
CLIP-ReID: Exploiting Vision-Language Model for Image Re-Identification without Concrete Text Labels
Person ReIDVehicle ReIDVision-LanguageCLIP430+AAAI 2023ECNUShanghai Key Lab
CLIP-ReID:在没有具体文本标签的情况下利用视觉-语言模型进行图像重识别
Abstract
Pre-trained vision-language models like CLIP have recently shown superior performances on various downstream tasks, including image classification and segmentation. However, in fine-grained image re-identification (ReID), the labels are indexes, lacking concrete text descriptions. Therefore, it remains to be determined how such models could be applied to these tasks. This paper first finds out that simply fine-tuning the visual model initialized by the image encoder in CLIP, has already obtained competitive performances in various ReID tasks. Then we propose a two-stage strategy to facilitate a better visual representation. The key idea is to fully exploit the cross-modal description ability in CLIP through a set of learnable text tokens for each ID and give them to the text encoder to form ambiguous descriptions. In the first training stage, image and text encoders from CLIP keep fixed, and only the text tokens are optimized from scratch by the contrastive loss computed within a batch. In the second stage, the ID-specific text tokens and their encoder become static, providing constraints for fine-tuning the image encoder. With the help of the designed loss in the downstream task, the image encoder is able to represent data as vectors in the feature embedding accurately. The effectiveness of the proposed strategy is validated on several datasets for the person or vehicle ReID tasks.
像 CLIP 这样的预训练视觉-语言模型最近在包括图像分类和分割在内的各种下游任务上表现优越。 然而,在细粒度图像重识别(ReID)中,标签是索引,缺少具体文本描述。 因此,这类模型如何应用到这些任务仍有待确定。 本文首先发现,仅对由 CLIP 图像编码器初始化的视觉模型进行微调,就已经在多种 ReID 任务中获得了有竞争力的性能。 随后作者提出一种两阶段策略,以促进更好的视觉表示。 关键思想是通过为每个 ID 设置一组可学习文本 token,充分利用 CLIP 中的跨模态描述能力,并将它们送入文本编码器以形成模糊描述。 在第一训练阶段,来自 CLIP 的图像编码器和文本编码器保持固定,只有文本 token 通过在一个 batch 内计算的对比损失从零开始优化。 在第二阶段,ID 特定文本 token 及其编码器变为静态,为微调图像编码器提供约束。 借助下游任务中设计的损失,图像编码器能够把数据准确表示为特征嵌入中的向量。 所提出策略的有效性在多个行人或车辆 ReID 任务数据集上得到验证。
1. Introduction
Image re-identification (ReID) aims to match the same object across different and non-overlapping camera views. Particularly, it focuses on detecting the same person or vehicle in the surveillance camera networks. ReID is a challenging task mainly due to the cluttered background, illumination variations, huge pose changes, or even occlusions. Most recent ReID models depend on building and training a convolution neural network (CNN) so that each image is mapped to a feature vector in the embedding space before the classifier. Images of the same object tend to be close, while different objects become far away in this space. The parameters of CNN can be effectively learned under the guidance of cross entropy loss together with the typical metric learning loss like center or triplet loss.
图像重识别(ReID)旨在跨不同且不重叠的相机视角匹配同一目标。 特别地,它关注在监控摄像机网络中检测同一个人或同一辆车。 ReID 是一项具有挑战性的任务,主要原因是背景杂乱、光照变化、姿态巨大变化,甚至遮挡。 最近大多数 ReID 模型依赖于构建和训练卷积神经网络(CNN),使每张图像在分类器之前被映射为嵌入空间中的特征向量。 同一目标的图像在这个空间中倾向于彼此接近,而不同目标会相距较远。 CNN 的参数可以在交叉熵损失以及 center loss 或 triplet loss 等典型度量学习损失的共同指导下有效学习。
Although CNN-based models for ReID have achieved good performance on some well-known datasets, it is still far from being used in a real application. CNN is often blamed for only focusing on a small irrelevant region in the image, which indicates that its feature is not robust and discriminative enough. Recently, vision transformers like ViT have become popular in many tasks, and they have also shown better performances in ReID. Compared to CNN, transformers can model the long-range dependency in the whole image. However, due to a large number of model parameters, they require a big training set and often perform erratically during optimization. Since ReID datasets are relatively small, the potential of these models is not fully exploited yet.
虽然基于 CNN 的 ReID 模型在一些知名数据集上已经取得良好性能,但它距离真实应用仍然很远。 CNN 常被认为只关注图像中一小块无关区域,这表明其特征还不够鲁棒且不够有判别力。 最近,像 ViT 这样的视觉 Transformer 已经在许多任务中流行起来,并且在 ReID 中也表现出更好的性能。 与 CNN 相比,Transformer 可以对整张图像中的长程依赖建模。 然而,由于模型参数数量很大,它们需要大型训练集,并且在优化过程中常常表现不稳定。 由于 ReID 数据集相对较小,这些模型的潜力尚未被充分开发。
Both CNN-based and ViT-based methods heavily rely on pre-training. Almost all ReID methods need an initial model trained on ImageNet, which contains images manually given one-hot labels from a pre-defined set. Visual contents describing rich semantics outside the set are completely ignored. Recently, cross-modal learning like CLIP connects the visual representation with its corresponding high-level language description. They not only train on a larger dataset but also change the pre-training task, matching visual features to their language descriptions. Therefore, the image encoder can sense a variety of high-level semantics from the text and learns transferable features, which can be adapted to many different tasks. E.g., given a particular image classification task, the candidate text labels are concrete and can be combined with a prompt, such as "A photo of a", to form the text descriptions. The classification is then realized by comparing image features with text features generated by the text encoder, which takes the text description of categories as input. Note that it is a zero-shot solution without tuning any parameters for downstream tasks but still gives satisfactory results. Based on this, CoOp incorporates a learnable prompt for different tasks. The optimized prompt further improves the performance.
基于 CNN 和基于 ViT 的方法都高度依赖预训练。 几乎所有 ReID 方法都需要一个在 ImageNet 上训练的初始模型,而 ImageNet 包含由人工从预定义集合中赋予 one-hot 标签的图像。 描述集合之外丰富语义的视觉内容被完全忽略。 最近,像 CLIP 这样的跨模态学习把视觉表示与其对应的高层语言描述连接起来。 它们不仅在更大的数据集上训练,还改变了预训练任务,使视觉特征与其语言描述匹配。 因此,图像编码器可以从文本中感知多种高层语义,并学习可迁移特征,从而适配许多不同任务。 例如,给定一个特定图像分类任务,候选文本标签是具体的,可以与 "A photo of a" 这样的提示组合,形成文本描述。 随后分类通过比较图像特征和文本编码器生成的文本特征来实现,其中文本编码器以类别文本描述作为输入。 注意,这是一种零样本方案,不需要为下游任务调节任何参数,但仍能给出令人满意的结果。 基于这一点,CoOp 为不同任务引入可学习提示。 优化后的提示进一步提升了性能。
CLIP and CoOp need text labels to form text descriptions in downstream tasks. However, in most ReID tasks, the labels are indexes, and there are no specific words to describe the images, so the vision-language model has not been widely adopted in ReID. In this paper, we intend to exploit CLIP fully. We first fine-tune the image encoder by directly using the common losses in ReID, which has already obtained high metrics compared to existing works. We use this model as our baseline and try to improve it by utilizing the text encoder in CLIP. A two-stage strategy is proposed, which aims to constrain the image encoder by generating language descriptions from the text encoder. A series of learnable text tokens are incorporated, and they are used to describe each ID ambiguously. In the first training stage, both the image and text encoder are fixed, and only these tokens are optimized. In the second stage, the description tokens and text encoder keep static, and they together provide ambiguous descriptions for each ID, which helps to build up the cross-modality image to text cross-entropy loss. Since CLIP has CNN-based and ViT-based models, the proposed method is validated on both ResNet-50 and ViT-B/16. The two types of the model achieve the state-of-the-art on different ReID datasets. Moreover, our method can also support the input of camera ID and overlapped token settings in its ViT-based version.
CLIP 和 CoOp 在下游任务中需要文本标签来形成文本描述。 然而,在大多数 ReID 任务中,标签是索引,并没有具体词语来描述图像,因此视觉-语言模型尚未在 ReID 中被广泛采用。 在本文中,作者希望充分利用 CLIP。 作者首先通过直接使用 ReID 中的常见损失来微调图像编码器,与现有工作相比,这已经获得了较高指标。 作者将该模型作为基线,并尝试通过利用 CLIP 中的文本编码器来改进它。 作者提出一种两阶段策略,旨在通过从文本编码器生成语言描述来约束图像编码器。 一系列可学习文本 token 被引入,并被用于模糊地描述每个 ID。 在第一训练阶段,图像编码器和文本编码器都固定,只有这些 token 被优化。 在第二阶段,描述 token 和文本编码器保持静态,它们共同为每个 ID 提供模糊描述,这有助于构建跨模态的图像到文本交叉熵损失。 由于 CLIP 同时具有基于 CNN 和基于 ViT 的模型,所提出方法在 ResNet-50 和 ViT-B/16 上都进行了验证。 这两类模型在不同 ReID 数据集上取得了最先进性能。 此外,作者的方法在其基于 ViT 的版本中还可以支持相机 ID 输入和重叠 token 设置。
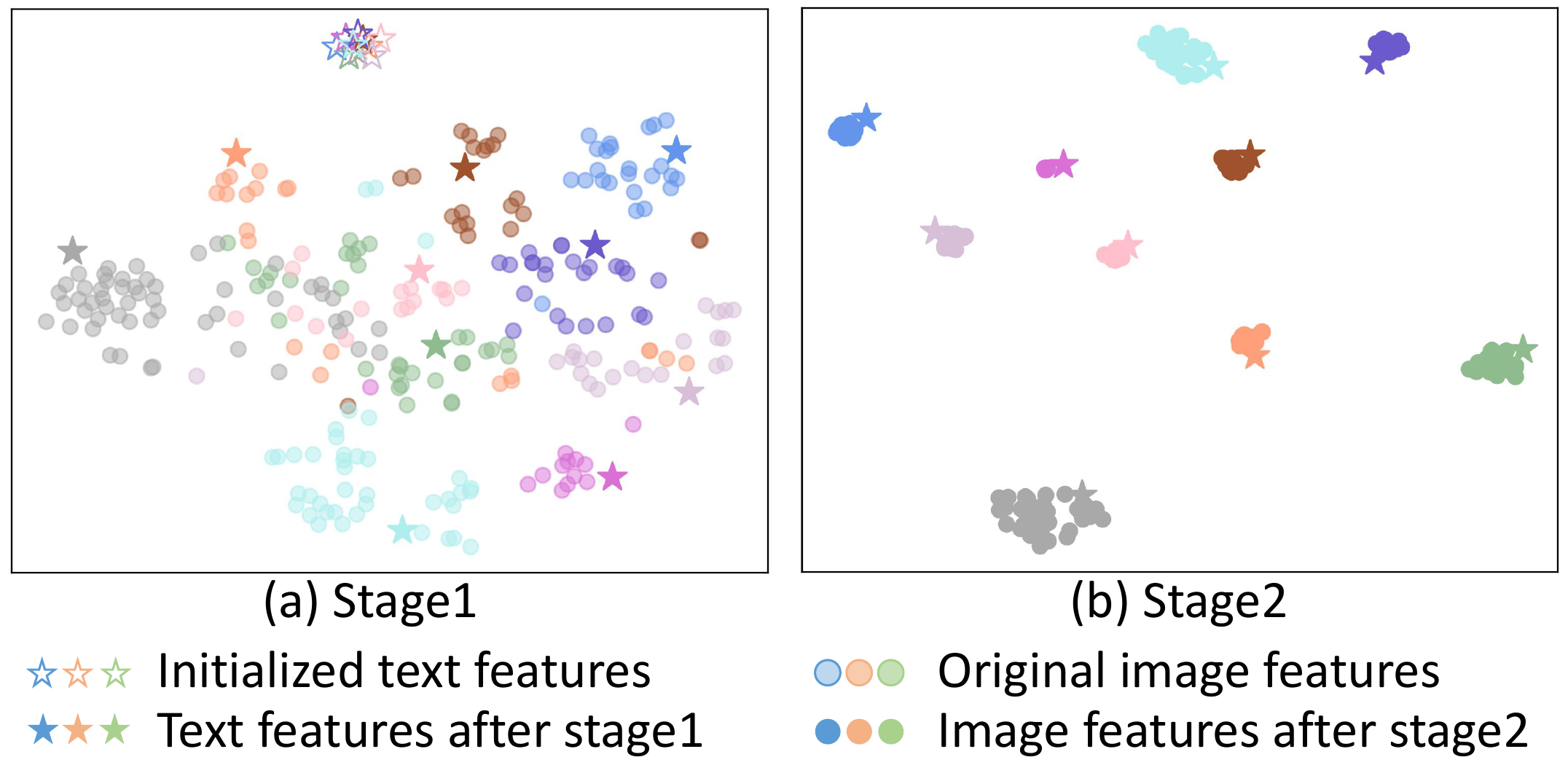
Figure Figure 1 simultaneously visualizes image and text features in 2D coordinates, which could help to understand our training strategy. In the first stage, the text feature of each ID is adapted to its corresponding image features, making it become ambiguous descriptions. In the second stage, image features gather around their text descriptions so that image features from different IDs become distant.
图1 同时在二维坐标中可视化了图像特征和文本特征,这有助于理解作者的训练策略。 在第一阶段,每个 ID 的文本特征适配其对应的图像特征,使其成为模糊描述。 在第二阶段,图像特征聚集在其文本描述周围,从而使不同 ID 的图像特征彼此远离。
In summary, the contributions of this paper lie in the following aspects:
总之,本文的贡献体现在以下几个方面:
- To our knowledge, we are the first to utilize CLIP for ReID.
- We provide competitive baseline models on several ReID datasets, which are the result of fine-tuning the visual model initialized by the CLIP image encoder.
- We propose the CLIP-ReID, which fully exploits the cross-modal describing ability of CLIP.
- In our model, the ID-specific learnable tokens are incorporated to give ambiguous text descriptions, and a two-stage training strategy is designed to take full advantage of the text encoder during training.
- We demonstrate that CLIP-ReID has achieved state-of-the-art performances on many ReID datasets, including both person and vehicle.
- 据作者所知,作者是首个将 CLIP 用于 ReID 的工作。
- 作者在多个 ReID 数据集上提供了有竞争力的基线模型,这些模型来自对由 CLIP 图像编码器初始化的视觉模型进行微调。
- 作者提出 CLIP-ReID,它充分利用 CLIP 的跨模态描述能力。
- 在作者模型中,引入了 ID 特定的可学习 token 来给出模糊文本描述,并设计两阶段训练策略以在训练期间充分利用文本编码器。
- 作者证明 CLIP-ReID 在许多 ReID 数据集上取得了最先进性能,包括行人和车辆。
2. Related Works
2.1 Image ReID
Previous ReID works focus on learning discriminative features like foreground histograms, local maximal occurrences, bag-of-visual words, or hierarchical Gaussian descriptors. On the other hand, it can also be solved as a metric learning problem, expecting a reasonable distance measurement for inter- and intra-class samples. These two aspects are naturally combined by the deep neural network, in which the parameters are optimized under an appropriate loss function with almost no intentional interference. Particularly, with the scale development of CNN on ImageNet, ResNet-50 has been regarded as the common model for most ReID datasets.
先前 ReID 工作关注学习有判别力的特征,例如前景直方图、局部最大出现、视觉词袋或层次高斯描述子。 另一方面,它也可以被作为度量学习问题来解决,期望为类间和类内样本提供合理的距离度量。 这两个方面由深度神经网络自然结合,其中参数在合适损失函数下优化,几乎不需要人为干预。 特别是,随着 CNN 在 ImageNet 上的规模化发展,ResNet-50 已经被视为大多数 ReID 数据集的通用模型。
Despite the powerful ability of CNN, it is blamed for its irrelevant highlighted regions, which is probably due to the overfitting of limited training data. OSNet gives a lightweight model to deal with it. Auto-ReID and CDNet employ network architecture search for a compact model. OfM proposes a data selection method for learning a sampler to choose generalizable data during training. Although they obtain good results on some small datasets, performances drop significantly on large ones like MSMT17.
尽管 CNN 能力强大,但它会因高亮无关区域而受到质疑,这可能是有限训练数据过拟合导致的。 OSNet 给出了一个轻量模型来处理这一问题。 Auto-ReID 和 CDNet 使用网络架构搜索来获得紧凑模型。 OfM 提出一种数据选择方法,用于学习一个采样器,在训练期间选择可泛化数据。 虽然它们在一些小数据集上获得良好结果,但在 MSMT17 这样的大型数据集上性能显著下降。
Introducing prior knowledge into the network can also alleviate overfitting. An intuitive idea is to use features from different regions for identification. PCB and SAN divides the feature into horizontal stripes to enhance its ability to represent the local region. MGN utilizes a multiple granularity scheme on feature division to enhance its expressive capabilities further, and it has several branches to capture features from different parts. Therefore, model complexity becomes its major issue. BDB has a simple structure with only two branches, one for global features and the other for local features, which employs a simple batch feature drop strategy to randomly erase a horizontal stripe for all samples within a batch. CBDB-Net enhances BDB with more types of feature dropping. Similar multi-branch approaches with the purpose of mining rich features from different locations are also proposed, and they can be improved if the semantic parsing map participates during training.
向网络中引入先验知识也可以缓解过拟合。 一个直观想法是使用来自不同区域的特征进行识别。 PCB 和 SAN 将特征划分为水平条带,以增强其表示局部区域的能力。 MGN 在特征划分上使用多粒度方案以进一步增强表达能力,并具有多个分支来捕获不同部位的特征。 因此,模型复杂度成为其主要问题。 BDB 结构简单,只有两个分支,一个用于全局特征,另一个用于局部特征;它采用简单的 batch feature drop 策略,随机擦除一个 batch 内所有样本的一条水平条带。 CBDB-Net 用更多类型的特征丢弃增强 BDB。 以从不同位置挖掘丰富特征为目的的类似多分支方法也被提出,如果语义解析图参与训练,它们还可以进一步改进。
Attention enlarges the receptive field, hence is another way to prevent the model from focusing on small areas. In RGA, non-local attention is performed along spatial and channel directions. ABDNet adopts a similar attention module and adds a regularization term to ensure feature orthogonality. HOReID extends the traditional attention into high-order computation, giving more discriminative features. CAL provides an attention scheme for counterfactual learning, which filters out irrelevant areas and increases prediction accuracy. Recently, due to the power of the transformer, it has become popular in ReID. PAT and DRL-Net build on ResNet-50, but they utilize a transformer decoder to exploit image features from CNN. In the decoder attention block, learnable queries first interact with key tokens from the image and then are updated by weighted image values. They are expected to reflect local features for ReID. TransReID, AAformer and DCAL all use encoder attention blocks in ViT, and they obtain better performance, especially on the large dataset.
注意力会扩大感受野,因此也是防止模型关注小区域的另一种方式。 在 RGA 中,非局部注意力沿空间和通道方向执行。 ABDNet 采用类似注意力模块,并添加正则化项以确保特征正交性。 HOReID 将传统注意力扩展到高阶计算,给出更有判别力的特征。 CAL 为反事实学习提供了一种注意力方案,它过滤无关区域并提高预测准确率。 最近,由于 Transformer 的能力,它已经在 ReID 中流行起来。 PAT 和 DRL-Net 建立在 ResNet-50 之上,但它们使用 Transformer 解码器来利用来自 CNN 的图像特征。 在解码器注意力块中,可学习查询首先与来自图像的 key token 交互,然后由加权图像 value 更新。 它们被期望反映用于 ReID 的局部特征。 TransReID、AAformer 和 DCAL 都在 ViT 中使用编码器注意力块,并获得了更好的性能,尤其是在大型数据集上。
This paper implements both CNN and ViT models initialized from CLIP. Benefiting from the two-stage training, both achieve SOTA on different datasets.
本文实现了由 CLIP 初始化的 CNN 和 ViT 模型。 得益于两阶段训练,二者都在不同数据集上达到 SOTA。
2.2 Vision-Language Learning
Compared to supervised pre-training on ImageNet, vision-language pre-training(VLP) has significantly improved the performance of many downstream tasks by training to match image and language. CLIP and ALIGN are good practices, which utilize a pair of image and text encoders, and two directional InfoNCE losses computed between their outputs for training. Built on CLIP, several works have been proposed to incorporate more types of learning tasks like image-to-text matching and mask image/text modeling. ALBEF aligns the image and text representation before fusing them through cross-model attention. SimVLM uses a single prefix language modeling objective for end-to-end training.
与 ImageNet 上的监督预训练相比,视觉-语言预训练(VLP)通过训练图像与语言匹配,显著提高了许多下游任务的性能。 CLIP 和 ALIGN 是良好实践,它们使用一对图像编码器和文本编码器,并在其输出之间计算两个方向的 InfoNCE 损失进行训练。 在 CLIP 的基础上,若干工作被提出,用来纳入更多类型的学习任务,例如图像到文本匹配和 mask image/text modeling。 ALBEF 在通过跨模态注意力融合图像和文本表示之前,先对齐二者。 SimVLM 使用单一前缀语言建模目标进行端到端训练。
Inspired by the recent advances in NLP, prompt or adapter-based tuning becomes prevalent in vision domain CoOp proposes to fit in a learnable prompt for image classification. CoCoOp learns a light-weight visual network to give meta tokens for each image, combined with a set of learnable context vectors. CLIP-Adapter adds a light-weight module on top of both image and text encoder.
受 NLP 近期进展启发,基于提示或适配器的调优在视觉领域变得流行。 CoOp 提出为图像分类拟合一个可学习提示。 CoCoOp 学习一个轻量视觉网络,为每张图像给出 meta token,并与一组可学习上下文向量结合。 CLIP-Adapter 在图像编码器和文本编码器之上都添加了轻量模块。
In addition, researchers investigate different downstream tasks to apply CLIP. DenseCLIP and MaskCLIP apply it for per-pixel prediction in segmentation. ViLD adapts image and text encoders in CLIP for object detection. EI-CLIP and CLIP4CirDemo use CLIP to solve retrieval problems. However, as far as we know, no works deal with ReID based on CLIP.
此外,研究者探索不同下游任务来应用 CLIP。 DenseCLIP 和 MaskCLIP 将它用于分割中的逐像素预测。 ViLD 将 CLIP 中的图像编码器和文本编码器适配到目标检测。 EI-CLIP 和 CLIP4CirDemo 使用 CLIP 解决检索问题。 然而,据作者所知,尚无工作基于 CLIP 处理 ReID。
Algorithm 1: CLIP-ReID's training process.
Input: batch of images
Parameter: a set of learnable text tokens
- Initialize
, , and from the pre-trained CLIP. - Initialize
( ) randomly. - while in the 1st stage do
-
- Optimize
by Equation (5). - end while
- for
to do -
- end for
- while in the 2nd stage do
-
- Optimize
by Equation (9). - end while
3. Method
3.1 Preliminaries: Overview of CLIP
We first briefly review CLIP. It consists of two encoders, an image encoder
作者首先简要回顾 CLIP。 它由两个编码器组成,即图像编码器
On the other hand, the text encoder
另一方面,文本编码器
Specifically,
具体而言,
where
其中
and the text-to-image contrastive loss
文本到图像对比损失
where numerators in Equation (2) and Equation (3) are the similarities of two embeddings from matched pair, and the denominators are all similarities with respect to anchor
其中,公式 (2) 和公式 (3) 中的分子是匹配对中两个嵌入的相似度,分母是相对于锚点
For regular classification tasks, CLIP converts the concrete labels of the dataset into text descriptions, then produces embedding feature
对于常规分类任务,CLIP 将数据集的具体标签转换为文本描述,然后生成嵌入特征
3.2 CLIP-ReID
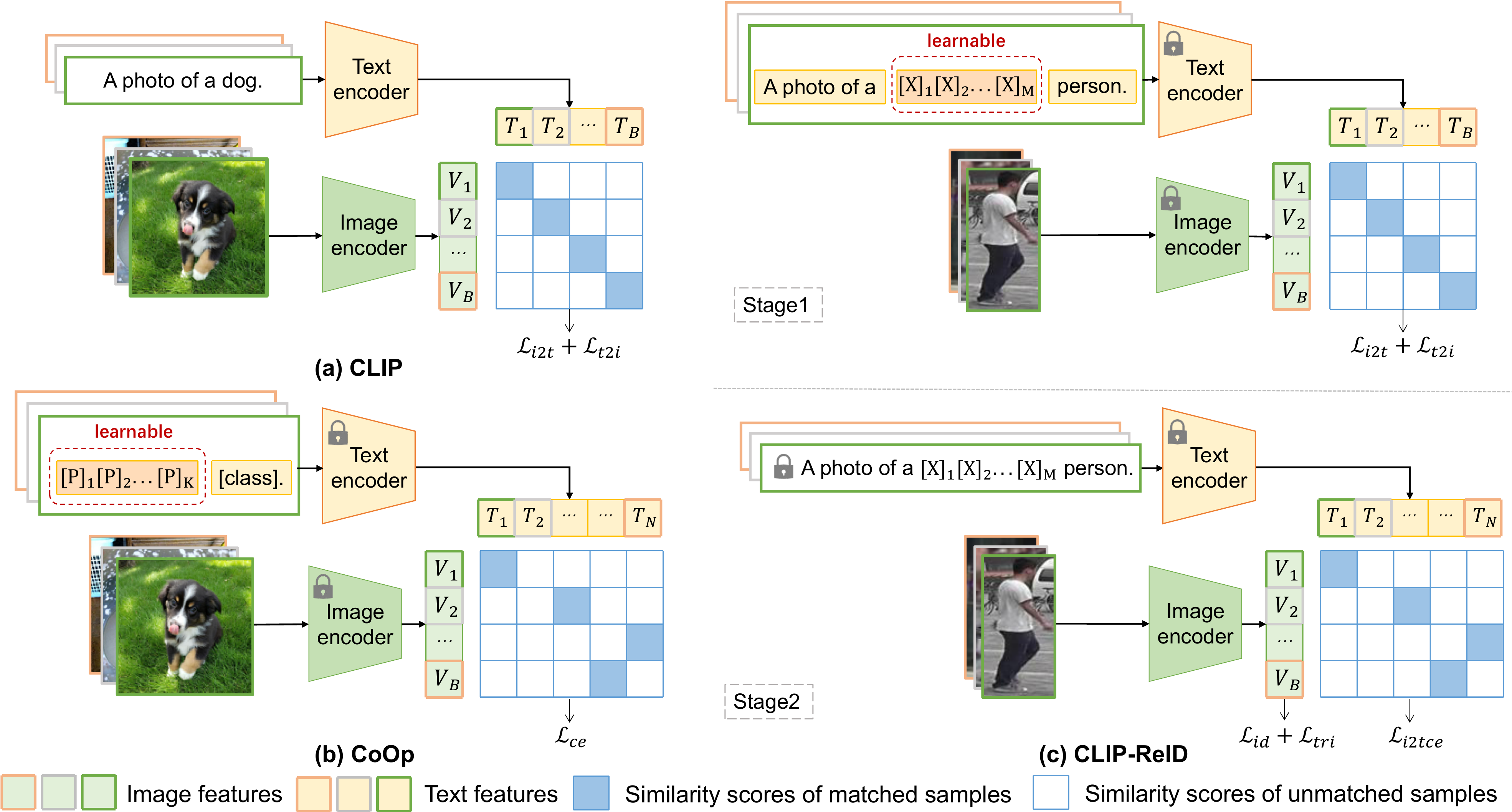
To deal with the above problem, we propose CLIP-ReID, which complements the lacking textual information by pre-training a set of learnable text tokens. As is shown in Figure Figure 2(c), our scheme is built by pre-trained CLIP with the two stages of training, and its metrics exceed our baseline.
为处理上述问题,作者提出 CLIP-ReID,通过预训练一组可学习文本 token 来补充缺失的文本信息。 如 图2(c) 所示,作者方案由预训练 CLIP 与两阶段训练构建而成,其指标超过作者的基线。
The first training stage. We first introduce ID-specific learnable tokens to learn ambiguous text descriptions, which are independent for each ID. Specifically, the text descriptions fed into
第一训练阶段。 作者首先引入 ID 特定可学习 token 来学习模糊文本描述,这些 token 对每个 ID 都是独立的。 具体而言,送入
Similar to CLIP, we use
与 CLIP 类似,作者使用
Here,
这里,
By minimizing the loss of
通过最小化
To improve the computation efficiency, we obtain all the image features by feeding the whole training set into
为提高计算效率,作者在第一训练阶段开始时,将整个训练集送入
The second training stage. In this stage, only parameters in
第二训练阶段。 在这一阶段,只有
where
其中,
To fully exploit CLIP, for each image, we can use the text features obtained in the first training stage to calculate image to text cross-entropy
为充分利用 CLIP,对于每张图像,作者可以使用第一训练阶段获得的文本特征来计算图像到文本交叉熵
Ultimately, the losses used in our second training stage are summarized as follows:
最终,作者第二训练阶段使用的损失总结如下:
The whole training process of the proposed CLIP-ReID, including both the first and second stages, is summarized in Algorithm Algorithm 1. We use the learnable prompts to mine and store the hidden states of the pre-trained image encoder and text encoder, allowing CLIP to retain its own advantages. During the second stage, these prompts can regularize the image encoder and thus increase its generalization ability.
所提出 CLIP-ReID 的完整训练过程,包括第一和第二阶段,总结于 算法1。 作者使用可学习提示来挖掘并存储预训练图像编码器和文本编码器的隐藏状态,使 CLIP 能够保留自身优势。 在第二阶段,这些提示可以正则化图像编码器,从而提升其泛化能力。
SIE and OLP. To make the model aware of the camera or viewpoint, we use Side Information Embeddings (SIE) to introduce relevant information. Unlike TransReID, we only add camera information to the [CLS] token, rather than all tokens, to avoid disturbing image details. Overlapping Patches (OLP) can further enhance the model with increased computational resources, which is realized simply by changing the stride in the token embedding.
SIE 和 OLP。 为了让模型感知相机或视角,作者使用侧信息嵌入(Side Information Embeddings, SIE)来引入相关信息。 不同于 TransReID,作者只把相机信息添加到 [CLS] token,而不是所有 token,以避免扰动图像细节。 Overlapping Patches(OLP)可以在增加计算资源的情况下进一步增强模型,它只需改变 token embedding 中的 stride 即可实现。
4. Experiments
4.1 Datasets and Evaluation Protocols
We evaluate our method on four person re-identification datasets, including MSMT17, Market-1501, DukeMTMC-reID, Occluded-Duke, and two vehicle ReID datasets, VeRi-776 and VehicleID. The details of these datasets are summarized in Table Table 1. Following common practices, we adapt the cumulative matching characteristics (CMC) at Rank-1 (R1) and the mean average precision (mAP) to evaluate the performance.
作者在四个行人重识别数据集上评估方法,包括 MSMT17、Market-1501、DukeMTMC-reID、Occluded-Duke,以及两个车辆 ReID 数据集 VeRi-776 和 VehicleID。 这些数据集的细节总结于 表1。 按照常见实践,作者采用 Rank-1(R1)处的累计匹配特性(CMC)和平均精度均值(mAP)评估性能。
| Dataset | Image | ID | Cam + View |
|---|---|---|---|
| MSMT17 | 126,441 | 4,101 | 15 |
| Market-1501 | 32,668 | 1,501 | 6 |
| DukeMTMC-reID | 36,411 | 1,404 | 8 |
| Occluded-Duke | 35,489 | 1,404 | 8 |
| VeRi-776 | 49,357 | 776 | 28 |
| VehicleID | 221,763 | 26,267 | - |
4.2 Implementations
Models. We adopt the visual encoder
模型。 作者采用来自 CLIP 的视觉编码器
Training details. In the first training stage, we use the Adam optimizer for both the CNN-based and the ViT-based models, with a learning rate initialized at
训练细节。 在第一训练阶段,作者对基于 CNN 和基于 ViT 的模型都使用 Adam 优化器,学习率初始化为
| Backbone | Methods | References | MSMT17 | Market-1501 | DukeMTMC | Occluded-Duke | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | R1 | mAP | R1 | mAP | R1 | mAP | R1 | |||
| CNN | PCB* | ECCV | - | - | 81.6 | 93.8 | 69.2 | 83.3 | - | - |
| MGN* | MM | - | - | 86.9 | 95.7 | 78.4 | 88.7 | - | - | |
| OSNeT | ICCV | 52.9 | 78.7 | 84.9 | 94.8 | 73.5 | 88.6 | - | - | |
| ABD-Net* | ICCV | 60.8 | 82.3 | 88.3 | 95.6 | 78.6 | 89.0 | - | - | |
| Auto-ReID* | ICCV | 52.5 | 78.2 | 85.1 | 94.5 | - | - | - | - | |
| HOReID | CVPR | - | - | 84.9 | 94.2 | 75.6 | 86.9 | 43.8 | 55.1 | |
| ISP | ECCV | - | - | 88.6 | 95.3 | 80.0 | 89.6 | 52.3 | 62.8 | |
| SAN | AAAI | 55.7 | 79.2 | 88.0 | 96.1 | 75.5 | 87.9 | - | - | |
| OfM | AAAI | 54.7 | 78.4 | 87.9 | 94.9 | 78.6 | 89.0 | - | - | |
| CDNet | CVPR | 54.7 | 78.9 | 86.0 | 95.1 | 76.8 | 88.6 | - | - | |
| PAT | CVPR | - | - | 88.0 | 95.4 | 78.2 | 88.8 | 53.6 | 64.5 | |
| CAL* | ICCV | 56.2 | 79.5 | 87.0 | 94.5 | 76.4 | 87.2 | - | - | |
| CBDB-Net* | TCSVT | - | - | 85.0 | 94.4 | 74.3 | 87.7 | 38.9 | 50.9 | |
| ALDER* | TIP | 59.1 | 82.5 | 88.9 | 95.6 | 78.9 | 89.9 | - | - | |
| LTReID* | TMM | 58.6 | 81.0 | 89.0 | 95.9 | 80.4 | 90.5 | - | - | |
| DRL-Net | TMM | 55.3 | 78.4 | 86.9 | 94.7 | 76.6 | 88.1 | 50.8 | 65.0 | |
| baseline | 60.7 | 82.1 | 88.1 | 94.7 | 79.3 | 88.6 | 47.4 | 54.2 | ||
| CLIP-ReID | 63.0 | 84.4 | 89.8 | 95.7 | 80.7 | 90.0 | 53.5 | 61.0 | ||
| ViT | AAformer* | arxiv | 63.2 | 83.6 | 87.7 | 95.4 | 80.0 | 90.1 | 58.2 | 67.0 |
| TransReID+SIE+OLP | ICCV | 67.4 | 85.3 | 88.9 | 95.2 | 82.0 | 90.7 | 59.2 | 66.4 | |
| TransReID+SIE+OLP* | 69.4 | 86.2 | 89.5 | 95.2 | 82.6 | 90.7 | - | - | ||
| DCAL | CVPR | 64.0 | 83.1 | 87.5 | 94.7 | 80.1 | 89.0 | - | - | |
| baseline | 66.1 | 84.4 | 86.4 | 93.3 | 80.0 | 88.8 | 53.5 | 60.8 | ||
| CLIP-ReID | 73.4 | 88.7 | 89.6 | 95.5 | 82.5 | 90.0 | 59.5 | 67.1 | ||
| CLIP-ReID+SIE+OLP | 75.8 | 89.7 | 90.5 | 95.4 | 83.1 | 90.8 | 60.3 | 67.2 | ||
| Backbone | Methods | VeRi-776 | VehicleID | ||
|---|---|---|---|---|---|
| mAP | R1 | R1 | R5 | ||
| CNN | PRN | 74.3 | 94.3 | 78.4 | 92.3 |
| PGAN | 79.3 | 96.5 | 77.8 | 92.1 | |
| SAN | 72.5 | 93.3 | 79.7 | 94.3 | |
| UMTS | 75.9 | 95.8 | 80.9 | - | |
| SPAN | 68.9 | 94.0 | - | - | |
| PVEN | 79.5 | 95.6 | 84.7 | 97.0 | |
| SAVER | 79.6 | 96.4 | 79.9 | 95.2 | |
| CFVMNet | 77.1 | 95.3 | 81.4 | 94.1 | |
| CAL | 74.3 | 95.4 | 82.5 | 94.7 | |
| EIA-Net | 79.3 | 95.7 | 84.1 | 96.5 | |
| FIDI | 77.6 | 95.7 | 78.5 | 91.9 | |
| baseline | 79.3 | 95.7 | 84.4 | 96.6 | |
| CLIP-ReID | 80.3 | 96.8 | 85.2 | 97.1 | |
| ViT | TransReID | 80.6 | 96.9 | 83.6 | 97.1 |
| TransReID! | 82.0 | 97.1 | 85.2 | 97.5 | |
| DCAL | 80.2 | 96.9 | - | - | |
| baseline | 79.3 | 95.7 | 84.2 | 96.6 | |
| CLIP-ReID | 83.3 | 97.4 | 85.3 | 97.6 | |
| CLIP-ReID! | 84.5 | 97.3 | 85.5 | 97.2 | |
4.3 Comparison with State-of-the-Art Methods
We compare our method with the state-of-the-art methods on three widely used person ReID benchmarks, one occluded ReID benchmark in Table Table 2, and two vehicle ReID benchmarks in Table Table 3. Despite being simple, CLIP-ReID achieves a strikingly good result. Note that all data listed here are without re-ranking.
作者在三个广泛使用的行人 ReID 基准、一个遮挡 ReID 基准上与最先进方法进行比较,结果见 表2;并在两个车辆 ReID 基准上比较,结果见 表3。 尽管方法简单,CLIP-ReID 取得了令人瞩目的良好结果。 注意,这里列出的所有数据都没有使用 re-ranking。
Person ReID. For both CNN-based and ViT-based methods, CLIP-ReID outperforms previous methods by a large margin on the most challenging dataset, MSMT17. Our method achieves
行人 ReID。 对于基于 CNN 和基于 ViT 的方法,CLIP-ReID 在最具挑战性的数据集 MSMT17 上都以很大幅度超过先前方法。 作者方法在基于 CNN 的主干上达到
Vehicle ReID. Our method achieves competitive performance compared to the prior CNN-based and ViT-based methods. With the ViT-based backbone, CLIP-ReID reaches
车辆 ReID。 与先前基于 CNN 和基于 ViT 的方法相比,作者方法取得了有竞争力的性能。 使用基于 ViT 的主干,CLIP-ReID 在 VehicleID 上达到
4.4 Ablation Studies and Analysis
We conduct comprehensive ablation studies on MSMT17 dataset to analyze the influences and sensitivity of some major parameters.
作者在 MSMT17 数据集上进行了全面消融研究,以分析若干主要参数的影响和敏感性。
Baseline comparison. Many CNN-based works are based on the strong baseline proposed by BoT. For ViT-based methods, TransReID's baseline is widely adopted, while AAformer also proposes a baseline. Although slightly different, both of them are pre-trained on ImageNet, which is different from ours. As shown in Table Table 4, due to the effectiveness of CLIP pre-training, our baseline achieves superior performance compared to other baselines.
基线比较。 许多基于 CNN 的工作都基于 BoT 提出的强基线。 对于基于 ViT 的方法,TransReID 的基线被广泛采用,同时 AAformer 也提出了一个基线。 虽然略有不同,但二者都在 ImageNet 上预训练,这与作者方法不同。 如 表4 所示,由于 CLIP 预训练的有效性,作者基线相比其他基线取得了更优性能。
| Backbones | Methods | mAP | Rank-1 |
|---|---|---|---|
| CNN | BoT | 51.3 | 75.3 |
| CLIP-ReID baseline | 60.7 | 82.1 | |
| ViT | AAformer baseline | 58.5 | 79.4 |
| TransReID baseline | 61.0 | 81.8 | |
| CLIP-ReID baseline | 66.1 | 84.4 |
Necessity of two-stage training. CLIP aligns embeddings from text and image domains, so it is important to exploit its text encoder. Since ReID has no specific text that distinguishes different IDs, we aim to provide this by pre-training a set of learnable text tokens. There are two ways to optimize them. One is one-stage training, in which we train the image encoder
两阶段训练的必要性。 CLIP 对齐文本域和图像域中的嵌入,因此利用其文本编码器很重要。 由于 ReID 没有能够区分不同 ID 的具体文本,作者旨在通过预训练一组可学习文本 token 来提供这种信息。 优化它们有两种方式。 一种是一阶段训练,其中作者训练图像编码器
| Backbone | Methods | mAP | Rank-1 |
|---|---|---|---|
| CNN | baseline | 60.7 | 82.1 |
| one stage | 61.9 | 82.8 | |
| two stage | 63.0 | 84.4 | |
| ViT | baseline | 66.1 | 84.4 |
| one stage | 68.9 | 85.9 | |
| two stage | 73.4 | 88.7 |
Constraint from text encoder in the second stage. There are
第二阶段中文本编码器的约束。 一个 batch 中有
| mAP | Rank-1 | |||
|---|---|---|---|---|
| - | - | - | 66.1 | 84.4 |
| - | ✓ | ✓ | 71.3 | 87.5 |
| - | ✓ | - | 71.7 | 87.6 |
| ✓ | - | ✓ | 73.2 | 88.6 |
| ✓ | - | - | 73.4 | 88.7 |
Number of learnable tokens M. To be consistent with CLIP, we set the text description to "A photo of a
可学习 token 数量 M。 为了与 CLIP 保持一致,作者将文本描述设为 "A photo of a
SIE and OLP. In Table Table 7, we evaluate the effectiveness of SIE and OLP on MSMT17. Using SIE only for [CLS] tokens works better than adding it for all global tokens. It gains
SIE 和 OLP。 在 表7 中,作者在 MSMT17 上评估 SIE 和 OLP 的有效性。 仅对 [CLS] token 使用 SIE 比将其添加到所有全局 token 效果更好。 当模型只使用 SIE-cls 时,它在 MSMT17 上获得
| SIE-all | SIE-cls | OLP | mAP | Rank-1 |
|---|---|---|---|---|
| - | - | - | 73.4 | 88.7 |
| ✓ | - | - | 74.3 | 88.6 |
| - | ✓ | - | 74.5 | 88.8 |
| - | - | ✓ | 74.6 | 89.5 |
| - | ✓ | ✓ | 75.8 | 89.7 |
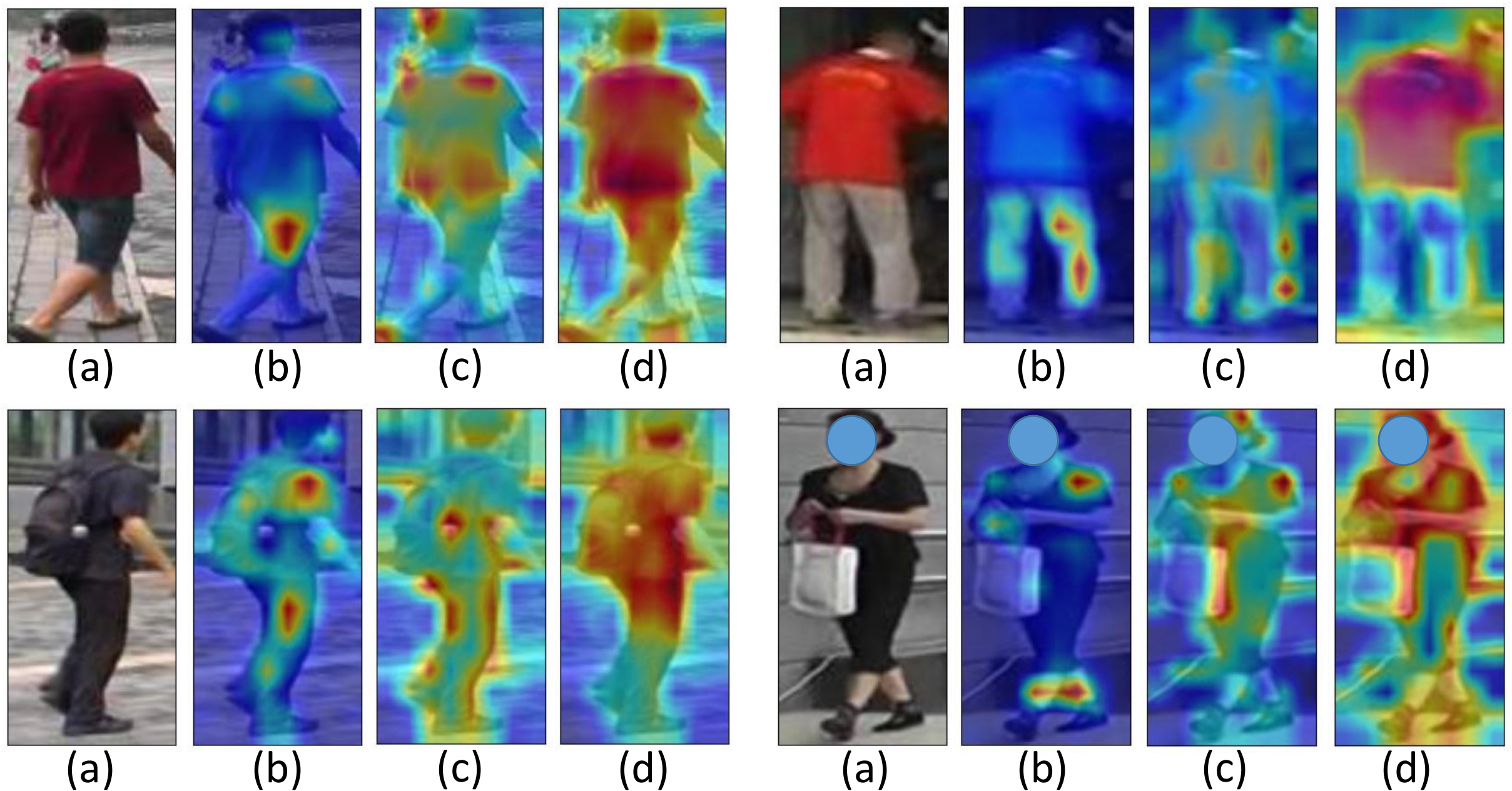
Visualization of CLIP-ReID. Finally, we perform visualization experiments using the method to show the focused areas of the model. Both TransReID's and our baselines focus on local areas, ignoring other details about the human body, while CLIP-ReID will focus on a more comprehensive area.
CLIP-ReID 的可视化。 最后,作者使用该方法进行可视化实验,以展示模型关注的区域。 TransReID 和作者的基线都关注局部区域,忽略了人体的其他细节,而 CLIP-ReID 会关注更全面的区域。
5. Conclusion
This paper investigates the way to apply the vision-language pre-training model in image ReID. We find that fine-tuning the visual model initialized by the CLIP image encoder, either ResNet-50 or ViT-B/16, gives a good performance compared to other baselines. To fully utilize the cross-modal description ability in the pre-trained model, we propose CLIP-ReID with a two-stage training strategy, in which the learnable text tokens shared within each ID are incorporated and augmented to describe different instances. In the first stage, only these tokens get optimized, forming ambiguous text descriptions. In the second stage, these tokens and text encoder together provide constraints for optimizing the parameters in the image encoder. We validate CLIP-ReID on several datasets of persons and vehicles, and the results demonstrate the effectiveness of text descriptions and the superiority of our model.
本文研究了将视觉-语言预训练模型应用于图像 ReID 的方式。 作者发现,对由 CLIP 图像编码器初始化的视觉模型进行微调,无论是 ResNet-50 还是 ViT-B/16,相比其他基线都给出了良好性能。 为了充分利用预训练模型中的跨模态描述能力,作者提出带有两阶段训练策略的 CLIP-ReID,其中引入并增强每个 ID 内共享的可学习文本 token,用来描述不同实例。 在第一阶段,只有这些 token 被优化,形成模糊文本描述。 在第二阶段,这些 token 和文本编码器共同为优化图像编码器中的参数提供约束。 作者在多个行人和车辆数据集上验证 CLIP-ReID,结果证明了文本描述的有效性和作者模型的优越性。