
ES-MemEval: Benchmarking Conversational Agents on Personalized Long-Term Emotional Support
MemoryEmotional SupportBenchmarkWWW 2026ES-MemEval:面向个性化长期情感支持的对话智能体基准评测
Abstract
Large Language Models (LLMs) have shown strong potential as conversational agents. Yet, their effectiveness remains limited by deficiencies in robust long-term memory—particularly in complex, long-term Web-based services such as online emotional support. However, existing long-term dialogue benchmarks primarily focus on static and explicit fact retrieval, failing to evaluate agents in these critical scenarios where user information is dispersed, implicit, and continuously evolving. To address this gap, we introduce ES-MemEval, a comprehensive benchmark that systematically evaluates five core memory capabilities—information extraction, temporal reasoning, conflict detection, abstention, and user modeling—in long-term emotional support scenarios, covering question answering, summarization, and dialogue generation tasks. To support the benchmark, we also propose EvoEmo, the first multi-session dataset for personalized long-term emotional support scenarios, capturing fragmented, implicit user disclosures and evolving user states. Extensive experiments on open-source long-context, commercial, and retrieval-augmented (RAG) LLMs reveal that explicit long-term memory is essential to reduce hallucinations and enable effective personalization. At the same time, RAG enhances factual consistency but struggles with temporal dynamics and evolving user states. These findings highlight both the potential and limitations of current paradigms, encouraging the development of more robust memory–retrieval integration in long-term personalized dialogue systems.
大型语言模型(LLM)作为对话智能体已经展现出很强潜力。 然而,它们的有效性仍受限于稳健长期记忆的不足,尤其是在在线情感支持这类复杂、长期的 Web 服务中。 可是,现有长期对话基准主要关注静态且显式的事实检索,无法评估这些关键信息分散、隐含并持续演化的场景中的智能体。 为弥补这一空白,作者提出 ES-MemEval,这是一个综合基准,用于系统评估长期情感支持场景中的五种核心记忆能力:信息抽取、时间推理、冲突检测、拒答和用户建模,覆盖问答、摘要和对话生成任务。 为支撑该基准,作者还提出 EvoEmo,这是首个面向个性化长期情感支持场景的多会话数据集,能够捕捉碎片化、隐含的用户披露以及不断演化的用户状态。 作者在开源长上下文模型、商业模型和检索增强(RAG)LLM 上开展的大量实验表明,显式长期记忆对于减少幻觉并实现有效个性化是必要的。 与此同时,RAG 能增强事实一致性,但难以处理时间动态和演化的用户状态。 这些发现揭示了当前范式的潜力与局限,也鼓励未来在长期个性化对话系统中发展更稳健的记忆-检索融合机制。
1. Introduction
| Benchmark | Statistics | Core Memory Abilities | Overall Goal | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Tot. Conv. | Avg. Sess. | Avg. Turn. | IE | TR | CD | Abs | UM | ||
| MSC | 5K | 3.4 | 12.6 | ✗ | ✗ | ✗ | ✗ | ✗ | Open-domain dyadic chit-chat |
| Conversation Chronicles | 200K | 5 | 11.7 | ✗ | ✗ | ✗ | ✗ | ✗ | Open-domain dyadic chit-chat |
| DuLeMon | - | 24.5K | 16.3 | ✗ | ✗ | ✗ | ✗ | ✓ | Personalized open-domain conversation |
| MemoryBank | 10 | 15 | 7.6 | ✓ | ✓ | ✗ | ✗ | ✗ | Personalized conversational QA |
| PerLTQA | 141 | 21.3 | 8.4 | ✓ | ✓ | ✗ | ✗ | ✓ | Personalized conversational QA |
| LOCOMO | 10 | 27.2 | 21.6 | ✓ | ✓ | ✗ | ✓ | ✗ | Open-domain dyadic chit-chat |
| LongMemEval | - | 50K | - | ✓ | ✓ | ✗ | ✓ | ✗ | Factual and behavioral assistant QA |
| MADial-Bench | 2 | 80 | 9.2 | ✓ | ✗ | ✗ | ✗ | ✗ | Child–assistant emotional dialogue |
| DialSim | 3 | 1.3K | - | ✓ | ✓ | ✗ | ✓ | ✗ | TV-script-based multi-party chit-chat |
| ES-MemEval | 18 | 22.3 | 23.4 | ✓ | ✓ | ✓ | ✓ | ✓ | Personalized emotional support conversation |
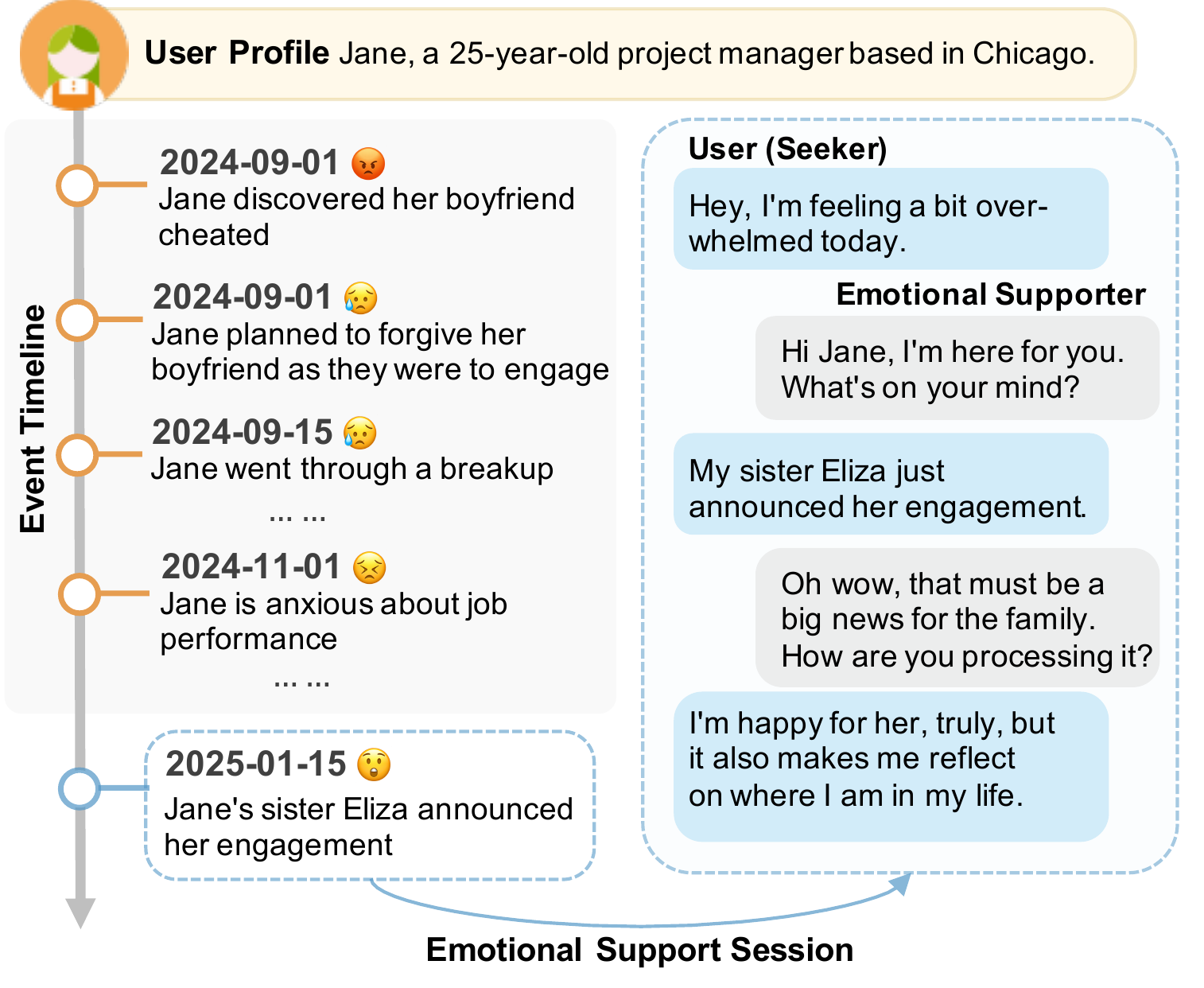
Large language models (LLMs) have demonstrated remarkable potential as conversational agents, enabling widespread deployment across Web platforms for applications such as customer support and mental health services. While they excel in short-term exchanges, their effectiveness remains limited in complex, long-term scenarios such as online emotional support (ES), which require agents to track evolving user states and integrate implicit, fragmented user disclosures across multiple sessions. As illustrated in Figure 1, robust long-term memory is therefore essential—not only to generate personalized and coherent responses, but also to mitigate hallucinations that could undermine user trust in these sensitive Web-based services.
大型语言模型(LLM)作为对话智能体已经展现出显著潜力,使其能够广泛部署于客户支持和心理健康服务等 Web 平台应用。 虽然它们擅长短期交流,但在在线情感支持(ES)这类复杂长期场景中的有效性仍然有限,因为这些场景要求智能体追踪不断演化的用户状态,并跨多个会话整合隐含且碎片化的用户披露。 如图1所示,稳健的长期记忆因此至关重要:它不仅用于生成个性化且连贯的回复,也用于减少可能损害用户信任的幻觉,尤其是在这些敏感的 Web 服务中。
However, existing dialogue benchmarks inadequately evaluate LLMs' long-term memory ability in such implicit, fragmented, and evolving contexts. Most current benchmarks narrowly focus on static and explicit fact retrieval—for instance, recalling named entities and event details in QA-style tasks—where relevant information is explicit and largely stable over time. Consequently, they capture only a limited facet of long-term memory, overlooking the reasoning and abstraction processes essential for emotional support dialogues. In these scenarios, agents must not only extract and comprehend dispersed user information but also summarize over evolving user states and ultimately generate personalized, contextually grounded responses across sessions. Yet, current benchmarks lack systematic means to evaluate how models integrate, abstract, and apply user information throughout extended, emotionally complex interactions.
然而,现有对话基准并不能充分评估 LLM 在这种隐含、碎片化且不断演化的语境中的长期记忆能力。 大多数当前基准狭窄地聚焦于静态且显式的事实检索,例如在问答式任务中回忆命名实体和事件细节,而相关信息是显式的,并且随时间基本稳定。 因此,这些基准只能捕捉长期记忆的有限侧面,忽略了情感支持对话中必需的推理和抽象过程。 在这些场景中,智能体不仅要抽取并理解分散的用户信息,还要概括不断演化的用户状态,并最终跨会话生成个性化且有上下文依据的回复。 然而,当前基准缺乏系统手段来评估模型如何在漫长且情绪复杂的交互中整合、抽象并应用用户信息。
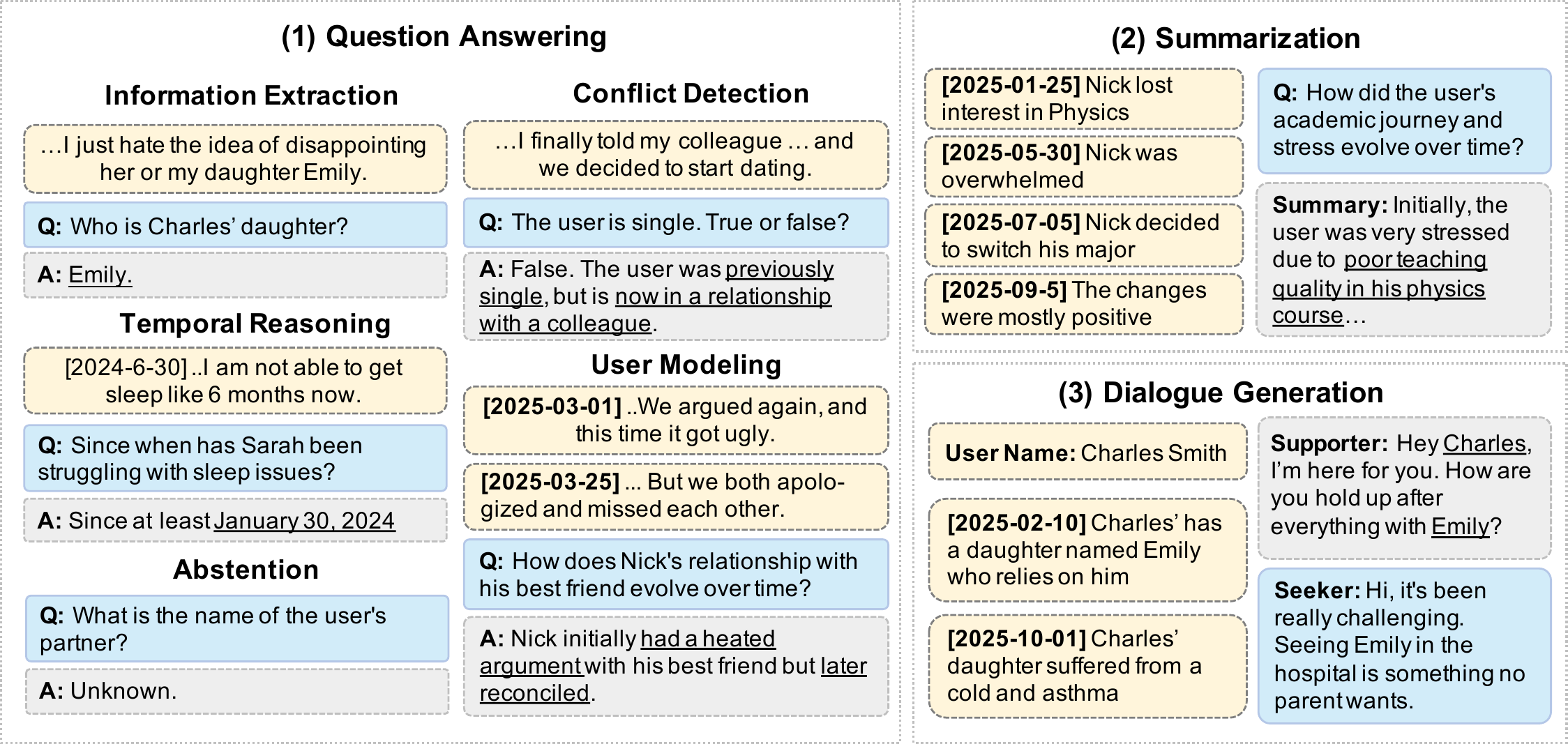
To bridge this gap, we introduce ES-MemEval, the first comprehensive benchmark tailored to long-term emotional support scenarios. Unlike prior benchmarks centered on static, explicit factual recall, ES-MemEval systematically evaluates LLMs’ ability to integrate, abstract, and apply evolving, implicit, and fragmented user information across multiple sessions. As illustrated in Figure 2, the benchmark comprises three complementary tasks: question answering, summarization, and dialogue generation. The question answering task examines models' ability to retrieve and comprehend information scattered across extended interactions. The summarization task assesses their capacity to abstract and synthesize user state dynamics over time. The dialogue generation task directly measures models' proficiency in effectively leveraging long-term memory to deliver personalized emotional support. Together, these tasks provide a rigorous evaluation of five key long-term memory capabilities—information extraction, temporal reasoning, conflict detection, abstention, and user modeling—that underpin trustworthy and personalized conversational agents.
为弥补这一空白,作者提出 ES-MemEval,这是首个面向长期情感支持场景的综合基准。 不同于以静态、显式事实回忆为中心的先前基准,ES-MemEval 系统评估 LLM 跨多个会话整合、抽象并应用演化、隐含、碎片化用户信息的能力。 如图2所示,该基准包含三项互补任务:问答、摘要和对话生成。 问答任务考察模型检索并理解分散于长期交互中的信息的能力。 摘要任务评估模型随时间抽象并综合用户状态动态的能力。 对话生成任务直接衡量模型有效利用长期记忆来提供个性化情感支持的能力。 这些任务共同对五种关键长期记忆能力进行严格评估:信息抽取、时间推理、冲突检测、拒答和用户建模,它们共同支撑可信且个性化的对话智能体。
To support the proposed benchmark, we construct EvoEmo, the first multi-session dataset for long-term emotional support scenarios featuring evolving user states. It contains multi-session conversations involving 18 virtual users seeking emotional support, averaging 510 turns (approximately 13.3k tokens) across up to 33 sessions per user. EvoEmo combines sessions drawn from real emotional support data with sessions generated from detailed user profiles and temporally and causally structured event timelines, thereby realistically capturing the fragmented user disclosures and longitudinal evolution of user states. This dataset offers a reliable foundation for studying longitudinal personalization and complex user modeling in emotionally sensitive contexts.
为支撑所提出的基准,作者构建了 EvoEmo,这是首个面向长期情感支持场景、包含演化用户状态的多会话数据集。 它包含 18 位寻求情感支持的虚拟用户的多会话对话,每位用户最多 33 个会话,平均 510 轮,约 13.3k token。 EvoEmo 将来自真实情感支持数据的会话与基于详细用户画像、具有时间与因果结构的事件时间线生成的会话结合起来,从而真实捕捉碎片化用户披露和用户状态的纵向演化。 该数据集为研究情绪敏感语境中的纵向个性化和复杂用户建模提供了可靠基础。
We further conduct systematic experiments on ES-MemEval with open-source long-context, commercial, and retrieval-augmented (RAG) LLMs across the aforementioned tasks. Experimental results yield several insights into long-term personalized emotional support. First, without explicit histories, models tend to hallucinate user experiences, undermining reliability and personalization. Second, while RAG enhances factual consistency and alignment with user experiences, it struggles with temporal dynamics and evolving user states, highlighting the necessity for retrieval-aware calibration. Third, personalization strongly correlates with long-term memory, whereas emotional support proves less memory-sensitive and often relies on general strategies. Fourth, session-level retrieval best captures evolving user information but may introduce redundancy. Fifth, smaller long-context models degrade with extra-long inputs, underscoring the need to integrate retrieval with external memory mechanisms. Finally, RAG narrows the gap between open-source and commercial systems by enhancing the personalization and memory alignment of generated responses. Collectively, these findings highlight the strengths and limitations of existing paradigms, suggesting promising directions for future research.
作者进一步在上述任务上,使用开源长上下文模型、商业模型和检索增强(RAG)LLM 对 ES-MemEval 开展系统实验。 实验结果为长期个性化情感支持提供了若干洞见。 第一,如果没有显式历史,模型倾向于虚构用户经历,从而削弱可靠性和个性化。 第二,虽然 RAG 能增强事实一致性以及与用户经历的对齐,但它难以处理时间动态和演化的用户状态,这凸显了检索感知校准的必要性。 第三,个性化与长期记忆高度相关,而情感支持对记忆的敏感性较低,常常依赖通用策略。 第四,会话级检索最能捕捉演化的用户信息,但可能引入冗余。 第五,较小的长上下文模型在超长输入下会退化,这强调了将检索与外部记忆机制结合的必要性。 最后,RAG 通过增强生成回复的个性化和记忆对齐,缩小了开源系统与商业系统之间的差距。 总体而言,这些发现揭示了现有范式的优势和局限,并指出了未来研究的有希望方向。
Our contributions can be summarized as follows: (1) We present EvoEmo, the first multi-session dataset specifically designed for personalized long-term emotional support scenarios, capturing evolving user states and implicit, fragmented disclosures. It provides a valuable foundation for studying longitudinal user modeling and personalization in emotionally sensitive contexts. (2) We introduce ES-MemEval, a novel and comprehensive benchmark that evaluates five essential long-term memory capabilities of dialogue agents across three tasks in complex, long-term emotional support scenarios. (3) We conduct extensive experiments across major LLM paradigms, yielding empirical insights into the strengths and limitations of existing paradigms and informing future research directions in long-term personalized emotional support.
本文贡献可概括如下:(1)作者提出 EvoEmo,这是首个专门面向个性化长期情感支持场景的多会话数据集,能够捕捉演化的用户状态以及隐含、碎片化的披露。 它为研究情绪敏感语境中的纵向用户建模和个性化提供了有价值的基础。 (2)作者提出 ES-MemEval,这是一个新颖且全面的基准,用于在复杂长期情感支持场景中,通过三项任务评估对话智能体的五种核心长期记忆能力。 (3)作者在主要 LLM 范式上开展大量实验,得到关于现有范式优势与局限的实证洞见,并为长期个性化情感支持的未来研究方向提供依据。
2. Related Work
2.1. Long-Term Dialogue Benchmarks
Effective long-term memory and support for multi-session interactions pose fundamental challenges in conversational AI. To evaluate these abilities, recent benchmarks have shifted from open-ended dialogue generation tasks to QA-style evaluations that more directly test retrieval and reasoning. Researchers offered multi-day dialogues with 15 virtual users and 194 QA samples for cross-session retrieval. Other work provided 10 extended dialogues with questions spanning single-hop, multi-hop, temporal, commonsense, and adversarial reasoning. Another benchmark contributed a large-scale QA benchmark of 3,409 dialogues and 8,593 questions covering world knowledge, personal profiles, social relations, and dialogue events. LongMemEval targeted chat assistants with 500 questions testing five memory-related skills: information extraction, multi-session reasoning, temporal reasoning, knowledge updating, and abstention. MADial-Bench constructed 160 simulated child–assistant dialogues and introduces a human-centered evaluation framework for proactive and passive recall.
有效的长期记忆以及对多会话交互的支持,是对话 AI 中的基础挑战。 为评估这些能力,近期基准已经从开放式对话生成任务转向问答式评估,以更直接测试检索和推理。 有研究提供了包含 15 个虚拟用户和 194 个问答样本的多日对话,用于跨会话检索。 也有工作提供了 10 段扩展对话,其中问题涵盖单跳、多跳、时间、常识和对抗性推理。 另一个基准贡献了一个大规模问答基准,包含 3,409 段对话和 8,593 个问题,覆盖世界知识、个人画像、社会关系和对话事件。 LongMemEval 面向聊天助手,提供 500 个问题来测试五种与记忆相关的技能:信息抽取、多会话推理、时间推理、知识更新和拒答。 MADial-Bench 构建了 160 段模拟儿童-助手对话,并提出了一个以人为中心的评估框架,用于主动和被动回忆。
Despite these advances, many benchmarks remain largely confined to fact-centric QA, where information is explicit and tasks are clearly defined. They fail to capture the complexities of real interactions, specifically implicit expressions, fragmented information, and evolving user states. Moreover, their reliance on narrow evaluation formats (e.g., QA or retrieval) constrains the assessment of cross-session reasoning and personalized response generation. To address these gaps, we introduce ES-MemEval, a benchmark for long-term emotional support dialogues that includes QA, summarization, and dialogue generation tasks, enabling systematic evaluation of memory utilization and personalized adaptation. Table 1 presents a comparative analysis of existing long-term dialogue benchmarks and datasets against ES-MemEval.
尽管已有这些进展,许多基准仍主要局限于以事实为中心的问答,其中信息是显式的,任务定义也很清楚。 它们无法捕捉真实交互的复杂性,特别是隐含表达、碎片化信息和不断演化的用户状态。 此外,它们依赖较窄的评估形式,例如问答或检索,这限制了对跨会话推理和个性化回复生成的评估。 为解决这些缺口,作者提出 ES-MemEval,这是一个面向长期情感支持对话的基准,包含问答、摘要和对话生成任务,从而能够系统评估记忆使用和个性化适应。 表1 将现有长期对话基准和数据集与 ES-MemEval 进行了对比分析。
2.2. Emotional Support Conversation
Emotional support aims to alleviate emotional distress and help individuals cope with life challenges. With increasing demand for mental health care and companionship, ES dialogue has become a growing research focus. Researchers collected approximately 25k short empathetic dialogues grounded in emotional scenarios. ESConv is a crowdsourced dataset of 1,035 multi-turn ES dialogues annotated with support strategies. Other work harvested large-scale counseling dialogues from an online platform to model real consultation processes, while another line of work released PsyDial, a de-identified and publicly available version. Beyond datasets, other works proposed diverse ES generation methods, such as positive guidance, reflection understanding, and self-disclosure, to improve supportiveness and interaction quality.
情感支持旨在缓解情绪痛苦,并帮助个体应对生活挑战。 随着心理健康关怀和陪伴需求增加,情感支持对话已经成为不断增长的研究重点。 有研究收集了约 25k 段基于情绪场景的短同理心对话。 ESConv 是一个众包数据集,包含 1,035 段多轮情感支持对话,并标注了支持策略。 其他工作从在线平台收集了大规模咨询对话,以建模真实咨询过程,而另一项工作发布了 PsyDial,这是一个去标识化且公开可用的版本。 除数据集外,还有研究提出了多种情感支持生成方法,例如积极引导、反思理解和自我披露,以提升支持性和交互质量。
Despite these advances, most efforts focus on limited-turn or single-session dialogues, with limited modeling of long-term user trajectories and evolving states. In practice, emotional support often spans days or weeks, posing higher demands on long-term memory utilization and personalized adaptation. To bridge this gap, we introduce EvoEmo, a dataset of long-term emotional support dialogues capturing the evolution of user states, and ES-MemEval, a benchmark for evaluating models’ ability to maintain and leverage long-term memory to support personalized adaptation.
尽管已有这些进展,大多数工作仍聚焦于轮数有限或单会话对话,对长期用户轨迹和演化状态的建模有限。 在实践中,情感支持往往会持续数天或数周,这对长期记忆使用和个性化适应提出了更高要求。 为弥补这一差距,作者提出 EvoEmo,这是一个捕捉用户状态演化的长期情感支持对话数据集;同时提出 ES-MemEval,用于评估模型维持并利用长期记忆以支持个性化适应的能力。
3. EvoEmo Dataset
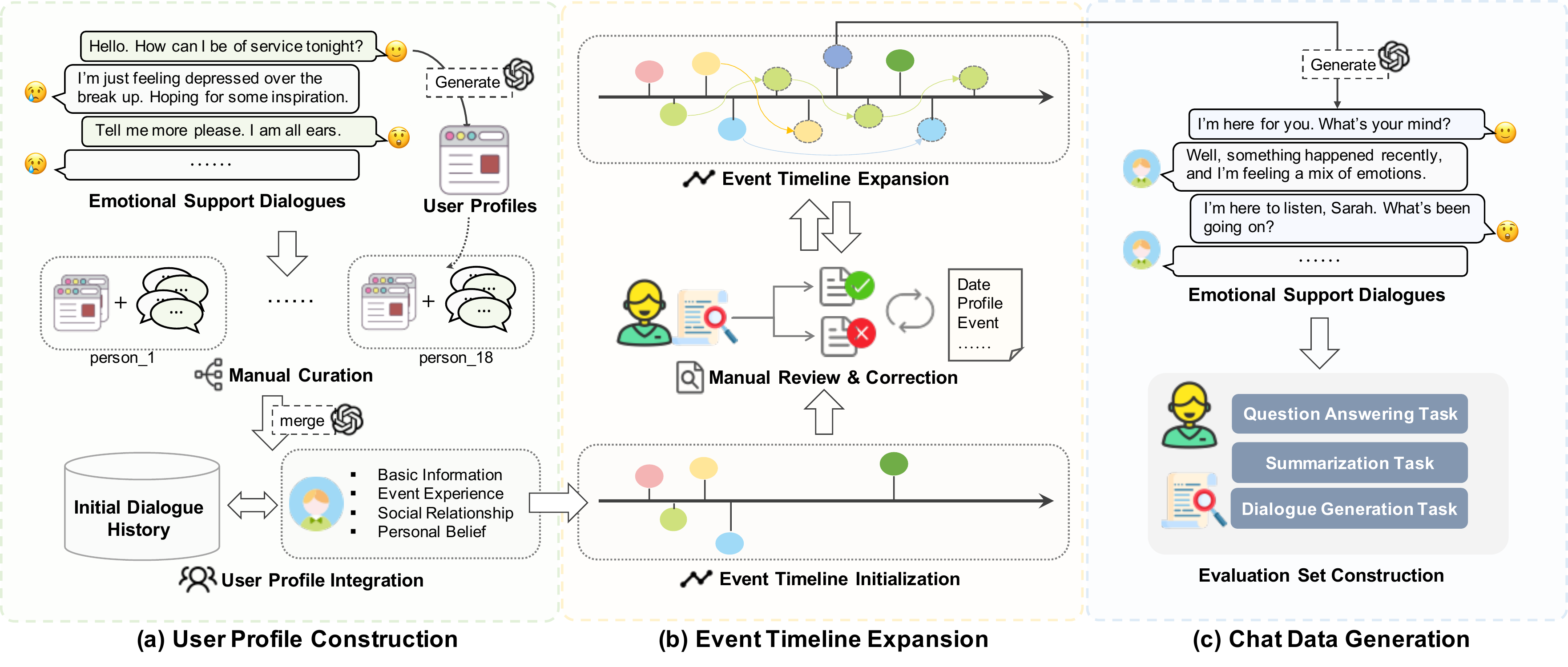
To facilitate the evaluation of personalized conversational agents in complex long-term scenarios, we propose EvoEmo, a long-term emotional support dialogue dataset that captures the dynamic evolution of user states. The data generation pipeline consists of three stages: user profile construction, event timeline expansion, and chat data generation, as shown in Figure 3.
为促进复杂长期场景中个性化对话智能体的评估,作者提出 EvoEmo,这是一个长期情感支持对话数据集,能够捕捉用户状态的动态演化。 如图3所示,数据生成流程包含三个阶段:用户画像构建、事件时间线扩展和聊天数据生成。
3.1. User Profile Construction
To model the longitudinal evolution of user states while preserving privacy, we created 18 virtual users with meticulously designed, diverse personality traits. Each user profile was manually curated based on multiple seed dialogues sampled from the ESConv dataset, a real-world collection of short-term emotional support conversations. The profiles were carefully expanded to include demographic information, social relationships, and core beliefs, thereby providing rich and realistic representations of users’ thoughts and behavior patterns. In addition, each user’s initial dialogue history consists of these seed dialogues, which inherently reflect implicit, fragmented user disclosures and evolving user states, forming a solid foundation for subsequent multi-session dialogue generation.
为在保护隐私的同时建模用户状态的纵向演化,作者创建了 18 位虚拟用户,并为其细致设计了多样化人格特征。 每个用户画像都基于从 ESConv 数据集中采样的多个种子对话进行人工整理,ESConv 是一个真实世界短期情感支持对话集合。 这些画像被仔细扩展,包含人口统计信息、社会关系和核心信念,从而为用户思想与行为模式提供丰富且真实的表示。 此外,每个用户的初始对话历史由这些种子对话组成,这些对话本身反映了隐含、碎片化的用户披露以及演化的用户状态,为后续多会话对话生成奠定了坚实基础。
3.2. Event Timeline Expansion
The initial sessions of each virtual user were derived from short-term ESConv dialogues of different emotional seekers, lacking long-term continuity and causal structure. Therefore, we constructed an event timeline for each user to simulate the longitudinal evolution of user states. The initial events were first generated by GPT-4o based on the initial sessions and refined by human annotators, including timestamps and event descriptions. After initialization, we employed GPT-4o to iteratively expand each event timeline in two rounds, where new events were generated conditioned on the existing event sequences and user profiles. Human annotators reviewed and adjusted each round to ensure temporal and causal consistency. By extending prior events and modeling user state evolution, the resulting timelines capture both causal and experiential variation, averaging 24.8 events per user. This iterative construction enables dynamic and causally coherent user trajectories, advancing beyond prior static user profile settings.
每位虚拟用户的初始会话来自不同情感寻求者的短期 ESConv 对话,因此缺乏长期连续性和因果结构。 因此,作者为每位用户构建事件时间线,以模拟用户状态的纵向演化。 初始事件首先由 GPT-4o 基于初始会话生成,并由人工标注者细化,其中包括时间戳和事件描述。 初始化后,作者使用 GPT-4o 对每条事件时间线进行两轮迭代扩展,新事件会基于已有事件序列和用户画像生成。 人工标注者在每一轮后进行审查和调整,以确保时间和因果一致性。 通过扩展既有事件并建模用户状态演化,最终时间线同时捕捉因果变化和经历变化,每位用户平均包含 24.8 个事件。 这种迭代构建方式支持动态且因果连贯的用户轨迹,超越了先前静态用户画像设定。
3.3. Chat Data Generation
Based on the constructed user profiles and event timelines, we prompted GPT-4o to generate multi-turn emotional support sessions for each user. GPT-4o was conditioned on structured inputs, including the current event, user profile, and summaries of relevant prior sessions, aiming to produce sessions that reflect the evolving user states and the implicit and fragmented user disclosures. The generated sessions were then enriched with auxiliary annotations, including emotion category, topic, summary, and turn-level user observations to facilitate downstream analyses. Six annotators subsequently reviewed each session for consistency with the corresponding user profile and across sessions, ensuring high data quality. Through this pipeline, we developed EvoEmo, a dataset simulating 18 virtual users with evolving states and event trajectories, providing a structured and curated testbed for research on long-term emotional support and longitudinal user modeling.
基于构建好的用户画像和事件时间线,作者提示 GPT-4o 为每位用户生成多轮情感支持会话。 GPT-4o 的输入包含当前事件、用户画像以及相关先前会话的摘要,目标是生成能够反映演化用户状态以及隐含、碎片化用户披露的会话。 随后,生成的会话被补充了辅助标注,包括情绪类别、主题、摘要和轮级用户观察,以支持下游分析。 之后,六名标注者审查每个会话,检查其与对应用户画像以及跨会话内容的一致性,从而保证高数据质量。 通过该流程,作者开发了 EvoEmo,这是一个模拟 18 位虚拟用户演化状态和事件轨迹的数据集,为长期情感支持和纵向用户建模研究提供了结构化且经过整理的测试平台。
4. ES-MemEval Benchmark
4.1. Task Formulation
To systematically assess dialogue agents’ long-term memory capabilities, we introduce ES-MemEval, a benchmark comprising question answering, summarization, and dialogue generation tasks, as illustrated in Figure 2.
为系统评估对话智能体的长期记忆能力,作者提出 ES-MemEval,这是一个包含问答、摘要和对话生成任务的基准,如图2所示。
4.1.1. Long-Term Memory Capabilities
ES-MemEval defines five core long-term memory capabilities: (1) Information Extraction—identifying key facts within and across sessions; (2) Temporal Reasoning—inferring temporal order and causal dependencies among events to track evolving user trajectories; (3) Conflict Detection—detecting and resolving contradictions in long-term memory units to maintain alignment with the user’s current state; (4) Abstention—withholding responses when available information is insufficient to ensure reliability; and (5) User Modeling—inferring and updating user traits, preferences, and states over time to enable personalized support.
ES-MemEval 定义了五种核心长期记忆能力:(1)信息抽取,即识别会话内和跨会话的关键事实;(2)时间推理,即推断事件之间的时间顺序和因果依赖,以追踪演化的用户轨迹;(3)冲突检测,即检测并解决长期记忆单元中的矛盾,以保持与用户当前状态一致;(4)拒答,即在可用信息不足时不作答,以确保可靠性;(5)用户建模,即随时间推断并更新用户特征、偏好和状态,以支持个性化帮助。
4.1.2. Evaluation Task Formats
ES-MemEval evaluates these capabilities via three complementary tasks: (1) Question Answering—assessing information retrieval and integration across sessions, spanning all five core capabilities; (2) Summarization—analyzing cross-session information and user state dynamics, which focuses on temporal reasoning and user modeling; (3) Dialogue Generation—simulating realistic interactions to evaluate context understanding, user modeling, and ES response generation, reflecting the holistic integration of multiple capabilities.
ES-MemEval 通过三项互补任务评估这些能力:(1)问答,用于评估跨会话信息检索和整合,覆盖全部五种核心能力;(2)摘要,用于分析跨会话信息和用户状态动态,重点关注时间推理和用户建模;(3)对话生成,用于模拟真实交互,以评估上下文理解、用户建模和情感支持回复生成,体现多种能力的整体整合。
4.2. Evaluation Sets
To operationalize the evaluation tasks, we construct three task-specific evaluation sets, with data statistics reported in Table 2.
为将评估任务具体化,作者构建了三个任务专用评估集,其数据统计见表2。
4.2.1. Question Answering
QA samples were generated using GPT-4o based on each virtual user’s multiple sessions and event timeline, designed to span all five core capabilities. Each sample includes a question type label, question text, reference answer, and supporting evidence passage. To ensure quality, each sample was reviewed and corrected by one of six annotators, addressing issues such as type mismatches, incorrect or incomplete answers, and missing evidence. Following the rigorous quality assurance process, we constructed a final QA evaluation set of 1,209 high-quality samples.
问答样本使用 GPT-4o 基于每位虚拟用户的多个会话和事件时间线生成,设计上覆盖全部五种核心能力。 每个样本包含问题类型标签、问题文本、参考答案和支持证据片段。 为确保质量,每个样本由六名标注者之一审查和修正,处理类型不匹配、答案错误或不完整、证据缺失等问题。 经过严格质量保障流程后,作者构建了最终包含 1,209 个高质量样本的问答评估集。
4.2.2. Summarization
Summarization cases were constructed to evaluate agents’ ability to abstract information and perform reasoning across multiple sessions. Specifically, GPT-4o first grouped sessions into thematic groups based on users’ event timelines. For each group, GPT-4o generated complex cross-session summarization questions and candidate answers, which were subsequently reviewed and refined by two annotators. The final evaluation set consists of 125 high-quality cases, each requiring models to extract, integrate, and summarize user states, temporal event sequences, and behavioral logic across multiple sessions.
摘要样例用于评估智能体跨多个会话抽象信息并进行推理的能力。 具体而言,GPT-4o 首先基于用户事件时间线将会话划分为主题组。 对每个组,GPT-4o 生成复杂的跨会话摘要问题和候选答案,随后由两名标注者审查和细化。 最终评估集包含 125 个高质量样例,每个样例都要求模型跨多个会话抽取、整合并总结用户状态、时间事件序列和行为逻辑。
4.2.3. Dialogue Generation
Dialogue scenarios were constructed to evaluate personalized dialogue generation under realistic conditions. GPT-4o generated candidate topics grounded in each user’s timeline and dialogue summaries. Each topic specification included an overview, specific details, the physical and psychological state of the user, and relevant prior sessions. After manual review and refinement, we obtained 34 topics designed to support extended conversations about users’ evolving experiences.
对话场景用于评估真实条件下的个性化对话生成。 GPT-4o 基于每位用户的时间线和对话摘要生成候选主题。 每个主题说明包含概述、具体细节、用户的身体和心理状态以及相关先前会话。 经过人工审查和细化后,作者得到 34 个主题,用于支持围绕用户演化经历展开的扩展对话。
4.3. Dataset Statistics and Analysis
| Conversation Statistics | # Count |
|---|---|
| Avg. time span (months) / conversation | 14.9 |
| Avg. sessions / conversation | 22.3 |
| Avg. turns / session | 23.4 |
| Avg. tokens / conversation | 13,291.6 |
| Avg. tokens / session | 596.6 |
| Total conversations | 18 |
| Total sessions | 401 |
| QA Benchmark Statistics | |
| Information extraction | 271 (22.4%) |
| Temporal reasoning | 236 (19.5%) |
| Conflict detection | 226 (18.7%) |
| User modeling | 251 (20.8%) |
| Abstention | 225 (18.6%) |
| Total questions | 1,209 |
| Summarization Benchmark Statistics | |
| Temporal reasoning | 74 (59.2%) |
| User modeling | 51 (40.8%) |
| Total summaries | 125 |
| Dialogue Generation Benchmark Statistics | |
| Avg. turns / session | 20 |
| Total scenarios | 34 |
Table 2 summarizes key statistics of EvoEmo and ES-MemEval. EvoEmo exhibits substantial length and complexity, with an average of 27.2 sessions and 13.3K tokens per conversation, reflecting the challenges of long-term emotional support interactions. The QA benchmark in ES-MemEval includes 1,209 questions evenly distributed across information extraction, temporal reasoning, user modeling, conflict detection, and abstention, enabling systematic evaluation of these essential competencies. The summarization benchmark comprises 125 cases, with 59.2% focused on temporal reasoning and 40.8% on user modeling, emphasizing the challenge of cross-session integration and evolving user state tracking. The dialogue generation benchmark contains 34 scenarios, designed to assess models’ ability to generate personalized, long-term ES responses while coordinating the five memory abilities across multiple sessions. Overall, these statistics highlight both the scale and balanced task design of ES-MemEval, providing a robust foundation for studying personalized long-term dialogue. Additional analyses of the dataset are provided in the appendix.
表2 总结了 EvoEmo 和 ES-MemEval 的关键统计信息。 EvoEmo 具有相当大的长度和复杂性,平均每段对话包含 27.2 个会话和 13.3K token,反映了长期情感支持交互的挑战。 ES-MemEval 的问答基准包含 1,209 个问题,并在信息抽取、时间推理、用户建模、冲突检测和拒答之间均衡分布,从而能够系统评估这些关键能力。 摘要基准包含 125 个样例,其中 59.2% 关注时间推理,40.8% 关注用户建模,强调跨会话整合和演化用户状态追踪的挑战。 对话生成基准包含 34 个场景,旨在评估模型在跨多个会话协调五种记忆能力的同时,生成个性化长期情感支持回复的能力。 总体而言,这些统计数据凸显了 ES-MemEval 的规模和均衡任务设计,为研究个性化长期对话提供了稳健基础。 数据集的更多分析见附录。
4.4. Evaluation Protocols
We design the following protocols to evaluate model performance across the three task formats.
作者设计了以下协议,用于评估模型在三种任务形式上的表现。
4.4.1. Question Answering
Answer quality is assessed using F1-Score, BERTScore, and LLM-as-Judge. F1-Score measures token-level overlap with the reference answer, while BERTScore computes semantic similarity through contextual embeddings. In addition, LLM-as-Judge enables flexible evaluation of model responses: GPT-4o receives the question, reference answer, and model response, and assigns a score of 0, 1, or 2 reflecting semantic consistency. The detailed prompt design is described in the appendix. To further evaluate memory recall, we also report Recall@k and nDCG@k for retrieval accuracy.
答案质量使用 F1-Score、BERTScore 和 LLM-as-Judge 进行评估。 F1-Score 衡量与参考答案的 token 级重叠,而 BERTScore 通过上下文嵌入计算语义相似度。 此外,LLM-as-Judge 支持对模型回复进行灵活评估:GPT-4o 接收问题、参考答案和模型回复,并给出 0、1 或 2 的分数来反映语义一致性。 详细提示设计见附录。 为进一步评估记忆回忆能力,作者还报告 Recall@k 和 nDCG@k 作为检索准确率指标。
4.4.2. Summarization
Summarization quality is evaluated using ROUGE, LLM-as-Judge, and event-based metrics inspired by FActScore. ROUGE-1, ROUGE-2, and ROUGE-L measure lexical overlap with reference summaries at unigram, bigram, and longest common subsequence levels. LLM-as-Judge enables semantic evaluation of summary quality: GPT-4o is prompted with the reference summary and the model-generated summary, and assigns a score from 0 to 5 evaluating semantic consistency and faithfulness. To further assess factual coverage, we design event-based metrics. GPT-4o extracts discrete events from both the reference and generated summaries, and Recall, Precision, and F1 are computed to assess alignment between these event sets.
摘要质量使用 ROUGE、LLM-as-Judge 以及受 FActScore 启发的事件级指标进行评估。 ROUGE-1、ROUGE-2 和 ROUGE-L 分别在 unigram、bigram 和最长公共子序列层面衡量与参考摘要的词汇重叠。 LLM-as-Judge 支持对摘要质量进行语义评估:GPT-4o 接收参考摘要和模型生成摘要,并给出 0 到 5 的分数来评估语义一致性和忠实性。 为进一步评估事实覆盖,作者设计了事件级指标。 GPT-4o 从参考摘要和生成摘要中抽取离散事件,并计算 Recall、Precision 和 F1 来评估这些事件集合之间的对齐。
4.4.3. Dialogue Generation
During evaluation, GPT-4o acted as the simulated user and generated coherent inputs from predefined scenarios to drive interactive sessions. To assess models under these open-ended and personalized conditions, we employed two LLM-based protocols: observation-based metrics and LLM rating metrics. The former assesses whether system responses accurately reflect user states and experiences, as captured by observation annotations from scenario-related sessions, and reports recall and weighted accuracy scores. The latter uses GPT-4o to rate overall dialogue quality on a 5-point scale across long-term memory, personalization, and emotional support, with the abbreviated prompt provided in the appendix. Together, these protocols provide a rigorous assessment of a model’s ability to integrate long-term memory with user information.
评估期间,GPT-4o 充当模拟用户,并基于预定义场景生成连贯输入来驱动交互式会话。 为在这些开放式和个性化条件下评估模型,作者采用了两种基于 LLM 的协议:观察级指标和 LLM 评分指标。 前者评估系统回复是否准确反映用户状态和经历,这些状态和经历由场景相关会话中的观察标注捕捉,并报告 recall 和加权准确率分数。 后者使用 GPT-4o 在长期记忆、个性化和情感支持三个维度上,以 5 分制对整体对话质量评分,简略提示见附录。 这些协议共同对模型整合长期记忆与用户信息的能力提供了严格评估。
5. Experimental Setup
Experiments on ES-MemEval evaluate three LLM paradigms: open-source long-context models, commercial models, and their retrieval-augmented variants. For open-source long-context models, we select three widely adopted representatives, each supporting a 128K-token context length: Ministral-8B-Instruct-2410, Phi-3-Medium-128k-Instruct, and Mistral-Small-3.1-24B-Instruct-2503. For commercial models, we include gpt-3.5-turbo with a 4K context window and gpt-4o with a 16K context window to provide mid-range closed-source baselines. In addition, we set up retrieval-augmented configurations for all five models, in which a dense retriever (bge-m3) retrieves the top-4 most relevant full-session contexts from a FAISS index to supply user information. These setups enable a systematic comparison of open-source long-context, commercial, and retrieval-augmented paradigms with the unified ES-MemEval framework, highlighting their relative strengths and limitations in long-term personalized emotional support. All experiments were conducted on an A100 GPU equipped with 80GB of memory.
ES-MemEval 上的实验评估三类 LLM 范式:开源长上下文模型、商业模型及其检索增强变体。 对于开源长上下文模型,作者选择三个广泛使用的代表模型,每个都支持 128K token 上下文长度:Ministral-8B-Instruct-2410、Phi-3-Medium-128k-Instruct 和 Mistral-Small-3.1-24B-Instruct-2503。 对于商业模型,作者纳入具有 4K 上下文窗口的 gpt-3.5-turbo 和具有 16K 上下文窗口的 gpt-4o,作为中等规模闭源基线。 此外,作者为全部五个模型设置检索增强配置,其中稠密检索器 bge-m3 从 FAISS 索引中检索最相关的 top-4 完整会话上下文,以提供用户信息。 这些设置使作者能够在统一的 ES-MemEval 框架下系统比较开源长上下文、商业和检索增强范式,揭示它们在长期个性化情感支持中的相对优势与局限。 所有实验均在配备 80GB 显存的 A100 GPU 上进行。
| F1 Score (%) ↑ | |||||||
|---|---|---|---|---|---|---|---|
| Category | Model | IE | TR | CD | Abs | UM | All |
| Base (128K) | Mistral-8B | 3.2 | 9.3 | 6.3 | 0.4 | 10.6 | 5.7 |
| Phi-3-Medium | 11.0 | 12.8 | 14.0 | 0.0 | 11.5 | 9.7 | |
| Mistral-24B | 13.4 | 18.0 | 20.1 | 15.6 | 10.9 | 15.5 | |
| Base + RAG | Mistral-8B + RAG | 8.4 | 13.3 | 18.4 | 0.2 | 12.6 | 10.3 |
| Phi-3-Medium + RAG | 13.2 | 16.8 | 18.7 | 0.0 | 13.4 | 12.2 | |
| Mistral-24B + RAG | 26.7 | 18.4 | 20.4 | 11.1 | 16.4 | 18.8 | |
| Commercial | GPT-3.5-turbo(4K) | 10.6 | 22.4 | 21.4 | 1.1 | 17.2 | 14.0 |
| GPT-4o(16K) | 20.2 | 19.6 | 12.1 | 66.7 | 21.7 | 26.6 | |
| Commercial+RAG | GPT-3.5 + RAG | 20.4 | 26.5 | 27.2 | 3.5 | 22.0 | 19.6 |
| GPT-4o + RAG | 29.3 | 27.6 | 28.9 | 12.7 | 21.2 | 23.9 | |
| BERTScore (%) ↑ | |||||||
|---|---|---|---|---|---|---|---|
| Category | Model | IE | TR | CD | Abs | UM | All |
| Base (128K) | Mistral-8B | 32.7 | 43.8 | 42.8 | 26.4 | 49.0 | 38.4 |
| Phi-3-Medium | 42.2 | 53.1 | 51.2 | 26.3 | 55.0 | 45.0 | |
| Mistral-24B | 42.3 | 53.4 | 54.2 | 37.0 | 52.7 | 47.4 | |
| Base + RAG | Mistral-8B + RAG | 39.7 | 50.1 | 52.3 | 28.1 | 51.5 | 43.8 |
| Phi-3-Medium + RAG | 43.3 | 54.9 | 55.1 | 27.0 | 56.1 | 46.6 | |
| Mistral-24B + RAG | 50.4 | 53.9 | 55.5 | 36.2 | 57.5 | 50.4 | |
| Commercial | GPT-3.5-turbo(4K) | 41.9 | 56.4 | 54.1 | 30.1 | 58.0 | 47.4 |
| GPT-4o(16K) | 48.3 | 57.1 | 49.9 | 57.0 | 60.4 | 54.2 | |
| Commercial+RAG | GPT-3.5 + RAG | 48.9 | 59.9 | 60.2 | 30.4 | 60.3 | 51.3 |
| GPT-4o + RAG | 52.2 | 60.7 | 61.9 | 37.1 | 61.5 | 54.2 | |
| LLM-as-Judge (0-2) ↑ | |||||||
|---|---|---|---|---|---|---|---|
| Category | Model | IE | TR | CD | Abs | UM | All |
| Base (128K) | Mistral-8B | 0.33 | 0.40 | 0.36 | 0.43 | 0.59 | 0.42 |
| Phi-3-Medium | 0.94 | 0.68 | 0.89 | 0.63 | 0.78 | 0.79 | |
| Mistral-24B | 1.03 | 0.84 | 0.96 | 1.20 | 0.96 | 1.01 | |
| Base + RAG | Mistral-8B + RAG | 0.94 | 0.76 | 1.11 | 0.63 | 0.78 | 0.85 |
| Phi-3-Medium + RAG | 1.21 | 0.68 | 1.25 | 0.73 | 1.04 | 0.99 | |
| Mistral-24B + RAG | 1.42 | 1.04 | 1.32 | 1.43 | 1.07 | 1.27 | |
| Commercial | GPT-3.5-turbo(4K) | 0.58 | 0.60 | 0.89 | 0.80 | 0.82 | 0.73 |
| GPT-4o(16K) | 1.22 | 1.13 | 1.00 | 1.67 | 1.13 | 1.25 | |
| Commercial+RAG | GPT-3.5 + RAG | 1.42 | 0.88 | 1.07 | 0.77 | 1.04 | 1.05 |
| GPT-4o + RAG | 1.46 | 1.20 | 1.46 | 1.30 | 1.19 | 1.33 | |
| Retrieval Granularity | Top-k | Answer Prediction | Retrieval Accuracy | |||
|---|---|---|---|---|---|---|
| F1 Score (%) ↑ | BERTScore (%) ↑ | LLM-as-Judge (0-2) ↑ | R@k (%) ↑ | NDCG@k (%) ↑ | ||
| Turn-level | 10 | 16.8 | 47.8 | 1.06 | 72.1 | 55.7 |
| 20 | 20.3 | 50.1 | 1.08 | 86.4 | 60.7 | |
| 30 | 18.7 | 49.5 | 1.15 | 94.2 | 63.1 | |
| Round-level | 5 | 19.4 | 49.6 | 1.06 | 57.6 | 51.7 |
| 10 | 20.4 | 50.1 | 1.15 | 70.8 | 56.6 | |
| 15 | 19.0 | 50.5 | 1.20 | 77.7 | 59.1 | |
| Session-level | 2 | 20.2 | 51.1 | 1.23 | 49.9 | 49.1 |
| 4 | 18.8 | 50.4 | 1.27 | 65.0 | 55.9 | |
| 8 | 16.7 | 49.6 | 1.25 | 81.7 | 62.4 | |
| Model | Context | F1 Score ↑ | BERTScore ↑ | LLM-as-Judge ↑ |
|---|---|---|---|---|
| Mistral-8B | 2K | 9.8 | 42.1 | 0.56 |
| 4K | 7.5 | 40.3 | 0.55 | |
| 8K | 7.7 | 38.9 | 0.55 | |
| 20K | 5.7 | 38.4 | 0.42 | |
| Mistral-24B | 2K | 16.2 | 47.2 | 0.80 |
| 4K | 14.4 | 46.9 | 0.82 | |
| 8K | 17.4 | 48.6 | 1.04 | |
| 20K | 15.5 | 47.4 | 1.01 |
6. Experimental Results
We conduct a comprehensive evaluation of baseline methods on ES-MemEval to assess their ability to maintain and leverage long-term memory in personalized emotional support conversations.
作者在 ES-MemEval 上对基线方法进行综合评估,以考察它们在个性化情感支持对话中维持并利用长期记忆的能力。
| Category | Model | ROUGE (%) ↑ | Event-based Metrics (%) ↑ | LLM Score (0-5) ↑ | ||||
|---|---|---|---|---|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | Precision | Recall | F1 | |||
| Base | Mistral-8B | 21.6 | 3.5 | 12.0 | 20.1 | 25.5 | 21.7 | 1.23 |
| Phi-3-Medium | 25.1 | 5.7 | 13.9 | 27.6 | 45.2 | 33.2 | 1.91 | |
| Mistral-24B | 19.8 | 5.1 | 10.9 | 24.1 | 32.0 | 26.8 | 1.45 | |
| Base+RAG | Mistral-8B + RAG | 32.6 | 6.7 | 17.8 | 39.2 | 44.1 | 40.6 | 2.34 |
| Phi-3-Medium + RAG | 28.0 | 6.3 | 15.2 | 34.0 | 50.2 | 39.6 | 2.34 | |
| Mistral-24B + RAG | 37.4 | 8.7 | 21.0 | 45.6 | 53.0 | 48.1 | 2.79 | |
| Commercial | GPT-3.5-turbo | 35.3 | 6.8 | 19.3 | 23.3 | 29.1 | 24.7 | 1.75 |
| GPT-4o | 35.0 | 8.6 | 19.1 | 34.0 | 48.5 | 38.8 | 2.36 | |
| Commercial+RAG | GPT-3.5-turbo + RAG | 39.3 | 9.3 | 21.7 | 44.3 | 50.0 | 46.2 | 2.93 |
| GPT-4o + RAG | 40.5 | 11.1 | 22.2 | 46.0 | 54.3 | 49.4 | 2.93 | |
6.1. Analysis of QA Performance
We conducted three QA experiments on ES-MemEval: (1) benchmarking models across five core memory abilities, (2) analyzing the impact of RAG configurations on answer quality and retrieval accuracy, and (3) evaluating the performance of Mistral models under varying context lengths.
作者在 ES-MemEval 上开展了三类问答实验:(1)在五种核心记忆能力上对模型进行基准测试;(2)分析 RAG 配置对答案质量和检索准确率的影响;(3)评估 Mistral 模型在不同上下文长度下的表现。
6.1.1. Comparison Across Models
As shown in Table 3, RAG consistently drives performance gains across both open-source and commercial models. For instance, Mistral-24B with RAG exhibits notable improvement, with its overall F1 score rising from 15.5 to 18.8, BERTScore from 47.4 to 50.4, and LLM-as-Judge Score from 1.01 to 1.27, indicating that RAG enhances model robustness and effectiveness in ultra-long dialogues. The gains are particularly pronounced for smaller models such as Mistral-8B, whose LLM Score increased by 0.43, highlighting that RAG is especially beneficial for models with limited capacity. Despite these improvements, RAG performance remains uneven across different capabilities. Specifically, model performance in user modeling and temporal reasoning remains suboptimal, as F1 scores seldom exceed 20.0 even under RAG augmentation. Abstention varies sharply—RAG improves performance for open-source models, but reduces it for commercial ones. GPT-4o is most affected, with its LLM Score declining from 1.67 to 1.30, suggesting that the added retrieved content may encourage overconfident responses. Overall, RAG enhances factual recall but does not uniformly benefit all capabilities, underscoring the persistent difficulty of long-term user modeling.
如表3所示,RAG 在开源模型和商业模型上都持续带来性能提升。 例如,带 RAG 的 Mistral-24B 表现出明显改进,整体 F1 从 15.5 提升到 18.8,BERTScore 从 47.4 提升到 50.4,LLM-as-Judge 分数从 1.01 提升到 1.27,说明 RAG 提升了模型在超长对话中的稳健性和有效性。 这些收益对 Mistral-8B 等小模型尤为明显,其 LLM Score 提升了 0.43,表明 RAG 对容量有限的模型尤其有益。 尽管有这些改进,RAG 在不同能力上的表现仍不均衡。 具体而言,模型在用户建模和时间推理上的表现仍不理想,即便在 RAG 增强下,F1 分数也很少超过 20.0。 拒答能力变化剧烈:RAG 提升了开源模型表现,却降低了商业模型表现。 GPT-4o 受影响最大,其 LLM Score 从 1.67 下降到 1.30,说明加入检索内容可能会鼓励模型过度自信作答。 总体而言,RAG 增强了事实回忆,但并不能均衡提升所有能力,这凸显了长期用户建模的持续困难。
6.1.2. Impact of Retrieval Configurations
We further investigate RAG configurations by varying both memory granularity and retrieval size k, as shown in Table 4. Table 4 presents the performance of Mistral-24B under three retrieval granularities: turn-level, round-level, and session-level. Among these, the session-level configuration, which retrieves entire sessions as memory units, achieves the highest performance, with an LLM-as-Judge score of 1.27 at k=4, surpassing the best round-level (1.20) and turn-level (1.15) settings. This finding indicates that session-level retrieval is more effective for long-term emotional support scenarios, where relevant information is sparsely distributed and only becomes meaningful when aggregated across multiple conversational turns. Regarding retrieval accuracy, Recall@k consistently improves as k increases, with values exceeding 75% across all granularities. However, NDCG@k remains moderate, with peak values ranging from 59% to 63%. These results suggest that while the retrieved units cover the majority of relevant content, their ranking quality is suboptimal, which may limit the effectiveness of downstream reasoning.
作者进一步通过改变记忆粒度和检索大小 k 来研究 RAG 配置,如表4所示。 表4 展示了 Mistral-24B 在三种检索粒度下的表现:轮级、回合级和会话级。 其中,以完整会话作为记忆单元进行检索的会话级配置表现最好,在 k=4 时 LLM-as-Judge 分数达到 1.27,超过最佳回合级(1.20)和轮级(1.15)设置。 这一发现表明,会话级检索更适合长期情感支持场景,因为相关信息分散稀疏,只有聚合多个对话轮次后才变得有意义。 在检索准确率方面,随着 k 增大,Recall@k 持续提升,并且在所有粒度上都超过 75%。 然而,NDCG@k 仍处于中等水平,峰值约为 59% 到 63%。 这些结果表明,虽然检索单元覆盖了大多数相关内容,但排序质量并不理想,这可能限制下游推理效果。
6.1.3. Effect of Context Length
Table 5 evaluates Mistral-8B and Mistral-24B under varying context lengths. In the benchmark, each user’s full dialogue history spans 11K–19K tokens, meaning that context windows shorter than 20K require truncation. Without RAG, Mistral-8B achieves optimal performance at 2K tokens, while Mistral-24B peaks at 8K. These results indicate that although both models nominally support up to 128K tokens, their effective performance substantially deteriorates as input context length increases. This degradation is particularly pronounced for the smaller 8B model, whose performance improves markedly when the context window is reduced, whereas Mistral-24B remains more robust, sustaining good performance at 20K tokens. Consistent downward trends across F1, BERTScore, and LLM-as-Judge further validate these findings. These results highlight the limitations of long-context processing for small- to medium-scale models. Based on the findings in Table 3, RAG can be considered as an effective approach to mitigate these limitations in dialogue system design.
表5 评估了 Mistral-8B 和 Mistral-24B 在不同上下文长度下的表现。 在该基准中,每位用户的完整对话历史跨越 11K 到 19K token,这意味着短于 20K 的上下文窗口需要截断。 在没有 RAG 的情况下,Mistral-8B 在 2K token 时达到最佳表现,而 Mistral-24B 在 8K 时达到峰值。 这些结果表明,虽然两个模型名义上都支持最高 128K token,但随着输入上下文长度增加,其有效性能会显著下降。 这种退化在较小的 8B 模型上尤其明显,当上下文窗口缩短时其表现显著改善,而 Mistral-24B 更稳健,在 20K token 下仍保持较好表现。 F1、BERTScore 和 LLM-as-Judge 上一致的下降趋势进一步验证了这些发现。 这些结果凸显了中小规模模型长上下文处理的局限。 基于表3中的发现,在对话系统设计中,RAG 可以被视为缓解这些局限的有效方法。
6.2. Analysis of Summarization
As shown in Table 6, RAG substantially improves summarization performance for both open-source and commercial models. Among open-source systems, Mistral-24B + RAG achieves the highest performance, with ROUGE-L increasing from 10.9 to 21.0, event-level F1 rising from 26.8 to 48.1, and the LLM Score improving from 1.45 to 2.79. These gains not only narrow the gap with commercial systems but also enable Mistral-24B + RAG to surpass GPT-3.5-turbo + RAG in event-level evaluations. Similar trends are observed in smaller open-source models such as Mistral-8B and Phi-3-Medium, although the improvements are less pronounced than those of Mistral-24B. On the commercial side, GPT-3.5-turbo + RAG and GPT-4o + RAG deliver the strongest overall performance, both attaining an LLM Score of 2.93, with GPT-4o + RAG achieving the highest event-level F1 (49.4). Overall, these results demonstrate that RAG markedly enhances models’ user modeling and temporal reasoning capabilities, enabling both open-source and commercial models to generate more coherent and information-rich summaries.
如表6所示,RAG 显著提升了开源模型和商业模型的摘要表现。 在开源系统中,Mistral-24B + RAG 表现最好,其 ROUGE-L 从 10.9 提升到 21.0,事件级 F1 从 26.8 提升到 48.1,LLM Score 从 1.45 提升到 2.79。 这些提升不仅缩小了与商业系统的差距,也使 Mistral-24B + RAG 在事件级评估中超过 GPT-3.5-turbo + RAG。 类似趋势也出现在 Mistral-8B 和 Phi-3-Medium 等较小开源模型中,不过提升幅度不如 Mistral-24B 明显。 在商业模型方面,GPT-3.5-turbo + RAG 和 GPT-4o + RAG 总体表现最强,两者的 LLM Score 都达到 2.93,其中 GPT-4o + RAG 获得最高事件级 F1(49.4)。 总体而言,这些结果表明 RAG 明显增强了模型的用户建模和时间推理能力,使开源模型和商业模型都能生成更连贯、信息更丰富的摘要。
| Memory Setting | Model | Recall ↑ | Weighted Score ↑ |
|---|---|---|---|
| No-Mem. | Mistral-8B | 0.28 | 0.28 |
| Phi-3-Medium | 0.25 | 0.26 | |
| Mistral-24B | 0.20 | 0.20 | |
| GPT-3.5-turbo | 0.26 | 0.30 | |
| GPT-4o | 0.23 | 0.29 | |
| Full-Hist. | Mistral-8B | 0.31 | 0.35 |
| Phi-3-Medium | 0.27 | 0.27 | |
| Mistral-24B | 0.33 | 0.33 | |
| GPT-3.5-turbo | 0.31 | 0.34 | |
| GPT-4o | 0.35 | 0.36 | |
| RAG | Mistral-8B | 0.34 | 0.40 |
| Phi-3-Medium | 0.29 | 0.32 | |
| Mistral-24B | 0.35 | 0.41 | |
| GPT-3.5-turbo | 0.37 | 0.44 | |
| GPT-4o | 0.38 | 0.45 |
| Memory Setting | Model | LT-Mem. ↑ | Pers. ↑ | ES ↑ |
|---|---|---|---|---|
| No-Mem. | Mistral-8B | 2.42 | 2.79 | 3.26 |
| Phi-3-Medium | 2.90 | 3.53 | 3.21 | |
| Mistral-24B | 1.42 | 2.84 | 2.53 | |
| GPT-3.5-turbo | 2.95 | 3.79 | 3.32 | |
| GPT-4o | 1.84 | 3.32 | 2.79 | |
| Full-Hist. | Mistral-8B | 4.53 | 4.58 | 4.58 |
| Phi-3-Medium | 3.68 | 4.05 | 3.90 | |
| Mistral-24B | 4.37 | 4.42 | 4.32 | |
| GPT-3.5-turbo | 4.68 | 4.74 | 4.68 | |
| GPT-4o | 5.00 | 5.00 | 5.00 | |
| RAG | Mistral-8B | 4.63 | 4.74 | 4.74 |
| Phi-3-Medium | 4.37 | 4.58 | 4.42 | |
| Mistral-24B | 4.90 | 4.90 | 4.90 | |
| GPT-3.5-turbo | 4.63 | 4.74 | 4.68 | |
| GPT-4o | 5.00 | 5.00 | 5.00 |
6.3. Analysis of Dialogue Generation
6.3.1. Observation-based Metrics
As shown in Table 7, under the No-Mem condition, scores remain low and any higher values in this setting largely reflect hallucinated user experiences rather than genuine memory use. By contrast, introducing Full-Hist or RAG substantially improved Recall and Weighted Score across all models—for example, Mistral-24B increased from 0.20 to 0.33—demonstrating that explicit histories provide more reliable representations of user states and enhance alignment with user observations. Moreover, RAG variants consistently outperformed Full-Hist (e.g., Mistral-24B achieved 0.41 in Weighted Score versus 0.33 for Full-Hist), suggesting that external retrieval mechanisms help models explicitly leverage user-relevant information, thereby improving personalization and factual consistency.
如表7所示,在 No-Mem 条件下,分数保持较低,并且该设置中任何较高值都主要反映模型虚构的用户经历,而不是真正使用记忆。 相比之下,引入 Full-Hist 或 RAG 后,所有模型的 Recall 和 Weighted Score 都显著提高,例如 Mistral-24B 从 0.20 提升到 0.33,这表明显式历史能够提供更可靠的用户状态表示,并增强与用户观察的对齐。 此外,RAG 变体持续优于 Full-Hist,例如 Mistral-24B 的 Weighted Score 达到 0.41,而 Full-Hist 为 0.33,说明外部检索机制有助于模型显式利用用户相关信息,从而提升个性化和事实一致性。
6.3.2. LLM Ratings
Table 8 presents GPT-4o’s ratings of overall dialogue quality. Under No-Mem conditions, some models (e.g., GPT-3.5-turbo, Phi-3-Medium) still scored relatively high on LT-Mem., a result largely driven by their tendency to hallucinate plausible user experiences when lacking explicit memory access. These results highlight the necessity of explicit long-term history: without it, models risk inconsistent personalization and compromised credibility. Compared to the No-Mem condition, access to long-term history markedly boosted long-term memory, personalization, and emotional support scores. Full-Hist and RAG achieved comparable performance, with RAG slightly better in some cases, indicating that retrieval can provide support comparable to full history while reducing context length. A key finding is the strong correlation between Pers. and LT-Mem., indicating that effective personalization depends on accurate memory recall. In contrast, ES scores are less sensitive to memory, suggesting that emotional support can partly rely on general strategies.
表8 展示了 GPT-4o 对整体对话质量的评分。 在 No-Mem 条件下,一些模型(如 GPT-3.5-turbo、Phi-3-Medium)在 LT-Mem. 上仍得分较高,这主要源于它们在缺乏显式记忆访问时倾向于虚构看似合理的用户经历。 这些结果凸显了显式长期历史的必要性:没有它,模型会面临个性化不一致和可信度受损的风险。 与 No-Mem 条件相比,访问长期历史显著提升了长期记忆、个性化和情感支持分数。 Full-Hist 和 RAG 取得了相近表现,RAG 在某些情况下略好,说明检索可以在减少上下文长度的同时提供接近完整历史的支持。 一个关键发现是 Pers. 与 LT-Mem. 高度相关,说明有效个性化依赖准确记忆回忆。 相比之下,ES 分数对记忆较不敏感,表明情感支持可以部分依赖通用策略。
7. Discussion and Future Directions
Our ES-MemEval experiments reveal six key insights into long-term personalized emotional support dialogues. (1) Long-term memory is essential: without explicit histories, models may hallucinate user experiences, undermining reliability and personalization. (2) RAG is effective but limited: retrieval improves factual consistency and alignment with user observations, yet modeling nuanced temporal dynamics remains challenging, motivating retrieval-aware calibration. (3) Memory drives personalization: personalization strongly depends on long-term memory, whereas emotional support can partly rely on general strategies with limited memory. (4) Retrieval configuration matters: session-level retrieval better captures sparse and evolving user signals, though redundancy remains a concern. (5) Long-context limits persist: smaller models degrade with extended contexts, highlighting the need for memory–retrieval integration. (6) RAG bridges system gaps: RAG narrows the performance gap between open-source and commercial models by improving personalization and memory alignment. Together, these findings point to retrieval-aware calibration, adaptive memory granularity, and hybrid memory–retrieval designs for sustained personalized dialogue.
ES-MemEval 实验揭示了长期个性化情感支持对话中的六个关键洞见。 (1)长期记忆至关重要:没有显式历史,模型可能虚构用户经历,从而削弱可靠性和个性化。 (2)RAG 有效但有限:检索提升了事实一致性以及与用户观察的对齐,但细腻时间动态的建模仍具挑战,因此需要检索感知校准。 (3)记忆驱动个性化:个性化强烈依赖长期记忆,而情感支持在记忆有限时也可以部分依赖通用策略。 (4)检索配置很重要:会话级检索更能捕捉稀疏且演化的用户信号,尽管冗余仍是问题。 (5)长上下文限制仍然存在:较小模型会随着上下文延长而退化,这凸显了记忆-检索融合的必要性。 (6)RAG 弥合系统差距:RAG 通过提升个性化和记忆对齐,缩小了开源模型与商业模型之间的性能差距。 这些发现共同指向检索感知校准、自适应记忆粒度以及混合记忆-检索设计,以支持持续个性化对话。
8. Conclusion
This paper presents the first benchmark study of long-term memory in personalized emotional support scenarios, a gap overlooked by prior long-term dialogue evaluations. We introduce EvoEmo, a dataset comprising 18 user trajectories with evolving user states across multiple sessions. Building on this resource, we propose ES-MemEval, a benchmark designed to systematically evaluate personalized dialogue agents' memory capabilities—including information extraction, temporal reasoning, conflict detection, abstention, and user modeling—through question answering, summarization, and dialogue generation tasks. Extensive experiments on open-source long-context, commercial, and retrieval-augmented models provide empirical insights into their ability to maintain and leverage long-term memory for personalization, highlighting the impact of factors such as memory granularity and retrieval strategies. Collectively, these contributions establish a high-quality, empirically grounded benchmark that facilitates the development of reliable, user-centered dialogue systems in complex, long-term settings.
本文首次针对个性化情感支持场景中的长期记忆开展基准研究,弥补了先前长期对话评估忽视的空白。 作者提出 EvoEmo,这是一个包含 18 条用户轨迹的数据集,覆盖跨多个会话演化的用户状态。 基于这一资源,作者提出 ES-MemEval,这是一个通过问答、摘要和对话生成任务,系统评估个性化对话智能体记忆能力的基准,能力包括信息抽取、时间推理、冲突检测、拒答和用户建模。 作者在开源长上下文模型、商业模型和检索增强模型上开展的大量实验,为这些模型维持并利用长期记忆进行个性化的能力提供了实证洞见,并凸显了记忆粒度和检索策略等因素的影响。 总体而言,这些贡献建立了一个高质量、具有实证基础的基准,有助于推动复杂长期环境中可靠、以用户为中心的对话系统发展。