
MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution
MemoryAgentMulti-Agent宾夕法尼亚州立大学AmazonMicrosoftMemMA:通过多智能体推理与原位自演化协调记忆循环
Abstract
Memory-augmented LLM agents maintain external memory banks to support long-horizon interaction, yet most existing systems treat construction, retrieval, and utilization as isolated subroutines. This creates two coupled challenges: strategic blindness on the forward path of the memory cycle, where construction and retrieval are driven by local heuristics rather than explicit strategic reasoning, and sparse, delayed supervision on the backward path, where downstream failures rarely translate into direct repairs of the memory bank. To address these challenges, we propose MemMA, a plug-and-play multi-agent framework that coordinates the memory cycle along both the forward and backward paths. On the forward path, a Meta-Thinker produces structured guidance that steers a Memory Manager during construction and directs a Query Reasoner during iterative retrieval. On the backward path, MemMA introduces in-situ self-evolving memory construction, which synthesizes probe QA pairs, verifies the current memory, and converts failures into repair actions before the memory is finalized. Extensive experiments on LoCoMo show that MemMA consistently outperforms existing baselines across multiple LLM backbones and improves three different storage backends in a plug-and-play manner.
记忆增强型 LLM 智能体维护外部记忆库以支持长程交互,但大多数现有系统将构建、检索和利用视为彼此孤立的子例程。 这产生了两个耦合挑战:在记忆循环的前向路径上存在 战略盲区,即构建和检索由局部启发式驱动,而不是由显式战略推理驱动;在反向路径上存在 稀疏且延迟的监督,即下游失败很少转化为对记忆库的直接修复。 为解决这些挑战,作者提出 MemMA,这是一个即插即用的多智能体框架,可沿前向和反向两条路径协调记忆循环。 在前向路径上,Meta-Thinker 生成结构化指导,在构建期间引导 Memory Manager,并在迭代检索期间指导 Query Reasoner。 在反向路径上,MemMA 引入原位自演化记忆构建:它合成探测问答对,验证当前记忆,并在记忆最终确定前将失败转化为修复动作。 在 LoCoMo 上的大量实验表明,MemMA 在多个 LLM 骨干模型上持续优于现有基线,并以即插即用方式改进了三种不同存储后端。
1. Introduction
Large language models (LLMs) are evolving from episodic chatbots into persistent agentic systems that execute complex workflows over days or weeks. In such settings, agents receive a continuous stream of observations---user constraints, tool outputs, and environmental feedback---whose consequences unfold over long horizons. This shift makes controllable, long-term memory a first-class requirement: relying solely on ephemeral context windows is insufficient, as they are computationally expensive and prone to attention dilution. To maintain coherence over time, agents must actively manage an external memory bank, deciding what to retain and how to retrieve it under uncertainty.
大语言模型(LLMs)正从短会话聊天机器人演化为持久的 智能体式系统,能够在数天或数周内执行复杂工作流。 在这样的设置中,智能体会接收连续的观测流,包括用户约束、工具输出和环境反馈,而这些信息的后果会在长时间范围内展开。 这一转变使 可控的长期记忆 成为一等需求:仅依赖短暂的上下文窗口是不够的,因为它们计算成本高且容易出现注意力稀释。 为了随时间保持连贯性,智能体必须主动管理外部记忆库,在不确定性下决定保留什么以及如何检索。
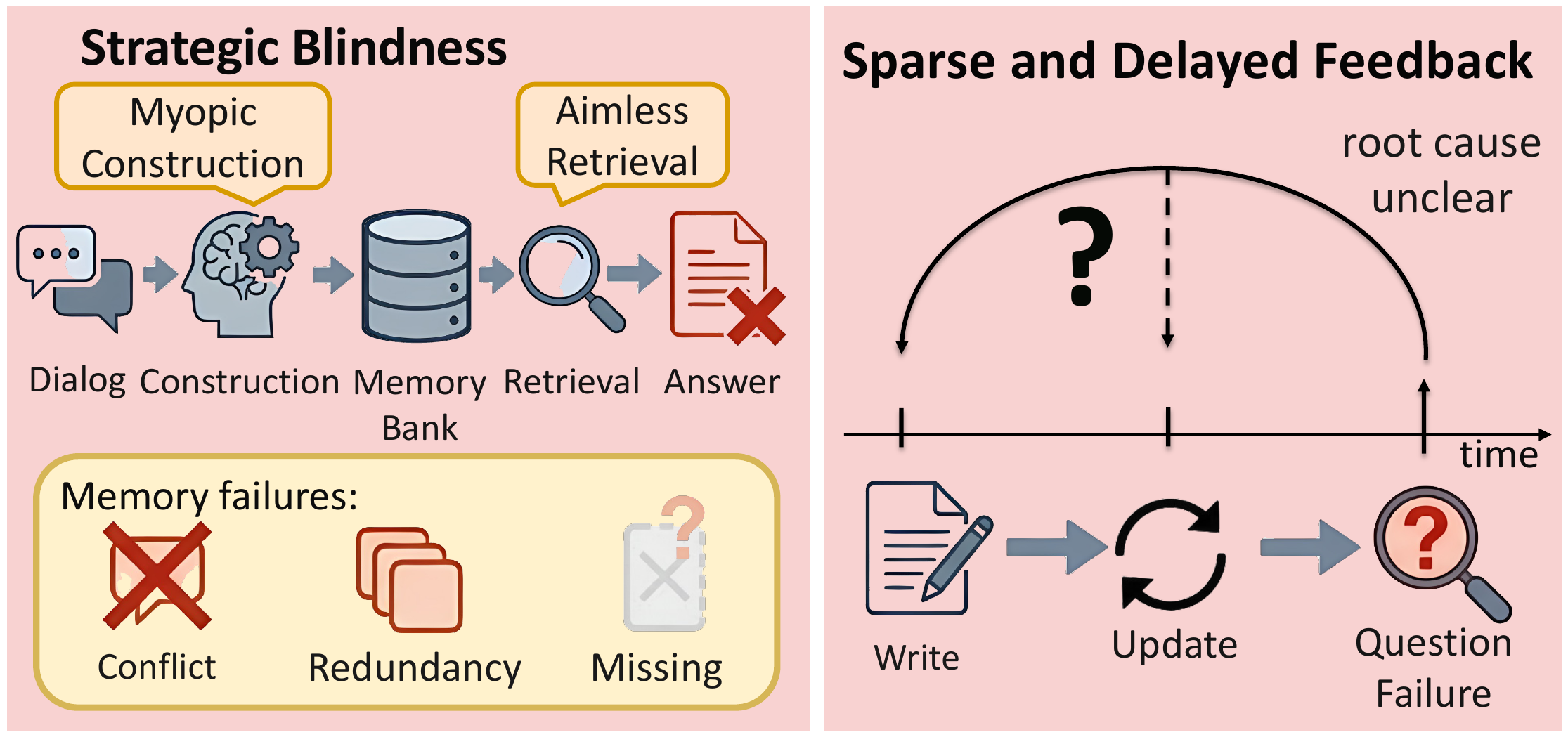
Effective memory, however, is not merely a storage utility; it is a closed-loop dynamic, conceptualized as the memory cycle effect. This cycle has three coupled phases: construction, retrieval, and utilization. Construction determines what information enters the memory bank and how it is organized; retrieval determines what stored information is surfaced as evidence; and utilization reveals whether the retrieved evidence is sufficient for downstream reasoning. This coupling implies that optimizing these stages in isolation is fundamentally suboptimal: a retrieval failure may stem from a much earlier construction error, while utilization outcomes should ideally feed back to improve future memory decisions. Despite this intrinsic dependency, most existing memory-augmented agents still treat memory operations as isolated, reactive subroutines, overlooking the coupling between stages. To leverage the memory cycle effect, two technical challenges must be addressed (Figure 1).
然而,有效记忆并不仅仅是一个存储工具;它是一种闭环动态,被概念化为 记忆循环效应。 这一循环包含三个耦合阶段:构建、检索 和 利用。 构建决定哪些信息进入记忆库以及如何组织;检索决定哪些已存信息会作为证据被呈现;利用则揭示检索到的证据是否足以支持下游推理。 这种耦合意味着孤立优化这些阶段从根本上是次优的:检索失败可能源于更早的构建错误,而利用结果理想情况下应反馈回来改进未来的记忆决策。 尽管存在这种内在依赖,大多数现有记忆增强型智能体仍将记忆操作视为孤立的、反应式的子例程,忽略了阶段之间的耦合。 为了利用记忆循环效应,必须解决两个技术挑战(图1)。
First, on the forward path of the memory cycle, current systems often suffer from strategic blindness: they possess the mechanisms to edit memory and issue retrieval queries, yet lack explicit meta-cognition to coordinate these actions toward downstream question answering. As our preliminary analysis shows (Section 3.3), this manifests as two pathologies: (i) Myopic Construction, where the agent accumulates or overwrites conflicting facts without resolution; and (ii) Aimless Retrieval, where the agent performs shallow or repetitive searches without narrowing the true information gap. These failures suggest that effective forward-path memory behavior requires explicit coordination between construction and retrieval, rather than isolated, short-sighted decisions.
第一,在记忆循环的 前向路径 上,当前系统经常遭遇 战略盲区:它们拥有编辑记忆和发起检索查询的机制,却缺少显式的 元认知来协调这些动作以服务下游问答。 如作者的预备分析所示(第 3.3 节),这表现为两类病症:(i) 短视构建(Myopic Construction),其中智能体积累或覆盖冲突事实却不解决冲突;(ii) 盲目检索(Aimless Retrieval),其中智能体执行浅层或重复搜索,却没有缩小真正的信息缺口。 这些失败表明,有效的前向路径记忆行为需要构建与检索之间的显式协调,而不是孤立、短视的决策。
Second, on the backward path of the memory cycle, feedback from utilization to construction is typically sparse and delayed. Whether a memory-writing decision is useful may become clear only much later, when the agent fails a downstream question. This makes credit assignment difficult: when an answer is wrong, it is hard to identify which earlier construction decision caused the failure, allowing omissions and unresolved conflicts to persist in the memory bank and affect later updates. Although recent methods use reflection or experiential learning to improve agent behavior, downstream failures are still rarely converted into direct signals for repairing the memory bank itself.
第二,在记忆循环的 反向路径 上,从利用到构建的反馈通常是 稀疏且延迟的。 一个记忆写入决策是否有用,可能要到很久之后,当智能体在下游问题上失败时才变得清楚。 这使信用分配变得困难:当答案错误时,很难识别是哪一个更早的构建决策导致了失败,从而让遗漏和未解决冲突持续存在于记忆库中并影响后续更新。 尽管近期方法使用反思或经验学习来改进智能体行为,下游失败仍然很少被转换为修复记忆库本身的直接信号。
To address these challenges, we propose MemMA (Memory Cycle Multi-Agent Coordination), a plug-and-play multi-agent framework that coordinates the memory cycle along its forward and backward paths. Specifically, for the forward path, MemMA separates strategic reasoning from low-level execution through a planner--worker architecture: a Meta-Thinker produces structured guidance that steers a Memory Manager during construction (what to retain, consolidate, or resolve), thereby mitigating Myopic Construction, and directs a Query Reasoner during retrieval by diagnosing missing evidence and how to retrieve it, replacing one-shot search with diagnosis-guided iterative refinement and thereby mitigating Aimless Retrieval. For the backward path, MemMA introduces in-situ self-evolving memory construction: after each session, the system synthesizes probe QA pairs, verifies the memory against them, and converts failures into repair actions on the memory bank through evidence-grounded critique and semantic consolidation, before the memory is committed for future use. This directly addresses sparse and delayed supervision by turning downstream failures into immediate, localized repair signals for the current memory state, before flawed memories propagate into future memory updates.
为解决这些挑战,作者提出 MemMA(Memory Cycle Multi-Agent Coordination),这是一个即插即用的多智能体框架,沿其前向和反向两条路径协调记忆循环。 具体来说,对于 前向路径,MemMA 通过规划器--执行器架构将战略推理与底层执行分离:Meta-Thinker 生成结构化指导,在构建期间引导 Memory Manager(决定保留、合并或解决什么),从而缓解 短视构建;并在检索期间通过诊断缺失证据及其检索方式来指导 Query Reasoner,用诊断引导的迭代细化替代一次性搜索,从而缓解 盲目检索。 对于 反向路径,MemMA 引入原位自演化记忆构建:每个会话之后,系统合成探测问答对,用它们验证记忆,并通过基于证据的批判和语义整合将失败转化为记忆库上的修复动作,然后再把记忆提交给未来使用。 这通过将下游失败转化为当前记忆状态的即时、局部化修复信号,直接解决 稀疏且延迟的监督,避免有缺陷的记忆传播到未来的记忆更新。
Our contributions are:
- Analysis. We identify two technical challenges in leveraging the memory cycle effect: strategic blindness on the forward path and sparse, delayed feedback on the backward path, and provide empirical evidence through a controlled preliminary study (Section 3.3).
- Framework. We propose MemMA, a plug-and-play multi-agent framework that coordinates the memory cycle along both its forward and backward paths, combining reasoning-aware coordination for construction and iterative retrieval with in-situ self-evolving memory construction for backward repair.
- Experiments. MemMA outperforms existing baselines on LoCoMo across multiple LLM backbones, and consistently improves three storage backends as a plug-and-play module.
作者的贡献如下:
- 分析。 作者识别出利用记忆循环效应的两个技术挑战:前向路径上的 战略盲区 以及反向路径上的 稀疏且延迟的反馈,并通过受控预备研究提供经验证据(第 3.3 节)。
- 框架。 作者提出 MemMA,这是一个即插即用的多智能体框架,沿前向和反向两条路径协调记忆循环,将用于构建与迭代检索的推理感知协调,和用于反向修复的原位自演化记忆构建结合起来。
- 实验。 MemMA 在 LoCoMo 上跨多个 LLM 骨干模型优于现有基线,并作为即插即用模块持续改进三种存储后端。
2. Related Work
Memory-Augmented LLM Agents. External memory has become a core component of LLM agents that operate over long horizons. Prior work improves long-term memory from several directions, including memory architecture, memory organization and consolidation, and memory retrieval. These methods substantially improve individual stages of the memory pipeline, but they primarily optimize storage, organization, or retrieval in isolation. Our work is inherently different from existing work: MemMA jointly coordinates memory construction and iterative retrieval, and converts utilization failures into direct repair signals for the memory bank. Full version is in Appendix.
记忆增强型 LLM 智能体。 外部记忆已成为长时间运行的 LLM 智能体的核心组件。 先前工作从多个方向改进长期记忆,包括记忆架构、记忆组织与整合,以及记忆检索。 这些方法显著改进了记忆流程的单个阶段,但它们主要是孤立地优化存储、组织或检索。 本文工作与现有工作本质不同:MemMA 联合协调记忆构建和迭代检索,并将利用失败转化为记忆库的直接修复信号。 完整版本见附录。
3. Preliminaries and Motivation
3.1 Problem Setting
Task Setup. We consider a long-horizon conversational setting in which an agent processes a stream of dialogue chunks
任务设置。 作者考虑一种长程对话设置,其中智能体随时间处理对话片段流
Challenges. This setting is challenging because success depends on both memory construction and memory retrieval. During construction, the agent must decide what to write, update, merge, or discard when a new chunk arrives. During retrieval and answering, it must identify the right evidence from memory under ambiguity, temporal dependencies, and incomplete or underspecified initial queries. The challenge is therefore not merely to improve answer generation, but to maintain a useful memory bank and retrieve the right evidence under bounded memory and retrieval budgets.
挑战。 这一设置具有挑战性,因为成功同时依赖记忆构建和记忆检索。 在 构建 期间,当新片段到来时,智能体必须决定写入、更新、合并或丢弃什么。 在 检索和回答 期间,它必须在歧义、时间依赖以及不完整或欠指定的初始查询下,从记忆中识别正确证据。 因此,挑战不仅是改进答案生成,而是在有界记忆和检索预算下维护有用的记忆库并检索正确证据。
3.2 Memory Cycle Effect as a Design Lens
The above challenges suggest that long-term memory should not be viewed as a linear pipeline of isolated modules. Instead, we adopt the memory cycle effect as a design lens for analyzing long-term memory systems. Under this view, memory forms a closed loop with three tightly coupled phases: construction, retrieval, and utilization. Construction determines what information enters the memory bank and how it is organized; retrieval determines what stored information is surfaced as evidence; and utilization reveals whether the retrieved evidence is sufficient for downstream answering.
上述挑战表明,长期记忆不应被视为由孤立模块组成的线性流程。 相反,作者采用 记忆循环效应 作为分析长期记忆系统的设计视角。 在这一视角下,记忆形成一个闭环,其中包含三个紧密耦合的阶段:构建、检索 和 利用。 构建决定哪些信息进入记忆库以及如何组织;检索决定哪些已存储信息作为证据被呈现;利用则揭示检索到的证据是否足以支持下游回答。
This perspective highlights two dependencies. First, there is a forward dependency: construction constrains retrieval, and retrieval in turn constrains utilization. A poorly constructed memory bank may omit important details, retain redundant entries, or leave conflicts unresolved, all of which degrade downstream retrieval quality. Second, there is a backward dependency: utilization outcomes expose deficiencies in upstream memory operations, since answering failures may stem from earlier storage omissions, unresolved contradictions, or poorly targeted retrieval. As a result, the utility of memory operations is often sparse and delayed, making isolated optimization of memory modules fundamentally suboptimal.
这一视角突出了两种依赖。 第一,存在 前向依赖:构建约束检索,而检索又约束利用。 构造不良的记忆库可能遗漏重要细节、保留冗余条目或留下未解决冲突,所有这些都会降低下游检索质量。 第二,存在 反向依赖:利用结果会暴露上游记忆操作中的缺陷,因为回答失败可能源于更早的存储遗漏、未解决矛盾或目标不准的检索。 因此,记忆操作的效用往往稀疏且延迟,使记忆模块的孤立优化从根本上次优。
Together, these dependencies suggest that long-term memory should be studied as a coupled cycle rather than independent storage and retrieval components. This motivates the need for mechanisms that explicitly coordinate forward memory execution and propagate utilization feedback backward to improve future memory decisions.
综合来看,这些依赖表明,长期记忆应作为一个耦合循环来研究,而不是作为彼此独立的存储和检索组件来研究。 这促使人们需要这样的机制:显式协调前向记忆执行,并将利用反馈向后传播,以改进未来的记忆决策。
| Method | F1 | B1 | ACC |
|---|---|---|---|
| Static Baseline | 22.64 | 17.24 | 52.60 |
| Unguided Active | 23.49 | 18.36 | 54.60 |
| Strategic Active | 24.78 | 17.73 | 59.21 |
3.3 Motivating Analysis: Strategic Blindness
The analysis above motivates coordination across the memory cycle, but do existing active memory agents achieve this in practice? Recent agents have moved beyond fully passive memory by introducing active updates or iterative retrieval. However, most still operate in a largely reactive manner: they trigger operations based on local context or immediate similarity signals rather than an explicit global strategy. We characterize this limitation as strategic blindness: the agent has the hands to edit memory and issue retrieval queries, but lacks the brain to coordinate these actions across the full memory cycle. This manifests as: (i) Myopic Construction: construction decisions are driven by local context rather than downstream utility. The agent indiscriminately appends, overwrites, or ignores information, leaving redundancy and conflicts unresolved. (ii) Aimless Retrieval: when the initial query is incomplete or semantically mismatched with stored memory, one-shot retrieval or shallow rewrites fail to surface the required evidence. Without strategic guidance, successive queries do not narrow the information gap.
上述分析激发了跨记忆循环进行协调的需求,但现有主动记忆智能体在实践中是否做到了这一点? 近期智能体通过引入主动更新或迭代检索,已经超越了完全被动的记忆。 然而,大多数仍主要以反应式方式运行:它们基于局部上下文或即时相似度信号触发操作,而不是基于显式全局策略。 作者将这一限制刻画为 战略盲区:智能体有编辑记忆和发出检索查询的“手”,却缺少跨完整记忆循环协调这些动作的“大脑”。 这表现为:(i) 短视构建:构建决策由局部上下文而非下游效用驱动。 智能体不加区分地追加、覆盖或忽略信息,留下冗余和冲突未解决。 (ii) 盲目检索:当初始查询不完整或与已存记忆存在语义不匹配时,一次性检索或浅层改写无法呈现所需证据。 如果没有战略指导,连续查询不会缩小信息缺口。
Setup. To empirically validate this diagnosis, we conduct a preliminary study on a subset of LoCoMo, focusing on reasoning-intensive queries by excluding adversarial samples. We compare three progressively stronger baselines using GPT-4o-mini as the backbone: (i) Static, which performs memory construction followed by one-shot top-
设置。 为了通过经验验证这一诊断,作者在 LoCoMo 的一个子集上进行预备研究,通过排除对抗样本专注于推理密集型查询。 作者使用 GPT-4o-mini 作为骨干模型,比较三个逐渐增强的基线:(i) Static,它执行记忆构建后进行一次性 top-
Empirical analysis. Table 1 reveals two findings: (i) Refinement provides capability: Unguided Active (54.6% Acc) outperforms Static (52.6%), confirming that one-shot retrieval often fails to surface the required evidence when the initial query is incomplete or mismatched with memory, which directly reflects Aimless Retrieval. (ii) Reasoning provides control: Strategic Active achieves a larger leap to 59.2% Acc. Since it shares the same active operators as Unguided Active, this gap reflects the value of explicit strategic guidance in addressing both Aimless Retrieval and Myopic Construction. Case studies in Appendix further illustrate both pathologies with concrete examples of redundant entries and retrieval drift. These findings suggest that active memory operations alone are insufficient: explicit strategic reasoning is needed to guide both construction and retrieval.
经验分析。 表1 揭示了两个发现:(i) 细化带来能力:Unguided Active(54.6% ACC)优于 Static(52.6%),证实当初始查询不完整或与记忆不匹配时,一次性检索经常无法呈现所需证据,这直接反映了 盲目检索。 (ii) 推理带来控制:Strategic Active 取得更大跃升,达到 59.2% ACC。 由于它与 Unguided Active 共享相同的主动算子,这一差距反映了显式战略指导在解决 盲目检索 和 短视构建 上的价值。 附录中的案例研究进一步用冗余条目和检索漂移的具体例子说明了两种病症。 这些发现表明,仅有主动记忆操作是不够的:需要显式战略推理来同时指导构建和检索。
4. Methodology
Motivated by the memory cycle effect (Section 3.2) and strategic blindness (Section 3.3), we present MemMA, a plug-and-play multi-agent framework that coordinates the memory cycle along its forward and backward paths (Figure 2). Section 4.1 describes the forward path: a planner--worker architecture that separates strategic reasoning from low-level execution to address strategic blindness. Section 4.2 describes the backward path: an in-situ self-evolution mechanism that addresses sparse, delayed feedback by generating synthetic probe QA immediately after each session, providing dense, localized supervision for memory repair before the current memory is committed.
受记忆循环效应(第 3.2 节)和战略盲区(第 3.3 节)启发,作者提出 MemMA,这是一个即插即用的多智能体框架,沿其前向和反向两条路径协调记忆循环(图2)。 第 4.1 节描述前向路径:一种规划器--执行器架构,它将战略推理与底层执行分离,以解决战略盲区。 第 4.2 节描述反向路径:一种原位自演化机制,它通过在每个会话后立即生成合成探测问答来解决稀疏且延迟的反馈,并在当前记忆提交前为记忆修复提供密集、局部化监督。
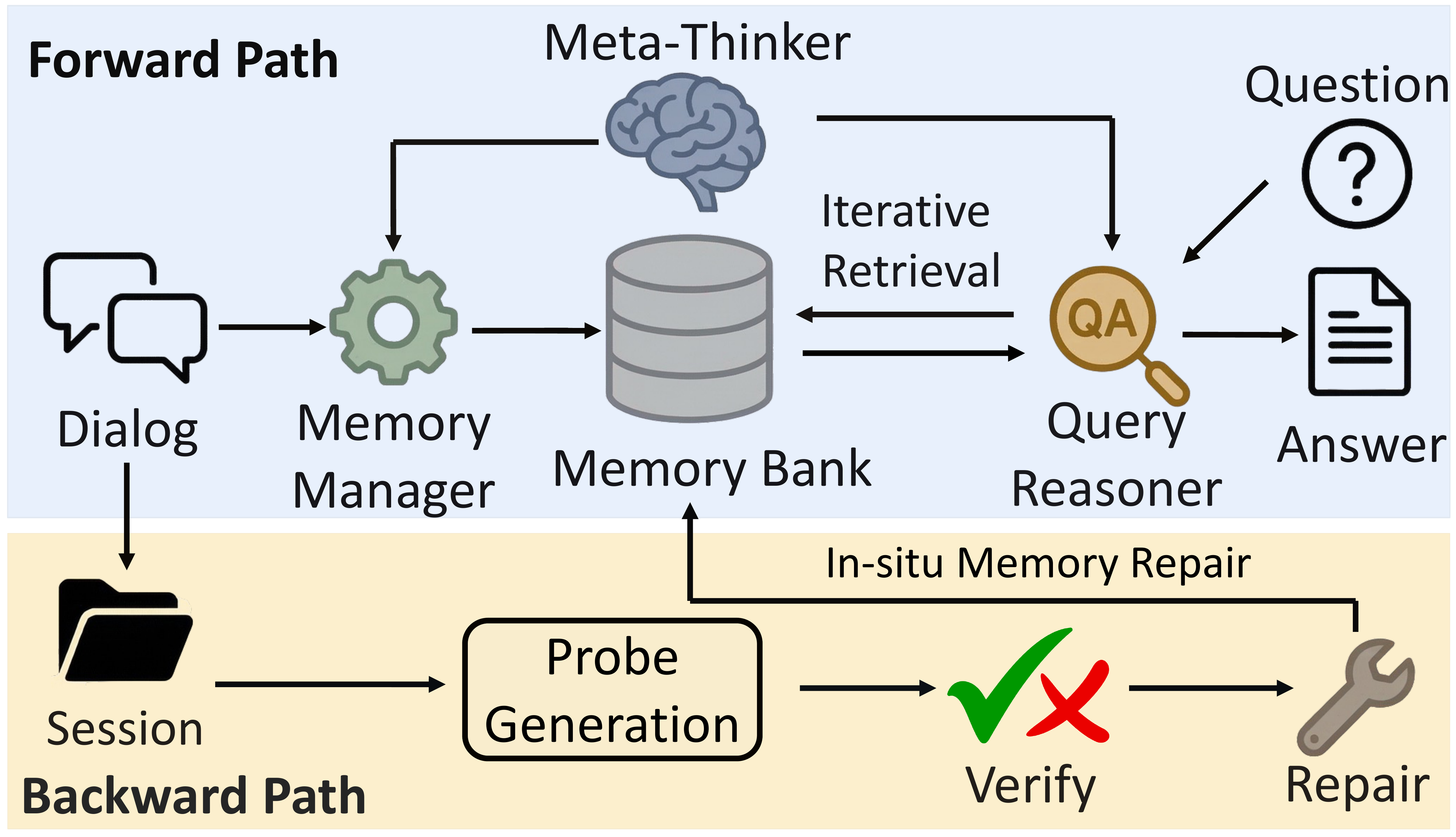
4.1 Reasoning-Aware Coordination over the Forward Path
MemMA coordinates online construction, iterative retrieval, and answer-time utilization through specialized yet tightly coupled agents. Its key design principle is to separate strategic reasoning (what to store, what is missing, and when to stop) from low-level execution (memory editing, evidence retrieval, and answer generation).
MemMA 通过专业化但紧密耦合的智能体来协调在线构建、迭代检索和答题时利用。 其关键设计原则是将战略推理(存什么、缺什么、何时停止)与底层执行(记忆编辑、证据检索和答案生成)分离。
Pipeline Overview. MemMA uses a planner--worker architecture with four roles: (i) a Meta-Thinker
流程概览。 MemMA 使用规划器--执行器架构,并包含四种角色:(i) 用于高层战略推理的 Meta-Thinker
Meta-Thinker
Meta-Thinker
where
其中
Memory Manager
Memory Manager
The guidance signal
指导信号
Query Reasoner
Query Reasoner
The loop terminates when
当
Answer Agent
Answer Agent
where
其中
4.2 In-Situ Self-Evolving Memory Construction
A major bottleneck in the memory cycle is that feedback for construction is typically sparse and delayed. The utility of a storage decision made in session
记忆循环中的一个主要瓶颈是构建反馈通常稀疏且延迟。 在会话
Probe Generation. Let
探测问题生成。 令
where each
其中每个
In-situ Verification. Given
原位验证。 给定
A probe is considered failed if
如果
Evidence-grounded Repair. For each failed probe, a reflection module converts the failure into a repair proposal. Conditioned on the question, gold answer, predicted answer, retrieved evidence, and the provisional memory state
基于证据的修复。 对于每个失败探测问题,反思模块会将失败转化为修复提案。 在问题、标准答案、预测答案、检索到的证据和临时记忆状态
where
其中
Semantic Consolidation. Applying all repairs in SKIP if it is redundant, MERGE if it complements an existing entry, or INSERT if it is novel. This resolves both conflicts with the existing memory and conflicts across repair proposals before any update is written back. The refined memory is obtained as
语义整合。 直接应用 SKIP,如果它补充现有条目则 MERGE,如果它是新的则 INSERT。 这会在任何更新写回之前,解决与现有记忆的冲突以及修复提案之间的冲突。 细化后的记忆得到为:
where
其中
5. Experiments
This section presents the experimental results. We first compare MemMA with existing baselines, then evaluate its flexibility across storage backends, and finally assess the contribution of each component and key design choices.
本节展示实验结果。 作者首先将 MemMA 与现有基线比较,然后评估其跨存储后端的灵活性,最后评估各组件和关键设计选择的贡献。
5.1 Experimental Setup
Datasets. We evaluate MemMA on LoCoMo, a benchmark for long-horizon conversational memory. Following prior work, we exclude the adversarial subset and focus on the reasoning-intensive QA setting. More dataset details are provided in Appendix.
数据集。 作者在 LoCoMo 上评估 MemMA,这是一个用于长程对话记忆的基准。 按照先前工作,作者排除对抗子集,并聚焦于推理密集型问答设置。 更多数据集细节见附录。
Baselines. We compare against two passive baselines: Full Text and Naive RAG, and four active memory systems: LangMem, Mem0, A-Mem, and LightMem. Additional baseline details are in Appendix.
基线。 作者与两个被动基线比较:Full Text 和 Naive RAG,以及四个主动记忆系统:LangMem、Mem0、A-Mem 和 LightMem。 额外基线细节见附录。
Evaluation Protocol. Following prior work, we report three metrics: token-level F1 (F1), BLEU-1 (B1), and LLM-as-a-Judge accuracy (ACC). F1 and B1 measure lexical overlap with the reference answer; ACC measures semantic correctness via a judge model. GPT-4o-mini and Claude-Haiku-4.5 are used as the backbones for the Memory Manager, Meta-Thinker, and Query Reasoner. To isolate memory construction quality from answer-generation capacity, we fix GPT-4o-mini as both the Answer Agent and the LLM judge across all experiments. The retrieval budget is top-
评估协议。 按照先前工作,作者报告三个指标:词元级 F1 (F1)、BLEU-1 (B1) 和 LLM 裁判准确率 (ACC)。 F1 和 B1 衡量与参考答案的词面重叠;ACC 通过裁判模型衡量语义正确性。 GPT-4o-mini 和 Claude-Haiku-4.5 被用作 Memory Manager、Meta-Thinker 和 Query Reasoner 的骨干模型。 为了将记忆构建质量与答案生成能力隔离开,作者在所有实验中固定 GPT-4o-mini 同时作为 Answer Agent 和 LLM 裁判。 检索预算为 top-
| Model | Method | Multi-Hop | Temporal | Open-Domain | Single-Hop | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | B1 | ACC | F1 | B1 | ACC | F1 | B1 | ACC | F1 | B1 | ACC | F1 | B1 | ACC | ||
| GPT | ||||||||||||||||
| Full Text | 29.41 | 21.16 | 43.75 | 29.95 | 19.33 | 51.35 | 18.25 | 19.56 | 61.54 | 41.45 | 29.96 | 74.29 | 34.13 | 24.63 | 61.18 | |
| Naive RAG | 15.84 | 9.50 | 31.25 | 17.30 | 12.36 | 35.14 | 17.40 | 16.65 | 46.15 | 39.32 | 30.35 | 58.57 | 27.14 | 20.41 | 46.05 | |
| LangMem | 12.55 | 9.22 | 25.00 | 15.23 | 11.53 | 21.62 | 14.91 | 14.03 | 38.46 | 23.52 | 17.59 | 35.71 | 18.46 | 14.05 | 30.26 | |
| A-Mem | 15.56 | 10.88 | 31.25 | 55.01 | 42.40 | 51.35 | 18.18 | 15.27 | 53.85 | 42.72 | 32.43 | 62.86 | 37.90 | 28.85 | 52.63 | |
| LightMem | 33.74 | 29.33 | 65.62 | 59.76 | 51.12 | 78.38 | 31.85 | 24.23 | 76.92 | 43.88 | 34.68 | 78.57 | 44.58 | 36.66 | 75.66 | |
| MemMALM | 48.15 | 39.67 | 78.12 | 57.21 | 41.94 | 83.78 | 24.58 | 22.44 | 76.92 | 50.45 | 38.66 | 82.86 | 49.40 | 38.28 | 81.58 | |
| Claude-Haiku | ||||||||||||||||
| Full Text | 29.41 | 21.16 | 43.75 | 29.95 | 19.33 | 51.35 | 18.25 | 19.56 | 61.54 | 41.45 | 29.96 | 74.29 | 34.13 | 24.63 | 61.18 | |
| Naive RAG | 15.84 | 9.50 | 31.25 | 17.30 | 12.36 | 35.14 | 17.40 | 16.65 | 46.15 | 39.32 | 30.35 | 58.57 | 27.14 | 20.41 | 46.05 | |
| LangMem | 20.05 | 14.85 | 34.38 | 34.72 | 26.33 | 37.84 | 20.01 | 20.85 | 69.23 | 22.65 | 16.19 | 48.57 | 24.81 | 18.78 | 44.74 | |
| A-Mem | 15.79 | 10.32 | 28.13 | 56.41 | 43.23 | 54.05 | 16.34 | 17.76 | 38.46 | 38.37 | 27.98 | 65.71 | 36.12 | 27.10 | 52.63 | |
| LightMem | 35.11 | 31.85 | 59.38 | 58.42 | 49.85 | 89.19 | 32.60 | 24.43 | 69.23 | 44.06 | 36.56 | 71.43 | 44.69 | 37.77 | 73.03 | |
| MemMALM | 35.38 | 32.48 | 65.62 | 59.25 | 44.66 | 83.78 | 28.59 | 26.86 | 84.62 | 45.31 | 35.85 | 77.14 | 45.10 | 36.53 | 76.97 | |
5.2 Main Comparison with Baselines
To evaluate MemMA, we compare it with baselines. We use LightMem as the storage backend of MemMA, denoted by
为了评估 MemMA,作者将其与基线进行比较。 作者使用 LightMem 作为 MemMA 的存储后端,记为
Table 2 reports the results. Three findings emerge: (i)
表2 报告了结果。 出现了三个发现:(i)
5.3 Flexibility across Storage Backends
To assess the flexibility of MemMA across storage backends, we instantiate it on top of three memory systems: Single-Agent (
为了评估 MemMA 跨存储后端的灵活性,作者将其实例化在三个记忆系统之上:Single-Agent(
| Method | F1 | B1 | ACC |
|---|---|---|---|
| Single-Agent | 22.64 | 17.24 | 52.60 |
| MemMASA | 23.64 | 12.94 | 84.87 |
| A-Mem | 37.90 | 28.85 | 52.63 |
| MemMAAM | 46.23 | 35.13 | 78.29 |
| LightMem | 44.58 | 36.66 | 75.66 |
| MemMALM | 49.40 | 38.28 | 81.58 |
Table 3 reports results on LoCoMo under GPT-4o-mini. Two observations emerge. (i) MemMA consistently improves all backends. In terms of ACC, MemMA improves the Single-Agent backend from
表3 报告了 GPT-4o-mini 下 LoCoMo 上的结果。 出现了两个观察。 (i) MemMA 持续改进所有后端。 就 ACC 而言,MemMA 将 Single-Agent 后端从
5.4 In-depth Dissection of MemMA
Ablation Studies. To understand the contributions of key components in MemMA, we implement three ablated variants on the Single-Agent backend: (i) MemMA/C removes Meta-Thinker guidance during construction and directly uses the Memory Manager for memory writing; (ii) MemMA/R removes iterative retrieval, reverting to one-shot retrieval based on semantic similarity; and (iii) MemMA/E removes the probe-and-repair loop of in-situ self-evolving memory construction and directly commits
消融研究。 为了理解 MemMA 中关键组件的贡献,作者在 Single-Agent 后端上实现三种消融变体:(i) MemMA/C 移除构建期间的 Meta-Thinker 指导,并直接使用 Memory Manager 进行记忆写入;(ii) MemMA/R 移除迭代检索,回退到基于语义相似度的一次性检索;(iii) MemMA/E 移除原位自演化记忆构建中的探测并修复循环,并直接将
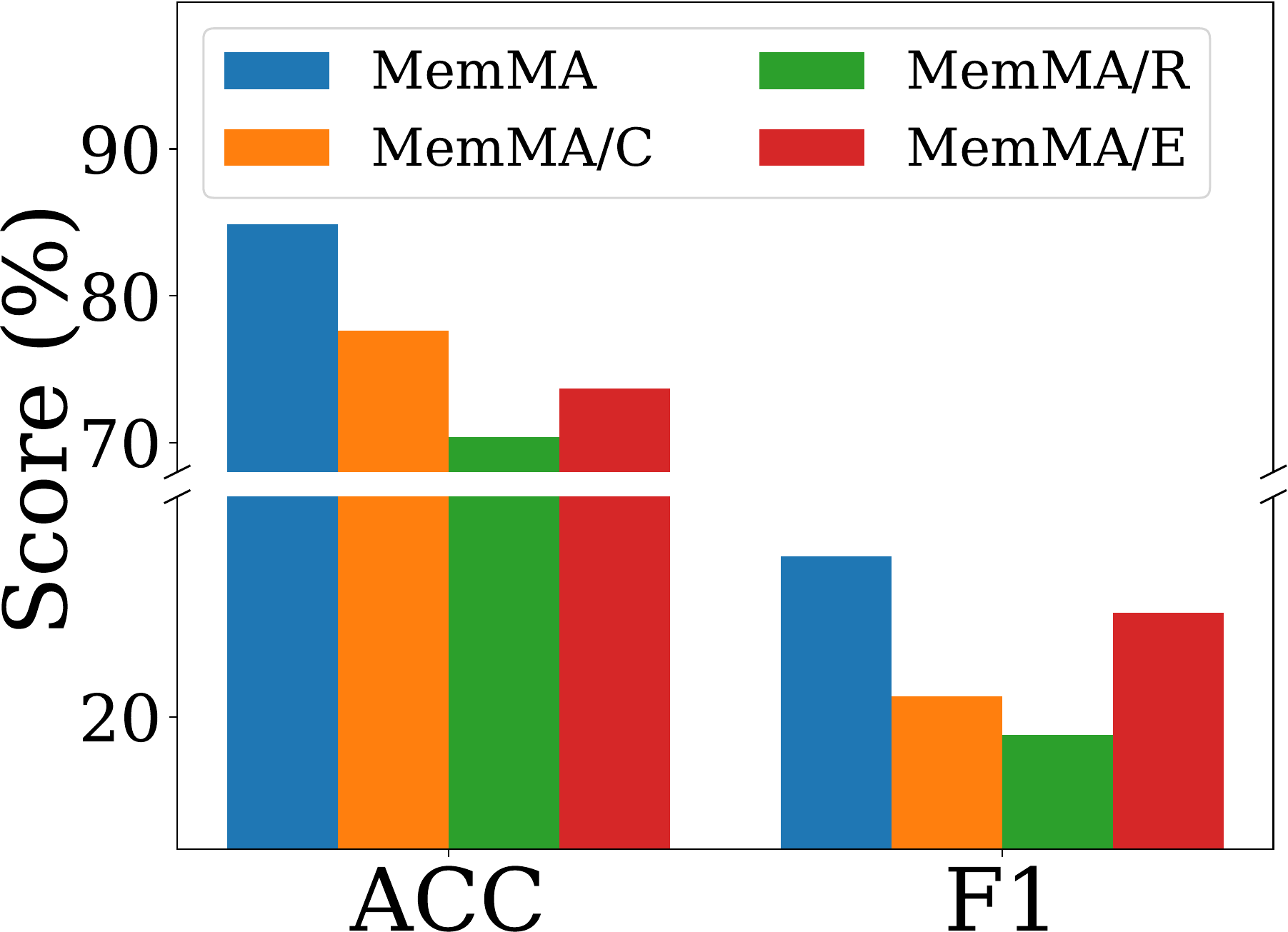
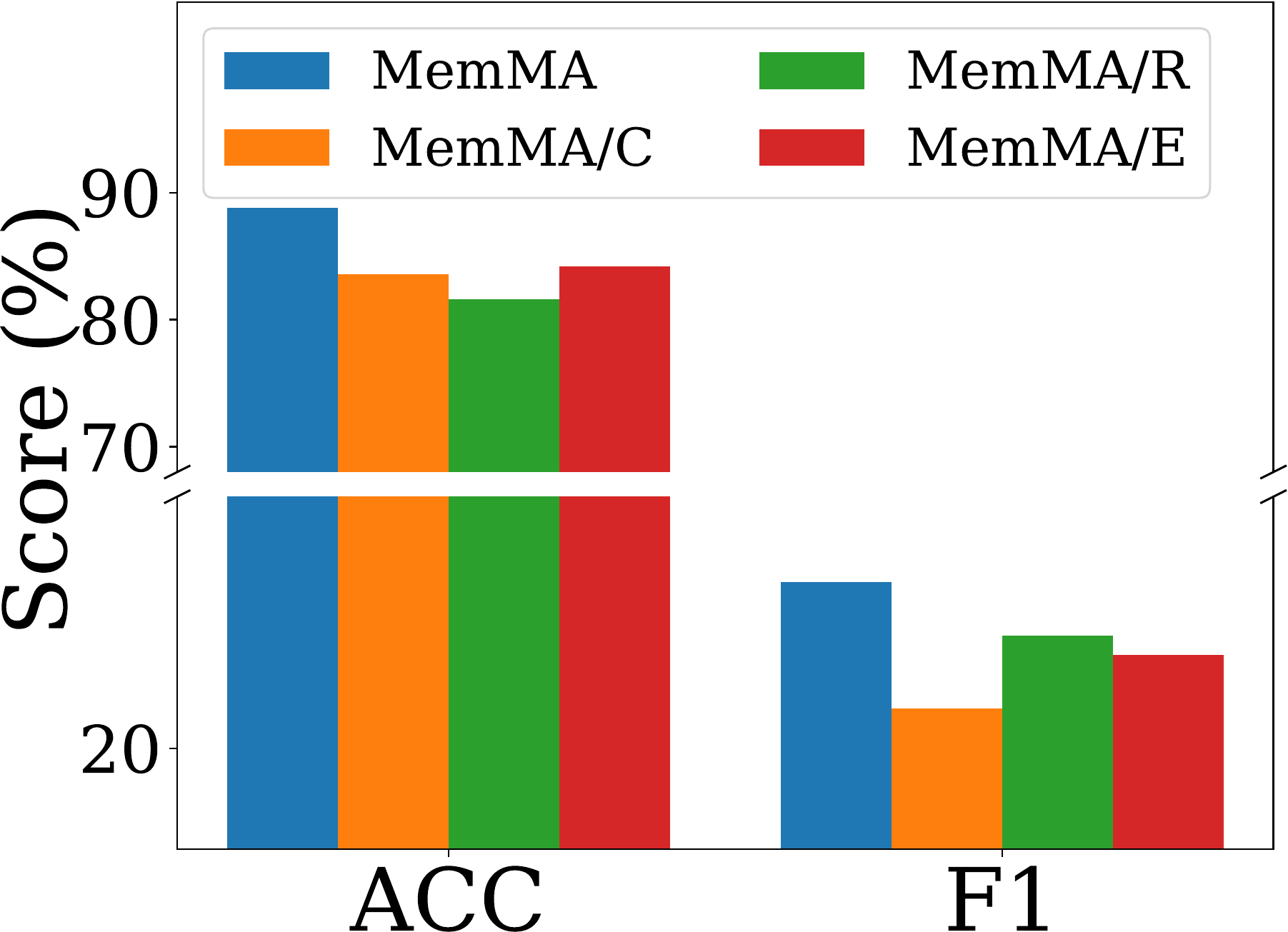
Figure 3 reports the results under GPT-4o-mini and Claude-Haiku-4.5. The full
图3 报告了 GPT-4o-mini 和 Claude-Haiku-4.5 下的结果。 完整的
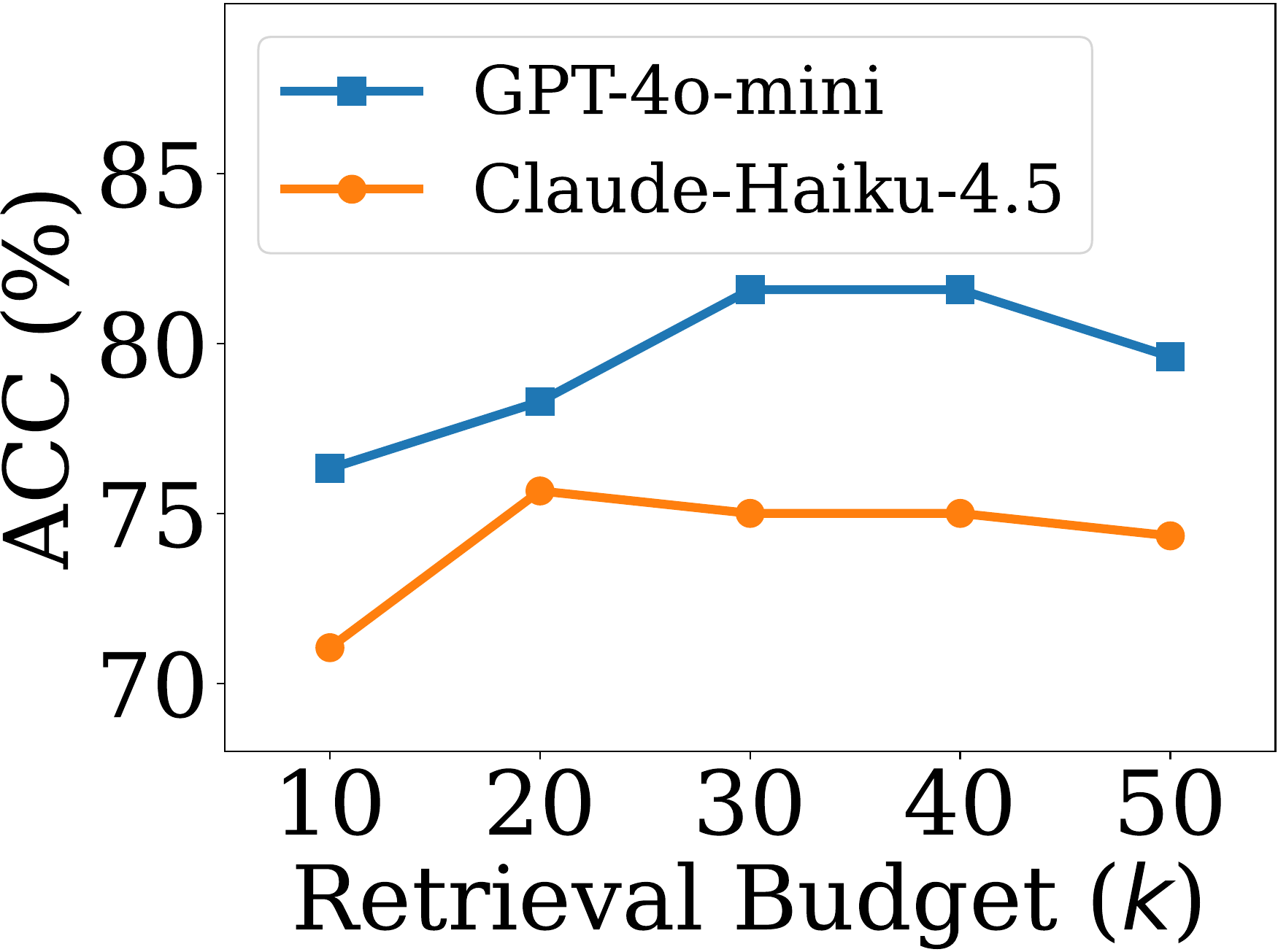
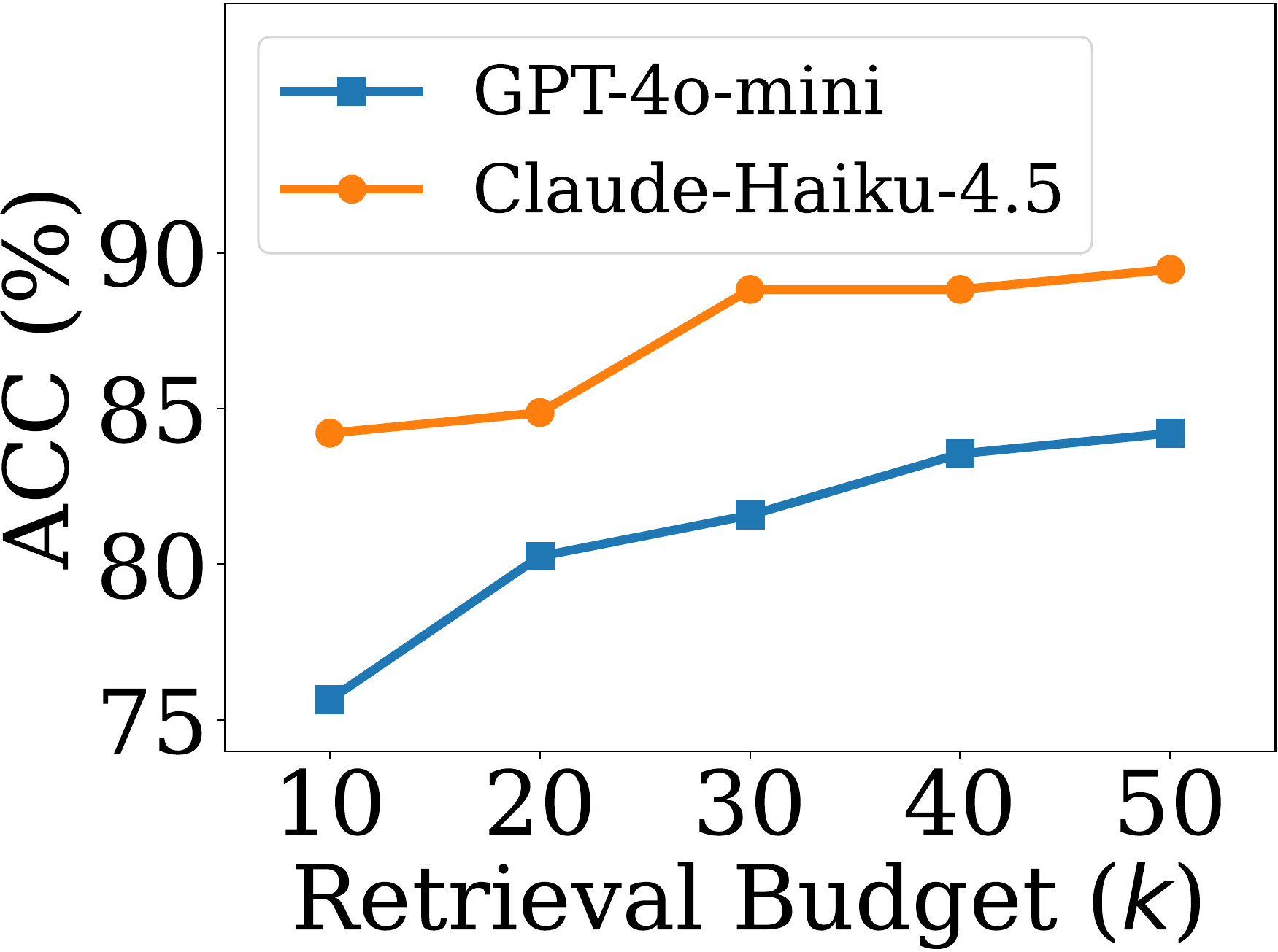
Impact of retrieval budget
检索预算
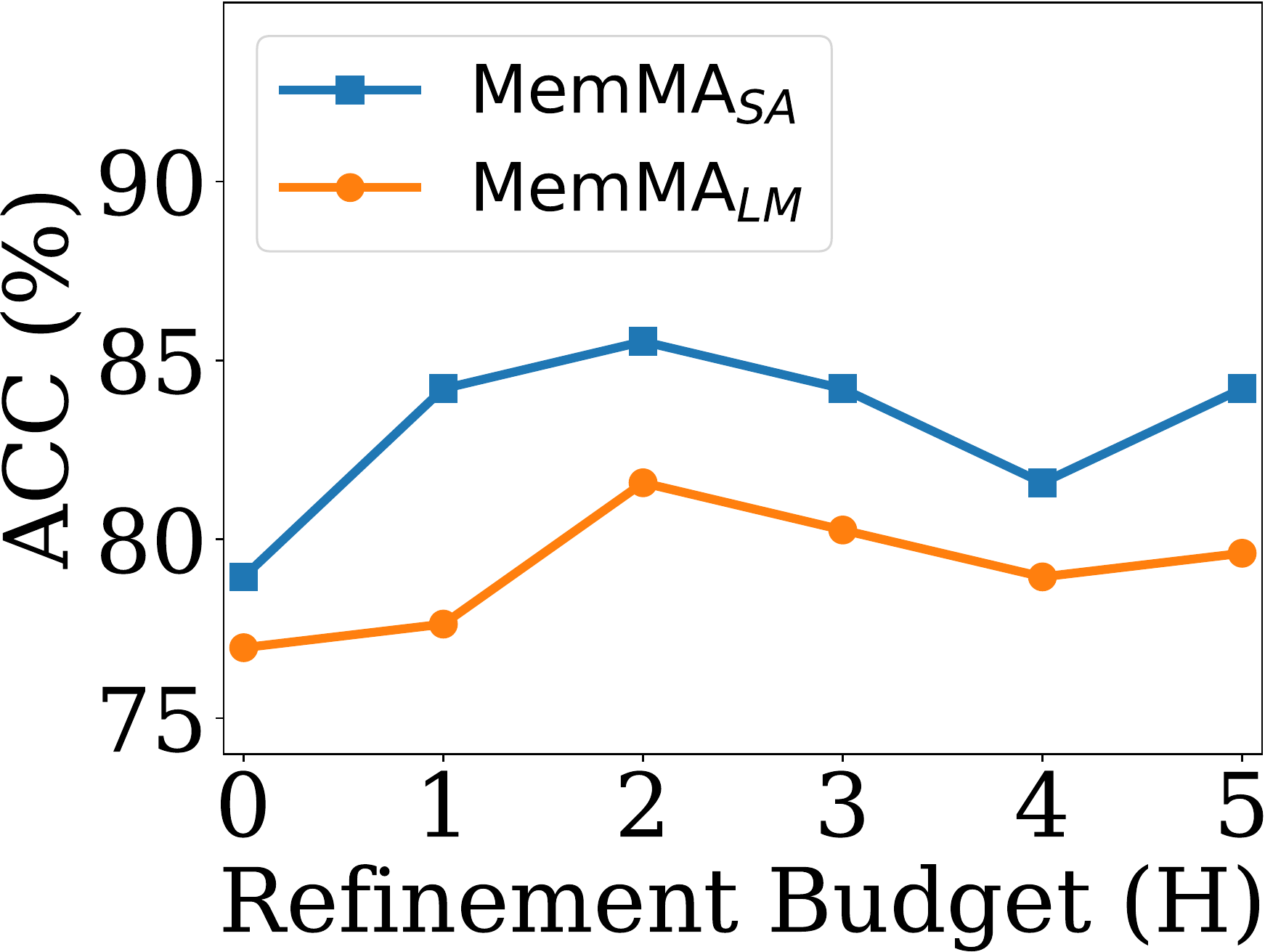
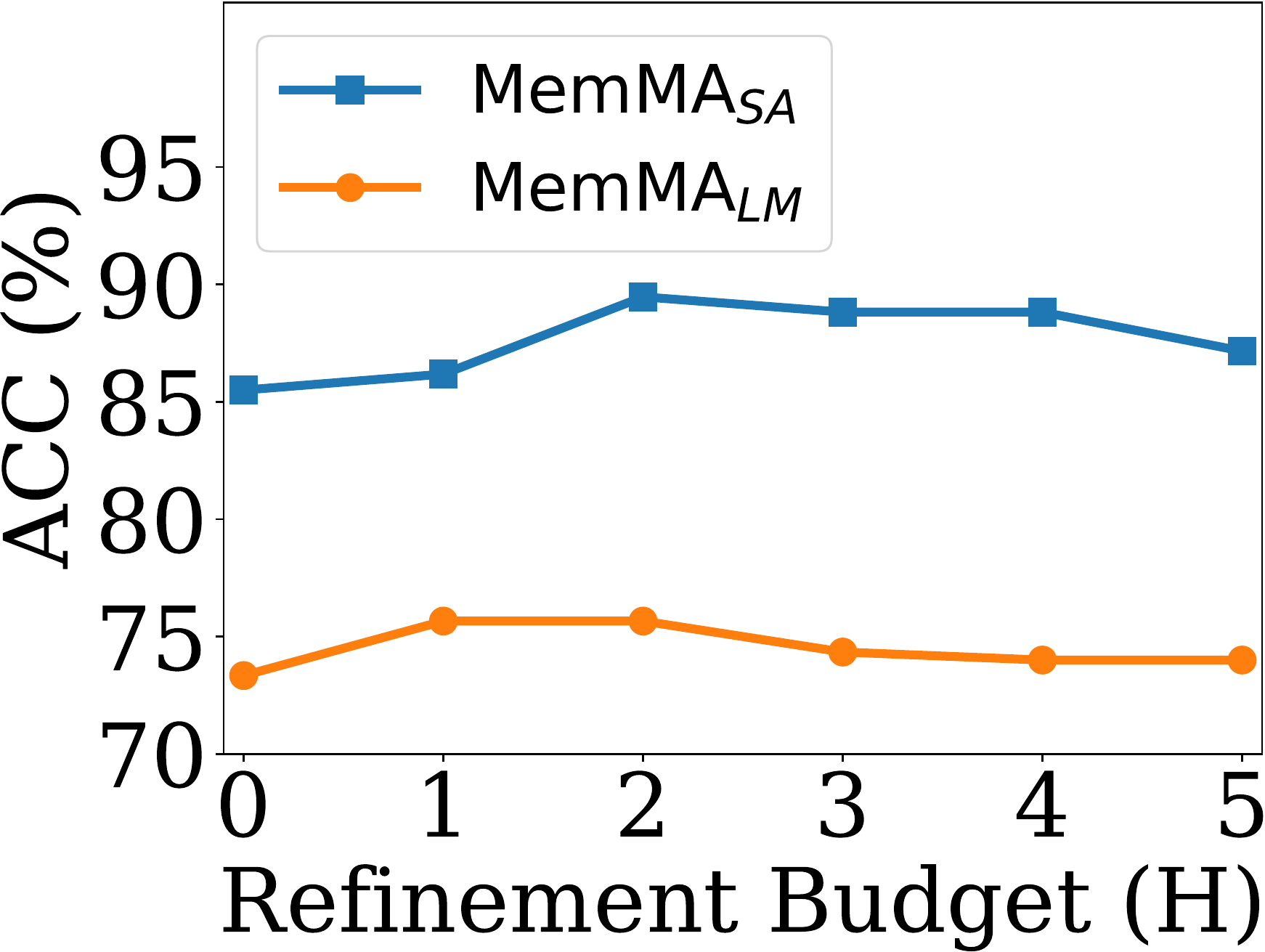
Impact of retrieval refinement budget
检索细化预算
5.5 Case Studies
We conduct a case study to better understand why MemMA improves long-horizon QA. Our findings indicate that: (i) on the forward path, construction-time Meta-Thinker guidance determines whether answer-bearing details survive in memory, while diagnosis-guided iterative retrieval determines whether missing evidence is surfaced before the system commits to an answer. Importantly, iterative retrieval cannot compensate for details that were never preserved during construction. The cases also show that the retrieval controller and the storage backend play distinct roles: the Meta-Thinker and Query Reasoner identify the information gap, while the backend determines whether the required evidence can actually be recovered; (ii) on the backward path, in-situ self-evolution converts local probe failures into targeted memory repairs that transfer to downstream QA, for example by inserting missing named entities, sharpening vague event descriptions, and completing partial evidence clusters. Detailed examples are in Appendix.
作者进行案例研究,以更好理解为什么 MemMA 能改进长程问答。 作者的发现表明:(i) 在前向路径上,构建时的 Meta-Thinker 指导决定承载答案的细节是否能在记忆中保留下来,而诊断引导的迭代检索决定缺失证据是否会在系统提交答案前被呈现。 重要的是,迭代检索无法补偿构建期间从未被保留的细节。 这些案例还表明,检索控制器和存储后端扮演不同角色:Meta-Thinker 和 Query Reasoner 识别信息缺口,而后端决定所需证据是否真的能够被恢复;(ii) 在反向路径上,原位自演化将局部探测失败转化为有针对性的记忆修复,并迁移到下游问答,例如插入缺失的命名实体、锐化模糊事件描述,以及补全部分证据簇。 详细示例见附录。
6. Conclusion
We introduce MemMA, a plug-and-play multi-agent framework that coordinates the memory cycle along its forward and backward paths. On the forward path, a Meta-Thinker separates strategic reasoning from low-level execution, addressing strategic blindness in construction and retrieval. On the backward path, in-situ self-evolution converts probe QA failures into direct memory repair before the memory is committed. Experiments on LoCoMo show that MemMA outperforms all baselines across multiple backbones and consistently improves three different storage backends.
作者提出 MemMA,这是一个即插即用的多智能体框架,沿前向和反向两条路径协调记忆循环。 在前向路径上,Meta-Thinker 将战略推理与底层执行分离,解决构建和检索中的战略盲区。 在反向路径上,原位自演化在记忆提交前将探测问答失败转化为直接记忆修复。 LoCoMo 上的实验表明,MemMA 跨多个骨干模型优于所有基线,并持续改进三种不同存储后端。
7. Limitations
Our evaluation focuses on a dialogue-centric long-horizon memory benchmark. While LoCoMo covers diverse question types, including single-hop, multi-hop, temporal, and open-domain reasoning, it does not capture all settings in which persistent memory may be needed.
作者的评估聚焦于一个以对话为中心的长程记忆基准。 虽然 LoCoMo 覆盖多样问题类型,包括单跳、多跳、时间和开放域推理,但它没有捕捉所有可能需要持久记忆的设置。
In addition, the backward path assumes that interaction streams can be organized into sessions and that synthetic probe QA can provide useful localized supervision. These assumptions are natural for the benchmark studied here, but may require adaptation in settings with less clear session boundaries or more open-ended interaction structure.
此外,反向路径假设交互流可以被组织成会话,并且合成探测问答能提供有用的局部监督。 这些假设对于本文研究的基准是自然的,但在会话边界不太清晰或交互结构更开放的设置中可能需要适配。
8. Ethics Statement
This work studies long-horizon memory management for LLM agents. All experiments are conducted on the publicly available benchmark, which consists of synthetic conversations and does not contain real user data. No personally identifiable information is collected, stored, or processed in this work. We note that improving memory quality in agent systems may raise broader considerations for real-world deployment, including user privacy, informed consent for data retention, controllability over stored memories, and the risk of persisting incorrect information through automated repair. While these concerns are beyond the scope of the present study, we believe they should be treated as first-class design requirements in any production deployment of memory-augmented agents.
本文研究 LLM 智能体的长程记忆管理。 所有实验都在公开可用基准上进行,该基准由合成对话构成,不包含真实用户数据。 本文没有收集、存储或处理个人身份信息。 作者指出,提高智能体系统中的记忆质量可能为真实世界部署带来更广泛考量,包括用户隐私、数据留存的知情同意、对已存记忆的可控性,以及通过自动化修复持久化错误信息的风险。 虽然这些问题超出了当前研究范围,但作者认为,在任何记忆增强型智能体的生产部署中,它们都应被视为一等设计要求。