
LightMem:轻量且高效的记忆增强生成
Abstract
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson–Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. On LongMemEval and LoCoMo, using GPT and Qwen backbones, LightMem consistently surpasses strong baselines, improving QA accuracy by up to 7.7% / 29.3%, reducing total token usage by up to
尽管大语言模型(LLM)能力卓越,但它们在动态且复杂的环境中仍难以有效利用历史交互信息。 记忆系统通过引入持久化的信息存储、检索和利用机制,使 LLM 能够超越无状态交互。 然而,现有记忆系统往往会带来显著的时间和计算开销。 为此,作者提出了一种新的记忆系统 LightMem,在记忆系统的性能与效率之间取得平衡。 受人类记忆的 Atkinson–Shiffrin 模型启发,LightMem 将记忆组织为三个互补阶段。 首先,受认知启发的感觉记忆通过轻量压缩快速过滤无关信息,并按主题对信息进行分组。 随后,主题感知的短期记忆会整合这些基于主题的分组,将内容组织并摘要为更结构化的访问形式。 最后,带有睡眠时更新的长期记忆采用离线过程,将记忆整合与在线推理解耦。 在 LongMemEval 和 LoCoMo 上,使用 GPT 与 Qwen 骨干模型时,LightMem 持续超过强基线:问答准确率最高提升 7.7% / 29.3%,总 token 用量最高降低
1. Introduction
Memory is fundamental to intelligent agent, enabling the assimilation of prior experiences, contextual cues, and task-specific knowledge that underpin robust reasoning and decision-making . While Large Language Models (LLMs) demonstrate remarkable capabilities across a wide range of tasks, they exhibit significant limitations when engaged in long-context or multi-turn interaction scenarios due to fixed context windows and the ``lost in the middle'' problem. Memory systems are pivotal for overcoming these limitations, as they allow LLMs to maintain a persistent state across extended interactions. Recent works address this challenge by building explicit external memory through sequential summarization and long term storage, enabling models to retain and retrieve relevant information over long horizons.
记忆是智能体的基础,使其能够吸收先前经验、上下文线索和任务特定知识,而这些正是稳健推理与决策的基础。 虽然大语言模型(LLM)在广泛任务中展现出卓越能力,但由于固定上下文窗口和“lost in the middle”问题,它们在长上下文或多轮交互场景中存在显著局限。 记忆系统对于克服这些限制至关重要,因为它们允许 LLM 在长时间交互中维持持久状态。 近期工作通过顺序摘要和长期存储来构建显式外部记忆,从而应对这一挑战,使模型能够在长时间跨度上保留并检索相关信息。
Note that a typical LLM memory system processes raw interaction data into manageable chunks, such as turn- or session-level in dialogue scenarios, organizes them into long-term memory (e.g., databases or knowledge graphs) by indexing them into memory units, and continuously updates by adding new information and discarding outdated or conflicting content. This enables retrieval of relevant memories, improving coherence, and personalization in long-context, multi-turn scenarios.
注意,典型的 LLM 记忆系统会将原始交互数据处理为可管理的块,例如对话场景中的 turn 级或 session 级块;再通过将其索引为记忆单元,把它们组织进长期记忆(例如数据库或知识图谱);并通过加入新信息、丢弃过时或冲突内容来持续更新。 这使系统能够检索相关记忆,从而在长上下文、多轮场景中提升连贯性和个性化。
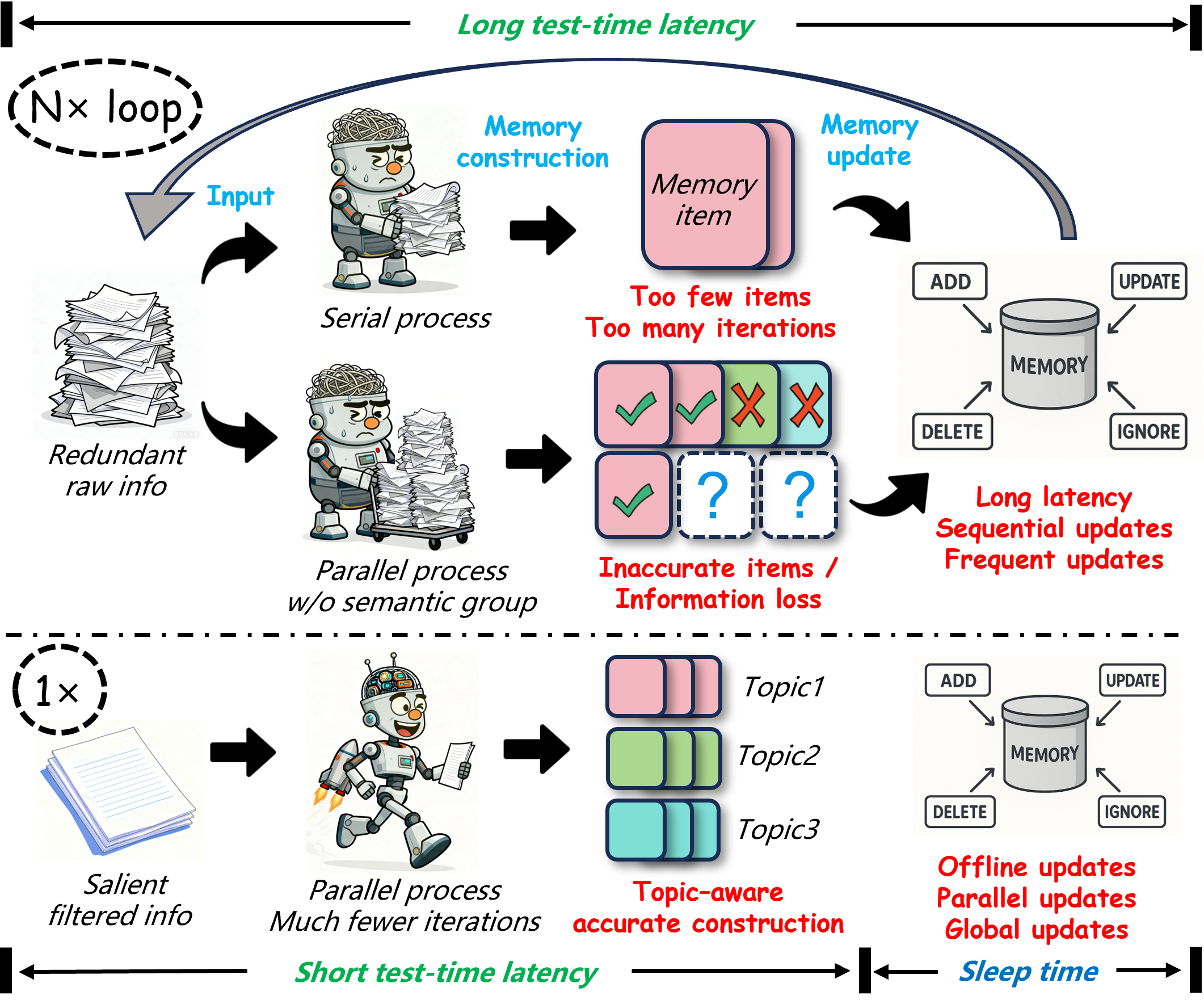
Challenges. Despite these advances, as shown in Figure 1, contemporary memory systems still suffer from significant inefficiencies and consistency issues. First, in long interactions (e.g., dialogue scenarios), both user inputs and model responses often contain substantial redundant information. Such information is typically irrelevant to downstream tasks or subsequent memory construction, and in some cases, may even negatively affect the model’s in-context learning capability. However, current mainstream memory-related studies generally process the raw information directly without any filtering or refinement, leading to high overhead from noisy or irrelevant data. This inflates token consumption without proportional gains in reasoning quality or coherence. Second, memory construction typically treats each turn in isolation or relies on rigid context-window boundaries, failing to model semantic connections across different turns. As a result, during subsequent memory item construction, the backbone LLM may generate inaccurate or incomplete item representations due to overly entangled topics or semantics, leading to the loss of crucial contextual details. Third, memory updates and forgetting are usually performed directly during inference and task execution. This tight coupling introduces long test-time latency in long-horizon tasks and prevents deeper, reflective processing of past experiences.
挑战。 尽管已有这些进展,如 图1 所示,当前记忆系统仍然存在显著的低效和一致性问题。 首先,在长交互(例如对话场景)中,用户输入和模型响应往往都包含大量冗余信息。 这些信息通常与下游任务或后续记忆构建无关,在某些情况下甚至可能负面影响模型的上下文学习能力。 然而,当前主流记忆相关研究通常直接处理原始信息,不进行任何过滤或精炼,因此会因噪声或无关数据产生高开销。 这会膨胀 token 消耗,却不能带来成比例的推理质量或连贯性收益。 其次,记忆构建通常孤立地处理每一轮,或者依赖僵硬的上下文窗口边界,无法建模不同轮次之间的语义连接。 因此,在后续记忆项构建过程中,骨干 LLM 可能因为主题或语义过度纠缠而生成不准确或不完整的条目表示,导致关键上下文细节丢失。 第三,记忆更新和遗忘通常直接在推理和任务执行期间完成。 这种紧耦合会在长程任务中引入较长的测试时延迟,并阻碍对过去经验进行更深入、反思式的处理。
Building Lightweight Memory. Inspired by the efficiency and structure of human memory, we introduce LightMem. In particular, LightMem emulates human memory through three key components: (1) A pre-compression sensory memory module that filters redundant or low-value tokens from raw input and buffers the distilled content. (2) A topic-aware short-term memory that leverages semantic and topical similarity to dynamically group related utterances into coherent segments. By adaptively determining segment boundaries based on content instead of fixed window sizes, this module produces more concentrated and meaningful memory units. This not only reduces the frequency of memory construction but also enables more precise and efficient retrieval during inference. (3) A sleep-time update mechanism for long-term memory maintenance. New memory entries are initially stored with timestamps to support immediate (``soft'') updates for real-time responsiveness. Later, during designated offline periods (i.e., ``sleep''), the system reorganizes, de-duplicates, and abstracts these entries, resolving inconsistencies and strengthening cross-knowledge connections. Crucially, this decouples expensive memory maintenance from real-time inference, enabling reflective, high-fidelity updates without introducing latency. By systematically filtering, organizing, and consolidating relevant information, LightMem substantially reduces computational overhead and API costs while sustaining accurate, coherent reasoning over extended interactions. We detail each component in Section 3.
构建轻量记忆。 受人类记忆的效率和结构启发,作者提出 LightMem。 具体而言,LightMem 通过三个关键组件来模拟人类记忆: (1)一个预压缩感觉记忆模块,它从原始输入中过滤冗余或低价值 token,并缓冲提炼后的内容。 (2)一个主题感知短期记忆,它利用语义和主题相似性,动态地将相关话语分组成连贯片段。 通过基于内容而非固定窗口大小来自适应确定片段边界,该模块会产生更集中、更有意义的记忆单元。 这不仅减少了记忆构建频率,也使推理时的检索更加精确和高效。 (3)一种用于长期记忆维护的睡眠时更新机制。 新的记忆条目最初会带时间戳存储,以支持实时响应所需的即时(“软”)更新。 随后,在指定的离线时段(即“睡眠”)中,系统会重组、去重并抽象这些条目,解决不一致并强化跨知识连接。 关键在于,这将昂贵的记忆维护与实时推理解耦,使系统能够进行反思式、高保真更新,同时不引入延迟。 通过系统性地过滤、组织和整合相关信息,LightMem 在维持长时交互中准确、连贯推理的同时,显著降低计算开销和 API 成本。 作者在第 3 节详细介绍各个组件。
Results and Evaluation. On LongMemEval, LightMem consistently outperforms the strongest baseline, improving accuracy by 2.09%–6.40% with GPT and up to 7.67% with Qwen. In terms of overall efficiency (online + offline), LightMem reduces total token usage by up to
结果与评估。 在 LongMemEval 上,LightMem 持续超过最强基线:在 GPT 上准确率提升 2.09%–6.40%,在 Qwen 上最高提升 7.67%。 从整体效率(在线 + 离线)来看,LightMem 对 GPT 的总 token 用量最高降低
2. Preliminary
2.1 Conventional Memory Systems for LLMs
We describe mainstream memory architectures pipeline in terms of two major stages. (I) Memory Bank Construction. This stage can be further decomposed into three sub-stages: (a) Raw data
作者从两个主要阶段来描述主流记忆架构流程。 (I)记忆库构建。 这一阶段可以进一步分解为三个子阶段: (a)原始数据
2.2 Limitations of Existing LLM Memory Systems
Compared to human memory, current LLM memory systems are burdened by high maintenance costs, mainly due to three limitations: 1) Redundant Sensory Memory. In current systems,
与人类记忆相比,当前 LLM 记忆系统主要由于三方面限制而承担较高维护成本: 1)冗余的感觉记忆。 在当前系统中,
3. LightMem Architecture
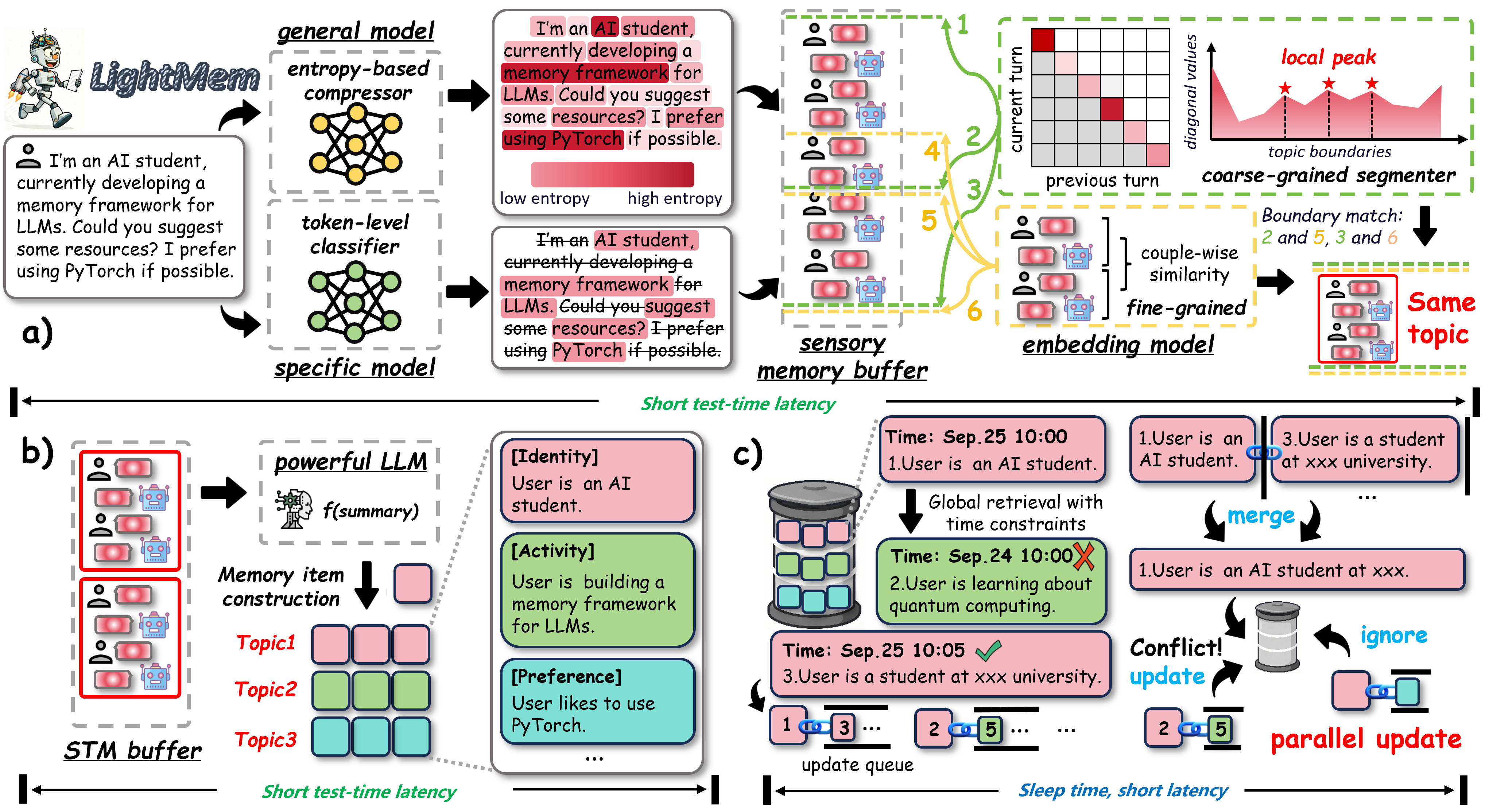
Analogous to the human memory, we design LightMem as shown in Figure 2, which consists of three light modules: Light1 implements an efficient Sensory Memory Module that selectively preserves salient information from raw input (Section 3.1), Light2 realizes a topic-aware STM Module for transient information processing (Section 3.2), and Light3 provides an LTM module designed to minimize test time update latency (Section 3.3) with a sleep time update mechanism. The overall pipeline framework of LightMem, its specific models, and comparisons with other memory frameworks are presented in Appendix. The complexity analysis for LightMem's efficiency gains is in Section 4.
类似人类记忆,作者将 LightMem 设计为 图2 所示的三个轻量模块: Light1 实现一个高效的感觉记忆模块,从原始输入中选择性保留显著信息(第 3.1 节)。 Light2 实现一个主题感知的 STM 模块,用于瞬时信息处理(第 3.2 节)。 Light3 则提供一个 LTM 模块,通过睡眠时更新机制来最小化测试时更新延迟(第 3.3 节)。 LightMem 的整体流水线框架、具体模型以及与其他记忆框架的比较见附录。 LightMem 效率收益的复杂度分析见第 4 节。
3.1 Light1: Cognitive-Inspired Sensory Memory
In long horizon interaction scenarios, such as user–assistant dialogues, a large portion of the information is redundant. Therefore, we design a Pre-Compressing Submodule to eliminate redundant tokens, followed by the Topic Segmentation Submodule that forms semantic topic-based segments for following faster and more accurate memory construction. Pre-Compressing Submodule. This module leverages a compression model
在长程交互场景中,例如用户—助手对话,大量信息是冗余的。 因此,作者设计了一个预压缩子模块来消除冗余 token,随后使用主题分段子模块形成基于语义主题的片段,以便后续更快、更准确地构建记忆。 预压缩子模块。 该模块利用压缩模型
Following TokenSkip, we use LLMLingua-2 as our compression model retain'' or discard''). For each token
遵循 TokenSkip,作者使用 LLMLingua-2 作为压缩模型
where the subscript
其中下标
where
其中
Specifically, dialogue scenarios possess natural semantic units, namely the conversational turn. We construct a turn-level attention matrix
具体而言,对话场景具有天然的语义单元,即对话轮次。 作者构造一个 turn 级注意力矩阵
3.2 Light2: Topic-Aware Short-Term Memory
After obtaining individual topic segments, forming an index structure of {topic, message turns}, where message turns = {
在获得各个主题片段后,系统会形成 {topic, message turns} 的索引结构,其中 message turns = {
where
其中
3.3 Light3: Long-Term Memory with Sleep-Time Update
Soft Updating at Test Time. At test time, when memory entries arrive, LightMem directly inserts them into LTM with soft updates, thereby decoupling the update process from online inference. Due to real-time updates being converted to direct insertions, interaction latency is significantly reduced. After all entries are inserted or when an update trigger arrives, we compute an update queue for every entry in LTM.
测试时软更新。 在测试时,当记忆条目到达时,LightMem 会通过软更新将它们直接插入 LTM,从而将更新过程与在线推理解耦。 由于实时更新被转换为直接插入,交互延迟显著降低。 在所有条目插入后,或当更新触发器到来时,作者会为 LTM 中的每个条目计算一个更新队列。
where
其中
4. Complexity Analysis about LightMem
| Method | Summary Tokens | Update Tokens | API Calls | Runtime |
|---|---|---|---|---|
| Baselines | ||||
| LightMem |
As shown in Table 1, we consider a dialogue with
如 表1 所示,作者考虑一个包含
In LightMem, each turn is first passed through iterative pre-compression submodule, retaining only
在 LightMem 中,每一轮首先经过迭代式预压缩子模块,经过
Overall, LightMem requires only
总体而言,LightMem 在摘要操作上仅需要
5. Experiments
5.1 Experimental Setup
Experimental Details. (1) Our experiments adopt a realistic Incremental Dialogue Turn Feeding setting, where the entire dialogue history is fed and processed at the turn level, one turn at a time. This reflects practical scenarios where interactions between user and model is incrementally formed turn by turn.. (2) For considerations of both efficiency and effectiveness, we employ LLMLingua-2 as our pre-compressor throughout all subsequent experiments. (3) The attention scores for topic segmentation are also obtained using LLMLingua-2, the size of the sensory memory buffer is 512 tokens.
实验细节。 (1)作者的实验采用真实的增量式对话轮次输入设置,其中整个对话历史会在 turn 级别逐轮输入和处理。 这反映了用户与模型之间交互逐轮增量形成的实际场景。 (2)同时考虑效率和效果,作者在后续所有实验中都使用 LLMLingua-2 作为预压缩器。 (3)主题分段的注意力分数同样由 LLMLingua-2 获得,感觉记忆缓冲区大小为 512 token。
Datasets & Baseline Methods. We use two well-known datasets, LongMemEval (specifically the LongMemEval-S split) and LoCoMo to evaluate memory ability. We compare LightMem against several representative baselines of conversational memory modeling. ① Full Text, ② Naive RAG, ③ LangMem, ④ A-MEM, ⑤ MemoryOS, ⑥ Mem0. In addition, all methods use GPT-4o-mini, Qwen3-30B-A3B-Instruct-2507 and GLM-4.6 as the LLM backbones. Details on dataset, baselines, and experimental settings are provided in the Appendix.
数据集与基线方法。 作者使用两个知名数据集 LongMemEval(具体为 LongMemEval-S split)和 LoCoMo 来评估记忆能力。 作者将 LightMem 与若干代表性对话记忆建模基线进行比较。 ① Full Text,② Naive RAG,③ LangMem,④ A-MEM,⑤ MemoryOS,⑥ Mem0。 此外,所有方法都使用 GPT-4o-mini、Qwen3-30B-A3B-Instruct-2507 和 GLM-4.6 作为 LLM 骨干。 数据集、基线和实验设置细节见附录。
Metrics. We evaluate these methods using both effectiveness and efficiency metrics. For effectiveness, we report Accuracy (ACC), defined as the proportion of correctly answered questions. The evaluation is conducted with GPT-4o-mini as an LLM judge, guided by a detailed evaluation prompt (see Appendix). For efficiency, we focus on tracking the computational costs of the LLM invocations in memory bank construction stage (see Section 2), all averaged across the entire dataset, as it is the one tied to the design and implementation differences of memory systems. The retrieval and usage stage is not our focus, because for fair comparison, The
指标。 作者使用效果和效率两类指标评估这些方法。 对于效果,作者报告 Accuracy(ACC),定义为正确回答问题的比例。 评估使用 GPT-4o-mini 作为 LLM 裁判,并由详细评估提示引导。 对于效率,作者重点跟踪记忆库构建阶段 LLM 调用的计算成本,并在整个数据集上取平均,因为这一阶段与记忆系统的设计和实现差异相关。 检索与使用阶段不是本文重点,因为为公平比较,所有方法的
| Method | ACC (%) | Summary Tokens (k) | Update Tokens (k) | Total (k) | Calls | Runtime (s) | ||
|---|---|---|---|---|---|---|---|---|
| In | Out | In | Out | |||||
| GPT-4o-mini | ||||||||
| FullText | 56.80 | - | - | - | - | 105.07 | - | - |
| NaiveRAG | 61.00 | - | - | - | - | - | - | 867.38 |
| LangMem | 37.20 | - | - | 982.68 | 119.48 | 1,102.16 | 520.62 | 2,293.70 |
| A-MEM | 62.60 | 214.66 | 42.82 | 1,157.52 | 190.81 | 1,605.81 | 986.55 | 5,132.06 |
| MemoryOS | 44.80 | 2,302.35 | 304.18 | 350.02 | 35.19 | 2,991.75 | 2,938.41 | 8,030.04 |
| Mem0 | 53.61 | 424.13 | 17.76 | 560.17 | 150.56 | 1,152.62 | 811.57 | 4,248.49 |
| LightMem | ||||||||
| r=0.5, th=256 | 64.29 | 20.80 | 10.01 | - | - | 30.81 | 25.67 | 302.69 |
| (OP-update) | 64.69 | - | - | 44.46 | 2.56 | 47.02 | 70.23 | 342.63 |
| r=0.6, th=256 | 67.78 | 24.58 | 10.53 | - | - | 35.11 | 30.47 | 329.61 |
| (OP-update) | 65.39 | - | - | 53.98 | 3.18 | 57.16 | 85.07 | 411.56 |
| r=0.7, th=512 | 68.64 | 18.88 | 9.37 | - | - | 28.25 | 18.43 | 283.76 |
| (OP-update) | 67.07 | - | - | 79.38 | 4.06 | 83.44 | 125.47 | 496.03 |
| Qwen3-30B-A3B-Instruct-2507 | ||||||||
| FullText | 54.80 | - | - | - | - | 105.07 | - | - |
| NaiveRAG | 60.80 | - | - | - | - | - | - | 659.09 |
| LangMem | 50.80 | - | - | 1,311.96 | 118.06 | 1,430.02 | 495.12 | 3,237.16 |
| A-MEM | 65.20 | 219.21 | 66.98 | 1,260.54 | 318.20 | 1,864.93 | 989.30 | 5,367.51 |
| MemoryOS | 49.60 | 2,101.54 | 510.88 | 305.12 | 27.43 | 2,944.97 | 2,922.28 | 8,721.78 |
| Mem0 | 39.51 | 424.20 | 15.34 | 411.50 | 111.35 | 1,001.90 | 722.76 | 2,239.94 |
| LightMem | ||||||||
| r=0.4, th=768 | 61.95 | 9.01 | 16.14 | - | - | 25.15 | 16.54 | 357.13 |
| (OP-update) | 62.34 | - | - | 111.13 | 7.88 | 119.01 | 176.02 | 1,036.47 |
| r=0.6, th=768 | 70.20 | 13.19 | 19.21 | - | - | 32.40 | 19.97 | 417.13 |
| (OP-update) | 65.14 | - | - | 97.11 | 5.92 | 103.03 | 152.93 | 1,023.56 |
| r=0.8, th=1024 | 68.69 | 14.82 | 18.49 | - | - | 33.31 | 9.43 | 355.71 |
| (OP-update) | 67.34 | - | - | 106.91 | 6.20 | 113.11 | 168.37 | 1,026.90 |
| GLM-4.6 | ||||||||
| FullText | 36.71 | - | - | - | - | 103.38 | - | - |
| NaiveRAG | 73.20 | - | - | - | - | - | - | 53,725.15 |
| LangMem | 49.20 | - | - | 3,052.42 | 7.03 | 3,059.45 | 314.61 | 5,577.91 |
| A-MEM | 70.60 | 444.95 | 63.40 | 1,992.04 | 403.39 | 2,903.78 | 450.40 | 8,068.80 |
| LightMem | ||||||||
| r=0.5, th=256 | 73.00 | 16.55 | 14.06 | - | - | 30.61 | 10.78 | 1,014.37 |
| r=0.6, th=256 | 73.20 | 16.55 | 13.99 | - | - | 30.54 | 10.78 | 1,077.69 |
| r=0.7, th=512 | 72.80 | 16.55 | 13.91 | - | - | 30.46 | 10.78 | 1,038.19 |
5.2 Main Results
| GPT-4o-mini | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | ACC (%) | Sum In | Sum Out | Upd In | Upd Out | Total | Calls | Runtime |
| FullText | 71.83 | - | - | - | - | - | - | - |
| NaiveRAG | 63.64 | - | - | - | - | - | - | - |
| LangMem | 57.20 | - | - | 898.27 | 111.95 | 1,010.22 | 920.62 | 2,229.37 |
| A-MEM | 64.16 | 182.74 | 49.29 | 729.89 | 187.52 | 1,149.43 | 1,175.47 | 6,060.73 |
| MemoryOS(locomo) | 58.25 | 110.98 | 33.40 | 78.08 | 64.54 | 287.00 | 553.45 | 2,422.05 |
| MemoryOS(regular) | 54.87 | 226.86 | 46.61 | 177.66 | 75.34 | 526.48 | 1,016.06 | 3,332.59 |
| Mem0 | 61.69 | 851.32 | 20.53 | 632.12 | 189.42 | 1,693.39 | 1,602.20 | 4,432.87 |
| LightMem(0.7,512) | 71.95 | 73.19 | 20.13 | 6.05 | 0.40 | 99.76 | 41.65 | 848.49 |
| LightMem(0.7,768) | 70.26 | 57.54 | 18.92 | 3.79 | 0.23 | 80.48 | 29.55 | 737.80 |
| LightMem(0.8,768) | 72.99 | 62.82 | 17.95 | 4.14 | 0.28 | 85.19 | 29.83 | 815.32 |
| Qwen3-30B-A3B-Instruct-2507 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | ACC (%) | Sum In | Sum Out | Upd In | Upd Out | Total | Calls | Runtime |
| FullText | 74.87 | - | - | - | - | - | - | - |
| NaiveRAG | 66.95 | - | - | - | - | - | - | - |
| LangMem | 60.53 | - | - | 1,004.35 | 138.02 | 1,142.37 | 1,005.37 | 2,268.57 |
| A-MEM | 56.10 | 158.29 | 60.85 | 924.19 | 483.51 | 1,626.80 | 1,175.40 | 5,543.90 |
| MemoryOS(locomo) | 61.04 | 122.21 | 53.12 | 104.43 | 81.75 | 361.51 | 414.70 | 1,269.70 |
| MemoryOS(regular) | 51.30 | 228.85 | 51.60 | 242.27 | 143.63 | 666.35 | 1,004.60 | 1,982.20 |
| Mem0 | 43.31 | 827.09 | 18.64 | 763.88 | 189.80 | 1,799.40 | 1,614.50 | 4,540.70 |
| LightMem(0.6,768) | 71.36 | 56.68 | 34.14 | 8.31 | 0.74 | 99.87 | 29.10 | 815.70 |
| LightMem(0.8,1024) | 72.60 | 61.38 | 36.33 | 9.86 | 0.88 | 108.45 | 32.00 | 1,079.40 |
As shown in Table 2 and Table 3, LightMem demonstrates superior effectiveness and efficiency on both datasets across both GPT and Qwen backbones. For a fair comparison, all efficiency metrics for LightMem in the following analysis refer to the combined online and offline costs. LongMemEval. On the LongMemEval benchmark, LightMem consistently outperforms the strongest baseline, A-Mem, in the ACC metric, improving accuracy by 2.09%–6.40% with GPT and up to 7.67% with Qwen. In terms of efficiency, for GPT, LightMem reduces total token consumption by
如 表2 和 表3 所示,LightMem 在两个数据集以及 GPT 和 Qwen 两类骨干上都表现出更好的效果和效率。 为公平比较,下文分析中 LightMem 的所有效率指标都指在线和离线合并成本。 LongMemEval。 在 LongMemEval 基准上,LightMem 在 ACC 指标上持续超过最强基线 A-Mem:在 GPT 上准确率提升 2.09%–6.40%,在 Qwen 上最高提升 7.67%。 就效率而言,对于 GPT,LightMem 将总 token 消耗降低
LoCoMo. On the LoCoMo dataset, LightMem also demonstrates superior performance over other memory baselines. For the GPT backbone, it improves ACC by 6.10%–18.12%, achieves a
LoCoMo。 在 LoCoMo 数据集上,LightMem 同样表现出优于其他记忆基线的性能。 对于 GPT 骨干,它使 ACC 提升 6.10%–18.12%,总 token 效率提升
MemoryOS(locomo) is the LoCoMo reproduction script in the MemoryOS library, simplifying the standard version, shown as MemoryOS(regular).
MemoryOS(locomo) 是 MemoryOS 库中的 LoCoMo 复现脚本,它简化了标准版本,在表中记为 MemoryOS(regular)。
5.3 Analysis of Pre-Compressing Submodule
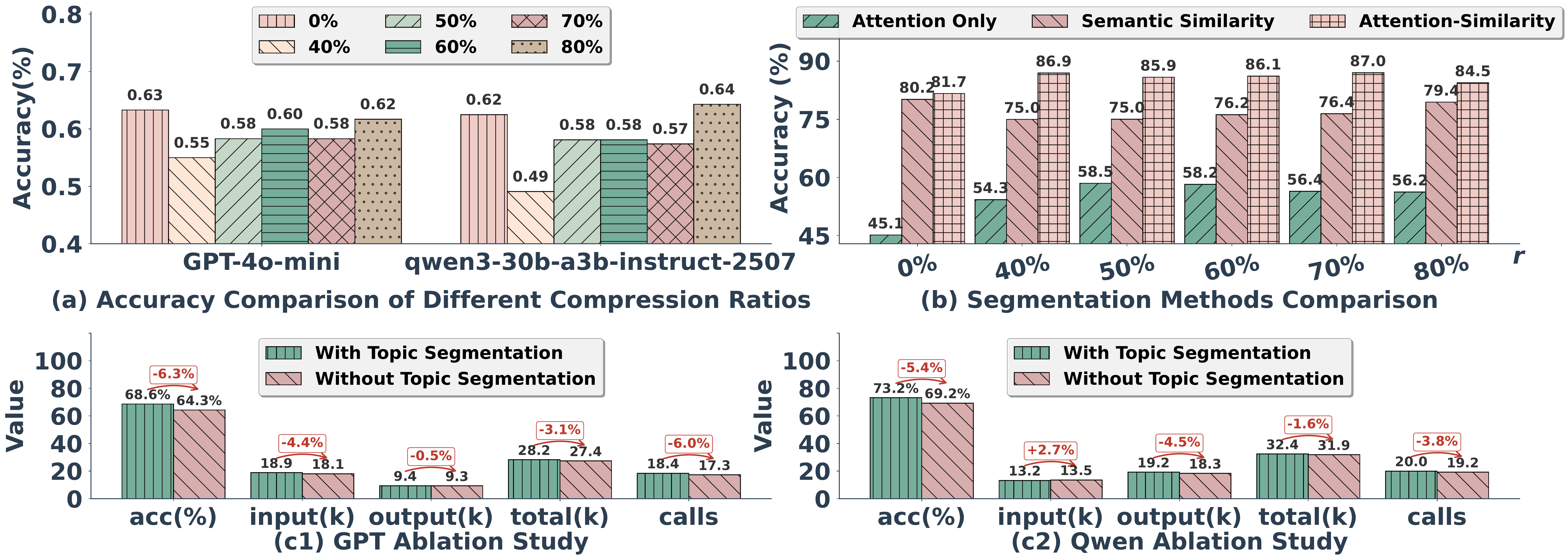
Performance and Overhead. LightMem uses an additional model for pre-compression. We evaluate its performance by randomly sampling 1/5 of LongMemEval and compressing it at ratios shown in Figure 3(a), then prompting LLMs for in-context QA. When compression ratio
性能与开销。 LightMem 使用一个额外模型 进行预压缩。 作者通过随机采样 1/5 的 LongMemEval,并按 图3(a) 所示比例压缩,然后提示 LLM 进行上下文内 QA,来评估其性能。 当压缩率
Impact of
5.4 Analysis of Topic Segmentation Submodule
Segmentation Accuracy. To validate the accuracy of our proposed hybrid topic segmentation method, we compare it with segmentation using only a single granularity: attention-only-based and similarity-only-based segmentation. Since the construction process of the LongMemEval indicates that different sessions naturally serve as topic boundaries, we directly use them as ground-truth labels. The final accuracy is calculated as the number of correctly identified segmentation points divided by the total number of labels. The results in Figure 3(b) validate the effectiveness of our method: it achieves higher accuracy than both individual segmentation methods across all compression ratios, with an absolute accuracy exceeding 80%.
分段准确率。 为验证作者提出的混合主题分段方法的准确性,作者将其与只使用单一粒度的分段方法进行比较:仅基于注意力的分段和仅基于相似度的分段。 由于 LongMemEval 的构造过程表明,不同 session 自然充当主题边界,作者直接将其用作真实标签。 最终准确率计算为正确识别出的分段点数量除以标签总数。 图3(b) 的结果验证了该方法的有效性:在所有压缩率下,它都比两种单独分段方法取得更高准确率,绝对准确率超过 80%。
Ablation Study. As shown in Figure 3(c), removing the topic segmentation submodule slightly improves efficiency but significantly harms accuracy, causing a 6.3% drop for GPT and 5.4% for Qwen. This indicates that the submodule effectively enables models to perceive semantic units in the input, facilitating subsequent memory unit generation.
消融研究。 如 图3(c) 所示,移除主题分段子模块会略微提升效率,但显著损害准确率,使 GPT 下降 6.3%,Qwen 下降 5.4%。 这表明该子模块能够有效帮助模型感知输入中的语义单元,从而促进后续记忆单元生成。
5.5 Analysis of the STM Threshold's Impact
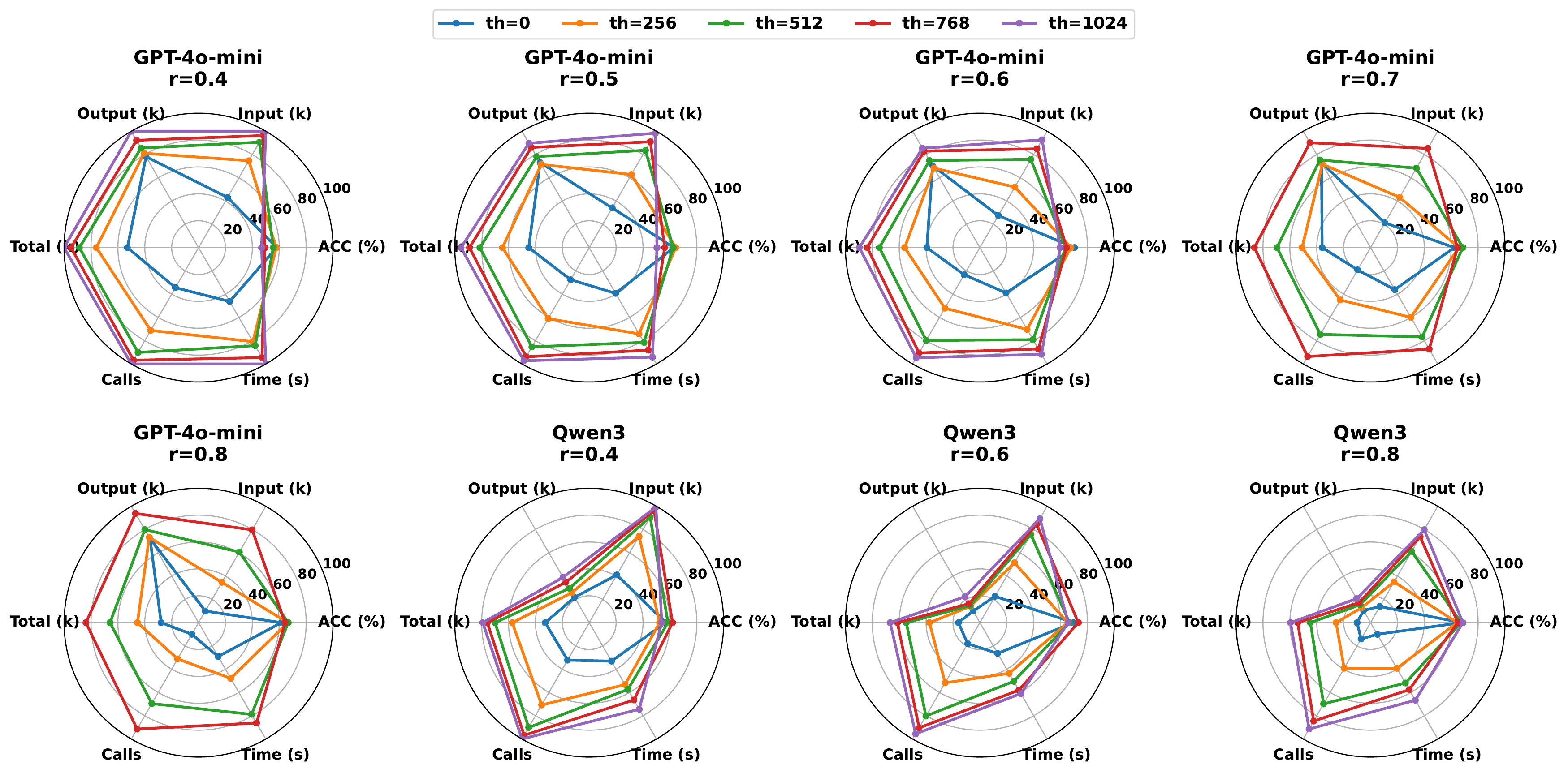
As illustrated in the Figure 4, the STM buffer threshold (
如 图4 所示,STM 缓冲区阈值(
5.6 Analysis of Sleep-Time Update
Why Soft Updates Work. A primary challenge in designing memory systems is handling updates. While powerful, LLMs can be unreliable when tasked with complex real-time update operations. For instance, when presented with two related but not contradictory pieces of information, an LLM might incorrectly interpret them as a conflict and delete the older memory entry, leading to irreversible information loss. Instead, the optimal operations might be to merge the information or simply add the new entry. In contrast, LightMem performs only incremental additions through soft updates during test time, which preserves global information and complete semantics.
为什么软更新有效。 设计记忆系统的一个主要挑战是处理更新。 LLM 虽然强大,但在执行复杂实时更新操作时可能并不可靠。 例如,当面对两条相关但并不矛盾的信息时,LLM 可能会错误地将其解释为冲突并删除较旧的记忆条目,导致不可逆的信息丢失。 相反,最优操作可能是合并信息,或者只是添加新条目。 相比之下,LightMem 在测试时只通过软更新执行增量添加,从而保留全局信息和完整语义。
-> "User plans Kyoto trip"
▲ Tokyo context lost
-> "Tokyo trip + Kyoto inquiry"
✓ Full context preserved
6. Related Work
Hard Prompt Compression for LLMs. Hard prompt compression improves LLM efficiency by removing redundant content from prompts . Methods recently have evolved from using smaller language models to query-aware approaches that preserve task-relevant information . Additionally, lightweight bidirectional encoders have demonstrated strong effectiveness and efficiency .
面向 LLM 的硬提示压缩。 硬提示压缩通过从提示中移除冗余内容来提升 LLM 效率。 近期方法已经从使用较小语言模型,发展到能够保留任务相关信息的查询感知方法。 此外,轻量双向编码器也展现出很强的效果和效率。
Chunking Strategies in RAG Systems. Retrieval-Augmented Generation (RAG) systems rely on chunking extrernal documents into smaller units for retrieval . Existing chunking strategies include rule-based methods creating fixed-size segments , semantic-based methods grouping content by topic , and LLM-driven methods leveraging model knowledge for splitting . However, all of these chunking strategies for RAG systems are tailored to static scenarios, not applicable to dynamic and open-ended environments.
RAG 系统中的切块策略。 检索增强生成(RAG)系统依赖于将外部文档切分成更小单元以便检索。 现有 chunking 策略包括创建固定长度片段的规则方法、按主题组织内容的语义方法,以及利用模型知识进行切分的 LLM 驱动方法。 然而,所有这些用于 RAG 系统的 chunking 策略都是面向静态场景设计的,并不适用于动态和开放式环境。
Memory Systems for LLM Agents. Memory systems help LLM agents move beyond stateless interactions to support flexible reasoning and adaptation in complex and changing environments . The earliest and most straightforward approaches store experiences as linear or sequential streams, sometimes enhanced with hierarchical structures . A more structured class of methods represents memories as nodes and their relationships as edges, using trees, graphs, or temporal knowledge structures to support retrieval and update . The latest trend integrates various types of memory, allowing them to interact and synergistically improve overall performance . Overall, existing memory systems for LLM agents have become increasingly complex and capable, leveraging hierarchical, structured, and multi-type memories. However, most focus on maximizing effectiveness, with limited consideration of efficiency. While some recent works share a similar motivation with our work, they focus on lightweight adaptations of GraphRAG where the corpus is predefined and static.
LLM 智能体记忆系统。 记忆系统帮助 LLM 智能体超越无状态交互,在复杂且变化的环境中支持灵活推理和适应。 最早也最直接的方法将经验存储为线性或顺序流,有时会用层级结构进行增强。 更结构化的一类方法将记忆表示为节点、将其关系表示为边,并使用树、图或时间知识结构来支持检索和更新。 最新趋势则整合多种类型的记忆,使它们能够交互并协同提升整体性能。 总体而言,现有 LLM 智能体记忆系统已经变得越来越复杂且能力更强,利用了层级化、结构化和多类型记忆。 然而,大多数工作关注最大化效果,而对效率考虑有限。 虽然一些近期工作与本文有相似动机,但它们关注的是 GraphRAG 的轻量适配,其中语料库是预定义且静态的。
7. Conclusion
In this work, we introduced LightMem, a lightweight and efficient memory framework designed to address the significant overhead of memory systems for LLM agents. Inspired by the multi-stage Atkinson-Shiffrin human memory model, LightMem's architecture effectively filters, organizes, and consolidates information. Our empirical evaluation demonstrates that this approach maintains strong task performance while sharply reducing computational costs. In the near future, we plan to accelerate LightMem’s update phase via offline pre-computed KV caches, reducing runtime overhead. We aim to integrate a lightweight knowledge graph memory for explicit multi-hop reasoning and structured retrieval. A multimodal memory extension will enable adaptation to visual, auditory, and textual inputs in embodied and real-world scenarios.
在本文中,作者提出 LightMem,一个轻量且高效的记忆框架,旨在解决 LLM 智能体记忆系统的显著开销问题。 受多阶段 Atkinson-Shiffrin 人类记忆模型启发,LightMem 的架构能够有效过滤、组织和整合信息。 实证评估表明,该方法在大幅降低计算成本的同时保持了较强任务性能。 在近期未来,作者计划通过离线预计算 KV cache 加速 LightMem 的更新阶段,从而降低运行时开销。 作者希望集成一种轻量知识图谱记忆,用于显式多跳推理和结构化检索。 多模态记忆扩展将使系统能够适应具身和真实世界场景中的视觉、听觉和文本输入。