
MemGen: Weaving Generative Latent Memory for Self-Evolving Agents
Memory390+50+ICLR 2026CCF-A新加坡国立大学MemGen:为自进化智能体编织生成式潜在记忆
Abstract
Agent memory shapes how Large Language Model (LLM)-powered agents, akin to the human brain, progressively refine themselves through environment interactions. Existing paradigms remain constrained: parametric memory forcibly adjusts model parameters, and retrieval-based memory externalizes experience into structured databases, yet neither captures the fluid interweaving of reasoning and memory that underlies human cognition. To address this gap, we propose MemGen, a dynamic generative memory framework that equips agents with a human-esque cognitive faculty. It consists of a memory trigger, which monitors the agent’s reasoning state to decide explicit memory invocation, and a memory weaver, which takes the agent's current state as stimulus to construct a latent token sequence as machine-native memory to enrich its reasoning. In this way, MemGen enables agents to recall and augment latent memory throughout reasoning, producing a tightly interwoven cycle of memory and cognition. Extensive experiments across eight benchmarks show that MemGen surpasses leading external memory systems such as ExpeL and AWM by up to
智能体记忆塑造了由大语言模型(LLM)驱动的智能体如何像人脑一样,通过与环境交互逐步完善自身。 现有范式仍然受限:参数化记忆强行调整模型参数,基于检索的记忆把经验外化到结构化数据库中,但二者都没有捕捉到人类认知中推理与记忆流动交织的过程。 为弥合这一差距,作者提出 MemGen,这是一个动态的生成式记忆框架,为智能体配备一种类人的认知能力。 它由两个部分组成:memory trigger 监控智能体的推理状态以决定是否显式调用记忆;memory weaver 则以智能体当前状态作为刺激,构造一段潜在 token 序列,作为机器原生记忆来增强推理。 通过这种方式,MemGen 使智能体能够在整个推理过程中回忆并增强潜在记忆,形成记忆与认知紧密交织的循环。 跨 8 个基准的大量实验表明,MemGen 相比 ExpeL 和 AWM 等领先外部记忆系统最高提升
1. Introduction
The ascent of Large Language Model (LLM)-powered agents marks a paradigm shift across diverse domains. Pivotal to this success is the concept of agent memory, which enables LLM agents to learn progressively from environmental interactions. Crucially, this conception of agent memory extends beyond that of conversational agents (i.e., personalized memory), whose primary role is to sustain coherence across long-horizon, multi-turn dialogues. Rather, the scope of this paper is primarily on enabling agents to internalize experience, simulate human-like cognitive iteration, and progressively enhance problem-solving competence.
由大语言模型(LLM)驱动的智能体兴起,标志着多个领域中的一次范式转变。 这一成功的关键在于 agent memory 这一概念,它使 LLM 智能体能够从环境交互中逐步学习。 关键的是,本文中的智能体记忆并不局限于对话智能体中的个性化记忆;后者的主要作用是在长程、多轮对话中维持连贯性。 相反,本文关注的主要是让智能体内化经验,模拟类人的认知迭代,并逐步提升解决问题的能力。
The memory serving as this self-evolving engine typically manifests in two dominant paradigms. The first is (I) parametric memory, which internalizes experiences by directly updating agents' parameters. While this approach can yield substantial performance gains, its reliance on parameter modification inevitably entails catastrophic forgetting, i.e., the erosion of general knowledge. Conversely, the second paradigm is (II) retrieval-based memory, which externalizes past experiences into a structured database, such as (i) raw trajectories, (ii) high-level experiences, and (iii) condensed skills like reusable APIs or MCP boxes. Although this non-invasive approach circumvents catastrophic forgetting, its efficacy is fundamentally tethered to context engineering. It adheres to a rigid execution pipeline, providing retrieved context to the agent without achieving the fluid, seamless integration characteristic of truly internalized memory.
作为这种自进化引擎的记忆,通常表现为两种主要范式。 第一种是 (I)参数化记忆,它通过直接更新智能体参数来内化经验。 虽然这种方法可以带来显著性能收益,但它对参数修改的依赖不可避免地会导致灾难性遗忘,也就是通用知识被侵蚀。 相反,第二种范式是 (II)基于检索的记忆,它把过去经验外化为结构化数据库,例如*(i)原始轨迹*、(ii)高层经验,以及*(iii)压缩技能*,如可复用 API 或 MCP box。 虽然这种非侵入式方法绕开了灾难性遗忘,但它的效果从根本上受制于上下文工程。 它遵循僵硬的执行管线,把检索到的上下文提供给智能体,却没有实现真正内化记忆那种流动、无缝的整合。
Given these deficiencies, latent memory offers a compelling alternative, leveraging latent states as a machine-native, high-density medium for memory. Existing approaches either use the (i) key-value (KV) cache to maintain dynamic memory set, yet which is primarily confined to addressing long-context issues, or (ii) latent token embeddings to store agent experiences, which still rely on invasive LLM parameter updates. LatentSeek and SoftCoT similarly belong to this category, utilizing latent embeddings to steer agent generation. Nevertheless, all these methods diverge from human cognition in two critical dimensions: they lack the seamless interleaving of reasoning and memory, a process where thought and memory dynamically reshape one another, and remain largely retrieval-based, fetching memories by embedding similarity rather than generatively reconstructing them into novel, coherent insights. This leads to our pivotal research question:
鉴于这些缺陷,潜在记忆提供了一个很有吸引力的替代方案:它使用潜在状态作为机器原生、高密度的记忆媒介。 现有方法要么使用 (i)键值(KV)缓存 来维护动态记忆集合,但这主要局限于解决长上下文问题;要么使用 (ii)潜在 token 嵌入 来存储智能体经验,但这仍然依赖侵入式的 LLM 参数更新。 LatentSeek 和 SoftCoT 也属于这一类,它们利用潜在嵌入来引导智能体生成。 然而,所有这些方法都在两个关键维度上偏离了人类认知:它们缺乏推理与记忆的无缝交织,也就是思想与记忆彼此动态重塑的过程;同时它们仍主要是基于检索的,通过嵌入相似度获取记忆,而不是把记忆生成式地重构为新颖而连贯的洞见。 这引出了本文的核心研究问题:
To address this challenge, we introduce MemGen, a dynamic and generative memory framework designed to endow any LLM agent with a more human-esque cognitive faculty. At its core, MemGen continuously monitors an agent's cognitive state, enabling it to dynamically invoke a generative process that synthesizes a bespoke latent memory at any critical juncture during its reasoning process. Practically, MemGen comprises two synergistic components: a reinforcement learning (RL)-trained
为应对这一挑战,作者提出 MemGen,一个动态且生成式的记忆框架,旨在为任意 LLM 智能体赋予更类人的认知能力。 其核心在于,MemGen 持续监控智能体的认知状态,使其能够在推理过程中的任意关键时刻动态调用生成过程,合成一段定制化的潜在记忆。 具体来说,MemGen 包含两个协同组件:一个经过强化学习(RL)训练的
Experimental Observation
Extensive experiments across nine benchmarks and four baseline categories demonstrate that MemGen delivers ① substantial performance gains, with improvements of up to
跨 9 个基准和 4 类基线的大量实验表明,MemGen 带来了 ① 显著性能提升:在 Qwen3-8B 上,ALFWorld 最高提升
Analysis & Interpretation
Beyond quantitative evaluation, we sought to interpret the learned behavior of MemGen. Through post-hoc interventions examining the impact of removing specific latent memory on different agent failure modes, we found that MemGen implicitly evolves a human-like memory hierarchy without any external guidance, including ① planning memory, where certain latent tokens specifically support high-level task planning, ② procedural memory, where some latent memory tokens facilitate the agent’s recall of task-specific procedural skills, such as tool usage and answer formatting, and ③ working memory, where certain tokens help the agent maintain coherence and understanding over long contexts within a single task session. These specializations strongly reveal that MemGen endows the agent with precise, functionally distinct memory.
除了定量评估之外,作者还试图解释 MemGen 学到的行为。 通过事后干预,考察移除特定潜在记忆对不同智能体失败模式的影响,作者发现 MemGen 在没有任何外部指导的情况下隐式演化出类人的记忆层级,包括 ① 规划记忆,某些潜在 token 专门支持高层任务规划;② 程序性记忆,一些潜在记忆 token 帮助智能体回忆任务特定的程序性技能,例如工具使用和答案格式;以及 ③ 工作记忆,某些 token 帮助智能体在单个任务会话的长上下文中保持连贯性和理解。 这些专门化强烈表明,MemGen 为智能体赋予了精确且功能各异的记忆。
2. Related Work
LLM & Agent Memory
As outlined in Section 1, existing memory mechanisms designed to evolve the problem-solving capacity of LLM agents can be broadly categorized into three classes: (I) parametric memory, which either integrates past experiences directly into agent parameters through finetuning, as in FireAct, AgentLumos, and others, or maintains them in external parameter modules; (II) retrieval-based memory, which abstracts prior experiences into transferable knowledge, or distills them into reusable tools and skills; and (III) latent memory, which leverages implicit representations to encode and retrieve experience. Our MemGen falls within the latent memory paradigm, yet distinguishes itself from prior approaches through its more human-esque interweaving of reasoning and memory, as well as its generative, rather than purely retrieval-based, nature.
如第 1 节所述,旨在演化 LLM 智能体问题解决能力的现有记忆机制,大体可以分为三类:(I)参数化记忆,它要么通过微调把过去经验直接整合进智能体参数,例如 FireAct、AgentLumos 等,要么把经验维护在外部参数模块中;(II)基于检索的记忆,它把先前经验抽象为可迁移知识,或蒸馏成可复用工具和技能;以及 (III)潜在记忆,它利用隐式表示来编码和检索经验。 MemGen 属于潜在记忆范式,但它与先前方法的区别在于,它以更类人的方式交织推理与记忆,并且本质上是生成式的,而不是纯检索式的。
Latent Computation
Our method is also closely related to latent computation, wherein latent states are employed to intervene in or reshape the LLM's reasoning process. Prominent paradigms include: (I) architecturally enabling native latent reasoning, exemplified by Coconut, CODI, LatentR3 and CoLaR, which render the LLM's inference process inherently latent and machine-native; and (II) employing latent computation to steer LLM generation, as in LaRS, LatentSeek, SoftCoT, and Coprocessor, which leverage latent representations to modulate the quality of generated outputs. These aforementioned works have greatly inspired the latent memory design in this paper: Latent memory can likewise be viewed as an instantiation of the latter, supplementing essential memory context to enhance the problem-solving capacity of agents.
本文方法也与潜在计算密切相关,在这类方法中,潜在状态被用来干预或重塑 LLM 的推理过程。 代表性范式包括:(I)在架构上支持原生潜在推理,例如 Coconut、CODI、LatentR3 和 CoLaR,它们使 LLM 的推理过程天然具有潜在且机器原生的形式;以及 (II)使用潜在计算来引导 LLM 生成,例如 LaRS、LatentSeek、SoftCoT 和 Coprocessor,它们利用潜在表示调节生成输出质量。 上述工作极大启发了本文的潜在记忆设计:潜在记忆同样可以被看作后一类方法的一个实例,通过补充必要的记忆上下文来增强智能体的问题解决能力。
LLM Decoding & RL
Two additional topics that relate to our work are LLM decoding and reinforcement learning (RL). From the decoding perspective, MemGen dynamically generates and inserts latent tokens, which shares similarity with speculative decoding where a drafter model receives the current decoding context and produces subsequent drafted tokens. . However, these methods primarily aim to accelerate LLM inference, whereas MemGen focuses on leveraging latent states as effective carriers of memory. From the RL perspective, MemGen employs rule-based RL to train the memory trigger, which is closely related to reinforcement learning with variable reward (RLVR), including GRPO from DeepSeek-R1 and its various derivatives. While there exist efforts combining RL with agent memory, to our knowledge, most do not address self-improving memory; for example, MemAgent and MEM1 focus on handling long-context inputs rather than evolving memory mechanisms.
另外两个与本文相关的主题是 LLM 解码和强化学习(RL)。 从解码视角看,MemGen 会动态生成并插入潜在 token,这与投机解码有相似之处:草稿模型接收当前解码上下文,并产生后续草稿 token。 。然而,这些方法主要旨在加速 LLM 推理,而 MemGen 关注的是把潜在状态作为有效的记忆载体。 从 RL 视角看,MemGen 使用基于规则的 RL 训练 memory trigger,这与可变奖励强化学习(RLVR)密切相关,包括 DeepSeek-R1 中的 GRPO 及其各种衍生方法。 虽然已有工作尝试把 RL 与智能体记忆结合,但据作者所知,多数并不处理自我改进记忆;例如 MemAgent 和 MEM1 关注的是长上下文输入处理,而不是记忆机制的演化。
3. Preliminary
Notation
We formalize the agent's interaction within an environment
作者将智能体在环境
After an entire action sequence
当完整动作序列
Problem Formalization
Given a history of past experiences
给定过去经验历史
During which
在这一过程中,
Which accommodates diverse memory invocation granularities. For task-level memory (e.g., Expel and G-Memory),
该表达能够容纳不同粒度的记忆调用。 对于任务级记忆(例如 Expel 和 G-Memory),
4. Methodology
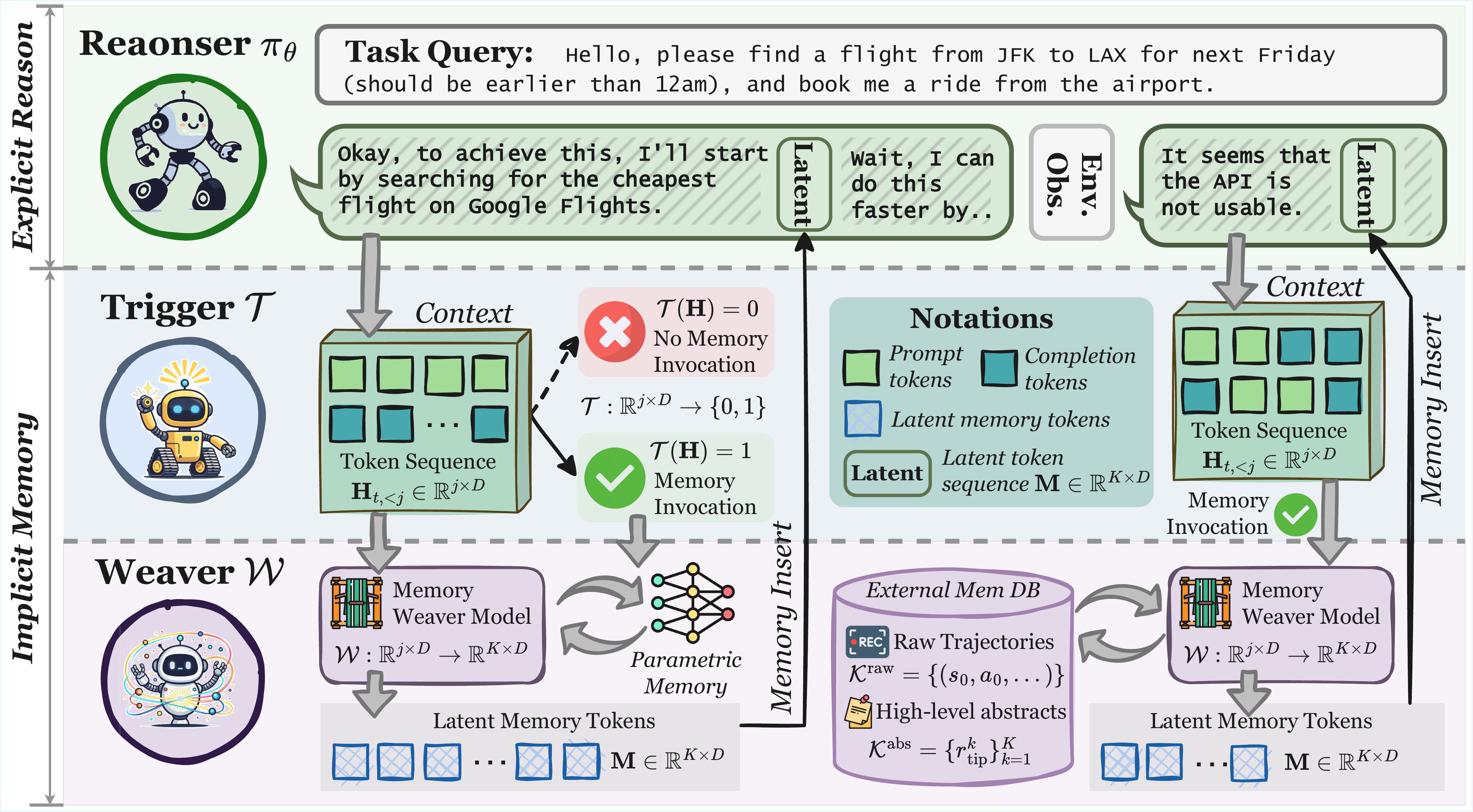
4.1. MemGen: Interleaving Memory and Reasoning
Just as a person is the sum of their past experiences, memory critically shapes an agent's actions. Existing agent memory systems, however, often lack the flexibility of human cognition. In the human brain, reasoning and memory form a seamless continuum: active reasoning in the frontoparietal control network and memory retrieval in the hippocampus and prefrontal cortices operate interweavingly, generating a “continuous flow of thoughts”. By contrast, many agent memory paradigms retrieve information once at task onset and append it coarsely to the query. MemGen is designed precisely to bridge this gap.
正如“一个人是其过往经历的总和”,记忆会关键性地塑造智能体的行动。 然而,现有智能体记忆系统往往缺乏人类认知的灵活性。 在人脑中,推理与记忆形成一个无缝连续体:额顶控制网络中的主动推理,以及海马体和前额叶皮层中的记忆检索,会以交织方式运作,产生“连续的思想流”。 相比之下,许多智能体记忆范式只在任务开始时检索一次信息,并粗粒度地附加到查询中。 MemGen 正是为了弥合这一差距而设计的。
As shown in Figure 2, the reasoning process in an agent equipped with MemGen unfolds autoregressively, driven by a frozen core LLM, the reasoner
如 图2 所示,配备 MemGen 的智能体推理过程由冻结的核心 LLM,也就是推理器
From which a binary decision, [SKIP], INVOKE, the reasoning process is momentarily paused. This summons the second core component of our framework: the memory weaver
随后从中采样一个二值决策 [SKIP],INVOKE,推理过程会被短暂停下。 这会召唤框架的第二个核心组件:memory weaver
Where the memory is generated not merely from the parametric knowledge encoded within
这里的记忆并不仅仅来自
This iterative cycle of generation, monitoring, invocation, weaving, and reintegration elevates reasoning from a linear unfolding to a recursive dialogue with memory, all without altering the frozen reasoner
这种生成、监控、调用、编织和重新整合的迭代循环,把推理从线性展开提升为与记忆的递归对话,而且全程不改变冻结推理器
4.2. Memory Trigger: Learning to Invocate Memory
In this section, we describe the concrete instantiation and training recipe of the memory trigger
本节描述 memory trigger
Instantiation
We instantiate
作者将
Which ensures that
这确保
Training Recipe
The memory trigger is trained via reinforcement learning, motivated by the need to balance two competing desiderata: ensuring that critical latent memories are invoked to improve task performance, while avoiding unnecessary or spurious invocations that could disrupt reasoning or incur computational overhead. Given a batch of seen tasks
memory trigger 通过强化学习训练,其动机在于平衡两个相互竞争的目标:确保关键潜在记忆被调用以提升任务表现,同时避免不必要或伪造的调用干扰推理或带来计算开销。 给定一批已见任务
Where
其中
Where ensures that
这确保
4.3. Memory Weaver: Synthesizing and Inserting Latent Memory
In this section, we elaborate on the weaver
本节进一步阐述 weaver
Instantiation
We instantiate
作者使用另一个附着在
Training Recipe
The training of
Where the gradients from
其中来自
Integration with Retrieval-based Memory
Although the memory generation above primarily draws on the weaver’s parametric knowledge, it can be combined with external memory sources. When triggered, any retrieval-based system (e.g., MemoryBank, ExpeL) can provide textual memory, which is merged with the hook
虽然上述记忆生成主要依赖 weaver 的参数化知识,但它也可以与外部记忆源结合。 当被触发时,任意基于检索的系统(例如 MemoryBank、ExpeL)都可以提供文本记忆;这些文本记忆会与 hook
5. Experiments
In this section, we conduct extensive experiments to answer the following research questions:
- (RQ1) Can MemGen surpass both parametric and retrieval-based memory?
- (RQ2) Is the memory learnt by MemGen generalizable across task domains? And why?
- (RQ3) Can MemGen facilitate continual learning and mitigate catastrophic forgetting?
- (RQ4) Does MemGen implicitly evolve human-like memory hierachy?
本节通过大量实验回答以下研究问题:
- (RQ1) MemGen 能否同时超越参数化记忆和基于检索的记忆?
- (RQ2) MemGen 学到的记忆能否跨任务领域泛化?为什么?
- (RQ3) MemGen 能否促进持续学习并缓解灾难性遗忘?
- (RQ4) MemGen 是否会隐式演化出类人记忆层级?
5.1. Experimental Setup
Evaluation and Benchmarks
Our evaluation covers nine datasets from five domains, including ① web search: TriviaQA and PopQA; ② embodied action: ALFWorld; ③ math reasoning: AQuA, GSM8K, and MATH; ④ scientific reasoning: GPQA; and ⑤ coding: KodCode and BigCodeBench.
评估覆盖来自 5 个领域的 9 个数据集,包括 ① Web 搜索:TriviaQA 和 PopQA;② 具身行动:ALFWorld;③ 数学推理:AQuA、GSM8K 和 MATH;④ 科学推理:GPQA;以及 ⑤ 编程:KodCode 和 BigCodeBench。
Baselines
We compare MemGen against twelve baselines, categorized into four groups: (I) Prompt-based methods: Vanilla model, CoT; (II) Parametric memory, where experiential knowledge directly modifies model parameters via: SFT, GRPO, REINFORCE, REINFORCE++, Agent-FLAN; (III) Retrieval-based memory, where processing tasks sequentially and storing the experiences in an external database, represented by MemoryBank, ExpeL, Agent Workflow Memory (AWM); and (IV) Latent computation, where leveraging latent tokens as carriers of experiential knowledge, including SoftCoT and Co-processor.
作者将 MemGen 与 12 个基线比较,并将它们分为 4 组:(I)基于提示的方法:Vanilla model、CoT;(II)参数化记忆:经验知识通过 SFT、GRPO、REINFORCE、REINFORCE++、Agent-FLAN 等方式直接修改模型参数;(III)基于检索的记忆:顺序处理任务并将经验存储在外部数据库中,代表方法包括 MemoryBank、ExpeL、Agent Workflow Memory(AWM);以及 (IV)潜在计算:利用潜在 token 作为经验知识载体,包括 SoftCoT 和 Co-processor。
| Method | ALFWorld | TrivialQA | PopQA | KodCode | BigCodeBench | GPQA | GSM8K | MATH |
|---|---|---|---|---|---|---|---|---|
| SmolLM3-3B | ||||||||
| Vanilla | 18.96 | 10.47 | 8.23 | 37.05 | 35.96 | 9.35 | 47.63 | 16.22 |
| CoT | 17.60 | 12.88 | 9.95 | 38.45 | 39.42 | 20.70 | 58.91 | 56.33 |
| SFT | 32.36 | 55.25 | 37.22 | 59.25 | 40.79 | 19.70 | 63.48 | 45.65 |
| GRPO | 55.35 | 65.88 | 45.16 | 68.48 | 72.44 | 22.73 | 80.03 | 61.23 |
| REINFORCE | 53.13 | 63.20 | 46.81 | 65.53 | 67.14 | 23.44 | 82.03 | 58.75 |
| REINFORCE++ | 53.95 | 63.20 | 44.10 | 65.90 | 68.80 | 22.73 | 81.50 | 59.89 |
| Agent-FLAN | 34.00 | 56.70 | 39.50 | 56.80 | 37.20 | 17.80 | 59.60 | 36.84 |
| ExpeL | 36.18 | 46.20 | 28.16 | 51.14 | 40.22 | 15.15 | 56.23 | 38.11 |
| MemoryBank | 32.80 | 43.30 | 25.81 | 44.50 | 31.80 | 10.20 | 58.30 | 43.53 |
| AWM | 40.50 | 49.80 | 29.60 | - | - | - | - | - |
| SoftCoT | 35.03 | 50.38 | 34.90 | 59.20 | 39.10 | 17.22 | 56.34 | 44.62 |
| Co-processor | 38.36 | 53.28 | 38.96 | 56.25 | 45.40 | 20.10 | 57.60 | 38.81 |
| MemGenSFT | 50.60 | 68.13 | 42.34 | 62.65 | 42.99 | 26.75 | 70.42 | 57.44 |
| MemGenGRPO | 63.60 | 79.30 | 58.60 | 72.85 | 74.24 | 25.20 | 83.47 | 63.65 |
| Qwen3-8B | ||||||||
| Vanilla | 58.93 | 52.18 | 34.13 | 49.10 | 33.33 | 38.18 | 89.48 | 79.82 |
| CoT | 57.10 | 53.80 | 33.20 | 51.25 | 35.59 | 35.15 | 87.67 | 78.24 |
| SFT | 83.59 | 74.55 | 51.12 | 64.75 | 41.33 | 40.33 | 90.76 | 81.35 |
| GRPO | 85.60 | 76.15 | 58.90 | 73.35 | 70.24 | 39.54 | 92.30 | 83.54 |
| REINFORCE | 82.10 | 75.22 | 57.96 | 72.11 | 70.20 | 37.12 | 91.25 | 83.27 |
| REINFORCE++ | 84.80 | 75.90 | 58.30 | 72.90 | 71.88 | 37.68 | 91.90 | 85.24 |
| Agent-FLAN | 80.32 | 70.32 | 50.08 | 62.99 | 43.40 | 39.50 | 87.60 | 80.05 |
| ExpeL | 78.97 | 65.54 | 40.33 | 57.20 | 34.23 | 35.15 | 86.20 | 77.40 |
| MemoryBank | 70.41 | 60.56 | 41.60 | 56.39 | 40.61 | 35.66 | 90.35 | 80.35 |
| AWM | 80.33 | 69.30 | 43.69 | - | - | - | - | - |
| SoftCoT | 75.60 | 59.42 | 39.42 | 63.28 | 38.27 | 39.60 | 86.30 | 76.23 |
| Co-processor | 73.28 | 61.42 | 45.55 | 64.90 | 42.19 | 39.15 | 76.23 | 79.20 |
| MemGenSFT | 85.82 | 77.22 | 54.65 | 66.15 | 40.35 | 43.23 | 91.25 | 83.30 |
| MemGenGRPO | 90.60 | 80.65 | 62.30 | 76.16 | 75.56 | 40.24 | 93.20 | 88.24 |
Implementation Details
We select LLM backbones of varying sizes, including Qwen-2.5-1.5B, HuggingFace's SmolLM3-3B, and Qwen3-8B. The length of each latent memory sequence
作者选择不同规模的 LLM backbone,包括 Qwen-2.5-1.5B、HuggingFace 的 SmolLM3-3B 和 Qwen3-8B。 每段潜在记忆序列的长度
5.2. Main Restuls
[For RQ1] MemGen provides high-performing memory across domains.
As shown in Appendix and Table 1, existing baselines exhibit clear limitations in cross-domain adaptivity. Retrieval-based memories (e.g., ExpeL, MemoryBank, AWM) occasionally surpass parazmetric tuning in embodied action; for instance, AWM reaches
如附录和 表1 所示,现有基线在跨域适应性上表现出明显局限。 基于检索的记忆(例如 ExpeL、MemoryBank、AWM)有时会在具身行动任务上超过 parazmetric tuning;例如,在 SmolLM3-3B 上,AWM 在 ALFWorld 达到
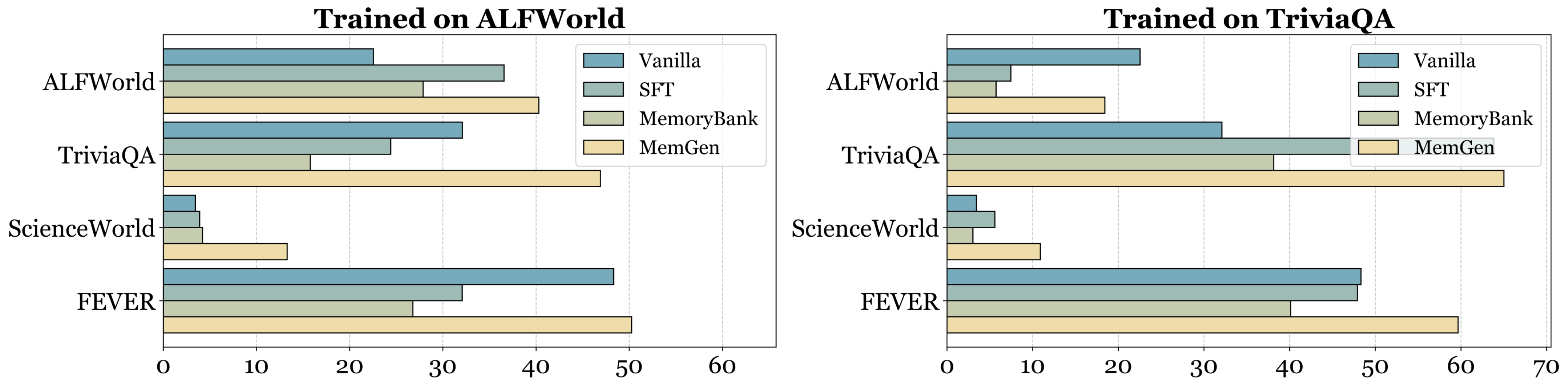
[For RQ2] MemGen Exhibits Strong Cross-Domain Generalization.
To evaluate whether the memory learned by MemGen can transfer across tasks, we train MemGen on one dataset and test it on several others. We include two out-of-domain datasets, ScienceWorld and FEVER, to further probe this. As shown in Figure 3 and Appendix, baselines such as SFT and MemoryBank achieve gains within their training domains (e.g., on ALFWorld, SFT
为评估 MemGen 学到的记忆能否跨任务迁移,作者在一个数据集上训练 MemGen,并在多个其他数据集上测试。 作者还加入两个域外数据集 ScienceWorld 和 FEVER,以进一步探查这一点。 如 图3 和附录所示,SFT、MemoryBank 等基线能在训练域内获得收益(例如在 ALFWorld 上,相比 vanilla,SFT
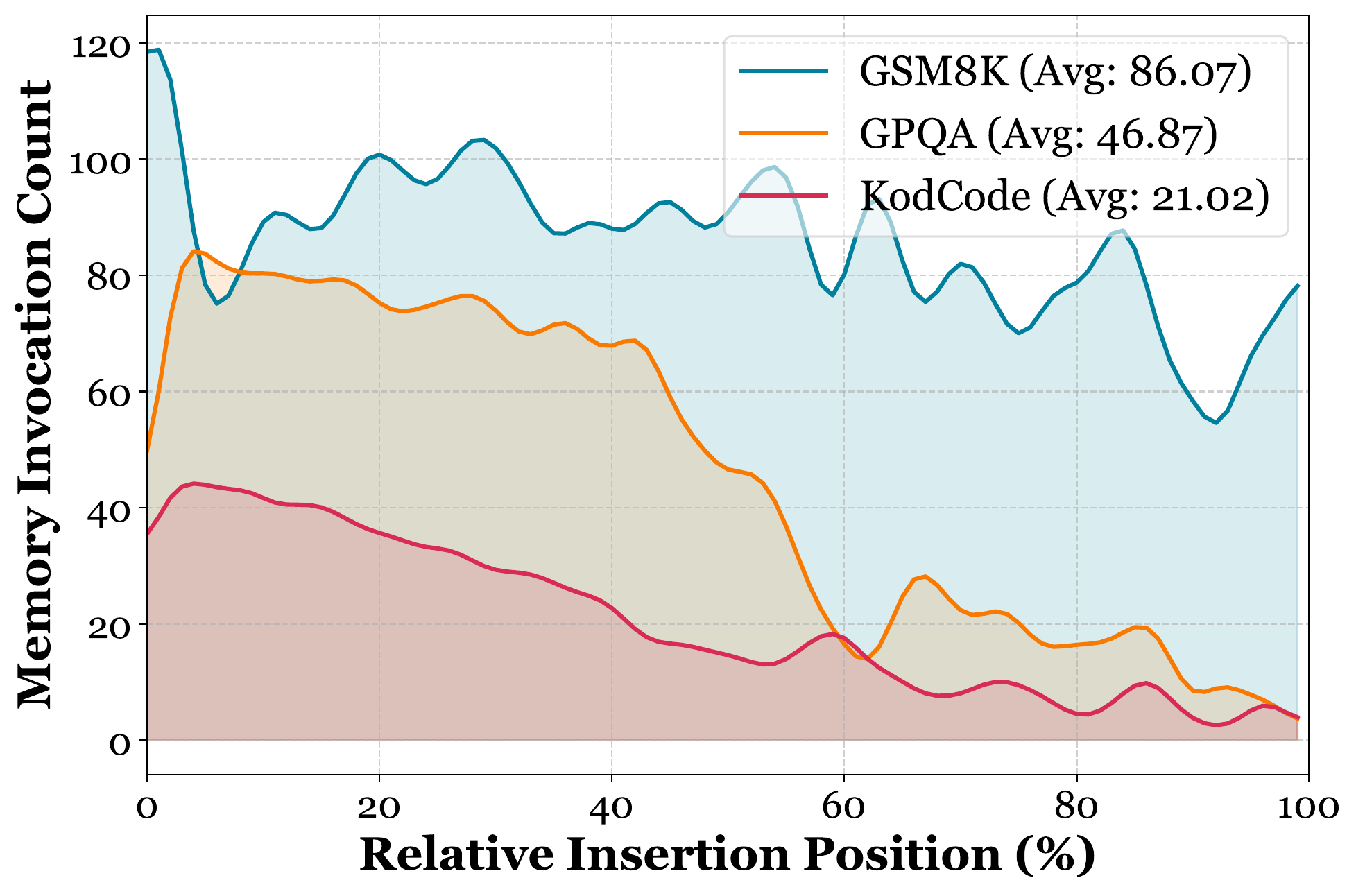
[For RQ2] The Memory Trigger Intelligently Determines When to Activate Memory Insertion, Mitigating Domain Conflict.
After training MemGen on GSM8K, we evaluate 150 samples each from GSM8K, KodCode, and GPQA, visualizing the frequency with which the memory trigger invoked the memory weaver at each relative position in the model output. We observe that the invocation frequency varies across domains and correlates directly with performance in Appendix: GSM8K exhibits the largest improvement (
在 GSM8K 上训练 MemGen 后,作者分别从 GSM8K、KodCode 和 GPQA 中评估 150 个样本,并可视化 memory trigger 在模型输出各相对位置调用 memory weaver 的频率。 作者观察到调用频率会随领域变化,并且与附录中的性能直接相关:GSM8K 提升最大(
[For RQ3] MemGen Effectively Mitigates Catastrophic Forgetting.
In Appendix, we sequentially train on four datasets and evaluate on all benchmarks after each stage, where MemGen exhibits stronger knowledge retention ability compared to baseline methods. For example, unlike SFT which primarily improves performance on the most recent task (
在附录中,作者依次在 4 个数据集上训练,并在每个阶段后评估所有基准;相比基线方法,MemGen 表现出更强的知识保持能力。 例如,SFT 主要提升最近任务上的表现(KodCode 上
5.3. Framework Analysis
Having established the expressive capabilities of MemGen, we further investigate its underlying mechanisms: what do the learned latent memories look like? Do they have specialized functions?
在确认 MemGen 的表达能力后,作者进一步研究其底层机制:学到的潜在记忆是什么样子? 它们是否具有专门功能?
_check 结尾。[For RQ4] The Latent Memory Is Machine-Native and Human-Unreadable.
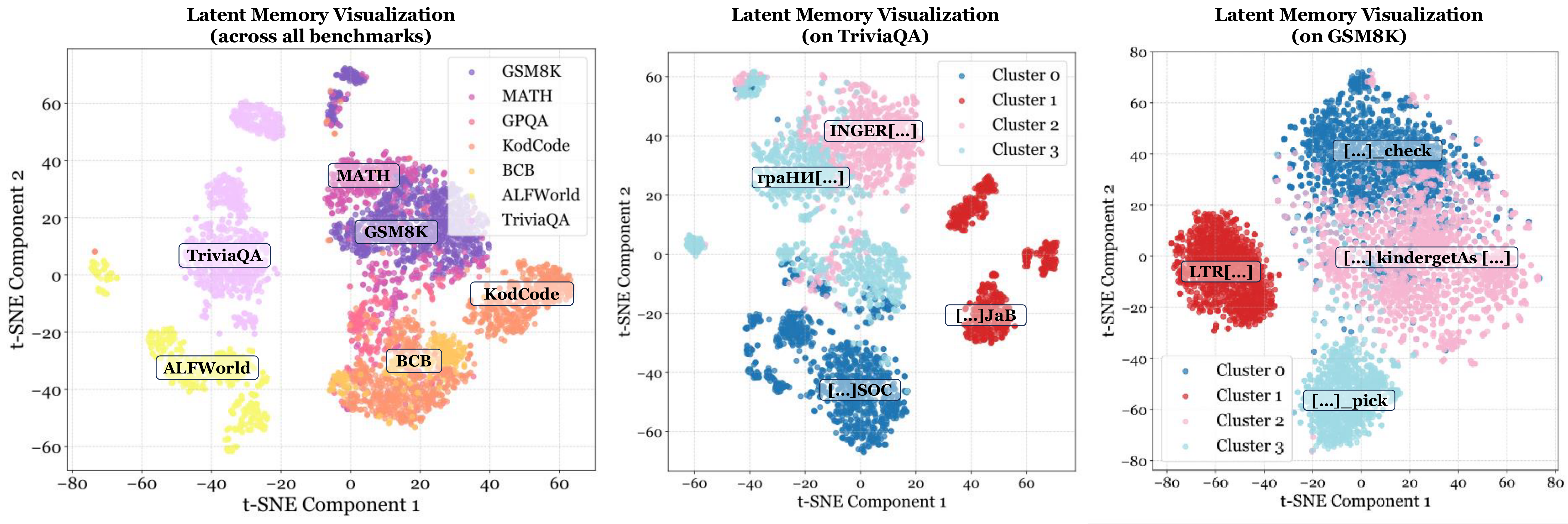
We first visualized the latent memory sequences learned by MemGen across different datasets using t-SNE in Figure 5 and Appendix. As shown in Figure 5 (Left), sequences from distinct domains form separate distributions, with related domains clustering closely (e.g., KodCode and BigCodeBench, GSM8K and MATH). Examining latent memories within the same dataset, we observed pronounced clustering patterns (as shown in Figure 5 (Middle and Right)). To explore potential commonalities within these clusters, we forcibly decoded the latent tokens. Although the decoded sequences are not human-readable, they exhibit intriguing regularities: many tokens within a cluster share structural conventions. For example, Cluster 0 in TriviaQA frequently follows the pattern "[...]SOC", whereas Cluster 3 in GSM8K often adopts the format "[...]_pick". A large corpus of latent memory tokens is provided in Appendix. Despite these sequences being machine-native and human-unreadable, we further investigate whether their underlying semantics can be interpreted.
作者首先在 图5 和附录中使用 t-SNE 可视化 MemGen 在不同数据集上学到的潜在记忆序列。 如 图5(左)所示,来自不同领域的序列形成分离分布,相关领域会聚得更近(例如 KodCode 和 BigCodeBench、GSM8K 和 MATH)。 考察同一数据集内的潜在记忆时,作者观察到明显的聚类模式(如 图5 中、右所示)。 为了探索这些簇内部可能存在的共性,作者强制解码潜在 token。 尽管解码后的序列不是人类可读的,它们却表现出有趣的规律性:同一簇中的许多 token 共享结构约定。 例如,TriviaQA 中的 Cluster 0 经常遵循 "[...]SOC" 模式,而 GSM8K 中的 Cluster 3 往往采用 "[...]_pick" 格式。 大量潜在记忆 token 语料见附录。 尽管这些序列是机器原生且人类不可读的,作者仍进一步研究其底层语义是否可以被解释。
[For RQ4] MemGen Implicitly Learns a Human-like Memory Hierarchy.
To uncover the functional roles of different latent memory clusters, we conducted a post-hoc intervention study. Following the taxonomy from prior work, we study eight distinct types of agent failure, including planning errors, tool response/parsing failures, answer formatting mistakes, etc, providing a structured framework to assess how memory influences performance. During evaluation, we selectively removed latent tokens close to a specific cluster while keeping others intact, measuring the resulting changes in these failure modes. Details on (1) the visualization process, (2) failure mode annotation, and (3) token filtration are in Appendix. As shown in Figure 6 (Right), distinct memory clusters exhibit varying influence on failure modes and can be mapped to different memory functions:
- Planning Memory supports high-level task planning and strategic reasoning.
Removal of Cluster 2 substantially increases planning and compositional reasoning failures, indicating that this cluster is crucial for guiding the LLM agent's decision-making and sequencing of reasoning steps.
- Procedural Memory captures task-specific operational knowledge, such as tool usage and formatting ability.
Cluster 3 corresponds to this role, as its removal leads to a marked increase in tool response errors, parsing failures, and answer formatting mistakes.
- Working Memory manages the retention and effective use of prior context to maintain reasoning consistency.
Clusters 1 and 4 contribute to this function: for instance, removing Cluster 1’s memory tokens results in more frequent task misunderstandings and think-act inconsistency.
为揭示不同潜在记忆簇的功能角色,作者进行了事后干预研究。 遵循先前工作的分类法,作者研究 8 种不同智能体失败类型,包括规划错误、工具响应/解析失败、答案格式错误等,从而提供一个结构化框架来评估记忆如何影响表现。 在评估时,作者选择性移除接近某个特定簇的潜在 token,同时保持其他 token 不变,并测量这些失败模式的变化。 关于(1)可视化过程、(2)失败模式标注和(3)token 过滤的细节见附录。 如 图6(右)所示,不同记忆簇对失败模式的影响不同,并且可以映射到不同记忆功能:
- 规划记忆 支持高层任务规划和战略推理。
移除 Cluster 2 会显著增加规划和组合推理失败,说明该簇对引导 LLM 智能体决策和安排推理步骤非常关键。
- 程序性记忆 捕捉任务特定的操作知识,例如工具使用和格式化能力。
Cluster 3 对应该角色,因为移除它会明显增加工具响应错误、解析失败和答案格式错误。
- 工作记忆 管理先前上下文的保持和有效使用,以维持推理一致性。
Cluster 1 和 4 贡献了这一功能:例如,移除 Cluster 1 的记忆 token 会导致任务误解和思考-行动不一致更频繁。
Nevertheless, these memory clusters are not entirely independent: for example, removing Cluster 1 also negatively affects planning ability, indicating that these memory faculties interact and jointly enable the LLM to leverage past experience effectively. This analysis reveals that MemGen spontaneously organizes latent memory into a structured, human-like hierarchy.
不过,这些记忆簇并非完全独立:例如,移除 Cluster 1 也会负面影响规划能力,这说明这些记忆能力会相互作用,并共同使 LLM 有效利用过去经验。 这一分析表明,MemGen 会自发地把潜在记忆组织成结构化、类人的层级。
Ablation Study & Sensitivity Analysis
We conduct a sensitivity analysis on the length of the latent memory sequence
作者对潜在记忆序列长度
Efficiency Analysis
To confirm that the memory insertion process of MemGen does not introduce significant inference overhead, we show in Appendix that, while achieving up to
为确认 MemGen 的记忆插入过程不会引入显著推理开销,作者在附录中表明:在相较 vanilla LLM 取得最高
6. Conclusion
In this work, we introduced MemGen, a dynamic and generative memory framework designed for LLM Agents. By interleaving reasoning with memory synthesis through a reinforcement-learned memory trigger and a generative memory weaver, MemGen transcends the limitations of parametric and retrieval-based paradigms. Extensive experiments showcase substantial performance gains, robust cross-domain generalization, strong continual learning ability, and MemGen's explicitly modeled memory hierarchy (i.e., planning, procedural, and working memory). These results suggest a promising path toward self-evolving LLM agents capable of fluid and reconstructive intelligence.
本文提出了 MemGen,一个面向 LLM 智能体的动态生成式记忆框架。 通过强化学习学到的 memory trigger 和生成式 memory weaver,把推理与记忆合成交织起来,MemGen 超越了参数化和基于检索的范式限制。 大量实验展示了显著性能提升、稳健跨域泛化、强持续学习能力,以及 MemGen 显式建模的记忆层级(即规划记忆、程序性记忆和工作记忆)。 这些结果为构建具备流动性和重构性智能的自进化 LLM 智能体指出了一条有前景的道路。