
Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs
Memory80+10+ICLR 2026CCF-A阿尔伯塔大学超越百万 token:基准评测并增强 LLM 的长期记忆
Abstract
Evaluating the abilities of large language models (LLMs) for tasks that require long-term memory and thus long-context reasoning, for example in conversational settings, is hampered by the existing benchmarks, which often lack narrative coherence, cover narrow domains, and only test simple recall-oriented tasks. This paper introduces a comprehensive solution to these challenges. First, we present a novel framework for automatically generating long (up to 10M tokens), coherent, and topically diverse conversations, accompanied by probing questions targeting a wide range of memory abilities. From this, we construct BEAM, a new benchmark comprising 100 conversations and 2,000 validated questions. Second, to enhance model performance, we propose LIGHT--a framework inspired by human cognition that equips LLMs with three complementary memory systems: a long-term episodic memory, a short-term working memory, and a scratchpad for accumulating salient facts. Our experiments on BEAM reveal that even LLMs with 1M token context windows (with and without retrieval-augmentation) struggle as dialogues lengthen. In contrast, LIGHT consistently improves performance across various models, achieving an average improvement of 3.5%–12.69% over the strongest baselines, depending on the backbone LLM. An ablation study further confirms the contribution of each memory component.
评估大语言模型在需要长期记忆、因而需要长上下文推理的任务上的能力,例如对话场景,会受到现有基准的限制;这些基准通常缺乏叙事连贯性,覆盖领域较窄,并且只测试简单的回忆导向任务。 本文为这些挑战提出了一个综合解决方案。 首先,作者提出一个新框架,能够自动生成长篇(最高 10M token)、连贯且主题多样的对话,并配套生成面向广泛记忆能力的 probing questions。 基于此,作者构建了 BEAM,这是一个新基准,包含 100 段对话和 2,000 个经过验证的问题。 其次,为了增强模型性能,作者提出 LIGHT:一个受人类认知启发的框架,为 LLM 配备三种互补的记忆系统:长期情景记忆、短期工作记忆,以及用于积累显著事实的 scratchpad。 作者在 BEAM 上的实验表明,即使拥有 1M token 上下文窗口的 LLM(无论是否使用检索增强),随着对话变长也会遇到困难。 相比之下,LIGHT 在不同模型上持续提升性能;根据 backbone LLM 的不同,相比最强基线平均提升 3.5%–12.69%。 消融研究进一步证实了每个记忆组件的贡献。
1. Introduction
Large language models (LLMs) have been deployed across diverse applications, including open-domain conversational agents, retrieval-augmented generation (RAG) for open-domain question answering and fact checking, long-document and code analysis, and scientific or legal research. Many of these tasks demand models capable of processing long inputs, motivating LLMs such as Gemini with input windows of up to 1M tokens. Among these domains, conversational systems present an intuitive and critical need for extended context, as users often engage in protracted, multi-session dialogues that require consistent memory across lengthy interactions. This highlights the importance of evaluating how well LLMs can reason over and utilize long conversational histories.
大语言模型已经被部署到多种应用中,包括开放域对话智能体、用于开放域问答和事实核查的检索增强生成(RAG)、长文档与代码分析,以及科学或法律研究。 许多这类任务都要求模型能够处理长输入,这也推动了 Gemini 这类拥有最高 1M token 输入窗口的 LLM。 在这些领域中,对话系统对扩展上下文有直观且关键的需求,因为用户常常进行漫长的多会话对话,而这些对话需要在长时间交互中保持一致记忆。 这凸显了评估 LLM 能否对长对话历史进行推理并加以利用的重要性。
While there are many prior efforts on studying and evaluating long-term memory of LLMs, existing benchmarks have fundamental limitations. Most extend conversation length by artificially concatenating short sessions of different users, producing dialogues with abrupt topic shifts and weak narrative coherence. Such a construction artificially simplifies evaluation because distinct segments are easily separable, reducing the need for true long-range reasoning. Furthermore, these datasets typically target narrow domains---often limited to personal-life scenarios---leaving many real-world application areas underrepresented. Finally, they emphasize simple context recall, overlooking other critical memory abilities such as contradiction resolution, recognizing evolving information, and instruction following.
尽管已有许多工作研究和评估 LLM 的长期记忆,现有基准仍存在根本限制。 大多数基准通过人为拼接不同用户的短会话来延长对话长度,导致对话出现突兀的主题转移和较弱的叙事连贯性。 这种构造方式会人为简化评估,因为不同片段很容易被分开,从而降低了对真正长程推理的需求。 此外,这些数据集通常面向狭窄领域,往往局限于个人生活场景,使许多真实应用领域代表性不足。 最后,它们强调简单的上下文回忆,忽略了其他关键记忆能力,例如矛盾消解、识别演化中的信息以及指令遵循。
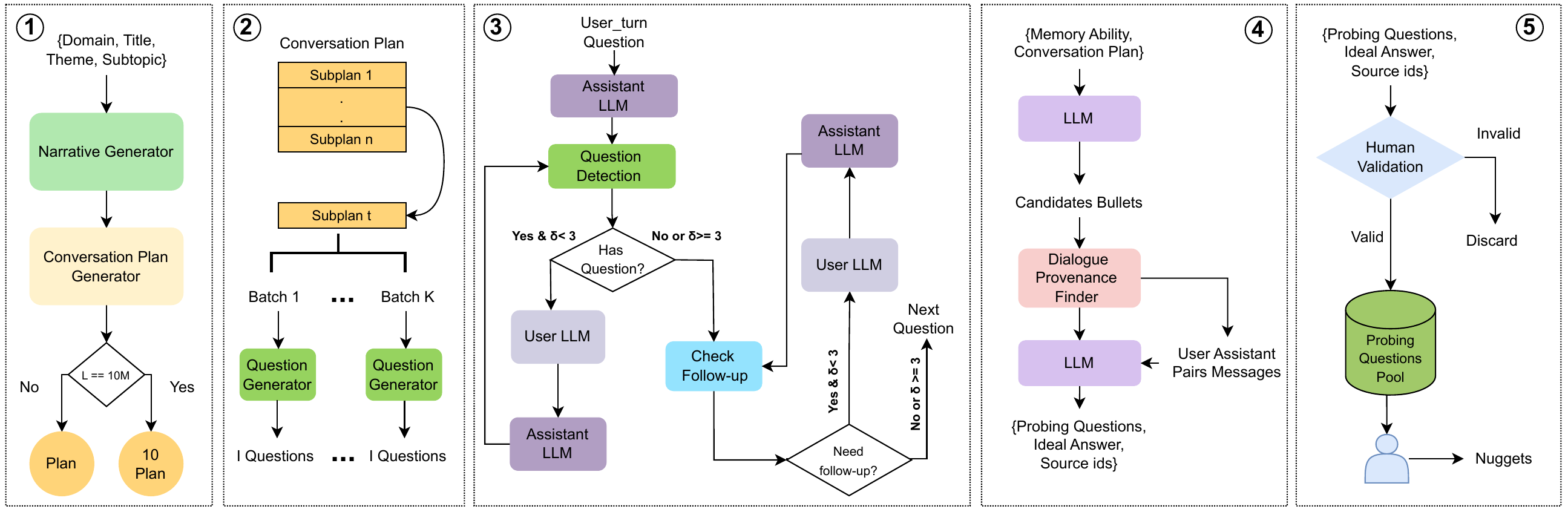
To address these limitations, this paper presents a framework for automatically generating long coherent conversations between a user and an AI assistant---scaling up to 10M tokens on diverse domains---with a set of probing questions designed to evaluate diverse memory abilities of any LLM on the generated dialogues. An overview of the data generation framework is shown in Figure 1. This framework begins by defining a high-level conversation plan---a narrative for a particular domain and a simulated user with generated attributes---that outlines the overall flow of the dialogue. This plan is recursively decomposed into finer sub-plans that specify the storyline and its progression. From these sub-plans we generate chronologically ordered user turns, which are then expanded with corresponding assistant responses. To increase realism, the system injects follow-up questions and clarifications from both sides. Finally, we automatically create a set of probing questions that target ten distinct memory dimensions, with a focus on complicated and multi-hop reasoning, which are then validated by human annotators to ensure high quality. Using this pipeline, we construct the BEAM dataset: 100 diverse conversations ranging from 100 K to 10 M tokens each, accompanied by 2000 probing questions to evaluate the memory capabilities of LLMs.
为解决这些限制,本文提出一个框架,可自动生成用户与 AI 助手之间的长篇连贯对话,在多样领域中可扩展到 10M token,并配套设计一组 probing questions,用于评估任意 LLM 在生成对话上的多种记忆能力。 数据生成框架概览如 图1 所示。 该框架首先定义一个高层 conversation plan,即针对特定领域和带有生成属性的模拟用户的一段叙事,用于勾勒对话整体流程。 该 plan 会递归分解为更细的 sub-plans,用来指定故事线及其推进过程。 作者从这些 sub-plans 中生成按时间顺序排列的用户轮次,然后再扩展出相应的助手回复。 为了提高真实性,系统会注入双方的追问和澄清。 最后,作者自动创建一组 probing questions,面向十种不同记忆维度,重点关注复杂推理和多跳推理;这些问题随后由人工标注者验证,以确保高质量。 通过该流程,作者构建了 BEAM 数据集:100 段多样对话,每段长度从 100K 到 10M token 不等,并配套 2000 个 probing questions,用于评估 LLM 的记忆能力。
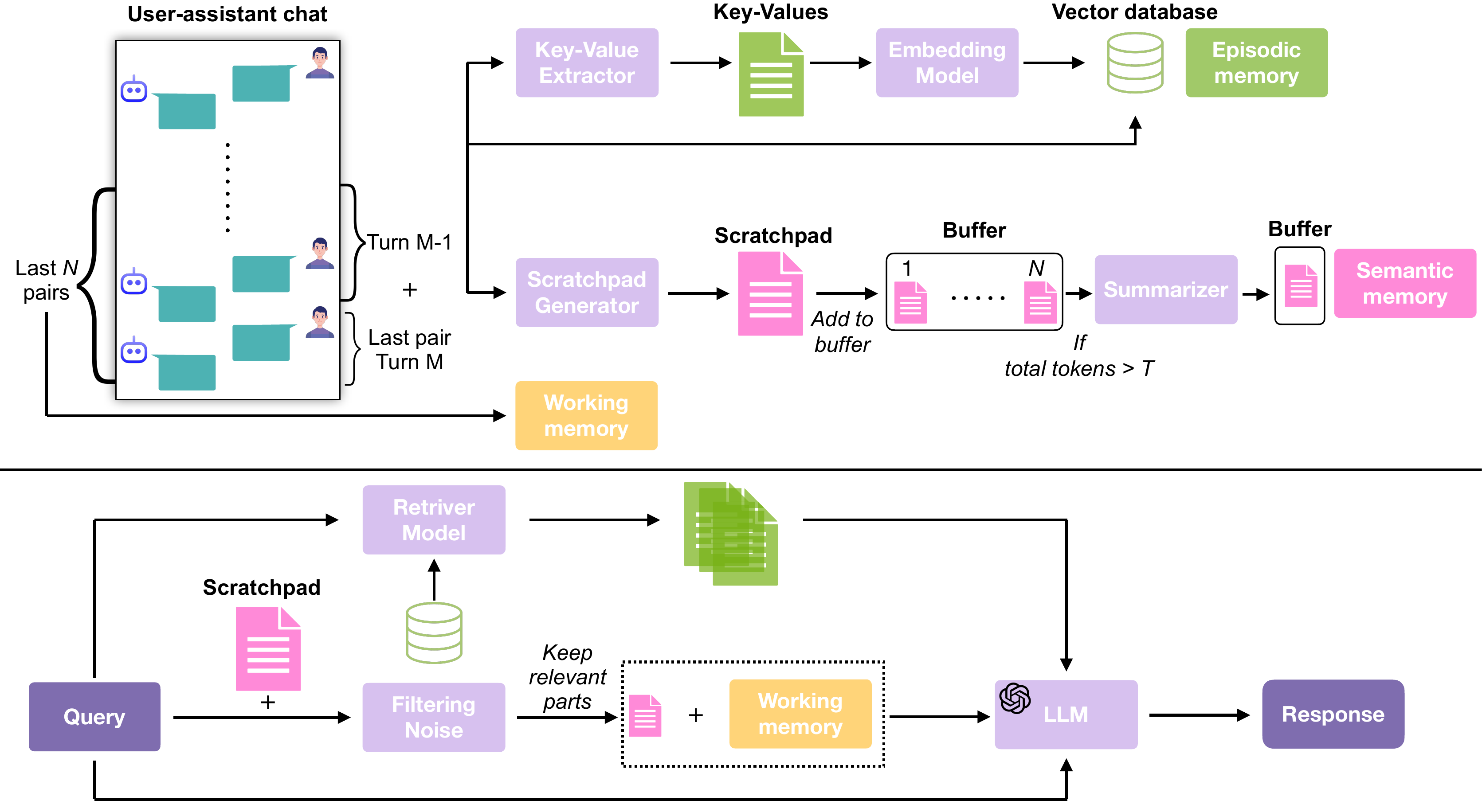
To improve LLM performance on probing questions, we introduce the LIGHT framework (Figure 2), which is applicable to both open-source and proprietary LLMs, inspired by research in human cognitive science and human's memorization and recall process. This framework integrates three complementary memories: (1) episodic memory, a long-term index of the full conversation used for retrieval; (2) working memory, capturing the most recent user–assistant turns; and (3) a scratchpad, where after each turn the model reasons over the dialogue and records salient facts for future use. At inference, the LLM draws jointly on retrieved episodic content, the working memory, and the accumulated scratchpad to generate accurate answers.
为了提升 LLM 在 probing questions 上的表现,作者提出 LIGHT 框架(图2),该框架适用于开源和闭源 LLM,并受到人类认知科学以及人类记忆与回忆过程研究的启发。 该框架整合了三种互补记忆:(1)情景记忆,即用于检索的完整对话长期索引;(2)工作记忆,用于捕捉最近的用户—助手轮次;(3)scratchpad,模型在每轮对话后对对话进行推理,并记录显著事实以供未来使用。 在推理时,LLM 会联合使用检索到的情景内容、工作记忆和累积的 scratchpad 来生成准确答案。
To evaluate LLM memory capabilities and the effectiveness of our method, we conduct experiments on the constructed dataset, BEAM, using both open-source and proprietary models. Results show that even LLMs with long context windows perform substantially worse as conversation length increases. Our method improves the LLM's performance in answering the probing questions by 3.5%–12.69% on average over the best-performing baseline, depending on the backbone model and conversation length. An ablation study further reveals the contribution of each LIGHT component on the performance. To support future work, we release all code, data, and evaluation scripts.
为了评估 LLM 的记忆能力和本文方法的有效性,作者使用构建的数据集 BEAM,在开源和闭源模型上进行实验。 结果表明,即使拥有长上下文窗口的 LLM,随着对话长度增加,其表现也会显著下降。 根据 backbone model 和对话长度的不同,本文方法相比最佳基线平均提升 LLM 回答 probing questions 的性能 3.5%–12.69%。 消融研究进一步揭示了 LIGHT 各组件对性能的贡献。 为支持后续研究,作者发布了全部代码、数据和评估脚本。
2. BEAM: Benchmarking memory Capabilities of LLMs
2.1 Problem Formulation
Let
令
2.2 Benchmark Creation
Our goal is to evaluate how well LLMs can answer questions that depend on long-term conversational memory. We measure performance across ten complementary abilities, seven drawn from prior benchmarks and three newly introduced here—Instruction Following, Event Ordering, and Contradiction Resolution. Abstention evaluates whether a model withholds answers when evidence is missing. Contradiction Resolution tests the capacity to detect and reconcile inconsistent statements across widely separated turns, maintaining global coherence. Event Ordering assesses whether a model can recognize and reconstruct the sequence of evolving information in the dialogue. Information Extraction measures recall of entities and factual details in long histories. Instruction Following examines sustained adherence to user-specified constraints over long contexts. Information Update evaluates revising stored facts as new ones appear. Multi-hop Reasoning probes inference that integrates evidence across multiple, non-adjacent dialogue segments. Preference Following captures personalized responses that adapt to evolving preferences. Summarization assesses the ability to abstract and compress dialogue content, while Temporal Reasoning tests reasoning about explicit and implicit time relations. Together, these abilities evaluate a system's capacity to maintain, update, and manipulate information throughout extended conversations. Given these abilities and the formulation in Section 2.1, the benchmark requires three components: 1) a user–assistant conversation, 2) probing questions targeting key memory abilities, and 3) an evaluation methodology to assess the model's responses. The rest of this section details the process used to construct these components.
作者的目标是评估 LLM 能否回答依赖长期对话记忆的问题。 作者从十种互补能力上衡量性能,其中七种来自已有基准,三种为本文新引入,即指令遵循、事件排序和矛盾消解。 拒答评估当证据缺失时模型是否会保留答案而不作答。 矛盾消解测试模型检测并调和相隔很远轮次中的不一致陈述、保持全局连贯性的能力。 事件排序评估模型能否识别并重建对话中演化信息的顺序。 信息抽取衡量模型对长历史中实体和事实细节的回忆。 指令遵循考察模型能否在长上下文中持续遵循用户指定约束。 信息更新评估当新事实出现时,模型能否修订已存储事实。 多跳推理探测模型能否整合多个非相邻对话片段中的证据进行推理。 偏好遵循捕捉能够适应不断变化偏好的个性化响应。 摘要评估抽象和压缩对话内容的能力,而时间推理测试关于显式和隐式时间关系的推理。 这些能力共同评估系统在长对话中维护、更新和操作信息的能力。 给定这些能力以及第 2.1 节中的形式化定义,该基准需要三个组件:1)用户—助手对话,2)面向关键记忆能力的 probing questions,3)用于评估模型响应的评价方法。 本节其余部分详细说明这些组件的构建过程。
The overview of our framework for creating conversations, probing questions, and the evaluation strategy is illustrated in Figure 1. The process begins by generating a simulated conversation between a user and an assistant. Structured conversation plans are first produced to guide the flow of the synthetic interactions. Each plan specifies sufficient information to generate both user and assistant turns, ensuring a coherent and natural conversational trajectory. While a typical exchange consists of a user question followed by an assistant response, realistic dialogues often involve follow-ups for clarification, elaboration, or related subtopics. To capture this, we incorporate two interaction-control modules. The question-detection module identifies whether an assistant response includes a query that requires a user reply; if triggered, the system generates the corresponding user response. The follow-up detection module determines when the user would naturally pose a clarifying or elaborative question; if triggered, it produces an additional user query for the assistant. Together, these mechanisms produce conversations that exhibit interactive, bidirectional behavior beyond simple turn-taking. After the conversation is generated, an automated procedure constructs a candidate set of probing questions, each tailored to the specific memory abilities in the benchmark. These candidates are then reviewed by a human evaluator, who selects valid questions and formulates the associated evaluation rubrics used for subsequent benchmarking.
作者创建对话、probing questions 以及评价策略的框架概览如 图1 所示。 该流程从生成用户与助手之间的模拟对话开始。 首先生成结构化 conversation plans,以引导合成交互的流程。 每个 plan 都指定足够信息来生成用户和助手轮次,确保对话轨迹连贯自然。 虽然典型交流由一个用户问题加一个助手响应组成,但真实对话常常包含用于澄清、展开或相关子话题的追问。 为捕捉这一点,作者引入两个交互控制模块。 问题检测模块识别助手响应是否包含需要用户回复的问题;如果触发,系统会生成相应用户回复。 追问检测模块判断用户何时会自然提出澄清性或展开性问题;如果触发,它会为助手生成额外的用户问题。 这些机制共同生成了超越简单轮流发言、具有交互式双向行为的对话。 对话生成后,自动化过程会构造一组候选 probing questions,每个问题都针对基准中的特定记忆能力。 这些候选问题随后由人工评估者审查,评估者选择有效问题,并制定后续基准测试所用的相关评价 rubrics。
Conversation Plan Generation
A conversation plan serves as the scaffold for each dialogue, providing a coherent storyline that unfolds chronologically. Each plan is generated using an LLM based on seed information, including: the conversation domain; a title and theme; subtopics outlining specific topics; a set of narratives defining evolving aspects (e.g., career progression, goals); a user profile with attributes such as name, age, gender, location, profession, and personality traits sampled from the Myers–Briggs Type Indicator (MBTI); a relationship graph linking the user to family, friends, and acquaintances, constrained for realism (e.g., age gaps); and an explicit timeline specifying the span of the conversation.
conversation plan 是每段对话的脚手架,提供一条按时间顺序展开的连贯故事线。 每个 plan 都由 LLM 基于种子信息生成,包括:对话领域;标题和主题;用于勾勒具体话题的子话题;定义演化方面的一组narratives(例如职业进展、目标);包含姓名、年龄、性别、地点、职业以及从 Myers–Briggs Type Indicator(MBTI)采样的人格特征等属性的用户画像;将用户与家人、朋友和熟人连接起来并受真实性约束(例如年龄差)的关系图;以及指定对话跨度的显式时间线。
To generate candidate titles and themes, human annotators specify target domains, then GPT-4.1 generates candidate titles, themes, and subtopics. Human reviewers refine outputs for topical diversity. For each conversation, we generate 15-20 narratives using the open-source LLaMA-3.3 70B model. Given the conversation seed, this model produces narrative elements capturing the evolving storyline, forming the backbone of a coherent conversation.
为了生成候选标题和主题,人工标注者会指定目标领域,然后 GPT-4.1 生成候选标题、主题和子话题。 人工审阅者会进一步优化输出,以提升主题多样性。 对于每段对话,作者使用开源 LLaMA-3.3 70B 模型生成 15–20 个 narratives。 给定对话种子,该模型会生成捕捉演化故事线的叙事元素,形成连贯对话的骨架。
Conversation plans consist of
Conversation plans 由
Sequential Expansion: The global seed defines the initial point in the conversation's chronology. Subsequent seeds represent successive events (e.g., a trip, job search, later milestones). Using the prompt in Appendix, each new seed is generated from the main seed, profile, and timeline. Plans are then produced sequentially, with each plan conditioned on its predecessor to maintain continuity. Core relationships (e.g., parents) remain fixed, while new acquaintances are gradually introduced to reflect the evolving context.
顺序扩展: 全局种子定义对话时间线中的初始点。 后续种子表示连续事件(例如旅行、求职、后续里程碑)。 使用附录中的提示词,每个新种子都由主种子、用户画像和时间线生成。 随后按顺序生成 plans,每个 plan 都以前一个 plan 为条件来保持连续性。 核心关系(例如父母)保持固定,而新的熟人会逐渐引入,以反映不断演化的上下文。
Hierarchical Decomposition: The main seed is decomposed into ten sub-seeds, each representing a distinct topical and temporal segment. Together, these sub-seeds span the full storyline (e.g., an international trip: first three for preparation, next five for trip events, final two for reflections). Similar to sequential expansion, the user's core relationships remain constant, while new acquaintances are introduced to reflect the evolving context. These ten sub-seeds are generated using the prompt in Appendix, conditioned on the main seed, profile, and timeline.
层级分解: 主种子被分解为十个子种子,每个子种子表示一个不同的主题和时间片段。 这些子种子共同覆盖完整故事线(例如一次国际旅行:前三个用于准备,接下来五个用于旅行事件,最后两个用于反思)。 与顺序扩展类似,用户核心关系保持不变,而新熟人会被引入以反映演化上下文。 这十个子种子使用附录中的提示词生成,并以主种子、用户画像和时间线为条件。
Each conversation plan is assigned explicit topical and temporal boundaries—encoded in the seed—to avoid redundancy and ensure sub-themes appear in the right narrative stage. For coherence, the LLM conditions on summaries of prior plans and future seeds when producing a new plan, allowing anticipation of upcoming events (e.g., reserving tickets for travel dates). Plans are generated using the prompt in Appendix, conditioned on the main seed, current sub-seed, number of sub-plans, narrative set, user profile, core and new relationships, preceding and subsequent sub-seeds, previous plan, a summary of earlier plans, current sub-seed index, and a binary flag for the first plan (triggering user introduction). Since initial plans may not sufficiently test three key memory abilities—contradiction resolution, information update, and instruction following—we apply a two-stage augmentation: first generate the base plan, then use GPT-4.1 to augment each sub-plan with three targeted bullet points. Performing augmentation separately improves coverage and fidelity. The refinement follows the prompt in Appendix, which takes plan as input and outputs the revised version. This stage corresponds to the first module in Figure 1, which forms the first step of the overall data-generation pipeline.
每个 conversation plan 都会被分配显式的主题和时间边界,并编码在种子中,以避免冗余并确保子主题出现在正确的叙事阶段。 为了保持连贯性,LLM 在生成新 plan 时会以前序 plans 的摘要和未来种子为条件,从而能够预见即将到来的事件(例如为旅行日期预订票)。 Plans 使用附录中的提示词生成,并以主种子、当前子种子、sub-plans 数量、narrative 集合、用户画像、核心关系和新关系、前后子种子、前一个 plan、早期 plans 的摘要、当前子种子索引,以及表示第一个 plan 的二值标志(触发用户介绍)为条件。 由于初始 plans 可能不足以测试三种关键记忆能力,即矛盾消解、信息更新和指令遵循,作者采用两阶段增强:先生成基础 plan,再使用 GPT-4.1 为每个 sub-plan 增加三个有针对性的 bullet points。 单独执行增强能够提升覆盖度和忠实度。 该 refinement 遵循附录中的提示词,以 plan 作为输入并输出修订版本。 这一阶段对应 图1 中的第一个模块,是整体数据生成流程的第一步。
User Utterance Generation
Once conversation plans are constructed, user utterances are synthesized from the sub-plans. Each sub-plan contains
一旦 conversation plans 构建完成,用户话语会从 sub-plans 中合成出来。 每个 sub-plan 包含
Assistant Utterance Generation
Assistant-side responses are generated iteratively in a role-playing setup, where one LLM assumes the assistant role and another the user role. For each sub-plan, the assistant LLM is conditioned on the conversation seed, prior sub-plans, a summary of the last
助手侧响应通过角色扮演设置迭代生成,其中一个 LLM 扮演助手角色,另一个扮演用户角色。 对于每个 sub-plan,助手 LLM 会以对话种子、先前 sub-plans、最近
2.3 Probing Questions Generation
After constructing conversations, we generate probing questions to evaluate memory abilities. The pipeline combines automated synthesis with human validation: an LLM first produces candidate probes, which annotators review to select valid ones. Probes are derived from both the conversation plan and chat to ensure each targets a specific ability, is grounded in dialogue turns, and includes explicit provenance. The process begins by passing the plan to GPT-4.1-mini, which selects candidate bullet points conditioned on the ability under evaluation. For example, knowledge-update probes require bullet pairs encoding an initial fact and its later revision, while summarization and event-ordering probes span multiple bullets. Each bullet is linked to its corresponding user and assistant turns through indices introduced during user-assistant turn generation, enabling retrieval of the precise dialogue segments in which the content was created. For abstention, candidate selection is unnecessary; probes are created directly from the plan using the prompt shown in Appendix.
构建对话后,作者生成 probing questions 来评估记忆能力。 该流程结合自动合成和人工验证:LLM 首先生成候选 probes,标注者再审查并选择有效样本。 Probes 同时来自 conversation plan 和 chat,以确保每个 probe 都针对特定能力、扎根于对话轮次,并包含显式来源。 该过程首先将 plan 传给 GPT-4.1-mini,由其根据待评估能力选择候选 bullet points。 例如,knowledge-update probes 需要成对 bullet 来编码初始事实及其后续修订,而 summarization 和 event-ordering probes 跨越多个 bullets。 每个 bullet 都通过用户—助手轮次生成时引入的索引,与对应的用户和助手轮次相连,从而能够检索内容产生时的精确对话片段。 对于 abstention,不需要候选选择;probes 会直接从 plan 中使用附录所示提示词创建。
Given the selected bullet points and aligned dialogue snippets, GPT-4.1-mini generates the probing question, a candidate answer, and source identifiers citing the specific messages containing the answer. For 10M-token dialogues, candidate selection and synthesis are performed with a sliding window across the ten interlocking plans, processing a limited number at a time to preserve topical locality and scalability. Probe generation uses ability-specific prompts for each memory ability, mapping candidate bullet points and contexts into fully formed questions. Finally, a human evaluator reviews the generated candidates and selects those that are valid and consistent with the conversation.
给定选中的 bullet points 和对齐的对话片段,GPT-4.1-mini 会生成 probing question、候选答案,以及引用包含答案的具体消息的来源标识。 对于 10M-token 对话,候选选择和合成会在十个相互衔接的 plans 上使用滑动窗口完成,每次处理有限数量,以保持主题局部性和可扩展性。 Probe 生成会针对每种记忆能力使用能力特定提示词,将候选 bullet points 和上下文映射为完整问题。 最后,人工评估者审查生成的候选项,并选择与对话有效且一致的问题。
2.4 Evaluation
We evaluate LLMs on the probing questions using nugget evaluation, a common approach for long-form text assessment. Each probing question is manually validated: invalid or unsupported questions are discarded, and minor inconsistencies are corrected. From the validated set, two questions per memory ability are chosen for each conversation, yielding 20 probing questions per conversation. Rubric nuggets are then derived for each question. A nugget is an atomic, self-contained criterion that a system response must satisfy. Annotators decompose the ideal reference answer into minimal semantic units, ensuring each nugget is both atomic and self-contained. System responses are scored against these nuggets by an LLM judge, which assigns 0 (unsatisfied), 0.5 (partially satisfied), or 1 (fully satisfied). Scores are averaged across nuggets to produce ability-level metrics.
作者使用 nugget evaluation 来评估 LLM 在 probing questions 上的表现,这是长文本评估中的常见方法。 每个 probing question 都会经过人工验证:无效或无依据的问题会被丢弃,轻微不一致会被修正。 从验证后的集合中,每段对话为每种记忆能力选择两个问题,因此每段对话包含 20 个 probing questions。 随后为每个问题派生 rubric nuggets。 Nugget 是系统响应必须满足的原子化、自包含标准。 标注者将理想参考答案分解为最小语义单元,确保每个 nugget 都既原子化又自包含。 系统响应由 LLM judge 根据这些 nuggets 打分,分数为 0(不满足)、0.5(部分满足)或 1(完全满足)。 分数会在 nuggets 上平均,以得到能力级指标。
This nugget-based procedure applies to nine memory abilities; the exception is event ordering, where quality depends on both recall and correct sequence. We evaluate event ordering using the Kendall tau-b coefficient, which considers both order and presence. To apply this metric, an LLM equivalence detector aligns events in system responses with nuggets, outputting yes if two snippets denote the same event/topic and no otherwise. Kendall tau-b is then computed over the aligned sequences, capturing both recall and ordering fidelity.
该基于 nugget 的流程适用于九种记忆能力;例外是 event ordering,其质量同时取决于回忆和正确顺序。 作者使用 Kendall tau-b 系数评估 event ordering,该系数同时考虑顺序和存在性。 为应用该指标,LLM equivalence detector 会将系统响应中的事件与 nuggets 对齐;如果两个片段表示同一事件或主题,则输出 yes,否则输出 no。 然后在对齐序列上计算 Kendall tau-b,从而同时捕捉回忆和排序保真度。
3. LIGHT: Improving Memory Capabilities of LLMs
Inspired by research in human cognitive science, humans employ two primary mechanisms for remembering and using knowledge: episodic memory, the ability to recall specific personal experiences along with their context, and working memory, the capacity to retain and manipulate information about recent events over short periods. In addition, maintaining notes on a scratchpad provides an external record that supports long-term recall and later retrieval. Since answering questions in long-context conversations similarly requires integrating past experiences and accumulated knowledge, we introduce a method that emulates these strategies by combining episodic recall, short-term working memory, and an external scratch-pad mechanism.
受人类认知科学研究启发,人类在记忆和使用知识时主要依赖两种机制:情景记忆,即回忆具体个人经历及其上下文的能力;以及工作记忆,即短时间内保留并操作近期事件信息的能力。 此外,在 scratchpad 上维护笔记提供了一种外部记录,支持长期回忆和后续检索。 由于回答长上下文对话中的问题同样需要整合过往经历和累积知识,作者提出一种模拟这些策略的方法,将情景回忆、短期工作记忆和外部 scratch-pad 机制结合起来。
3.1 Overview
An overview of our method is shown in Figure 2. Given a question
本文方法概览如 图2 所示。 给定关于对话
3.2 Retrieval from the Conversation
After each user–assistant turn (Figure 2, top), we apply Qwen2.5-32B-AWQ with the prompt in Appendix to extract key–value pairs and a summary of the interaction. Keys represent entities and values capture attributes or descriptive details, providing fine-grained, event-level indices analogous to hippocampal memory traces. These key–value pairs and summaries are embedded using the BAAI/bge-small-en-v1.5 embedding model and stored in a vector database as keys, while the original dialogue segments are kept as values to ensure faithful grounding.
在每个用户—助手轮次之后(图2 顶部),作者使用 Qwen2.5-32B-AWQ 和附录中的提示词来抽取 key–value pairs 以及交互摘要。 Keys 表示实体,values 捕捉属性或描述性细节,从而提供细粒度、事件级索引,类似海马记忆痕迹。 这些 key–value pairs 和摘要会使用 BAAI/bge-small-en-v1.5 embedding model 进行嵌入,并作为 keys 存储在向量数据库中,而原始对话片段则作为 values 保留,以确保忠实接地。
To retrieve information from the conversation as episodic memory, we embed the question
为了将对话中的信息作为情景记忆检索出来,作者使用同一 embedding model 对问题
3.3 Scratchpad Formation and Utilization
In addition to episodic memory (Figure 2, middle pathway), we build a higher-level representation that preserves information beyond individual dialogue events. It integrates semantic knowledge (facts and concepts), autobiographical details (life events), prospective memory (future intentions), and contextual metadata (time, place, acquisition context). For each dialogue pair, we use Qwen2.5-32B-AWQ with the prompt in Appendix to reason over the current and preceding turn and extract salient content. The resulting “scratchpad'' is iteratively merged with earlier versions; once content exceeds a 30K-token threshold—substantially shorter than the raw conversation—it is compressed into a 15K-token summary by GPT-4.1-nano using the prompt in Appendix. This process maintains efficiency and long-term coherence, analogous to the gradual abstraction of semantic memory in humans. Unlike the episodic index, the scratchpad is not stored in a retrieval database but is provided directly as contextual input during inference.
除情景记忆之外(图2 中间路径),作者还构建一种更高层表示,用于保存超越单个对话事件的信息。 它整合语义知识(事实和概念)、自传式细节(生活事件)、前瞻记忆(未来意图)以及上下文元数据(时间、地点、获取上下文)。 对于每个对话对,作者使用 Qwen2.5-32B-AWQ 和附录中的提示词,对当前轮和前一轮进行推理并抽取显著内容。 生成的 “scratchpad” 会与早期版本迭代合并;一旦内容超过 30K-token 阈值,显著短于原始对话,它会由 GPT-4.1-nano 使用附录中的提示词压缩为 15K-token 摘要。 该过程保持效率和长期连贯性,类似人类语义记忆逐渐抽象化的过程。 不同于情景索引,scratchpad 不存储在检索数据库中,而是在推理期间直接作为上下文输入提供。
During inference, the scratchpad is selectively filtered with respect to the question. It is first divided into semantically coherent chunks using semantic chunking. Each chunk is evaluated by Qwen2.5-32B-AWQ with the prompt in Appendix, which assigns a binary relevance label (yes/no). Only the chunks judged relevant are retained, producing a condensed representation of scratchpad that is passed to the response generator.
推理期间,scratchpad 会相对于问题被选择性过滤。 它首先使用语义分块划分为语义连贯的 chunks。 每个 chunk 都由 Qwen2.5-32B-AWQ 结合附录中的提示词进行评估,并分配二值相关性标签(yes/no)。 只有被判定为相关的 chunks 会被保留,从而形成 scratchpad 的压缩表示,并传给响应生成器。
4. Experiments
4.1 Experimental Setup
We evaluate our approach against two types of baselines: long-context LLMs and a RAG method. For long-context LLMs, the entire conversation history is provided, followed by the probing question. We include two proprietary LLMs (GPT-4.1-nano, Gemini-2.0-flash, both 1M context) and two open-source models (Qwen2.5-32B-AWQ, Llama-4-Maverick-fp8). For long-context experiments, Qwen2.5-32B-AWQ is evaluated with a 128K context length, while for the RAG baseline and our proposed method a 32K context length is used. At the 10M-token, since none of the four models support this length, they are evaluated on the largest recent dialogue segment fitting their window. For RAG baselines, each user–assistant turn pair is treated as a document, embedded and stored in a vector database. At inference, the top five most similar documents are retrieved and passed to the LLM using the prompt in Appendix.
作者将本文方法与两类基线比较:长上下文 LLM 和 RAG 方法。 对于长上下文 LLM,输入会提供完整对话历史,然后接 probing question。 作者包含两个闭源 LLM(GPT-4.1-nano、Gemini-2.0-flash,二者均为 1M context)和两个开源模型(Qwen2.5-32B-AWQ、Llama-4-Maverick-fp8)。 在长上下文实验中,Qwen2.5-32B-AWQ 使用 128K 上下文长度评估;而在 RAG 基线和本文方法中,使用 32K 上下文长度。 在 10M-token 设置下,由于四个模型都不支持该长度,因此它们在能放入窗口的最近最大对话片段上评估。 对于 RAG 基线,每个用户—助手轮次对被视为一个文档,嵌入后存储在向量数据库中。 推理时,系统检索 top five 最相似文档,并使用附录中的提示词传给 LLM。
| Length | Memory Ability | Qwen 2.5 | Llama Maverick | Gemini 2 Flash | GPT-4.1-nano | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vanilla | RAG | Ours | Vanilla | RAG | Ours | Vanilla | RAG | Ours | Vanilla | RAG | Ours | ||
| 100K | Abstention | 0.300 | 0.650 | 0.475 | 0.200 | 0.800 | 0.600 | 0.800 | 0.800 | 0.675 | 0.475 | 0.800 | 0.575 |
| Contradiction Resolution | 0.031 | 0.025 | 0.037 | 0.025 | 0.031 | 0.031 | 0.006 | 0.050 | 0.018 | 0.012 | 0.018 | 0.031 | |
| Event Ordering | 0.192 | 0.201 | 0.205 | 0.190 | 0.162 | 0.166 | 0.181 | 0.191 | 0.166 | 0.181 | 0.169 | 0.177 | |
| Information Extraction | 0.425 | 0.338 | 0.479 | 0.510 | 0.392 | 0.518 | 0.333 | 0.341 | 0.464 | 0.273 | 0.362 | 0.538 | |
| Instruction Following | 0.400 | 0.375 | 0.362 | 0.412 | 0.375 | 0.412 | 0.275 | 0.287 | 0.362 | 0.425 | 0.350 | 0.400 | |
| Knowledge Update | 0.437 | 0.275 | 0.362 | 0.300 | 0.350 | 0.450 | 0.125 | 0.325 | 0.300 | 0.275 | 0.375 | 0.375 | |
| Multi-Hop Reasoning | 0.222 | 0.203 | 0.281 | 0.152 | 0.225 | 0.353 | 0.200 | 0.148 | 0.225 | 0.178 | 0.263 | 0.365 | |
| Preference Following | 0.554 | 0.379 | 0.566 | 0.450 | 0.512 | 0.625 | 0.300 | 0.416 | 0.462 | 0.437 | 0.550 | 0.625 | |
| Summarization | 0.128 | 0.074 | 0.232 | 0.065 | 0.111 | 0.238 | 0.018 | 0.093 | 0.139 | 0.028 | 0.083 | 0.202 | |
| Temporal Reasoning | 0.112 | 0.162 | 0.112 | 0.100 | 0.275 | 0.187 | 0.187 | 0.150 | 0.125 | 0.112 | 0.125 | 0.162 | |
| Average | 0.280 | 0.269 | 0.311 | 0.240 | 0.323 | 0.358 | 0.242 | 0.280 | 0.294 | 0.239 | 0.309 | 0.345 | |
| 500K | Abstention | 0.314 | 0.728 | 0.571 | 0.185 | 0.785 | 0.628 | 0.714 | 0.800 | 0.685 | 0.557 | 0.828 | 0.600 |
| Contradiction Resolution | 0.053 | 0.017 | 0.017 | 0.035 | 0.028 | 0.042 | 0.010 | 0.021 | 0.021 | 0.017 | 0.025 | 0.035 | |
| Event Ordering | 0.185 | 0.221 | 0.244 | 0.209 | 0.186 | 0.197 | 0.215 | 0.189 | 0.200 | 0.188 | 0.180 | 0.204 | |
| Information Extraction | 0.166 | 0.400 | 0.506 | 0.608 | 0.402 | 0.535 | 0.469 | 0.343 | 0.478 | 0.142 | 0.382 | 0.491 | |
| Instruction Following | 0.304 | 0.350 | 0.295 | 0.403 | 0.447 | 0.390 | 0.133 | 0.334 | 0.280 | 0.244 | 0.286 | 0.342 | |
| Knowledge Update | 0.111 | 0.226 | 0.278 | 0.276 | 0.338 | 0.264 | 0.171 | 0.180 | 0.223 | 0.107 | 0.288 | 0.240 | |
| Multi-Hop Reasoning | 0.125 | 0.187 | 0.214 | 0.219 | 0.313 | 0.350 | 0.198 | 0.135 | 0.157 | 0.070 | 0.233 | 0.266 | |
| Preference Following | 0.567 | 0.477 | 0.571 | 0.560 | 0.525 | 0.623 | 0.379 | 0.427 | 0.532 | 0.450 | 0.577 | 0.684 | |
| Summarization | 0.137 | 0.187 | 0.344 | 0.266 | 0.197 | 0.373 | 0.136 | 0.165 | 0.250 | 0.109 | 0.184 | 0.334 | |
| Temporal Reasoning | 0.035 | 0.114 | 0.121 | 0.064 | 0.078 | 0.190 | 0.150 | 0.078 | 0.092 | 0.057 | 0.161 | 0.154 | |
| Average | 0.200 | 0.291 | 0.316 | 0.283 | 0.330 | 0.359 | 0.257 | 0.267 | 0.292 | 0.194 | 0.314 | 0.335 | |
| 1M | Abstention | 0.342 | 0.650 | 0.500 | 0.221 | 0.742 | 0.435 | 0.642 | 0.750 | 0.735 | 0.492 | 0.778 | 0.678 |
| Contradiction Resolution | 0.035 | 0.035 | 0.021 | 0.046 | 0.028 | 0.042 | 0.010 | 0.028 | 0.007 | 0.050 | 0.028 | 0.021 | |
| Event Ordering | 0.183 | 0.195 | 0.200 | 0.214 | 0.179 | 0.193 | 0.190 | 0.198 | 0.185 | 0.191 | 0.179 | 0.211 | |
| Information Extraction | 0.138 | 0.407 | 0.366 | 0.489 | 0.431 | 0.474 | 0.374 | 0.380 | 0.341 | 0.153 | 0.399 | 0.410 | |
| Instruction Following | 0.383 | 0.300 | 0.419 | 0.440 | 0.338 | 0.433 | 0.120 | 0.290 | 0.380 | 0.226 | 0.271 | 0.394 | |
| Knowledge Update | 0.064 | 0.378 | 0.357 | 0.164 | 0.342 | 0.414 | 0.107 | 0.278 | 0.264 | 0.150 | 0.342 | 0.392 | |
| Multi-Hop Reasoning | 0.102 | 0.163 | 0.209 | 0.174 | 0.245 | 0.270 | 0.083 | 0.134 | 0.147 | 0.091 | 0.293 | 0.278 | |
| Preference Following | 0.486 | 0.491 | 0.551 | 0.535 | 0.514 | 0.610 | 0.273 | 0.470 | 0.472 | 0.435 | 0.513 | 0.576 | |
| Summarization | 0.122 | 0.157 | 0.316 | 0.207 | 0.145 | 0.315 | 0.091 | 0.125 | 0.224 | 0.060 | 0.152 | 0.290 | |
| Temporal Reasoning | 0.073 | 0.078 | 0.154 | 0.097 | 0.107 | 0.176 | 0.104 | 0.057 | 0.085 | 0.061 | 0.064 | 0.107 | |
| Average | 0.193 | 0.285 | 0.309 | 0.259 | 0.307 | 0.336 | 0.199 | 0.271 | 0.284 | 0.191 | 0.302 | 0.336 | |
| 10M | Abstention | 0.250 | 0.600 | 0.550 | 0.050 | 0.700 | 0.450 | 0.750 | 0.650 | 0.650 | 0.450 | 0.650 | 0.400 |
| Contradiction Resolution | 0.050 | 0.000 | 0.012 | 0.025 | 0.000 | 0.000 | 0.000 | 0.025 | 0.000 | 0.000 | 0.012 | 0.025 | |
| Event Ordering | 0.180 | 0.221 | 0.197 | 0.190 | 0.220 | 0.176 | 0.220 | 0.266 | 0.193 | 0.215 | 0.201 | 0.173 | |
| Information Extraction | 0.100 | 0.350 | 0.350 | 0.075 | 0.375 | 0.300 | 0.075 | 0.275 | 0.150 | 0.050 | 0.300 | 0.350 | |
| Instruction Following | 0.175 | 0.200 | 0.350 | 0.250 | 0.350 | 0.500 | 0.025 | 0.125 | 0.250 | 0.075 | 0.175 | 0.250 | |
| Knowledge Update | 0.100 | 0.300 | 0.275 | 0.100 | 0.375 | 0.325 | 0.050 | 0.325 | 0.200 | 0.050 | 0.325 | 0.300 | |
| Multi-Hop Reasoning | 0.125 | 0.050 | 0.125 | 0.000 | 0.075 | 0.125 | 0.000 | 0.125 | 0.125 | 0.012 | 0.091 | 0.135 | |
| Preference Following | 0.241 | 0.291 | 0.308 | 0.291 | 0.316 | 0.483 | 0.075 | 0.300 | 0.150 | 0.175 | 0.366 | 0.425 | |
| Summarization | 0.114 | 0.106 | 0.220 | 0.065 | 0.053 | 0.277 | 0.000 | 0.045 | 0.136 | 0.020 | 0.063 | 0.179 | |
| Temporal Reasoning | 0.000 | 0.000 | 0.000 | 0.000 | 0.025 | 0.025 | 0.025 | 0.025 | 0.075 | 0.050 | 0.000 | 0.025 | |
| Average | 0.133 | 0.211 | 0.238 | 0.104 | 0.249 | 0.266 | 0.122 | 0.216 | 0.192 | 0.109 | 0.218 | 0.226 | |
For inference, we use Nucleus with temperature 0, except for conversation plan, user-turn, and assistant-turn generation, where temperature is 0.1 to encourage diversity. All open-source LLMs are served via VLLM for efficient inference. For Llama3.3-70B, we set the maximum output length to 6K tokens during user-turn generation, while for other LLMs we adopt their default maximum output length. For experiments involving both the RAG baseline and our proposed method, we employ FAISS as the vector database. For dense retrieval, we use the embedding model BAAI/bge-small-en-v1.5.
推理时,作者使用 Nucleus,并将 temperature 设为 0;但在 conversation plan、user-turn 和 assistant-turn 生成中,temperature 设为 0.1 以鼓励多样性。 所有开源 LLM 都通过 VLLM 提供服务,以进行高效推理。 对于 Llama3.3-70B,作者在用户轮次生成时将最大输出长度设为 6K token;对于其他 LLM,则采用其默认最大输出长度。 对于同时涉及 RAG 基线和本文方法的实验,作者使用 FAISS 作为向量数据库。 对于 dense retrieval,作者使用 BAAI/bge-small-en-v1.5 embedding model。
4.2 Empirical Findings
Across all four conversation lengths (100K–10M tokens), our method consistently outperforms both long-context LLMs and RAG baselines (Table 1). At shorter contexts (100K), we observe strong gains, such as +49.1% for Llama-4-Maverick and +44.3% for GPT-4.1-nano over long-context baselines, showing that structured memory helps even when full history can be processed. The benefits grow with context length: at 1M tokens, improvements reach +75.9% for GPT-4.1-nano and +60.1% for Qwen2.5-32B. At 10M tokens—where no baseline natively supports the full context—our method achieves dramatic improvements, including +155.7% for Llama-4-Maverick and +107.3% for GPT-4.1-nano. The only exception is Gemini-2.0-flash at 10M, where our method surpasses the long-context baseline (+57.3%) but slightly trails RAG, likely due to model-specific retrieval behavior. Overall, these findings underscore the scalability and robustness of our framework across diverse architectures and extreme context lengths.
在四种对话长度(100K–10M token)上,本文方法都持续优于长上下文 LLM 和 RAG 基线(表1)。 在较短上下文(100K)中,作者观察到显著增益,例如相对于长上下文基线,Llama-4-Maverick 提升 +49.1%,GPT-4.1-nano 提升 +44.3%,说明即使完整历史可以被处理,结构化记忆仍然有帮助。 收益会随着上下文长度增长而增大:在 1M token 时,GPT-4.1-nano 的提升达到 +75.9%,Qwen2.5-32B 的提升达到 +60.1%。 在 10M token 时,没有基线原生支持完整上下文,本文方法取得显著提升,包括 Llama-4-Maverick +155.7%、GPT-4.1-nano +107.3%。 唯一例外是 10M 下的 Gemini-2.0-flash,此时本文方法超过长上下文基线(+57.3%),但略低于 RAG,这可能源于模型特定的检索行为。 总体而言,这些发现强调了该框架在不同架构和极端上下文长度下的可扩展性与鲁棒性。
When evaluated across the ten memory abilities, our method shows the largest relative gains in summarization (+160.6%), multi-hop reasoning (+27.2%), and preference following (+76.5%). Strong improvements are also observed in information extraction (+56.7%), instruction following (+39.5%), and temporal reasoning (+56.3%). These results highlight that our method is particularly effective for tasks requiring long-range recall and integration of dispersed information. In contrast, all methods---including ours---perform strongest in abstention and weakest in contradiction resolution, indicating that contradiction detection remains a challenging open problem.
在十种记忆能力上评估时,本文方法在 summarization(+160.6%)、multi-hop reasoning(+27.2%)和 preference following(+76.5%)上取得最大相对增益。 在 information extraction(+56.7%)、instruction following(+39.5%)和 temporal reasoning(+56.3%)上也观察到显著提升。 这些结果表明,本文方法对需要长程回忆和整合分散信息的任务尤其有效。 相比之下,所有方法(包括本文方法)都在 abstention 上表现最强,在 contradiction resolution 上表现最弱,说明矛盾检测仍是一个具有挑战性的开放问题。
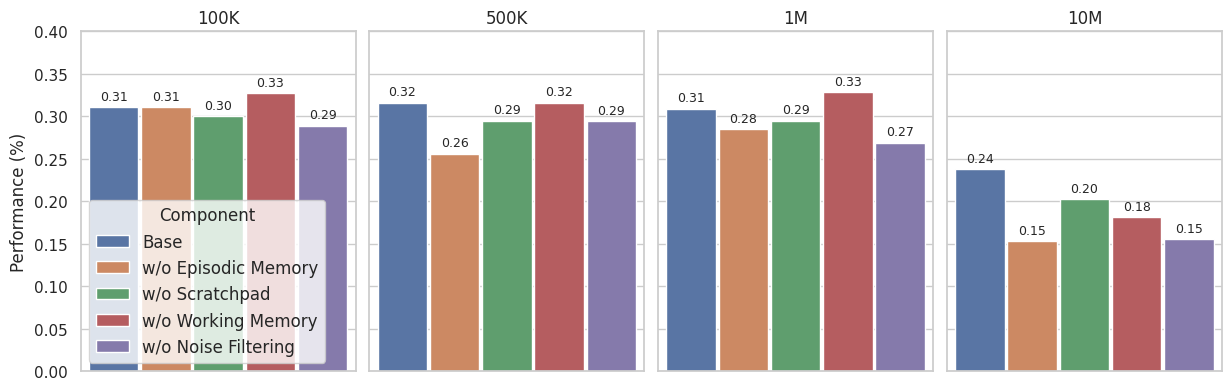
Ablation
We conduct an ablation to assess the role of each component—episodic memory, scratchpad, working memory, and noise filtering—across conversation lengths (Figure 3). At 100K, removing retrieval does not change performance and it remains steady, since the scratchpad alone suffices, while removing scratchpad or noise filtering reduces performance (–1.1%, –2.2%). Working memory also degrades results here (–1.6%). At 500K, removing any component reduces performance except working memory, where removal enhances performance very slightly. At 1M, retrieval, scratchpad, and noise filtering remain beneficial, but removing working memory slightly improves performance, again reflecting its limited usefulness when few questions depend on the most recent turns. By 10M, all components are essential, with removals leading to large drops (–8.5% for retrieval, –3.7% for scratchpad, –5.7% for working memory, –8.3% for noise filtering). Overall, the ablations show that each module contributes increasingly as context length grows, and the full architecture consistently achieves the best performance.
作者进行了消融实验,以评估各组件,即情景记忆、scratchpad、工作记忆和噪声过滤,在不同对话长度下的作用(图3)。 在 100K 时,移除 retrieval 不会改变性能,性能保持稳定,因为仅 scratchpad 已经足够;而移除 scratchpad 或 noise filtering 会降低性能(–1.1%、–2.2%)。 Working memory 在这里也会使结果下降(–1.6%)。 在 500K 时,除 working memory 外,移除任何组件都会降低性能;移除 working memory 会带来非常轻微的性能提升。 在 1M 时,retrieval、scratchpad 和 noise filtering 仍然有益,但移除 working memory 会略微提升性能,这再次反映出当很少问题依赖最近轮次时,它的作用有限。 到 10M 时,所有组件都必不可少;移除组件会导致大幅下降(retrieval 为 –8.5%,scratchpad 为 –3.7%,working memory 为 –5.7%,noise filtering 为 –8.3%)。 总体而言,消融结果表明,随着上下文长度增长,每个模块的贡献都会越来越大,完整架构始终取得最佳性能。
Effect of Retrieval Budget
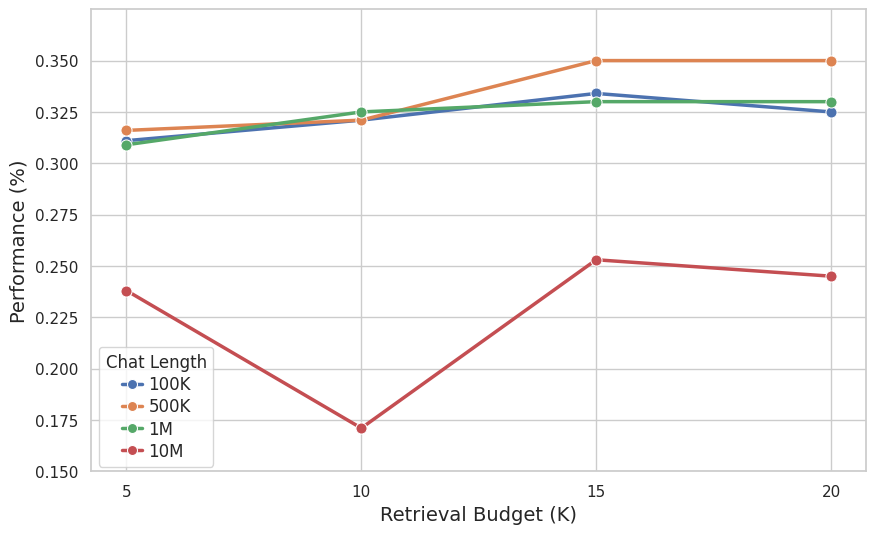
We examine the effect of retrieval budget (K), testing 5, 10, 15, and 20 documents (Figure 4). Performance consistently improves when increasing K from 5 to 15, with the best results at K=15 (+7.39%, +10.75%, +6.79%, and +6.3% at 100K, 500K, 1M, and 10M). Increasing further to K=20 slightly degrades performance, likely due to noisy context. Results at K=10 are mixed---helpful at 100K, 500K and 1M but harmful at 10M---indicating additional documents sometimes add noisy information. We also conducted complementary experiments analyzing the effect of retriever choice, where we observed that at 100K, 500K, and 1M token lengths, using a sparse retriever improves performance, whereas at 10M tokens, the dense retriever achieves better results.
作者考察了检索预算(K)的影响,测试了 5、10、15 和 20 个文档(图4)。 当 K 从 5 增加到 15 时,性能持续提升,在 K=15 时取得最佳结果(在 100K、500K、1M 和 10M 下分别为 +7.39%、+10.75%、+6.79% 和 +6.3%)。 进一步增加到 K=20 会使性能略微下降,这可能是由于噪声上下文造成的。 K=10 的结果较为混合:在 100K、500K 和 1M 下有帮助,但在 10M 下有害,说明额外文档有时会引入噪声信息。 作者还进行了补充实验来分析 retriever choice 的影响;结果显示,在 100K、500K 和 1M token 长度下,使用 sparse retriever 会提升性能,而在 10M token 下,dense retriever 取得更好结果。
Human Evaluation
We conducted a human evaluation to assess the quality of the generated conversations. Three dimensions were considered: Coherence and Flow, Realism, and Complexity and Depth, each rated on a 5-point Likert scale (1 = lowest, 5 = highest). The average scores across all conversations were 4.53, 4.57, and 4.64, respectively, indicating consistently high quality. We further present a qualitative error analysis characterizing LIGHT’s failure modes across memory abilities in Appendix.
作者进行了人工评估,以评估生成对话的质量。 评估考虑三个维度:Coherence and Flow、Realism 和 Complexity and Depth,每个维度都采用 5 点 Likert 量表评分(1 = 最低,5 = 最高)。 所有对话的平均分分别为 4.53、4.57 和 4.64,表明整体质量持续较高。 作者还在附录中给出了定性错误分析,用于刻画 LIGHT 在不同记忆能力上的失败模式。
5. Related Work
The detailed related work is provided in Appendix; here we present a concise summary. Context windows of LLMs have expanded dramatically, from early limits of 512–2K tokens to 128K–1M and even 10M. This growth is driven by advances in efficient attention, improved positional encodings, long-context training strategies, and inference optimizations such as paged attention, KV-cache compression, and distributed attention. Such capabilities are especially valuable for applications involving conversational histories, the main focus of our work.
详细 related work 见附录;这里作者给出简要总结。 LLM 的上下文窗口已经显著扩展,从早期 512–2K token 的限制,发展到 128K–1M,甚至 10M。 这种增长由高效 attention、改进的位置编码、长上下文训练策略,以及 paged attention、KV-cache compression 和 distributed attention 等推理优化推动。 这些能力对涉及对话历史的应用尤其有价值,而这正是本文的主要关注点。
Beyond expanding context windows, models incorporate additional mechanisms for persistent memory. These include recurrence and compression, state-space architectures, external memory modules, context summarization, and retrieval-augmented generation. These approaches complement larger windows by enabling scalable and persistent long-term reasoning.
除了扩展上下文窗口,模型还会引入额外机制来实现持久记忆。 这些机制包括 recurrence and compression、state-space architectures、external memory modules、context summarization 和 retrieval-augmented generation。 这些方法通过支持可扩展且持久的长期推理,与更大的上下文窗口形成互补。
Existing benchmarks such as DialSim, MSC, LoCoMo, MemoryBank, DuLeMon, PerLTQA, LongMemEval, and MemBench evaluate recall, temporal reasoning, and multi-session reasoning, but typically span narrow domains, exhibit shallow dependencies, and concatenate separate user sessions to simulate long context, reducing realism. Recent work such as MemoryCode generates multi-session dialogues from template-driven instruction seeds to assess long-context reasoning, but focuses on a single domain. Our benchmark instead scales to 10M tokens across diverse topics and introduces new tasks such as contradiction resolution, event ordering, and instruction following, generating coherent, single-user conversations that preserve narrative continuity for a more faithful assessment of long-term conversational memory.
现有基准如 DialSim、MSC、LoCoMo、MemoryBank、DuLeMon、PerLTQA、LongMemEval 和 MemBench 会评估 recall、temporal reasoning 和 multi-session reasoning,但通常覆盖领域狭窄、依赖关系较浅,并通过拼接独立用户会话来模拟长上下文,从而降低真实性。 近期工作如 MemoryCode 会从模板驱动的 instruction seeds 生成多会话对话来评估长上下文推理,但聚焦单一领域。 相比之下,本文基准在多样话题上扩展到 10M token,并引入 contradiction resolution、event ordering 和 instruction following 等新任务,生成保持叙事连续性的连贯单用户对话,从而更忠实地评估长期对话记忆。
6. Conclusion
This paper addresses the shortcomings of existing benchmarks for evaluating long-term memory in conversational systems. We introduce a scalable framework to generate BEAM, a new benchmark with long, coherent dialogues (up to 10M tokens) and diverse memory probes. To improve LLMs performance, we develop LIGHT, a cognitive-inspired framework combining episodic, working, and scratchpad memories. Our experiments show that while standard LLMs' performance degrades over long contexts, LIGHT provides substantial improvements, boosting memory performance by an average of 3.5%-12.69%. By offering a more robust evaluation and an effective memory enhancement technique, this work helps the development of more reliable long-context conversational systems.
本文解决了现有基准在评估对话系统长期记忆方面的不足。 作者提出一个可扩展框架来生成 BEAM,这是一个新基准,包含长篇连贯对话(最高 10M token)和多样记忆 probes。 为了提升 LLM 性能,作者开发了 LIGHT,这是一个受认知启发的框架,结合了情景记忆、工作记忆和 scratchpad 记忆。 实验表明,虽然标准 LLM 在长上下文上的性能会下降,但 LIGHT 能带来显著提升,使记忆性能平均提高 3.5%-12.69%。 通过提供更稳健的评估和有效的记忆增强技术,本文有助于开发更可靠的长上下文对话系统。