
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
MemoryBenchmark350+100+ICLR 2026CCF-A加利福尼亚大学圣迭戈分校通过增量多轮交互评估 LLM 智能体记忆
Abstract
Recent benchmarks for Large Language Model (LLM) agents primarily focus on evaluating reasoning, planning, and execution capabilities, while another critical component—memory, encompassing how agents memorize, update, and retrieve long-term information—is under-evaluated due to the lack of benchmarks. We term agents with memory mechanisms as memory agents. In this paper, based on classic theories from memory science and cognitive science, we identify four core competencies essential for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting. Existing benchmarks either rely on limited context lengths or are tailored for static, long-context settings like book-based QA, which do not reflect the interactive, multi-turn nature of memory agents that incrementally accumulate information. Moreover, no existing benchmarks cover all four competencies. We introduce MemoryAgentBench, a new benchmark specifically designed for memory agents. Our benchmark transforms existing long-context datasets and incorporates newly constructed datasets into a multi-turn format, effectively simulating the incremental information processing characteristic of memory agents. By carefully selecting and curating datasets, our benchmark provides comprehensive coverage of the four core memory competencies outlined above, thereby offering a systematic and challenging testbed for assessing memory quality. We evaluate a diverse set of memory agents, ranging from simple context-based and retrieval-augmented generation (RAG) systems to advanced agents with external memory modules and tool integration. Empirical results reveal that current methods fall short of mastering all four competencies, underscoring the need for further research into comprehensive memory mechanisms for LLM agents.
近期针对大语言模型(LLM)智能体的基准主要关注推理、规划和执行能力的评估,而另一个关键组成部分——记忆,即智能体如何记住、更新和检索长期信息——由于缺乏基准而评估不足。 作者将具备记忆机制的智能体称为记忆智能体。 本文基于记忆科学和认知科学中的经典理论,识别出记忆智能体所必需的四项核心能力:准确检索、测试时学习、长程理解和选择性遗忘。 现有基准要么依赖有限的上下文长度,要么面向书籍问答等静态长上下文场景,无法反映记忆智能体通过交互式多轮过程逐步积累信息的特性。 此外,目前还没有基准能够覆盖全部四项能力。 作者提出了 MemoryAgentBench,这是一个专门面向记忆智能体的新基准。 该基准将已有长上下文数据集转换为多轮形式,并纳入新构造的数据集,从而有效模拟记忆智能体的增量信息处理特征。 通过精心选择和整理数据集,该基准全面覆盖上述四项核心记忆能力,为评估记忆质量提供了系统且具有挑战性的测试平台。 作者评估了多种记忆智能体,从简单的上下文式和检索增强生成(RAG)系统,到具有外部记忆模块和工具集成的高级智能体。 实验结果表明,当前方法尚未掌握全部四项能力,这凸显出进一步研究 LLM 智能体综合记忆机制的必要性。
1. Introduction
Large Language Model (LLM) agents have rapidly transitioned from proof-of-concept chatbots to end-to-end systems that can write software, control browsers, and reason over multi-modal inputs. Frameworks such as Manus, OWL, OpenHands, and Codex routinely solve complex, tool-rich tasks and achieve state-of-the-art results on agentic benchmarks like GAIA and SWE-Bench. Yet these evaluations focus almost exclusively on reasoning (planning, tool using, code synthesis) and leave the equally important question of memorization (abstraction, storing, updating, retrieving) largely under-explored. Recent memory-centric architectures—ranging from parametric memory systems like MemoryLLM, SELF-PARAM, and M+ to commercial token-level memory solutions such as MemGPT, Mem0, Cognee, Zep and MIRIX—employ diverse strategies for storing and retrieving past information. Despite growing interest, their real-world effectiveness remains largely anecdotal, and there is currently no unified benchmark for systematically evaluating the quality of memory in agents. In this paper, we refer to agents equipped with memory mechanisms as Memory Agents, where memory can take various forms, including parameters, vectors, textual histories, or external databases. In this paper, we primarily focus on memory agents that utilize textual histories and external databases, as these approaches are most commonly deployed in real-world applications. In contrast, memory encoded in model parameters remains largely within academic research and is typically less capable than proprietary memory systems equipped on closed-sourced API models.
大语言模型(LLM)智能体已经迅速从概念验证式聊天机器人发展为端到端系统,能够编写软件、控制浏览器并对多模态输入进行推理。 Manus、OWL、OpenHands 和 Codex 等框架能够常规解决复杂且工具密集的任务,并在 GAIA 和 SWE-Bench 等智能体基准上取得最先进结果。 然而,这些评估几乎完全聚焦于推理(规划、工具使用、代码合成),而同样重要的记忆问题(抽象、存储、更新、检索)在很大程度上仍未得到充分探索。 近期以记忆为中心的架构——从 MemoryLLM、SELF-PARAM 和 M+ 等参数式记忆系统,到 MemGPT、Mem0、Cognee、Zep 和 MIRIX 等商业 token 级记忆方案——采用了多种存储和检索过去信息的策略。 尽管相关兴趣不断增长,它们在真实世界中的有效性仍主要停留在轶事层面,目前也没有统一基准来系统评估智能体中的记忆质量。 本文将配备记忆机制的智能体称为记忆智能体,其中记忆可以采取多种形式,包括参数、向量、文本历史或外部数据库。 本文主要关注利用文本历史和外部数据库的记忆智能体,因为这些方法在真实应用中最常部署。 相比之下,编码在模型参数中的记忆仍主要停留在学术研究中,并且通常不如闭源 API 模型所配备的专有记忆系统强大。
Based on some classic theories in memory and cognitive science, we identify four complementary competencies (Examples shown in Figure 1) to evaluate memory agents: (1) Accurate Retrieval (AR): The ability to extract the correct snippet in response to a query. This can involve one-hop or multi-hop retrieval, as long as the relevant information can be accessed with a single query. (2) Test-Time Learning (TTL): The capacity to incorporate new behaviors or acquire new skills during deployment, without additional training. (3) Long-Range Understanding (LRU): The ability to integrate information distributed across extended contexts (
基于记忆和认知科学中的一些经典理论,作者识别出四项互补能力(示例见 图1)来评估记忆智能体: (1)准确检索(AR):响应查询时提取正确片段的能力。 只要相关信息能够通过单次查询访问,这可以涉及一跳或多跳检索。 (2)测试时学习(TTL):在部署期间无需额外训练即可纳入新行为或获得新技能的能力。 (3)长程理解(LRU):整合分布在扩展上下文(

Previous datasets developed to evaluate memory in language models have notable limitations. Early benchmarks such as LOCOMO (
此前用于评估语言模型记忆的数据集存在明显局限。 LOCOMO(
To address these limitations, we introduce a unified benchmark, MemoryAgentBench, specifically designed to evaluate a broad spectrum of memory mechanisms in agent systems. We also provide a framework for memory agent evaluation. In this framework, agents are presented with sequences of textual inputs that simulate multi-turn interactions with users. We reconstructed existing datasets originally developed for long-context LLM evaluation by segmenting and reconstructing inputs into multiple dialogue chunks and feeding them incrementally to the agent in a time order. However, since these datasets do not fully capture all four targeted memory competencies, we also introduce two new datasets: EventQA and FactConsolidation, designed to evaluate accurate retrieval and selective forgetting, respectively. Our benchmark includes evaluations of state-of-the-art commercial memory agents (such as MIRIX and MemGPT), long-context agents that treat the full input as memory, and RAG agents that extend their memory through retrieval methods. We examine how techniques developed for long-context models and RAG transfer to the memory agent setting. By providing a consistent evaluation protocol across diverse agent architectures and datasets, MemoryAgentBench delivers comprehensive insights into agent performance across the four core memory competencies. In Table 1, we compare MemoryAgentBench with previous representative benchmarks across multiple dimensions.
为了解决这些局限,作者提出了一个统一基准 MemoryAgentBench,专门用于评估智能体系统中广泛的记忆机制。 作者还提供了一个记忆智能体评估框架。 在这一框架中,智能体会接收一系列文本输入,用于模拟与用户的多轮交互。 作者将原本为长上下文 LLM 评估开发的现有数据集进行重构:把输入切分并重组为多个对话 chunk,然后按时间顺序逐步喂给智能体。 不过,由于这些数据集无法完整覆盖四项目标记忆能力,作者还引入了两个新数据集:EventQA 和 FactConsolidation,分别用于评估准确检索和选择性遗忘。 该基准评估了最先进的商业记忆智能体(如 MIRIX 和 MemGPT)、将完整输入视为记忆的长上下文智能体,以及通过检索方法扩展记忆的 RAG 智能体。 作者考察了为长上下文模型和 RAG 开发的技术如何迁移到记忆智能体设定中。 通过为多样化的智能体架构和数据集提供一致的评估协议,MemoryAgentBench 能够全面洞察智能体在四项核心记忆能力上的表现。 在 表1 中,作者从多个维度将 MemoryAgentBench 与以往代表性基准进行比较。
Our contributions are summarized as follows:
- Datasets: We reconstruct existing datasets and create two new datasets to construct a comprehensive benchmark, covering four distinct memory competencies.
- Framework: We provide a unified evaluation framework, and open-source the codebase and datasets to encourage reproducibility and further research.
- Empirical Study: We implement various simple agents with diverse memory mechanisms, adopt commercial agents, and evaluate these agents on our proposed benchmark.
Our results demonstrate that existing memory agents, although effective in some tasks, still face significant challenges in certain aspects.
本文贡献总结如下:
- 数据集: 作者重构现有数据集,并创建两个新数据集来构建综合基准,覆盖四种不同的记忆能力。
- 框架: 作者提供统一评估框架,并开源代码库和数据集,以鼓励可复现性和进一步研究。
- 实证研究: 作者实现了多种具有不同记忆机制的简单智能体,采用商业智能体,并在所提出的基准上评估这些智能体。
结果表明,现有记忆智能体虽然在某些任务上有效,但在某些方面仍面临显著挑战。
2. Related Work
2.1 Benchmarks on Long-Context and Memory
In this section, we review prior work on evaluation benchmarks, categorizing them into three domains: long-context understanding, retrieval-augmented generation, and memory agents.
在本节中,作者回顾此前的评估基准工作,并将其分为三个领域:长上下文理解、检索增强生成和记忆智能体。
Benchmarks for Long-Context LLMs. Early benchmarks designed for long-context evaluation include LongBench and LooGLE, with average input lengths of approximately 20k and 24k tokens, respectively. More recent benchmarks--such as
长上下文 LLM 基准。 早期为长上下文评估设计的基准包括 LongBench 和 LooGLE,平均输入长度分别约为 20k 和 24k token。 较新的基准——例如
Benchmarks for Retrieval-Augmented Generation. Beyond pure long-context evaluation, a line of benchmarks targets retrieval-augmented generation (RAG) for knowledge-intensive tasks such as open-domain QA, fact checking, and document ranking over fixed corpora, e.g., KILT and BEIR. More recent work explicitly evaluates end-to-end RAG systems under long-context or application-specific scenarios, including LaRA, LONG
检索增强生成基准。 除了纯长上下文评估之外,还有一类基准面向检索增强生成(RAG),用于固定语料库上的开放域问答、事实核查、文档排序等知识密集型任务,例如 KILT 和 BEIR。 近期工作进一步显式评估长上下文或特定应用场景下的端到端 RAG 系统,包括 LaRA、LONG
Benchmarks for Memory Agents. More recently, benchmarks such as LOCOMO, LongMemEval, RealTalk and StoryBench have been proposed specifically for evaluating memory agents. While promising, LOCOMO still features relatively short conversations (
记忆智能体基准。 更近期,LOCOMO、LongMemEval、RealTalk 和 StoryBench 等基准被专门提出用于评估记忆智能体。 这些工作很有前景,但 LOCOMO 的对话仍相对较短(
| Benchmark | #Q | Context Depth | AR | TTL | LRU | SF | LCA | RAG | AM |
|---|---|---|---|---|---|---|---|---|---|
| MemoryBank | 194 | 5k | ✓ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| LoCoMo | 7512 | 10k | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| PerLTQA | 8593 | 1M* | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| RealTalk | 728 | 375k* | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
| LongMemEval | 500 | 115k, 1.5M | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ |
| StoryBench | 86 | - | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ |
| MemoryAgentBench | 2071 | 103k-1.44M | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
2.2 Agents with Memory Mechanisms
Memory mechanisms are attracting more and more attention lately. Recent advancements in LLMs have demonstrated the capability to process extended context lengths, ranging from 100K to over 1 million tokens. For instance, models such as GPT-4o and Claude 3.7 can handle inputs of approximately 100K to 200K tokens, while models like Gemini 2.0 Pro and the GPT-4.1 series extend this capacity beyond 1 million tokens. These strong long-context capabilities enable a simple yet effective form of memory: storing information directly within the context window. However, this approach is inherently constrained by a hard limit--once the context window is exceeded, earlier information must be discarded.
记忆机制近期正受到越来越多关注。 LLM 的最新进展表明,模型已经具备处理扩展上下文长度的能力,范围从 100K 到超过 100 万 token。 例如,GPT-4o 和 Claude 3.7 等模型可以处理约 100K 到 200K token 的输入,而 Gemini 2.0 Pro 和 GPT-4.1 系列等模型将这一能力扩展到超过 100 万 token。 这些强大的长上下文能力带来了一种简单而有效的记忆形式:直接在上下文窗口中存储信息。 然而,这种方法受到硬性上限的固有限制——一旦超过上下文窗口,较早的信息就必须被丢弃。
In parallel, RAG continues to serve as a dominant paradigm for managing excessive context. By retrieving relevant information from earlier context and feeding it to the LLM, RAG allows systems to overcome context length limitations. For example, OpenAI's recent memory functionality combines explicit user preference tracking with retrieval-based methods that reference prior interactions. RAG methods can be broadly classified into three categories: Simple RAG: These methods rely on string-matching techniques such as TF-IDF, BM25, and BMX, which are entirely non-neural and operate on string-level similarity. Embedding-based RAG: This class leverages neural encoders, primarily transformers, to map text into dense vector representations. Early methods like DPR and Contriever are based on BERT, while more recent models such as Qwen3-Embedding achieve significantly improved retrieval performance. Structure-Augmented RAG: These approaches enhance retrieval with structural representations such as graphs or trees. Representative systems include GraphRAG, RAPTOR, HippoRAG-V2, Cognee, Zep, MemoRAG, Mem0, MemoryOS, Memary and Memobase. Despite their effectiveness, RAG-based methods face challenges with ambiguous queries, multi-hop reasoning, and long-range comprehension. When questions require integrating knowledge across an entire session or learning from long, skill-encoding inputs, the retrieval mechanism--limited to the top-k most relevant passages--may fail to surface the necessary information.
与此同时,RAG 仍然是管理超长上下文的主导范式。 通过从早期上下文中检索相关信息并输入给 LLM,RAG 使系统能够克服上下文长度限制。 例如,OpenAI 近期的记忆功能将显式用户偏好跟踪与基于检索的方法结合起来,用于引用先前交互。 RAG 方法大体可分为三类: 简单 RAG:这些方法依赖 TF-IDF、BM25 和 BMX 等字符串匹配技术,它们完全非神经化,并基于字符串级相似度运行。 基于嵌入的 RAG:这一类方法利用神经编码器(主要是 Transformer)将文本映射为稠密向量表示。 DPR 和 Contriever 等早期方法基于 BERT,而 Qwen3-Embedding 等较新模型显著提升了检索性能。 结构增强 RAG:这些方法使用图或树等结构化表示增强检索。 代表性系统包括 GraphRAG、RAPTOR、HippoRAG-V2、Cognee、Zep、MemoRAG、Mem0、MemoryOS、Memary 和 Memobase。 尽管这些方法有效,基于 RAG 的方法在模糊查询、多跳推理和长程理解方面仍面临挑战。 当问题需要整合整个 session 中的知识,或需要从很长的技能编码输入中学习时,检索机制由于受限于 top-k 最相关片段,可能无法呈现必要信息。
To address these limitations, Agentic Memory Agents introduce an iterative, decision-driven framework. Rather than relying on a single-pass retrieval, these agents dynamically process the query, retrieve evidence, reflect, and iterate through multiple retrieval and reasoning cycles. Examples include MemGPT, Self-RAG, Auto-RAG, A-MEM, Mem1, MemAgent, and MIRIX. This agentic design is particularly effective for resolving ambiguous or multi-step queries. Nonetheless, these methods remain fundamentally constrained by the limitations of RAG--namely, the inability to fully understand or learn from long-range context that is inaccessible via retrieval alone.
为了解决这些局限,智能体式记忆智能体引入了一种迭代式、决策驱动的框架。 这些智能体不是依赖单次检索,而是动态处理查询、检索证据、反思,并在多个检索和推理循环中迭代。 例子包括 MemGPT、Self-RAG、Auto-RAG、A-MEM、Mem1、MemAgent 和 MIRIX。 这种智能体式设计对解决模糊或多步骤查询特别有效。 尽管如此,这些方法仍从根本上受限于 RAG 的局限,也就是无法充分理解或学习那些仅靠检索无法访问的长程上下文。
3. MemoryAgentBench
3.1 Dataset Preperation
In this section, we describe how we reconstruct existing datasets and build new ones for evaluating each competency aspect. All datasets with their categories are shown in Table 2. We introduce the details in datasets curation in Appendix.
本节描述作者如何重构现有数据集并构建新数据集,以评估每个能力方面。 所有数据集及其类别如 表2 所示。 作者在附录中介绍数据集整理的细节。
Datasets for Accurate Retrieval (AR) We adopt four datasets to evaluate the accurate retrieval capability of memory agents. Three are reconstructed from existing benchmarks, and one is newly created: (1) Document Question Answering: This is a NIAH-style QA task where a long passage contains single (SH-QA) or multiple (MH-QA) documents answering the input question. The agent must identify and extract relevant snippets from the extended context. (2) LongMemEval: This benchmark evaluates memory agents on long dialogue histories. Although task types like information extraction (IE) or multi-session reasoning are included, most tasks can be reformulated as single-retrieval problems requiring agents to retrieve the correct segments spanning a long multi-turn conversation. We reformulated chat history into five long dialogues (
准确检索(AR)数据集 作者采用四个数据集来评估记忆智能体的准确检索能力。 其中三个由现有基准重构而来,一个是新创建的:(1)文档问答:这是一个 NIAH 风格的问答任务,长篇段落中包含能够回答输入问题的单个(SH-QA)或多个(MH-QA)文档。 智能体必须从扩展上下文中识别并提取相关片段。 (2)LongMemEval:该基准在长对话历史上评估记忆智能体。 尽管其中包含信息抽取(IE)或多会话推理等任务类型,但多数任务都可以重构为单次检索问题,要求智能体检索跨越长多轮对话的正确片段。 作者将聊天历史重构为五段长对话(
Datasets for Test-Time Learning (TTL) We evaluate TTL via two task categories: (1) Multi-Class Classification (MCC): We reconstructed five classification datasets used in prior TTL work: BANKING77, CLINC150, TREC-Coarse, TREC-Fine, and NLU. Each task requires the agent to map sentences to class labels, leveraging previously seen labeled examples in context. (2) Recommendation: Based on the setup from previous work, we construct a dataset to evaluate movie recommendation via dialogue history. The agent is exposed to thousands of movie-related dialogue turns and is asked to recommend twenty relevant movies based on the long interaction history.
测试时学习(TTL)数据集 作者通过两类任务评估 TTL:(1)多类别分类(MCC):作者重构了此前 TTL 工作中使用的五个分类数据集:BANKING77、CLINC150、TREC-Coarse、TREC-Fine 和 NLU。 每个任务都要求智能体利用上下文中先前见过的带标签样例,将句子映射到类别标签。 (2)推荐:基于先前工作的设置,作者构建了一个数据集,通过对话历史评估电影推荐。 智能体会接触数千轮与电影相关的对话,并被要求基于长交互历史推荐二十部相关电影。
Datasets for Long Range Understanding (LRU) We evaluate LRU via two tasks: (1) Novel Summarization (Summ.): We adopt the Summarization task En.Sum from
长程理解(LRU)数据集 作者通过两个任务评估 LRU:(1)小说摘要(Summ.):作者采用 En.Sum。 智能体需要分析并组织小说的情节和人物,然后撰写一篇 1000 到 1200 词的摘要。 (2)Detective QA(Det QA):作者还从 Detective QA 创建了一个困难问题集,其中包含十部小说和 71 个问题,这些问题要求智能体在更长的叙事范围内进行推理。
Datasets for Selective Forgetting (SF) To assess whether an agent can forget out of date memory and reason over them, we construct a new dataset called FactConsolidation. Specifically, We build this benchmark using counterfactual edit pairs from MQUAKE. Each pair contains a true fact and a rewritten, contradictory version. These are ordered such that the rewritten (new) fact appears after the original, simulating a realistic update scenario. We concatenate multiple such edit pairs to create long contexts of length {6K, 32K, 64K, 262K}. We then adpot MQUAKE's original questions and categorize them into: (1) FactConsolidation-SH (Ours) (SH means Single-Hop), requiring direct factual recall (e.g., "Which country was tool
选择性遗忘(SF)数据集 为了评估智能体是否能够遗忘过期记忆并基于它们推理,作者构建了一个名为 FactConsolidation 的新数据集。 具体来说,作者使用 MQUAKE 中的反事实编辑对来构建该基准。 每一对都包含一个真实事实和一个重写后的矛盾版本。 它们被排列为重写后的(新)事实出现在原始事实之后,从而模拟真实的更新场景。 作者拼接多个这样的编辑对,创建长度为 {6K, 32K, 64K, 262K} 的长上下文。 随后,作者采用 MQUAKE 的原始问题,并将其分为:(1)FactConsolidation-SH(作者构建)(SH 表示 Single-Hop),要求直接事实回忆(例如,“工具
| Dataset | Metrics | AvgL. | Description |
|---|---|---|---|
| Accurate Retrieval | |||
| SH-Doc QA | Accuracy | 197K | Single-Hop Gold passage retrieval QA. |
| MH-Doc QA | Accuracy | 421K | Multiple-Hop Gold passage retrieval QA. |
| LongMemEval (S*) | Accuracy | 355K | Dialogues based QA. |
| EventQA | Accuracy | 534K | Novel multiple-choice QA on characters events. |
| Test-time Learning | |||
| BANKING77 | Accuracy | 103K | Banking-related intent classification. |
| CLINC150 | Accuracy | 103K | General-domain intent classification. |
| NLU | Accuracy | 103K | Natural language understanding benchmark. |
| TREC Coarse | Accuracy | 103K | Question type classification. |
| TREC Fine | Accuracy | 103K | Fine-grained question type classification. |
| Movie Recommendation | Recall@5 | 1.44M | Recommend movies based on provided dialogues examples. |
| Long Range Understanding | |||
| ∞Bench-Sum | F1-Score | 172K | Novel summarization with entity replacement. |
| Detective QA | Accuaracy | 124K | Long-range reasoning QA on detective novels. |
| Selective Forgetting | |||
| FactConsolidation-SH | Accuracy | 262K | Single hop reasoning in facts judgment. |
| FactConsolidation-MH | Accuracy | 262K | Multiple hop reasoning in facts judgment. |
3.2 Different Categories of Memory Agents
We evaluate three major types of memory agents that reflect common strategies for handling long-term information: Long-Context Agents, RAG Agents, and Agentic Memory Agents. These approaches differ in how they store, retrieve, and reason over past inputs.
作者评估三类主要记忆智能体,它们反映了处理长期信息的常见策略:长上下文智能体、RAG 智能体和智能体式记忆智能体。 这些方法在如何存储、检索并基于过去输入进行推理方面有所不同。
(1) Long Context Agents Modern language models often support extended context windows ranging from 128K to over 1M tokens. A straightforward strategy for memory is to maintain a context buffer of the most recent tokens. For example, in a model with a 128K-token limit, the agent concatenates all incoming chunks until the total exceeds the window size. Once the limit is reached, the earliest chunks are evicted in a FIFO (first-in, first-out) manner. This agent design relies solely on positional recency and assumes the model can attend effectively over the current context window.
(1)长上下文智能体 现代语言模型通常支持从 128K 到超过 1M token 的扩展上下文窗口。 一种直接的记忆策略是维护一个最近 token 的上下文缓冲区。 例如,在一个具有 128K token 上限的模型中,智能体会拼接所有输入 chunk,直到总长度超过窗口大小。 一旦达到上限,最早的 chunk 会以 FIFO(先进先出)方式被驱逐。 这种智能体设计完全依赖位置新近性,并假设模型能够有效关注当前上下文窗口。
(2) RAG Agents RAG-based agents address context limitations by storing past information in an external memory pool and retrieving relevant content as needed. We consider three RAG variants: Simple RAG Agents: All input chunks are stored as raw text. During inference, a keyword or rule-based string matching mechanism retrieves relevant passages. Embedding-based RAG Agents: Each input chunk is embedded and saved. At query time, the agent embeds the query and performs retrieval using cosine similarity between embeddings. Structure-Augmented RAG Agents: After ingesting all input chunks, the agent constructs a structured representation (e.g., knowledge graph or event timeline). Subsequent queries are answered based on this structured memory.
(2)RAG 智能体 基于 RAG 的智能体通过将过去信息存储在外部记忆池中,并按需检索相关内容,来解决上下文限制。 作者考虑三种 RAG 变体:简单 RAG 智能体:所有输入 chunk 都以原始文本形式存储。 推理时,关键词或基于规则的字符串匹配机制会检索相关段落。 基于嵌入的 RAG 智能体:每个输入 chunk 都会被嵌入并保存。 查询时,智能体嵌入查询,并使用嵌入之间的余弦相似度进行检索。 结构增强 RAG 智能体:在摄入所有输入 chunk 后,智能体构建结构化表示(例如知识图谱或事件时间线)。 后续查询会基于这种结构化记忆来回答。
(3) Agentic Memory Agents Agentic memory agents extend beyond static memory stores by employing agentic loops--iterative reasoning cycles in which the agent may reformulate questions, perform memory lookups, and update its working memory. These agents are designed to simulate a more human-like process of recalling, verifying, and integrating knowledge.
(3)智能体式记忆智能体 智能体式记忆智能体通过使用智能体循环,超越静态记忆存储;这种循环是迭代推理过程,智能体可以在其中重写问题、执行记忆查找,并更新工作记忆。 这些智能体旨在模拟更类似人类的回忆、验证和整合知识过程。
3.3 Datasets and Agents Formulation
Datasets Formulation We standardize all datasets into the format:
数据集形式化 作者将所有数据集标准化为以下格式:
Prompt Formulation and Interaction Protocol Unlike standard long-context evaluations that input raw text, we wrap all input chunks within a simulated User-Assistant dialogue to explicitly trigger the agent's memory mechanism. Each input chunk
提示形式化与交互协议 不同于输入原始文本的标准长上下文评估,作者将所有输入 chunk 包装在模拟的 User-Assistant 对话中,以显式触发智能体的记忆机制。 每个输入 chunk
Agents Formulation In our framework, all agents are required to take the chunks one by one, absorb them into memory, and incrementally update the memory. After seeing all the chunks, we ask the agent to answer the related questions. To guarantee fair comparison, we employed standardized prompt templates across all agents within each evaluation category, with only minimal adaptations where necessary.
智能体形式化 在作者的框架中,所有智能体都需要逐个接收 chunk,将其吸收到记忆中,并增量更新记忆。 在看到所有 chunk 后,作者要求智能体回答相关问题。 为了保证公平比较,作者在每个评估类别内对所有智能体使用标准化提示模板,只在必要时进行最小适配。
4. Experiments
4.1 Experimental Setup
The datasets are split into four categories and the statistics of all datasets are also shown in Table 2. The evaluation metrics for all datasets are shown in Table 2, along with more dataset details. For the agents, as described in Section 3.2, we consider three categories of agents: Long-Context Agents, RAG agents and Agentic Memory Agents, where RAG Agents can be further split into Simple RAG Agents, Embedding-based RAG Agents and Structure-Augmented RAG Agents. We give the detailed introduction of each memory agent in Appendix. For chunk size settings, we choose a chunk size of 512 for the SH-Doc QA, MH-Doc QA, and LME(S*) tasks in AR, as well as for all tasks in SF. This is mainly because these tasks are composed of long texts synthesized from multiple short texts. For other tasks, we use a chunk size of 4096. Considering computational overhead and API cost, we uniformly use a chunk size of 4096 for Mem0, Cognee, Zep, and MIRIX. We report the detailed settings of the chunk size in Appendix.
数据集被分为四个类别,所有数据集的统计信息也显示在 表2 中。 所有数据集的评估指标也显示在 表2 中,并附有更多数据集细节。 对于智能体,如第 3.2 节所述,作者考虑三类智能体:长上下文智能体、RAG 智能体 和 智能体式记忆智能体,其中 RAG 智能体 又可以进一步分为 简单 RAG 智能体、基于 Embedding 的 RAG 智能体 和 结构增强 RAG 智能体。 作者在附录中给出了每个记忆智能体的详细介绍。 对于 chunk size 设置,作者为 AR 中的 SH-Doc QA、MH-Doc QA 和 LME(S*) 任务,以及 SF 中的所有任务选择 512 的 chunk size。 这主要是因为这些任务由多个短文本合成的长文本组成。 对于其他任务,作者使用 4096 的 chunk size。 考虑到计算开销和 API 成本,作者对 Mem0、Cognee、Zep 和 MIRIX 统一使用 4096 的 chunk size。 作者在附录中报告了 chunk size 的详细设置。
4.2 Overall Performance Comparison
Table 3 presents the overall performance across different benchmarks. We summarize the key findings as follows: (1) Superiority of RAG methods in Accurate Retrieval Tasks. Most RAG Agents are better than the backbone model "GPT-4o-mini" in the tasks within the Accurate Retrieval Category. This matches our intuition where RAG agents typically excel at extracting a small snippet of text that is crucial for answering the question. (2) Superiority of Long-Context Models in Test-Time Learning and Long-Range Understanding. Long-context models achieve the best performance on TTL and LRU. This highlights a fundamental limitation of RAG methods and commercial memory agents, which still follow an agentic RAG paradigm. These systems retrieve only partial information from the past context, lacking the ability to capture a holistic understanding of the input—let alone perform learning across it. (3) Limitation of All Existing Methods on Selective Forgetting. Although being a well-discussed task in model-editing community, forgetting out-of-date memory poses a significant challenge on memory agents. We observe that all methods fail on the multi-hop situation (with achieving at most 7% accuracy). Only long context agents can achieve fairly reasonable results on single-hop scenarios. In Section 4.3.4, we show that current reasoning models can have much better performance, while it does not change the conclusion that Selective Forgetting still poses a significant challenge to all memory mechanisms.
表3 展示了不同基准上的总体性能。 作者将关键发现总结如下:(1)RAG 方法在准确检索任务中的优势。 在准确检索类别中的任务上,大多数 RAG 智能体都优于 backbone model “GPT-4o-mini”。 这符合作者的直觉,因为 RAG 智能体通常擅长抽取一小段对回答问题至关重要的文本。 (2)长上下文模型在测试时学习和长程理解中的优势。 长上下文模型在 TTL 和 LRU 上取得最佳表现。 这凸显了 RAG 方法和商业记忆智能体的一个根本局限:它们仍然遵循一种 agentic RAG 范式。 这些系统只从过去上下文中检索部分信息,缺乏捕获输入整体理解的能力,更不用说在其上执行学习。 (3)所有现有方法在选择性遗忘上的局限。 尽管遗忘过期记忆是模型编辑领域中一个被充分讨论的任务,但它仍然对记忆智能体构成显著挑战。 作者观察到,所有方法在多跳场景中都失败了(最高也只有 7% 的准确率)。 只有长上下文智能体能够在单跳场景中取得相对合理的结果。 在第 4.3.4 节中,作者展示了当前推理模型可以取得好得多的表现,但这并不改变选择性遗忘仍然对所有记忆机制构成显著挑战这一结论。
| Agent Type | AR | TTL | LRU | SF | Overall | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SH | MH | LME | Event | Avg. | MCC | Recom. | Avg. | Summ. | DetQA | Avg. | FC-SH | FC-MH | Avg. | ||
| Long-Context Agents | |||||||||||||||
| GPT-4o | 72.0 | 51.0 | 32.0 | 77.2 | 58.1 | 87.6 | 12.3 | 50.0 | 32.2 | 77.5 | 54.9 | 60.0 | 5.0 | 32.5 | 48.8 |
| GPT-4o-mini | 64.0 | 43.0 | 30.7 | 59.0 | 49.2 | 82.0 | 15.1 | 48.6 | 28.9 | 63.4 | 46.2 | 45.0 | 5.0 | 25.0 | 42.2 |
| GPT-4.1-mini | 83.0 | 66.0 | 55.7 | 82.6 | 71.8 | 75.6 | 16.7 | 46.2 | 41.9 | 56.3 | 49.1 | 36.0 | 5.0 | 20.5 | 46.9 |
| Gemini-2.0-Flash | 87.0 | 59.0 | 47.0 | 67.2 | 65.1 | 84.0 | 8.7 | 46.4 | 23.9 | 59.2 | 41.6 | 30.0 | 3.0 | 16.5 | 42.4 |
| Claude-3.7-Sonnet | 77.0 | 53.0 | 34.0 | 74.6 | 59.7 | 89.4 | 18.3 | 53.9 | 52.5 | 71.8 | 62.2 | 43.0 | 2.0 | 22.5 | 49.6 |
| Reference | |||||||||||||||
| GPT-4o-mini | 64.0 | 43.0 | 30.7 | 59.0 | 49.2 | 82.0 | 15.1 | 48.6 | 28.9 | 63.4 | 46.2 | 45.0 | 5.0 | 25.0 | 42.3 |
| Simple RAG Agents | |||||||||||||||
| BM25 | 66.0 | 56.0 | 45.3 | 74.6 | 60.5 | 75.4 | 13.6 | 44.5 | 19.0 | 52.1 | 35.6 | 48.0 | 3.0 | 25.5 | 41.5 |
| Embedding RAG Agents | |||||||||||||||
| Contriever | 22.0 | 31.0 | 15.7 | 66.8 | 33.9 | 70.6 | 15.2 | 42.9 | 17.2 | 42.3 | 29.8 | 18.0 | 7.0 | 12.5 | 29.8 |
| Text-Embed-3-Small | 60.0 | 44.0 | 48.3 | 63.0 | 53.8 | 70.0 | 15.3 | 42.7 | 17.7 | 54.9 | 36.3 | 28.0 | 3.0 | 15.5 | 37.1 |
| Text-Embed-3-Large | 54.0 | 44.0 | 50.3 | 70.0 | 54.6 | 72.4 | 16.2 | 44.3 | 18.2 | 56.3 | 37.3 | 28.0 | 4.0 | 16.0 | 38.0 |
| Qwen3-Embedding-4B | 57.0 | 47.0 | 43.3 | 71.4 | 54.7 | 78.0 | 12.2 | 45.1 | 14.8 | 59.2 | 37.0 | 29.0 | 3.0 | 16.0 | 38.2 |
| Structure-Augmented RAG Agents | |||||||||||||||
| RAPTOR | 29.0 | 38.0 | 34.3 | 45.8 | 36.8 | 59.4 | 12.3 | 35.9 | 13.4 | 42.3 | 27.9 | 14.0 | 1.0 | 7.5 | 27.0 |
| GraphRAG | 47.0 | 47.0 | 35.0 | 34.4 | 40.9 | 39.8 | 9.8 | 24.8 | 0.4 | 39.4 | 19.9 | 14.0 | 2.0 | 8.0 | 23.4 |
| MemoRAG | 29.0 | 33.0 | 20.0 | 56.0 | 34.5 | 77.0 | 13.1 | 45.1 | 9.2 | 50.7 | 30.0 | 21.0 | 7.0 | 14.0 | 30.9 |
| HippoRAG-v2 | 76.0 | 66.0 | 50.7 | 67.6 | 65.1 | 61.4 | 10.2 | 35.8 | 14.6 | 57.7 | 36.2 | 54.0 | 5.0 | 29.5 | 41.6 |
| Mem0 | 25.0 | 32.0 | 36.0 | 37.5 | 32.6 | 32.4 | 10.0 | 21.2 | 4.8 | 36.6 | 20.7 | 18.0 | 2.0 | 10.0 | 21.1 |
| Cognee | 31.0 | 26.0 | 29.3 | 26.8 | 28.3 | 35.4 | 10.1 | 22.8 | 2.3 | 29.6 | 16.0 | 28.0 | 3.0 | 15.5 | 20.6 |
| Zep | 44.0 | 25.0 | 38.3 | 42.5 | 37.5 | 62.8 | 12.1 | 37.5 | 4.2 | 28.2 | 16.2 | 7.0 | 3.0 | 5.0 | 24.0 |
| Agentic Memory Agents | |||||||||||||||
| Self-RAG | 35.0 | 42.0 | 25.7 | 31.8 | 33.6 | 11.6 | 12.8 | 12.2 | 0.9 | 35.2 | 18.1 | 19.0 | 3.0 | 11.0 | 18.7 |
| MemGPT | 41.0 | 38.0 | 32.0 | 26.2 | 34.3 | 67.6 | 14.0 | 40.8 | 2.5 | 42.3 | 22.4 | 28.0 | 3.0 | 15.5 | 28.3 |
| MIRIX | 62.0 | 61.0 | 37.3 | 29.8 | 47.5 | 38.4 | 9.8 | 24.1 | 9.9 | 40.8 | 25.4 | 14.0 | 2.0 | 8.0 | 26.2 |
| MIRIX (4.1-mini) | 73.0 | 75.0 | 51.0 | 53.0 | 63.0 | 61.0 | 10.3 | 35.7 | 18.9 | 62.0 | 40.5 | 20.0 | 3.0 | 11.5 | 37.7 |
4.3 Analysis and Ablation Study
In this section, we present experiments and analysis along five dimensions: input chunk size, retrieval top-
在本节中,作者从五个维度展示实验和分析:输入 chunk size、retrieval top-
4.3.1 Ablation Study on Input Chunk Size
To understand how chunk size impacts performance, particularly for RAG methods and agentic memory agents, we conduct an additional analysis where we vary the chunk size while fixing the number of retrieved chunks to 10. The results are presented in Figure 2. From the figure, we observe that in the SH-Doc QA task, reducing chunk size has little effect on BM25 performance. This is expected, as BM25 relies on term-frequency-based scoring and document-level ranking, and does not inherently benefit from finer-grained segmentation beyond the impact on term distributions. In contrast, embedding-based methods—including MemGPT, which uses text-embedding-3-small as its retriever—consistently perform better with smaller chunks. This suggests that finer segmentation improves the granularity and relevance of retrieved results for models that rely on dense semantic representations. In
为了理解 chunk size 如何影响性能,尤其是对 RAG 方法和智能体式记忆智能体的影响,作者进行了额外分析:在固定检索 chunk 数为 10 的情况下改变 chunk size。 结果如 图2 所示。 从图中可以观察到,在 SH-Doc QA 任务中,减小 chunk size 对 BM25 性能影响很小。 这是符合预期的,因为 BM25 依赖基于词频的打分和文档级排序,除非影响词项分布,否则它本身并不会从更细粒度的分段中受益。 相比之下,基于 embedding 的方法——包括使用 text-embedding-3-small 作为检索器的 MemGPT——在较小 chunk 下始终表现更好。 这说明,对于依赖稠密语义表示的模型,更细的分段会提升检索结果的粒度和相关性。 然而,在
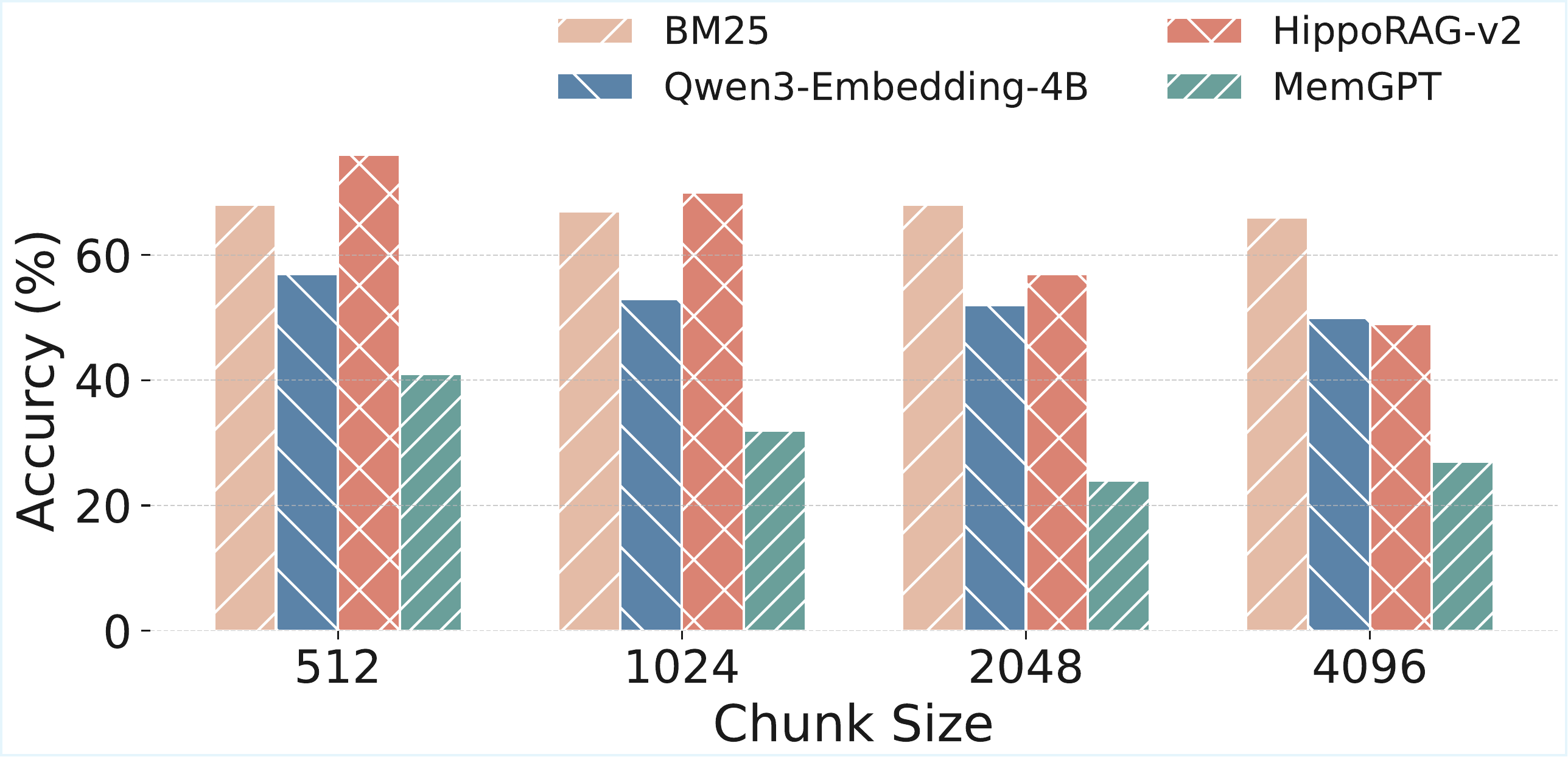
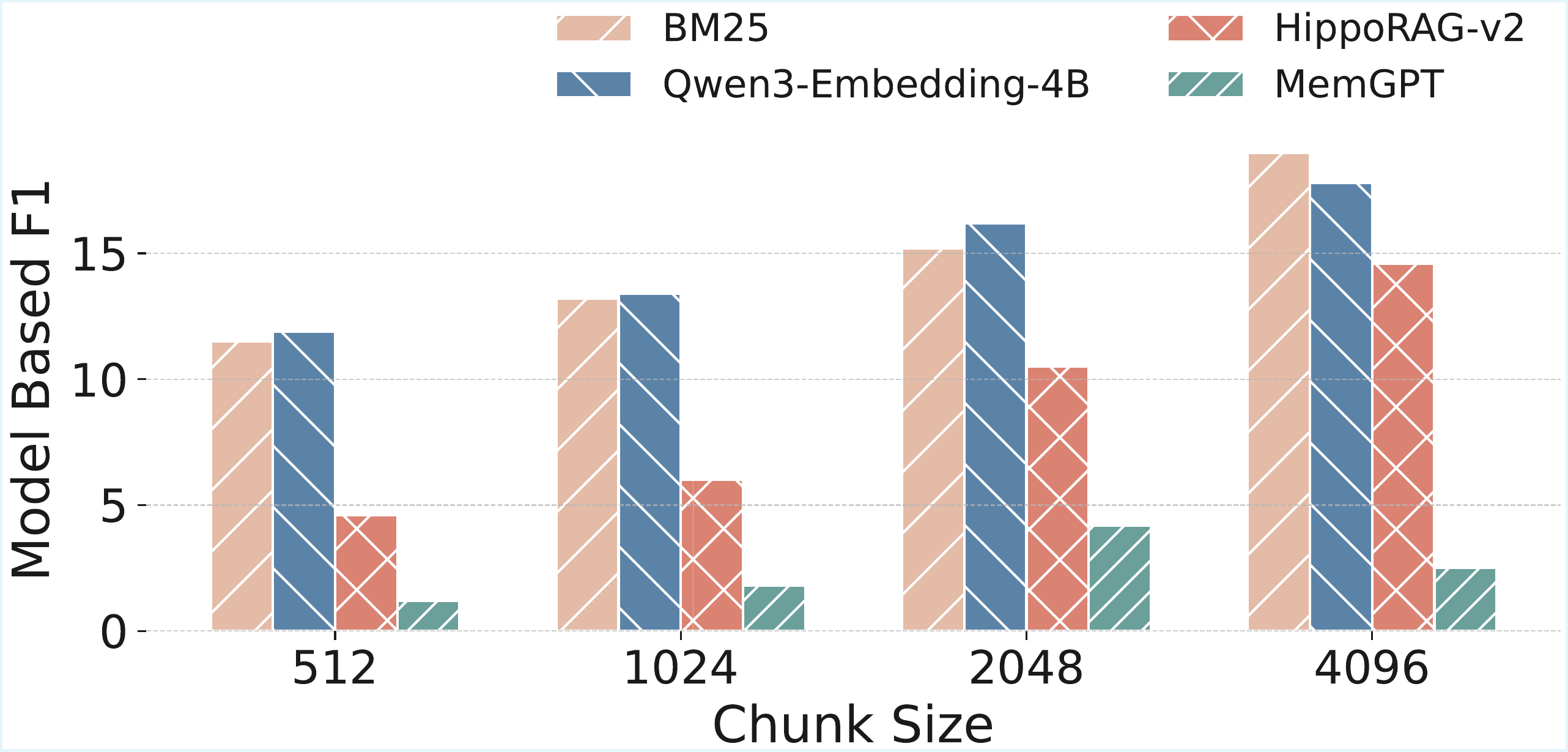
4.3.2 Ablation Study on Retrieval TopK
In our experiments, although we report most results with the number of retrieved chunks set to 10 in Table 3, we also conducted ablation studies with varying retrieval sizes. A subset of these results is visualized in Figure 3, with the full results provided in Appendix. The results indicate that increasing the number of retrieved chunks generally improves performance across most tasks. It is worth noting that, with a chunk size of 4096 tokens, retrieving 10 chunks already yields an input of approximately 40k tokens. This places significant demands on model capacity. Due to this high token volume, we do not evaluate settings with 20 retrieved chunks.
在实验中,尽管作者在 表3 中报告的大多数结果都将检索 chunk 数设置为 10,但作者也进行了不同检索规模的消融研究。 这些结果的一个子集可视化在 图3 中,完整结果见附录。 结果表明,增加检索 chunk 的数量通常会提升大多数任务的性能。 值得注意的是,当 chunk size 为 4096 token 时,检索 10 个 chunk 已经会产生大约 40k token 的输入。 这对模型能力提出了很高要求。 由于 token 量很高,作者没有评估检索 20 个 chunk 的设置。
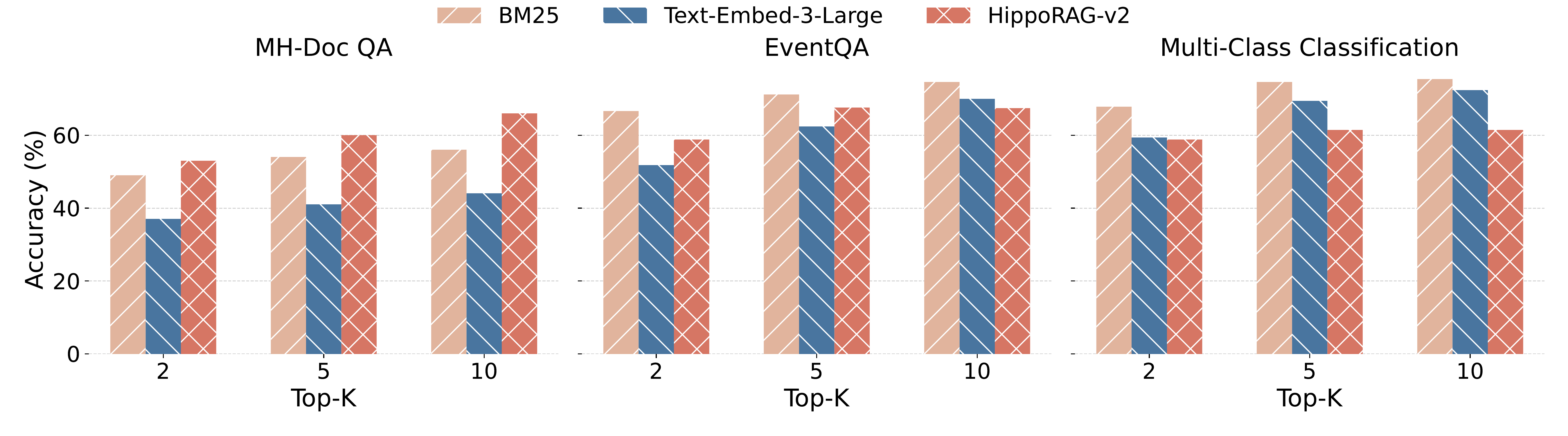
4.3.3 Ablation Study on Backbone Model
To investigate how different backbone models impact the performance of various memory agents, we experimented with three different backbone models and selected four representative methods from both the RAG Agents and Agentic Memory categories. The complete experimental results are presented in Table 4. Our findings show that for RAG Agents, once the backbone is sufficiently strong, it no longer serves as the main performance bottleneck. Compared to the default setup, upgrading to a more powerful model like GPT-4.1-mini yields only marginal improvements. In contrast, the main results in Table 3 for the MIRIX method under the Agentic Memory category, using a stronger backbone leads to substantial performance gains. This suggests that future advances in backbone models could further boost the effectiveness of Agentic Memory methods.
为了研究不同 backbone model 如何影响各种记忆智能体的性能,作者使用三个不同 backbone model 进行了实验,并从 RAG 智能体和智能体式记忆类别中各选择了四个代表性方法。 完整实验结果见 表4。 作者的发现表明,对于 RAG 智能体,一旦 backbone 足够强,它就不再是主要性能瓶颈。 与默认设置相比,升级到 GPT-4.1-mini 这样更强的模型只带来边际提升。 相比之下,在 表3 中,智能体式记忆类别下的 MIRIX 方法使用更强 backbone 时会带来显著性能提升。 这说明,未来 backbone model 的进展可能会进一步提升智能体式记忆方法的有效性。
| RAG Method | Backbone Model | EventQA | Movie Rec | ∞Bench-Sum | FC-SH | Avg. |
|---|---|---|---|---|---|---|
| BM25 | ||||||
| BM25 | GPT-4o-mini | 74.6 | 13.6 | 19.0 | 48.0 | 38.8 |
| BM25 | GPT-4.1-mini | 76.4 | 14.0 | 19.4 | 51.0 | 40.2 |
| BM25 | Gemini-2.0-Flash | 70.8 | 10.0 | 18.9 | 47.0 | 36.7 |
| Text-Embed-3-Small | ||||||
| Text-Embed-3-Small | GPT-4o-mini | 63.0 | 15.3 | 17.7 | 28.0 | 31.0 |
| Text-Embed-3-Small | GPT-4.1-mini | 62.0 | 15.5 | 17.9 | 30.0 | 31.4 |
| Text-Embed-3-Small | Gemini-2.0-Flash | 64.0 | 10.3 | 17.2 | 27.0 | 29.6 |
| GraphRAG | ||||||
| GraphRAG | GPT-4o-mini | 34.4 | 9.8 | 0.4 | 14.0 | 14.7 |
| GraphRAG | GPT-4.1-mini | 39.0 | 10.3 | 1.2 | 16.0 | 16.6 |
| GraphRAG | Gemini-2.0-Flash | 36.2 | 7.2 | 0.8 | 13.0 | 14.3 |
| MIRIX | ||||||
| MIRIX | GPT-4o-mini | 29.8 | 9.8 | 9.9 | 14.0 | 15.9 |
| MIRIX | GPT-4.1-mini | 53.0 (23.2↑) | 10.3 (0.5↑) | 18.9 (9.0↑) | 20.0 (6.0↑) | 25.6 (9.7↑) |
4.3.4 Validation of Dataset FactConsolidation
As the performance of different models on this dataset remains drastically low, we turn to the stronger reasoning model o4-mini and validate our dataset by checking the performance of o4-mini on a smaller version of this dataset. The results are shown in Table 5. We found that on the 6K version of the FactCon-SH dataset, both models perform well and are generally able to complete the task effectively. However, their performance drops when the context length increases to 32K. Similarly, on the 6K version of the FactCon-MH dataset, the stronger O4-mini reasoning model achieves a decent score of 80.0, but its performance significantly drops to 14.0 when the context window reaches 32K. This indicates that our dataset is solvable under short-context settings, but current memory agents still lack strong long-range reasoning capabilities, making them unable to handle the task when presented with longer historical inputs.
由于不同模型在该数据集上的表现仍然极低,作者转向更强的推理模型 o4-mini,并通过检查 o4-mini 在该数据集较小版本上的表现来验证数据集。 结果如 表5 所示。 作者发现,在 FactCon-SH 数据集的 6K 版本上,两个模型表现都很好,通常能够有效完成任务。 然而,当上下文长度增加到 32K 时,它们的性能下降。 类似地,在 FactCon-MH 数据集的 6K 版本上,更强的 O4-mini 推理模型取得了 80.0 的不错分数,但当上下文窗口达到 32K 时,其性能显著下降到 14.0。 这表明该数据集在短上下文设置下是可解的,但当前记忆智能体仍然缺乏强大的长程推理能力,因此在面对更长历史输入时无法处理该任务。
| Model | FactCon-SH | FactCon-MH | ||
|---|---|---|---|---|
| 6K | 32K | 6K | 32K | |
| GPT-4o | 92.0 | 88.0 | 28.0 | 10.0 |
| O4-mini | 100.0 | 61.0 | 80.0 | 14.0 |
5. Conclusion
In this paper, we introduce MemoryAgentBench, a unified benchmark designed to evaluate memory agents across four essential competencies: accurate retrieval, test-time learning, long-range understanding, and selective forgetting. While prior benchmarks focus largely on skill execution or long-context question answering, MemoryAgentBench fills a critical gap by assessing how agents store, update, and utilize long-term information across multi-turn interactions. To build this benchmark, we restructure existing datasets and propose two new ones—EventQA and FactConsolidation—tailored to stress specific memory behaviors often overlooked in prior work. We evaluate a wide spectrum of agents, including long-context models, RAG-based systems, and commercial memory agents, under a consistent evaluation protocol. Our results reveal that, despite recent advances, current memory agents still exhibit substantial limitations when faced with tasks requiring dynamic memory updates and long-range consistency. One limitation of our work is that due to budget constraints, so we could only conduct experiments on some relatively representative Memory Agents. As future work, we aim to provide more evaluation results for more memory agents.
本文提出了 MemoryAgentBench,这是一个统一基准,用于评估记忆智能体的四项关键能力:准确检索、测试时学习、长程理解和选择性遗忘。 尽管以往基准主要关注技能执行或长上下文问答,MemoryAgentBench 通过评估智能体如何在多轮交互中存储、更新和利用长期信息,填补了一个关键空白。 为了构建该基准,作者重构了现有数据集,并提出两个新数据集——EventQA 和 FactConsolidation——用于压力测试以往工作中常被忽视的特定记忆行为。 作者在一致的评估协议下评估了广泛的智能体,包括长上下文模型、基于 RAG 的系统和商业记忆智能体。 结果表明,尽管近期已有进展,但当前记忆智能体在面对需要动态记忆更新和长程一致性的任务时仍表现出明显局限。 本文的一个局限是,由于预算约束,作者只能在一些相对具有代表性的记忆智能体上进行实验。 作为未来工作,作者希望为更多记忆智能体提供更多评估结果。