
Learning to Prompt for Vision-Language Models
Vision-LanguagePrompt LearningCLIP5310+NTU S-LabZhou K, Yang J, Loy C C, Liu Z. Learning to Prompt for Vision-Language Models.
为视觉-语言模型学习提示
Abstract
Large pre-trained vision-language models like CLIP have shown great potential in learning representations that are transferable across a wide range of downstream tasks. Different from the traditional representation learning that is based mostly on discretized labels, vision-language pre-training aligns images and texts in a common feature space, which allows zero-shot transfer to a downstream task via prompting, i.e., classification weights are synthesized from natural language describing classes of interest. In this work, we show that a major challenge for deploying such models in practice is prompt engineering, which requires domain expertise and is extremely time-consuming---one needs to spend a significant amount of time on words tuning since a slight change in wording could have a huge impact on performance. Inspired by recent advances in prompt learning research in natural language processing (NLP), we propose Context Optimization (CoOp), a simple approach specifically for adapting CLIP-like vision-language models for downstream image recognition. Concretely, CoOp models a prompt's context words with learnable vectors while the entire pre-trained parameters are kept fixed. To handle different image recognition tasks, we provide two implementations of CoOp: unified context and class-specific context. Through extensive experiments on 11 datasets, we demonstrate that CoOp requires as few as one or two shots to beat hand-crafted prompts with a decent margin and is able to gain significant improvements over prompt engineering with more shots, e.g., with 16 shots the average gain is around 15% (with the highest reaching over 45%). Despite being a learning-based approach, CoOp achieves superb domain generalization performance compared with the zero-shot model using hand-crafted prompts.
像 CLIP 这样的大型预训练视觉-语言模型,已经展现出学习可迁移到广泛下游任务的表示的巨大潜力。 不同于主要基于离散标签的传统表示学习,视觉-语言预训练在一个共同特征空间中对齐图像和文本,使模型能够通过提示零样本迁移到下游任务,也就是说,分类权重由描述目标类别的自然语言合成得到。 在本文中,作者表明,将这类模型部署到实践中的一个主要挑战是提示工程;它需要领域专业知识并且极其耗时,因为措辞的轻微变化就可能对性能产生巨大影响,所以需要花费大量时间调词。 受自然语言处理(NLP)中提示学习研究近期进展的启发,作者提出了上下文优化(CoOp),这是一种专门用于将 CLIP 类视觉-语言模型适配到下游图像识别任务的简单方法。 具体来说,CoOp 用可学习向量对提示中的上下文词建模,同时保持整个预训练参数固定。 为了处理不同的图像识别任务,作者提供了 CoOp 的两种实现:统一上下文和类别特定上下文。 通过在 11 个数据集上的大量实验,作者证明 CoOp 只需一两个样本就能以不错的幅度超过手工提示,并且在更多样本下能够相较提示工程获得显著提升,例如在 16-shot 时平均增益约为 15%(最高超过 45%)。 尽管 CoOp 是一种基于学习的方法,但与使用手工提示的零样本模型相比,它取得了出色的领域泛化性能。
1. Introduction

A common approach for building state-of-the-art visual recognition systems is to train vision models to predict for a fixed set of object categories using discrete labels. From a technical point of view, this is achieved by matching image features---produced by a vision model like ResNet or ViT---with a fixed set of weights that are seen as visual concepts and initialized randomly. Although training categories often have a textual form, such as "goldfish" or "toilet paper," they will be converted into discrete labels just for easing the computation of the cross-entropy loss, leaving the semantics encapsulated in texts largely unexploited. Such a learning paradigm limits visual recognition systems to closed-set visual concepts, making them unable to deal with new categories since additional data are required for learning a new classifier.
构建最先进视觉识别系统的一种常见方法,是训练视觉模型使用离散标签预测一组固定目标类别。 从技术角度看,这是通过把图像特征与一组固定权重匹配来实现的;这些图像特征由 ResNet 或 ViT 等视觉模型产生,而这些权重被视为视觉概念并随机初始化。 尽管训练类别通常具有文本形式,例如 "goldfish" 或 "toilet paper",但它们会被转换为离散标签,只是为了便于计算交叉熵损失,这使封装在文本中的语义基本没有被利用。 这种学习范式把视觉识别系统限制在闭集视觉概念中,使它们无法处理新类别,因为学习新分类器需要额外数据。
Recently, vision-language pre-training such as CLIP and ALIGN has emerged as a promising alternative for visual representation learning. The main idea is to align images and raw texts using two separate encoders---one for each modality. For instance, both CLIP and ALIGN formulate the learning objective as a contrastive loss, which pulls together images and their textual descriptions while pushes away unmatched pairs in the feature space. By pre-training at a large scale, models can learn diverse visual concepts and can readily be transferred to any downstream task through prompting. In particular, for any new classification task one can first synthesize the classification weights by giving sentences describing task-relevant categories to the text encoder, and then compare with image features produced by the image encoder.
近来,CLIP 和 ALIGN 等视觉-语言预训练已经成为视觉表示学习的一种有前景替代方案。 其核心思想是使用两个独立编码器对齐图像和原始文本,每种模态对应一个编码器。 例如,CLIP 和 ALIGN 都把学习目标形式化为对比损失,在特征空间中拉近图像及其文本描述,同时推远不匹配的图文对。 通过大规模预训练,模型可以学习多样的视觉概念,并且可以通过提示直接迁移到任何下游任务。 特别地,对于任何新的分类任务,可以先把描述任务相关类别的句子输入文本编码器来合成分类权重,然后再与图像编码器产生的图像特征进行比较。
We observe that for pre-trained vision-language models, the text input, known as prompt, plays a key role in downstream datasets. However, identifying the right prompt is a non-trivial task, which often takes a significant amount of time for words tuning---a slight change in wording could make a huge difference in performance. For instance, for Caltech101 (Figure Figure 1(a), 2nd vs 3rd prompt), adding "a" before the class token brings more than 5% increase in accuracy. Moreover, prompt engineering also requires prior knowledge about the task and ideally the language model's underlying mechanism. This is exemplified in Figure Figure 1(b-d) where adding task-relevant context can lead to significant improvements, i.e., "flower" for Flowers102, "texture" for DTD and "satellite" for EuroSAT. Tuning the sentence structure could bring further improvements, e.g., putting "a type of flower" after the class token for Flowers102, keeping only "texture" in the context for DTD, and adding "centered" before "satellite photo" for EuroSAT. However, even with extensive tuning, the resulting prompts are by no means guaranteed to be optimal for these downstream tasks.
作者观察到,对于预训练视觉-语言模型,被称为提示的文本输入在下游数据集中起关键作用。 然而,确定正确提示并不是一个简单任务,通常需要大量时间调词,因为措辞的轻微改变就可能造成巨大的性能差异。 例如,对于 Caltech101(图1(a),第 2 个提示与第 3 个提示),在类别 token 前加入 "a" 会带来超过 5% 的准确率提升。 此外,提示工程还需要关于任务的先验知识,并且理想情况下还需要了解语言模型的底层机制。 图1(b-d) 就说明了这一点:加入与任务相关的上下文可以带来显著提升,即 Flowers102 中的 "flower"、DTD 中的 "texture" 和 EuroSAT 中的 "satellite"。 调整句子结构可以带来进一步提升,例如在 Flowers102 中把 "a type of flower" 放在类别 token 之后,在 DTD 中只保留上下文里的 "texture",以及在 EuroSAT 中把 "centered" 加在 "satellite photo" 之前。 然而,即使经过大量调优,得到的提示也绝不能保证对这些下游任务是最优的。
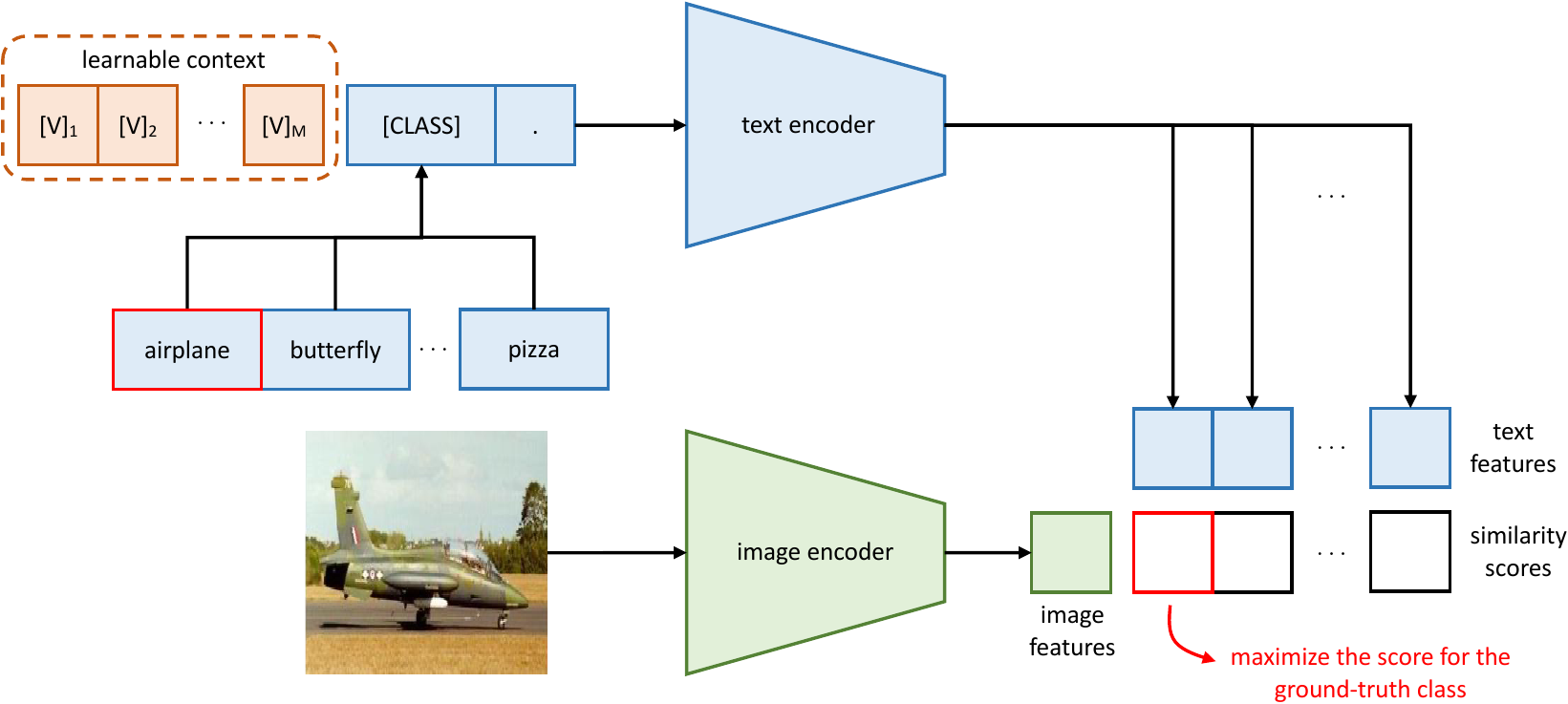
Inspired by recent prompt learning research in natural language processing (NLP), we propose a simple approach called Context Optimization (CoOp) (CoOp is pronounced as /ku:p/) to automate prompt engineering, specifically for pre-trained vision-language models. Concretely, CoOp models a prompt's context words with learnable vectors, which could be initialized with either random values or pre-trained word embeddings (see Figure Figure 2). Two implementations are provided to handle tasks of different natures: one is based on unified context, which shares the same context with all classes and works well on most categories; while the other is based on class-specific context, which learns a specific set of context tokens for each class and is found to be more suitable for some fine-grained categories. During training, we simply minimize prediction errors using the cross-entropy loss with respect to the learnable context vectors while keeping the entire pre-trained parameters fixed. The gradients can be back-propagated all the way through the text encoder, distilling the rich knowledge encoded in the parameters for learning task-relevant context.
受自然语言处理(NLP)中近期提示学习研究的启发,作者提出了一种名为上下文优化(CoOp)(CoOp 发音为 /ku:p/)的简单方法,专门用于为预训练视觉-语言模型自动化提示工程。 具体来说,CoOp 用可学习向量对提示中的上下文词建模,这些向量可以用随机值或预训练词嵌入初始化(见 图2)。 作者提供了两种实现来处理不同性质的任务:一种基于统一上下文,对所有类别共享同一上下文,并且在大多数类别上效果良好;另一种基于类别特定上下文,为每个类别学习一组特定上下文 token,并且被发现更适合某些细粒度类别。 训练时,作者只需针对可学习上下文向量最小化交叉熵损失下的预测误差,同时保持整个预训练参数固定。 梯度可以一路反向传播通过文本编码器,从参数中蒸馏出丰富知识,用于学习任务相关上下文。
To demonstrate the effectiveness of CoOp, we benchmark on 11 datasets, which cover a diverse set of visual recognition tasks including classification on generic objects, scenes, actions and fine-grained categories, as well as specialized tasks like recognizing textures and satellite imagery. The results show that CoOp effectively turns pre-trained vision-language models into data-efficient visual learners, requiring as few as one or two shots to beat hand-crafted prompts with a decent margin. The performance can be further boosted by using more shots, e.g., with 16 shots the margin over hand-crafted prompts averages at around 15% and reaches over 45% for the highest. CoOp also outperforms the linear probe model, which is known as a strong few-shot learning baseline. Furthermore, CoOp demonstrates much stronger robustness than the zero-shot model (which uses manual prompts) to domain shifts, despite being a learning-based approach.
为了证明 CoOp 的有效性,作者在 11 个数据集上进行基准评测,这些数据集覆盖了多样的视觉识别任务,包括通用目标、场景、动作和细粒度类别分类,以及识别纹理和卫星图像等专门任务。 结果表明,CoOp 有效地把预训练视觉-语言模型转变为数据高效的视觉学习器,只需要一两个样本就能以不错的幅度超过手工提示。 使用更多样本可以进一步提升性能,例如在 16-shot 时,相对于手工提示的平均幅度约为 15%,最高超过 45%。 CoOp 还优于线性探测模型,而后者被认为是强 few-shot 学习基线。 此外,尽管 CoOp 是一种基于学习的方法,但它相较零样本模型(使用人工提示)对领域偏移表现出强得多的鲁棒性。
In summary, we make the following contributions:
1. We present a timely study on the adaptation of recently proposed vision-language models in downstream applications and identify a critical problem associated with the deployment efficiency, i.e., prompt engineering.
2. To automate prompt engineering specifically for pre-trained vision-language models, we propose a simple approach based on continuous prompt learning and provide two implementations that can handle different recognition tasks.
3. We for the first time show that the proposed prompt learning-based approach outperforms both hand-crafted prompts and the linear probe model in terms of downstream transfer learning performance and robustness under domain shifts for large vision-language models.
总之,作者做出如下贡献:
1. 作者对近期提出的视觉-语言模型在下游应用中的适配进行了及时研究,并识别出一个与部署效率相关的关键问题,即提示工程。
2. 为了专门针对预训练视觉-语言模型自动化提示工程,作者提出了一种基于连续提示学习的简单方法,并提供了两种可以处理不同识别任务的实现。
3. 作者首次表明,在大型视觉-语言模型的下游迁移学习性能和领域偏移下的鲁棒性方面,所提出的基于提示学习的方法同时优于手工提示和线性探测模型。
We hope the findings together with the open-source code can inspire and facilitate future research on efficient adaptation methods for large vision-language models---an emerging topic related to democratization of foundation models i.e., making them easier and cheaper to adapt for the wider community.
作者希望这些发现和开源代码能够启发并促进关于大型视觉-语言模型高效适配方法的未来研究;这是一个与基础模型民主化相关的新兴主题,也就是让更广泛的社区能够更容易、更低成本地适配这些模型。
2. Related Work
2.1 Vision-Language Models
Vision-language models have recently demonstrated great potential in learning generic visual representations and allowing zero-shot transfer to a variety of downstream classification tasks via prompting.
视觉-语言模型近来在学习通用视觉表示方面展现出巨大潜力,并且允许通过提示零样本迁移到多种下游分类任务。
To our knowledge, the recent developments in vision-language learning, particularly CLIP and ALIGN, are largely driven by advances in the following three areas: i) text representation learning with Transformers, ii) large-minibatch contrastive representation learning, and iii) web-scale training datasets---CLIP benefits from 400 million curated image-text pairs while ALIGN exploits 1.8 billion noisy image-text pairs.
据作者所知,视觉-语言学习近期的发展,尤其是 CLIP 和 ALIGN,主要由以下三个方面的进步推动:i)使用 Transformer 进行文本表示学习,ii)大 mini-batch 对比表示学习,以及 iii)网络规模训练数据集;CLIP 受益于 4 亿个经过整理的图文对,而 ALIGN 利用了 18 亿个噪声图文对。
The idea of mapping images and text onto a common embedding space has been studied since nearly a decade ago, but with drastically different technologies. For text features extraction, early work has mainly utilized pre-trained word vectors or the hand-crafted TF-IDF features. Matching images and text features has been formulated as metric learning, multi-label classification, n-gram language learning, and the recently proposed captioning.
把图像和文本映射到共同嵌入空间的思想早在近十年前就已经被研究,但当时使用的技术截然不同。 对于文本特征提取,早期工作主要使用预训练词向量或手工设计的 TF-IDF 特征。 图像和文本特征匹配曾被形式化为度量学习、多标签分类、n-gram 语言学习,以及近期提出的图像描述生成。
Our work is orthogonal to recent research in vision-language models, aiming to facilitate the adaptation and deployment of such models in downstream datasets.
作者的工作与近期视觉-语言模型研究正交,目标是促进这类模型在下游数据集上的适配和部署。
2.2 Prompt Learning in NLP
Knowledge probing for large pre-trained language models, formally defined by Petroni et al. as "fill-in-the-blank" cloze tests, has recently sparked interest in prompt learning research in NLP.
针对大型预训练语言模型的知识探测,被 Petroni 等人正式定义为“填空式”完形测试,近来激发了 NLP 中对提示学习研究的兴趣。
The basic idea of knowledge probing is to induce pre-trained language models to generate answers given cloze-style prompts, which can benefit a number of downstream tasks, such as sentiment analysis. Jiang et al. propose to generate candidate prompts through text mining and paraphrasing, and identify the optimal ones that give the highest training accuracy. Shin et al. introduce a gradient-based approach, which searches for tokens with the largest gradient changes in the label likelihood.
知识探测的基本思想是诱导预训练语言模型在给定完形风格提示时生成答案,这可以使情感分析等许多下游任务受益。 Jiang 等人提出通过文本挖掘和改写生成候选提示,并识别出训练准确率最高的最优提示。 Shin 等人引入了一种基于梯度的方法,搜索在标签似然上梯度变化最大的 token。
Most related to our work are continuous prompt learning methods which optimize continuous vectors in the word embedding space. A drawback of such methods compared to searching discrete tokens is the lack of a clear way to visualize what "words" are learned for the vectors. We refer readers to Liu et al. for a comprehensive survey in the topic of prompt learning in NLP.
与作者工作最相关的是连续提示学习方法,它们在词嵌入空间中优化连续向量。 这类方法相较搜索离散 token 的一个缺点是,缺少清晰方式来可视化这些向量学到了哪些“词”。 关于 NLP 中提示学习主题的全面综述,作者请读者参考 Liu 等人的工作。
It is worth noting that we are the first to apply prompt learning to the adaptation of large vision-language models in computer vision---which we view as an important topic for democratizing foundation models---and justify that prompt learning not only brings significant improvements to computer vision tasks in terms of transfer learning performance but also produces robust models that can handle domain shifts.
值得注意的是,作者是首个把提示学习应用于计算机视觉中大型视觉-语言模型适配的团队;作者认为这是基础模型民主化的重要主题,并证明提示学习不仅能在迁移学习性能方面为计算机视觉任务带来显著提升,还能产生可以处理领域偏移的鲁棒模型。
3. Methodology
3.1 Vision-Language Pre-training
We briefly introduce vision-language pre-training with a particular focus on CLIP. Our approach is applicable to broader CLIP-like vision-language models.
作者简要介绍视觉-语言预训练,并特别关注 CLIP。 作者的方法适用于更广泛的 CLIP 类视觉-语言模型。
Models. CLIP consists of two encoders, one for images and the other for text. The image encoder aims to map high-dimensional images into a low-dimensional embedding space. The architecture of the image encoder can take the form of a CNN like ResNet-50 or a ViT. On the other hand, the text encoder is built on top of a Transformer and aims to generate text representations from natural language.
模型。 CLIP 由两个编码器组成,一个用于图像,另一个用于文本。 图像编码器旨在把高维图像映射到低维嵌入空间。 图像编码器的架构可以采用 ResNet-50 这样的 CNN,也可以采用 ViT。 另一方面,文本编码器建立在 Transformer 之上,旨在从自然语言生成文本表示。
Specifically, given a sequence of words (tokens), such as "a photo of a dog," CLIP first converts each one of the token (including punctuation) into a lower-cased byte pair encoding (BPE) representation, which is essentially a unique numeric ID. The vocabulary size in CLIP is 49,152. To facilitate minibatch processing, each text sequence is encompassed with the [SOS] and [EOS] tokens and capped at a fixed length of 77. After that, the IDs are mapped to 512-D word embedding vectors, which are then passed on to the Transformer. Finally, the features at the [EOS] token position are layer normalized and further processed by a linear projection layer.
具体而言,给定一个词(token)序列,例如 "a photo of a dog,",CLIP 首先把每个 token(包括标点)转换为小写字节对编码(BPE)表示,本质上就是一个唯一的数字 ID。 CLIP 的词表大小为 49,152。 为了便于 mini-batch 处理,每个文本序列都会由 [SOS] 和 [EOS] token 包围,并被截断到固定长度 77。 之后,这些 ID 被映射到 512 维词嵌入向量,然后传入 Transformer。 最后,位于 [EOS] token 位置的特征会经过层归一化,并进一步由线性投影层处理。
Training. CLIP is trained to align the two embedding spaces learned for images and text respectively. Specifically, the learning objective is formulated as a contrastive loss. Given a batch of image-text pairs, CLIP maximizes the cosine similarity for matched pairs while minimizes the cosine similarity for all other unmatched pairs. To learn diverse visual concepts that are more transferable to downstream tasks, CLIP's team collects a large training dataset consisting of 400 million image-text pairs.
训练。 CLIP 被训练为对齐分别为图像和文本学习到的两个嵌入空间。 具体而言,学习目标被形式化为对比损失。 给定一个图文对 batch,CLIP 最大化匹配对的余弦相似度,同时最小化所有其他不匹配对的余弦相似度。 为了学习更能迁移到下游任务的多样视觉概念,CLIP 团队收集了一个包含 4 亿个图文对的大型训练数据集。
Zero-Shot Inference. Since CLIP is pre-trained to predict whether an image matches a textual description, it naturally fits zero-shot recognition. This is achieved by comparing image features with the classification weights synthesized by the text encoder, which takes as input textual descriptions specifying classes of interest. Formally, let
零样本推理。 由于 CLIP 被预训练为预测一张图像是否匹配某个文本描述,因此它天然适合零样本识别。 这是通过把图像特征与文本编码器合成的分类权重进行比较来实现的;文本编码器的输入是指定目标类别的文本描述。 形式上,令
where
其中
Compared with the traditional classifier learning approach where closed-set visual concepts are learned from random vectors, vision-language pre-training allows open-set visual concepts to be explored through a high-capacity text encoder, leading to a broader semantic space and in turn making the learned representations more transferable to downstream tasks.
与从随机向量学习闭集视觉概念的传统分类器学习方法相比,视觉-语言预训练允许通过高容量文本编码器探索开集视觉概念,从而带来更广阔的语义空间,并进一步使学习到的表示更能迁移到下游任务。
3.2 Context Optimization
We propose Context Optimization (CoOp), which avoids manual prompt tuning by modeling context words with continuous vectors that are end-to-end learned from data while the massive pre-trained parameters are frozen. An overview is shown in Figure Figure 2. Below we provide several different implementations.
作者提出上下文优化(CoOp),它通过用连续向量对上下文词建模来避免人工提示调优;这些向量从数据中端到端学习,而大规模预训练参数保持冻结。 概览如 图2 所示。 下面作者提供几种不同实现。
Unified Context. We first introduce the unified context version, which shares the same context with all classes. Specifically, the prompt given to the text encoder
统一上下文。 作者首先介绍统一上下文版本,它对所有类别共享同一上下文。 具体而言,给文本编码器
where each
其中每个
By forwarding a prompt [EOS] token position). The prediction probability is computed as
把提示 [EOS] token 位置)。 预测概率计算为
where the class token within each prompt
其中每个提示
Other than placing the class token at the end of a sequence as in Equation (1), we can also put it in the middle like
除了像公式 (1) 那样把类别 token 放在序列末尾外,作者也可以把它放在中间,如
which increases flexibility for learning---the prompt is allowed to either fill the latter cells with supplementary descriptions or cut off the sentence earlier by using a termination signal such as full stop.
这增加了学习的灵活性:提示既可以用补充描述填充后面的单元,也可以使用句号等终止信号更早截断句子。
Class-Specific Context. Another option is to design class-specific context (CSC) where context vectors are independent to each class, i.e.,
类别特定上下文。 另一种选择是设计类别特定上下文(CSC),其中上下文向量对每个类别都是独立的,即对于
Training. is performed to minimize the standard classification loss based on the cross-entropy, and the gradients can be back-propagated all the way through the text encoder
训练。 训练通过最小化基于交叉熵的标准分类损失来进行,并且梯度可以一路反向传播通过文本编码器
3.3 Discussion
Our approach specifically addresses the emerging problem of the adaptation of recently proposed large vision-language models such as CLIP. There are some differences that distinguish our approach from the prompt learning methods developed in NLP for language models (e.g., GPT-3). First, the backbone architectures are clearly different for CLIP-like models and language models---the former take both visual and textual data as input and produce alignment scores used for image recognition, while the latter are tailored to handle textual data only. Second, the pre-training objectives are different: contrastive learning vs autoregressive learning. This would lead to different model behaviors and thus require different module designs.
作者的方法专门处理近期提出的大型视觉-语言模型(例如 CLIP)适配这一新兴问题。 作者的方法与 NLP 中为语言模型(例如 GPT-3)开发的提示学习方法存在一些区别。 首先,CLIP 类模型和语言模型的主干架构明显不同:前者同时以视觉和文本数据为输入,并产生用于图像识别的对齐分数;后者则专门用于处理文本数据。 其次,预训练目标不同:对比学习对比自回归学习。 这会导致不同的模型行为,因此需要不同的模块设计。
4. Experiments
4.1 Few-Shot Learning
Datasets. We select 11 publicly available image classification datasets used in CLIP: ImageNet, Caltech101, OxfordPets, StanfordCars, Flowers102, Food101, FGVCAircraft, SUN397, DTD, EuroSAT and UCF101 (see appendix for their statistics). These datasets constitute a comprehensive benchmark, which covers a diverse set of vision tasks including classification on generic objects, scenes, actions and fine-grained categories, as well as specialized tasks like recognizing textures and satellite imagery. We follow the few-shot evaluation protocol adopted in CLIP, using 1, 2, 4, 8 and 16 shots for training respectively and deploying models in the full test sets. The average results over three runs are reported for comparison.
数据集。 作者选择 CLIP 中使用的 11 个公开图像分类数据集:ImageNet、Caltech101、OxfordPets、StanfordCars、Flowers102、Food101、FGVCAircraft、SUN397、DTD、EuroSAT 和 UCF101(它们的统计信息见附录)。 这些数据集构成了一个全面基准,覆盖了多样的视觉任务,包括通用目标、场景、动作和细粒度类别分类,以及识别纹理和卫星图像等专门任务。 作者遵循 CLIP 采用的 few-shot 评估协议,分别使用 1、2、4、8 和 16 个样本进行训练,并在完整测试集上部署模型。 为便于比较,作者报告三次运行的平均结果。
Training Details. CoOp has four versions: positioning the class token in the end or middle; unified context vs CSC. Unless otherwise stated, ResNet-50 is used as the image encoder's backbone and the number of context tokens
训练细节。 CoOp 有四个版本:把类别 token 放在末尾或中间;统一上下文或 CSC。 除非另有说明,作者使用 ResNet-50 作为图像编码器主干,并将上下文 token 数量
Baseline Methods. We compare CoOp with two baseline methods. The first is zero-shot CLIP, which is based on hand-crafted prompts. We follow the guideline of prompt engineering introduced by Radford et al. For generic objects and scenes, "a photo of a [CLASS]." is adopted. For fine-grained categories, task-relevant context is added like "a type of pet" for OxfordPets and "a type of food" for Food101. When it comes to specialized tasks such as recognizing textures in DTD, the prompt is customized as "[CLASS] texture." where the class names are adjectives like "bubbly" and "dotted." See appendix for the details. The second baseline is the linear probe model. As suggested by Radford et al. and a recent study on few-shot learning, training a linear classifier on top of high-quality pre-trained models' features (like CLIP) can easily achieve performance that is on a par with that of state-of-the-art few-shot learning methods, which are often much more sophisticated. We follow the same training method used by Radford et al. to train the linear probe model.
基线方法。 作者将 CoOp 与两种基线方法比较。 第一种是零样本 CLIP,它基于手工提示。 作者遵循 Radford 等人提出的提示工程指南。 对于通用目标和场景,采用 "a photo of a [CLASS]."。 对于细粒度类别,会加入任务相关上下文,例如 OxfordPets 使用 "a type of pet",Food101 使用 "a type of food"。 当涉及 DTD 中识别纹理等专门任务时,提示被定制为 "[CLASS] texture.",其中类别名是 "bubbly" 和 "dotted" 等形容词。 细节见附录。 第二种基线是线性探测模型。 正如 Radford 等人以及一项近期 few-shot 学习研究所建议的,在高质量预训练模型(如 CLIP)的特征之上训练线性分类器,很容易达到与最先进 few-shot 学习方法相当的性能,而后者通常复杂得多。 作者采用 Radford 等人使用的相同训练方法来训练线性探测模型。
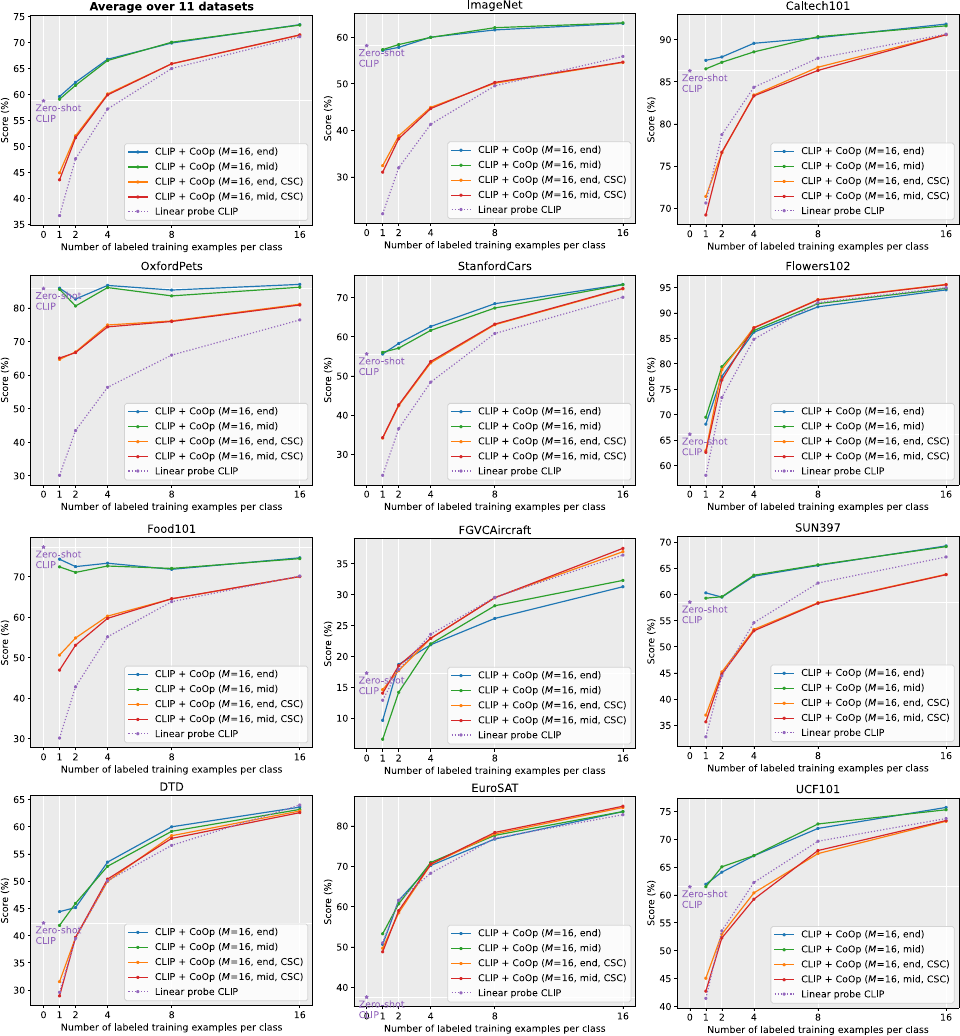
Comparison with Hand-Crafted Prompts. Figure Figure 3 summarizes the results. Our default model is CLIP+CoOp with the class token positioned in the end. The two different ways of positioning the class token achieve similar performance as their curves highly overlap. From the average performance displayed in the top-left corner, we observe that CLIP+CoOp is a strong few-shot learner, requiring only two shots on average to obtain a decent margin over zero-shot CLIP. Given 16 shots for training, the average gap brought by CoOp can be further increased to around 15%.
与手工提示比较。 图3 总结了结果。 作者的默认模型是将类别 token 放在末尾的 CLIP+CoOp。 两种不同的类别 token 放置方式取得相似性能,因为它们的曲线高度重合。 从左上角显示的平均性能来看,作者观察到 CLIP+CoOp 是一个强 few-shot 学习器,平均只需要两个样本就能相对零样本 CLIP 获得不错的幅度。 给定 16 个样本进行训练时,CoOp 带来的平均差距可以进一步增加到约 15%。
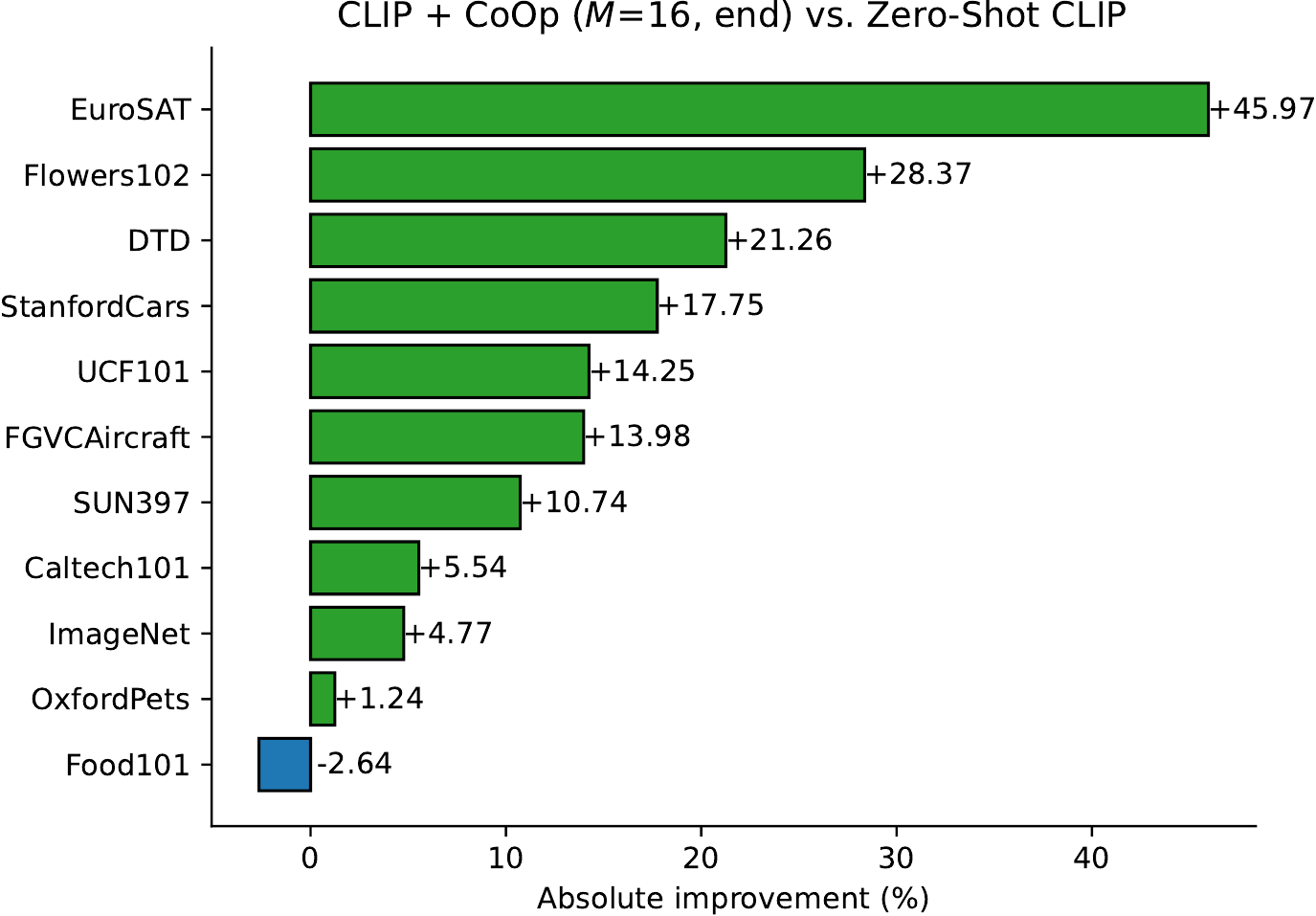
Figure Figure 4 ranks the absolute improvements obtained by CoOp at 16 shots over hand-crafted prompts. Huge improvements are observed on specialized tasks namely EuroSAT and DTD where the increase in performance reaches over 45% and 20% respectively. The jumps in performance are also significant (those more than 10%) on most fine-grained datasets including Flowers102, StanfordCars and FGVCAircraft, as well as on scene and action recognition datasets (i.e., SUN397 & UCF101). Since ImageNet is a challenging dataset that contains 1,000 classes, the 4.77% improvement is also noteworthy. In contrast, the increases on the two fine-grained datasets, OxfordPets and Food101, are less appealing. We find that the negative results on Food101, for learning-based models including CoOp and linear probe, are caused by the noisy training data with "intense colors and sometimes wrong labels." By digging into CLIP+CoOp's curves on these two datasets in Figure Figure 3, we find there is a loss of momentum in performance improvements even with more shots used, seemingly an overfitting problem. A potential solution is to impose higher regularization like increasing the weight decay. Nonetheless, the overall results are strong enough to serve as evidence of CoOp's capability of learning task-relevant prompts in a data-efficient manner.
图4 对 CoOp 在 16-shot 时相对手工提示取得的绝对提升进行排序。 在 EuroSAT 和 DTD 这两个专门任务上可以观察到巨大提升,性能增幅分别超过 45% 和 20%。 在大多数细粒度数据集(包括 Flowers102、StanfordCars 和 FGVCAircraft)以及场景和动作识别数据集(即 SUN397 和 UCF101)上,性能跳升也很显著(超过 10%)。 由于 ImageNet 是一个包含 1,000 个类别的挑战性数据集,4.77% 的提升也值得注意。 相比之下,在 OxfordPets 和 Food101 这两个细粒度数据集上的提升就不那么吸引人。 作者发现,对于 CoOp 和线性探测等基于学习的模型,Food101 上的负面结果是由“颜色强烈且有时标签错误”的噪声训练数据造成的。 进一步查看 图3 中 CLIP+CoOp 在这两个数据集上的曲线后,作者发现即使使用更多样本,性能提升的势头也会减弱,看起来像是过拟合问题。 一个潜在解决方案是施加更强正则化,例如增加权重衰减。 尽管如此,整体结果已经足够有力,可以证明 CoOp 以数据高效方式学习任务相关提示的能力。
| Source | Target | ||||
|---|---|---|---|---|---|
| Method | ImageNet | -V2 | -Sketch | -A | -R |
| ResNet-50 | |||||
| Zero-Shot CLIP | 58.18 | 51.34 | 33.32 | 21.65 | 56.00 |
| Linear Probe CLIP | 55.87 | 45.97 | 19.07 | 12.74 | 34.86 |
| CLIP + CoOp ($M=16$) | 62.95 | 55.11 | 32.74 | 22.12 | 54.96 |
| CLIP + CoOp ($M=4$) | 63.33 | 55.40 | 34.67 | 23.06 | 56.60 |
| ResNet-101 | |||||
| Zero-Shot CLIP | 61.62 | 54.81 | 38.71 | 28.05 | 64.38 |
| Linear Probe CLIP | 59.75 | 50.05 | 26.80 | 19.44 | 47.19 |
| CLIP + CoOp ($M=16$) | 66.60 | 58.66 | 39.08 | 28.89 | 63.00 |
| CLIP + CoOp ($M=4$) | 65.98 | 58.60 | 40.40 | 29.60 | 64.98 |
| ViT-B/32 | |||||
| Zero-Shot CLIP | 62.05 | 54.79 | 40.82 | 29.57 | 65.99 |
| Linear Probe CLIP | 59.58 | 49.73 | 28.06 | 19.67 | 47.20 |
| CLIP + CoOp ($M=16$) | 66.85 | 58.08 | 40.44 | 30.62 | 64.45 |
| CLIP + CoOp ($M=4$) | 66.34 | 58.24 | 41.48 | 31.34 | 65.78 |
| ViT-B/16 | |||||
| Zero-Shot CLIP | 66.73 | 60.83 | 46.15 | 47.77 | 73.96 |
| Linear Probe CLIP | 65.85 | 56.26 | 34.77 | 35.68 | 58.43 |
| CLIP + CoOp ($M=16$) | 71.92 | 64.18 | 46.71 | 48.41 | 74.32 |
| CLIP + CoOp ($M=4$) | 71.73 | 64.56 | 47.89 | 49.93 | 75.14 |
Comparison with Linear Probe CLIP. In terms of the overall performance (Figure Figure 3, top-left), CLIP+CoOp demonstrates clear advantages over the linear probe model. The latter requires more than 4 shots on average to match the zero-shot's performance while CoOp's average gain at 4 shots is already impressive. It is also clear that the gaps in the extreme low-data regime such as one or two shots are much larger, suggesting that CoOp is much more effective than learning a linear classifier from scratch for few-shot learning. We also observe that the linear probe model is comparable to CLIP+CoOp on the two specialized tasks (DTD & EuroSAT) as well as on a couple of fine-grained datasets (Flowers102 & FGVCAircraft)---this is not too surprising as the pre-trained CLIP space has been proved powerful, making the linear probe model a strong competitor. Nevertheless, CoOp's CSC version can beat the linear probe CLIP on the aforementioned datasets, and moreover, shows much better potential when more shots become available. We later show that CoOp obtains much stronger performance than the linear probe model in domain generalization.
与线性探测 CLIP 比较。 从整体性能来看(图3 左上),CLIP+CoOp 相较线性探测模型展现出明显优势。 后者平均需要超过 4 个样本才能达到零样本模型的性能,而 CoOp 在 4-shot 时的平均增益已经令人印象深刻。 同样明显的是,在一两个样本这样的极低数据场景下,差距要大得多,这表明在 few-shot 学习中,CoOp 比从头学习线性分类器有效得多。 作者还观察到,线性探测模型在两个专门任务(DTD 和 EuroSAT)以及若干细粒度数据集(Flowers102 和 FGVCAircraft)上与 CLIP+CoOp 相当;这并不太令人意外,因为预训练 CLIP 空间已被证明很强,使线性探测模型成为强竞争者。 尽管如此,CoOp 的 CSC 版本可以在上述数据集上击败线性探测 CLIP,并且当更多样本可用时显示出更好的潜力。 作者稍后表明,CoOp 在领域泛化中取得了比线性探测模型强得多的性能。
Unified vs Class-Specific Context. On average, using unified context leads to better performance. In terms of when to apply CSC and when not to, we have the following suggestions. For generic objects (ImageNet & Caltech101), scenes (SUN397) and actions (UCF101), using unified context is clearly better. Unified context also works better on some fine-grained datasets including OxfordPets and Food101, but on others like StanfordCars, Flowers102 and FGVCAircraft the CSC version is preferred. CSC also yields better performance on the two specialized tasks, DTD and EuroSAT, at 16 shots in particular. However, CSC mostly underperforms unified context in challenging low-data scenarios (fewer than 8 shots), which makes sense because CSC has more parameters than unified context and needs more data for training.
统一上下文与类别特定上下文。 平均而言,使用统一上下文会带来更好性能。 关于什么时候应用 CSC、什么时候不应用,作者有以下建议。 对于通用目标(ImageNet 和 Caltech101)、场景(SUN397)和动作(UCF101),使用统一上下文明显更好。 统一上下文在 OxfordPets 和 Food101 等一些细粒度数据集上也表现更好,但在 StanfordCars、Flowers102 和 FGVCAircraft 等其他数据集上则更偏好 CSC 版本。 CSC 在 DTD 和 EuroSAT 这两个专门任务上也带来更好性能,尤其是在 16-shot 时。 然而,CSC 在具有挑战性的低数据场景(少于 8 个样本)中大多弱于统一上下文,这是合理的,因为 CSC 参数多于统一上下文,需要更多数据来训练。
| Method | ResNet-50 | ResNet-101 | ViT-B/32 | ViT-B/16 |
|---|---|---|---|---|
| Prompt engineering | 58.18 | 61.26 | 62.05 | 66.73 |
| Prompt ensembling | 60.41 | 62.54 | 63.71 | 68.74 |
| CoOp | 62.95 | 66.60 | 66.85 | 71.92 |
4.2 Domain Generalization
Since CoOp requires training on a specific data distribution, it risks learning spurious correlations that are detrimental to generalization in unseen distributions (domains), as suggested in recent studies. On the contrary, zero-shot CLIP is not tied to a specific data distribution and has exhibited strong robustness to distribution shifts. In this section, we aim to unveil how robust CoOp is to distribution shifts, in comparison to zero-shot CLIP and the linear probe model.
由于 CoOp 需要在特定数据分布上训练,它有可能学习到对未见分布(领域)泛化有害的虚假相关性,正如近期研究所指出的那样。 相反,零样本 CLIP 不绑定到特定数据分布,并且已经表现出对分布偏移的强鲁棒性。 在本节中,作者旨在揭示 CoOp 相比零样本 CLIP 和线性探测模型,对分布偏移究竟有多鲁棒。
Datasets. The source dataset is ImageNet. The target datasets are ImageNetV2, ImageNet-Sketch, ImageNet-A and ImageNet-R, all of which have compatible class names with ImageNet allowing seamless transfer for the prompts learned by CoOp. ImageNetV2 is a reproduced test set using different sources while following ImageNet's data collection process. ImageNet-Sketch contains sketch images belonging to the same 1,000 ImageNet classes. Both ImageNet-A and -R contain 200 classes derived from a subset of ImageNet's 1,000 classes. The former consists of real-world adversarially filtered images that cause current ImageNet classifiers to produce low results, whereas the latter features a rendition of the ImageNet classes in diverse image styles such as paintings, cartoons and sculptures.
数据集。 源数据集是 ImageNet。 目标数据集是 ImageNetV2、ImageNet-Sketch、ImageNet-A 和 ImageNet-R,它们都具有与 ImageNet 兼容的类别名,使 CoOp 学到的提示可以无缝迁移。 ImageNetV2 是一个复现测试集,使用不同来源但遵循 ImageNet 的数据收集过程。 ImageNet-Sketch 包含属于同一 1,000 个 ImageNet 类别的素描图像。 ImageNet-A 和 -R 都包含从 ImageNet 的 1,000 个类别子集中派生出的 200 个类别。 前者由现实世界中经过对抗过滤、会导致当前 ImageNet 分类器产生较低结果的图像组成,而后者以绘画、卡通和雕塑等多样图像风格呈现 ImageNet 类别。
Results. Table Table 1 summarizes the results (with a variety of vision backbones). It is surprising that CoOp enhances CLIP's robustness to distribution shifts, despite the exposure to the source dataset. This suggests that the learned prompts are also generalizable. Moreover, it is interesting to see that using fewer context tokens leads to better robustness. In contrast, the linear probe model obtains much worse results on these target datasets, exposing its weakness in domain generalization. In the appendix, we provide the domain generalization results on DOSCO-2k, a recently proposed benchmark focusing on contextual domain shift.
结果。 表1 总结了结果(使用多种视觉主干)。 令人惊讶的是,CoOp 尽管接触了源数据集,却增强了 CLIP 对分布偏移的鲁棒性。 这表明学到的提示同样具有泛化性。 此外,有趣的是,使用更少的上下文 token 会带来更好的鲁棒性。 相比之下,线性探测模型在这些目标数据集上得到差得多的结果,暴露出它在领域泛化中的弱点。 在附录中,作者提供了 DOSCO-2k 上的领域泛化结果;这是一个近期提出、关注上下文领域偏移的基准。
4.3 Further Analysis
| Avg % | |
|---|---|
| 72.65 | |
| "a photo of a" | 72.65 |
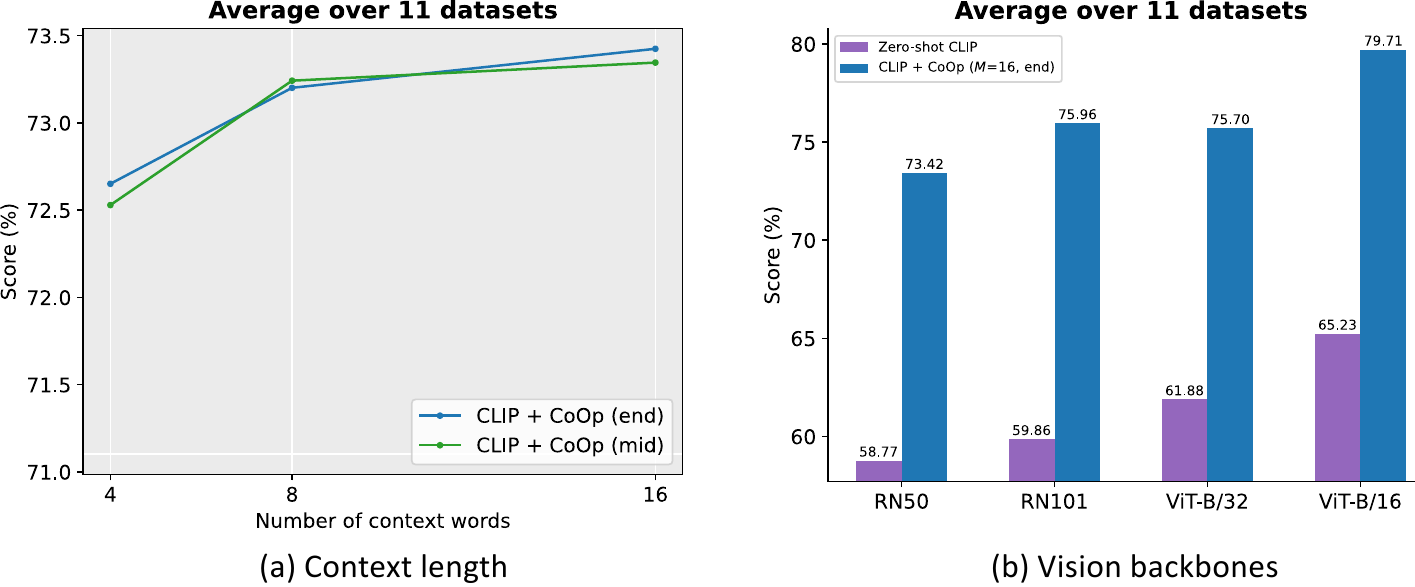
Context Length. How many context tokens should be used? And is it better to have more context tokens? The results in Section 4.2 suggest having a shorter context length benefits domain generalization (probably due to less overfitting as fewer parameters are learned). Here we study this hyperparameter for source datasets. Specifically, we repeat experiments on the 11 datasets by varying the context length from 4 to 8 to 16. The average results are shown in Figure Figure 5(a), which indicate that having more context tokens leads to better performance and that positioning the class token in the middle gains more momentum with longer context length. To sum up, there is no golden rule for selecting perfect context length since one needs to balance between performance and robustness to distribution shift.
上下文长度。 应该使用多少个上下文 token? 拥有更多上下文 token 是否更好? 第 4.2 节中的结果表明,较短的上下文长度有利于领域泛化(可能是因为学习到的参数更少,过拟合更轻)。 这里作者研究源数据集上的这一超参数。 具体而言,作者在 11 个数据集上重复实验,将上下文长度从 4 变为 8 再到 16。 平均结果如 图5(a) 所示,表明更多上下文 token 会带来更好性能,并且随着上下文长度变长,把类别 token 放在中间会获得更多提升势头。 总之,选择完美上下文长度没有黄金规则,因为需要在性能与对分布偏移的鲁棒性之间做平衡。
Vision Backbones. Figure Figure 5(b) summarizes the results on the 11 datasets using a variety of vision backbones covering both CNNs and ViTs. The results are expected: the more advanced the backbone, the better the performance. The gap between CoOp and hand-crafted prompts is significant across all architectures.
视觉主干。 图5(b) 总结了在 11 个数据集上使用多种视觉主干的结果,这些主干覆盖 CNN 和 ViT。 结果符合预期:主干越先进,性能越好。 在所有架构上,CoOp 与手工提示之间的差距都很显著。
Comparison with Prompt Ensembling. The authors of CLIP have suggested that additional improvements can be obtained by ensembling over multiple zero-shot classifiers generated using different hand-crafted prompts, such as "a photo of the large [CLASS].", "a bad photo of the [CLASS]." and "a origami [CLASS].", which reflect a different scale, view and abstraction respectively for an image. We are interested to know whether the prompts learned by CoOp can still maintain advantages when compared with prompt ensembling. For fair comparison, we use the select prompts from Radford et al., which have been extensively tuned on ImageNet, to construct the ensemble classifier. Table Table 2 shows the comparison and justifies the superiority of CoOp. Given the potential of prompt ensembling, future work could investigate how to improve CoOp from the ensembling perspective.
与提示集成比较。 CLIP 的作者指出,通过集成多个使用不同手工提示生成的零样本分类器可以获得额外提升,例如 "a photo of the large [CLASS]."、"a bad photo of the [CLASS]." 和 "a origami [CLASS].",它们分别反映图像的不同尺度、视角和抽象程度。 作者想知道,与提示集成相比,CoOp 学到的提示是否仍能保持优势。 为公平比较,作者使用 Radford 等人中经过 ImageNet 大量调优的精选提示来构造集成分类器。 表2 展示了比较结果,并证明了 CoOp 的优越性。 考虑到提示集成的潜力,未来工作可以从集成角度研究如何改进 CoOp。
| # | ImageNet | Food101 | OxfordPets | DTD | UCF101 |
|---|---|---|---|---|---|
| 1 | potd (1.7136) | lc (0.6752) | tosc (2.5952) | boxed (0.9433) | meteorologist (1.5377) |
| 2 | that (1.4015) | enjoyed (0.5305) | judge (1.2635) | seed (1.0498) | exe (0.9807) |
| 3 | filmed (1.2275) | beh (0.5390) | fluffy (1.6099) | anna (0.8127) | parents (1.0654) |
| 4 | fruit (1.4864) | matches (0.5646) | cart (1.3958) | mountain (0.9509) | masterful (0.9528) |
| 5 | ,... (1.5863) | nytimes (0.6993) | harlan (2.2948) | eldest (0.7111) | fe (1.3574) |
| 6 | ° (1.7502) | prou (0.5905) | paw (1.3055) | pretty (0.8762) | thof (1.2841) |
| 7 | excluded (1.2355) | lower (0.5390) | incase (1.2215) | faces (0.7872) | where (0.9705) |
| 8 | cold (1.4654) | N/A | bie (1.5454) | honey (1.8414) | kristen (1.1921) |
| 9 | stery (1.6085) | minute (0.5672) | snuggle (1.1578) | series (1.6680) | imam (1.1297) |
| 10 | warri (1.3055) | along (1.8298) | coca (1.5571) | near (0.8942) | |
| 11 | marvelcomics (1.5638) | well (0.5659) | enjoyment (2.3495) | moon (1.2775) | tummy (1.4303) |
| 12 | .: (1.7387) | ends (0.6113) | jt (1.3726) | lh (1.0382) | hel (0.7644) |
| 13 | N/A | mis (0.5826) | improving (1.3198) | won (0.9314) | boop (1.0491) |
| 14 | lation (1.5015) | somethin (0.6041) | srsly (1.6759) | replied (1.1429) | N/A |
| 15 | muh (1.4985) | seminar (0.5274) | asteroid (1.3395) | sent (1.3173) | facial (1.4452) |
| 16 | .# (1.9340) | N/A | N/A | piedmont (1.5198) | during (1.1755) |
Comparison with Other Fine-tuning Methods. We further compare CoOp with other fine-tuning methods: i) fine-tuning CLIP's image encoder; ii) optimizing a transformation layer added to the text encoder's output; iii) optimizing a bias term added to the text encoder's output. The results are shown in Table Table 5. Obviously, fine-tuning the image encoder does not work well. Adding a transformation layer slightly improves upon the zero-shot model. Adding a bias term shows promising results, but still largely underperforms CoOp, which suggests that the gradients that went through the text encoder provide more useful information.
与其他微调方法比较。 作者进一步将 CoOp 与其他微调方法比较:i)微调 CLIP 的图像编码器;ii)优化添加到文本编码器输出上的变换层;iii)优化添加到文本编码器输出上的偏置项。 结果如 表5 所示。 显然,微调图像编码器效果不好。 添加变换层相较零样本模型略有提升。 添加偏置项显示出有前景的结果,但仍大幅弱于 CoOp,这表明经过文本编码器的梯度提供了更有用的信息。
| ImageNet | $\Delta$ | |
|---|---|---|
| Zero-shot CLIP | 58.18 | - |
| Linear probe | 55.87 | -2.31 |
| Fine-tuning CLIP's image encoder | 18.28 | -39.90 |
| Optimizing transformation layer (text) | 58.86 | 0.68 |
| Optimizing bias (text) | 60.93 | +2.75 |
| CoOp | 62.95 | +4.77 |
Initialization. We compare random initialization with manual initialization. The latter uses the embeddings of "a photo of a" to initialize the context vectors for the 11 datasets. For fair comparison, we also set the context length to 4 when using random initialization. Table Table 3 suggests a "good" initialization does not make much difference. Though further tuning of the initialization words might help, in practice we suggest using the simple random initialization method.
初始化。 作者比较随机初始化和人工初始化。 后者使用 "a photo of a" 的嵌入来初始化 11 个数据集上的上下文向量。 为公平比较,作者在使用随机初始化时也将上下文长度设为 4。 表3 表明“好的”初始化并不会带来太大差异。 虽然进一步调优初始化词可能有帮助,但实践中作者建议使用简单的随机初始化方法。
Interpreting the Learned Prompts. is difficult because the context vectors are optimized in a continuous space. We resort to an indirect way by searching within the vocabulary for words that are closest to the learned vectors based on the Euclidean distance. Note that CLIP uses the BPE representation for tokenization, so the vocabulary includes subwords that frequently appear in text, such as "hu" (subsumed by many words like "hug" and "human"). Table Table 4 shows the searched results on some datasets. We observe that a few words are somewhat relevant to the tasks, such as "enjoyed" for Food101, "fluffy" and "paw" for OxfordPets, and "pretty" for DTD. But when connecting all the nearest words together, the prompts do not make much sense. We also observe that when using manual initialization (like "a photo of a"), the nearest words for the converged vectors are mostly the ones used for initialization. We conjecture that the learned vectors might encode meanings that are beyond the existing vocabulary. Overall, we are unable to draw any firm conclusion based on the observations because using nearest words to interpret the learned prompts could be inaccurate---the semantics of the vectors is not necessarily correlated with the nearest words.
解释学到的提示。 解释学到的提示很困难,因为上下文向量是在连续空间中优化的。 作者采用一种间接方式,即在词表中基于欧氏距离搜索最接近学到向量的词。 注意,CLIP 使用 BPE 表示进行 tokenization,因此词表包含文本中频繁出现的子词,例如 "hu"(被许多词包含,如 "hug" 和 "human")。 表4 展示了部分数据集上的搜索结果。 作者观察到少数词与任务有一定相关性,例如 Food101 的 "enjoyed"、OxfordPets 的 "fluffy" 和 "paw",以及 DTD 的 "pretty"。 但当把所有最近词连接起来时,这些提示并没有多少意义。 作者还观察到,当使用人工初始化(如 "a photo of a")时,收敛向量的最近词大多就是用于初始化的词。 作者猜测,学到的向量可能编码了超出现有词表的含义。 总体而言,作者无法基于这些观察得出任何确定结论,因为用最近词解释学到的提示可能不准确,向量语义不一定与最近词相关。
5. Conclusion, Limitations and Future Work
Large pre-trained vision-language models have shown surprisingly powerful capabilities in diverse downstream applications. However, these models, also called vision foundation models given their "critically central yet incomplete" nature, need to be adapted using automated techniques for better downstream performance and efficiency.
大型预训练视觉-语言模型已经在多样下游应用中展现出惊人的强大能力。 然而,考虑到这些模型“极其核心但尚不完整”的性质,它们也被称为视觉基础模型,并且需要使用自动化技术进行适配,以获得更好的下游性能和效率。
Our research provides timely insights on how CLIP-like models can be turned into a data-efficient learner by using prompt learning, and reveals that despite being a learning-based approach, CoOp performs much better in domain generalization than manual prompts. The results serve as strong evidence that prompt learning has potential for large vision models. It is worth noting that our paper presents the first comprehensive study about adapting large vision models with prompt learning.
作者的研究及时提供了关于如何通过提示学习把 CLIP 类模型转变为数据高效学习器的洞见,并揭示尽管 CoOp 是一种基于学习的方法,它在领域泛化上比人工提示表现好得多。 这些结果有力证明了提示学习对大型视觉模型具有潜力。 值得注意的是,本文呈现了首个关于用提示学习适配大型视觉模型的全面研究。
Though the performance is excellent, the results of CoOp are relatively difficult to interpret, like other continuous prompt learning methods in NLP. The experiments also reveal that CoOp is sensitive to noisy labels given the weak performance on Food101.
尽管性能出色,但与 NLP 中其他连续提示学习方法一样,CoOp 的结果相对难以解释。 实验还表明,考虑到 Food101 上较弱的性能,CoOp 对噪声标签较敏感。
Nevertheless, the simplicity of CoOp allows easy extension for future work and there remain many interesting questions to explore, such as cross-dataset transfer and test-time adaptation. It would also be interesting to investigate more generic adaptation methods for mega-size vision models. In summary, we hope the empirical findings and insights presented in this work could pave the way for future research on efficient adaptation methods for emerging foundation models, which is still a nascent research topic.
尽管如此,CoOp 的简单性使其很容易在未来工作中扩展,并且仍有许多有趣问题值得探索,例如跨数据集迁移和测试时适配。 研究面向超大规模视觉模型的更通用适配方法也会很有趣。 总之,作者希望本文呈现的经验发现和洞见能够为新兴基础模型高效适配方法的未来研究铺平道路,而这仍然是一个处于萌芽阶段的研究主题。