
High-Resolution Image Synthesis with Latent Diffusion Models
DiffusionLatent DiffusionImage Synthesis35360+CVPR 2022CCF-ALMUHeidelbergRunway ML
利用潜在扩散模型进行高分辨率图像合成
Abstract
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve new state-of-the-art scores for image inpainting and class-conditional image synthesis and highly competitive performance on various tasks, including text-to-image synthesis, unconditional image generation and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.
通过把图像形成过程分解为去噪自编码器的顺序应用,扩散模型(DM)在图像数据及其他领域取得了最先进的合成结果。 此外,其形式化还允许使用一种引导机制,在无需重新训练的情况下控制图像生成过程。 然而,由于这些模型通常直接在像素空间中运行,优化强大的 DM 往往会消耗数百个 GPU 日,而且由于需要顺序评估,推理成本也很高。 为了在有限计算资源上训练 DM,同时保留其质量和灵活性,作者将它们应用于强大的预训练自编码器的潜在空间。 与先前工作不同,在这种表示上训练扩散模型首次能够在降低复杂度和保留细节之间达到接近最优的平衡点,从而大幅提升视觉保真度。 通过在模型架构中引入交叉注意力层,作者把扩散模型转变为强大且灵活的生成器,可处理文本或边界框等通用条件输入,并能以卷积方式实现高分辨率合成。 作者的潜在扩散模型(LDM)在图像修复和类别条件图像合成上取得新的最先进分数,并在文本到图像合成、无条件图像生成和超分辨率等多种任务上表现出高度竞争力,同时相比基于像素的 DM 显著降低计算需求。
1. Introduction
PSNR: 27.4 R-FID: 0.58
PSNR: 22.8 R-FID: 32.01
PSNR: 19.9 R-FID: 4.98








Image synthesis is one of the computer vision fields with the most spectacular recent development, but also among those with the greatest computational demands. Especially high-resolution synthesis of complex, natural scenes is presently dominated by scaling up likelihood-based models, potentially containing billions of parameters in autoregressive (AR) transformers. In contrast, the promising results of GANs have been revealed to be mostly confined to data with comparably limited variability as their adversarial learning procedure does not easily scale to modeling complex, multi-modal distributions. Recently, diffusion models, which are built from a hierarchy of denoising autoencoders, have shown to achieve impressive results in image synthesis and beyond, and define the state-of-the-art in class-conditional image synthesis and super-resolution. Moreover, even unconditional DMs can readily be applied to tasks such as inpainting and colorization or stroke-based synthesis, in contrast to other types of generative models. Being likelihood-based models, they do not exhibit mode-collapse and training instabilities as GANs and, by heavily exploiting parameter sharing, they can model highly complex distributions of natural images without involving billions of parameters as in AR models.
图像合成是计算机视觉中近期发展最引人注目的领域之一,同时也是计算需求最高的领域之一。 尤其是复杂自然场景的高分辨率合成,目前主要由基于似然模型的扩展所主导,这类模型可能是在自回归(AR)Transformer 中包含数十亿参数。 相比之下,GAN 展示出的有前景结果大多被证明局限于变化相对有限的数据,因为其对抗学习过程并不容易扩展到复杂、多模态分布的建模。 近来,由去噪自编码器层级构成的扩散模型已经在图像合成及其他领域取得了令人印象深刻的结果,并定义了类别条件图像合成和超分辨率的最先进水平。 此外,与其他类型生成模型不同,即使是无条件 DM 也可以直接应用于图像修复、着色或基于笔画的合成等任务。 作为基于似然的模型,它们不像 GAN 那样表现出模式坍塌和训练不稳定,并且通过大量利用参数共享,它们无需像 AR 模型那样涉及数十亿参数,就能建模自然图像的高度复杂分布。
Democratizing High-Resolution Image Synthesis. DMs belong to the class of likelihood-based models, whose mode-covering behavior makes them prone to spend excessive amounts of capacity (and thus compute resources) on modeling imperceptible details of the data. Although the reweighted variational objective aims to address this by undersampling the initial denoising steps, DMs are still computationally demanding, since training and evaluating such a model requires repeated function evaluations (and gradient computations) in the high-dimensional space of RGB images. As an example, training the most powerful DMs often takes hundreds of GPU days (e.g. 150 - 1000 V100 days) and repeated evaluations on a noisy version of the input space render also inference expensive, so that producing 50k samples takes approximately 5 days on a single A100 GPU. This has two consequences for the research community and users in general: Firstly, training such a model requires massive computational resources only available to a small fraction of the field, and leaves a huge carbon footprint. Secondly, evaluating an already trained model is also expensive in time and memory, since the same model architecture must run sequentially for a large number of steps (e.g. 25 - 1000 steps). To increase the accessibility of this powerful model class and at the same time reduce its significant resource consumption, a method is needed that reduces the computational complexity for both training and sampling. Reducing the computational demands of DMs without impairing their performance is, therefore, key to enhance their accessibility.
让高分辨率图像合成更加普及。 DM 属于基于似然的模型,其覆盖模式的行为使它们容易把过多容量(也就是计算资源)花在建模数据中不可感知的细节上。 虽然重新加权的变分目标试图通过欠采样初始去噪步骤来解决这一点,但 DM 仍然计算开销很大,因为训练和评估这类模型需要在 RGB 图像的高维空间中反复进行函数评估(以及梯度计算)。 例如,训练最强大的 DM 往往需要数百个 GPU 日(例如 150 到 1000 个 V100 日),而在输入空间的噪声版本上反复评估也使推理代价高昂,因此在单张 A100 GPU 上生成 5 万个样本大约需要 5 天。 这对研究社区和普通用户有两个后果:首先,训练这样的模型需要大量计算资源,而这些资源只有该领域的一小部分人能够获得,并且会留下巨大的碳足迹。 其次,评估一个已经训练好的模型在时间和内存上也很昂贵,因为同一模型架构必须顺序运行大量步骤(例如 25 到 1000 步)。 为了提高这一强大模型类别的可访问性,同时降低其显著的资源消耗,需要一种同时降低训练和采样计算复杂度的方法。 因此,在不损害 DM 性能的情况下降低其计算需求,是提升其可访问性的关键。
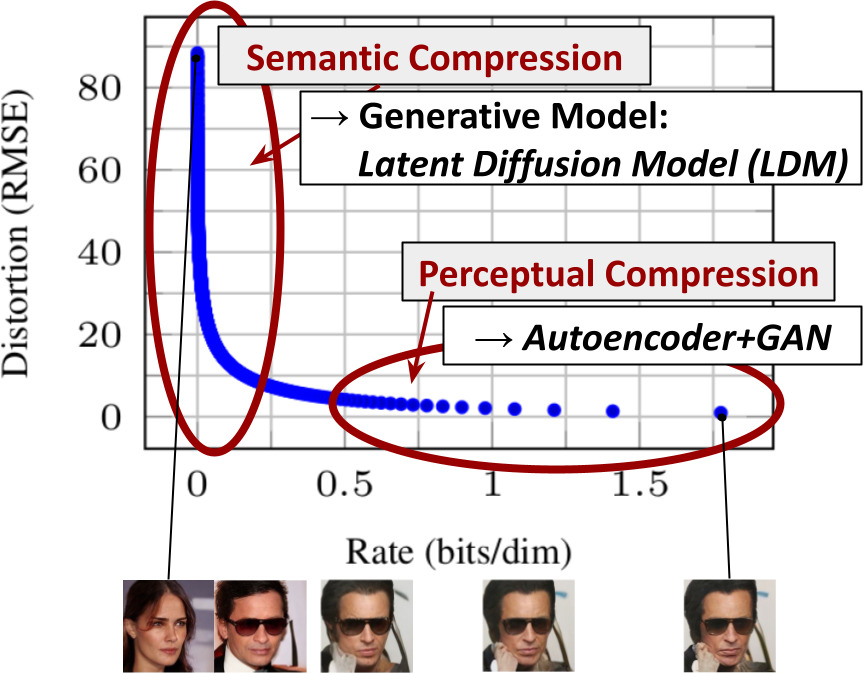
Departure to Latent Space. Our approach starts with the analysis of already trained diffusion models in pixel space: Figure Figure 2 shows the rate-distortion trade-off of a trained model. As with any likelihood-based model, learning can be roughly divided into two stages: First is a perceptual compression stage which removes high-frequency details but still learns little semantic variation. In the second stage, the actual generative model learns the semantic and conceptual composition of the data (semantic compression). We thus aim to first find a perceptually equivalent, but computationally more suitable space, in which we will train diffusion models for high-resolution image synthesis. Following common practice, we separate training into two distinct phases: First, we train an autoencoder which provides a lower-dimensional (and thereby efficient) representational space which is perceptually equivalent to the data space. Importantly, and in contrast to previous work, we do not need to rely on excessive spatial compression, as we train DMs in the learned latent space, which exhibits better scaling properties with respect to the spatial dimensionality. The reduced complexity also provides efficient image generation from the latent space with a single network pass. We dub the resulting model class Latent Diffusion Models (LDMs). A notable advantage of this approach is that we need to train the universal autoencoding stage only once and can therefore reuse it for multiple DM trainings or to explore possibly completely different tasks. This enables efficient exploration of a large number of diffusion models for various image-to-image and text-to-image tasks. For the latter, we design an architecture that connects transformers to the DM's UNet backbone and enables arbitrary types of token-based conditioning mechanisms, see Section 3.3.
走向潜在空间。 作者的方法从分析已经在像素空间中训练好的扩散模型开始:图2 展示了一个训练好模型的率失真权衡。 与任何基于似然的模型一样,学习过程大致可以分为两个阶段:第一阶段是感知压缩阶段,它会去除高频细节,但仍然只学习到很少的语义变化。 在第二阶段,实际的生成模型学习数据的语义和概念组成(语义压缩)。 因此,作者的目标是先找到一个感知上等价、但计算上更合适的空间,并在其中训练用于高分辨率图像合成的扩散模型。 遵循常见做法,作者把训练分成两个不同阶段:首先训练一个自编码器,它提供一个低维(因此高效)的表示空间,并且该空间在感知上等价于数据空间。 重要的是,与先前工作不同,作者不需要依赖过度的空间压缩,因为作者在学习到的潜在空间中训练 DM,而该空间在空间维度方面具有更好的扩展性质。 降低后的复杂度还使得从潜在空间进行高效图像生成成为可能,只需一次网络前向传播。 作者将得到的模型类别称为潜在扩散模型(LDM)。 这一方法的一个显著优势是,通用自编码阶段只需要训练一次,因此可以复用于多个 DM 训练,或用于探索可能完全不同的任务。 这使作者能够高效探索大量用于不同图像到图像和文本到图像任务的扩散模型。 对于后者,作者设计了一种把 Transformer 连接到 DM 的 UNet 主干的架构,并支持任意类型的基于 token 的条件机制,见第 3.3 节。
In sum, our work makes the following contributions:
总之,作者的工作做出了以下贡献:
- In contrast to purely transformer-based approaches, our method scales more graceful to higher dimensional data and can thus (a) work on a compression level which provides more faithful and detailed reconstructions than previous work (see Figure Figure 1) and (b) can be efficiently applied to high-resolution synthesis of megapixel images.
- We achieve competitive performance on multiple tasks (unconditional image synthesis, inpainting, stochastic super-resolution) and datasets while significantly lowering computational costs.
- Compared to pixel-based diffusion approaches, we also significantly decrease inference costs.
- We show that, in contrast to previous work which learns both an encoder/decoder architecture and a score-based prior simultaneously, our approach does not require a delicate weighting of reconstruction and generative abilities.
- This ensures extremely faithful reconstructions and requires very little regularization of the latent space.
- We find that for densely conditioned tasks such as super-resolution, inpainting and semantic synthesis, our model can be applied in a convolutional fashion and render large, consistent images of
px. - Moreover, we design a general-purpose conditioning mechanism based on cross-attention, enabling multi-modal training.
- We use it to train class-conditional, text-to-image and layout-to-image models.
- Finally, we release pretrained latent diffusion and autoencoding models at
https://github.com/CompVis/latent-diffusionwhich might be reusable for a various tasks besides training of DMs.
- 与纯 Transformer 方法不同,作者的方法能够更优雅地扩展到更高维数据,因此 (a) 可以在一种压缩级别上工作,相比先前工作提供更忠实、更细致的重建(见 图1),并且 (b) 可以高效应用于百万像素图像的高分辨率合成。
- 作者在多个任务(无条件图像合成、图像修复、随机超分辨率)和数据集上取得了有竞争力的性能,同时显著降低计算成本。
- 与基于像素的扩散方法相比,作者还显著降低了推理成本。
- 作者表明,与同时学习编码器/解码器架构和基于分数的先验的先前工作不同,作者的方法不需要在重建能力和生成能力之间进行精细加权。
- 这确保了极其忠实的重建,并且只需要对潜在空间施加很少的正则化。
- 作者发现,对于超分辨率、图像修复和语义合成等密集条件任务,该模型可以以卷积方式应用,并渲染约
像素的大尺寸一致图像。 - 此外,作者设计了一种基于交叉注意力的通用条件机制,从而支持多模态训练。
- 作者使用它训练类别条件、文本到图像和布局到图像模型。
- 最后,作者在
https://github.com/CompVis/latent-diffusion发布了预训练的潜在扩散和自编码模型,这些模型除了训练 DM 外,也可能在多种任务中复用。
2. Related Work
Generative Models for Image Synthesis. The high dimensional nature of images presents distinct challenges to generative modeling. Generative Adversarial Networks (GAN) allow for efficient sampling of high resolution images with good perceptual quality, but are difficult to optimize and struggle to capture the full data distribution. In contrast, likelihood-based methods emphasize good density estimation which renders optimization more well-behaved. Variational autoencoders (VAE) and flow-based models enable efficient synthesis of high resolution images, but sample quality is not on par with GANs. While autoregressive models (ARM) achieve strong performance in density estimation, computationally demanding architectures and a sequential sampling process limit them to low resolution images. Because pixel based representations of images contain barely perceptible, high-frequency details, maximum-likelihood training spends a disproportionate amount of capacity on modeling them, resulting in long training times. To scale to higher resolutions, several two-stage approaches use ARMs to model a compressed latent image space instead of raw pixels.
用于图像合成的生成模型。 图像的高维性质给生成建模带来了独特挑战。 生成对抗网络(GAN)能够高效采样感知质量良好的高分辨率图像,但难以优化,并且难以捕获完整的数据分布。 相比之下,基于似然的方法强调良好的密度估计,这使优化行为更加良好。 变分自编码器(VAE)和基于流的模型能够高效合成高分辨率图像,但样本质量无法与 GAN 相当。 虽然自回归模型(ARM)在密度估计方面表现强劲,但计算需求高的架构和顺序采样过程将它们限制在低分辨率图像上。 由于图像的像素表示包含几乎不可感知的高频细节,最大似然训练会把不成比例的容量花在建模这些细节上,从而导致训练时间很长。 为了扩展到更高分辨率,若干两阶段方法使用 ARM 来建模压缩后的潜在图像空间,而不是原始像素。
Recently, Diffusion Probabilistic Models (DM), have achieved state-of-the-art results in density estimation as well as in sample quality. The generative power of these models stems from a natural fit to the inductive biases of image-like data when their underlying neural backbone is implemented as a UNet. The best synthesis quality is usually achieved when a reweighted objective is used for training. In this case, the DM corresponds to a lossy compressor and allow to trade image quality for compression capabilities. Evaluating and optimizing these models in pixel space, however, has the downside of low inference speed and very high training costs. While the former can be partially adressed by advanced sampling strategies and hierarchical approaches, training on high-resolution image data always requires to calculate expensive gradients. We adress both drawbacks with our proposed LDMs, which work on a compressed latent space of lower dimensionality. This renders training computationally cheaper and speeds up inference with almost no reduction in synthesis quality (see Figure Figure 1).
近来,扩散概率模型(DM)已经在密度估计和样本质量方面取得最先进结果。 这些模型的生成能力来自这样一个自然契合:当其底层神经主干实现为 UNet 时,它们非常适合图像式数据的归纳偏置。 最佳合成质量通常在使用重新加权目标进行训练时获得。 在这种情况下,DM 对应于一种有损压缩器,并允许在图像质量和压缩能力之间进行权衡。 然而,在像素空间中评估和优化这些模型的缺点是推理速度低、训练成本很高。 虽然前者可以通过先进采样策略和层级方法部分解决,但在高分辨率图像数据上训练始终需要计算昂贵的梯度。 作者提出的 LDM 同时解决这两个缺点,它在维度更低的压缩潜在空间中工作。 这使训练在计算上更便宜,并且在几乎不降低合成质量的情况下加速推理(见 图1)。
Two-Stage Image Synthesis. To mitigate the shortcomings of individual generative approaches, a lot of research has gone into combining the strengths of different methods into more efficient and performant models via a two stage approach. VQ-VAEs use autoregressive models to learn an expressive prior over a discretized latent space. DALL-E extend this approach to text-to-image generation by learning a joint distributation over discretized image and text representations. More generally, conditional invertible networks uses conditionally invertible networks to provide a generic transfer between latent spaces of diverse domains. Different from VQ-VAEs, VQGANs employ a first stage with an adversarial and perceptual objective to scale autoregressive transformers to larger images. However, the high compression rates required for feasible ARM training, which introduces billions of trainable parameters, limit the overall performance of such approaches and less compression comes at the price of high computational cost. Our work prevents such trade-offs, as our proposed LDMs scale more gently to higher dimensional latent spaces due to their convolutional backbone. Thus, we are free to choose the level of compression which optimally mediates between learning a powerful first stage, without leaving too much perceptual compression up to the generative diffusion model while guaranteeing high-fidelity reconstructions (see Figure Figure 1). While approaches to jointly or separately learn an encoding/decoding model together with a score-based prior exist, the former still require a difficult weighting between reconstruction and generative capabilities and are outperformed by our approach (Section 4), and the latter focus on highly structured images such as human faces.
两阶段图像合成。 为了缓解单一生成方法的缺点,许多研究通过两阶段方法把不同方法的优势结合进更高效、性能更好的模型中。 VQ-VAE 使用自回归模型来学习离散化潜在空间上的表达性先验。 DALL-E 通过学习离散化图像和文本表示上的联合分布,将这一方法扩展到文本到图像生成。 更一般地,条件可逆网络使用条件可逆网络,在不同领域的潜在空间之间提供通用迁移。 不同于 VQ-VAE,VQGAN 使用带有对抗目标和感知目标的第一阶段,把自回归 Transformer 扩展到更大图像。 然而,可行 ARM 训练所需的高压缩率会引入数十亿可训练参数,限制这类方法的整体性能;而较低压缩率又会带来很高的计算成本。 作者的工作避免了这种权衡,因为提出的 LDM 由于卷积主干的存在,可以更平缓地扩展到更高维潜在空间。 因此,作者可以自由选择一种压缩级别,在学习强大第一阶段和不过多把感知压缩留给生成扩散模型之间实现最优折中,同时保证高保真重建(见 图1)。 虽然已有方法联合或分别学习编码/解码模型与基于分数的先验,但前者仍然需要在重建能力和生成能力之间进行困难加权,并且被作者的方法超越(第 4 节),后者则聚焦于人脸等高度结构化图像。
3. Method
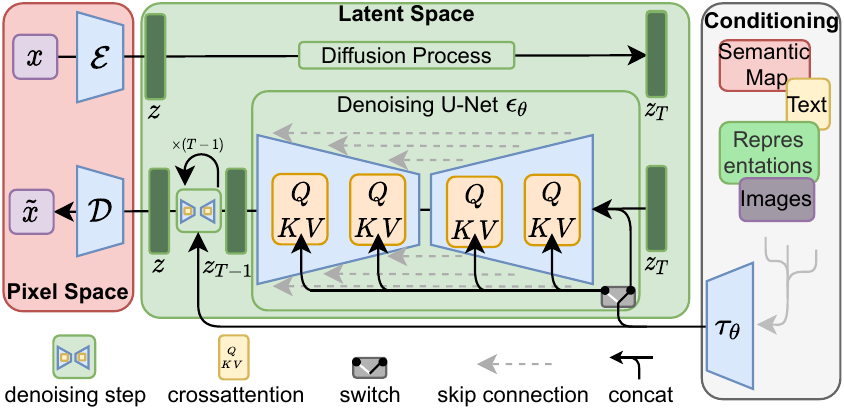
To lower the computational demands of training diffusion models towards high-resolution image synthesis, we observe that although diffusion models allow to ignore perceptually irrelevant details by undersampling the corresponding loss terms, they still require costly function evaluations in pixel space, which causes huge demands in computation time and energy resources. We propose to circumvent this drawback by introducing an explicit separation of the compressive from the generative learning phase (see Figure Figure 2). To achieve this, we utilize an autoencoding model which learns a space that is perceptually equivalent to the image space, but offers significantly reduced computational complexity. Such an approach offers several advantages: (i) By leaving the high-dimensional image space, we obtain DMs which are computationally much more efficient because sampling is performed on a low-dimensional space. (ii) We exploit the inductive bias of DMs inherited from their UNet architecture, which makes them particularly effective for data with spatial structure and therefore alleviates the need for aggressive, quality-reducing compression levels as required by previous approaches. (iii) Finally, we obtain general-purpose compression models whose latent space can be used to train multiple generative models and which can also be utilized for other downstream applications such as single-image CLIP-guided synthesis.
为了降低面向高分辨率图像合成训练扩散模型的计算需求,作者观察到,虽然扩散模型可以通过欠采样相应损失项来忽略感知上无关的细节,但它们仍然需要在像素空间中进行代价高昂的函数评估,这会造成巨大的计算时间和能源资源需求。 作者提出通过显式分离压缩学习阶段和生成学习阶段来绕过这一缺点(见 图2)。 为此,作者使用一个自编码模型来学习一个在感知上等价于图像空间、但计算复杂度显著降低的空间。 这种方法有若干优势:(i) 通过离开高维图像空间,作者得到计算效率高得多的 DM,因为采样是在低维空间中执行的。 (ii) 作者利用了 DM 从其 UNet 架构继承来的归纳偏置,这使它们对具有空间结构的数据尤其有效,因此缓解了先前方法所需的激进且降低质量的压缩级别。 (iii) 最后,作者得到通用压缩模型,其潜在空间可用于训练多个生成模型,也可用于单图像 CLIP 引导合成等其他下游应用。
3.1 Perceptual Image Compression
Our perceptual compression model is based on previous work and consists of an autoencoder trained by combination of a perceptual loss and a patch-based adversarial objective. This ensures that the reconstructions are confined to the image manifold by enforcing local realism and avoids bluriness introduced by relying solely on pixel-space losses such as
作者的感知压缩模型基于先前工作,由一个结合感知损失和基于图像块的对抗目标训练的自编码器组成。 这通过强制局部真实感来确保重建结果被限制在图像流形上,并避免仅依赖像素空间损失(如
| R-FID ↓ | R-IS ↑ | PSNR ↑ | PSIM ↓ | SSIM ↑ | |||
|---|---|---|---|---|---|---|---|
| 16 VQGAN | 16384 | 256 | 4.98 | -- | 19.9 ± 3.4 | 1.83 ± 0.42 | 0.51 ± 0.18 |
| 16 VQGAN | 1024 | 256 | 7.94 | -- | 19.4 ± 3.3 | 1.98 ± 0.43 | 0.50 ± 0.18 |
| 8 DALL-E | 8192 | - | 32.01 | -- | 22.8 ± 2.1 | 1.95 ± 0.51 | 0.73 ± 0.13 |
| 32 | 16384 | 16 | 31.83 | 40.40 ± 1.07 | 17.45 ± 2.90 | 2.58 ± 0.48 | 0.41 ± 0.18 |
| 16 | 16384 | 8 | 5.15 | 144.55 ± 3.74 | 20.83 ± 3.61 | 1.73 ± 0.43 | 0.54 ± 0.18 |
| 8 | 16384 | 4 | 1.14 | 201.92 ± 3.97 | 23.07 ± 3.99 | 1.17 ± 0.36 | 0.65 ± 0.16 |
| 8 | 256 | 4 | 1.49 | 194.20 ± 3.87 | 22.35 ± 3.81 | 1.26 ± 0.37 | 0.62 ± 0.16 |
| 4 | 8192 | 3 | 0.58 | 224.78 ± 5.35 | 27.43 ± 4.26 | 0.53 ± 0.21 | 0.82 ± 0.10 |
4 | 8192 | 3 | 1.06 | 221.94 ± 4.58 | 25.21 ± 4.17 | 0.72 ± 0.26 | 0.76 ± 0.12 |
| 4 | 256 | 3 | 0.47 | 223.81 ± 4.58 | 26.43 ± 4.22 | 0.62 ± 0.24 | 0.80 ± 0.11 |
| 2 | 2048 | 2 | 0.16 | 232.75 ± 5.09 | 30.85 ± 4.12 | 0.27 ± 0.12 | 0.91 ± 0.05 |
| 2 | 64 | 2 | 0.40 | 226.62 ± 4.83 | 29.13 ± 3.46 | 0.38 ± 0.13 | 0.90 ± 0.05 |
| 32 | KL | 64 | 2.04 | 189.53 ± 3.68 | 22.27 ± 3.93 | 1.41 ± 0.40 | 0.61 ± 0.17 |
| 32 | KL | 16 | 7.3 | 132.75 ± 2.71 | 20.38 ± 3.56 | 1.88 ± 0.45 | 0.53 ± 0.18 |
| 16 | KL | 16 | 0.87 | 210.31 ± 3.97 | 24.08 ± 4.22 | 1.07 ± 0.36 | 0.68 ± 0.15 |
| 16 | KL | 8 | 2.63 | 178.68 ± 4.08 | 21.94 ± 3.92 | 1.49 ± 0.42 | 0.59 ± 0.17 |
| 8 | KL | 4 | 0.90 | 209.90 ± 4.92 | 24.19 ± 4.19 | 1.02 ± 0.35 | 0.69 ± 0.15 |
| 4 | KL | 3 | 0.27 | 227.57 ± 4.89 | 27.53 ± 4.54 | 0.55 ± 0.24 | 0.82 ± 0.11 |
| 2 | KL | 2 | 0.086 | 232.66 ± 5.16 | 32.47 ± 4.19 | 0.20 ± 0.09 | 0.93 ± 0.04 |
3.2 Latent Diffusion Models
Diffusion Models are probabilistic models designed to learn a data distribution
扩散模型 是一种概率模型,旨在通过逐步去噪一个正态分布变量来学习数据分布
with
其中
The neural backbone
作者模型的神经主干
3.3 Conditioning Mechanisms
Similar to other types of generative models, diffusion models are in principle capable of modeling conditional distributions of the form
类似其他类型的生成模型,扩散模型原则上能够建模形式为
Here,
这里,
where both
其中
4. Experiments













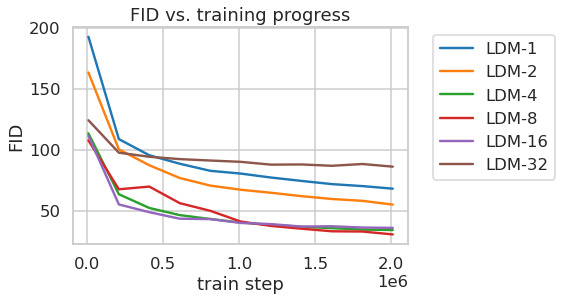
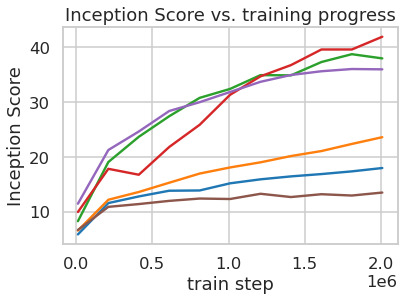
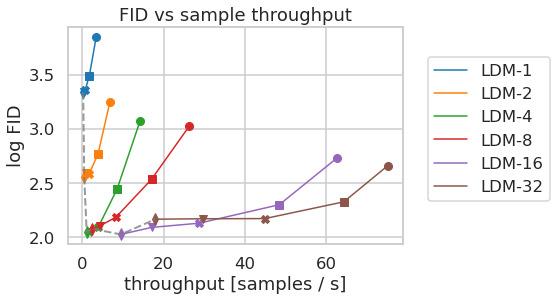
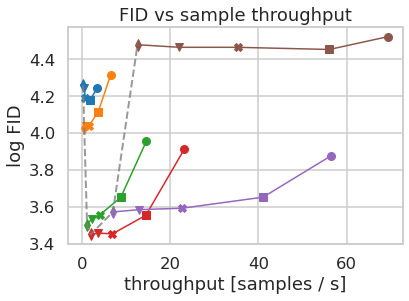
LDMs provide means to flexible and computationally tractable diffusion based image synthesis of various image modalities, which we empirically show in the following. Firstly, however, we analyze the gains of our models compared to pixel-based diffusion models in both training and inference. Interestingly, we find that LDMs trained in VQ-regularized latent spaces sometimes achieve better sample quality, even though the reconstruction capabilities of VQ-regularized first stage models slightly fall behind those of their continuous counterparts, cf. the appendix table. A visual comparison between the effects of first stage regularization schemes on LDM training and their generalization abilities to resolutions
LDM 为各种图像模态提供了灵活且计算可行的基于扩散的图像合成手段,作者在下文中通过经验结果展示这一点。 不过,作者首先分析模型相比基于像素的扩散模型在训练和推理两方面的收益。 有趣的是,作者发现,在 VQ 正则化潜在空间中训练的 LDM 有时会获得更好的样本质量,尽管 VQ 正则化第一阶段模型的重建能力略落后于其连续对应模型,参见附表。 关于第一阶段正则化方案对 LDM 训练的影响及其泛化到
4.1 On Perceptual Compression Tradeoffs
This section analyzes the behavior of our LDMs with different downsampling factors
本节分析作者的 LDM 在不同下采样因子
CelebA-HQ | FFHQ | |||||||
|---|---|---|---|---|---|---|---|---|
| Method | FID ↓ | Prec. ↑ | Recall ↑ | Method | FID ↓ | Prec. ↑ | Recall ↑ | |
| DC-VAE | 15.8 | - | - | ImageBART | 9.57 | - | - | |
| VQGAN+T. (k=400) | 10.2 | - | - | U-Net GAN (+aug) | 10.9 (7.6) | - | - | |
| PGGAN | 8.0 | - | - | UDM | 5.54 | - | - | |
| LSGM | 7.22 | - | - | StyleGAN | 4.16 | 0.71 | 0.46 | |
| UDM | 7.16 | - | - | ProjectedGAN | 3.08 | 0.65 | 0.46 | |
LDM-4 (ours, 500-s | 5.11 | 0.72 | 0.49 | LDM-4 (ours, 200-s) | 4.98 | 0.73 | 0.50 | |
LSUN-Churches | LSUN-Bedrooms | |||||||
| DDPM | 7.89 | - | - | ImageBART | 5.51 | - | - | |
| ImageBART | 7.32 | - | - | DDPM | 4.9 | - | - | |
| PGGAN | 6.42 | - | - | UDM | 4.57 | - | - | |
| StyleGAN | 4.21 | - | - | StyleGAN | 2.35 | 0.59 | 0.48 | |
| StyleGAN2 | 3.86 | - | - | ADM | 1.90 | 0.66 | 0.51 | |
| ProjectedGAN | 1.59 | 0.61 | 0.44 | ProjectedGAN | 1.52 | 0.61 | 0.34 | |
LDM-8 | 4.02 | 0.64 | 0.52 | LDM-4 (ours, 200-s) | 2.95 | 0.66 | 0.48 | |
| Text-Conditional Image Synthesis | ||||
|---|---|---|---|---|
| Method | FID ↓ | IS ↑ | Setting | |
CogView | 27.10 | 18.20 | 4B | self-ranking, rejection rate 0.017 |
LAFITE | 26.94 | 26.02 | 75M | |
GLIDE | 12.24 | - | 6B | 277 DDIM steps, c.f.g. |
Make-A-Scene | 11.84 | - | 4B | c.f.g for AR models |
| LDM-KL-8 | 23.31 | 20.03 ± 0.33 | 1.45B | 250 DDIM steps |
LDM-KL-8-G | 12.63 | 30.29 ± 0.42 | 1.45B | 250 DDIM steps, c.f.g. $s=1.5$ |
4.2 Image Generation with Latent Diffusion













































We train unconditional models of
作者在 CelebA-HQ、FFHQ、LSUN-Churches 和 LSUN-Bedrooms 上训练
4.3 Conditional Latent Diffusion
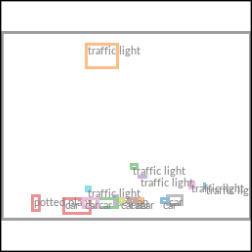












Transformer Encoders for LDMs. By introducing cross-attention based conditioning into LDMs we open them up for various conditioning modalities previously unexplored for diffusion models. For text-to-image image modeling, we train a 1.45B parameter KL-regularized LDM conditioned on language prompts on LAION-400M. We employ the BERT-tokenizer and implement
用于 LDM 的 Transformer 编码器。 通过把基于交叉注意力的条件机制引入 LDM,作者让它们能够处理此前在扩散模型中尚未探索过的各种条件模态。 对于文本到图像图像建模,作者在 LAION-400M 上训练一个以语言提示为条件、具有 14.5 亿参数的 KL 正则化 LDM。 作者采用 BERT tokenizer,并把
| Method | FID ↓ | IS ↑ | Precision ↑ | Recall ↑ | Setting | |
|---|---|---|---|---|---|---|
| BigGan-deep | 6.95 | 203.6 ± 2.6 | 0.87 | 0.28 | 340M | - |
| ADM | 10.94 | 100.98 | 0.69 | 0.63 | 554M | 250 DDIM steps |
| ADM-G | 4.59 | 186.7 | 0.82 | 0.52 | 608M | 250 DDIM steps |
| LDM-4 (ours) | 10.56 | 103.49 ± 1.24 | 0.71 | 0.62 | 400M | 250 DDIM steps |
| LDM-4-G (ours) | 3.60 | 247.67 ± 5.59 | 0.87 | 0.48 | 400M | 250 steps, c.f.g., |

Convolutional Sampling Beyond
超过
4.4 Super-Resolution with Latent Diffusion






LDMs can be efficiently trained for super-resolution by diretly conditioning on low-resolution images via concatenation (cf. Section 3.3). In a first experiment, we follow SR3 and fix the image degradation to a bicubic interpolation with
LDM 可以通过拼接方式直接以低分辨率图像为条件,从而高效地训练用于超分辨率(参见第 3.3 节)。 在第一个实验中,作者遵循 SR3,将图像退化固定为
| SR on ImageNet | Inpainting on Places | ||||
|---|---|---|---|---|---|
| User Study | Pixel-DM ( | LDM-4 | LAMA | LDM-4 | |
| Task 1: Preference vs GT ↑ | 16.0% | 30.4% | 13.6% | 21.0% | |
| Task 2: Preference Score ↑ | 29.4% | 70.6% | 31.9% | 68.1% | |
| Method | FID ↓ | IS ↑ | PSNR ↑ | SSIM ↑ | samples/s | |
|---|---|---|---|---|---|---|
| Image Regression | 15.2 | 121.1 | 27.9 | 0.801 | 625M | N/A |
| SR3 | 5.2 | 180.1 | 26.4 | 0.762 | 625M | N/A |
| LDM-4 (ours, 100 steps) | 2.8 | 166.3 | 24.4 ± 3.8 | 0.69 ± 0.14 | 169M | 4.62 |
| LDM-4 (ours, big, 100 steps) | 2.4 | 174.9 | 24.7 ± 4.1 | 0.71 ± 0.15 | 552M | 4.5 |
| LDM-4 (ours, 50 steps, guiding) | 4.4 | 153.7 | 25.8 ± 3.7 | 0.74 ± 0.12 | 184M | 0.38 |
4.5 Inpainting with Latent Diffusion






Inpainting is the task of filling masked regions of an image with new content either because parts of the image are are corrupted or to replace existing but undesired content within the image. We evaluate how our general approach for conditional image generation compares to more specialized, state-of-the-art approaches for this task. Our evaluation follows the protocol of LaMa, a recent inpainting model that introduces a specialized architecture relying on Fast Fourier Convolutions. The exact training & evaluation protocol on Places is described in the supplement. We first analyze the effect of different design choices for the first stage. In particular, we compare the inpainting efficiency of LDM-1 (i.e. a pixel-based conditional DM) with LDM-4, for both KL and VQ regularizations, as well as VQ-LDM-4 without any attention in the first stage (see the appendix table), where the latter reduces GPU memory for decoding at high resolutions. For comparability, we fix the number of parameters for all models. Table Table 6 reports the training and sampling throughput at resolution
图像修复是用新内容填充图像中被遮罩区域的任务,原因可能是图像部分区域被破坏,也可能是为了替换图像中已有但不想要的内容。 作者评估其用于条件图像生成的通用方法与该任务上更专门化的最先进方法相比如何。 作者的评估遵循 LaMa 的协议,LaMa 是一种近期图像修复模型,引入了依赖快速傅里叶卷积的专用架构。 Places 上的确切训练和评估协议见补充材料。 作者首先分析第一阶段不同设计选择的影响。 具体而言,作者比较了 LDM-1(即基于像素的条件 DM)和 LDM-4 的图像修复效率,后者同时考虑 KL 与 VQ 正则化,以及第一阶段不含任何注意力的 VQ-LDM-4(见附表),其中后者能减少高分辨率解码时的 GPU 内存。 为了可比性,作者固定所有模型的参数数量。 表6 报告了
| Model (reg.-type) | train throughput samples/sec. | sampling throughput | train+val hours/epoch | FID@2k epoch 6 | |
|---|---|---|---|---|---|
| @256 | @512 | ||||
| LDM-1 (no first stage) | 0.11 | 0.26 | 0.07 | 20.66 | 24.74 |
| LDM-4 (KL, w/ attn) | 0.32 | 0.97 | 0.34 | 7.66 | 15.21 |
| LDM-4 (VQ, w/ attn) | 0.33 | 0.97 | 0.34 | 7.04 | 14.99 |
| LDM-4 (VQ, w/o attn) | 0.35 | 0.99 | 0.36 | 6.66 | 15.95 |
The comparison with other inpainting approaches in Table Table 7 shows that our model with attention improves the overall image quality as measured by FID over that of LaMa. LPIPS between the unmasked images and our samples is slightly higher than that of LaMa. We attribute this to LaMa only producing a single result which tends to recover more of an average image compared to the diverse results produced by our LDM cf. the supplement. Additionally in a user study (Table Table 4) human subjects favor our results over those of LaMa. Based on these initial results, we also trained a larger diffusion model (big in Table Table 7) in the latent space of the VQ-regularized first stage without attention. Following ADM, the UNet of this diffusion model uses attention layers on three levels of its feature hierarchy, the BigGAN residual block for up- and downsampling and has 387M parameters instead of 215M. After training, we noticed a discrepancy in the quality of samples produced at resolutions
与其他图像修复方法在 表7 中的比较表明,作者带注意力的模型在 FID 衡量的整体图像质量上优于 LaMa。 未遮罩图像与作者样本之间的 LPIPS 略高于 LaMa。 作者将其归因于 LaMa 只生成单一结果,而该结果相比作者 LDM 产生的多样化结果,更倾向于恢复一张平均图像,参见补充材料。 此外,在用户研究(表4)中,人类受试者也更偏好作者的结果而不是 LaMa。 基于这些初步结果,作者还在不含注意力的 VQ 正则化第一阶段潜在空间中训练了一个更大的扩散模型(表7 中的 big)。 遵循 ADM,这个扩散模型的 UNet 在其特征层级的三个层次上使用注意力层,使用 BigGAN 残差块进行上采样和下采样,并具有 3.87 亿参数,而不是 2.15 亿。 训练后,作者注意到在
| 40-50% masked | All samples | |||
|---|---|---|---|---|
| Method | FID ↓ | LPIPS ↓ | FID ↓ | LPIPS ↓ |
| LDM-4 (ours, big, w/ ft) | 9.39 | 0.246 ± 0.042 | 1.50 | 0.137 ± 0.080 |
| LDM-4 (ours, big, w/o ft) | 12.89 | 0.257 ± 0.047 | 2.40 | 0.142 ± 0.085 |
| LDM-4 (ours, w/ attn) | 11.87 | 0.257 ± 0.042 | 2.15 | 0.144 ± 0.084 |
| LDM-4 (ours, w/o attn) | 12.60 | 0.259 ± 0.041 | 2.37 | 0.145 ± 0.084 |
LaMa | 12.31 | 0.243 ± 0.038 | 2.23 | 0.134 ± 0.080 |
| LaMa | 12.0 | 0.24 | 2.21 | 0.14 |
| CoModGAN | 10.4 | 0.26 | 1.82 | 0.15 |
| RegionWise | 21.3 | 0.27 | 4.75 | 0.15 |
| DeepFill v2 | 22.1 | 0.28 | 5.20 | 0.16 |
| EdgeConnect | 30.5 | 0.28 | 8.37 | 0.16 |
5. Limitations & Societal Impact
Limitations. While LDMs significantly reduce computational requirements compared to pixel-based approaches, their sequential sampling process is still slower than that of GANs. Moreover, the use of LDMs can be questionable when high precision is required: although the loss of image quality is very small in our
局限性。 虽然 LDM 相比基于像素的方法显著降低了计算需求,但其顺序采样过程仍然比 GAN 更慢。 此外,当需要高精度时,使用 LDM 可能是有疑问的:虽然作者的
Societal Impact. Generative models for media like imagery are a double-edged sword: On the one hand, they enable various creative applications, and in particular approaches like ours that reduce the cost of training and inference have the potential to facilitate access to this technology and democratize its exploration. On the other hand, it also means that it becomes easier to create and disseminate manipulated data or spread misinformation and spam. In particular, the deliberate manipulation of images ("deep fakes") is a common problem in this context, and women in particular are disproportionately affected by it. Generative models can also reveal their training data, which is of great concern when the data contain sensitive or personal information and were collected without explicit consent. However, the extent to which this also applies to DMs of images is not yet fully understood. Finally, deep learning modules tend to reproduce or exacerbate biases that are already present in the data. While diffusion models achieve better coverage of the data distribution than e.g. GAN-based approaches, the extent to which our two-stage approach that combines adversarial training and a likelihood-based objective misrepresents the data remains an important research question. For a more general, detailed discussion of the ethical considerations of deep generative models, see e.g. Denton et al.
社会影响。 面向图像等媒体的生成模型是一把双刃剑:一方面,它们支持多种创造性应用,尤其是像作者这样降低训练和推理成本的方法,有潜力促进这项技术的获取,并让其探索更加普及。 另一方面,这也意味着创建和传播被操纵数据,或传播错误信息和垃圾信息会变得更容易。 尤其是,蓄意操纵图像(“deep fakes”)是这一语境中的常见问题,女性尤其会受到不成比例的影响。 生成模型还可能泄露其训练数据;当数据包含敏感或个人信息且是在没有明确同意的情况下收集时,这一点非常令人担忧。 然而,这在多大程度上也适用于图像 DM,目前尚未被充分理解。 最后,深度学习模块往往会复现或加剧数据中已经存在的偏差。 虽然扩散模型相比例如基于 GAN 的方法能更好地覆盖数据分布,但作者这种结合对抗训练和基于似然目标的两阶段方法在多大程度上会错误表征数据,仍然是一个重要研究问题。 关于深度生成模型伦理考量的更一般、更详细讨论,可参见 Denton 等人的工作。
6. Conclusion
We have presented latent diffusion models, a simple and efficient way to significantly improve both the training and sampling efficiency of denoising diffusion models without degrading their quality. Based on this and our cross-attention conditioning mechanism, our experiments could demonstrate favorable results compared to state-of-the-art methods across a wide range of conditional image synthesis tasks without task-specific architectures.
作者提出了潜在扩散模型,这是一种简单而高效的方法,能够在不降低质量的情况下显著提升去噪扩散模型的训练和采样效率。 基于这一点以及作者的交叉注意力条件机制,实验表明,在不使用任务特定架构的情况下,该方法在广泛的条件图像合成任务上相比最先进方法取得了有利结果。