
重新思考如何记忆:超越终身 LLM 智能体记忆中的原子事实
Abstract
To enable reliable long-term interaction, LLM agents require a memory system that can faithfully store, efficiently retrieve, and deeply reason over accumulated dialogue history. Most existing methods adopt an extracted fact based paradigm: handcrafted static prompts compress raw dialogues into atomic facts, which are then stored, matched, and injected into downstream reasoning. Nevertheless, such fact-centric designs inevitably discard fine-grained details in original dialogues and fail to support deep reasoning over scattered isolated facts. Moreover, static prompts cannot maintain consistent extraction granularity across diverse dialogue styles. To address these limitations, we propose TriMem, which maintains three coexisting representation granularities, including raw dialogue segments anchored by source identifiers for storage fidelity, extracted atomic facts for efficient memory retrieval, synthesized profiles that aggregate dispersed facts into holistic semantic understanding for deep reasoning. We further adopt TextGrad-based prompt optimization, which iteratively refines extraction and profiling prompts via response quality feedback, achieving lifelong evolution without any parameter updating. Extensive experiments on LoCoMo and PerLTQA across multiple LLM backbones demonstrate that TriMem consistently outperforms strong memory baselines.
为了支持可靠的长期交互,LLM 智能体需要一种记忆系统,能够忠实存储、高效检索,并对累积的对话历史进行深入推理。 大多数现有方法采用基于抽取事实的范式:人工编写的静态提示将原始对话压缩成原子事实,随后这些事实被存储、匹配,并注入下游推理。 然而,这种以事实为中心的设计不可避免地丢弃原始对话中的细粒度细节,也无法支持对分散孤立事实的深层推理。 此外,静态提示无法在多样化对话风格中维持一致的抽取粒度。 为了解决这些限制,作者提出 TriMem,它维护三种共存的表示粒度:由来源标识锚定的原始对话片段用于保证存储保真度,抽取出的原子事实用于高效记忆检索,合成画像则聚合分散事实,形成用于深度推理的整体语义理解。 作者进一步采用基于 TextGrad 的提示优化,通过回答质量反馈迭代细化抽取提示和画像提示,在不更新任何参数的情况下实现终身演化。 在 LoCoMo 和 PerLTQA 上跨多个 LLM 骨干进行的大量实验表明,TriMem 持续优于强记忆基线。
1. Introduction
The rapid development of large language models (LLMs) has driven significant breakthroughs in agent technology, which has demonstrated remarkable capabilities in a wide range of scenarios. However, in practical applications, constrained by the capacity of the context window, text overflow inevitably occurs when it comes to long-context and multi-turn interaction scenarios, leading to significant limitations in agents due to the loss of key historical interaction information and broken context logic. To enable reliable long-term interaction, LLM agents require a robust memory system to effectively manage and leverage historical experiences.
大语言模型(LLM)的快速发展推动了智能体技术的重大突破,并在广泛场景中展现出显著能力。 然而在实际应用中,受上下文窗口容量限制,在长上下文和多轮交互场景中不可避免会出现文本溢出,关键历史交互信息丢失和上下文逻辑断裂会严重限制智能体能力。 为了支持可靠的长期交互,LLM 智能体需要一个稳健的记忆系统,来有效管理并利用历史经验。
Recent research has extensively investigated the design of memory modules for LLM agents, with the overarching goal of realizing three core functional capabilities: storing information from historical interactions, retrieving relevant memories upon query, and incorporating them into prompts to support reasoning. As shown on the left side of Figure 1, existing systems typically rely on extracted factual information generated by static hand-written prompts to fulfill these three objectives. They only store extracted key facts produced by fixed prompts, perform retrieval based on similarity matching against these facts, and utilize the relevant information to support reasoning, which naturally raises two critical questions: Can extracted facts beneficially affect all three stages of agent memory systems? and can static fixed prompts adaptively maintain consistent and rational extraction granularity when facing highly heterogeneous real-world dialogue scenarios?
近期研究已经广泛探索了 LLM 智能体记忆模块的设计,其总体目标是实现三种核心功能能力:存储历史交互中的信息,在查询时检索相关记忆,并将其纳入提示以支持推理。 如 图1 左侧所示,现有系统通常依赖由静态人工提示生成的抽取事实信息来完成这三个目标。 它们只存储固定提示产生的关键事实,基于这些事实进行相似度匹配检索,并利用相关信息支持推理,这自然引出两个关键问题:抽取事实是否能对智能体记忆系统的三个阶段都产生有益影响?面对高度异质的真实对话场景时,静态固定提示能否自适应地维持一致且合理的抽取粒度?

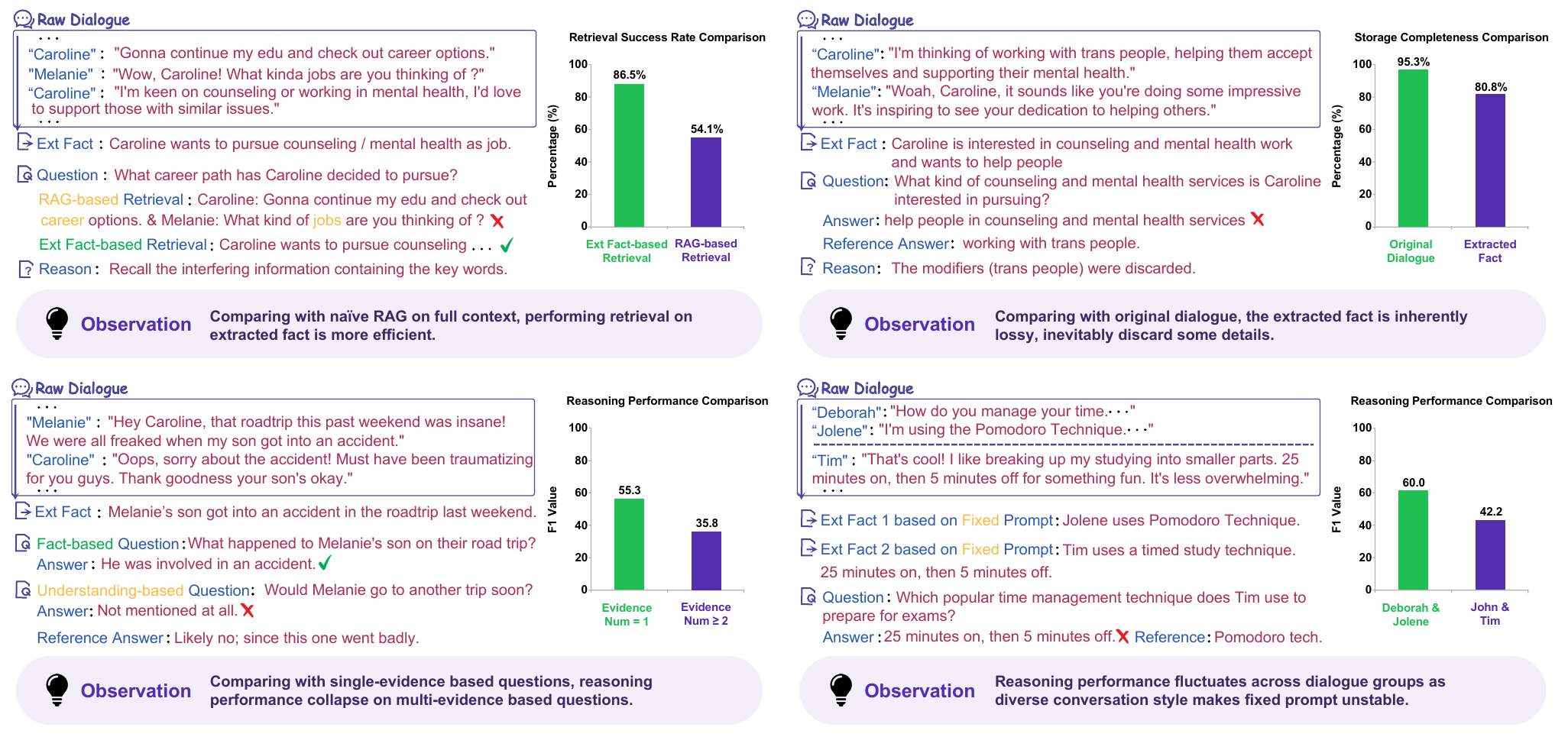
In this paper, we start by highlighting two concerning phenomena: extracted facts suffer from information loss, and reasoning for many real-world questions relies on understanding rather than simple fact matching. As shown in Figure 2, we analyze the performance of existing memory systems from storage fidelity, retrieval efficiency, and reasoning quality. The results demonstrate that although structured factual information ensures efficient retrieval, some precise details are inevitably lost since fact extraction necessarily compresses lengthy dialogues into concise representations. Fortunately, the original dialogue preserves complete information and can serve as an auxiliary source to recover these unstored details. Furthermore, while some questions can be answered using a single retrieved fact, others require integrating scattered information to form a comprehensive understanding. This suggests that a memory system should be capable of further information integration and in-depth comprehension beyond discrete factual pieces. Such a three-level architecture, consisting of raw dialogue storage, extracted fact based retrieval, and understanding-aided reasoning, offers potential for balancing the three core functionalities of a memory system. We also illustrate that the diversity of information styles leads to inconsistent extraction granularity, which significantly degrade system performance. Therefore, we require a mechanism that can continuously optimize prompts, enabling the system to adaptively balance storage depth, retrieval efficiency, and reasoning quality over time.
本文首先强调两个值得关注的现象:抽取事实会遭受信息损失,而许多真实问题的推理依赖理解,而不是简单的事实匹配。 如 图2 所示,作者从存储保真度、检索效率和推理质量三个角度分析现有记忆系统的表现。 结果表明,尽管结构化事实信息能够保证高效检索,但由于事实抽取必然将长对话压缩成简洁表示,一些精确细节不可避免会丢失。 幸运的是,原始对话保留了完整信息,可以作为辅助来源来恢复这些未被存储的细节。 此外,有些问题可以用单个检索事实回答,而另一些问题则需要整合分散信息以形成综合理解。 这表明,记忆系统应具备超越离散事实片段的进一步信息整合和深入理解能力。 这种由原始对话存储、基于抽取事实的检索和理解辅助推理构成的三层架构,有潜力平衡记忆系统的三种核心功能。 作者还说明,信息风格的多样性会导致抽取粒度不一致,从而显著降低系统性能。 因此,需要一种能够持续优化提示的机制,使系统随时间自适应地平衡存储深度、检索效率和推理质量。
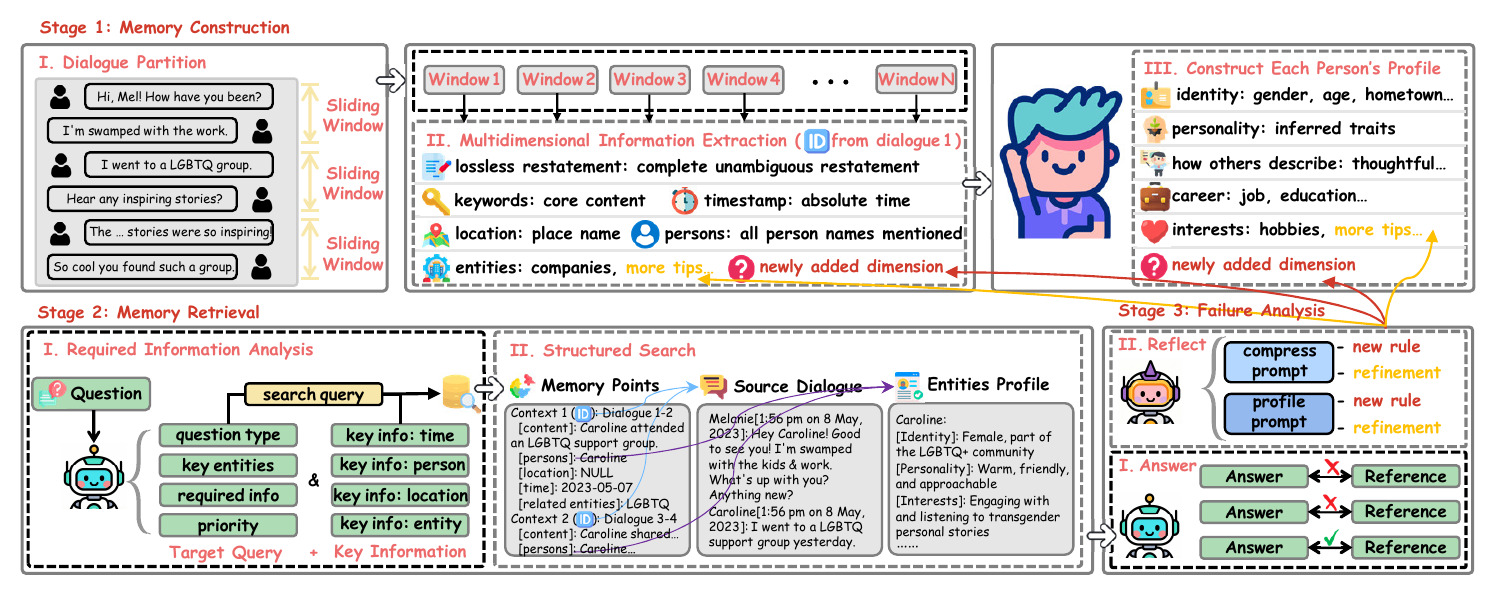
Based on our findings in the analysis, we propose Tri-Granularity Memory (TriMem), a memory architecture that maintains three coexisting granularities of representation, including verbatim dialogues, extracted facts, and synthesized profiles. In general, it builds source dialogue identifiers to preserve pointers to original dialogue segments for each compressed memory entry and employs a profile module that incrementally integrates scattered facts during ingestion to form understanding (as shown in the right part of Figure 1). On the one hand, considering the insufficient retention of detailed information, a traceable link is created for each compressed memory entry, which is directly associated with the original dialogue from which the entry is derived. On the other hand, considering the lack of in-depth understanding of factual information, incremental profile is constructed based on the new information of each window and pre-integrated understanding is provided at reasoning time, thus eliminating the need to perform complex comprehensive analysis among scattered facts. Furthermore, unlike previous methods that utilize hand-written prompts, we employ TextGrad-based prompt optimization to iteratively refine system prompts, thereby achieving the precise and high-quality construction of the memory module. To demonstrate the effectiveness of our method, we conduct extensive experiments on commonly used benchmarks and provide discussions on various ablations to justify the rationality. Our main contributions are summarized as follows:
基于上述分析发现,作者提出 Tri-Granularity Memory(TriMem),这是一种维护三种共存表示粒度的记忆架构,包括逐字原始对话、抽取事实和合成画像。 总体而言,它为每个压缩记忆条目构建来源对话标识,用于保留指向原始对话片段的指针,并使用画像模块在摄取过程中增量整合分散事实以形成理解(如 图1 右侧所示)。 一方面,考虑到详细信息保留不足,系统为每个压缩记忆条目创建可追踪链接,直接关联到该条目来源的原始对话。 另一方面,考虑到对事实信息缺乏深入理解,系统基于每个窗口的新信息构建增量画像,并在推理时提供预整合理解,从而无需在分散事实之间执行复杂综合分析。 此外,不同于使用人工提示的既有方法,作者采用基于 TextGrad 的提示优化来迭代细化系统提示,从而实现记忆模块的精确高质量构建。 为了展示方法有效性,作者在常用基准上进行了大量实验,并讨论多种消融以证明设计合理性。 主要贡献总结如下:
- Conceptually, we revisit the memory systems of LLM agents from a novel three-dimensional perspective, systematically exploring the limitations of existing paradigms spanning storage fidelity, indexing efficiency and reasoning quality (in Section 2).
- Technically, we propose TriMem, which innovatively introduces entity profile module to avoid shallow reasoning, preserves raw dialogue identifier to avoid detail loss and iteratively optimize system prompts to avoid performance fluctuation (in Section 3).
- Experimentally, we conduct extensive explorations to verify the effectiveness of TriMem under different scenarios, including the significant improvement across various benchmarks, compatibility with diverse model structure and model size, etc (in Section 4).
- 从概念上,作者从一种新的三维视角重新审视 LLM 智能体的记忆系统,系统探索现有范式在存储保真度、索引效率和推理质量方面的限制(见第 2 节)。
- 从技术上,作者提出 TriMem,创新性地引入实体画像模块以避免浅层推理,保留原始对话标识以避免细节丢失,并迭代优化系统提示以避免性能波动(见第 3 节)。
- 从实验上,作者在不同场景中进行广泛探索,验证 TriMem 的有效性,包括在多个基准上的显著提升、对不同模型结构和模型规模的兼容性等(见第 4 节)。
2. Preliminary and Motivation
In this section, we review the preliminaries of conventional agent memory systems (in Section 2.1), and conduct an in-depth analysis of the inherent limitations of existing agent memory systems (in Section 2.2). The experimental details of our analysis can be found in Appendix.
本节回顾传统智能体记忆系统的预备知识(见第 2.1 节),并深入分析现有智能体记忆系统的内在限制(见第 2.2 节)。 相关分析的实验细节可见附录。
2.1 Conventional Agent Memory Systems
We characterize the mainstream memory architecture into three core phases: (I) Storage. Given a historical dialogue
作者将主流记忆架构刻画为三个核心阶段:(I)存储。 给定历史对话
2.2 Analysis of Existing Systems
Efficient Retrieval. As illustrated in Figure 2, we compare one representative system with full-context based RAG strategy, in terms of the ratio of successfully retrieved question-related evidence. It can be seen that the extracted fact based retrieval enables more efficient and accurate localization of relevant memory entries. This alleviates the critical limitation of full-context based retrieval, which tends to introduce massive irrelevant and distracting content. For instance, when a query contains the keyword career, the full-context based RAG strategy retrieves massive sentences containing lexical variants such as job and career, where redundant noise severely degrades retrieval efficiency. In contrast, extracted facts are summarized across multi-turn dialogues, thus enabling precise semantic matching and substantially improving retrieval performance. However, the heavy reliance of subsequent phases on these extracted fact introduces several limitations we examine next.
高效检索。 如 图2 所示,作者从成功检索到问题相关证据的比例出发,将一种代表性系统与基于 full-context 的 RAG 策略进行比较。 可以看到,基于抽取事实的检索能够更高效、更准确地定位相关记忆条目。 这缓解了基于 full-context 检索的关键限制,即它往往会引入大量无关且分散注意力的内容。 例如,当查询包含关键词 career 时,基于 full-context 的 RAG 策略会检索大量包含 job 和 career 等词汇变体的句子,而冗余噪声会严重降低检索效率。 相比之下,抽取事实是跨多轮对话总结得到的,因此能够进行精确语义匹配,并显著提升检索表现。 然而,后续阶段对这些抽取事实的高度依赖,也引入了作者接下来要考察的若干限制。
Lossy Storage. Although retrieval on extracted facts enables accurate memory localization, the fact extraction process inevitably introduces lossy compression of raw information, where fine-grained details are discarded, resulting in inherent information incompleteness within stored memory entries. As illustrated in Figure 2, we calculate the coverage rate of reference answer token, it can be seen that the extracted fact loss 14.5% more information than original dialogue. For example, the modifier trans in the original dialogue is omitted during fact extraction. This directly leads to a critical issue: even if the system retrieves topically relevant entries, it still fails to provide accurate and complete answers due to missing key contextual details from raw dialogues. This implies that completely abandoning raw dialogues and relying solely on extracted facts for storage will result in permanent loss of semantic details. Such systems become incapable of solving detail-dependent and high-precision constrained queries, thus suffering from inevitable performance degradation.
有损存储。 尽管在抽取事实上进行检索能够准确定位记忆,但事实抽取过程不可避免地会对原始信息进行有损压缩,细粒度细节被丢弃,导致存储记忆条目存在固有的信息不完整。 如 图2 所示,作者计算参考答案 token 覆盖率,可以看到抽取事实相比原始对话多丢失 14.5% 的信息。 例如,原始对话中的修饰词 trans 在事实抽取过程中被遗漏。 这直接导致一个关键问题:即使系统检索到了主题相关条目,由于缺少来自原始对话的关键上下文细节,它仍然无法提供准确完整的答案。 这意味着,完全放弃原始对话、仅依赖抽取事实进行存储,会造成语义细节的永久损失。 这样的系统无法解决依赖细节和高精度约束的查询,因此不可避免地遭受性能下降。
Shallow Reasoning. Beyond the aforementioned issue of irreversible information loss during extraction, existing extracted fact based memory systems additionally suffer from a fundamental capability bottleneck of shallow reasoning. As illustrated in Figure 2, we test the reasoning performance of those correctly retrieved questions. The results reveal that the reasoning performance on multi-evidence questions is considerably inferior to that on single-evidence ones, as single-evidence questions mostly rely on explicit factual content and can be answered by directly restating content in retrieved memory entries. In contrast, multi-evidence questions demand deep understanding of dispersed facts, such as emotional inference and logical induction. This phenomenon adequately demonstrates that reasoning mechanisms solely relying on extracted fact completely lack the ability of deep comprehension towards entity semantic portraits or behavioral tendency modeling, thereby severely hindering the comprehensive performance of LLM agents in long-term interactions.
浅层推理。 除了抽取过程中不可逆信息损失的问题,现有基于抽取事实的记忆系统还面临浅层推理这一根本能力瓶颈。 如 图2 所示,作者测试了那些已正确检索问题的推理表现。 结果显示,多证据问题上的推理表现明显低于单证据问题,因为单证据问题大多依赖显式事实内容,可以通过直接复述检索记忆条目中的内容来回答。 相比之下,多证据问题要求对分散事实进行深度理解,例如情感推断和逻辑归纳。 这一现象充分说明,仅依赖抽取事实的推理机制完全缺乏对实体语义画像或行为倾向建模的深层理解能力,从而严重阻碍 LLM 智能体在长期交互中的综合表现。
Suboptimal Prompt. In addition to the information loss and shallow reasoning issues incurred by extracted facts, practical real-world deployments further suffer from performance degradation caused by unstable extraction granularity with fixed prompts. Realistic long-term interactions involve highly diverse information styles, expression patterns and content categories, whereas conventional systems rely on static hand-written extraction prompts. Such fixed prompts fail to adaptively accommodate heterogeneous dialogue content, making it impossible to maintain consistent and rational fact extraction granularity. As illustrated in Figure 2, we compare the reasoning performance across dialogues between different speakers where the performance severely fluctuate. For example, the Pomodoro technique is sometimes explicitly mentioned by name, while in other cases it is implicitly described as 25 minutes on and 5 minutes off. The fixed prompt cannot recognize such high-level semantic concepts, resulting in inconsistent extraction granularity. This discrepancy further degrades the overall performance and stability of the memory system.
次优提示。 除了抽取事实带来的信息损失和浅层推理问题,真实部署还会受到固定提示下抽取粒度不稳定所造成的性能下降影响。 真实长期交互包含高度多样的信息风格、表达模式和内容类别,而传统系统依赖静态人工抽取提示。 这类固定提示无法自适应地适配异质对话内容,因此不可能维持一致且合理的事实抽取粒度。 如 图2 所示,作者比较了不同说话者对话中的推理表现,发现性能严重波动。 例如,Pomodoro technique 有时会被直接按名称提及,而在其他情况下会被隐式描述为 25 minutes on and 5 minutes off。 固定提示无法识别这种高层语义概念,导致抽取粒度不一致。 这种差异进一步削弱记忆系统的整体性能和稳定性。
3. Method
In this section, we present TriMem, which constructs a three-level architecture, from raw dialogue to extracted key fact and integrated profiles (in Section 3.1). Specially, we construct index between raw dialogue and extracted fact to improve storage fidelity while keeping retrieval efficiency (in Section 3.2), integrate scattered facts to profiles to support understanding based reasoning (in Section 3.3), optimize prompts via failure case analysis to realize lifelong evolution (in Section 3.4).
本节介绍 TriMem,它构建了一种从原始对话到抽取关键事实再到整合画像的三层架构(见第 3.1 节)。 具体来说,作者在原始对话和抽取事实之间构建索引,在保持检索效率的同时提升存储保真度(见第 3.2 节);将分散事实整合为画像以支持基于理解的推理(见第 3.3 节);并通过失败案例分析优化提示以实现终身演化(见第 3.4 节)。
3.1 Overall Pipeline
As shown in Figure 3, our framework consists of the following three core components: (1) Given a set of dialogue, we extract factual information and bind each fact with raw dialogue identifier and profile identifier to implement memory construction. (2) Given a question, the agent first analyzes the required information and keywords to generate search query. It then matches with extracted facts to retrieve relevant memory, and further obtains raw dialogues with full details and integrated profiles via predefined index to complete memory retrieval. (3) According to the reasoning performance, we invoke a powerful senior model to conduct failure analysis and provide revision suggestions for system prompts. In the following subsections, we will elaborate on these components in detail.
如 图3 所示,框架包含三个核心组件:(1)给定一组对话,系统抽取事实信息,并将每个事实与原始对话标识和画像标识绑定,以实现记忆构建。 (2)给定问题,智能体首先分析所需信息和关键词,生成搜索查询。 随后,它与抽取事实匹配以检索相关记忆,并通过预定义索引进一步获得包含完整细节的原始对话和整合画像,从而完成记忆检索。 (3)根据推理表现,系统调用强大的 senior model 进行失败分析,并为系统提示提供修订建议。 接下来的小节会详细说明这些组件。
3.2 Dense Storage with Efficient Retrieval
Same as conventional systems, we also perform fact extraction on original dialogue. We first partition the raw dialogue
与传统系统相同,TriMem 也会在原始对话上执行事实抽取。 作者首先通过滑动窗口
where
其中
where each dimension corresponds to a dedicated extraction function capturing a distinct semantic aspect of the dialogue content:
其中每个维度对应一个专门的抽取函数,用于捕获对话内容的不同语义方面:
3.3 Scattered Fact with Integrated Profile
To address the shallow reasoning problem, we construct structured profiles over scattered fact. We first group extracted fact according to different person
为了解决浅层推理问题,作者在分散事实之上构建结构化画像。 系统首先按照不同人物
where
其中
3.4 Lifelong Evolution with Optimized Prompt
In order to maintain the fine-grained consistency, we utilize TextGrad to optimize the prompts. Given the retrieved context
为了维持细粒度一致性,作者利用 TextGrad 优化提示。 给定检索上下文
where
其中
The prompts are then updated by applying these textual gradients as rewriting instructions:
随后,系统将这些文本梯度作为重写指令来更新提示:
4. Experiments
In this section, we provide comprehensive verification of TriMem. First, we introduce several critical parts of experimental setups (in Section 4.1). Second, we provide performance comparison and compatibility experiments of Entity Profile with different previous methods (in Section 4.2). Third, we conduct extensive ablation studies to better understand our TriMem (in Section 4.3).
本节对 TriMem 进行全面验证。 首先,作者介绍实验设置中的几个关键部分(见第 4.1 节)。 其次,作者给出实体画像与不同既有方法的性能比较和兼容性实验(见第 4.2 节)。 第三,作者进行大量消融研究,以更好理解 TriMem(见第 4.3 节)。
4.1 Experimental Setups
Baselines and Benchmarks. We compare our method with Naive RAG and several competitive agent memory systems, including Mem0, MemoryOS, A-Mem, LightMem, SimpleMem and xMemory. For a fair comparison, we keep the original hyperparameter setups of the comparative methods. The evaluation is conducted in two commonly used benchmarks, LoCoMo and PerLTQA. More details of each system are provided in Appendix.
基线和基准。 作者将方法与 Naive RAG 以及若干有竞争力的智能体记忆系统进行比较,包括 Mem0、MemoryOS、A-Mem、LightMem、SimpleMem 和 xMemory。 为了公平比较,作者保留对比方法的原始超参数设置。 评测在两个常用基准 LoCoMo 和 PerLTQA 上进行。 每个系统的更多细节见附录。
Implementation Details. We set the size of the window to 40 and stride to 38. The Qwen3-embedding-0.6b model is utilized to encode the extracted fact. During retrieval, the maximum number of relevant entries is set to 25. The number of optimization rounds for prompts is set to 4 to enable in-depth reasoning. We perform prompt training on LoCoMo with Qwen3-8B model, and then directly apply the optimized prompts to other models and benchmark. The failure analysis is conducted by Claude Opus 4.6. The prompts used in our experiments are provided in Appendix.
实现细节。 作者将窗口大小设为 40,步长设为 38。 使用 Qwen3-embedding-0.6b 模型编码抽取事实。 检索时,相关条目的最大数量设为 25。 提示优化轮数设为 4,以支持深入推理。 作者使用 Qwen3-8B 模型在 LoCoMo 上进行提示训练,然后将优化后的提示直接应用到其他模型和基准。 失败分析由 Claude Opus 4.6 执行。 实验中使用的提示见附录。
4.2 Main Results
| Model | Method | MultiHop | Temporal | OpenDomain | SingleHop | Average | Token | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | Cost | ||
| GPT-4.1-mini | LoCoMo | 8.00 | 17.26 | 10.17 | 14.89 | 8.29 | 16.28 | 17.43 | 19.36 | 13.62 | 17.85 | 16863 |
| Naïve RAG | 11.49 | 13.24 | 20.52 | 28.80 | 11.79 | 10.75 | 22.85 | 30.29 | 19.59 | 25.64 | 1119 | |
| Mem0 | 28.81 | 31.44 | 35.41 | 46.24 | 18.51 | 17.93 | 31.25 | 35.34 | 30.88 | 35.81 | 1153 | |
| MemoryOS | 16.46 | 24.02 | 34.78 | 46.52 | 14.89 | 19.58 | 36.18 | 43.92 | 30.95 | 39.30 | 936 | |
| A-Mem | 15.11 | 20.66 | 41.57 | 50.94 | 11.18 | 13.20 | 38.25 | 43.72 | 33.01 | 39.10 | 1276 | |
| LightMem | 32.93 | 40.33 | 47.53 | 55.23 | 18.31 | 21.91 | 37.68 | 48.39 | 37.66 | 46.69 | 695 | |
| SimpleMem | 32.40 | 39.33 | 43.69 | 58.01 | 19.56 | 24.50 | 43.41 | 53.99 | 39.97 | 50.30 | 587 | |
| Ours | 35.20 | 42.59 | 49.56 | 64.72 | 36.86 | 43.88 | 45.25 | 55.36 | 43.79 | 54.26 | 1217 | |
| GPT-4o | LoCoMo | 19.64 | 19.20 | 9.50 | 13.95 | 11.87 | 16.60 | 13.81 | 16.12 | 13.86 | 16.26 | 16863 |
| Naïve RAG | 14.36 | 15.35 | 11.48 | 16.17 | 9.03 | 9.09 | 26.67 | 35.03 | 20.15 | 25.88 | 1119 | |
| Mem0 | 25.52 | 32.36 | 32.48 | 42.70 | 14.50 | 18.50 | 30.02 | 39.84 | 28.74 | 37.74 | 1195 | |
| MemoryOS | 22.52 | 31.76 | 38.31 | 47.08 | 12.91 | 18.06 | 38.26 | 43.67 | 33.81 | 40.60 | 944 | |
| A-Mem | 20.90 | 26.12 | 35.39 | 48.64 | 10.74 | 12.33 | 37.11 | 42.08 | 32.14 | 38.67 | 1152 | |
| LightMem | 35.30 | 45.16 | 43.60 | 58.57 | 10.56 | 23.20 | 36.72 | 46.60 | 36.26 | 47.37 | 677 | |
| SimpleMem | 31.34 | 35.58 | 35.78 | 46.96 | 18.96 | 17.01 | 37.11 | 43.94 | 34.64 | 41.36 | 627 | |
| Ours | 40.36 | 46.00 | 51.39 | 60.41 | 39.27 | 50.15 | 40.61 | 47.78 | 42.73 | 50.23 | 1272 | |
| GPT-5-nano | LoCoMo | 20.45 | 19.04 | 12.69 | 16.56 | 13.83 | 20.85 | 13.50 | 15.23 | 14.62 | 16.56 | 16863 |
| Naïve RAG | 10.13 | 13.29 | 8.78 | 13.09 | 9.25 | 12.24 | 20.29 | 28.44 | 15.34 | 21.46 | 1119 | |
| Mem0 | 22.55 | 28.58 | 35.52 | 48.82 | 18.33 | 16.75 | 28.99 | 35.65 | 28.51 | 35.92 | 1074 | |
| MemoryOS | 10.74 | 23.50 | 32.50 | 39.71 | 10.02 | 20.30 | 34.28 | 40.34 | 28.09 | 35.88 | 952 | |
| A-Mem | 15.54 | 20.11 | 27.23 | 32.43 | 10.86 | 12.55 | 27.26 | 31.91 | 24.09 | 28.65 | 1175 | |
| LightMem | 28.63 | 38.21 | 39.72 | 55.51 | 18.79 | 22.74 | 31.19 | 42.01 | 31.73 | 42.93 | 723 | |
| SimpleMem | 25.42 | 33.28 | 32.15 | 45.75 | 20.77 | 24.31 | 39.65 | 46.71 | 34.30 | 42.65 | 655 | |
| Ours | 34.86 | 45.25 | 42.45 | 57.05 | 33.55 | 40.52 | 54.26 | 62.88 | 46.96 | 57.04 | 1256 | |
| Model | Method | MultiHop | Temporal | OpenDomain | SingleHop | Average | Token | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | BLEU | F1 | Cost | ||
| Qwen3-8B | LoCoMo | 12.67 | 20.54 | 12.32 | 18.55 | 10.59 | 14.39 | 19.76 | 23.78 | 16.34 | 21.51 | 16863 |
| Naïve RAG | 13.75 | 15.83 | 8.86 | 13.53 | 9.68 | 10.77 | 21.57 | 28.76 | 16.75 | 22.10 | 1119 | |
| Mem0 | 28.32 | 30.07 | 23.15 | 26.15 | 11.79 | 15.15 | 30.75 | 34.97 | 27.54 | 30.10 | 1140 | |
| MemoryOS | 14.38 | 22.72 | 18.67 | 22.79 | 11.06 | 13.52 | 25.65 | 33.52 | 21.22 | 28.06 | 911 | |
| A-Mem | 16.02 | 21.08 | 28.10 | 37.51 | 14.01 | 14.19 | 33.60 | 40.77 | 28.01 | 34.83 | 1180 | |
| LightMem | 22.84 | 32.54 | 37.62 | 48.37 | 18.05 | 19.02 | 23.03 | 31.37 | 25.73 | 34.36 | 740 | |
| SimpleMem | 23.39 | 30.39 | 24.66 | 34.51 | 14.04 | 15.39 | 35.73 | 41.26 | 29.81 | 36.25 | 608 | |
| xMemory | 28.44 | 39.13 | 28.65 | 35.41 | 17.76 | 21.57 | 40.66 | 50.57 | 34.49 | 43.51 | 2230 | |
| Ours | 33.09 | 41.22 | 38.71 | 53.13 | 30.59 | 37.64 | 45.10 | 52.52 | 40.66 | 49.65 | 1339 | |
| Llama-3.1-8B-Ins | LoCoMo | 13.73 | 23.36 | 13.15 | 20.30 | 11.54 | 19.42 | 18.64 | 25.86 | 16.15 | 23.84 | 16863 |
| Naïve RAG | 14.31 | 16.18 | 7.63 | 12.28 | 9.09 | 11.58 | 22.99 | 31.02 | 17.33 | 23.18 | 1119 | |
| Mem0 | 13.27 | 16.40 | 8.26 | 12.62 | 7.45 | 8.45 | 21.75 | 31.28 | 16.49 | 23.24 | 1085 | |
| MemoryOS | 13.57 | 22.63 | 19.18 | 23.31 | 10.59 | 13.01 | 23.46 | 31.05 | 19.95 | 26.77 | 964 | |
| A-Mem | 15.80 | 22.84 | 23.79 | 36.19 | 11.19 | 12.51 | 31.19 | 37.86 | 25.58 | 33.18 | 1340 | |
| LightMem | 13.19 | 19.64 | 16.93 | 28.06 | 17.39 | 20.68 | 27.62 | 41.06 | 22.11 | 33.16 | 758 | |
| SimpleMem | 18.81 | 26.22 | 21.15 | 30.44 | 15.81 | 18.77 | 26.79 | 31.23 | 23.47 | 29.37 | 674 | |
| xMemory | 21.89 | 31.24 | 21.78 | 26.84 | 12.37 | 16.62 | 27.75 | 41.36 | 24.47 | 34.94 | 2375 | |
| Ours | 25.42 | 34.56 | 25.98 | 32.36 | 28.40 | 32.71 | 35.76 | 43.20 | 31.37 | 38.70 | 1388 | |
gpt-4.1-mini 判断预测答案是否匹配真实答案。TriMem 在不同子任务中均取得最佳表现。| Method | Qwen3-8B | Llama-3.1-8B-Ins | ||||||
|---|---|---|---|---|---|---|---|---|
| Profile | Social Rel. | Events | Dialogues | Profile | Social Rel. | Events | Dialogues | |
| Full-Context | 65.80 | 56.72 | 52.75 | 18.51 | 52.46 | 54.58 | 47.54 | 17.27 |
| Mem0 | 89.56 | 76.46 | 66.48 | 27.59 | 73.04 | 72.29 | 57.14 | 26.31 |
| LightMem | 64.93 | 78.00 | 73.03 | 47.01 | 53.85 | 74.08 | 69.21 | 44.72 |
| SimpleMem | 88.12 | 82.40 | 79.87 | 42.09 | 84.64 | 76.46 | 70.39 | 37.90 |
| TriMem | 92.46 | 83.23 | 85.72 | 55.79 | 92.17 | 82.28 | 78.17 | 45.01 |
Performance on High-Capability Models. In Table 1, we compare representative agent memory systems to validate the effectiveness of TriMem. Results demonstrate that our method consistently outperforms prior approaches when integrated with various high-capability models, including GPT-4o, GPT-4.1-mini and GPT-5-nano. Meanwhile, to illustrate the information density of TriMem, we report the average tokens consumption of retrieved contexts. It can be seen that our system only consumes around 1.2k tokens. Although retrieving raw dialogues and entity profiles slightly increases the token overhead, it brings substantial performance gains.
高能力模型上的表现。 在 表1 中,作者比较代表性智能体记忆系统,以验证 TriMem 的有效性。 结果表明,当与 GPT-4o、GPT-4.1-mini 和 GPT-5-nano 等多种高能力模型集成时,TriMem 持续优于既有方法。 同时,为了说明 TriMem 的信息密度,作者报告了检索上下文的平均 token 消耗。 可以看到,系统仅消耗约 1.2k token。 尽管检索原始对话和实体画像会略微增加 token 开销,但它带来了显著性能收益。
Compatibility with Efficient Models. To evaluate the capability of TriMem to support small-parameter efficient models, we conduct experiments on lightweight models including Qwen3-8B and Llama-3.1-8B-Instruct. As shown in Table 2, our system still achieves substantial performance improvements. Unlike xMemory, which only supports limited open-source models due to its requirement for model output logits, TriMem is compatible with models of various parameter sizes. This verifies the extensive superiority and broad applicability of our method.
与高效模型的兼容性。 为了评估 TriMem 支持小参数高效模型的能力,作者在 Qwen3-8B 和 Llama-3.1-8B-Instruct 等轻量模型上进行实验。 如 表2 所示,系统仍然取得显著性能提升。 与 xMemory 不同,xMemory 由于需要模型输出 logits,只支持有限的开源模型;TriMem 则兼容多种参数规模的模型。 这验证了方法的广泛优势和普遍适用性。
Generalization on Different Datasets. PerLTQA is also a widely adopted benchmark for long-term agent QA, consisting of multi-dimensional evaluations covering personal profiles, social relationship, historical events and dialogue memories. To comprehensively validate the effectiveness of our proposed method, we additionally report experimental results on this dataset (see Table 3), which demonstrates the strong generalization ability of TriMem.
在不同数据集上的泛化。 PerLTQA 也是一个被广泛采用的长期智能体问答基准,包含覆盖个人画像、社会关系、历史事件和对话记忆的多维评测。 为了全面验证所提方法的有效性,作者还在该数据集上报告实验结果(见 表3),展示了 TriMem 的强泛化能力。



4.3 Ablation and Further Analysis
Ablation of Profile and Raw Dialogue. To verify the necessity of entity profiles and raw dialogues for reasoning reliability and storage fidelity, we conduct ablation experiments on LoCoMo by removing these two contextual components. The results are presented in Figure 4, it can be seen that the agent suffers a noticeable performance drop when either component is excluded. This demonstrates that incorporating entity profiles and raw dialogues is a reasonable design which effectively boosts the overall capability of agent memory systems. More detailed results can be found in Appendix.
画像和原始对话消融。 为了验证实体画像和原始对话对于推理可靠性与存储保真度的必要性,作者在 LoCoMo 上移除这两个上下文组件进行消融实验。 结果见 图4,可以看到任一组件被排除时,智能体都会出现明显性能下降。 这说明引入实体画像和原始对话是一种合理设计,能够有效提升智能体记忆系统的整体能力。 更详细结果见附录。
Impact of Varying Evolution Step. We perform multi-step iterative evolution of prompt. To evaluate the impact of different evolution steps on overall system performance, we conduct an ablation study by increasing the number of update steps from 1 to 5. As shown in Figure 5, the performance gradually improves with the increase of evolution steps, and reaches the optimal level when the number of steps is set to 4. Further updates lead to excessive refinement of the prompt's granularity, which may exceed the model's capability boundary and result in performance degradation. Therefore, we set the number of evolution steps to 4. Visualization of update process can be found in Appendix.
不同演化步数的影响。 作者对提示进行多步迭代演化。 为了评估不同演化步数对整体系统性能的影响,作者将更新步数从 1 增加到 5 进行消融研究。 如 图5 所示,性能随着演化步数增加逐渐提升,并在步数设为 4 时达到最优水平。 进一步更新会导致提示粒度过度细化,可能超过模型能力边界并造成性能下降。 因此,作者将演化步数设为 4。 更新过程可视化见附录。
Performance in Different Retrieval Numbers. In Figure 6, we present the performance of our method when retrieving different numbers of memory entries. It can be observed that when the number of retrieved memory entries is too low, key information may fail to be effectively retrieved, resulting in suboptimal performance. When the number of retrieved entries is excessively high, irrelevant redundant information is likely to be introduced, interfering with model reasoning and leading to performance degradation. Overall, setting the number of retrieved memory entries to 25 is a reasonable choice. Visualization of the retrieved memory entries can be found in Appendix.
不同检索数量下的性能。 在 图6 中,作者展示了检索不同数量记忆条目时的方法表现。 可以观察到,当检索记忆条目数量过低时,关键信息可能无法被有效检索,导致次优表现。 当检索条目数量过高时,可能引入无关冗余信息,干扰模型推理并导致性能下降。 总体而言,将检索记忆条目数量设为 25 是一个合理选择。 检索记忆条目的可视化见附录。


Necessity of Search Query. In the retrieval phase, instead of directly relying on the original question for retrieval, we prompt the agent to first analyze the required information and keywords of the question, and then perform retrieval based on the analysis results. To verify the necessity of this module, we compare the system performance with and without search query in Figure 7. The experimental results show that although the generation process of search query increase the retrieval time, the performance is significantly improved after adding the search query, indicating that the search query helps the model achieve more accurate retrieval, thus confirming the necessity of this module. We show some obtained search queries of different questions in Appendix.
搜索查询的必要性。 在检索阶段,系统不是直接依赖原始问题进行检索,而是提示智能体先分析问题所需信息和关键词,再基于分析结果执行检索。 为了验证该模块的必要性,作者在 图7 中比较有无搜索查询时的系统表现。 实验结果表明,虽然搜索查询的生成过程增加了检索时间,但加入搜索查询后性能显著提升,说明搜索查询帮助模型实现更准确的检索,从而确认该模块的必要性。 不同问题获得的若干搜索查询见附录。
Comparison with Diverse Window Size. To compare the system performance under different window sizes, we present the performance comparison with various window settings in Figure 8. It can be observed that, although the model can also achieve good performance with smaller windows, the number of communications with the agent significantly increases. As shown on the right side of Figure 7, although the inference time is not affected, the memory construction time highly extends. Therefore, to balance system performance and efficiency, we finally set the window size to 40. Examples of information extraction under different window sizes can be found in Appendix.
不同窗口大小比较。 为了比较不同窗口大小下的系统性能,作者在 图8 中展示了多种窗口设置的性能比较。 可以观察到,尽管模型在较小窗口下也能取得良好性能,但与智能体的通信次数显著增加。 如 图7 右侧所示,虽然推理时间不受影响,但记忆构建时间大幅延长。 因此,为了平衡系统性能和效率,作者最终将窗口大小设为 40。 不同窗口大小下的信息抽取示例见附录。
5. Related Work
Memory Systems for LLM Agents. Long-term memory has emerged as a key capability for LLM agents engaged in multi-session interactions, with most existing systems organized around three functional stages: memory construction, memory retrieval, and memory-supported reasoning. For memory construction, Mem0, A-Mem, and MemoryOS prompt LLMs to extract atomic facts from dialogues and consolidate them via dynamic updates or hierarchical stores. For memory retrieval, methods from Naive RAG to xMemory match queries with fact embeddings through similarity search. For memory-supported reasoning, retrieved facts are concatenated into the prompt as contextual supplements. Despite their differences, these systems share a common design choice: extracted facts serve as the atomic unit across all three stages, i.e., what is stored, what is matched, and what is injected into the prompt. This fact-centric pipeline risks losing fidelity to the original dialogue and limits the agent's ability to handle queries that require holistic understanding rather than discrete fact lookup. In contrast, our work revisits the role of each stage, establishing index between extracted facts and source dialogues to ensure storage fidelity and constructing entity profiles from these facts to support comprehension-oriented reasoning that goes beyond fact recall. This perspective also clarifies why the three stages should not be designed in isolation: the granularity of what is stored constrains what can be retrieved, and the granularity of what is retrieved in turn dictates the kind of reasoning the agent can perform downstream. Treating the three stages as a single pipeline with consistent yet multi-level representations, rather than three independently optimized modules over the same atomic unit, is therefore central to our design.
LLM 智能体的记忆系统。 长期记忆已经成为参与多会话交互的 LLM 智能体的一项关键能力,大多数现有系统围绕三个功能阶段组织:记忆构建、记忆检索和记忆支持推理。 在记忆构建方面,Mem0、A-Mem 和 MemoryOS 会提示 LLM 从对话中抽取原子事实,并通过动态更新或层次化存储进行整合。 在记忆检索方面,从 Naive RAG 到 xMemory 的方法通过相似度搜索将查询与事实嵌入匹配。 在记忆支持推理方面,检索事实会作为上下文补充拼接进提示。 尽管这些系统存在差异,它们共享一个共同设计选择:抽取事实作为三个阶段的原子单位,即被存储的内容、被匹配的内容以及被注入提示的内容。 这种以事实为中心的流程存在丧失原始对话保真度的风险,并限制智能体处理那些需要整体理解而非离散事实查找的问题。 相比之下,TriMem 重新审视每个阶段的作用,在抽取事实和来源对话之间建立索引以保证存储保真度,并基于这些事实构建实体画像,以支持超越事实回忆的理解导向推理。 这一视角也说明为什么三个阶段不应孤立设计:被存储内容的粒度会限制可检索内容,而被检索内容的粒度又会决定智能体下游能够执行何种推理。 因此,将三个阶段视为一个具有一致但多层表示的单一流程,而不是围绕同一原子单位独立优化的三个模块,是 TriMem 设计的核心。
Lifelong Evolution Agents. Lifelong evolution has emerged as a key capability for LLM agents that need to improve from accumulated experience over long horizons. One prominent line formulates memory management as a reinforcement learning problem: MemAgent reshapes long-context LLMs into multi-conversation memory agents, MemBuilder reinforces memory construction with attributed dense rewards, AgentFold learns proactive context management for long-horizon web agents, MemGen weaves generative latent memories into self-evolving agents, and MEM1 jointly synergizes memory and reasoning for efficient execution. While effective, these methods all require RL-based parameter updates that disrupt the original pretrained weights, incur substantial training cost, and are impractical when only API-accessible models are available. Motivated by these limitations, a complementary line pursues lifelong evolution without altering model parameters: Voyager maintains a skill library of executable code, ExpeL distills cross-task experience into natural-language rules, and MemSkill learns task-agnostic skill memories that transfer to unseen tasks. In line with this paradigm, our work applies TextGrad to evolve the fact extraction and entity profile construction prompts, achieving lifelong adaptability without tuning parameters. Compared with skill or rule based externalizations that target the agent's action space, prompt-level evolution directly reshapes how raw experience is parsed into memory, which is particularly suited to memory systems whose behavior is largely determined by the extraction and synthesis prompts rather than by a fixed policy network.
终身演化智能体。 终身演化已经成为 LLM 智能体的一项关键能力,这类智能体需要从长期积累经验中持续改进。 一条重要路线将记忆管理表述为强化学习问题:MemAgent 将长上下文 LLM 重塑为多对话记忆智能体,MemBuilder 用归因密集奖励强化记忆构建,AgentFold 学习长程网页智能体的主动上下文管理,MemGen 将生成式潜在记忆编织进自演化智能体,而 MEM1 联合协同记忆和推理以实现高效执行。 这些方法虽然有效,但都需要基于 RL 的参数更新,这会扰动原始预训练权重,带来大量训练成本,并且在只能访问 API 的模型场景中并不现实。 受这些限制启发,另一条互补路线追求在不改变模型参数的情况下实现终身演化:Voyager 维护可执行代码技能库,ExpeL 将跨任务经验蒸馏为自然语言规则,MemSkill 学习可迁移到未见任务的任务无关技能记忆。 与这一范式一致,TriMem 应用 TextGrad 来演化事实抽取和实体画像构建提示,在不调参的情况下实现终身适应。 与面向智能体动作空间的技能或规则外化相比,提示级演化直接重塑原始经验被解析为记忆的方式,因此特别适合那些行为主要由抽取和合成提示,而非固定策略网络决定的记忆系统。
6. Conclusion
In this work, we revisit the design of memory systems for LLM agents and identify three concrete limitations of the prevailing extracted fact based paradigm: lossy storage, shallow reasoning, and suboptimal prompts under heterogeneous dialogue styles. Motivated by these findings, we propose TriMem, which maintains three coexisting representation granularities, including verbatim dialogues for storage fidelity, atomic facts for retrieval efficiency and progressively synthesized profiles for deep reasoning. TextGrad-based prompt optimization is further employed to evolve the extraction and profile construction prompts from accumulated experience, enabling lifelong adaptation without modifying the underlying model parameters and thus remaining applicable to API-only LLMs. Extensive experiments on LoCoMo and PerLTQA across various LLMs confirm the effectiveness of our method. We hope TriMem can bring new insights for future researches on agent memory system.
本文重新审视 LLM 智能体记忆系统的设计,并识别出当前基于抽取事实范式的三个具体限制:有损存储、浅层推理,以及异质对话风格下的次优提示。 受这些发现启发,作者提出 TriMem,它维护三种共存的表示粒度,包括用于存储保真度的逐字对话、用于检索效率的原子事实,以及用于深度推理的渐进合成画像。 系统进一步采用基于 TextGrad 的提示优化,从累积经验中演化抽取和画像构建提示,在不修改底层模型参数的情况下实现终身适应,因此也适用于仅 API 可访问的 LLM。 在 LoCoMo 和 PerLTQA 上跨多种 LLM 进行的大量实验确认了方法有效性。 作者希望 TriMem 能为未来智能体记忆系统研究带来新的启发。