
Mem0:构建具有可扩展长期记忆的生产级 AI 智能体
Abstract
Large Language Models (LLMs) have demonstrated remarkable prowess in generating contextually coherent responses, yet their fixed context windows pose fundamental challenges for maintaining consistency over prolonged multi-session dialogues. We introduce Mem0, a scalable memory-centric architecture that addresses this issue by dynamically extracting, consolidating, and retrieving salient information from ongoing conversations. Building on this foundation, we further propose an enhanced variant that leverages graph-based memory representations to capture complex relational structures among conversational elements. Through comprehensive evaluations on the LOCOMO benchmark, we systematically compare our approaches against six baseline categories: (i) established memory-augmented systems, (ii) retrieval-augmented generation (RAG) with varying chunk sizes and
大型语言模型在生成上下文连贯的回答方面展现出了卓越能力,但其固定上下文窗口给长期、多会话对话中的一致性维护带来了根本挑战。 我们提出 Mem0,这是一种以记忆为中心的可扩展架构,通过从持续对话中动态提取、整合和检索关键信息来解决这一问题。 在此基础上,我们进一步提出了一个增强变体,它利用基于图的记忆表示来捕捉对话元素之间复杂的关系结构。 通过在 LOCOMO 基准上的全面评估,我们系统地将方法与六类基线进行比较:(i)已有的记忆增强系统,(ii)采用不同分块大小和
1. Introduction
Human memory is a foundation of intelligence—it shapes our identity, guides decision-making, and enables us to learn, adapt, and form meaningful relationships. Among its many roles, memory is essential for communication: we recall past interactions, infer preferences, and construct evolving mental models of those we engage with. This ability to retain and retrieve information over extended periods enables coherent, contextually rich exchanges that span days, weeks, or even months. AI agents, powered by large language models (LLMs), have made remarkable progress in generating fluent, contextually appropriate responses. However, these systems are fundamentally limited by their reliance on fixed context windows, which severely restrict their ability to maintain coherence over extended interactions.
人类记忆是智能的基础,它塑造我们的身份,指导决策,并使我们能够学习、适应以及建立有意义的关系。 在记忆的诸多作用中,它对于交流尤为重要:我们会回忆过去的互动,推断偏好,并为交流对象构建不断演化的心理模型。 这种在较长时间内保留和检索信息的能力,使得跨越数天、数周甚至数月的连贯且富含上下文的交流成为可能。 由大型语言模型驱动的 AI 智能体在生成流畅且上下文适当的回答方面已经取得了显著进展。 然而,这些系统从根本上受限于对固定上下文窗口的依赖,这严重限制了它们在长期交互中保持连贯性的能力。
This limitation stems from LLMs' lack of persistent memory mechanisms that can extend beyond their finite context windows. While humans naturally accumulate and organize experiences over time, forming a continuous narrative of interactions, AI systems cannot inherently persist information across separate sessions or after context overflow. The absence of persistent memory creates a fundamental disconnect in human-AI interaction. Without memory, AI agents forget user preferences, repeat questions, and contradict previously established facts.
这种限制源于大型语言模型缺乏能够超越有限上下文窗口的持久记忆机制。 人类会随着时间自然地积累和组织经验,形成一条连续的互动叙事,而 AI 系统本身并不能在不同会话之间,或在上下文溢出之后持续保存信息。 持久记忆的缺失在人机交互中造成了根本性的断裂。 没有记忆时,AI 智能体会忘记用户偏好,重复提问,并与先前已经确立的事实相矛盾。
Consider a simple example illustrated in 图1, where a user mentions being vegetarian and avoiding dairy products in an initial conversation. In a subsequent session, when the user asks about dinner recommendations, a system without persistent memory might suggest chicken, completely contradicting the established dietary preferences. In contrast, a system with persistent memory would maintain this critical user information across sessions and suggest appropriate vegetarian, dairy-free options. This common scenario highlights how memory failures can fundamentally undermine user experience and trust.
考虑图1中展示的一个简单例子:用户在初始对话中提到自己是素食者,并且不吃乳制品。 在之后的某次会话中,当用户询问晚餐推荐时,一个没有持久记忆的系统可能会推荐鸡肉,从而完全违背已经建立的饮食偏好。 相反,拥有持久记忆的系统会在多次会话之间保留这一关键用户信息,并推荐合适的素食、无乳制品选项。 这个常见场景说明,记忆失败会从根本上削弱用户体验和信任。
Beyond conversational settings, memory mechanisms have been shown to dramatically enhance agent performance in interactive environments. Agents equipped with memory of past experiences can better anticipate user needs, learn from previous mistakes, and generalize knowledge across tasks. Research demonstrates that memory-augmented agents improve decision-making by leveraging causal relationships between actions and outcomes, leading to more effective adaptation in dynamic scenarios. Hierarchical memory architectures and agentic memory systems capable of autonomous evolution have further shown that memory enables more coherent, long-term reasoning across multiple dialogue sessions.
除了对话场景之外,研究也表明,记忆机制可以显著提升智能体在交互式环境中的表现。 具备过往经验记忆的智能体能够更好地预判用户需求,从先前错误中学习,并在不同任务之间泛化知识。 相关研究表明,记忆增强智能体可以利用行动与结果之间的因果关系来改进决策,从而在动态场景中实现更有效的适应。 分层记忆架构以及能够自主演化的智能体记忆系统进一步表明,记忆能够支持跨越多轮对话会话的、更连贯的长期推理。
Unlike humans, who dynamically integrate new information and revise outdated beliefs, LLMs effectively “reset” once information falls outside their context window. Even as models like OpenAI's GPT-4 (128K tokens), o1 (200K context), Anthropic's Claude 3.7 Sonnet (200K tokens), and Google's Gemini (at least 10M tokens) push the boundaries of context length, these improvements merely delay rather than solve the fundamental limitation.
人类会动态整合新信息并修正过时的信念,而大型语言模型则不同:一旦信息落到上下文窗口之外,它们实际上就会“重置”。 即便 OpenAI 的 GPT-4(128K 词元)、o1(200K 上下文)、Anthropic 的 Claude 3.7 Sonnet(200K 词元)以及 Google 的 Gemini(至少 10M 词元)不断推动上下文长度边界,这些改进也只是延缓了问题,而没有解决这一根本限制。
In practical applications, even these extended context windows prove insufficient for two critical reasons. First, as meaningful human-AI relationships develop over weeks or months, conversation history inevitably exceeds even the most generous context limits. Second, and perhaps more importantly, real-world conversations rarely maintain thematic continuity. A user might mention dietary preferences (being vegetarian), then engage in hours of unrelated discussion about programming tasks, before returning to food-related queries about dinner options. In such scenarios, a full-context approach would need to reason through mountains of irrelevant information, with the critical dietary preferences potentially buried among thousands of tokens of coding discussions. Moreover, simply presenting longer contexts does not ensure effective retrieval or utilization of past information, as attention mechanisms degrade over distant tokens.
在实际应用中,即使这些扩展后的上下文窗口仍然不足,主要有两个关键原因。 第一,随着有意义的人机关系在数周或数月中发展,对话历史不可避免地会超过哪怕是最宽松的上下文限制。 第二,也许更重要的是,真实世界的对话很少保持主题连续。 用户可能先提到饮食偏好(例如自己是素食者),随后花数小时讨论与此无关的编程任务,最后又回到关于晚餐选择的食物相关问题。 在这种场景下,全上下文方法需要在大量无关信息中推理,而关键的饮食偏好可能被埋在数千个关于代码讨论的词元之中。 此外,仅仅提供更长上下文并不能保证模型有效检索或利用过去的信息,因为注意力机制在远距离词元上会退化。
This limitation is particularly problematic in high-stakes domains such as healthcare, education, and enterprise support, where maintaining continuity and trust is crucial. To address these challenges, AI agents must adopt memory systems that go beyond static context extension. A robust AI memory should selectively store important information, consolidate related concepts, and retrieve relevant details when needed—mirroring human cognitive processes. By integrating such mechanisms, we can develop AI agents that maintain consistent personas, track evolving user preferences, and build upon prior exchanges. This shift will transform AI from transient, forgetful responders into reliable, long-term collaborators, fundamentally redefining the future of conversational intelligence.
这一限制在医疗、教育和企业支持等高风险领域尤其成问题,因为这些场景中保持连续性和信任至关重要。 为了解决这些挑战,AI 智能体必须采用超越静态上下文扩展的记忆系统。 一个稳健的 AI 记忆系统应当能够选择性地存储重要信息,整合相关概念,并在需要时检索相关细节,从而模拟人类认知过程。 通过整合这些机制,我们可以开发出能够保持一致人格、追踪不断变化的用户偏好,并基于先前交流继续推进的 AI 智能体。 这种转变将使 AI 从短暂、健忘的回应者,转变为可靠的长期协作者,从根本上重新定义对话智能的未来。
In this paper, we address a fundamental limitation in AI systems: their inability to maintain coherent reasoning across extended conversations across different sessions, which severely restricts meaningful long-term interactions with users. We introduce Mem0 (pronounced as mem-zero), a novel memory architecture that dynamically captures, organizes, and retrieves salient information from ongoing conversations. Building on this foundation, we develop
本文解决 AI 系统中的一个根本限制:它们无法在跨不同会话的长时间对话中保持连贯推理,这严重限制了与用户进行有意义的长期交互。 我们提出 Mem0(读作 mem-zero),这是一种新型记忆架构,能够从持续对话中动态捕获、组织和检索关键信息。 在此基础上,我们进一步开发了
Our experimental results on the LOCOMO benchmark demonstrate that our approaches consistently outperform existing memory systems—including memory-augmented architectures, retrieval-augmented generation (RAG) methods, and both open-source and proprietary solutions—across diverse question types, while simultaneously requiring significantly lower computational resources. Latency measurements further reveal that Mem0 operates with 91% lower response times than full-context approaches, striking an optimal balance between sophisticated reasoning capabilities and practical deployment constraints. These contributions represent a meaningful step toward AI systems that can maintain coherent, context-aware conversations over extended durations—mirroring human communication patterns and opening new possibilities for applications in personal tutoring, healthcare, and personalized assistance.
我们在 LOCOMO 基准上的实验结果表明,我们的方法在多种问题类型上持续优于现有记忆系统,包括记忆增强架构、检索增强生成方法,以及开源和专有解决方案,同时所需计算资源显著更低。 延迟测量进一步显示,相比全上下文方法,Mem0 的响应时间降低了 91%,在复杂推理能力与实际部署约束之间取得了最佳平衡。 这些贡献代表着迈向能够在长时间跨度内保持连贯、上下文感知对话的 AI 系统的重要一步,它们模拟了人类交流模式,并为个人辅导、医疗健康和个性化助手等应用打开了新的可能性。
2. Proposed Methods
We introduce two memory architectures for AI agents. (1) Mem0 implements a novel paradigm that extracts, evaluates, and manages salient information from conversations through dedicated modules for memory extraction and updation. The system processes a pair of messages between either two user participants or a user and an assistant. (2)
我们提出了两种面向 AI 智能体的记忆架构。 (1) Mem0 实现了一种新的范式,通过专门的记忆提取和更新模块,从对话中提取、评估并管理关键信息。 该系统处理两个用户参与者之间,或用户与助手之间的一对消息。 (2)
2.1. Mem0
Our architecture follows an incremental processing paradigm, enabling it to operate seamlessly within ongoing conversations. As illustrated in 图2, the complete pipeline architecture consists of two phases: extraction and update.
我们的架构遵循增量式处理范式,使其能够在持续进行的对话中无缝运行。 如图2所示,完整的流水线架构由两个阶段组成:提取和更新。
The extraction phase initiates upon ingestion of a new message pair (1) a conversation summary (2) a sequence of recent messages
提取阶段在系统接收到新的消息对 (1) 从数据库中检索到的对话摘要 (2) 对话历史中的近期消息序列
To support context-aware memory extraction, we implement an asynchronous summary generation module that periodically refreshes the conversation summary. This component operates independently of the main processing pipeline, ensuring that memory extraction consistently benefits from up-to-date contextual information without introducing processing delays. While
为了支持上下文感知的记忆提取,我们实现了一个异步摘要生成模块,用于周期性刷新对话摘要。 该组件独立于主处理流水线运行,确保记忆提取能够持续受益于最新的上下文信息,同时不会引入处理延迟。
This dual contextual information, combined with the new message pair, forms a comprehensive prompt
这两类上下文信息与新的消息对结合在一起,形成一个完整提示
Following extraction, the update phase evaluates each candidate fact against existing memories to maintain consistency and avoid redundancy. This phase determines the appropriate memory management operation for each extracted fact tool call.
在提取之后,更新阶段会将每个候选事实与已有记忆进行比较,以维持一致性并避免冗余。 该阶段会为每个被提取出的事实 tool call 的函数调用接口呈现给 LLM。
The LLM itself determines which of four distinct operations to execute: ADD for creation of new memories when no semantically equivalent memory exists; UPDATE for augmentation of existing memories with complementary information; DELETE for removal of memories contradicted by new information; and NOOP when the candidate fact requires no modification to the knowledge base. Rather than using a separate classifier, we leverage the LLM's reasoning capabilities to directly select the appropriate operation based on the semantic relationship between the candidate fact and existing memories. Following this determination, the system executes the provided operations, thereby maintaining knowledge base coherence and temporal consistency.
LLM 自身会决定执行四种不同操作中的哪一种:当不存在语义等价记忆时,使用 ADD 创建新记忆;当新信息可以补充已有记忆时,使用 UPDATE 增强现有记忆;当新信息与已有记忆矛盾时,使用 DELETE 移除相应记忆;当候选事实不需要修改知识库时,使用 NOOP。 我们没有使用单独的分类器,而是利用 LLM 的推理能力,根据候选事实与已有记忆之间的语义关系,直接选择合适操作。 在完成判断后,系统执行相应操作,从而维护知识库的连贯性和时间一致性。
In our experimental evaluation, we configured the system with GPT-4o-mini as the inference engine. The vector database employs dense embeddings to facilitate efficient similarity search during the update phase.
在实验评估中,我们将系统配置为使用 GPT-4o-mini 作为推理引擎。 向量数据库采用稠密嵌入,以便在更新阶段进行高效的相似性搜索。
2.2.
The
- Nodes
represent entities, e.g., Alice, San Francisco. - Edges
represent relationships between entities, e.g., lives_in. - Labels
assign semantic types to nodes, e.g., Alice - Person, San Francisco - City.
- 节点
表示实体,例如 Alice、San Francisco。 - 边
表示实体之间的关系,例如 lives_in。 - 标签
为节点分配语义类型,例如 Alice - Person、San Francisco - City。
Each entity node
每个实体节点
The extraction process employs a two-stage pipeline leveraging LLMs to transform unstructured text into structured graph representations. First, an entity extractor module processes the input text to identify a set of entities along with their corresponding types. In our framework, entities represent the key information elements in conversations—including people, locations, objects, concepts, events, and attributes that merit representation in the memory graph. The entity extractor identifies these diverse information units by analyzing the semantic importance, uniqueness, and persistence of elements in the conversation. For instance, in a conversation about travel plans, entities might include destinations, transportation modes, dates, activities, and participant preferences—essentially any discrete information that could be relevant for future reference or reasoning.
提取过程采用两阶段流水线,利用 LLM 将非结构化文本转换为结构化图表示。 首先,实体提取器模块处理输入文本,识别一组实体及其对应类型。 在我们的框架中,实体表示对话中的关键信息元素,包括人物、地点、物体、概念、事件以及值得在记忆图中表示的属性。 实体提取器通过分析对话中元素的语义重要性、唯一性和持久性,识别这些不同类型的信息单元。 例如,在关于旅行计划的对话中,实体可能包括目的地、交通方式、日期、活动和参与者偏好,本质上就是任何未来参考或推理时可能相关的离散信息。
Next, a relationship generator component derives meaningful connections between these entities, establishing a set of relationship triplets that capture the semantic structure of the information. This LLM-based module analyzes the extracted entities and their context within the conversation to identify semantically significant connections. It works by examining linguistic patterns, contextual cues, and domain knowledge to determine how entities relate to one another. For each potential entity pair, the generator evaluates whether a meaningful relationship exists and, if so, classifies this relationship with an appropriate label, e.g., lives_in, prefers, owns, happened_on. The module employs prompt engineering techniques that guide the LLM to reason about both explicit statements and implicit information in the dialogue, resulting in relationship triplets that form the edges in our memory graph and enable complex reasoning across interconnected information.
接下来,关系生成器组件会推导这些实体之间有意义的连接,建立一组关系三元组,以捕捉信息的语义结构。 这个基于 LLM 的模块会分析被提取出的实体及其在对话中的上下文,从而识别语义上重要的连接。 它通过检查语言模式、上下文线索和领域知识,判断实体之间如何关联。 对于每一对潜在实体,生成器会评估是否存在有意义的关系;如果存在,则用合适的标签对该关系进行分类,例如 lives_in、prefers、owns、happened_on。 该模块采用提示工程技术,引导 LLM 对对话中的显式陈述和隐含信息进行推理,最终得到构成记忆图中边的关系三元组,并支持跨互联信息的复杂推理。
When integrating new information,
在整合新信息时,
The memory retrieval functionality in
From an implementation perspective, the system utilizes [Neo4j](https://neo4j. com/) as the underlying graph database. LLM-based extractors and update module leverage GPT-4o-mini with function calling capabilities, allowing for structured extraction of information from unstructured text. By combining graph-based representations with semantic embeddings and LLM-based information extraction,
从实现角度看,系统使用 [Neo4j](https://neo4j. com/) 作为底层图数据库。 基于 LLM 的提取器和更新模块利用具备函数调用能力的 GPT-4o-mini,从而能够从非结构化文本中进行结构化信息提取。 通过结合基于图的表示、语义嵌入以及基于 LLM 的信息提取,
3. Experimental Setup
3.1. Dataset
The LOCOMO dataset is designed to evaluate long-term conversational memory in dialogue systems. It comprises 10 extended conversations, each containing approximately 600 dialogues and 26000 tokens on average, distributed across multiple sessions. Each conversation captures two individuals discussing daily experiences or past events. Following these multi-session dialogues, each conversation is accompanied by 200 questions on an average with corresponding ground truth answers. These questions are categorized into multiple types: single-hop, multi-hop, temporal, and open-domain. The dataset originally included an adversarial question category, which was designed to test systems' ability to recognize unanswerable questions. However, this category was excluded from our evaluation because ground truth answers were unavailable, and the expected behavior for this question type is that the agent should recognize them as unanswerable.
LOCOMO 数据集旨在评估对话系统中的长期对话记忆能力。 它包含 10 段长对话,每段对话平均约有 600 轮对话和 26000 个 token,并分布在多个会话中。 每段对话记录了两个人讨论日常经历或过往事件的过程。 在这些多会话对话之后,每段对话平均配有 200 个问题及其对应的标准答案。 这些问题被划分为多种类型:单跳问题、多跳问题、时间问题和开放域问题。 该数据集最初还包含一个对抗性问题类别,用于测试系统识别不可回答问题的能力。 不过,我们在评估中排除了这一类别,因为它缺少标准答案,并且这类问题的预期行为是智能体应该识别出它们不可回答。
3.2. Evaluation Metrics
Our evaluation framework implements a comprehensive approach to assess long-term memory capabilities in dialogue systems, considering both response quality and operational efficiency. We categorize our metrics into two distinct groups that together provide a holistic understanding of system performance.
我们的评估框架采用一种综合方法来评估对话系统的长期记忆能力,同时考虑回答质量和运行效率。 我们将指标分为两个不同的组,这两组指标共同提供对系统性能的整体理解。
(1) Performance Metrics Previous research in conversational AI has predominantly relied on lexical similarity metrics such as F1 Score (F1) and BLEU-1 (BLEU-1). However, these metrics exhibit significant limitations when evaluating factual accuracy in conversational contexts. Consider a scenario where the ground truth answer is "Alice was born in March" and a system generates "Alice is born in July." Despite containing a critical factual error regarding the birth month, traditional metrics would assign relatively high scores due to lexical overlap in the remaining tokens ("Alice," "born," etc.). This fundamental limitation can lead to misleading evaluations that fail to capture semantic correctness.
(1) 性能指标 以往的对话式 AI 研究主要依赖词面相似度指标,例如 F1 Score(F1)和 BLEU-1(BLEU-1)。 然而,在评估对话场景中的事实准确性时,这些指标存在明显局限。 设想一种情况:标准答案是“Alice was born in March”,而系统生成的答案是“Alice is born in July”。 虽然这个回答在出生月份这一关键信息上存在事实错误,但由于其余 token(例如“Alice”“born”等)存在词面重叠,传统指标仍可能给出相对较高的分数。 这种根本性局限可能导致误导性评估,因为它无法真正捕捉语义正确性。
To address these shortcomings, we use LLM-as-a-Judge (Judge) as a complementary evaluation metric. This approach leverages a separate, more capable LLM to assess response quality across multiple dimensions, including factual accuracy, relevance, completeness, and contextual appropriateness. The judge model analyzes the question, ground truth answer and the generated answer, providing a more nuanced evaluation that aligns better with human judgment. Due to the stochastic nature of Judge evaluations, we conducted 10 independent runs for each method on the entire dataset and report the mean scores along with Judge is present in Appendix.
为了解决这些不足,我们使用 LLM-as-a-Judge(Judge)作为补充评估指标。 该方法利用一个单独的、更强的 LLM,从多个维度评估回答质量,包括事实准确性、相关性、完整性和上下文适配性。 裁判模型会分析问题、标准答案和生成答案,从而给出更细致、也更符合人类判断的评估。 由于 Judge 评估本身具有随机性,我们对整个数据集上的每种方法进行了 10 次独立运行,并报告平均分以及 Judge 的更多细节见附录。
(2) Deployment Metrics Beyond response quality, practical deployment considerations are crucial for real-world applications of long-term memory in AI agents. We systematically track Token Consumption, using cl100k_base encoding from tiktoken, measuring the number of tokens extracted during retrieval that serve as context for answering queries. For our memory-based models, these tokens represent the memories retrieved from the knowledge base, while for RAG-based models, they correspond to the total number of tokens in the retrieved text chunks. This distinction is important as it directly affects operational costs and system efficiency—whether processing concise memory facts or larger raw text segments. We further monitor Latency, (i) search latency: which captures the total time required to search the memory (in memory-based solutions) or chunk (in RAG-based solutions) and (ii) total latency: time to generate appropriate responses, consisting of both retrieval time (accessing memories or chunks) and answer generation time using the LLM.
(2) 部署指标 除了回答质量之外,实际部署因素对于 AI 智能体中长期记忆的真实应用也非常关键。 我们系统性地跟踪 Token Consumption,使用 tiktoken 中的 cl100k_base 编码,衡量检索过程中被取出并作为回答查询上下文的 token 数量。 对于基于记忆的模型,这些 token 表示从知识库中检索出的记忆;而对于基于 RAG 的模型,它们对应的是被检索文本块中的 token 总数。 这一区分很重要,因为它会直接影响运行成本和系统效率,也就是系统处理的是简洁的记忆事实,还是更大的原始文本片段。 我们还进一步监控 Latency:(i)搜索延迟,即搜索记忆(在基于记忆的方案中)或文本块(在基于 RAG 的方案中)所需的总时间;(ii)总延迟,即生成合适回答所需的时间,它由检索时间(访问记忆或文本块)和使用 LLM 生成答案的时间共同组成。
The relationship between these metrics reveals important trade-offs in system design. For instance, more sophisticated memory architectures might achieve higher factual accuracy but at the cost of increased token consumption and latency. Our multi-dimensional evaluation methodology enables researchers and practitioners to make informed decisions based on their specific requirements, whether prioritizing response quality for critical applications or computational efficiency for real-time deployment scenarios.
这些指标之间的关系揭示了系统设计中的重要权衡。 例如,更复杂的记忆架构可能获得更高的事实准确性,但代价是 token 消耗和延迟增加。 我们的多维评估方法使研究人员和实践者能够根据自身需求做出更有依据的决策,无论他们是优先考虑关键应用中的回答质量,还是优先考虑实时部署场景中的计算效率。
3.3. Baselines
To comprehensively evaluate our approach, we compare against six distinct categories of baselines that represent the current state of conversational memory systems. These diverse baselines collectively provide a robust framework for evaluating the effectiveness of different memory architectures across various dimensions, including factual accuracy, computational efficiency, and scalability to extended conversations. Where applicable, unless otherwise specified, we set the temperature to 0 to ensure the runs are as reproducible as possible.
为了全面评估我们的方法,我们将其与六类不同的基线进行比较,这些基线代表了当前对话记忆系统的发展状态。 这些多样化的基线共同构成了一个稳健的评估框架,用于从多个维度衡量不同记忆架构的有效性,包括事实准确性、计算效率,以及扩展到长对话时的可扩展性。 在适用情况下,除非另有说明,我们将温度设置为 0,以尽可能保证运行结果可复现。
Established LOCOMO Benchmarks We first establish a comparative foundation by evaluating previously benchmarked methods on the LOCOMO dataset. These include five established approaches: LoCoMo, ReadAgent, MemoryBank, MemGPT, and A-Mem. These established benchmarks not only provide direct comparison points with published results but also represent the evolution of conversational memory architectures across different algorithmic paradigms. For our evaluation, we select the metrics where gpt-4o-mini was used for the evaluation. More details about these benchmarks are mentioned in Appendix.
已有的 LOCOMO 基准 我们首先通过评估此前已在 LOCOMO 数据集上测试过的方法,建立比较基础。 这些方法包括五个已有方案:LoCoMo、ReadAgent、MemoryBank、MemGPT 和 A-Mem。 这些已有基准不仅提供了与已发表结果直接比较的参照点,也代表了不同算法范式下对话记忆架构的演进。 在我们的评估中,我们选择使用 gpt-4o-mini 作为评估模型时对应的指标。 关于这些基准的更多细节见附录。
Open-Source Memory Solutions Our second category consists of promising open-source memory architectures such as LangMem (Hot Path) that have demonstrated effectiveness in related conversational tasks but have not yet been evaluated on the LOCOMO dataset. By adapting these systems to our evaluation framework, we broaden the comparative landscape and identify potential alternative approaches that may offer competitive performance. We initialized the LLM with gpt-4o-mini and used text-embedding-small-3 as the embedding model.
开源记忆方案 第二类基线由一些有潜力的开源记忆架构组成,例如 LangMem(Hot Path)。这些系统已经在相关对话任务中展示出有效性,但尚未在 LOCOMO 数据集上进行评估。 通过将这些系统适配到我们的评估框架中,我们拓宽了比较范围,并识别出可能具有竞争性能的替代方案。 我们使用 gpt-4o-mini 初始化 LLM,并使用 text-embedding-small-3 作为嵌入模型。
Retrieval-Augmented Generation (RAG) As a baseline, we treat the entire conversation history as a document collection and apply a standard RAG pipeline. We first segment each conversation into fixed-length chunks (128, 256, 512, 1024, 2048, 4096, and 8192 tokens), where 8192 is the maximum chunk size supported by our embedding model. All chunks are embedded using OpenAI's text-embedding-small-3 to ensure consistent vector quality across configurations. At query time, we retrieve the top
检索增强生成(RAG) 作为一个基线,我们将完整对话历史视为文档集合,并应用标准 RAG 流水线。 我们首先将每段对话切分为固定长度的文本块(128、256、512、1024、2048、4096 和 8192 个 token),其中 8192 是我们的嵌入模型支持的最大块大小。 所有文本块都使用 OpenAI 的 text-embedding-small-3 进行嵌入,以确保不同配置下的向量质量一致。 在查询时,我们根据语义相似度检索 top-
Full-Context Processing We adopt a straightforward approach by passing the entire conversation history within the context window of the LLM. This method leverages the model's inherent ability to process sequential information without additional architectural components. While conceptually simple, this approach faces practical limitations as conversation length increases, eventually increasing token cost and latency. Nevertheless, it establishes an important reference point for understanding the value of more sophisticated memory mechanisms compared to direct processing of available context.
全上下文处理 我们采用一种直接方法:将完整对话历史放入 LLM 的上下文窗口中。 该方法利用模型自身处理序列信息的能力,不需要额外架构组件。 虽然这个思路在概念上很简单,但随着对话长度增加,它会面临实际限制,最终导致 token 成本和延迟上升。 尽管如此,它仍然提供了一个重要参照点,有助于理解更复杂的记忆机制相对于直接处理可用上下文的价值。
Proprietary Models We evaluate OpenAI's memory feature available in their ChatGPT interface, specifically using gpt-4o-mini for consistency. We ingest entire LOCOMO conversations with a prompt into single chat sessions, prompting memory generation with timestamps, participant names, and conversation text. These generated memories are then used as complete context for answering questions about each conversation, intentionally granting the OpenAI approach privileged access to all memories rather than only question-relevant ones. This methodology accommodates the lack of external API access for selective memory retrieval in OpenAI's system for benchmarking.
专有模型 我们评估了 OpenAI 在 ChatGPT 界面中提供的记忆功能,并专门使用 gpt-4o-mini 以保持一致性。 我们通过提示词将完整的 LOCOMO 对话导入单个聊天会话,并要求系统根据时间戳、参与者姓名和对话文本生成记忆。 随后,这些生成的记忆会作为完整上下文,用于回答每段对话相关的问题。这里我们有意让 OpenAI 方法能够访问全部记忆,而不只是与问题相关的记忆。 由于 OpenAI 系统缺少用于选择性记忆检索的外部 API,这种方法用于适配其基准评测。
Memory Providers We incorporate Zep, a memory management platform designed for AI agents. Using their platform version, we conduct systematic evaluations across the LOCOMO dataset, maintaining temporal fidelity by preserving timestamp information alongside conversational content. This temporal anchoring ensures that time-sensitive queries can be addressed through appropriately contextualized memory retrieval, particularly important for evaluating questions that require chronological awareness. This baseline represents an important commercial implementation of memory management specifically engineered for AI agents.
记忆服务提供方 我们纳入了 Zep,这是一个面向 AI 智能体设计的记忆管理平台。 我们使用其平台版本,在 LOCOMO 数据集上进行系统性评估,并通过在对话内容旁保留时间戳信息来维持时间一致性。 这种时间锚定确保了涉及时间的问题可以通过适当的上下文化记忆检索来回答,尤其适合评估需要时间顺序意识的问题。 该基线代表了一种专门为 AI 智能体设计的商业记忆管理实现。
| 方法 | 单跳 | 多跳 | ||||
|---|---|---|---|---|---|---|
| F1 ↑ | BLEU-1 ↑ | LLM裁判 ↑ | F1 ↑ | BLEU-1 ↑ | LLM裁判 ↑ | |
| LoCoMo | 25.02 | 19.75 | -- | 12.04 | 11.16 | -- |
| ReadAgent | 9.15 | 6.48 | -- | 5.31 | 5.12 | -- |
| MemoryBank | 5.00 | 4.77 | -- | 5.56 | 5.94 | -- |
| MemGPT | 26.65 | 17.72 | -- | 9.15 | 7.44 | -- |
| A-Mem | 27.02 | 20.09 | -- | 12.14 | 12.00 | -- |
| A-Mem* | 20.76 | 14.90 | 39.79 ± 0.38 | 9.22 | 8.81 | 18.85 ± 0.31 |
| LangMem | 35.51 | 26.86 | 62.23 ± 0.75 | 26.04 | 22.32 | 47.92 ± 0.47 |
| Zep | 35.74 | 23.30 | 61.70 ± 0.32 | 19.37 | 14.82 | 41.35 ± 0.48 |
| OpenAI | 34.30 | 23.72 | 63.79 ± 0.46 | 20.09 | 15.42 | 42.92 ± 0.63 |
| Mem0 | 38.72 | 27.13 | 67.13 ± 0.65 | 28.64 | 21.58 | 51.15 ± 0.31 |
| Mem0g | 38.09 | 26.03 | 65.71 ± 0.45 | 24.32 | 18.82 | 47.19 ± 0.67 |
| 方法 | 开放域 | 时间 | ||||
|---|---|---|---|---|---|---|
| F1 ↑ | BLEU-1 ↑ | LLM裁判 ↑ | F1 ↑ | BLEU-1 ↑ | LLM裁判 ↑ | |
| LoCoMo | 40.36 | 29.05 | -- | 18.41 | 14.77 | -- |
| ReadAgent | 9.67 | 7.66 | -- | 12.60 | 8.87 | -- |
| MemoryBank | 6.61 | 5.16 | -- | 9.68 | 6.99 | -- |
| MemGPT | 41.04 | 34.34 | -- | 25.52 | 19.44 | -- |
| A-Mem | 44.65 | 37.06 | -- | 45.85 | 36.67 | -- |
| A-Mem* | 33.34 | 27.58 | 54.05 ± 0.22 | 35.40 | 31.08 | 49.91 ± 0.31 |
| LangMem | 40.91 | 33.63 | 71.12 ± 0.20 | 30.75 | 25.84 | 23.43 ± 0.39 |
| Zep | 49.56 | 38.92 | 76.60 ± 0.13 | 42.00 | 34.53 | 49.31 ± 0.50 |
| OpenAI | 39.31 | 31.16 | 62.29 ± 0.12 | 14.04 | 11.25 | 21.71 ± 0.20 |
| Mem0 | 47.65 | 38.72 | 72.93 ± 0.11 | 48.93 | 40.51 | 55.51 ± 0.34 |
| Mem0g | 49.27 | 40.30 | 75.71 ± 0.21 | 51.55 | 40.28 | 58.13 ± 0.44 |
4. Evaluation Results, Analysis and Discussion
4.1. Performance Comparison Across Memory-Enabled Systems
Table 1 reports F1, BLEU-1 and Judge scores for our two architectures, Mem0 and
表1报告了我们两个架构 Mem0 和 F1、BLEU-1 与 Judge 分数,并将它们与一系列有竞争力的基线进行了比较。 总体而言,对于大多数问题类型,我们的两个模型在三个评估指标上都达到了新的最优水平。
Single-Hop Question Performance Single-hop queries involve locating a single factual span contained within one dialogue turn. Leveraging its dense memories in natural language text, Mem0 secures the strongest results: F1 = 38.72, BLEU-1 = 27.13, and Judge = 67.13. Augmenting the natural language memories with graph memory (OpenAI run attains the next-best Judge score, reflecting the benefits of retaining the entire conversation in context, while LangMem and Zep both score around 8% relatively less against our models on Judge score. Previous LOCOMO benchmarks such as A-Mem lag by more than 25 points in Judge, underscoring the necessity of fine-grained, structured memory indexing even for simple retrieval tasks.
单跳问题表现 单跳查询需要定位包含在某一轮对话中的单个事实片段。 凭借自然语言文本形式的稠密记忆,Mem0 取得了最强结果:F1 = 38.72,BLEU-1 = 27.13,Judge = 67.13。 相比 Mem0,在自然语言记忆上加入图记忆的 OpenAI 运行取得了次优 Judge 分数,体现了将完整对话保留在上下文中的好处;而 LangMem 和 Zep 在 Judge 分数上相对我们的模型低约 8%。 此前的 LOCOMO 基准方法如 A-Mem 在 Judge 上落后超过 25 分,这说明即使对于简单检索任务,细粒度、结构化的记忆索引也很重要。
Multi-Hop Question Performance Multi-hop queries require synthesizing information dispersed across multiple conversation sessions, posing significant challenges in memory integration and retrieval. Mem0 clearly outperforms other methods with an F1 score of 28.64 and a Judge score of 51.15, reflecting its capability to efficiently retrieve and integrate disparate information stored across sessions. Interestingly, the addition of graph memory in
多跳问题表现 多跳查询需要综合分散在多个对话会话中的信息,这对记忆整合和检索提出了显著挑战。 Mem0 明显优于其他方法,取得了 28.64 的 F1 分数和 51.15 的 Judge 分数,反映出它能够高效检索并整合跨会话存储的分散信息。 有趣的是,
Open-Domain Performance In open-domain settings, the baseline Zep achieves the highest F1 (49.56) and Judge (76.60) scores, edging out our methods by a narrow margin. In particular, Zep's Judge score of 76.60 surpasses Judge of 75.71 reflecting high factual retrieval precision, while Mem0 follows with 72.93, demonstrating robust coherence. These results underscore that although structured relational memories, as in Mem0 and
开放域表现 在开放域设置中,基线 Zep 取得了最高的 F1(49.56)和 Judge(76.60)分数,以很小优势超过我们的方法。 具体而言,Zep 的 Judge 分数为 76.60,仅比 Judge 分数为 75.71,反映出较高的事实检索精度;Mem0 的分数为 72.93,也表现出稳健的一致性。 这些结果说明,尽管 Mem0 和
Temporal Reasoning Performance Temporal reasoning tasks hinge on accurate modeling of event sequences, their relative ordering, and durations within conversational history. Our architectures demonstrate substantial improvements across all metrics, with F1 (51.55) and Judge (58.13), suggesting that structured relational representations in addition to natural language memories significantly aid in temporally grounded judgments. Notably, the base variant, Mem0, also provide a decent Judge score (55.51), suggesting that natural language alone can aid in temporally grounded judgments. Among baselines, OpenAI notably underperforms, with scores below 15%, primarily due to missing timestamps in most generated memories despite explicit prompting in the OpenAI ChatGPT to extract memories with timestamps. Other baselines such as A-Mem achieve respectable results, yet our models clearly advance the state-of-the-art, emphasizing the critical advantage of accurately leveraging both natural language contextualization and structured graph representations for temporal reasoning.
时间推理表现 时间推理任务依赖于对对话历史中事件序列、相对顺序和持续时间的准确建模。 我们的架构在所有指标上都取得了显著提升,其中 F1(51.55)和 Judge(58.13),这说明在自然语言记忆之外加入结构化关系表示,可以显著帮助基于时间的判断。 值得注意的是,基础版本 Mem0 也取得了不错的 Judge 分数(55.51),说明单独的自然语言记忆也能帮助时间判断。 在基线中,OpenAI 表现明显较弱,分数低于 15%,主要原因是尽管我们在 ChatGPT 中明确提示其提取带时间戳的记忆,但大多数生成记忆仍然缺少时间戳。 其他基线如 A-Mem 取得了尚可的结果,但我们的模型明显推进了当前最优水平,强调了同时准确利用自然语言上下文化和结构化图表示进行时间推理的关键优势。
4.2. Cross-Category Analysis
The comprehensive evaluation across diverse question categories reveals that our proposed architectures, Mem0 and Judge scores. This indicates that graph structures are more beneficial in scenarios involving nuanced relational context rather than straightforward retrieval. For multi-hop questions, Mem0 exhibits clear advantages by effectively synthesizing dispersed information across multiple sessions, confirming that natural language memories provide sufficient representational richness for these integrative tasks. Surprisingly, the expected relational advantages of
跨多种问题类别的综合评估表明,我们提出的 Mem0 和 Judge 分数可以看出,它显著增强了语义一致性。 这说明图结构更适用于涉及细微关系上下文的场景,而不是直接检索场景。 对于多跳问题,Mem0 通过有效综合跨多个会话的分散信息展现出明显优势,说明自然语言记忆已经为这类整合任务提供了足够丰富的表示。 令人意外的是,
LOCOMO 数据集上的回答质量。| 方法 | K | 块大小 / 记忆 token | 延迟(秒) | 总体 J | |||
|---|---|---|---|---|---|---|---|
| 搜索 | 总响应 | ||||||
| p50 | p95 | p50 | p95 | ||||
| RAG | 1 | 128 | 0.281 | 0.823 | 0.774 | 1.825 | 47.77 ± 0.23% |
| 256 | 0.251 | 0.710 | 0.745 | 1.628 | 50.15 ± 0.16% | ||
| 512 | 0.240 | 0.639 | 0.772 | 1.710 | 46.05 ± 0.14% | ||
| 1024 | 0.240 | 0.723 | 0.821 | 1.957 | 40.74 ± 0.17% | ||
| 2048 | 0.255 | 0.752 | 0.996 | 2.182 | 37.93 ± 0.12% | ||
| 4096 | 0.254 | 0.719 | 1.093 | 2.711 | 36.84 ± 0.17% | ||
| 8192 | 0.279 | 0.838 | 1.396 | 4.416 | 44.53 ± 0.13% | ||
| 2 | 128 | 0.267 | 0.624 | 0.766 | 1.829 | 59.56 ± 0.19% | |
| 256 | 0.255 | 0.699 | 0.802 | 1.907 | 60.97 ± 0.20% | ||
| 512 | 0.247 | 0.746 | 0.829 | 1.729 | 58.19 ± 0.18% | ||
| 1024 | 0.238 | 0.702 | 0.860 | 1.850 | 50.68 ± 0.13% | ||
| 2048 | 0.261 | 0.829 | 1.101 | 2.791 | 48.57 ± 0.22% | ||
| 4096 | 0.266 | 0.944 | 1.451 | 4.822 | 51.79 ± 0.15% | ||
| 8192 | 0.288 | 1.124 | 2.312 | 9.942 | 60.53 ± 0.16% | ||
| Full-context | -- | 26031 | -- | -- | 9.870 | 17.117 | 72.90 ± 0.19% |
| A-Mem | -- | 2520 | 0.668 | 1.485 | 1.410 | 4.374 | 48.38 ± 0.15% |
| LangMem | -- | 127 | 17.99 | 59.82 | 18.53 | 60.40 | 58.10 ± 0.21% |
| Zep | -- | 3911 | 0.513 | 0.778 | 1.292 | 2.926 | 65.99 ± 0.16% |
| OpenAI | -- | 4437 | -- | -- | 0.466 | 0.889 | 52.90 ± 0.14% |
| Mem0 | -- | 1764 | 0.148 | 0.200 | 0.708 | 1.440 | 66.88 ± 0.15% |
| Mem0g | -- | 3616 | 0.476 | 0.657 | 1.091 | 2.590 | 68.44 ± 0.17% |
In temporal reasoning,
在时间推理中,
Overall, our analysis indicates complementary strengths of Mem0 and
总体而言,我们的分析表明 Mem0 和
图4(a):不同记忆方法的搜索延迟对比。柱状高度表示 Judge 分数,折线表示搜索延迟,右轴采用对数尺度。
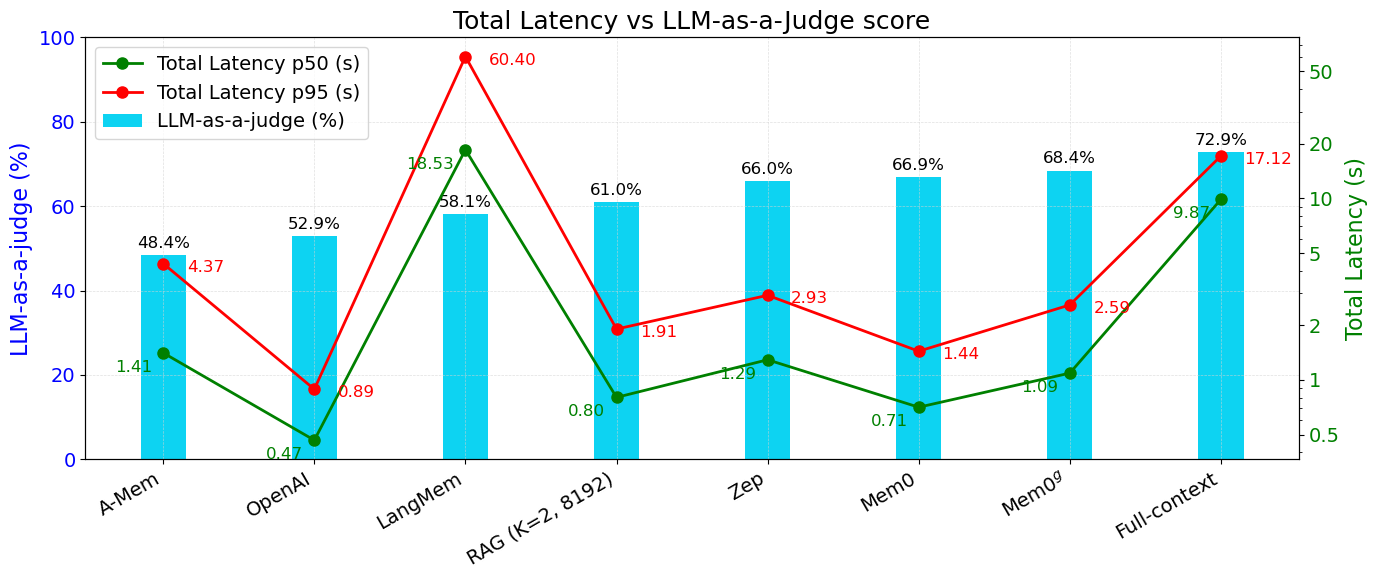
图4(b):不同记忆方法的总响应延迟对比。柱状高度表示 Judge 分数,折线表示端到端延迟,右轴采用对数尺度。
图4:不同记忆方法的延迟分析。图4(a) 展示答案生成前的搜索/检索延迟,图4(b) 展示包含 LLM 推理在内的总延迟。
4.3. Performance Comparison of Mem0 and
Comparisons in Table 2, focusing on the Overall Judge column, reveal that both Mem0 and Judge metric, whereas Mem0 reaches 67%, about a 10% relative improvement, and Judge).
从表2的 Overall Judge 列可以看出,Mem0 和 Judge 指标上也只有约 61%;而 Mem0 达到 67%,相对提升约 10%;Judge)评估下生成更好的答案。
Despite these improvements, a full-context method that ingests a chunk of roughly 26000 tokens still achieves the highest Judge score, approximately 73%. However, as shown in Figure 4(b), it also incurs a very high total p95 latency, around 17 seconds, since the model must read the entire conversation on every query. By contrast, Mem0 and
尽管有这些提升,输入约 26000 个 token 的全上下文方法仍然取得了最高的 Judge 分数,约为 73%。 但是,如图4(b)所示,它也带来了很高的总 p95 延迟,约 17 秒,因为模型每次查询都必须读取完整对话。 相比之下,Mem0 和
As conversation length increases, full-context approaches suffer from exponential growth in computational overhead, evident in Table 2 where total p95 latency increases significantly with larger
随着对话长度增加,全上下文方法会面临计算开销的快速增长。表2中可以看到,当
4.4. Latency Analysis
Table 2 provides a comprehensive performance comparison of various retrieval and memory methodologies, presenting median (p50) and tail (p95) latencies for both the search phase and total response generation across the LOCOMO dataset. Our analysis reveals distinct performance patterns governed by architectural choices. Memory-centric architectures demonstrate different performance characteristics. A-Mem, despite its larger memory store, incurs substantial search overhead (p50: 0.668s), resulting in total median latencies of 1.410s. LangMem exhibits even higher search latencies (p50: 17.99s, p95: 59.82s), rendering it impractical for interactive applications. Zep achieves moderate performance (p50 total: 1.292s).
表2全面比较了不同检索和记忆方法的性能,展示了 LOCOMO 数据集上搜索阶段和总响应生成阶段的中位数延迟(p50)与尾部延迟(p95)。 我们的分析揭示了由架构选择决定的不同性能模式。 以记忆为中心的架构表现出不同特征。 A-Mem 尽管拥有较大的记忆存储,但搜索开销较高(p50: 0.668s),导致总中位延迟为 1.410s。 LangMem 的搜索延迟更高(p50: 17.99s,p95: 59.82s),使其不适合交互式应用。 Zep 表现中等,总 p50 延迟为 1.292s。
The full-context baseline, which processes the entire conversation history without retrieval, fundamentally differs from retrieval-based approaches. By passing the entire conversation context (26000 tokens) directly to the LLM, it eliminates search overhead but incurs extreme total latencies (p50: 9.870s, p95: 17.117s). Similarly, the OpenAI implementation does not perform memory search, as it processes manually extracted memories from their playground. While this approach achieves impressive response generation times (p50: 0.466s, p95: 0.889s), it requires pre-extraction of relevant context, which is not reflected in the reported metrics.
全上下文基线与基于检索的方法存在根本差异,因为它不进行检索,而是处理完整对话历史。 通过将完整对话上下文(26000 个 token)直接传给 LLM,它消除了搜索开销,但带来了极高的总延迟(p50: 9.870s,p95: 17.117s)。 类似地,OpenAI 实现也不执行记忆搜索,因为它处理的是从 playground 中手动提取出的记忆。 虽然该方法取得了很快的回答生成时间(p50: 0.466s,p95: 0.889s),但它需要预先提取相关上下文,而这部分成本没有反映在报告指标中。
Our proposed Mem0 approach achieves the lowest search latency among all methods (p50: 0.148s, p95: 0.200s) as illustrated in Figure 4(a). This efficiency stems from our selective memory retrieval mechanism and infrastructure improvements that dynamically identifies and retrieves only the most salient information rather than fixed-size chunks. Consequently, Mem0 maintains the lowest total median latency (0.708s) with remarkably contained p95 values (1.440s), making it particularly suitable for latency-sensitive applications such as interactive AI agents. The graph-enhanced Judge score (68.44%) across all methods, trailing only the computationally prohibitive full-context approach. This performance profile demonstrates our methods' ability to balance response quality and computational efficiency, offering a compelling solution for production AI agents where both factors are critical constraints.
如图4(a)所示,我们提出的 Mem0 在所有方法中取得了最低搜索延迟(p50: 0.148s,p95: 0.200s)。 这种效率来自我们的选择性记忆检索机制和基础设施改进,它们能够动态识别并检索最关键的信息,而不是固定大小的文本块。 因此,Mem0 保持了最低的总中位延迟(0.708s),并将 p95 延迟控制在很低水平(1.440s),特别适合交互式 AI 智能体等延迟敏感应用。 图增强版本 Judge 分数(68.44%),仅低于计算成本很高的全上下文方法。 这一性能画像表明,我们的方法能够平衡回答质量和计算效率,为两者都是关键约束的生产级 AI 智能体提供了有吸引力的方案。
4.5. Memory System Overhead: Token Analysis and Construction Time
We measure the average token budget required to materialise each system's long-term memory store. Mem0 encodes complete dialogue turns in a natural language representation and therefore occupies only 7k tokens per conversation on an average. Whereas
我们衡量了每个系统构建长期记忆存储所需的平均 token 预算。 Mem0 使用自然语言表示编码完整对话轮次,因此每段对话平均只占用约 7k token。 而
Beyond token inefficiency, our experiments revealed significant operational bottlenecks with Zep. After adding memories to Zep's system, we observed that immediate memory retrieval attempts often failed to answer our queries correctly. Interestingly, re-running identical searches after a delay of several hours yielded considerably better results. This latency suggests that Zep's graph construction involves multiple asynchronous LLM calls and extensive background processing, making the memory system impractical for real-time applications. In contrast, Mem0 graph construction completes in under a minute even in worst-case scenarios, allowing users to immediately leverage newly added memories for query responses.
除了 token 效率低之外,我们的实验还发现 Zep 存在显著的运行瓶颈。 在向 Zep 系统添加记忆后,我们观察到立即进行记忆检索时,系统往往无法正确回答查询。 有趣的是,等待数小时后重新运行相同搜索,会得到明显更好的结果。 这种延迟表明,Zep 的图构建涉及多次异步 LLM 调用和大量后台处理,使得该记忆系统不适合实时应用。 相比之下,即使在最坏情况下,Mem0 的图构建也能在一分钟内完成,使用户可以立即利用新加入的记忆回答查询。
These findings highlight that Zep not only replicates identical knowledge fragments across multiple nodes, but also introduces significant operational delays. Our architectures, Mem0 and
这些发现表明,Zep 不仅会在多个节点之间复制相同知识片段,还会引入显著的运行延迟。 我们的架构 Mem0 和
5. Conclusion and Future Work
We have introduced Mem0 and LOCOMO benchmark, our methods deliver 5%, 11%, and 7% relative improvements in single-hop, temporal, and multi-hop reasoning question types over best performing methods in respective question type and reduce p95 latency by over 91% compared to full-context baselines, demonstrating a powerful balance between precision and responsiveness. Mem0's dense memory pipeline excels at rapid retrieval for straightforward queries, minimizing token usage and computational overhead. In contrast,
我们提出了 Mem0 和 LOCOMO 基准上,相比各自问题类型中表现最好的方法,我们的方法在单跳、时间和多跳推理问题上分别带来了 5%、11% 和 7% 的相对提升,并且相比全上下文基线将 p95 延迟降低了超过 91%,展示了准确性与响应速度之间的强大平衡。 Mem0 的稠密记忆流水线擅长对直接查询进行快速检索,能够最小化 token 使用量和计算开销。 相比之下,
Future research directions include optimizing graph operations to reduce the latency overhead in
未来研究方向包括:优化图操作以降低