
Memory-R2: Fair Credit Assignment for Long-Horizon Memory-Augmented LLM Agents
MemoryAgentRLGRPOLMUMCMLHuawei MunichTUMMemory-R2:面向长程记忆增强 LLM 智能体的公平信用分配
Abstract
Memory-augmented LLM agents enable interactions that extend beyond finite context windows by storing, updating, and reusing information across sessions. However, training such agents with reinforcement learning in multi-session environments is challenging because memory turns the agent's past actions into part of its future environment. Once different rollouts write, update, or delete different memories, they no longer share the same intermediate memory state, making trajectory-level comparisons fundamentally unfair. This violates a key assumption behind group-relative methods such as GRPO, where rollouts are compared as if they were sampled from the same effective environment. Consequently, trajectory-level rewards provide noisy or biased credit signals for long-horizon memory operations. To address this challenge, we introduce Memory-R2, a training framework for long-horizon memory-augmented LLM agents. Its core algorithm, LoGo-GRPO, combines local and global group-relative optimization. The global objective preserves end-to-end learning from long-horizon trajectory-level rewards, while local rerollouts compare different memory-operation outcomes from the same intermediate memory state, yielding fairer group comparisons and more precise supervision for memory construction. Beyond credit assignment, Memory-R2 jointly optimizes memory formation and memory evolution with a shared-parameter co-learning design, where a fact extractor and a memory manager are instantiated from the same LLM backbone through role-specific prompts. To stabilize multi-step RL over long memory horizons, we adopt a progressive curriculum that increases the training horizon from 8 to 16 to 32 sessions. Together, these components provide an effective training paradigm for memory-augmented LLM agents in long-horizon multi-session settings.
记忆增强 LLM 智能体通过跨会话存储、更新和复用信息,使交互能够超越有限上下文窗口。 然而,在多会话环境中用强化学习训练这类智能体具有挑战性,因为记忆会把智能体过去的动作变成其未来环境的一部分。 一旦不同 rollout 写入、更新或删除了不同记忆,它们就不再共享相同的中间记忆状态,使轨迹级比较从根本上变得不公平。 这违反了 GRPO 等组相对方法背后的一项关键假设:这些方法把 rollout 当作是从同一个有效环境中采样出来的来进行比较。 因此,轨迹级奖励会为长程记忆操作提供带噪声或有偏的信用信号。 为了解决这一挑战,我们提出 Memory-R2,这是一个面向长程记忆增强 LLM 智能体的训练框架。 它的核心算法 LoGo-GRPO 结合了局部和全局组相对优化。 全局目标保留来自长程轨迹级奖励的端到端学习,而局部重新 rollout 会从同一中间记忆状态比较不同记忆操作结果,从而得到更公平的组比较和更精确的记忆构建监督。 除了信用分配之外,Memory-R2 还通过共享参数协同学习设计联合优化记忆形成和记忆演化,其中事实抽取器和记忆管理器通过角色特定提示从同一个 LLM backbone 实例化。 为了稳定长记忆跨度上的多步强化学习,我们采用渐进课程,将训练跨度从 8 个会话增加到 16 个会话,再增加到 32 个会话。 这些组件共同为长程多会话设置中的记忆增强 LLM 智能体提供了有效的训练范式。
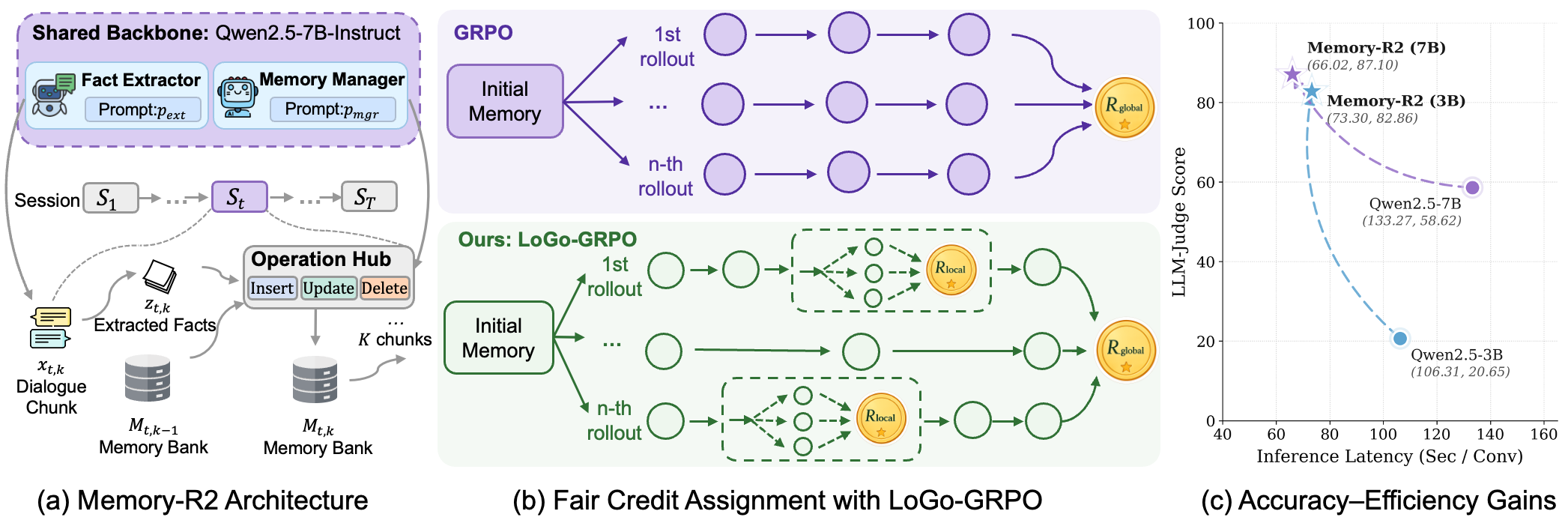
1. Introduction
Large language models (LLMs) have rapidly evolved from standalone text generators into agentic systems that can plan, use tools, and interact over long horizons. A central requirement for such agents is the ability to accumulate, update, and reuse information across interactions. However, despite strong in-context reasoning ability, LLM agents remain fundamentally constrained by finite context windows and the lack of persistent state, making it difficult to retain salient user information, track long-term goals, or maintain consistency over extended multi-session interactions.
大语言模型(LLM)已经从独立文本生成器迅速演化为能够规划、使用工具并进行长程交互的智能体系统。 这类智能体的一项核心需求,是能够跨交互积累、更新和复用信息。 然而,尽管 LLM 智能体具有很强的上下文内推理能力,它们仍从根本上受限于有限上下文窗口和缺少持久状态,因此难以保留关键用户信息、跟踪长期目标,或在扩展的多会话交互中保持一致性。
To address this limitation, a growing body of work augments LLM agents with explicit memory systems. Existing research broadly follows two directions. The first focuses on memory infrastructure, including graph-structured memory, structured memory schemas, and system-inspired memory organization. The second focuses on memory policy learning, where reinforcement learning (RL) is used to decide what to extract, how to update memory, and how to use retrieved memory. While these efforts have substantially improved long-horizon agent behavior, training memory agents in multi-session environments remains fundamentally challenging.
为了解决这一局限,越来越多工作用显式记忆系统增强 LLM 智能体。 现有研究大体沿着两个方向展开。 第一个方向关注记忆基础设施,包括图结构记忆、结构化记忆模式以及受系统启发的记忆组织方式。 第二个方向关注记忆策略学习,其中使用强化学习(RL)来决定抽取什么、如何更新记忆以及如何使用检索到的记忆。 虽然这些努力已经显著改善了长程智能体行为,但在多会话环境中训练记忆智能体仍然存在根本挑战。
The core difficulty is that memory makes the environment non-stationary. In multi-session agent training, memory turns the agent's past actions into part of its future environment: what the agent writes, updates, or deletes in one session becomes the state inherited by subsequent sessions. This creates a fundamental challenge for trajectory-level RL, especially for group-relative methods such as GRPO, which rely on comparing rollouts sampled from the same effective environment. Once rollouts modify memory differently, they no longer share the same intermediate memory state, yet GRPO still normalizes their rewards within a single comparison group, leading to unfair comparisons and biased credit assignment. The problem is further amplified by trajectory-level rewards: when a downstream failure occurs, it is difficult to determine whether it comes from the current session's memory operation, corrupted memory inherited from earlier sessions, or later updates that overwrite useful information. This raises a simple but important question:
核心困难在于,记忆会使环境变成非平稳的。 在多会话智能体训练中,记忆会把智能体过去的动作变成其未来环境的一部分:智能体在一个会话中写入、更新或删除的内容,会成为后续会话继承的状态。 这给轨迹级强化学习带来根本挑战,尤其是对于 GRPO 等组相对方法,因为这些方法依赖于比较从同一有效环境中采样的 rollout。 一旦 rollout 以不同方式修改记忆,它们就不再共享相同的中间记忆状态,但 GRPO 仍会在同一个比较组内归一化它们的奖励,从而导致不公平比较和有偏信用分配。 轨迹级奖励会进一步放大这一问题:当下游失败发生时,很难判断它来自当前会话的记忆操作、早期会话继承的损坏记忆,还是来自后续更新覆盖了有用信息。 这引出了一个简单但重要的问题:
How can we design a training paradigm for memory-augmented agents that provides more accurate and fair credit assignment across sessions?
我们如何为记忆增强智能体设计一种训练范式,使其能够跨会话提供更准确、更公平的信用分配?
In this work, we present Memory-R2, a training framework for long-horizon memory-augmented LLM agents, as illustrated in Figure 1. At its core is LoGo-GRPO, a credit-assignment algorithm that combines global and local group-relative optimization. LoGo-GRPO preserves a trajectory-level global reward for end-to-end long-horizon optimization, while additionally introducing session-wise attribution signals and local rerollouts that compare trajectories starting from identical intermediate memory states. This yields fairer group comparison and cleaner supervision for memory operations.
在本文中,我们提出 Memory-R2,这是一个面向长程记忆增强 LLM 智能体的训练框架,如图1所示。 其核心是 LoGo-GRPO,这是一种结合全局和局部组相对优化的信用分配算法。 LoGo-GRPO 保留轨迹级全局奖励以进行端到端长程优化,同时额外引入会话级归因信号和局部重新 rollout,用于比较从相同中间记忆状态出发的轨迹。 这带来了更公平的组比较和更干净的记忆操作监督。
Beyond fair credit assignment, Memory-R2 is designed to optimize the whole memory lifecycle. Recent analyses decompose agentic memory into memory formation, memory evolution, and memory retrieval, whereas prior RL-based memory work has focused primarily on evolution and retrieval. Our framework targets memory formation and evolution through two cooperative roles: a fact extractor, which identifies salient information from the interaction context, and a memory manager, which decides whether to insert, update, or delete memory entries. Inspired by shared-policy multi-agent RL, we instantiate both roles with a shared LLM backbone and role-specific prompts, enabling parameter-efficient co-learning and tighter coordination between extraction and memory editing.
除了公平信用分配之外,Memory-R2 还旨在优化整个记忆生命周期。 近期分析把智能体记忆分解为记忆形成、记忆演化和记忆检索,而此前基于强化学习的记忆工作主要关注演化和检索。 我们的框架通过两个协作角色来处理记忆形成和演化:事实抽取器从交互上下文中识别关键信息,记忆管理器决定是否插入、更新或删除记忆条目。 受共享策略多智能体强化学习启发,我们用共享 LLM backbone 和角色特定提示实例化这两个角色,从而实现参数高效的协同学习,并加强抽取与记忆编辑之间的协调。
We further formulate memory construction as a multi-step decision process within each session. Rather than treating a session as a single monolithic transition, we divide it into chunks and allow the fact extractor and memory manager to alternate over them, turning memory construction into a temporally extended process that can be refined as more evidence becomes available. To stabilize long-horizon optimization, we also introduce a curriculum over session horizon, progressively scaling training from 8 to 16 to 32 sessions so that the model first acquires reliable short-horizon memory behavior before adapting to more challenging long-context settings. Our contributions are summarized as follows:
我们进一步把每个会话内的记忆构建表述为一个多步决策过程。 与其把一个会话看成单一的整体转移,我们把它划分为多个块,并让事实抽取器和记忆管理器在这些块上交替工作,从而把记忆构建变成一个随更多证据出现而逐步细化的时间扩展过程。 为了稳定长程优化,我们还引入跨会话跨度的课程学习,将训练逐步从 8 个会话扩展到 16 个会话再到 32 个会话,使模型先获得可靠的短程记忆行为,再适应更具挑战性的长上下文设置。 我们的贡献总结如下:
- We propose Memory-R2, a training framework for long-horizon memory-augmented LLM agents, whose core algorithm LoGo-GRPO improves fairness and session-level credit assignment through global-local group-relative optimization.
- We introduce a shared-parameter extractor--manager architecture and formulate memory construction as a multi-step decision process over chunked sessions, enabling joint optimization of memory formation and evolution.
- We develop a curriculum learning strategy over session horizon that stabilizes long-horizon RL training, and show that the resulting system is highly data-efficient, achieving strong gains over prior memory-agent baselines using only two training conversations while generalizing across benchmarks, model scales, and answer agents.
- 我们提出 Memory-R2,这是一个面向长程记忆增强 LLM 智能体的训练框架,其核心算法 LoGo-GRPO 通过全局-局部组相对优化提升公平性和会话级信用分配。
- 我们引入 共享参数抽取器-管理器架构,并把记忆构建表述为分块会话上的 多步决策过程,从而支持记忆形成和记忆演化的联合优化。
- 我们开发了一种跨会话跨度的 课程学习策略,用于稳定长程强化学习训练,并表明由此得到的系统具有很高的 数据效率:它仅使用两个训练对话就相较以往记忆智能体基线取得显著提升,并能跨基准、模型规模和答案智能体泛化。
2. Related Work
2.1 Memory Agent Architectures
Explicit memory has become a standard way to extend LLM agents beyond finite context windows and support long-horizon interaction. Prior work mainly differs in how memory is represented and managed. Representative examples include graph- or structure-based memory systems such as Zep, G-Memory, A-MEM, Mem0, and CAM, as well as system-inspired designs such as MemOS and MemoryOS. While these methods propose increasingly expressive memory substrates, they mostly rely on heuristic or prompt-based policies for deciding what to store, update, or discard. In contrast, our work retains a modular extractor--manager architecture but optimizes the memory lifecycle directly with reinforcement learning.
显式记忆已经成为把 LLM 智能体扩展到有限上下文窗口之外并支持长程交互的标准方式。 以往工作的主要差异在于如何表示和管理记忆。 代表性例子包括 Zep、G-Memory、A-MEM、Mem0 和 CAM 等基于图或结构的记忆系统,以及 MemOS 和 MemoryOS 等受系统启发的设计。 虽然这些方法提出了越来越有表达力的记忆载体,但它们大多依赖启发式或基于提示的策略来决定存储、更新或丢弃什么。 相比之下,我们的工作保留模块化抽取器-管理器架构,但直接用强化学习优化记忆生命周期。
2.2 Reinforcement Learning for Memory Agents
Reinforcement learning has recently become an effective paradigm for training LLM agents in interactive settings such as tool use, web navigation, and reasoning. This is particularly suitable for memory agents, where the quality of extraction, memory editing, and retrieval decisions is only revealed through downstream task performance. Existing RL-based memory methods, such as Memory-R1 and Mem-
强化学习近期已经成为在工具使用、网页导航和推理等交互式设置中训练 LLM 智能体的有效范式。 这尤其适合记忆智能体,因为抽取、记忆编辑和检索决策的质量只有通过下游任务表现才会显现。 Memory-R1 和 Mem-
3. Method
3.1 Problem Formulation: Multi-step Memory Bank Construction
We study memory bank construction for long-horizon multi-session interactions. Let
我们研究长程多会话交互中的记忆库构建。 令
and a memory manager then chooses an operation conditioned on the extracted content and current memory state,
随后,记忆管理器在抽取内容和当前记忆状态条件下选择一个操作,
where INSERT, UPDATE, and DELETE. The memory bank is updated by a deterministic transition operator
其中 INSERT、UPDATE 和 DELETE 等操作。 记忆库由一个确定性转移算子更新:
This yields a chunk-wise memory construction process over session
这给出了会话
Across the full dialogue trajectory, let
在完整对话轨迹上,令
In our framework, the extractor and the manager are implemented as two cooperative roles instantiated from a shared LLM backbone with role-specific prompts:
在我们的框架中,抽取器和管理器被实现为两个协作角色,它们通过角色特定提示从共享 LLM backbone 实例化:
where
其中
3.2 Length-Normalized Step-level RL with Shared Extractor--Manager Policy
While Section 3.1 defines memory construction as a multi-step process, optimizing it with a shared LLM policy introduces length-induced bias. We instantiate fact extraction and memory management as two roles of a shared policy with role-specific prompts. Since the two roles produce outputs of different lengths, token-level RL assigns more loss terms to longer generations, biasing the shared policy toward verbose outputs and roles with longer outputs. To address this, we use a length-normalized step-level objective, treating each extractor or manager call as one generation step. For a generation step
虽然第 3.1 节把记忆构建定义为多步过程,但用共享 LLM 策略优化它会引入由长度造成的偏差。 我们把事实抽取和记忆管理实例化为共享策略的两个角色,并使用角色特定提示。 由于两个角色产生不同长度的输出,token 级强化学习会给更长生成分配更多损失项,使共享策略偏向冗长输出和输出更长的角色。 为了解决这一点,我们使用长度归一化的步骤级目标,把每次抽取器或管理器调用视为一个生成步骤。 对于生成 token 索引为
where
其中
3.3 LoGo-GRPO for Multi-session Credit Assignment
The formulation in Section 3.1 defines memory construction as a chunk-wise multi-step process, but learning still requires fair credit assignment across sessions. Trajectory-level GRPO is problematic in memory-augmented settings because memory turns an agent's past actions into part of its future environment. Once rollouts write, update, or delete different memories, they no longer share the same intermediate memory state, making group-relative comparisons unfair and credit signals noisy or biased. To address this, we propose LoGo-GRPO, which combines a global trajectory-level branch with a local rerollout branch. As shown in Figure 1 (b), the global branch preserves end-to-end optimization over the full multi-session trajectory, while the local branch rerolls a stochastically sampled subset of sessions from shared memory states, yielding lower-bias session-level credit assignment at manageable cost.
第 3.1 节中的表述把记忆构建定义为分块的多步过程,但学习仍然需要跨会话的公平信用分配。 在记忆增强设置中,轨迹级 GRPO 存在问题,因为记忆会把智能体过去的动作变成未来环境的一部分。 一旦 rollout 写入、更新或删除了不同记忆,它们就不再共享相同的中间记忆状态,使组相对比较变得不公平,信用信号也会带噪或有偏。 为了解决这一点,我们提出 LoGo-GRPO,它把全局轨迹级分支与局部重新 rollout 分支结合起来。 如图1(b) 所示,全局分支保留完整多会话轨迹上的端到端优化,而局部分支从共享记忆状态对随机采样的会话子集重新 rollout,从而以可管理成本得到偏差更低的会话级信用分配。
Reward function. Let
奖励函数。 令
To discourage unbounded memory growth, we penalize memory tokens exceeding an
为了抑制无界记忆增长,我们惩罚超过截至会话
The session-level reward is
会话级奖励为
where
其中
Global branch. For rollout
全局分支。 对于 rollout
Following GRPO, we compute group-relative advantages across the
按照 GRPO,我们在
While this branch provides full-horizon supervision, it still suffers from reward contamination: at session
虽然这一分支提供完整跨度监督,但它仍受到奖励污染影响:在会话
Local branch with stochastic rerollout. To reduce this contamination, the local branch performs rerollouts from shared intermediate memory states. After the global rollout phase, each session is independently selected with probability
带随机重新 rollout 的局部分支。 为了减少这种污染,局部分支会从共享的中间记忆状态执行重新 rollout。 在全局 rollout 阶段之后,每个会话都会以概率
For each selected session
对于每个被选中的会话
The corresponding local advantages are computed within the rerollout group:
对应的局部优势在重新 rollout 组内计算:
Because local advantages are computed among rerollouts from the same anchor memory state
由于局部优势是在来自同一锚点记忆状态
Unified training objective. We optimize the shared memory policy using both global rollouts and local rerollouts. For each generation step
统一训练目标。 我们同时使用全局 rollout 和局部重新 rollout 来优化共享记忆策略。 对于每个生成步骤
where
其中
where
其中
3.4 Curriculum Learning for Long-Horizon Credit Assignment
Directly training on long multi-session trajectories is unstable before the model acquires reliable memory manipulation skills. Because memory operations shape the future environment, early insert, update, or delete errors can propagate across sessions and make long-horizon credit assignment increasingly noisy. We therefore adopt a curriculum over session horizon: training starts from shorter sessions, where memory effects are easier to observe and attribute, and gradually increases the horizon as the policy stabilizes. Concretely, we train in three stages with the maximum number of sessions increasing from 8 to 16 to 32. The 8-session stage learns basic memory operations under limited error propagation, the 16-session stage introduces stronger inter-session dependencies, and the 32-session stage enables full long-horizon optimization. For each stage, we select the best validation checkpoint as the initialization for the next stage, providing a stable starting point for longer-horizon training.
在模型获得可靠记忆操作技能之前,直接在长多会话轨迹上训练是不稳定的。 因为记忆操作会塑造未来环境,早期插入、更新或删除错误可能跨会话传播,并使长程信用分配越来越嘈杂。 因此,我们采用跨会话跨度的课程学习:训练从较短会话开始,在那里记忆效应更容易观察和归因,并随着策略稳定逐渐增加跨度。 具体而言,我们分三阶段训练,最大会话数从 8 增加到 16,再增加到 32。 8 会话阶段在有限错误传播下学习基本记忆操作,16 会话阶段引入更强的会话间依赖,32 会话阶段支持完整长程优化。 对于每个阶段,我们选择最佳验证 checkpoint 作为下一阶段初始化,为更长跨度训练提供稳定起点。
4. Experiments
4.1 Experiment Setup
Datasets and Evaluation Metrics. We train on LoCoMo, a long-term persona-grounded conversation benchmark, using a 2:1:7 train/validation/test split. For out-of-distribution evaluation, we additionally test on LongMemEval, MSC-Self-Instruct, and MemBench. We report token-level F1, BLEU-1 (B1), and LLM-as-a-Judge (J) as the primary metrics, and additionally use M-Fail, the percentage of required evidence location IDs that are missing from the memory bank, as a diagnostic measure of memory-construction quality. Further details on the M-Fail metric can be found in Appendix.
数据集与评估指标。 我们在 LoCoMo 上训练,它是一个长期、以 persona 为基础的对话基准,并使用 2:1:7 的训练/验证/测试划分。 对于分布外评估,我们还在 LongMemEval、MSC-Self-Instruct 和 MemBench 上测试。 我们报告 token 级 F1、BLEU-1(B1)和 LLM-as-a-Judge(J)作为主要指标,并额外使用 M-Fail,即记忆库中缺失的必需证据 location ID 的百分比,作为记忆构建质量的诊断指标。 关于 M-Fail 指标的更多细节见附录。
Baselines and Implementation Details. We compare against A-MEM, Mem0, MemoryOS, a RAG variant implemented within the Mem0 framework, MEM1, MemAgent, and Memory-R1. Our work primarily targets the memory construction stage: the memory extractor and memory manager share a Qwen2.5-7B-Instruct backbone and are jointly trained, while the answer agent is held fixed during training to provide stable reward signals. We use GPT-OSS-120B as this fixed answer agent, since a weaker answer model would yield noisy reward signals that conflate memory-construction quality with answer-generation errors. To remain consistent with this training pipeline, all reported results in our ablation and analysis experiments use the same GPT-OSS-120B answer agent. In Table 1, however, we additionally train a Qwen2.5-7B-Instruct answer agent and report a backbone-controlled variant of Memory-R2 in which all components share the same 7B backbone, enabling a fair comparison against the baselines. Unless otherwise noted, all baselines also use Qwen2.5-7B-Instruct as the backbone. Additional details are provided in Appendix.
基线与实现细节。 我们与 A-MEM、Mem0、MemoryOS、Mem0 框架内实现的一个 RAG 变体、MEM1、MemAgent 和 Memory-R1 进行比较。 我们的工作主要针对记忆构建阶段:记忆抽取器和记忆管理器共享 Qwen2.5-7B-Instruct backbone 并联合训练,而答案智能体在训练期间保持固定,以提供稳定奖励信号。 我们使用 GPT-OSS-120B 作为这个固定答案智能体,因为较弱的答案模型会产生带噪声的奖励信号,把记忆构建质量与答案生成错误混在一起。 为了与这一训练流程保持一致,我们在消融和分析实验中报告的所有结果都使用同一个 GPT-OSS-120B 答案智能体。 然而,在表1中,我们额外训练了一个 Qwen2.5-7B-Instruct 答案智能体,并报告了 Memory-R2 的 backbone 控制变体,其中所有组件共享同一个 7B backbone,从而能够与基线进行公平比较。 除非另有说明,所有基线也使用 Qwen2.5-7B-Instruct 作为 backbone。 更多细节见附录。
| Model | Multi-hop | Open Domain | Single Hop | Temporal | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | B1 | J | F1 | B1 | J | F1 | B1 | J | F1 | B1 | J | F1 | B1 | J | |
| Training-free Methods | |||||||||||||||
| RAG† | 9.57 | 7.00 | 15.06 | 11.84 | 10.02 | 19.28 | 8.67 | 6.52 | 12.79 | 8.35 | 8.74 | 5.43 | 8.97 | 7.27 | 12.17 |
| A-MEM† | 18.92 | 12.86 | 40.78 | 14.73 | 12.66 | 31.32 | 30.58 | 26.14 | 46.90 | 23.67 | 20.67 | 28.68 | 26.08 | 21.78 | 40.78 |
| Mem0† | 24.96 | 18.05 | 61.92 | 20.31 | 15.82 | 48.19 | 32.74 | 25.27 | 65.20 | 33.16 | 26.28 | 38.76 | 30.61 | 23.55 | 53.30 |
| MemoryOS† | 29.55 | 22.59 | 48.12 | 21.03 | 18.41 | 38.55 | 40.85 | 36.26 | 63.14 | 26.26 | 19.70 | 24.81 | 34.64 | 29.36 | 51.26 |
| Trained Methods | |||||||||||||||
| MEM1 | 17.15 | 12.72 | 41.29 | 22.67 | 14.72 | 43.10 | 28.05 | 22.96 | 57.22 | 31.77 | 26.40 | 44.73 | 26.55 | 21.38 | 50.78 |
| MemAgent | 35.95 | 24.56 | 70.65 | 29.20 | 25.48 | 62.07 | 50.55 | 43.89 | 78.61 | 23.15 | 16.55 | 56.96 | 40.72 | 33.36 | 71.52 |
| Memory-R1† | 33.64 | 26.06 | 62.34 | 23.55 | 20.71 | 40.96 | 46.86 | 40.92 | 67.81 | 47.75 | 38.49 | 49.61 | 43.14 | 36.44 | 61.51 |
| Memory-R2 (GPT-OSS) | 36.37 | 29.79 | 85.07 | 30.22 | 24.50 | 74.14 | 50.98 | 45.79 | 90.58 | 62.48 | 55.33 | 83.33 | 49.67 | 43.77 | 87.10 |
| Memory-R2 | 38.41 | 30.90 | 80.93 | 20.76 | 16.78 | 67.53 | 54.06 | 48.73 | 86.80 | 59.65 | 50.05 | 69.90 | 50.60 | 44.01 | 80.99 |
4.2 Main Results
Fair Comparison. Table 1 reports the main results on LoCoMo. Under the backbone-controlled setting, Memory-R2 achieves the best overall F1 and BLEU-1 among all training-free and trained baselines, including MEM1, MemAgent, and Memory-R1. Compared with the closely related RL baseline Memory-R1, Memory-R2 improves overall F1 from 43.14 to 50.60 and B1 from 36.44 to 44.01, while also reaching a strong judge score of 80.99. These gains are obtained with a simple memory-agent pipeline, suggesting that the improvement mainly comes from the proposed training algorithm rather than additional system complexity. We additionally report Memory-R2 (GPT-OSS), which uses the same memory construction module but replaces the answer agent with GPT-OSS-120B. Memory-R2 with the 7B answer agent achieves higher F1 and BLEU-1 than the GPT-OSS-120B variant, demonstrating that a task-aligned small model can rival a much larger frozen one when paired with a well-trained memory module.
公平比较。 表1报告了 LoCoMo 上的主结果。 在 backbone 控制设置下,Memory-R2 在所有免训练和训练基线中取得最佳 overall F1 和 BLEU-1,包括 MEM1、MemAgent 和 Memory-R1。 与密切相关的强化学习基线 Memory-R1 相比,Memory-R2 将 overall F1 从 43.14 提升到 50.60,将 B1 从 36.44 提升到 44.01,同时也达到 80.99 的强 judge score。 这些收益来自一个简单的记忆智能体流程,说明提升主要来自所提出的训练算法,而不是额外系统复杂性。 我们还报告 Memory-R2 (GPT-OSS),它使用相同的记忆构建模块,但把答案智能体替换为 GPT-OSS-120B。 使用 7B 答案智能体的 Memory-R2 取得了高于 GPT-OSS-120B 变体的 F1 和 BLEU-1,说明当搭配训练良好的记忆模块时,任务对齐的小模型可以媲美大得多的冻结模型。
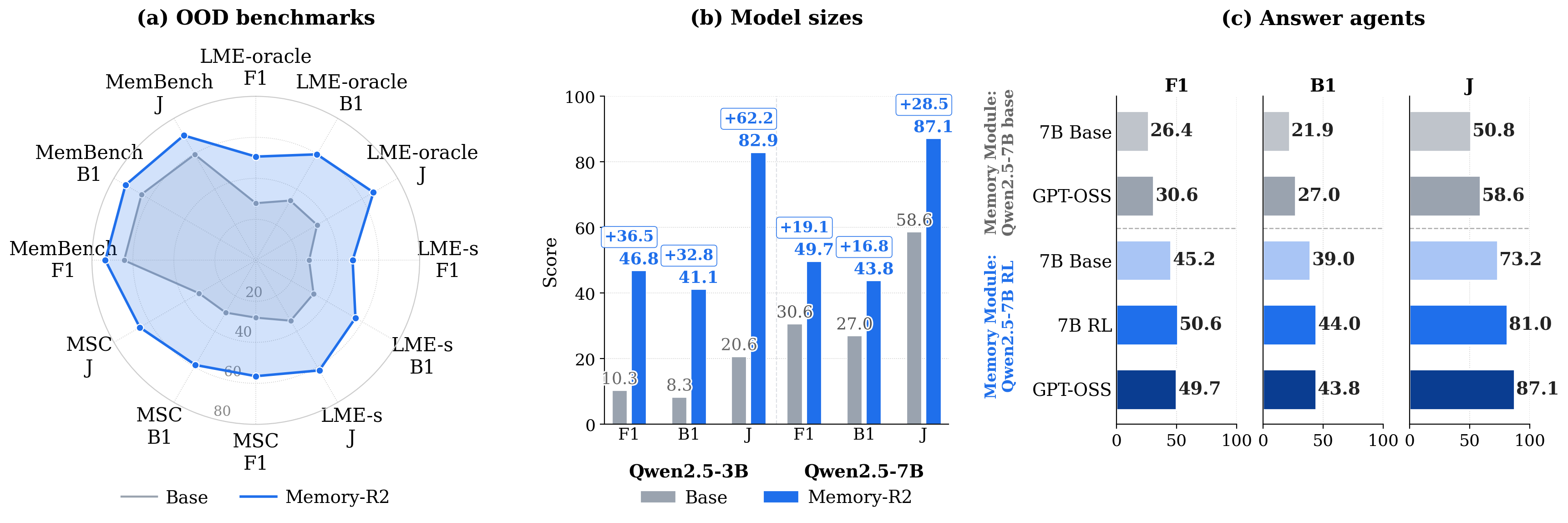
Strong Generalization. Figure 2 further demonstrates the strong generalization ability of Memory-R2 from three complementary perspectives. Notably, these gains are achieved even though the model is trained on only two LoCoMo conversations, suggesting that the proposed training paradigm is highly data-efficient. First, Figure 2(a) shows strong transfer to out-of-distribution benchmarks. When evaluated zero-shot on LongMemEval-oracle, LongMemEval-s, MSC-Self-Instruct, and MemBench, Memory-R2 consistently improves over the base model across all reported metrics. For example, on LongMemEval-oracle, the F1 score improves from 27.88 to 50.60, and similar gains are observed on the other benchmarks, indicating that the learned memory-construction policy does not simply overfit to the training benchmark. Second, Figure 2(b) shows that the gains also transfer across model scales. The improvement is especially pronounced for Qwen2.5-3B, where F1 increases from 10.3 to 46.8, suggesting that our training paradigm is particularly beneficial for smaller-capacity models, for which effective long-horizon memory construction is otherwise difficult to learn. Third, Figure 2(c) decomposes the contribution of training the memory module versus the answer agent. The dominant gain comes from training the memory module (e.g., F1 from 26.4 to 45.2 with a 7B-Base answer agent; F1 from 30.6 to 49.7 with a GPT-OSS answer agent), while varying the answer agent at fixed RL-trained memory yields comparably high scores. This indicates that the benefits of Memory-R2 transfer across diverse downstream answer agents. Taken together, these results indicate that Memory-R2 learns a robust and transferable memory-construction policy rather than overfitting to a specific benchmark, model scale, or answer agent.
强泛化能力。 图2进一步从三个互补角度展示了 Memory-R2 的强泛化能力。 值得注意的是,尽管模型只在两个 LoCoMo 对话上训练,也能获得这些收益,这说明所提出训练范式具有很高的数据效率。 首先,图2(a) 显示了向分布外基准的强迁移能力。 当在 LongMemEval-oracle、LongMemEval-s、MSC-Self-Instruct 和 MemBench 上进行零样本评估时,Memory-R2 在所有报告指标上都持续优于基础模型。 例如,在 LongMemEval-oracle 上,F1 分数从 27.88 提升到 50.60,其他基准上也观察到类似收益,说明学习到的记忆构建策略并不是简单过拟合训练基准。 其次,图2(b) 显示这些收益也能跨模型规模迁移。 对于 Qwen2.5-3B,提升尤其明显,F1 从 10.3 增加到 46.8,这说明我们的训练范式对容量较小的模型尤其有益,因为有效长程记忆构建对它们来说原本很难学习。 第三,图2(c) 分解了训练记忆模块与训练答案智能体的贡献。 主要收益来自训练记忆模块(例如,使用 7B-Base 答案智能体时 F1 从 26.4 到 45.2;使用 GPT-OSS 答案智能体时 F1 从 30.6 到 49.7),而在固定强化学习训练过的记忆时改变答案智能体,也能得到相当高的分数。 这表明 Memory-R2 的收益能够迁移到多种下游答案智能体。 总体而言,这些结果表明 Memory-R2 学到的是稳健且可迁移的记忆构建策略,而不是过拟合到特定基准、模型规模或答案智能体。
| Variants | F1 ↑ | B1 ↑ | J ↑ | M-Fail ↓ |
|---|---|---|---|---|
| LoGo-GRPO (full) | 49.67 | 43.77 | 87.10 | 6.72 |
| RL Algorithm Ablation | ||||
| GRPO | 46.62 (-3.05) | 40.97 (-2.80) | 82.76 (-4.34) | 10.20 (+3.48) |
| -curriculum | 24.12 (-25.55) | 20.67 (-23.10) | 45.99 (-41.11) | 46.50 (+39.78) |
| -length norm. | 43.53 (-6.14) | 38.10 (-5.67) | 77.20 (-9.90) | 8.30 (+1.58) |
| Architecture Ablation | ||||
| Single agent | 39.14 (-10.53) | 33.93 (-9.84) | 72.63 (-14.47) | 18.00 (+11.28) |
| Separate params | 44.31 (-5.36) | 38.59 (-5.18) | 78.89 (-8.21) | 33.00 (+26.28) |
| Chunks Ablation | ||||
| N = 4 | 40.39 (-9.28) | 35.16 (-8.61) | 73.92 (-13.18) | 14.50 (+7.78) |
| N = 8 | 41.37 (-8.30) | 36.15 (-7.62) | 75.58 (-11.52) | 22.70 (+15.98) |
| N = 10 | 37.61 (-12.06) | 32.61 (-11.16) | 70.05 (-17.05) | 37.20 (+30.48) |
| Training Target Ablation | ||||
| memory manager | 45.34 (-4.33) | 39.99 (-3.78) | 81.20 (-5.90) | 16.10 (+9.38) |
| fact extractor | 28.30 (-21.37) | 24.41 (-19.36) | 52.90 (-34.20) | 56.50 (+49.78) |
4.3 Ablation Studies
Table 2 summarizes ablations on the major components of our method, with M-Fail reported as a diagnostic measure of memory quality. Replacing LoGo-GRPO with standard GRPO degrades F1 from 49.67 to 46.62 and B1 from 43.77 to 40.97, confirming the benefit of global-local credit assignment. Figure 3(a, b) shows this gap holds at every stage across question types, indicating that local rerollouts consistently mitigate credit-assignment bias. Removing curriculum learning (
表2总结了我们方法主要组件的消融,并报告 M-Fail 作为记忆质量的诊断度量。 用标准 GRPO 替换 LoGo-GRPO 会使 F1 从 49.67 降到 46.62、B1 从 43.77 降到 40.97,确认了全局-局部信用分配的收益。 图3(a, b) 表明这一差距在各个阶段和问题类型上都成立,说明局部重新 rollout 持续缓解了信用分配偏差。 移除课程学习(
For the memory-construction architecture, a single-agent variant merging extraction and editing into one role drops to 39.14 F1, and a separate-params variant where the extractor and manager use disjoint parameters also underperforms (44.31 F1), supporting both explicit role decomposition and parameter sharing. Alternative interaction depths likewise underperform the full multi-step design (40.39 / 41.37 / 37.61 F1 for
对于记忆构建架构,把抽取和编辑合并到一个角色中的单智能体变体会降到 39.14 F1,而抽取器和管理器使用互不相交参数的 separate-params 变体也表现更差(44.31 F1),这同时支持显式角色分解和参数共享。 替代交互深度同样不如完整多步设计(
4.4 More Analysis: Latency and Compression
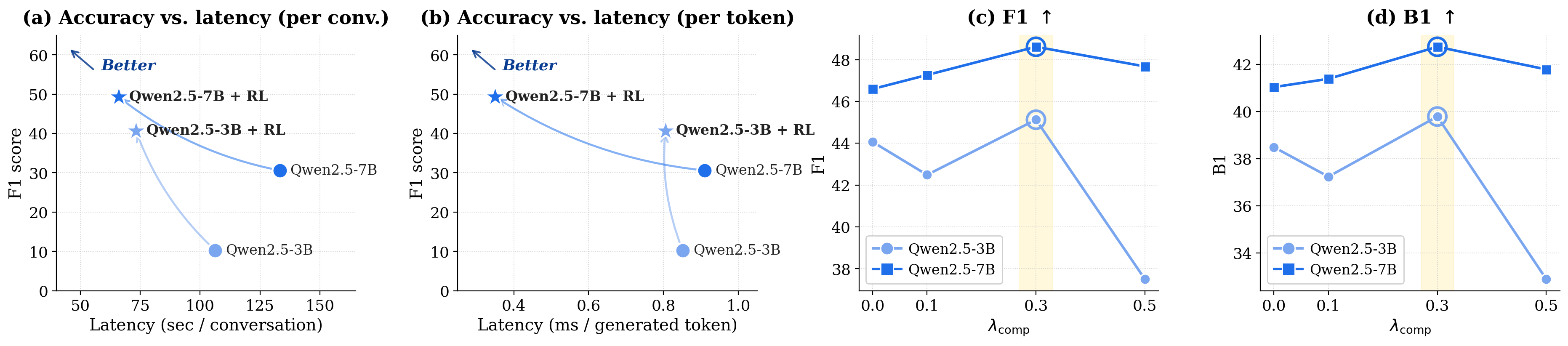
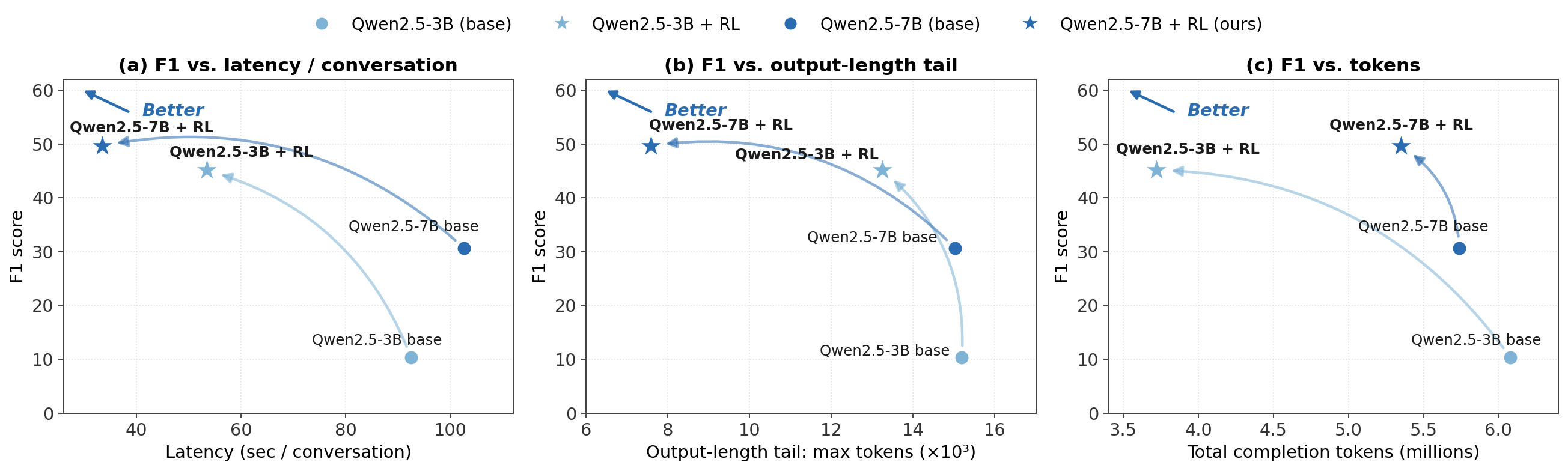
Latency. Figure 4(a,b) compares F1 and inference latency before and after Memory-R2 training. Memory-R2 improves F1 while reducing latency for both Qwen2.5-3B and Qwen2.5-7B under the per-conversation measurement, moving both models toward a better quality--efficiency regime. The source of this latency reduction differs across scales. For Qwen2.5-3B, the gain is mainly driven by more concise generations: the trained policy emits fewer tokens per memory-construction turn. For Qwen2.5-7B, the gain comes not only from shorter generations, but also from a more stable generation-length distribution: the untrained policy occasionally produces overly long memory-management outputs, whereas Memory-R2 suppresses these unnecessary generations, reducing decoding work and making memory construction more stable. We provide a diagnostic breakdown of these scale-dependent mechanisms in Appendix Figure 1. These results suggest that better-trained memory policies can improve answer quality without incurring additional inference overhead, and can even reduce latency by making memory construction more concise and stable.
延迟。 图4(a,b) 比较了 Memory-R2 训练前后的 F1 和推理延迟。 在按每个对话测量时,Memory-R2 对 Qwen2.5-3B 和 Qwen2.5-7B 都同时提升 F1 并降低延迟,使两个模型都进入更好的质量-效率区间。 这种延迟下降的来源在不同规模上有所不同。 对于 Qwen2.5-3B,收益主要来自更简洁的生成:训练后的策略在每个记忆构建轮次中输出更少 token。 对于 Qwen2.5-7B,收益不仅来自更短的生成,也来自更稳定的生成长度分布:未训练策略偶尔会产生过长的记忆管理输出,而 Memory-R2 抑制了这些不必要生成,从而减少解码工作并使记忆构建更稳定。 我们在附图1中提供了这些规模相关机制的诊断分解。 这些结果表明,更好训练的记忆策略可以在不增加额外推理开销的情况下提升答案质量,甚至可以通过让记忆构建更简洁、更稳定来降低延迟。
Compression. Figure 4(c,d) studies the effect of the compression penalty
压缩。 图4(c,d) 研究了压缩惩罚
gpt-4o-mini 作为 judge model 计算。| Model | Category | F1 ↑ | B1 ↑ | J ↑ |
|---|---|---|---|---|
| Memory-R2 | Single-hop | 54.06 ± 2.12 | 48.73 ± 2.26 | 86.80 ± 0.48 |
| Multi-hop | 38.41 ± 0.91 | 30.90 ± 0.46 | 80.93 ± 1.52 | |
| Temporal | 59.65 ± 1.00 | 50.05 ± 1.10 | 69.90 ± 1.34 | |
| Open-domain | 20.76 ± 1.06 | 16.78 ± 0.66 | 67.53 ± 2.04 | |
| Overall | 50.60 ± 1.34 | 44.01 ± 1.37 | 80.99 ± 0.28 | |
| Memory-R2 (OSS) | Single-hop | 50.98 ± 0.45 | 45.79 ± 0.48 | 90.58 ± 1.56 |
| Multi-hop | 36.37 ± 1.63 | 29.79 ± 1.91 | 85.07 ± 1.41 | |
| Temporal | 62.48 ± 0.52 | 55.33 ± 0.42 | 83.33 ± 1.49 | |
| Open-domain | 30.22 ± 0.71 | 24.50 ± 1.11 | 74.14 ± 0.00 | |
| Overall | 49.67 ± 0.60 | 43.77 ± 0.59 | 87.10 ± 1.43 |
5. Conclusion
In this paper, we present Memory-R2, a training framework for long-horizon memory-augmented LLM agents that addresses a fundamental challenge in multi-session reinforcement learning: fair credit assignment under diverging memory states. Our method, LoGo-GRPO, combines global trajectory-level optimization with local rerollouts from shared intermediate memory states, enabling fairer session-level comparisons while preserving end-to-end long-horizon learning. Beyond credit assignment, Memory-R2 jointly optimizes memory formation and memory evolution through a shared extractor--manager policy, formulates memory construction as a multi-step decision process over chunked sessions, and stabilizes training with a curriculum over session horizon. Experiments show that Memory-R2 consistently outperforms prior memory-agent baselines on LoCoMo and generalizes well across out-of-distribution benchmarks, model scales, and answer agents. These results suggest that improving credit assignment is a key ingredient for training robust long-horizon memory agents, and we hope this work provides a useful foundation for future research on memory-centric RL for LLM agents.
在本文中,我们提出 Memory-R2,这是一个面向长程记忆增强 LLM 智能体的训练框架,用于解决多会话强化学习中的根本挑战:分化记忆状态下的公平信用分配。 我们的方法 LoGo-GRPO 将全局轨迹级优化与来自共享中间记忆状态的局部重新 rollout 结合起来,在保留端到端长程学习的同时实现更公平的会话级比较。 除了信用分配之外,Memory-R2 还通过共享抽取器-管理器策略联合优化记忆形成和记忆演化,把记忆构建表述为分块会话上的多步决策过程,并使用跨会话跨度的课程学习稳定训练。 实验表明,Memory-R2 在 LoCoMo 上持续优于以往记忆智能体基线,并且能很好地跨分布外基准、模型规模和答案智能体泛化。 这些结果表明,改进信用分配是训练稳健长程记忆智能体的关键要素;我们希望这项工作为未来面向记忆的 LLM 智能体强化学习研究提供有用基础。