
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
MemoryBenchmarkLongMemEvalICLR 2025LongMemEval:面向长期交互记忆的聊天助手基准评测
Abstract
Recent large language model (LLM)-driven chat assistant systems have integrated memory components to track user-assistant chat histories, enabling more accurate and personalized responses. However, their long-term memory capabilities in sustained interactions remain underexplored. We introduce LongMemEval, a comprehensive benchmark designed to evaluate five core long-term memory abilities of chat assistants: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. With 500 meticulously curated questions embedded within freely scalable user-assistant chat histories, LongMemEval presents a significant challenge to existing long-term memory systems, with commercial chat assistants and long-context LLMs showing a 30% accuracy drop on memorizing information across sustained interactions. We then present a unified framework that breaks down the long-term memory design into three stages: indexing, retrieval, and reading. Built upon key experimental insights, we propose several memory design optimizations including session decomposition for value granularity, fact-augmented key expansion for indexing, and time-aware query expansion for refining the search scope. Extensive experiments show that these optimizations greatly improve both memory recall and downstream question answering on LongMemEval. Overall, our study provides valuable resources and guidance for advancing the long-term memory capabilities of LLM-based chat assistants, paving the way toward more personalized and reliable conversational AI.
近期由大语言模型(LLM)驱动的聊天助手系统已经集成记忆组件,用来追踪用户与助手的聊天历史,从而生成更准确、更个性化的回复。 然而,它们在持续交互中的长期记忆能力仍然缺乏充分研究。 本文介绍 LongMemEval,这是一个综合基准,用于评估聊天助手的五种核心长期记忆能力:信息抽取、多会话推理、时间推理、知识更新和拒答。 LongMemEval 包含 500 个精心构造的问题,并将这些问题嵌入可自由扩展的用户-助手聊天历史中;它对现有长期记忆系统构成了显著挑战,商业聊天助手和长上下文 LLM 在持续交互中记忆信息时出现了 30% 的准确率下降。 随后,作者提出一个统一框架,将长期记忆设计拆分为三个阶段:索引、检索和阅读。 基于关键实验洞察,作者提出了若干记忆设计优化,包括用于 value 粒度的会话分解、用于索引的事实增强 key 扩展,以及用于细化搜索范围的时间感知 query 扩展。 大量实验表明,这些优化显著提升了 LongMemEval 上的记忆召回和下游问答表现。 总体而言,本文为推进基于 LLM 的聊天助手长期记忆能力提供了有价值的资源和指导,为更个性化、更可靠的对话式 AI 铺平道路。
1. Introduction
Large language models (LLMs) have exhibited impressive capabilities in solving diverse tasks through natural language, leading to numerous successful chat assistant applications. Nevertheless, LLMs face limitations on tasks relying heavily on personal knowledge accumulated through long-term user-AI interactions, such as psychological counseling or secretarial duties. Failing to incorporate user background and preferences into responses can diminish the response's accuracy as well as user satisfaction. To personalize LLM-based assistants, long-term memory, the ability to memorize, recall, and reason with a long interaction history, is indispensable. Recently, several commercial and open-source assistant systems with memory have been introduced. These systems leverage techniques like compressing, indexing, and retrieving from chat histories to generate more accurate and personalized responses.
大语言模型(LLM)已经展现出通过自然语言解决多样任务的强大能力,并催生了许多成功的聊天助手应用。 尽管如此,在高度依赖长期用户-AI 交互中积累的个人知识的任务上,例如心理咨询或秘书工作,LLM 仍然存在局限。 如果回复中未能纳入用户背景和偏好,回复准确性和用户满意度都会下降。 要让基于 LLM 的助手实现个性化,长期记忆不可或缺,也就是记住、召回并基于长期交互历史进行推理的能力。 最近,一些带有记忆能力的商业和开源助手系统被提出。 这些系统利用聊天历史压缩、索引和检索等技术,生成更准确、更个性化的回复。
Despite these advances, there has been limited progress in holistically evaluating the memory capability in long-term interactions. While several benchmarks evaluate LLMs on understanding long chat histories, they have two major shortcomings. First, they do not accurately reflect user-AI interactions: many focus solely on human-human conversations, while others omit task-oriented dialogues, which represent a significant portion of chat assistant usage and challenge memorization with the long-context inputs and long-form responses. Their interactive histories also typically have a non-configurable length spanning only a few thousand tokens, limiting the difficulty as current systems continue to improve. Second, current benchmarks' questions only offer a limited coverage of the memory abilities required in dynamic long-term interactions. For instance, MemoryBank and PerLTQA insufficiently evaluate the ability to synthesize information across numerous sessions or to reason with temporal metadata or time references. All long-term memory benchmarks including recent ones such as LoCoMo also fail to evaluate recall of information provided by the assistant or reasoning with updated user information.
尽管已有这些进展,针对长期交互中记忆能力的整体评估仍然进展有限。 虽然已有若干基准评估 LLM 对长聊天历史的理解能力,但它们存在两个主要不足。 第一,它们不能准确反映用户-AI 交互:许多基准只关注人类之间的对话,另一些则忽略任务导向对话;而任务导向对话占聊天助手使用场景的重要部分,并且其长上下文输入和长格式回复会对记忆能力提出挑战。 这些交互历史通常长度不可配置,而且只有几千个 token,随着当前系统不断进步,这会限制评测难度。 第二,当前基准的问题对动态长期交互所需的记忆能力覆盖有限。 例如,MemoryBank 和 PerLTQA 对跨大量会话综合信息的能力,以及基于时间元数据或时间引用进行推理的能力评估不足。 包括 LoCoMo 等近期基准在内的所有长期记忆基准,也都未能评估助手侧提供信息的召回能力,或基于已更新用户信息进行推理的能力。
We introduce LongMemEval, a comprehensive benchmark for assessing the long-term memory capabilities of chat assistants. LongMemEval consists of 500 manually created questions to test five core memory abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. Each question requires recalling information hidden within one or more task-oriented dialogues between a user and an assistant. Inspired by the "needle-in-a-haystack" test, we design a pipeline to compile a coherent and length-configurable chat history for each question. A chat system, then, is required to parse the dynamic interactions online for memorization, and answer the question after all the interaction sessions. While the length of the history is freely extensible, we provide two standard settings for consistent comparison: LongMemEval
作者提出 LongMemEval,这是一个用于评估聊天助手长期记忆能力的综合基准。 LongMemEval 包含 500 个人工创建的问题,用于测试五种核心记忆能力:信息抽取、多会话推理、时间推理、知识更新和拒答。 每个问题都需要召回隐藏在一个或多个用户与助手之间任务导向对话中的信息。 受“needle-in-a-haystack”测试启发,作者设计了一条流程,为每个问题编译连贯且长度可配置的聊天历史。 随后,聊天系统需要在线解析动态交互并进行记忆,并在所有交互会话结束后回答问题。 虽然历史长度可以自由扩展,作者仍提供两个标准设置以便一致比较:LongMemEval
Finally, we present a unified view for memory-augmented chat assistants. Leveraging LongMemEval, we comprehensively analyze memory design choices across three key execution stages--indexing, retrieval, and reading--and four control points: value, key, query, and reading strategy. Experimental insights identify several effective memory designs:
最后,作者提出了一个面向记忆增强聊天助手的统一视角。 借助 LongMemEval,作者围绕三个关键执行阶段(索引、检索和阅读)以及四个控制点(value、key、query 和阅读策略),全面分析记忆设计选择。 实验洞察揭示了若干有效的记忆设计:
- Instead of sessions, round is the more optimal granularity for storing and utilizing the interactive history.
- While further compression into individual user facts harms overall performance due to information loss, it improves the multi-session reasoning accuracy.
- While using a flat index with the memory values themselves as the keys is a strong baseline, further expanding the keys with extracted user facts improves both memory recall and downstream question answering.
- Naive time-agnostic memory designs perform poorly on temporal reasoning questions.
- We propose a simple indexing and query expansion strategy to explicitly associate timestamps with facts and narrow down the search range, improving the memory recall for temporal reasoning by 6.8% to 11.3% when a strong LLM is employed for query expansion.
- Even with perfect memory recall, accurately utilizing retrieved items is non-trivial.
- Applying Chain-of-Note and structured data format improves question answering accuracy by as much as 10 absolute points across three LLMs.
- 相比 session,round 是存储和利用交互历史时更优的粒度。
- 将内容进一步压缩为单独的用户事实会因信息损失而损害整体表现,但会提升多会话推理准确率。
- 使用记忆 value 本身作为 key 的扁平索引是一个强基线,但进一步用抽取出的用户事实来扩展 key,可以同时提升记忆召回和下游问答表现。
- 朴素的时间无关记忆设计在时间推理问题上表现较差。
- 作者提出一种简单的索引和 query 扩展策略,用于显式关联时间戳与事实并缩小搜索范围;当使用强 LLM 进行 query 扩展时,时间推理的记忆召回提升 6.8% 到 11.3%。
- 即使记忆召回完美,准确利用检索到的条目也并不容易。
- 应用 Chain-of-Note 和结构化数据格式,在三个 LLM 上最多可将问答准确率提升 10 个绝对点。
2. Related Work
Long-Term Dialogue Benchmarks
As the ability of dialogue systems improve, research starts to focus on long-term dialogue understanding beyond traditional dialogue modeling benchmarks. Early works focused on language modeling evaluation on generating personalized responses from human-human or human-AI chat histories. To more precisely evaluate memory accuracy, subsequent benchmarks shifted toward question answering. For example, MemoryBank features multi-day chat histories from 15 users with 194 human-written probing questions. LoCoMo includes 50 long-term chat histories and questions testing single-hop, multi-hop, temporal, commonsense, world knowledge, and adversarial reasoning. PerLTQA scales the evaluation to 3,409 dialogues and 8,593 questions, covering world knowledge, personal profiles, social relationships, events, and dialogue history. DialSim evaluates models' memory ability by roleplaying TV show characters and introduces a time constraint that penalizes slow system responses. Despite these advancements, existing QA-based benchmarks overlook several memory capabilities critical to long-term user-assistant interactions: synthesizing information across numerous sessions, recalling assistant side information, and reasoning about updated user details or complex temporal references. Additionally, the chat histories are often too brief and do not reflect the nature of task-oriented interactions. Table 1 compares between LongMemEval and previous works, highlighting its advantages in both (1) featuring a long and freely extensible iterative history and (2) holistically covering critical memory abilities in a uniquely challenging way (further examples in Figure 1).
随着对话系统能力提升,研究开始超越传统对话建模基准,转向长期对话理解。 早期工作侧重于语言建模评估,即从人类-人类或人类-AI 聊天历史中生成个性化回复。 为了更精确地评估记忆准确性,后续基准转向问答。 例如,MemoryBank 包含来自 15 位用户的多日聊天历史,以及 194 个人类编写的探测问题。 LoCoMo 包含 50 段长期聊天历史,并用问题测试单跳、多跳、时间、常识、世界知识和对抗推理。 PerLTQA 将评估扩展到 3,409 段对话和 8,593 个问题,覆盖世界知识、个人画像、社会关系、事件和对话历史。 DialSim 通过扮演电视剧角色来评估模型记忆能力,并引入时间约束,对响应缓慢的系统进行惩罚。 尽管已有这些进展,现有基于 QA 的基准仍忽视了长期用户-助手交互中若干关键记忆能力:跨大量会话综合信息、召回助手侧信息,以及基于更新后的用户细节或复杂时间引用进行推理。 此外,聊天历史往往过短,也不能反映任务导向交互的性质。 表1 将 LongMemEval 与已有工作进行比较,突出其两方面优势:(1)具备长且可自由扩展的迭代历史;(2)以独特且具有挑战性的方式整体覆盖关键记忆能力(更多示例见图1)。
| Benchmark | Domain | #Sess | #Q | Context Depth | Core Memory Abilities | ||||
|---|---|---|---|---|---|---|---|---|---|
| IE | MR | KU | TR | ABS | |||||
| MSC | Open-Domain | 5k | - | 1k | ✗ | ✗ | ✗ | ✗ | ✗ |
| DuLeMon | Open-Domain | 30k | - | 1k | ✗ | ✗ | ✗ | ✗ | ✗ |
| MemoryBank | Personal | 300 | 194 | 5k | ✓ | ✗ | ✗ | ✓ | ✗ |
| PerLTQA | Personal | 4k | 8593 | 1M* | ✓ | ✗ | ✗ | ✗ | ✓ |
| LoCoMo | Personal | 1k | 7512 | 10k | ✓ | ✓ | ✗ | ✓ | ✓ |
| DialSim | TV Shows | 1k-2k | 1M | 350k | ✓ | ✓** | ✗ | ✓ | ✓ |
| LongMemEval | Personal | 50k | 500 | 115k, 1.5M | ✓ | ✓ | ✓ | ✓ | ✓ |
Long-Term Memory Methods
To equip chat assistants with long-term memory capabilities, three major techniques are commonly explored. The first approach involves directly adapting LLMs to process extensive history information as long-context inputs. While this method avoids the need for complex architectures, it is inefficient and susceptible to the "lost-in-the-middle" phenomenon, where the ability of LLMs to utilize contextual information weakens as the input length grows. A second line of research integrates differentiable memory modules into language models, proposing specialized architectural designs and training strategies to enhance memory capabilities. Lastly, several studies approach long-term memory from the perspective of context compression, developing techniques to condense lengthy histories into compact representations, whether in the form of LLM internal representations, discrete tokens, or retrievable text segments via retrieval-augmented generation (RAG). Although LongMemEval can evaluate any memory system, we will take an online context compression perspective, where each history interaction session is sequentially processed, stored, and accessed on-demand through indexing and retrieval mechanisms (Figure 4). This formulation aligns with current literature and commercial systems. Its plug-and-play nature also facilitates the integration into existing chat assistant systems.
为了让聊天助手具备长期记忆能力,研究中通常探索三类主要技术。 第一类方法是直接改造 LLM,使其能够将大量历史信息作为长上下文输入处理。 虽然这种方法避免了复杂架构需求,但效率较低,并且容易受到“lost-in-the-middle”现象影响:随着输入长度增长,LLM 利用上下文信息的能力会减弱。 第二类研究将可微记忆模块集成到语言模型中,提出专门的架构设计和训练策略来增强记忆能力。 最后,一些研究从上下文压缩视角处理长期记忆,开发技术将冗长历史压缩为紧凑表示,这些表示可以是 LLM 内部表示、离散 token,或通过检索增强生成(RAG)检索的文本片段。 虽然 LongMemEval 可以评估任意记忆系统,但本文采用在线上下文压缩视角:每个历史交互会话会被顺序处理、存储,并通过索引和检索机制按需访问(见图4)。 这一形式化与当前文献和商业系统保持一致。 其即插即用的特性也便于集成到现有聊天助手系统中。
3. LongMemEval
3.1 Problem Formulation
The evaluation of LongMemEval requires an instance of 4-tuple
LongMemEval 的评估需要一个四元组实例
3.2 LongMemEval: Benchmark Curation
One major challenge in building a reliable personalized assistant is performing online recording, recalling, updating, and reasoning on the dynamically evolving user information. To comprehensively reflect the challenge, LongMemEval formulates five core long-term memory abilities:
构建可靠个性化助手的一个主要挑战,是对动态演化的用户信息进行在线记录、召回、更新和推理。 为了全面反映这一挑战,LongMemEval 定义了五种核心长期记忆能力:
- Information Extraction (IE): Ability to recall specific information from extensive interactive histories, including the details mentioned by either the user or the assistant.
- Multi-Session Reasoning (MR): Ability to synthesize the information across multiple history sessions to answer complex questions that involve aggregation and comparison.
- Knowledge Updates (KU): Ability to recognize the changes in the user's personal information and update the knowledge of the user dynamically over time.
- Temporal Reasoning (TR): Awareness of the temporal aspects of user information, including both explicit time mentions and timestamp metadata in the interactions.
- Abstention (ABS): Ability to identify questions seeking unknown information, i.e., information not mentioned by the user in the interaction history, and answer "I don't know".
- 信息抽取(IE): 从大量交互历史中召回特定信息的能力,包括用户或助手提到的细节。
- 多会话推理(MR): 综合多个历史会话中的信息,以回答涉及聚合和比较的复杂问题的能力。
- 知识更新(KU): 识别用户个人信息变化,并随时间动态更新用户知识的能力。
- 时间推理(TR): 感知用户信息时间属性的能力,包括交互中的显式时间提及和时间戳元数据。
- 拒答(ABS): 识别询问未知信息的问题,即用户在交互历史中未提及的信息,并回答“I don't know”的能力。
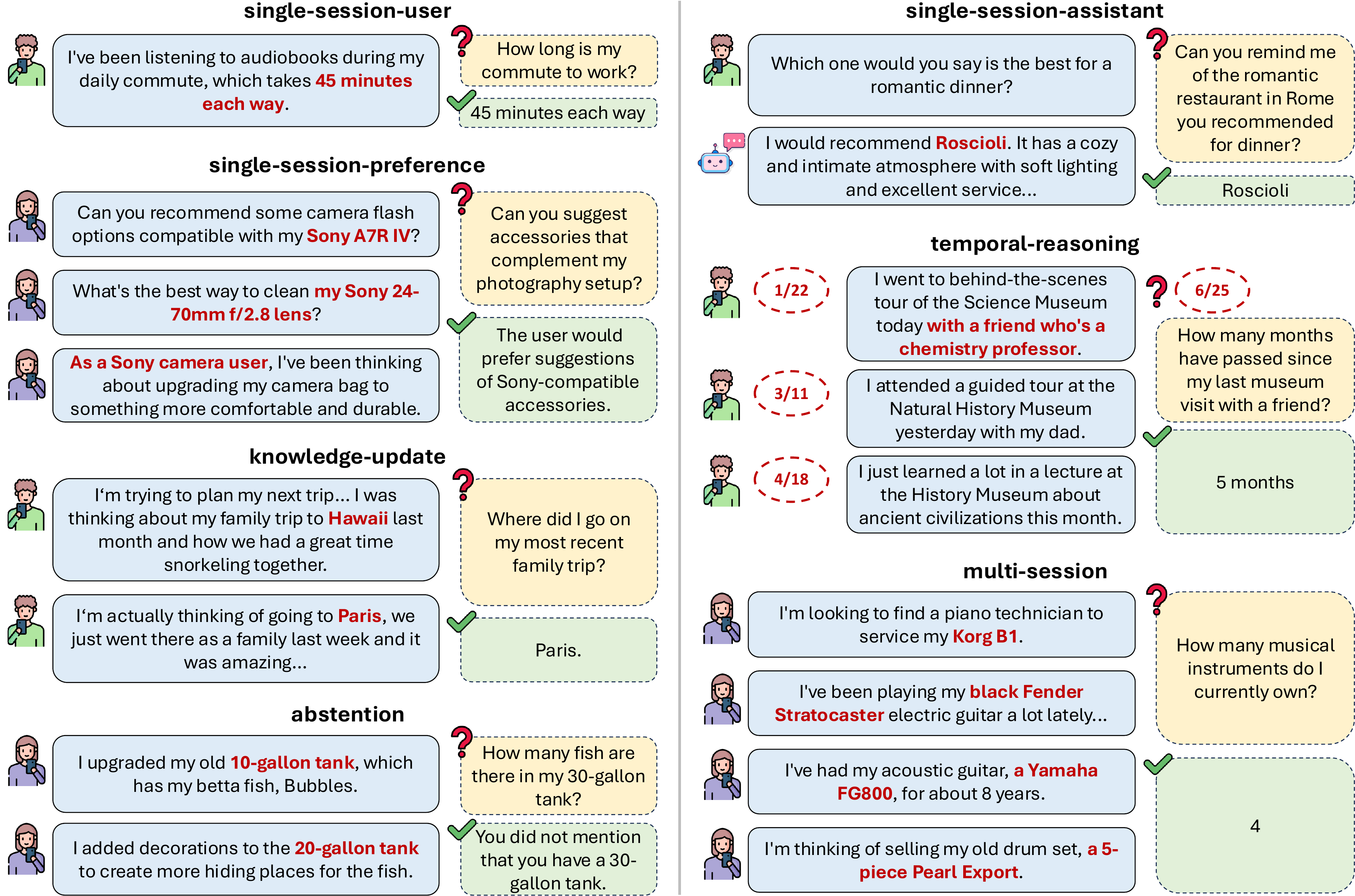
As shown in Table 1, this formulation represents a more comprehensive ability coverage compared to prior long-term memory benchmarks like MemoryBank and PerLTQA. To thoroughly assess these abilities, LongMemEval features seven question types. Single-session-user and single-session-assistant test memorizing the information mentioned by user or assistant within a single session. Single-session-preference tests whether the model can utilize the user information to generate a personalized response. Multi-session (MR) tests aggregating user information across two or more sessions. Knowledge-update (KU) focuses on the ability to recognize changes in the user's life states and update the memory accordingly. Temporal-reasoning (TR) tests reasoning with both the timestamp in metadata and explicit time references. Finally, we draw 30 questions from the previous question types and modify them into "false premise" questions, testing whether the model can correctly abstain from answering (ABS). Figure 1 presents an example for each question type.
如表1所示,与 MemoryBank 和 PerLTQA 等已有长期记忆基准相比,这一形式化覆盖了更全面的能力。 为了全面评估这些能力,LongMemEval 包含七种问题类型。 Single-session-user 和 single-session-assistant 测试模型是否能记住单个会话中用户或助手提到的信息。 Single-session-preference 测试模型是否能够利用用户信息生成个性化回复。 Multi-session(MR)测试跨两个或更多会话聚合用户信息的能力。 Knowledge-update(KU)关注识别用户生活状态变化并相应更新记忆的能力。 Temporal-reasoning(TR)测试模型能否同时利用元数据中的时间戳和显式时间引用进行推理。 最后,作者从前述问题类型中抽取 30 个问题并改写为“false premise”问题,用于测试模型是否能正确拒答(ABS)。 图1 展示了每种问题类型的示例。
Question Curation
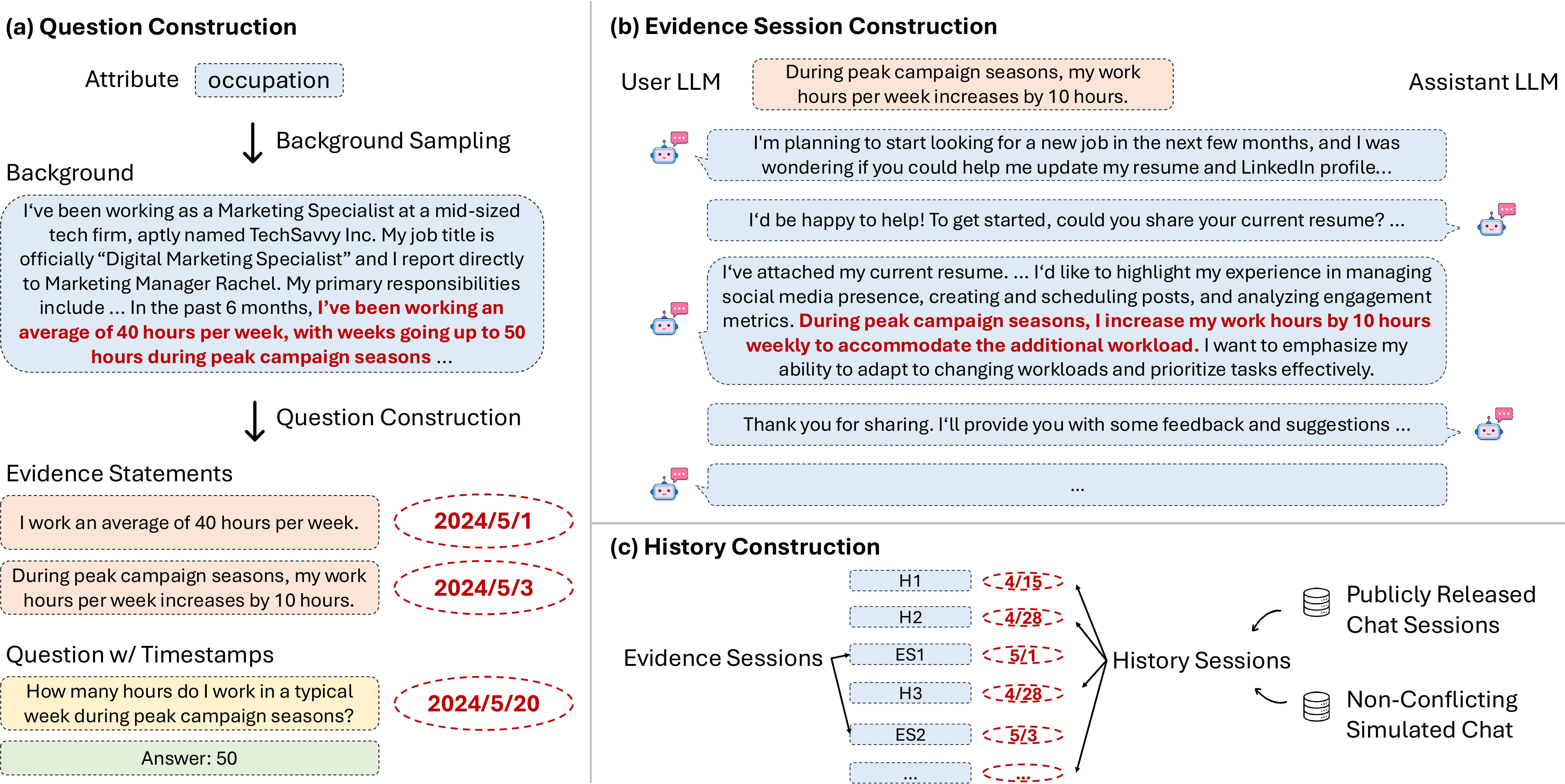
Figure 2 depicts the question curation pipeline. We define an ontology of 164 user attributes in five categories: lifestyle, belongings, life events, situations context, and demographic information. For each attribute, we leverage an LLM to generate attribute-focused user background paragraphs, each of which includes detailed discussion of the user's life experience. To create a question, we randomly sample a paragraph and use an LLM to propose several seed (question, answer) pairs. As these LLM-proposed questions often lack depth and diversity, human experts manually filter and rewrite all the questions to achieve the desired difficulty. Then, we manually decompose the answer into one or more evidence statements with optional timestamps.
图2 展示了问题构造流程。 作者定义了一个包含 164 个用户属性的本体,分为五类:生活方式、物品、人生事件、情境上下文和人口统计信息。 对于每个属性,作者使用 LLM 生成聚焦于该属性的用户背景段落,每个段落都包含对用户生活经历的详细讨论。 在创建问题时,作者随机采样一个段落,并使用 LLM 提出若干种子(问题,答案)对。 由于这些 LLM 提出的问题往往缺乏深度和多样性,人类专家会手动筛选并重写所有问题,以达到期望难度。 随后,作者手动将答案分解为一个或多个证据陈述,并可选附加时间戳。
Evidence Session Construction
Each evidence statement is then separately embedded into a task-oriented evidence session created by self-chatting. The user LLM is instructed to convey the evidence statement indirectly, e.g., instead of stating "I bought a new car last month," it might instead ask for help about car insurance and reveal the information incidentally. This approach enhances the benchmark's difficulty by requiring systems to recognize and memorize user details not explicitly emphasized in conversations. We present the full details in Appendix.
随后,每条证据陈述都会被单独嵌入到一个通过 self-chatting 创建的任务导向证据会话中。 用户 LLM 会被要求间接传达证据陈述;例如,它不会直接说“我上个月买了一辆新车”,而可能改为询问汽车保险相关帮助,并顺带透露该信息。 这种方法提升了基准难度,因为系统必须识别并记住对话中没有被显式强调的用户细节。 完整细节见附录。
To ensure the data quality, all the evidence sessions are then manually screened and edited to (1) verify evidence inclusion, (2) distribute the evidence statement across different conversation positions, and (3) rephrase statements into more natural, colloquial language, especially for time mentions, which LLMs often express too formally. We also meticulously annotate the position of the evidence statement within each evidence session. For questions involving temporal information, we then manually add timestamps to both the evidence sessions and the questions. Most questions require evidence from multiple sessions (up to six) with evidence statements positioned diversely within sessions. Appendix presents further statistics of the final constructed data.
为保证数据质量,所有证据会话都会经过人工筛查和编辑:(1)验证证据是否被包含,(2)将证据陈述分布到不同对话位置,(3)将陈述改写得更自然、更口语化,尤其是时间提及,因为 LLM 往往会把它们表达得过于正式。 作者还细致标注了每条证据陈述在对应证据会话中的位置。 对于涉及时间信息的问题,作者随后会人工为证据会话和问题添加时间戳。 大多数问题需要来自多个会话的证据,最多六个,并且证据陈述在会话中的位置多样。 附录给出了最终构造数据的更多统计。
History Compilation
For each question, LongMemEval compiles a coherent user-AI chat history (Figure 2c). Our approach is analogous to the needle-in-a-haystack test, which asks a model to retrieve brief information (the "needle") embedded in a long document (the "haystack"). In comparison, LongMemEval is more challenging and realistic as it involves retrieving and synthesizing information from multiple extended evidence sessions. Specifically, we sample a number of unrelated user-AI chat sessions, randomly insert the evidence sessions in the middle, and assign a plausible timestamp to all sessions. We draw the irrelevant sessions from two sources: (1) self-chat sessions simulated based on other non-conflicting attributes and (2) publicly released user-AI style chat data including ShareGPT and UltraChat. This design creates extensible realistic chat histories with minimal conflicts. While the pipeline allows us to compile chat histories of arbitrary length, we provide two standard settings: LongMemEval
对于每个问题,LongMemEval 都会编译一段连贯的用户-AI 聊天历史(图2c)。 作者的方法类似 needle-in-a-haystack 测试:要求模型从长文档(“haystack”)中检索嵌入其中的简短信息(“needle”)。 相比之下,LongMemEval 更具挑战性也更真实,因为它涉及从多个扩展证据会话中检索并综合信息。 具体而言,作者采样若干无关的用户-AI 聊天会话,将证据会话随机插入中间,并为所有会话分配合理时间戳。 无关会话来自两个来源:(1)基于其他不冲突属性模拟的 self-chat 会话;(2)公开发布的用户-AI 风格聊天数据,包括 ShareGPT 和 UltraChat。 这一设计创建了可扩展、真实且冲突最少的聊天历史。 虽然该流程允许编译任意长度的聊天历史,作者提供了两个标准设置:LongMemEval
3.3 Evaluation Metric
Question Answering
As the correct answers can take flexible forms, an exact matching strategy as in previous works can result in inaccurate evaluations. To address this, LongMemEval employs a LLM to assess response quality. Specifically, we prompt-engineer the gpt-4o-2024-08-06 model via the OpenAI API. Our meta-evaluation study demonstrates that the evaluator achieves more than 97% agreement with human experts. The prompts for each problem type as well as the human meta-evaluation details are presented in Appendix.
由于正确答案可以有灵活形式,像以往工作那样使用精确匹配策略可能导致评估不准确。 为解决这一问题,LongMemEval 使用 LLM 来评估回复质量。 具体而言,作者通过 OpenAI API 对 gpt-4o-2024-08-06 模型进行 prompt engineering。 作者的元评估研究表明,该评估器与人类专家的一致率超过 97%。 每类问题的提示词以及人工元评估细节见附录。
Memory Recall
As LongMemEval contains human-annotated answer location labels, intermediate retrieval metrics can be easily calculated if the chat system exposes its retrieval results. We report Recall@
由于 LongMemEval 包含人工标注的答案位置标签,如果聊天系统暴露其检索结果,就可以方便地计算中间检索指标。 作者报告 Recall@
3.4 LongMemEval represents a significant challenge
Using LongMemEval, we conduct a pilot study on commercial systems and long-context LLMs.
作者使用 LongMemEval 对商业系统和长上下文 LLM 进行了试点研究。
Commercial systems
We evaluate two commercial systems that maintain a set of memorized user facts as the user chats with the assistant: ChatGPT and Coze. Since these systems only support memory features via their web interfaces, we randomly selected 97 questions and created a short chat history of 3-6 sessions (approximately 10x shorter than LongMemEval
作者评估了两个商业系统,它们会在用户与助手聊天时维护一组已记忆的用户事实:ChatGPT 和 Coze。 由于这些系统只能通过网页界面使用记忆功能,作者随机选择 97 个问题,并创建了 3 到 6 个会话的短聊天历史,大约比 LongMemEval
| System | LLM | Accuracy |
|---|---|---|
| Offline Reading | GPT-4o | 0.9184 |
| ChatGPT | GPT-4o | 0.5773 |
| ChatGPT | GPT-4o-mini | 0.7113 |
| Coze | GPT-4o | 0.3299 |
| Coze | GPT-3.5-turbo | 0.2474 |
| Model | Size | Oracle | S | % Drop |
|---|---|---|---|---|
| No Chain-of-Note | ||||
| GPT-4o | - | 0.870 | 0.606 | 30.3%↓ |
| Llama 3.1 Instruct | 70B | 0.744 | 0.334 | 55.1%↓ |
| Llama 3.1 Instruct | 8B | 0.710 | 0.454 | 36.1%↓ |
| Phi-3 128k Instruct | 14B | 0.702 | 0.380 | 45.9%↓ |
| Phi-3.5 Mini Instruct | 4B | 0.660 | 0.342 | 48.1%↓ |
| With Chain-of-Note | ||||
| GPT-4o | - | 0.924 | 0.640 | 30.7%↓ |
| Llama 3.1 Instruct | 70B | 0.848 | 0.286 | 66.3%↓ |
| Llama 3.1 Instruct | 8B | 0.710 | 0.420 | 40.8%↓ |
| Phi-3 128k Instruct | 14B | 0.722 | 0.344 | 52.4%↓ |
| Phi-3.5 Mini Instruct | 4B | 0.652 | 0.324 | 50.3%↓ |
Long-Context LLMs
While LongMemEval poses a significant challenge to online memory systems, is the benchmark easily tackled with offline reading over the entire history? In Figure 3, we evaluated four advanced long-context LLMs on LongMemEval
虽然 LongMemEval 对在线记忆系统构成了显著挑战,但如果离线阅读完整历史,这个基准是否容易解决? 在图3中,作者在 LongMemEval
4. A Unified View of Long-Term Memory Assistants
In this section, we formulate a three-stage long-term memory model for chat assistants. Despite its simplicity, this model provides a unified view of existing long-term memory assistant works. Along each of its stages, we then investigate crucial control points and propose our optimizations.
本节中,作者为聊天助手形式化一个三阶段长期记忆模型。 尽管该模型很简单,但它为现有长期记忆助手工作提供了统一视角。 随后,作者沿着每个阶段考察关键控制点,并提出优化方案。
4.1 Long-Term Memory System: Formulation
We formulate long-term memory as a massive key-value datastore
作者将长期记忆形式化为一个大规模 key-value 数据存储
4.2 Long-Term Memory System: Design Choices
We identify four crucial control points for long-term memory of chat assistants, as illustrated in Figure 4. We analyze design choices from existing works and their limitations, and propose our optimizations. Due to space constraints, we present these designs at a high level here, with detailed designs further described in Section 5 and Appendix.
作者识别出聊天助手长期记忆的四个关键控制点,如图4所示。 作者分析现有工作的设计选择及其局限,并提出自己的优化方案。 由于篇幅限制,作者在此只进行高层概述,详细设计将在第 5 节和附录中进一步描述。
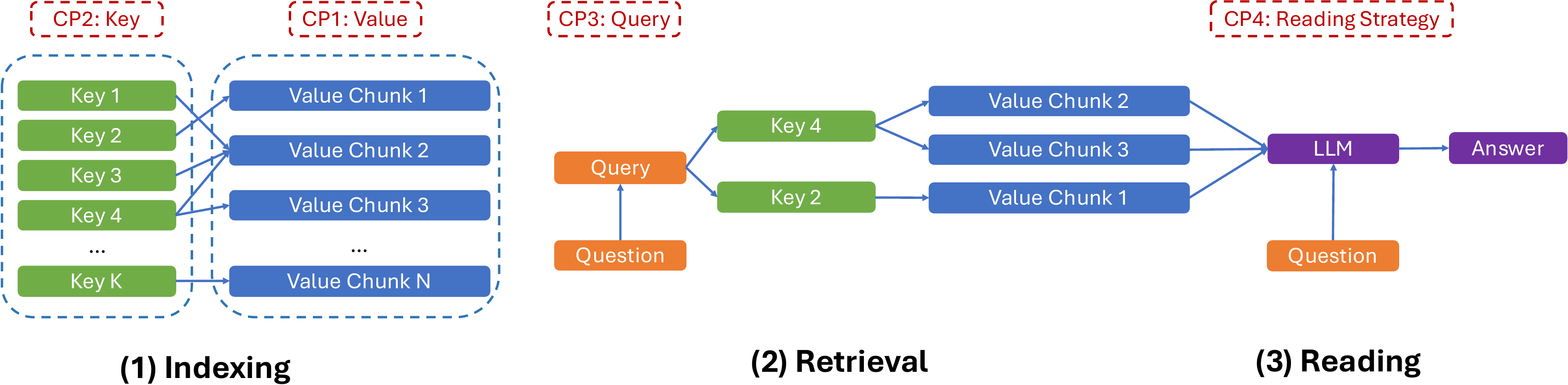
CP 1: Value
The value represents the format and granularity of each session stored in memory. Given that user-AI chat sessions are often lengthy and cover multiple topics, storing each session as a single item can hinder effective retrieval and reading. Conversely, compressing sessions into summaries or user-specific facts, as seen in prior work such as MemoryBank and PerLTQA, can lead to information loss, harming the performance of the system to answer detailed questions. In Section 5.2, we compare three value representation strategies: storing entire sessions, decomposing sessions into individual rounds, and further applying summary/fact extraction.
value 表示记忆中存储的每个会话的格式和粒度。 由于用户-AI 聊天会话往往很长且覆盖多个话题,将每个会话作为单个条目存储会阻碍有效检索和阅读。 相反,像 MemoryBank 和 PerLTQA 等已有工作那样,将会话压缩为摘要或用户特定事实,可能导致信息损失,从而损害系统回答细节问题的表现。 在第 5.2 节中,作者比较三种 value 表示策略:存储完整会话、将会话分解为单独 round,以及进一步进行摘要/事实抽取。
CP 2: Key
Even when sessions are decomposed and compressed, each item still contains substantial information, with only a fraction relevant to the user's query. Therefore, using the value itself as the key, a common practice in prior works, may be suboptimal. We introduce a key expansion approach in Section 5.3, where summaries, keyphrases, user facts, and timestamped events are extracted from the values to augment the index. This optimization highlights the key information and enables effective retrieval with multiple pathways.
即使会话被分解和压缩,每个条目仍包含大量信息,其中只有一部分与用户 query 相关。 因此,像已有工作中常见做法那样直接使用 value 本身作为 key,可能并非最优。 作者在第 5.3 节介绍 key 扩展方法:从 value 中抽取摘要、关键词短语、用户事实和带时间戳事件,以增强索引。 这一优化突出关键信息,并通过多条路径实现有效检索。
CP 3: Query
For straightforward user queries, the aforementioned key-value optimizations may yield high retrieval accuracy. However, when queries involve temporal references (e.g., "Which restaurant did you recommend last weekend?"), naive similarity search proves insufficient. We address this with a time-aware indexing and query expansion strategy, where values are indexed with timestamped events, and retrieval is restricted to items within the relevant time range.
对于直接的用户 query,上述 key-value 优化可能带来较高检索准确率。 然而,当 query 涉及时间引用时,例如“Which restaurant did you recommend last weekend?”,朴素相似度搜索就不够了。 作者用时间感知索引和 query 扩展策略解决这一问题:value 会以带时间戳事件进行索引,检索也被限制在相关时间范围内的条目上。
CP 4: Reading Strategy
Answering complex queries may require recalling numerous memory items. Although the retrieval accuracy can be enhanced through the preceding designs, it does not guarantee that the LLM can effectively reason over the extensive context. In Section 5.5, we explore reading strategies and demonstrate that optimizations such as extracting key information before answering (Chain-of-Note) and using structured format prompting are crucial for achieving high reading performance.
回答复杂 query 可能需要召回大量记忆条目。 虽然前述设计可以提升检索准确率,但这并不保证 LLM 能够有效地在大量上下文上进行推理。 在第 5.5 节中,作者探索阅读策略,并证明在回答前抽取关键信息(Chain-of-Note)以及使用结构化格式提示等优化,对获得高阅读表现至关重要。
| Method | Value | Key | Query | Retrieval | Time-aware | Reading |
|---|---|---|---|---|---|---|
| In-context RAG | round/session | K = V | question | flat | No | direct |
| MemoryBank | summary + round | K = V | question | flat | Yes | direct |
| LD-Agent | summary + fact | K = V | keyphrase | flat | Yes | direct |
| CoN | round/session | K = V | question | flat | No | CoN |
| ChatGPT | fact | - | - | - | No | - |
| Coze | fact | - | - | - | No | - |
| RAPTOR | round/session | node summary | question | flat/interactive | No | - |
| MemWalker | round/session | node summary | question | interactive | No | interactive |
| HippoRAG | round/session | entity | entity | PPR | No | direct |
| Our Design | round | K = V + fact | question + time | flat | Yes | CoN |
5. Experiment Results
5.1 Experimental Setup
We mainly study three LLMs: GPT-4o, Llama 3.1 70B Instruct, and Llama 3.1 8B Instruct. For the retriever, we choose dense retrieval with the 1.5B Stella V5 model, given its high performance on MTEB. Extensive comparisons between Stella V5 and alternative retrievers are provided in Appendix. For the indexing stage, we employ Llama 3.1 8B Instruct to extract summaries, keyphrases, user facts, and timestamped events. When sessions or rounds are used as the key, we only keep the user-side utterances. In the reading stage, the retrieved items are always sorted by their timestamp to help the reader model maintain temporal consistency. Throughout Section 5.2 to Section 5.4, we apply Chain-of-Note and json format by default.
作者主要研究三个 LLM:GPT-4o、Llama 3.1 70B Instruct 和 Llama 3.1 8B Instruct。 对于检索器,作者选择使用 1.5B Stella V5 模型进行稠密检索,因为它在 MTEB 上表现很高。 Stella V5 与其他检索器的广泛比较见附录。 对于索引阶段,作者使用 Llama 3.1 8B Instruct 抽取摘要、关键词短语、用户事实和带时间戳事件。 当 session 或 round 被用作 key 时,作者只保留用户侧话语。 在阅读阶段,检索到的条目始终按时间戳排序,以帮助 reader 模型保持时间一致性。 从第 5.2 节到第 5.4 节,作者默认应用 Chain-of-Note 和 json 格式。
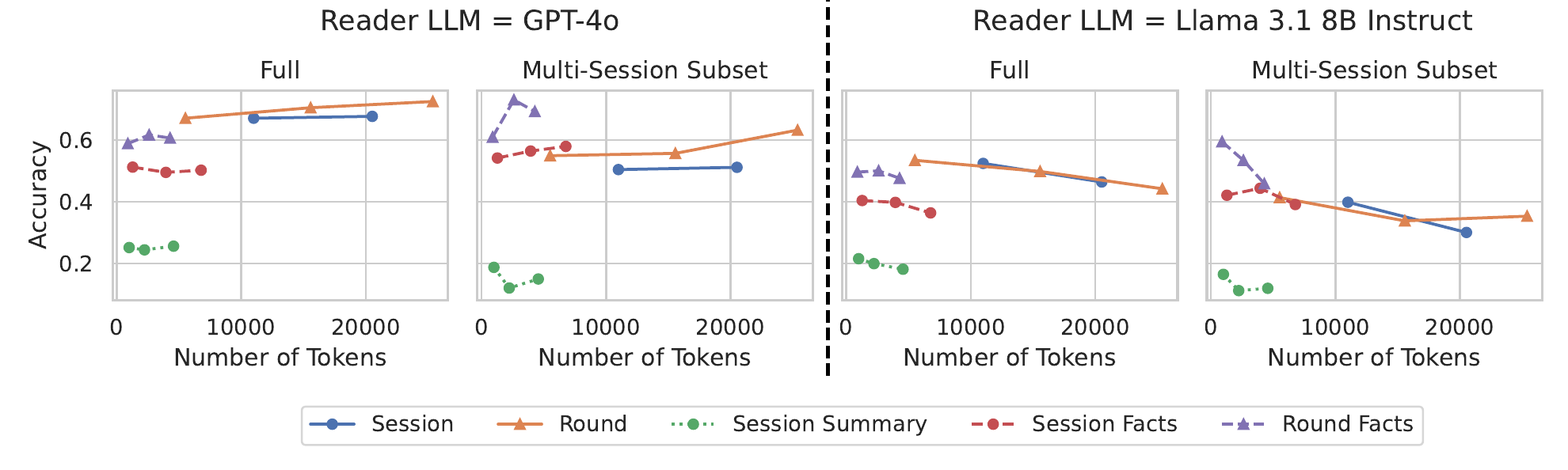
5.2 Value: Decomposition improves RAG performance
Using LongMemEval
作者使用 LongMemEval
5.3 Key: Multi-key indexing improves retrieval and RAG
In Table 3, we explore whether summaries, keyphrases, or user facts condensed from the value can serve as better keys than the value itself. Interestingly, despite their more focused semantics, using these condensed forms alone does not enhance the memory recall performance. We hypothesize that this is due to the retriever's ability to already effectively handle long-text semantics.
在表3中,作者探索从 value 中压缩出的摘要、关键词短语或用户事实,能否作为比 value 本身更好的 key。 有趣的是,尽管这些压缩形式语义更聚焦,但单独使用它们并不会增强记忆召回表现。 作者推测,这是因为检索器已经能够有效处理长文本语义。
To leverage both the highlighted information from compression and the completeness of the original value, we applied a simple document expansion technique, where the compressed information is concatenated with the original value to form the key during indexing. This approach, particularly when using user facts, yielded an average improvement of 9.4% in recall@
为了同时利用压缩突出信息和原始 value 的完整性,作者采用了一种简单的文档扩展技术:在索引阶段,将压缩信息与原始 value 拼接起来形成 key。 这种方法尤其在使用用户事实时,在所有模型上平均带来 9.4% 的 recall@
| Key Design | Retrieval | End-to-End QA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics@5 | Metrics@10 | GPT-4o | L3.1 70B | L3.1 8B | ||||||
| Recall | NDCG | Recall | NDCG | Top-5 | Top-10 | Top-5 | Top-10 | Top-5 | Top-10 | |
| K = V | 0.582 | 0.481 | 0.692 | 0.512 | 0.615 | 0.670 | 0.600 | 0.624 | 0.518 | 0.534 |
| K = fact | 0.530 | 0.411 | 0.654 | 0.449 | 0.588 | 0.664 | 0.564 | 0.610 | 0.510 | 0.534 |
| K = keyphrase | 0.282 | 0.159 | 0.392 | 0.303 | 0.425 | 0.489 | 0.404 | 0.450 | 0.378 | 0.432 |
| K = V + fact | 0.644 | 0.498 | 0.784 | 0.536 | 0.657 | 0.720 | 0.638 | 0.682 | 0.566 | 0.572 |
| K = V + keyphrase | 0.478 | 0.359 | 0.636 | 0.410 | 0.541 | 0.652 | 0.538 | 0.620 | 0.472 | 0.524 |
| Key Design | Retrieval | End-to-End QA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metrics@5 | Metrics@10 | GPT-4o | L3.1 70B | L3.1 8B | ||||||
| Recall | NDCG | Recall | NDCG | Top-5 | Top-10 | Top-5 | Top-10 | Top-5 | Top-10 | |
| K = V | 0.706 | 0.617 | 0.783 | 0.638 | 0.670 | 0.676 | 0.592 | 0.570 | 0.524 | 0.464 |
| K = summary | 0.572 | 0.448 | 0.648 | 0.468 | 0.554 | 0.252 | 0.498 | 0.512 | 0.444 | 0.216 |
| K = fact | 0.642 | 0.524 | 0.814 | 0.571 | 0.644 | 0.512 | 0.544 | 0.550 | 0.470 | 0.404 |
| K = keyphrase | 0.482 | 0.375 | 0.576 | 0.401 | 0.618 | 0.498 | 0.440 | 0.450 | 0.388 | 0.414 |
| K = V + summary | 0.689 | 0.608 | 0.749 | 0.624 | 0.658 | 0.666 | 0.568 | 0.560 | 0.518 | 0.494 |
| K = V + fact | 0.732 | 0.620 | 0.862 | 0.652 | 0.714 | 0.700 | 0.588 | 0.584 | 0.530 | 0.490 |
| K = V + keyphrase | 0.710 | 0.587 | 0.768 | 0.602 | 0.665 | 0.672 | 0.590 | 0.566 | 0.526 | 0.508 |
5.4 Query: Time-aware query expansion improves temporal reasoning
A key challenge highlighted by LongMemEval in building real-world assistant systems is the need to utilize temporal information present in both metadata and user utterances to correctly answer time-sensitive queries. To address this need, we introduce a simple yet effective time-aware indexing and query expansion scheme. Specifically, values are additionally indexed by the dates of the events they contain. During retrieval, an LLM
LongMemEval 凸显了构建真实助手系统中的一个关键挑战:需要利用元数据和用户话语中存在的时间信息,正确回答时间敏感 query。 为满足这一需求,作者提出一种简单但有效的时间感知索引和 query 扩展方案。 具体而言,value 会额外根据其包含事件的日期进行索引。 在检索期间,LLM
As shown in Table 4, this simple design improves recall by an average of 11.3% when using rounds as the value and by 6.8% when using sessions as the value. This improvement remains consistent when key expansion is applied during indexing. We also find that the effectiveness of this method depends on using a strong LLM for
如表4所示,这一简单设计在使用 round 作为 value 时平均提升 11.3% 的 recall,在使用 session 作为 value 时平均提升 6.8%。 当在索引阶段应用 key 扩展时,这种提升仍然一致。 作者还发现,该方法的有效性依赖于使用强 LLM 作为
| Key Setting | Metric@5 | Metric@10 | ||
|---|---|---|---|---|
| Recall | NDCG | Recall | NDCG | |
| (1) K = V | 0.639 | 0.630 | 0.651 | 0.707 |
(1) w/ Query Expansion ( | 0.654 | 0.660 | 0.707 | 0.679 |
(1) w/ Query Expansion ( | 0.624 | 0.627 | 0.647 | 0.692 |
| (2) K = V + fact | 0.684 | 0.688 | 0.721 | 0.782 |
(2) w/ Query Expansion ( | 0.722 | 0.732 | 0.797 | 0.758 |
(2) w/ Query Expansion ( | 0.677 | 0.688 | 0.711 | 0.744 |
| Key Setting | Metric@5 | Metric@10 | ||
|---|---|---|---|---|
| Recall | NDCG | Recall | NDCG | |
| (1) K = V | 0.421 | 0.462 | 0.499 | 0.511 |
(1) w/ Query Expansion ( | 0.451 | 0.565 | 0.495 | 0.538 |
(1) w/ Query Expansion ( | 0.384 | 0.448 | 0.489 | 0.488 |
| (2) K = V + fact | 0.489 | 0.500 | 0.550 | 0.598 |
(2) w/ Query Expansion ( | 0.526 | 0.548 | 0.722 | 0.669 |
(2) w/ Query Expansion ( | 0.481 | 0.532 | 0.570 | 0.647 |
5.5 Improving reading with chain-of-note and structured format
As LongMemEval requires syntheses across multiple sessions, even an optimal memory retrieval mechanism needs to return a long context to capture all relevant information. To enhance the model's ability to handle long retrieved contexts, we apply two key optimizations. First, we present retrieved items in a structured JSON format, which helps the model clearly recognize memory items as the data for reading. Additionally, we apply the Chain-of-Note (CoN) reading approach, instructing the LLM to first extract information from each memory item and then reason based on these notes. This effectively decomposes long-context reading into two simpler subtasks: copying important details and reasoning with more concise notes.
由于 LongMemEval 需要跨多个会话进行综合,即使最优记忆检索机制也需要返回较长上下文,以捕获所有相关信息。 为了增强模型处理长检索上下文的能力,作者应用两项关键优化。 首先,作者以结构化 JSON 格式呈现检索条目,这有助于模型清楚识别哪些记忆条目是用于阅读的数据。 此外,作者应用 Chain-of-Note(CoN)阅读方法,指示 LLM 先从每个记忆条目中抽取信息,再基于这些 notes 进行推理。 这有效地将长上下文阅读分解为两个更简单的子任务:复制重要细节,以及基于更简洁的 notes 进行推理。
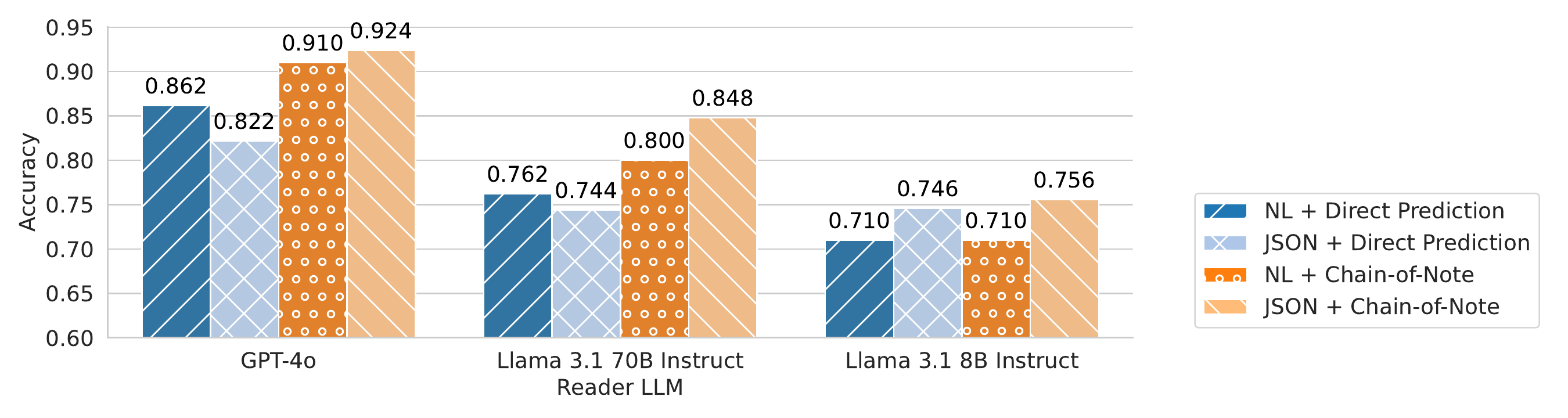
In Figure 6, we evaluate the reading designs under the oracle retrieval setting, where only evidence sessions are provided. Surprisingly, even with perfect retrieval, a suboptimal reading strategy results in up to a 10-point absolute performance drop compared to the best approach for GPT-4o. Notably, when CoN is not applied, JSON format does not consistently outperform the natural language format. However, with CoN, JSON format consistently benefits reader LLMs of various capabilities. Appendix further analyzes error patterns of LLMs with the enhanced reading strategy.
在图6中,作者在 oracle retrieval 设置下评估阅读设计,此时只提供证据会话。 令人意外的是,即使检索完美,对于 GPT-4o 而言,次优阅读策略相较最佳方法仍会导致最高 10 个绝对点的性能下降。 值得注意的是,当不应用 CoN 时,JSON 格式并不会稳定超过自然语言格式。 然而,在使用 CoN 时,JSON 格式会稳定惠及不同能力水平的 reader LLM。 附录进一步分析了增强阅读策略下 LLM 的错误模式。
6. Conclusion
In this paper, we introduced LongMemEval, a comprehensive and challenging benchmark designed to evaluate the long-term memory abilities of chat assistants across five core memory tasks: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. Through extensive experiments with both commercial systems and long-context LLMs, we demonstrated the significant challenges posed by LongMemEval, with current systems exhibiting substantial performance drops. By analyzing key design choices across indexing, retrieval, and reading stages, we proposed effective strategies such as session decomposition, fact-augmented key expansion, and time-aware query expansion, which collectively improved both memory recall and the question answering performance. Our findings highlight the need for more sophisticated memory mechanisms to achieve personalized and reliable conversational AI, and LongMemEval offers a valuable benchmark to drive future advancements in long-term memory capabilities for chat assistants.
本文介绍了 LongMemEval,这是一个综合且具有挑战性的基准,用于围绕五个核心记忆任务评估聊天助手的长期记忆能力:信息抽取、多会话推理、时间推理、知识更新和拒答。 通过对商业系统和长上下文 LLM 的大量实验,作者证明 LongMemEval 带来了显著挑战,当前系统出现了明显性能下降。 通过分析索引、检索和阅读阶段的关键设计选择,作者提出了有效策略,例如 session 分解、事实增强 key 扩展和时间感知 query 扩展,这些策略共同提升了记忆召回和问答表现。 作者的发现强调了更复杂记忆机制的必要性,以实现个性化且可靠的对话式 AI;LongMemEval 也提供了一个有价值的基准,用于推动聊天助手长期记忆能力的未来发展。