
MemAgent:用基于多对话强化学习的记忆智能体重塑长上下文 LLM
Abstract
Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss below 5% and achieves 95%+ in 512K RULER test.
尽管长度外推、高效注意力和记忆模块已经带来改进,但如何用线性复杂度处理无限长文档,并且在外推时不出现性能退化,仍然是长文本处理的终极挑战。 作者以端到端方式直接优化长文本任务,并提出一种新的智能体工作流 MemAgent:它分段阅读文本,并使用覆盖式策略更新记忆。 作者扩展了 DAPO 算法,使其能够通过独立上下文的多对话生成来完成训练。 MemAgent 展现出很强的长上下文能力:模型在 32K 文本上训练、实际上下文窗口只有 8K,却能外推到 3.5M token 的问答任务,性能损失低于 5%,并且在 512K RULER 测试上达到 95% 以上。
1. Introduction
While having demonstrated impressive capabilities, industry-level Large Language Model (LLM) systems still face a critical challenge: how to handle long contexts effectively. Processing an entire book, executing a complex chain of reasoning over many steps, or managing the long-term memory of an agent system can all generate overflowing text that quickly exceeds the typical context window of current LLMs.
尽管大型语言模型(LLM)系统已经展现出很强能力,工业级 LLM 系统仍然面临一个关键挑战:如何有效处理长上下文。 无论是处理整本书、执行跨越许多步骤的复杂推理链,还是管理智能体系统的长期记忆,都可能产生大量文本,并迅速超出当前 LLM 常见的上下文窗口。
Existing approaches to long-context tasks are three-pronged. The first involves length extrapolation methods by shifting positional embeddings to extend the model's context window, plus continued pre-training. Despite promising potential, these methods often suffer from performance degradation and slow processing speed due to
现有长上下文方法大致分为三类。 第一类是长度外推方法,通过调整位置嵌入来扩展模型上下文窗口,并配合持续预训练。 这类方法虽然很有潜力,但在极长文本上往往会因为
Hence, a successful LLM with strong long-context capabilities requires the trinity of processing infinite length of text, scaling without performance drop, and efficient decoding with linear complexity. To pursue this quest, the authors return to the basic intuition behind long-context modeling. When humans process long-context information, we tend to abstract the main concepts that capture the essence of the whole text, often by making notes of critical details or using shorthand to record key points while discarding redundant and irrelevant data. We do not attempt to memorize every single fact or each small piece of information; instead, we focus intellectual energy on more important aspects of the task at hand. This selective attention simplifies the process and helps tackle complex problems more efficiently.
因此,一个真正具备强长上下文能力的 LLM 需要同时满足三点:能处理无限长度文本、扩展时性能不下降、并且能以线性复杂度高效解码。 为了实现这一目标,作者回到长上下文建模背后的基本直觉。 人类处理长上下文信息时,通常会抽象出能够概括全文本质的主要概念,例如记录关键细节或用速记方式保留要点,同时丢弃冗余和无关数据。 我们并不会试图记住每一个事实或每一小块信息,而是把认知资源集中在当前任务中更重要的部分。 这种选择性注意不仅简化了处理过程,也有助于更高效地解决复杂问题。
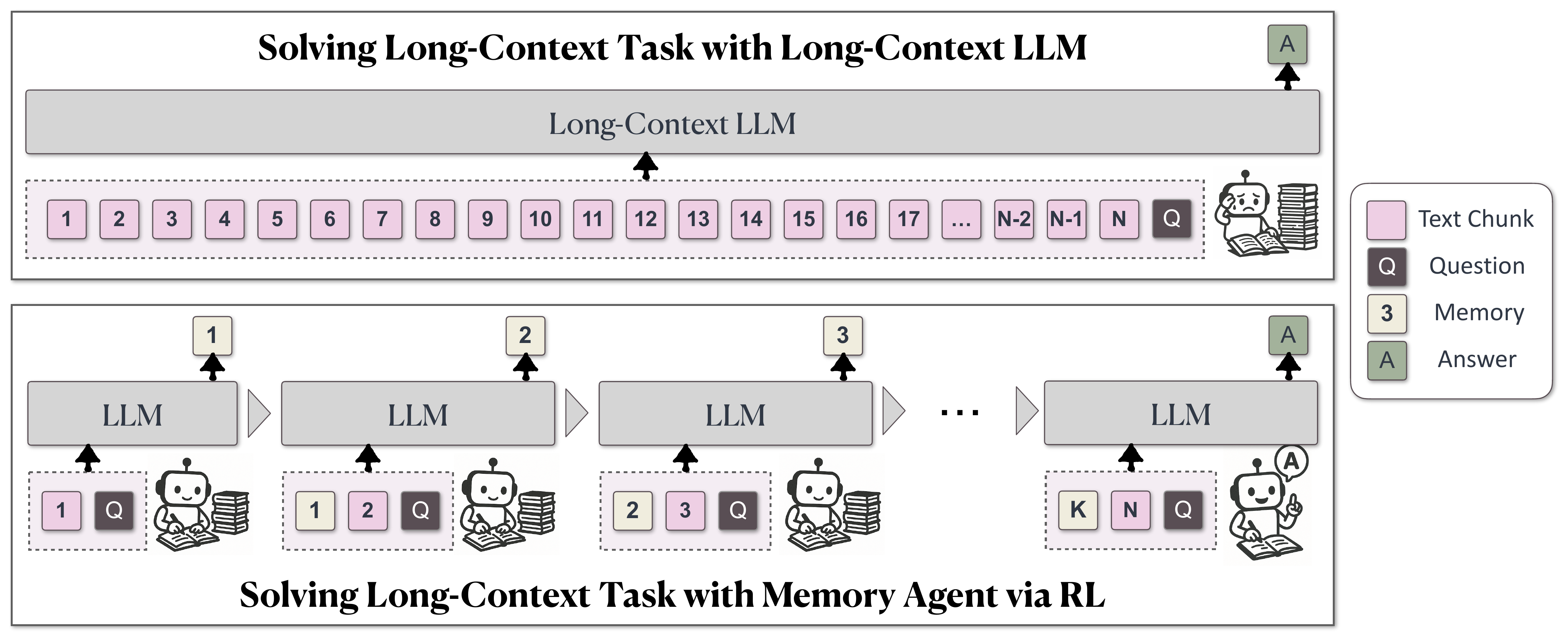
Following this anthropocentric intuition, the authors propose a novel use of Reinforcement Learning (RL) to equip LLMs with a dynamically updated fixed-length memory, as illustrated in Figure 2. During inference, the LLM processes the input text segment by segment. As it reads each segment, the model proactively and selectively updates the memory, which then contributes to the generation of the final output after all relevant messages are aggregated and synergized in the memory. This mechanism allows the LLM to handle arbitrary text lengths while maintaining linear time complexity during processing, since the memory length is fixed and therefore the model always sees a fixed-size context window. This segment-based approach generates multiple outputs from a single long-text input, requiring multiple rounds of memory updates and a final round for generating the final response.
基于这种以人为中心的直觉,作者提出一种新的强化学习(RL)用法:为 LLM 配备一个动态更新的固定长度记忆,如图2所示。 在推理阶段,LLM 会逐段处理输入文本。 每读入一段文本,模型都会主动且选择性地更新记忆;当所有相关信息被汇聚并整合到记忆中后,模型再利用这些记忆生成最终输出。 由于记忆长度固定,模型始终面对固定大小的上下文窗口,因此这个机制允许 LLM 处理任意长度文本,同时保持线性时间复杂度。 这种分段式方法会从一个长文本输入中生成多个输出,需要多轮记忆更新,并在最后一轮生成最终回答。
Training this type of agent workflow, which enables dialogues across multiple independent contexts, is still unexplored in current LLM study. Existing systems typically handle workflow trajectories via alternating tool calls or environment feedback by either simply concatenating them or using a sliding window approach, which lacks flexibility and scalability in practice. The MemAgent approach instead treats each context-independent conversation as an optimization objective. Based on the DAPO algorithm, the authors implement Multi-Conv DAPO to optimize an arbitrary agent workflow by verifiable outcome reward.
训练这种智能体工作流仍然是当前 LLM 研究中尚未充分探索的问题,因为它涉及跨多个独立上下文的对话。 现有系统通常通过交替工具调用或环境反馈来处理工作流轨迹,要么简单拼接,要么使用滑动窗口,但实践中灵活性和可扩展性都不足。 MemAgent 则把每个上下文独立的对话都视为一个优化目标。 基于 DAPO 算法,作者实现了 Multi-Conv DAPO,用可验证的结果奖励来优化任意智能体工作流。
In the experiments, an RL-trained model with a modest 8K context window, including a 1024-token memory and a 5000-token document chunk, is trained on 32K documents. It exhibits consistently strong capabilities for Question Answering (QA) tasks on documents up to 4 million tokens, without performance drop and with linear computation cost. This demonstrates the efficiency and scalability of the proposed long-context memory approach.
在实验中,一个经过强化学习训练的模型仅使用 8K 上下文窗口,其中包括 1024 token 的记忆和 5000 token 的文档块,并在 32K 文档上训练。 它在最长 400 万 token 文档的问答任务上持续表现很强,同时没有明显性能下降,并保持线性计算成本。 这说明本文提出的长上下文记忆方法具有效率和可扩展性。
The major contributions are threefold. First, the authors introduce a novel approach that enables LLMs to process arbitrarily long inputs within a limited context window under linear time complexity during inference, overcoming a significant bottleneck in long-context processing. Second, they design an agent workflow to implement this mechanism and propose an end-to-end training approach using the multi-conversation DAPO algorithm. Third, they empirically demonstrate that the RL-trained method allows models to extrapolate to vastly long documents with minimal performance degradation, pushing the boundaries of what is currently achievable in long-context LLM systems.
本文主要贡献有三点。 第一,作者提出一种新方法,使 LLM 能够在有限上下文窗口内以线性时间复杂度处理任意长度输入,从而突破长上下文处理的重要瓶颈。 第二,作者设计了一个智能体工作流来实现这一机制,并提出使用多对话 DAPO 算法进行端到端训练。 第三,实验表明,经过强化学习训练的方法可以让模型外推到极长文档,同时只产生极小的性能退化,推动了当前长上下文 LLM 系统能力边界。
2. Related Work
Long Context LLMs. Extrapolation methods for RoPE-based LLMs, such as NTK, PI, YaRN and DCA, modify the base frequency, position index and other components of positional embeddings, enabling the model to capture long-range semantic dependencies. On the other hand, linear attention mechanisms, Recurrent Neural Networks (RNNs), and State Space Models (SSMs) leverage different architectures to achieve
长上下文 LLM。 针对 RoPE 系 LLM 的外推方法,如 NTK、PI、YaRN 和 DCA,会修改位置嵌入中的基础频率、位置索引等组件,使模型能够捕捉长距离语义依赖。 另一方面,线性注意力机制、循环神经网络(RNN)和状态空间模型(SSM)通过不同架构实现
Reinforcement Learning for LLMs. In recent RL studies, reward signals have gradually shifted from human preferences or reward models distilled from them to rule-based feedback, which has demonstrated strong potential in enhancing model reasoning capabilities. Key contributions include PPO based on GAE, the Actor-Critic framework, and GRPO that utilizes group normalization. Algorithmic enhancements have mostly focused on improving training sustainability and sample efficiency. To further release the potential of RL, recent works such as Search-R1, Agent-R1 and RAGEN have explored training tool-using agents based on multi-turn chat. However, these multi-turn chats are constructed by alternately concatenating tool responses and model replies, with the ultimate optimization goal being a single conversation with tool masking. GiGPO further investigates using multiple independent contexts in agent training with environment feedback and sliding window trajectories. However, these approaches are limited to optimizing interleaved trajectories of observation and generation, making them difficult to apply to more general agent workflows.
面向 LLM 的强化学习。 近期强化学习研究中,奖励信号逐渐从人类偏好或由人类偏好蒸馏得到的奖励模型,转向基于规则的反馈,而这种反馈在增强模型推理能力方面展现出很大潜力。 代表性贡献包括基于 GAE 的 PPO、Actor-Critic 框架,以及使用组归一化的 GRPO。 后续算法改进大多集中在提升训练可持续性和样本效率。 为了进一步释放强化学习潜力,Search-R1、Agent-R1 和 RAGEN 等近期工作探索了基于多轮对话训练工具使用智能体。 然而,这些多轮对话通常由工具响应和模型回复交替拼接而成,最终优化目标仍然是一个带工具 mask 的单一对话。 GiGPO 进一步研究了在带环境反馈的智能体训练中使用多个独立上下文和滑动窗口轨迹。 不过,这些方法仍局限于优化观察与生成交错的轨迹,难以应用到更通用的智能体工作流。
3. The Proposed MemAgent
In this section, the authors describe the details of MemAgent for solving long-context tasks, including the overall workflow, the Multi-Conv RL algorithm for training MemAgent, reward modeling, and architecture implementation.
本节介绍 MemAgent 解决长上下文任务的具体细节,包括整体工作流、用于训练 MemAgent 的 Multi-Conv RL 算法、奖励建模,以及架构实现设计。
3.1. The MemAgent Workflow: RL-shaped Memory for Unbounded Contexts
As illustrated in Figure 2, MemAgent views an arbitrarily long document not as a monolithic block but as a controlled stream of evidence. At every step, the model sees exactly two things: the next chunk of text and a compact, fixed-length memory that summarizes everything deemed important so far. Crucially, the memory is just a sequence of ordinary tokens inside the context window, so the core generation process of the base LLM remains unchanged.
如图2所示,MemAgent 不把任意长文档看成一个整体块,而是看成一个可控的证据流。 每一步中,模型只看到两样东西:下一段文本,以及一段紧凑的固定长度记忆,用来总结目前为止被认为重要的所有信息。 关键在于,这段记忆只是上下文窗口中的普通 token 序列,因此基础 LLM 的核心生成过程保持不变。
After reading a new chunk, the model overwrites the previous memory with an updated one. This overwrite strategy seems almost too simple, yet it is precisely what enables the system to scale: because memory length never grows, the total compute per chunk stays
读完新文本块后,模型会用更新后的记忆覆盖上一轮记忆。 这个覆盖策略看似过于简单,但正是它让系统具备可扩展性:由于记忆长度永不增长,每个文本块的总计算量保持
The workflow naturally decomposes inference into two modules. Within the Context-Processing module, the model iterates over chunks and updates memory with a prompt template, shown in Table 1. Once the stream is exhausted, a final Answer-Generation module is invoked where the model consults only the problem statement and the memory to produce its boxed answer. Because positional embeddings are never rescaled or patched, the same tokenization and attention layout apply in both modules, unlocking the model's latent length-extrapolation capability without architectural modifications.
该工作流自然地把推理分解成两个模块。 在上下文处理模块中,模型会遍历文本块,并使用表1所示的提示模板更新记忆。 当整个文本流处理完后,系统调用最终回答生成模块,此时模型只参考问题陈述和记忆,生成带框的答案。 由于位置嵌入从未被重新缩放或修补,两个模块使用相同的分词和注意力布局,因此无需修改架构就能释放模型潜在的长度外推能力。
MemAgent therefore enjoys three benefits from this design. First, unlimited length: the document can be millions of tokens because it is processed as a stream. Second, no performance cliff: RL encourages the memory to retain exactly the information needed, yielding near-lossless extrapolation. Third, linear cost: a constant window size implies decoding time and memory consumption grow linearly with input length. This provides a practical recipe for turning any moderately context-sized LLM into an efficient long-context reasoner with minimal engineering overhead.
因此,MemAgent 从这一设计中获得三项优势。 第一,长度不受限:由于文档以流式方式处理,它可以达到数百万 token。 第二,没有明显性能悬崖:强化学习鼓励记忆只保留真正需要的信息,从而实现近乎无损的外推。 第三,线性成本:固定窗口大小意味着解码时间和内存消耗都随输入长度线性增长。 这为把任意中等上下文大小的 LLM 转换成高效长上下文推理器提供了实用方案,并且工程开销很小。
| Context-processing prompt You are presented with a problem, a section of an article that may contain the answer, and a previous memory. Please read the section carefully and update the memory with new information that helps to answer the problem, while retaining all relevant details from the previous memory. <problem> {prompt} </problem><memory> {memory} </memory><section> {chunk} </section>Updated memory: |
| Answer-generation prompt You are presented with a problem and a previous memory. Please answer the problem based on the previous memory and put the answer in \boxed{}.<problem> {prompt} </problem><memory> {memory} </memory>Your answer: |
3.2. Training MemAgent with Multi-Conv RL
By viewing memory update in context processing for answer-generation tasks as part of the policy to be optimized by RL, the authors adopt the RLVR recipe to train MemAgent. For the base algorithm, they adopt Group Relative Policy Optimization (GRPO) for its simplicity and effectiveness in RLVR. In the rollout phase of GRPO, the policy model
作者把答案生成任务中的上下文处理记忆更新视为策略的一部分,并用强化学习优化这一策略,因此采用 RLVR 配方来训练 MemAgent。 基础算法方面,作者采用 Group Relative Policy Optimization(GRPO),因为它在 RLVR 中简单且有效。 在 GRPO 的 rollout 阶段,策略模型
GRPO adopts a clipped objective with a KL penalty term. In the following objective,
GRPO 使用带 KL 惩罚项的裁剪目标。 在下面的目标函数中,
However, due to the nature of MemAgent, it generates multiple context-independent conversations for a single query, as illustrated in Figure 2. Therefore, policy optimization cannot be implemented by simply applying the attention mask as is done in multi-turn tool-calling optimization. To address this issue, the authors treat each conversation as an independent optimization target, as shown in Figure 3. Let
然而,由于 MemAgent 的机制特点,对于同一个查询,它会生成多个上下文相互独立的对话,如图2所示。 因此,不能像多轮工具调用优化那样简单地套用 attention mask 来实现策略优化。 为了解决这个问题,作者把每个对话都视为一个独立优化目标,如图3所示。 令
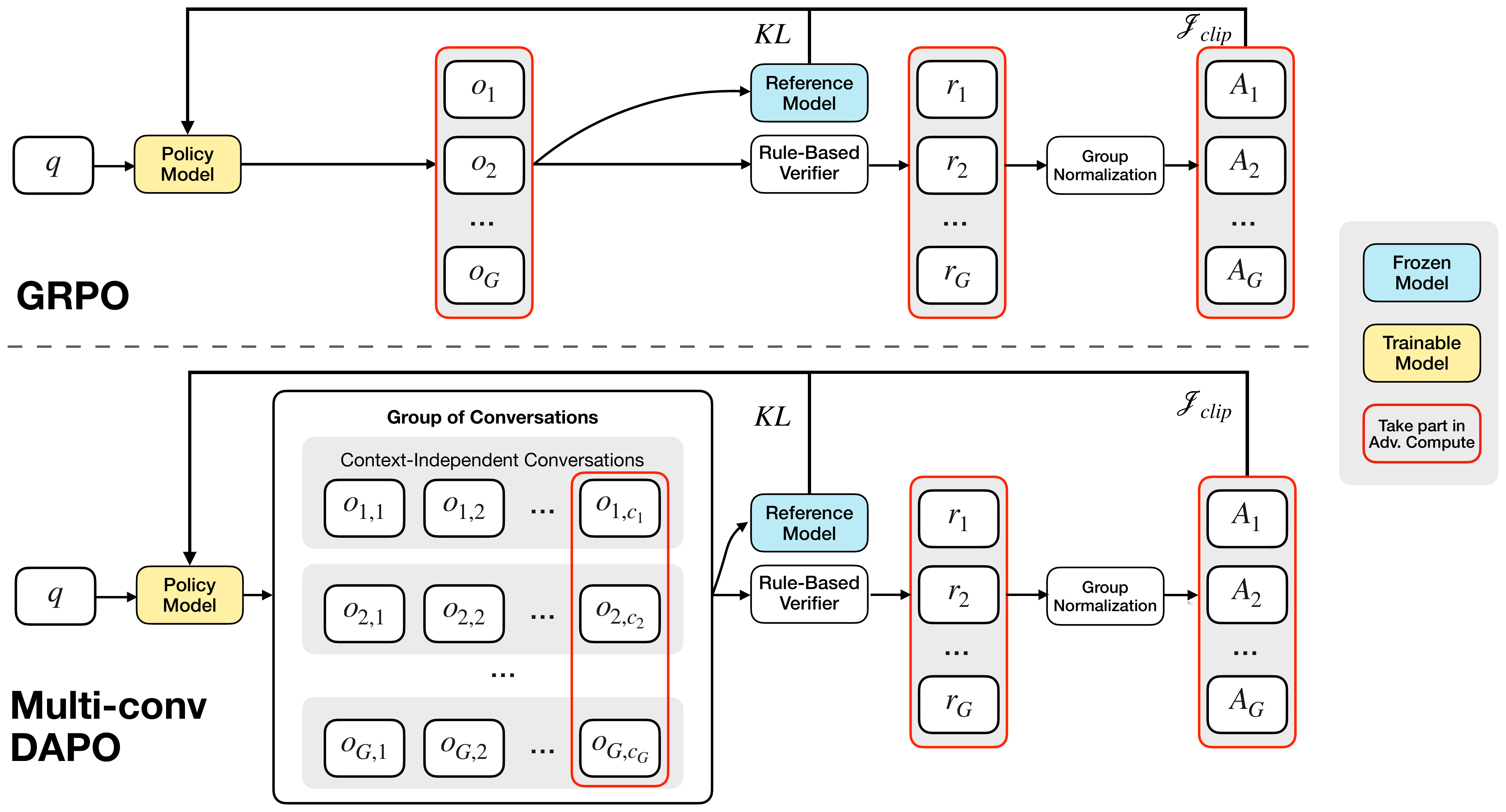
The advantage value is derived from the conversation that contains the final answer, then uniformly applied across all conversations originating from the same sample. The loss function is analogous to DAPO, which incorporates a token-level averaging loss. Furthermore, the authors extend the dimensionality of the loss computation from the conventional (group, token) structure to (group, conversation, token). Following DrGRPO, they do not normalize the advantage by the standard deviation of rewards.
优势值来自包含最终答案的对话,然后被统一应用到同一样本产生的所有对话上。 损失函数与 DAPO 类似,包含 token 级平均损失。 进一步地,作者把损失计算维度从传统的 (group, token) 扩展为 (group, conversation, token)。 按照 DrGRPO 的做法,作者不再用奖励标准差对优势值归一化。
3.3. Reward Modeling
Following the RLVR recipe, the authors train the model with a final outcome reward computed by a rule-based verifier. In RULER and other datasets, questions may have multiple ground-truth answers. For some tasks, such as question answering, these ground truths are considered equivalent. Given a set of multiple ground-truth answers
按照 RLVR 配方,作者使用基于规则验证器计算得到的最终结果奖励来训练模型。 在 RULER 和其他数据集中,问题可能有多个真实答案。 对于问答等任务,这些真实答案被认为是等价的。 给定多个真实答案组成的集合
Here,
其中,
3.4. Rethinking MemAgent from Autoregressive Modeling Perspectives
Finally, to get a deeper sense of the MemAgent design, the authors rethink language-model factorization. A standard autoregressive LLM factorizes the joint likelihood of a sequence
最后,为了更深入理解 MemAgent 的设计,作者重新思考语言模型的因子分解方式。 标准自回归 LLM 会把序列
MemAgent replaces the unbounded history with a fixed-length memory
MemAgent 用固定长度记忆
Introducing the latent sequence
引入潜在序列
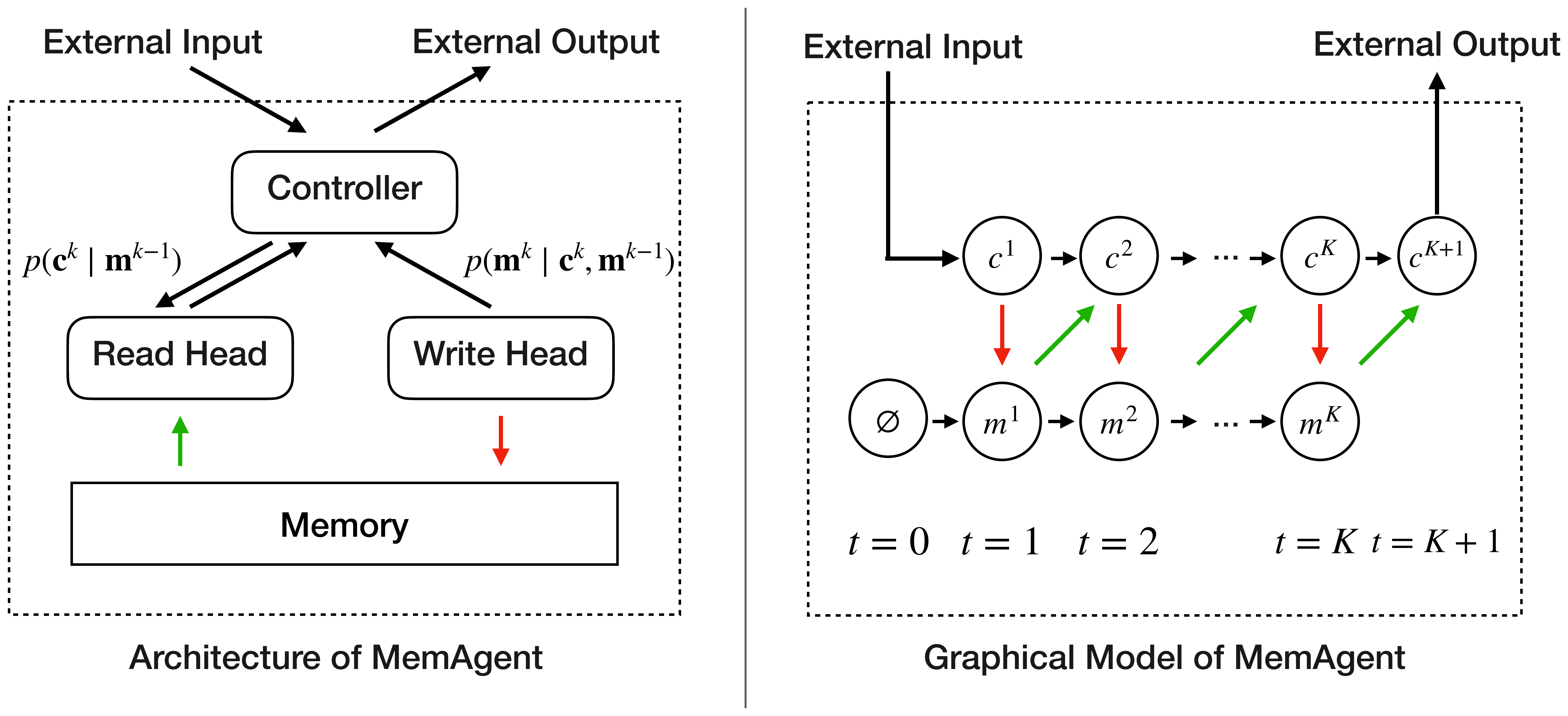
MemAgent enjoys token-level compression of context, while local-global or linear-attention models compress long context in feature space; their summaries are implicit and opaque. MemAgent's summaries reside in token space, so every intermediate memory is human-readable and can be inspected or even edited. Conceptually, the likelihood decomposition turns the Transformer into a recurrent network whose state size is user-controllable.
MemAgent 实现的是上下文的 token 级压缩,而 local-global 或线性注意力模型通常是在特征空间中压缩长上下文;它们的摘要是隐式且不透明的。 MemAgent 的摘要存在于 token 空间中,因此每个中间记忆都是人类可读的,可以被检查,甚至可以被编辑。 从概念上看,上述似然分解把 Transformer 转换成了一种状态大小可由用户控制的循环网络。
RL is essential because memory tokens are latent and updated via a discrete overwrite rule, so back-propagation alone cannot teach the model what to keep and what to discard. The multi-conversation GRPO algorithm treats each read-write-read loop as an RL transition, directly rewarding memories that lead to a correct final answer. This bridges the gap between explicit supervision, namely answers, and implicit structure, namely good memories, completing the training pipeline. The resulting MemAgent architecture preserves the vanilla decoder's training recipe, requires no exotic attention kernels, and satisfies the long-context trilemma of arbitrary length, lossless extrapolation, and linear cost.
强化学习之所以必要,是因为记忆 token 是潜在变量,并且通过离散覆盖规则更新,仅靠反向传播无法教会模型应该保留什么、丢弃什么。 多对话 GRPO 算法把每个 read-write-read 循环视为一个强化学习转移,直接奖励那些能导向正确最终答案的记忆。 这弥合了显式监督(答案)和隐式结构(好记忆)之间的差距,也补全了训练流程。 最终得到的 MemAgent 架构保留了 vanilla decoder 的训练方式,不需要特殊注意力 kernel,并同时满足任意长度、无损外推和线性成本这三个长上下文目标。
4. Experiments
For training and primary evaluation, the authors use multi-hop long-text question answering tasks, and further conduct evaluations on various other long-text tasks. They select prior long-context methods as baselines to evaluate long-text extrapolation capabilities by comparing performance changes as the test data length increases.
在训练和主要评估中,作者使用多跳长文本问答任务,并进一步在其他多种长文本任务上进行评估。 作者选择已有长上下文方法作为基线,通过比较测试数据长度增加时的性能变化,评估模型的长文本外推能力。
4.1. Datasets
RULER comprises various synthetic tasks with controllable context lengths, making it an ideal benchmark for investigating how model performance varies with increasing context length. The Question Answering subset of RULER adapts existing short-context QA datasets for long-context evaluation by embedding golden paragraphs within extensive distractor content sampled from the same dataset. This configuration represents a real-world adaptation of the Needle in a Haystack paradigm, where questions serve as queries, golden paragraphs function as needles, and distractor paragraphs constitute the haystack. This task bridges synthetic evaluation and practical long-context applications, making it suitable for assessing whether a model can locate and extract relevant information from realistic document collections.
RULER 包含多种上下文长度可控的合成任务,因此很适合研究模型性能如何随上下文长度增加而变化。 RULER 的问答子集通过把包含正确答案的 golden paragraph 嵌入到同一数据集采样的大量干扰内容中,将已有短上下文问答数据集改造成长上下文评估。 这种设置可以看作 Needle in a Haystack 范式的真实世界改造:问题是 query,golden paragraph 是 needle,干扰段落是 haystack。 该任务连接了合成评估和实际长上下文应用,适合评估模型能否从真实文档集合中定位并抽取相关信息。
The authors synthesize training samples from HotpotQA using this methodology. The synthetic data comprises 200 articles with an approximate token length of 28K. They clean the dataset by filtering out questions where the Best-Of-2 score is 100% without requiring any context for Qwen2.5-7B-Base or Qwen2.5-7B-Instruct. These questions likely represent common knowledge already internalized within the models' memories. Using this method, they process 80,000 samples from the HotpotQA training split. Approximately 50% of the data are filtered out, and from the remaining samples the first 32,768 samples are selected for further use.
作者使用这一方法从 HotpotQA 中合成训练样本。 合成数据包含 200 篇文章,长度约为 28K token。 作者会清理数据集:如果某些问题在不需要任何上下文的情况下,Qwen2.5-7B-Base 或 Qwen2.5-7B-Instruct 的 Best-Of-2 分数就达到 100%,则过滤掉这些问题。 这些问题很可能是模型已经内化的常识。 使用该方法,作者处理了 HotpotQA 训练集中的 80,000 个样本。 其中约 50% 数据被过滤,剩余样本中前 32,768 个被选作后续使用。
The authors then apply a similar approach to synthesize 128 samples from the HotpotQA validation set. To further investigate how performance varies with length, they synthesize test sets with different context lengths using the same questions. The number of articles ranges from 50 and 100 up to 6400, corresponding to context lengths from approximately 7K and 14K up to 3.5M tokens.
随后,作者用类似方法从 HotpotQA 验证集中合成 128 个样本。 为了进一步研究性能如何随长度变化,作者使用相同问题合成了不同上下文长度的测试集。 文章数量从 50、100 一直增加到 6400,对应上下文长度大约从 7K、14K 到 3.5M token。
4.2. Experimental Setup
Training Details. To maintain comparability with previous work, the authors choose Qwen2.5-7B-Instruct and Qwen2.5-14B-Instruct as base models. They implement the framework for multi-conversation with independent contexts based on verl. During training, they intentionally limit the model to an 8K context window to highlight extrapolation capabilities. This 8K window is allocated as 1024 tokens for the query, 5000 tokens for the context chunk, 1024 tokens for the memory, and 1024 tokens for the output, with remaining tokens reserved for the chat template. Consequently, the model typically requires 5 to 7 conversational turns to process the entire context.
训练细节。 为了保持与已有工作的可比性,作者选择 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作为基础模型。 作者基于 verl 实现了带独立上下文的多对话框架。 训练过程中,作者故意将模型限制在 8K 上下文窗口,以突出其外推能力。 这个 8K 窗口被分配为:1024 token 用于 query,5000 token 用于上下文块,1024 token 用于记忆,1024 token 用于输出,剩余 token 留给 chat template。 因此,模型通常需要 5 到 7 轮对话来处理完整上下文。
Hyperparameters. The authors use GRPO for training, applying a KL factor of 1e-3 and disabling entropy loss. They use the AdamW optimizer with a learning rate of 1e-6, scheduled with a constant learning rate and linear warm-up. They use rollout batch sizes of 128 and 256 for 7B and 14B models, respectively, and a group size of 16. The ratio of sample batch size to backpropagation batch size is set to 16.
超参数。 作者使用 GRPO 训练,KL 系数设为 1e-3,并关闭 entropy loss。 优化器采用 AdamW,学习率为 1e-6,使用常数学习率并配合线性 warm-up。 7B 和 14B 模型的 rollout batch size 分别为 128 和 256,group size 为 16。 sample batch size 与 backpropagation batch size 的比例设为 16。
Model Configuration. The authors use DeepSeek-R1-Distill-Qwen, Qwen-2.5-Instruct-1M, and QwenLong-L1 as baselines. They follow official configurations of baseline models to set context lengths. For the Qwen2.5-Instruct-1M series, they further extrapolate the context length to 1M tokens using DCA. For the DeepSeek-R1-Distill-Qwen series and QwenLong, the context length is set to 128K tokens. For the model with 128K context length, the input consists of 120,000 tokens and the output is 10,000 tokens. For the model with 1M context length, the input is 990,000 tokens and the output is 10,000 tokens.
模型配置。 作者使用 DeepSeek-R1-Distill-Qwen、Qwen-2.5-Instruct-1M 和 QwenLong-L1 作为基线。 作者遵循这些基线模型的官方配置来设置上下文长度。 对于 Qwen2.5-Instruct-1M 系列,作者进一步使用 DCA 将上下文长度外推到 1M token。 对于 DeepSeek-R1-Distill-Qwen 系列和 QwenLong,上下文长度设为 128K token。 对于 128K 上下文长度模型,输入包含 120,000 token,输出为 10,000 token。 对于 1M 上下文长度模型,输入为 990,000 token,输出为 10,000 token。
4.3. Main Results
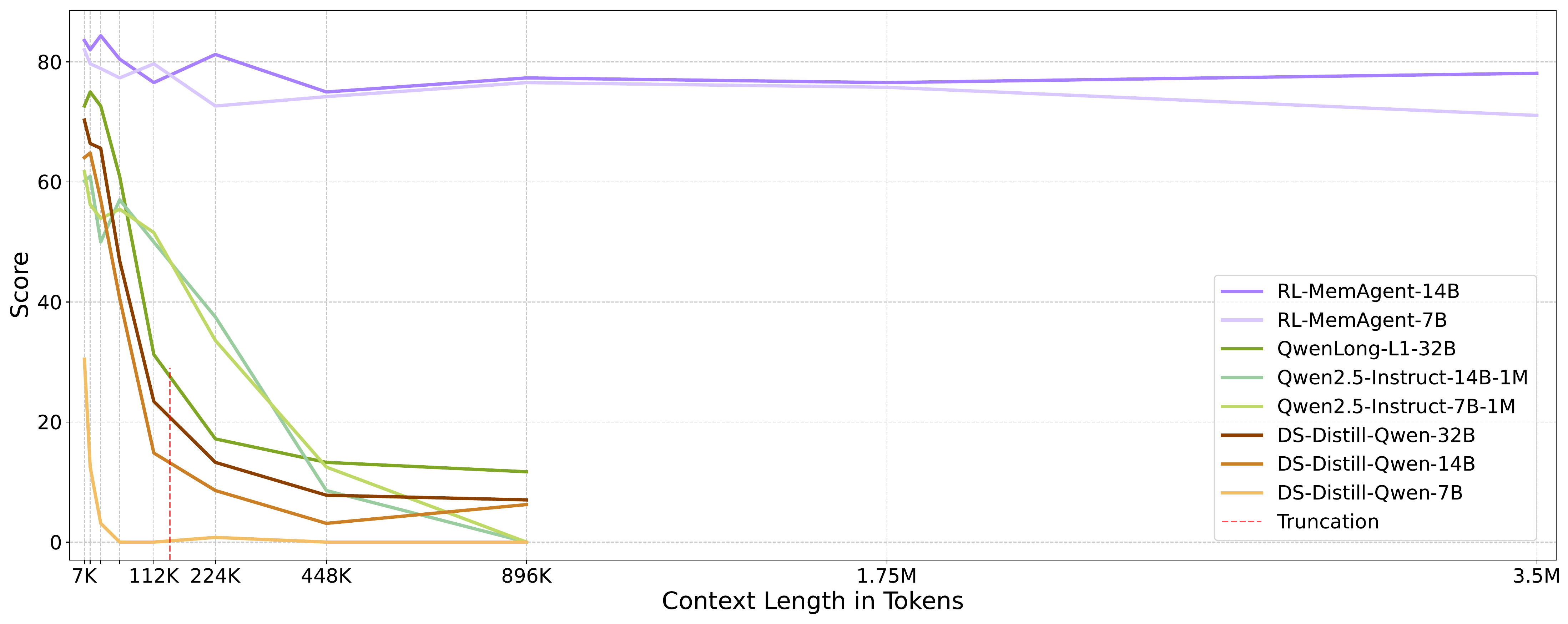
The main experimental results are reported in Table 2. The authors compare all model performances within context lengths ranging from 7K to 896K. For MemAgent, they extend evaluation to ultra-long contexts of 1.75M and 3.5M to assess how the model generalizes beyond the standard context range.
主要实验结果见表2。 作者比较了所有模型在 7K 到 896K 上下文长度范围内的表现。 对于 MemAgent,作者进一步评估 1.75M 和 3.5M 的超长上下文,以测试模型如何泛化到标准上下文范围之外。
| Model | Length | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 7K | 14K | 28K | 56K | 112K | 224K | 448K | 896K | 1.75M | 3.5M | |
| QwenLong-L1-32B | 72.66 | 75.00 | 72.66 | 60.94 | 31.25 | 17.19 | 13.28 | 11.72 | N/A | N/A |
| Qwen2.5-Instruct-14B-1M | 60.16 | 60.94 | 50.00 | 57.03 | 50.00 | 37.50 | 8.59 | 0.00 | N/A | N/A |
| Qwen2.5-Instruct-7B-1M | 61.72 | 56.25 | 53.91 | 55.47 | 51.56 | 33.59 | 12.50 | 0.00 | N/A | N/A |
| DS-Distill-Qwen-32B | 70.31 | 66.41 | 65.62 | 46.88 | 23.44 | 13.28 | 7.81 | 7.03 | N/A | N/A |
| DS-Distill-Qwen-14B | 64.06 | 64.84 | 57.03 | 40.62 | 14.84 | 8.59 | 3.12 | 6.25 | N/A | N/A |
| DS-Distill-Qwen-7B | 30.47 | 12.50 | 3.12 | 0.00 | 0.00 | 0.78 | 0.00 | 0.00 | N/A | N/A |
| RL-MemAgent-14B | 83.59 | 82.03 | 84.38 | 80.47 | 76.56 | 81.25 | 75.00 | 77.34 | 76.56 | 78.12 |
| RL-MemAgent-7B | 82.03 | 79.69 | 78.91 | 77.34 | 79.69 | 72.66 | 74.22 | 76.56 | 75.78 | 71.09 |
From these results, the authors observe that MemAgent exhibits remarkable length extrapolation capabilities with only marginal performance decay as input context length increases. This demonstrates the effectiveness of the proposed memory mechanism combined with reinforcement learning for handling ultra-long context scenarios. In contrast, baseline models demonstrate distinct failure patterns even within the context window. Reasoning models such as DS-Distill-Qwen show rapid performance degradation, while QwenLong-L1 maintains reasonable performance within its training length of 60K but experiences substantial degradation afterward. The Qwen2.5-Instruct-1M models maintain acceptable performance within 112K tokens, but deteriorate to zero at 896K tokens, well before reaching their theoretical 1M token capacity. This suggests that despite extended context windows, these models struggle with effective information utilization in ultra-long contexts.
从结果可以看到,MemAgent 展现出显著的长度外推能力,随着输入上下文长度增加只出现轻微性能下降。 这说明本文提出的记忆机制与强化学习结合后,能有效处理超长上下文场景。 相比之下,基线模型即使在上下文窗口内部也表现出不同的失败模式。 DS-Distill-Qwen 等推理模型性能下降很快,而 QwenLong-L1 在其 60K 训练长度内保持合理表现,但之后明显退化。 Qwen2.5-Instruct-1M 系列模型在 112K token 内表现尚可,但在 896K token 时退化到 0,远未达到其理论 1M token 容量。 这说明即使上下文窗口被扩展,这些模型在超长上下文中仍然难以有效利用信息。
4.4. Ablation Study
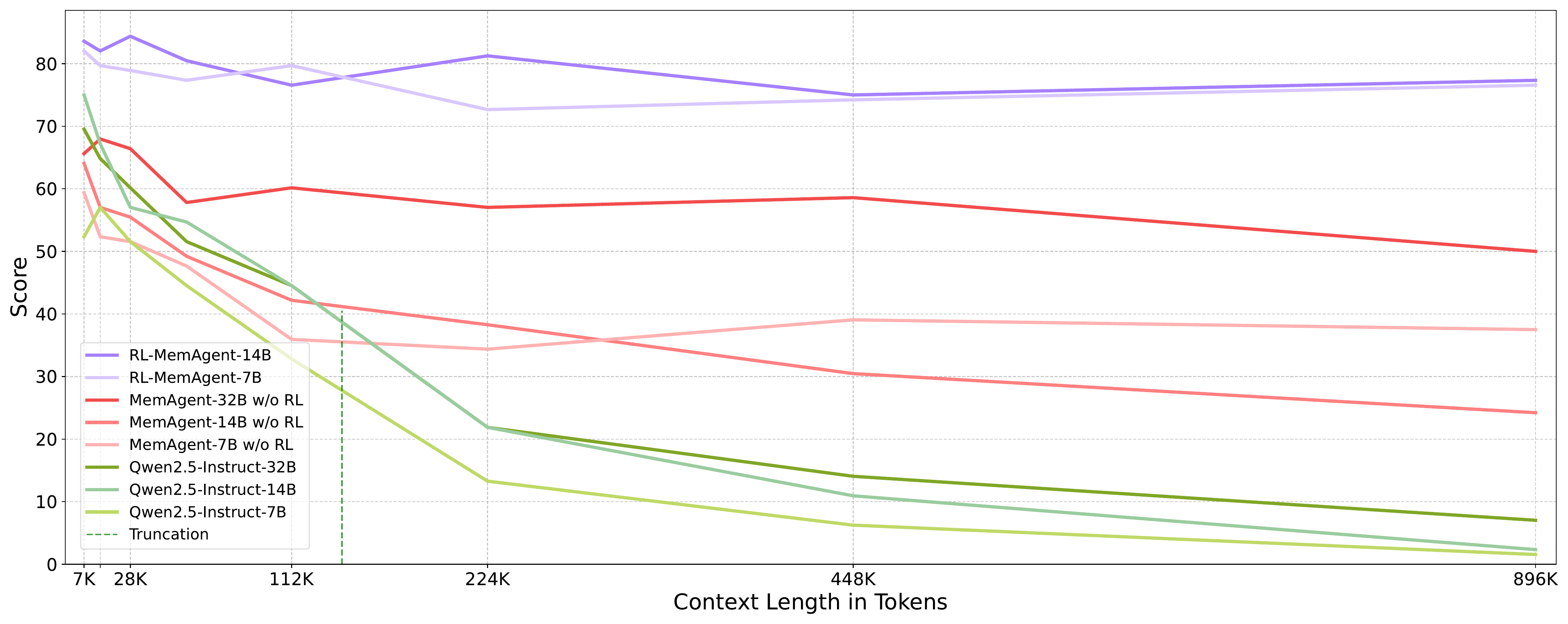
RL Training. To investigate the impact of reinforcement learning on the memory mechanism, the authors conduct further ablation experiments. The baselines are Qwen2.5-Instruct series models and Qwen2.5-Instruct models equipped with the memory mechanism but without RL training. As shown in Figure 5, vanilla models exhibit severe performance degradation as context length increases, especially after 112K where the inputs are truncated because of the context window. While the model equipped with memory but without RL training demonstrates better performance and maintains reasonable performance on tasks exceeding the context length, it still experiences an overall decline as input length increases. In contrast, RL-trained models maintain consistently high performance across all context lengths with minimal degradation. This demonstrates that while the memory mechanism provides structural support for long contexts, reinforcement learning is essential for teaching models to properly leverage memory.
强化学习训练。 为了研究强化学习对记忆机制的影响,作者进一步进行了消融实验。 基线包括 Qwen2.5-Instruct 系列模型,以及配备记忆机制但没有强化学习训练的 Qwen2.5-Instruct 模型。 如图5所示,原始模型会随着上下文长度增加而严重退化,尤其是在 112K 之后,由于上下文窗口限制,输入会被截断。 虽然配备记忆但没有强化学习训练的模型表现更好,并且在超过上下文长度的任务上仍能保持一定性能,但随着输入长度增加,它整体仍然会下降。 相比之下,经过强化学习训练的模型在所有上下文长度上都保持稳定高性能,退化很小。 这说明记忆机制虽然能为长上下文提供结构支撑,但强化学习对于教会模型正确使用记忆是必要的。
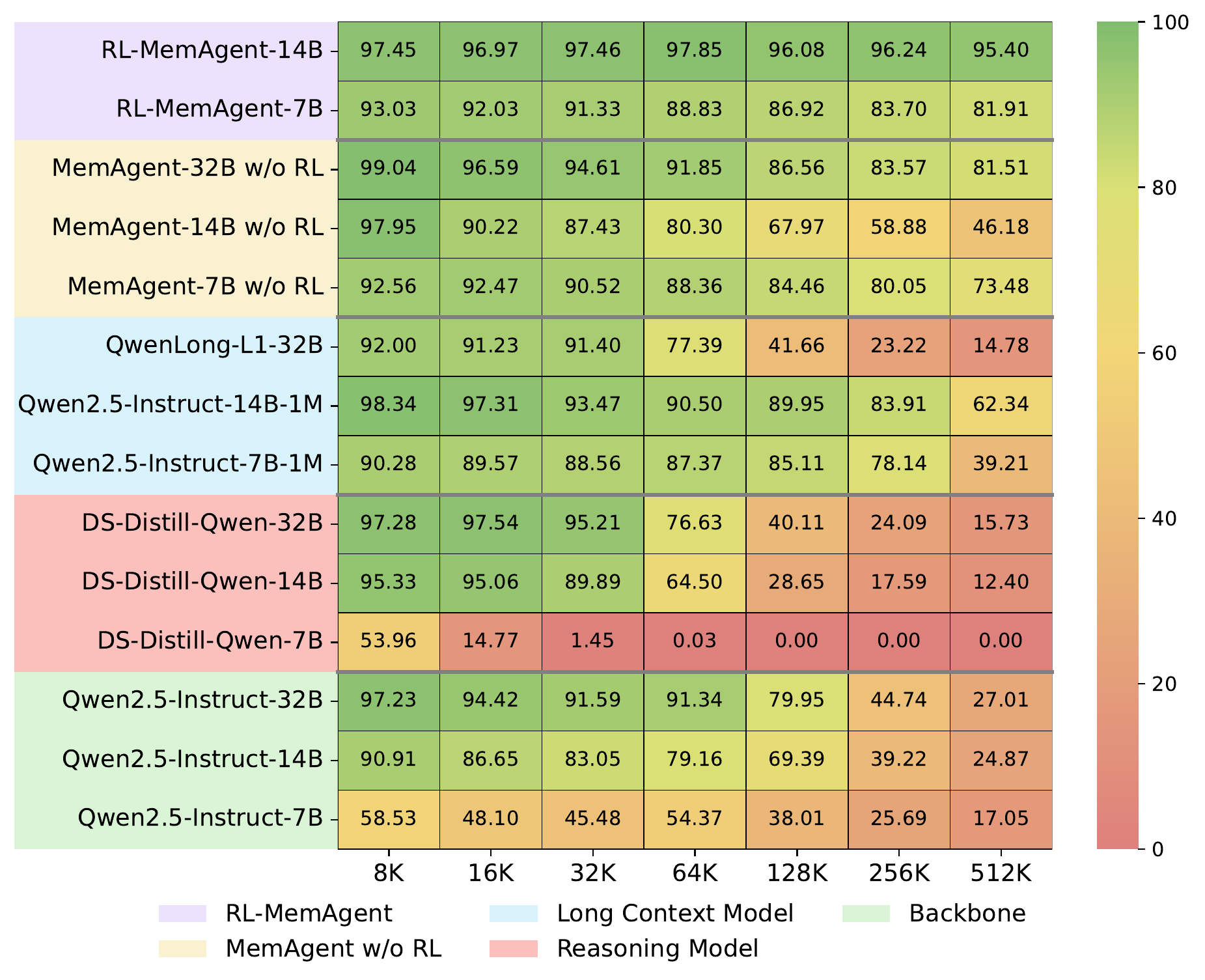
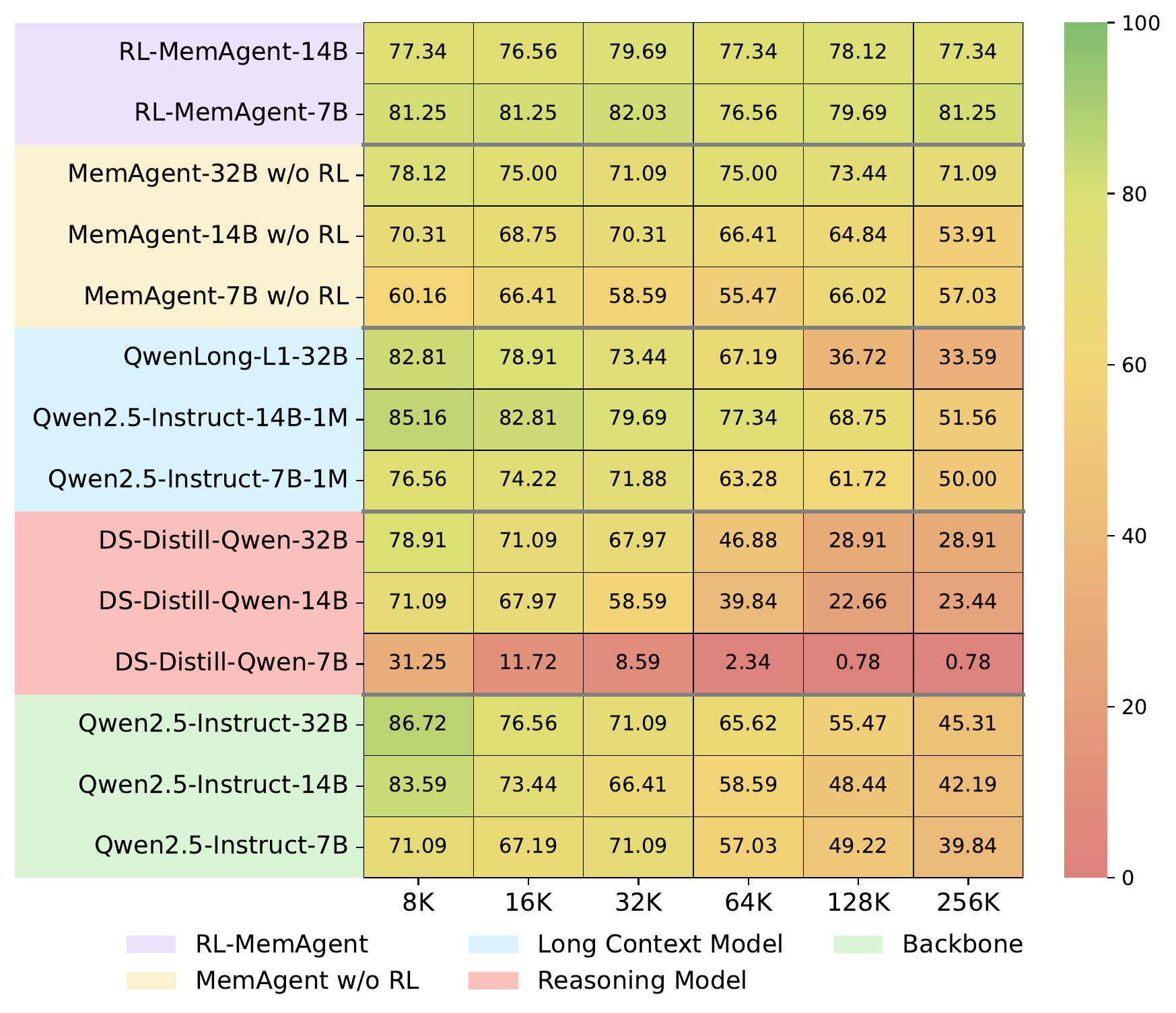
Out-of-Distribution Tasks. To evaluate generalization, the authors conduct comprehensive experiments on OOD tasks in the RULER benchmark, including needle-in-a-haystack variants, variable tracking, frequent words extraction, and question answering synthesized from SQuAD. They synthesize context lengths ranging from 8K to 512K tokens for these tasks, except that SQuAD extends only to 256K tokens due to limited document length. Figure 6 presents the performance comparison across different task categories. The results demonstrate that MemAgent maintains consistently superior performance across diverse task types. Particularly, MemAgent-14B achieves over 95% accuracy on the average RULER tasks in contexts ranging from 8K to 512K, while MemAgent-7B achieves the best performance, surpassing the 32B model without RL training and long-context post-trained models. Both MemAgent-7B and MemAgent-14B maintain stable performance on the SQuAD-based QA task, indicating that memorizing ability can generalize beyond training data. In contrast, baseline models show significant degradation beyond 128K tokens across all task categories.
分布外任务。 为了评估泛化能力,作者在 RULER 基准的 OOD 任务上进行了全面实验,包括 needle-in-a-haystack 变体、变量跟踪、高频词抽取,以及由 SQuAD 合成的问答任务。 除 SQuAD 由于文档长度限制只扩展到 256K token 外,其余任务的上下文长度覆盖 8K 到 512K token。 图6展示了不同任务类别上的性能对比。 结果表明,MemAgent 在多样化任务类型上持续保持更优表现。 尤其是 MemAgent-14B 在 8K 到 512K 上下文范围内的 RULER 平均任务上达到超过 95% 的准确率,而 MemAgent-7B 表现最好,超过了没有强化学习训练的 32B 模型和长上下文后训练模型。 MemAgent-7B 和 MemAgent-14B 在基于 SQuAD 的问答任务上也都保持稳定表现,说明记忆能力可以泛化到训练数据之外。 相比之下,基线模型在所有任务类别上超过 128K token 后都出现显著退化。
4.5. Case Study
To further illustrate the proposed memory mechanism in detail, the authors conduct a case study on a generation trajectory of MemAgent-14B. The input question is: The director of the romantic comedy "Big Stone Gap" is based in what New York city? This is a 2-hop question with two relevant Wikipedia entries. First, Big Stone Gap is a 2014 American drama romantic comedy film written and directed by Adriana Trigiani. Second, Adriana Trigiani is an Italian American author, television writer, film director, and entrepreneur based in Greenwich Village, New York City.
为了更细致地展示所提出的记忆机制,作者对 MemAgent-14B 的一条生成轨迹进行了案例分析。 输入问题是:浪漫喜剧《Big Stone Gap》的导演位于纽约市的什么地方? 这是一个 2-hop 问题,包含两个相关 Wikipedia 条目。 第一,Big Stone Gap 是一部 2014 年美国剧情浪漫喜剧电影,由 Adriana Trigiani 编剧并执导。 第二,Adriana Trigiani 是一位意大利裔美国作家、电视编剧、电影导演和企业家,居住在纽约市 Greenwich Village。
In the first round, the model is presented with the entry Ghost, which refers to a production team also based in New York. The model chooses to retain this potentially useful information for future use. In the second round, no relevant context is provided; nevertheless, the model maintains its agent state, demonstrating robustness against distraction. In the third round, both relevant entries are presented. The model correctly identifies critical information and updates its memory accordingly, leading to the correct answer: Greenwich Village, New York City. At this point, the reasoning process is complete; in the remaining rounds, the model's memory remains unchanged and is used to produce the final response.
第一轮中,模型看到的是 Ghost 条目,该条目指的是一个同样位于 New York 的制作团队。 模型选择保留这一可能有用的信息,以便后续使用。 第二轮没有提供相关上下文,但模型仍保持了智能体状态,展现出抵抗干扰的鲁棒性。 第三轮中,两个相关条目都出现了。 模型正确识别关键知识,并相应更新记忆,最终得到正确答案:Greenwich Village, New York City。 此时推理过程已经完成;后续轮次中,模型记忆保持不变,并用于生成最终回答。
Chunk 1 / Memory 1
Chunk. Document 20: Ghost (production team). Ghost is a Swedish record producing and songwriting team, composed of Ulf Lindström and Johan Ekhé, based in New York City.
Memory. The provided section does not contain information about the director of "Big Stone Gap", but it mentions a production team called "Ghost" based in New York City. The model stores this potentially relevant fact while noting that the problem remains unanswered.
Chunk 2 / Memory 2
Chunk. No relevant document.
Memory. The model keeps the previous memory unchanged: Ghost is based in New York City, but there is still no information about the director of "Big Stone Gap".
Chunk 3 / Memory 3
Chunk. Document 81: Big Stone Gap is written and directed by Adriana Trigiani. Document 96: Adriana Trigiani is based in Greenwich Village, New York City.
Memory. The model updates memory with both relevant facts and concludes that the director of "Big Stone Gap" is Adriana Trigiani, who is based in Greenwich Village, New York City.
This trajectory highlights several core capabilities learned by the memory agent: estimating potentially relevant content from query keywords and storing it preemptively, immediately updating memory upon encountering context that matches the query, and remaining unaffected by irrelevant information. Notably, these memory behaviors are not the result of architectural attention mechanisms, but emerge as text generation abilities reinforced through RL.
这条轨迹展示了记忆智能体学到的几项核心能力:根据查询关键词估计潜在相关内容并提前存储;遇到与查询匹配的上下文时立即更新记忆;以及不受无关信息影响。 值得注意的是,这些记忆行为并不是架构注意力机制直接带来的,而是通过强化学习增强出来的文本生成能力。
5. Conclusion
The authors propose a novel approach to modeling long-context tasks by introducing a latent variable memory. This enables the decomposition of continuous autoregressive generation into a series of steps that sequentially generate context from memory. The method can handle infinitely long input text with
作者通过引入潜在变量记忆,提出了一种建模长上下文任务的新方法。 这使得连续自回归生成过程可以分解为一系列步骤,在这些步骤中模型按顺序从记忆生成上下文。 该方法基于现有 dense-attention Transformer,就能以
Experiments show that when trained on 32K-length data with an 8K context, including a 1024-token memory and 5000 tokens of input per step, the model can extrapolate to 3.5M with almost lossless performance during testing. Ablation studies demonstrate the effectiveness of using memory itself as a long-context processing mechanism, as well as the benefits of further RL training on top of it. Results on both in-domain and out-of-domain tasks show that MemAgent surpasses long-context post-trained models, reasoning models, and other baselines, achieving state-of-the-art performance on long-context tasks.
实验表明,当模型在 32K 长度数据上训练、上下文窗口为 8K(包含 1024 token 记忆,并且每步处理 5000 token 输入)时,测试阶段可以外推到 3.5M token,且几乎没有性能损失。 消融实验说明,把记忆本身作为长上下文处理机制是有效的,在此基础上进一步进行强化学习训练也能带来明显收益。 在域内和分布外任务上的结果表明,MemAgent 超越了长上下文后训练模型、推理模型以及其他基线,在长上下文任务上达到当前最优表现。