
AdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
MemoryAgentUser-CentricTsinghuaAdaMem:面向长程对话智能体的自适应用户中心记忆
Abstract
Large language model (LLM) agents increasingly rely on external memory to support long-horizon interaction, personalized assistance, and multi-step reasoning. However, existing memory systems still face three core challenges: they often rely too heavily on semantic similarity, which can miss evidence crucial for user-centric understanding; they frequently store related experiences as isolated fragments, weakening temporal and causal coherence; and they typically use static memory granularities that do not adapt well to the requirements of different questions. We propose AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem organizes dialogue history into working, episodic, persona, and graph memories, enabling the system to preserve recent context, structured long-term experiences, stable user traits, and relation-aware connections within a unified framework. At inference time, AdaMem first resolves the target participant, then builds a question-conditioned retrieval route that combines semantic retrieval with relation-aware graph expansion only when needed, and finally produces the answer through a role-specialized pipeline for evidence synthesis and response generation. We evaluate AdaMem on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling. Experimental results show that AdaMem achieves state-of-the-art performance on both benchmarks. The code will be released upon acceptance.
大语言模型(LLM)智能体越来越依赖外部记忆来支持长程交互、个性化辅助和多步推理。 然而,现有记忆系统仍面临三项核心挑战:它们往往过度依赖语义相似度,可能错过对用户中心理解至关重要的证据;它们经常把相关经历存成孤立片段,削弱时间和因果连贯性;并且它们通常使用静态记忆粒度,难以适应不同问题的需求。 我们提出 AdaMem,这是一个面向长程对话智能体的自适应用户中心记忆框架。 AdaMem 将对话历史组织为工作记忆、情景记忆、人格记忆和图记忆,使系统能够在统一框架内保留近期上下文、结构化长期经历、稳定用户特征以及关系感知连接。 在推理时,AdaMem 首先解析目标参与者,然后构建问题条件化检索路径,该路径只在需要时结合语义检索和关系感知图扩展,最后通过角色专门化流水线进行证据综合和回答生成。 我们在 LoCoMo 和 PERSONAMEM 基准上评估 AdaMem,以考察长程推理和用户建模能力。 实验结果表明,AdaMem 在两个基准上都达到最先进性能。 代码将在接收后发布。
1. Introduction
Recent advances in large language model (LLM)-based agents have enabled increasingly capable systems for open-ended dialogue, multi-step reasoning, and interactive assistance. Yet these settings are inherently long-horizon: an agent must continually accumulate information across many turns, preserve salient details as user goals evolve, and recover the right evidence when it becomes relevant again. This makes memory a central requirement rather than a peripheral add-on. A useful memory system should not only store past interactions, but also organize them in a form that remains queryable, coherent, and robust as the conversation grows longer and more diverse. Otherwise, memory can become redundant, fragmented, or misaligned with the needs of downstream reasoning, leading to inconsistent behavior and poorly grounded responses.
近期基于大语言模型(LLM)的智能体取得进展,使面向开放式对话、多步推理和交互式辅助的系统能力越来越强。 然而,这些设置本质上都是长程的:智能体必须在许多轮次中持续积累信息,随着用户目标演化保留重要细节,并在证据再次变得相关时恢复正确证据。 这使记忆成为核心需求,而不是外围附加组件。 有用的记忆系统不仅应存储过去交互,还应把它们组织成随着对话变得更长、更复杂仍然可查询、连贯且稳健的形式。 否则,记忆可能变得冗余、碎片化,或与下游推理需求错位,从而导致不一致行为和缺乏根据的回答。
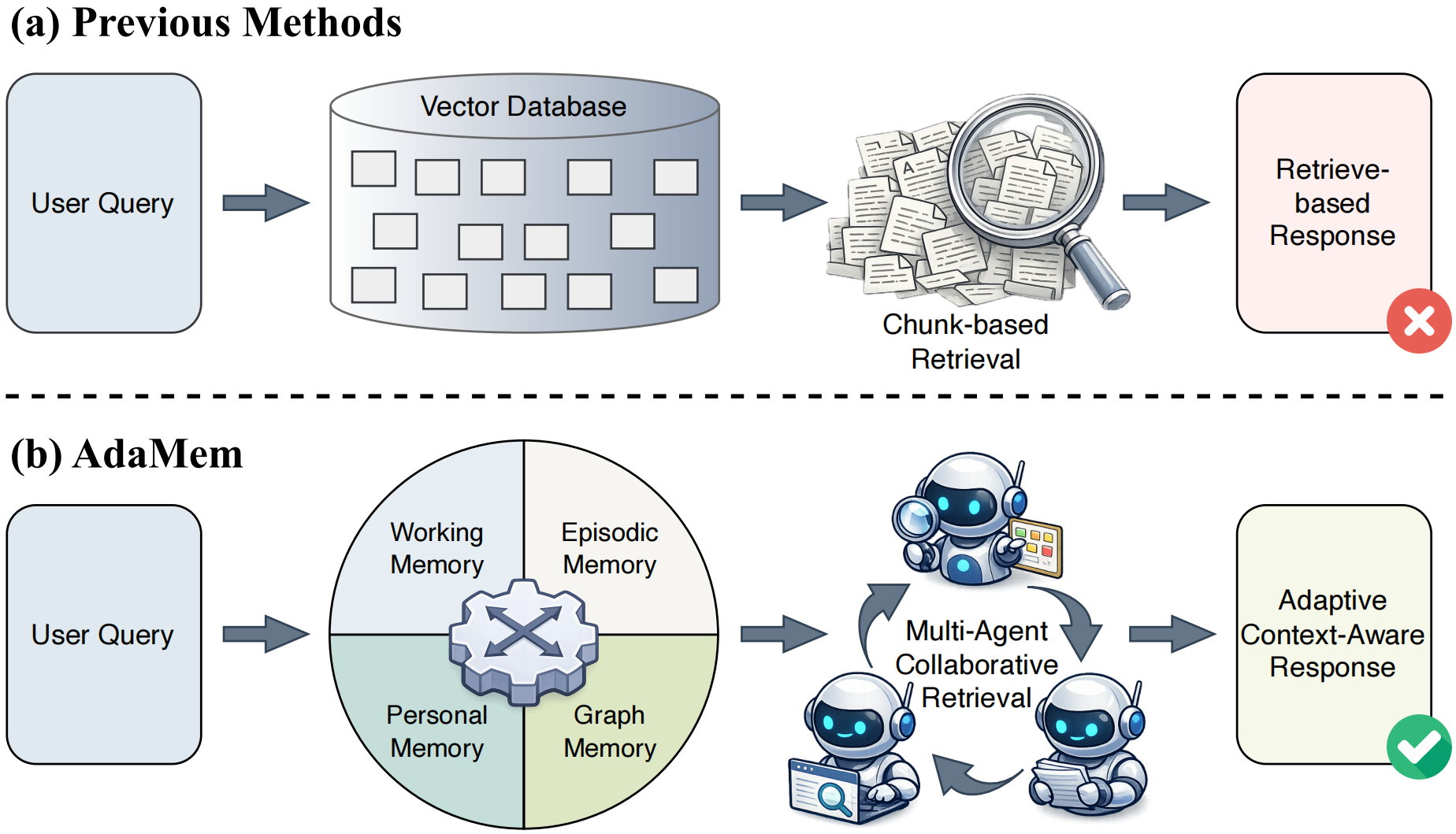
Many recent agent frameworks therefore augment LLMs with explicit external memory modules that support incremental writing, updating, and retrieval throughout interaction. Despite this progress, current approaches still face three limitations.
因此,许多近期智能体框架为 LLM 增加显式外部记忆模块,以便在整个交互过程中支持增量写入、更新和检索。 尽管有这些进展,当前方法仍面临三项限制。
Limitation 1: Memory systems that rely primarily on semantic retrieval may overlook evidence that is not lexically or semantically similar to the query, but is still crucial for user-centric understanding, such as stable preferences, personal attributes, or broader behavioral patterns.
限制 1: 主要依赖语义检索的记忆系统可能忽略那些在词汇或语义上与查询不相似、但对用户中心理解仍然至关重要的证据,例如稳定偏好、个人属性或更广泛的行为模式。
Limitation 2: When related experiences are stored as isolated fragments, their temporal and causal coherence can be weakened, making it difficult to reconstruct how events unfolded and how different pieces of evidence should be connected during reasoning.
限制 2: 当相关经历被存储为孤立片段时,它们的时间和因果连贯性可能被削弱,使推理时难以重建事件如何展开,以及不同证据片段应如何连接。
Limitation 3: Different questions require different memory structures and retrieval strategies. As illustrated in Figure 1, many systems construct memory entries using either fixed-length text chunks. Such static segmentation is often a poor fit for long-horizon reasoning: overly coarse memories may introduce substantial irrelevant context, while overly fine-grained fragments can obscure dependencies across events and topics.
限制 3: 不同问题需要不同的记忆结构和检索策略。 如图1所示,许多系统使用固定长度文本块构建记忆条目。 这种静态切分通常并不适合长程推理:过粗的记忆可能引入大量无关上下文,而过细的片段可能掩盖事件和主题之间的依赖关系。
These limitations suggest that effective long-horizon memory should be both structured and adaptive: it should preserve information at multiple levels of abstraction while dynamically selecting retrieval routes that match each question. Motivated by this observation, we propose
这些限制表明,有效的长程记忆应同时是结构化和自适应的:它应在多个抽象层级保存信息,同时动态选择与每个问题匹配的检索路径。 受这一观察启发,我们提出
In summary, our contributions are:
- We introduce AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents that organizes dialogue history into complementary working, episodic, persona, and graph-based memory structures.
- We propose a question-conditioned retrieval and response pipeline that resolves target participants, invokes relation-aware graph expansion only when needed, and uses specialized agents for evidence synthesis and answer generation.
- We validate our approach on the LoCoMo and PERSONAMEM benchmarks, achieving state-of-the-art performance and demonstrating its strong effectiveness.
总之,我们的贡献如下:
- 我们提出 AdaMem,这是一个面向长程对话智能体的自适应用户中心记忆框架,它把对话历史组织为互补的工作记忆、情景记忆、人格记忆和基于图的记忆结构。
- 我们提出一个问题条件化检索与回答流水线,它解析目标参与者,只在需要时调用关系感知图扩展,并使用专门化智能体进行证据综合和答案生成。
- 我们在 LoCoMo 和 PERSONAMEM 基准上验证我们的方法,达到最先进性能并展示其强有效性。
2. Related Works
2.1 Agentic Memory
Recent research on memory systems for large language model agents has evolved from simple context extension toward more structured and adaptive management. Early approaches typically process long contexts by partitioning them into smaller chunks. Subsequent work introduces more advanced memory mechanisms. For instance, MemGPT manages long-term memory through paging and segmentation. Later studies explore more modular and system-level designs; Mem0 abstracts memory as an independent layer for long-term management. Meanwhile, several works investigate structured memory representations to improve organization, including graph-based memories such as A-Mem and semantic memory structures built upon events or temporal knowledge graphs, such as Zep. Despite these advances, many existing approaches still rely on static retrieval strategies or largely unstructured storage, which may lead to information fragmentation and limited coordination across different abstraction levels and task categories. Designing a unified and adaptive memory system that robustly supports long-term interactions therefore remains an important challenge.
近期关于大语言模型智能体记忆系统的研究,已经从简单上下文扩展演进到更结构化、更自适应的管理。 早期方法通常通过把长上下文划分为更小块来处理长上下文。 后续工作引入更高级的记忆机制。 例如,MemGPT 通过分页和分段管理长期记忆。 后来的研究探索更模块化和系统层面的设计;Mem0 将记忆抽象为用于长期管理的独立层。 与此同时,一些工作研究结构化记忆表示以改进组织方式,包括 A-Mem 等基于图的记忆,以及 Zep 等建立在事件或时间知识图谱之上的语义记忆结构。 尽管有这些进展,许多现有方法仍依赖静态检索策略或基本非结构化存储,这可能导致信息碎片化,以及不同抽象层级和任务类别之间的协调受限。 因此,设计一个能稳健支持长期交互的统一且自适应的记忆系统,仍然是一项重要挑战。
2.2 Multi-Agent LLMs
Recent studies have shown that multi-agent LLMs can effectively address complex tasks by enabling role specialization, collaborative problem solving, and interactive decision making. At the same time, an increasing number of works on agentic memory aim to enhance the capability of large language model agents to model and retain long-term information. Although these efforts provide useful perspectives on coordination and task decomposition, they typically do not focus on how long-horizon dialogue evidence should be organized and adaptively retrieved in a user-centric manner. A recent study, MIRIX, takes an initial step in this direction by introducing specialized agents for memory organization. However, it does not provide explicit mechanisms to ensure the consistency of long-term memory. Motivated by these observations, our work draws on role specialization from the multi-agent literature, but focuses primarily on user-centric memory construction and question-conditioned retrieval for long-horizon dialogue agents.
近期研究表明,多智能体 LLM 可以通过角色专门化、协作式问题求解和交互式决策来有效处理复杂任务。 与此同时,越来越多关于智能体记忆的工作旨在增强大语言模型智能体建模和保留长期信息的能力。 虽然这些努力为协调和任务分解提供了有用视角,但它们通常并不聚焦于长程对话证据应如何以用户中心方式组织并自适应检索。 近期研究 MIRIX 通过引入用于记忆组织的专门化智能体,在这一方向上迈出了初步一步。 然而,它没有提供显式机制来确保长期记忆的一致性。 受这些观察启发,我们的工作借鉴多智能体文献中的角色专门化,但主要聚焦于长程对话智能体的用户中心记忆构建和问题条件化检索。
3. Approach
We present AdaMem, a memory-augmented dialogue framework that continuously organizes user-centric memories at inference time and answers questions through adaptive retrieval over heterogeneous memory sources. AdaMem consists of four tightly coupled components: memory construction, question-conditioned retrieval planning, evidence fusion, and response generation. The overall pipeline is illustrated in Figure 2.
我们提出 AdaMem,这是一个记忆增强对话框架,它在推理时持续组织用户中心记忆,并通过对异质记忆源的自适应检索回答问题。 AdaMem 由四个紧密耦合的组件组成:记忆构建、问题条件化检索规划、证据融合和回答生成。 整体流水线如图2所示。
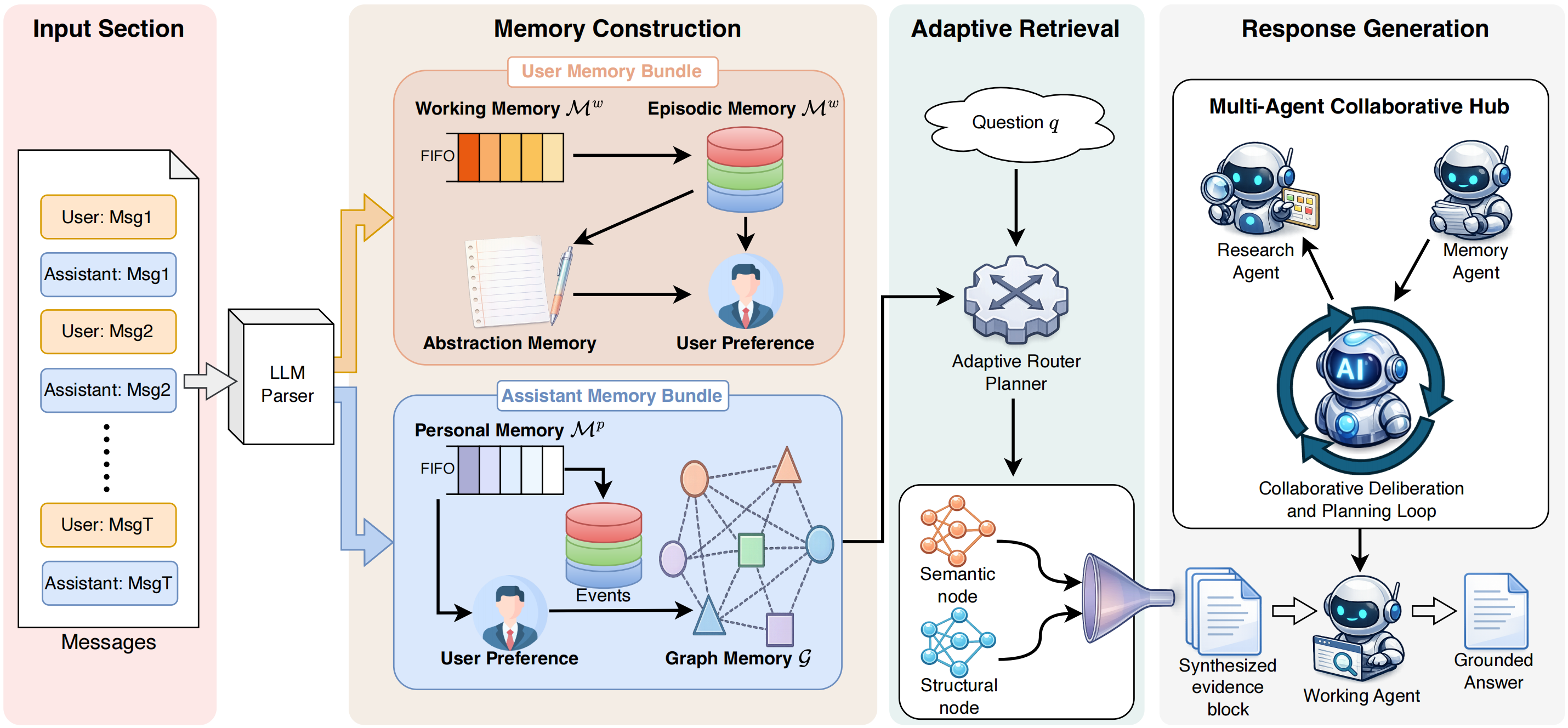
3.1 Method Overview
Given a dialogue history
- Working Memory
: a bounded FIFO buffer that preserves recent conversational context and short-term discourse states.
- Episodic Memory
: long-term structured records including events, facts, attributes, and topic-centric summaries.
- Persona Memory
: compact user profiles distilled from episodic evidence to capture relatively stable preferences and traits.
- Graph Memory
: a heterogeneous graph connecting messages, topics, facts, attributes, and event or persona snapshots for relation-aware retrieval.
This participant-specific organization is important because many questions in multi-party conversations implicitly target one speaker, both speakers, or an ambiguous referent. Accordingly, AdaMem follows a single end-to-end pipeline: it first writes each utterance into structured participant memories, then resolves the likely target participant for
给定对话历史
- 工作记忆
:一个有界 FIFO 缓冲区,保存近期对话上下文和短期话语状态。
- 情景记忆
:长期结构化记录,包括事件、事实、属性和以主题为中心的摘要。
- 人格记忆
:从情景证据中蒸馏出的紧凑用户画像,用于捕捉相对稳定的偏好和特征。
- 图记忆
:一个异质图,连接消息、主题、事实、属性以及事件或人格快照,用于关系感知检索。
这种特定于参与者的组织方式很重要,因为多方对话中的许多问题会隐式指向某一说话者、双方说话者或模糊指代对象。 因此,AdaMem 遵循单一端到端流水线:它首先把每个话语写入结构化参与者记忆,然后解析
3.2 Memory Construction
Message understanding and normalized write. For each incoming utterance
消息理解和规范化写入。 对于来自参与者
Working-to-episodic consolidation. For each participant, working memory is a bounded FIFO queue with capacity ADD, UPDATE, or IGNORE, together with a target key if an existing entry should be revised. The resulting updates populate event, fact, and attribute stores, while the original messages remain available as cacheable provenance for later evidence recovery.
从工作记忆到情景记忆的整合。 对每个参与者而言,工作记忆是一个容量为 ADD、UPDATE 或 IGNORE 之一,并在需要修订现有条目时给出目标键。 由此产生的更新填充事件、事实和属性存储,而原始消息仍作为可缓存来源保留,以便之后恢复证据。
Topic regrouping, persona refresh, and graph synchronization. After consolidation, AdaMem converts fine-grained episodic keys into reusable higher-level memories in two stages. First, event or attribute keys are embedded and linked by a sparse nearest-neighbor graph: each key is connected to its most similar peer, and the connected components define merge groups. Second, an LLM merge prompt rewrites each group into a topic-centric or aspect-centric summary. Topic groups are used to build topic episodic memories and preference-oriented persona descriptors, while clustered attributes are merged into aspect-based persona summaries. In parallel, both message-level and consolidated records are indexed into
主题重组、人格刷新和图同步。 整合之后,AdaMem 通过两个阶段把细粒度情景键转换为可复用的更高层记忆。 首先,事件或属性键被嵌入并通过稀疏最近邻图连接:每个键连接到其最相似的同伴,连通分量定义合并组。 其次,一个 LLM 合并提示将每个组重写为以主题为中心或以方面为中心的摘要。 主题组用于构建主题情景记忆和面向偏好的人格描述符,而聚类后的属性会合并为基于方面的人格摘要。 同时,消息级记录和整合后的记录都会索引到
3.3 Question-Conditioned Retrieval
Target participant resolution. Before retrieval, AdaMem resolves whether
目标参与者解析。 在检索之前,AdaMem 解析
Route planning. Given
路径规划。 给定
Target-aware baseline retrieval. For a selected participant bundle, baseline retrieval aggregates semantic candidates from persona summaries, episodic facts, and topic-linked messages:
目标感知基线检索。 对于选定的参与者记忆束,基线检索会从人格摘要、情景事实和主题链接消息中聚合语义候选:
where attribute candidates come from persona summaries, fact candidates come from episodic fact memory, and topic candidates are linked back to original messages through topic-to-message maps. Beyond pure top-
其中,属性候选来自人格摘要,事实候选来自情景事实记忆,主题候选通过主题到消息映射链接回原始消息。 除了纯 top-
Graph retrieval and evidence fusion. When
图检索和证据融合。 当
where
其中
Here
这里,
3.4 Multi-Agent Collaboration
Memory Agent. The Memory Agent is responsible for online message understanding and memory updates. For each new utterance, it extracts a normalized representation, writes it into the participant-specific working memory, triggers working-to-episodic consolidation when the short-term buffer saturates, and synchronizes the resulting message and memory artifacts to graph memory. Persona descriptors are then refreshed from aggregated episodic evidence at the indexing stage, so the system maintains both up-to-date local context and compact long-term user models.
Memory Agent。 Memory Agent 负责在线消息理解和记忆更新。 对于每个新话语,它抽取规范化表示,将其写入特定于参与者的工作记忆,在短期缓冲区饱和时触发从工作记忆到情景记忆的整合,并把得到的消息和记忆工件同步到图记忆。 随后,人格描述符会在索引阶段从聚合情景证据中刷新,因此系统同时维护最新局部上下文和紧凑长期用户模型。
Research Agent. At question answering time, the Research Agent performs iterative evidence gathering over the unified retrieval interface described above. It follows a Planning
Research Agent。 在问答时,Research Agent 会在上述统一检索接口上执行迭代证据收集。 它遵循 Planning
Working Agent. The Working Agent converts the research summary into the final concise answer. It conditions generation primarily on the integrated summary returned by the Research Agent and, when needed, supplements it with high-confidence persona attributes or factual snippets as auxiliary grounding. This separation allows evidence collection and answer realization to be optimized for different roles while preserving a single memory interface. AdaMem answers each question through a fixed collaboration order among these roles. As a result, response generation remains tightly coupled with the same user-centric memory interface and retrieval backbone introduced above, while allocating explicit deliberation to multi-step evidence synthesis before final answer generation.
Working Agent。 Working Agent 将研究摘要转换为最终简洁答案。 它主要以 Research Agent 返回的整合摘要为条件生成,并在需要时用高置信度人格属性或事实片段作为辅助依据补充。 这种分离使证据收集和答案实现可以面向不同角色优化,同时保留单一记忆接口。 AdaMem 通过这些角色之间固定的协作顺序回答每个问题。 因此,回答生成与上文介绍的同一个用户中心记忆接口和检索骨干保持紧密耦合,同时在最终答案生成之前为多步证据综合分配显式审议过程。
4. Experiments
4.1 Experimental Setting
Benchmarks. To assess the effectiveness of our approach, we conduct experiments on the LoCoMo benchmark. LoCoMo poses a challenging setting for long-context modeling, consisting of dialogue histories that span an average of 35 sessions and roughly 9,000 tokens. Following the benchmark’s standard evaluation protocol, we report quantitative results across four core capabilities: single-hop reasoning, multi-hop reasoning, temporal reasoning, and open-domain question answering. The original benchmark also includes an adversarial question category designed to test a model’s ability to identify unanswerable queries.
基准。 为评估我们方法的有效性,我们在 LoCoMo 基准上进行实验。 LoCoMo 为长上下文建模提出了具有挑战性的设置,其对话历史平均跨越 35 个会话,约 9,000 个 token。 遵循该基准的标准评估协议,我们报告四项核心能力上的定量结果:single-hop reasoning、multi-hop reasoning、temporal reasoning 和 open-domain question answering。 原始基准还包含一个 adversarial question 类别,用于测试模型识别不可回答查询的能力。
To further examine the generalization capability of our approach, we conduct additional experiments on the PERSONAMEM benchmark. It is designed to assess how well large language models maintain and update user representations and produce personalized responses over extended interactions. The benchmark comprises multi-session dialogue histories in which user attributes and preferences gradually evolve as a result of life events and changing contexts. Following its standard evaluation protocol, we report quantitative results across seven categories, each targeting different aspects of user modeling and memory utilization.
为进一步考察我们方法的泛化能力,我们在 PERSONAMEM 基准上进行额外实验。 该基准旨在评估大语言模型在扩展交互中维护和更新用户表示并生成个性化回答的能力。 该基准包含多会话对话历史,其中用户属性和偏好会随着生活事件和上下文变化逐渐演化。 遵循其标准评估协议,我们报告七个类别上的定量结果,每个类别针对用户建模和记忆利用的不同方面。
Evaluation Metrics. For the LoCoMo benchmark, we follow the standard evaluation protocol and report F1 and BLEU-1 as the primary metrics. For the PERSONAMEM benchmark, which primarily consists of multiple-choice questions, we evaluate model performance using accuracy.
评估指标。 对于 LoCoMo 基准,我们遵循标准评估协议,并报告 F1 和 BLEU-1 作为主要指标。 对于主要由多项选择题组成的 PERSONAMEM 基准,我们使用准确率评估模型性能。
4.2 Implementation Details
We conduct experiments on both closed-source APIs and open-source models. The closed-source models include GPT-4.1-mini and GPT-4o-mini. For open-source models, we evaluate Qwen3-4B-Instruct and Qwen3-30B-A3B-Instruct. Experiments are conducted on a NVIDIA RTX A800 GPU. We ensure that the AdaMem framework uses the same backbone model as the response generator. To ensure reproducibility, the temperature is fixed to 0 in all experiments. For the RAG component in our framework, the retrieval top-all-MiniLM-L6-v2 model. More implementation details and prompt templates are provided in the appendix.
我们在闭源 API 和开源模型上都进行实验。 闭源模型包括 GPT-4.1-mini 和 GPT-4o-mini。 对于开源模型,我们评估 Qwen3-4B-Instruct 和 Qwen3-30B-A3B-Instruct。 实验在 NVIDIA RTX A800 GPU 上进行。 我们确保 AdaMem 框架使用与回答生成器相同的 backbone 模型。 为确保可复现性,所有实验中的温度都固定为 0。 对于我们框架中的 RAG 组件,检索 top-all-MiniLM-L6-v2 模型计算。 更多实现细节和提示模板见附录。
4.3 Comparison to Competitive Approaches
Baselines. We compare AdaMem with five representative open-source memory frameworks: (1) MemGPT, a framework that addresses long-context limitations through an OS-inspired memory management mechanism; (2) A-Mem, an agentic memory system that enables dynamic organization and evolution of long-term memory; (3) Mem0, a memory-centric architecture that provides scalable long-term memory; (4) LangMem, a framework that explicitly models long-term memory; (5) Zep, a memory layer that represents conversational memory using a temporally aware knowledge graph.
基线。 我们将 AdaMem 与五个代表性开源记忆框架比较:(1) MemGPT,一个通过受操作系统启发的记忆管理机制处理长上下文限制的框架;(2) A-Mem,一个支持长期记忆动态组织和演化的智能体记忆系统;(3) Mem0,一个提供可扩展长期记忆的记忆中心架构;(4) LangMem,一个显式建模长期记忆的框架;(5) Zep,一个使用时间感知知识图谱表示对话记忆的记忆层。
Results on LoCoMo. The quantitative results on the LoCoMo benchmark using closed-source backbones are summarized in Table 1. With GPT-4.1-mini, AdaMem achieves an overall F1 score of 44.65%, corresponding to a +4.4% relative improvement over the previous state-of-the-art method. The improvement is consistent across evaluation metrics, with the largest gain observed in the temporal question category, where AdaMem improves the F1 score by up to +23.4%. Using GPT-4o-mini, AdaMem achieves an overall F1 score of 41.84%, which corresponds to a larger relative improvement of +12.8% over the previous state-of-the-art method. AdaMem does not outperform the strongest baselines in the Open Domain categories, likely because some tasks favor methods tailored to specific structural assumptions. This result suggests a trade-off between optimizing for specialized task structures and achieving consistent performance across diverse long-horizon interactions. Overall, the results demonstrate the effectiveness and robustness of our approach across different closed-source backbones. We further report results using open-source models in Table 4. Case studies are provided in the appendix.
LoCoMo 结果。 使用闭源 backbone 在 LoCoMo 基准上的定量结果汇总于表1。 使用 GPT-4.1-mini 时,AdaMem 达到 44.65% 的 overall F1 分数,对应相对于先前最先进方法 +4.4% 的相对提升。 该提升在各项评估指标上保持一致,最大增益出现在 temporal question 类别,AdaMem 在该类别上将 F1 分数最高提升 +23.4%。 使用 GPT-4o-mini 时,AdaMem 达到 41.84% 的 overall F1 分数,对应相对于先前最先进方法更大的 +12.8% 相对提升。 AdaMem 在 Open Domain 类别中没有超过最强基线,这可能是因为某些任务偏好针对特定结构假设调优的方法。 这一结果表明,在为专门任务结构优化和跨多样长程交互实现一致性能之间存在权衡。 总体而言,结果展示了我们方法在不同闭源 backbone 上的有效性和稳健性。 我们进一步在表4报告使用开源模型的结果。 案例研究见附录。
| Method | Multi-hop | Temporal | Open Domain | Single-hop | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| GPT-4.1-mini | ||||||||||
| MemGPT | 10.35 | 10.26 | 30.06 | 24.03 | 28.35 | 23.49 | 22.95 | 17.10 | 22.50 | 17.64 |
| A-Mem | 11.16 | 11.07 | 42.30 | 33.75 | 30.69 | 25.38 | 24.84 | 18.54 | 26.37 | 20.70 |
| Mem0 | 35.19 | 26.55 | 34.38 | 29.07 | 20.88 | 15.57 | 42.66 | 36.90 | 38.16 | 32.04 |
| LangMem | 36.45 | 28.53 | 42.57 | 35.91 | 28.80 | 23.13 | 44.82 | 38.25 | 41.76 | 35.10 |
| Zep | 26.73 | 17.91 | 20.97 | 17.55 | 21.24 | 16.92 | 39.96 | 35.10 | 32.40 | 27.09 |
| AdaMem | 37.70 | 32.08 | 55.90 | 42.37 | 25.87 | 21.70 | 44.84 | 40.02 | 44.65 | 37.92 |
| GPT-4o-mini | ||||||||||
| MemGPT | 10.08 | 9.99 | 29.34 | 23.49 | 27.72 | 22.95 | 22.41 | 16.74 | 21.96 | 17.28 |
| A-Mem | 10.89 | 10.80 | 41.31 | 33.03 | 29.97 | 24.84 | 24.30 | 18.09 | 25.74 | 22.95 |
| Mem0 | 30.60 | 22.50 | 39.60 | 33.57 | 24.21 | 17.28 | 39.69 | 30.60 | 37.08 | 30.51 |
| LangMem | 30.24 | 21.60 | 28.89 | 23.67 | 26.55 | 21.24 | 35.01 | 29.88 | 32.31 | 26.55 |
| Zep | 24.57 | 17.28 | 39.96 | 34.02 | 20.43 | 14.04 | 35.46 | 30.06 | 33.48 | 27.63 |
| AdaMem | 35.18 | 26.32 | 51.49 | 37.06 | 25.82 | 21.46 | 42.21 | 36.43 | 41.84 | 33.78 |
Results on PERSONAMEM. To evaluate the generalization capability of AdaMem across benchmarks, we further evaluate it on the PERSONAMEM benchmark. As shown in Table 2, AdaMem achieves 63.25% accuracy, outperforming all baselines with a relative improvement of 5.9%. Notably, AdaMem demonstrates a substantial advantage on the generalize to new scenarios task, achieving a relative improvement of 27.3%. These consistent gains across benchmarks with different data distributions suggest that AdaMem generalizes effectively to diverse long-term reasoning scenarios.
PERSONAMEM 结果。 为评估 AdaMem 跨基准的泛化能力,我们进一步在 PERSONAMEM 基准上评估它。 如表2所示,AdaMem 达到 63.25% 准确率,以 5.9% 的相对提升超过所有基线。 值得注意的是,AdaMem 在 generalize to new scenarios 任务上展现出显著优势,达到 27.3% 的相对提升。 这些在不同数据分布基准上的一致增益表明,AdaMem 能有效泛化到多样长期推理场景。
| Method | Recall user shared facts | Suggest new ideas | Track full preference evolution | Revisit reasons behind preference updates | Provide preference- aligned recommendations | Generalize to new scenarios | Average |
|---|---|---|---|---|---|---|---|
| A-Mem | 63.01 | 27.96 | 54.68 | 85.86 | 69.09 | 57.89 | 59.75 |
| Mem0 | 32.13 | 15.05 | 54.68 | 80.81 | 52.73 | 57.89 | 48.55 |
| LangMem | 31.29 | 24.73 | 53.24 | 81.82 | 40.00 | 8.77 | 40.64 |
| AdaMem | 67.81 | 21.51 | 61.15 | 89.90 | 65.45 | 73.68 | 63.25 |
4.4 Ablation Study
Unless otherwise stated, we perform all ablations of AdaMem on the LoCoMo benchmark using the GPT-4.1-mini backbone.
除非另有说明,我们在 LoCoMo 基准上使用 GPT-4.1-mini backbone 进行 AdaMem 的所有消融。
Components. We perform component ablations to quantify the contribution of AdaMem's main design choices. As shown in Table 3, removing any one of the three components consistently reduces performance, suggesting that the improvement of AdaMem does not come from a single dominant module. Disabling graph memory produces the largest drop, reducing overall F1 from 44.65 to 42.63. This result is consistent with our motivation in Section 3: relation-aware memory is important for recovering cross-turn dependencies and temporally linked evidence that may be missed by semantic retrieval alone. Removing the fusion module also leads to clear degradation (42.77 F1), indicating that jointly combining baseline retrieval, graph evidence, and lightweight temporal/factual signals yields more reliable evidence selection than relying on a single signal source. Replacing the multi-agent response pipeline with a single-agent variant causes a smaller but still consistent decline (43.24 F1), suggesting that role specialization mainly improves evidence organization and final answer synthesis after retrieval. Overall, the three components are complementary: graph memory improves structural evidence coverage, fusion improves evidence aggregation, and multi-agent coordination improves downstream reasoning quality.
组件。 我们进行组件消融,以量化 AdaMem 主要设计选择的贡献。 如表3所示,移除三个组件中的任何一个都会持续降低性能,表明 AdaMem 的改进并不来自单个主导模块。 禁用图记忆会产生最大下降,使 overall F1 从 44.65 降至 42.63。 这一结果与我们在第 3 节中的动机一致:关系感知记忆对于恢复跨轮依赖和时间关联证据很重要,而这些证据可能被单独的语义检索错过。 移除融合模块也会导致明显退化(42.77 F1),说明联合组合基线检索、图证据和轻量时间/事实信号,比依赖单一信号源能产生更可靠的证据选择。 用单智能体变体替换多智能体回答流水线会造成较小但仍一致的下降(43.24 F1),说明角色专门化主要改进检索后的证据组织和最终答案综合。 总体而言,三个组件是互补的:图记忆改进结构证据覆盖,融合改进证据聚合,多智能体协调改进下游推理质量。
| Configuration | Graph | Fusion | Multi-agent | F1 | BLEU-1 |
|---|---|---|---|---|---|
| AdaMem (full) | ✓ | ✓ | ✓ | 44.65 | 37.92 |
| w/o graph | × | ✓ | ✓ | 42.63 | 35.85 |
| w/o fusion | ✓ | × | ✓ | 42.77 | 36.26 |
| w/o multi-agent | ✓ | ✓ | × | 43.24 | 36.34 |
Model Sizes. We further study whether AdaMem remains effective when the response backbone changes in both scale and model family. Table 4 compares two closed-source GPT-4 backbones with two open-source Qwen3 models while keeping the AdaMem framework unchanged. AdaMem generalizes well across backbone families. Even with the smaller open-source Qwen3-4B-Instruct model, AdaMem still reaches 36.78 F1 on LoCoMo, showing that the memory architecture remains useful under a constrained model budget. Scaling the backbone to Qwen3-30B-A3B-Instruct yields consistent gains on every category, improving overall performance by +6.24 F1 over Qwen3-4B. The largest gain appears on temporal reasoning (+13.17 F1), followed by multi-hop reasoning (+6.91 F1), which suggests that larger models make better use of AdaMem's structured evidence when questions require linking events over time or synthesizing multiple memory fragments. Overall, this experiment shows that AdaMem is both robust under smaller models and able to translate additional model capacity into stronger long-horizon reasoning.
模型规模。 我们进一步研究当回答 backbone 在规模和模型家族上变化时,AdaMem 是否仍然有效。 表4在保持 AdaMem 框架不变的情况下,比较两个闭源 GPT-4 backbone 和两个开源 Qwen3 模型。 AdaMem 能很好地跨 backbone 家族泛化。 即使使用较小的开源 Qwen3-4B-Instruct 模型,AdaMem 在 LoCoMo 上仍达到 36.78 F1,表明该记忆架构在受限模型预算下仍然有用。 将 backbone 扩展到 Qwen3-30B-A3B-Instruct 会在每个类别上带来一致增益,相比 Qwen3-4B 将 overall 性能提升 +6.24 F1。 最大增益出现在 temporal reasoning(+13.17 F1),其次是 multi-hop reasoning(+6.91 F1),这表明当问题需要随时间链接事件或综合多个记忆片段时,更大的模型能更好利用 AdaMem 的结构化证据。 总体而言,该实验表明 AdaMem 在较小模型下稳健,并能把额外模型容量转化为更强的长程推理能力。
| Model | Multi-hop | Temporal | Open Domain | Single-hop | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| GPT-4o-mini | 35.18 | 26.32 | 51.49 | 37.06 | 25.82 | 21.46 | 42.21 | 36.43 | 41.84 | 33.78 |
| GPT-4.1-mini | 37.70 | 32.08 | 55.90 | 42.37 | 25.87 | 21.70 | 44.84 | 40.02 | 44.65 | 37.92 |
| Qwen3-4B-Instruct | 29.50 | 23.35 | 40.45 | 29.74 | 20.05 | 17.68 | 39.74 | 34.98 | 36.78 | 30.68 |
| Qwen3-30B-A3B-Instruct | 30.82 | 25.17 | 43.51 | 30.90 | 26.55 | 23.31 | 40.68 | 35.99 | 38.58 | 32.16 |
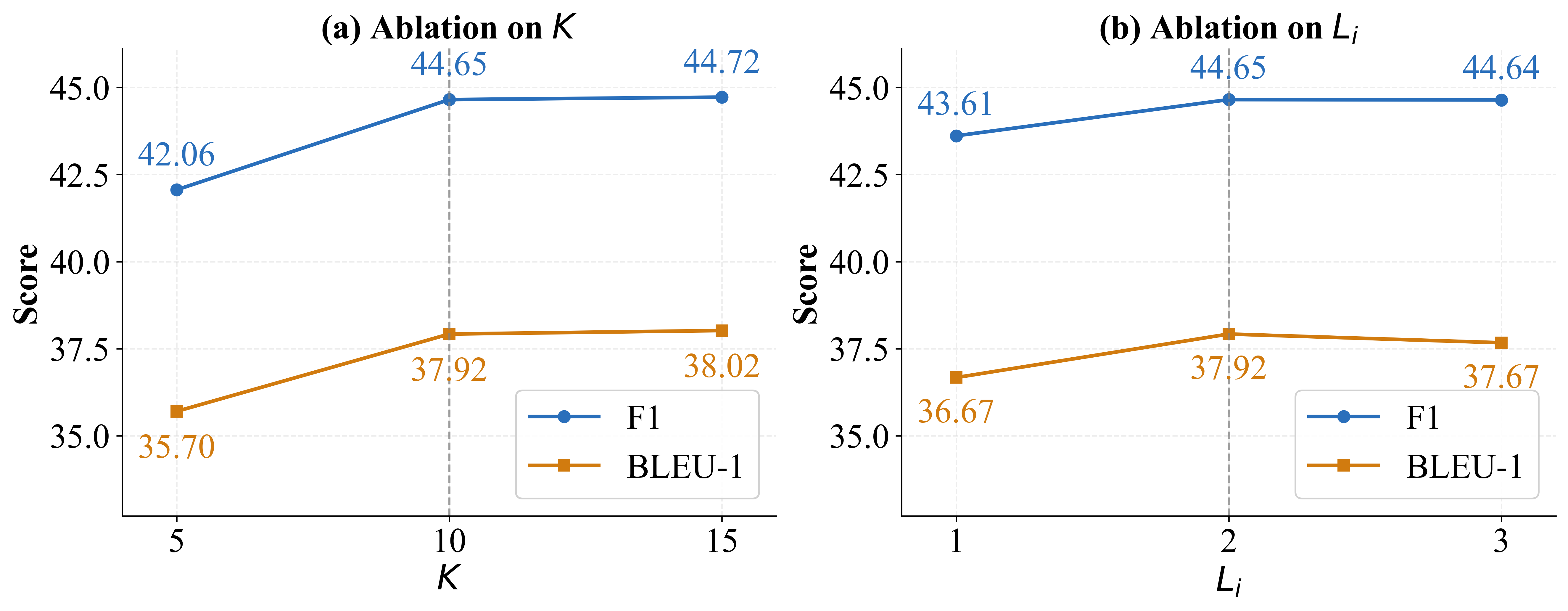
Hyperparameters. We study the sensitivity of AdaMem to two key hyperparameters that directly control evidence breadth and deliberation depth: the retrieval top-
超参数。 我们研究 AdaMem 对两个关键超参数的敏感性,这两个超参数直接控制证据广度和审议深度:检索 top-
Fixing
固定
Fixing
固定
4.5 Efficiency Analysis
We analyze the performance-efficiency trade-off of AdaMem. Table 5 reports the average input token budget, end-to-end inference latency, and overall F1 and BLEU-1. AdaMem is not the cheapest system in raw computation: Mem0 uses fewer input tokens and lower latency. However, AdaMem delivers the strongest answer quality, reaching 44.65 F1, which corresponds to absolute gains of +7.57 F1 over Mem0. Compared with A-Mem and Zep, AdaMem also achieves substantially better accuracy while operating with a token budget of the same order.
我们分析 AdaMem 的性能--效率权衡。 表5报告平均输入 token 预算、端到端推理延迟,以及 overall F1 和 BLEU-1。 AdaMem 在原始计算上并不是最便宜的系统:Mem0 使用更少输入 token,并且延迟更低。 然而,AdaMem 提供最强回答质量,达到 44.65 F1,相比 Mem0 对应 +7.57 F1 的绝对增益。 与 A-Mem 和 Zep 相比,AdaMem 也在相同量级 token 预算下达到显著更好的准确率。
These results suggest that AdaMem's advantage does not come from aggressively minimizing retrieval cost, but from allocating a moderate amount of additional computation to recover higher-quality evidence. The extra latency is consistent with our design: question-conditioned route planning, graph-based expansion, and the role-specialized response loop introduce overhead, but they also improve evidence coverage and synthesis for long-horizon questions. Overall, AdaMem occupies a favorable operating point among memory-based methods, converting a moderate increase in token usage and latency into clearly stronger reasoning performance.
这些结果表明,AdaMem 的优势并不来自激进地最小化检索成本,而是来自分配适量额外计算来恢复更高质量的证据。 额外延迟与我们的设计一致:问题条件化路径规划、基于图的扩展以及角色专门化回答循环会引入开销,但它们也改善了长程问题的证据覆盖和综合。 总体而言,AdaMem 在基于记忆的方法中处于有利工作点,将 token 使用和延迟的适度增加转化为明显更强的推理性能。
| Method | F1 | BLEU-1 | Tokens | Latency (s) |
|---|---|---|---|---|
| A-Mem | 26.37 | 20.70 | 2720 | 3.227 |
| Mem0 | 38.16 | 32.04 | 1340 | 3.739 |
| Zep | 32.40 | 27.09 | 2461 | 3.255 |
| AdaMem | 44.65 | 37.92 | 2248 | 4.722 |
5. Conclusion
In this paper, we presented AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem combines participant-specific working, episodic, persona, and graph-based memories with question-conditioned retrieval planning and unified evidence fusion, enabling the system to retrieve and integrate evidence in a more structured and target-aware manner. Experiments on long-horizon reasoning and user modeling benchmarks demonstrate the effectiveness of our framework. In particular, AdaMem achieves state-of-the-art performance on LoCoMo, showing the value of adaptive memory organization and retrieval for complex multi-session interactions. More broadly, our results suggest that memory for long-horizon dialogue agents should move beyond uniform storage and fixed retrieval heuristics toward more adaptive, question-aware, and user-centric designs.
在本文中,我们提出 AdaMem,这是一个面向长程对话智能体的自适应用户中心记忆框架。 AdaMem 将特定于参与者的工作记忆、情景记忆、人格记忆和基于图的记忆,与问题条件化检索规划和统一证据融合结合起来,使系统能够以更结构化和目标感知的方式检索并整合证据。 在长程推理和用户建模基准上的实验展示了我们框架的有效性。 特别是,AdaMem 在 LoCoMo 上达到最先进性能,显示出自适应记忆组织和检索对于复杂多会话交互的价值。 更广泛地说,我们的结果表明,长程对话智能体的记忆应超越统一存储和固定检索启发式,走向更自适应、问题感知和用户中心的设计。
Limitations
AdaMem improves answer quality through structured memories, adaptive retrieval, and role-specialized evidence synthesis, but this design also increases system complexity, token cost, and latency. In addition, the framework still depends on upstream parsing and backbone reasoning, making errors in target resolution, entity linking, and temporal normalization difficult to recover. In future work, we intend to explore solutions to these challenges in order to further enhance both the efficiency and the generality of the proposed framework.
AdaMem 通过结构化记忆、自适应检索和角色专门化证据综合提升回答质量,但这一设计也增加了系统复杂性、token 成本和延迟。 此外,该框架仍依赖上游解析和 backbone 推理,使目标解析、实体链接和时间规范化中的错误难以恢复。 在未来工作中,我们计划探索这些挑战的解决方案,以进一步增强所提出框架的效率和通用性。