ENGRAM: Effective, Lightweight Memory Orchestration for Conversational Agents
MemoryAgentDense RetrievalRutgersENGRAM:面向对话智能体的有效轻量级记忆编排
Abstract
Large language models (LLMs) deployed in user-facing applications require long-horizon consistency: the capacity to remember prior interactions, respect user preferences, and ground reasoning in past events. However, contemporary memory systems often adopt complex architectures such as knowledge graphs, multi-stage retrieval, and operating-system–style schedulers, which introduce engineering complexity and reproducibility challenges. We present ENGRAM, a lightweight state-of-the-art memory system that organizes conversation into three canonical memory types—episodic, semantic, and procedural—through a single router and retriever. Each user turn is converted into typed memory records with normalized schemas and embeddings and persisted in a database. At query time, the system retrieves top-k dense neighbors per type, merges results with simple set operations, and provides relevant evidence as context to the model. ENGRAM attains state-of-the-art results on the LoCoMo benchmark, a realistic multi-session conversational question-answering (QA) suite for long-horizon memory, and exceeds the full-context baseline by 15 absolute points on LongMemEval, an extended-horizon conversational benchmark, while using only
部署在面向用户应用中的大语言模型(LLM)需要长程一致性:也就是记住先前交互、尊重用户偏好,并把推理建立在过往事件之上的能力。 然而,当代记忆系统常采用知识图谱、多阶段检索和操作系统式调度器等复杂架构,这会引入工程复杂性和可复现性挑战。 我们提出 ENGRAM,这是一个轻量级的最先进记忆系统,它通过单个路由器和检索器,将对话组织为三种标准记忆类型:情景记忆、语义记忆和程序记忆。 每个用户轮次都会被转换为带有规范化 schema 和嵌入的类型化记忆记录,并持久化到数据库中。 在查询时,系统按类型检索 top-k 密集邻居,用简单集合操作合并结果,并把相关证据作为上下文提供给模型。 ENGRAM 在 LoCoMo 基准上达到最先进结果,该基准是用于长程记忆的现实多会话对话问答(QA)套件;在扩展长程对话基准 LongMemEval 上,ENGRAM 比 full-context 基线高出 15 个绝对点,同时只使用约
1. Introduction
LLMs are now embedded in personal assistants, tutoring systems, productivity tools and many other user-facing applications. These deployments demand long-horizon consistency, meaning remembering prior interactions, respecting user preferences, and grounding reasoning in past events. However, unlike humans, LLMs reset once input falls outside the context window. This leads to brittle behaviors such as forgetting, contradictions, or reliance on pre-training. Prior efforts extended the Transformer architecture to increase effective context, but they do not obviate the need for external memory.
LLM 现在已经嵌入个人助手、辅导系统、生产力工具以及许多其他面向用户的应用中。 这些部署需要长程一致性,也就是记住先前交互、尊重用户偏好,并把推理建立在过往事件之上。 然而,与人类不同,一旦输入落到上下文窗口之外,LLM 就会重置。 这会导致遗忘、矛盾或依赖预训练等脆弱行为。 先前工作扩展了 Transformer 架构以增加有效上下文,但它们并不能消除对外部记忆的需求。
Contemporary memory systems have converged on increasingly elaborate architectures, often involving knowledge graphs, multi-stage retrieval pipelines, or operating-system style schedulers. These designs introduce engineering complexity and many degrees of freedom, making reproducibility and analysis difficult. In contrast, we argue for a different point on the design spectrum: a compact memory layer that is intentionally simple yet sufficient to deliver state-of-the-art accuracy and reliable performance.
当代记忆系统已经逐渐汇聚到越来越精巧的架构上,通常涉及知识图谱、多阶段检索流水线或操作系统式调度器。 这些设计引入工程复杂性和许多自由度,使可复现性和分析变得困难。 相比之下,我们主张设计谱系上的另一种位置:一个刻意保持简单、但足以提供最先进准确率和可靠性能的紧凑记忆层。
We introduce ENGRAM, a lightweight memory system that separates three memory types — episodic, semantic, and procedural — and combines them through a single router and a single retriever. Each user message is converted into typed memory records with normalized JSON schemas and embeddings. Records are persisted in a local SQLite store, and at query time the system retrieves top-k neighbors from each memory type, merges results, and provides the evidence set as context to the answering prompt.
我们提出 ENGRAM,这是一个轻量级记忆系统,它区分三种记忆类型:情景记忆、语义记忆和程序记忆,并通过单个路由器和单个检索器把它们组合起来。 每条用户消息都会被转换成带有规范化 JSON schema 和嵌入的类型化记忆记录。 记录会被持久化到本地 SQLite 存储中;在查询时,系统从每种记忆类型中检索 top-k 邻居,合并结果,并把证据集作为上下文提供给回答提示。
Our central claim is that careful memory typing, minimal routing, and straightforward retrieval suffice to achieve state-of-the-art performance on LoCoMo, and to surpass full-context baselines on LongMemEval. We demonstrate consistent gains across single-hop, multi-hop, open-domain, and temporal categories. Beyond headline metrics, the simplicity of ENGRAM makes it an attractive foundation for principled experimentation: each component is small, interpretable, and easy to swap out. Finally, we provide a complete implementation and evaluation harness to support rigorous comparison and foster adoption by the community.
我们的核心主张是,细致的记忆类型划分、最小化路由和直接检索,足以在 LoCoMo 上达到最先进性能,并在 LongMemEval 上超过 full-context 基线。 我们在 single-hop、multi-hop、open-domain 和 temporal 类别上都展示出稳定增益。 除 headline 指标之外,ENGRAM 的简单性也使它成为原则性实验的有吸引力基础:每个组件都很小、可解释,并且易于替换。 最后,我们提供完整实现和评估框架,以支持严格比较并促进社区采用。
2. Related Work
Existing work on long-term memory for language models spans non-parametric retrieval methods, graph-based structures, and system-level abstractions. Non-parametric approaches augment a model with an external store accessed through dense or lexical retrieval. Nearest-neighbor LMs and large-scale retrieval-pretraining extend this line. They are attractive for mutability, yet often depend on retriever calibration and heuristic chunking. Graph-based methods organize memories as nodes and relations to support structured traversal and multi-hop reasoning. These designs capture compositional structure but introduce orchestration complexity and latency overhead at inference time. System-level approaches treat memory as a schedulable resource, adding lifecycle management and governance primitives.
关于语言模型长期记忆的现有工作涵盖非参数检索方法、基于图的结构和系统级抽象。 非参数方法用可通过密集检索或词法检索访问的外部存储来增强模型。 最近邻 LM 和大规模检索预训练扩展了这条路线。 它们因可变性而有吸引力,但通常依赖检索器校准和启发式 chunking。 基于图的方法把记忆组织为节点和关系,以支持结构化遍历和多跳推理。 这些设计能捕获组合结构,但在推理时引入编排复杂性和延迟开销。 系统级方法把记忆视为可调度资源,加入生命周期管理和治理原语。
Our work is closest to recent memory modules aimed at practical deployment. In contrast to multi-layer schedulers and heavy graph construction, ENGRAM retains the benefits of typed memory and semantic retrieval while minimizing moving parts, yielding a system that is straightforward to operate in both research and production at scale.
我们的工作最接近面向实际部署的近期记忆模块。 与多层调度器和繁重图构建不同,ENGRAM 保留了类型化记忆和语义检索的好处,同时最小化运动部件,从而得到一个在研究和规模化生产中都易于运行的系统。
3. The ENGRAM Architecture
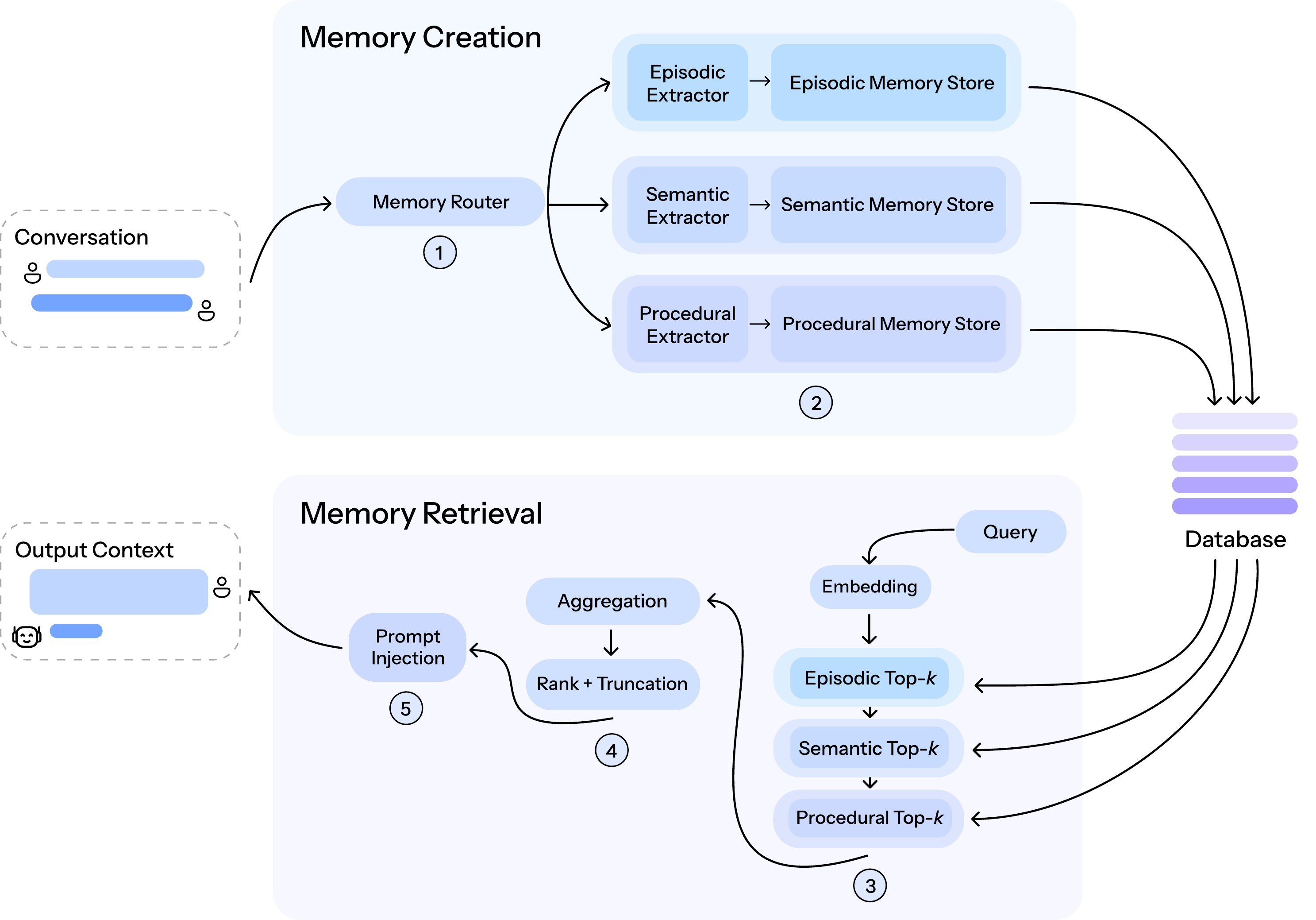
A router (1) determines which memory buckets apply to an incoming utterance. For each selected bucket, a lightweight extractor converts the utterance into a normalized record and requests an embedding (2). Records are persisted in SQLite together with their embeddings. At query time, the system retrieves the top-
路由器 (1) 决定传入话语适用于哪些记忆桶。 对于每个被选中的桶,轻量级抽取器把该话语转换为规范化记录,并请求一个嵌入 (2)。 记录会连同其嵌入一起持久化到 SQLite 中。 在查询时,系统从所有桶中按余弦相似度检索 top-
3.1 Problem Setup
We model a dialogue as a sequence of turns
我们把一个对话建模为轮次序列
where
其中
3.2 Routing and Storage
Every turn must be mapped into one or more memory types. ENGRAM employs a router (1) that decides which of the three stores a turn
每个轮次都必须被映射到一种或多种记忆类型。 ENGRAM 使用路由器 (1) 决定一个轮次
When the router outputs a one for a given type
当路由器对给定类型
3.3 Typed Memory Stores
Once turns are routed and stored, ENGRAM organizes them into three typed stores (2): episodic
一旦轮次被路由并存储,ENGRAM 就把它们组织成三种类型化存储 (2):情景记忆
where
其中
where each
其中每个
3.4 Dense Retrieval
Given the memory state
给定记忆状态
3.5 Answer Generation
At this stage, the retrieved memories are organized into speaker-specific banks to handle multi-speaker settings. Given a query
在这一阶段,检索到的记忆被组织成说话者特定的记忆库,以处理多说话者设置。 给定一个关于说话者
which produces a compact representation
这会产生紧凑表示
This prompt is passed to the language model to produce the answer
该提示被传给语言模型以产生答案
4. Evaluation
We evaluate ENGRAM on two complementary long-horizon conversational benchmarks. LoCoMo compresses realistic two-speaker dialogues into long, multi-session conversations that probe diverse reasoning categories. LongMemEval instead embeds QA tasks in extended user–assistant histories, stressing durability, updates, and abstention. Our evaluation covers dataset-specific preprocessing, answer-quality and retrieval metrics, a principled baseline suite, and latency analysis. Numerical results appear in the next section.
我们在两个互补的长程对话基准上评估 ENGRAM。 LoCoMo 把现实的双人对话压缩成长的多会话对话,用来探测多样化推理类别。 LongMemEval 则把 QA 任务嵌入扩展的用户-助手历史中,强调持久性、更新和拒答。 我们的评估覆盖特定数据集预处理、答案质量和检索指标、有原则的基线套件以及延迟分析。 数值结果见下一节。
4.1 Benchmarks
LoCoMo LoCoMo comprises long-term multi-session dialogues constructed via a human--machine pipeline grounded in personas and event graphs, followed by human edits for long-range consistency. The released benchmark contains 10 dialogues, each averaging
LoCoMo。 LoCoMo 包含长期多会话对话,这些对话通过基于 persona 和事件图的人机流水线构建,随后由人类编辑以保证长程一致性。 发布的基准包含 10 个对话,每个对话平均约
LongMemEval LongMemEval targets interactive memory in user--assistant settings and evaluates five core abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention (i.e. declining to answer when evidence is insufficient). The benchmark provides 500 curated questions embedded in length-configurable chat histories. We evaluate on LongMemEval
LongMemEval。 LongMemEval 面向用户-助手设置中的交互式记忆,并评估五项核心能力:信息抽取、多会话推理、时间推理、知识更新和拒答(即在证据不足时拒绝回答)。 该基准提供 500 个经策划的问题,它们嵌入在长度可配置的聊天历史中。 我们在 LongMemEval
4.2 Metrics
We report a suite of metrics that capture semantic correctness, lexical fidelity, retrieval quality, and efficiency. F1 and B1 (lexical fidelity). We report token-level F1 and BLEU-1/2 or B1-1/2 with smoothing as conventional indicators of surface-level agreement. Prior to scoring, predictions and references undergo deterministic normalization (Unicode NFKC, lower-casing, removal of articles and punctuation, whitespace compaction, light numeric canonicalization and resolution of relative temporal forms to ISO-8601). These metrics quantify wording overlap and enable comparability with prior work, but they are insensitive to factual inversions (e.g., Fiona was born in March'' vs. Fiona is born in February'' yields high overlap despite a critical error in semantic meaning). Consequently, F1/B1 are treated as complementary diagnostics rather than primary measures of correctness.
我们报告一组指标,用来捕获语义正确性、词法忠实度、检索质量和效率。 F1 和 B1(词法忠实度)。 我们报告 token 级 F1 以及带平滑的 BLEU-1/2 或 B1-1/2,把它们作为表层一致性的常规指标。 在打分前,预测和参考答案会经过确定性规范化(Unicode NFKC、小写化、移除冠词和标点、压缩空白、轻量数值规范化,以及把相对时间形式解析为 ISO-8601)。 这些指标量化措辞重叠,并支持与先前工作比较,但它们对事实反转不敏感(例如,“Fiona was born in March” 与 “Fiona is born in February” 尽管在语义意义上有关键错误,仍会得到较高重叠)。 因此,F1/B1 被视为互补诊断,而不是主要正确性度量。
LLM-as-a-Judge (semantic correctness). To capture factual accuracy beyond lexical overlap, we employ an independent LLM that, given the question, gold answer(s), and prediction, renders a binary semantic-correctness decision based on factual fidelity, relevance, completeness, and contextual appropriateness. We use GPT-4o-mini as the judging model. Because judge inferences are stochastic, each method is evaluated three times over the full test set and we report the mean
LLM-as-a-Judge(语义正确性)。 为了捕获超出词法重叠的事实准确性,我们使用一个独立 LLM;给定问题、标准答案和预测,它会基于事实忠实度、相关性、完整性和上下文适切性,给出二元语义正确性判断。 我们使用 GPT-4o-mini 作为评判模型。 由于 judge 推理具有随机性,每种方法都会在完整测试集上评估三次,我们报告均值
Latency (efficiency). We measure per-question retrieval latency. This involves the search process for memories (e.g., similarity computation, ranking). Additionally, we sum the retrieval latency time and the answer generation time in order to report a full end-to-end latency metric.
延迟(效率)。 我们测量每个问题的检索延迟。 这包括针对记忆的搜索过程(例如相似度计算、排序)。 此外,我们把检索延迟时间和答案生成时间相加,以报告完整端到端延迟指标。
4.3 Baselines
Our comparison strategy separates breadth and depth to provide clear, high-signal conclusions. LoCoMo (breadth). LoCoMo’s realistic two-speaker dialogues and rich category labels make it well-suited for a broad baseline matrix that teases apart design choices. We therefore compare against a diverse set of memory systems, including Mem0 (API-based memory), MemOS (operating-system–style scheduler with MemCubes), LangMem and Zep (commercial or open-source APIs), RAG (retrieval-augmented generation without persistent stores), and a full-context control (upper bound with the entire conversation in context). This suite isolates the contributions of typed memory, minimal routing, and dense-only retrieval against widely used alternatives, enabling category-wise attribution of gains.
我们的比较策略把广度和深度分开,以提供清晰且高信号的结论。 LoCoMo(广度)。 LoCoMo 的现实双人对话和丰富类别标签,使它非常适合用于拆解设计选择的宽基线矩阵。 因此,我们与多样化记忆系统比较,包括 Mem0(基于 API 的记忆)、MemOS(带 MemCubes 的操作系统式调度器)、LangMem 和 Zep(商业或开源 API)、RAG(没有持久存储的检索增强生成),以及 full-context 对照(把整个对话放入上下文的上界)。 这一套件把类型化记忆、最小化路由和纯密集检索相对于广泛使用替代方案的贡献隔离出来,从而支持按类别归因增益。
LongMemEval (depth). LongMemEval serves as a generalization stress test rather than a leaderboard battleground. The guiding research question is: How does ENGRAM behave when conversational horizons expand by orders of magnitude? To answer this cleanly, we freeze the LoCoMo-validated configuration and compare only against a strong, architecture-agnostic, full-context control. This isolates horizon generalization effects while avoiding confounds from retriever engineering that a broad baseline panel would reintroduce. It also respects reproducibility constraints on a benchmark whose histories are already very long and heavy.
LongMemEval(深度)。 LongMemEval 作为泛化压力测试,而不是 leaderboard 战场。 其指导性研究问题是: 当对话跨度扩展几个数量级时,ENGRAM 会如何表现? 为了干净地回答这个问题,我们冻结在 LoCoMo 上验证过的配置,并且只与一个强大的、架构无关的 full-context 对照比较。 这会隔离跨度泛化效果,同时避免宽基线面板重新引入检索器工程造成的混淆。 它也尊重该基准的可复现性约束,因为其历史已经非常长且沉重。
5. Results
5.1 Performance on LoCoMo
To contextualize ENGRAM’s performance, we evaluate against a diverse set of strong baselines spanning the principal design axes of previous state-of-the-art long-horizon memory systems (described in Section 4.3) while holding the LLM backbone fixed (gpt-4o-mini) to ensure consistency on the LoCoMo benchmark.
为了给 ENGRAM 的性能提供背景,我们在固定 LLM backbone(gpt-4o-mini)以确保 LoCoMo 基准一致性的同时,与一组多样化强基线进行评估,这些基线覆盖先前最先进长程记忆系统的主要设计轴(见第 4.3 节)。
| Category | Method | Chunk/Mem Tok | Top-K | LLM-as-Judge Score | F1 | B1 |
|---|---|---|---|---|---|---|
| single hop | langmem | 167 | -- | 67.32 ± 0.10 | 41.74 | 34.82 |
| mem0 | 1182 | 20 | 73.65 ± 0.12 | 46.26 | 40.54 | |
| memOS | 1596 | 20 | 78.32 ± 0.16 | 45.35 | 38.31 | |
| openai | 4104 | -- | 61.73 ± 0.24 | 36.78 | 30.45 | |
| zep | 2301 | 20 | 51.42 ± 0.17 | 32.44 | 27.37 | |
| ENGRAM | 919 | 20 | 79.90 ± 0.12 | 23.13 | 13.68 | |
| multi hop | langmem | 188 | -- | 56.71 ± 0.12 | 36.02 | 27.23 |
| mem0 | 1160 | 20 | 57.85 ± 0.20 | 35.43 | 25.87 | |
| memOS | 1534 | 20 | 63.70 ± 0.01 | 35.37 | 26.56 | |
| openai | 3967 | -- | 59.82 ± 0.04 | 33.02 | 23.18 | |
| zep | 2343 | 20 | 42.10 ± 0.06 | 23.11 | 14.69 | |
| ENGRAM | 919 | 20 | 79.79 ± 0.06 | 18.32 | 13.23 | |
| open domain | langmem | 211 | -- | 49.56 ± 0.16 | 29.63 | 23.12 |
| mem0 | 1151 | 20 | 44.93 ± 0.02 | 27.67 | 19.97 | |
| memOS | 1504 | 20 | 54.56 ± 0.24 | 29.46 | 22.32 | |
| openai | 4080 | -- | 32.87 ± 0.00 | 17.17 | 11.01 | |
| zep | 2284 | 20 | 39.12 ± 0.14 | 19.98 | 13.67 | |
| ENGRAM | 895 | 20 | 72.92 ± 0.17 | 8.56 | 5.47 | |
| temporal reasoning | langmem | 138 | -- | 24.21 ± 0.21 | 38.30 | 32.21 |
| mem0 | 1185 | 20 | 53.34 ± 0.33 | 45.20 | 38.03 | |
| memOS | 1662 | 20 | 72.68 ± 0.16 | 53.34 | 45.95 | |
| openai | 4042 | -- | 29.26 ± 0.02 | 23.40 | 18.36 | |
| zep | 2302 | 20 | 19.47 ± 0.31 | 18.62 | 14.43 | |
| ENGRAM | 911 | 20 | 70.79 ± 0.19 | 21.90 | 14.74 | |
| overall | langmem | 168 | -- | 55.28 ± 0.13 | 39.22 | 32.16 |
| mem0 | 1177 | 20 | 64.73 ± 0.17 | 42.90 | 36.05 | |
| memOS | 1593 | 20 | 72.99 ± 0.14 | 44.20 | 36.75 | |
| openai | 4064 | -- | 52.81 ± 0.14 | 32.08 | 25.39 | |
| zep | 2308 | 20 | 42.29 ± 0.18 | 27.07 | 21.50 | |
| ENGRAM | 916 | 20 | 77.55 ± 0.13 | 21.08 | 13.31 |
Table 1 reports category-wise and overall performance on LoCoMo. ENGRAM achieves the highest overall semantic correctness, with an LLM-as-Judge score of 77.55 under a shared backbone and prompt. By category, the largest margins appear on multi-hop (79.79) and open-domain (72.92), and ENGRAM also leads on single hop reasoning (79.90). For temporal-reasoning questions, performance is stronger on all baselines except for memOS (72.68).
表1报告 LoCoMo 上按类别和 overall 的性能。 ENGRAM 达到最高 overall 语义正确性,在共享 backbone 和 prompt 下的 LLM-as-Judge 分数为 77.55。 按类别看,最大优势出现在 multi-hop(79.79)和 open-domain(72.92)上,ENGRAM 也在 single hop reasoning(79.90)上领先。 对于 temporal-reasoning 问题,除 memOS(72.68)之外,ENGRAM 的表现强于所有基线。
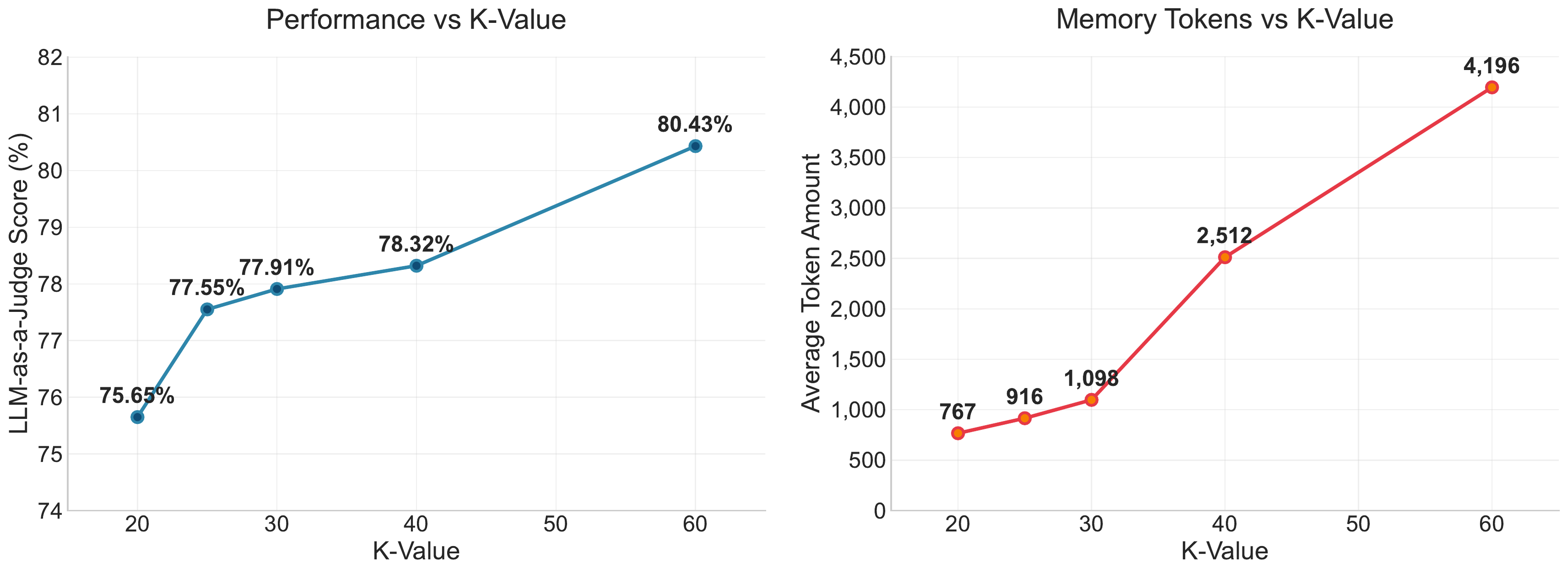
Importantly, these accuracy gains come with a smaller evidence budget (reported as “Chunk / Mem Tok”), which on average is 916 tokens for ENGRAM. This is more than a 35% decrease in memory tokens when compared to almost all of the other baselines, indicating that typed dense retrieval concentrates support into a compact context while preserving (and often improving) correctness. As anticipated in Section 4.2, F1/B1 solely reward surface-level overlap, not semantic accuracy. Despite leading LLM-as-Judge scores across all categories, we find that ENGRAM’s lexical scores appear lower because some responses are longer. We therefore include F1/B1 simply as complementary diagnostics and use the LLM-Judge as the principal correctness signal.
重要的是,这些准确率增益伴随更小的证据预算(报告为 “Chunk / Mem Tok”),ENGRAM 平均为 916 个 token。 与几乎所有其他基线相比,这意味着记忆 token 减少超过 35%,说明类型化密集检索能把支持证据集中到紧凑上下文中,同时保持(并常常改进)正确性。 正如第 4.2 节所预期,F1/B1 只奖励表层重叠,而不是语义准确性。 尽管 ENGRAM 在所有类别上的 LLM-as-Judge 分数都领先,我们发现它的词法分数看起来较低,因为有些响应更长。 因此,我们只把 F1/B1 作为互补诊断,并把 LLM-Judge 作为主要正确性信号。
To better understand the impact of the specific ENGRAM architecture, we conduct an ablation that removes typed routing, collapsing all utterances into one undifferentiated store. As reported in Appendix, Appendix Table 1, this configuration produces a noticeable decline in semantic correctness, with overall performance dropping to 46.56%. These results confirm that typed separation is not merely an architectural convenience but a key factor in concentrating relevant evidence and sustaining accuracy at long horizons.
为了更好地理解 ENGRAM 具体架构的影响,我们进行了一项移除类型化路由的消融,把所有话语折叠到一个未区分的存储中。 如附录的附表1所报告,该配置导致语义正确性明显下降,overall 性能降至 46.56%。 这些结果证实,类型化分离不只是架构便利,而是在长跨度上集中相关证据并维持准确率的关键因素。
5.2 Latency Analysis
| Method | K | Search (s) | Total (s) | Overall J | ||
|---|---|---|---|---|---|---|
| p50 | p95 | p50 | p95 | |||
| RAG, K=1 | 128 | 0.285 | 0.825 | 0.776 | 1.828 | 47.78 ± 0.05 |
| 256 | 0.251 | 0.713 | 0.748 | 1.631 | 50.23 ± 0.12 | |
| 512 | 0.242 | 0.641 | 0.775 | 1.723 | 46.23 ± 0.17 | |
| 1024 | 0.242 | 0.721 | 0.823 | 1.961 | 41.02 ± 0.06 | |
| 2048 | 0.256 | 0.754 | 0.998 | 2.184 | 38.02 ± 0.08 | |
| 4096 | 0.258 | 0.719 | 1.096 | 2.714 | 36.09 ± 0.11 | |
| 8192 | 0.275 | 0.841 | 1.402 | 4.482 | 43.57 ± 0.16 | |
| RAG, K=2 | 128 | 0.265 | 0.768 | 0.774 | 1.845 | 60.03 ± 0.07 |
| 256 | 0.257 | 0.804 | 0.821 | 1.909 | 60.45 ± 0.24 | |
| 512 | 0.245 | 0.833 | 0.832 | 1.745 | 58.27 ± 0.02 | |
| 1024 | 0.234 | 0.862 | 0.861 | 1.880 | 50.34 ± 0.19 | |
| 2048 | 0.265 | 1.106 | 1.104 | 2.794 | 49.16 ± 0.08 | |
| 4096 | 0.271 | 1.461 | 1.461 | 4.832 | 51.82 ± 0.13 | |
| 8192 | 0.292 | 2.367 | 2.347 | 9.949 | 61.26 ± 0.06 | |
| full-context | -- | -- | -- | 9.940 | 17.832 | 72.60 ± 0.07 |
| langMem | -- | 16.36 | 54.34 | 18.43 | 61.22 | 55.28 ± 0.13 |
| mem0 | 20 | 0.154 | 0.210 | 0.718 | 1.630 | 64.73 ± 0.17 |
| memOS | 20 | 1.806 | 1.983 | 4.965 | 7.957 | 72.99 ± 0.14 |
| openAI | -- | -- | -- | 0.524 | 0.912 | 52.81 ± 0.14 |
| zep | 20 | 0.554 | 0.812 | 1.347 | 3.031 | 42.29 ± 0.18 |
| ENGRAM | 20 | 0.603 | 0.806 | 1.487 | 1.819 | 77.55 ± 0.13 |
Table 2 shows that ENGRAM achieves both low latency and high semantic correctness on LoCoMo. Its median search and total times are 0.603 s and 1.487 s, alongside an LLM-as-Judge score of 77.55. Relative to full-context, which reports a median total of 9.940 s and 72.60 J, ENGRAM is significantly faster (
表2显示,ENGRAM 在 LoCoMo 上同时实现低延迟和高语义正确性。 它的 median search 和 total time 分别为 0.603 s 和 1.487 s,同时 LLM-as-Judge 分数为 77.55。 相对于 full-context(其 median total 为 9.940 s,J 为 72.60),ENGRAM 明显更快(约
5.3 Testing with Scale
We probe scaling behavior on LongMemEval
我们使用在 LoCoMo 上验证过的相同配置,探测 LongMemEval
| Question Type | Full-context (101K tokens) | ENGRAM (1.0K-1.2K tokens) |
|---|---|---|
| single-session-preference | 23.33% | 93.33% |
| single-session-assistant | 92.86% | 87.50% |
| temporal-reasoning | 37.59% | 55.64% |
| multi-session | 39.10% | 60.15% |
| knowledge-update | 79.49% | 74.36% |
| single-session-user | 82.86% | 97.14% |
| Overall J | 56.20% | 71.40% |
The qualitative implication is that ENGRAM’s architectural bias, typed writes and dense set aggregation, acts as an effective information bottleneck at extreme horizons. Instead of amplifying “lost-in-the-middle” effects, the system consistently surfaces high-signal events, facts, and procedures that are causally relevant to the query. We view this as evidence that typed dense memory constitutes a scalable prior for long-horizon reasoning: the same design that produces competitive accuracy and latency on realistic, category-rich conversations also transfers to histories that are orders of magnitude longer, maintaining correctness while drastically reducing the contextual burden placed on the base model. This suggests that ENGRAM’s architectural bias is not only effective for benchmarks, but also promising for deployment in real-world systems where long histories and strict efficiency constraints are the norm.
定性含义是,ENGRAM 的架构偏置,即类型化写入和密集集合聚合,在极长跨度下充当有效的信息瓶颈。 系统没有放大 “lost-in-the-middle” 效应,而是持续浮现与查询有因果相关性的高信号事件、事实和程序。 我们把这视为证据,表明类型化密集记忆构成了长程推理的可扩展先验:同一设计在现实的、类别丰富的对话上产生有竞争力的准确率和延迟,也能迁移到长几个数量级的历史上,在大幅降低基础模型上下文负担的同时保持正确性。 这说明 ENGRAM 的架构偏置不仅对基准有效,也有希望部署到长历史和严格效率约束成为常态的真实系统中。
6. Discussion
Why a simple memory layer works. Across both LoCoMo and LongMemEval
为什么简单记忆层有效。 在 LoCoMo 和 LongMemEval
Typed separation reduces competition at retrieval. A key ingredient is the typed partitioning of memory into episodic, semantic, and procedural stores. By performing per-type top-
类型化分离减少检索竞争。 关键成分是把记忆类型化划分为情景、语义和程序存储。 通过执行按类型 top-
Accuracy--efficiency frontier. The latency comparison in Table 2 shows that ENGRAM shifts the accuracy--efficiency frontier favorably. It achieves high semantic correctness while keeping response times low. This is not only a systems win; it is a modeling win. By constraining the prompt to a compact, high-signal subset, retrieval frees capacity for the answering model to reason, rather than forcing it to sift through long contexts that are prone to distraction and ``lost-in-the-middle'' effects.
准确率--效率前沿。 表2中的延迟比较显示,ENGRAM 有利地移动了准确率--效率前沿。 它在保持响应时间较低的同时达到高语义正确性。 这不仅是系统层面的胜利,也是建模层面的胜利。 通过把提示约束为紧凑、高信号子集,检索释放了回答模型的推理容量,而不是迫使它从容易受到干扰和 “lost-in-the-middle” 效应影响的长上下文中筛选信息。
Token economy without accuracy loss. On LoCoMo, ENGRAM operates with a smaller evidence budget than most baselines while still maintaining the strongest semantic correctness. On LongMemEval
不损失准确率的 token 经济性。 在 LoCoMo 上,ENGRAM 使用比多数基线更小的证据预算,同时仍保持最强语义正确性。 在 LongMemEval
The results suggest several promising directions. First, learning to route could be guided by weak supervision from Judge-derived gradients or distillation from stronger backbones, complementing reinforcement-learning approaches to memory management. Second, dynamic
这些结果提示了几个有前景的方向。 第一,学习路由可以由来自 Judge 派生梯度的弱监督或更强 backbone 的蒸馏来引导,从而补充面向记忆管理的强化学习方法。 第二,动态
7. Conclusion
In this work, we introduced ENGRAM, a compact memory architecture that couples typed extraction with minimal routing and dense-only retrieval via set aggregation. Despite its simplicity, ENGRAM delivers strong empirical performance: it achieves state-of-the-art semantic correctness on LoCoMo (LLM-as-a-Judge 77.55%) under a shared backbone and prompt (Table 1), pairs this accuracy with low latency (median total
在这项工作中,我们提出 ENGRAM,这是一个紧凑记忆架构,它把类型化抽取与最小化路由、以及通过集合聚合实现的纯密集检索结合起来。 尽管简单,ENGRAM 展现出强劲实证性能:在共享 backbone 和 prompt 下,它在 LoCoMo 上达到最先进语义正确性(LLM-as-a-Judge 77.55%;表1),同时具有低延迟(median total
Limitations and future work. Like any system, ENGRAM has constraints. Its effectiveness depends on dense retrieval quality, and catastrophic misses (e.g., paraphrased facts outside the embedder’s neighborhood) can propagate directly to answers. The router is intentionally minimal, so complex utterances spanning multiple categories may require soft routing or overlapping writes. Our evaluation employs GPT-4o-mini as the judging model, and while we report mean
局限与未来工作。 与任何系统一样,ENGRAM 也有约束。 它的有效性依赖密集检索质量,灾难性漏检(例如处于嵌入器邻域之外的改写事实)可能直接传播到答案中。 路由器被有意保持最小化,因此跨多个类别的复杂话语可能需要软路由或重叠写入。 我们的评估使用 GPT-4o-mini 作为评判模型;虽然我们报告跨运行的均值
Taken together, the ENGRAM rows across Tables Table 1, Table 2, and Table 3 tell a coherent story: a simple, typed memory layer can be both accurate and efficient at long horizons. In doing so, we directly challenge the prevailing trend toward increasingly complex graph schedulers and multi-stage pipelines, showing instead that careful memory typing and straightforward dense retrieval suffice to deliver state-of-the-art long-term consistency. We hope ENGRAM and its accompanying artifacts serve the community as a transparent, reproducible baseline and a principled foundation for advancing long-term memory in language models.
综合来看,表1、表2和表3中的 ENGRAM 行讲述了一个一致故事:一个简单的类型化记忆层可以在长跨度上同时做到准确且高效。 这样一来,我们直接挑战了走向越来越复杂图调度器和多阶段流水线的主流趋势,转而表明细致记忆类型划分和直接密集检索足以提供最先进长期一致性。 我们希望 ENGRAM 及其配套 artifacts 能作为透明、可复现的基线和推进语言模型长期记忆的原则性基础服务社区。
Reproducibility Statement
We provide an anonymized repository at https://anonymous.4open.science/r/engram-68FF/ containing code for the ENGRAM system and its evaluation, experiment scripts to reproduce all main results, and detailed setup files that specify datasets and parameters. Implementation specifics and additional analyses are documented in the appendix. Together, these materials are intended to enable an independent reader to reproduce our results with ease and to encourage open discussion.
我们在 https://anonymous.4open.science/r/engram-68FF/ 提供一个匿名仓库,其中包含 ENGRAM 系统及其评估代码、用于复现所有主结果的实验脚本,以及指定数据集和参数的详细设置文件。 实现细节和额外分析记录在附录中。 这些材料共同旨在让独立读者能够轻松复现我们的结果,并鼓励开放讨论。
| Category | LLM Score |
|---|---|
| single hop | 72.06% |
| multi hop | 61.70% |
| open domain | 45.83% |
| temporal reasoning | 67.60% |
| overall | 66.60% |
| Category | LLM Score |
|---|---|
| single hop | 65.40% |
| multi hop | 58.87% |
| open domain | 41.67% |
| temporal reasoning | 59.81% |
| overall | 61.56% |
| Category | LLM Score |
|---|---|
| single hop | 65.28% |
| multi hop | 53.19% |
| open domain | 47.92% |
| temporal reasoning | 32.09% |
| overall | 55.06% |
| Category | LLM Score |
|---|---|
| single hop | 46.10% |
| multi hop | 35.51% |
| open domain | 33.33% |
| temporal reasoning | 52.44% |
| overall | 46.56% |