
CNN 卷积神经网络
Convolutional Neural Network [1989]
CNN 的结构可以分为 5 层:
- 输入层 Input Layer
- 卷积层 Convolutional Layer 提取图像的底层特征
- 池化层 Pooling Layer 防止过拟合,将数据维度减少
- 全连接层 Fully Connected Layer
- 输出层 Output Layer
输入层
卷积层
卷积运算公式:
符号说明
输入矩阵:
卷积核:
输出矩阵:
索引范围:
对于输入尺寸为
- 示例
输入矩阵:
TIP
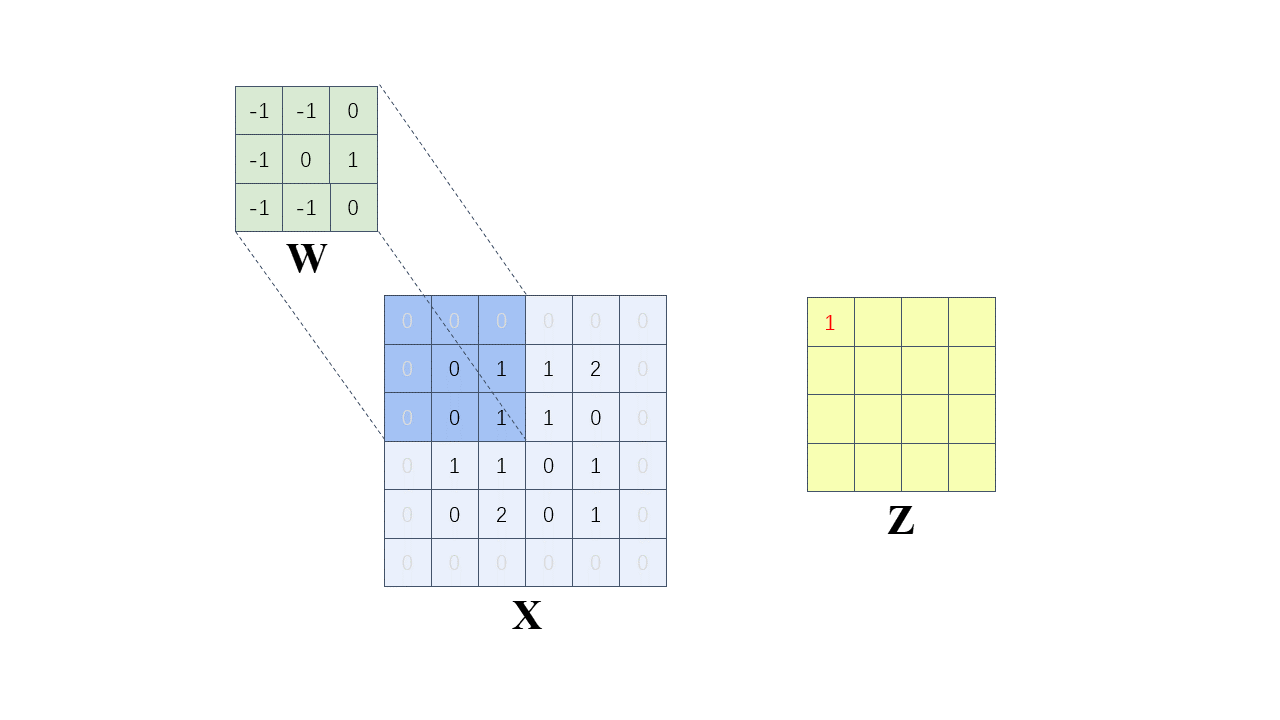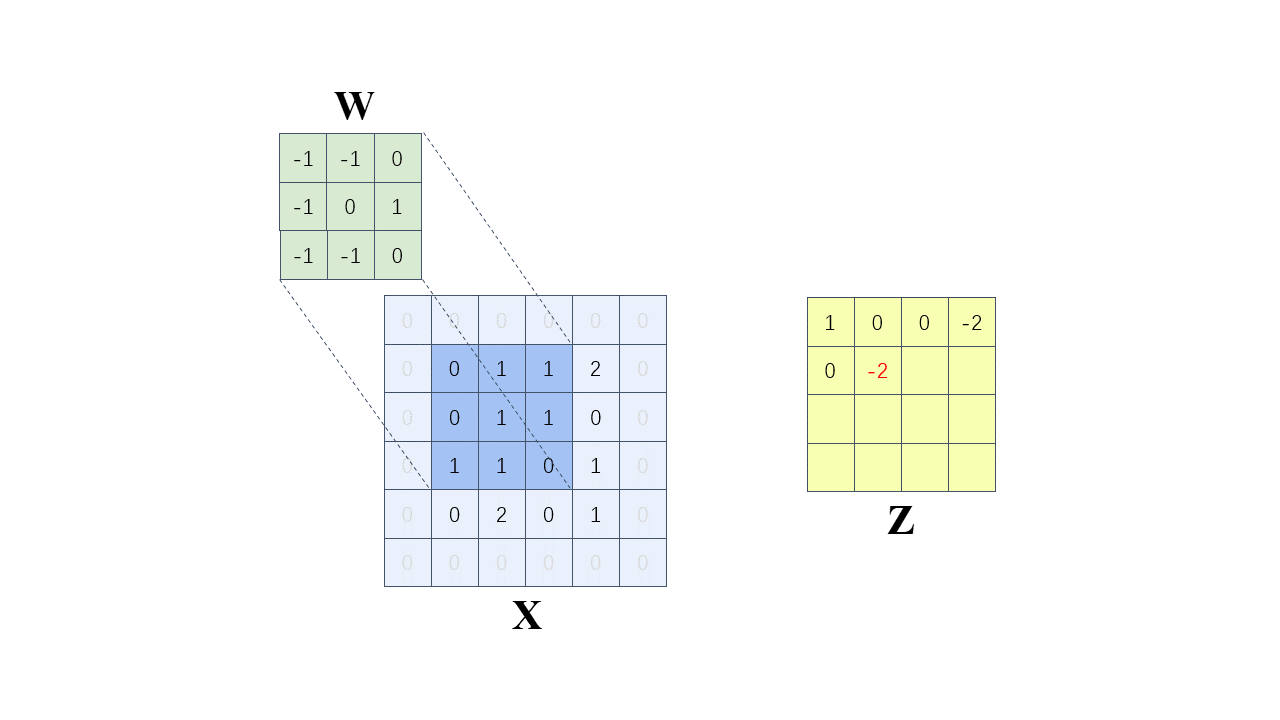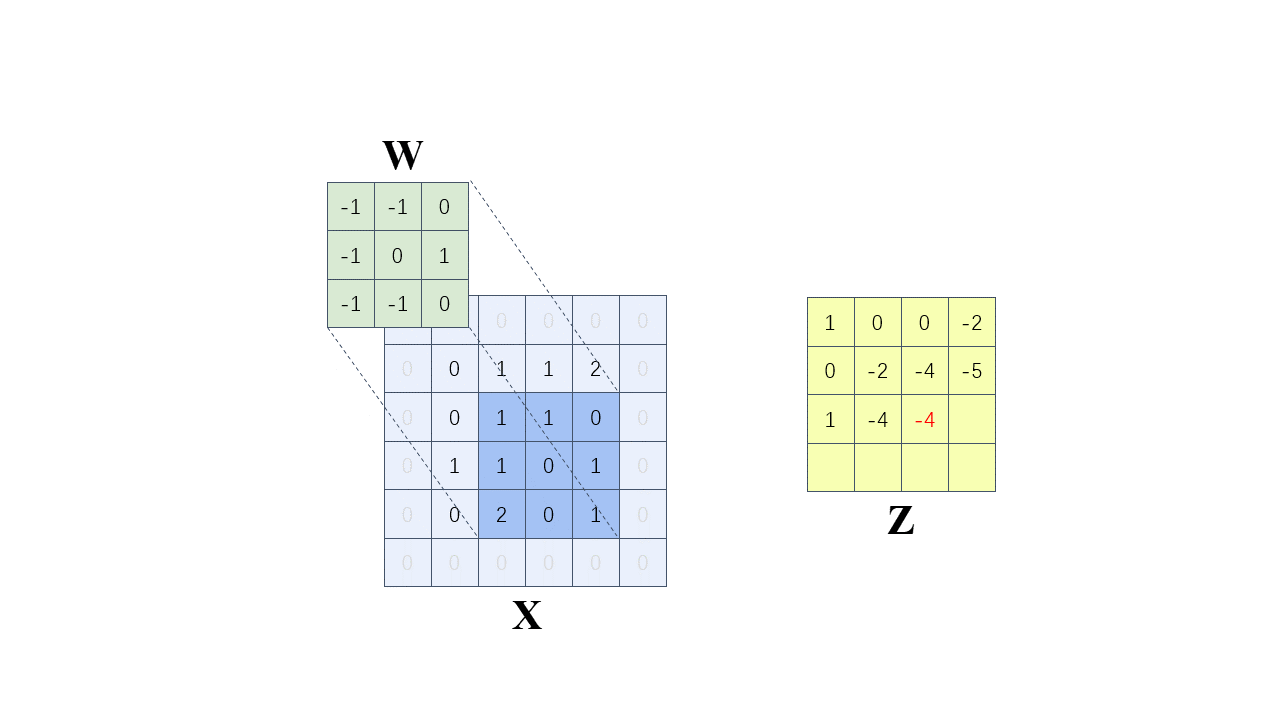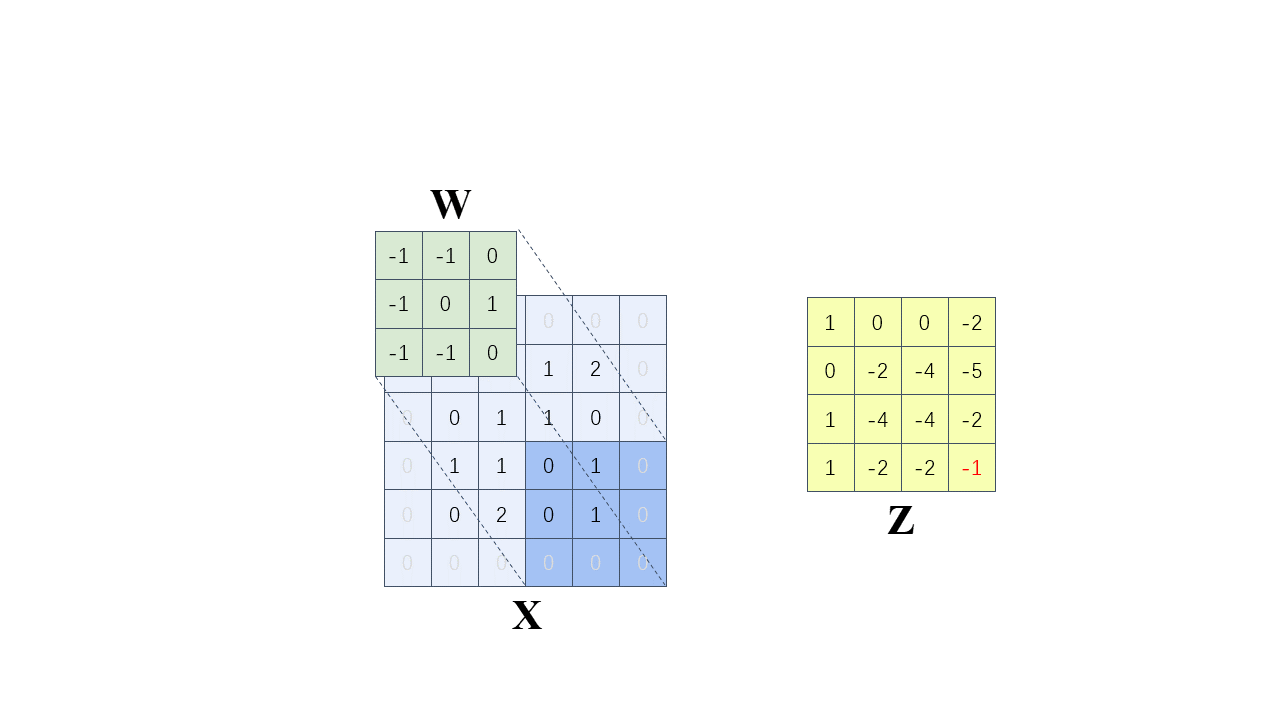
每次计算的时候,边缘只被计算一次,而中间被多次计算,那么得到的特征图也会丢失边缘特征,最终会导致特征提取不准确,那为了解决这个问题,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈,在这里我们扩展一圈。
这种通过拓展解决特征丢失的方法又被称为 Padding
卷积核为:
以左上角第一个有效位置为例:

全部计算过程如下(步长 = 1):
池化层

图:池化层
全连接层
前向传播
定义:
| 符号 | 全称 | 意义 | 示例 |
|---|---|---|---|
| Kernel Size | 卷积核/池化窗口的边长 | 3×3 卷积核时 | |
| Channels | 输入数据的通道数 | RGB 图像 | |
| Depth | 卷积层输出通道数(滤波器数量) | 64 个滤波器时 | |
| Height | 输入特征图的高度 | 输入图像高度为 256 时 | |
| Width | 输入特征图的宽度 | 输入图像宽度为 256 时 | |
| Stride | 卷积操作的步长 | 通常设为 1 |
卷积层
输入特征图
激活输出:
其中
池化层 (Max Pooling)
全连接层
与普通神经网络相同:
反向传播
全连接层
池化层 (Max Pooling)
卷积层
权重梯度:
偏置梯度:
输入梯度:
代码
最常见的用法
python
import torch
import torch.nn as nn
conv = nn.Conv2d(
in_channels=3,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
bias=True,
)
x = torch.randn(8, 3, 224, 224)
y = conv(x)
print(y.shape) # [8, 64, 224, 224]Conv2d.init()
简化版:
python
class Conv2d(_ConvNd):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode="zeros",
device=None,
dtype=None,
):
factory_kwargs = {"device": device, "dtype": dtype}
kernel_size_ = _pair(kernel_size)
stride_ = _pair(stride)
padding_ = padding if isinstance(padding, str) else _pair(padding)
dilation_ = _pair(dilation)
super().__init__(
in_channels,
out_channels,
kernel_size_,
stride_,
padding_,
dilation_,
False, # transposed=False,说明不是反卷积
_pair(0), # output_padding,只给 ConvTranspose 用
groups,
bias,
padding_mode,
**factory_kwargs,
)_ConvNd.init():检查参数是否合法
python
if groups <= 0:
raise ValueError("groups must be a positive integer")
if in_channels % groups != 0:
raise ValueError("in_channels must be divisible by groups")
if out_channels % groups != 0:
raise ValueError("out_channels must be divisible by groups")即:
- groups 必须是正整数
- in_channels 必须能被 groups 整除
- out_channels 也必须能被 groups 整除
创建 weight
普通 Conv2d 的权重创建逻辑是:
python
self.weight = Parameter(
torch.empty(
(out_channels, in_channels // groups, *kernel_size),
**factory_kwargs,
)
)所以普通 2D 卷积的权重 shape 是:[out_channels, in_channels // groups, kernel_h, kernel_w]
比如:
python
conv = nn.Conv2d(
in_channels=3,
out_channels=64,
kernel_size=3,
groups=1,
)它的 conv.weight.shape 就是 [64, 3, 3, 3],即:一共有 64 个卷积核,每个卷积核看 3 个输入通道,每个卷积核空间大小是 3x3
创建 bias
python
if bias:
self.bias = Parameter(torch.empty(out_channels, **factory_kwargs))
else:
self.register_parameter("bias", None)reset_parameters()
创建完 weight 和 bias 后,源码会调用 self.reset_parameters()
python
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
init.uniform_(self.bias, -bound, bound)weight 用 kaiming_uniform_ 初始化
bias 用 U(-1/sqrt(fan_in), 1/sqrt(fan_in)) 初始化
Conv2d.forward()
python
def forward(self, input):
return self._conv_forward(input, self.weight, self.bias)python
def _conv_forward(self, input, weight, bias):
if self.padding_mode != "zeros":
return F.conv2d(
F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode),
weight,
bias,
self.stride,
_pair(0),
self.dilation,
self.groups,
)
return F.conv2d(
input,
weight,
bias,
self.stride,
self.padding,
self.dilation,
self.groups,
)非零填充模式是通过先 pad 再 conv 实现的。