
MemGPT: Towards LLMs as Operating Systems
Packer C, Fang V, Patil S G, et al. MemGPT: towards LLMs as operating systems[J]. 2023.
MemGPT:迈向作为操作系统的 LLM
Abstract
Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems which provide the illusion of an extended virtual memory via paging between physical memory and disk. Using this technique, we introduce MemGPT (MemoryGPT), a system that intelligently manages different storage tiers in order to effectively provide extended context within the LLM's limited context window. We evaluate our OS-inspired design in two domains where the limited context windows of modern LLMs severely handicaps their performance: document analysis, where MemGPT is able to analyze large documents that far exceed the underlying LLM's context window, and multi-session chat, where MemGPT can create conversational agents that remember, reflect, and evolve dynamically through long-term interactions with their users.
大型语言模型(LLM)彻底改变了人工智能,但它们受限于有限的上下文窗口,因而在长对话和文档分析等任务中的实用性受到限制。 为了能够使用超出有限上下文窗口的上下文,我们提出了虚拟上下文管理,这一技术借鉴了传统操作系统中的分层内存系统;后者通过在物理内存和磁盘之间分页,营造出扩展虚拟内存的假象。 利用这一技术,我们引入 MemGPT(MemoryGPT),一个能够智能管理不同存储层级的系统,从而在 LLM 有限的上下文窗口内有效提供扩展上下文。 我们在两个现代 LLM 因有限上下文窗口而性能严重受限的领域中评估这种受操作系统启发的设计:文档分析中,MemGPT 能够分析远超底层 LLM 上下文窗口的大型文档;多会话聊天中,MemGPT 能够创建会通过与用户长期交互而记住、反思并动态演化的对话智能体。
1. Introduction
In recent years, large language models (LLMs) and their underlying transformer architecture (Vaswani et al., 2017; Devlin et al., 2018; Brown et al., 2020; Ouyang et al., 2022) have become the cornerstone of conversational AI and have led to a wide array of consumer and enterprise applications. Despite these advances, the limited fixed-length context windows used by LLMs significantly hinders their applicability to long conversations or reasoning about long documents. For example, the most widely used open-source LLMs can only support a few dozen back-and-forth messages or reason about a short document before exceeding their maximum input length (Touvron et al., 2023).
近年来,大型语言模型(LLM)及其底层 Transformer 架构(Vaswani 等,2017;Devlin 等,2018;Brown 等,2020;Ouyang 等,2022)已经成为对话式 AI 的基石,并催生了广泛的消费级和企业级应用。 尽管取得了这些进展,LLM 所使用的固定长度上下文窗口仍然显著限制了它们在长对话或长文档推理中的适用性。 例如,最常用的开源 LLM 在超过最大输入长度之前,只能支持几十轮来回消息,或者只能对一篇短文档进行推理(Touvron 等,2023)。
Directly extending the context length of transformers incurs a quadratic increase in computational time and memory cost due to the transformer architecture's self-attention mechanism, making the design of new long-context architectures a pressing research challenge (Dai et al., 2019; Kitaev et al., 2020; Beltagy et al., 2020). While developing longer models is an active area of research (Dong et al., 2023), even if we could overcome the computational challenges of context scaling, recent research shows that long-context models struggle to utilize additional context effectively (Liu et al., 2023a). As consequence, given the considerable resources needed to train state-of-the-art LLMs and diminishing returns of context scaling, there is a critical need for alternative techniques to support long context.
由于 Transformer 架构的自注意力机制,直接扩展 Transformer 的上下文长度会带来计算时间和内存成本的二次增长,因此设计新的长上下文架构成为一个紧迫的研究挑战(Dai 等,2019;Kitaev 等,2020;Beltagy 等,2020)。 虽然开发更长的模型是一个活跃研究方向(Dong 等,2023),但即使我们能够克服上下文扩展带来的计算挑战,近期研究也表明,长上下文模型很难有效利用额外上下文(Liu 等,2023a)。 因此,考虑到训练最先进 LLM 所需的大量资源,以及上下文扩展收益递减的问题,我们迫切需要支持长上下文的替代技术。
In this paper, we study how to provide the illusion of an infinite context while continuing to use fixed-context models. Our approach borrows from the idea of virtual memory paging that was developed to enable applications to work on datasets that far exceed the available memory by paging data between main memory and disk. We leverage the recent progress in function calling abilities of LLM agents (Schick et al., 2023; Liu et al., 2023b) to design MemGPT, an OS-inspired LLM system for virtual context management. Using function calls, LLM agents can read and write to external data sources, modify their own context, and choose when to return responses to the user.
本文研究如何在继续使用固定上下文模型的同时,提供一种无限上下文的假象。 我们的方法借鉴了虚拟内存分页思想:这种机制通过在主内存和磁盘之间分页数据,使应用程序能够处理远超可用内存的数据集。 我们利用 LLM 智能体函数调用能力的最新进展(Schick 等,2023;Liu 等,2023b),设计了 MemGPT,一个受操作系统启发、用于虚拟上下文管理的 LLM 系统。 借助函数调用,LLM 智能体可以读写外部数据源、修改自身上下文,并选择何时向用户返回响应。
These capabilities allow LLMs to effective "page" in and out information between context windows (analogous to "main memory" in operating systems) and external storage, similar to hierarchical memory in traditional OSes. In addition, function calls can be leveraged to manage control flow between context management, response generation, and user interactions. This allows for an agent to choose to iteratively modify what is in its context for a single task, thereby more effectively utilizing its limited context.
这些能力使 LLM 能够像传统操作系统中的分层内存一样,在上下文窗口(类似操作系统中的“主内存”)和外部存储之间有效地“分页”换入换出信息。 此外,函数调用还可以用于管理上下文管理、响应生成和用户交互之间的控制流。 这使得智能体能够为单个任务选择迭代地修改自身上下文中的内容,从而更有效地利用有限上下文。
In MemGPT, we treat context windows as a constrained memory resource, and design a memory hiearchy for LLMs analogous to memory tiers used in traditional OSes (Patterson et al., 1988). Applications in traditional OSes interact with virtual memory, which provides an illusion of there being more memory resources than are actually available in physical (i.e., main) memory by the OS paging overflow data to disk and retrieving data (via a page fault) back into memory when accessed by applications. To provide a similar illusion of longer context length (analogous to virtual memory), we allow the LLM to manage what is placed in its own context (analogous to physical memory) via an "LLM OS", which we call MemGPT. MemGPT enables the LLM to retrieve relevant historical data missing from what is placed in-context, and also evict less relevant data from context and into external storage systems. Figure 3 illustrates the components of MemGPT.
在 MemGPT 中,我们将上下文窗口视为一种受限的内存资源,并为 LLM 设计了一个类似传统操作系统内存层级的内存层次结构(Patterson 等,1988)。 传统操作系统中的应用程序与虚拟内存交互;操作系统会把溢出数据分页到磁盘,并在应用程序访问时(通过缺页中断)将数据取回内存,从而营造出物理内存(即主内存)实际可用资源更多的假象。 为了提供类似的更长上下文长度假象(类似虚拟内存),我们允许 LLM 通过一个称为 MemGPT 的 "LLM OS" 来管理放入自身上下文(类似物理内存)的内容。 MemGPT 使 LLM 能够检索当前上下文中缺失但相关的历史数据,也能将较不相关的数据从上下文中驱逐到外部存储系统。 图3 展示了 MemGPT 的组件。
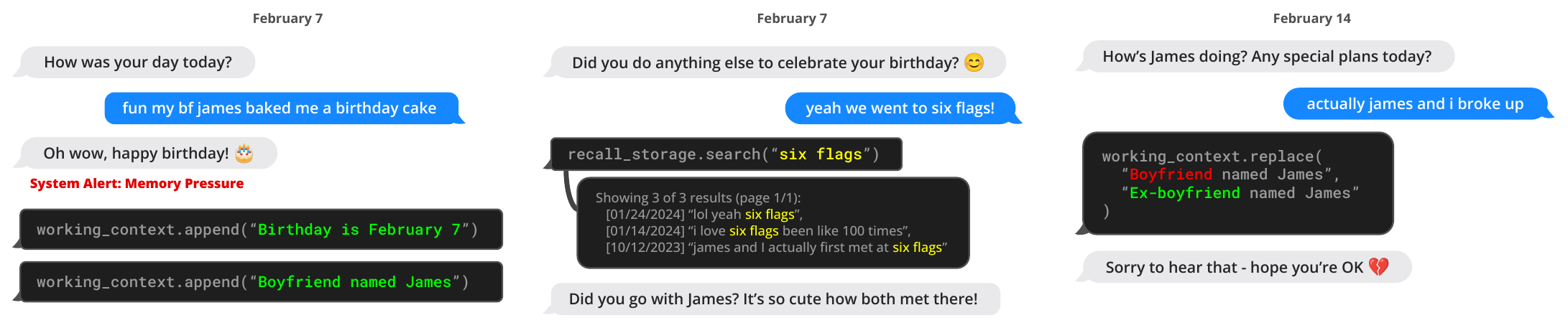
The combined use of a memory-hierarchy, OS functions and event-based control flow allow MemGPT to handle unbounded context using LLMs that have finite context windows. To demonstrate the utility of our new OS-inspired LLM system, we evaluate MemGPT on two domains where the performance of existing LLMs is severely limited by finite context: document analysis, where the length of standard text files can quickly exceed the input capacity of modern LLMs, and conversational agents, where LLMs bound by limited conversation windows lack context awareness, persona consistency, and long-term memory during extended conversations. In both settings, MemGPT is able to overcome the limitations of finite context to outperform existing LLM-based approaches.
内存层次结构、操作系统函数以及基于事件的控制流结合起来,使 MemGPT 能够用具有有限上下文窗口的 LLM 处理无界上下文。 为了展示这一受操作系统启发的新 LLM 系统的实用性,我们在两个现有 LLM 性能因有限上下文而严重受限的领域中评估 MemGPT:文档分析中,标准文本文件长度可能很快超过现代 LLM 的输入容量;对话智能体中,受限于有限对话窗口的 LLM 在长时间对话中缺乏上下文感知、角色一致性和长期记忆。 在这两种设置下,MemGPT 都能够克服有限上下文的限制,并优于现有基于 LLM 的方法。
request_heartbeat=true,请求立即进行后续 LLM 推理以把函数调用链接起来;函数链式调用使 MemGPT 能够执行多步检索来回答用户查询。2. MemGPT (MemoryGPT)
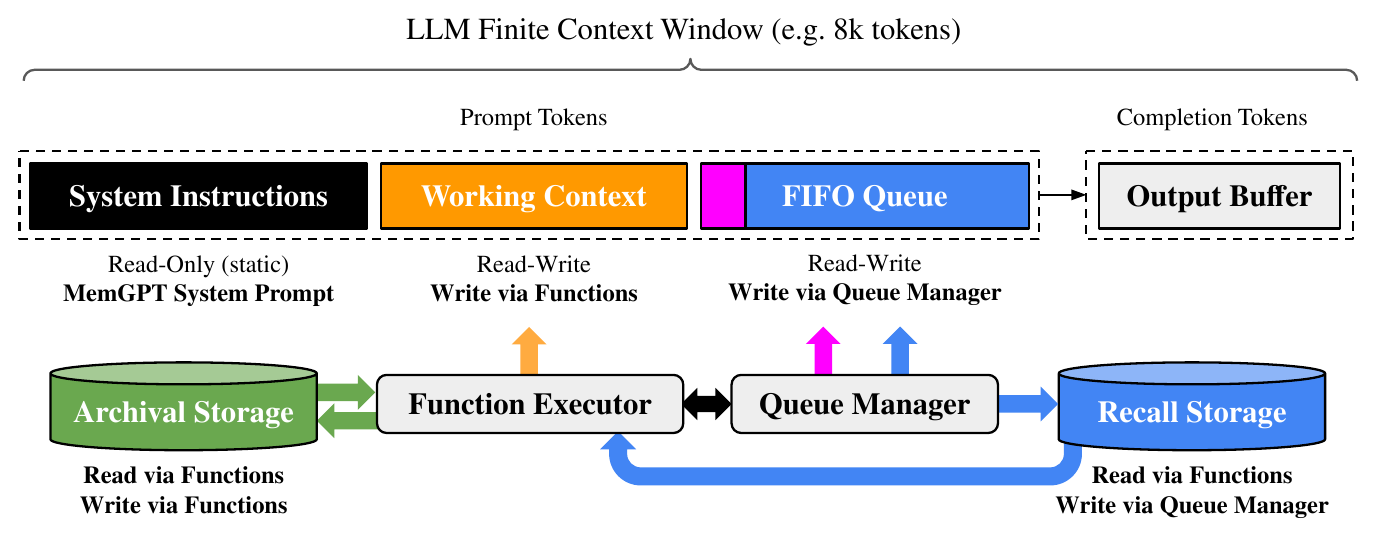
MemGPT's OS-inspired multi-level memory architecture delineates between two primary memory types: main context (analogous to main memory/physical memory/RAM) and external context (analogous to disk memory/disk storage). Main context consists of the LLM prompt tokens---anything in main context is considered in-context and can be accessed by the LLM processor during inference. External context refers to any information that is held outside of the LLMs fixed context window. This out-of-context data must always be explicitly moved into main context in order for it to be passed to the LLM processor during inference. MemGPT provides function calls that the LLM processor to manage its own memory without any user intervention.
MemGPT 受操作系统启发的多级记忆架构区分了两种主要记忆类型:主上下文(类似主内存/物理内存/RAM)和外部上下文(类似磁盘内存/磁盘存储)。 主上下文由 LLM 的提示词元组成,主上下文中的任何内容都被视为上下文内,可在推理期间被 LLM 处理器访问。 外部上下文指保存在 LLM 固定上下文窗口之外的任何信息。 这些上下文外数据必须始终被显式移动到主上下文中,才能在推理期间传给 LLM 处理器。 MemGPT 提供函数调用,使 LLM 处理器能够在没有任何用户干预的情况下管理自身记忆。
2.1. Main context (prompt tokens)
The prompt tokens in MemGPT are split into three contiguous sections: the system instructions, working context, and FIFO Queue. The system instructions are read-only (static) and contain information on the MemGPT control flow, the intended usage of the different memory levels, and instructions on how to use the MemGPT functions (e.g. how to retrieve out-of-context data). Working context is a fixed-size read/write block of unstructured text, writeable only via MemGPT function calls. In conversational settings, working context is intended to be used to store key facts, preferences, and other important information about the user and the persona the agent is adopting, allowing the agent to converse fluently with the user. The FIFO queue stores a rolling history of messages, including messages between the agent and user, as well as system messages (e.g. memory warnings) and function call inputs and outputs. The first index in the FIFO queue stores a system message containing a recursive summary of messages that have been evicted from the queue.
MemGPT 中的提示词元被划分为三个连续部分:系统指令、工作上下文和 FIFO 队列。 系统指令是只读的(静态的),其中包含 MemGPT 控制流、不同记忆层级的预期用途,以及如何使用 MemGPT 函数的说明(例如如何检索上下文外数据)。 工作上下文是一个固定大小的非结构化文本读写块,只能通过 MemGPT 函数调用写入。 在对话场景中,工作上下文旨在存储关于用户和智能体所扮演角色的关键事实、偏好以及其他重要信息,使智能体能够与用户流畅对话。 FIFO 队列存储滚动消息历史,包括智能体与用户之间的消息,以及系统消息(例如记忆警告)和函数调用的输入输出。 FIFO 队列的第一个位置存储一条系统消息,其中包含已从队列中驱逐消息的递归摘要。
2.2. Queue Manager
The queue manager manages messages in recall storage and the FIFO queue. When a new message is received by the system, the queue manager appends the incoming messages to the FIFO queue, concatenates the prompt tokens and triggers the LLM inference to generate LLM output (the completion tokens). The queue manager writes both the incoming message and the generated LLM output to recall storage (the MemGPT message database). When messages in recall storage are retrieved via a MemGPT function call, the queue manager appends them to the back of the queue to reinsert them into the LLM's context window.
队列管理器负责管理召回存储和 FIFO 队列中的消息。 当系统收到新消息时,队列管理器会把传入消息追加到 FIFO 队列,拼接提示词元,并触发 LLM 推理以生成 LLM 输出(完成词元)。 队列管理器会把传入消息和生成的 LLM 输出都写入召回存储(MemGPT 消息数据库)。 当召回存储中的消息通过 MemGPT 函数调用被检索出来时,队列管理器会把它们追加到队列末尾,从而重新插入 LLM 的上下文窗口。
The queue manager is also responsible for controlling context overflow via a queue eviction policy. When the prompt tokens exceed the warning token count of the underlying LLM's context window (e.g. 70% of the context window), the queue manager inserts a system message into the queue warning the LLM of an impending queue eviction (a memory pressure warning) to allow the LLM to use MemGPT functions to store important information contained in the FIFO queue to working context or archival storage (a read/write database storing arbitrary length text objects). When the prompt tokens exceed the "flush token count" (e.g. 100% of the context window), the queue manager flushes the queue to free up space in the context window: the queue manager evicts a specific count of messages (e.g. 50% of the context window), generates a new recursive summary using the existing recursive summary and evicted messages. Once the queue is flushed, the evicted messages are no longer in-context and immediately viewable to the LLM, however they are stored indefinitely in recall storage and readable via MemGPT function calls.
队列管理器还负责通过队列驱逐策略控制上下文溢出。 当提示词元超过底层 LLM 上下文窗口的 warning token count(例如上下文窗口的 70%)时,队列管理器会向队列中插入一条系统消息,警告 LLM 即将发生队列驱逐(即 memory pressure 警告),使 LLM 能够使用 MemGPT 函数把 FIFO 队列中的重要信息存入工作上下文或归档存储(一个存储任意长度文本对象的读写数据库)。 当提示词元超过 "flush token count"(例如上下文窗口的 100%)时,队列管理器会刷新队列以释放上下文窗口空间:队列管理器会驱逐特定数量的消息(例如上下文窗口的 50%),并使用现有递归摘要和被驱逐消息生成新的递归摘要。 队列刷新后,被驱逐的消息不再处于上下文内,LLM 也无法立即看到它们;不过它们会被无限期保存在召回存储中,并可通过 MemGPT 函数调用读取。
2.3. Function executor (handling of completion tokens)
MemGPT orchestrates data movement between main context and external context via function calls that are generated by the LLM processor. Memory edits and retrieval are entirely self-directed: MemGPT autonomously updates and searches through its own memory based on the current context. For instance, it can decide when to move items between contexts (e.g. when the conversation history is becoming too long, as show in Figure 1) and modify its main context to better reflect its evolving understanding of its current objectives and responsibilities (as shown in Figure 3). We implement self-directed editing and retrieval by providing explicit instructions within the system instructions that guide the LLM on how to interact with the MemGPT memory systems. These instructions comprise two main components: (1) a detailed description of the memory hierarchy and their respective utilities, and (2) a function schema (complete with their natural language descriptions) that the system can call to access or modify its memory.
MemGPT 通过 LLM 处理器生成的函数调用,在主上下文和外部上下文之间编排数据移动。 记忆编辑和检索完全是自我导向的:MemGPT 会根据当前上下文自主更新和搜索自身记忆。 例如,它可以决定何时在不同上下文之间移动项目(例如当对话历史变得过长时,如 图1 所示),并修改其主上下文,使其更好地反映对当前目标和职责不断演化的理解(如 图3 所示)。 我们通过在系统指令中提供显式说明来实现自我导向的编辑和检索,这些说明会指导 LLM 如何与 MemGPT 记忆系统交互。 这些说明包含两个主要组成部分:(1)对记忆层次结构及其各自用途的详细描述;(2)函数 schema(包含自然语言描述),系统可调用这些函数来访问或修改自身记忆。
During each inference cycle, LLM processor takes main context (concatenated into a single string) as input, and generates an output string. This output string is parsed by MemGPT to ensure correctness, and if the parser validates the function arguments the function is executed. The results, including any runtime errors that occur (e.g. trying to add to main context when it is already at maximum capacity), are then fed back to the processor by MemGPT. This feedback loop enables the system to learn from its actions and adjust its behavior accordingly. Awareness of context limits is a key aspect in making the self-editing mechanism work effectively, to this end MemGPT prompts the processor with warnings regarding token limitations to guide its memory management decisions. Additionally, our memory retrieval mechanisms are designed to be cognizant of these token constraints and implement pagination to prevent retrieval calls from overflowing the context window.
在每个推理周期中,LLM 处理器以主上下文(拼接成单个字符串)作为输入,并生成一个输出字符串。 该输出字符串由 MemGPT 解析以确保正确性;如果解析器验证函数参数有效,则执行对应函数。 随后,MemGPT 会把结果反馈给处理器,其中包括任何运行时错误(例如在主上下文已经达到最大容量时仍尝试添加内容)。 这种反馈循环使系统能够从自身动作中学习,并相应调整行为。 对上下文限制的感知是让自我编辑机制有效运作的关键;为此,MemGPT 会用关于词元限制的警告提示处理器,以指导其记忆管理决策。 此外,我们的记忆检索机制在设计时也会感知这些词元约束,并实现分页,以防止检索调用溢出上下文窗口。
*Messages 为近似消息数,假设预提示为 1k tokens,平均每条消息约 50 tokens(约 250 字符)。Open 表示模型是开源或开放权重,而不是只能通过 API 使用。| Model / API name | Open? | Tokens | *Messages |
|---|---|---|---|
| Llama (1) | ✓ | 2k | 20 |
| Llama 2 | ✓ | 4k | 60 |
| GPT-3.5 Turbo (release) | × | 4k | 60 |
| Mistral 7B | ✓ | 8k | 140 |
| GPT-4 (release) | × | 8k | 140 |
| GPT-3.5 Turbo | × | 16k | 300 |
| GPT-4 | × | 32k | ~600 |
| Claude 2 | × | 100k | ~2000 |
| GPT-4 Turbo | × | 128k | ~2600 |
| Yi-34B-200k | ✓ | 200k | ~4000 |
2.4. Control flow and function chaining
In MemGPT, events trigger LLM inference: events are generalized inputs to MemGPT and can consist of user messages (in chat applications), system messages (e.g. main context capacity warnings), user interactions (e.g. an alert that a user just logged in, or an alert that they finished uploading a document), and timed events that are run on a regular schedule (allowing MemGPT to run "unprompted" without user intervention). MemGPT processes events with a parser to convert them into plain text messages that can be appended to main context and eventually be fed as input into the LLM processor.
在 MemGPT 中,事件会触发 LLM 推理:事件是 MemGPT 的泛化输入,可以包括用户消息(在聊天应用中)、系统消息(例如主上下文容量警告)、用户交互(例如用户刚登录的提醒,或用户完成文档上传的提醒),以及按固定时间表运行的定时事件(使 MemGPT 能够在没有用户干预的情况下“无提示”运行)。 MemGPT 会用解析器处理事件,将其转换成可追加到主上下文中的纯文本消息,并最终作为输入传给 LLM 处理器。
Many practical tasks require calling multiple functions in sequence, for example, navigating through multiple pages of results from a single query or collating data from different documents in main context from separate queries. Function chaining allows MemGPT to execute multiple function calls sequentially before returning control to the user. In MemGPT, functions can be called with a special flag that requests control be immediately returned to the processor after the requested function completes execution. If this flag is present, MemGPT will add the function output to main context and (as opposed to pausing processor execution). If this flag is not present (a yield), MemGPT will not run the LLM processor until the next external event trigger (e.g. a user message or scheduled interrupt).
许多实际任务需要按顺序调用多个函数,例如浏览单个查询返回的多页结果,或从多个独立查询得到的不同文档中汇总主上下文中的数据。 函数链式调用允许 MemGPT 在把控制权交还给用户之前,顺序执行多个函数调用。 在 MemGPT 中,可以用一个特殊标志调用函数,请求在所请求的函数完成执行后立即把控制权交还给处理器。 如果存在该标志,MemGPT 会把函数输出加入主上下文,并继续处理器执行,而不是暂停处理器执行。 如果不存在该标志(即 yield),MemGPT 将不会运行 LLM 处理器,直到下一个外部事件触发(例如用户消息或计划中断)。
3. Experiments
We assess MemGPT in two long-context domains: conversational agents and document analysis. For conversational agents, we expand the existing Multi-Session Chat dataset (Xu et al., 2021) and introduce two new dialogue tasks that evaluate an agent's ability to retain knowledge across long conversations. For document analysis, we benchmark MemGPT on existing tasks from Liu et al. (2023a) for question answering and key-value retrieval over lengthy documents. We also propose a new nested key-value retrieval task requiring collating information across multiple data sources, which tests the ability of an agent to collate information from multiple data sources (multi-hop retrieval). We publicly release our augmented MSC dataset, nested KV retrieval dataset, and a dataset of embeddings for 20M Wikipedia articles to facilitate future research. Our code for the benchmarks is available at https://research.memgpt.ai/.
我们在两个长上下文领域评估 MemGPT:对话智能体和文档分析。 对于对话智能体,我们扩展了现有 Multi-Session Chat 数据集(Xu 等,2021),并引入两个新的对话任务,用于评估智能体在长对话中保留知识的能力。 对于文档分析,我们在 Liu 等(2023a)的长文档问答和键值检索现有任务上对 MemGPT 进行基准测试。 我们还提出了一个新的嵌套键值检索任务,它要求从多个数据源中汇总信息,用于测试智能体从多个数据源汇总信息的能力(多跳检索)。 我们公开发布增强后的 MSC 数据集、嵌套 KV 检索数据集,以及包含 2000 万篇 Wikipedia 文章嵌入的数据集,以促进未来研究。 我们的基准测试代码可在 https://research.memgpt.ai/ 获取。
Implementation details. When discussing OpenAI models, unless otherwise specified "GPT-4 Turbo" refers to the specific gpt-4-1106-preview model endpoint (context window of 128,000), GPT-4 refers to gpt-4-0613 (context window of 8,192), and GPT-3.5 Turbo refers to gpt-3.5-turbo-1106 (context window of 16,385). In experiments, we run MemGPT with all baseline models (GPT-4, GPT-4 Turbo, and GPT 3.5) to show how the underlying model performance affects MemGPT's.
实现细节。 在讨论 OpenAI 模型时,除非另有说明,"GPT-4 Turbo" 指特定的 gpt-4-1106-preview 模型端点(上下文窗口为 128,000),GPT-4 指 gpt-4-0613(上下文窗口为 8,192),GPT-3.5 Turbo 指 gpt-3.5-turbo-1106(上下文窗口为 16,385)。 在实验中,我们用所有基线模型(GPT-4、GPT-4 Turbo 和 GPT 3.5)运行 MemGPT,以展示底层模型性能如何影响 MemGPT 的表现。
3.1. MemGPT for conversational agents
Conversational agents like virtual companions and personalized assistants aim to engage users in natural, long-term interactions, potentially spanning weeks, months, or even years. This creates challenges for models with fixed-length contexts, which can only reference a limited history of the conversation. An "infinite context" agent should seamlessly handle continuous exchanges without boundary or reset. When conversing with a user, such an agent must satisfy two key criteria: (1) Consistency - The agent should maintain conversational coherence. New facts, preferences, and events mentioned should align with prior statements from both the user and agent. (2) Engagement - The agent should draw on long-term knowledge about the user to personalize responses. Referencing prior conversations makes dialogue more natural and engaging.
虚拟陪伴和个性化助手等对话智能体旨在与用户进行自然、长期的交互,这种交互可能持续数周、数月甚至数年。 这给固定长度上下文模型带来了挑战,因为它们只能引用有限的对话历史。 一个“无限上下文”智能体应该能够无缝处理连续交流,而不需要边界或重置。 与用户对话时,这样的智能体必须满足两个关键标准:(1)一致性:智能体应保持对话连贯性。 新提到的事实、偏好和事件应与用户和智能体此前的陈述一致。 (2)参与感:智能体应利用关于用户的长期知识来个性化响应。 引用先前对话会使对话更加自然、更有吸引力。
We therefore assess our proposed system, MemGPT, on these two criteria: (1) Does MemGPT leverage its memory to improve conversation consistency? Can it remember relevant facts, preferences, and events from past interactions to maintain coherence? (2) Does MemGPT produce more engaging dialogue by taking advantage of memory? Does it spontaneously incorporate long-range user information to personalize messages? By evaluating on consistency and engagement, we can determine how well MemGPT handles the challenges of long-term conversational interaction compared to fixed-context baselines. Its ability to satisfy these criteria will demonstrate whether unbounded context provides meaningful benefits for conversational agents.
因此,我们根据这两个标准评估所提出的系统 MemGPT:(1)MemGPT 是否利用其记忆来提升对话一致性? 它能否记住过去交互中的相关事实、偏好和事件,以保持连贯性? (2)MemGPT 是否利用记忆产生更有吸引力的对话? 它是否会自发纳入长程用户信息来个性化消息? 通过评估一致性和参与感,我们可以确定 MemGPT 相比固定上下文基线,在处理长期对话交互挑战方面表现如何。 它满足这些标准的能力将表明,无界上下文是否能为对话智能体带来有意义的收益。
| Model | Accuracy ↑ | ROUGE-L (R) ↑ |
|---|---|---|
| GPT-3.5 Turbo | 38.7% | 0.394 |
| + MemGPT | 66.9% | 0.629 |
| GPT-4 | 32.1% | 0.296 |
| + MemGPT | 92.5% | 0.814 |
| + MemGPT (GPT-4 Turbo) | 93.4% | 0.827 |
Dataset. We evaluate MemGPT and our fixed-context baselines on the Multi-Session Chat (MSC) dataset introduced by Xu et al. (2021), which contains multi-session chat logs generated by human labelers, each of whom was asked to play a consistent persona for the duration of all sessions. Each multi-session chat in MSC has five total sessions, and each session consists of a roughly a dozen messages. As part of our consistency experiments, we created a new session (session 6) that contains a single question-answer response pair between the same two personas.
数据集。 我们在 Xu 等(2021)提出的 Multi-Session Chat(MSC)数据集上评估 MemGPT 和固定上下文基线;该数据集包含由人工标注者生成的多会话聊天日志,每位标注者都被要求在所有 session 中扮演一致的角色。 MSC 中每个多会话聊天总共有五个 session,每个 session 大约包含十几条消息。 作为一致性实验的一部分,我们创建了一个新的 session(session 6),其中包含同两个角色之间的一组问答响应对。
Deep memory retrieval task (consistency).
We introduce a new "deep memory retrieval" (DMR) task based on the MSC dataset designed to test the consistency of a conversational agent. In DMR, the conversational agent is asked a question by the user that explicitly refers back to a prior conversation and has a very narrow expected answer range. We generated the DMR question-answer (QA) pairs using a separate LLM that was instructed to write a question from one user to another that could only be answered correctly using knowledge gained from the past sessions (see Appendix for further details).
我们基于 MSC 数据集引入了一个新的 "deep memory retrieval"(DMR)任务,用于测试对话智能体的一致性。 在 DMR 中,用户会向对话智能体提出一个明确指向先前对话的问题,并且该问题的预期答案范围非常窄。 我们使用一个单独的 LLM 生成 DMR 问答(QA)对,并指示它写出一个用户问另一个用户的问题;该问题只能用过去 session 中获得的知识正确回答(更多细节见附录)。
We evaluate the quality of the generated response against the "gold response" using ROUGE-L scores (Lin, 2004) and an "LLM judge", which is instructed to evaluate whether or not the generated response is consistent with the gold response (GPT-4 has been shown to have high agreement with human evaluators (Zheng et al., 2023)). In practice, we notice that the generated responses (from both MemGPT and the baselines) were generally more verbose than the gold responses. We use the ROUGE-L recall (R) metric to account for the verbosity of the generated agent replies compared to the relatively short gold answer labels.
我们使用 ROUGE-L 分数(Lin,2004)和“LLM 裁判”将生成响应与“标准响应”进行比较,以评估生成响应质量;该 LLM 裁判被指示判断生成响应是否与标准响应一致(已有研究表明 GPT-4 与人类评估者高度一致(Zheng 等,2023))。 实践中,我们注意到生成响应(无论来自 MemGPT 还是基线)通常比标准响应更冗长。 相比相对较短的标准答案标签,我们使用 ROUGE-L recall(R)指标来考虑生成智能体回复的冗长程度。
| Method | SIM-1 ↑ | SIM-3 | SIM-H |
|---|---|---|---|
| Human | 0.800 | 0.800 | 1.000 |
| GPT-3.5 Turbo | 0.830 | 0.812 | 0.817 |
| GPT-4 | 0.868 | 0.843 | 0.773 |
| GPT-4 Turbo | 0.857 | 0.828 | 0.767 |
MemGPT utilizes memory to maintain coherence: Table 2 shows the performance of MemGPT vs the fixed-memory baselines. We compare MemGPT using different underlying LLMs, and compare against using the base LLM without MemGPT as a baseline. The baselines are able to see a lossy summarization of the past five conversations to mimic an extended recursive summarization procedure, while MemGPT instead has access to the full conversation history but must access it via paginated search queries to recall memory (in order to bring them into main context). In this task, we see that MemGPT clearly improves the performance of the underlying base LLM: there is a clear drop in both accuracy and ROUGE scores when going from MemGPT to the corresponding LLM baselines.
MemGPT 利用记忆来保持连贯性: 表2 展示了 MemGPT 与固定记忆基线的性能对比。 我们比较了使用不同底层 LLM 的 MemGPT,并以不使用 MemGPT 的基础 LLM 作为基线。 基线能够看到过去五次对话的有损摘要,以模拟扩展递归摘要过程;而 MemGPT 能访问完整对话历史,但必须通过分页搜索查询来召回记忆(以便把它们带入主上下文)。 在该任务中,我们看到 MemGPT 明显提升了底层基础 LLM 的性能:从 MemGPT 切换到相应 LLM 基线时,准确率和 ROUGE 分数都会明显下降。
Conversation opener task (engagement).
In the "conversation opener" task we evaluate an agent's ability to craft engaging messages to the user that draw from knowledge accumulated in prior conversations. To evaluate the "engagingness" of a conversation opener using the MSC dataset, we compare the generated opener to the gold personas: an engaging conversation opener should draw from one (or several) of the data points contained in the persona, which in MSC effectively summarize the knowledge accumulated throughout all prior sessions. We also compare to the human-generated gold opener, i.e., the first response in the following session. We report the CSIM scores of MemGPT's openers in Table 3. We test several variations of MemGPT using different base LLMs.
在 "conversation opener" 任务中,我们评估智能体利用先前对话中积累的知识,为用户编写有吸引力消息的能力。 为了使用 MSC 数据集评估 conversation opener 的“吸引力”,我们将生成的 opener 与 gold personas 进行比较:一个有吸引力的 conversation opener 应该利用 persona 中包含的一个(或多个)数据点,而在 MSC 中,这些数据点实际上总结了所有先前 session 中积累的知识。 我们还将其与人工生成的 gold opener 进行比较,即后续 session 中的第一条回复。 我们在 表3 中报告 MemGPT 的 opener 的 CSIM 分数。 我们使用不同基础 LLM 测试了 MemGPT 的若干变体。
MemGPT utilizes memory to increase engagement: As seen in Table 3, MemGPT is able to craft engaging openers that perform similarly to and occasionally exceed the hand-written human openers. We observe that MemGPT tends to craft openers that are both more verbose and cover more aspects of the persona information than the human baseline. Additionally, we can see the storing information in working context is key to generating engaging openers.
MemGPT 利用记忆提升参与感: 如 表3 所示,MemGPT 能够编写有吸引力的 opener,其表现与人工编写的 opener 相近,有时甚至超过后者。 我们观察到,与人工基线相比,MemGPT 往往会编写更冗长、覆盖更多 persona 信息方面的 opener。 此外,我们可以看到,把信息存储在工作上下文中是生成有吸引力 opener 的关键。
3.2. MemGPT for document analysis
Document analysis also faces challenges due to the limited context windows of today's transformer models. As shown in Table 1, both open and closed source models suffer from constrained context length (up to 128k tokens for OpenAI's models). However many documents easily surpass these lengths; for example, legal or financial documents such as Annual Reports (SEC Form 10-K) can easily pass the million token mark. Moreover, many real document analysis tasks require drawing connections across multiple such lengthy documents. Anticipating these scenarios, it becomes difficult to envision blindly scaling up context as a solution to the fixed-context problem. Recent research (Liu et al., 2023a) also raises doubts about the utility of simply scaling contexts, since they find uneven attention distributions in large context models (the model is more capable of recalling information at the beginning or end of its context window, vs tokens in the middle). To enable reasoning across documents, more flexible memory architectures like MemGPT are needed.
由于当今 Transformer 模型上下文窗口有限,文档分析同样面临挑战。 如 表1 所示,开源和闭源模型都受到上下文长度约束(OpenAI 模型最高可达 128k tokens)。 然而,许多文档很容易超过这些长度;例如,年度报告(SEC Form 10-K)等法律或金融文档很容易超过百万 token。 此外,许多真实文档分析任务需要跨多个这样的长文档建立联系。 面对这些场景,很难想象盲目扩大上下文能够解决固定上下文问题。 近期研究(Liu 等,2023a)也质疑了单纯扩展上下文的效用,因为它们发现长上下文模型中的注意力分布并不均匀(相比中间 token,模型更擅长回忆上下文窗口开头或结尾的信息)。 为了实现跨文档推理,需要像 MemGPT 这样更灵活的记忆架构。

Multi-document question-answering.
To evaluate MemGPT's ability to analyze documents, we benchmark MemGPT against fixed-context baselines on the retriever-reader document QA task from Liu et al. (2023a). In this task, a question is selected from the NaturalQuestions-Open dataset, and a retriever selects relevant Wikipedia documents for the question. A reader model (the LLM) is then fed these documents as input, and is asked to use the provided documents to answer the question. Similar to Liu et al. (2023a), we evaluate reader accuracy as the number of retrieved documents
为了评估 MemGPT 分析文档的能力,我们在 Liu 等(2023a)的 retriever-reader 文档 QA 任务上将 MemGPT 与固定上下文基线进行比较。 在该任务中,一个问题从 NaturalQuestions-Open 数据集中选出,检索器会为该问题选择相关 Wikipedia 文档。 随后,这些文档会作为输入提供给读者模型(LLM),并要求它使用所提供文档回答问题。 与 Liu 等(2023a)类似,我们随着检索文档数量
In our evaluation setup, both the fixed-context baselines and MemGPT use the same retriever, which selects the top text-embedding-ada-002 embeddings. We use MemGPT's default storage settings which uses PostgreSQL for archival memory storage with vector search enabled via the pgvector extention. We pre-compute embeddings and load them into the database, which uses an HNSW index to enable approximate, sub-second query times. In MemGPT, the entire embedding document set is loaded into archival storage, and the retriever naturally emerges via the archival storage search functionality (which performs vector search based on cosine similarity). In the fixed-context baselines, the top-
在我们的评估设置中,固定上下文基线和 MemGPT 都使用同一个检索器,该检索器根据 OpenAI text-embedding-ada-002 嵌入上的相似度搜索(余弦距离)选择前
We use a dump of Wikipedia from late 2018, following past work on NaturalQuestions-Open (Izacard and Grave, 2020; Izacard et al., 2021), and sampled a subset of 50 questions for evaluation. Both the sampled questions and embedded Wikipedia passages are publicaly released. We evaluate the performance of both MemGPT and baselines with an LLM-judge, to ensure that the the answer is properly derived from the retrieved documents and to avoid non-exact string matches being considered incorrect.
我们沿用 NaturalQuestions-Open 先前工作的做法(Izacard 和 Grave,2020;Izacard 等,2021),使用 2018 年末的 Wikipedia dump,并采样了 50 个问题子集用于评估。 采样的问题和嵌入后的 Wikipedia 段落均已公开发布。 我们使用 LLM-judge 评估 MemGPT 和基线的性能,以确保答案确实来自检索到的文档,并避免把非精确字符串匹配误判为错误。
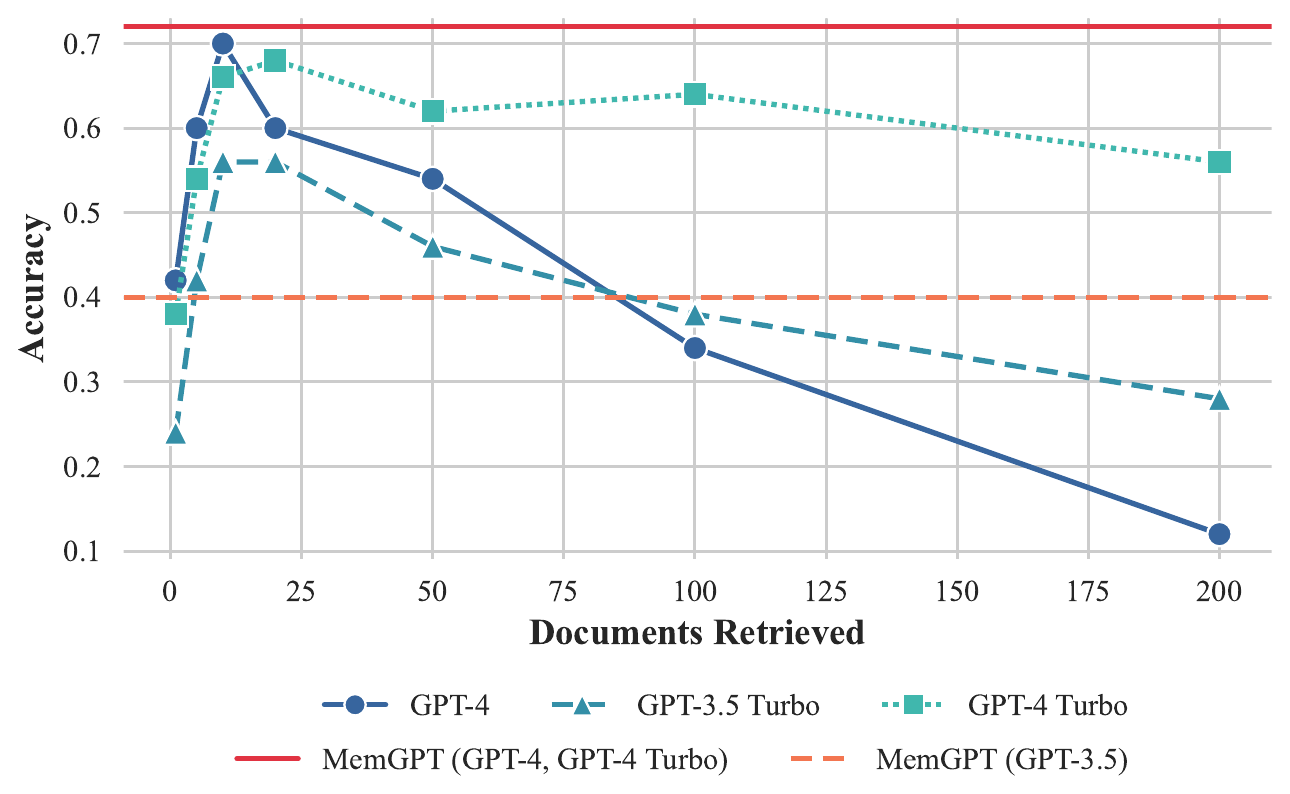
We show the results for the document QA task in Figure 5. The fixed-context baselines performance is capped roughly at the performance of the retriever, as they use the information that is presented in their context window (e.g. if the embedding search retriever fails to surface the gold article using the provided question, the fixed-context baselines are guaranteed to never see the gold article). By contrast, MemGPT is effectively able to make multiple calls to the retriever by querying archival storage, allowing it to scale to larger effective context lengths. MemGPT actively retrieves documents from its archival storage (and can iteratively page through results), so the total number of documents available to MemGPT is no longer limited by the number of documents that fit within the LLM processor's context window.
我们在 图5 中展示文档 QA 任务结果。 固定上下文基线的性能大致受检索器性能上限约束,因为它们只使用呈现在其上下文窗口中的信息(例如,如果嵌入搜索检索器未能根据给定问题返回 gold article,那么固定上下文基线必然永远看不到该 gold article)。 相比之下,MemGPT 能够通过查询归档存储有效地多次调用检索器,从而扩展到更大的有效上下文长度。 MemGPT 会主动从其归档存储中检索文档(并且可以迭代翻页浏览结果),因此 MemGPT 可用的文档总数不再受限于 LLM 处理器上下文窗口能够容纳的文档数量。
The document QA task is challenging for all methods due to the limitations of embedding-based similarity search. We observe that the golden document for chosen question (as annotated by NaturalQuestions-Open) often appears outside of the first dozen retrieved results, if not even further. The retriever performance translates directly to the fixed-context baseline results: GPT-4's accuracy is relatively low with few retrieved documents, and continues to improve as additional documents are added to the context window, as it correctly limits itself to answering questions based on information in retrieved documents. While MemGPT is theoretically not limited by sub-optimal retriever performance (even if the embedding-based ranking is noisy, as long as the full retriever ranking contains the gold document it can still be found with enough retriever calls via pagination), we observe that MemGPT will often stop paging through retriever results before exhausting the retriever database.
由于基于嵌入的相似度搜索存在局限,文档 QA 任务对所有方法都具有挑战性。 我们观察到,所选问题的 golden document(由 NaturalQuestions-Open 标注)经常出现在前十几个检索结果之外,甚至更靠后。 检索器性能会直接反映到固定上下文基线结果中:当检索文档很少时,GPT-4 的准确率相对较低;随着更多文档被加入上下文窗口,其准确率持续提升,因为它会正确地限制自己基于检索文档中的信息回答问题。 虽然理论上 MemGPT 不受次优检索器性能限制(即使基于嵌入的排序有噪声,只要完整检索排序包含 gold document,就仍可通过足够多次分页检索调用找到它),但我们观察到 MemGPT 往往会在耗尽检索器数据库之前停止翻页浏览检索结果。

831..ea5 → 5b8..4c3 → f37...617。当对最终值(f37...617)的查询只返回一个结果时,MemGPT 智能体会返回最终答案,这表明它不再同时也是一个 key。To evaluate the fixed-context baselines against MemGPT past their default context lengths, we truncate the document segments returned by the retriever to fix the same number of documents into the available context. As expected, document truncation reduces accuracy as documents shrink as the chance of the relevant snippet (in the gold document) being omitted grows, as shown in Figure 5. MemGPT has significantly degraded performance using GPT-3.5, due to its limited function calling capabilities, and performs best using GPT-4.
为了在超过默认上下文长度后将固定上下文基线与 MemGPT 比较,我们截断检索器返回的文档片段,使相同数量的文档能够放入可用上下文。 如预期所示,随着文档被缩短,gold document 中相关片段被省略的概率增大,因此文档截断会降低准确率,如 图5 所示。 由于 GPT-3.5 的函数调用能力有限,使用 GPT-3.5 的 MemGPT 性能显著下降,而使用 GPT-4 的 MemGPT 表现最好。
Nested key-value retrieval (KV).
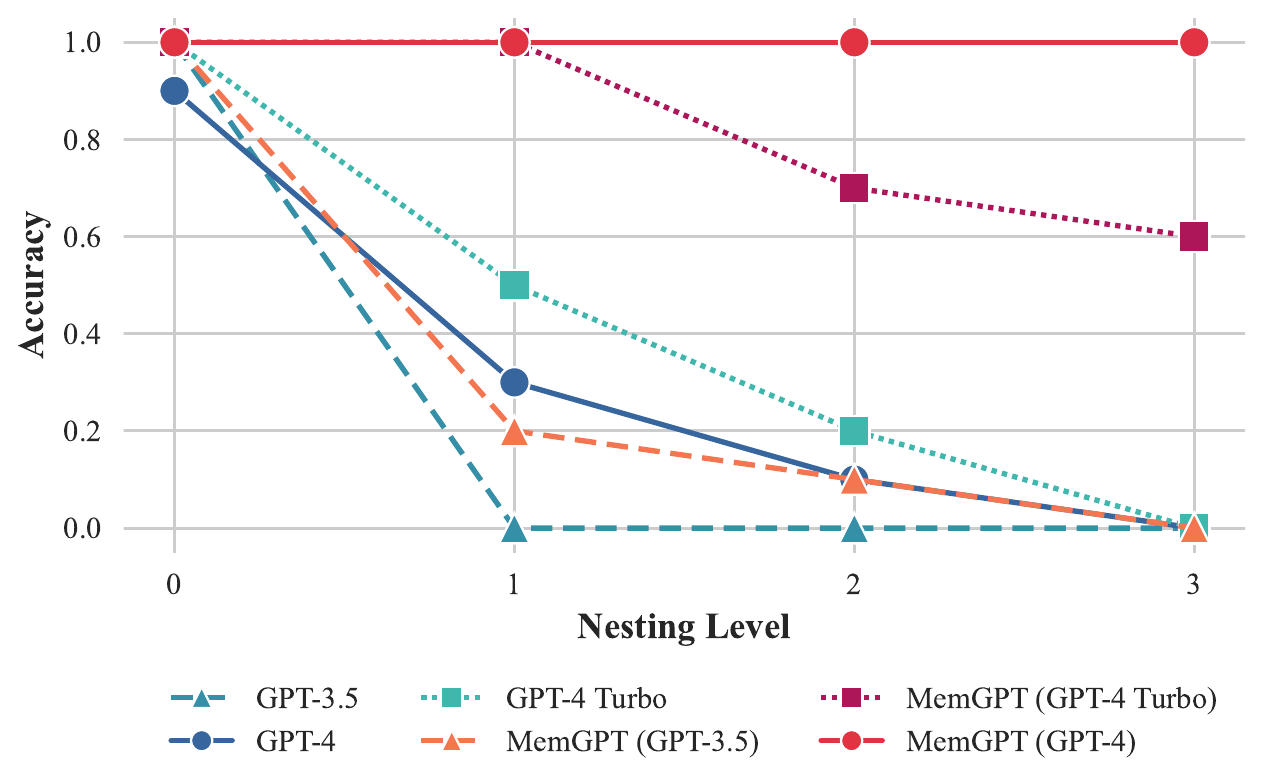
We introduce a new task based on the synthetic Key-Value retrieval proposed in prior work (Liu et al., 2023a). The goal of this task is to demonstrate how MemGPT can collate information from multiple data sources. In the original KV task, the authors generated a synthetic dataset of key-value pairs, where each key and value is a 128-bit UUID (universally unique identifier). The agent is then given a key, and asked to return the associated value for the key. We create a version of the KV task, nested KV retrieval, where values themselves may be keys, thus requiring the agent to perform a multi-hop lookup. In our setup, we fix the total number of UUIDs pairs to 140, corresponding to roughly 8k tokens (the context length of our GPT-4 baseline). We vary the total number of nesting levels from 0 (the initial key-value pair's value is not a key) to 4 (ie 4 total KV lookups are required to find the final value), and sample 30 different ordering configurations including both the initial key position and nesting key positions.
我们基于先前工作(Liu 等,2023a)提出的合成 Key-Value 检索,引入一个新任务。 该任务的目标是展示 MemGPT 如何从多个数据源汇总信息。 在原始 KV 任务中,作者生成了一个合成键值对数据集,其中每个 key 和 value 都是一个 128 位 UUID(universally unique identifier)。 随后,智能体会被给定一个 key,并被要求返回该 key 关联的 value。 我们创建了一个 KV 任务变体,即 nested KV retrieval,其中 value 本身也可能是 key,因此要求智能体执行多跳查找。 在我们的设置中,UUID 对总数固定为 140,大约对应 8k tokens(即 GPT-4 基线的上下文长度)。 我们将总嵌套层数从 0(初始键值对的 value 不是 key)变化到 4(即需要总共 4 次 KV 查找才能找到最终值),并采样 30 种不同排序配置,其中包括初始 key 位置和嵌套 key 位置。
While GPT-3.5 and GPT-4 have good performance on the original KV tasks, both struggle in the nested KV task. GPT-3.5 is unable to complete the nested variant of the task and has an immediate dropoff in performance, hitting 0 percent accuracy at 1 nesting level (we observe that its primary failure mode is to simply returns the original value). GPT-4 and GPT-4 Turbo are better than GPT-3.5, but also suffer from a similar dropoff, and hit 0 percent accuracy by 3 nesting levels. MemGPT with GPT-4 on the other hand is unaffected with the number of nesting levels and is able to perform the nested lookup by accessing the key-value pairs stored in main context repeatedly via function queries. MemGPT with GPT-4 Turbo and GPT-3.5 also have better performance than the corresponding baseline models, but still begin to drop off in performance at 2 nesting levels as a result of failing to perform enough lookups. MemGPT performance on the nested KV task demonstrates its ability to combine multiple queries to perform multi-hop lookups.
虽然 GPT-3.5 和 GPT-4 在原始 KV 任务上表现良好,但二者在 nested KV 任务中都遇到困难。 GPT-3.5 无法完成该任务的嵌套变体,并且性能立即下降,在 1 层嵌套时准确率降至 0%(我们观察到它的主要失败模式是简单返回原始 value)。 GPT-4 和 GPT-4 Turbo 优于 GPT-3.5,但也出现类似下降,并在 3 层嵌套时准确率降至 0%。 另一方面,使用 GPT-4 的 MemGPT 不受嵌套层数影响,并能够通过函数查询反复访问存储在主上下文中的键值对来执行嵌套查找。 使用 GPT-4 Turbo 和 GPT-3.5 的 MemGPT 也优于相应基线模型,但由于未能执行足够多次查找,在 2 层嵌套时性能仍开始下降。 MemGPT 在 nested KV 任务上的表现展示了它组合多个查询以执行多跳查找的能力。
4. Related Work
Long-context LLMs. Several lines of work have improved the context length of LLMs. For instance, more efficient transformer architectures via sparsifying the attention (Child et al., 2019; Beltagy et al., 2020), low-rank approximations (Wang et al., 2020), and neural memory (Lee et al., 2019). Another line of work aims to extend context windows beyond the length they were original trained for, their training size, such as ALiBi and position interpolation methods (Press et al., 2022; Chen et al., 2023). MemGPT builds upon these improvements in context length as they improve the size of the main memory in MemGPT. Our main contribution is a hierarchical tiered memory that uses a long-context LLM as the implementation of main memory.
长上下文 LLM。 多条研究路线已经改进了 LLM 的上下文长度。 例如,通过稀疏化注意力(Child 等,2019;Beltagy 等,2020)、低秩近似(Wang 等,2020)和神经记忆(Lee 等,2019)来构建更高效的 Transformer 架构。 另一条研究路线旨在把上下文窗口扩展到超出模型原始训练长度(即训练规模)的范围,例如 ALiBi 和位置插值方法(Press 等,2022;Chen 等,2023)。 MemGPT 建立在这些上下文长度改进之上,因为它们提升了 MemGPT 中主内存的大小。 我们的主要贡献是一种分层层级记忆,它使用长上下文 LLM 作为主内存的实现。
Retrieval-Augmented Models. The design of the external memory of MemGPT builds upon much prior work augmenting LLMs with relevant inputs from external retrievers (Ram et al., 2023; Borgeaud et al., 2022; Karpukhin et al., 2020; Lewis et al., 2020; Guu et al., 2020; Sarthi et al., 2023). In particular, Jiang et al. (2023) propose FLARE, a method that allows the LLM to actively decide when and what to retrieve during the course of generation. Trivedi et al. (2022) interleave retrieval with Chain-of-Thoughts reasoning to improve multi-step question answering.
检索增强模型。 MemGPT 外部记忆的设计建立在许多先前工作之上,这些工作使用来自外部检索器的相关输入来增强 LLM(Ram 等,2023;Borgeaud 等,2022;Karpukhin 等,2020;Lewis 等,2020;Guu 等,2020;Sarthi 等,2023)。 特别地,Jiang 等(2023)提出了 FLARE,一种允许 LLM 在生成过程中主动决定何时检索以及检索什么的方法。 Trivedi 等(2022)将检索与 Chain-of-Thoughts 推理交错起来,以改进多步问答。
LLMs as agents. Recent work has explored augmenting LLMs with additional capabilities to act as agents in interactive environments. Park et al. (2023) propose adding memory to LLMs and using the LLM as a planner, and observe emergent social behaviors in a multi-agent sandbox environment (inspired by The Sims video game) where agents can perform basic activities such as doing chores/hobbies, going to work, and conversing with other agents. Nakano et al. (2021) train models to search the web before answering questions, and use similar pagination concepts to MemGPT to control the underlying context size in their web-browsing environment. Yao et al. (2022) showed that interleaving chain-of-thought reasoning (Wei et al., 2022) can further improve the planning ability of interactive LLM-based agents; similarly in MemGPT, LLM is able to "plan out loud" when executing functions. Liu et al. (2023b) introduced a suite of LLM-as-an-agent benchmarks to evaluate LLMs in interactive environments, including video games, thinking puzzles, and web shopping. In contrast, our work focuses on tackling the problem of equipping agents with long-term memory of user inputs.
作为智能体的 LLM。 近期工作探索了为 LLM 增加额外能力,使其能够在交互式环境中充当智能体。 Park 等(2023)提出为 LLM 添加记忆并将 LLM 用作规划器,并在一个多智能体沙盒环境中观察到涌现的社会行为;该环境受到 The Sims 游戏启发,智能体可以执行做家务/爱好、上班和与其他智能体交谈等基本活动。 Nakano 等(2021)训练模型在回答问题之前搜索网页,并使用与 MemGPT 类似的分页概念来控制其网页浏览环境中的底层上下文大小。 Yao 等(2022)表明,交错 chain-of-thought 推理(Wei 等,2022)可以进一步提升交互式 LLM 智能体的规划能力;类似地,在 MemGPT 中,LLM 能够在执行函数时 "plan out loud"。 Liu 等(2023b)引入了一套 LLM-as-an-agent 基准,用于评估 LLM 在交互式环境中的表现,包括电子游戏、思维谜题和网页购物。 相比之下,我们的工作聚焦于解决为智能体配备用户输入长期记忆的问题。
5. Conclusion
In this paper, we introduced MemGPT, a novel LLM system inspired by operating systems to manage the limited context windows of large language models. By designing a memory hierarchy and control flow analogous to traditional OSes, MemGPT provides the illusion of larger context resources for LLMs. This OS-inspired approach was evaluated in two domains where existing LLM performance is constrained by finite context lengths: document analysis and conversational agents. For document analysis, MemGPT could process lengthy texts well beyond the context limits of current LLMs by effectively paging relevant context in and out of memory. For conversational agents, MemGPT enabled maintaining long-term memory, consistency, and evolvability over extended dialogues. Overall, MemGPT demonstrates that operating system techniques like hierarchical memory management and interrupts can unlock the potential of LLMs even when constrained by fixed context lengths. This work opens numerous avenues for future exploration, including applying MemGPT to other domains with massive or unbounded contexts, integrating different memory tier technologies like databases or caches, and further improving control flow and memory management policies. By bridging concepts from OS architecture into AI systems, MemGPT represents a promising new direction for maximizing the capabilities of LLMs within their fundamental limits.
本文介绍了 MemGPT,一个受操作系统启发的新型 LLM 系统,用于管理大型语言模型有限的上下文窗口。 通过设计类似传统操作系统的内存层次结构和控制流,MemGPT 为 LLM 提供了更大上下文资源的假象。 这种受操作系统启发的方法在两个现有 LLM 性能受有限上下文长度约束的领域中进行了评估:文档分析和对话智能体。 对于文档分析,MemGPT 能够通过有效地将相关上下文分页换入换出记忆,处理远超当前 LLM 上下文限制的长文本。 对于对话智能体,MemGPT 使其能够在长时间对话中保持长期记忆、一致性和可演化性。 总体而言,MemGPT 表明,即使受到固定上下文长度约束,分层内存管理和中断等操作系统技术也能够释放 LLM 的潜力。 这项工作为未来探索开辟了许多方向,包括将 MemGPT 应用于具有海量或无界上下文的其他领域,集成数据库或缓存等不同记忆层技术,以及进一步改进控制流和记忆管理策略。 通过把操作系统架构中的概念引入 AI 系统,MemGPT 代表了一条有前景的新方向,可在 LLM 的根本限制内最大化其能力。