
Cognitive Architectures for Language Agents
CoALA:面向语言智能体的认知架构
Abstract
Recent efforts have augmented large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning, leading to a new class of language agents. While these agents have achieved substantial empirical success, we lack a framework to organize existing agents and plan future developments. In this paper, we draw on the rich history of cognitive science and symbolic artificial intelligence to propose Cognitive Architectures for Language Agents (CoALA). CoALA describes a language agent with modular memory components, a structured action space to interact with internal memory and external environments, and a generalized decision-making process to choose actions. We use CoALA to retrospectively survey and organize a large body of recent work, and prospectively identify actionable directions towards more capable agents. Taken together, CoALA contextualizes today's language agents within the broader history of AI and outlines a path towards language-based general intelligence.
近期工作为大型语言模型(LLM)接入外部资源(例如互联网)或内部控制流(例如提示链),以完成需要接地或推理的任务,由此产生了一类新的语言智能体。 尽管这些智能体已经取得了相当多的经验成功,但我们仍缺少一个框架来组织现有智能体,并规划未来的发展。 本文借鉴认知科学和符号人工智能的丰富历史,提出面向语言智能体的认知架构(Cognitive Architectures for Language Agents,CoALA)。 CoALA 将语言智能体描述为:具有模块化记忆组件、能够与内部记忆和外部环境交互的结构化动作空间,以及用于选择动作的通用决策过程。 我们使用 CoALA 回顾性地梳理和组织大量近期工作,并前瞻性地识别通向更强智能体的可执行方向。 总体而言,CoALA 将当下的语言智能体放回 AI 更广阔的历史脉络之中,并勾勒出一条通向基于语言的通用智能的路径。
1. Introduction
Language agents are an emerging class of artifical intelligence (AI) systems that use large language models (LLMs) to interact with the world. They apply the latest advances in LLMs to the existing field of agent design. Intriguingly, this synthesis offers benefits for both fields. On one hand, LLMs possess limited knowledge and reasoning capabilities. Language agents mitigate these issues by connecting LLMs to internal memory and environments, grounding them to existing knowledge or external observations. On the other hand, traditional agents often require handcrafted rules or reinforcement learning, making generalization to new environments challenging. Language agents leverage commonsense priors present in LLMs to adapt to novel tasks, reducing the dependence on human annotation or trial-and-error learning.
语言智能体是一类新兴的人工智能(AI)系统,它们使用大型语言模型(LLM)与世界交互。 它们把 LLM 的最新进展应用到既有的智能体设计领域。 有意思的是,这种综合对两个领域都有益处。 一方面,LLM 的知识和推理能力是有限的。 语言智能体通过把 LLM 连接到内部记忆和环境,将其接地到已有知识或外部观测,从而缓解这些问题。 另一方面,传统智能体通常需要手写规则或强化学习,因此很难泛化到新环境。 语言智能体利用 LLM 中已有的常识先验来适应新任务,从而减少对人工标注或试错学习的依赖。
While the earliest agents used LLMs to directly select or generate actions (Figure 1B), more recent agents additionally use them to reason, plan, and manage long-term memory to improve decision-making. This latest generation of cognitive language agents use remarkably sophisticated internal processes (Figure 1C). Today, however, individual works use custom terminology to describe these processes (such as tool use, grounding, actions), making it difficult to compare different agents, understand how they are evolving over time, or build new agents with clean and consistent abstractions.
最早的智能体使用 LLM 直接选择或生成动作(图1B),而更新近的智能体还会使用 LLM 来推理、规划和管理长期记忆,以改进决策。 这一代最新的认知型语言智能体使用了相当复杂的内部过程(图1C)。 然而,目前不同工作会使用自定义术语来描述这些过程(例如 tool use、grounding、actions),这使得我们难以比较不同智能体,难以理解它们如何随时间演化,也难以用清晰一致的抽象来构建新智能体。
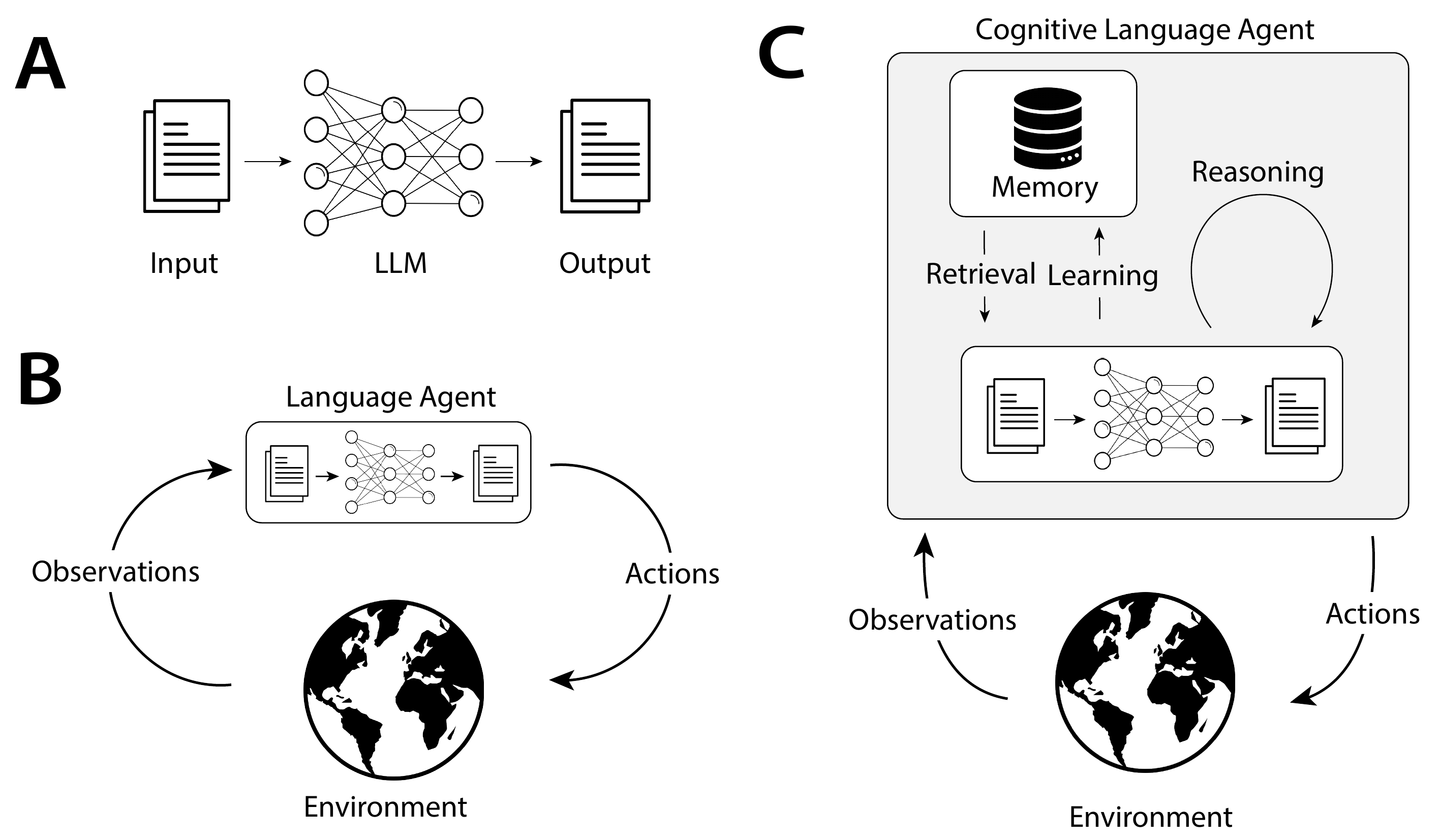
In order to establish a conceptual framework organizing these efforts, we draw parallels with two ideas from the history of computing and artificial intelligence (AI): production systems and cognitive architectures. Production systems generate a set of outcomes by iteratively applying rules. They originated as string manipulation systems -- an analog of the problem that LLMs solve -- and were subsequently adopted by the AI community to define systems capable of complex, hierarchically structured behaviors. To do so, they were incorporated into cognitive architectures that specified control flow for selecting, applying, and even generating new productions. We suggest a meaningful analogy between production systems and LLMs: just as productions indicate possible ways to modify strings, LLMs define a distribution over changes or additions to text. This further suggests that controls from cognitive architectures used with production systems might be equally applicable to transform LLMs into language agents.
为了建立一个能够组织这些工作的概念框架,我们把它们与计算和人工智能(AI)历史中的两个思想进行类比:产生式系统和认知架构。 产生式系统通过反复应用规则来生成一组结果。 它们最初是字符串操作系统,也就是与 LLM 所解决问题相对应的一类形式系统,随后被 AI 社区采纳,用于定义能够产生复杂层级化行为的系统。 为此,产生式系统被纳入认知架构中;认知架构会指定用于选择、应用甚至生成新产生式的控制流。 我们认为产生式系统和 LLM 之间存在有意义的类比:正如产生式表示修改字符串的可能方式,LLM 也定义了对文本进行改变或补充的分布。 这进一步表明,原本用于产生式系统的认知架构控制机制,也可能同样适用于把 LLM 转化为语言智能体。
Thus, we propose Cognitive Architectures for Language Agents (CoALA), a conceptual framework to characterize and design general purpose language agents. CoALA organizes agents along three key dimensions: their information storage (divided into working and long-term memories); their action space (divided into internal and external actions); and their decision-making procedure (which is structured as an interactive loop with planning and execution). Through these three concepts (memory, action, and decision-making), we show CoALA can neatly express a large body of existing agents and identify underexplored directions to develop new ones. Notably, while several recent papers propose conceptual architectures for general intelligence or empirically survey language models and agents, this paper combines elements of both: we propose a theoretical framework and use it to organize diverse empirical work. This grounds our theory to existing practices and allows us to identify both short-term and long-term directions for future work.
因此,我们提出 Cognitive Architectures for Language Agents(CoALA),这是一个用于刻画和设计通用语言智能体的概念框架。 CoALA 从三个关键维度组织智能体:其信息存储(分为工作记忆和长期记忆)、其动作空间(分为内部动作和外部动作),以及其决策过程(被组织为包含规划和执行的交互循环)。 通过记忆、动作和决策这三个概念,我们展示了 CoALA 能够清晰表达大量现有智能体,并识别出用于发展新智能体的尚未充分探索的方向。 值得注意的是,虽然近期一些论文提出了通用智能的概念架构,另一些论文则从经验角度综述语言模型和智能体,本文结合了二者:我们提出一个理论框架,并且用它来组织多样的经验工作。 这使我们的理论扎根于已有实践,也让我们能够识别未来工作的短期和长期方向。
The plan for the rest of the paper is as follows. We first introduce production systems and cognitive architectures (Section 2) and show how these recent developments in LLMs and language agents recapitulate these historical ideas (Section 3). Motivated by these parallels, Section 4 introduces the CoALA framework and uses it to survey existing language agents. Section 5 provides a deeper case study of several prominent agents. Section 6 suggests actionable steps to construct future language agents, while Section 7 highlights open questions in the broader arc of cognitive science and AI. Finally, Section 8 concludes. Readers interested in applied agent design may prioritize Sections 4-6.
本文余下部分安排如下。 我们首先介绍产生式系统和认知架构(第 2 节),并展示 LLM 和语言智能体的近期发展如何重演这些历史思想(第 3 节)。 在这些类比的启发下,第 4 节介绍 CoALA 框架,并用它来综述现有语言智能体。 第 5 节对若干代表性智能体进行更深入的案例研究。 第 6 节提出构建未来语言智能体的可执行步骤,而第 7 节则强调认知科学和 AI 更广阔发展脉络中的开放问题。 最后,第 8 节作总结。 对应用型智能体设计感兴趣的读者,可以优先阅读第 4–6 节。
2. Background: From Strings to Symbolic AGI
We first introduce production systems and cognitive architectures, providing a historical perspective on cognitive science and artificial intelligence: beginning with theories of logic and computation, and ending with attempts to build symbolic artificial general intelligence. We then briefly introduce language models and language agents. Section 3 will connect these ideas, drawing parallels between production systems and language models.
我们首先介绍产生式系统和认知架构,从历史角度审视认知科学和人工智能:从逻辑和计算理论开始,到构建符号式通用人工智能的尝试结束。 随后,我们简要介绍语言模型和语言智能体。 第 3 节将把这些思想连接起来,说明产生式系统和语言模型之间的相似之处。
2.1. Production systems for string manipulation
In the first half of the twentieth century, a significant line of intellectual work led to the reduction of mathematics and computation to symbolic manipulation. Production systems are one such formalism. Intuitively, production systems consist of a set of rules, each specifying a precondition and an action. When the precondition is met, the action can be taken. The idea originates in efforts to characterize the limits of computation. Post proposed thinking about arbitrary logical systems in these terms, where formulas are expressed as strings and the conclusions they license are identified by production rules (as one string "produces" another). This formulation was subsequently shown to be equivalent to a simpler string rewriting system. In such a system, we specify rules of the form
在二十世纪上半叶,一条重要的思想线索把数学和计算归约为符号操作。 产生式系统就是这样一种形式化工具。 直观地说,产生式系统由一组规则构成,每条规则都指定一个前置条件和一个动作。 当前置条件满足时,就可以执行相应动作。 这个思想源于刻画计算极限的努力。 Post 提出可以用这种方式理解任意逻辑系统:公式被表示为字符串,而它们所允许推出的结论由产生式规则标识,也就是一个字符串“产生”另一个字符串。 后来人们证明,这种表述等价于一种更简单的字符串重写系统。 在这样的系统中,我们会指定如下形式的规则:
indicating that the string
这表示字符串
2.2. Control flow: From strings to algorithms
By itself, a production system simply characterizes the set of strings that can be generated from a starting point. However, they can be used to specify algorithms if we impose control flow to determine which productions are executed. For example, Markov algorithms are production systems with a priority ordering. The following algorithm implements division-with-remainder by converting a number written as strokes
单独来看,产生式系统只是刻画从某个起点可以生成哪些字符串。 不过,如果我们加入控制流来决定执行哪些产生式,它们就可以用来指定算法。 例如,Markov 算法就是带有优先级顺序的产生式系统。 下面这个算法通过把由竖线
where the priority order runs from top to bottom, productions are applied to the first substring matching their preconditions when moving from left to right (including the empty substring, in the last production), and
其中优先级从上到下排列;从左到右扫描时,产生式会应用到第一个满足前置条件的子串上(最后一条规则中还包括空子串);
2.3. Cognitive architectures: From algorithms to agents
Production systems were popularized in the AI community by Allen Newell, who was looking for a formalism to capture human problem solving. Productions were generalized beyond string rewriting to logical operations: preconditions that could be checked against the agent's goals and world state, and actions that should be taken if the preconditions were satisfied. In their landmark book Human Problem Solving, Allen Newell and Herbert Simon gave the example of a simple production system implementing a thermostat agent:
Allen Newell 在寻找刻画人类问题解决的形式化工具时,使产生式系统在 AI 社区中流行起来。 产生式被从字符串重写推广到逻辑操作:可以根据智能体目标和世界状态检查的前置条件,以及当前置条件满足时应执行的动作。 在里程碑式著作《Human Problem Solving》中,Allen Newell 和 Herbert Simon 给出了一个实现恒温器智能体的简单产生式系统例子:
Following this work, production systems were adopted by the AI community. The resulting agents contained large production systems connected to external sensors, actuators, and knowledge bases -- requiring correspondingly sophisticated control flow. AI researchers defined "cognitive architectures" that mimicked human cognition -- explicitly instantiating processes such as perception, memory, and planning to achieve flexible, rational, real-time behaviors. This led to applications from psychological modeling to robotics, with hundreds of architectures and thousands of publications.
在这项工作之后,产生式系统被 AI 社区采纳。 由此产生的智能体包含大型产生式系统,并与外部传感器、执行器和知识库相连,因此需要相应复杂的控制流。 AI 研究者定义了模仿人类认知的“认知架构”,显式实例化感知、记忆和规划等过程,以实现灵活、理性、实时的行为。 这推动了从心理建模到机器人学的应用,也产生了数百种架构和数千篇论文。
A canonical example is the Soar architecture (Figure 2A). Soar stores productions in long-term memory and executes them based on how well their preconditions match working memory (Figure 2B). These productions specify actions that modify the contents of working and long-term memory. We next provide a brief overview of Soar and refer readers to deeper introductions for more details.
一个典型例子是 Soar 架构(图2A)。 Soar 将产生式存储在长期记忆中,并根据其前置条件与工作记忆的匹配程度来执行它们(图2B)。 这些产生式指定了会修改工作记忆和长期记忆内容的动作。 接下来我们会简要概述 Soar,并请读者参考更深入的介绍了解细节。
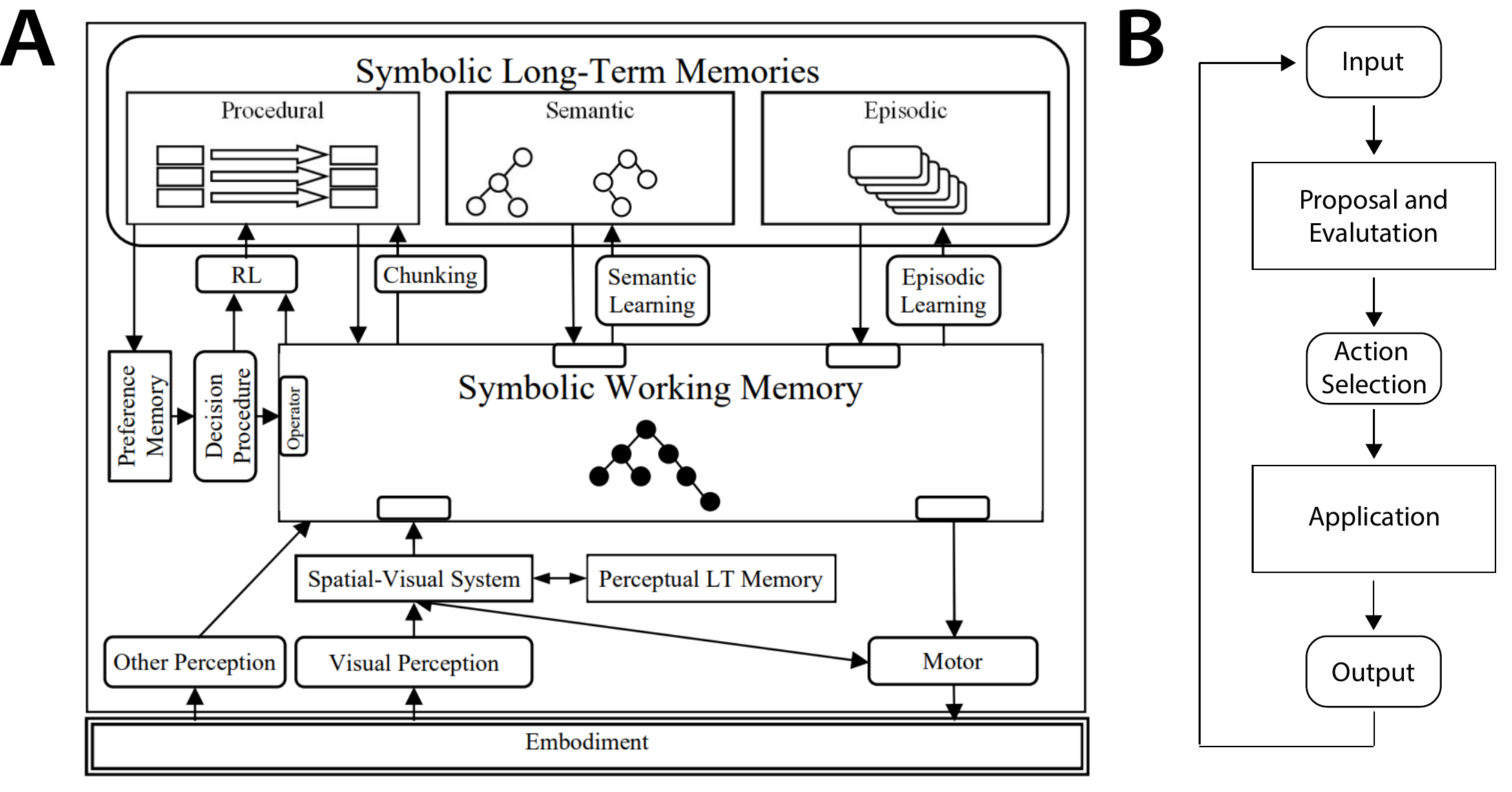
Memory. Building on psychological theories, Soar uses several types of memory to track the agent's state. Working memory reflects the agent's current circumstances: it stores the agent's recent perceptual input, goals, and results from intermediate, internal reasoning. Long term memory is divided into three distinct types. Procedural memory stores the production system itself: the set of rules that can be applied to working memory to determine the agent's behavior. Semantic memory stores facts about the world, while episodic memory stores sequences of the agent's past behaviors.
记忆。 基于心理学理论,Soar 使用多种记忆来追踪智能体状态。 工作记忆反映智能体当前所处的情境:它存储智能体最近的感知输入、目标,以及中间内部推理的结果。 长期记忆被分为三种不同类型。 程序性记忆存储产生式系统本身,也就是可应用于工作记忆、用来决定智能体行为的一组规则。 语义记忆存储关于世界的事实,而情节记忆存储智能体过去行为的序列。
Grounding. Soar can be instantiated in simulations or real-world robotic systems. In embodied contexts, a variety of sensors stream perceptual input into working memory, where it is available for decision-making. Soar agents can also be equipped with actuators, allowing for physical actions and interactive learning via language.
接地。 Soar 可以被实例化到仿真环境或真实机器人系统中。 在具身场景中,多种传感器会把感知输入流式送入工作记忆,供决策使用。 Soar 智能体也可以配备执行器,从而能够进行物理动作,并通过语言进行交互式学习。
Decision making. Soar implements a decision loop that evaluates productions and applies the one that matches best (Figure 2B). Productions are stored in long-term procedural memory. During each decision cycle, their preconditions are checked against the agent's working memory. In the proposal and evaluation phase, a set of productions is used to generate and rank a candidate set of possible actions. The best action is then chosen. Another set of productions is then used to implement the action -- for example, modifying the contents of working memory or issuing a motor command.
决策。 Soar 实现了一个决策循环,用于评估产生式并应用匹配度最高的产生式(图2B)。 产生式被存储在长期程序性记忆中。 在每个决策周期内,系统会根据智能体的工作记忆检查它们的前置条件。 在提出与评估阶段,一组产生式会被用来生成并排序一组候选动作。 随后系统选择最佳动作。 另一组产生式随后用于实现该动作,例如修改工作记忆内容或发出运动命令。
Learning. Soar supports multiple modes of learning. First, new information can be stored directly in long-term memory: facts can be written to semantic memory, while experiences can be written to episodic memory. This information can later be retrieved back into working memory when needed for decision-making. Second, behaviors can be modified. Reinforcement learning can be used to up-weight productions that have yielded good outcomes, allowing the agent to learn from experience. Most remarkably, Soar is also capable of writing new productions into its procedural memory -- effectively updating its source code.
学习。 Soar 支持多种学习模式。 首先,新信息可以被直接存入长期记忆:事实可以写入语义记忆,经历可以写入情节记忆。 这些信息之后可以在决策需要时被取回到工作记忆中。 其次,行为也可以被修改。 强化学习可用于提高那些带来好结果的产生式权重,从而让智能体从经验中学习。 最值得注意的是,Soar 还能把新的产生式写入其程序性记忆中,相当于更新自己的源代码。
Cognitive architectures were used broadly across psychology and computer science, with applications including robotics, military simulations, and intelligent tutoring. Yet they have become less popular in the AI community over the last few decades. This decrease in popularity reflects two of the challenges involved in such systems: they are limited to domains that can be described by logical predicates and require many pre-specified rules to function.
认知架构曾广泛用于心理学和计算机科学,应用包括机器人学、军事仿真和智能辅导。 但在过去几十年里,它们在 AI 社区中的热度有所下降。 这种热度下降反映了此类系统面临的两个挑战:它们受限于可由逻辑谓词描述的领域,并且需要大量预先指定的规则才能运行。
Intriguingly, LLMs appear well-posed to meet these challenges. First, they operate over arbitrary text, making them more flexible than logic-based systems. Second, rather than requiring the user to specify productions, they learn a distribution over productions via pre-training on an internet corpus. Recognizing this, researchers have begun to use LLMs within cognitive architectures, leveraging their implicit world knowledge to augment traditional symbolic approaches. Here, we instead import principles from cognitive architecture to guide the design of LLM-based agents.
有趣的是,LLM 似乎很适合应对这些挑战。 首先,它们在任意文本上运行,因此比基于逻辑的系统更加灵活。 其次,它们不要求用户指定产生式,而是通过在互联网语料上预训练来学习产生式分布。 认识到这一点后,研究者已经开始在认知架构中使用 LLM,借助其隐含的世界知识来增强传统符号方法。 而本文则反过来引入认知架构原则,用于指导基于 LLM 的智能体设计。
2.4. Language models and agents
Language modeling is a decades-old endeavor in the NLP and AI communities, aiming to develop systems that can generate text given some context. Formally, language models learn a distribution
语言建模是 NLP 和 AI 社区持续了数十年的工作,目标是开发能够在给定上下文时生成文本的系统。 形式上,语言模型学习分布
Unexpectedly, training these models on internet-scale text also made them useful for many tasks beyond generating text, such as writing code, modeling proteins, and acting in interactive environments. The latter has led to the rise of "language agents" -- systems that use LLMs as a core computation unit to reason, plan, and act -- with applications in areas such as robotics, manufacturing, web manipulation, puzzle solving and interactive code generation. The combination of language understanding and decision-making capabilities is an exciting and emerging direction that promises to bring these agents closer to human-like intelligence.
出乎意料的是,在互联网规模文本上训练这些模型,也使它们能够用于生成文本之外的许多任务,例如编写代码、建模蛋白质,以及在交互环境中行动。 后者推动了“语言智能体”的兴起:这类系统使用 LLM 作为核心计算单元来推理、规划和行动,应用领域包括机器人学、制造、网页操作、谜题求解和交互式代码生成。 语言理解能力与决策能力的结合,是一个令人兴奋的新兴方向,有望让这些智能体更接近类人智能。
3. Connections between Language Models and Production Systems
Based on their common origins in processing strings, there is a natural analogy between production systems and language models. We develop this analogy, then show that prompting methods recapitulate the algorithms and agents based on production systems. The correspondence between production systems and language models motivates our use of cognitive architectures to build language agents, which we introduce in Section 4.
由于二者都源于对字符串的处理,产生式系统和语言模型之间存在自然类比。 我们会展开这个类比,然后说明提示方法如何重演基于产生式系统的算法和智能体。 产生式系统和语言模型之间的对应关系,激发了我们使用认知架构构建语言智能体;相关框架将在第 4 节介绍。
3.1. Language models as probabilistic production systems
In their original instantiation, production systems specified the set of strings that could be generated from a starting point, breaking this process down into a series of string rewriting operations. Language models also define a possible set of expansions or modifications of a string -- the prompt provided to the model. For example, we can formulate the problem of completing a piece of text as a production. If
在最初形式中,产生式系统指定从一个起点可以生成的字符串集合,并将这个过程分解为一系列字符串重写操作。 语言模型同样定义了对一个字符串进行可能扩展或修改的集合,也就是提供给模型的提示。 例如,我们可以把补全文本片段的问题表述为一个产生式。 如果
This probabilistic form offers both advantages and disadvantages compared to traditional production systems. The primary disadvantage of LLMs is their inherent opaqueness: while production systems are defined by discrete and human-legible rules, LLMs consist of billions of uninterpretable parameters. This opaqueness -- coupled with inherent randomness from their probabilistic formulation -- makes it challenging to analyze or control their behaviors. Nonetheless, their scale and pre-training provide massive advantages over traditional production systems. LLMs pre-trained on large-scale internet data learn a remarkably effective prior over string completions, allowing them to solve a wide range of tasks out of the box.
与传统产生式系统相比,这种概率形式既有优势,也有劣势。 LLM 的主要劣势在于其固有不透明性:产生式系统由离散且人类可读的规则定义,而 LLM 由数十亿个难以解释的参数构成。 这种不透明性,加上概率形式带来的固有随机性,使得分析或控制其行为变得困难。 尽管如此,它们的规模和预训练仍然比传统产生式系统带来巨大优势。 在大规模互联网数据上预训练的 LLM 学到了非常有效的字符串补全先验,因此能够开箱即用地解决广泛任务。
3.2. Prompt engineering as control flow
The weights of an LLM define a prioritization over output strings (completions), conditioned by the input string (the prompt). The resulting distribution can be interpreted as a task-specific prioritization of productions -- in other words, a simple control flow. Tasks such as question answering can be formulated directly as an input string (the question), yielding conditional distributions over completions (possible answers).
LLM 的权重定义了在输入字符串(提示)条件下,对输出字符串(补全)的优先级排序。 所得分布可以被解释为针对特定任务的产生式优先级,也就是一种简单控制流。 问答等任务可以直接表述为输入字符串(问题),从而得到补全(可能答案)上的条件分布。
| Prompting Method | Production Sequence |
|---|---|
| Zero-shot | |
| Few-shot | |
| Retrieval Augmented Generation | |
| Socratic Models | |
| Self-Critique |
Early work on few-shot learning and prompt engineering found that the LLM could be further biased towards high-quality productions by pre-processing the input string. These simple manipulations -- typically concatenating additional text to the input -- can themselves be seen as productions, meaning that these methods define a sequence of productions (Table 1). Later work extended these approaches to dynamic, context-sensitive prompts: for example, selecting few-shot examples that are maximally relevant to the input or populating a template with external observations from video or databases. For a survey of such prompting techniques, see Liu et al.
关于 few-shot 学习和提示工程的早期工作发现,可以通过预处理输入字符串,让 LLM 进一步偏向高质量产生式。 这些简单操作通常是向输入拼接额外文本,它们本身也可以被看作产生式,这意味着这些方法定义了一段产生式序列(表1)。 后续工作把这些方法扩展到动态且上下文敏感的提示,例如选择与输入最相关的 few-shot 示例,或用来自视频或数据库的外部观测填充模板。 关于这类提示技术的综述,可参见 Liu 等人的工作。
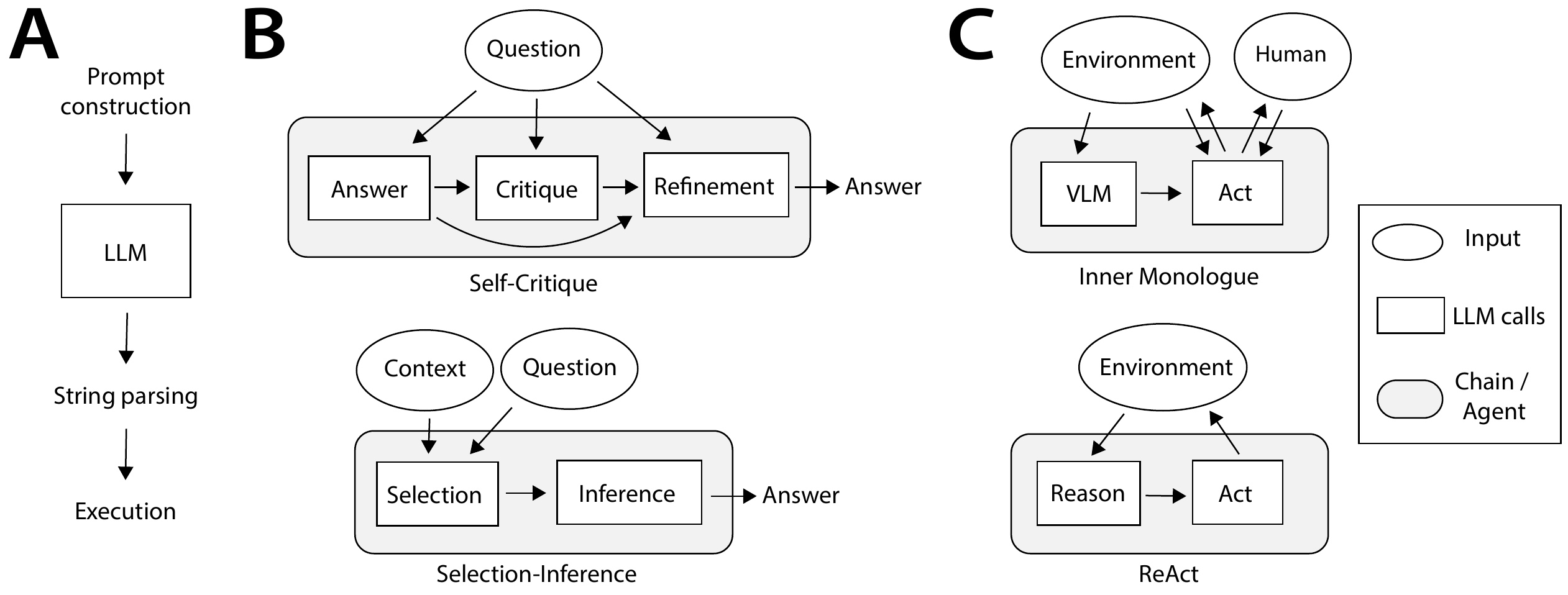
Subsequent work used the LLM itself as a pre-processing step, eliciting targeted reasoning to foreground a particular aspect of the problem or generate intermediate reasoning steps before returning an answer. Chaining multiple calls to an LLM allows for increasingly complicated algorithms (Figure 3).
后续工作把 LLM 本身用作预处理步骤,在返回答案之前诱导针对性推理,以突出问题的某个特定方面,或生成中间推理步骤。 把多次 LLM 调用链接起来,可以形成越来越复杂的算法(图3)。
3.3. Towards cognitive language agents
Language agents move beyond pre-defined prompt chains and instead place the LLM in a feedback loop with the external environment (Figure 1B). These approaches first transform multimodal input into text and pass it to the LLM. The LLM's output is then parsed and used to determine an external action (Figure 3C). Early agents interfaced the LLM directly with the external environment, using it to produce high-level instructions based on the agent's state. Later work developed more sophisticated language agents that use the LLM to perform intermediate reasoning before selecting an action. The most recent agents incorporate sophisticated learning strategies such as reflecting on episodic memory to generate new semantic inferences or modifying their program code to generate procedural knowledge, using their previous experience to adapt their future behaviors.
语言智能体超越了预定义提示链,而是把 LLM 放入与外部环境的反馈循环中(图1B)。 这些方法首先把多模态输入转换为文本,并传给 LLM。 随后,LLM 的输出会被解析,并用于决定一个外部动作(图3C)。 早期智能体直接把 LLM 接入外部环境,并根据智能体状态用它生成高层指令。 后续工作发展出了更复杂的语言智能体,在选择动作之前使用 LLM 执行中间推理。 最新的智能体还引入了复杂学习策略,例如反思情节记忆以生成新的语义推断,或修改程序代码以生成程序性知识,从而利用过去经验适应未来行为。
These cognitive language agents employ nontrivial LLM-based reasoning and learning (Figure 1C). Just as cognitive architectures were used to structure production systems' interactions with agents' internal state and external environments, we suggest that they can help design LLM-based cognitive agents. In the remainder of the paper, we use this perspective to organize existing approaches and highlight promising extensions.
这些认知型语言智能体使用了非平凡的基于 LLM 的推理和学习(图1C)。 正如认知架构曾被用来组织产生式系统与智能体内部状态和外部环境的交互,我们认为它们也能帮助设计基于 LLM 的认知智能体。 在本文余下部分,我们将使用这一视角来组织现有方法,并强调有前景的扩展方向。
4. Cognitive Architectures for Language Agents (CoALA): A Conceptual Framework
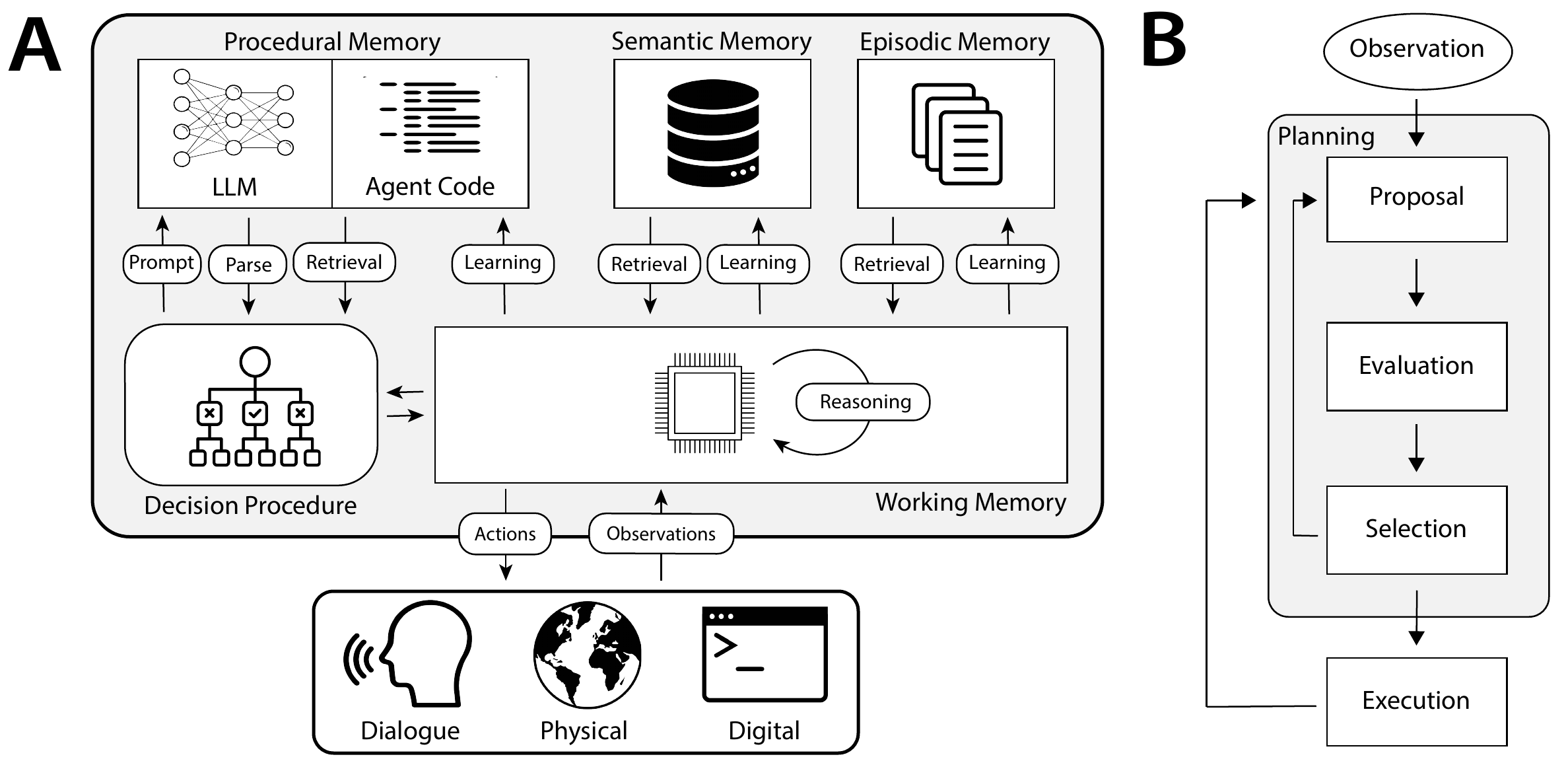
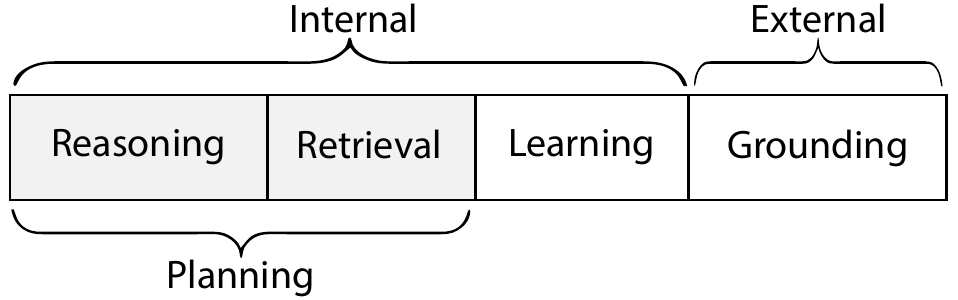
We present Cognitive Architectures for Language Agents (CoALA) as a framework to organize existing language agents and guide the development of new ones. CoALA positions the LLM as the core component of a larger cognitive architecture (Figure 4). Under CoALA, a language agent stores information in memory modules (Section 4.1), and acts in an action space structured into external and internal parts (Figure 5). External actions interact with external environments (e.g., control a robot, communicate with a human, navigate a website) through grounding (Section 4.2). Internal actions interact with internal memories. Depending on which memory gets accessed and whether the access is read or write, internal actions can be further decomposed into three kinds: retrieval (read from long-term memory; Section 4.3), reasoning (update the short-term working memory with LLM; Section 4.4), and learning (write to long-term memory; Section 4.5).
我们将面向语言智能体的认知架构(CoALA)作为一个框架,用于组织现有语言智能体,并指导新智能体的发展。 CoALA 把 LLM 定位为更大认知架构中的核心组件(图4)。 在 CoALA 中,语言智能体把信息存储在记忆模块中(第 4.1 节),并在由外部部分和内部部分构成的动作空间中行动(图5)。 外部动作通过接地与外部环境交互(例如控制机器人、与人交流、浏览网站;第 4.2 节)。 内部动作与内部记忆交互。 根据访问的是哪种记忆,以及访问是读还是写,内部动作可以进一步分解为三类:检索(从长期记忆读取;第 4.3 节)、推理(用 LLM 更新短期工作记忆;第 4.4 节)和学习(写入长期记忆;第 4.5 节)。
Language agents choose actions via decision-making, which follows a repeated cycle (Section 4.6, Figure 4B). In each cycle, the agent can use reasoning and retrieval actions to plan. This planning subprocess selects a grounding or learning action, which is executed to affect the outside world or the agent's long-term memory. CoALA's decision cycle is analogous to a program's "main" procedure (a method without return values, as opposed to functions) that runs in loops continuously, accepting new perceptual input and calling various action procedures in response.
语言智能体通过决策来选择动作,而决策遵循一个反复执行的周期(第 4.6 节,图4B)。 在每个周期中,智能体可以使用推理和检索动作来进行规划。 这个规划子过程会选择一个接地动作或学习动作,随后执行该动作以影响外部世界或智能体的长期记忆。 CoALA 的决策周期类似于程序中持续循环运行的 “main” 过程(与函数相对,指没有返回值的方法):它接收新的感知输入,并相应调用各种动作过程。
CoALA (Figure 4) is inspired by the decades of research in cognitive architectures (Section 2.3), leveraging key concepts such as memory, grounding, learning, and decision-making. Yet the incorporation of an LLM leads to the addition of "reasoning" actions, which can flexibly produce new knowledge and heuristics for various purposes -- replacing hand-written rules in traditional cognitive architectures. It also makes text the de facto internal representation, streamlining agents' memory modules. Finally, recent advances in vision-language models (VLMs) can simplify grounding by providing a straightforward translation of perceptual data into text.
CoALA(图4)受到数十年认知架构研究的启发(第 2.3 节),利用了记忆、接地、学习和决策等关键概念。 不过,引入 LLM 会带来“推理”动作;这些动作能够灵活地为不同目的生成新知识和启发式规则,从而替代传统认知架构中的手写规则。 这也让文本成为事实上的内部表示,从而简化智能体的记忆模块。 最后,视觉语言模型(VLM)的近期进展可以通过把感知数据直接转换为文本来简化接地。
The rest of this section details key concepts in CoALA: memory, actions (grounding, reasoning, retrieval, and learning), and decision-making. For each concept, we use existing language agents (or relevant NLP/RL methods) as examples -- or note gaps in the literature for future directions.
本节余下部分将详细介绍 CoALA 的关键概念:记忆,动作(接地、推理、检索和学习),以及决策。 对于每个概念,我们会使用现有语言智能体(或相关 NLP/RL 方法)作为例子,或者指出文献中的空白以作为未来方向。
4.1. Memory
Language models are stateless: they do not persist information across calls. In contrast, language agents may store and maintain information internally for multi-step interaction with the world. Under the CoALA framework, language agents explicitly organize information (mainly textural, but other modalities also allowed) into multiple memory modules, each containing a different form of information. These include short-term working memory and several long-term memories: episodic, semantic, and procedural.
语言模型是无状态的:它们不会在多次调用之间持久保存信息。 相比之下,语言智能体可以在内部存储并维护信息,以便与世界进行多步交互。 在 CoALA 框架下,语言智能体会把信息(主要是文本,但也允许其他模态)显式组织到多个记忆模块中,每个模块包含不同形式的信息。 这些记忆包括短期工作记忆,以及若干长期记忆:情节记忆、语义记忆和程序性记忆。
Working memory. Working memory maintains active and readily available information as symbolic variables for the current decision cycle (Section 4.6). This includes perceptual inputs, active knowledge (generated by reasoning or retrieved from long-term memory), and other core information carried over from the previous decision cycle (e.g., agent's active goals). Previous methods encourage the LLM to generate intermediate reasoning, using the LLM's own context as a form of working memory. CoALA's notion of working memory is more general: it is a data structure that persists across LLM calls. On each LLM call, the LLM input is synthesized from a subset of working memory (e.g., a prompt template and relevant variables). The LLM output is then parsed back into other variables (e.g., an action name and arguments) which are stored back in working memory and used to execute the corresponding action (Figure 3A). Besides the LLM, the working memory also interacts with long-term memories and grounding interfaces. It thus serves as the central hub connecting different components of a language agent.
工作记忆。 工作记忆会把当前决策周期中活跃且随时可用的信息维护为符号变量(第 4.6 节)。 这包括感知输入、活跃知识(由推理生成或从长期记忆检索得到),以及从上一个决策周期带来的其他核心信息(例如智能体当前目标)。 以往方法鼓励 LLM 生成中间推理,并把 LLM 自身上下文用作一种工作记忆。 CoALA 对工作记忆的理解更加一般:它是一个能够跨 LLM 调用持久存在的数据结构。 在每次 LLM 调用中,LLM 输入会由工作记忆的一个子集综合而成(例如提示模板和相关变量)。 随后,LLM 输出会被解析回其他变量(例如动作名和参数),这些变量会被存回工作记忆,并用于执行相应动作(图3A)。 除了 LLM 之外,工作记忆还会与长期记忆和接地接口交互。 因此,它是连接语言智能体不同组件的中央枢纽。
Episodic memory. Episodic memory stores experience from earlier decision cycles. This can consist of training input-output pairs, history event flows, game trajectories from previous episodes, or other representations of the agent's experiences. During the planning stage of a decision cycle, these episodes may be retrieved into working memory to support reasoning. An agent can also write new experiences from working to episodic memory as a form of learning (Section 4.5).
情节记忆。 情节记忆存储早期决策周期中的经验。 它可以由训练输入输出对、历史事件流、过往回合的游戏轨迹,或智能体经验的其他表示构成。 在决策周期的规划阶段,这些情节可能被检索到工作记忆中以支持推理。 智能体也可以把新的经验从工作记忆写入情节记忆,作为一种学习形式(第 4.5 节)。
Semantic memory. Semantic memory stores an agent's knowledge about the world and itself. Traditional NLP or RL approaches that leverage retrieval for reasoning or decision-making initialize semantic memory from an external database for knowledge support. For example, retrieval-augmented methods in NLP can be viewed as retrieving from a semantic memory of unstructured text (e.g., Wikipedia). In RL, "reading to learn" approaches leverage game manuals and facts as a semantic memory to affect the policy. While these examples essentially employ a fixed, read-only semantic memory, language agents may also write new knowledge obtained from LLM reasoning into semantic memory as a form of learning (Section 4.5) to incrementally build up world knowledge from experience.
语义记忆。 语义记忆存储智能体关于世界和自身的知识。 传统 NLP 或 RL 方法若使用检索来支持推理或决策,通常会从外部数据库初始化语义记忆,以获得知识支持。 例如,NLP 中的检索增强方法可以被看作从非结构化文本(如 Wikipedia)的语义记忆中检索。 在 RL 中,“通过阅读学习”的方法会把游戏手册和事实作为语义记忆来影响策略。 虽然这些例子本质上使用的是固定、只读的语义记忆,但语言智能体也可以把由 LLM 推理得到的新知识作为学习形式写入语义记忆(第 4.5 节),从而从经验中逐步构建世界知识。
Procedural memory. Language agents contain two forms of procedural memory: implicit knowledge stored in the LLM weights, and explicit knowledge written in the agent's code. The agent's code can be further divided into two types: procedures that implement actions (reasoning, retrieval, grounding, and learning procedures), and procedures that implement decision-making itself (Section 4.6). During a decision cycle, the LLM can be accessed via reasoning actions, and various code-based procedures can be retrieved and executed. Unlike episodic or semantic memory that may be initially empty or even absent, procedural memory must be initialized by the designer with proper code to bootstrap the agent. Finally, while learning new actions by writing to procedural memory is possible (Section 4.5), it is significantly riskier than writing to episodic or semantic memory, as it can easily introduce bugs or allow an agent to subvert its designers' intentions.
程序性记忆。 语言智能体包含两种形式的程序性记忆:存储在 LLM 权重中的隐式知识,以及写在智能体代码中的显式知识。 智能体代码可以进一步分为两类:实现动作的过程(推理、检索、接地和学习过程),以及实现决策本身的过程(第 4.6 节)。 在一个决策周期中,可以通过推理动作访问 LLM,也可以检索并执行各种基于代码的过程。 不同于初始可能为空甚至不存在的情节记忆或语义记忆,程序性记忆必须由设计者用适当代码初始化,以便启动智能体。 最后,虽然通过写入程序性记忆来学习新动作是可能的(第 4.5 节),但这比写入情节记忆或语义记忆风险大得多,因为它很容易引入 bug,或让智能体违背设计者意图。
4.2. Grounding actions
Grounding procedures execute external actions and process environmental feedback into working memory as text. This effectively simplifies the agent's interaction with the outside world as a "text game" with textual observations and actions. We categorize three kinds of external environments.
接地过程执行外部动作,并把环境反馈处理为文本写入工作记忆。 这实际上把智能体与外部世界的交互简化成一个由文本观测和文本动作构成的“文本游戏”。 我们将外部环境分为三类。
Physical environments. Physical embodiment is the oldest instantiation envisioned for AI agents. It involves processing perceptual inputs (visual, audio, tactile) into textual observations (e.g., via pre-trained captioning models), and affecting the physical environments via robotic planners that take language-based commands. Recent advances in LLMs have led to numerous robotic projects that leverage LLMs as a "brain" for robots to generate actions or plans in the physical world. For perceptual input, vision-language models are typically used to convert images to text, providing additional context for the LLM.
物理环境。 物理具身是 AI 智能体最早被设想的实例化形式。 它需要把感知输入(视觉、听觉、触觉)处理成文本观测(例如通过预训练图像描述模型),并通过接收基于语言命令的机器人规划器影响物理环境。 LLM 的近期进展催生了许多机器人项目,它们把 LLM 作为机器人的“大脑”,用于在物理世界中生成动作或计划。 对于感知输入,通常会使用视觉语言模型把图像转换为文本,为 LLM 提供额外上下文。
Dialogue with humans or other agents. Classic linguistic interactions allow the agent to accept instructions or learn from people. Agents capable of generating language may ask for help or clarification -- or entertain or emotionally help people. Recent work also investigates interaction among multiple language agents for social simulation, debate, improved safety, or collabrative task solving.
与人或其他智能体对话。 经典语言交互允许智能体接受指令,或向人学习。 能够生成语言的智能体可以寻求帮助或澄清,也可以用于娱乐或提供情感支持。 近期工作还研究了多个语言智能体之间的交互,用于社会模拟、辩论、提升安全性或协作式任务求解。
Digital environments. This includes interacting with games, APIs, and websites as well as general code execution. Such digital grounding is cheaper and faster than physical or human interaction. It is thus a convenient testbed for language agents and has been studied with increasing intensity in recent years. In particular, for NLP tasks that require augmentation of external knowledge or computation, stateless digital APIs (e.g., search, calculator, translator) are often packaged as "tools", which can be viewed as special "single-use" digital environments.
数字环境。 这包括与游戏、API 和网站交互,以及一般的代码执行。 这种数字接地比物理交互或人类交互更便宜、更快速。 因此,它是语言智能体的便利测试床,并且近年来受到越来越多研究。 特别是,对于需要外部知识或计算增强的 NLP 任务,无状态数字 API(例如搜索、计算器、翻译器)常被封装为“工具”,可以看作特殊的“一次性”数字环境。
4.3. Retrieval actions
In CoALA, a retrieval procedure reads information from long-term memories into working memory. Depending on the information and memory type, it could be implemented in various ways, e.g., rule-based, sparse, or dense retrieval. For example, Voyager loads code-based skills from a skill library via dense retrieval to interact with the Minecraft world -- effectively retrieving grounding procedures from a procedural memory. Generative Agents retrieves relevant events from episodic memory via a combination of recency (rule-based), importance (reasoning-based), and relevance (embedding-based) scores. DocPrompting proposes to leverage library documents to assist code generation, which can be seen as retrieving knowledge from semantic memory. While retrieval plays a key role in human decision-making, adaptive and context-specific recall remains understudied in language agents. In Section 6, we suggest a principled integration of decision-making and retrieval as an important future direction.
在 CoALA 中,检索过程会把信息从长期记忆读入工作记忆。 根据具体信息和记忆类型,它可以用不同方式实现,例如基于规则、稀疏检索或稠密检索。 例如,Voyager 通过稠密检索从技能库中加载基于代码的技能来与 Minecraft 世界交互,这实际上是在从程序性记忆中检索接地过程。 Generative Agents 通过新近性(基于规则)、重要性(基于推理)和相关性(基于嵌入)分数的组合,从情节记忆中检索相关事件。 DocPrompting 提出利用库文档辅助代码生成,这可以被看作从语义记忆中检索知识。 虽然检索在人类决策中起关键作用,但语言智能体中自适应且依赖上下文的回忆仍研究不足。 在第 6 节中,我们提出将决策和检索原则性地整合起来,作为一个重要未来方向。
4.4. Reasoning actions
Reasoning allows language agents to process the contents of working memory to generate new information. Unlike retrieval (which reads from long-term memory into working memory), reasoning reads from and writes to working memory. This allows the agent to summarize and distill insights about the most recent observation, the most recent trajectory, or information retrieved from long-term memory. Reasoning can be used to support learning (by writing the results into long-term memory) or decision-making (by using the results as additional context for subsequent LLM calls).
推理使语言智能体能够处理工作记忆中的内容并生成新信息。 不同于检索(从长期记忆读入工作记忆),推理会从工作记忆中读取信息,并且写回工作记忆。 这使智能体能够对最新观测、最新轨迹或从长期记忆中检索出的信息进行总结和提炼。 推理可以用于支持学习(把结果写入长期记忆),也可以用于支持决策(把结果作为后续 LLM 调用的额外上下文)。
4.5. Learning actions
Learning occurs by writing information to long-term memory, which includes a spectrum of diverse procedures.
学习通过把信息写入长期记忆发生,其中包含一系列多样化过程。
Updating episodic memory with experience. It is common practice for RL agents to store episodic trajectories to update a parametric policy or establish a non-parametric policy. For language agents, added experiences in episodic memory may be retrieved later as examples and bases for reasoning or decision-making.
用经验更新情节记忆。 RL 智能体通常会存储情节轨迹,用于更新参数化策略或建立非参数策略。 对于语言智能体,添加到情节记忆中的经验之后可以被检索出来,作为推理或决策的示例和依据。
Updating semantic memory with knowledge. Recent work has applied LLMs to reason about raw experiences and store the resulting inferences in semantic memory. For example, Reflexion uses an LLM to reflect on failed episodes and stores the results (e.g., "there is no dishwasher in kitchen") as semantic knowledge to be attached to LLM context for solving later episodes. Finally, work in robotics uses vision-language models to build a semantic map of the environment, which can later be queried to execute instructions.
用知识更新语义记忆。 近期工作已经使用 LLM 对原始经验进行推理,并把所得推断存储到语义记忆中。 例如,Reflexion 使用 LLM 反思失败回合,并把结果(例如“厨房里没有洗碗机”)作为语义知识存储起来,附加到 LLM 上下文中以解决后续回合。 最后,机器人学中的工作使用视觉语言模型构建环境的语义地图,之后可以查询该地图来执行指令。
Updating LLM parameters (procedural memory). The LLM weights represent implicit procedural knowledge. These can be adjusted to an agent's domain by fine-tuning during the agent's lifetime. Such fine-tuning can be accomplished via supervised or imitation learning, reinforcement learning (RL) from environment feedback, human feedback (RLHF), or AI feedback. Classic LLM self-improvement methods use an external measure such as consistency to select generations to fine-tune on. In reinforcement learning settings, this can be extended to use environmental feedback instead: for example, XTX periodically fine-tunes a small language model on high-scoring trajectories stored in episodic memory, which serves as a robust "exploitation" policy to reach exploration frontiers in the face of stochasity. Fine-tuning the agent's LLM is a costly form of learning; thus, present studies specify learning schedules. However, as training becomes more efficient -- or if agents utilize smaller subtask-specific LLMs -- it may be possible to allow language agents to autonomously determine when and how to fine-tune their LLMs.
更新 LLM 参数(程序性记忆)。 LLM 权重表示隐式程序性知识。 这些权重可以在智能体生命周期内通过微调来适应智能体所在领域。 这种微调可以通过监督学习或模仿学习、来自环境反馈的强化学习(RL)、人类反馈(RLHF)或 AI 反馈完成。 经典 LLM 自我改进方法会使用一致性等外部度量来选择用于微调的生成结果。 在强化学习场景中,这可以扩展为使用环境反馈;例如,XTX 会定期用情节记忆中存储的高分轨迹微调一个小语言模型,该模型作为稳健的“利用”策略,在随机性面前到达探索前沿。 微调智能体的 LLM 是一种昂贵的学习形式,因此当前研究通常会指定学习日程。 不过,随着训练变得更高效,或者如果智能体使用更小的子任务专用 LLM,也许可以让语言智能体自主决定何时以及如何微调自己的 LLM。
Updating agent code (procedural memory). CoALA allows agents to update their source code, thus modifying the implementation of various procedures. These can be broken down as follows.
- Updating reasoning (e.g., prompt templates).
For example, APE infers prompt instructions from input-output examples, then uses these instructions as part of the LLM prompt to assist task solving. Such a prompt update can be seen as a form of learning to reason.
- Updating grounding (e.g., code-based skills).
For example, Voyager maintains a curriculum library. Notably, current methods are limited to creating new code skills to interact with external environments.
- Updating retrieval.
To our knowledge, these learning options are not studied in recent language agents. Retrieval is usually considered a basic action designed with some fixed implementation (e.g., BM25 or dense retrieval), but research in query/document expansion or retrieval distillion may be helpful for language agents to learn better retrieval procedures.
- Updating learning or decision-making.
Finally, it is theoretically possible for CoALA agents to learn new procedures for learning or decision-making, thus providing significant adaptability. In general, however, updates to these procedures are risky both for the agent's functionality and alignment. At present, we are not aware of any language agents that implement this form of learning; we discuss such possibilities more in Section 6.
更新智能体代码(程序性记忆)。 CoALA 允许智能体更新自己的源代码,从而修改各种过程的实现。 这些更新可以分解如下。
- 更新推理(例如提示模板)。
例如,APE 会从输入输出示例中推断提示指令,然后把这些指令作为 LLM 提示的一部分来辅助任务求解。 这样的提示更新可以被看作一种学习如何推理的形式。
- 更新接地(例如基于代码的技能)。
例如,Voyager 维护一个课程库。 值得注意的是,当前方法仅限于创建新的代码技能来与外部环境交互。
- 更新检索。
据我们所知,近期语言智能体还没有研究这些学习选项。 检索通常被视为一种用固定实现(例如 BM25 或稠密检索)设计的基本动作,但查询/文档扩展或检索蒸馏方面的研究,可能有助于语言智能体学习更好的检索过程。
- 更新学习或决策。
最后,从理论上说,CoALA 智能体可以学习新的学习过程或决策过程,从而获得显著适应性。 不过总体而言,更新这些过程对于智能体功能和对齐都很有风险。 目前,我们尚不知道有语言智能体实现了这种学习形式;第 6 节会进一步讨论这些可能性。
While RL agents usually fix one way of learning (e.g., Q-learning, PPO, or A3C) and learn by updating model parameters, language agents can select from a diversity of learning procedures. This allows them to learn rapidly by storing task-relevant language (cheaper and quicker than parameter updates), and leverage multiple forms of learning to compound their self-improvement (e.g., Generative Agents discussed in Section 5). Finally, while our discussion has mostly focused on adding to memory, modifying and deleting (a case of "unlearning") are understudied in recent language agents. We address these areas more in Section 6.
RL 智能体通常固定一种学习方式(例如 Q-learning、PPO 或 A3C),并通过更新模型参数进行学习;而语言智能体可以从多种学习过程中进行选择。 这使它们能够通过存储任务相关语言来快速学习(比参数更新更便宜、更快速),并利用多种学习形式叠加自我改进效果(例如第 5 节讨论的 Generative Agents)。 最后,虽然我们的讨论主要聚焦于向记忆中添加内容,但修改和删除(一种“反学习”)在近期语言智能体中研究不足。 我们将在第 6 节进一步讨论这些领域。
4.6. Decision making
With various actions (grounding, learning, reasoning, retrieval) in the action space, how should a language agent choose which action to apply? This is handled by the decision-making procedure, which is effectively the top-level or "main" agent program. CoALA structures this top-level program into decision cycles (Figure 4B) which yield an external grounding action (Section 4.2) or internal learning action (Section 4.5). In each cycle, program code defines a sequence of reasoning and retrieval actions to propose and evaluate alternatives (planning stage), then executes the selected action (execution stage) -- then the cycle loops again.
在动作空间中有各种动作(接地、学习、推理、检索)时,语言智能体应该如何选择要应用哪个动作? 这由决策过程处理;决策过程实际上是顶层或“main”智能体程序。 CoALA 把这个顶层程序组织为决策周期(图4B),每个周期会产生一个外部接地动作(第 4.2 节)或内部学习动作(第 4.5 节)。 在每个周期中,程序代码定义一系列推理和检索动作,以提出并评估备选项(规划阶段),然后执行选定动作(执行阶段),随后再次循环。
Planning stage. During planning, reasoning and retrieval can be flexibly applied to propose, evaluate, and select actions, and these sub-stages could interleave or iterate to build up multi-step simulations before taking an external action. It also enables agents to iteratively improve candidate solutions -- for example, by using the LLM to simulate them, identifying defects, and proposing modifications that address those defects.
- Proposal. The proposal sub-stage generates one or more action candidates.
The usual approach is to use reasoning (and optionally retrieval) to sample one or more external grounding actions from the LLM. For simple domains with limited actions, the proposal stage might simply include all actions (e.g., SayCan in Section 5). More sophisticated agents use if-else or while-if code structures; while agents deployed in well-defined domains may utilize structured simulators to generate plausible rollouts.
- Evaluation. If multiple actions are proposed, the evaluation sub-stage assigns a value to each.
This may use heuristic rules, LLM (perplexity) values, learned values, LLM reasoning, or some combination. Particularly, LLM reasoning can help evaluate actions by internally simulating their grounding feedback from the external world.
- Selection. Given a set of actions and their values, the selection step either selects one to execute or rejects them and loops back to the proposal step.
Depending on the form of action values, selection may occur via argmax, softmax, or an alternative such as majority vote.
规划阶段。 在规划过程中,推理和检索可以被灵活用于提出、评估和选择动作,并且这些子阶段可以交错或迭代,以便在采取外部动作之前构建多步仿真。 这也使智能体能够迭代改进候选方案,例如使用 LLM 模拟这些方案、识别缺陷,并提出解决缺陷的修改。
- 提出。 提出子阶段会生成一个或多个候选动作。
通常做法是使用推理(也可以选择使用检索)从 LLM 中采样一个或多个外部接地动作。 对于动作有限的简单领域,提出阶段可能直接包含所有动作(例如第 5 节中的 SayCan)。 更复杂的智能体会使用 if-else 或 while-if 代码结构;而部署在定义良好领域中的智能体,则可能使用结构化模拟器生成合理 rollout。
- 评估。 如果提出了多个动作,评估子阶段会为每个动作分配一个价值。
这可以使用启发式规则、LLM(困惑度)值、学习得到的价值、LLM 推理,或它们的组合。 尤其是,LLM 推理可以通过在内部模拟外部世界的接地反馈来帮助评估动作。
- 选择。 给定一组动作及其价值,选择步骤要么选择一个动作执行,要么拒绝它们并循环回提出步骤。
根据动作价值的形式,选择可以通过 argmax、softmax,或多数投票等替代方式发生。
Execution. The selected action is applied by executing the relevant procedures from the agent's source code. Depending on the agent implementation, this might be an external grounding action (e.g., an API call; Section 4.2) or an internal learning action (e.g., a write to episodic memory; Section 4.5). An observation can be made from the environment, providing feedback from the agent's action, and the cycle loops again.
执行。 选定动作会通过执行智能体源代码中的相关过程来应用。 根据智能体实现,这可能是外部接地动作(例如 API 调用;第 4.2 节),也可能是内部学习动作(例如写入情节记忆;第 4.5 节)。 随后可以从环境中得到一次观测,为智能体动作提供反馈,然后周期再次循环。
Empirically, many early language agents simply use LLMs to propose an action, a sequence of actions, or evaluate a fixed set of actions without intermediate reasoning or retrieval. Followup work has exploited intermediate reasoning and retrieval to analyze the situation, make and maintain action plans, refine the previous action given the environmental feedback, and leveraged a more complex procedure to propose a single action. Most recently, research has started to investigate more complex decision-making employing iterative proposal and evaluation to consider multiple actions. These procedures are modeled after classical planning algorithms: for example, Tree of Thoughts and RAP use LLMs to implement BFS/DFS and Monte Carlo Tree Search (MCTS) respectively. LLMs are used to generate proposals (i.e., to simulate rollouts conditioned on an action) and evaluate them (i.e., to value the outcome of the proposed action).
从经验上看,许多早期语言智能体只是使用 LLM 来提出一个动作、一个动作序列,或评估一组固定动作,而不进行中间推理或检索。 后续工作利用中间推理和检索来分析情境、制定并维护行动计划、根据环境反馈改进上一个动作,并使用更复杂的过程来提出单个动作。 最近,研究开始探索更复杂的决策方式,通过迭代提出和评估来考虑多个动作。 这些过程仿照经典规划算法:例如,Tree of Thoughts 和 RAP 分别使用 LLM 实现 BFS/DFS 与蒙特卡洛树搜索(MCTS)。 LLM 被用于生成提案(即在给定动作条件下模拟 rollout)并评估它们(即估计所提动作结果的价值)。
5. Case Studies
With variations and ablations of the memory modules, action space, and decision-making procedures, CoALA can express a wide spectrum of language agents. Table 2 lists some popular recent methods across diverse domains --- from Minecraft to robotics, from pure reasoning to social simulacra. CoALA helps characterize their internal mechanisms and reveal their similarities and differences in a simple and structured way.
通过改变和消融记忆模块、动作空间和决策过程,CoALA 可以表达广泛的语言智能体。 表2列出了近期一些热门方法,覆盖多样领域——从 Minecraft 到机器人学,从纯推理到社会仿真。 CoALA 有助于用简单且结构化的方式刻画它们的内部机制,并揭示它们的相似点与差异。
| Agent | Long-term Memory | External Grounding | Internal Actions | Decision Making |
|---|---|---|---|---|
| SayCan | - | physical | - | evaluate |
| ReAct | - | digital | reason | propose |
| Voyager | procedural | digital | reason / retrieve / learn | propose |
| Generative Agents | episodic / semantic | digital / agent | reason / retrieve / learn | propose |
| Tree of Thoughts | - | digital | reason | propose, evaluate, select |
SayCan grounds a language model to robotic interactions in a kitchen to satisfy user commands (e.g., "I just worked out, can you bring me a drink and a snack to recover?"). Its long-term memory is procedural only (an LLM and a learned value function). The action space is external only -- a fixed set of 551 grounding skills (e.g., "find the apple", "go to the table"), with no internal actions of reasoning, retrieval, or learning. During decision-making, SayCan evaluates each action using a combination of LLM and learned values, which balance a skill's usefulness and groundedness. SayCan therefore employs the LLM (in conjunction with the learned value function) as a single-step planner.
SayCan 将语言模型接地到厨房中的机器人交互,以满足用户命令(例如,“我刚锻炼完,你能给我拿点饮料和零食恢复一下吗?”)。 它的长期记忆只有程序性记忆(一个 LLM 和一个学习得到的价值函数)。 动作空间只有外部动作,即固定的 551 个接地技能(例如“找到苹果”“去桌子那里”),没有推理、检索或学习等内部动作。 在决策时,SayCan 使用 LLM 值和学习得到的价值组合来评估每个动作,在技能有用性和接地性之间取得平衡。 因此,SayCan 把 LLM(结合学习到的价值函数)用作单步规划器。
ReAct is a language agent grounded to various digital environments (e.g., Wikipedia API, text game, website). Like SayCan, it lacks semantic or episodic memory and therefore has no retrieval or learning actions. Its action space consists of (internal) reasoning and (external) grounding. Its decision cycle is fixed to use a single reasoning action to analyze the situation and (re)make action plans, then generates a grounding action without evaluation or selection stages. ReAct can be considered the simplest language agent that leverages both internal and external actions, and is the initial work that demonstrates their synergizing effects: reasoning helps guide acting, while acting provides environmental feedback to support reasoning.
ReAct 是一个接地到多种数字环境的语言智能体(例如 Wikipedia API、文本游戏、网站)。 与 SayCan 类似,它缺少语义记忆和情节记忆,因此没有检索或学习动作。 它的动作空间由(内部)推理和(外部)接地构成。 它的决策周期固定为使用单个推理动作分析情境并(重新)制定行动计划,然后生成一个接地动作,没有评估或选择阶段。 ReAct 可以看作同时利用内部动作和外部动作的最简单语言智能体,也是最早展示二者协同效果的工作:推理帮助指导行动,而行动提供环境反馈来支持推理。
Voyager is a language agent grounded to the Minecraft API. Unlike SayCan, which grounds to perception via the learned value function, Voyager's grounding is text-only. It has a long-term procedural memory that stores a library of code-based grounding procedures a.k.a. skills (e.g., "combatZombie", "craftStoneSword"). This library is hierarchical: complex skills can use simpler skills as sub-procedures (e.g., "combatZombie" may call "craftStoneSword" if no sword is in inventory). Most impressively, its action space has all four kinds of actions: grounding, reasoning, retrieval, and learning (by adding new grounding procedures). During a decision cycle, Voyager first reasons to propose a new task objective if it is missing in the working memory, then reasons to propose a code-based grounding procedure to solve the task. In the next decision cycle, Voyager reasons over the environmental feedback to determine task completion. If successful, Voyager selects a learning action adding the grounding procedure to procedural memory; otherwise, it uses reasoning to refine the code and re-executes it. The importance of long-term memory and procedural learning is empirically verified by comparing to baselines like ReAct and AutoGPT and ablations without the procedural memory. Voyager is shown to better explore areas, master the tech tree, and zero-shot generalize to unseen tasks.
Voyager 是一个接地到 Minecraft API 的语言智能体。 SayCan 通过学习到的价值函数接地到感知,而 Voyager 不同,它的接地完全是文本形式。 它具有长期程序性记忆,用来存储基于代码的接地过程库,也就是技能库(例如 "combatZombie"、"craftStoneSword")。 这个库是层级化的:复杂技能可以把简单技能用作子过程(例如,如果物品栏中没有剑,"combatZombie" 可能调用 "craftStoneSword")。 最令人印象深刻的是,它的动作空间包含全部四类动作:接地、推理、检索和学习(通过添加新的接地过程)。 在一个决策周期中,如果工作记忆中缺少任务目标,Voyager 会先通过推理提出新任务目标,然后再通过推理提出一个基于代码的接地过程来解决任务。 在下一个决策周期中,Voyager 会对环境反馈进行推理,以判断任务是否完成。 如果成功,Voyager 会选择一个学习动作,把该接地过程加入程序性记忆;否则,它会使用推理来改进代码并重新执行。 通过与 ReAct、AutoGPT 等基线以及不带程序性记忆的消融进行比较,论文经验证实了长期记忆和程序性学习的重要性。 实验显示,Voyager 能更好地探索区域、掌握科技树,并零样本泛化到未见任务。
Generative Agents are language agents grounded to a sandbox game affording interaction with the environment and other agents. Its action space also has all four kinds of actions: grounding, reasoning, retrieval, and learning. Each agent has a long-term episodic memory that stores events in a list. These agents use retrieval and reasoning to generate reflections on their episodic memory (e.g., "I like to ski now.") which are then written to long-term semantic memory. During decision-making, it retrieves relevant reflections from semantic memory, then reasons to make a high-level plan of the day. While executing the plan, the agent receives a stream of grounding observations; it can reason over these to maintain or adjust the plan.
Generative Agents 是接地到沙盒游戏中的语言智能体,可以与环境和其他智能体交互。 它的动作空间同样包含全部四类动作:接地、推理、检索和学习。 每个智能体都有一个长期情节记忆,以列表形式存储事件。 这些智能体使用检索和推理对情节记忆生成反思(例如“我现在喜欢滑雪。”),随后把这些反思写入长期语义记忆。 在决策时,它会从语义记忆中检索相关反思,然后通过推理制定当天的高层计划。 执行计划时,智能体会接收一连串接地观测;它可以对这些观测进行推理,以维持或调整计划。
Tree of Thoughts (ToT) can be seen as a special kind of language agent with only one external action: submitting a final solution to a reasoning problem (game of 24, creative writing, crosswords puzzle). It has no long-term memory, and only reasoning in its internal action space, but differs from all previous agents in its deliberate decision-making. During planning, ToT iteratively proposes, evaluates, and selects "thoughts" (reasoning actions) based on LLM reasoning, and maintains them via a tree search algorithm to enable global exploration as well as local backtrack and foresight.
Tree of Thoughts(ToT) 可以看作一种特殊语言智能体,它只有一个外部动作:提交某个推理问题(24 点游戏、创意写作、填字谜)的最终解。 它没有长期记忆,内部动作空间中只有推理,但它与此前所有智能体的不同之处在于其审慎的决策方式。 在规划期间,ToT 基于 LLM 推理迭代地提出、评估并选择“thoughts”(推理动作),并通过树搜索算法维护它们,从而支持全局探索以及局部回溯和前瞻。
6. Actionable Insights
Compared to some recent empirical surveys around language agents, CoALA offers a theoretical framework grounded in the well-established research of cognitive architectures. This leads to a unique and complementary set of actionable insights.
相较于近期围绕语言智能体的一些经验综述,CoALA 提供了一个扎根于成熟认知架构研究的理论框架。 这带来了一组独特且互补的可执行洞见。
Modular agents: thinking beyond monoliths. Perhaps our most important suggestion is that agents should be structured and modular. Practically, just as standardized software is used across robotics platforms, a framework for language agents would consolidate technical investment and improve compatibility.
- In academic research, standardized terms allow conceptual comparisons across works (Table 2), and open-source implementations would further facilitate modular plug-and-play and re-use.
For example, the theoretical framework of Markov Decision Processes provides a standardized set of concepts and terminology (e.g., state, action, reward, transition) for reinforcement learning. Correspondingly, empirical frameworks like OpenAI Gym provided standardized abstractions (e.g., obs, reward, done, info = env.step(action)) that facilitate empirical RL work. Thus, it would be timely and impactful to also implement useful abstractions (e.g., Memory, Action, Agent classes) for language agents, and cast simpler agents into such an empirical CoALA framework as examples for building more complex agents.
- In industry applications, maintaining a single company-wide "language agent library" would reduce technical debt by facilitating testing and component re-use across individual agent deployments.
It could also standardize the customer experience: rather than interacting with a hodgepodge of language agents developed by individual teams, end users would experience a context-specific instantiation of the same base agent.
- LLMs vs. code in agent design. CoALA agents possess two forms of procedural memory: agent code (deterministic rules) and LLM parameters (a large, stochastic production system).
Agent code is interpretable and extensible, but often brittle in face of stochasticity and limited to address situations the designer anticipates. In contrast, LLM parameters are hard to interpret, but offer significant zero-shot flexibility in new contexts. CoALA thus suggests using code sparingly to implement generic algorithms that complement LLM limitations, e.g., implementing tree search to mitigate myopia induced by autoregressive generation.
模块化智能体:超越单体系统来思考。 我们最重要的建议也许是:智能体应该结构化并模块化。 从实践角度看,正如标准化软件会跨机器人平台使用,语言智能体框架也能整合技术投入并提升兼容性。
- 在学术研究中,标准化术语可以支持跨工作概念比较(表2),而开源实现还会进一步促进模块化即插即用和复用。
例如,马尔可夫决策过程这一理论框架为强化学习提供了一组标准概念和术语(如状态、动作、奖励、转移)。 相应地,OpenAI Gym 等经验框架提供了标准化抽象(例如 obs, reward, done, info = env.step(action)),促进了经验 RL 工作。 因此,为语言智能体实现有用抽象(例如 Memory、Action、Agent 类),并把更简单智能体纳入这样的经验性 CoALA 框架,作为构建更复杂智能体的例子,将会非常及时且有影响力。
- 在工业应用中,维护单一的公司级“语言智能体库”可以通过促进测试和组件复用,减少各个智能体部署中的技术债。
它还可以标准化客户体验:终端用户不再面对由不同团队开发的一堆杂乱语言智能体,而是体验同一个基础智能体在特定上下文中的实例化。
- 智能体设计中的 LLM 与代码。 CoALA 智能体拥有两种程序性记忆:智能体代码(确定性规则)和 LLM 参数(大型随机产生式系统)。
智能体代码可解释、可扩展,但在面对随机性时常常脆弱,并且只能处理设计者预想到的情境。 相比之下,LLM 参数难以解释,但在新上下文中提供了显著的零样本灵活性。 因此,CoALA 建议谨慎使用代码来实现通用算法,以补充 LLM 的局限,例如实现树搜索来缓解自回归生成带来的短视性。
Agent design: thinking beyond simple reasoning. CoALA defines agents over three distinct concepts: (i) internal memory, (ii) a set of possible internal and external actions, and (iii) a decision making procedure over those actions. Using CoALA to develop an application-specific agent consists of specifying implementations for each of these components in turn. We assume that the agent's environment and external action space are given, and show how CoALA can be used to determine an appropriate high-level architecture. For example, we can imagine designing a personalized retail assistant that helps users find relevant items based on their queries and purchasing history. In this case, the external actions would consist of dialogue or returning search results to the user.
- Determine what memory modules are necessary. In our retail assistant example, it would be helpful for the agent to have semantic memory containing the set of items for sale, as well as episodic memory about each customer's previous purchases and interactions.
It will need procedural memory defining functions to query these datastores, as well as working memory to track the dialogue state.
- Define the agent's internal action space. This consists primarily of defining read and write access to each of the agent's memory modules.
In our example, the agent should have read and write access to episodic memory (so it can store new interactions with customers), but read-only access to semantic and procedural memory (since it should not update the inventory or its own code).
- Define the decision-making procedure. This step specifies how reasoning and retrieval actions are taken in order to choose an external or learning action.
In general, this requires a tradeoff between performance and generalization: more complex procedures can better fit to a particular problem (e.g., Voyager for Minecraft) while simpler ones are more domain-agnostic and generalizable (e.g., ReAct). For our retail assistant, we may want to encourage retrieval of episodic memory of interactions with a user to provide a prior over their search intent, as well as an explicit evaluation step reasoning about whether a particular set of search results will satisfy that intent. We can simplify the decision procedure by deferring learning to the end of the interaction, summarizing the episode prior to storing it in episodic memory.
智能体设计:超越简单推理来思考。 CoALA 用三个不同概念定义智能体:(i)内部记忆,(ii)一组可能的内部和外部动作,(iii)作用于这些动作的决策过程。 使用 CoALA 开发特定应用智能体,就是依次指定这些组件的实现。 我们假设智能体的环境和外部动作空间已经给定,并展示如何使用 CoALA 确定合适的高层架构。 例如,我们可以设想设计一个个性化零售助手,根据用户查询和购买历史帮助用户寻找相关商品。 在这种情况下,外部动作将包括对话或向用户返回搜索结果。
- 确定需要哪些记忆模块。 在零售助手例子中,让智能体拥有包含待售商品集合的语义记忆,以及关于每位顾客过往购买和互动的情节记忆,会很有帮助。
它还需要定义查询这些数据存储函数的程序性记忆,以及用于跟踪对话状态的工作记忆。
- 定义智能体的内部动作空间。 这主要包括定义对每个记忆模块的读写访问。
在我们的例子中,智能体应该拥有对情节记忆的读写权限(以便存储与顾客的新互动),但只应对语义记忆和程序性记忆有只读权限(因为它不应更新库存或自身代码)。
- 定义决策过程。 这一步指定如何采取推理和检索动作,以选择一个外部动作或学习动作。
总体而言,这需要在性能和泛化之间权衡:更复杂的过程可以更好地拟合特定问题(例如用于 Minecraft 的 Voyager),而更简单的过程则更领域无关、更容易泛化(例如 ReAct)。 对于零售助手,我们可能希望鼓励检索与用户互动的情节记忆,以提供关于其搜索意图的先验;同时还需要一个显式评估步骤,推理某组搜索结果是否会满足该意图。 我们可以通过把学习推迟到交互结束来简化决策过程,在把片段存入情节记忆之前先对其进行总结。
Structured reasoning: thinking beyond prompt engineering. Early work on prompt engineering manipulated the LLM's input and output via low-level string operations. CoALA suggests a more structured reasoning procedure to update working memory variables.
- Prompting frameworks like LangChain and LlamaIndex can be used to define higher-level sequences of reasoning steps, reducing the burden of reasoning per LLM call and the low-level prompt crafting efforts.
Structural output parsing solutions such as Guidance and OpenAI function calling can help update working memory variables. Defining and building good working memory modules will also be an important direction of future research. Such modules may be especially important for industry solutions where LLM reasoning needs to seamlessly integrate with large-scale code infrastructure.
- Reasoning usecases in agents can inform and reshape LLM training in terms of the types (e.g., reasoning for self-evaluation, reflection, action generation, etc.) and formats (e.g., CoT, ReAct, Reflexion) of training instances.
By default, existing LLMs are trained and optimized for NLP tasks, but agent applications have explored new modes of LLM reasoning (e.g., self-evaluation) that have proven broadly useful. LLMs trained or finetuned towards these capabilities will more likely be the backbones of future agents.
结构化推理:超越提示工程来思考。 早期提示工程工作通过低层字符串操作来操纵 LLM 的输入和输出。 CoALA 建议采用更结构化的推理过程来更新工作记忆变量。
- LangChain 和 LlamaIndex 等提示框架可用于定义更高层次的推理步骤序列,从而减少每次 LLM 调用的推理负担和低层提示编写工作。
Guidance 和 OpenAI function calling 等结构化输出解析方案可以帮助更新工作记忆变量。 定义和构建良好的工作记忆模块,也将是未来研究的重要方向。 对于需要让 LLM 推理与大规模代码基础设施无缝集成的工业解决方案,这类模块可能尤其重要。
- 智能体中的推理用例可以告知并重塑 LLM 训练,包括训练样本的类型(例如用于自我评估、反思、动作生成等的推理)和格式(例如 CoT、ReAct、Reflexion)。
默认情况下,现有 LLM 针对 NLP 任务训练和优化,但智能体应用探索了新的 LLM 推理模式(例如自我评估),并证明这些模式具有广泛用途。 朝这些能力训练或微调的 LLM,更有可能成为未来智能体的骨干模型。
Long-term memory: thinking beyond retrieval augmentation. While traditional retrieval-augmented language models only read from human-written corpora, memory-augmented language agents can both read and write self-generated content autonomously. This opens up numerous possibilities for efficient lifelong learning.
- Combining existing human knowledge with new experience and skills can help agents bootstrap to learn efficiently.
For example, a code-writing agent could be endowed with semantic programming knowledge in the form of manuals or textbooks. It could then generate its own episodic knowledge from experience; reflect on these experiences to generate new semantic knowledge; and gradually create procedural knowledge in the form of a code library storing useful methods.
- Integrating retrieval and reasoning can help to better ground planning.
Recent computational psychological models implicate an integrated process of memory recall and decision-making -- suggesting that adaptive mechanisms interleaving memory search and forward simulation will allow agents to make the most of their knowledge.
长期记忆:超越检索增强来思考。 传统检索增强语言模型只会从人类撰写的语料中读取,而记忆增强语言智能体可以自主读写自生成内容。 这为高效终身学习打开了许多可能性。
- 结合现有人类知识与新经验、新技能可以帮助智能体自举并高效学习。
例如,可以为代码编写智能体赋予手册或教材形式的语义编程知识。 随后,它可以从经验中生成自己的情节知识;反思这些经验以生成新的语义知识;并逐渐以代码库形式创建程序性知识,存储有用方法。
- 整合检索和推理有助于更好地接地规划。
近期计算心理学模型表明,记忆回忆和决策是一个整合过程;这说明交错进行记忆搜索和前向仿真的自适应机制,将使智能体充分利用其知识。
Learning: thinking beyond in-context learning or finetuning. CoALA's definition of "learning" encompasses these methods, but extends further to storing new experience or knowledge, or writing new agent code (Section 4.5). Important future directions include:
- Meta-learning by modifying agent code would allow agents to learn more effectively.
For example, learning better retrieval procedures could enable agents to make better use of their experience. Recent expansion-based techniques could allow agents to reason about when certain knowledge would be useful, and store this as metadata to facilitate later recall. These forms of meta-learning would enable agents to go beyond human-written code, yet are understudied due to their difficulty and risk.
- New forms of learning (and unlearning) could include fine-tuning smaller models for specific reasoning sub-tasks, deleting unneeded memory items for "unlearning", and studying the interaction effects between multiple forms of learning.
学习:超越上下文学习或微调来思考。 CoALA 对“学习”的定义包含这些方法,但进一步扩展到存储新经验或知识,以及编写新的智能体代码(第 4.5 节)。 重要未来方向包括:
- 通过修改智能体代码进行元学习可以让智能体更有效地学习。
例如,学习更好的检索过程可以让智能体更好利用经验。 近期基于扩展的技术可以让智能体推理某些知识何时有用,并把它存储为元数据以便之后回忆。 这些元学习形式会让智能体超越人类编写的代码,但由于难度和风险,它们仍研究不足。
- 新的学习(和反学习)形式可以包括:为特定推理子任务微调更小模型、删除不需要的记忆条目以实现“反学习”,以及研究多种学习形式之间的交互效应。
Action space: thinking beyond external tools or actions. Although "action space" is a standard term in reinforcement learning, it has been used sparingly with language agents. CoALA argues for defining a clear and task-suitable action space with both internal (reasoning, retrieval, learning) and external (grounding) actions, which will help systematize and inform the agent design.
- Size of the action space. More capable agents (e.g., Voyager, Generative Agents) have larger action spaces -- which in turn means they face a more complex decision-making problem.
As a result, these agents rely on more customized or hand-crafted decision procedures. The tradeoff of the action space vs. decision-making complexities is a basic problem to be considered before agent development, and taking the minimal action space necessary to solve a given task might be preferred.
- Safety of the action space. Some parts of the action space are inherently riskier.
"Learning" actions (especially procedural deletion and modification) could cause internal harm, while "grounding" actions (e.g., "rm" in bash terminal, harmful speech in human dialog, holding a knife in physical environments) could cause external harm. Today, safety measures are typically task-specific heuristics. However, as agents are grounded to more complex environments with richer internal mechanisms, it may be necessary to specify and ablate the agent's action space for worst-case scenario prediction and prevention.
动作空间:超越外部工具或动作来思考。 虽然“动作空间”是强化学习中的标准术语,但在语言智能体中使用得并不多。 CoALA 主张定义清晰且适合任务的动作空间,同时包含内部动作(推理、检索、学习)和外部动作(接地),这有助于系统化并指导智能体设计。
- 动作空间大小。 更强的智能体(例如 Voyager、Generative Agents)拥有更大的动作空间,这反过来意味着它们面临更复杂的决策问题。
因此,这些智能体依赖更定制化或手工设计的决策过程。 动作空间与决策复杂度之间的权衡,是开发智能体前需要考虑的基本问题;最好采用能够解决给定任务所必需的最小动作空间。
- 动作空间安全性。 动作空间中的某些部分天然更有风险。
“学习”动作(尤其是程序性删除和修改)可能造成内部伤害,而“接地”动作(例如 bash 终端中的 "rm"、人类对话中的有害言论、在物理环境中持刀)可能造成外部伤害。 目前,安全措施通常是任务特定的启发式规则。 不过,随着智能体接地到更复杂环境,并拥有更丰富的内部机制,可能需要指定并消融智能体动作空间,以预测和预防最坏情况。
Decision making: thinking beyond action generation. We believe one of the most exciting future directions for language agents is decision-making: as detailed in Section 4.6, most works are still confined to proposing (or directly generating) a single action. Present agents have just scratched the surface of more deliberate, propose-evaluate-select decision-making procedures.
- Mixing language-based reasoning and code-based planning may offer the best of both worlds.
Existing approaches either plan directly in natural language or use LLMs to translate from natural language to structured world models. Future work could integrate these: just as Soar incorporates a simulator for physical reasoning, agents may write and execute simulation code on the fly to evaluate the consequences of plans.
- Extending deliberative reasoning to real-world settings. Initial works have implemented classical planning and tree search, using toy tasks such as game of 24 or block building.
Extending these schemes to more complicated tasks with grounding and long-term memory is an exciting direction.
- Metareasoning to improve efficiency. LLM calls are both slow and computationally intensive.
Using LLMs for decision-making entails a balance between their computational cost and the utility of the resulting improved plan. Most LLM reasoning methods fix a search budget by specifying a depth of reasoning, but humans appear to adaptively allocate computation. Future work should develop mechanisms to estimate the utility of planning and modify the decision procedure accordingly, either via amortization, routing among several decision sub-procedures, or updates to the decision-making procedure.
- Calibration and alignment. More complex decision-making is currently bottlenecked by issues such as over-confidence and miscalibration, misalignment with human values or bias, hallucinations in self-evaluation, and lack of human-in-the-loop mechanisms in face of uncertainties.
Solving these issues will significantly improve LLMs' utilities as agent backbones.
决策:超越动作生成来思考。 我们认为,语言智能体最令人兴奋的未来方向之一是决策;如第 4.6 节所述,多数工作仍局限于提出(或直接生成)单个动作。 当前智能体只是刚刚触及更审慎的“提出—评估—选择”决策过程。
- 混合基于语言的推理和基于代码的规划可能同时获得两者优势。
现有方法要么直接用自然语言规划,要么使用 LLM 把自然语言转换为结构化世界模型。 未来工作可以把二者整合起来:正如 Soar 纳入用于物理推理的模拟器,智能体也可以即时编写并执行仿真代码,以评估计划后果。
- 把审慎推理扩展到真实世界场景。 初始工作已经在 24 点游戏或积木搭建等玩具任务中实现了经典规划和树搜索。
把这些方案扩展到带接地和长期记忆的更复杂任务,是一个令人兴奋的方向。
- 用元推理提升效率。 LLM 调用既慢又计算密集。
使用 LLM 进行决策,需要在计算成本和改进计划带来的效用之间取得平衡。 多数 LLM 推理方法通过指定推理深度来固定搜索预算,但人类似乎会自适应分配计算。 未来工作应开发机制来估计规划效用,并据此修改决策过程,可以通过摊销、在多个决策子过程之间路由,或更新决策过程来实现。
- 校准和对齐。 更复杂的决策目前受到过度自信和校准不佳、与人类价值或偏见不对齐、自我评估中的幻觉,以及面对不确定性时缺乏人在环机制等问题的制约。
解决这些问题将显著提升 LLM 作为智能体骨干模型的效用。
7. Discussion
In addition to the practical insights presented above, CoALA raises a number of open conceptual questions. We briefly highlight the most interesting as important directions for future research and debate.
除了上文提出的实践洞见之外,CoALA 还提出了若干开放的概念问题。 我们简要强调其中最有趣的问题,作为未来研究和讨论的重要方向。
LLMs vs VLMs: should reasoning be language-only or multimodal? Most language agents use language-only models for decision-making, employing a separate captioning model to convert environment observations to text when necessary. However, the latest generation of language models are multimodal, allowing interleaved image and text input. Language agents built on such multimodal models natively reason over both image and text input, allowing them to ingest perceptual data and directly produce actions. This bypasses the lossy image-to-text conversion; however, it also tightly couples the reasoning and planning process to the model's input modalities.
LLM 与 VLM:推理应该只基于语言,还是应该多模态? 多数语言智能体使用纯语言模型进行决策,并在必要时使用单独的图像描述模型把环境观测转换为文本。 然而,最新一代语言模型是多模态的,允许图像和文本交错输入。 基于这类多模态模型构建的语言智能体,能够原生地在图像和文本输入上推理,使其能够摄取感知数据并直接生成动作。 这绕过了有损的图像到文本转换;但它也把推理和规划过程与模型输入模态紧密耦合起来。
At a high level, the two approaches can be seen as different tokenization schemes to convert non-linguistic modalities into the core reasoning model's language domain. The modular approach uses a separate image-to-text model to convert perceptual data into language, while the integrated approach projects images directly into the language model's representation space. Integrated, multimodal reasoning may allow for more human-like behaviors: a VLM-based agent could "see" a webpage, whereas a LLM-based agent would more likely be given raw HTML. However, coupling the agent's perception and reasoning systems makes the agent more domain-specific and difficult to update. In either case, the basic architectural principles described by CoALA --- internal memories, a structured action space, and generalized decision-making --- can be used to guide agent design.
从高层看,这两种方法可以被视为两种不同的 token 化方案,用于把非语言模态转换到核心推理模型的语言域中。 模块化方法使用单独的图像到文本模型把感知数据转换为语言,而集成方法则直接把图像投影到语言模型的表示空间中。 集成式多模态推理可能支持更类人的行为:基于 VLM 的智能体可以“看到”网页,而基于 LLM 的智能体更可能被给到原始 HTML。 不过,把智能体的感知系统和推理系统耦合起来,会让智能体更领域特定,也更难更新。 无论哪种情况,CoALA 描述的基本架构原则——内部记忆、结构化动作空间和通用决策——都可以用于指导智能体设计。
Internal vs. external: what is the boundary between an agent and its environment? While humans or robots are clearly distinct from their embodied environment, digital language agents have less clear boundaries. For example, is a Wikipedia database an internal semantic memory or an external digital environment? If an agent iteratively executes and improves code before submitting an answer, is the code execution internal or external? If a method consists of proposal and evaluation prompts, should it be considered a single agent or two collaborating simpler agents (proposer and evaluator)?
内部与外部:智能体和环境之间的边界在哪里? 人类或机器人与其具身环境之间边界清晰,但数字语言智能体的边界没有那么明确。 例如,Wikipedia 数据库是内部语义记忆,还是外部数字环境? 如果智能体在提交答案前反复执行并改进代码,那么代码执行是内部动作还是外部动作? 如果一个方法由提出提示和评估提示组成,它应该被视为一个智能体,还是两个协作的更简单智能体(提出者和评估者)?
We suggest the boundary question can be answered in terms of controllability and coupling. For example, Wikipedia is not controllable: it is an external environment that may be unexpectedly modified by other users. However, an offline version that only the agent may write to is controllable, and thus can be considered an internal memory. Similarly, code execution on a internal virtual environment should be considered an internal reasoning action, whereas code execution on an external machine (which may possess security vulnerabilities) should be considered an external grounding action. Lastly, if aspects of the agent -- such as proposal and evaluation prompts -- are designed for and dependent on each other, then they are tightly coupled and best conceptualized as components in an individual agent. In contrast, if the steps are independently useful, a multi-agent perspective may be more appropriate. While these dilemmas are primarily conceptual, such understanding can support agent design and help the field align on shared terminology. Practioners may also just choose their preferred framing, as long as it is consistent and useful for their own work.
我们认为,可以从可控性和耦合性来回答边界问题。 例如,Wikipedia 并不可控:它是一个外部环境,可能被其他用户意外修改。 但是,如果有一个只有智能体可以写入的离线版本,它就是可控的,因此可以被视为内部记忆。 类似地,在内部虚拟环境中执行代码,应被视为内部推理动作;而在外部机器上执行代码(可能存在安全漏洞),则应被视为外部接地动作。 最后,如果智能体的若干方面(例如提出和评估提示)是相互依赖、共同设计的,那么它们就是紧密耦合的,最好被概念化为单个智能体中的组件。 相反,如果这些步骤可以独立发挥作用,多智能体视角可能更合适。 虽然这些困境主要是概念性的,但这种理解可以支持智能体设计,并帮助该领域在共享术语上达成一致。 实践者也可以选择自己偏好的框架,只要它对自己的工作一致且有用即可。
Physical vs. digital: what differences beget attention? While animals only live once in the physical world, digital environments (e.g., the Internet) often allow sequential (via resets) and parallel trials. This means digital agents can more boldly explore (e.g., open a million webpages) and self-clone for parallel task solving (e.g., a million web agents try different web paths), which may result in decision-making procedures different from current ones inspired by human cognition.
物理与数字:哪些差异值得注意? 动物在物理世界中只能活一次,而数字环境(例如互联网)通常允许顺序试验(通过重置)和平行试验。 这意味着数字智能体可以更大胆地探索(例如打开一百万个网页),并自我复制来并行求解任务(例如一百万个网页智能体尝试不同网页路径),这可能带来不同于当前受人类认知启发的决策过程。
Learning vs. acting: how should agents continuously and autonomously learn? In the CoALA framework, learning is a result action of a decision-making cycle just like grounding: the agent deliberately chooses to commit information to long-term memory. This is in contrast to most agents, which simply fix a learning schedule and only use decison making for external actions. Biological agents, however, do not have this luxury: they must balance learning against external actions in their lifetime, choosing when and what to learn. More flexible language agents would follow a similar design and treat learning on par with external actions. Learning could be proposed as a possible action during regular decision-making, allowing the agent to "defer" it until the appropriate time.
学习与行动:智能体应该如何持续且自主地学习? 在 CoALA 框架中,学习和接地一样,是决策周期的结果动作:智能体会有意选择把信息提交到长期记忆。 这不同于大多数智能体;后者只是固定一个学习日程,并且只把决策用于外部动作。 然而,生物智能体并没有这种奢侈:它们必须在生命周期中平衡学习和外部动作,选择何时学习以及学习什么。 更灵活的语言智能体会遵循类似设计,把学习放在与外部动作同等的位置。 学习可以作为常规决策中的一个可能动作被提出,使智能体能够把它“推迟”到合适时机。
GPT-4 vs GPT-N: how would agent design change with more powerful LLMs? Agent design is a moving target as new LLM capabilities emerge with scale. For example, earlier language models such as GPT-2 would not support LLM agents --- indeed, work at that time needed to combine GPT-2 with reinforcement learning for action generation; GPT-3 unlocked flexible few-shot and zero-shot reasoning for NLP tasks; while only GPT-4 starts to afford more reliable self-evaluation and self-refinement. Will future LLMs further reduce the need for coded rules and extra-learned models? Will this necessitate changes to the CoALA framework?
GPT-4 与 GPT-N:更强 LLM 会如何改变智能体设计? 随着新的 LLM 能力随规模涌现,智能体设计本身也是一个移动靶。 例如,GPT-2 等早期语言模型并不支持 LLM 智能体;事实上,当时的工作需要把 GPT-2 与强化学习结合起来生成动作;GPT-3 解锁了 NLP 任务上的灵活 few-shot 和 zero-shot 推理;而只有 GPT-4 才开始提供更可靠的自我评估和自我改进。 未来 LLM 是否会进一步减少对代码规则和额外学习模型的需求? 这是否需要改变 CoALA 框架?
As a thought experiment, imagine GPT-N could "simulate" memory, grounding, learning, and decision-making in context: list all the possible actions, simulate and evaluate each one, and maintain its entire long-term memory explicitly in a very long context. Or even more boldly: perhaps GPT-N+1 succeeds at generating the next action by simulating these implicitly in neurons, without any intermediate reasoning in context. While these extreme cases seem unlikely in the immediate future, incremental improvements may alter the importance of different CoALA components. For example, a longer context window could reduce the importance of long-term memory, while more powerful reasoning for internal evaluation and simulation could allow longer-horizon planning. In general, LLMs are not subject to biological limitations, and their emergent properties have been difficult to predict. Nonetheless, CoALA -- and cognitive science more generally -- may still help organize tasks where language agents succeed or fail, and suggest code-based procedures to complement a given LLM on a given task. Even in the most extreme case, where GPT implements all of CoALA's mechanisms in neurons, it may be helpful to leverage CoALA as a conceptual guide to discover and interpret those implicit circuits. Of course, as discussed in Section 6, agent usecases will also help discover, define and shape LLM capabilities. Similar to how chips and computer architectures have co-evolved, language model and agent design should also develop a reciprocal path forward.
作为一个思想实验,设想 GPT-N 可以在上下文中“模拟”记忆、接地、学习和决策:列出所有可能动作,模拟并评估每个动作,并在一个非常长的上下文中显式维护其全部长期记忆。 甚至可以更大胆地设想:也许 GPT-N+1 能够通过在神经元中隐式模拟这些机制来生成下一个动作,而无需任何上下文中的中间推理。 虽然这些极端情况在近期似乎不太可能出现,但渐进式改进可能会改变不同 CoALA 组件的重要性。 例如,更长的上下文窗口可能降低长期记忆的重要性,而更强的内部评估和仿真推理可能允许更长时域的规划。 总体而言,LLM 不受生物限制约束,而且其涌现性质一直难以预测。 尽管如此,CoALA,以及更广义的认知科学,仍可能帮助组织语言智能体在哪些任务上成功或失败,并建议基于代码的过程来补充给定任务上的给定 LLM。 即使在最极端情况下,也就是 GPT 在神经元中实现了 CoALA 的全部机制,利用 CoALA 作为概念指南来发现和解释这些隐式电路,仍可能是有帮助的。 当然,正如第 6 节所讨论,智能体用例也会帮助发现、定义和塑造 LLM 能力。 类似于芯片和计算机架构如何共同演化,语言模型和智能体设计也应发展出一条相互促进的前进路径。
8. Conclusion
We proposed Cognitive Architectures for Language Agents (CoALA), a conceptual framework to describe and build language agents. Our framework draws inspiration from the rich history of symbolic artificial intelligence and cognitive science, connecting decades-old insights to frontier research on large language models. We believe this approach provides a path towards developing more general and more human-like artificial intelligence.
我们提出了面向语言智能体的认知架构(CoALA),这是一个用于描述和构建语言智能体的概念框架。 我们的框架从符号人工智能和认知科学的丰富历史中汲取灵感,把几十年前的洞见与大型语言模型的前沿研究连接起来。 我们相信,这种方法为发展更通用、更类人的人工智能提供了一条路径。