
Muon
MomentUm Orthogonalized by Newton-schulz
作者并没有发表论文,只有博客:
以下是博客的翻译:
Muon:面向神经网络隐藏层的优化器
Muon:面向神经网络隐藏层的优化器
2024年12月8日
Muon 是一个针对神经网络隐藏层的优化器。它目前被用于 NanoGPT 和 CIFAR-10 极速训练的记录中。
关于 Muon 的许多实证结果已经发布,因此本文将主要聚焦于 Muon 的设计。首先,我们将定义 Muon 并概述它迄今为止所取得的实证结果。然后,我们将详细讨论其设计,包括与先前研究的联系以及我们对它为何有效的最佳理解。最后,我们将以对优化研究中证据标准的讨论作为结束。
定义
Muon 是一个针对神经网络隐藏层二维参数的优化器。其定义如下:
算法 2 Muon
需要: 学习率
- Initialize
- for
do - Compute gradient
-
-
- Update parameters
- end for
- return
其中 NewtonSchulz5 被定义为以下的牛顿-舒尔茨矩阵迭代
# Pytorch code
def newtonschulz5(G, steps=5, eps=1e-7):
assert G.ndim == 2
a, b, c = (3.4445, -4.7750, 2.0315)
X = G.bfloat16()
X /= (X.norm() + eps)
if G.size(0) > G.size(1):
X = X.T
for _ in range(steps):
A = X @ X.T
B = b * A + c * A @ A
X = a * X + B @ X
if G.size(0) > G.size(1):
X = X.T
return X一个即用型的 Muon PyTorch 实现可在此处找到。在当前 NanoGPT 极速训练记录中的一个使用示例可在此处找到。
当使用 Muon 训练神经网络时,网络的标量和向量参数,以及输入层和输出层,应由 AdamW 等标准方法进行优化。Muon 可用于四维卷积参数,通过将其最后三个维度展平来实现,就像这样
Muon 的设计
Muon(通过牛顿-舒尔茨正交化的动量)优化二维神经网络参数的方法是:先获取由 SGD-momentum 生成的更新,然后在将其应用于参数之前,对每个更新应用牛顿-舒尔茨迭代作为后处理步骤。
NS 迭代的功能是近似正交化更新矩阵,即执行以下操作:
换句话说,NS 迭代有效地将 SGD-momentum 的更新矩阵替换为与其最接近的半正交矩阵。这等价于将更新替换为
为什么对更新进行正交化是好的?
我们首先想指出,一个有效的答案可能是:它本来就有效?(Shazeer 2020)
为了实现这一点,并给出一个好的解释。对于这些架构为何有效,我们不提供任何解释;我们将它们的成功,如同一切事物一样,归因于上天的恩赐。
但是,如果想了解源自 Bernstein & Newhouse (2024) 对 Shampoo (Gupta et al. 2018) 分析的理论动机,请参阅“与 Shampoo 的关系”一节。
而基于实证的动机,我们观察到,根据人工检查,由 SGD-momentum 和 Adam 为基于 Transformer 的神经网络中的二维参数生成的更新通常具有非常高的条件数。也就是说,它们几乎是低秩矩阵,所有神经元的更新仅由少数几个方向主导。我们推测,正交化有效地增加了其他“罕见方向”的尺度,这些方向在更新中幅度很小,但对学习仍然很重要。
排除牛顿-舒尔茨迭代的替代方案
除了牛顿-舒尔茨迭代之外,还有几种用于正交化矩阵的其他选项。在本小节中,我将描述为什么我们没有使用其中两种。有关更完整的方法列表,请参阅 Bernstein & Newhouse (2024) 的附录 A。
SVD很容易理解,但我们没有使用它,因为它太慢了。
耦合牛顿迭代(Coupled Newton iteration)在 Shampoo 的实现中被用来执行四次逆根运算,并且可以很容易地适配来执行正交化。但我们没有使用它,因为我们发现它必须至少在 float32 精度下运行才能避免数值不稳定性,这使得它在现代 GPU 上运行缓慢。
相比之下,我们发现牛顿-舒尔茨迭代可以在 bfloat16 精度下稳定运行。因此,我们选择它作为正交化更新的方法。
证明NS迭代正交化更新
为了理解为什么NS迭代能正交化更新,设
一般而言,如果我们定义五次多项式
因此,要保证NS迭代收敛到
为了满足第一个条件,我们只需在开始NS迭代之前将
为了满足当
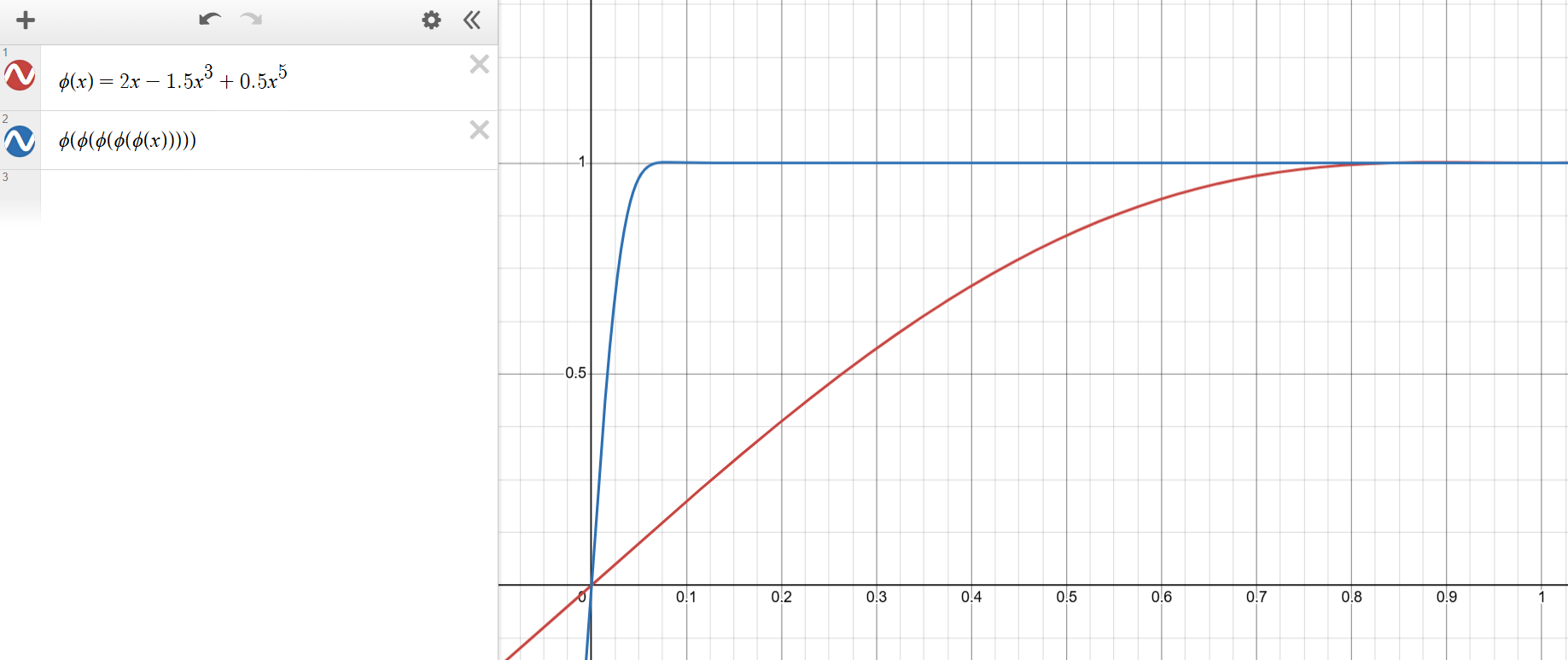
图3:牛顿-舒尔茨迭代的基线系数。
调整系数
尽管NS系数
调整系数
- 我们希望
尽可能大,因为 意味着这个系数控制着较小初始奇异值的收敛速度。 - 对于每个
,我们希望当 时 收敛到区间 内的一个值,这样NS迭代的结果就不会偏离 太远。
这里令人惊讶的观察是,根据经验,
解决这个约束优化问题有许多可能的方法。我们使用了一种基于梯度的特定方法,最终得到了系数
这就是我们在Muon的最终设计中使用的系数。这些系数的行为可以在下图中看到。注意在
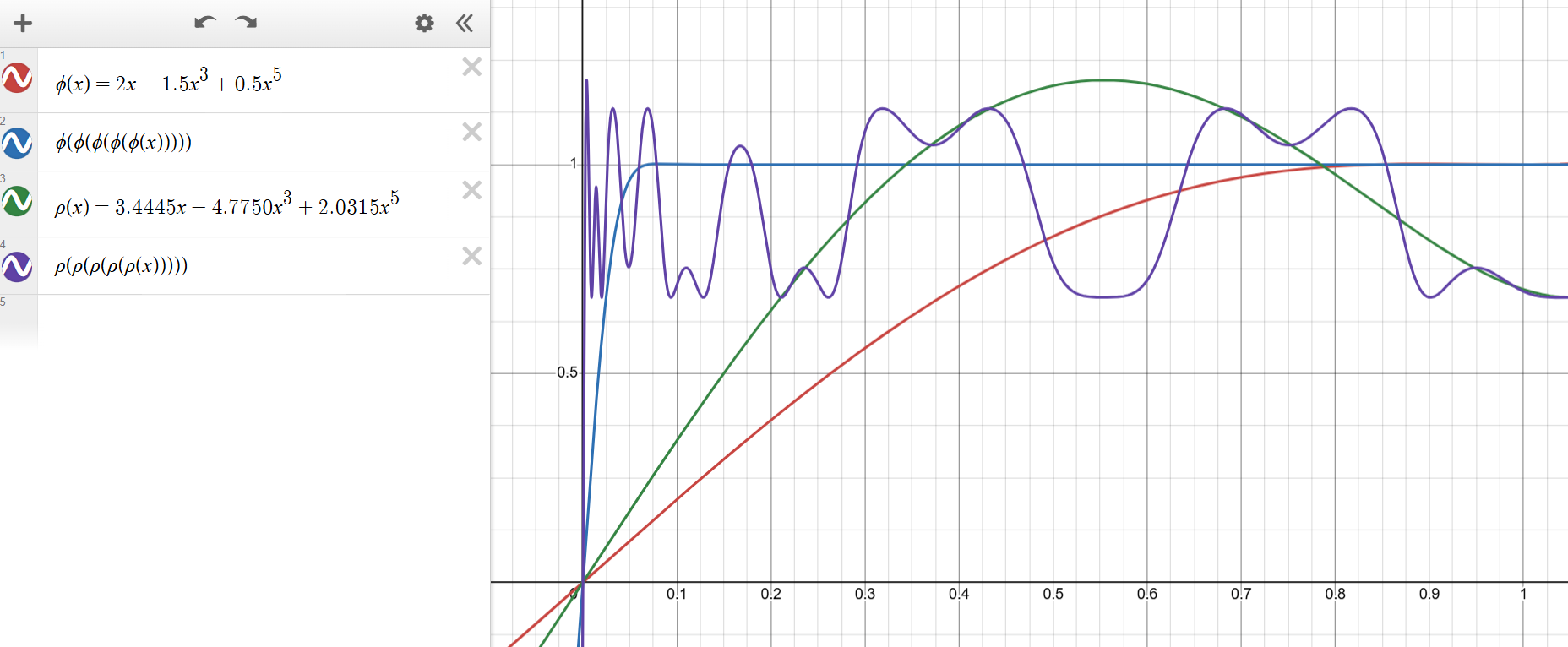
图4:我们优化后的牛顿-舒尔茨迭代系数。
在我们的实验中,当使用带有这些系数的 Muon 训练 Transformer 语言模型和小型卷积网络时,只需运行 5 步 NS 迭代就足够了。
我们还考虑了在 NS 迭代中使用三阶和七阶多项式,但发现这些无法进一步改善实际时间开销。
运行时分析
在本节中,我们分析 Muon 的运行时和内存需求。
在应用 NS 迭代之前,Muon 就是标准的 SGD-momentum,因此它具有相同的内存需求。
对于网络中的每个
如果该参数是线性层的参数,那么执行一步训练所需的基线 FLOP 量是
因此,Muon 的 FLOP 开销最多为
我们现在为两个具体的训练场景计算此开销:NanoGPT 极速训练和 Llama 405B 训练。
- 对于当前的 NanoGPT 极速训练记录,模型维度为
,每批次的词元数量为 。因此,开销为 . - 对于 Llama 405B 训练,模型维度为
,据报道每批次的词元数量为 。因此,在此训练中使用 Muon 的开销为 .
我们得出结论,对于典型的小规模和大规模语言模型训练场景,Muon 的 FLOP 开销均低于 1%。
与先前优化器的关系
Shampoo
Shampoo 优化器的定义如下:
算法 1 Shampoo,矩阵情况
- Initialize
; ; - for
do - Receive loss function
- Compute gradient
- Update preconditioners:
- Update parameters:
如果移除预条件器累积,Bernstein & Newhouse (2024) 观察到更新将变为以下形式:
这就是正交化梯度。如果在正交化之前加入动量,我们就恢复了Muon更新,但由于使用了四次逆根而不是牛顿-舒尔茨迭代,这会带来更高的实际时间和FLOP开销。
因此,可以将关闭动量的Muon解释为一种“瞬时”或“无累积”的Shampoo。
正交化SGD-Momentum
Tuddenham等人提出通过SVD正交化梯度,对结果应用动量,然后将动量项用作更新来优化神经网络,并将此优化器称为Orthogonal-SGDM。这与Muon类似,不同之处在于Muon将动量移到正交化之前,我们发现这样做在经验上表现更好,并且使用牛顿-舒尔茨迭代而非SVD来实现更高效的正交化。在他们表现最佳的实验设置中,Tuddenham等人报告说,他们的方法被调整良好的标准SGD-Momentum所超越,这或许解释了为什么这篇文章在此之前未被引用。
随机谱下降和RMSspectral
注:此小节于2025年12月7日添加。
更早的基于正交化的优化示例可以在Carlson等人的工作中找到,他们提出通过SVD正交化梯度估计,然后用核范数缩放,以此来优化受限玻尔兹曼机和离散图模型,并将此方法称为随机谱下降。此外,Carlson等人提出使用随机谱下降和RMSprop的混合方法来优化前馈神经网络,称为RMSspectral。考虑到加速正交化的需求,RMSspectral使用随机SVD代替完整SVD来近似正交化操作。与Muon相比,这些早期的基于正交化的优化器使用SVD变体而非牛顿-舒尔茨迭代进行正交化,并且缺少任何形式的动量。我们发现使用动量对于获得最佳经验性能是必要的。
经验性考虑
根据设计,Muon仅适用于二维参数,因此网络中剩余的标量和向量参数必须使用标准方法进行优化。根据经验,我们发现使用AdamW优化输入和输出参数也很重要,即使它们通常是二维的。特别是在训练Transformer时,应使用AdamW优化嵌入层和最终分类器头层,以获得最佳性能。嵌入层的优化动态应与其他层不同,这符合模长理论。而输出层的优化动态也不同似乎并不遵循该理论,而是由经验驱动。
另一个纯粹的经验结果是,在我们测试的每种情况下,对Muon使用Nesterov风格的动量比普通的SGD动量效果稍好。因此,我们已在公开的Muon实现中将其设为默认值。
第三个结果是,如果对Transformer的Q、K、V参数分别应用Muon,而不是像通常那样将它们合并为一个输出后被分割的单一线性层进行优化,那么Muon的效果更好。
讨论:用竞争性任务框架解决基线调优不足的问题
神经网络优化研究文献如今大多充斥着已失效优化器的坟场,这些优化器曾声称以巨大优势击败了 AdamW,但最终从未被社区采用。我知道这个观点很尖锐。
由于急于寻找降低成本方法的行业在神经网络训练上花费了数十亿美元,我们可以推断问题出在研究社区而非潜在采用者身上。也就是说,研究本身出了问题。仔细审视单个论文时,人们发现最常见的罪魁祸首是糟糕的基线。论文在将新提出的优化器与 AdamW 基线进行比较之前,通常没有充分调优 AdamW。
我想指出,发表声称有巨大改进但无法复现或达到预期的新方法并非无受害者犯罪,因为它浪费了大量独立研究人员和小型实验室的时间、金钱和士气,他们每天都在尝试复现和基于这些方法进行研究,却因失败尝试而失望。
为了纠正这种情况,我提议采用以下证据标准:研究社区应要求,只要可能,神经网络训练的新方法应在竞争性训练任务中证明其成功。
竞争性任务通过两种方式解决基线调优不足的问题。首先,竞争性任务中的基线是之前的记录,如果该任务很受欢迎,那么这个基线很可能已经得到了充分调优。其次,即使在极少数情况下之前的记录没有得到充分调优,也可以通过新的记录进行自我修正,将训练恢复为标准方法。这之所以应该可能,是因为标准方法通常有快速的硬件优化实现可用,而新方法通常会引入一些额外的实际时间开销;因此,仅仅抛弃新提出的方法就足以创造新记录。结果是,对于流行的竞争性任务,一个巨大但虚假的对标准方法的改进持续出现在记录历史中的可能性很小。
举个例子,我将描述 Muon 目前的证据。它优于 AdamW 的主要证据来自其在竞争性任务“NanoGPT 极速训练”中的成功。具体来说,在 2024 年 10 月 15 日,从 AdamW 切换到 Muon 创造了新的 NanoGPT 训练速度记录,Muon 将训练速度提高了 35%。自那时起,Muon 一直是所有 12 项新的 NanoGPT 极速训练记录的首选优化器,这些记录由 7 位不同的研究人员创造。
Muon 的每步实际时间比 AdamW 慢,因此如果存在能使 AdamW 具有与 Muon 相同样本效率的超参数,那么只需抛弃 Muon,换回老牌的 AdamW 就能创造新记录。因此,要相信 Muon 优于 AdamW,至少对于训练小型语言模型而言,你实际上完全不需要相信我。相反,你只需要相信社区中存在知道如何调优 AdamW 并且有兴趣创造新的 NanoGPT 极速训练记录的研究人员。这难道不是很美妙吗?
尚待解决的问题
- Muon 能否扩展到更大规模的训练?
- 是否有可能将 Muon 使用的牛顿-舒尔茨迭代恰当地分布到大规模 GPU 集群上?
- Muon 是否可能仅适用于预训练,而不适用于微调或强化学习任务?
在撰写本文时,我尚不知道这些问题的答案。