
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
arXiv 2026Agent Memoryhttps://arxiv.org/abs/2602.02474
https://github.com/ViktorAxelsen/MemSkill
MemSkill:为自进化智能体学习和演化记忆技能
Abstract
Most Large Language Model (LLM) agent memory systems rely on a small set of static, hand-designed operations for extracting memory. These fixed procedures hard-code human priors about what to store and how to revise memory, making them rigid under diverse interaction patterns and inefficient on long histories. To this end, we present MemSkill, which reframes these operations as learnable and evolvable memory skills, structured and reusable routines for extracting, consolidating, and pruning information from interaction traces. Inspired by the design philosophy of agent skills, MemSkill employs a controller that learns to select a small set of relevant skills, paired with an LLM-based executor that produces skill-guided memories. Beyond learning skill selection, MemSkill introduces a designer that periodically reviews hard cases where selected skills yield incorrect or incomplete memories, and evolves the skill set by proposing refinements and new skills. Together, MemSkill forms a closed-loop procedure that improves both the skill-selection policy and the skill set itself. Experiments on LoCoMo, LongMemEval, HotpotQA, and ALFWorld demonstrate that MemSkill improves task performance over strong baselines and generalizes well across settings. Further analyses shed light on how skills evolve, offering insights toward more adaptive, self-evolving memory management for LLM agents.
大多数大语言模型(LLM)智能体记忆系统依赖少量静态、人工设计的操作来抽取记忆。 这些固定流程把人类关于“该存什么、如何修改记忆”的先验硬编码进去,使其在多样交互模式下僵硬,并且在长历史上效率较低。 为此,作者提出 MemSkill,它把这些操作重新表述为可学习、可演化的记忆技能,也就是用于从交互轨迹中抽取、整合和剪枝信息的结构化可复用例程。 受智能体技能设计哲学启发,MemSkill 使用一个会学习选择少量相关技能的控制器,并搭配一个基于 LLM 的执行器来生成技能引导的记忆。 除了学习技能选择之外,MemSkill 还引入一个设计器,定期审查所选技能产生错误或不完整记忆的困难案例,并通过提出细化和新技能来演化技能集合。 整体而言,MemSkill 形成了一个闭环过程,同时改进技能选择策略和技能集合本身。 在 LoCoMo、LongMemEval、HotpotQA 和 ALFWorld 上的实验表明,MemSkill 相比强基线能提升任务表现,并且能很好地跨场景泛化。 进一步分析揭示了技能如何演化,为更自适应、自进化的 LLM 智能体记忆管理提供了启发。
1. Introduction
As Large Language Model (LLM) agents engage in longer, open-ended interactions, they must handle growing histories that are essential yet challenging to leverage, motivating memory for retaining experience and maintaining coherence. This need has driven rapid progress in agent memory, including approaches that summarize and retrieve past interactions or manage external memory stores. However, most methods still rely on static, hand-designed memory mechanisms, including fixed operation primitives (e.g., add/update/delete/skip) and heuristic modules that govern what to store, how to revise it, and when to prune it. Such designs bake in strong human assumptions and often suffer under diverse interaction patterns, scaling poorly as histories grow.
随着大语言模型(LLM)智能体参与更长、更开放的交互,它们必须处理不断增长的历史;这些历史至关重要,却又很难充分利用,因此需要记忆来保留经验并维持连贯性。 这一需求推动了智能体记忆的快速发展,包括总结和检索过去交互,或管理外部记忆存储的方法。 然而,大多数方法仍依赖静态、人工设计的记忆机制,包括固定操作原语(例如 add/update/delete/skip),以及决定存什么、如何修改、何时剪枝的启发式模块。 这类设计嵌入了很强的人类假设,在多样交互模式下往往表现不佳,并且随着历史增长扩展性较差。
We argue that this formulation fundamentally limits the adaptability of agent memory. Rather than treating memory as the output of fixed operations or hand-designed modules, we propose to elevate memory extraction itself into a learnable abstraction. Concretely, we view memory construction as the outcome of applying a small set of generic, reusable memory skills: structured behaviors that specify when and how interaction traces should be transformed into memory and revised over time. This perspective reveals a key bottleneck of prior pipelines: they hard-code memory behaviors into fixed procedural workflows that interleave heuristics with LLM-mediated extraction and revision, making them brittle under distribution shift.
作者认为,这种表述从根本上限制了智能体记忆的适应性。 与其把记忆看成固定操作或人工设计模块的输出,作者提出应将记忆抽取本身提升为一种可学习抽象。 具体而言,作者把记忆构建看成应用少量通用、可复用记忆技能的结果:这些结构化行为规定了何时以及如何把交互轨迹转化为记忆,并随时间进行修改。 这一视角揭示了既有流程的一个关键瓶颈:它们把记忆行为硬编码进固定过程式工作流,在其中交织启发式规则与 LLM 介导的抽取和修改,因此在分布转移下很脆弱。
Under this view, an ideal agent memory system should satisfy three properties. (i) Minimal reliance on human priors. Instead of manually encoding what is worth remembering for a domain, memory behaviors should be shaped by interaction data and updated as task demands evolve. (ii) Support for larger extraction granularity. Many approaches are tuned to a fixed unit, such as per-turn processing, and can weaken when applied to longer spans. A practical system should be able to operate at larger extraction granularity when needed. (iii) Skill-conditioned, compositional memory construction. Existing systems often decompose memory construction into specialized modules. In contrast, we prefer to select and compose a small set of relevant skills for the current context and apply them in one generation step, enabling flexible reuse and evolution of memory behaviors.
在这一视角下,一个理想的智能体记忆系统应满足三个性质。 (i)尽量少依赖人类先验。 记忆行为不应手工编码某个领域中什么值得记住,而应由交互数据塑造,并随着任务需求演化而更新。 (ii)支持更大的抽取粒度。 许多方法被调到固定单位上,例如逐轮处理;当应用到更长跨度时,它们可能变弱。 实用系统应能在需要时以更大的抽取粒度运行。 (iii)技能条件化、组合式的记忆构建。 现有系统通常把记忆构建拆解为专门模块。 相比之下,作者倾向于为当前上下文选择并组合少量相关技能,并在一次生成步骤中应用它们,从而让记忆行为可以灵活复用和演化。
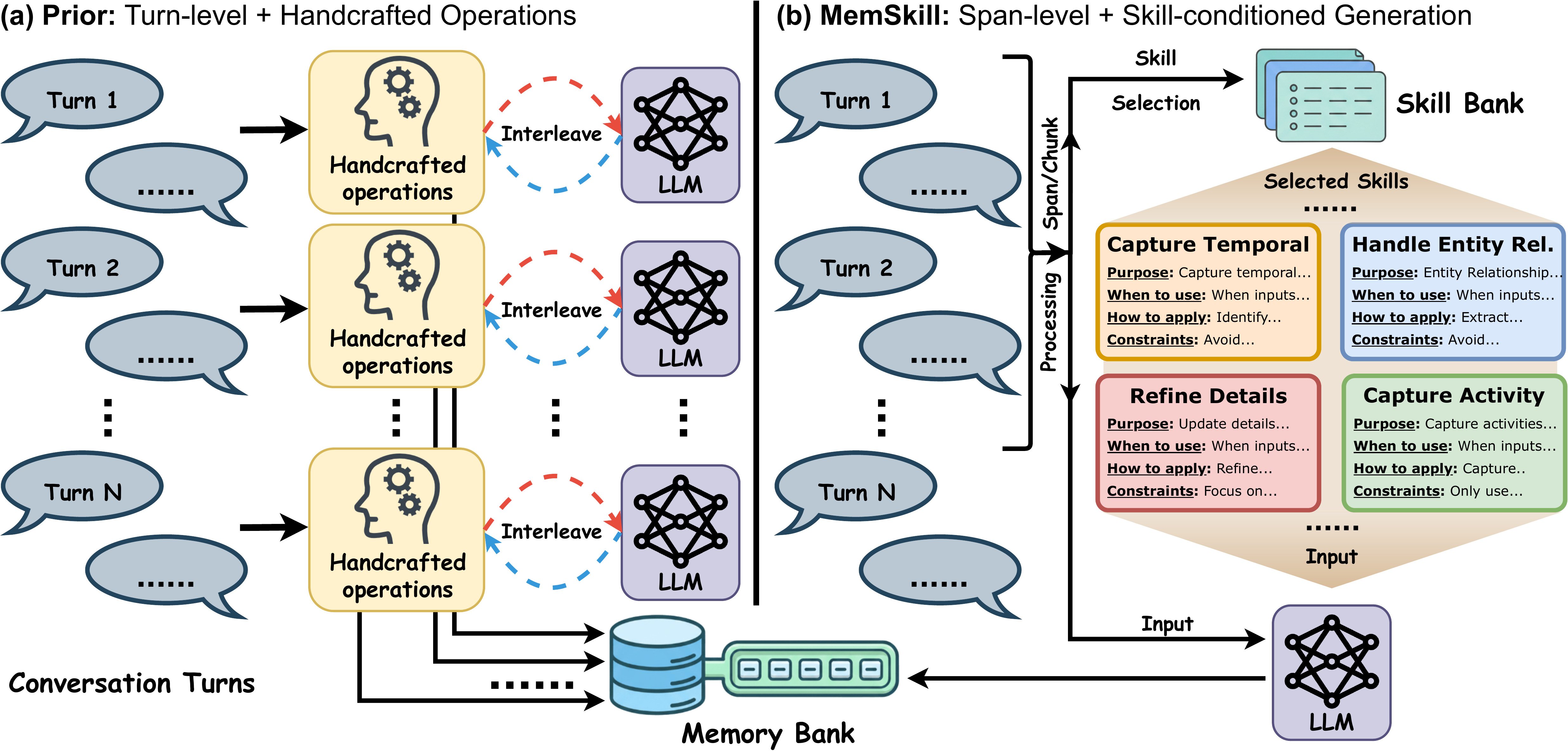
Based on the above observations, we introduce MemSkill, which reframes memory operations as a learnable and evolvable set of memory skills. MemSkill maintains a shared skill bank, where each skill captures a reusable way to extract, consolidate, or revise memories from interaction text (Figure 1 shows the structured template of a memory skill). Given the current context, a controller learns to select a small set of relevant skills, and an LLM-based executor conditions on these skills to generate skill-guided memories in one pass. This skill-conditioned formulation is not tied to a fixed extraction unit and can be applied to different span lengths when processing long interaction histories.
基于以上观察,作者提出 MemSkill,它把记忆操作重新表述为一组可学习、可演化的记忆技能。 MemSkill 维护一个共享的技能库,其中每个技能都刻画了一种可复用方式,用于从交互文本中抽取、整合或修改记忆(图1 展示了记忆技能的结构化模板)。 给定当前上下文,控制器会学习选择少量相关技能,而基于 LLM 的执行器以这些技能为条件,一次性生成技能引导的记忆。 这种技能条件化表述不绑定固定抽取单位,在处理长交互历史时可以应用到不同跨度长度。
Crucially, MemSkill goes beyond learning how to use a fixed set of skills. We introduce a closed-loop evolution process that alternates between learning to use the current skill bank and evolving the skill bank itself. Specifically, we train the controller with reinforcement learning (RL) using downstream task signals as feedback for skill selection. Periodically, a designer aggregates the hardest cases produced during training, selects representative failures, and uses an LLM to refine existing skills and propose new ones. After each evolution step, the controller continues training on the evolved skill bank, with additional exploration to facilitate adopting newly introduced skills. Overall, this process gradually strengthens both the skill selection policy and the evolving skill bank, moving toward a more adaptive memory management system driven by interaction data.
关键的是,MemSkill 不只是学习如何使用一组固定技能。 作者引入一个闭环演化过程,在学习使用当前技能库和演化技能库本身之间交替进行。 具体而言,作者使用强化学习(RL)训练控制器,并把下游任务信号作为技能选择的反馈。 周期性地,设计器会聚合训练中产生的最难案例,选择代表性失败,并使用 LLM 细化现有技能、提出新技能。 每次演化步骤后,控制器会在演化后的技能库上继续训练,并增加额外探索以促进新引入技能的采用。 总体而言,这一过程逐渐增强技能选择策略和演化中的技能库,迈向由交互数据驱动的更自适应记忆管理系统。
Experiments on LoCoMo, LongMemEval, HotpotQA, and ALFWorld show that MemSkill consistently improves task performance and generalizes well. Further analyses validate key components and showcase representative evolved skills, offering insights toward more adaptive, self-evolving memory management for LLM agents.
在 LoCoMo、LongMemEval、HotpotQA 和 ALFWorld 上的实验表明,MemSkill 持续提升任务表现,并具有良好泛化性。 进一步分析验证了关键组件,并展示了代表性的演化技能,为更自适应、自进化的 LLM 智能体记忆管理提供了启发。
Our contributions can be summarized as follows.
- We propose MemSkill, an agent memory method that represents memory operations as an evolving skill bank, where each skill provides reusable guidance for selecting, extracting, and organizing useful memories. This turns memory construction from a fixed handcrafted pipeline into an adaptive skill-conditioned generation process.
- We introduce a closed-loop optimization recipe that combines reinforcement learning for skill selection with LLM-guided skill evolution from hard cases, enabling continual refinement of the skill bank and taking a step toward self-evolving agent memory systems.
- We evaluate MemSkill on LoCoMo, LongMemEval, HotpotQA, and ALFWorld, demonstrating consistent gains and strong transfer ability across conversational QA and embodied interaction settings, offering insights for self-evolving memory in LLM agents.
本文贡献可以概括如下。
- 作者提出 MemSkill,一种智能体记忆方法,把记忆操作表示为演化技能库,其中每个技能都为选择、抽取和组织有用记忆提供可复用指导。这将记忆构建从固定手工流程转变为自适应的技能条件化生成过程。
- 作者提出一种闭环优化方案,将用于技能选择的强化学习与来自困难案例的 LLM 引导技能演化结合起来,使技能库能够持续细化,并朝自进化智能体记忆系统迈进一步。
- 作者在 LoCoMo、LongMemEval、HotpotQA 和 ALFWorld 上评估 MemSkill,展示了它在对话 QA 和具身交互场景中的稳定收益与强迁移能力,为 LLM 智能体中的自进化记忆提供了启发。
2. Related Work
2.1. LLM Agent Memory Systems
Prior work on agent memory focuses on constructing external memories from interaction histories and leveraging them to support downstream reasoning and decision making. Typical pipelines periodically extract salient information into a memory store, retrieve relevant entries for a new query, and update the store via consolidation or pruning. More recently, learning-based approaches such as Memory-R1 and Mem-
关于智能体记忆的已有工作主要关注从交互历史中构建外部记忆,并利用它们支持下游推理和决策。 典型流程会周期性地把显著信息抽取到记忆存储中,为新查询检索相关条目,并通过整合或剪枝更新存储。 更近一些,Memory-R1 和 Mem-
Several concurrent works also explore self-evolving memory in agent settings, but differ from our focus. Evo-Memory evaluates streaming memory evolution, MemEvolve optimizes predefined memory architectures, MemGen targets latent memory for reasoning, and ReasoningBank distills reasoning strategies from experience. By contrast, we target the evolution of memory skills themselves, enabling the system to refine and grow reusable memory operations over time.
一些同期工作也在智能体场景中探索自进化记忆,但关注点与本文不同。 Evo-Memory 评估流式记忆演化,MemEvolve 优化预定义记忆架构,MemGen 面向推理中的潜在记忆,ReasoningBank 则从经验中蒸馏推理策略。 相比之下,本文关注记忆技能本身的演化,使系统能够随时间细化并扩展可复用记忆操作。
2.2. Self-Evolving LLM Agents
Recent work on self-evolving LLM agents studies how agents can improve from interaction experience with minimal manual supervision. ExpeL distills trajectories into editable natural-language insights and retrieves relevant experiences to guide future decisions, while EvolveR formalizes an experience lifecycle that consolidates interactions into reusable principles and closes the loop with reinforcement learning updates. A complementary line reduces reliance on curated data via self-play style curricula: Absolute Zero Reasoner trains a proposer and solver with verifiable rewards from a code executor, and Multi-Agent Evolve extends this to a proposer solver judge triad with LLM-based evaluation; R-Zero follows a similar challenger solver co-evolution pattern. Beyond curricula, systems such as AgentEvolver and RAGEN study efficient agent learning dynamics and stabilization in multi-turn RL settings, while ADAS and AlphaEvolve explore automated discovery and evolutionary improvement of agent designs. Finally, SkillWeaver shows that agents can discover and refine reusable skills for web interaction. In contrast, our focus is on self-evolving memory skills that govern how agents construct and revise memories over time.
近期关于自进化 LLM 智能体的工作研究智能体如何在最少人工监督下从交互经验中改进。 ExpeL 将轨迹蒸馏成可编辑的自然语言洞见,并检索相关经验来指导未来决策;EvolveR 则形式化了一个经验生命周期,把交互整合成可复用原则,并通过强化学习更新闭合循环。 另一条互补路线通过自博弈式课程减少对人工整理数据的依赖:Absolute Zero Reasoner 使用代码执行器给出的可验证奖励训练 proposer 和 solver,Multi-Agent Evolve 将其扩展为带 LLM 评估的 proposer-solver-judge 三元组;R-Zero 也遵循类似的 challenger-solver 共演化模式。 在课程之外,AgentEvolver 和 RAGEN 等系统研究多轮 RL 场景中高效的智能体学习动态与稳定化,而 ADAS 和 AlphaEvolve 探索智能体设计的自动发现和演化式改进。 最后,SkillWeaver 表明智能体可以发现并细化用于网页交互的可复用技能。 与之不同,本文关注自进化的记忆技能,也就是支配智能体如何随时间构建和修改记忆的技能。
3. Method
In this section, we first provide an overview of MemSkill (Section 3.1), then detail the skill bank (Section 3.2) and the three core components (controller (Section 3.3), executor (Section 3.4), and designer (Section 3.5)), and finally summarize the closed-loop optimization procedure that alternates between learning to use the current skills and evolving the skill bank from hard cases (Section 3.6).
本节首先概述 MemSkill(第 3.1 节),然后介绍技能库(第 3.2 节)以及三个核心组件:控制器(第 3.3 节)、执行器(第 3.4 节)和设计器(第 3.5 节),最后总结在学习使用当前技能与从困难案例演化技能库之间交替进行的闭环优化过程(第 3.6 节)。
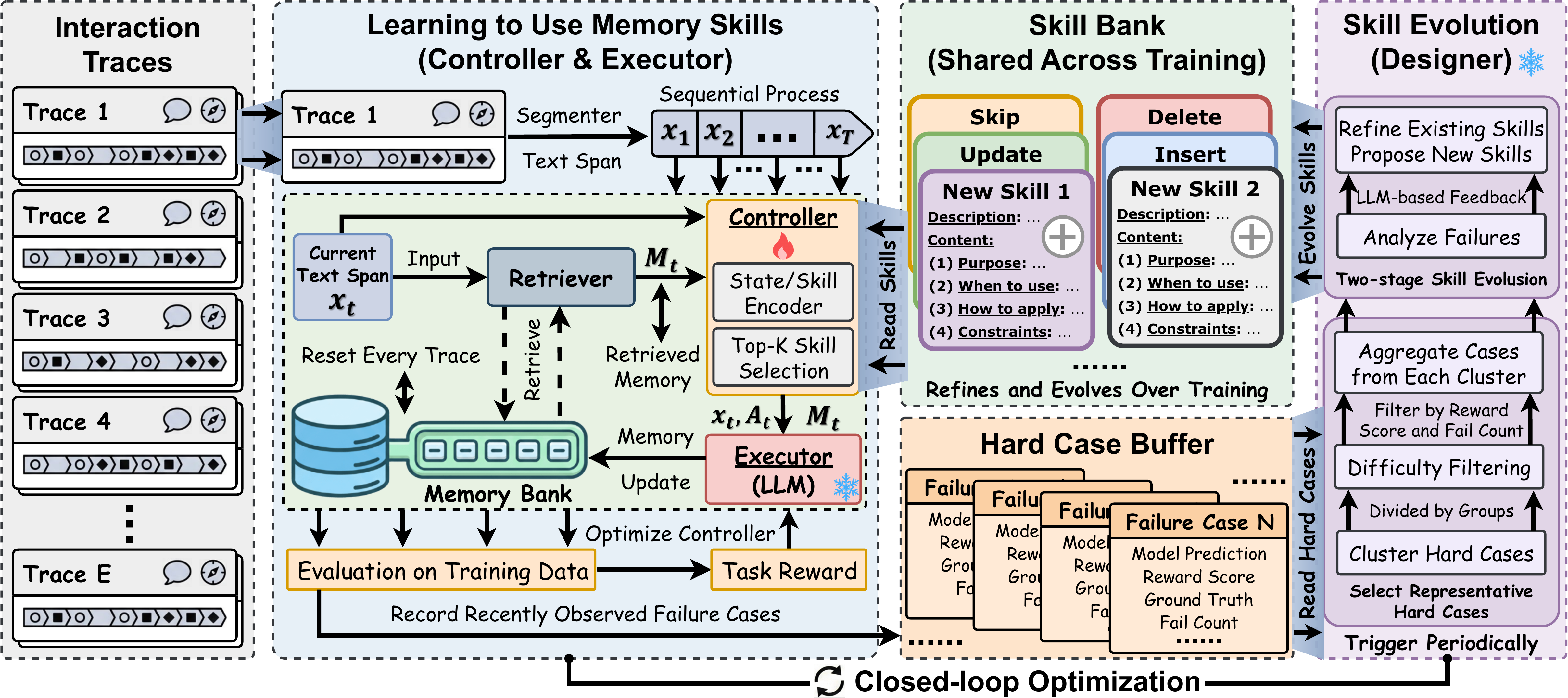
3.1. Overview
As shown in Figure 2, we propose MemSkill, which optimizes agent memory through two intertwined processes. First, it learns to use a given skill bank: a controller selects context-relevant skills, and an executor applies them to produce memory updates. Second, it improves the skill bank itself: a designer periodically revises existing skills and adds new ones based on challenging training cases.
如 图2 所示,作者提出 MemSkill,它通过两个交织过程优化智能体记忆。 第一,它学习使用给定技能库:控制器选择与上下文相关的技能,执行器应用这些技能来产生记忆更新。 第二,它改进技能库本身:设计器会基于具有挑战性的训练案例,周期性地修改现有技能并添加新技能。
To disentangle trace-specific memories from reusable memory management knowledge, MemSkill maintains two stores. The memory bank is trace-specific and stores memories for each training trace (e.g., a long dialogue). In contrast, the skill bank is shared across traces and contains reusable memory skills. During training, the controller and executor build each trace's memory bank, while the designer updates the shared skill bank between phases. This alternating procedure gradually improves both the skill selection policy and the skill bank for memory construction.
为了将轨迹特定记忆与可复用记忆管理知识解耦,MemSkill 维护两个存储。 记忆库是轨迹特定的,用来存储每条训练轨迹(例如一段长对话)的记忆。 相比之下,技能库在不同轨迹之间共享,包含可复用的记忆技能。 训练期间,控制器和执行器构建每条轨迹的记忆库,而设计器在不同阶段之间更新共享技能库。 这一交替过程会逐渐改进用于记忆构建的技能选择策略和技能库。
3.2. Skill Bank
As shown in Figure 2, a memory skill specifies a reusable memory operation as structured guidance, including when it is applicable and how it should be applied to the current context. Concretely, each skill
如 图2 所示,记忆技能以结构化指导的形式指定一种可复用记忆操作,包括它何时适用,以及应如何应用到当前上下文。 具体而言,每个技能
We start from a minimal set of general-purpose primitives to ensure a stable and functional initialization. Specifically, we initialize the skill bank with four basic skills corresponding to canonical memory operations: Insert, Update, Delete, and Skip. Starting from this minimal set, the designer progressively refines existing skills and expands the bank by proposing new skills that address uncovered failure modes. Appendix details skill description.
作者从最小的一组通用原语开始,以保证稳定且可用的初始化。 具体而言,作者使用对应经典记忆操作的四个基础技能初始化技能库:Insert、Update、Delete 和 Skip。 从这一最小集合出发,设计器会逐步细化现有技能,并通过提出解决未覆盖失败模式的新技能来扩展技能库。 技能描述的细节见附录。
3.3. Learning to Use Memory Skills
In this part, we describe how MemSkill learns to use memory skills, covering (i) the skill-selection policy and (ii) skill-conditioned memory construction.
这一部分描述 MemSkill 如何学习使用记忆技能,包括(i)技能选择策略,以及(ii)技能条件化记忆构建。
Controller: Skill Selection Policy
To enable effective skill selection as the skill bank evolves, we introduce a controller that selects a small set of relevant memory skills for the current context. At each memory construction step, we update memory at the span level: we split each interaction trace (e.g., a dialogue) into fixed-length contiguous spans by token count and process them sequentially. For each span, the controller conditions its selection on (i) the current text span and (ii) the retrieved existing memories from the current trace's memory bank (empty for initial span), rather than operating turn by turn.
为了在技能库演化时仍能有效选择技能,作者引入一个控制器,为当前上下文选择少量相关记忆技能。 在每个记忆构建步骤中,作者在 span 层级更新记忆:按 token 数把每条交互轨迹(例如对话)切分成固定长度的连续 span,并依次处理。 对于每个 span,控制器不是逐轮操作,而是基于(i)当前文本 span,以及(ii)从当前轨迹记忆库中检索出的已有记忆(初始 span 为空)来进行选择。
To remain compatible with a variable-size skill bank as it continuously evolves, the controller scores each skill by measuring the semantic distance between the current state and skill representations, supporting a changing skill set while staying sensitive to what is already stored in memory.
为了在技能库持续演化且大小可变时仍保持兼容,控制器通过度量当前状态与技能表示之间的语义距离来给每个技能打分,从而既支持变化的技能集合,又对记忆中已经存储的内容保持敏感。
State and skill representations. Formally, let
状态和技能表示。 形式化地,令
where
其中
Compatibility with an evolving skill bank. Instead of producing a fixed-dimensional action head tied to a fixed number of skills, the controller concatenates the state representation with each candidate skill representation and applies a shared scorer to all such state-skill pairs in parallel:
与演化技能库兼容。 控制器不是产生一个绑定固定技能数量的固定维度动作头,而是将状态表示与每个候选技能表示拼接,并对所有这类状态-技能对并行应用一个共享打分器:
where
其中
Top-
Top-
Executor: Skill-Conditioned Memory Extraction
Given the selected skills
给定被选中的技能
Controller Optimization
We train the controller with reinforcement learning, using downstream task performance as feedback for its skill selections. For each training trace, the controller makes a sequence of Top-
作者使用强化学习训练控制器,并把下游任务表现作为其技能选择的反馈。 对于每条训练轨迹,控制器会做出一系列 Top-
A key technical detail is that the controller's action is an ordered Top-
一个关键技术细节是,控制器的动作不是单个离散动作,而是无放回选择出的有序 Top-
which reduces to the single-action case when
当
3.4. Skill Evolution through Designer Feedback
Beyond learning to select from a fixed set of skills, MemSkill evolves the skill bank using an LLM-based designer (fixed) that operates periodically during training.
除了学习从固定技能集合中选择技能之外,MemSkill 还使用一个基于 LLM 的固定设计器来演化技能库,该设计器会在训练期间周期性运行。
Hard-case buffer. During controller training, we maintain a sliding-window buffer of challenging cases observed recently. Each case is query-centric, recording the query along with its ground-truth and metadata (e.g., retrieved memories and model prediction), as well as summary statistics such as task performance and the number of failures observed so far. The buffer uses two expiration rules: cases are removed if they become too old (exceeding a maximum training step gap) or if the buffer reaches its capacity limit, which tracks recent failure patterns without growing unbounded.
困难案例缓冲区。 在控制器训练期间,作者维护一个滑动窗口缓冲区,存放最近观察到的具有挑战性的案例。 每个案例以查询为中心,记录查询及其真实答案和元数据(例如检索到的记忆和模型预测),以及任务表现和目前观察到的失败次数等汇总统计。 缓冲区使用两种过期规则:如果案例太旧(超过最大训练步间隔)或缓冲区达到容量上限,就会移除案例,从而在不无限增长的情况下跟踪近期失败模式。
Selecting representative hard cases. To focus designer updates on impactful failures, we cluster cases (e.g., KMeans) into groups that naturally reflect different query or error types. Within each cluster, we prioritize representative cases using a difficulty score that increases when task performance is low and when the same case fails repeatedly. This produces a compact set of high-value cases for skill evolution while preserving diversity across error types.
选择代表性困难案例。 为了让设计器更新聚焦在有影响的失败上,作者将案例聚类(例如 KMeans)成自然反映不同查询或错误类型的组。 在每个簇内,作者用难度分数优先选择代表性案例;当任务表现较低且同一案例反复失败时,该分数会升高。 这会为技能演化产生一个紧凑的高价值案例集合,同时保持不同错误类型之间的多样性。
Two-stage skill evolution. The designer updates the skill bank in two stages. First, it employs an LLM to analyze the selected hard cases and identify what memory behaviors are missing or mis-specified. Second, it uses the resulting analysis to propose concrete edits to existing skills and to introduce new skills. We keep the designer description concise and provide prompts in Appendix.
两阶段技能演化。 设计器分两个阶段更新技能库。 首先,它使用 LLM 分析被选中的困难案例,并识别哪些记忆行为缺失或定义不当。 其次,它使用分析结果提出对现有技能的具体编辑,并引入新技能。 作者在正文中保持设计器描述简洁,并在附录中提供提示。
Notably, we maintain snapshots of the best-performing skill bank and roll back if an update degrades performance, with early stopping when repeated designer updates fail to improve the training signal. After each evolution step, we also briefly increase exploration by biasing selection toward newly introduced skills, encouraging the controller to try them and facilitating efficient learning of their utility. Due to page limit, more details about the designer can be found in Appendix.
值得注意的是,作者会维护表现最佳技能库的快照;如果某次更新降低性能,就回滚,并且当重复的设计器更新无法改善训练信号时提前停止。 每次演化步骤后,作者还会短暂增加探索:让选择偏向新引入的技能,鼓励控制器尝试它们,并促进其效用的高效学习。 由于篇幅限制,关于设计器的更多细节见附录。
3.5. Closed-Loop Optimization
MemSkill alternates between (i) learning to select and apply skills to build memory banks and (ii) evolving the skill bank from hard cases mined during training. Each cycle begins with controller training on the current skill bank, where the executor constructs memories and accumulates challenging cases. The designer then updates the skill bank using representative hard cases, optionally rolling back to a prior snapshot if performance regresses. The next cycle resumes controller training on the updated skill bank, with additional exploration to encourage early use of new skills. Over cycles, this closed loop gradually improves how skills are selected, applied, and refined for memory construction.
MemSkill 在两个过程之间交替:(i)学习选择并应用技能来构建记忆库;(ii)从训练中挖掘的困难案例演化技能库。 每个循环从在当前技能库上训练控制器开始,此时执行器会构建记忆并积累具有挑战性的案例。 随后,设计器使用代表性困难案例更新技能库;如果性能退化,则可回滚到先前快照。 下一个循环在更新后的技能库上恢复控制器训练,并增加额外探索以鼓励尽早使用新技能。 随着循环推进,这个闭环会逐渐改进记忆构建中技能的选择、应用和细化方式。
4. Experiments
| Model | Method | Conversational Benchmarks | Embodied Interactive Tasks | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| LoCoMo | ▲LongMemEval | Avg. | ALF-Seen† | ALF-Unseen† | Avg. | ||||||
| F1 | L-J | F1 | L-J | L-J | SR | #Stps↓ | SR | #Stps↓ | SR | ||
| LLaMA3.3 70B-Instruct | |||||||||||
| No-Memory | - | - | - | - | - | 62.14 | 26.10 | 73.88 | 21.36 | 68.01 | |
| CoN | 30.86 | 41.72 | 30.78 | 56.44 | 49.08 | 75.00 | 19.15 | 80.60 | 17.38 | 77.80 | |
| ReadAgent | 28.63 | 38.25 | 24.48 | 42.62 | 40.44 | 62.86 | 26.14 | 71.64 | 22.88 | 67.25 | |
| MemoryBank | 36.80 | 44.43 | 30.56 | 41.96 | 43.20 | 60.71 | 28.23 | 66.42 | 24.64 | 63.57 | |
| A-MEM | 39.39 | 49.71 | 25.83 | 38.04 | 43.88 | 62.86 | 27.53 | 70.15 | 23.79 | 66.51 | |
| Mem0 | 25.48 | 34.58 | 30.25 | 46.81 | 40.70 | 74.29 | 19.77 | 81.34 | 17.15 | 77.82 | |
| LangMem | 30.91 | 35.82 | 18.36 | 24.35 | 30.09 | 72.86 | 21.25 | 79.85 | 18.30 | 76.36 | |
| MemoryOS | 41.39 | 48.64 | 17.59 | 39.83 | 44.24 | 57.86 | 27.94 | 65.67 | 24.46 | 61.77 | |
| MemSkill | 44.21 | 53.82 | 31.12 | 60.89 | 57.36 | 77.14 | 18.91 | 83.58 | 16.63 | 80.36 | |
| Qwen3-Next 80B-A3B-Instruct | |||||||||||
| No-Memory | - | - | - | - | - | 63.57 | 24.61 | 60.45 | 26.57 | 62.01 | |
| CoN | 38.46 | 50.96 | 29.19 | 44.06 | 47.51 | 77.14 | 17.59 | 70.90 | 20.74 | 74.02 | |
| ReadAgent | 25.89 | 34.26 | 24.13 | 42.25 | 38.26 | 73.57 | 20.21 | 65.67 | 23.28 | 69.62 | |
| MemoryBank | 29.56 | 44.15 | 8.45 | 26.37 | 35.26 | 63.57 | 23.68 | 52.24 | 29.01 | 57.91 | |
| A-MEM | 36.43 | 50.30 | 13.84 | 36.59 | 43.45 | 55.71 | 27.42 | 54.48 | 28.60 | 55.10 | |
| Mem0 | 23.29 | 33.68 | 27.36 | 46.20 | 39.94 | 71.43 | 19.89 | 64.93 | 23.32 | 68.18 | |
| LangMem | 28.17 | 32.94 | 18.35 | 23.86 | 28.40 | 73.57 | 19.76 | 64.18 | 23.58 | 68.88 | |
| MemoryOS | 39.86 | 47.37 | 15.97 | 39.25 | 43.31 | 62.14 | 25.64 | 50.75 | 30.35 | 56.45 | |
| MemSkill | 42.08 | 54.14 | 25.29 | 60.40 | 57.27 | 85.71 | 13.84 | 76.87 | 18.16 | 81.29 | |
4.1. Experiment Setup
Datasets and Baselines. We evaluate MemSkill on four benchmarks: LoCoMo, LongMemEval, HotpotQA, and ALFWorld, where HotpotQA is used in Section 4.3 to study skill transfer under distribution shift. The remaining three benchmarks cover two representative settings. (i) Conversational Benchmarks include LoCoMo and LongMemEval, which evaluate memory construction from long, dialogue-style interaction histories. For these datasets, we report F1-score (F1) and an LLM-based judge score (L-J). (ii) Embodied Interactive Tasks are evaluated on ALFWorld with two standard subsets, ALF-Seen and ALF-Unseen, and we report success rate (SR) and the number of environment interaction steps (#Stps). Appendix provides dataset splits.
数据集和基线。 作者在四个基准上评估 MemSkill:LoCoMo、LongMemEval、HotpotQA 和 ALFWorld,其中 HotpotQA 用于第 4.3 节研究分布转移下的技能迁移。 其余三个基准覆盖两种代表性设置。 (i)对话基准包括 LoCoMo 和 LongMemEval,它们评估从长对话式交互历史中构建记忆的能力。 对于这些数据集,作者报告 F1-score(F1)和基于 LLM 的裁判分数(L-J)。 (ii)具身交互任务在 ALFWorld 的两个标准子集 ALF-Seen 和 ALF-Unseen 上评估,并报告成功率(SR)和环境交互步数(#Stps)。 数据集划分见附录。
We compare MemSkill against several strong baselines: (1) No-Memory, which answers directly without an external memory; (2) CoN; (3) ReadAgent; (4) MemoryBank; (5) A-MEM; (6) Mem0; (7) LangMem; and (8) MemoryOS. Overall, this setup spans diverse benchmarks and baselines, enabling a broad and consistent comparison across diverse settings.
作者将 MemSkill 与若干强基线比较:(1)No-Memory,不使用外部记忆直接回答;(2)CoN;(3)ReadAgent;(4)MemoryBank;(5)A-MEM;(6)Mem0;(7)LangMem;以及(8)MemoryOS。 总体而言,这一设置覆盖多样基准和基线,使作者能够在多种场景中进行广泛且一致的比较。
Implementation Details. We instantiate
实现细节。 作者将
During training, we optimize the controller with PPO. MemSkill constructs memory at the span level; on conversational benchmarks, each dialogue session is a processing unit, and the controller selects
训练期间,作者使用 PPO 优化控制器。 MemSkill 在 span 层级构建记忆;在对话基准上,每个对话 session 是一个处理单位,控制器为每个单位选择
At evaluation time, we keep the same span-level formulation and set the span/chunk size to 512 by default, while keeping the overall procedure unchanged. Unless otherwise specified, we use
评估时,作者保持相同的 span 层级表述,并默认将 span/chunk size 设为 512,同时整体流程保持不变。 除非另有说明,评估时 LoCoMo 和 LongMemEval 使用
4.2. Comparison Experiments
Effectiveness across conversational and embodied settings. Table 1 summarizes the main comparison results on LoCoMo, LongMemEval, and ALFWorld. Across these datasets, MemSkill achieves the strongest overall performance among all compared methods. On conversational benchmarks, MemSkill attains the best LLM-judge scores on both LoCoMo and LongMemEval within each base-model block, indicating higher-quality constructed memories. In comparison, prior methods such as MemoryBank, A-MEM, and MemoryOS use fixed, manually specified memory procedures for extraction and revision, whereas MemSkill learns and evolves its skills from interaction, enabling better adaptation across contexts. On ALFWorld, MemSkill achieves the highest success rates on both seen and unseen splits, indicating that skill-guided memory construction can benefit interactive decision making, whereas other baselines are less reliable at leveraging memory to support long-horizon action execution. Overall, the results show that MemSkill is effective across diverse settings.
在对话和具身场景中的有效性。 表1 总结了 LoCoMo、LongMemEval 和 ALFWorld 上的主要比较结果。 在这些数据集上,MemSkill 在所有比较方法中取得最强整体表现。 在对话基准上,MemSkill 在每个基础模型块内都在 LoCoMo 和 LongMemEval 上取得最佳 LLM-judge 分数,说明构建出的记忆质量更高。 相比之下,MemoryBank、A-MEM 和 MemoryOS 等先前方法使用固定、人工指定的记忆流程进行抽取和修改,而 MemSkill 从交互中学习并演化技能,因此能更好适应不同上下文。 在 ALFWorld 上,MemSkill 在 seen 和 unseen 两个划分上都取得最高成功率,说明技能引导的记忆构建可以帮助交互式决策;其他基线在利用记忆支持长程动作执行时则不够可靠。 总体而言,结果表明 MemSkill 在多样场景中有效。
Generalization across base models. A key advantage of MemSkill is strong generalization across base models. We train MemSkill only with LLaMA and directly transfer the learned skills to Qwen without retraining. Despite this strict transfer setting, MemSkill remains competitive and outperforms strong baselines on both conversational and embodied evaluations, showing that the evolved skills capture reusable memory behaviors that can be instantiated by different underlying LLMs.
跨基础模型泛化。 MemSkill 的一个关键优势是跨基础模型的强泛化能力。 作者只用 LLaMA 训练 MemSkill,并将学到的技能直接迁移到 Qwen,不进行再训练。 即便在这种严格迁移设置下,MemSkill 仍保持竞争力,并在对话和具身评估中超过强基线,说明演化出的技能捕捉了可由不同底层 LLM 实例化的可复用记忆行为。
Cross-dataset transfer. MemSkill also generalizes across datasets within the same broad setting. In particular, LongMemEval is evaluated purely by transferring the skill bank learned on LoCoMo, yet MemSkill achieves the best results among all methods, suggesting that the learned skills are not overfit to a single benchmark. Section 4.3 studies transfer under more pronounced distribution shifts.
跨数据集迁移。 MemSkill 也能在同一大类场景内跨数据集泛化。 特别是,LongMemEval 完全通过迁移 LoCoMo 上学到的技能库进行评估,但 MemSkill 仍在所有方法中取得最佳结果,说明所学技能并未过拟合到单一基准。 第 4.3 节研究更显著分布转移下的迁移。
4.3. Skill Generalization Under Distribution Shift
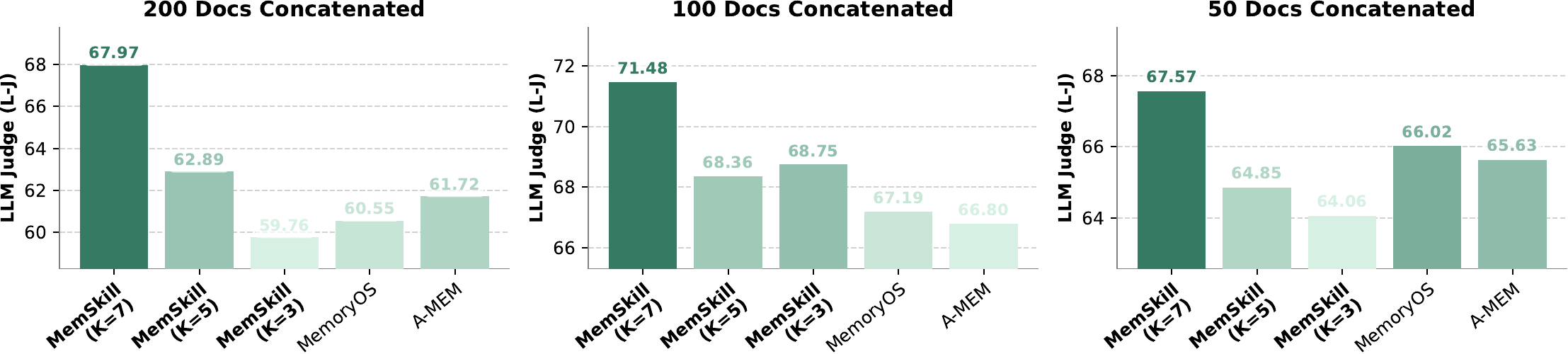
Beyond transfer within dialogue-style memory benchmarks, we evaluate whether learned skills generalize under a distribution shift in interaction format and evidence structure. Concretely, we directly apply the skill bank trained on LoCoMo to HotpotQA, where inputs are long-form, document-style narratives rather than multi-turn dialogues. Following the protocol in MemAgent, we test three context-length settings with increasing difficulty, corresponding to different numbers of concatenated documents (i.e., 50/100/200). All results in this section use LLaMA as the base model and report the LLM-judge score (L-J). For baselines, we include MemoryOS and A-MEM, the most competitive methods on conversational benchmarks in Table 1, and omit weaker alternatives for clarity.
除了对话式记忆基准内部的迁移,作者还评估所学技能是否能在交互格式和证据结构发生分布转移时泛化。 具体而言,作者将 LoCoMo 上训练出的技能库直接应用到 HotpotQA;该任务输入是长篇文档式叙事,而不是多轮对话。 按照 MemAgent 中的协议,作者测试了三种难度逐渐增加的上下文长度设置,对应不同数量的拼接文档(即 50/100/200)。 本节所有结果都使用 LLaMA 作为基础模型,并报告 LLM-judge 分数(L-J)。 对于基线,作者纳入 表1 中对话基准上最具竞争力的 MemoryOS 和 A-MEM,并为清晰起见省略较弱替代方法。
Figure 3 shows that MemSkill transfers strongly to HotpotQA across all three context sizes. MemSkill consistently outperforms strong baselines such as MemoryOS and A-MEM, with gains becoming more pronounced in the challenging long-context setting. These results suggest that the learned memory skills are not tied to dialogue-specific surface forms, but capture reusable extraction and revision behaviors that remain effective as input structure and retrieval demands change.
图3 表明,MemSkill 在三种上下文长度下都能强力迁移到 HotpotQA。 MemSkill 持续优于 MemoryOS 和 A-MEM 等强基线,并且在具有挑战性的长上下文设置中收益更加明显。 这些结果说明,所学记忆技能并不绑定对话特有的表面形式,而是捕捉到了可复用的抽取和修改行为;即使输入结构和检索需求变化,这些行为仍然有效。
The same plots also reveal mild sensitivity to the number of selected skills
同一组图还显示,模型对所选技能数量
4.4. Ablation Study
We perform ablations to disentangle the contributions of (i) learning to select skills and (ii) evolving the skill bank. Table 2 reports LLM Judge (L-J) results on LoCoMo under both base models (LLaMA and Qwen). As shown, w/o controller (w/o Ctrl) replaces the learned controller with random skill selection while keeping the rest of the pipeline unchanged. w/o designer (w/o Des) disables the designer and fixes the skill bank to the four initial primitives. Refine-only (Ref.-only) allows the designer to refine existing skills but prohibits adding new ones.
作者进行消融实验,以区分(i)学习选择技能和(ii)演化技能库的贡献。 表2 报告了两个基础模型(LLaMA 和 Qwen)在 LoCoMo 上的 LLM Judge(L-J)结果。 如表所示,w/o controller(w/o Ctrl) 用随机技能选择替换学习得到的控制器,其余流程保持不变。 w/o designer(w/o Des) 禁用设计器,并将技能库固定为四个初始原语。 Refine-only(Ref.-only) 允许设计器细化现有技能,但禁止添加新技能。
Across both base models, removing either component consistently degrades performance, confirming that MemSkill benefits from both targeted skill selection and skill evolution. In particular, random skill selection leads to a clear drop from the default setting, highlighting the importance of learning to choose relevant skills rather than providing arbitrary ones. Disabling the designer yields an even larger degradation, especially under Qwen, suggesting that evolving the skill bank is important for learning reusable memory behaviors that generalize beyond a fixed, manually specified operation set. Finally, refinement-only consistently outperforms static skills on both LLaMA and Qwen, with a particularly large gain under Qwen, yet remains below the default setting, indicating that introducing new skills yields additional benefits beyond refining the initial primitives.
在两个基础模型上,移除任一组件都会持续降低性能,确认 MemSkill 同时受益于有针对性的技能选择和技能演化。 特别是,随机技能选择相较默认设置会明显下降,凸显了学习选择相关技能,而不是任意提供技能的重要性。 禁用设计器会造成更大退化,尤其是在 Qwen 下,这说明演化技能库对于学习可复用记忆行为很重要;这些行为能泛化到固定、人工指定操作集合之外。 最后,refinement-only 在 LLaMA 和 Qwen 上都持续优于静态技能,在 Qwen 下收益尤其明显,但仍低于默认设置,说明除了细化初始原语之外,引入新技能还会带来额外收益。
| Variant | LLaMA | Qwen |
|---|---|---|
| MemSkill | 53.82 | 54.14 |
| w/o Ctrl | 48.43 | 42.84 |
| w/o Des | 46.50 | 36.15 |
| Ref.-only | 47.45 | 48.88 |
4.5. Discussion
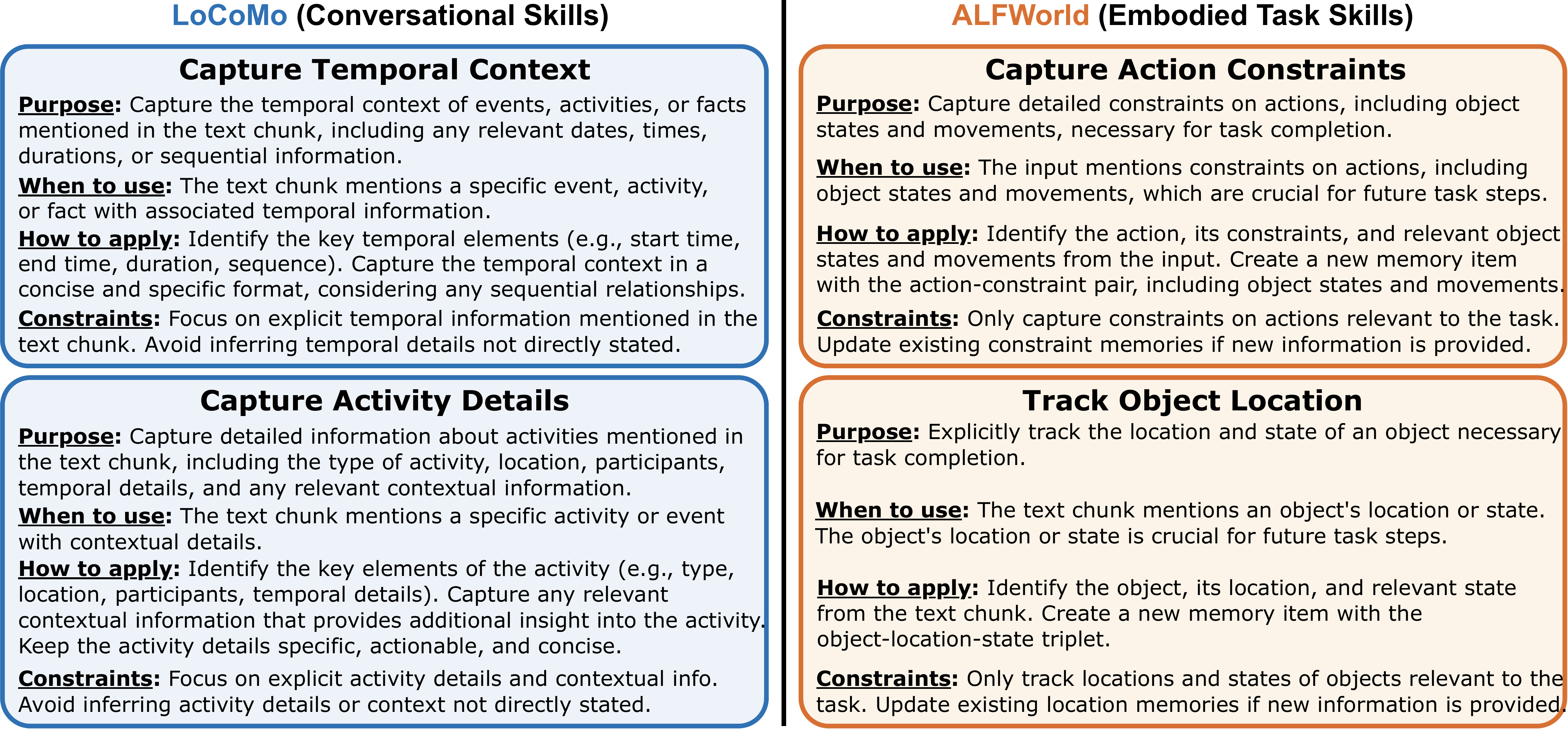
Case study. To make MemSkill more interpretable, we inspect the final evolved skill bank and report representative skills from LoCoMo and ALFWorld. As shown in Figure 4, the learned skills show clear domain specialization. LoCoMo skills emphasize temporal context and activity details, suggesting that dialogue memory benefits from lightweight event structure. In contrast, ALFWorld skills focus on action constraints and object locations, showing that embodied tasks require actionable world-state memories for multi-step execution. Overall, the evolved skill bank reflects recurring information needs from the data, rather than a fixed notion of what to remember.
案例研究。 为了让 MemSkill 更可解释,作者检查最终演化出的技能库,并报告来自 LoCoMo 和 ALFWorld 的代表性技能。 如 图4 所示,所学技能呈现出清晰的领域专门化。 LoCoMo 技能强调时间上下文和活动细节,说明对话记忆受益于轻量事件结构。 相比之下,ALFWorld 技能关注动作约束和物体位置,说明具身任务需要可执行的世界状态记忆来完成多步执行。 总体而言,演化后的技能库反映了数据中反复出现的信息需求,而不是关于“该记住什么”的固定观念。
Together, these skills show that MemSkill distills and refines reusable memory behaviors from interaction data, reducing reliance on hand-crafted memory designs. Appendix gives more examples.
这些技能共同表明,MemSkill 从交互数据中蒸馏并细化可复用记忆行为,减少了对手工记忆设计的依赖。 更多示例见附录。
Cost analysis. We conduct a runtime cost analysis on LoCoMo using LLaMA, additionally including LightMem as a baseline. We report L-J, input/output tokens, and LLM calls, accounting for all inference-time LLM calls from memory extraction and query answering, excluding LLM-judge calls used only for evaluation. Since MemSkill learns and evolves the skill bank before deployment, this preparation cost is amortized over repeated use, with further evolution triggered only occasionally. We therefore focus on runtime cost as the practical efficiency measure. At inference time, MemSkill constructs memory at the span level rather than turn by turn, substantially reducing LLM calls. To show this trade-off, we vary the span size (SS) and report the quality-cost frontier in Table 3.
成本分析。 作者使用 LLaMA 在 LoCoMo 上进行运行时成本分析,并额外纳入 LightMem 作为基线。 作者报告 L-J、输入/输出 token 和 LLM 调用次数,统计来自记忆抽取和查询回答的所有推理时 LLM 调用,但排除仅用于评估的 LLM-judge 调用。 由于 MemSkill 在部署前学习并演化技能库,这一准备成本会在重复使用中摊销,而进一步演化只会偶尔触发。 因此,作者把运行时成本作为实际效率度量。 推理时,MemSkill 在 span 层级而不是逐轮构建记忆,从而大幅减少 LLM 调用。 为了展示这一权衡,作者改变 span size(SS),并在 表3 中报告质量-成本前沿。
MemSkill achieves a stronger quality-cost trade-off than prior baselines. With moderate span sizes, it obtains higher L-J scores while using fewer input/output tokens and LLM calls. In particular, Span Size=512 offers the best overall balance, achieving the highest quality with much lower runtime cost than MemoryOS, A-MEM, and LightMem. This suggests span-level construction reduces redundant LLM calls without sacrificing memory quality. Larger span sizes reduce cost, but may hurt performance because each memory update covers a longer span. This makes span size a knob for adapting MemSkill to different efficiency requirements.
MemSkill 相比先前基线取得了更强的质量-成本权衡。 在中等 span size 下,它用更少的输入/输出 token 和 LLM 调用取得更高 L-J 分数。 特别是,Span Size=512 提供了最佳整体平衡:它以远低于 MemoryOS、A-MEM 和 LightMem 的运行时成本取得最高质量。 这说明 span 层级构建能在不牺牲记忆质量的情况下减少冗余 LLM 调用。 更大的 span size 会降低成本,但也可能损害性能,因为每次记忆更新覆盖更长 span。 这使 span size 成为一个旋钮,可用于让 MemSkill 适配不同效率需求。
| Setting | L-J | In (K) | Out (K) | Calls |
|---|---|---|---|---|
| MemoryOS | 48.64 | 1013 | 165 | 1288 |
| A-MEM | 49.71 | 2850 | 362 | 1548 |
| LightMem | 51.95 | 789 | 209 | 685 |
| Ours (SS=128) | 53.14 | 622 | 57 | 376 |
| Ours (SS=256) | 51.61 | 390 | 19 | 270 |
| Ours (SS=512) | 53.82 | 249 | 18 | 215 |
| Ours (SS=1024) | 48.11 | 188 | 11 | 187 |
| Ours (SS=2048) | 50.46 | 178 | 10 | 185 |
5. Conclusion
We present MemSkill, an agent memory method that reframes memory operations as an evolving skill bank. MemSkill learns to select relevant skills for each context span and conditions an LLM executor on them to construct skill-guided memories. Beyond learning to use a fixed skill set, MemSkill introduces a designer that improves the skill bank by refining existing skills and proposing new ones from challenging cases, forming a closed-loop training procedure. Experiments on LoCoMo, LongMemEval, HotpotQA, and ALFWorld show consistent improvements over strong baselines, while qualitative analyses illustrate how evolving skills enable more adaptive memory management. We hope MemSkill encourages future work on self-improving agent memory systems that learn not only to use memory, but also to continually improve how memory is constructed and maintained.
本文提出 MemSkill,一种把记忆操作重新表述为演化技能库的智能体记忆方法。 MemSkill 学习为每个上下文 span 选择相关技能,并让 LLM 执行器以这些技能为条件来构建技能引导的记忆。 除了学习使用固定技能集合外,MemSkill 还引入一个设计器,通过从困难案例中细化现有技能并提出新技能来改进技能库,形成闭环训练过程。 在 LoCoMo、LongMemEval、HotpotQA 和 ALFWorld 上的实验显示,MemSkill 相对强基线有稳定提升;定性分析则说明演化技能如何支持更自适应的记忆管理。 作者希望 MemSkill 能促进关于自改进智能体记忆系统的未来工作:这类系统不仅学习如何使用记忆,也持续改进记忆的构建和维护方式。