
AMA: Adaptive Memory via Multi-Agent Collaboration
MemoryAgentACL 2026 Findings HKUST(GZ)SDUNTUSUSTechAMA:通过多智能体协作实现自适应记忆
Abstract
The rapid evolution of Large Language Model (LLM) agents has necessitated robust memory systems to support cohesive long-term interaction and complex reasoning. Benefiting from the strong capabilities of LLMs, recent research focus has shifted from simple context extension to the development of dedicated agentic memory systems. However, existing approaches typically rely on rigid retrieval granularity, accumulation-heavy maintenance strategies, and coarse-grained update mechanisms. These design choices create a persistent mismatch between stored information and task-specific reasoning demands, while leading to the unchecked accumulation of logical inconsistencies over time. To address these challenges, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), a novel framework that leverages coordinated agents to manage memory across multiple granularities. AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity. Specifically, the Constructor and Retriever jointly enable multi-granularity memory construction and adaptive query routing. The Judge verifies the relevance and consistency of retrieved content, triggering iterative retrieval when evidence is insufficient or invoking the Refresher upon detecting logical conflicts. The Refresher then enforces memory consistency by performing targeted updates or removing outdated entries. Extensive experiments on challenging long-context benchmarks show that AMA significantly outperforms state-of-the-art baselines while reducing token consumption by approximately 80% compared to full-context methods, demonstrating its effectiveness in maintaining retrieval precision and long-term memory consistency.
大语言模型(LLM)智能体的快速演进,使稳健的记忆系统成为支持连贯长期交互和复杂推理的必要条件。 得益于 LLM 的强大能力,近期研究重点已经从简单的上下文扩展转向专门的智能体记忆系统开发。 然而,现有方法通常依赖僵化的检索粒度、偏重累积的维护策略以及粗粒度更新机制。 这些设计选择造成了存储信息与任务特定推理需求之间的持续错配,同时导致逻辑不一致随时间不受控制地累积。 为了解决这些挑战,我们提出 Adaptive Memory via Multi-Agent Collaboration(AMA),这是一个利用协同智能体在多种粒度上管理记忆的新框架。 AMA 采用层级化记忆设计,动态地将检索粒度与任务复杂度对齐。 具体而言,Constructor 和 Retriever 共同支持多粒度记忆构建与自适应查询路由。 Judge 验证检索内容的相关性和一致性,在证据不足时触发迭代检索,或在检测到逻辑冲突时调用 Refresher。 随后,Refresher 通过执行定向更新或移除过时条目来强制保证记忆一致性。 在具有挑战性的长上下文基准上的大量实验表明,AMA 显著优于最先进基线,同时相比全上下文方法将 token 消耗减少约 80%,证明了它在保持检索精度和长期记忆一致性方面的有效性。
1. Introduction
Large Language Model (LLM) agents have demonstrated strong capabilities in complex reasoning, tool use, and multi-turn interaction scenarios. Supporting such behaviors requires long-term memory to preserve contextual coherence and consistency. Existing approaches to long-term memory can be broadly categorized into internal and external memory paradigms. Internal memory implicitly absorbs historical information into model parameters, but is constrained by limited capacity and incurs substantial costs for continual updates. In contrast, external memory relies on explicit storage and retrieval, providing superior scalability and editability. As a result, it has become the dominant approach, making the design of efficient and reliable external memory systems a critical foundation for sustained agent evolution.
大语言模型(LLM)智能体已经在复杂推理、工具使用和多轮交互场景中展示出强大能力。 支持这些行为需要长期记忆来保持上下文连贯性和一致性。 现有长期记忆方法大体可以分为内部记忆和外部记忆范式。 内部记忆将历史信息隐式吸收到模型参数中,但受容量限制,并且持续更新的成本很高。 相比之下,外部记忆依赖显式存储和检索,提供更好的可扩展性和可编辑性。 因此,它已经成为主导方法,使高效可靠的外部记忆系统设计成为持续智能体演化的关键基础。
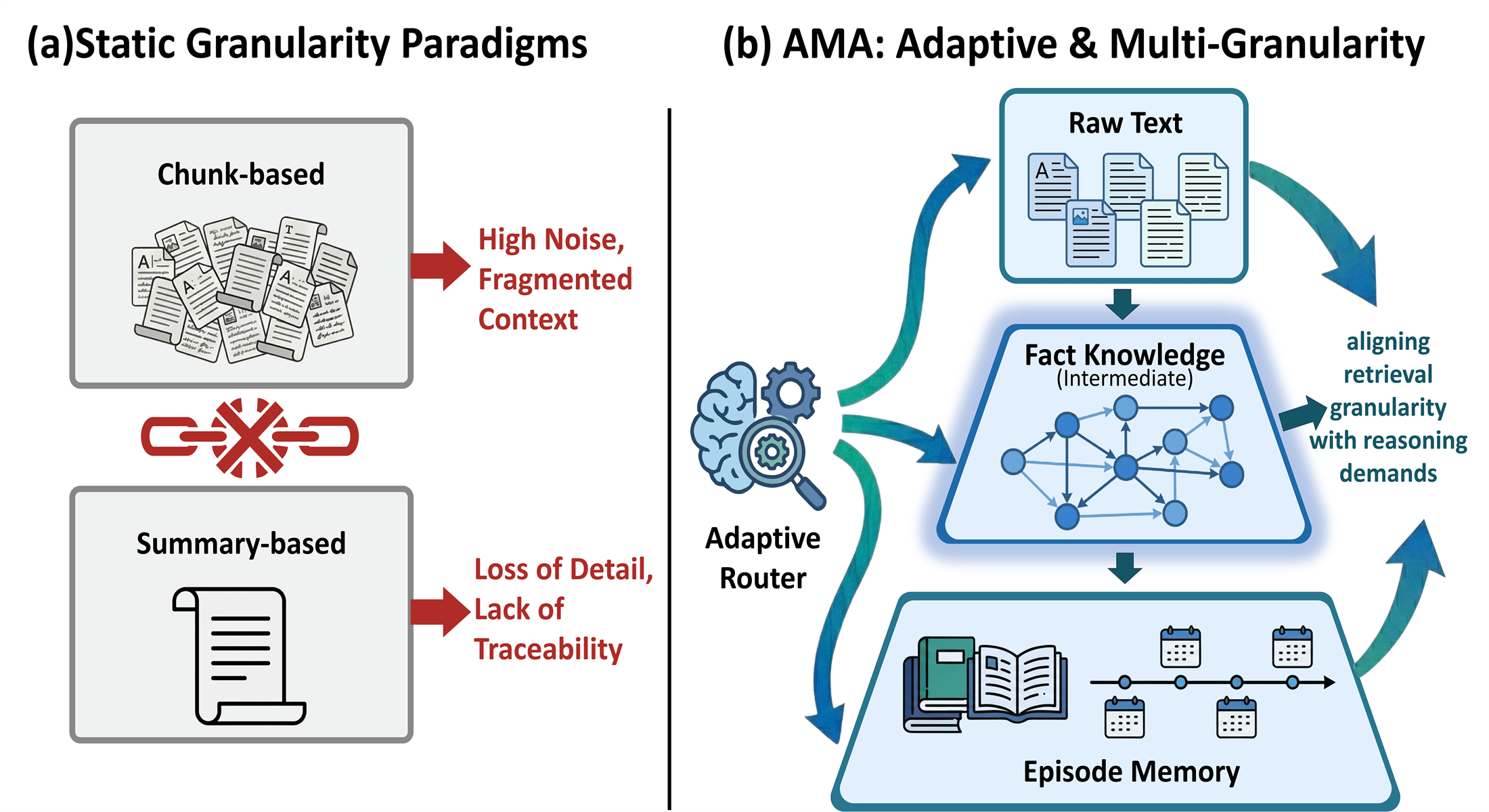
Building on the growing adoption of external memory, many systems support dynamic memory management through explicit Create-Read-Update-Delete operations, enabling agents to incrementally maintain memory over time. Despite these advantages, they exhibit a fundamental limitation: a mismatch between the granularity at which memories are stored and the granularity required for effective retrieval and reasoning. As illustrated in Figure 1, these approaches typically rely on static text chunking with fixed lengths or coarse-grained summaries. Such static strategies often disrupt the inherent semantic coherence of stored information, which in turn leads to suboptimal retrieval behavior: overly coarse retrieval introduces substantial irrelevant noise, while excessively fine-grained or isolated chunks fragment essential logical dependencies, ultimately leading to reasoning failures in complex tasks. These limitations highlight the necessity of an adaptive memory paradigm capable of dynamically aligning memory granularity with task-specific requirements.
随着外部记忆被越来越多地采用,许多系统通过显式的 Create-Read-Update-Delete 操作支持动态记忆管理,使智能体能够随时间增量维护记忆。 尽管有这些优势,它们仍表现出一项根本限制:记忆存储粒度与有效检索和推理所需粒度之间存在错配。 如图1所示,这些方法通常依赖固定长度的静态文本分块或粗粒度摘要。 这种静态策略经常破坏存储信息内在的语义连贯性,进而导致次优检索行为:过粗的检索会引入大量无关噪声,而过细或孤立的块会切碎关键逻辑依赖,最终在复杂任务中导致推理失败。 这些限制凸显了自适应记忆范式的必要性,它需要能够动态地将记忆粒度与任务特定需求对齐。
To address these challenges, recent work has shifted toward agentic memory mechanisms, leveraging the generative capabilities of LLMs to mitigate the rigidity of static storage granularity. Typically, these frameworks employ LLMs to synthesize interaction history into flexible representations like summaries or vector entries, extending the effective context window. While these designs improve representation flexibility, they leave two fundamental challenges largely unaddressed. First, the absence of an explicit adaptive routing mechanism prevents agents from selecting the appropriate memory granularity at inference time, leading to persistent mismatches with task demands. Second, reliance on accumulation-heavy strategies and coarse-grained update mechanisms fails to support precise modifications, resulting in the unchecked accumulation of redundancy and errors.
为了解决这些挑战,近期工作转向智能体式记忆机制,利用 LLM 的生成能力缓解静态存储粒度的僵化。 通常,这些框架使用 LLM 将交互历史合成为摘要或向量条目等灵活表示,从而扩展有效上下文窗口。 虽然这些设计提高了表示灵活性,但它们很大程度上没有解决两个根本挑战。 首先,缺少显式自适应路由机制会阻止智能体在推理时选择合适的记忆粒度,从而与任务需求持续错配。 其次,依赖偏重累积的策略和粗粒度更新机制无法支持精确修改,导致冗余和错误不受控制地累积。
To overcome the coupled challenges of adaptive retrieval control and long-term memory evolution, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), as illustrated in Figures Figure 1 and Figure 2. Unlike prior agentic memory systems that mainly rely on a monolithic controller, AMA adopts a multi-agent design that decomposes the memory lifecycle into four functionally distinct yet interdependent roles: the Constructor, Retriever, Judge, and Refresher. Specifically, the Constructor transforms unstructured dialogue streams into hierarchical granularities, including Raw Text, Fact Knowledge, and Episode Memory, to accommodate diverse storage requirements. The Retriever acts as an adaptive gateway, dynamically routing queries to the most appropriate memory form based on current reasoning demands. To ensure consistency, the Judge serves as a logic auditor, verifying relevance to trigger feedback loops and detecting conflicts to activate the Refresher for updates. This separation of responsibilities enables fine-grained control over retrieval, verification, and memory evolution, which would be difficult to achieve within a single-agent design without entangling conflicting objectives. Extensive experiments across multiple long-term memory benchmarks demonstrate that AMA consistently outperforms strong memory baselines. By adaptively controlling retrieval granularity and explicitly maintaining memory consistency over time, AMA achieves state-of-the-art performance while reducing token consumption by up to 80% compared to using full context. Moreover, our analysis highlight the importance of the logic-driven Refresher, which plays a critical role in dynamic knowledge maintenance and enables AMA to achieve nearly 90% accuracy in knowledge update scenarios.
为克服自适应检索控制和长期记忆演化这两个相互耦合的挑战,我们提出 Adaptive Memory via Multi-Agent Collaboration(AMA),如图1和图2所示。 不同于主要依赖单体控制器的先前智能体记忆系统,AMA 采用多智能体设计,将记忆生命周期分解为四个功能不同但相互依赖的角色:Constructor、Retriever、Judge 和 Refresher。 具体而言,Constructor 将非结构化对话流转化为层级化粒度,包括 Raw Text、Fact Knowledge 和 Episode Memory,以适应多样化存储需求。 Retriever 充当自适应网关,基于当前推理需求将查询动态路由到最合适的记忆形式。 为确保一致性,Judge 作为逻辑审计器,验证相关性以触发反馈循环,并检测冲突以激活 Refresher 进行更新。 这种职责分离使检索、验证和记忆演化能够被细粒度控制;如果在单智能体设计中不让相互冲突的目标纠缠在一起,这一点很难实现。 在多个长期记忆基准上的大量实验表明,AMA 持续优于强记忆基线。 通过自适应控制检索粒度,并随时间显式维护记忆一致性,AMA 达到最先进性能,同时相比使用完整上下文将 token 消耗最多减少 80%。 此外,我们的分析强调了逻辑驱动 Refresher 的重要性,它在动态知识维护中发挥关键作用,并使 AMA 在知识更新场景中达到接近 90% 的准确率。
In summary, our main contributions are threefold:
1. We introduce a comprehensive memory paradigm featuring multi-granularity storage and adaptive routing, which incorporates logic-driven conflict detection to maintain long-term consistency and reasoning fidelity.
2. We design a unified multi-agent framework to orchestrate storage, retrieval, and maintenance, facilitating robust memory evolution in long-context applications.
3. Through extensive experiments and analysis, we demonstrate that AMA significantly outperforms state-of-the-art baselines, verifying its effectiveness and robustness in complex long-context tasks.
总之,我们的主要贡献有三点:
1. 我们提出一个综合记忆范式,具备多粒度存储和自适应路由,并纳入逻辑驱动的冲突检测,以维护长期一致性和推理忠实性。
2. 我们设计了一个统一的多智能体框架来编排存储、检索和维护,从而促进长上下文应用中的稳健记忆演化。
3. 通过大量实验和分析,我们证明 AMA 显著优于最先进基线,验证了它在复杂长上下文任务中的有效性和稳健性。

2. Related Work
2.1 Memory for LLM Agents
Prior research on memory for LLM agents has investigated a wide range of approaches, ranging from full interaction storage to system-level frameworks. These methods typically evolve from context extension to structured organization. Specifically, MemGPT focuses on context management, adopting a cache-like organization to prioritize salient information. Moving towards modularity, Mem0 abstracts memory as an independent layer dedicated to long-term management. To further enhance retrieval precision, Nemori and Zep introduce semantic structures, leveraging self-organizing events and temporal knowledge graphs, respectively. Despite their progress, these methods rely on static retrieval strategies, which limits their ability to adaptively coordinate information across different abstraction levels and task stages. Therefore, designing an adaptive memory system that can robustly support long-term interactions remains a critical challenge.
关于 LLM 智能体记忆的既有研究考察了广泛方法,从完整交互存储到系统级框架都有涉及。 这些方法通常从上下文扩展演进到结构化组织。 具体来说,MemGPT 专注于上下文管理,采用类似缓存的组织方式来优先保留显著信息。 向模块化方向发展时,Mem0 将记忆抽象为专用于长期管理的独立层。 为了进一步增强检索精度,Nemori 和 Zep 分别引入语义结构,利用自组织事件和时间知识图谱。 尽管取得了进展,这些方法仍依赖静态检索策略,限制了它们在不同抽象层级和任务阶段之间自适应协调信息的能力。 因此,设计一个能够稳健支持长期交互的自适应记忆系统仍是一项关键挑战。
2.2 Multi-Agent System
Multi-agent systems have demonstrated clear advantages in tackling complex tasks by enabling role-based collaboration and interactive decision making. In software engineering, multi-agent approaches improve system reliability through explicit role specialization and structured workflows. In mathematical reasoning, multi-agent frameworks enhance solution accuracy via collaborative interaction and process-level verification. In parallel, a growing body of work on agentic memory focuses on improving long-term information modeling for LLM agents. While this line of research provides valuable insights into memory abstraction and maintenance, most existing approaches are built around a monolithic controller and do not explicitly leverage multi-agent collaboration. A notable recent exception is MIRIX, which explores assigning specialized agents for memory organization, but lacks dedicated mechanisms for long-term memory consistency. We did not include MIRIX as a baseline in this work because its official implementation was not publicly available during our experimental phase. Building on these complementary lines of research, our work integrates multi-agent collaboration with agentic memory design to support long-term memory for LLM agents.
多智能体系统通过支持基于角色的协作和交互式决策,在处理复杂任务方面展示出明显优势。 在软件工程中,多智能体方法通过显式角色专门化和结构化工作流提升系统可靠性。 在数学推理中,多智能体框架通过协作交互和过程级验证提高解题准确性。 与此同时,越来越多关于智能体记忆的工作专注于改进 LLM 智能体的长期信息建模。 虽然这条研究线为记忆抽象和维护提供了有价值的见解,但大多数现有方法都围绕单体控制器构建,并没有显式利用多智能体协作。 一个值得注意的近期例外是 MIRIX,它探索为记忆组织分配专门智能体,但缺少长期记忆一致性的专用机制。 我们没有在本文中把 MIRIX 纳入基线,因为其实验阶段官方实现尚未公开。 基于这些互补研究线,我们的工作将多智能体协作与智能体记忆设计结合起来,以支持 LLM 智能体的长期记忆。
3. Method
We introduce Adaptive Memory via Multi-Agent Collaboration (AMA) to address the critical challenge of aligning retrieval granularity with diverse task requirements, as well as the unchecked accumulation of logical inconsistencies. As illustrated in Figure 2, the framework operates through a coordinated multi-agent pipeline. The process begins with the Retriever, which accesses memory across multiple granularities based on the input intent. The Judge then evaluates the relevance of the retrieved content and identifies potential conflicts, triggering feedback retrieval or activating the Refresher to perform targeted memory updates when necessary. Finally, the Constructor consolidates the validated information and organizes it into memory representations at different granularities, supporting continual memory evolution. In the following sections, we present the detailed design of the Constructor, Retriever, Judge, and Refresher.
我们引入 Adaptive Memory via Multi-Agent Collaboration(AMA),以解决检索粒度与多样化任务需求对齐这一关键挑战,以及逻辑不一致不受控制地累积的问题。 如图2所示,该框架通过协同多智能体流水线运行。 流程从 Retriever 开始,它基于输入意图跨多种粒度访问记忆。 随后,Judge 评估检索内容的相关性并识别潜在冲突,在必要时触发反馈检索或激活 Refresher 执行定向记忆更新。 最后,Constructor 巩固验证后的信息,并将其组织为不同粒度的记忆表示,从而支持持续记忆演化。 在以下小节中,我们给出 Constructor、Retriever、Judge 和 Refresher 的详细设计。
3.1 Constructor
To clearly delineate the functional roles of different memory granularities within the overall pipeline, we begin by introducing the Constructor. Its primary responsibility is to construct multi-granular memory by generating structured semantic components from the current input
为了清晰划分整体流水线中不同记忆粒度的功能角色,我们首先介绍 Constructor。 它的主要职责是构建多粒度记忆,即在精心设计的提示
The set
集合

Raw Text Memory. This component records the content of the current turn in its original form
Raw Text Memory。 该组件以原始形式
Fact Knowledge Memory. Each extracted fact is treated as an independent memory unit. Accordingly, we define Fact Knowledge Memory as
Fact Knowledge Memory。 每个抽取出的事实都被视为独立记忆单元。 因此,我们将 Fact Knowledge Memory 定义为
Episode Memory. It is designed to capture high-level abstractions across turns. Following a gatekeeping mechanism inspired by prior work, we introduce a trigger function with prompt
Episode Memory。 它被设计用于捕获跨轮次的高层抽象。 遵循受先前工作启发的门控机制,我们引入带提示
Memory Encoding. To support efficient retrieval across memory granularities, we compute a dense vector representation for each memory entry based on its primary semantic content. For a memory entry
Memory Encoding。 为支持跨记忆粒度的高效检索,我们基于每个记忆条目的主要语义内容计算稠密向量表示。 对于记忆条目
3.2 Retriever
The Retriever functions as the memory access gateway within the AMA framework. Its primary role is to dynamically route queries to the most appropriate memory granularity. To address referential ambiguity and missing context commonly observed in raw dialogue, the Retriever first rewrites the query into a self-contained form and then performs adaptive retrieval based on multi-dimensional intent analysis.
Retriever 是 AMA 框架中的记忆访问网关。 它的主要作用是将查询动态路由到最合适的记忆粒度。 为处理原始对话中常见的指代歧义和上下文缺失,Retriever 首先将查询改写为自包含形式,然后基于多维意图分析执行自适应检索。
Query Rewriting and Intent Routing. Given the current input
Query Rewriting and Intent Routing。 给定当前输入
The rewritten query
改写后的查询
This routing strategy explicitly prioritizes specialized retrieval intents. When fine-grained detail is required (
这一路由策略显式优先处理专门化检索意图。 当需要细粒度细节(
Similarity-based Retrieval. Once the target memory repository
Similarity-based Retrieval。 一旦确定目标记忆仓库
Memory entries are ranked by their similarity scores, with the Top-
记忆条目按相似度分数排序,Top-
3.3 Judge
While the Retriever recalls a candidate memory set
虽然 Retriever 基于向量相似度召回候选记忆集合
Relevance Assessment. The Judge first evaluates the pragmatic utility of the retrieved content with respect to the current input
Relevance Assessment。 Judge 首先评估检索内容相对于当前输入
Conflict Detection. Subsequently, the Judge conducts logical consistency checks to identify contradictions between the current input
Conflict Detection。 随后,Judge 进行逻辑一致性检查,以识别当前输入
where
1.
2.
3.
其中
1. 当检索相关性不足时触发
2. 当检测到非空冲突集合
3. 当记忆既相关又一致时发生
3.4 Refresher
Drawing inspiration from prior studies on dynamic memory maintenance, we introduce the Refresher to ensure the logical validity of memory storage. This component is triggered exclusively when the Judge detects a conflict set
受动态记忆维护相关研究启发,我们引入 Refresher 来确保记忆存储的逻辑有效性。 该组件只在 Judge 检测到冲突集合
Delete. This operation is triggered only under two rigorous conditions: (1) in response to explicit user instructions to forget specific information, and (2) when the lifespan of a conflicting memory entry exceeds a predefined maximum retention limit. In such cases, the system permanently removes the entry to purge the storage space.
Delete。 该操作只在两个严格条件下被触发:(1)响应用户明确要求遗忘特定信息的指令;(2)冲突记忆条目的生命周期超过预定义的最大保留限制。 在这些情况下,系统会永久移除该条目以清理存储空间。
Update. For all remaining conflict scenarios, the Refresher defaults to an update operation. Specifically, it performs a state modification
Update。 对于所有其余冲突场景,Refresher 默认执行更新操作。 具体而言,它执行状态修改
4. Experiment
4.1 Experimental Setup
Datasets and Metrics. We evaluate long-term memory capabilities on two established benchmarks: LoCoMo and LongMemEval_s. Detailed statistics for both datasets are provided in Appendix A.1. For LoCoMo, we report F1 and BLEU-1 scores in addition to the LLM Score. For LongMemEval_s, we specifically select the more challenging Pass@1 accuracy evaluated by an LLM judge to rigorously test performance. Following Achiam et al. and Maharana et al., we employ GPT-4o-mini as the unified judge for all model-based evaluations.
Datasets and Metrics。 我们在两个成熟基准 LoCoMo 和 LongMemEval_s 上评估长期记忆能力。 两个数据集的详细统计见附录 A.1。 对于 LoCoMo,除 LLM Score 外,我们还报告 F1 和 BLEU-1 分数。 对于 LongMemEval_s,我们专门选择更具挑战性的由 LLM 评判的 Pass@1 准确率,以严格测试性能。 遵循 Achiam 等人和 Maharana 等人的做法,我们使用 GPT-4o-mini 作为所有基于模型评估的统一裁判。
Baselines. We compare AMA with various baselines, starting with FullContext and a standard Retrieval-Augmented Generation (RAG) implemented with 2048-token chunks. We then evaluate representative memory frameworks including: LangMem, MemGPT, Zep, A-Mem, Mem0, Nemori.
Baselines。 我们将 AMA 与多种基线比较,首先包括 FullContext 和一个使用 2048-token 块实现的标准检索增强生成(RAG)。 随后,我们评估代表性记忆框架,包括 LangMem、MemGPT、Zep、A-Mem、Mem0 和 Nemori。
Implementation Details. We conduct experiments using both closed-source APIs (GPT-4o-mini, GPT-4.1-mini) and open-source models (Qwen3-8B-Instruct, Qwen3-30B-Instruct), ensuring that the AMA framework utilizes the identical backbone model as the response generator. To ensure reproducibility, we fix the temperature to 0 for all experiments. For RAG, the retrieval top-text-embedding-3-large model. Due to the commercial nature of Zep, Mem0, and MemGPT, we exclude these frameworks from evaluations involving open-source models. Additionally, given the substantial scale of LongMemEval_s (approximately 58M tokens), we restrict its evaluation exclusively to GPT-4o-mini for computational feasibility. Prompts used in AMA and descriptions of the baselines are provided in Appendix A and Appendix B.
Implementation Details。 我们使用闭源 API(GPT-4o-mini、GPT-4.1-mini)和开源模型(Qwen3-8B-Instruct、Qwen3-30B-Instruct)进行实验,并确保 AMA 框架使用与回答生成器相同的 backbone 模型。 为确保可复现性,我们将所有实验的 temperature 固定为 0。 对于 RAG,检索 top-text-embedding-3-large 模型计算。 由于 Zep、Mem0 和 MemGPT 的商业性质,我们在涉及开源模型的评估中排除了这些框架。 此外,考虑到 LongMemEval_s 规模很大(约 58M token),出于计算可行性,我们将其评估仅限制在 GPT-4o-mini 上。 AMA 使用的提示和基线描述见附录 A 和附录 B。
4.2 Main Results
| Method | Single-Hop | Multi-Hop | Temporal Reasoning | Open Domain | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLM | F1 | B1 | LLM | F1 | B1 | LLM | F1 | B1 | LLM | F1 | B1 | LLM | F1 | B1 | |
| GPT-4o-mini | |||||||||||||||
| FullContext | 0.823 | 0.526 | 0.443 | 0.663 | 0.351 | 0.259 | 0.557 | 0.437 | 0.358 | 0.482 | 0.243 | 0.171 | 0.717 | 0.458 | 0.375 |
| RAG | 0.318 | 0.220 | 0.185 | 0.311 | 0.184 | 0.116 | 0.235 | 0.194 | 0.156 | 0.323 | 0.189 | 0.134 | 0.300 | 0.206 | 0.163 |
| LangMem | 0.616 | 0.389 | 0.332 | 0.526 | 0.336 | 0.240 | 0.250 | 0.321 | 0.263 | 0.477 | 0.295 | 0.236 | 0.515 | 0.359 | 0.295 |
| MemGPT | 0.479 | 0.249 | 0.186 | 0.229 | 0.112 | 0.111 | 0.388 | 0.326 | 0.261 | 0.500 | 0.308 | 0.255 | 0.415 | 0.244 | 0.192 |
| Zep | 0.627 | 0.394 | 0.334 | 0.501 | 0.273 | 0.192 | 0.584 | 0.444 | 0.378 | 0.393 | 0.227 | 0.156 | 0.580 | 0.372 | 0.307 |
| A-Mem | 0.518 | 0.270 | 0.201 | 0.248 | 0.121 | 0.120 | 0.546 | 0.459 | 0.367 | 0.541 | 0.333 | 0.276 | 0.476 | 0.286 | 0.225 |
| Mem0 | 0.676 | 0.441 | 0.340 | 0.598 | 0.340 | 0.250 | 0.500 | 0.440 | 0.373 | 0.403 | 0.269 | 0.192 | 0.608 | 0.412 | 0.339 |
| Nemori | 0.817 | 0.541 | 0.430 | 0.650 | 0.363 | 0.255 | 0.707 | 0.564 | 0.463 | 0.446 | 0.207 | 0.150 | 0.740 | 0.492 | 0.383 |
| AMA | 0.849 | 0.622 | 0.548 | 0.681 | 0.423 | 0.303 | 0.748 | 0.589 | 0.461 | 0.479 | 0.283 | 0.228 | 0.774 | 0.558 | 0.465 |
| GPT-4.1-mini | |||||||||||||||
| FullContext | 0.848 | 0.599 | 0.521 | 0.753 | 0.431 | 0.329 | 0.723 | 0.463 | 0.390 | 0.552 | 0.277 | 0.217 | 0.786 | 0.519 | 0.439 |
| RAG | 0.351 | 0.252 | 0.215 | 0.309 | 0.196 | 0.125 | 0.267 | 0.217 | 0.186 | 0.281 | 0.174 | 0.136 | 0.321 | 0.229 | 0.187 |
| LangMem | 0.824 | 0.498 | 0.425 | 0.693 | 0.405 | 0.317 | 0.496 | 0.473 | 0.399 | 0.575 | 0.320 | 0.257 | 0.717 | 0.464 | 0.390 |
| MemGPT | 0.490 | 0.255 | 0.190 | 0.234 | 0.115 | 0.114 | 0.397 | 0.334 | 0.267 | 0.512 | 0.315 | 0.261 | 0.425 | 0.250 | 0.196 |
| Zep | 0.652 | 0.444 | 0.390 | 0.523 | 0.297 | 0.199 | 0.587 | 0.233 | 0.195 | 0.427 | 0.236 | 0.188 | 0.601 | 0.360 | 0.301 |
| A-Mem | 0.530 | 0.276 | 0.206 | 0.254 | 0.124 | 0.123 | 0.559 | 0.470 | 0.375 | 0.553 | 0.341 | 0.282 | 0.487 | 0.293 | 0.230 |
| Mem0 | 0.697 | 0.474 | 0.410 | 0.666 | 0.391 | 0.295 | 0.555 | 0.382 | 0.323 | 0.468 | 0.232 | 0.173 | 0.647 | 0.424 | 0.356 |
| Nemori | 0.828 | 0.573 | 0.502 | 0.732 | 0.407 | 0.311 | 0.757 | 0.562 | 0.490 | 0.498 | 0.252 | 0.188 | 0.774 | 0.521 | 0.445 |
| AMA | 0.888 | 0.636 | 0.570 | 0.716 | 0.453 | 0.324 | 0.764 | 0.608 | 0.484 | 0.514 | 0.333 | 0.251 | 0.805 | 0.580 | 0.492 |
| Qwen3-30B-Instruct | |||||||||||||||
| FullContext | 0.845 | 0.528 | 0.453 | 0.665 | 0.369 | 0.273 | 0.555 | 0.443 | 0.369 | 0.551 | 0.273 | 0.185 | 0.733 | 0.466 | 0.390 |
| RAG | 0.327 | 0.221 | 0.188 | 0.312 | 0.193 | 0.122 | 0.234 | 0.197 | 0.160 | 0.368 | 0.219 | 0.146 | 0.307 | 0.209 | 0.169 |
| LangMem | 0.633 | 0.390 | 0.337 | 0.529 | 0.353 | 0.254 | 0.253 | 0.325 | 0.270 | 0.545 | 0.341 | 0.249 | 0.525 | 0.365 | 0.309 |
| A-Mem | 0.518 | 0.270 | 0.201 | 0.248 | 0.121 | 0.120 | 0.546 | 0.459 | 0.367 | 0.541 | 0.333 | 0.276 | 0.476 | 0.286 | 0.225 |
| Nemori | 0.839 | 0.543 | 0.439 | 0.652 | 0.381 | 0.269 | 0.704 | 0.571 | 0.477 | 0.510 | 0.239 | 0.163 | 0.756 | 0.500 | 0.399 |
| AMA | 0.872 | 0.625 | 0.560 | 0.703 | 0.445 | 0.318 | 0.751 | 0.597 | 0.475 | 0.505 | 0.327 | 0.247 | 0.791 | 0.570 | 0.483 |
| Qwen3-8B-Instruct | |||||||||||||||
| FullContext | 0.803 | 0.502 | 0.430 | 0.632 | 0.351 | 0.259 | 0.527 | 0.421 | 0.351 | 0.523 | 0.259 | 0.176 | 0.696 | 0.443 | 0.371 |
| RAG | 0.317 | 0.214 | 0.182 | 0.303 | 0.187 | 0.118 | 0.227 | 0.191 | 0.155 | 0.357 | 0.212 | 0.142 | 0.298 | 0.203 | 0.164 |
| LangMem | 0.617 | 0.380 | 0.328 | 0.515 | 0.344 | 0.247 | 0.246 | 0.317 | 0.263 | 0.531 | 0.332 | 0.243 | 0.512 | 0.356 | 0.301 |
| A-Mem | 0.504 | 0.263 | 0.196 | 0.241 | 0.118 | 0.117 | 0.532 | 0.447 | 0.357 | 0.527 | 0.324 | 0.269 | 0.464 | 0.279 | 0.219 |
| Nemori | 0.762 | 0.493 | 0.399 | 0.592 | 0.346 | 0.244 | 0.639 | 0.519 | 0.433 | 0.463 | 0.217 | 0.148 | 0.686 | 0.454 | 0.362 |
| AMA | 0.780 | 0.559 | 0.500 | 0.628 | 0.398 | 0.284 | 0.671 | 0.533 | 0.424 | 0.482 | 0.292 | 0.221 | 0.707 | 0.510 | 0.432 |
| Question Type | Full-ctx | RAG | LangMem | A-Mem | MemGPT | Mem0 | Zep | Nemori | AMA |
|---|---|---|---|---|---|---|---|---|---|
| single-session-pref. | 0.300 | 0.333 | 0.267 | 0.367 | 0.200 | 0.333 | 0.533 | 0.467 | 0.467 |
| single-session-asst. | 0.818 | 0.714 | 0.777 | 0.804 | 0.857 | 0.875 | 0.750 | 0.839 | 0.964 |
| temporal-reasoning | 0.365 | 0.280 | 0.353 | 0.398 | 0.451 | 0.399 | 0.541 | 0.617 | 0.444 |
| multi-session | 0.406 | 0.254 | 0.424 | 0.451 | 0.549 | 0.481 | 0.474 | 0.511 | 0.624 |
| knowledge-update | 0.769 | 0.385 | 0.578 | 0.602 | 0.410 | 0.654 | 0.744 | 0.615 | 0.897 |
| single-session-user | 0.814 | 0.686 | 0.750 | 0.750 | 0.814 | 0.857 | 0.929 | 0.886 | 0.986 |
| Average | 0.548 | 0.374 | 0.528 | 0.538 | 0.554 | 0.574 | 0.632 | 0.642 | 0.698 |
We first evaluate AMA on the LoCoMo benchmark using closed-source backbones. As shown in Table 1, with GPT-4o-mini, AMA achieves an overall LLM Score of 0.774, substantially outperforming the strongest baseline Nemori (0.740) and all other memory-based methods by a clear margin. When scaled to the more capable GPT-4.1-mini, AMA further improves to 0.805. Notably, under this setting, AMA is the only approach that surpasses FullContext (0.786), demonstrating that AMA effectively distills raw history into critical facts and episodes, thereby filtering out noise to support reasoning beyond the raw context window.
我们首先使用闭源 backbone 在 LoCoMo 基准上评估 AMA。 如表1所示,在 GPT-4o-mini 上,AMA 达到 0.774 的 overall LLM Score,显著优于最强基线 Nemori(0.740)以及所有其他基于记忆的方法,优势清晰。 当扩展到能力更强的 GPT-4.1-mini 时,AMA 进一步提升到 0.805。 值得注意的是,在这一设置下,AMA 是唯一超过 FullContext(0.786)的方法,这表明 AMA 能够有效地将原始历史提炼为关键事实和 episode,从而过滤噪声,支持超越原始上下文窗口的推理。
We further assess robustness by extending the evaluation to open-source models on LoCoMo. With Qwen3-30B-Instruct, AMA attains a dominant LLM Score of 0.791, exceeding FullContext (0.733) by a large margin of 0.058. This advantage persists even with the smaller Qwen3-8B-Instruct backbone, where AMA (0.707) continues to outperform FullContext (0.696). These results demonstrate that AMA consistently enhances complex reasoning performance across backbones of varying capacity.
我们进一步将评估扩展到 LoCoMo 上的开源模型,以考察稳健性。 在 Qwen3-30B-Instruct 上,AMA 取得主导性的 0.791 LLM Score,以 0.058 的大幅优势超过 FullContext(0.733)。 即便使用更小的 Qwen3-8B-Instruct backbone,这一优势仍然存在,其中 AMA(0.707)继续优于 FullContext(0.696)。 这些结果表明,AMA 能够在不同容量的 backbone 上持续增强复杂推理性能。
Finally, we evaluate the generalization of AMA on another benchmark, LongMemEval_s (Table 2). AMA again achieves the highest average accuracy of 0.698, outperforming the two strongest baselines, Nemori and Zep, by 0.056 and 0.066, respectively. Notably, AMA attains near-perfect accuracy on single-session-user tasks (0.986) and shows a pronounced advantage on knowledge-update tasks (0.897), where dynamic knowledge maintenance and conflict resolution are critical. These consistent improvements across benchmarks with different data distributions indicate that AMA generalizes effectively to diverse long-term reasoning scenarios while robustly supporting dynamic knowledge evolution.
最后,我们在另一个基准 LongMemEval_s 上评估 AMA 的泛化能力(表2)。 AMA 再次取得最高平均准确率 0.698,分别以 0.056 和 0.066 的优势超过两个最强基线 Nemori 和 Zep。 值得注意的是,AMA 在 single-session-user 任务上达到接近完美的准确率(0.986),并在 knowledge-update 任务上表现出明显优势(0.897),而这些任务中动态知识维护和冲突解决至关重要。 这些在不同数据分布基准上的一致提升表明,AMA 能够有效泛化到多样化长期推理场景,同时稳健支持动态知识演化。
4.3 Ablation Studies
| Method | LoCoMo | LongMemEval_s | ||||||
|---|---|---|---|---|---|---|---|---|
| RT | FK | EP | RF | LLM Score | F1 | BLEU-1 | Knowledge-update | Average |
| ✓ | × | × | ✓ | 0.669 | 0.484 | 0.401 | 0.767 | 0.614 |
| × | ✓ | × | ✓ | 0.712 | 0.502 | 0.424 | 0.804 | 0.642 |
| × | × | ✓ | ✓ | 0.688 | 0.495 | 0.407 | 0.748 | 0.630 |
| ✓ | ✓ | × | ✓ | 0.752 | 0.538 | 0.448 | 0.863 | 0.686 |
| ✓ | × | ✓ | ✓ | 0.725 | 0.515 | 0.428 | 0.804 | 0.656 |
| × | ✓ | ✓ | ✓ | 0.741 | 0.529 | 0.435 | 0.842 | 0.680 |
| ✓ | ✓ | ✓ | ✓ | 0.774 | 0.558 | 0.465 | 0.897 | 0.710 |
| ✓ | ✓ | ✓ | × | 0.771 | 0.556 | 0.462 | 0.568 | 0.634 |
We conduct ablation studies on LoCoMo and LongMemEval_s, with results in Table 3.
我们在 LoCoMo 和 LongMemEval_s 上进行消融研究,结果见表3。
Impact of Memory Granularities. We first analyze the contribution of individual memory granularities. Under single-granularity settings, Fact Knowledge Memory performs best, achieving an LLM Score of 0.712 on LoCoMo and the highest average accuracy of 0.642 on LongMemEval_s, indicating the effectiveness of structured factual representations for long-term retrieval and reasoning. Moreover, jointly enabling Raw Text, Fact Knowledge, and Episodic Memory yields the strongest overall performance across both benchmarks, outperforming any single-granularity configuration. This result highlights the complementary nature of different memory forms and underscores the importance of multi-granularity collaboration.
Impact of Memory Granularities。 我们首先分析各个记忆粒度的贡献。 在单粒度设置下,Fact Knowledge Memory 表现最好,在 LoCoMo 上达到 0.712 的 LLM Score,并在 LongMemEval_s 上取得最高平均准确率 0.642,表明结构化事实表示对长期检索和推理有效。 此外,同时启用 Raw Text、Fact Knowledge 和 Episodic Memory 会在两个基准上得到最强整体性能,优于任何单粒度配置。 这一结果凸显了不同记忆形式的互补性,并强调了多粒度协作的重要性。
Effectiveness of the Refresher. Beyond memory representation, we evaluate the role of the Refresher in maintaining long-term consistency. Under the full multi-granularity setting, enabling the Refresher substantially improves performance on knowledge-update scenarios in LongMemEval_s, achieving an accuracy of 0.897. In contrast, removing the Refresher leads to a sharp drop to 0.568. This pronounced degradation indicates that accurate long-term memory requires not only multi-granularity storage, but also explicit mechanisms for conflict resolution and memory updating.
Effectiveness of the Refresher。 除记忆表示之外,我们评估 Refresher 在维护长期一致性中的作用。 在完整多粒度设置下,启用 Refresher 显著提升 LongMemEval_s 中 knowledge-update 场景的性能,准确率达到 0.897。 相比之下,移除 Refresher 会导致性能急剧下降到 0.568。 这种明显退化表明,准确的长期记忆不仅需要多粒度存储,还需要显式的冲突解决和记忆更新机制。
4.4 Efficiency Analysis
| Method | Tokens | Latency (s) | LLM Score |
|---|---|---|---|
| FullContext | 18625 | 7.206 | 0.717 |
| RAG | 5800 | 2.983 | 0.300 |
| Nemori | 2925 | 3.152 | 0.740 |
| Zep | 2461 | 3.255 | 0.580 |
| Mem0 | 1340 | 3.739 | 0.608 |
| A-Mem | 2720 | 3.227 | 0.476 |
AMA ( | 2491 | 3.124 | 0.723 |
AMA ( | 3613 | 3.910 | 0.774 |
We evaluate the efficiency-performance trade-off of AMA on the LoCoMo benchmark, with results reported in Table 4. Compared to FullContext, which processes 18625 input tokens with a latency of 7.21 seconds, AMA substantially reduces input length while maintaining strong performance. With the default setting
我们在 LoCoMo 基准上评估 AMA 的效率-性能权衡,结果见表4。 与处理 18625 个输入 token、延迟为 7.21 秒的 FullContext 相比,AMA 在保持强性能的同时显著减少输入长度。 在默认设置
4.5 Analysis of the Retrieval Round Limit
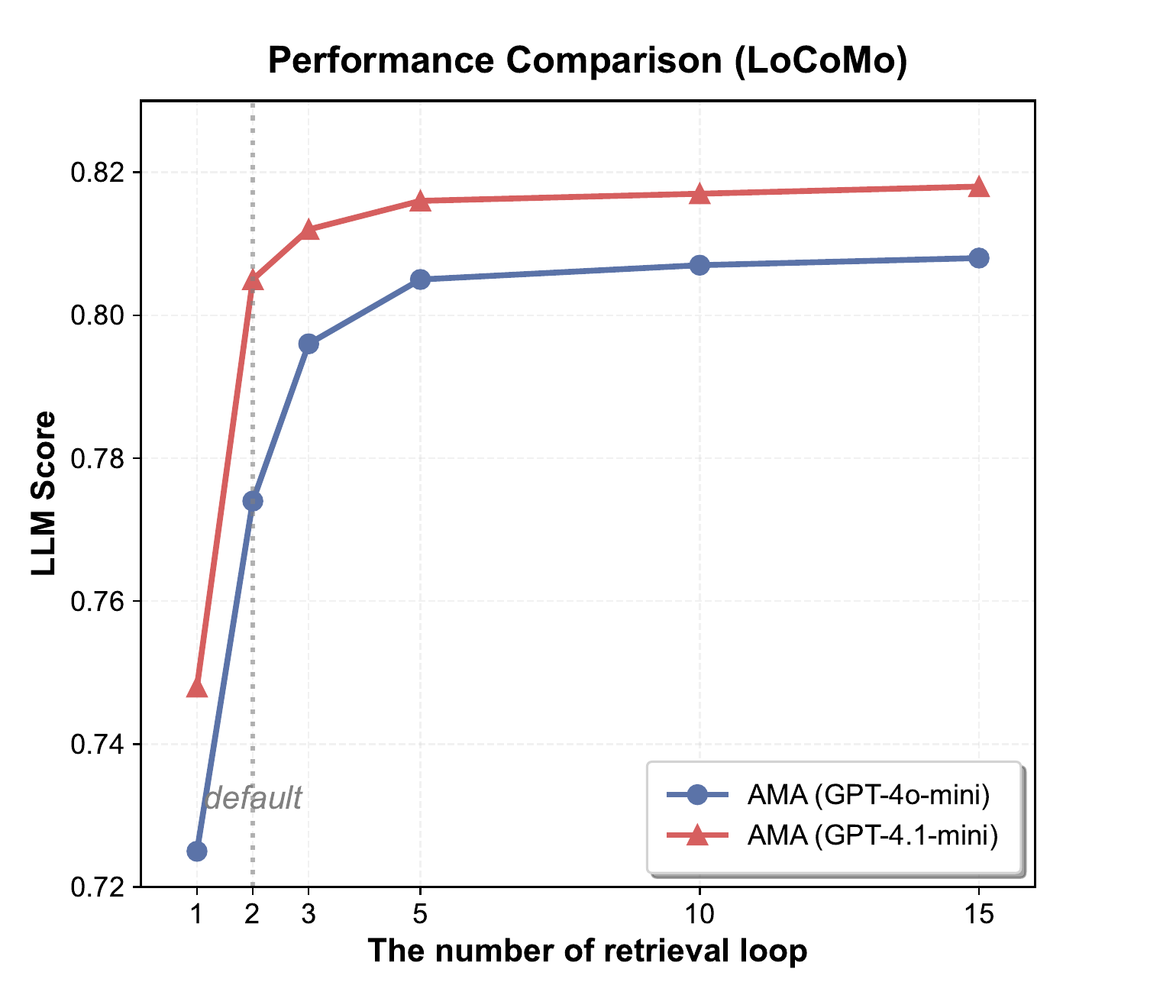
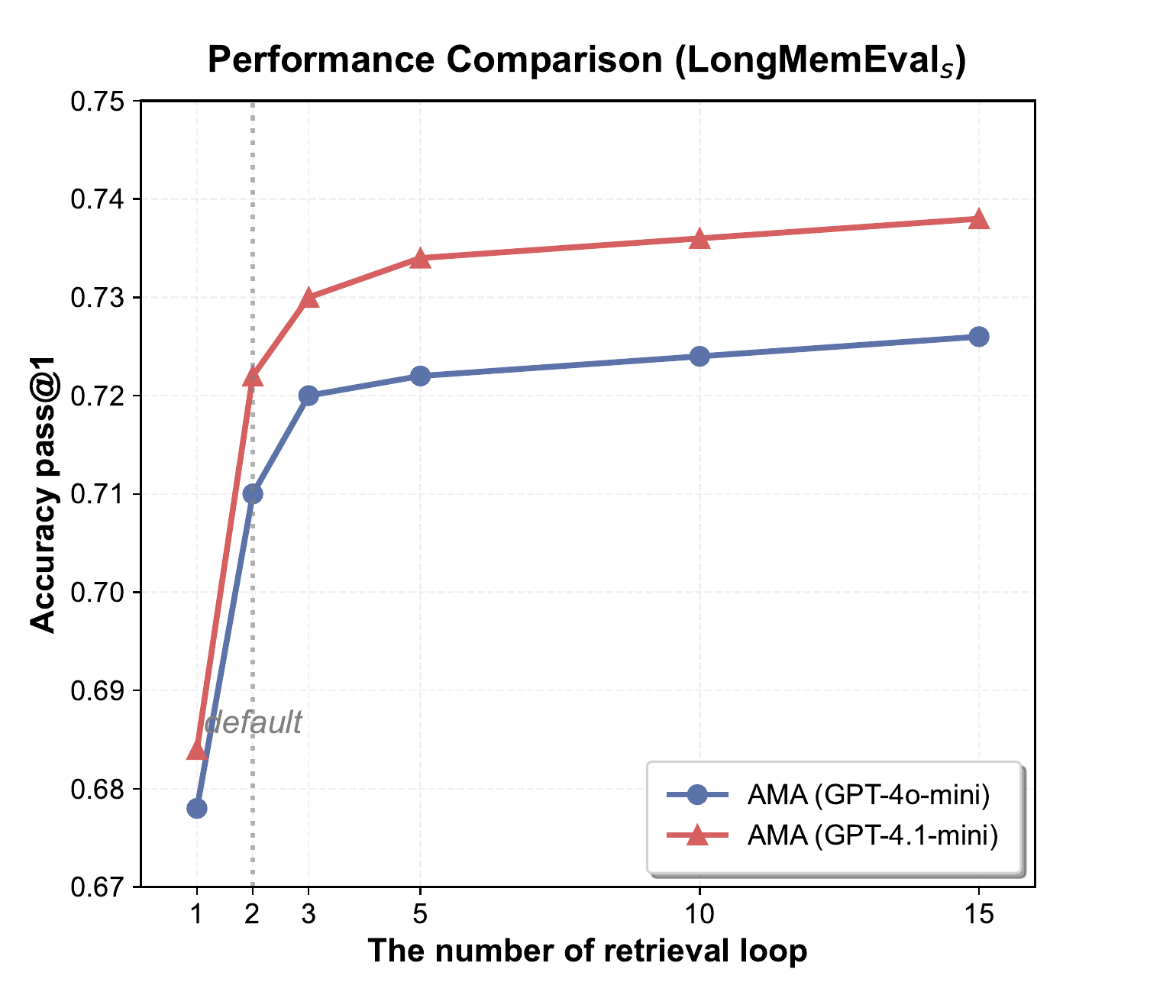
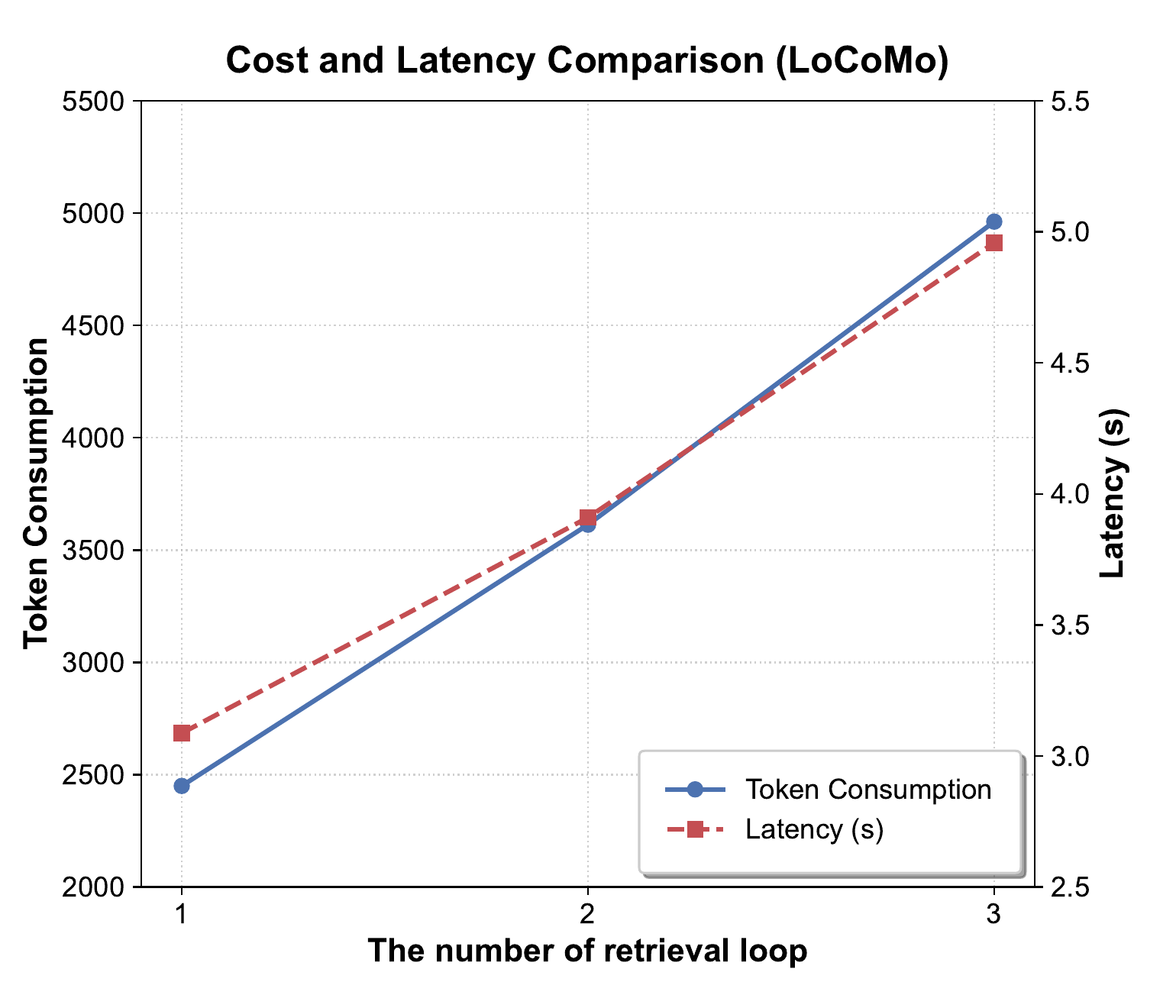
Figure 4 analyzes the impact of the retrieval round limit
图4分析了检索轮数上限
5. Conclusion
In this work, we introduce AMA, a multi-agent memory framework for long-term interactions that integrates multi-granularity memory, adaptive routing, and principled memory maintenance. By decomposing the memory lifecycle into coordinated agent roles, AMA dynamically aligns retrieval granularity with task demands while maintaining memory consistency over time. Extensive experiments demonstrate that AMA consistently outperforms strong baselines across challenging long-context benchmarks, validating the effectiveness of our design. Overall, this work underscores the importance of adaptive retrieval control and long-term memory management for building robust and scalable LLM agents.
在本文中,我们提出 AMA,这是一个面向长期交互的多智能体记忆框架,集成了多粒度记忆、自适应路由和原则化记忆维护。 通过将记忆生命周期分解为协同智能体角色,AMA 在随时间保持记忆一致性的同时,动态地将检索粒度与任务需求对齐。 大量实验证明,AMA 在具有挑战性的长上下文基准上持续优于强基线,验证了我们设计的有效性。 总体而言,这项工作强调了自适应检索控制和长期记忆管理对于构建稳健且可扩展 LLM 智能体的重要性。
Limitations
Despite the significant performance gains, the multi-agent collaboration incurs a moderate computational overhead compared to static retrieval baselines. Additionally, the reliance on the backbone model's reasoning capabilities suggests that the system's efficiency on smaller architectures has room for further optimization. We aim to address these challenges in future work to further enhance the efficiency and universality of the framework.
尽管性能提升显著,但与静态检索基线相比,多智能体协作会带来中等程度的计算开销。 此外,对 backbone 模型推理能力的依赖表明,系统在较小架构上的效率仍有进一步优化空间。 我们计划在未来工作中解决这些挑战,以进一步增强框架的效率和通用性。