
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
MemoryAgentRLLMUMCMLTUMCambridgeMemory-R1:通过强化学习增强大语言模型智能体管理和利用记忆的能力
Abstract
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking a learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns structured operations, including ADD, UPDATE, DELETE, and NOOP; and an Answer Agent that pre-selects and reasons over relevant entries. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management with minimal supervision. With only 152 training QA pairs, Memory-R1 outperforms strong baselines and generalizes across diverse question types, three benchmarks (LoCoMo, MSC, LongMemEval), and multiple model scales (3B–14B).
大语言模型(LLMs)在广泛的 NLP 任务中展现出令人印象深刻的能力,但它们本质上仍然是 无状态的,受限于有限的上下文窗口,从而妨碍长程推理。 近期为解决这一局限的工作通常为 LLM 增加外部记忆库,但大多数现有流程是静态且由启发式驱动的,缺少一种学习到的机制来决定应该存储、更新或检索什么。 我们提出 Memory-R1,这是一个强化学习(RL)框架,通过两个专门化智能体赋予 LLM 主动管理和利用外部记忆的能力:一个 Memory Manager 学习结构化操作,包括 ADD、UPDATE、DELETE 和 NOOP;一个 Answer Agent 预先选择相关条目并基于它们进行推理。 两个智能体都使用结果驱动的 RL(PPO 和 GRPO)进行微调,从而以最少监督实现自适应记忆管理。 仅使用 152 个训练问答对,Memory-R1 就优于强基线,并能泛化到多样问题类型、三个基准(LoCoMo、MSC、LongMemEval)以及多个模型规模(3B–14B)。
1. Introduction
Large Language Models (LLMs) have shown remarkable ability in understanding and generating natural language, making them central to recent advances in AI. Yet, they remain fundamentally stateless: their memory is bounded by a finite context window and any information that falls outside this window is forgotten, preventing them from maintaining knowledge across long conversations or evolving tasks.
大语言模型(LLMs)在理解和生成自然语言方面展现出卓越能力,使其成为近期 AI 进展的核心。 然而,它们本质上仍然是 无状态的:它们的记忆受有限上下文窗口约束,任何落在该窗口之外的信息都会被遗忘,从而阻止它们在长对话或演化任务中维持知识。
One early effort is the Tensor Brain framework, which uses a bilayer tensor network with index and representation layers to model episodic, semantic, and working memory. Recent studies augment LLMs with explicit external memory modules, most of which adopt the retrieval-augmented generation (RAG) paradigm, appending retrieved memory entries to the model's input prompt. While this extends access to past information, it also creates a fundamental retrieval challenge: heuristics may return too few entries, omitting crucial context, or too many, flooding the model with irrelevant information and degrading performance. In this paradigm, retrieved memories are passed to the LLM without meaningful filtering or prioritization, forcing the model to reason over both relevant and irrelevant content, which makes it prone to distraction by noise. Humans, by contrast, retrieve broadly but then filter, integrating only the most useful pieces to maintain coherent, evolving knowledge.
一个早期尝试是 Tensor Brain 框架,它使用包含索引层和表示层的双层张量网络来建模情景记忆、语义记忆和工作记忆。 近期研究为 LLM 增加显式外部记忆模块,其中大多数采用检索增强生成(RAG)范式,将检索到的记忆条目附加到模型输入提示中。 虽然这扩展了对过去信息的访问,但也带来了一个根本性的检索挑战:启发式方法可能返回过少条目,遗漏关键上下文;也可能返回过多条目,用无关信息淹没模型并降低性能。 在这一范式中,检索记忆未经有意义的过滤或优先级排序就传给 LLM,迫使模型同时基于相关和无关内容进行推理,使其容易被噪声分散注意力。 相比之下,人类会先广泛检索,再进行过滤,只整合最有用的片段以维持连贯且不断演化的知识。
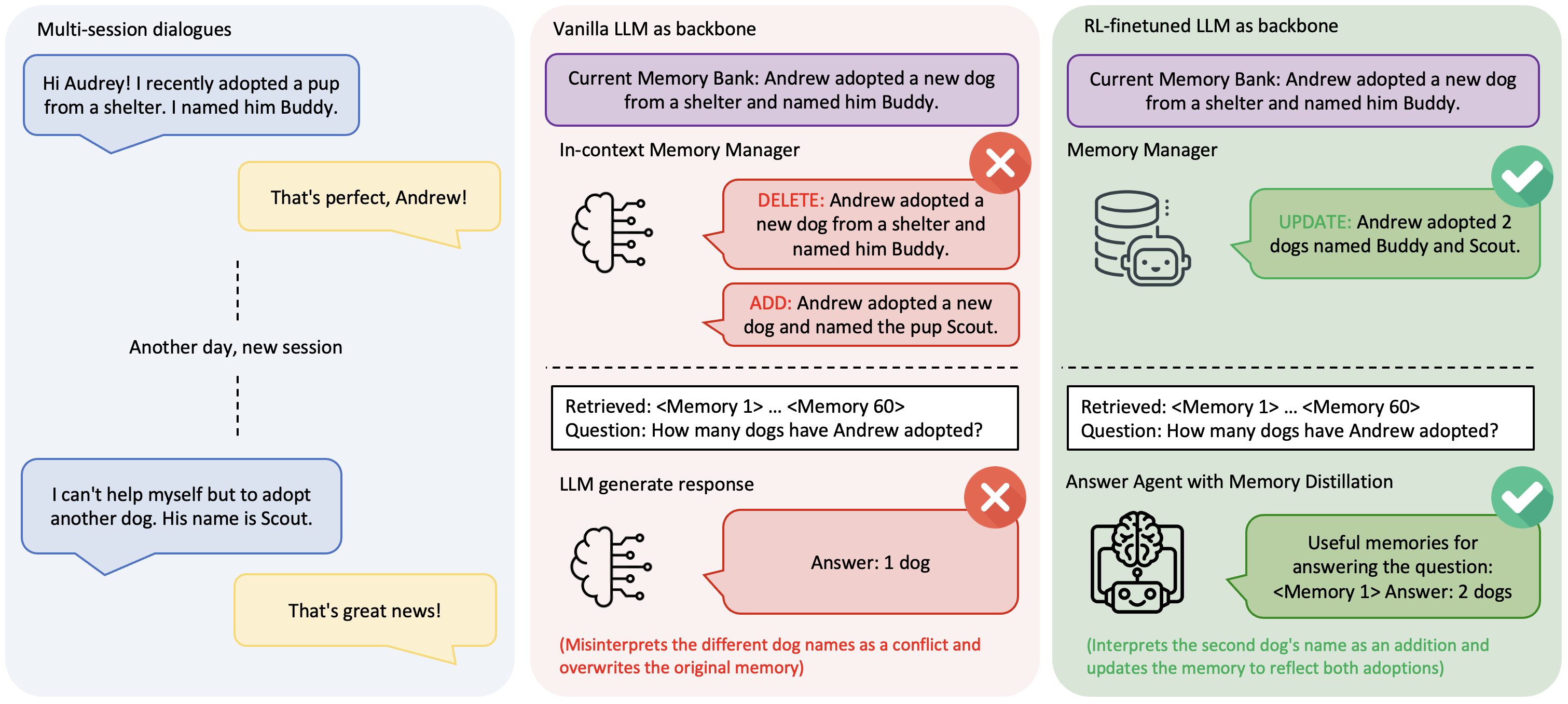
Equally important is the challenge of memory management: deciding what to remember, update, or discard. Some systems adopt CRUD-style operations, namely create, read, update, and delete, which are adapted from databases. A more recent work augments this paradigm with a search operator, while Mem0 investigates the operator set {ADD, UPDATE, DELETE, NOOP}. We adopt this setting, as it provides a minimal yet expressive framework for modeling memory dynamics. Existing approaches mainly rely on vanilla LLMs to choose operations from in-context instructions without any learning signal tied to correctness. Even simple cases can fail. Figure 1, a simplified example drawn from a LoCoMo conversation, shows how a user says "I adopted a dog named Buddy" and later adds "I adopted another dog named Scout". A vanilla system misinterprets this as a contradiction, issuing DELETE+ADD and overwriting the original memory. A trained agent instead consolidates with an UPDATE: "Andrew adopted two dogs, Buddy and Scout." Appendix provides a real dialogue trace illustrating this case in practice.
同样重要的是 记忆管理 挑战:决定应该记住、更新或丢弃什么。 一些系统采用 CRUD 风格的操作,即创建、读取、更新和删除,这些操作改编自数据库。 一项更近期的工作在这一范式中加入搜索算子,而 Mem0 则研究 {ADD, UPDATE, DELETE, NOOP} 这一操作集合。 我们采用这一设置,因为它为建模记忆动态提供了一个极简但表达力充足的框架。 现有方法主要依赖普通 LLM 根据上下文指令选择操作,却没有任何与正确性绑定的学习信号。 即使简单案例也可能失败。 图1 展示了一个来自 LoCoMo 对话的简化示例:用户先说 “I adopted a dog named Buddy”,之后又补充 “I adopted another dog named Scout”。 普通系统将其误解为矛盾,发出 DELETE+ADD 并覆盖原始记忆。 训练后的智能体则用 UPDATE 进行合并:"Andrew adopted two dogs, Buddy and Scout." 附录提供了一个真实对话轨迹,说明这一案例在实践中的表现。
These challenges of retrieving and managing memory remain largely unsolved. Supervised fine-tuning provides limited help because it is impractical to label every memory operation or retrieval decision. Reinforcement learning (RL), in contrast, has recently shown strong potential for aligning LLM behavior with high-level objectives, including tool use, web navigation, and search optimization. Building on this success, we argue that RL is the missing ingredient for adaptive memory in LLM agents. By optimizing outcome-based rewards, models can learn when to add, update, delete, or retain information and how to use retrieved memories for reasoning.
这些记忆检索和管理挑战在很大程度上仍未解决。 监督微调帮助有限,因为为每一次记忆操作或检索决策标注标签并不现实。 相比之下,强化学习(RL)近期在将 LLM 行为与高层目标对齐方面展现出强大潜力,包括工具使用、网页导航和搜索优化。 基于这些成功,我们认为 RL 是 LLM 智能体自适应记忆所缺失的关键要素。 通过优化基于结果的奖励,模型可以学习何时添加、更新、删除或保留信息,以及如何使用检索到的记忆进行推理。
In this paper, we present Memory-R1, an RL fine-tuned, memory-augmented LLM framework with two specialized agents: (1) a Memory Manager that performs structured memory operations to maintain and evolve the memory bank, and (2) an Answer Agent that applies a Memory Distillation policy to filter memories retrieved via Retrieval-Augmented Generation (RAG) and reason over the selected entries to produce answers. Both agents are fine-tuned using PPO or GRPO, achieving strong performance with as few as 152 question-answer pairs. On the LoCoMo benchmark, Memory-R1 delivers substantial gains over the most competitive baseline, Mem0. Using the LLaMA-3.1-8B-Instruct backbone, Memory-R1-GRPO achieves relative improvements of 28% in F1, 34% in BLEU-1, and 30% in LLM-as-a-Judge. These improvements set a new state of the art on LoCoMo and underscore Memory-R1's ability to achieve large performance gains with minimal supervision, highlighting its efficiency.
在本文中,我们提出 Memory-R1,这是一个经过 RL 微调的记忆增强型 LLM 框架,包含两个专门化智能体:(1)Memory Manager 执行结构化记忆操作以维护并演化记忆库;(2)Answer Agent 应用 Memory Distillation 策略,过滤通过检索增强生成(RAG)检索到的记忆,并基于所选条目进行推理以生成答案。 两个智能体都使用 PPO 或 GRPO 微调,仅需 152 个问答对就能取得强性能。 在 LoCoMo 基准上,Memory-R1 相比最具竞争力的基线 Mem0 取得显著提升。 使用 LLaMA-3.1-8B-Instruct 骨干时,Memory-R1-GRPO 在 F1、BLEU-1 和 LLM-as-a-Judge 上分别取得 28%、34% 和 30% 的相对提升。 这些改进在 LoCoMo 上建立了新的最优结果,并凸显 Memory-R1 能够以最少监督获得大幅性能提升,体现出其效率。
Our contributions are summarized as follows: (1) We introduce Memory-R1, the first RL framework for memory-augmented LLMs, consisting of a Memory Manager to perform structured memory operations and an Answer Agent to filter and reason over memories retrieved via RAG. (2) We develop a data-efficient fine-tuning strategy using PPO and GRPO that enables Memory-R1 to achieve strong performance with as few as 152 question-answer pairs, demonstrating that large memory improvements can be achieved with minimal supervision. (3) We provide in-depth analysis of RL choices, model size, and memory design, offering actionable insights for building the next generation of memory-aware, reasoning-capable LLM agents.
我们的贡献总结如下:(1)我们提出 Memory-R1,这是首个用于记忆增强型 LLM 的 RL 框架,由用于执行结构化记忆操作的 Memory Manager 和用于过滤并推理 RAG 检索记忆的 Answer Agent 组成。 (2)我们开发了一种使用 PPO 和 GRPO 的数据高效微调策略,使 Memory-R1 仅用 152 个问答对就能取得强性能,表明用最少监督即可实现大幅记忆能力提升。 (3)我们深入分析 RL 选择、模型规模和记忆设计,为构建下一代具备记忆感知和推理能力的 LLM 智能体提供可执行洞见。
2. Related Work
2.1 Memory Augmented LLM-based Agents
LLMs have emerged as powerful general-purpose reasoners, capable of engaging in multi-turn dialogues, decomposing tasks into actionable steps, and leveraging prior context to guide decision making. However, their reliance on fixed-length context windows limits their ability to retain information over extended interactions. To overcome this, recent work augments LLM agents with external memory modules, enabling long-horizon reasoning and persistent knowledge accumulation through selective storage, retrieval, and updating of information. Several approaches illustrate this trend. LoCoMo introduces a benchmark to evaluate agents' ability to retrieve and reason over temporally distant conversational history. ReadAgent proposes a human-inspired reading agent that uses gist-based memory for reasoning over very long contexts. MemoryBank proposes a compositional memory controller for lifelong agent memory. MemGPT introduces working and long-term buffers with scheduling policies. For a broader perspective, we refer readers to the recent survey on memory systems in AI agents. While most existing approaches rely on static memory designs, our work instead develops a learnable memory system trained with reinforcement learning.
LLM 已成为强大的通用推理器,能够进行多轮对话、将任务分解为可执行步骤,并利用先前上下文来指导决策。 然而,它们依赖固定长度上下文窗口,这限制了它们在长期交互中保留信息的能力。 为克服这一问题,近期工作为 LLM 智能体增加外部记忆模块,通过选择性存储、检索和更新信息,实现长程推理和持久知识积累。 若干方法体现了这一趋势。 LoCoMo 引入了一个基准,用于评估智能体检索并推理时间上遥远的对话历史的能力。 ReadAgent 提出一种受人类启发的阅读智能体,使用基于要点的记忆来推理超长上下文。 MemoryBank 为终身智能体记忆提出组合式记忆控制器。 MemGPT 引入带调度策略的工作缓冲区和长期缓冲区。 关于更广泛的视角,我们建议读者参考近期关于 AI 智能体记忆系统的综述。 虽然大多数现有方法依赖静态记忆设计,但我们的工作转而开发一种通过强化学习训练的可学习记忆系统。
2.2 LLM and Reinforcement Learning
The intersection of LLM and RL has received increasing attention as researchers seek to move beyond static supervised fine-tuning and enable models to learn from dynamic, interactive feedback. Reinforcement Learning from Human Feedback (RLHF) is a foundational method used to align LLM outputs with human preferences. Recent works extend RL to more structured decision-making tasks for LLMs. For instance, Toolformer and ReAct-style agents frame tool use as an RL problem, where the LLM learns when to query external tools or APIs. Search-R1 trains LLMs to issue web search queries using RL to maximize final answer correctness. Similarly, the Trial and Error approach optimizes agents to select better reasoning paths. These approaches demonstrate that RL can improve complex behavior sequences in LLMs. However, memory management and utilization in LLMs remain underexplored in the RL setting. Existing memory-augmented LLM systems typically rely on heuristics to control memory operations, lacking adaptability and long-term optimization. Our work, Memory-R1, is among the first to frame memory operation selection, and the utilization of relevant memories as an RL problem.
随着研究者试图超越静态监督微调,并让模型从动态交互反馈中学习,LLM 与 RL 的交叉受到越来越多关注。 基于人类反馈的强化学习(RLHF)是一种用于将 LLM 输出与人类偏好对齐的基础方法。 近期工作将 RL 扩展到 LLM 的更结构化决策任务。 例如,Toolformer 和 ReAct 风格智能体将工具使用表述为 RL 问题,其中 LLM 学习何时查询外部工具或 API。 Search-R1 使用 RL 训练 LLM 发出网页搜索查询,以最大化最终答案正确性。 类似地,Trial and Error 方法优化智能体以选择更好的推理路径。 这些方法表明,RL 能改进 LLM 中复杂的行为序列。 然而,在 RL 设置下,LLM 的记忆管理和利用仍然探索不足。 现有记忆增强型 LLM 系统通常依赖启发式方法来控制记忆操作,缺乏适应性和长期优化。 我们的工作 Memory-R1 是首批将记忆操作选择以及相关记忆利用表述为 RL 问题的方法之一。
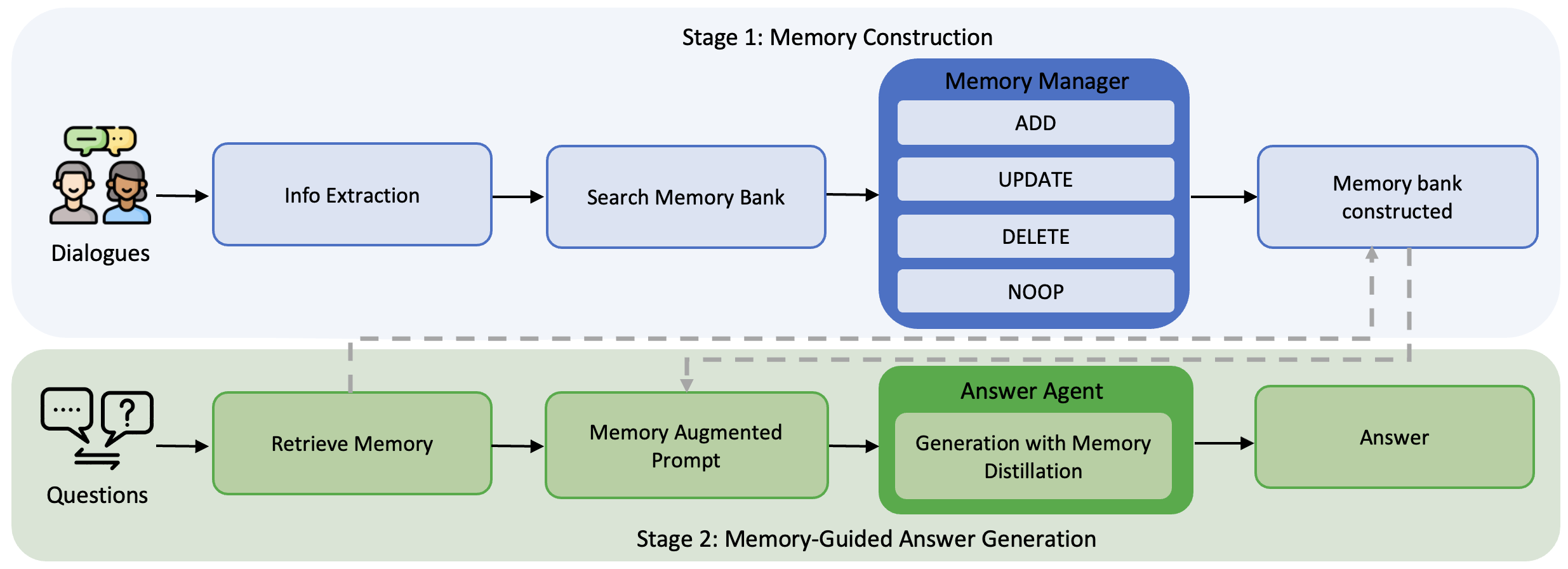
{ADD, UPDATE, DELETE, NOOP} 操作。阶段 2(绿色)通过 Answer Agent 回答用户问题,后者应用 Memory Distillation 策略,对检索记忆进行推理。3. Method
We present Memory-R1, a reinforcement learning framework for multi-session dialogue tasks, where each dialogue contains multiple sessions (separate interactions occurring at different times) and each session consists of several turns (a back-and-forth exchange between two users). Answering a question always requires synthesizing information spread across sessions, posing a strong challenge for long-horizon memory management and reasoning. Figure 2 illustrates the overall pipeline. At each dialogue turn, the LLM extracts and summarizes information worth remembering, then retrieves related entries from the memory bank as part of the Retrieval-Augmented Generation (RAG) framework. The Memory Manager decides whether to ADD, UPDATE, DELETE, or NOOP, thereby maintaining and evolving the memory state. For question answering, the Answer Agent applies a memory distillation policy over retrieved memories to filter noise and reason over the most relevant content. Both agents are fine-tuned with PPO or GRPO, enabling outcome-driven learning of memory operations and selective utilization. Further implementation details, such as model hyperparameters, optimization schedule, and training setup, are provided in Appendix.
我们提出 Memory-R1,这是一个用于多会话对话任务的强化学习框架,其中每个对话包含多个 会话(发生在不同时间的独立交互),每个会话由若干 轮次(两个用户之间的一来一回交流)组成。 回答问题总是需要综合分布在多个会话中的信息,因此对长程记忆管理和推理提出了强挑战。 图2 展示了整体流程。 在每个对话轮次中,LLM 抽取并总结值得记住的信息,然后作为检索增强生成(RAG)框架的一部分,从记忆库中检索相关条目。 Memory Manager 决定是否执行 ADD、UPDATE、DELETE 或 NOOP,从而维护并演化记忆状态。 对于问答,Answer Agent 在检索记忆上应用记忆蒸馏策略,以过滤噪声并基于最相关内容进行推理。 两个智能体都使用 PPO 或 GRPO 进行微调,从而实现结果驱动的记忆操作学习和选择性利用。 更多实现细节,如模型超参数、优化调度和训练设置,见附录。
3.1 RL Fine-tuning for Memory Manager
Task Formulation. The Memory Manager maintains the memory bank by selecting one of {ADD, UPDATE, DELETE, NOOP} for each new piece of information extracted from a dialogue, outputting both the operation and updated content
任务形式化。 Memory Manager 通过为从对话中抽取出的每条新信息选择 {ADD, UPDATE, DELETE, NOOP} 之一来维护记忆库,并同时输出操作和更新后的内容
where
其中
PPO for Memory Manager. We fine-tune the Memory Manager with Proximal Policy Optimization (PPO). Given candidate memory
Memory Manager 的 PPO。 我们使用 Proximal Policy Optimization(PPO)微调 Memory Manager。 给定候选记忆
where
其中
GRPO for Memory Manager. We also train the Memory Manager with Group Relative Policy Optimization (GRPO), which samples a group of
Memory Manager 的 GRPO。 我们还使用 Group Relative Policy Optimization(GRPO)训练 Memory Manager,它为每个状态采样一组
where each candidate
其中每个候选
Reward Design for Memory Manager. We use an outcome-driven reward: the Memory Manager's operations are judged by their effect on downstream QA. After applying operation
Memory Manager 的奖励设计。 我们使用结果驱动的奖励:Memory Manager 的操作根据其对下游问答的影响来评判。 在应用操作
where
其中
3.2 RL Fine-Tuning for Answer Agent
Task Formulation. The Answer Agent leverages the memory bank maintained by the Memory Manager to answer questions in multi-session dialogues. Following Mem0, 60 candidate memories are retrieved for each question via similarity-based RAG, and the agent performs memory distillation to select the most relevant entries before generating an answer. We model the agent as a policy
任务形式化。 Answer Agent 利用 Memory Manager 维护的记忆库来回答多会话对话中的问题。 遵循 Mem0,每个问题会通过基于相似度的 RAG 检索 60 条候选记忆,并且智能体在生成答案前执行 记忆蒸馏,选择最相关的条目。 我们将该智能体建模为策略
PPO for Answer Agent. We fine-tune the Answer Agent using the same PPO algorithm as in Section 3.1. The agent takes the question
Answer Agent 的 PPO。 我们使用与第 3.1 节相同的 PPO 算法来微调 Answer Agent。 该智能体接收问题
where
其中
GRPO for Answer Agent. We also fine-tune the Answer Agent with GRPO, following the formulation in Section 3.1. For each
Answer Agent 的 GRPO。 我们还遵循第 3.1 节的形式,使用 GRPO 微调 Answer Agent。 对于每个
Reward Design for Answer Agent. We use the Exact Match (EM) score between the generated answer
Answer Agent 的奖励设计。 我们使用生成答案
| Method | Single Hop | Multi-Hop | Open Domain | Temporal | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | F1↑ | B1↑ | J↑ | |
| LLaMA-3.1-8B-Instruct | |||||||||||||||
| LoCoMo (RAG) | 12.25 | 9.77 | 13.81 | 13.69 | 10.96 | 20.48 | 11.59 | 8.30 | 15.96 | 9.38 | 8.15 | 4.65 | 11.41 | 8.71 | 13.62 |
| A-Mem | 21.62 | 16.93 | 44.76 | 13.82 | 11.45 | 34.93 | 34.67 | 29.13 | 49.38 | 25.77 | 22.14 | 36.43 | 29.20 | 24.40 | 44.76 |
| Mem0 | 27.29 | 18.63 | 43.93 | 18.59 | 13.86 | 37.35 | 34.03 | 24.77 | 52.27 | 26.90 | 21.06 | 31.40 | 30.41 | 22.22 | 45.68 |
| MemoryOS | 31.89 | 23.05 | 52.72 | 13.80 | 12.78 | 31.33 | 40.74 | 33.67 | 57.36 | 28.74 | 21.44 | 23.64 | 35.04 | 27.99 | 48.20 |
| Memory-SFT | 34.64 | 23.73 | 56.90 | 20.80 | 16.26 | 37.35 | 46.47 | 37.35 | 63.27 | 47.18 | 34.58 | 54.65 | 42.81 | 32.98 | 58.76 |
| Memory-R1-PPO | 32.52 | 24.47 | 53.56 | 26.86 | 23.47 | 42.17 | 45.30 | 39.18 | 64.10 | 41.57 | 26.11 | 47.67 | 41.05 | 32.91 | 57.54 |
| Memory-R1-GRPO | 35.73 | 27.70 | 59.83 | 35.65 | 30.77 | 53.01 | 47.42 | 41.24 | 68.78 | 49.86 | 38.27 | 51.55 | 45.02 | 37.51 | 62.74 |
| Qwen-2.5-7B-Instruct | |||||||||||||||
| LoCoMo (RAG) | 9.57 | 7.00 | 15.06 | 11.84 | 10.02 | 19.28 | 8.67 | 6.52 | 12.79 | 8.35 | 8.74 | 5.43 | 8.97 | 7.27 | 12.17 |
| A-Mem | 18.96 | 12.86 | 40.78 | 14.73 | 12.66 | 31.32 | 30.58 | 26.14 | 46.90 | 23.67 | 20.67 | 28.68 | 26.08 | 21.78 | 40.78 |
| Mem0 | 24.96 | 18.05 | 61.92 | 20.31 | 15.82 | 48.19 | 32.74 | 25.27 | 65.20 | 33.16 | 26.28 | 38.76 | 30.61 | 23.55 | 53.30 |
| MemoryOS | 29.55 | 22.59 | 48.12 | 21.03 | 18.41 | 38.55 | 40.85 | 36.26 | 63.14 | 26.26 | 19.70 | 24.81 | 34.64 | 29.36 | 51.26 |
| Memory-SFT | 27.81 | 20.25 | 57.74 | 24.62 | 22.28 | 46.99 | 43.33 | 34.06 | 66.85 | 44.41 | 34.32 | 52.71 | 39.51 | 30.84 | 61.13 |
| Memory-R1-PPO | 34.22 | 23.61 | 57.74 | 32.87 | 29.48 | 53.01 | 44.78 | 38.72 | 66.99 | 42.88 | 30.30 | 42.25 | 41.72 | 33.70 | 59.53 |
| Memory-R1-GRPO | 33.64 | 26.06 | 62.34 | 23.55 | 20.71 | 40.96 | 46.86 | 40.92 | 67.81 | 47.75 | 38.49 | 49.61 | 43.14 | 36.44 | 61.51 |
4. Experiments
4.1 Experimental Setup
Dataset and Model. We evaluate Memory-R1 on three benchmarks: LoCoMo, MSC, and LongMemEval. LoCoMo contains long multi-session dialogues (about 600 turns, 26k tokens) with QA pairs covering single-hop, multi-hop, open-domain, and temporal reasoning. Following prior work, we exclude the adversarial subset and use a 1:1:8 train/validation/test split (152/81/1307 questions). Models are trained only on LoCoMo and evaluated zero-shot on MSC and LongMemEval. We use LLaMA-3.1-8B-Instruct and Qwen-2.5 Instruct backbones (3B, 7B, 14B). Dataset construction details are provided in Appendix.
数据集和模型。 我们在三个基准上评估 Memory-R1:LoCoMo、MSC 和 LongMemEval。 LoCoMo 包含长多会话对话(约 600 轮、26k token),问答对覆盖单跳、多跳、开放域和时间推理。 遵循先前工作,我们排除对抗子集,并使用 1:1:8 的训练/验证/测试划分(152/81/1307 个问题)。 模型仅在 LoCoMo 上训练,并在 MSC 和 LongMemEval 上进行零样本评估。 我们使用 LLaMA-3.1-8B-Instruct 和 Qwen-2.5 Instruct 骨干(3B、7B、14B)。 数据集构造细节见附录。
Evaluation Metrics. We evaluate performance using three metrics: token-level F1 (F1), BLEU-1 (B1), and LLM-as-a-Judge (J). F1 and B1 measure lexical overlap with ground-truth answers, while J uses a separate LLM to assess semantic correctness, relevance, completeness, and contextual appropriateness. Implementation details for LLM-as-a-Judge are provided in Appendix.
评估指标。 我们使用三个指标评估性能:token 级 F1(F1)、BLEU-1(B1)和 LLM-as-a-Judge(J)。 F1 和 B1 衡量与真实答案的词汇重叠,而 J 使用一个独立 LLM 来评估语义正确性、相关性、完整性和上下文适切性。 LLM-as-a-Judge 的实现细节见附录。
Baselines. To evaluate the effectiveness of Memory-R1, we compare it against several established baselines for multi-session dialogue reasoning: (1) LoCoMo, a RAG-style framework that converts entire dialogues into chunks and retrieves relevant segments for answering questions, serving as the benchmark baseline for long-range, multi-session conversation reasoning; (2) A-Mem, a dynamic agentic memory system that creates, links, and updates structured memories to enhance reasoning across sessions; (3) Mem0, a modular memory system with explicit in context memory operations designed for scalable deployment; (4) MemoryOS, a system-level framework that treats memory as an operating system abstraction for LLMs, providing unified mechanisms for memory read, write, and management across sessions to support long-horizon reasoning; (5) Memory-SFT. To isolate the effect of RL, we implement a supervised fine-tuning variant of our framework. Memory-SFT uses the same architecture and training data as Memory-R1 but replaces RL optimization with behavior cloning from GPT-5-generated trajectories. For a fair comparison, we re-implemented all baselines using both the LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct models as backbones, with temperature set to 0 and a maximum token limit of 2048. This consistent setup ensures reproducibility and allows us to assess how each method performs across different model architectures.
基线。 为评估 Memory-R1 的有效性,我们将其与若干成熟的多会话对话推理基线比较:(1)LoCoMo,一个 RAG 风格框架,将完整对话转换为分块并检索相关片段来回答问题,作为长距离多会话对话推理的基准基线;(2)A-Mem,一个动态智能体式记忆系统,创建、链接并更新结构化记忆,以增强跨会话推理;(3)Mem0,一个具有显式上下文内记忆操作的模块化记忆系统,面向可扩展部署而设计;(4)MemoryOS,一个系统级框架,将记忆视为 LLM 的操作系统抽象,为跨会话记忆读取、写入和管理提供统一机制,以支持长程推理;(5)Memory-SFT。 为隔离 RL 的作用,我们实现了框架的监督微调变体。 Memory-SFT 使用与 Memory-R1 相同的架构和训练数据,但将 RL 优化替换为来自 GPT-5 生成轨迹的行为克隆。 为了公平比较,我们使用 LLaMA-3.1-8B-Instruct 和 Qwen-2.5-7B-Instruct 作为骨干重新实现所有基线,温度设为 0,最大 token 限制为 2048。 这一一致设置确保了可复现性,并使我们能够评估每种方法在不同模型架构上的表现。

4.2 Main Results
Table 1 reports the performance of Memory-R1 across LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct models on the LoCoMo benchmark, covering diverse question types including single-hop, multi-hop, open-domain, and temporal reasoning. We evaluate two variants of Memory-R1, one fine-tuned with PPO and another with GRPO, and benchmark them against leading memory-augmented baselines, including LoCoMo (RAG), A-Mem, Mem0, MemoryOS and Memory-SFT.
表1 报告了 Memory-R1 在 LoCoMo 基准上跨 LLaMA-3.1-8B-Instruct 和 Qwen-2.5-7B-Instruct 模型的表现,覆盖单跳、多跳、开放域和时间推理等多样问题类型。 我们评估 Memory-R1 的两个变体,一个使用 PPO 微调,另一个使用 GRPO 微调,并将它们与领先的记忆增强基线比较,包括 LoCoMo (RAG)、A-Mem、Mem0、MemoryOS 和 Memory-SFT。
Across both model families, Memory-R1 consistently achieves new state-of-the-art performance. On LLaMA-3.1-8B, Memory-R1-GRPO delivers the strongest overall performance, improving F1 by 28.5%, B1 by 34.0%, and J by 30.2% relatively over the strongest baseline MemoryOS. Similarly, Memory-R1-PPO also yields substantial improvements, raising overall F1, B1, and J scores by 17.2%, 17.6%, and 19.4%, respectively. When applied to Qwen-2.5-7B-Instruct, Memory-R1-GRPO again emerges as the top performer, surpassing MemoryOS by margins of 24.5% (F1), 24.1% (B1), and 20.0% (J). PPO remains competitive, delivering strong gains over all non-RL baselines. Notably, while Memory-SFT benefits from guidance by a powerful teacher model (GPT-5), our reinforcement learning approach still outperforms it, highlighting the effectiveness of outcome-driven optimization over purely supervised imitation.
在两个模型家族上,Memory-R1 都持续取得新的最优性能。 在 LLaMA-3.1-8B 上,Memory-R1-GRPO 取得最强整体性能,相比最强基线 MemoryOS,F1、B1 和 J 分别相对提升 28.5%、34.0% 和 30.2%。 类似地,Memory-R1-PPO 也带来显著提升,使整体 F1、B1 和 J 分数分别提高 17.2%、17.6% 和 19.4%。 当应用于 Qwen-2.5-7B-Instruct 时,Memory-R1-GRPO 仍然是表现最佳者,分别以 24.5%(F1)、24.1%(B1)和 20.0%(J)的幅度超过 MemoryOS。 PPO 仍然具有竞争力,相比所有非 RL 基线都取得强提升。 值得注意的是,尽管 Memory-SFT 受益于强大教师模型(GPT-5)的指导,我们的强化学习方法仍然优于它,凸显了结果驱动优化相较纯监督模仿的有效性。
4.3 Generalization and Scalability
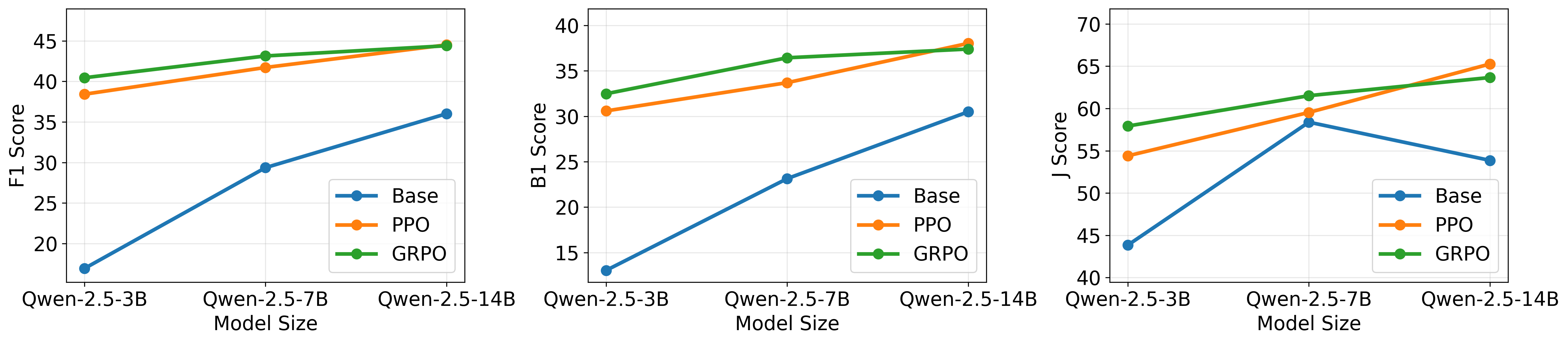
We further investigate the robustness of Memory-R1 across model scales and datasets. Figure 3 shows results on the Qwen-2.5 family (3B, 7B, 14B). Memory-R1 consistently outperforms the base model at every scale, with PPO and GRPO delivering clear gains in F1, BLEU-1, and J scores. These improvements persist as models scale, demonstrating that reinforcement learning remains effective in teaching LLMs memory management regardless of backbone capacity.
我们进一步研究 Memory-R1 在模型规模和数据集上的鲁棒性。 图3 展示了 Qwen-2.5 家族(3B、7B、14B)上的结果。 Memory-R1 在每个规模上都持续优于基础模型,PPO 和 GRPO 在 F1、BLEU-1 和 J 分数上都带来清晰收益。 这些改进在模型扩展时仍然保持,说明无论骨干容量如何,强化学习在教授 LLM 记忆管理方面仍然有效。
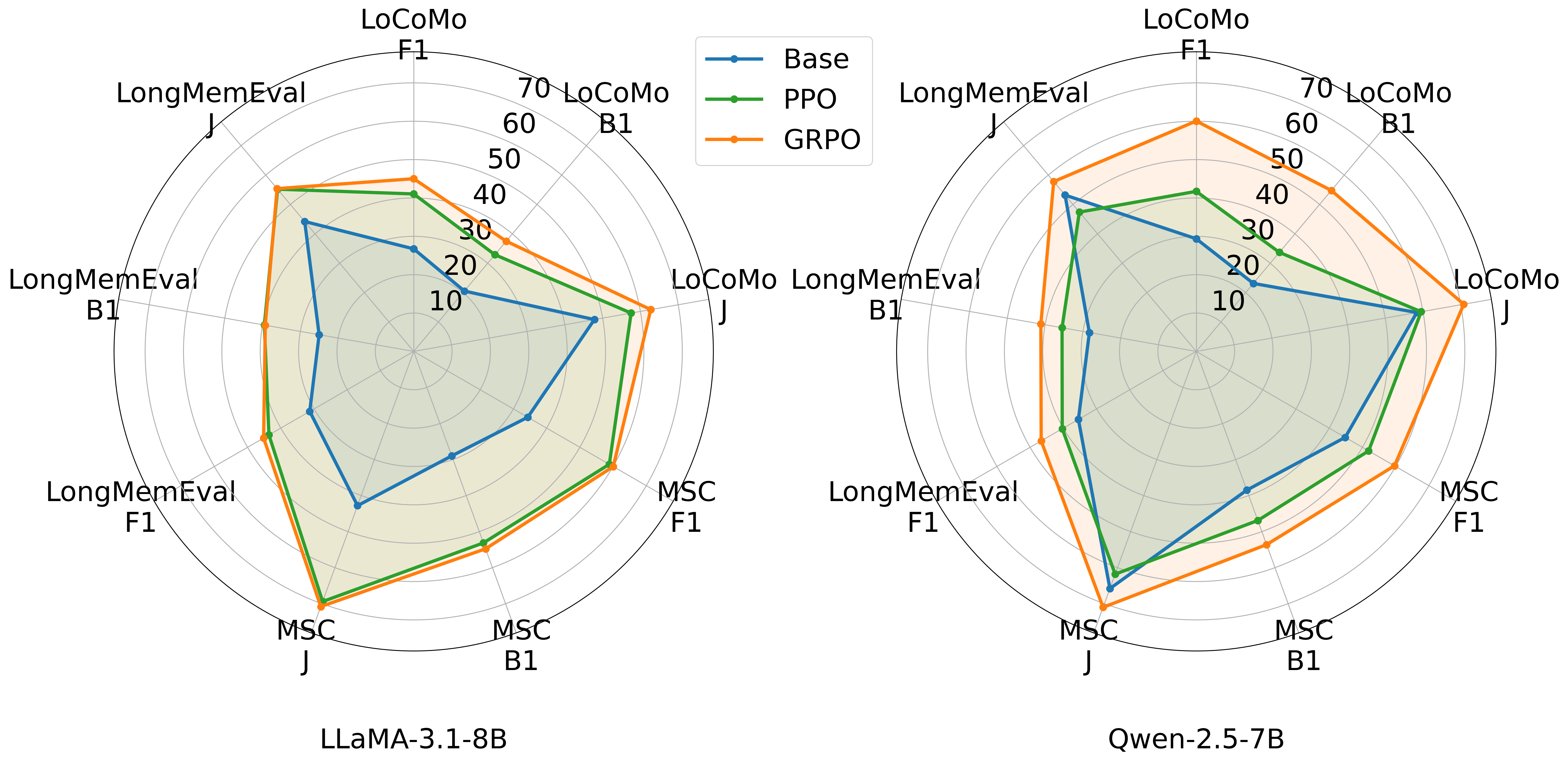
To evaluate cross-task generalization, we apply the pipeline fine-tuned only on LoCoMo directly to two additional benchmarks: MSC and LongMemEval. As shown in Figure 4, Memory-R1 with both PPO and GRPO continues to achieve consistent improvements across all three datasets and metrics, despite never being trained on MSC or LongMemEval. This zero-shot transfer highlights the robustness of Memory-R1 and shows its ability to generalize beyond its training distribution. The gains extend across single-hop, multi-hop, open-domain, and temporal questions, demonstrating Memory-R1 as a generalizable framework for adaptive, memory-augmented LLMs capable of long-horizon reasoning. Detailed results on LoCoMo, MSC, and LongMemEval, with type-level breakdowns, are provided in Appendix.
为评估跨任务泛化,我们将仅在 LoCoMo 上微调的流程直接应用到另外两个基准:MSC 和 LongMemEval。 如 图4 所示,尽管从未在 MSC 或 LongMemEval 上训练,使用 PPO 和 GRPO 的 Memory-R1 仍在三个数据集和三个指标上持续取得一致改进。 这种零样本迁移凸显了 Memory-R1 的鲁棒性,并展示了其泛化到训练分布之外的能力。 这些收益覆盖单跳、多跳、开放域和时间问题,表明 Memory-R1 是一个可泛化框架,能支持具备长程推理能力的自适应记忆增强型 LLM。 LoCoMo、MSC 和 LongMemEval 的详细结果及类型级拆解见附录。
4.4 Ablation Studies
We conduct ablation studies to assess the contribution of each component in Memory-R1, isolating the effects of the Memory Manager, the Answer Agent, and the Memory Distillation mechanism. We also compare the training dynamics of PPO and GRPO.
我们进行消融研究,以评估 Memory-R1 中每个组件的贡献,分别隔离 Memory Manager、Answer Agent 和 Memory Distillation 机制的影响。 我们还比较 PPO 和 GRPO 的训练动态。
Effect of Memory Manager. We compare the full Memory-R1 pipeline with an ablated variant without RL fine-tuning of the Memory Manager, both using LLaMA-3.1-8B-Instruct. As shown in Figure 5 (a,d), removing the RL-fine-tuned Memory Manager consistently degrades performance. Under PPO, F1, BLEU-1, and LLM-as-a-Judge drop from 41.0, 32.9, and 57.5 to 34.5, 28.1, and 49.0, respectively. Under GRPO, the corresponding scores decrease to 37.5, 30.6, and 52.9. These results confirm that outcome-driven RL enables more effective memory operations than scripted control.
Memory Manager 的影响。 我们比较完整 Memory-R1 流程与去除 Memory Manager 的 RL 微调后的消融变体,二者都使用 LLaMA-3.1-8B-Instruct。 如 图5 (a,d) 所示,移除 RL 微调后的 Memory Manager 会持续降低性能。 在 PPO 下,F1、BLEU-1 和 LLM-as-a-Judge 分别从 41.0、32.9 和 57.5 下降到 34.5、28.1 和 49.0。 在 GRPO 下,对应分数下降到 37.5、30.6 和 52.9。 这些结果确认,结果驱动的 RL 能实现比脚本化控制更有效的记忆操作。
Effect of Answer Agent. Figure 5 (b,d) shows that RL fine-tuning the Answer Agent substantially improves answer quality. Without the Memory-R1 Answer Agent, PPO achieves F1, BLEU-1, and J scores of 32.5, 24.6, and 59.4, while GRPO reaches 33.0, 24.9, and 59.9. With the full pipeline, PPO improves to 41.0, 32.9, and 57.5, and GRPO further increases performance to 45.0, 37.5, and 62.7. This demonstrates that reward-driven fine-tuning enhances answer quality beyond static retrieval. A case study is provided in Appendix.
Answer Agent 的影响。 图5 (b,d) 表明,对 Answer Agent 进行 RL 微调显著提升答案质量。 没有 Memory-R1 Answer Agent 时,PPO 的 F1、BLEU-1 和 J 分数为 32.5、24.6 和 59.4,而 GRPO 达到 33.0、24.9 和 59.9。 使用完整流程后,PPO 提升到 41.0、32.9 和 57.5,GRPO 进一步提升到 45.0、37.5 和 62.7。 这表明,奖励驱动微调能在静态检索之外提升答案质量。 案例研究见附录。
Effect of Memory Distillation. We evaluate memory distillation by comparing Answer Agents trained with and without distillation (Figure 5 (c,d)). With distillation enabled, PPO improves from 39.3, 30.9, and 57.4 to 41.0, 32.9, and 57.5 on F1, BLEU-1, and J, respectively. GRPO shows larger gains, increasing from 41.0, 34.4, and 60.1 to 45.0, 37.5, and 62.7. These results indicate that filtering irrelevant memories reduces noise and improves reasoning.
Memory Distillation 的影响。 我们通过比较带蒸馏和不带蒸馏训练的 Answer Agent 来评估记忆蒸馏(图5 (c,d))。 启用蒸馏后,PPO 在 F1、BLEU-1 和 J 上分别从 39.3、30.9 和 57.4 提升到 41.0、32.9 和 57.5。 GRPO 显示出更大收益,从 41.0、34.4 和 60.1 增加到 45.0、37.5 和 62.7。 这些结果表明,过滤无关记忆能减少噪声并改进推理。
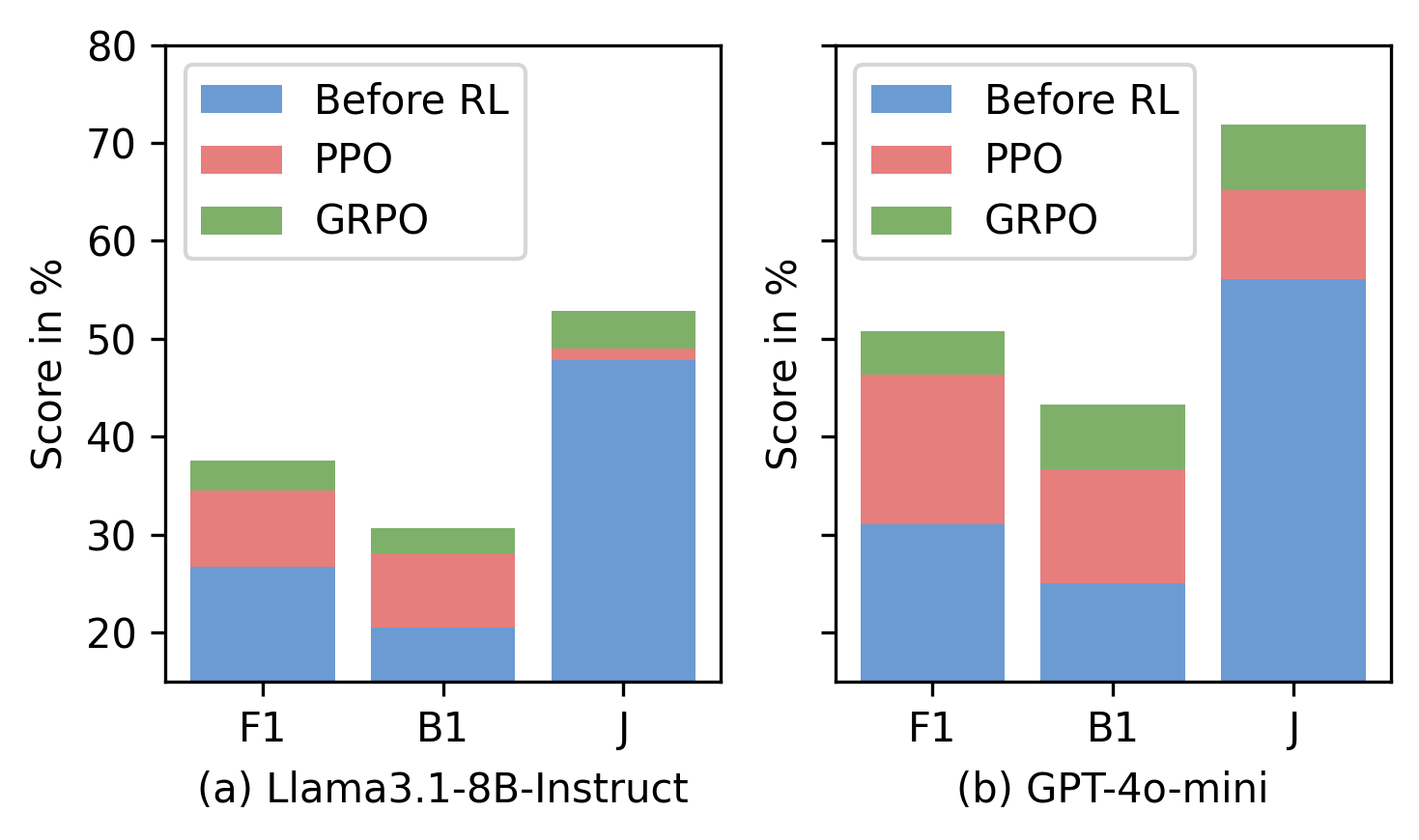
RL-Fine-Tuned Answer Agent Gains More with Stronger Memory Manager. We test whether Answer Agent gains depend on Memory Manager quality. Figure 6 compares PPO/GRPO agents with a LLaMA-3.1-8B manager versus a stronger GPT-4o-mini manager. Improvements are larger with the stronger manager (F1: +10.10 vs. +19.72; BLEU-1: +10.81 vs. +18.19; J: +5.05 vs. +15.76), showing that Memory-R1 compounds benefits and the Answer Agent scales with memory quality.
RL 微调 Answer Agent 在更强 Memory Manager 下获得更大收益。 我们测试 Answer Agent 的收益是否依赖 Memory Manager 质量。 图6 比较了使用 LLaMA-3.1-8B manager 与更强 GPT-4o-mini manager 时的 PPO/GRPO 智能体。 在更强 manager 下,改进更大(F1:+10.10 vs. +19.72;BLEU-1:+10.81 vs. +18.19;J:+5.05 vs. +15.76),说明 Memory-R1 的收益会叠加,且 Answer Agent 会随记忆质量扩展。
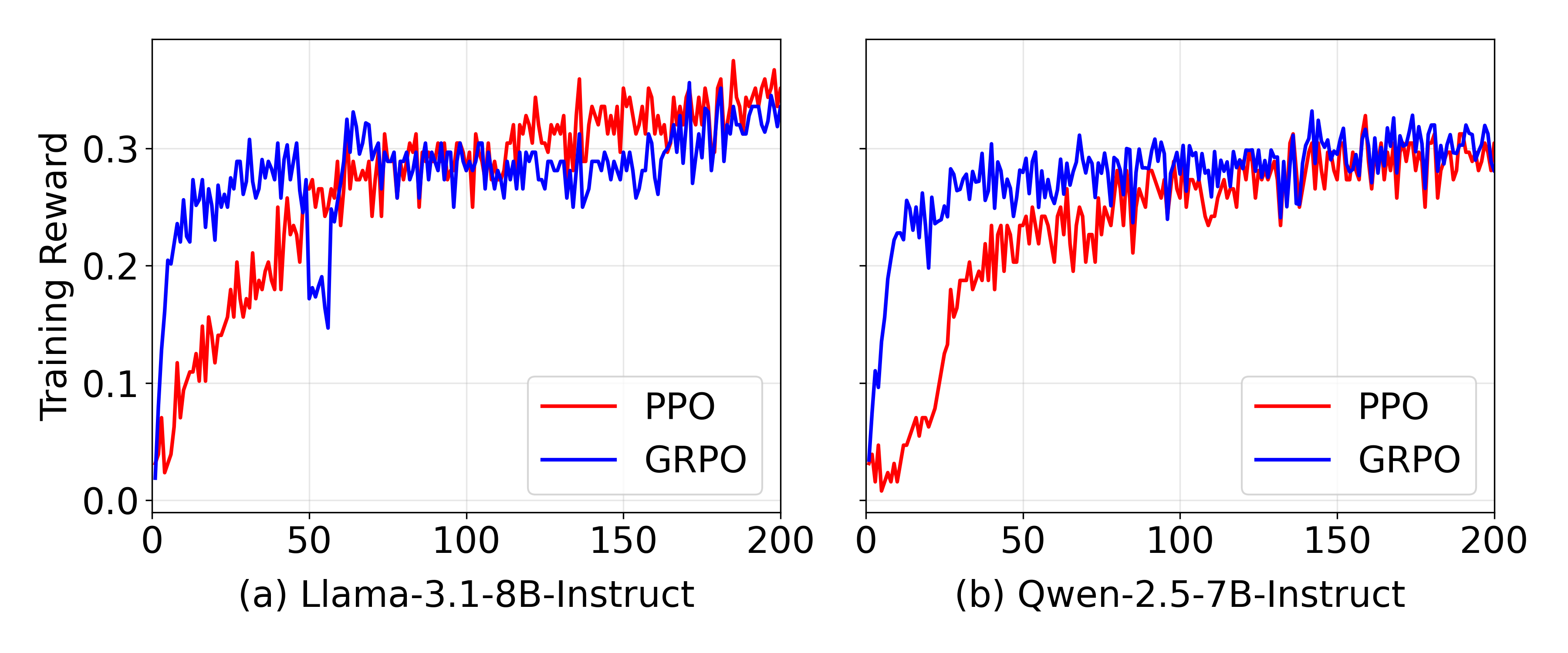
Comparison of RL Policies. We compare PPO and GRPO for training the Answer Agent, using exact match against ground-truth answers as the reward signal. As shown in Figure 7, GRPO exhibits faster initial convergence, likely due to its grouped return normalization providing stronger early guidance. However, as training progresses, both methods steadily improve and ultimately reach comparable final reward levels.
RL 策略比较。 我们比较 PPO 和 GRPO 在训练 Answer Agent 时的表现,使用相对于真实答案的精确匹配作为奖励信号。 如 图7 所示,GRPO 表现出更快的初始收敛,这可能是因为其分组回报归一化提供了更强的早期指导。 然而,随着训练推进,两种方法都稳定改进,并最终达到相近的最终奖励水平。
Reward Design Analysis. We experimented with different reward models for fine-tuning the Answer Agent. As shown in Table 2, using the LLM-as-a-Judge value as reward leads to the highest J score (63.58), but performs poorly on F1 and BLEU-1. This is because the reward encourages longer, descriptive answers, which misaligns with string-overlap metrics. For example, when asked "Did John and James study together?", the EM-based model outputs "Yes", while the LLM-as-a-Judge-based model produces "Yes, John and James studied together, as they were part of the same online programming group, as implied by the memories above." Although both are semantically correct, the latter is penalized under F1 and BLEU-1. This makes direct comparison with baselines difficult, since responses are no longer length-controlled. To avoid bias from relying on a single metric, we adopt the EM reward, which yields balanced improvements across all three metrics.
奖励设计分析。 我们尝试了不同奖励模型来微调 Answer Agent。 如 表2 所示,使用 LLM-as-a-Judge 值作为奖励会得到最高 J 分数(63.58),但在 F1 和 BLEU-1 上表现较差。 这是因为该奖励鼓励更长、更描述性的答案,而这与字符串重叠指标不一致。 例如,当被问到 “Did John and James study together?” 时,基于 EM 的模型输出 “Yes”,而基于 LLM-as-a-Judge 的模型输出 “Yes, John and James studied together, as they were part of the same online programming group, as implied by the memories above.” 虽然二者语义上都正确,但后者在 F1 和 BLEU-1 下会受到惩罚。 这使得与基线直接比较变得困难,因为回答长度不再受控。 为避免依赖单一指标带来的偏差,我们采用 EM 奖励,它在三个指标上都产生了更均衡的改进。
| Method | F1↑ | B1↑ | J↑ |
|---|---|---|---|
| PPO (J-based reward model) | 33.69 | 23.36 | 63.58 |
| PPO (EM-based reward model) | 41.05 | 32.91 | 57.54 |
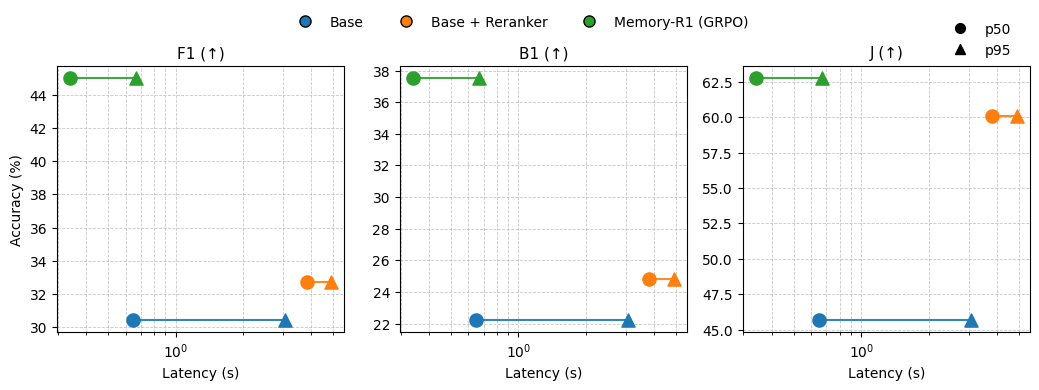
Comparison of Learned Memory Distillation and Reranking. We compare learned memory distillation in Memory-R1 with reranker-based pipelines in terms of accuracy and inference latency across three settings: Base, Base + Reranker, and Memory-R1 with a GRPO-trained Answer Agent (Figure 8). While reranking provides modest accuracy gains, it incurs substantial latency overhead. In contrast, Memory-R1 achieves higher accuracy with lower median and tail latency, demonstrating a more favorable accuracy-latency trade-off. Additional analyses are provided in Appendix.
学习式 Memory Distillation 与重排序比较。 我们在准确率和推理延迟方面比较 Memory-R1 中的学习式记忆蒸馏与基于重排序器的流程,覆盖三种设置:Base、Base + Reranker,以及带 GRPO 训练 Answer Agent 的 Memory-R1(图8)。 虽然重排序能带来适度准确率提升,但会产生显著延迟开销。 相比之下,Memory-R1 以更低的中位数和尾部延迟取得更高准确率,展示出更有利的准确率-延迟权衡。 更多分析见附录。
5. Conclusion
We presented Memory-R1, a reinforcement learning framework that enables LLM-based agents to effectively manage and utilize external memory. Unlike heuristic pipelines, Memory-R1 learns memory operations as well as memory distillation and usage for answering. With only 152 training examples, it achieves state-of-the-art results on LoCoMo, scales across model sizes, and generalizes to MSC and LongMemEval without retraining. Ablation studies confirm that reinforcement learning improves every component of the system. Overall, Memory-R1 highlights reinforcement learning as a promising direction for adaptive and agentic memory in LLMs.
我们提出了 Memory-R1,这是一个强化学习框架,使基于 LLM 的智能体能够有效管理和利用外部记忆。 不同于启发式流程,Memory-R1 会学习记忆操作,以及用于回答的记忆蒸馏和记忆使用。 仅用 152 个训练样本,它就在 LoCoMo 上取得最优结果,能跨模型规模扩展,并在无需重新训练的情况下泛化到 MSC 和 LongMemEval。 消融研究确认,强化学习改进了系统的每个组件。 总体而言,Memory-R1 凸显出强化学习是 LLM 中自适应且智能体式记忆的一个有前景方向。
Limitations
Our evaluation focuses on dialogue-centric datasets. While these benchmarks cover a wide range of reasoning types, extending Memory-R1 to multimodal data may introduce challenges beyond the scope of this work. Additionally, we train the Memory Manager and Answer Agent separately to ensure stability under sparse rewards. This separation is necessary but makes the process less straightforward. An end-to-end multi-agent reinforcement learning approach could simplify training and enable richer coordination, which we view as a promising direction for future work.
我们的评估聚焦于以对话为中心的数据集。 虽然这些基准覆盖广泛推理类型,但将 Memory-R1 扩展到多模态数据可能会引入超出本文范围的挑战。 此外,我们分别训练 Memory Manager 和 Answer Agent,以确保在稀疏奖励下的稳定性。 这种分离是必要的,但也使流程不够直接。 端到端多智能体强化学习方法可以简化训练并实现更丰富的协同,我们认为这是未来工作的一个有前景方向。