
E-mem: Multi-Agent Based Episodic Context Reconstruction for LLM Agent Memory
MemoryAgentMulti-AgentLong-contextICML 2026CCF-ASJTUState Key Lab of Digital FinanceSJTU SuzhouE-mem:面向 LLM 智能体记忆的多智能体情景上下文重构
Abstract
The evolution of Large Language Model (LLM) agents towards System 2 reasoning, characterized by deliberative, high-precision problem-solving, requires maintaining rigorous logical integrity over extended horizons. However, prevalent memory preprocessing paradigms suffer from destructive de-contextualization. By compressing complex sequential dependencies into pre-defined structures (e.g., embeddings or graphs), these methods sever the contextual integrity essential for deep reasoning. To address this, we propose E-mem, a framework shifting from memory preprocessing to episodic context reconstruction inspired by biological engrams. E-mem employs a heterogeneous hierarchical architecture where multiple assistant agents maintain uncompressed memory contexts, while a central master agent orchestrates global planning. Unlike passive retrieval, our mechanism empowers assistants to locally reason within activated segments, extracting context-aware evidence before aggregation. Evaluations on the LoCoMo benchmark demonstrate that E-mem achieves over 54% F1, surpassing the state-of-the-art GAM by 7.75%, while reducing token cost by over 70%. Our work is available on https://github.com/dog-last/E-mem.
大语言模型(LLM)智能体正在走向 System 2 推理,这类推理以审慎、高精度的问题求解为特征,因此需要在更长时域中保持严格的逻辑完整性。 然而,主流记忆预处理范式会遭受破坏性的去上下文化。 这些方法把复杂的序列依赖压缩成预定义结构(例如 embedding 或图),从而切断深度推理所必需的上下文完整性。 为了解决这一问题,我们提出 E-mem,这是一个从记忆预处理转向情景上下文重构的框架,其灵感来自生物 engram。 E-mem 采用异构分层架构,其中多个助手智能体(assistant agents)维护未压缩的记忆上下文,而一个中心主智能体(master agent)负责全局规划。 不同于被动检索,我们的机制使助手智能体能够在被激活的片段内进行局部推理,并在聚合前抽取上下文感知的证据。 LoCoMo 基准上的评估表明,E-mem 达到超过 54% 的 F1,超过此前最优的 GAM 7.75%,同时把 token 成本降低超过 70%。 我们的工作可在 https://github.com/dog-last/E-mem 获取。
1. Introduction
Large Language Models (LLMs) have evolved from stochastic text generators into the central cognitive controllers of autonomous agents. Empowered by advanced planning capabilities and external tool integration, these systems are now transitioning towards System 2 reasoning—characterized by deliberative, sequential problem-solving in dynamic environments. However, supporting this shift demands rigorous adherence to causal chains. In such scenarios, maintaining extensive history becomes pivotal to preserving the logical integrity essential for deep, long-horizon planning.
大语言模型(LLM)已经从随机文本生成器演化为自主智能体的核心认知控制器。 在高级规划能力和外部工具集成的支持下,这些系统正在转向 System 2 推理,即在动态环境中进行审慎、序列化的问题求解。 然而,支撑这种转变需要严格遵循因果链。 在这类场景中,维护大量历史信息对于保留深度、长程规划所需的逻辑完整性至关重要。
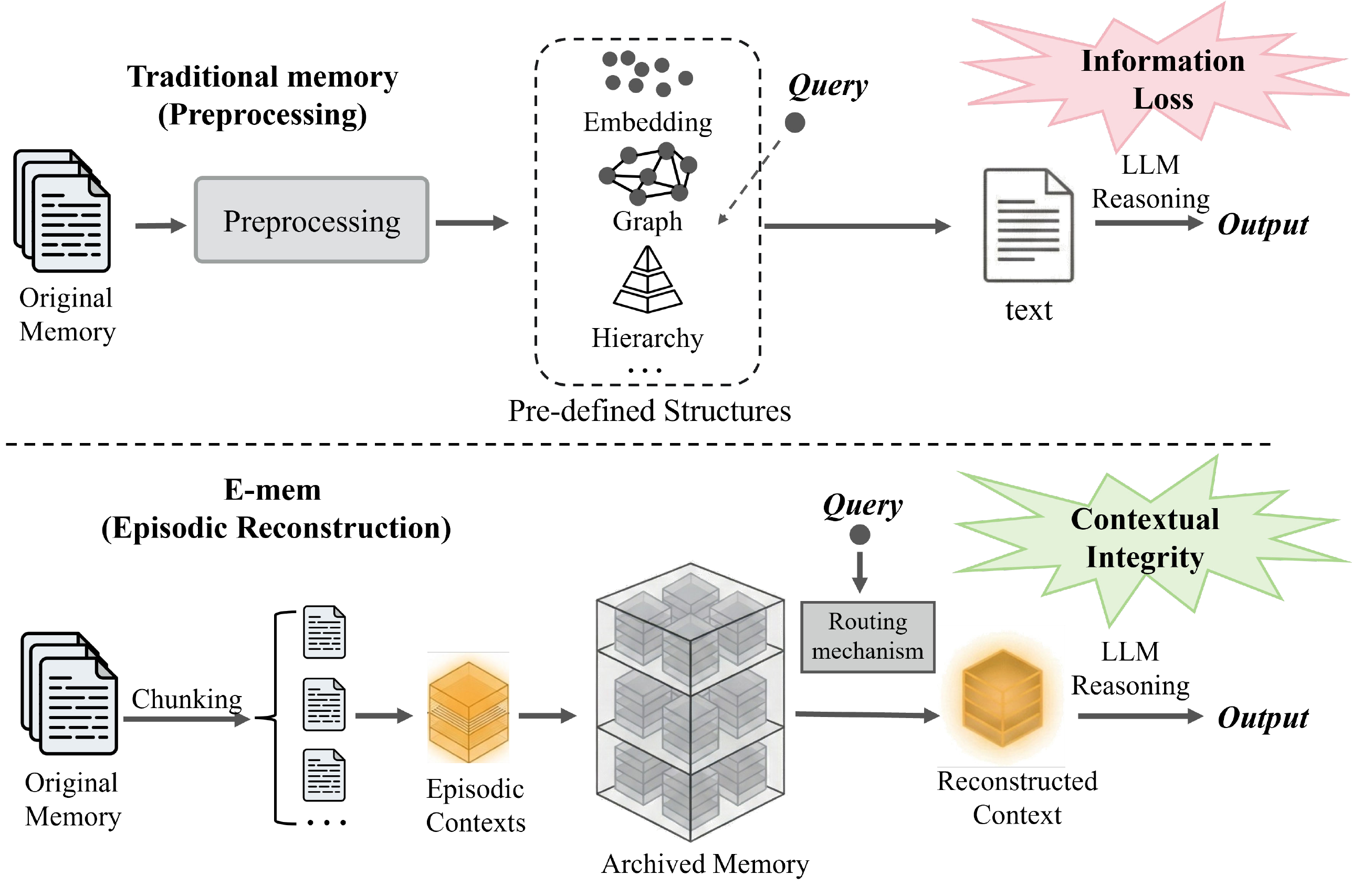
However, expanding operational horizons presents significant challenges. Merely extending context windows often triggers the "Lost-in-the-Middle" phenomenon, explicitly necessitating robust memory management mechanisms. Existing approaches primarily rely on preprocessing to index memory, mapping raw, unstructured contexts into pre-defined structures (e.g., static embeddings, knowledge graphs, or hierarchical archives). While enabling efficient lookup, this strategy results in destructive de-contextualization: by compressing complex sequential dependencies into rigid representations, it disrupts the critical integrity required for deep reasoning (as shown at the top of Figure 1). Consequently, such methods struggle to reconstruct complex causal chains or comprehend memories within their original sequential contexts, ultimately yielding suboptimal performance on information-dense benchmarks like LoCoMo.
然而,扩展操作时域会带来显著挑战。 仅仅延长上下文窗口往往会触发 “Lost-in-the-Middle” 现象,因此明确需要稳健的记忆管理机制。 现有方法主要依赖预处理来索引记忆,把原始、非结构化上下文映射到预定义结构中(例如静态 embedding、知识图谱或分层档案)。 虽然这种策略支持高效查找,但它会导致破坏性的去上下文化:通过把复杂序列依赖压缩成刚性表示,它破坏了深度推理所需的关键完整性(如 图1 顶部所示)。 因此,这类方法难以重构复杂因果链,也难以在记忆原本的序列上下文中理解记忆,最终在 LoCoMo 这类信息密集型基准上表现不佳。
To address these limitations and strictly ensure logical deduction over memory, we introduce E-mem. This framework transitions from memory preprocessing to episodic context reconstruction (as shown at the bottom of Figure 1). (i) Inspired by biological engrams, E-mem preserves the full episodic context of original experiences, enabling the active re-experiencing of past events. (ii) To mitigate the information distortion inherent in ultra-long contexts while ensuring cost-effectiveness for scalable deployment, E-mem adopts a heterogeneous hierarchical master-assistant architecture. In this design, a central master agent orchestrates global planning, while multiple assistant agents (implemented as small language models, SLMs) serve as memory units. Each assistant agent maintains the raw memory context of a specific segment. (iii) For each query, a routing mechanism selectively activates a relevant subset of assistant agents. Crucially, instead of merely retrieving text chunks, these agents execute episodic context reconstruction—a process where they actively re-experience and reason within the restored native contexts to derive precise, local evidence for the master agent. This mechanism not only mitigates context window constraints and reduces computational costs but also ensures high-fidelity, context-preserving inference, offering a distinct advantage in complex, multi-hop reasoning tasks where traditional retrieval mechanisms fall short.
为了解决这些局限,并严格保证基于记忆的逻辑推演,我们引入 E-mem。 该框架从记忆预处理转向情景上下文重构(如 图1 底部所示)。 (i) 受生物 engram 启发,E-mem 保留原始经历的完整情景上下文,从而支持主动重新体验过去事件。 (ii) 为了缓解超长上下文中固有的信息失真,并保证可扩展部署的成本效益,E-mem 采用异构分层的主-助手架构。 在这种设计中,一个中心主智能体负责全局规划,多个助手智能体(实现为小语言模型,SLM)作为记忆单元。 每个助手智能体维护某个特定片段的原始记忆上下文。 (iii) 对于每个查询,路由机制会选择性激活相关的助手智能体子集。 关键在于,这些智能体并不只是检索文本块,而是执行情景上下文重构:它们在恢复后的原生上下文中主动重新体验并推理,为主智能体推导精确的局部证据。 该机制不仅缓解上下文窗口限制并降低计算成本,还保证高保真、上下文保持的推理,在传统检索机制力有不逮的复杂多跳推理任务中提供了明显优势。
Empirical evaluations on LoCoMo and HotpotQA confirm that E-mem achieves state-of-the-art performance. The system delivers superior accuracy compared to SOTA baselines while significantly reducing token cost, validating the efficiency of the proposed episodic context reconstruction paradigm. In summary, our main contributions are as follows:
LoCoMo 和 HotpotQA 上的实证评估确认,E-mem 取得了最优性能。 与最优基线相比,该系统在显著降低 token 成本的同时获得更高准确率,验证了所提出情景上下文重构范式的效率。 总之,我们的主要贡献如下:
- Episodic Context Reconstruction. To address the destructive de-contextualization inherent in traditional memory preprocessing, we introduce E-mem, a framework that centered on episodic context reconstruction.
- Unlike static retrieval methods that sever sequential dependencies, our approach delegates active reasoning to assistant agents.
- They preserve and process the full context of memory segments locally, ensuring that only logically deduced evidence—rather than raw, noisy fragments—is surfaced to master agents.
- Heterogeneous Hierarchical Master-Assistant Architecture. We propose E-mem, a scalable framework that decouples high-level planning from memory retention.
- By coordinating a master agent with lightweight, SLM-based assistant agents, our design mitigates the information loss inherent in preprocessing, ensuring high-fidelity reasoning across long horizons without suffering from the "lost-in-the-middle" phenomenon.
- SOTA Performance with Token Efficiency. Extensive evaluations on LoCoMo and HotpotQA demonstrate that E-mem outperforms strong baselines by an average of 7.75% (F1), with notable gains in complex multi-hop (+8.56%) and temporal reasoning (+8.87%).
- Crucially, these improvements are realized while reducing token cost by over 70%.
- These results confirm E-mem as a vital complement to traditional memory paradigms for System 2 reasoning.
- 情景上下文重构。 为了解决传统记忆预处理中固有的破坏性去上下文化,我们引入 E-mem,这是一个以情景上下文重构为中心的框架。
- 不同于会切断序列依赖的静态检索方法,我们的方法把主动推理委托给助手智能体。
- 它们在本地保留并处理记忆片段的完整上下文,确保浮现给主智能体的是经过逻辑推导的证据,而不是原始、含噪的碎片。
- 异构分层主-助手架构。 我们提出 E-mem,这是一个将高层规划与记忆保留解耦的可扩展框架。
- 通过协调一个主智能体和基于轻量 SLM 的助手智能体,我们的设计缓解了预处理固有的信息损失,确保在长时域上进行高保真推理,同时避免 “lost-in-the-middle” 现象。
- 具备 token 效率的最优性能。 在 LoCoMo 和 HotpotQA 上的大量评估表明,E-mem 平均超过强基线 7.75%(F1),并在复杂多跳(+8.56%)和时间推理(+8.87%)上取得显著提升。
- 关键的是,这些改进是在降低超过 70% token 成本的同时实现的。
- 这些结果确认,E-mem 是传统记忆范式在 System 2 推理上的重要补充。
2. Related Work
Retrieval-Augmented Generation. RAG has established itself as a fundamental paradigm to mitigate LLM hallucination and knowledge obsolescence by grounding generation in external corpora. While standard frameworks typically employ a vector-based "retrieve-then-generate" pipeline, recent Agentic RAG grants systems greater autonomy in retrieval planning and iterative context refinement. Despite these advancements in retrieval logic, the underlying storage mechanism remains predominantly reliant on preprocessing. This approach inherently compresses rich sequential contexts into fixed geometric points, risking the loss of fine-grained sequential dependencies essential for reasoning.
检索增强生成。 RAG 已经成为缓解 LLM 幻觉和知识过时问题的基础范式,它通过把生成过程建立在外部语料之上来实现这一点。 标准框架通常采用基于向量的“先检索后生成”流程,而近期的 Agentic RAG 赋予系统在检索规划和迭代式上下文细化方面更大的自主性。 尽管检索逻辑已有这些进展,底层存储机制仍主要依赖预处理。 这种方法会把丰富的序列上下文压缩成固定的几何点,从而有丢失推理所需细粒度序列依赖的风险。
Memory Systems for Autonomous Agents. Beyond simple retrieval, persistent and adaptive memory systems are critical for agents to maintain long-term interaction coherence. Addressing the finite context window, MemGPT employs an operating system-inspired virtual context management technique via hierarchical paging. However, this paradigm relies on swapping fragmented chunks, necessitating redundant re-processing to restore sequential dependencies. Other works focus on optimizing memory structure and active evolution. For instance, G-Memory introduces a graph-based hierarchical structure to enable navigation between global macro-views and local micro-interactions. Similarly, A-Mem adopts a self-evolving framework based on the Zettelkasten method, while GAM and ReasoningBank leverage multi-agent deep research and reasoning trajectory storage, respectively. Although recent efforts extend to personalization (Mem0) and benchmarking (MemoryBench), these approaches remain bound to text-based preprocessing paradigms. By compressing complex contexts into rigid structures, they often disrupt the contextual integrity required for deep reasoning.
自主智能体的记忆系统。 除了简单检索之外,持久且自适应的记忆系统对于智能体维持长期交互一致性至关重要。 为了解决有限上下文窗口问题,MemGPT 通过分层分页采用了一种受操作系统启发的虚拟上下文管理技术。 然而,这一范式依赖交换碎片化文本块,因此需要冗余的再处理来恢复序列依赖。 其他工作关注优化记忆结构和主动演化。 例如,G-Memory 引入基于图的分层结构,以支持在全局宏观视图和局部微观交互之间导航。 类似地,A-Mem 采用基于 Zettelkasten 方法的自演化框架,而 GAM 和 ReasoningBank 分别利用多智能体深度研究和推理轨迹存储。 尽管近期工作扩展到个性化(Mem0)和基准测试(MemoryBench),这些方法仍受限于基于文本的预处理范式。 通过把复杂上下文压缩成刚性结构,它们往往会破坏深度推理所需的上下文完整性。
In contrast, E-mem introduces episodic context reconstruction, which ensures seamless inference integrity and serves as a critical complement to existing paradigms for high-precision, complex reasoning tasks.
相比之下,E-mem 引入情景上下文重构,确保无缝的推理完整性,并成为现有范式在高精度复杂推理任务中的关键补充。
3. Method
Cognitive science defines memory as the re-experience of intact episodic contexts rather than static retrieval. In contrast, prevalent preprocessing paradigms force dynamic inputs into fixed structures, resulting in destructive de-contextualization. This rigid compression disrupts sequential dependencies, severing the contextual integrity essential for deep reasoning.
认知科学把记忆定义为对完整情景上下文的重新体验,而不是静态检索。 相比之下,主流预处理范式会把动态输入强行放入固定结构,从而造成破坏性的去上下文化。 这种刚性压缩会破坏序列依赖,切断深度推理所必需的上下文完整性。
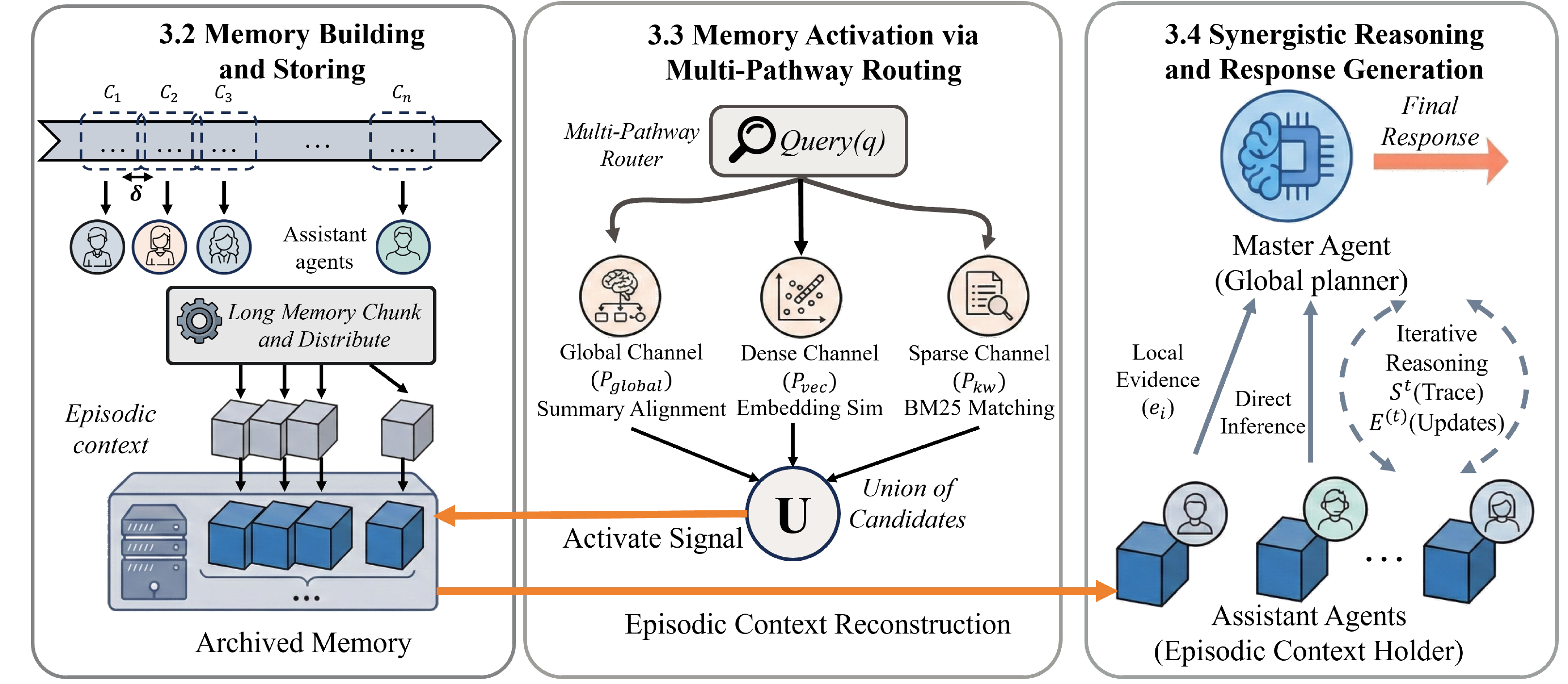
We propose E-mem, a framework centered on episodic context reconstruction, designed to explicitly preserve uncompressed memory segments and their inherent sequential dependencies (as shown in Figure 2). Implemented via a heterogeneous hierarchical architecture, the system functions through a streamlined three-stage process: first, a routing mechanism performs coarse-grained localization to selectively activate relevant archived memory units; subsequently, multiple assistant agents execute parallel fine-grained reasoning within these raw contexts to derive specific evidence; finally, the central master agent aggregates these distributed insights into a coherent, synergistic response.
我们提出 E-mem,这是一个以情景上下文重构为中心的框架,旨在显式保留未压缩的记忆片段及其内在序列依赖(如 图2 所示)。 该系统通过异构分层架构实现,并以简洁的三阶段流程运行:首先,路由机制执行粗粒度定位,以选择性激活相关的归档记忆单元;随后,多个助手智能体在这些原始上下文中并行执行细粒度推理,以推导具体证据;最后,中心主智能体把这些分布式洞见聚合成一个连贯、协同的响应。
3.1 Architecture
We propose E-mem, a heterogeneous hierarchical architecture designed to scale long-context reasoning by decoupling high-level planning from low-level memory retention. Formally, the system is defined as a collaborative tuple:
我们提出 E-mem,这是一种异构分层架构,旨在通过解耦高层规划和低层记忆保留来扩展长上下文推理。 形式上,该系统被定义为一个协作元组:
where
其中,
Master Agent (
主智能体(
where
其中,
Assistant Agents (
助手智能体(
where
其中,
Multi-Pathway Routing Mechanism (
多路径路由机制(
where
其中,
3.2 Memory Building and Storing
To transform the unbounded input stream into manageable memory contexts, E-mem implements a block-wise handling strategy. This approach is designed to preserve the full episodic contexts, avoiding the information loss typical of preprocessing.
为了把无界输入流转换为可管理的记忆上下文,E-mem 实现了一种分块处理策略。 该方法旨在保留完整的情景上下文,避免预处理中常见的信息损失。
Sliding Window Segmentation with Overlap. Given an unbounded input stream
带重叠的滑动窗口切分。 给定无界输入流
This overlap buffer ensures that tokens at the segment edges retain their immediate predecessor context, thereby maintaining semantic coherence during the routing and reconstruction phases.
这个重叠缓冲确保片段边缘处的 token 保留其直接前驱上下文,从而在路由和重构阶段维持语义连贯性。
Episodic Memory Context Retention and Isolation. Each
情景记忆上下文保留与隔离。 每个
Incremental Updates. E-mem supports efficient
增量更新。 E-mem 支持高效的
This context transfer acts as a continuity bridge, ensuring that sequential flow remains uninterrupted and logically consistent as the system scales linearly.
这种上下文转移充当连续性桥梁,确保系统线性扩展时,序列流仍然不被打断且逻辑一致。
3.3 Memory Activation via Multi-Pathway Routing
E-mem formulates activation as a Hierarchical Associative Routing process, which performs coarse-grained localization to selectively transition archived memory units to active inference. To accommodate the multifaceted nature of recall—ranging from broad narrative intents to precise entity details—we introduce a Multi-Pathway Activation framework. This mechanism routes the input query
E-mem 把激活形式化为一个分层关联路由过程,该过程执行粗粒度定位,以选择性地把归档记忆单元转入活跃推理。 为了适应回忆的多面性,从宽泛叙事意图到精确实体细节,我们引入多路径激活框架。 该机制把输入查询
- Global Alignment (
): Activates memories via macroscopic narrative anchoring.
- By efficiently computing the dense vector similarity and sparse lexical alignment between the query and the concise semantic summaries (
), this pathway leverages the "frozen reasoning" of the summarization phase.
- It functions as a high-pass semantic filter, capturing the user's broader intent to exclude irrelevant noise and identify logically relevant segments.
- Semantic Association (
): Activates memories based on implicit latent alignment between the query and the full episodic context ( ).
- Unlike the summary-based global path, this pathway utilizes high-dimensional vector similarity against the raw chunk embeddings.
- It serves as a robust failsafe to identify chunks that resonate with the query's abstract intent, specifically compensating for cases where critical semantic nuances may have been lost or distorted during the summarization process.
- Symbolic Trigger (
): Activates memories via explicit entity matching between the query and the original raw text content.
- Analogous to how a specific name triggers a flashback, this pathway employs sparse retrieval (e.g., BM25) to detect exact lexical overlaps.
- This ensures the high-precision recall of unique factual anchors (such as specific IDs or names) that might be omitted in the high-level summaries, guaranteeing that fine-grained details are not overlooked.
- 全局对齐(
): 通过宏观叙事锚定激活记忆。
- 该路径高效计算查询与简洁语义摘要(
)之间的密集向量相似度和稀疏词汇对齐,从而利用摘要阶段的“冻结推理”。
- 它作为高通语义过滤器,捕捉用户更宽泛的意图,以排除无关噪声并识别逻辑相关片段。
- 语义关联(
): 基于查询与完整情景上下文( )之间的隐式潜在对齐来激活记忆。
- 与基于摘要的全局路径不同,该路径利用针对原始块 embedding 的高维向量相似度。
- 它作为稳健的安全补偿机制,用于识别与查询抽象意图产生共振的块,尤其补偿摘要过程中关键语义细节可能丢失或失真的情况。
- 符号触发(
): 通过查询与原始文本内容之间的显式实体匹配来激活记忆。
- 类似于某个具体名字会触发闪回,该路径采用稀疏检索(例如 BM25)来检测精确词汇重叠。
- 这确保对可能在高层摘要中被省略的独特事实锚点(例如特定 ID 或名字)进行高精度回忆,保证细粒度细节不会被忽略。
Episodic Context Reconstruction via Activation Union. To ensure comprehensive routing we employ a Multi-Source Activation Union strategy. A memory unit
通过激活并集进行情景上下文重构。 为了保证全面路由,我们采用多源激活并集策略。 如果记忆单元
Notably, the total number of activated memory chunks, denoted as
值得注意的是,被激活记忆块总数记为
3.4 Synergistic Reasoning and Response Generation
Upon identifying the candidate set
在识别候选集合
where
其中,
Direct Inference. Tailored for queries necessitating explicit fact retrieval, this mode focuses on synthesizing the evidence set
直接推理。 该模式面向需要显式事实检索的查询,重点综合由助手智能体生成的证据集合
where
其中,
Iterative Reasoning. Beyond single-pass retrieval, the E-mem architecture is naturally extensible to an iterative Refine-and-Query framework for complex tasks requiring sequential deduction. In this operational protocol, the master agent maintains a dynamic reasoning trace
迭代推理。 除了单轮检索之外,E-mem 架构可以自然扩展为迭代式 Refine-and-Query 框架,用于需要序列推导的复杂任务。 在这一操作协议中,主智能体维护动态推理轨迹
to probe relevant assistant agents. These assistants execute local inference over their encapsulated episodic contexts
以探查相关的助手智能体。 这些助手智能体在其封装的情景上下文
| Method | Overall | Single-Hop | Multi-Hop | Temporal | Open Domain | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| GPT-4o-mini | ||||||||||
| Long-Context | 37.31 | 29.57 | 46.68 | 37.54 | 29.23 | 22.76 | 25.97 | 19.42 | 16.87 | 13.70 |
| RAG | 44.73 | 39.40 | 52.45 | 47.94 | 27.50 | 20.13 | 46.07 | 40.35 | 23.23 | 17.94 |
| A-mem | 39.65 | 32.31 | 44.65 | 37.06 | 27.02 | 20.09 | 45.85 | 36.67 | 12.14 | 12.01 |
| Mem0 | 45.10 | 35.08 | 47.65 | 37.82 | 38.72 | 27.13 | 48.93 | 40.15 | 28.64 | 21.58 |
| MEMORYOS | 42.84 | 35.54 | 48.62 | 42.99 | 35.27 | 25.22 | 41.15 | 30.76 | 20.02 | 16.52 |
| LIGHTMEM | 38.44 | 34.37 | 41.79 | 37.83 | 29.78 | 24.90 | 43.71 | 39.72 | 16.89 | 13.92 |
| GAM | 45.31 | 37.78 | 47.74 | 40.90 | 34.84 | 27.72 | 53.91 | 43.93 | 26.03 | 19.48 |
| E-mem | 54.17 | 44.34 | 59.23 | 50.58 | 42.64 | 34.38 | 59.82 | 44.57 | 24.89 | 18.15 |
| Qwen2.5-14B | ||||||||||
| Long-Context | 38.31 | 31.89 | 46.05 | 39.56 | 32.08 | 24.46 | 30.51 | 24.45 | 14.89 | 11.41 |
| RAG | 38.27 | 33.07 | 47.87 | 42.89 | 26.38 | 19.54 | 30.78 | 25.97 | 14.16 | 10.52 |
| A-mem | 28.98 | 24.47 | 33.75 | 30.04 | 22.09 | 15.28 | 27.19 | 22.05 | 13.49 | 10.74 |
| Mem0 | 36.04 | 29.91 | 42.58 | 35.15 | 31.73 | 24.82 | 28.96 | 26.24 | 15.03 | 11.28 |
| MEMORYOS | 40.28 | 34.72 | 46.33 | 41.32 | 38.19 | 29.26 | 32.24 | 27.86 | 20.27 | 15.94 |
| LIGHTMEM | 31.39 | 27.15 | 34.92 | 31.22 | 25.45 | 19.61 | 32.03 | 27.70 | 15.81 | 11.81 |
| GAM | 50.41 | 43.48 | 56.35 | 51.07 | 38.94 | 28.55 | 53.76 | 50.01 | 20.84 | 15.09 |
| E-mem | 57.04 | 46.75 | 61.14 | 52.50 | 49.15 | 34.87 | 63.59 | 50.61 | 22.38 | 18.41 |
4. Experiments
We evaluate E-mem against state-of-the-art memory mechanisms for LLM agents, focusing on performance, robustness, and cost. Our analysis addresses three core questions: RQ1: Comparative Efficacy. How does E-mem compare against state-of-the-art RAG and agentic memory systems on complex long-context reasoning? RQ2: Component & Scaling Analysis. How do specific architectural components and backbone model sizes impact the system's overall effectiveness? RQ3: Cost-Efficiency. Does E-mem achieve a superior trade-off between token consumption and reasoning performance compared to baselines?
我们从性能、稳健性和成本三个方面评估 E-mem,并将其与 LLM 智能体的最优记忆机制进行比较。 我们的分析回答三个核心问题: RQ1:比较有效性。 在复杂长上下文推理上,E-mem 与最优 RAG 和智能体式记忆系统相比如何? RQ2:组件与扩展分析。 具体架构组件和骨干模型规模如何影响系统整体有效性? RQ3:成本效率。 与基线相比,E-mem 是否在 token 消耗和推理性能之间实现了更优权衡?
4.1 Experiment Settings
Datasets. We evaluate E-mem against competitive baselines on two benchmarks: LoCoMo: A benchmark assessing long-term memory in multi-session dialogues. It evaluates coherence across long horizons via five sub-tasks: single-hop retrieval, multi-hop reasoning, temporal understanding, open-ended generation, and adversarial tasks. HotpotQA: A Wikipedia-based multi-hop QA dataset. To test scalability with ultra-long contexts (over 200K tokens), we adapt it into a streaming setting across three scales (400, 800, and 1600 documents), stress-testing evidence recall from extensive archives.
数据集。 我们在两个基准上将 E-mem 与有竞争力的基线进行评估:LoCoMo:一个评估多会话对话中长期记忆的基准。 它通过五个子任务评估跨长时域的一致性:单跳检索、多跳推理、时间理解、开放式生成和对抗任务。 HotpotQA:一个基于 Wikipedia 的多跳问答数据集。 为了测试超长上下文(超过 200K token)下的可扩展性,我们将其改造成跨三个规模(400、800 和 1600 个文档)的流式设置,从而压力测试从大规模档案中回忆证据的能力。
| HotpotQA | GPT4o-mini | Qwen2.5-14B | ||||
|---|---|---|---|---|---|---|
| 400 F1 | 800 F1 | 1600 F1 | 400 F1 | 800 F1 | 1600 F1 | |
| Long-Context | 56.56 | 49.71 | 53.92 | 49.75 | 46.82 | 43.17 |
| RAG | 52.71 | 51.84 | 54.01 | 51.81 | 46.72 | 48.36 |
| A-mem | 33.90 | 30.22 | 31.37 | 27.04 | 25.65 | 22.92 |
| Mem0 | 32.85 | 31.74 | 27.41 | 30.12 | 32.44 | 26.55 |
| MEMORYOS | 26.47 | 23.10 | 24.16 | 24.58 | 30.25 | 23.13 |
| LIGHTMEM | 40.93 | 35.28 | 30.02 | 37.30 | 27.72 | 28.25 |
| GAM | 54.75 | 52.86 | 53.71 | 48.40 | 41.10 | 44.32 |
| E-mem | 61.46 | 55.46 | 55.76 | 61.13 | 47.91 | 54.87 |
Baselines. We benchmark E-mem against two categories: Memory-Free Baselines. Direct context processing without explicit maintenance. (1) Long-Context Windowing: Uses a sliding window to segment history into chunks processed independently, selecting the highest-confidence output as the answer. (2) Standard RAG: Retrieves the top-
基线。 我们从两个类别将 E-mem 与基线进行比较: 无记忆基线。 直接处理上下文而不进行显式维护。 (1) Long-Context Windowing:使用滑动窗口把历史切分为独立处理的块,并选择置信度最高的输出作为答案。 (2) Standard RAG:通过密集向量相似度检索 top-
Implementation details. Experiments were conducted on four NVIDIA RTX 4090 GPUs. We instantiate E-mem with GPT-4o-mini and Qwen2.5-14B as master agents, supported by a set of Qwen3-4B assistant agents. To ensure a fair comparison, E-mem and all baselines utilize the same master LLM backbone and are restricted to the same number of retrieval rounds. Evaluation is performed using the F1 score and BLEU-1 metrics.
实现细节。 实验在四块 NVIDIA RTX 4090 GPU 上进行。 我们用 GPT-4o-mini 和 Qwen2.5-14B 作为主智能体实例化 E-mem,并由一组 Qwen3-4B 助手智能体支持。 为了保证公平比较,E-mem 和所有基线使用相同的主 LLM 骨干,并限制为相同的检索轮数。 评估使用 F1 分数和 BLEU-1 指标进行。
| assistant agent | ||
|---|---|---|
| F1 | BLEU-1 | |
| Qwen3-0.6B | 85.11 | 80.14 |
| Qwen3-1.7B | 87.31 | 83.17 |
| Qwen3-4B | 89.94 | 85.51 |
| Qwen3-8B | 95.74 | 88.09 |
| Qwen3-14B | 95.03 | 88.06 |
| master agent | ||
|---|---|---|
| F1 | BLEU-1 | |
| GPT4o-mini | 89.94 | 85.51 |
| GPT4o | 89.37 | 86.52 |
| Gemini2.5-flash | 93.62 | 90.3 |
| DeepseekV3 | 75.87 | 73.4 |
| Grok4-fast | 77.80 | 75.53 |
| Model | Overall | Single Hop | Multi-Hop | Temporal | Open Domain | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| Assistant Agent Model | ||||||||||
| Qwen3-0.6B | 28.89 | 22.26 | 26.40 | 21.19 | 17.32 | 18.35 | 46.44 | 33.49 | 20.77 | 12.75 |
| Qwen3-1.7B | 44.78 | 35.10 | 40.82 | 34.30 | 35.64 | 29.53 | 65.03 | 48.63 | 31.02 | 14.66 |
| Qwen3-4B | 50.70 | 40.93 | 49.46 | 41.21 | 42.66 | 35.38 | 66.91 | 51.45 | 31.08 | 23.15 |
| Qwen3-8B | 49.80 | 40.94 | 45.98 | 37.05 | 52.11 | 47.45 | 62.28 | 49.29 | 29.11 | 22.11 |
| Qwen3-14B | 50.02 | 40.27 | 49.96 | 41.43 | 46.38 | 37.25 | 64.53 | 51.66 | 30.32 | 24.41 |
| Master Agent Model | ||||||||||
| GPT-4o-mini | 50.70 | 40.93 | 49.46 | 41.21 | 42.66 | 35.38 | 66.91 | 51.45 | 31.08 | 23.15 |
| GPT-4o | 51.73 | 43.70 | 51.04 | 43.04 | 45.88 | 42.37 | 64.77 | 52.83 | 32.74 | 24.53 |
| Gemini2.5-flash | 49.05 | 41.15 | 49.57 | 41.26 | 38.20 | 34.17 | 65.87 | 54.57 | 25.08 | 19.53 |
| Grok4-fast | 46.34 | 36.13 | 46.75 | 36.87 | 35.65 | 26.72 | 65.34 | 52.29 | 30.28 | 20.51 |
| Deepseekv3 | 50.88 | 42.25 | 51.80 | 43.27 | 43.16 | 37.13 | 62.64 | 51.07 | 31.42 | 24.30 |
4.2 Performance Analysis
Results on LoCoMo Benchmark. Table 1 details the LoCoMo evaluation, where E-mem consistently establishes a new state-of-the-art across diverse backbones. Specifically, it surpasses the strongest baseline (GAM) by substantial margins, achieving +8.86% on GPT-4o-mini and +6.63% on Qwen2.5-14B in overall F1 scores. This performance advantage is critical in complex reasoning tasks like Multi-hop and Temporal subsets, where standard RAG often falters due to severe context fragmentation. In contrast, E-mem significantly boosts Multi-hop F1 by over 10 points (49.15% vs. 38.94%) on the Qwen backbone. This confirms that our episodic context reconstruction paradigm effectively preserves the autoregressive dependencies typically lost in preprocessing de-contextualization, ensuring deep reasoning capabilities and robustness.
LoCoMo 基准上的结果。 表1 详细展示了 LoCoMo 评估,其中 E-mem 在不同骨干上都持续建立新的最优结果。 具体而言,它以显著幅度超过最强基线(GAM),在整体 F1 分数上分别比 GPT-4o-mini 和 Qwen2.5-14B 设置高出 +8.86% 和 +6.63%。 这种性能优势在 Multi-hop 和 Temporal 子集这类复杂推理任务中尤为关键,因为标准 RAG 往往因严重上下文碎片化而表现不佳。 相比之下,在 Qwen 骨干上,E-mem 将 Multi-hop F1 大幅提升超过 10 分(49.15% vs. 38.94%)。 这确认了我们的情景上下文重构范式能够有效保留预处理式去上下文化通常会丢失的自回归依赖,从而确保深度推理能力和稳健性。
Results on HotpotQA Benchmark. As illustrated in Table 2, E-mem demonstrates exceptional stability in ultra-long context scenarios, consistently maintaining the highest F1 scores against all baselines. A particularly notable observation is the performance of RAG compared to other complex memory-based baselines, representing a clear divergence from the trends observed in the LoCoMo results. We attribute this discrepancy to the distinct information density inherent in the benchmarks: while LoCoMo features high-similarity, dense dialogues laden with adversarial noise that significantly impairs vector retrieval, HotpotQA comprises distinct, low-interference evidence passages that are structurally favorable for semantic matching. Nevertheless, E-mem still outperforms RAG by a substantial margin (
HotpotQA 基准上的结果。 如 表2 所示,E-mem 在超长上下文场景中展现出卓越稳定性,相比所有基线始终保持最高 F1 分数。 一个特别值得注意的现象是,RAG 相比其他复杂的基于记忆的基线表现更强,这与 LoCoMo 结果中的趋势明显不同。 我们认为这种差异来自两个基准固有的信息密度不同:LoCoMo 具有相似度高、信息密集且充满对抗噪声的对话,会显著损害向量检索;而 HotpotQA 由清晰、低干扰的证据段落组成,在结构上更有利于语义匹配。 尽管如此,E-mem 仍以显著幅度超过 RAG(在 1600 文档设置中 F1 为
4.3 Robustness Against Hallucination
To rigorously assess resilience against context noise, we conducted experiments on the LoCoMo adversarial subset by cross-evaluating varying Assistant scales and master backbones. Results (Table 3) demonstrate E-mem's robustness, achieving a peak F1 of 95.74%. Crucially, our analysis reveals that optimal performance relies on the synergistic collaboration between both agents. While scaling the Assistant from 0.6B to 8B consistently enhances local episodic context reconstruction, the master agent's reasoning capability proves equally decisive. We observe significant performance variance across backbones, indicating that powerful global orchestration is indispensable for final reasoning and filtering hallucinations.
为了严格评估对上下文噪声的韧性,我们在 LoCoMo 对抗子集上进行了实验,交叉评估不同助手规模和主智能体骨干。 结果(表3)展示了 E-mem 的稳健性,最高 F1 达到 95.74%。 关键的是,我们的分析表明,最优性能依赖两个智能体之间的协同合作。 虽然将助手智能体从 0.6B 扩展到 8B 会持续增强局部情景上下文重构,但主智能体的推理能力同样关键。 我们观察到不同骨干之间存在显著性能差异,这表明强大的全局协调对于最终推理和过滤幻觉不可或缺。
| Chunk Size | Overall | Single Hop | Multi-Hop | Temporal | Open Domain | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | F1 | BLEU-1 | |
| 4K | 45.89 | 37.35 | 47.05 | 38.76 | 34.67 | 28.62 | 59.37 | 47.56 | 28.93 | 22.19 |
| 8K | 50.70 | 40.93 | 49.46 | 41.21 | 42.66 | 35.38 | 66.91 | 51.45 | 31.08 | 23.15 |
| 12K | 47.97 | 37.85 | 47.63 | 38.24 | 38.04 | 29.67 | 65.44 | 49.89 | 24.51 | 13.43 |
| 16K | 47.08 | 37.19 | 44.81 | 36.25 | 37.18 | 32.83 | 66.24 | 50.79 | 29.11 | 14.30 |
| 32K | 43.00 | 33.92 | 44.50 | 36.70 | 33.79 | 28.52 | 55.30 | 42.47 | 22.64 | 7.92 |
4.4 Ablation Study
Backbone Sensitivity Analysis. We evaluate model capacity by cross-evaluating master backbones and assistant scales (0.6B--14B) on LoCoMo conversation 1. As shown in Table 4, overall performance plateaus around the 4B mark (F1
骨干敏感性分析。 我们通过在 LoCoMo conversation 1 上交叉评估主智能体骨干和助手智能体规模(0.6B--14B)来评估模型容量。 如 表4 所示,整体性能在 4B 左右进入平台期(F1
Impact of Memory Chunk Granularity. We further investigate the sensitivity of E-mem to memory chunk size (
记忆块粒度的影响。 我们进一步研究 E-mem 对记忆块大小(
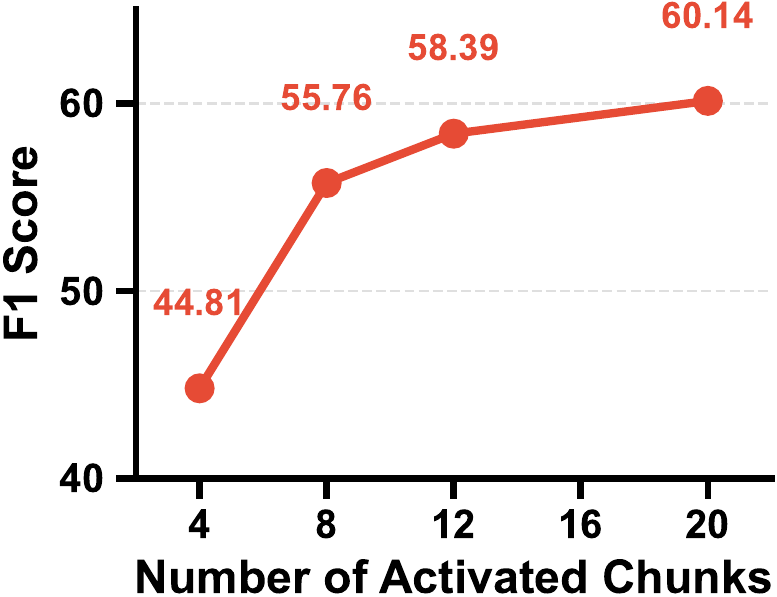
Router Ablation Study. We evaluate the scalability of the multi-pathway routing mechanism on the HotpotQA-1600 dataset. Empirical results (Figure 3) indicate that activating a minimal subset of memory chunks (e.g.,
路由器消融研究。 我们在 HotpotQA-1600 数据集上评估多路径路由机制的可扩展性。 实证结果(图3)表明,激活一个极小的记忆块子集(例如
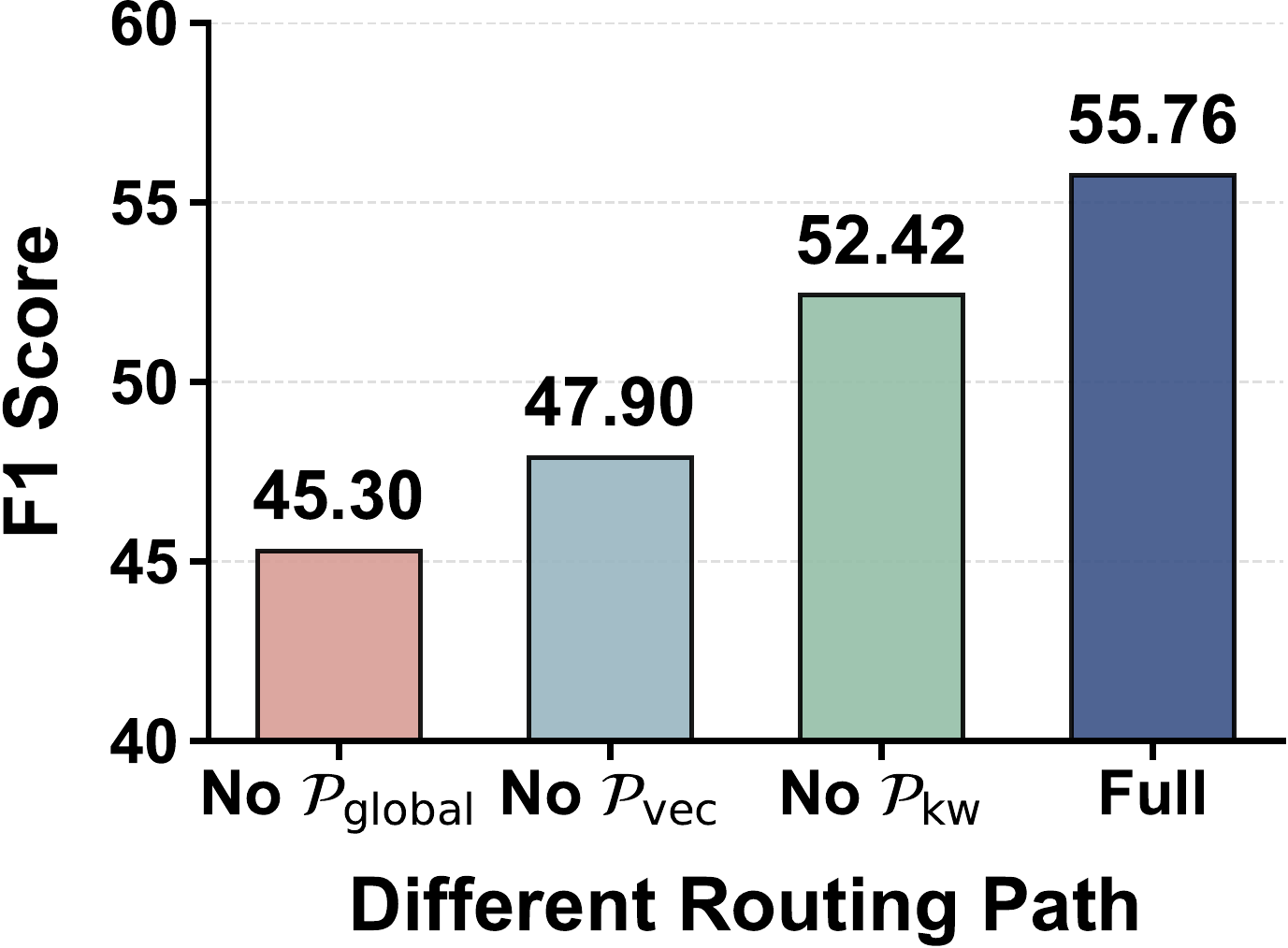
We further conduct an ablation study to evaluate the contribution of individual routing pathways. The results (Figure 3) show that the full model achieves a peak F1 of 55.76. Removing Global Alignment (
我们进一步进行消融研究,以评估单个路由路径的贡献。 结果(图3)显示,完整模型达到 55.76 的峰值 F1。 移除全局对齐(
Multi-Agent Architecture. To investigate whether a simpler pipeline—where retrieved text chunks are directly fed into a single LLM—is sufficient, we conducted an ablation study on the LoCoMo benchmark by removing the Assistant agents. In this setting, the Master LLM directly processes the concatenated raw episodic contexts.
多智能体架构。 为了研究更简单的流程是否足够,即把检索到的文本块直接输入单个 LLM,我们通过移除助手智能体,在 LoCoMo 基准上进行了消融研究。 在这一设置中,主 LLM 直接处理拼接后的原始情景上下文。
| Architecture | Overall F1 | Single-Hop | Multi-Hop | Temporal | Open Domain |
|---|---|---|---|---|---|
| Simpler Pipeline (Direct Read) | 38.27 | 48.83 | 30.62 | 31.87 | 18.55 |
| E-mem (MAS) | 54.17 | 59.23 | 42.64 | 59.82 | 24.89 |
As shown in Table 6, the drastic performance collapse in the simpler pipeline confirms that our multi-agent design is fundamentally essential rather than an optional add-on. We attribute this to the following factors:
如 表6 所示,更简单流程中的性能大幅崩塌确认了我们的多智能体设计在根本上是必要的,而不是可选附加项。 我们将其归因于以下因素:
- Cognitive Decoupling: Forcing a single LLM to process concatenated raw text chunks requires it to simultaneously execute low-level detail extraction and high-level logical synthesis, leading to severe "attention dilution."
- Our MAS strictly decouples these tasks: Assistant agents specialize in local, noise-resistant extraction, while the Master agent focuses purely on global aggregation and planning.
- Overcoming "Lost-in-the-Middle": Concatenating multiple raw chunks often exceeds the effective reasoning window of standard models.
- Assistant agents process their assigned episodic contexts in complete isolation, performing parallel local distillation to shield the Master agent from raw distractor noise.
- Cost Efficiency: By delegating the heavy, complex reasoning of raw texts to multiple cost-effective Small Language Models (SLMs) and reserving the expensive Master LLM strictly for final aggregation, E-mem avoids context window explosion.
- This heterogeneous compute strategy significantly reduces token consumption and overall deployment costs.
- 认知解耦: 迫使单个 LLM 处理拼接后的原始文本块,需要它同时执行低层细节抽取和高层逻辑综合,从而导致严重的“注意力稀释”。
- 我们的 MAS 严格解耦这些任务:助手智能体专门负责局部、抗噪抽取,而主智能体只专注于全局聚合和规划。
- 克服 “Lost-in-the-Middle”: 拼接多个原始块往往会超过标准模型的有效推理窗口。
- 助手智能体完全隔离地处理其分配到的情景上下文,执行并行局部蒸馏,从而使主智能体免受原始干扰噪声影响。
- 成本效率: E-mem 把原始文本中繁重、复杂的推理委托给多个成本更低的小语言模型(SLM),并把昂贵的主 LLM 严格保留给最终聚合,从而避免上下文窗口爆炸。
- 这种异构计算策略显著降低 token 消耗和整体部署成本。
4.5 Cost Effectiveness Analysis
To evaluate the deployment costs, we report the average number of tokens required per query on the LoCoMo. We categorize the computational overhead into Large Model Tokens (
为了评估部署成本,我们报告 LoCoMo 上每个查询所需的平均 token 数。 我们把计算开销分为大模型 token(
As shown in Table 7, full-context methods like Long-Context incur a prohibitive normalized cost (169k units), driven entirely by expensive large model processing. While retrieval baselines like RAG reduce this, they still depend on the large model for reasoning. In contrast, E-mem strategically offloads episodic context processing. Even under our conservative 1:10 assumption, E-mem reduces the normalized cost to approx. 3.6k units---a 43
如 表7 所示,像 Long-Context 这样的全上下文方法会产生高得难以承受的归一化成本(169k 单位),其成本完全由昂贵的大模型处理驱动。 虽然 RAG 这类检索基线降低了这一成本,但它们仍然依赖大模型进行推理。 相比之下,E-mem 有策略地卸载情景上下文处理。 即使在我们保守的 1:10 假设下,E-mem 也把归一化成本降低到约 3.6k 单位,相比 Long-Context 降低 43
| Method | F1 | BLEU-1 | TS | TL | Total Cost |
|---|---|---|---|---|---|
| Long-Context | 37.31 | 29.57 | none | 16910 | 169100 |
| RAG | 44.73 | 39.40 | none | 643 | 6430 |
| A-mem | 39.65 | 32.31 | none | 2520 | 25200 |
| Mem0 | 45.1 | 34.92 | none | 973 | 9730 |
| MEMORYOS | 42.84 | 35.54 | none | 3874 | 38740 |
| LIGHTMEM | 38.44 | 34.37 | none | 612 | 6120 |
| GAM | 45.31 | 37.78 | none | 1254 | 12540 |
| E-mem | 54.17 | 44.34 | 2271 | 135 | 3621 |
5. Conclusion
In this paper, we presented E-mem, a framework that shifts from destructive de-contextualization to episodic context reconstruction, which effectively preserves the contextual integrity essential for deep reasoning. Technically, we implement this by encapsulating episodic contexts managed by a heterogeneous hierarchical master-assistant architecture, which enables the precise reactivation of archived memory units within the active reasoning contexts. Extensive evaluations on both LoCoMo and HotpotQA benchmarks validate that our approach establishes a comprehensive performance lead, significantly outperforming existing preprocessing paradigms---particularly in complex multi-hop tasks---while maintaining low token cost via heterogeneous collaboration. We believe that E-mem serves as a vital complement to existing memory paradigms, offering a robust solution for high-precision, complex System 2 reasoning.
在本文中,我们提出 E-mem,这是一个从破坏性去上下文化转向情景上下文重构的框架,能够有效保留深度推理所必需的上下文完整性。 在技术上,我们通过封装由异构分层主-助手架构管理的情景上下文来实现这一点,使归档记忆单元能够在活跃推理上下文中被精确重新激活。 在 LoCoMo 和 HotpotQA 两个基准上的大量评估验证了我们的方法建立了全面的性能领先,在显著超过现有预处理范式的同时,尤其是在复杂多跳任务中,通过异构协作保持低 token 成本。 我们认为,E-mem 是现有记忆范式的重要补充,为高精度、复杂的 System 2 推理提供了稳健解决方案。
Impact Statement
This paper introduces E-mem, a framework designed to enhance the long-context reasoning capabilities of LLM agents via episodic context reconstruction. Our work primarily aims to advance the reliability and precision of autonomous systems in complex domains such as legal forensics, scientific discovery, and medical diagnosis.
本文介绍 E-mem,这是一个通过情景上下文重构增强 LLM 智能体长上下文推理能力的框架。 我们的工作主要旨在提升自主系统在法律取证、科学发现和医学诊断等复杂领域中的可靠性和精度。
However, we acknowledge potential societal implications associated with memory-augmented agents. First, the persistence of episodic memory raises privacy concerns regarding the storage and retrieval of sensitive user data. While our hierarchical architecture separates low-level storage from high-level planning, rigorous data governance and access control mechanisms are essential for real-world deployment. Second, as agents gain deeper reasoning capabilities (System 2), ensuring their alignment with human values and preventing the hallucination of false memories remains critical to mitigating safety risks. We believe this work encourages further research into robust, accountable, and transparent memory systems for AI agents.
然而,我们承认记忆增强智能体可能带来社会影响。 首先,情景记忆的持久性会引发关于敏感用户数据存储和检索的隐私担忧。 虽然我们的分层架构把低层存储与高层规划分离,但真实部署仍然需要严格的数据治理和访问控制机制。 其次,随着智能体获得更深层推理能力(System 2),确保其与人类价值对齐并防止虚假记忆幻觉,对于缓解安全风险仍然至关重要。 我们相信,这项工作会鼓励对稳健、可问责且透明的 AI 智能体记忆系统开展进一步研究。