
Goal-Directed Search Outperforms Goal-Agnostic Memory Compression in Long-Context Memory Tasks
MemoryAgentRLVRAstera Institute在长上下文记忆任务中,目标导向搜索优于目标无关记忆压缩
Abstract
How to enable human-like long-term memory in large language models (LLMs) has been a central question for unlocking more general capabilities such as few-shot generalization. Existing memory frameworks and benchmarks focus on finding the optimal memory compression algorithm for higher performance in tasks that require recollection and sometimes further reasoning. However, such efforts have ended up building more human bias into the compression algorithm, through the search for the best prompts and memory architectures that suit specific benchmarks, rather than finding a general solution that would work on other data distributions. On the other hand, goal-directed search on uncompressed information could potentially exhibit superior performance because compression is lossy, and a predefined compression algorithm will not fit all raw data distributions. Here we present SUMER (Search in Uncompressed Memory via Experience Replay), an end-to-end reinforcement learning agent with verifiable reward (RLVR) that learns to use search tools to gather information and answer a target question. On the LoCoMo dataset for long-context conversation understanding, SUMER with Qwen2.5-7B-Instruct learned to use search tools and outperformed all other biased memory compression approaches and also the full-context baseline, reaching SOTA performance (43% gain over the prior best). We demonstrate that a simple search method applied to raw data outperforms goal-agnostic and biased compression algorithms in current long-context memory tasks, arguing for new paradigms and benchmarks that are more dynamic and autonomously scalable.
如何让大语言模型(LLM)具备类似人类的长期记忆,一直是解锁少样本泛化等更通用能力的核心问题。 现有记忆框架和基准聚焦于寻找最优的记忆压缩算法,以便在需要回忆、有时还需要进一步推理的任务中取得更高性能。 然而,这些努力最终通过搜索适合特定基准的最佳提示和记忆架构,把更多人类偏置注入了压缩算法,而不是找到一个能在其他数据分布上工作的通用方案。 另一方面,由于压缩是有损的,而且预定义的压缩算法无法适配所有原始数据分布,对未压缩信息进行目标导向搜索可能展现出更强性能。 在这里,我们提出 SUMER(Search in Uncompressed Memory via Experience Replay),这是一个带可验证奖励(RLVR)的端到端强化学习智能体,它学习使用搜索工具来收集信息并回答目标问题。 在用于长上下文对话理解的 LoCoMo 数据集上,使用 Qwen2.5-7B-Instruct 的 SUMER 学会了使用搜索工具,并超过所有其他带偏置的记忆压缩方法以及 full-context 基线,达到 SOTA 性能(相对先前最佳提升 43%)。 我们证明,在当前长上下文记忆任务中,应用于原始数据的简单搜索方法优于目标无关且带偏置的压缩算法,并据此主张需要更动态、更能自主扩展的新范式和新基准。
1. Introduction
Large language models (LLMs) excel as general-purpose reasoners within a bounded context window, but their performance can degrade as inputs grow long or when relevant evidence is far from the query. Empirically, models often over-weight local or recent tokens and miss salient information in the middle of long inputs. Scaling context windows to hundreds of thousands or even millions of tokens (e.g., Gemini 1.5) improves access to evidence but does not fully resolve potential interference issues. In more recent agentic settings, LLM agents often face issues when their context window is filled up fast and therefore require techniques to store and reuse information in an effective way.
大语言模型(LLM)在有界上下文窗口内擅长作为通用推理器,但当输入变长,或相关证据距离查询很远时,它们的性能会下降。 从经验上看,模型常常过度重视局部或近期 token,并错过长输入中间的关键信息。 把上下文窗口扩展到数十万甚至数百万 token(例如 Gemini 1.5)可以改善对证据的访问,但并不能完全解决潜在干扰问题。 在更新近的智能体设置中,LLM 智能体常常在上下文窗口很快被填满时遇到问题,因此需要用有效方式存储和复用信息的技术。
There are two broad lines of work tackling long-horizon information use. The first seeks architectural solutions: recurrence and state-space models (SSMs) that can carry state across unbounded sequences (e.g., RWKV, RetNet, Mamba) reduce quadratic attention costs and enable stateful processing that, in principle, extrapolates beyond a fixed window. The second couples LLMs to external memory or tools. Early neural memory systems (NTM, DNC, etc.) showed that differentiable read/write can extend algorithmic capabilities. In modern LLMs, retrieval-augmented generation (RAG) conditions generation on retrieved context, with a design space spanning query rewriting, dense/sparse/hybrid retrieval, reranking, and compression. Agentic tool use further allows models to plan multi-step queries, browse, and call APIs (WebGPT, Toolformer, ReAct). Recent memory frameworks (MemGPT, A-MEM, Mem0, etc.) focus on what to store and how to retrieve memories across long horizons.
处理长程信息使用的工作大致有两条路线。 第一条寻求架构方案:能够跨无界序列携带状态的循环模型和状态空间模型(SSM,例如 RWKV、RetNet、Mamba)降低二次注意力成本,并支持原则上可外推到固定窗口之外的有状态处理。 第二条把 LLM 与外部记忆或工具连接起来。 早期神经记忆系统(NTM、DNC 等)表明,可微读写能够扩展算法能力。 在现代 LLM 中,检索增强生成(RAG)会基于检索到的上下文进行生成,其设计空间涵盖查询改写、密集/稀疏/混合检索、重排序和压缩。 智能体式工具使用进一步允许模型规划多步查询、浏览以及调用 API(WebGPT、Toolformer、ReAct)。 近期记忆框架(MemGPT、A-MEM、Mem0 等)聚焦于在长时间跨度中存储什么,以及如何检索记忆。
Long-context benchmarks (e.g., RULER, LongBench, and very long conversational memory in LoCoMo) highlight that even with long windows or standard RAG pipelines, models still underperform on temporal, causal, and multi-session reasoning. Many “memory” systems depend on goal-agnostic compression and fixed CRUD heuristics, which inject human design biases and could potentially discard details crucial for a downstream query unknown at compression time. By contrast, the “bitter lesson” in AI suggests that search and learning, rather than hand-crafted knowledge representations, tend to win as tasks scale. In games, for example, search plus learned value/policy produces superhuman play that was impossible with human-designed playing algorithms (AlphaGo/Zero). For language agents, an analogous strategy is to defer compression and instead learn goal-directed search over raw, uncompressed memory streams—only bringing in what is needed, when it is needed.
长上下文基准(例如 RULER、LongBench,以及 LoCoMo 中的超长对话记忆)凸显出,即使有长窗口或标准 RAG 流水线,模型在时间、因果和多会话推理上仍表现不足。 许多“记忆”系统依赖目标无关压缩和固定 CRUD 启发式,这会注入人类设计偏置,并可能丢弃压缩时未知的下游查询所需的关键细节。 相比之下,AI 中的“苦涩教训”表明,随着任务规模扩大,搜索和学习往往会胜过手工设计的知识表示。 例如在游戏中,搜索加上学得的价值/策略能够产生超人表现,而这是人工设计的对弈算法无法实现的(AlphaGo/Zero)。 对于语言智能体,一个类似策略是推迟压缩,转而学习在原始、未压缩记忆流上的目标导向搜索,只在需要时取回所需内容。
Here we present SUMER (Search in Uncompressed Memory via Experience Replay): an end-to-end reinforcement learning (RL) agent with verifiable reward (RLVR) that learns to use simple tools to search, inspect, and answer from raw conversational memory, rather than relying on pre-defined compression. SUMER is trained with group relative policy optimization (GRPO) and multi-turn masking so that tool responses are treated as context, while gradients flow only through the agent’s own actions and reasoning. Conceptually, our setup is complementary to recent RL-for-reasoning efforts (DeepSeek-R1) and multi-turn search-RL frameworks (Search-R1), but targets long-context memory tasks where the evidence is distributed across many sessions; we adapt RLVR to reward only correct final answers while letting the agent discover effective search strategies.
在这里,我们提出 SUMER(Search in Uncompressed Memory via Experience Replay):这是一个带可验证奖励(RLVR)的端到端强化学习(RL)智能体,它学习使用简单工具从原始对话记忆中搜索、检查并回答,而不是依赖预定义压缩。 SUMER 使用 group relative policy optimization(GRPO)和多轮 masking 训练,使工具响应被视为上下文,而梯度只流经智能体自己的动作和推理。 从概念上看,我们的设置与近期面向推理的 RL 工作(DeepSeek-R1)以及多轮搜索 RL 框架(Search-R1)互补,但目标是证据分散在许多会话中的长上下文记忆任务;我们调整 RLVR,使其只奖励正确的最终答案,同时让智能体发现有效搜索策略。
On LoCoMo’s long-term conversational QA, SUMER starts from low zero-shot accuracy, learns to chain search calls over training, and ultimately surpasses hand-engineered memory baselines and full context, achieving new SOTA results with a net gain of 43% over prior best.
在 LoCoMo 的长期对话问答上,SUMER 从较低的零样本准确率出发,在训练过程中学会串联搜索调用,并最终超过人工设计的记忆基线和 full context,以相对先前最佳净提升 43% 的结果达到新的 SOTA。
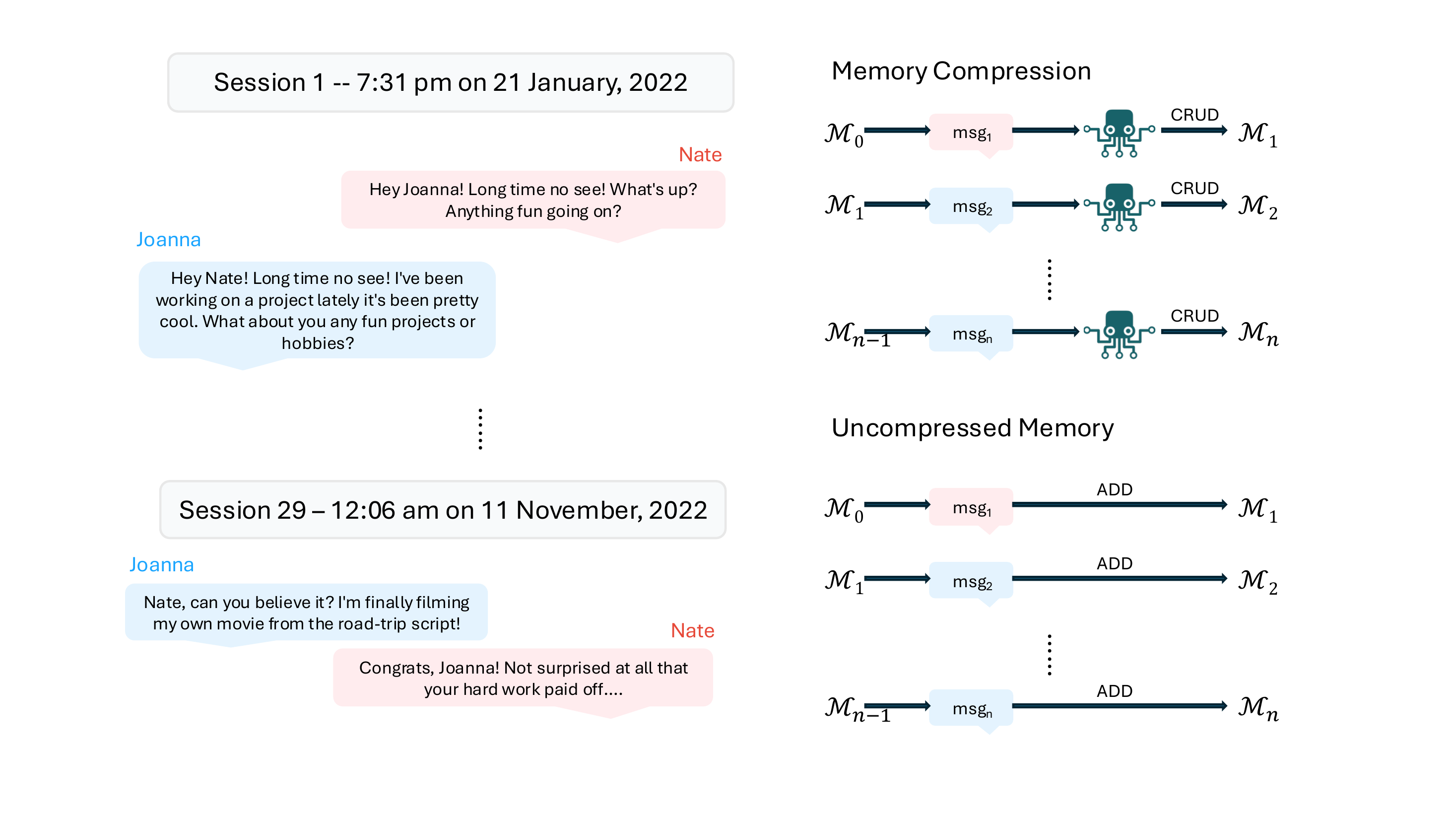
2. Related Works
2.1 External Memory in LLMs
Neural networks paired with external memory have long been used to extend algorithmic and reasoning capabilities beyond what standard sequence models can manage, from Neural Turing Machines and Memory Networks to Differentiable Neural Computers and many more. For large language models, the most popular method is retrieval-augmented generation (RAG), which retrieves task-relevant information from an external store using embedding vectors and conditions the model’s generation on it. Recent surveys organize RAG systems into stages covering query preparation, retrieval/indexing, and post-retrieval conditioning, and highlight design choices such as dense vs. sparse/hybrid retrieval, reranking, query rewriting, and compression/summarization for memory efficiency, etc.
长期以来,配有外部记忆的神经网络被用于扩展标准序列模型难以处理的算法和推理能力,从 Neural Turing Machines、Memory Networks 到 Differentiable Neural Computers 以及更多系统。 对于大语言模型,最流行的方法是检索增强生成(RAG),它使用嵌入向量从外部存储中检索任务相关信息,并让模型基于这些信息生成。 近期综述把 RAG 系统组织为查询准备、检索/索引和检索后调节等阶段,并强调密集检索与稀疏/混合检索、重排序、查询改写以及为提高记忆效率而进行的压缩/摘要等设计选择。
One recent line of work on agentic LLMs aims to improve their performance on long tasks with many steps by implementing more sophisticated memory systems. MemGPT introduces virtual context management and a tiered memory hierarchy, paging information in and out of the context window so the LLM operates over a manageable working set while keeping a persistent long-term state externally in disk memory. A-MEM proposes agentic memory that dynamically organizes experiences using Zettelkasten-like “notes,” explicit links between memories, and memory evolution (updates to prior notes when new information arrives), improving multi-hop and temporal retrieval for agents. Mem0 frames memory as production-ready infrastructure with LLM-driven ADD/UPDATE/DELETE/NOOP operations and reports strong long-horizon results, and graph-structured variants for relational reasoning, while Memory-R1 adds reinforcement learning (RL) of a memory manager and an answer agent to achieve stronger performance; GraphRAG builds knowledge graphs to support multi-hop discovery and retrieval beyond flat chunks; MemMachine positions itself as a dedicated memory layer for agents, separating profile, short-term (episodic/summaries), and long-term stores with reranking and consolidation.
近期关于智能体式 LLM 的一条工作线通过实现更复杂的记忆系统,试图提升它们在许多步骤组成的长任务上的表现。 MemGPT 引入虚拟上下文管理和分层记忆结构,把信息换入换出上下文窗口,使 LLM 在可管理的工作集上运行,同时把持久长期状态保存在外部磁盘记忆中。 A-MEM 提出智能体式记忆,使用类似 Zettelkasten 的“笔记”、记忆之间的显式链接以及记忆演化(当新信息到达时更新先前笔记)来动态组织经验,从而提升智能体的多跳和时间检索。 Mem0 把记忆定位为可生产部署的基础设施,由 LLM 驱动 ADD/UPDATE/DELETE/NOOP 操作,并报告了强劲的长程结果以及用于关系推理的图结构变体;与此同时,Memory-R1 为记忆管理器和答案智能体加入强化学习(RL)以取得更强性能;GraphRAG 构建知识图,以支持超越扁平 chunk 的多跳发现与检索;MemMachine 则把自身定位为智能体专用记忆层,通过重排序和整合把 profile、short-term(情景/摘要)和 long-term 存储分开。
2.2 RLVR and Multi-Turn Agentic Tool Use
RLVR refers to doing RL on tasks whose outcomes can be automatically checked by a program (and are therefore verifiable). For example, math problems with exact answers or code judged by test suites. Recent work shows that large-scale RLVR can elicit stronger multi-step reasoning than SFT alone, including GRPO objectives that stabilize training by normalizing rewards within sets of candidates. Building on this, DeepSeek-AI et al. train reasoning models (R1/R1-Zero) with RL to improve stepwise solutions, reporting emergent behaviors like self-verification.
RLVR 指的是在结果可以由程序自动检查(因此可以验证)的任务上做 RL。 例如有精确答案的数学题,或由测试套件评判的代码。 近期工作表明,大规模 RLVR 能比单独 SFT 激发更强的多步推理,包括通过在候选集合内归一化奖励来稳定训练的 GRPO 目标。 在此基础上,DeepSeek-AI 等人用 RL 训练推理模型(R1/R1-Zero)以改进逐步解答,并报告了自我验证等涌现行为。
Early agentic methods taught models to interleave reasoning with actions (e.g., search APIs) within a single trajectory via prompting or supervised traces, for example, ReAct couples thoughts and acts, and WebGPT uses browsing with imitation learning + preference optimization. Recent RLVR work extends this to multi-turn settings where the model repeatedly queries tools, reads results, and adapts its plan before committing to a final answer. Jin et al. (Search-R1) demonstrate end-to-end RL that teaches an LLM when to query a searcher and how to reason over retrieved evidence.
早期智能体方法通过提示或监督轨迹,教模型在单条轨迹中交替进行推理和动作(例如搜索 API);例如,ReAct 把思考与动作结合起来,WebGPT 则把浏览与模仿学习 + 偏好优化结合。 近期 RLVR 工作把这一点扩展到多轮设置,在这种设置中,模型会反复查询工具、阅读结果,并在提交最终答案之前调整计划。 Jin 等人(Search-R1)展示了端到端 RL,它教会 LLM 何时查询搜索器,以及如何基于检索到的证据进行推理。
2.3 Trainable Search over Memory
For LLMs, test-time search improves reasoning and problem solving: Self-Consistency searches over multiple chains-of-thought; Tree-of-Thoughts explores/prunes thought trees; and DeepSWE selects from sampled agentic coding trajectories for higher accuracy in coding tasks. With RLVR, a model can be trained to when and how to search according to a policy that is optimal for the target task. Search-R1 uses outcome rewards to teach when to search, what to query, and how to integrate results across multiple turns. Our setting mirrors this but targets long-term conversational memory: instead of compress-then-retrieve, SUMER performs task-conditioned search over uncompressed logs and optimizes the search policy for response accuracy. More recently, MEM1 learns to modify its memory bank to better perform tasks like Q&A, outperforming methods that only compress memory, such as A-MEM. Similar to Search-R1, MEM1 targets knowledge corpuses like Wikipedia, and demonstrates the advantages of learned, goal-directed search over memory compression.
对于 LLM,测试时搜索可以改进推理和问题求解:Self-Consistency 会在多条思维链上搜索;Tree-of-Thoughts 会探索/剪枝思维树;DeepSWE 会从采样的智能体式代码轨迹中选择,以提高代码任务准确率。 借助 RLVR,模型可以按照对目标任务最优的策略,学习何时以及如何搜索。 Search-R1 使用结果奖励来教模型何时搜索、查询什么,以及如何跨多轮整合结果。 我们的设置与此类似,但目标是长期对话记忆:SUMER 不采用先压缩再检索,而是在未压缩日志上进行任务条件化搜索,并优化搜索策略以提高响应准确率。 更近期,MEM1 学习修改自己的记忆库,以便更好地执行问答等任务,并超过 A-MEM 等只压缩记忆的方法。 与 Search-R1 类似,MEM1 面向 Wikipedia 等知识语料,并展示了学得的目标导向搜索相对于记忆压缩的优势。
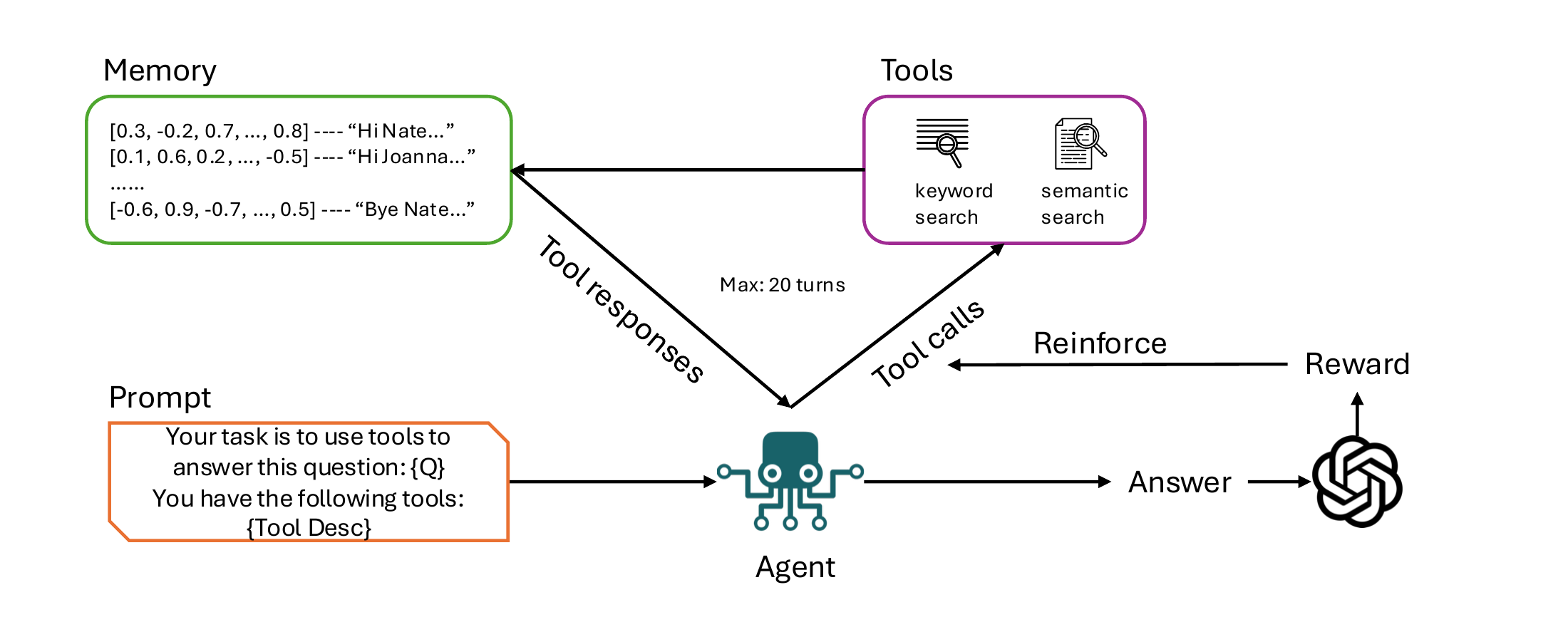
3. Method
We present SUMER, a RL framework that trains LLM agents to autonomously discover and utilize relevant memories through multi-turn tool interactions for question-answering tasks. Unlike traditional memory management approaches with explicit CRUD operations, SUMER empowers agents to learn effective memory search and retrieval strategies through outcome-driven rewards.
我们提出 SUMER,这是一个 RL 框架,用于训练 LLM 智能体在问答任务中通过多轮工具交互自主发现并利用相关记忆。 不同于带显式 CRUD 操作的传统记忆管理方法,SUMER 让智能体能够通过结果驱动的奖励学习有效的记忆搜索与检索策略。
3.1 Problem Formulation
Consider a multi-session dialogue comprising
考虑一个由
Given a target question search_memory for semantic/RAG-based and keyword-based retrieval and submit_answer for final response generation. The challenge lies in learning effective search strategies and memory utilization patterns that maximize answer accuracy through RL.
给定目标问题 search_memory 用于基于语义/RAG 的检索和基于关键词的检索,submit_answer 用于生成最终响应。 挑战在于通过 RL 学习有效搜索策略和记忆利用模式,以最大化答案准确率。
3.2 System Architecture
SUMER employs a single LLM agent trained via GRPO to interact with memory through a tool-augmented framework. The policy
SUMER 使用一个通过 GRPO 训练的单个 LLM 智能体,在工具增强框架中与记忆交互。 策略
where
其中
During preprocessing, conversation-level memories (i.e., individual messages with metadata) are initialized from the LoCoMo dataset and embedded using the Qwen3-Embedding-0.6B model, which generates 1024-dimensional dense vectors. These pre-computed embeddings were then added as-is to the Langmem memory bank to enable efficient semantic search during training. During memory search, to enrich the context of each memory, 2 messages right before and 2 messages right after the found memory were concatenated with the memory to form a memory group and fed to the agent. The search_memory tool provides two search modes:
在预处理期间,对话级记忆(即带有元数据的单条消息)从 LoCoMo 数据集初始化,并使用 Qwen3-Embedding-0.6B 模型嵌入,该模型生成 1024 维密集向量。 这些预计算嵌入随后按原样加入 Langmem 记忆库,以便在训练期间进行高效语义搜索。 在记忆搜索期间,为丰富每条记忆的上下文,我们把找到的记忆前 2 条和后 2 条消息与该记忆拼接起来形成一个记忆组,并喂给智能体。 search_memory 工具提供两种搜索模式:
- Semantic Search: Uses pre-computed Qwen3-Embedding-0.6B embeddings to find the
most similar memories to a natural language query.
- The 1024-dimensional embeddings are compared using cosine similarity in the embedding space.
- Keyword Search: Returns all memories where all specified keywords appear in either the content or metadata fields.
- This enables precise filtering when the agent knows specific terms to search for.
- 语义搜索: 使用预计算的 Qwen3-Embedding-0.6B 嵌入,找到与自然语言查询最相似的
条记忆。
- 这些 1024 维嵌入在嵌入空间中使用余弦相似度进行比较。
- 关键词搜索: 返回所有指定关键词都出现在内容字段或元数据字段中的记忆。
- 当智能体知道要搜索的具体术语时,这支持精确过滤。
Both search modes support filtering by speaker and session, allowing the agent to narrow its search scope. The agent must learn through RL which search strategy and filters are most effective for different question types.
两种搜索模式都支持按说话者和会话过滤,使智能体能够缩小搜索范围。 智能体必须通过 RL 学习对于不同问题类型,哪种搜索策略和过滤器最有效。
The generated answer is saved and compared with ground truth when submit_answer is called, or when one the following conditions is met: 1) length of agent-environment interaction history exceeding context window of the LLM; 2) agent reaching maximum tool use turns (20); 3) no tool calls detected.
当 submit_answer 被调用,或者满足以下条件之一时,生成答案会被保存并与真实答案比较:1) 智能体-环境交互历史长度超过 LLM 的上下文窗口;2) 智能体达到最大工具使用轮数(20);3) 未检测到工具调用。
3.3 Reinforcement Learning with GRPO
We train the agent with GRPO, which replaces critic-based advantages with group-normalized rewards computed from
我们使用 GRPO 训练智能体,它用每个提示采样得到的
Here
这里
3.3.1 GRPO Objective
Let
令
where
其中
where
其中
Our training objective is based on GRPO, with higher clipping, without any KL regularization term, and without entropy loss:
我们的训练目标基于 GRPO,使用更高的 clipping,不包含任何 KL 正则项,也不包含熵损失:
3.3.2 Multi-Turn Tool Interactions and Masking
Each trajectory
每条轨迹
where
其中
During training, we apply selective masking to focus learning on agent-generated content while providing tool responses as context. Specifically, we mask out prompts and tool responses and only train on the tokens that the agent generated. This masking ensures the agent learns to generate effective tool calls and reasoning while not focusing on predicting prompts or tool responses.
在训练期间,我们应用选择性 masking,使学习聚焦于智能体生成的内容,同时把工具响应作为上下文提供。 具体而言,我们 mask 掉提示和工具响应,只训练智能体生成的 token。 这种 masking 确保智能体学习生成有效工具调用和推理,而不是聚焦于预测提示或工具响应。
3.4 Reward Function
The agent is trained with a reward combining an LLM-judge correctness signal and an F1 score between the predicted and gold answers:
智能体使用一种奖励进行训练,该奖励结合了 LLM judge 正确性信号,以及预测答案与标准答案之间的 F1 分数:
Correctness is evaluated using an LLM-as-judge approach with the gpt-oss-120b model. The judge checks semantic equivalence rather than exact string matching, allowing paraphrases as long as the answer is factually correct. To shape the output format, we additionally compute the token-level F1 score:
正确性使用 gpt-oss-120b 模型和 LLM-as-judge 方法评估。 judge 检查语义等价,而不是精确字符串匹配,只要答案在事实上正确,就允许改写。 为了塑造输出格式,我们还计算 token 级 F1 分数:
where Precision and Recall are computed over the sets of tokens in the predicted and gold answers. This encourages the agent to match the style and brevity of the gold answers (typically short phrases) rather than producing overly long explanations that would still satisfy the LLM judge on semantics.
其中 Precision 和 Recall 在预测答案和标准答案的 token 集合上计算。 这鼓励智能体匹配标准答案的风格和简洁性(通常是短语),而不是生成过长解释,即使这些解释在语义上仍能满足 LLM judge。
The LLM judge uses a structured prompt requesting binary classification (CORRECT/WRONG) in JSON format, with evaluation criteria emphasizing topical alignment and factual accuracy over exact wording. Importantly, only trajectories that successfully call submit_answer receive non-zero rewards. This encourages the agent to learn when it has gathered sufficient information to answer, rather than searching indefinitely. Trajectories that exceed the turn limit without submitting an answer receive
LLM judge 使用结构化提示,请求以 JSON 格式进行二分类(CORRECT/WRONG),评估标准强调主题对齐和事实准确性,而不是精确措辞。 重要的是,只有成功调用 submit_answer 的轨迹会获得非零奖励。 这鼓励智能体学习何时已经收集到足够信息可以回答,而不是无限搜索。 超过轮次限制但未提交答案的轨迹会得到
3.5 Training and Validation Data
Training uses 1 conversation (conv-48, first conversation after shuffling with a seed=42) out of the 10 conversations in LoCoMo, with the 9 other conversations used as validation data. LoCoMo is a benchmark for evaluating very long-term conversational memory, consisting of 10 high-quality multi-session conversations generated through a machine-human pipeline and verified by human annotators for consistency and grounding.
训练使用 LoCoMo 10 个对话中的 1 个对话(conv-48,即以 seed=42 打乱后的第一个对话),其余 9 个对话用作验证数据。 LoCoMo 是用于评估超长期对话记忆的基准,由 10 个通过机器-人类流水线生成的高质量多会话对话组成,并由人类标注者验证一致性和事实依据。
Each conversation in LoCoMo contains an average of 27.2 sessions (ranging from 19 to 32 sessions), 588.2 turns (ranging from 369 to 689 turns), and approximately 17,390 tokens (ranging from 10,424 to 21,014 tokens). Token counts are estimated using word count
LoCoMo 中每个对话平均包含 27.2 个会话(范围为 19 到 32 个会话)、588.2 个轮次(范围为 369 到 689 个轮次),以及约 17,390 个 token(范围为 10,424 到 21,014 个 token)。 Token 数量使用词数
The benchmark includes 1,540 question-answer pairs across all 10 conversations (conv-48 contains 191 questions), categorized into four types: (1) single-hop questions answerable from a single turn (54.6% of questions), (2) multi-hop questions requiring reasoning across multiple conversation turns (18.3%), (3) open-domain questions requiring inference beyond explicitly stated information (6.2%), and (4) temporal questions requiring temporal understanding of events (20.8%). The dataset also contains adversarial questions (category 5), but these are excluded from evaluation as they lack ground truth labels.
该基准在全部 10 个对话中包含 1,540 个问答对(conv-48 包含 191 个问题),分为四类:(1) 单跳问题,可由单个轮次回答(占问题的 54.6%);(2) 多跳问题,需要跨多个对话轮次推理(18.3%);(3) 开放域问题,需要超出明示信息进行推断(6.2%);以及 (4) 时间问题,需要理解事件的时间关系(20.8%)。 该数据集还包含对抗性问题(类别 5),但这些问题缺少真实答案,因此被排除在评估之外。
Validation uses greedy decoding (sampling temperature 0) with a single trajectory per question. We evaluate every 50 steps.
验证使用贪心解码(采样温度为 0),每个问题使用单条轨迹。 我们每 50 步评估一次。
4. Experiments
4.1 Experiment Setup
Dataset We performed minimal preprocessing to the LoCoMo dataset to include timestamp of sessions and individual messages and then directly added each individual message as memory into the Langmem data structure (which could be replaced by a simple dictionary). We split the dataset to have 1 conversation as training data, and the other 9 conversations as validation data. We omitted the adversarial category due to lack of ground truth labels.
数据集。 我们对 LoCoMo 数据集做了最少量预处理,以包含会话和单条消息的时间戳,然后直接把每条单独消息作为记忆加入 Langmem 数据结构(也可以替换为简单字典)。 我们把数据集划分为 1 个对话作为训练数据,另外 9 个对话作为验证数据。 由于缺少真实标签,我们省略了对抗性类别。
Baselines We obtained baseline code from the following repositories: Mem0, A-MEM, and MemMachine. We compare with the following baselines after adapting their code to use our local LLM setting and keeping other configurations the same (see Appendix Table 2):
基线。 我们从以下仓库获得基线代码:Mem0、A-MEM 以及 MemMachine。 在调整它们的代码以使用我们的本地 LLM 设置,并保持其他配置相同之后,我们与以下基线进行比较(见附表2):
1. RAG: We segmented the entire conversation into chunks of 500 tokens and retrieved the most relevant chunk using the target question as the query. We appended the retrieved text to the target question and obtained the answer from the LLM.
2. Full Context: Similar to RAG, except that instead of chunks of 500 tokens we used the entire conversation history as context.
3. Langmem: We used autonomous LangGraph agents for each speaker to manage their own memories. The agents processed conversations, autonomously stored relevant information in a local vector store, and independently searched memories to generate responses that were combined to obtain the final answer from the LLM. Because the Qwen-2.5-7B-Instruct model only has a context window of 32k, we had to cut the agent generation window down to 8k and left 24k for agent trajectory to run the eval script without error.
4. A-Mem: The system uses Zettelkasten-inspired memory organization with explicit links between memories, hybrid retrieval combining BM25 (Best Matching 25) and semantic search (
5. Mem0: We extracted personalized memories from paired conversation messages for each speaker using Mem0's API as of October 29, 2025 (non-local LLM) and retrieved the top 30 most relevant memories per speaker using the target question as the query to obtain the answer from the local LLM.
6. MemMachine: We ingested each conversation into MemMachine's episodic memory system, where each message was stored as a memory episode with its speaker, timestamp, and metadata. During evaluation, for each target question, we queried the episodic memory system to retrieve up to 30 most relevant memory episodes. The retrieved episodes were provided as context to the LLM to answer the question.
1. RAG: 我们把整个对话切分为 500 token 的 chunk,并使用目标问题作为查询来检索最相关的 chunk。我们把检索到的文本追加到目标问题后,并从 LLM 获得答案。
2. Full Context: 与 RAG 类似,只是我们不使用 500 token 的 chunk,而是把整个对话历史作为上下文。
3. Langmem: 我们为每位说话者使用自主 LangGraph 智能体来管理自己的记忆。这些智能体处理对话,自主把相关信息存入本地向量存储,并独立搜索记忆以生成响应,随后把响应合并起来,从 LLM 获得最终答案。由于 Qwen-2.5-7B-Instruct 模型只有 32k 上下文窗口,我们不得不把智能体生成窗口缩短到 8k,并留下 24k 给智能体轨迹,以便无错误运行评估脚本。
4. A-Mem: 该系统使用受 Zettelkasten 启发的记忆组织方式,包含记忆之间的显式链接、结合 BM25(Best Matching 25)和语义搜索的混合检索(
5. Mem0: 我们使用截至 2025 年 10 月 29 日的 Mem0 API(非本地 LLM),从每位说话者的成对对话消息中抽取个性化记忆,并使用目标问题作为查询,为每位说话者检索最相关的前 30 条记忆,以从本地 LLM 获得答案。
6. MemMachine: 我们把每个对话摄取到 MemMachine 的情景记忆系统中,其中每条消息都作为一个记忆情节存储,并带有说话者、时间戳和元数据。在评估期间,对于每个目标问题,我们查询情景记忆系统,检索最多 30 个最相关的记忆情节。检索到的情节作为上下文提供给 LLM,用来回答问题。
Implementation Details We implement SUMER using the VERL framework for distributed reinforcement learning. Our system runs on 8 NVIDIA H100 GPUs (80GB each) with tensor model parallelism (size=2) and Ulysses sequence parallelism (size=4) for efficient distributed training. We use Qwen-2.5-7B-Instruct as the base model with gradient checkpointing and FSDP offloading to manage memory constraints. The system supports prompts up to 8192 tokens and responses up to 24576 tokens with overflow filtering disabled to accommodate long multi-turn conversations. As a design choice, we used Qwen3-Embedding-0.6B instead of the more commonly used text-embedding-3-small for embedding, and gpt-oss-120b instead of gpt-4o-mini for LLM judge, which led to faster iteration of experiments.
实现细节。 我们使用 VERL 框架实现 SUMER,以进行分布式强化学习。 我们的系统运行在 8 张 NVIDIA H100 GPU(每张 80GB)上,并使用张量模型并行(大小为 2)和 Ulysses 序列并行(大小为 4)来高效分布式训练。 我们使用 Qwen-2.5-7B-Instruct 作为基础模型,并使用梯度检查点和 FSDP offloading 来管理内存约束。 系统支持最长 8192 token 的提示和最长 24576 token 的响应,并关闭溢出过滤,以适应长多轮对话。 作为一项设计选择,我们使用 Qwen3-Embedding-0.6B 而不是更常用的 text-embedding-3-small 进行嵌入,并使用 gpt-oss-120b 而不是 gpt-4o-mini 作为 LLM judge,这带来了更快的实验迭代。
During training, we use temperature
训练期间,我们使用温度
| Method | Single-Hop | Multi-Hop | Open Domain | Temporal | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | |
| RAG | 25.90 | 12.09 | 12.09 | 17.02 | 12.09 | 21.28 | 17.20 | 13.90 | 37.50 | 15.37 | 12.80 | 13.08 | 24.97 | 19.89 | 35.84 |
| Full Context | 27.10 | 18.25 | 63.02 | 19.42 | 14.62 | 33.69 | 12.88 | 11.35 | 39.58 | 10.59 | 7.95 | 17.45 | 21.37 | 15.01 | 46.69 |
| Langmem | 8.42 | 10.04 | 21.20 | 13.41 | 15.91 | 21.63 | 9.95 | 10.62 | 25.00 | 6.25 | 6.18 | 4.36 | 10.35 | 8.98 | 17.99 |
| A-MEM | 35.36 | 30.46 | 46.70 | 20.54 | 13.85 | 24.11 | 11.91 | 10.62 | 27.34 | 31.34 | 26.32 | 25.23 | 27.28 | 23.13 | 32.00 |
| Mem0 | 34.38 | 29.76 | 46.25 | 27.83 | 20.27 | 31.56 | 14.97 | 11.65 | 31.25 | 36.20 | 28.89 | 22.43 | 32.35 | 26.71 | 37.66 |
| MemMachine | 48.18 | 41.78 | 44.35 | 32.86 | 23.18 | 24.82 | 14.76 | 11.20 | 19.79 | 37.60 | 28.85 | 17.76 | 41.09 | 33.77 | 33.70 |
| SUMER-Base | 34.98 | 30.30 | 64.45 | 16.90 | 13.36 | 36.78 | 13.48 | 11.53 | 36.05 | 25.10 | 21.22 | 22.22 | 28.07 | 23.95 | 48.55 |
| SUMER-GRPO | 61.82 | 56.55 | 79.53 | 28.45 | 21.85 | 44.83 | 19.98 | 17.45 | 39.53 | 42.23 | 37.66 | 62.72 | 48.65 | 43.44 | 66.79 |
4.2 Main Results
Table 1 compares SUMER (SUMER-Base: pre-RL, SUMER-GRPO: post-RL) against standard RAG, full-context prompting, and several goal-agnostic memory systems on LoCoMo, reporting token-level F1, BLEU-1 (B1), and LLM-judge correctness (J). Across all question types, SUMER trained with GRPO (SUMER-GRPO) achieves the best overall performance, nearly doubling judge accuracy relative to the strongest compression-based baseline. Specifically, compared to MemMachine, SUMER-GRPO improves overall F1 from 41.09 to 48.65 (+7.56), B1 from 33.77 to 43.44 (+9.67), and J from 33.70 to 66.79 (+33.09,
表1在 LoCoMo 上比较 SUMER(SUMER-Base:RL 前;SUMER-GRPO:RL 后)与标准 RAG、full-context prompting 以及若干目标无关记忆系统,并报告 token 级 F1、BLEU-1(B1)和 LLM-judge correctness(J)。 在所有问题类型上,使用 GRPO 训练的 SUMER(SUMER-GRPO)取得最佳整体性能,相比最强的基于压缩的基线,judge 准确率几乎翻倍。 具体而言,与 MemMachine 相比,SUMER-GRPO 把 overall F1 从 41.09 提升到 48.65(+7.56),把 B1 从 33.77 提升到 43.44(+9.67),并把 J 从 33.70 提升到 66.79(+33.09,约
Decomposed by question type, SUMER-GRPO dominates or matches baselines everywhere. On single-hop questions, it attains 61.82 F1 / 56.55 B1 / 79.53 J, improving J by more than 15 points over the best non-RL variant. Multi-hop questions remain the most challenging regime: SUMER-GRPO improves J to 44.83, outperforming all baselines on judge accuracy while exhibiting a modest trade-off in F1 and B1 relative to MemMachine. Open-domain questions show smaller absolute gains, but SUMER-GRPO still matches or slightly exceeds the best prior J while delivering higher F1/B1 scores. For temporal reasoning, where correctly locating events in a long conversation is critical, SUMER-GRPO achieves 42.23 F1 / 37.66 B1 / 62.72 J, achieving large margins over all other baselines.
按问题类型拆分后,SUMER-GRPO 在各处都主导或追平基线。 在 single-hop 问题上,它达到 61.82 F1 / 56.55 B1 / 79.53 J,相比最佳非 RL 变体,J 提高超过 15 分。 Multi-hop 问题仍是最具挑战性的设置:SUMER-GRPO 把 J 提升到 44.83,在 judge 准确率上超过所有基线,同时相对于 MemMachine 在 F1 和 B1 上表现出适度权衡。 Open-domain 问题的绝对增益较小,但 SUMER-GRPO 仍追平或略高于先前最佳 J,同时给出更高的 F1/B1 分数。 对于需要在长对话中正确定位事件的 temporal reasoning,SUMER-GRPO 达到 42.23 F1 / 37.66 B1 / 62.72 J,相比所有其他基线都有大幅优势。
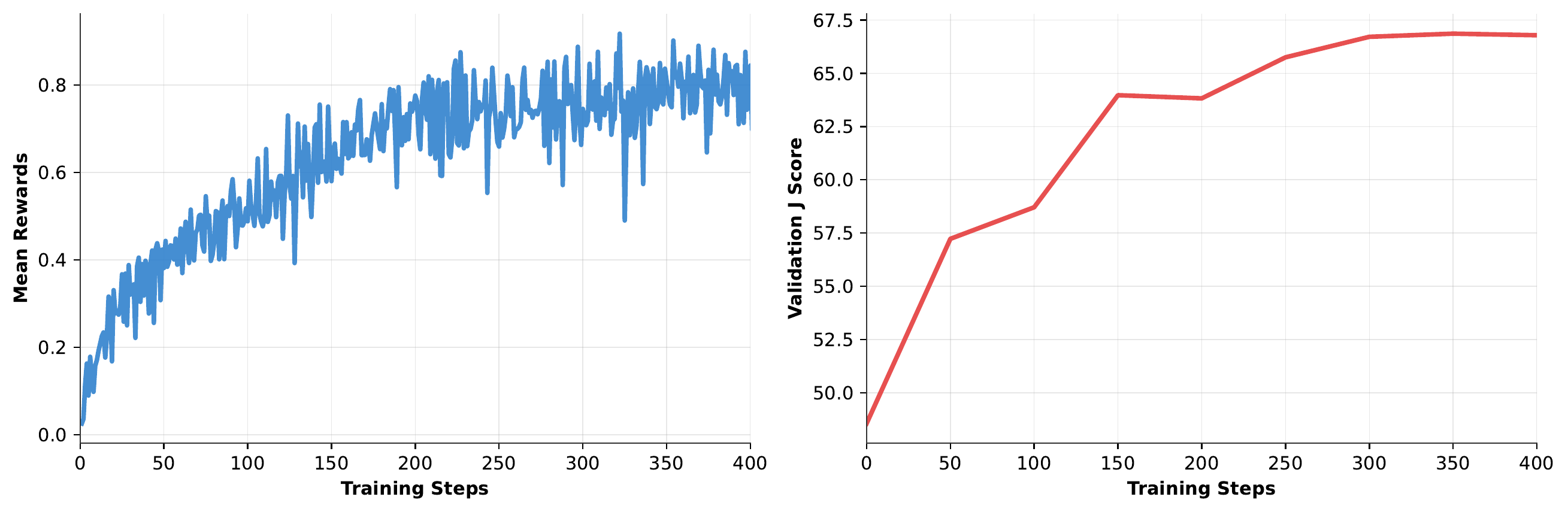
Figure 3 illustrates that these improvements are realized through a stable RL learning process. The mean reward climbs steadily from around 0 to around 0.8 over 400 training steps, while validation J increases from 48.55 to 66.79. This indicates that SUMER learns more effective search strategies over time rather than simply overfitting to the training conversation. Overall, the results support our central claim: a goal-directed search policy over uncompressed conversational memory can outperform hand-engineered CRUD-style compression pipelines on long-context memory QA.
图3表明,这些改进是通过稳定的 RL 学习过程实现的。 在 400 个训练 step 中,平均奖励从约 0 稳定爬升到约 0.8,同时验证 J 从 48.55 增加到 66.79。 这说明 SUMER 随时间学习到了更有效的搜索策略,而不是简单过拟合训练对话。 总体而言,结果支持我们的核心主张:在未压缩对话记忆上的目标导向搜索策略,可以在长上下文记忆问答中超过人工设计的 CRUD 风格压缩流水线。
4.3 Ablation Studies
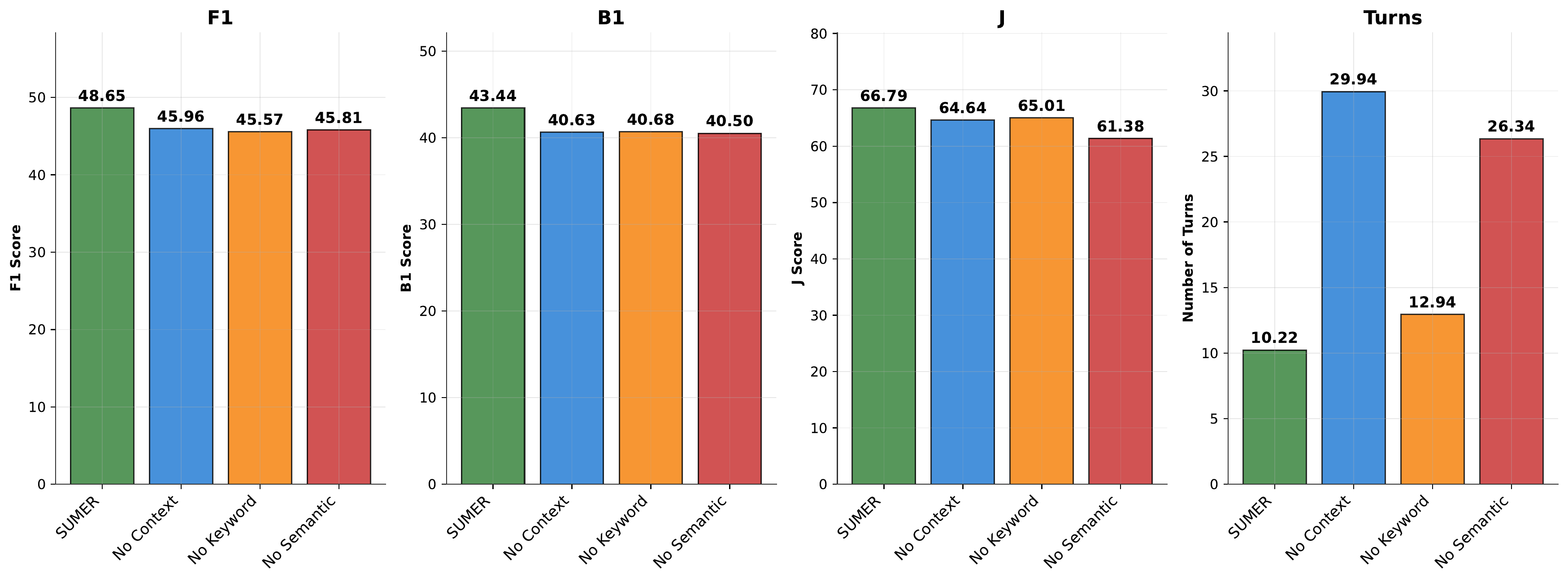
To understand which components of SUMER contribute most to performance, we conduct ablations that disable 1) temporal context around retrieved memories (No Context), 2) keyword-based search (No Keyword), and 3) semantic search over embeddings (No Semantic). Figure 4 summarizes final validation performance and the average number of search turns, and Appendix Table 1 reports initial, final, and peak metrics for each configuration.
为理解 SUMER 的哪些组件对性能贡献最大,我们进行消融,分别禁用 1) 检索记忆周围的时间上下文(No Context),2) 基于关键词的搜索(No Keyword),以及 3) 基于嵌入的语义搜索(No Semantic)。 图4总结了最终验证性能和平均搜索轮数,附表1报告每个配置的初始、最终和峰值指标。
All ablated variants still benefit substantially from GRPO training. For example, No Context improves its overall J from 38.32 to 64.64 (+26.32, +68.67% relative), No Semantic improves from 40.47 to 61.38 (+20.90, +51.65%), and No Keyword improves from 49.52 to 65.01 (+15.49, +31.29%). This indicates that RL is powerful enough to discover reasonably effective search strategies even when the toolset is partially crippled.
所有消融变体仍然都能从 GRPO 训练中显著受益。 例如,No Context 的 overall J 从 38.32 提升到 64.64(+26.32,相对 +68.67%),No Semantic 从 40.47 提升到 61.38(+20.90,+51.65%),No Keyword 从 49.52 提升到 65.01(+15.49,+31.29%)。 这说明,即使工具集被部分削弱,RL 仍足够强大,能够发现相当有效的搜索策略。
Nonetheless, the full SUMER configuration consistently achieves the best trade-off between accuracy and efficiency. With all tools enabled, SUMER reaches 48.65 F1 / 43.44 B1 / 66.79 J while requiring only 10.22 tool-using turns on average. Removing temporal context around retrieved messages (No Context) leads to slightly lower final J (64.64) but almost triples the number of turns (29.94), suggesting that local temporal neighborhoods are important for quickly gathering sufficient evidence. Disabling semantic search (No Semantic) has the largest negative effect on J among the ablations (down to 61.38) and substantially increases the number of turns (26.34), implying that keyword search alone is a less efficient way to navigate long conversational histories. In contrast, removing keyword search (No Keyword) yields relatively mild degradation (65.01 J, 12.94 turns), indicating that semantic retrieval is still more efficient at finding the most semantically relevant information while keyword search provides complementary precision in a subset of cases.
尽管如此,完整 SUMER 配置始终取得准确率与效率之间的最佳权衡。 在启用所有工具时,SUMER 达到 48.65 F1 / 43.44 B1 / 66.79 J,同时平均只需要 10.22 个工具使用轮次。 移除检索消息周围的时间上下文(No Context)会导致最终 J 略低(64.64),但轮数几乎增加两倍(29.94),说明局部时间邻域对于快速收集足够证据很重要。 禁用语义搜索(No Semantic)在消融中对 J 的负面影响最大(降到 61.38),并显著增加轮数(26.34),这意味着仅靠关键词搜索在长对话历史中导航效率较低。 相比之下,移除关键词搜索(No Keyword)只造成相对轻微的退化(65.01 J,12.94 轮),说明语义检索仍然更高效地找到最语义相关的信息,而关键词搜索在部分情形中提供互补的精确性。
Taken together, these ablations support two conclusions. First, RL consistently improves performance across a range of configurations, showing that SUMER is robust to imperfections in the memory contents and tools provided. Second, the combination of semantic search, keyword search, and local temporal context yields both higher correctness and more efficient trajectories, confirming that more efficient search over richer raw information benefits current long-context memory tasks. Even without aggressive optimization, search over raw contents is still preferred to goal-agnostic compression in this setting.
综合来看,这些消融支持两个结论。 第一,RL 在一系列配置上都能稳定提升性能,表明 SUMER 对所提供记忆内容和工具的不完美具有鲁棒性。 第二,语义搜索、关键词搜索和局部时间上下文的组合同时带来更高正确性和更高效轨迹,证实在更丰富原始信息上的更高效搜索有利于当前长上下文记忆任务。 即使没有激进优化,在这一设置中,对原始内容的搜索仍优于目标无关压缩。
5. Discussion
5.1 Limitations and future directions
This work is not primarily a proposal for a new search algorithm, but rather an argument about the relative value of search versus compression for long-context memory tasks. Our results suggest that when the end goal is accurate recovery of information from the original interaction history, aggressive compression of episodic memory may be counterproductive. Many current memory frameworks introduce additional inductive biases and discard information in ways that can help on narrowly defined benchmarks, but are not aligned with schema-based generalization in humans, where shared structures across diverse experiences are extracted to form abstractions.
这项工作主要不是提出一种新的搜索算法,而是论证在长上下文记忆任务中搜索相对于压缩的相对价值。 我们的结果表明,当最终目标是从原始交互历史中准确恢复信息时,对情景记忆进行激进压缩可能适得其反。 许多当前记忆框架引入额外归纳偏置,并以某些方式丢弃信息,这些方式可能有助于狭义定义的基准,但与人类基于图式的泛化并不一致;在人类泛化中,会从多样化经验中抽取共享结构来形成抽象。
From a broader perspective, a genuinely strong lifelong agent should be equipped with at least: 1) the ability to continually update an internal state of the world as new information arrives; 2) the ability to reliably access and reuse past experiences, so as not to repeat the same mistakes; 3) the ability to extract common patterns across experiences to support genuine generalization, akin to continued pretraining but with some control over what data to learn from. Existing long-context benchmarks such as LoCoMo do not meaningfully probe any of these capabilities. Instead, they largely resemble extended pattern-matching and question-answering setups similar in spirit to benchmarks before the LLM era. As a result, they may systematically under-estimate the importance of world-modeling and schema learning, and over-emphasize local retrieval over relatively short conversational horizons.
从更广视角看,一个真正强大的终身智能体至少应具备:1) 随新信息到来持续更新内部世界状态的能力;2) 可靠访问并复用过往经验、从而不重复相同错误的能力;3) 从经验中抽取共同模式以支持真正泛化的能力,这类似持续预训练,但对要学习的数据有一定控制。 LoCoMo 等现有长上下文基准并没有真正探测这些能力。 相反,它们很大程度上类似扩展版的模式匹配和问答设置,与 LLM 时代之前的基准精神相近。 因此,它们可能系统性低估世界建模和图式学习的重要性,并过度强调相对较短对话跨度上的局部检索。
Our experimental setup also has practical limitations. Due to API and resource constraints, we were unable to train with the same GPT-4o-mini and text-embedding-3-small configurations used in prior work, and instead relied on Qwen-based models for both policy learning and retrieval. This mismatch makes it difficult to directly compare our absolute numbers to previously reported results. In addition, the LoCoMo dataset we study does not exceed the base model’s context window, so our experiments do not fully capture the regime where the conversation history is vastly longer than what can be naively fed into the model. In realistic long-term memory scenarios, quality of search and the biases in compression are likely to matter more differently.
我们的实验设置也有实际局限。 由于 API 和资源约束,我们无法使用先前工作中的相同 GPT-4o-mini 和 text-embedding-3-small 配置进行训练,而是在策略学习和检索上都依赖基于 Qwen 的模型。 这种不匹配使我们难以把绝对数值与先前报告结果直接比较。 此外,我们研究的 LoCoMo 数据集并未超过基础模型的上下文窗口,因此我们的实验没有完全覆盖对话历史远长于可天真喂入模型长度的情形。 在现实长期记忆场景中,搜索质量和压缩中的偏置很可能以更不同的方式发挥作用。
Finally, the search policy we study is deliberately simple. The current paper does not introduce a sophisticated new agentic search method; rather, it demonstrates that a minimal agentic search procedure, when trained with RL, can already outperform SOTA compression-based memory frameworks and full context. Future work can move in two complementary directions. On the algorithmic side, more expressive search policies, richer tool use, and tighter integration between retrieval, world modeling, and planning may further improve performance. On the evaluation side, there is a clear need for more demanding benchmarks that require longer-term memory over histories far beyond the context window, and create conditions under which compression is plausibly beneficial (e.g., for distilling stable facts or schemas), while naive search alone may underperform. Such benchmarks would provide a more realistic testbed for studying the trade-offs between search, compression, and schema formation in agents.
最后,我们研究的搜索策略有意保持简单。 当前论文没有引入复杂的新型智能体式搜索方法;相反,它证明一个最小化的智能体式搜索过程,在使用 RL 训练后,已经能够超过 SOTA 的基于压缩的记忆框架和 full context。 未来工作可以沿两个互补方向推进。 在算法侧,更具表达力的搜索策略、更丰富的工具使用,以及检索、世界建模和规划之间更紧密的整合,可能进一步提升性能。 在评估侧,我们显然需要更高要求的基准,它们要求在远超上下文窗口的历史上进行更长期记忆,并创造压缩可能真正有益的条件(例如用于蒸馏稳定事实或图式),同时仅靠朴素搜索可能表现不足。 这样的基准将为研究智能体中搜索、压缩和图式形成之间的权衡,提供更现实的测试平台。
5.2 Conclusion
We instantiated a simple search-based agent that operates directly over uncompressed conversational histories and trained it with RL to optimize downstream QA performance. On the LoCoMo benchmark, this agent substantially outperforms a range of compression-based memory systems, nearly doubling LLM-judge accuracy while using a relatively lightweight search procedure. These results show that, on current long-context benchmarks, a straightforward goal-directed search policy can be markedly more effective than carefully engineered compression pipelines.
我们实例化了一个简单的基于搜索的智能体,它直接在未压缩对话历史上运行,并用 RL 训练它以优化下游问答性能。 在 LoCoMo 基准上,该智能体显著超过一系列基于压缩的记忆系统,并在使用相对轻量搜索过程的同时,让 LLM-judge 准确率几乎翻倍。 这些结果表明,在当前长上下文基准上,一个直接的目标导向搜索策略可以显著比精心设计的压缩流水线更有效。
| Configuration | Metric | Initial | Final | Δ Abs | Δ Rel (%) |
|---|---|---|---|---|---|
| SUMER | F1 | 28.07 | 48.65 | +20.58 | +73.32 |
| SUMER | B1 | 23.95 | 43.44 | +19.49 | +81.37 |
| SUMER | J | 48.55 | 66.79 | +18.24 | +37.56 |
| No Context | F1 | 24.29 | 45.96 | +21.67 | +89.24 |
| No Context | B1 | 20.68 | 40.63 | +19.96 | +96.51 |
| No Context | J | 38.32 | 64.64 | +26.32 | +68.67 |
| No Keyword | F1 | 30.06 | 45.57 | +15.51 | +51.60 |
| No Keyword | B1 | 25.66 | 40.68 | +15.02 | +58.52 |
| No Keyword | J | 49.52 | 65.01 | +15.49 | +31.29 |
| No Semantic | F1 | 23.54 | 45.81 | +22.27 | +94.60 |
| No Semantic | B1 | 19.97 | 40.50 | +20.53 | +102.83 |
| No Semantic | J | 40.47 | 61.38 | +20.90 | +51.65 |
| Parameter | Value |
|---|---|
| Model | Qwen-2.5-7B-Instruct |
| Embedding Model | Qwen3-Embedding-0.6B |
| Judge Model | gpt-oss-120b |
| Training Algorithm | GRPO |
| Training Steps | 400 |
| Batch Size | 32 |
| Rollout Trajectories (G) | 8 |
| Max Assistant Turns | 20 |
| Max Parallel Tool Calls | 5 |
| Training Temperature | 1.0 |
| Validation Temperature | 0.0 |
| Learning Rate | $1 \times 10^{-6}$ |
| Clip Ratio High | 0.28 |
| Context Length | 8192 tokens |
| Response Length | 24576 tokens |
| Memory Shards | 32 Ray Actors |
| Hardware | 8x NVIDIA H100 (80GB) |
| Model Parallelism | Tensor=2, Sequence=4 |
| GPU Memory Utilization | 0.5 |
| Validation Frequency | Every 50 steps |