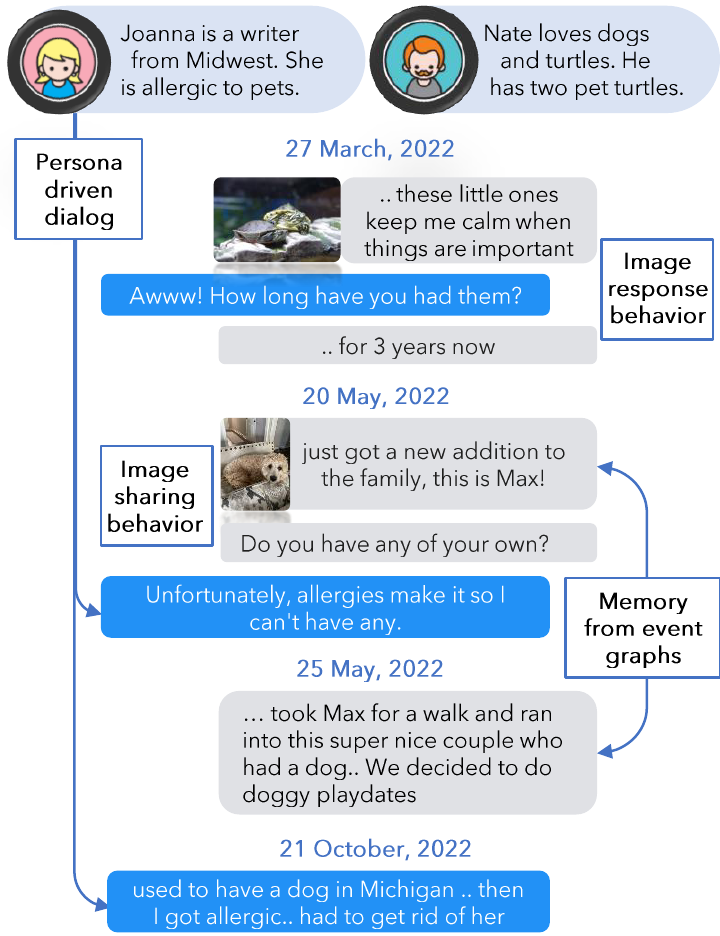
Despite recent advancements in dialogue models based on LLMs for extended contexts, as well as the integration of retrieval augmented generation (RAG) techniques, there is still a need for thorough evaluation of their efficacy in handling very long conversations. Indeed, studies in long-term open-domain dialogues have concentrated on assessing model responses within limited contexts, e.g., around 1K tokens over five chat sessions. This long term evaluation is crucial for refining engaging chatbots capable of remembering key information from past interactions, to generate empathetic, consistent, and useful responses.
尽管基于 LLM 的长上下文对话模型已经取得了进展,检索增强生成(RAG)技术也被不断引入,但这些方法在处理超长对话时到底有多有效,仍然需要更系统的评估。 事实上,已有长期开放域对话研究主要集中在有限上下文中评估模型回复,例如大约 1000 个 token、跨 5 个聊天会话的场景。 这类长期评估非常关键,因为它有助于改进能够记住过去交互中关键信息的聊天机器人,使其生成更有同理心、更一致且更有用的回复。
To this end, we present the first study of very long-term open-domain multi-modal dialogues, closely mirroring real-world online interactions, collected via a human-machine pipeline where we first use LLM-based generative agents to generate conversations and then ask human annotators to fix any long-term inconsistencies in the conversations. Specifically, drawing on the understanding that real-world conversations are a complex blend of collective memories, individual viewpoints, external influences, and the unique persona of the speakers, we create very long-term dialogues based on LLM agents with the following features: (1) a unique persona; (2) a timeline of causally interlinked events in their lives; and (3) a reflect & response mechanism to respond based on dialogue history and image sharing & image reaction behavior which sends or reacts to images. Finally, human annotators fix long-range inconsistencies in dialogues, remove irrelevant images, and verify the grounding of dialogs to events. With this pipeline, we create LoCoMo, a dataset of 50 very long-term dialogues, each consisting of 300 turns and 9K tokens on average, over up to 35 sessions (see Figure 1 and Table 1).
为此,我们提出了首个关于超长期开放域多模态对话的研究。它尽可能贴近真实世界的线上交互,并通过一套人机协作流程收集:我们首先使用基于 LLM 的生成式智能体生成对话,然后让人工标注者修正对话中的长期不一致问题。 具体来说,真实世界的对话往往是集体记忆、个体视角、外部影响和说话者独特人设的复杂混合。基于这一理解,我们让 LLM 智能体生成具备以下特征的超长期对话:(1)独特的人设;(2)由因果关系连接的人生事件时间线;(3)基于对话历史进行回应的 reflect & response 机制,以及能够发送图片或回应图片的 image sharing & image reaction 行为。 最后,人工标注者会修正对话中的长程不一致,移除无关图片,并验证对话是否与事件保持一致。 通过这套流程,我们构建了 LoCoMo:它包含 50 段超长期对话,每段平均 300 轮、9000 个 token,最多跨越 35 个会话(见图1和表1)。
| Dataset | Avg. turns per conv. | Avg. sessions per conv. | Avg. tokens per conv. | Time Interval | Multimodal | Collection |
|---|---|---|---|---|---|---|
| MPChat | 2.8 | 1 | 53.3 | - | ✓ | |
| MMDialog | 4.6 | 1 | 72.5 | - | ✓ | Social media |
| Daily Dialog | 7.9 | 1 | 114.7 | - | ✗ | Crowdsourcing |
| SODA | 7.6 | 1 | 122.4 | - | ✗ | LLM-generated |
| MSC (train; 1-4 sessions) | 53.3 | 4 | 1,225.9 | few days | ✗ | Crowdsourcing |
| Conversation Chronicles | 58.5 | 5 | 1,054.7 | few hours - years | ✗ | LLM-generated |
| LoCoMo (ours) | 304.9 | 19.3 | 9,209.2 | few months | ✓ | LLM-gen. + crowdsourc. |
Conventional approaches for evaluating conversational agents in open-domain dialogues involve directly evaluating the agent response based on past dialogue history. They often employ lexical overlap and semantic overlap between the ground truth and the agent response, or consistency, contradiction, and empathy of the agent response. However, these evaluation metrics are not well-suited for directly assessing the agent's comprehension of long-term contexts.
开放域对话中评估对话智能体的传统做法,通常是基于过去的对话历史,直接评价智能体生成的回复。 这些方法常使用标准答案与智能体回复之间的词面重叠、语义重叠,或评估回复的一致性、矛盾性和同理心。 然而,这些指标并不适合直接衡量智能体对长期上下文的理解能力。
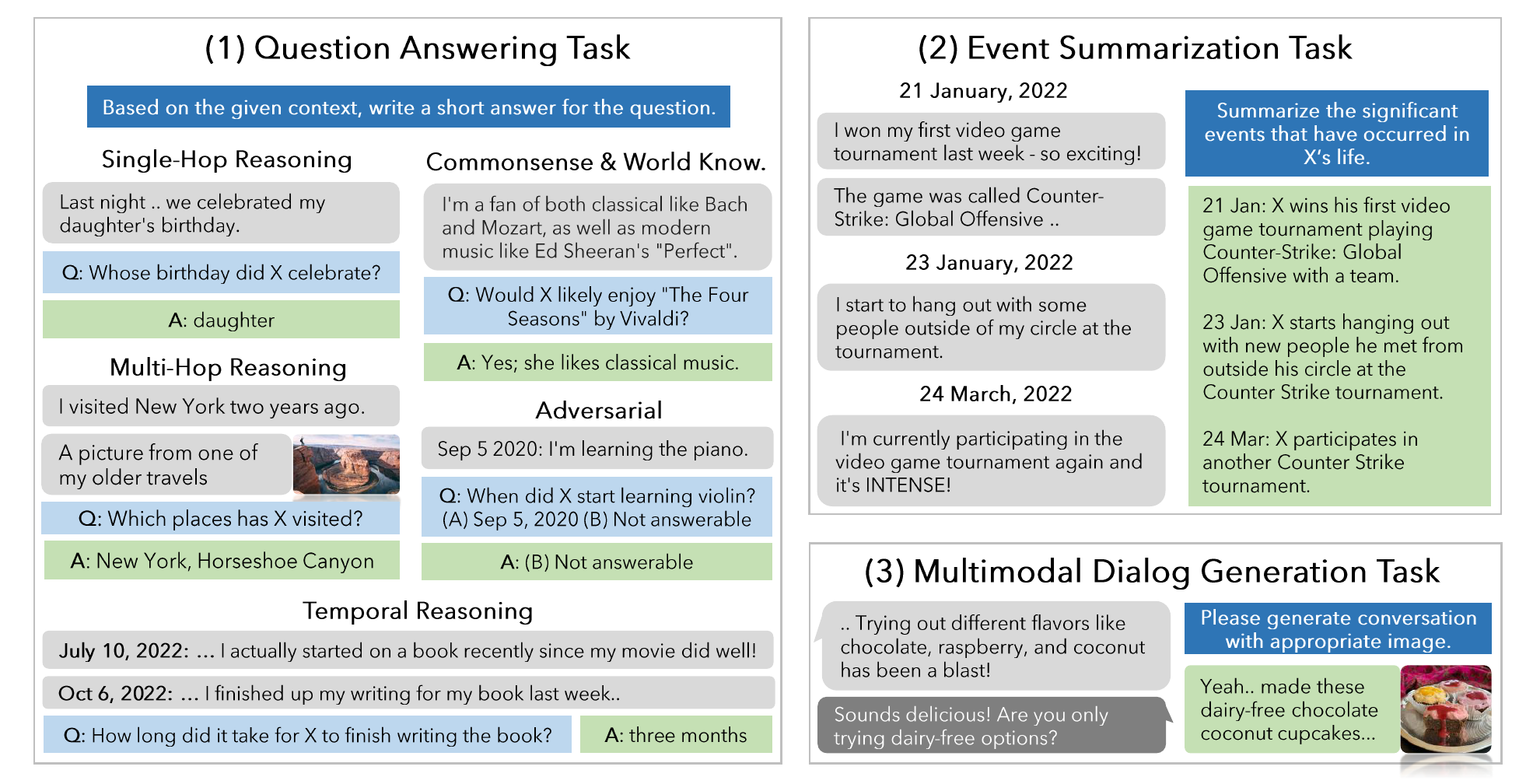
In this study, we present a holistic evaluation framework to assess an agent's proficiency in managing and responding within long-term contexts (see Figure 2). First, agents need to "recall" past context correctly to integrate relevant information into future responses. We present a direct examination of their memory via a question answering (QA) task. We classify questions into five distinct reasoning types to evaluate memory from multiple perspectives: single-hop, multi-hop, temporal, commonsense or world knowledge, and adversarial. Second, agents also need to recognize long-range causal and temporal connections in the dialogues to generate empathetic and relevant responses. We propose a measurement of their causal and temporal understanding with an event graph summarization task. In this task, the event graphs linked to each LLM speaker serve as the correct answers, and models are tasked with extracting this information from the conversation history. Third, conversational agents need to utilize relevant context recalled from past conversations to generate responses that are consistent with the ongoing narrative. We assess this ability via the multi-modal dialog generation task.
在本研究中,我们提出了一个整体评测框架,用来评估智能体在长期上下文中管理信息并作出回应的能力(见图2)。 第一,智能体需要正确“回忆”过去的上下文,并把相关信息整合到未来回复中。 因此,我们通过问答(QA)任务直接检验模型的记忆能力。 我们将问题分成五种推理类型,从多个角度评估记忆:单跳、多跳、时间推理、常识或世界知识,以及对抗性问题。 第二,智能体还需要识别对话中的长程因果关系和时间关系,才能生成有同理心且相关的回复。 为此,我们提出用事件图摘要任务衡量模型的因果和时间理解能力。 在该任务中,每个 LLM 说话者对应的事件图作为正确答案,模型需要从对话历史中抽取这些信息。 第三,对话智能体还需要利用从过去对话中回忆出的相关上下文,生成与当前叙事一致的回复。 我们通过多模态对话生成任务评估这种能力。
We present extensive experimental results on the LoCoMo benchmark using instruction-based LLMs, long-context LLMs, and RAG techniques. Our findings include: (1) Long-context LLMs and RAG demonstrate effectiveness in QA tasks, improving "memory" capabilities of LLMs with improvements ranging from 22-66%, but still significantly lag behind human levels by 56%, especially in temporal reasoning, where the gap reaches 73%; (2) long-context LLMs demonstrate significant difficulty with adversarial questions in the QA task, showing a performance that is 83% lower than the base model. They are especially prone to misassigning dialogs or events to the wrong speaker. Moreover, they show poor performance on event graph summarization, lagging behind the base model by 14%, indicating that they may grasp the factual elements within the entire conversation but do not accurately comprehend the context; and (3) RAG offers a balanced compromise, combining the accuracy of short-context LLMs with the extensive comprehension of wide-context LLMs, and does particularly well when dialogues are transformed into a database of assertions (observations) about each speaker's life and persona.
我们在 LoCoMo 基准上,使用指令型 LLM、长上下文 LLM 和 RAG 技术进行了大量实验。 主要发现包括:(1)长上下文 LLM 和 RAG 在 QA 任务中是有效的,能够提升 LLM 的“记忆”能力,提升幅度为 22-66%;但它们仍显著落后于人类水平,整体差距为 56%,在时间推理上差距尤其明显,达到 73%。(2)长上下文 LLM 在 QA 任务中的对抗性问题上表现出显著困难,性能比基础模型低 83%。 它们尤其容易把对话或事件错误归属给错误的说话者。 此外,它们在事件图摘要任务上表现较差,比基础模型低 14%,这表明它们也许能够抓住整段对话中的事实元素,但并不能准确理解上下文。(3)RAG 提供了一种较均衡的折中方案,结合了短上下文 LLM 的准确性和宽上下文 LLM 的广泛理解能力;尤其当对话被转换为关于每个说话者生活和人设的断言数据库(即 observations)时,RAG 表现较好。
2. Related Work
2.1. Long-term Dialogue
Recent approaches involve retrieving historical context from a range of previous dialogues and reasoning over retrieved segments in a temporal order, and/or using events to scaffold the dialogues to enable consistency in long-term conversations. Some limitations of such frameworks are: (1) the accuracy of retrieval can be compromised, as the retrieval model is generally trained on tasks focusing on semantic similarity rather than specifically on such dialogues. Additionally, real-world dialogues often feature co-references and missing content, i.e., anaphora, which further complicate the retrieval process. (2) challenges arise in reasoning over retrieved documents, especially when the model struggles to identify the correct context among the retrieved data. (3) reasoning over time intervals presents challenges. For example, the way a system responds about past events can vary depending on the amount of time that has passed since the last conversation. Therefore, it is essential to have conversations of considerable length, as well as a systematic evaluation framework, to accurately assess the effectiveness of approaches to long-term dialogue generation. We design a long-term conversation generation pipeline based on retrieval augmentation and event graphs and propose a framework for evaluating long-term dialog agents.
近期方法通常会从过去多段对话中检索历史上下文,并按时间顺序对检索到的片段进行推理;也有方法使用事件来支撑对话,从而维持长期对话中的一致性。 这类框架存在一些局限:(1)检索准确性可能受到影响,因为检索模型通常是在语义相似度任务上训练的,而不是专门针对这种长期对话场景训练的。 此外,真实世界对话经常包含共指和缺失内容,也就是照应现象,这会进一步增加检索难度。 (2)对检索文档进行推理也存在挑战,尤其是当模型难以从检索结果中识别正确上下文时。 (3)围绕时间间隔进行推理也很困难。 例如,系统如何回应过去事件,可能会随着距离上次对话过去了多久而变化。 因此,要准确评估长期对话生成方法的有效性,需要足够长的对话,也需要系统性的评测框架。 本文设计了一套基于检索增强和事件图的长期对话生成流程,并提出了用于评估长期对话智能体的框架。
2.2. Multi-modal Dialogue
Multi-modal dialogue primarily consists of two types of tasks: image-grounded dialogue and image-sharing dialogue. The image-grounded dialogue task is centered around responding to questions or creating natural conversations related to specific images. Conversely, the image-sharing dialogue task focuses on selecting images that semantically align with the provided dialogue context. We use a method from the image-sharing dialogue task to create multimodal dialogs which are then evaluated as an image-grounded dialogue task.
多模态对话主要包含两类任务:图像扎根对话和图像分享对话。 图像扎根对话的核心,是围绕特定图像回答问题,或生成与特定图像相关的自然对话。 相反,图像分享对话关注的是从语义上选择与给定对话上下文匹配的图像。 本文使用图像分享对话任务中的方法来创建多模态对话,随后再将这些对话作为图像扎根对话任务来评估。
2.3. Synthetic Evaluation Benchmark
Faced with a shortage of human-generated data and observing that LLMs are approaching the quality of human-level annotations, there has been a surge in research drawing inspiration from this development. Consequently, numerous studies have started utilizing LLMs to augment or synthesize large-scale dialogue benchmarks for assessing responses in everyday social interactions, examining responses in multi-modal environments, and evaluating responses that align with specific persona. We leverage LLMs to create data but ensure its high quality with human verification and editing.
由于人工生成数据短缺,同时 LLM 的标注质量正在接近人类水平,越来越多研究开始受到这一趋势启发。 因此,大量工作开始利用 LLM 来扩充或合成大规模对话基准,用于评估日常社交互动中的回复、多模态环境中的回复,以及是否符合特定人设的回复。 本文同样利用 LLM 创建数据,但通过人工验证和编辑来保证数据的高质量。
3. Generative Pipeline for LoCoMo
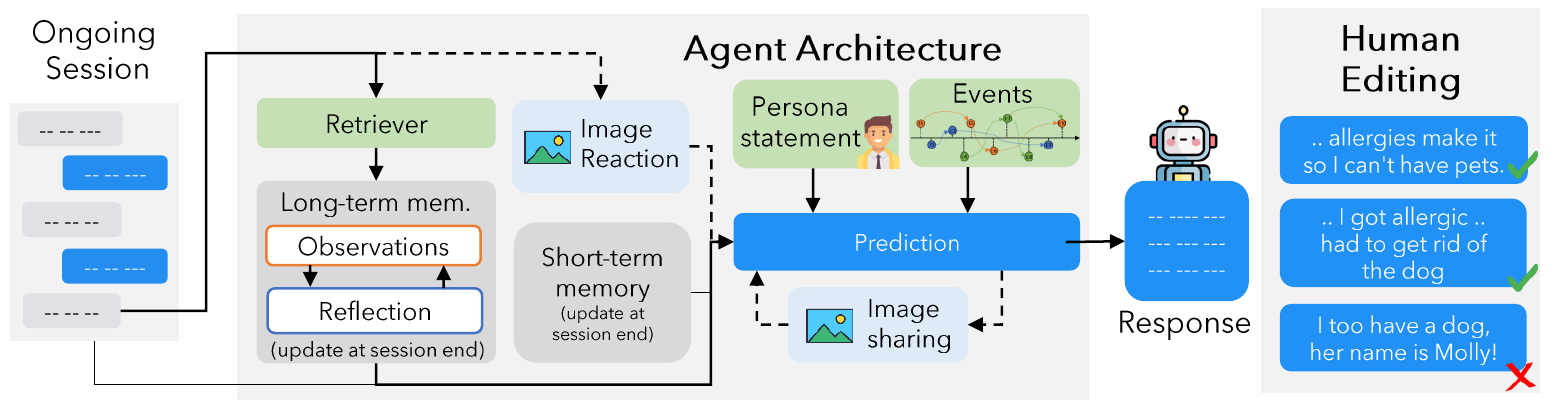
An overview of our generative pipeline for LoCoMo is shown in Figure 3. We create two virtual agents, named gpt-3.5-turbo. To start, unique persona statements
LoCoMo 的生成流程概览如图3所示。 作者创建了两个虚拟智能体,分别记为 gpt-3.5-turbo。 首先,每个智能体
3.1. Persona
We select an initial persona statement gpt-3.5-turbo as
作者从 MSC 数据集中选择一个初始人设描述 gpt-3.5-turbo 作为
3.2. Temporal Event Graph
To utilize the real-life experiences of each agent in the conversation, we construct a temporal event graph, labeled as text-davinci-003, on a designated persona
为了在对话中利用每个智能体的真实生活经历,作者为每个智能体构建一个时间事件图,记为 text-davinci-003。 每个事件
3.3. Virtual Agent Architecture
Every agent
每个智能体
Reflect & Respond The fundamental process for each agent to reflect and respond involves the concept of short-term and long-term memory. During inference, agent
每个智能体进行反思并回应的基本过程涉及短期记忆和长期记忆。 在推理时,智能体
Then, agent
随后,智能体
Image Sharing & Image Reaction The image sharing & image reaction functions are integrated to add a multi-modal dimension to the long-term dialogues. Image captions are also saved to long-term memory. The image sharing function is called when the agent decides to send an image. This process includes: (1) generate a caption
图片分享与图片回应功能被整合进系统,用于为长期对话加入多模态维度。 图片说明也会被保存到长期记忆中。 图片分享功能会在智能体决定发送图片时被调用,流程包括:(1)使用
3.4. Human Verification & Editing
In the concluding phase, human annotators are tasked with (1) editing the dialogue to eliminate long-term inconsistencies, (2) removing or substituting irrelevant images, and (3) verifying and editing for alignment between event graphs and the content of the conversations. Overall, we observed that annotators edited nearly 15% of the dialog turns and removed or substituted approximately 19% images present in the LLM-generated dataset.
在最后阶段,人工标注者需要完成三项工作:(1)编辑对话,消除长期不一致;(2)删除或替换无关图片;(3)验证并编辑事件图与对话内容之间的一致性。 总体来看,作者观察到标注者编辑了将近 15% 的对话轮次,并删除或替换了 LLM 生成数据集中约 19% 的图片。
4. LoCoMo Evaluation Benchmark
Based on the dialogues generated in the previous section, we introduce an evaluation benchmark (see Figure 2) composed of three tasks to assess the accuracy of long-term memory.
基于上一章生成的对话,作者提出了一个评测基准(见图2),由三个任务组成,用来评估模型长期记忆的准确性。
4.1. Question Answering Task
A conversational agent is expected to possess a memory to remember previous dialogues, reflecting it to create more engaging responses in future conversations. For a comprehensive assessment of this memory, we introduce a question-answering task divided into five distinct reasoning categories: (1) Single-hop questions require answers based on a single session; (2) Multi-hop questions require synthesizing information from multiple different sessions; (3) Temporal reasoning questions can be answered through temporal reasoning and capturing time-related data cues within the conversation; (4) Open-domain knowledge questions can be answered by integrating a speaker's provided information with external knowledge such as commonsense or world facts; (5) Adversarial questions are designed to trick the agent into providing wrong answers, with the expectation that the agent will correctly identify them as unanswerable.
对话智能体应该具备一种记忆能力,能够记住过去的对话,并在未来对话中反映这些记忆,从而生成更有吸引力的回复。 为了全面评估这种记忆,作者设计了一个问答任务,并将问题分为五类不同的推理类型:(1)单跳问题,答案只需要基于单个会话即可得到;(2)多跳问题,需要综合多个不同会话中的信息;(3)时间推理问题,需要进行时间推理,并捕捉对话中的时间相关线索;(4)开放域知识问题,需要将说话者提供的信息与外部知识结合,例如常识或世界事实;(5)对抗性问题,这些问题被设计用来诱导智能体给出错误答案,期望模型能够正确识别这些问题是不可回答的。
For each category, we calculate the F1 score for exact matches, following the normalization of both the predicted and the actual ground truth answers. However, evaluating long-form answers with automated metrics often presents challenges. LLMs tend to produce paraphrased responses in varied formats, complicating exact match evaluation. To simplify evaluation in our task, we ensure that answers in our QA annotations are directly taken from the conversations as much as possible. We instruct the LLMs to replicate the exact wording in the conversation when feasible and employ the F1 partial match metric for evaluating the predictions. Each QA sample is also annotated with the turn IDs in the conversation logs that contain the answer. We report the accuracy of retrieving the correct context for RAG models.
对于每一类问题,作者会在对预测答案和真实答案进行归一化之后,计算精确匹配的 F1 分数。 不过,用自动指标评估长答案通常很困难。 LLM 往往会用不同格式生成改写后的答案,这会让精确匹配评估变复杂。 为了简化这个任务中的评估,作者尽可能确保 QA 标注中的答案直接来自对话本身,并要求 LLM 在可行时复现对话中的原始措辞,然后使用 F1 部分匹配指标评估预测结果。 每个 QA 样本还会标注包含答案的对话轮次 ID。 对于 RAG 模型,作者还会报告其是否检索到正确上下文的准确率。
4.2. Event Summarization Task
The conversation is generated based on a temporal event graph
这些对话是基于时间事件图
Traditional metrics like BLEU and ROUGE focus on lexical similarity between the reference and generated summaries, not meeting our needs as we emphasize factual accuracy in summarization. In this context, we employ FactScore, a method that evaluates the factuality of generated text by decomposing both the reference and hypothesis into atomic facts. We adapt the metric to measure (1) precision of the summarized content by counting the number of atomic facts within the content that correspond with those in
BLEU 和 ROUGE 这类传统指标关注的是参考摘要与生成摘要之间的词面相似度,但这不符合本文需求,因为这里更强调摘要中的事实准确性。 因此,作者采用 FactScore。FactScore 会将参考文本和生成文本都拆解成原子事实,从而评估生成文本的事实性。 作者对该指标进行了适配,用来衡量:(1)摘要内容的精确率,即统计摘要中有多少原子事实能够对应到
4.3. Multi-Modal Dialogue Generation Task
The conversations in our dataset are anchored to specific personas
数据集中的对话都锚定在特定人设
5. Experimental Setup
For the question-answering and event summarization tasks, we replace images in LoCoMo with their captions, and use state-of-the-art LLMs to reason over text-only dialogues interleaved with image captions. We use images directly for the multimodal dialog generation task only.
对于问答任务和事件摘要任务,作者将 LoCoMo 中的图片替换成对应的图片描述,然后使用先进的 LLM 在纯文本对话上进行推理;这些纯文本对话中会穿插图片描述。 只有在多模态对话生成任务中,作者才直接使用图片本身。
5.1. Question Answering
We evaluate three types of models: (1) Base LLMs operating with constrained context lengths where earlier dialogues are omitted, i.e., Mistral-7B, Llama-70B-chat, gpt-3.5-turbo, and gpt-4-turbo; (2) Long-context LLMs with an extended context window, i.e., gpt-3.5-turbo-16k; (3) Retrieval-augmented Generation (RAG) involves retrieving relevant context from a database of dialog history, observations (assertions about speakers), or session-level summaries. We employ DRAGON as retriever and gpt-3.5-turbo-16k as reader.
作者评估了三类模型:(1)基础模型,也就是上下文长度受限的 LLM,早期对话会被省略,包括 Mistral-7B、Llama-70B-chat、gpt-3.5-turbo 和 gpt-4-turbo;(2)长上下文模型,也就是具备扩展上下文窗口的 LLM,这里使用 gpt-3.5-turbo-16k;(3)检索增强生成(RAG),它会从对话历史、观察(关于说话者的断言)或会话级摘要数据库中检索相关上下文。 作者使用 DRAGON 作为检索器,并使用 gpt-3.5-turbo-16k 作为阅读器。
5.2. Event Summarization
We present experiments using Base and Long-context setups from the question-answering task, but refrain from including RAG since summarization requires a comprehensive understanding of the entire dialogue, rather than just retrieving a specific portion. We implement incremental summarization, i.e., iteratively create a summary of preceding sessions and then use that summary as a basis to summarize the subsequent sessions.
作者在事件摘要任务中使用了问答任务里的 Base 和 Long-context 设置,但没有加入 RAG,因为摘要任务需要对整段对话进行整体理解,而不是只检索某个特定片段。 作者实现了增量式摘要:先迭代生成前面若干会话的摘要,再用这个摘要作为基础,继续总结后续会话。
5.3. Multi-modal Dialogue Generation
We generate 50 conversations using our automated pipeline without human filtering for training data and train three versions of MiniGPT-5: (1) Base trains on prior dialogue turns only; (2) + summary trains on prior dialogue turns and a global summary of the ongoing conversation; (3) + observation trains on prior dialogue turns and observations retrieved from conversation history. Each run is initialized with a MiniGPT-5 checkpoint finetuned on MMDialog.
对于多模态对话生成任务,作者使用自动化流程生成了 50 段对话作为训练数据,这些数据没有经过人工过滤,并训练了三个版本的 MiniGPT-5:(1)Base,只基于先前对话轮次训练;(2)+ summary,基于先前对话轮次以及当前对话的全局摘要训练;(3)+ observation,基于先前对话轮次以及从对话历史中检索到的观察训练。 每次实验都使用在 MMDialog 上微调过的 MiniGPT-5 checkpoint 初始化。
6. Experimental Results
We evaluate and analyze the comprehensive performance of all baseline methods for question answering, event graph summarization, and multi-modal dialogue generation.
作者对所有基线方法在问答、事件图摘要和多模态对话生成三个任务上的综合表现进行了评估和分析。
6.1. Question Answering Task
| Category | Model | Context Length | Answer Prediction (F1) | |||||
|---|---|---|---|---|---|---|---|---|
| Single Hop | Multi Hop | Temporal | Open Domain | Adversarial | Overall | |||
| Human | Human | - | 95.1 | 85.8 | 92.6 | 75.4 | 89.4 | 87.9 |
| Base | Mistral-Instruct-7B | 8K | 10.2 | 12.8 | 16.1 | 19.5 | 17.0 | 13.9 |
Llama-2-Chat-70B | 4,096 | 19.7 | 14.4 | 13.3 | 15.9 | 22.1 | 17.9 | |
GPT-3.5-turbo | 4,096 | 29.9 | 23.3 | 17.5 | 29.5 | 12.8 | 22.4 | |
GPT-4-turbo | 4,096 | 23.4 | 23.4 | 10.4 | 24.6 | 70.2 | 32.1 | |
| Long context | GPT-3.5-turbo-16K | 4K | 31.7 | 25.4 | 16.8 | 27.6 | 13.1 | 24.1 |
| 8K | 38.8 | 31.2 | 21.0 | 35.0 | 8.4 | 25.2 | ||
| 12K | 51.1 | 40.4 | 25.0 | 36.5 | 6.4 | 33.5 | ||
| 16K | 56.4 | 42.0 | 20.3 | 37.2 | 2.1 | 37.8 | ||
GPT-3.5-turbo-16k 的问答表现。结果基于答案预测的 F1 分数和 Recall@k,越高越好,最优结果用粗体表示。| Retrieval Unit | top-k | Answer Prediction (F1 score) | |||||
|---|---|---|---|---|---|---|---|
| Single Hop | Multi Hop | Temporal | Open Domain | Adversarial | Overall | ||
None | - | 29.9 | 23.3 | 17.5 | 29.5 | 12.8 | 22.4 |
Dialog | 5 | 42.9 | 19.4 | 21.3 | 35.8 | 31.9 | 31.7 |
| 10 | 46.3 | 26.8 | 24.8 | 37.5 | 29.8 | 34.6 | |
| 25 | 48.1 | 36.1 | 26.2 | 43.4 | 23.4 | 35.8 | |
| 50 | 50.9 | 37.2 | 24.6 | 38.3 | 17.0 | 34.8 | |
Observation | 5 | 44.3 | 30.6 | 41.9 | 40.2 | 44.7 | 41.4 |
| 10 | 42.2 | 30.5 | 42.1 | 41.9 | 36.2 | 38.8 | |
| 25 | 44.6 | 33.2 | 41.8 | 41.9 | 27.7 | 38.0 | |
| 50 | 44.0 | 34.5 | 41.1 | 41.9 | 27.7 | 37.8 | |
Summary | 2 | 34.6 | 15.7 | 26.9 | 26.5 | 36.2 | 29.9 |
| 5 | 36.6 | 16.6 | 31.0 | 34.7 | 38.3 | 32.5 | |
| 10 | 34.5 | 14.7 | 29.3 | 31.6 | 40.4 | 31.5 | |
| Retrieval Unit | top-k | Recall Accuracy (R@k) | |||||
|---|---|---|---|---|---|---|---|
| Single Hop | Multi Hop | Temporal | Open Domain | Adversarial | Overall | ||
None | - | - | - | - | - | - | - |
Dialog | 5 | 66.2 | 34.4 | 89.2 | 38.5 | 45.7 | 58.8 |
| 10 | 72.8 | 247.4 | 97.3 | 53.8 | 54.3 | 67.5 | |
| 25 | 87.5 | 64.1 | 97.3 | 67.9 | 69.1 | 79.9 | |
| 50 | 90.4 | 75.5 | 97.3 | 67.9 | 77.7 | 84.8 | |
Observation | 5 | 52.9 | 40.1 | 81.1 | 38.5 | 29.8 | 49.6 |
| 10 | 57.4 | 53.1 | 83.8 | 46.2 | 41.5 | 57.1 | |
| 25 | 71.3 | 63.8 | 83.8 | 66.7 | 45.7 | 66.0 | |
| 50 | 72.8 | 73.2 | 83.8 | 74.4 | 56.4 | 71.1 | |
Summary | 2 | 68.4 | 39.6 | 56.8 | 50.0 | 73.4 | 61.5 |
| 5 | 81.6 | 57.0 | 70.3 | 60.3 | 86.2 | 75.1 | |
| 10 | 93.4 | 82.3 | 91.9 | 80.8 | 94.7 | 90.7 | |
Tables 2 and 3 present the performance results for the question answering task. We find that: (1) LLMs with limited context length face challenges in understanding extremely long conversations due to truncated context windows. Despite gpt-4-turbo emerging as the top-performing model with an overall score of 32.4, it notably lags behind the human benchmark of 87.9; (2) long-context LLMs can comprehend longer narratives, yet they are prone to generating hallucinations. gpt-3.5-turbo-16k outperforms other approaches, but its performance on adversarial questions drops to a mere 2.1%, compared to 22.1% using Llama-2-Chat and 70.2% using GPT-4-turbo with 4K context windows. This indicates that LLMs can be easily misled into generating hallucinations when they are subjected to long contexts; (3) RAG is effective when conversations are stored as observations. There is a noticeable 5% improvement with gpt-3.5-turbo when the input is top 5 relevant observations instead of pure conversation logs. This improvement falters with an increase in the number of retrieved observations, suggesting that it is important to reduce the signal-to-noise ratio in retrieved contexts for models to utilize the context accurately. Conversely, using session summaries as context does not significantly improve the performance despite high recall accuracies, likely due to loss of information during the conversion of dialogs to summaries.
表2和表3展示了问答任务的性能结果。 作者发现:(1)上下文长度受限的 LLM 难以理解极长对话,这是因为上下文窗口会被截断。 尽管 gpt-4-turbo 是基础模型中表现最好的模型,总体分数达到 32.4,但仍明显落后于人类基准 87.9。(2)长上下文 LLM 能理解更长叙事,但更容易产生幻觉。 gpt-3.5-turbo-16k 整体优于其他方法,但它在对抗性问题上的表现降到了仅 2.1%;相比之下,4K 上下文窗口下的 Llama-2-Chat 为 22.1%,GPT-4-turbo 为 70.2%。 这说明当 LLM 面对长上下文时,很容易被误导并生成幻觉。(3)当对话被存储为 observations 时,RAG 是有效的。 与输入纯对话日志相比,输入 top-5 相关 observations 时,gpt-3.5-turbo 有明显的 5% 提升。 但随着检索到的 observations 数量增加,这种提升会减弱,说明降低检索上下文中的信噪比很重要,模型才能准确利用上下文。 相反,尽管基于会话摘要的 RAG 召回准确率较高,但使用会话摘要作为上下文并没有显著提升性能,这可能是因为从对话转换为摘要时损失了信息。
The interesting finding is that time reasoning and open-domain knowledge questions are the most challenging scenarios. (1) LLMs face challenges in understanding time concepts within dialogues, which is consistent with findings from other single-turn-based benchmarks focused on temporal reasoning capabilities for LLMs. (2) LLMs struggle with open-domain knowledge and degrade in the RAG setting. This suggests that while certain open-domain knowledge may be embedded within the model's parameters, introducing improper context from inaccurate retrieval can lead to a decline in performance.
一个有意思的发现是:时间推理和开放域知识问题是最具挑战性的场景。 (1)LLM 难以理解对话中的时间概念,这与其他基于单轮任务、关注 LLM 时间推理能力的基准结果一致。 (2)LLM 在开放域知识问题上表现困难,而且在 RAG 设置下性能会下降。 这说明,某些开放域知识可能已经存储在模型参数中,但如果检索引入了不准确或不合适的上下文,反而会导致性能下降。
6.2. Event Summarization Task
| Category | Model | Context Length | ROUGE | FactScore | ||||
|---|---|---|---|---|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | Precision | Recall | F1 | |||
| Base | Mistral-Instruct-7B | 8K | 29.4 | 7.2 | 14.1 | 27.1 | 19.8 | 23.0 |
Llama-2-Chat-70B | 4,096 | 28.1 | 9.3 | 14.8 | 36.3 | 22.7 | 28.3 | |
GPT-4-turbo | 4,096 | 38.8 | 11.4 | 20.6 | 51.6 | 41.8 | 45.1 | |
GPT-3.5-turbo | 4,096 | 41.1 | 13.5 | 20.9 | 45.3 | 46.5 | 45.9 | |
| Long context | GPT-3.5-turbo-16K | 16K | 36.2 | 8.5 | 16.4 | 42.3 | 37.8 | 39.9 |
Table 4 presents results for the event summarization task. The use of incremental summarization with gpt-3.5-turbo leads to the highest performance in both recall and F1 score. While gpt-4-turbo records a 5.3% improvement in precision over gpt-3.5-turbo, it does not fare as well in terms of recall. The event summarization task requires long-range dependency to understand the temporal and causal connections between the events discussed by the speaker in multiple sessions. Contrary to expectations, the long-context model does not surpass the base model, despite its capability for extended-range reasoning facilitated by a larger context window. gpt-3.5-turbo-16k exhibits a decline in both precision by 3.0% and recall by 8.7% compared to gpt-3.5-turbo, which has a 4K context window. This suggests that long-context models may not be proficient at utilizing their context appropriately, which also aligns with similar findings in the QA task in LoCoMo. In terms of both the ROUGE and FactScore metrics, commercial models (gpt-4-turbo, gpt-3.5-turbo) significantly outshine their open-source counterparts. Nonetheless, there remains considerable scope for improving performance on this task.
表4展示了事件摘要任务的结果。 使用 gpt-3.5-turbo 进行增量式摘要,在召回率和 F1 分数上取得了最高表现。 虽然 gpt-4-turbo 相比 gpt-3.5-turbo 在精确率上提高了 5.3%,但召回率不如后者。 事件摘要任务需要模型具备长程依赖能力,理解说话者在多个会话中讨论的事件之间的时间和因果连接。 与预期相反,尽管长上下文模型拥有更大的上下文窗口、理论上具备更长范围推理能力,但长上下文模型并没有超过基础模型。 与 4K 上下文窗口的 gpt-3.5-turbo 相比,gpt-3.5-turbo-16k 的精确率下降了 3.0%,召回率下降了 8.7%。 这说明长上下文模型可能并不擅长恰当地利用其上下文,这也与 LoCoMo 问答任务中的类似发现一致。 在 ROUGE 和 FactScore 指标上,商业模型(gpt-4-turbo、gpt-3.5-turbo)明显优于开源模型。 不过,该任务仍有很大的提升空间。
From a manual analysis of predicted summaries, we identify five broad categories of event summarization errors made by LLMs: (1) missing information in events because the model fails to make temporal and/or causal connections over a lengthy conversation; (2) hallucinations, i.e., models pad extra details that are either not present in the conversation or are part of a different event in the same session; (3) errors from misunderstanding of dialog cues such as humor or sarcasm, which is a distinctive issue with comprehension of dialogs; (4) inaccurate speaker attributions; and (5) insignificant dialogs that are wrongly considered as salient events.
通过对预测摘要进行人工分析,作者总结出 LLM 在事件摘要中常见的五类错误:(1)信息缺失,也就是模型无法在长对话中建立时间或因果连接,从而遗漏事件信息;(2)幻觉,模型补充了对话中不存在的额外细节,或把同一会话中另一个事件的内容混入当前事件;(3)误解对话线索,例如幽默或讽刺,这是对话理解中特有的问题;(4)说话者归属错误;(5)把不重要的对话错误地当成显著事件。
6.3. Multi-Modal Dialog Generation Task

Figure 4 illustrates the effectiveness of various MiniGPT-5 training variants in multi-modal dialogue generation. Incorporating context into training enhances performance, with the inclusion of observation as context yielding significantly improved results. For instance, in Figure 4A, the retrieved observations contain information about the speaker's experience in video game tournaments, which leads to the prediction of dialog and images that are more faithful to the speaker's persona. This observation is consistent with earlier findings from the QA task as well. Also, we observe that the MM-Relevance score drops with an increase in the length of dialog history. Retrieval-augmented generation alleviates the drop in MM-Relevance to some extent.
图4展示了不同 MiniGPT-5 训练变体在多模态对话生成中的效果。 将上下文纳入训练可以提升性能,其中把 observation 作为上下文带来的提升尤其明显。 例如在图4A中,检索到的 observations 包含了说话者参加电子游戏锦标赛的经历,因此模型预测出的对话和图片更符合说话者的人设。 这一观察也与前面 QA 任务中的发现一致。 此外,作者还观察到,随着对话历史长度增加,MM-Relevance 分数会下降。 检索增强生成在一定程度上缓解了 MM-Relevance 的下降。
7. Conclusion
We develop a human-machine pipeline to collect LoCoMo, a dataset of 50 high-quality very long conversations, each encompassing 300 turns and 9K tokens on average, over up to 35 sessions, and propose an evaluation framework consisting of three tasks that evaluate models' proficiency in long conversations. Our experiments show that LLMs struggle to comprehend long-term narratives within the dialog and fail to draw temporal and causal connections between events discussed by speakers.
本文开发了一套人机协作流程,用于收集 LoCoMo。LoCoMo 是一个包含 50 段高质量超长对话的数据集,每段对话平均包含 300 轮、9000 个 token,最多跨越 35 个会话。 作者还提出了一个由三个任务组成的评测框架,用于评估模型处理长对话的能力。实验表明,LLM 难以理解对话中的长期叙事,也难以建立说话者所讨论事件之间的时间和因果连接。
8. Limitations
8.1. Hybrid Human-Machine Generated Data
Our dataset is sourced primarily from text generated by LLMs. We pursued this method, which has quickly emerged as a popular alternative to time-intensive manual data collection, to avoid the logistical and legal complexities of collecting very long-term real-world conversations at scale. We ensure that the dataset mirrors real-world interactions as much as possible by having human annotators verify and edit the generated conversations. However, we acknowledge that this dataset may not fully reflect the nuances of real-world online conversations.
本文数据集主要来源于 LLM 生成的文本。 作者采用这种方式,是因为它已经迅速成为一种流行的替代方案,可以避免耗时的人工数据收集;同时也能绕开大规模收集真实超长期对话时面临的组织和法律复杂性。 作者通过让人工标注者验证和编辑生成对话,尽可能确保数据集贴近真实世界交互。 不过,作者也承认,该数据集可能无法完全反映真实线上对话中的细微差别。
8.2. Limited Exploration of Multimodal Behavior
Since the images in our dataset are sourced from the web, they do not demonstrate the visual long-term consistencies that are usually exhibited in personal photos, e.g., appearance, home environment, people and pets. Consequently, we find that the images in our dataset can be replaced with their captions without much loss of information, except for cases where OCR is required. Nevertheless, our work is a first step toward research into the multimodal aspect of very long-term conversations.
由于数据集中的图片来自网络,它们并不能体现个人照片中常见的视觉长期一致性,例如外貌、家庭环境、人物和宠物等。 因此,作者发现,除非需要 OCR,否则数据集中的图片可以被图片描述替代,而不会损失太多信息。 尽管如此,这项工作仍然是研究超长期对话中多模态维度的第一步。
8.3. Language
Our LLM-based pipeline for generating long-term conversations has been developed for the English language only. However, our pipeline can be made to work with any other language using an LLM that is proficient at that language and appropriate translations of our prompts.
作者基于 LLM 的长期对话生成流程目前只针对英语开发。 不过,只要使用擅长目标语言的 LLM,并对提示词进行适当翻译,这套流程也可以扩展到其他语言。
8.4. Closed-Source LLMs
We use state-of-the-art LLMs in our dialog generation pipeline to create a dialog dataset that is as realistic as possible. Unfortunately, this meant employing the strongest commercial LLMs available through a paid API, similar to many concurrent works that generate synthetic conversations. We will make the code for our generative pipeline publicly available in the hope that it can be made to work effectively with state-of-the-art open-source LLMs in the future.
作者在对话生成流程中使用了先进 LLM,以尽可能创建真实感更强的对话数据集。 但这也意味着,他们不得不使用通过付费 API 提供的强大商业 LLM,这与许多同期生成合成对话的工作类似。 作者表示会公开生成流程的代码,希望未来它能够与先进开源 LLM 有效配合使用。
8.5. Evaluation of Long-Form NLG
LLMs are prone to generating verbose answers even when prompted to answer in short phrases. This creates challenges in evaluating the correctness of answers provided by LLMs and has been widely documented in NLP literature. Our evaluation framework suffers from the same challenges when used for experimenting with LLMs.
即使提示 LLM 用短语作答,它们也很容易生成冗长答案。 这会给评估 LLM 答案正确性带来困难,而这一问题在 NLP 文献中已经被广泛记录。 本文的评测框架在用于 LLM 实验时,也会面临同样的挑战。
9. Broader Impacts
We adopt and improve a framework of generative agents introduced in prior work for the generation of long-term conversations. Consequently, the ethical concerns of generative agents outlined in that prior work apply to our work as well, especially since the goal of our framework is to make the conversations as realistic as possible.
本文采用并改进了先前工作中提出的生成式智能体框架,用于生成长期对话。 因此,先前工作中关于生成式智能体的伦理担忧同样适用于本文,尤其是因为本文框架的目标就是让对话尽可能真实。
Specifically, conversational agents that can pose as human beings with a realistic life, as enabled by the temporal event graphs in our framework, pose the risk that users may form parasocial relationships with such agents that may affect their lives adversely. We recommend that any practical deployment of the generative frameworks mentioned in our work be always prefaced with a disclaimer about the source of the dialogs.
具体来说,本文框架中的时间事件图使对话智能体能够表现得像拥有真实生活的人类,这会带来一种风险:用户可能与这类智能体形成拟社会关系,并对自身生活产生负面影响。 因此,作者建议,在实际部署本文提到的生成框架时,应始终提前声明对话的来源。
Second, the use of multimodal LLMs to generate images conditioned on dialog can lead to the propagation of misinformation and social biases, especially if the conversational agent can be coerced into parroting false information or dangerous opinions.
第二,使用多模态 LLM 根据对话生成图像,可能会导致错误信息和社会偏见传播。尤其当对话智能体可能被诱导去重复虚假信息或危险观点时,这一风险会更加明显。
Third, it is tempting to use generative agents to substitute real humans for a process, especially when there are significant challenges in working with humans for a particular goal, e.g., collecting real-world interactions between humans over a year or more. Care must be taken to ensure that such substitutes are not made in studies whose outcomes may be used to make real-world decisions with tangible impacts on humans. Our work is merely a study of model comprehension in very long-term conversations. We do not make any recommendations for real-world policies based on this study and advise potential users of our framework to avoid making such recommendations as well.
第三,在某些流程中使用生成式智能体替代真实人类是很有诱惑力的,尤其是在某个目标下与人类合作存在巨大挑战时,例如收集持续一年或更久的真实人类互动。 但需要格外小心,不能在那些研究结果可能被用于现实决策、并对人类产生实际影响的研究中随意使用这种替代。 本文只是关于模型在超长期对话中理解能力的研究,并不基于该研究提出任何现实政策建议;作者也建议潜在使用者不要基于该框架提出此类建议。