
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
MemoryAgentGraphMAGACL 2026CCF-AUT DallasUniversity of FloridaMAGMA:面向 AI 智能体的基于多图的智能体记忆架构
Abstract
Memory-Augmented Generation (MAG) extends Large Language Models with external memory to support long-context reasoning, but existing approaches largely rely on semantic similarity over monolithic memory stores, entangling temporal, causal, and entity information. This design limits interpretability and alignment between query intent and retrieved evidence, leading to suboptimal reasoning accuracy. In this paper, we propose MAGMA, a multi-graph agentic memory architecture that represents each memory item across orthogonal semantic, temporal, causal, and entity graphs. MAGMA formulates retrieval as policy-guided traversal over these relational views, enabling query-adaptive selection and structured context construction. By decoupling memory representation from retrieval logic, MAGMA provides transparent reasoning paths and fine-grained control over retrieval. Experiments on LoCoMo and LongMemEval demonstrate that MAGMA consistently outperforms state-of-the-art agentic memory systems in long-horizon reasoning tasks.
记忆增强生成(MAG)用外部记忆扩展大语言模型,以支持长上下文推理,但现有方法大多依赖单体记忆存储上的语义相似度,把时间、因果和实体信息纠缠在一起。 这种设计限制了可解释性,也削弱了查询意图与检索证据之间的对齐,从而导致次优的推理准确率。 在本文中,我们提出 MAGMA,这是一种多图智能体记忆架构,它在相互正交的语义、时间、因果和实体图上表示每个记忆项。 MAGMA 将检索表述为在这些关系视图上的策略引导遍历,从而支持查询自适应选择和结构化上下文构建。 通过将记忆表示与检索逻辑解耦,MAGMA 提供透明的推理路径以及对检索的细粒度控制。 在 LoCoMo 和 LongMemEval 上的实验表明,MAGMA 在长程推理任务中持续优于最先进的智能体记忆系统。
1. Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet they remain limited in their ability to maintain and reason over long-term context. These models process information within a finite attention window, and their internal representations do not persist across interactions, causing earlier details to be forgotten once they fall outside the active context. Even within a single long sequence, attention effectiveness degrades with distance due to attention dilution, positional encoding limitations, and token interference, leading to the well-known “lost-in-the-middle” and context-decay phenomena. Moreover, LLMs lack native mechanisms for stable and structured memory, resulting in inconsistent recall, degraded long-horizon reasoning, and limited support for tasks requiring persistent and organized memory.
大语言模型(LLM)已经在广泛任务上展示出卓越能力,但它们维护并推理长期上下文的能力仍然有限。 这些模型在有限注意力窗口内处理信息,而且其内部表示不会跨交互持久存在,因此早期细节一旦落到活跃上下文之外就会被遗忘。 即便在单个长序列内,注意力效果也会因注意力稀释、位置编码限制和 token 干扰而随距离下降,导致众所周知的“lost-in-the-middle”和上下文衰减现象。 此外,LLM 缺乏稳定且结构化记忆的原生机制,导致回忆不一致、长程推理退化,并且对需要持久、有组织记忆的任务支持有限。
To address these inherent limitations, Memory-Augmented Generation (MAG) systems have emerged as a promising direction for enabling LLMs to operate beyond the boundaries of their fixed context windows. MAG equips an agent with an external memory continuously recording interaction histories and allowing the agents to retrieve and reintegrate past experiences when generating new responses. By offloading long-term context to an explicit memory module, MAG systems provide a means for agents to accumulate knowledge over time, support multi-session coherence, and adapt to evolving conversational or task contexts. In this paradigm, memory is no longer implicit in internal activations but becomes a persistent, queryable resource that substantially enhances long-horizon reasoning, personalized behavior, and stable agent identity.
为了解决这些内在局限,记忆增强生成(MAG)系统成为一个有前景的方向,使 LLM 能够在其固定上下文窗口边界之外运行。 MAG 为智能体配备外部记忆,持续记录交互历史,并允许智能体在生成新回答时检索并重新整合过去经历。 通过把长期上下文卸载到显式记忆模块,MAG 系统为智能体提供了一种随时间积累知识、支持多会话连贯性并适应不断演化的对话或任务上下文的方式。 在这一范式中,记忆不再隐含于内部激活,而是成为一种持久、可查询的资源,显著增强长程推理、个性化行为和稳定的智能体身份。
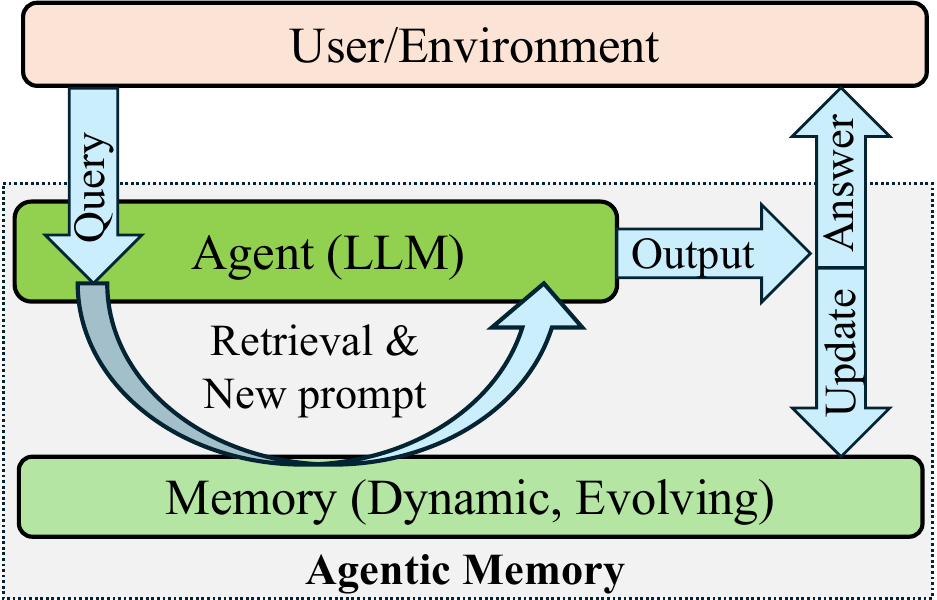
Despite their promise, current MAG systems exhibit structural and operational limitations that constrain their effectiveness in long-term reasoning. Most existing approaches store past interactions in monolithic repositories or minimally structured memory buffers, relying primarily on semantic similarity, recency, or heuristic scoring to retrieve relevant content. For example, A-Mem organizes past interactions into Zettelkasten-like memory units that are incrementally linked and refined, yet their retrieval pipelines rely primarily on semantic embedding similarity, missing the relations such as temporal or causal relationships. Cognitive-inspired frameworks like Nemori introduce principled episodic segmentation and representation alignment, enabling agents to detect event boundaries and construct higher-level semantic summaries. However, their memory structures are still narrative and undifferentiated, with no explicit modeling of distinct relational dimensions.
尽管前景可观,当前 MAG 系统仍表现出结构和运行层面的局限,限制了它们在长期推理中的有效性。 大多数现有方法把过去交互存储在单体仓库或最小结构化记忆缓冲区中,主要依靠语义相似度、近因性或启发式评分来检索相关内容。 例如,A-Mem 将过去交互组织成类似 Zettelkasten 的记忆单元,并进行增量链接和细化,但其检索流水线主要依赖语义嵌入相似度,遗漏时间关系或因果关系等联系。 像 Nemori 这样的认知启发框架引入原则化的情景切分和表示对齐,使智能体能够检测事件边界并构建更高层语义摘要。 然而,它们的记忆结构仍然是叙事式且未区分的,没有显式建模不同关系维度。
To address the structural limitations of existing MAG systems, we propose MAGMA, a multi-graph agentic memory architecture that explicitly models heterogeneous relational structure in an agent’s experience. MAGMA represents each memory item across four orthogonal relational graphs (i.e., semantic, temporal, causal, and entity), yielding a disentangled representation of how events, concepts, and participants are related.
为了解决现有 MAG 系统的结构局限,我们提出 MAGMA,这是一种多图智能体记忆架构,显式建模智能体经历中的异构关系结构。 MAGMA 在四个相互正交的关系图(即语义、时间、因果和实体)上表示每个记忆项,从而得到事件、概念和参与者之间关系的解耦表示。
Built on this unified multi-graph substrate, MAGMA introduces a hierarchical, intent-aware query mechanism that selects relevant relational views, traverses them independently, and fuses the resulting subgraphs into a compact, type-aligned context for generation. By decoupling memory representation from retrieval logic, MAGMA enables transparent reasoning paths, fine-grained control over memory selection, and improved alignment between query intent and retrieved evidence. This relational formulation provides a principled and extensible foundation for agentic memory, improving both long-term coherence and interpretability.
基于这一统一多图基底,MAGMA 引入层级化、意图感知的查询机制,选择相关关系视图、独立遍历它们,并把所得子图融合成紧凑且类型对齐的生成上下文。 通过将记忆表示与检索逻辑解耦,MAGMA 支持透明推理路径、对记忆选择的细粒度控制,并改进查询意图与检索证据之间的对齐。 这种关系化表述为智能体记忆提供了原则化且可扩展的基础,同时提升长期连贯性和可解释性。
Our contributions are summarized as follows:
1. We propose MAGMA, a multi-graph agentic memory architecture that explicitly models semantic, temporal, causal, and entity relations essential for long-horizon reasoning.
2. We introduce an Adaptive Traversal Policy that routes retrieval based on query intent, enabling efficient pruning of irrelevant graph regions and achieving lower latency and reduced token usage.
3. We design a dual-stream memory evolution mechanism that decouples latency-sensitive event ingestion from asynchronous structural consolidation, preserving responsiveness while refining relational structure.
4. We demonstrate that MAGMA consistently outperforms state-of-the-art agentic memory systems on long-context benchmarks including LoCoMo and LongMemEval, while reducing retrieval latency and token consumption relative to prior systems. The code is open-sourced.
我们的贡献总结如下:
1. 我们提出 MAGMA,这是一种多图智能体记忆架构,显式建模对长程推理至关重要的语义、时间、因果和实体关系。
2. 我们引入 Adaptive Traversal Policy,它基于查询意图路由检索,从而高效剪除无关图区域,并实现更低延迟和更少 token 使用。
3. 我们设计双流记忆演化机制,将延迟敏感的事件摄取与异步结构巩固解耦,在细化关系结构的同时保持响应性。
4. 我们证明 MAGMA 在包括 LoCoMo 和 LongMemEval 在内的长上下文基准上持续优于最先进的智能体记忆系统,同时相对于先前系统降低检索延迟和 token 消耗。代码已开源。
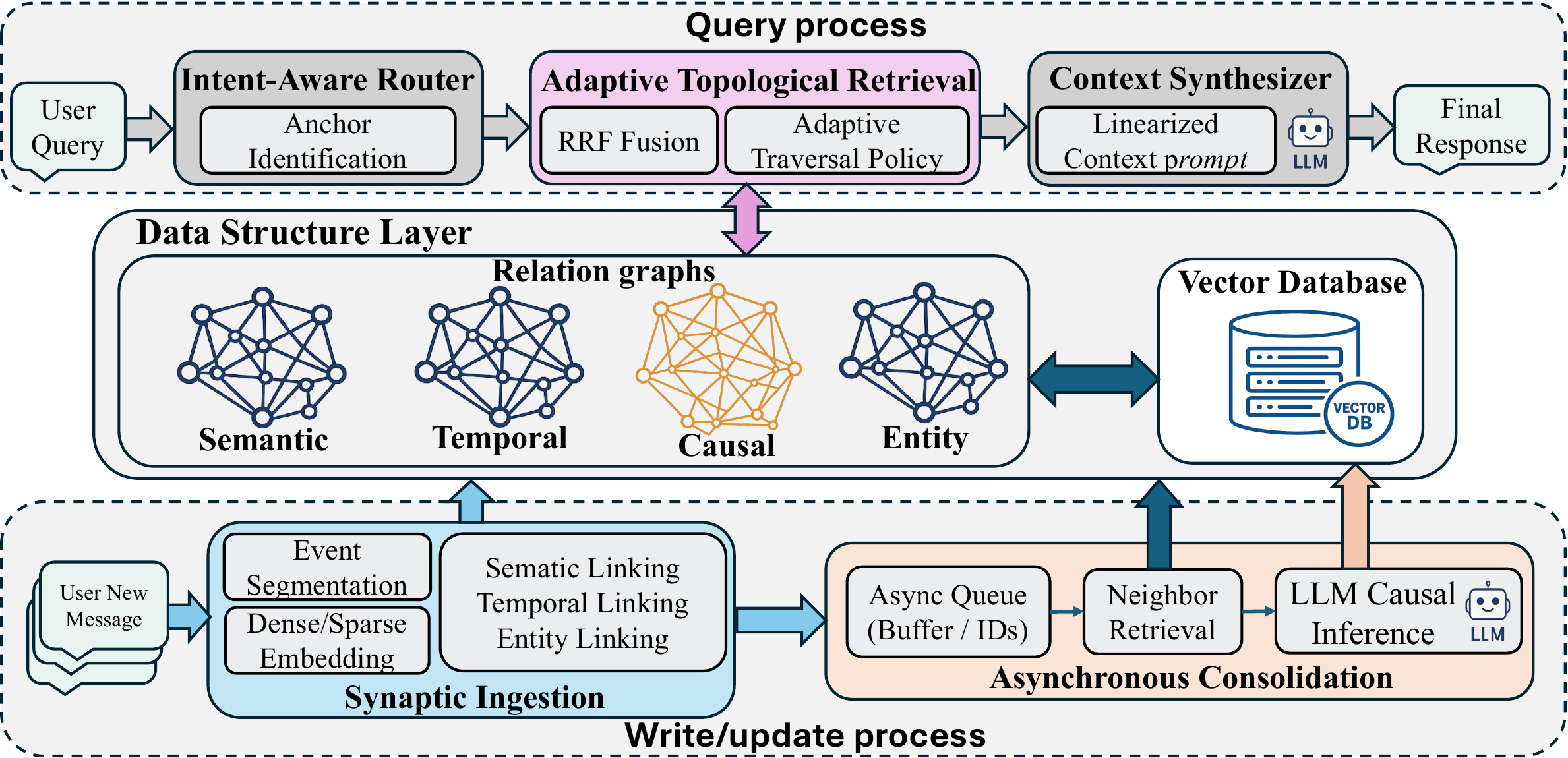
2. Background
Existing Large Language Models (LLMs) face fundamental challenges in handling long-term agentic interactions. These challenges stem from the inherent limitations of fixed-length contexts, which result in fragmented memory and an inability to maintain narrative coherence over time. The evolution of long-term consistency in LLMs is shifted from Context-Window Extension, Retrieval-Augmented Generation (RAG) to Memory-Augmented Generation (MAG).
现有大语言模型(LLM)在处理长期智能体交互时面临根本挑战。 这些挑战来自固定长度上下文的内在限制,它们导致记忆碎片化,并使模型无法随时间保持叙事连贯性。 LLM 中长期一致性的演进路径已经从上下文窗口扩展、检索增强生成(RAG)转向记忆增强生成(MAG)。
Retrieval-oriented approaches enrich the model with an external, dynamic memory library, giving rise to the paradigm of Memory-Augmented Generation (MAG). Formally, unlike static RAG, MAG maintains a time-variant memory
面向检索的方法用外部动态记忆库增强模型,由此产生记忆增强生成(MAG)范式。 形式上,与静态 RAG 不同,MAG 维护一个随时间变化的记忆
As shown in Figure 1, this feedback loop enables the memory module to evolve over time: the user query is combined with retrieved information to form an augmented prompt, and the model’s output is subsequently written back to refine
如图1所示,这一反馈循环使记忆模块能够随时间演化:用户查询与检索信息结合形成增强提示,随后模型输出被写回以细化
Some prior schemes focused on structuring the intermediate states or relationships of memory to enable better reasoning. Think-in-Memory (TiM) stores evolving chains-of-thought to maintain consistency. A-MEM draws inspiration from the Zettelkasten method, organizing knowledge into an interconnected note network. More recently, graph-based approaches like GraphRAG and Zep structure memory into knowledge graphs to capture cross-document dependencies. We provide a detailed discussion of related work in the appendix.
一些先前方案关注对记忆的中间状态或关系进行结构化,以支持更好的推理。 Think-in-Memory(TiM)存储不断演化的思维链以保持一致性。 A-MEM 从 Zettelkasten 方法获得启发,将知识组织为互联笔记网络。 更近期的 GraphRAG 和 Zep 等基于图的方法把记忆结构化为知识图谱,以捕获跨文档依赖。 我们在附录中对相关工作提供详细讨论。
However, prior work typically organizes memory around associative proximity (e.g., semantic similarity) rather than mechanistic dependency. As a result, such methods can retrieve what occurred but struggle to reason about why, since they lack explicit representations of causal structure, leading to reduced accuracy in complex reasoning tasks.
然而,先前工作通常围绕关联邻近性(例如语义相似度)而非机制性依赖来组织记忆。 因此,这类方法可以检索发生了什么,但难以推理为什么,因为它们缺乏因果结构的显式表示,进而降低复杂推理任务中的准确率。
3. MAGMA Design
In this section, we introduce the proposed Multi-Graph based Agentic Memory (MAGMA) design and its components in detail.
在本节中,我们详细介绍所提出的基于多图的智能体记忆(MAGMA)设计及其组件。
3.1 Architectural Overview
MAGMA architecture is organized into the following three logical layers, orchestrating the interaction between control logic and the memory substrate as illustrated in Figure 2.
MAGMA 架构被组织为以下三个逻辑层,如图2所示,它们协调控制逻辑与记忆基底之间的交互。
Query Process: The inference engine responsible for retrieving and synthesizing information. It comprises the Intent-Aware Router for dispatching tasks, the Adaptive Topological Retrieval module for executing graph traversals, and the Context Synthesizer for generating the final narrative response.
查询过程: 负责检索和综合信息的推理引擎。 它包含用于分派任务的 Intent-Aware Router、用于执行图遍历的 Adaptive Topological Retrieval 模块,以及用于生成最终叙事回答的 Context Synthesizer。
Data Structure (
数据结构(
Write/Update Process: A dual-stream pipeline manages memory evolution. It decouples latency-sensitive operations via Synaptic Ingestion (Fast Path) from compute-intensive reasoning via Asynchronous Consolidation (Slow Path), ensuring the system remains responsive while continuously deepening its memory structure. Functionally, the Query Layer interacts with the Data Structure Layer to execute the synchronous Query Process (Section 3.3), while the Write/Update Layer manages the continuous Memory Evolution (Section 3.4).
写入/更新过程: 一个双流流水线管理记忆演化。 它通过 Synaptic Ingestion(快速路径)把延迟敏感操作与通过 Asynchronous Consolidation(慢速路径)进行的计算密集型推理解耦,确保系统在持续深化记忆结构的同时保持响应性。 在功能上,查询层与数据结构层交互以执行同步查询过程(第 3.3 节),而写入/更新层管理持续记忆演化(第 3.4 节)。
3.2 Data Structure Layer
As the core component of Memory-Augmented Generation (MAG), the data structure layer is responsible for storing, organizing, and evolving past information to support future retrieval and updates. In MAGMA, we formalize this layer as a time-variant directed multigraph
作为记忆增强生成(MAG)的核心组件,数据结构层负责存储、组织和演化过去信息,以支持未来检索和更新。 在 MAGMA 中,我们将这一层形式化为随时间变化的有向多重图
Unified node representation: The node set
统一节点表示: 节点集合
where
其中
Relation graphs (edge space): The edge set
- Temporal Graph (
): Defined as strictly ordered pairs where . This immutable chain provides the ground truth for chronological reasoning.
- Causal Graph (
): Directed edges representing logical entailment. An edge exists if , explicitly inferred by the consolidation module to support “Why” queries.
- Semantic Graph (
): Undirected edges connecting conceptually similar events, formally defined by .
- Entity Graph (
): Edges connecting events to abstract entity nodes, solving the object permanence problem across disjoint timeline segments.
关系图(边空间): 边集合
- 时间图(
): 定义为严格有序对 ,其中 。这条不可变链为时间顺序推理提供事实基础。
- 因果图(
): 表示逻辑蕴含的有向边。如果 ,则存在边 ,它由巩固模块显式推断,用于支持 “Why” 查询。
- 语义图(
): 连接概念上相似事件的无向边,形式化定义为 。
- 实体图(
): 将事件连接到抽象实体节点的边,用于解决不连续时间线片段中的对象恒存问题。
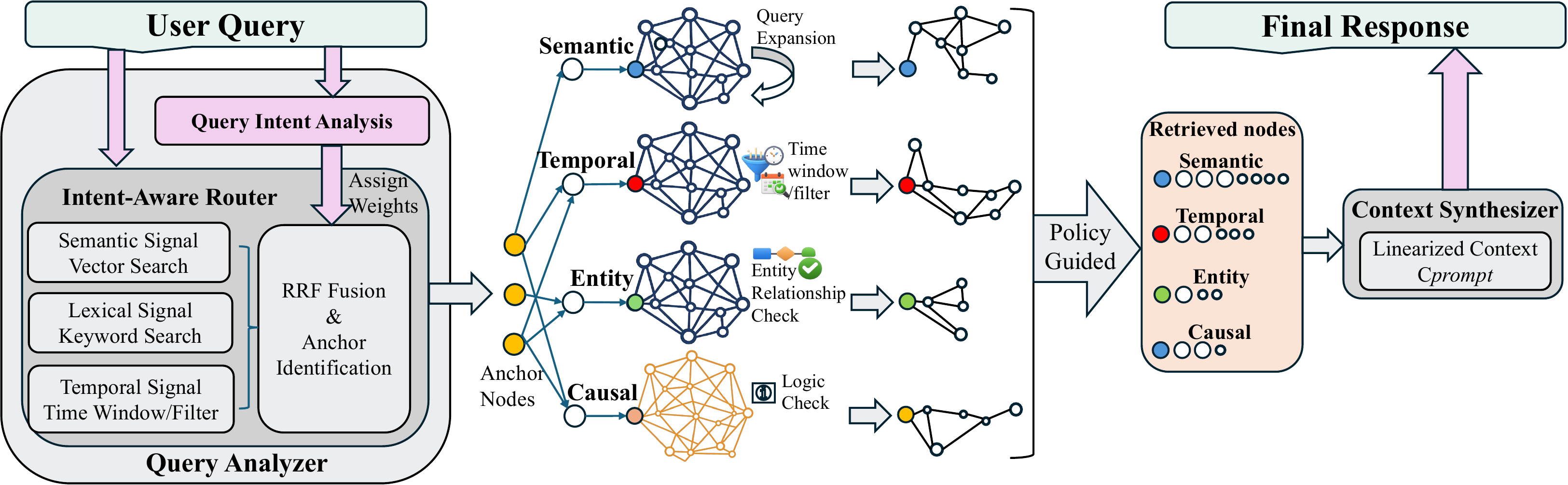
3.3 Query Process: Adaptive Hierarchical Retrieval
As illustrated in Figure 3, retrieval in MAGMA is formulated as a policy-guided graph traversal rather than a static lookup operation. The query process is orchestrated by a Router
如图3所示,MAGMA 中的检索被表述为策略引导的图遍历,而不是静态查找操作。 查询过程由 Router
Stage 1 - Query Analysis & Decomposition: The process begins by decomposing the raw user query
- Intent Classification (
): A lightweight classifier maps to a specific intent type . This acts as the “steering wheel,” determining which graph edges will later be prioritized (e.g., “Why” queries trigger a bias for Causal edges).
- Temporal Parsing (
): A temporal tagger resolves relative expressions (e.g., “last Friday”) into absolute timestamps, defining a hard time window for filtering.
- Representation Extraction: The system simultaneously generates a dense embedding
for semantic search and extracts sparse keywords for exact lexical matching.
阶段 1 - 查询分析与分解: 该过程首先将原始用户查询
- 意图分类(
): 轻量分类器将 映射到特定意图类型 。它充当“方向盘”,决定之后哪些图边会被优先考虑(例如,“Why” 查询会触发对因果边的偏置)。
- 时间解析(
): 时间标注器将相对表达(例如 “last Friday”)解析为绝对时间戳,为过滤定义硬时间窗口。
- 表示抽取: 系统同时生成用于语义搜索的稠密嵌入
,并抽取用于精确词汇匹配的稀疏关键词 。
Stage 2 - Multi-Signal Anchor Identification: Before initiating graph traversal, the system first identifies a set of anchor nodes that serve as entry points into the memory graph. To ensure robustness across query modalities, we fuse signals from dense semantic retrieval, lexical keyword matching, and temporal filtering using Reciprocal Rank Fusion (RRF):
阶段 2 - 多信号锚点识别: 在启动图遍历之前,系统首先识别一组锚节点,作为进入记忆图的入口点。 为确保跨查询模态的稳健性,我们使用 Reciprocal Rank Fusion(RRF)融合来自稠密语义检索、词汇关键词匹配和时间过滤的信号:
This ensures robust starting points regardless of query modality.
这确保无论查询模态如何,都能得到稳健的起始点。
Stage 3 - Adaptive Traversal Policy: Starting from the anchor set
阶段 3 - 自适应遍历策略: 从锚点集合
Here,
这里,
where CAUSAL edges for “Why” queries), and
其中 CAUSAL 边分配高权重),
Algorithm 1: Adaptive Hybrid Retrieval (Heuristic Beam Search)
Input: Query
Output: Narrative Context
- // Phase 1: Initialization
- for
to do for do for do if then end if end for end for if break - end for
- return
Stage 4: Narrative Synthesis via Graph Linearization: The final phase transforms the retrieved subgraph
阶段 4:通过图线性化进行叙事综合: 最后阶段把检索到的子图
1. Topological Ordering: Raw nodes are reorganized to reflect the logic of the query. For temporal queries (
1. 拓扑排序: 原始节点会被重新组织,以反映查询逻辑。 对于时间查询(
2. Context Scaffolding with Provenance: To mitigate hallucination, each node is serialized into a structured block containing its timestamp, content, and explicit reference ID. We define the linearized context
2. 带出处的上下文脚手架: 为缓解幻觉,每个节点会被序列化为包含其时间戳、内容和显式引用 ID 的结构化块。 我们将线性化上下文
where
其中
3.4 Memory Evolution (Write and Update)
Long-term reasoning requires not only effective retrieval, but also a memory substrate that can adapt and reorganize as experience accumulates. MAGMA addresses this requirement through a structured memory evolution scheme that incrementally refines its multi-relational graph over time. Specifically, the transition from
长期推理不仅需要有效检索,还需要一个能够随着经历积累而适应并重组的记忆基底。 MAGMA 通过结构化记忆演化方案满足这一要求,该方案随时间增量细化其多关系图。 具体而言,从
Fast path ( synaptic ingestion): The Fast Path operates on the critical path of interaction, constrained by strict latency requirements. It performs non-blocking operations: event segmentation, vector indexing, and updating the immutable temporal backbone (
快速路径(突触摄取): Fast Path 运行在交互的关键路径上,受到严格延迟要求约束。 它执行非阻塞操作:事件切分、向量索引,以及更新不可变时间骨干(
Algorithm 2: Fast Path: Synaptic Ingestion
Input: User Interaction
Output: Updated Graph
- // Update Temporal Backbone
- // Indexing
- return
Slow path (structural consolidation): Asynchronously, the slow path performs Memory Consolidation (Algorithm 3). It functions as a background worker that dequeues events and densifies the graph structure. By analyzing the local neighborhood
慢速路径(结构巩固): 慢速路径异步执行 Memory Consolidation(算法3)。 它作为后台 worker 运行,出队事件并稠密化图结构。 通过分析近期事件的局部邻域
This process constructs high-value
这一过程构造高价值的
Algorithm 3: Slow Path: Structural Consolidation
- Worker Process:
- loop
if is null continue // Infer latent Causal and Entity structures - end loop
3.5 Implementation
We implement MAGMA as a modular three-layer architecture designed for extensibility, scalability, and deployment flexibility. The storage layer abstracts over heterogeneous physical backends, providing unified interfaces for managing the typed memory graph, dense vector indices, and sparse keyword indices. This abstraction cleanly separates the logical memory model from its physical realization, enabling seamless substitution of storage backends (e.g., in-memory data structures versus production-grade graph or vector databases) with minimal engineering effort.
我们将 MAGMA 实现为模块化三层架构,设计目标是可扩展性、可伸缩性和部署灵活性。 存储层对异构物理后端进行抽象,为管理类型化记忆图、稠密向量索引和稀疏关键词索引提供统一接口。 这一抽象清晰地将逻辑记忆模型与其物理实现分离,使存储后端(例如内存数据结构与生产级图数据库或向量数据库)能够以最少工程工作量无缝替换。
The retrieval layer coordinates the core algorithmic components, including memory construction, multi-stage ranking, and policy-guided graph traversal. It is supported by specialized utility modules for episodic segmentation and temporal normalization, which provide structured signals to downstream retrieval and traversal policies. The application layer manages the interaction loop, evaluation harnesses, and prompt construction, serving as the interface between the agent and the underlying memory system.
检索层协调核心算法组件,包括记忆构建、多阶段排序和策略引导图遍历。 它由用于情景切分和时间归一化的专门工具模块支持,这些模块为下游检索和遍历策略提供结构化信号。 应用层管理交互循环、评估框架和提示构建,作为智能体与底层记忆系统之间的接口。
| Method | Multi-Hop | Temporal | Open-Domain | Single-Hop | Adversarial | Overall |
|---|---|---|---|---|---|---|
| Full Context | 0.468 | 0.562 | 0.486 | 0.630 | 0.205 | 0.481 |
| A-MEM | 0.495 | 0.474 | 0.385 | 0.653 | 0.616 | 0.580 |
| MemoryOS | 0.552 | 0.422 | 0.504 | 0.674 | 0.428 | 0.553 |
| Nemori | 0.569 | 0.649 | 0.485 | 0.764 | 0.325 | 0.590 |
| MAGMA (ours) | 0.528 | 0.650 | 0.517 | 0.776 | 0.742 | 0.700 |
4. Experiments
We conduct comprehensive experiments to evaluate both the reasoning effectiveness and systems properties of the proposed MAGMA architecture over state-of-the-art baselines.
我们开展综合实验,在最先进基线之上评估所提出 MAGMA 架构的推理有效性和系统属性。
4.1 Experimental Setup
Datasets. We evaluate long-term conversational capability using two widely adopted benchmarks: (1) LoCoMo: which contains ultra-long conversations (average length of 9K tokens) designed to assess long-range temporal and causal retrieval. (2) LongMemEval: a large-scale stress-test benchmark with an average context length exceeding 100K tokens, used to evaluate scalability and memory retention stability over extended interaction horizons.
数据集。 我们使用两个广泛采用的基准评估长期对话能力:(1)LoCoMo:包含超长对话(平均长度为 9K token),用于评估长距离时间和因果检索。(2)LongMemEval:一个大规模压力测试基准,平均上下文长度超过 100K token,用于评估扩展交互跨度上的可扩展性和记忆保留稳定性。
Baselines. We compare MAGMA against four state-of-the-art memory architectures. For fair comparison, all methods employ the same backbone LLMs.
- Full Context: Feeds the entire conversation history into the LLM.
- A-MEM: A biological-inspired, self-evolving memory system that dynamically organizes agent experiences.
- Nemori: A graph-based memory utilizing a “predict-calibrate” mechanism for episodic segmentation.
- MemoryOS: A semantic-focused memory operating system employing a hierarchical storage strategy.
基线。 我们将 MAGMA 与四种最先进记忆架构进行比较。 为公平比较,所有方法都使用相同的骨干 LLM。
- Full Context: 将完整对话历史输入 LLM。
- A-MEM: 一种受生物启发的自演化记忆系统,可动态组织智能体经历。
- Nemori: 一种基于图的记忆,利用 “predict-calibrate” 机制进行情景切分。
- MemoryOS: 一种语义聚焦的记忆操作系统,采用层级存储策略。
Metrics. Following standard evaluation protocols, we primarily use the LLM-as-a-Judge score to assess the accuracy of different methods. The detailed evaluation prompt used for the judge model is provided in the appendix. For completeness, we also report token-level F1 and BLEU-1.
指标。 遵循标准评估协议,我们主要使用 LLM-as-a-Judge 分数评估不同方法的准确率。 judge 模型使用的详细评估提示在附录中提供。 为完整起见,我们也报告 token-level F1 和 BLEU-1。
4.2 Overall Comparison
This section introduces the accuracy performance comparison between all methods on the LoCoMo benchmark based on LLM-as-a-judge. As shown in Table 1, MAGMA achieves the highest overall judge score of 0.7, substantially outperforming the other baselines: Full Context (0.481), A-MEM (0.58), MemoryOS (0.553) and Nemori (0.59) by relative margins of 18.6% to 45.5%. This result demonstrates that explicitly modeling multi-relational structure enables more accurate long-horizon reasoning than flat or purely semantic memory architectures.
本节基于 LLM-as-a-judge 介绍 LoCoMo 基准上所有方法的准确率性能比较。 如表1所示,MAGMA 取得最高 overall judge 分数 0.7,相比 Full Context(0.481)、A-MEM(0.58)、MemoryOS(0.553)和 Nemori(0.59)等其他基线,以 18.6% 到 45.5% 的相对幅度显著领先。 这一结果表明,相比平坦或纯语义记忆架构,显式建模多关系结构能够实现更准确的长程推理。
A closer analysis reveals that MAGMA’s advantage is particularly pronounced in reasoning-intensive settings. In the Temporal category, MAGMA slightly but consistently outperforms others (Judge: 0.650 for MAGMA vs. 0.422 - 0.649 for others), validating the effectiveness of our Temporal Inference Engine in resolving relative temporal expressions into grounded chronological representations. The performance gap further widens under adversarial conditions, where MAGMA attains a judge score of 0.742. This robustness stems from the Adaptive Traversal Policy, which prioritizes causal and entity-consistent paths and avoids semantically similar yet structurally irrelevant distractors that often mislead vector-based retrieval systems. Additional results and analyzes, including case studies and evaluations under alternative metrics, are provided in the appendix.
更细致的分析显示,MAGMA 的优势在推理密集型设置中尤其明显。 在 Temporal 类别中,MAGMA 轻微但稳定地优于其他方法(Judge:MAGMA 为 0.650,其他方法为 0.422 - 0.649),验证了我们的 Temporal Inference Engine 在把相对时间表达解析为有依据的时间顺序表示方面的有效性。 在 adversarial 条件下,性能差距进一步扩大,MAGMA 达到 0.742 的 judge 分数。 这种稳健性来自 Adaptive Traversal Policy,它优先选择因果一致和实体一致的路径,并避开语义相似但结构上无关的干扰项,而这类干扰项常常误导基于向量的检索系统。 包括案例研究和替代指标评估在内的额外结果与分析在附录中提供。
| Question Type | Full-context (101K tokens) | Nemori (3.7--4.8K tokens) | MAGMA (0.7--4.2K tokens) |
|---|---|---|---|
| gpt-4o-mini | |||
| single-session-preference | 6.7% | 62.7% | 73.3% |
| single-session-assistant | 89.3% | 73.2% | 83.9% |
| temporal-reasoning | 42.1% | 43.0% | 45.1% |
| multi-session | 38.3% | 51.4% | 50.4% |
| knowledge-update | 78.2% | 52.6% | 66.7% |
| single-session-user | 78.6% | 77.7% | 72.9% |
| Average | 55.0% | 56.2% | 61.2% |
4.3 Generalization Study
To evaluate generalization under extreme context lengths, we compare MAGMA against prior methods on the LongMemEval benchmark. LongMemEval poses a substantial scalability challenge, with an average context length exceeding 100k tokens, and therefore serves as a rigorous stress test for long-term memory retention and retrieval under strict computational constraints. As summarized in Table 2, MAGMA achieves the highest average accuracy (61.2%), outperforming both the Full-context baseline (55.0%) and the Nemori system (56.2%). These results indicate that MAGMA generalizes effectively to ultra-long interaction histories while maintaining strong retrieval precision.
为评估极端上下文长度下的泛化能力,我们在 LongMemEval 基准上将 MAGMA 与先前方法进行比较。 LongMemEval 带来显著的可扩展性挑战,平均上下文长度超过 100k token,因此可作为严格计算约束下长期记忆保留和检索的严苛压力测试。 如表2所总结,MAGMA 取得最高平均准确率(61.2%),超过 Full-context 基线(55.0%)和 Nemori 系统(56.2%)。 这些结果表明,MAGMA 能够有效泛化到超长交互历史,同时保持强检索精度。
At the same time, the results highlight a favorable efficiency–granularity trade-off. Although the Full-context baseline performs strongly on single-session-assistant tasks (89.3%), this performance comes at a prohibitive computational cost, requiring over 100k tokens per query. MAGMA achieves competitive accuracy (83.9%) while using only 0.7k--4.2k tokens per query, representing a reduction of more than 95%. This demonstrates that MAGMA effectively compresses long interaction histories into compact, reasoning-dense subgraphs, preserving essential information while substantially reducing inference-time overhead.
与此同时,结果凸显出有利的效率-粒度权衡。 尽管 Full-context 基线在 single-session-assistant 任务上表现很强(89.3%),但这一性能带来高昂计算成本,每个查询需要超过 100k token。 MAGMA 在每个查询仅使用 0.7k--4.2k token 的同时取得有竞争力的准确率(83.9%),降幅超过 95%。 这表明 MAGMA 能够有效地把长交互历史压缩为紧凑且推理密集的子图,在保留关键信息的同时显著减少推理时开销。
4.4 System Efficiency Analysis
To evaluate the system efficiency of MAGMA, two metrics are focused: (1) memory build time (the time required to construct the memory graph) and (2) token cost (the average tokens processed per query). Table Table 3 reports the comparative results. While A-MEM achieves the lowest token consumption (2.62k) due to its aggressive summarization, it sacrifices reasoning depth (see Table 1). In contrast, MAGMA achieves the lowest query latency (1.47s) about 40% faster than the next best retrieval baseline (A-MEM) while maintaining a competitive token cost (3.37k). This efficiency stems from our Adaptive Traversal Policy, which prunes irrelevant subgraphs early, and the dual-stream architecture that offloads complex indexing to the background.
为评估 MAGMA 的系统效率,我们关注两个指标:(1)记忆构建时间(构建记忆图所需时间)和(2)token 成本(每个查询平均处理的 token 数)。 表3报告了比较结果。 虽然 A-MEM 因其激进摘要而实现最低 token 消耗(2.62k),但它牺牲了推理深度(见表1)。 相比之下,MAGMA 达到最低查询延迟(1.47s),比次优检索基线(A-MEM)快约 40%,同时保持有竞争力的 token 成本(3.37k)。 这种效率来自我们的 Adaptive Traversal Policy,它会早期剪除无关子图,以及把复杂索引卸载到后台的双流架构。
| Method | Build Time (h) | Tokens/Query (k) | Latency (s) |
|---|---|---|---|
| Full Context | N/A | 8.53 | 1.74 |
| A-MEM | 1.01 | 2.62 | 2.26 |
| MemoryOS | 0.91 | 4.76 | 32.68 |
| Nemori | 0.29 | 3.46 | 2.59 |
| MAGMA | 0.39 | 3.37 | 1.47 |
| MAGMA schemes | Judge | F1 | BLEU-1 |
|---|---|---|---|
| w/o Adaptive Policy | 0.637 | 0.413 | 0.357 |
| w/o Causal Links | 0.644 | 0.439 | 0.354 |
| w/o Temporal Backbone | 0.647 | 0.438 | 0.349 |
| w/o Entity Links | 0.666 | 0.451 | 0.363 |
| MAGMA (Full) | 0.700 | 0.467 | 0.378 |
| Graph Configuration | Multi-Hop | Temporal | Open-Domain | Single-Hop | Adversarial | Overall |
|---|---|---|---|---|---|---|
| Causal Only | 0.470 | 0.460 | 0.430 | 0.650 | 0.680 | 0.590 |
| Temporal Only | 0.440 | 0.620 | 0.450 | 0.650 | 0.520 | 0.577 |
| Entity Only | 0.485 | 0.420 | 0.460 | 0.640 | 0.450 | 0.531 |
| Full MAGMA | 0.528 | 0.650 | 0.517 | 0.776 | 0.742 | 0.700 |
4.5 Ablation Study
In this subsection, we conduct a systematic ablation study to assess the contribution of individual components in MAGMA. By selectively disabling edge types and traversal mechanisms, we isolate the sources of its reasoning capability. The results in Table 4 reveal three main findings. First, removing the Adaptive Policy results in the largest performance drop, with the Judge score decreasing from 0.700 to 0.637. This confirms that intent-aware routing is critical: without it, retrieval degenerates into a static graph walk that introduces structurally irrelevant information and degrades reasoning quality. Second, removing either Causal Links or the Temporal Backbone leads to comparable and substantial performance losses (0.644 and 0.647, respectively), indicating that causal structure and temporal ordering provide complementary, non-substitutable axes of reasoning. Finally, removing Entity Links causes a smaller but consistent decline (0.700 to 0.666), highlighting their role in maintaining entity permanence and reducing hallucinations in entity-centric queries.
在本小节中,我们进行系统消融研究,以评估 MAGMA 中各个组件的贡献。 通过选择性禁用边类型和遍历机制,我们隔离其推理能力的来源。 表4中的结果揭示了三项主要发现。 首先,移除 Adaptive Policy 会导致最大性能下降,Judge 分数从 0.700 降至 0.637。 这确认了意图感知路由至关重要:没有它,检索会退化为静态图游走,引入结构上无关的信息并降低推理质量。 其次,移除 Causal Links 或 Temporal Backbone 会带来相近且显著的性能损失(分别为 0.644 和 0.647),表明因果结构和时间排序提供互补且不可替代的推理轴。 最后,移除 Entity Links 会造成较小但稳定的下降(0.700 到 0.666),突出它们在维持实体恒存性和减少实体中心查询幻觉方面的作用。
To further isolate the contribution of each relation type, we additionally conducted a single-graph-only ablation on LoCoMo, shown in Table 5. The results are consistent with the leave-one-out findings in Table 4. Among single-graph variants, Causal Only achieves the highest overall score (0.590), suggesting that causal relations provide strong logical filtering and robustness against distractor noise. Temporal Only performs best on temporal questions (0.620), confirming that explicit temporal structure is particularly important for sequential reasoning. In contrast, Entity Only obtains the lowest overall score (0.531): while it remains helpful for concept bridging in multi-hop reasoning, it lacks both timeline awareness and logical filtering, which explains why removing entity links causes the smallest drop in the full-system ablation. Overall, these results show that no single relation type is sufficient to recover MAGMA's full reasoning capability, as all single-graph variants remain below 0.60 overall. By explicitly decoupling causal, temporal, and entity relations and combining them with adaptive traversal, MAGMA leverages their complementary strengths to achieve the best overall performance.
为进一步隔离每种关系类型的贡献,我们还在 LoCoMo 上进行了仅使用单图的消融,如表5所示。 结果与表4中的留一法发现一致。 在单图变体中,Causal Only 取得最高 overall 分数(0.590),说明因果关系能够提供强逻辑过滤能力和对干扰噪声的稳健性。 Temporal Only 在 temporal questions 上表现最佳(0.620),确认显式时间结构对于顺序推理尤其重要。 相比之下,Entity Only 得到最低 overall 分数(0.531):虽然它仍有助于多跳推理中的概念桥接,但它缺乏时间线感知和逻辑过滤,这解释了为什么在完整系统消融中移除实体链接造成的下降最小。 总体而言,这些结果表明,没有单一关系类型足以恢复 MAGMA 的完整推理能力,因为所有单图变体的 overall 分数都保持在 0.60 以下。 通过显式解耦因果、时间和实体关系并将它们与自适应遍历结合,MAGMA 利用它们的互补优势取得最佳整体性能。
5. Conclusion
We introduced MAGMA, a multi-graph agentic memory architecture that models semantic, temporal, causal, and entity relations within a unified yet disentangled memory substrate. By formulating retrieval as a policy-guided graph traversal and decoupling memory ingestion from asynchronous structural consolidation, MAGMA enables effective long-horizon reasoning while maintaining low inference-time latency. Empirical results on LoCoMo and LongMemEval demonstrate that MAGMA consistently outperforms state-of-the-art memory systems while achieving substantial efficiency gains under ultra-long contexts.
我们提出了 MAGMA,这是一种多图智能体记忆架构,在统一但解耦的记忆基底中建模语义、时间、因果和实体关系。 通过将检索表述为策略引导的图遍历,并把记忆摄取与异步结构巩固解耦,MAGMA 在保持低推理时延迟的同时支持有效的长程推理。 在 LoCoMo 和 LongMemEval 上的实证结果表明,MAGMA 在超长上下文下持续优于最先进记忆系统,同时取得显著效率收益。
Limitations
While MAGMA demonstrates strong empirical performance, it has several limitations. First, the quality of the constructed memory graph depends on the reasoning fidelity of the underlying Large Language Models used during asynchronous consolidation. This dependency is a shared limitation of agentic memory systems that rely on LLM-based structural inference, as they are susceptible to extraction errors and hallucinations. Although MAGMA employs structured prompts and conservative inference thresholds to reduce spurious links, erroneous or missing relations may still arise and propagate to downstream retrieval. Nevertheless, our experimental results indicate that, even under these constraints, agentic memory systems such as MAGMA substantially outperform traditional baselines, including full-context approaches, in long-horizon reasoning tasks.
虽然 MAGMA 展示出强实证性能,但它仍有若干局限。 首先,构建出的记忆图质量依赖于异步巩固期间所用底层大语言模型的推理保真度。 这种依赖是依靠 LLM 结构推断的智能体记忆系统的共同局限,因为它们容易受到抽取错误和幻觉影响。 尽管 MAGMA 使用结构化提示和保守推断阈值来减少伪链接,错误或缺失关系仍可能出现并传播到下游检索。 不过,我们的实验结果表明,即使在这些约束下,MAGMA 等智能体记忆系统在长程推理任务中仍然显著优于包括 full-context 方法在内的传统基线。
Second, multi-graph substrate may introduce additional storage and engineering complexity compared to flat, vector-only memory systems. Maintaining multiple relational views and dual-stream processing incurs a little higher implementation and memory overhead, which may limit applicability in highly resource-constrained environments.
其次,与平坦的纯向量记忆系统相比,多图基底可能引入额外存储和工程复杂度。 维护多个关系视图和双流处理会带来略高的实现和内存开销,这可能限制其在高度资源受限环境中的适用性。
Finally, most existing agentic memory systems, including MAGMA, are primarily evaluated on long-context conversational and agentic benchmarks such as LoCoMo and LongMemEval. While these benchmarks effectively stress temporal and causal reasoning, they do not cover the full range of settings in which agentic memory may be required. Extending MAGMA to other scenarios, such as multimodal agents or environments with heterogeneous observation streams, may require additional adaptation and calibration. Addressing these broader evaluation settings remains an important research direction for future work.
最后,包括 MAGMA 在内的大多数现有智能体记忆系统主要在 LoCoMo 和 LongMemEval 等长上下文对话和智能体基准上评估。 虽然这些基准能有效强调时间和因果推理,但它们并未覆盖可能需要智能体记忆的全部设置。 将 MAGMA 扩展到其他场景,例如多模态智能体或具有异构观察流的环境,可能需要额外适配和校准。 处理这些更广泛的评估设置仍是未来工作的重要研究方向。